4. Discussion
The presented methodology integrates all the available data, from both stopes and boreholes, and takes into consideration the particular characteristics of the data, namely, the different sampling methods and distinct spatial biases. These data characteristics made it unfeasible to use conventional non-geostatistical methods to model the deposit, meaning that an optimized methodology had to be developed in order to combine all the data and to avoid bias.
An initial overview of the problem showed that the greatest challenge in defining a methodology for modelling the deposit was to adjust the methods to the data and sampling characteristics, namely: the different data sources and sampling patterns; which information or data source should be defined as primary; which data source better represents the distributional behavior of the variables; the sampling and data biases; the data types (continuous and categorical); and the adaption of traditional geostatistical methods to the problem.
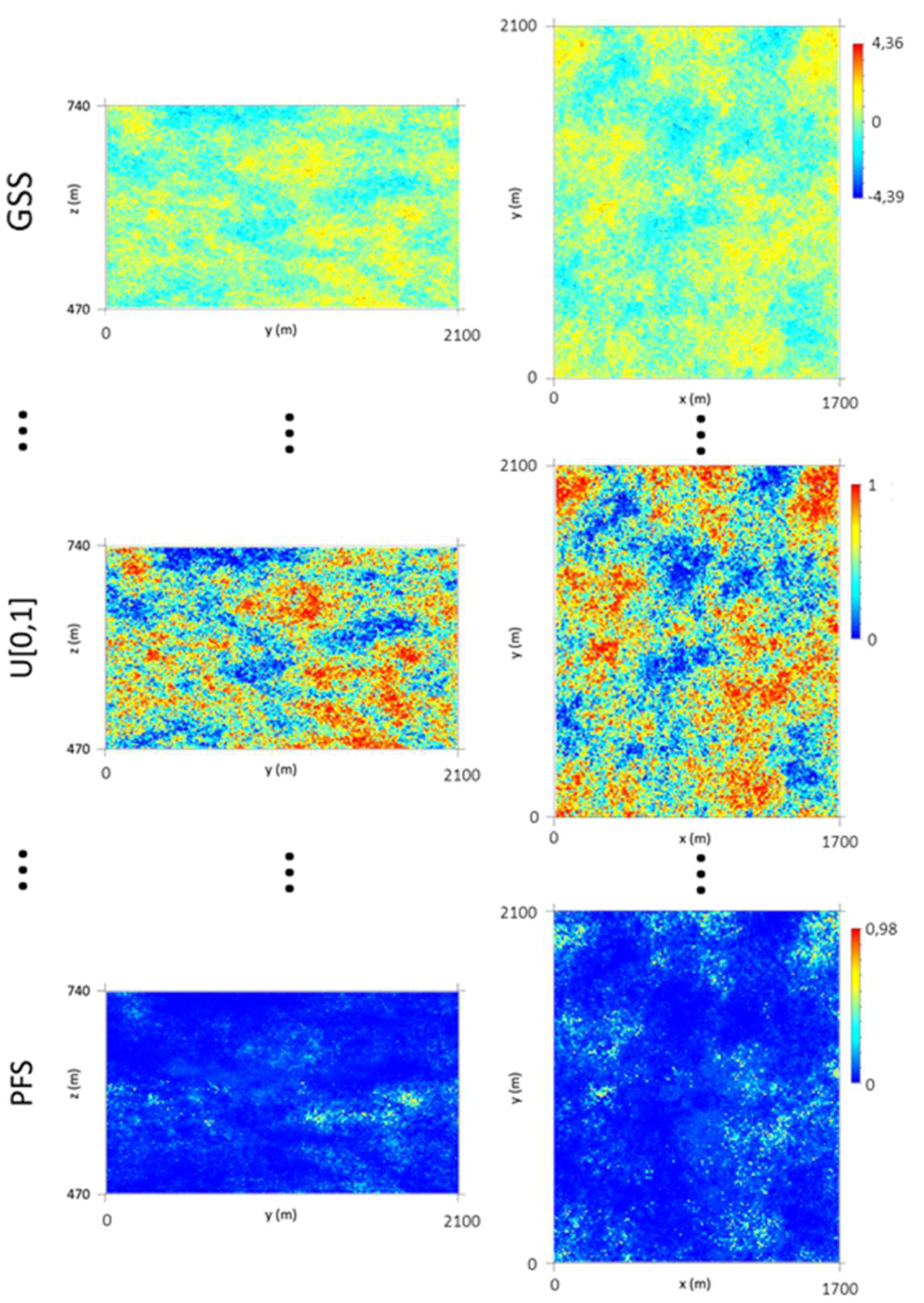
Geostatistical methods for estimation did not correspond to the requirements imposed by the data and sampling, as they did not allow combining large amounts of information, divided into primary and secondary information, and in different sampling patterns and sizes, characteristics that assumed an important role in the interpretation of the results. Therefore, we used stochastic simulation, whose algorithms are easily modified and adapted to the needs of the problem and which allow the local uncertainty to be quantified through the samples’ proximity and heterogeneity.
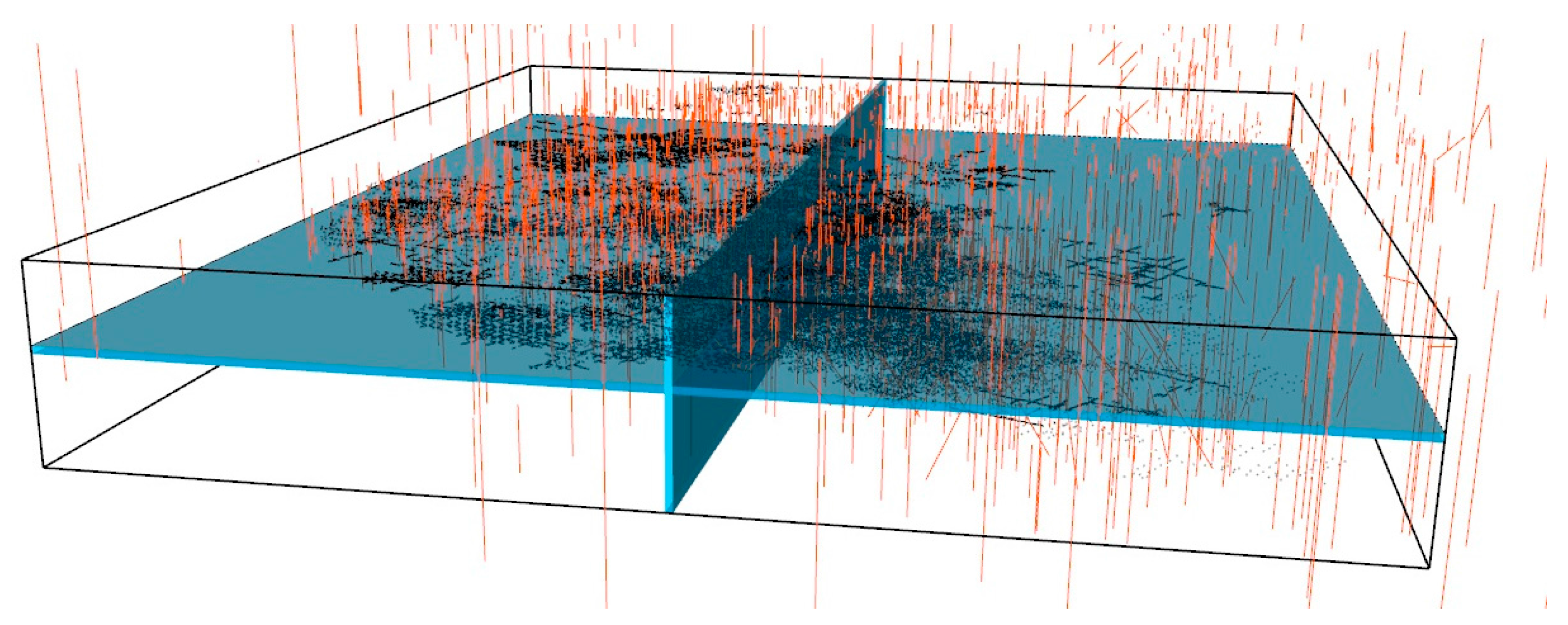
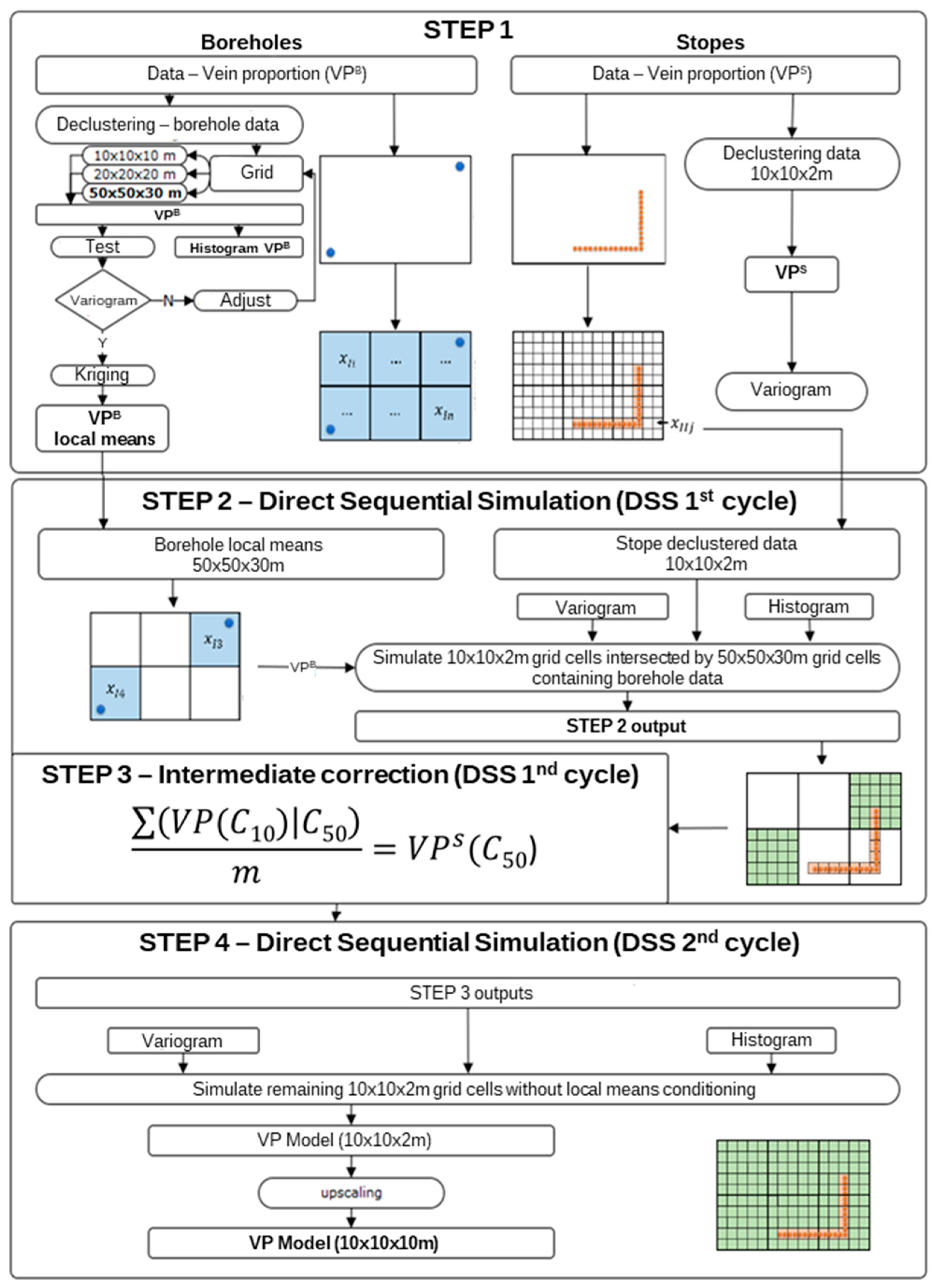
The proposed methodology considered all the presented conditions, allowing two independent models to be built, namely, models of morphology and wolframite content, which were subsequently crossed to quantify the mineral potential in each model cell (10 m × 10 m × 10 m). The available information was integrated into the models as hard data (stopes) and as soft data (boreholes).
The integration of some data as soft data into the methodology developed was shown to be valid and efficient because it allowed a model to be created that was conditioned to the spatial structure and statistics of the boreholes, which are considered more representative of the volume compared with the stopes. Although borehole data are less abundant than stope data in some parts of the deposit, these soft data are globally less skewed than the stope data, so they better represent the true behavior of the property of interest (VP).
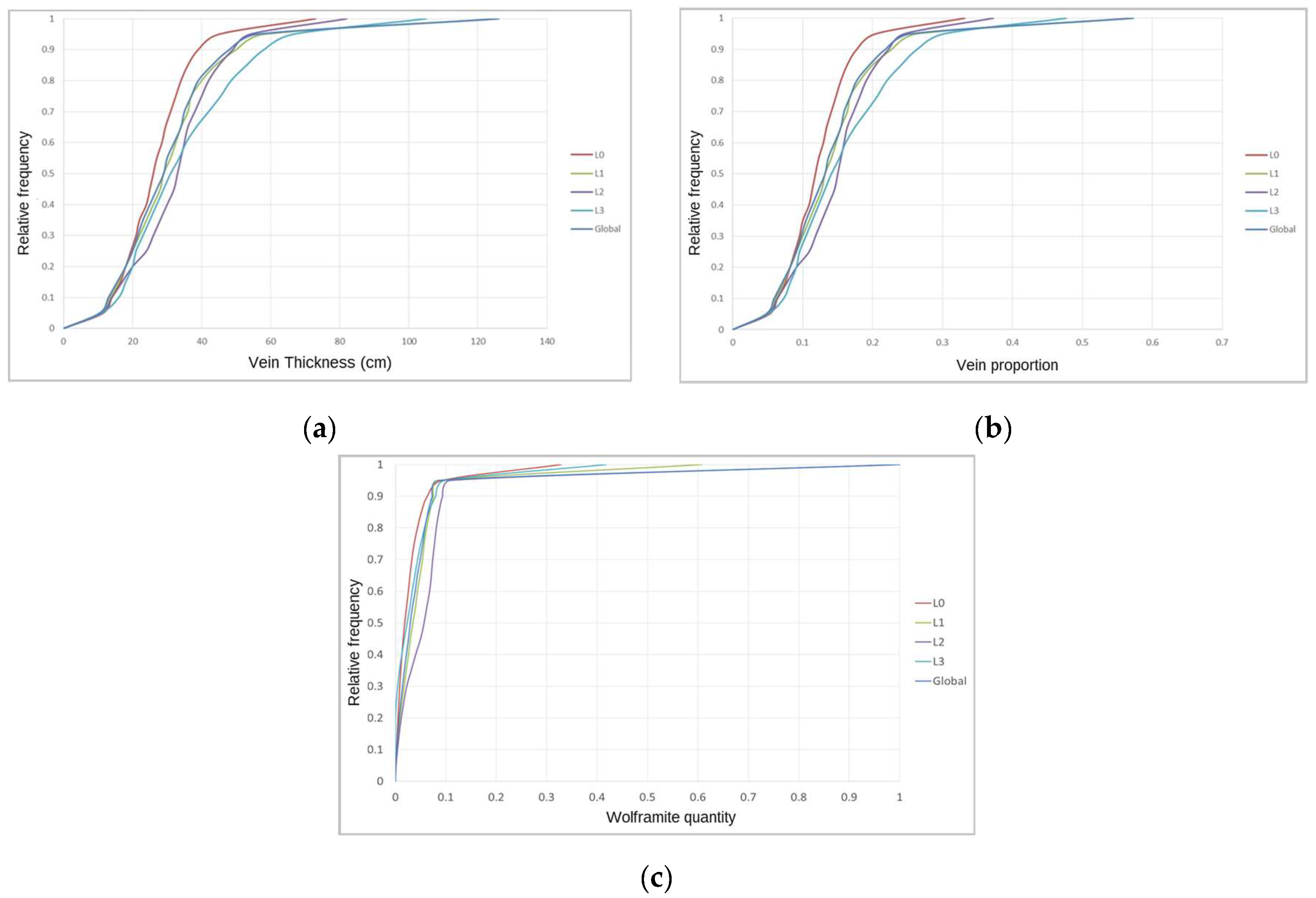
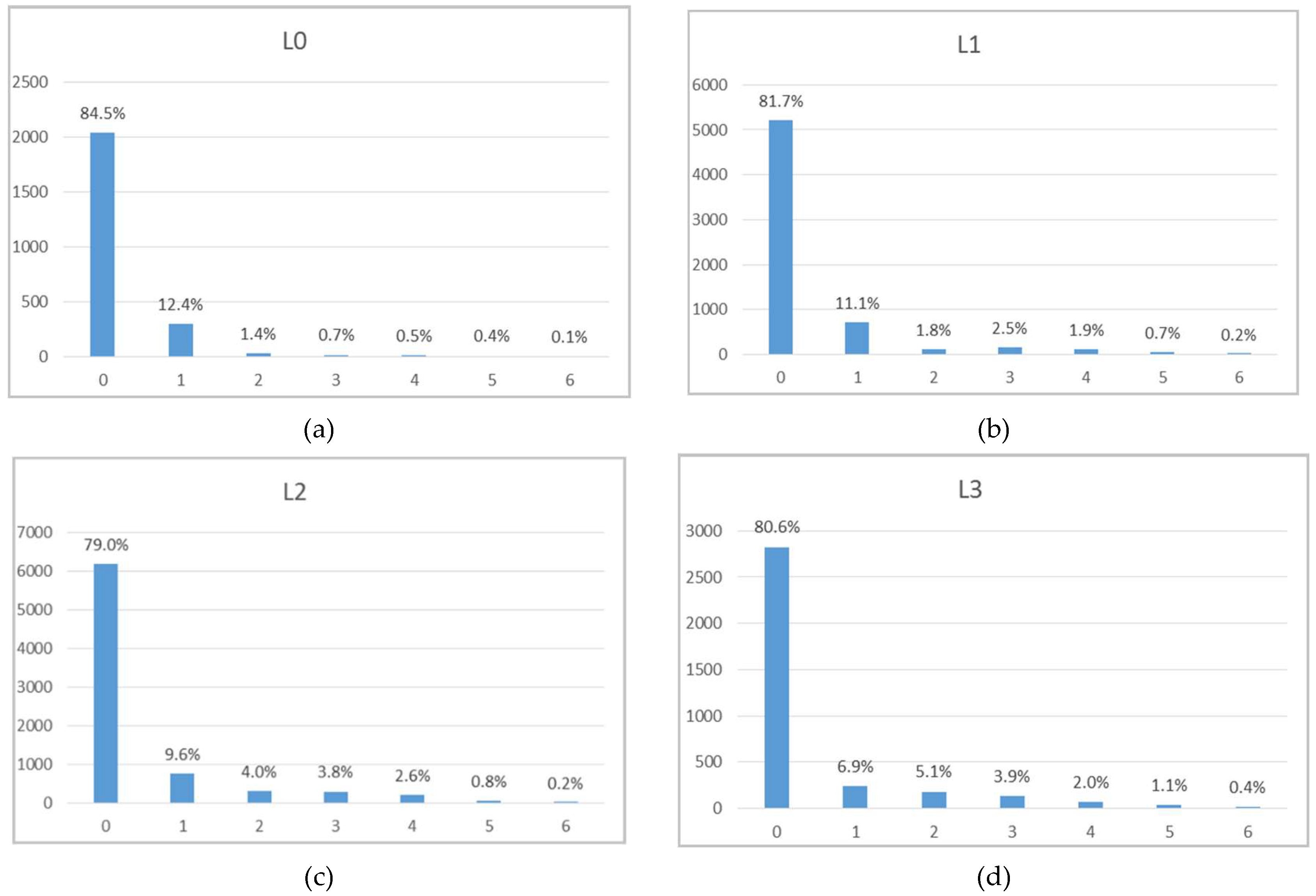
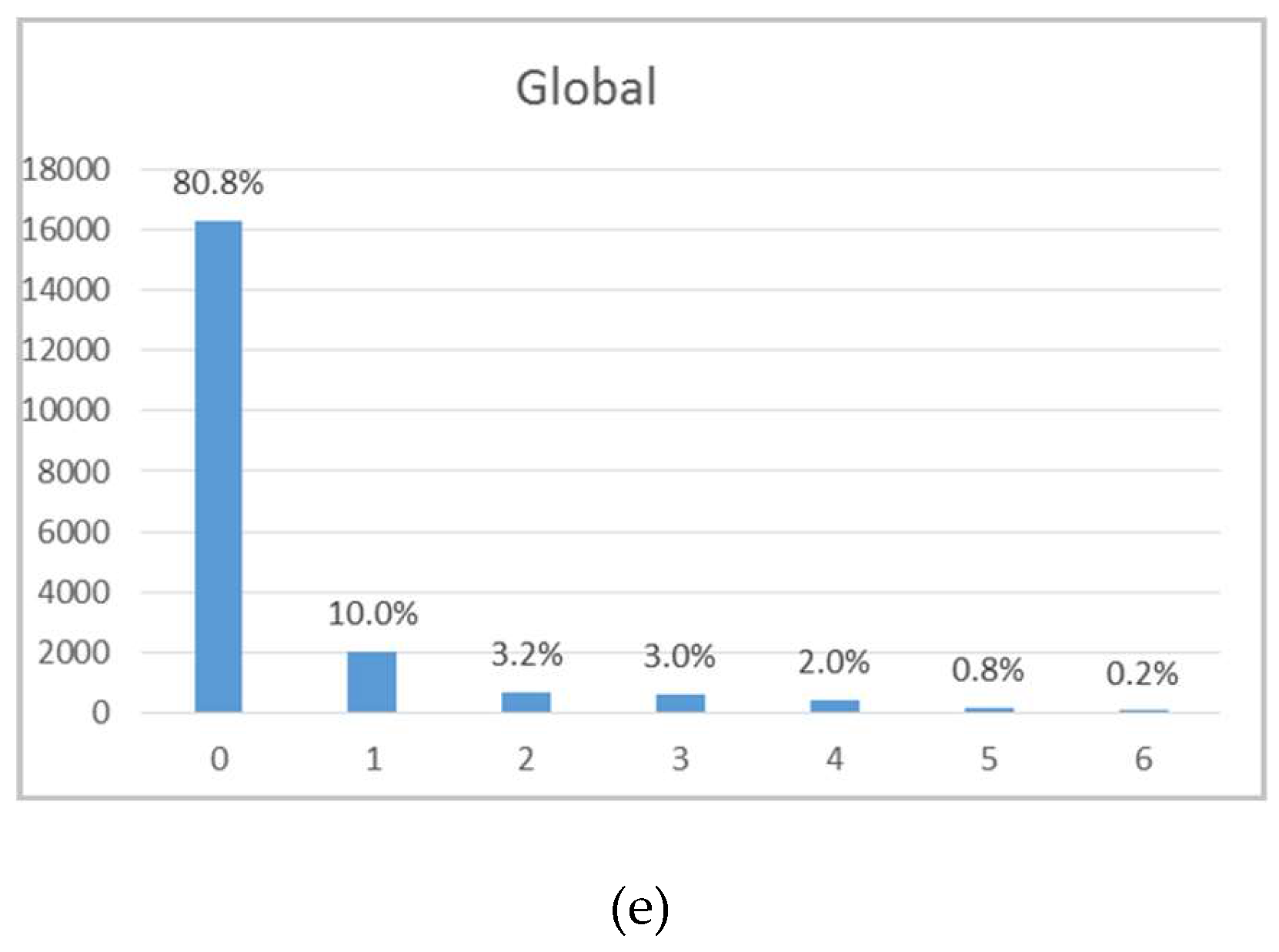
The univariate statistical analysis of the variables showed the following: (i) There is an obvious sampling bias, with the stope average VP being seven times greater than the borehole average VP; (ii) mine levels L1 and L2 are the richest in wolframite; and (iii) the majority of borehole modal WQ measurements belong to classes 0 and 1, representing low wolframite contents.
The high bias identified in the stope-derived VP variable can be explained in terms of the fact that stoping operations follow the presence of veins. On the other hand, the sampling in the boreholes is conducted continuously along/down each borehole, meaning that the data are close to reality.
An initial study of the stope and borehole vein proportion variables helped to establish that the VP simulation needs to be conditioned to the stope data (hard data) and the spatial structure of those data, to the ungrouped borehole statistics, and to the borehole data, as local means in a 50 m × 50 m × 30 m grid (soft data).
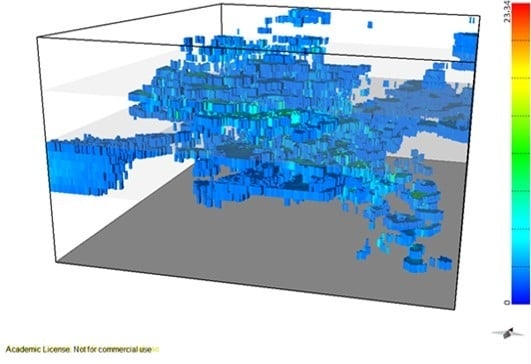
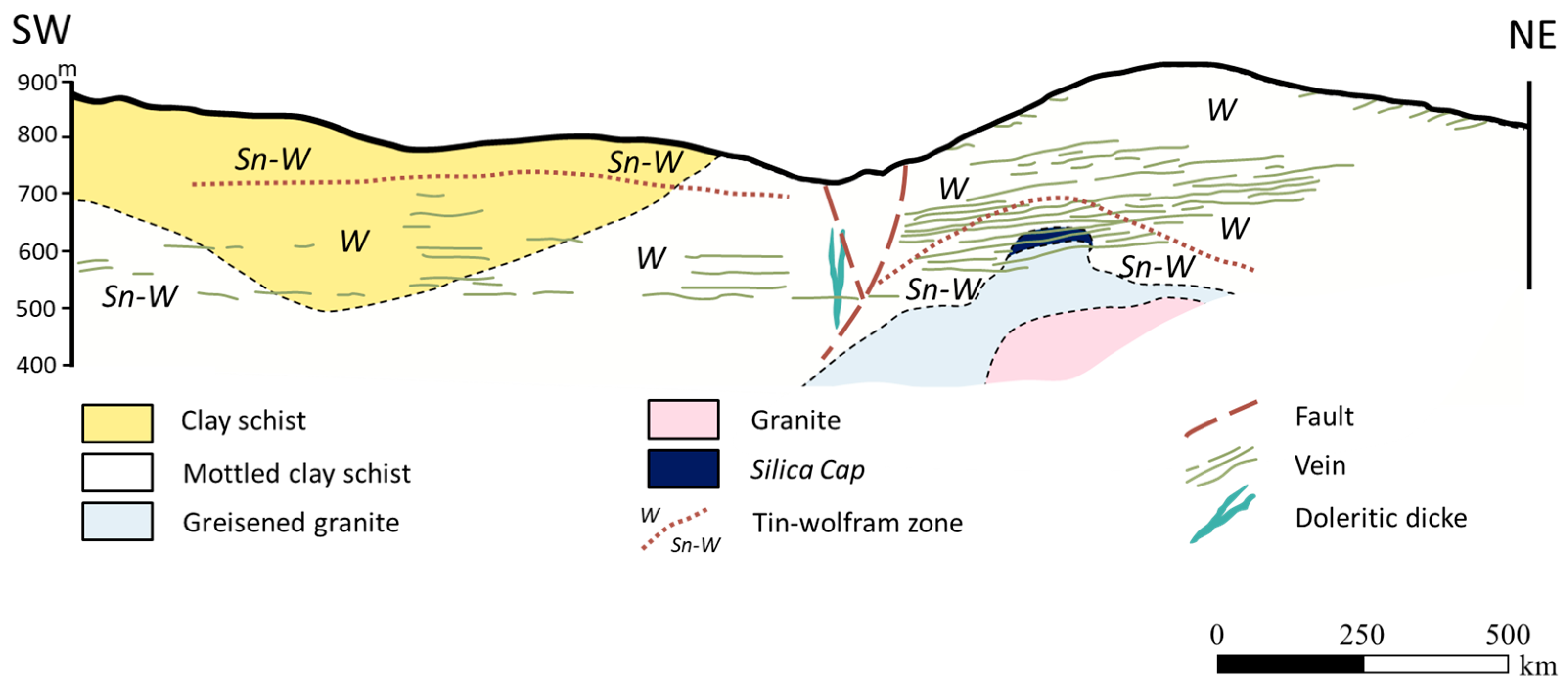
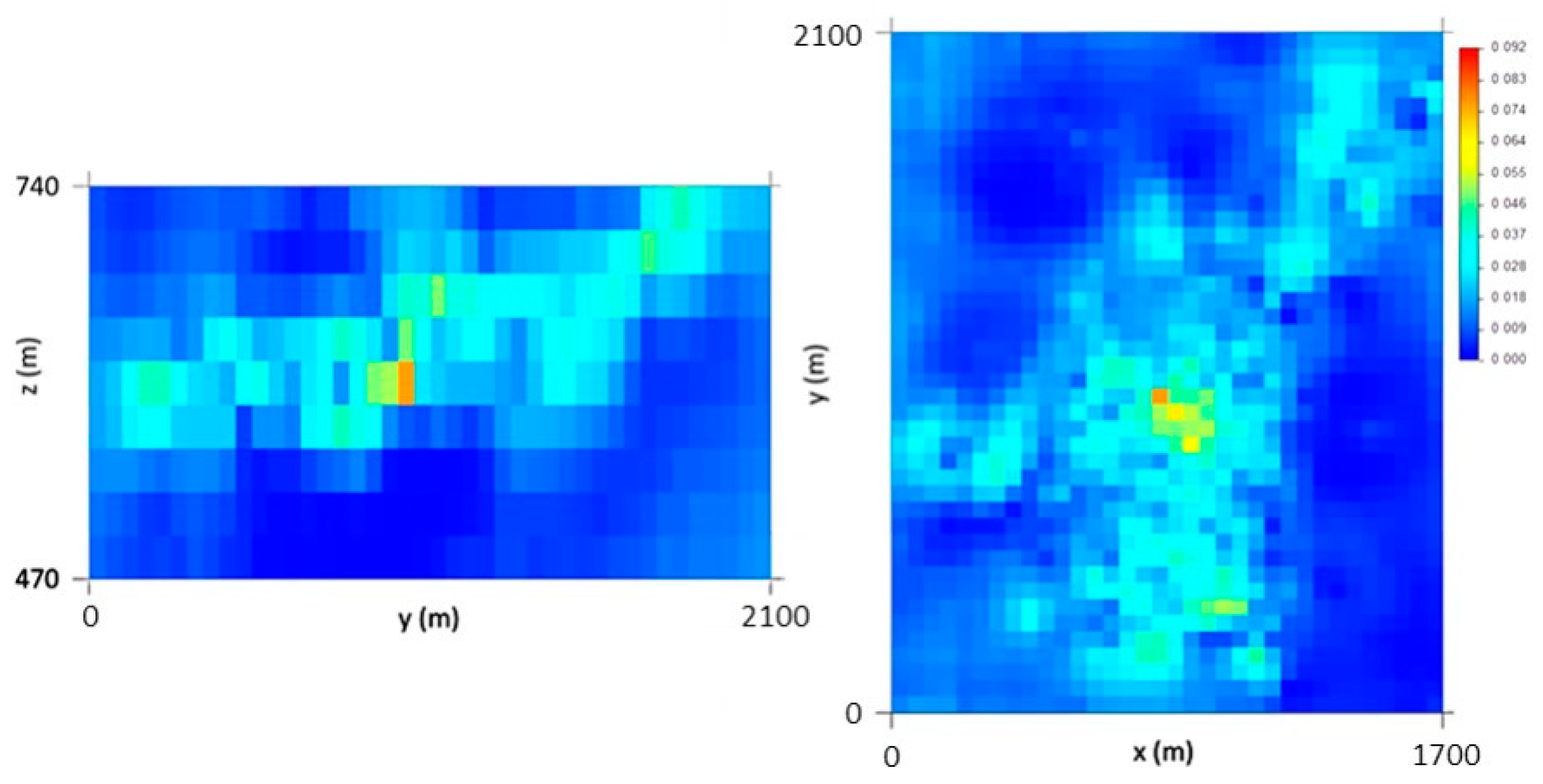
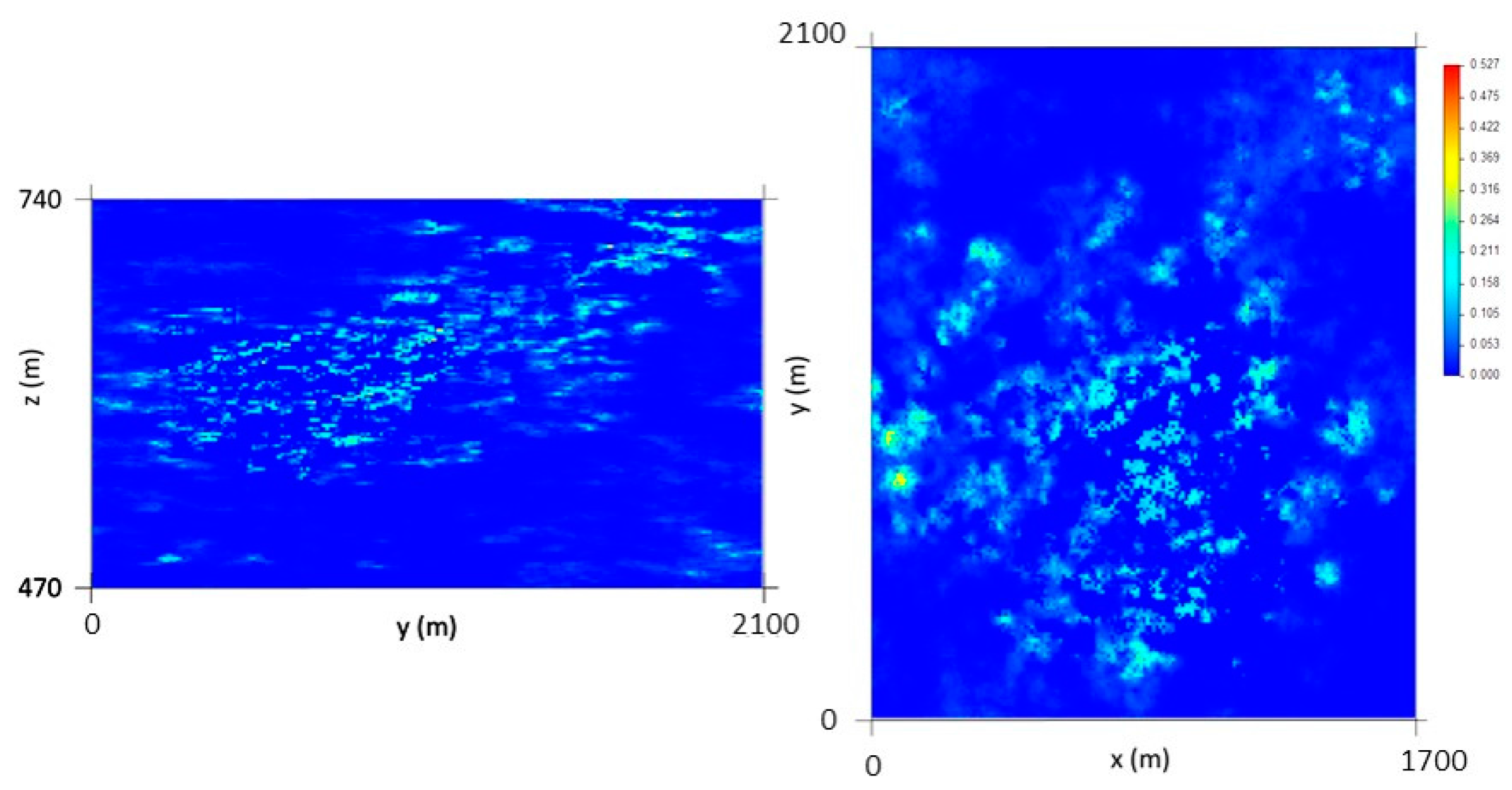
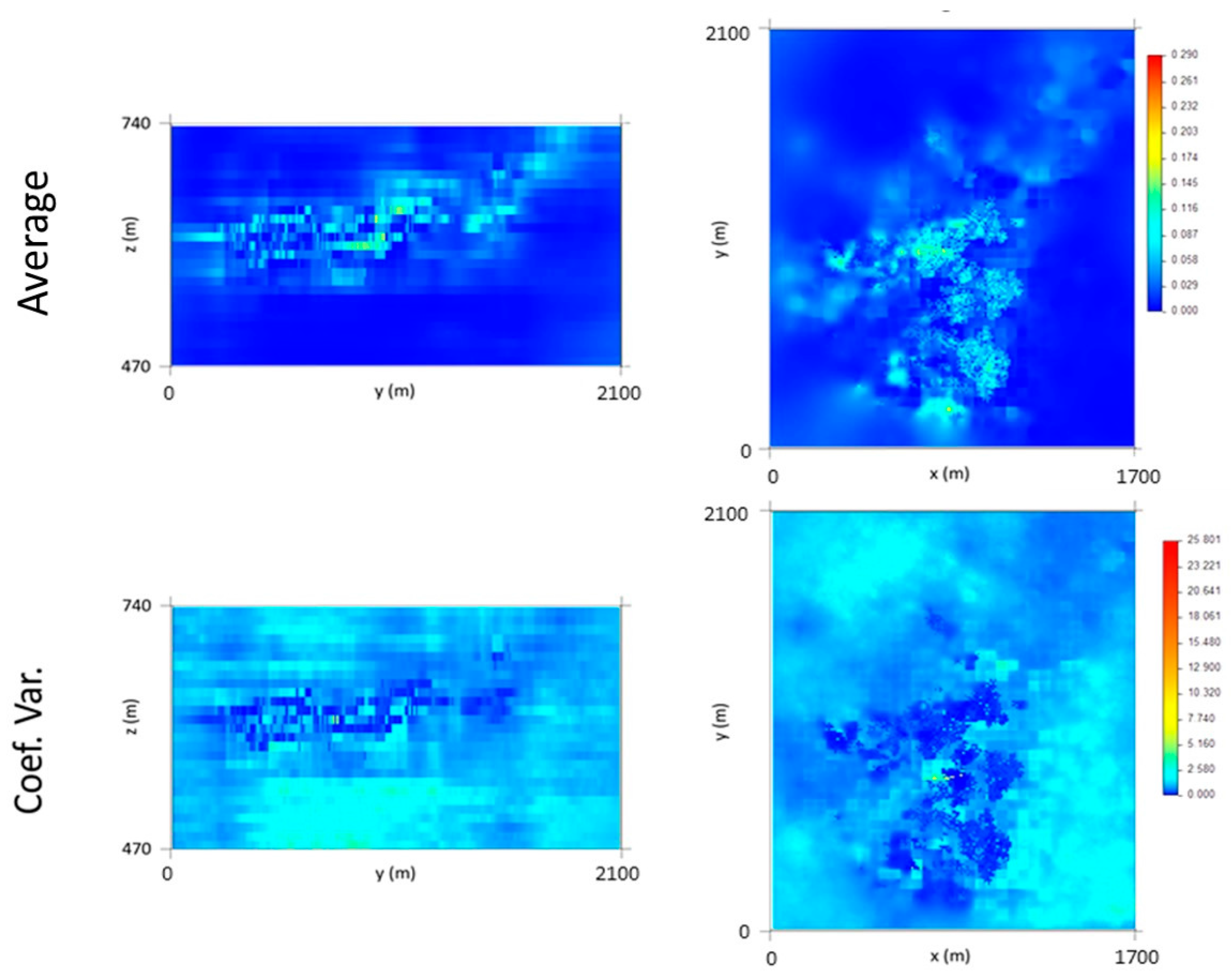
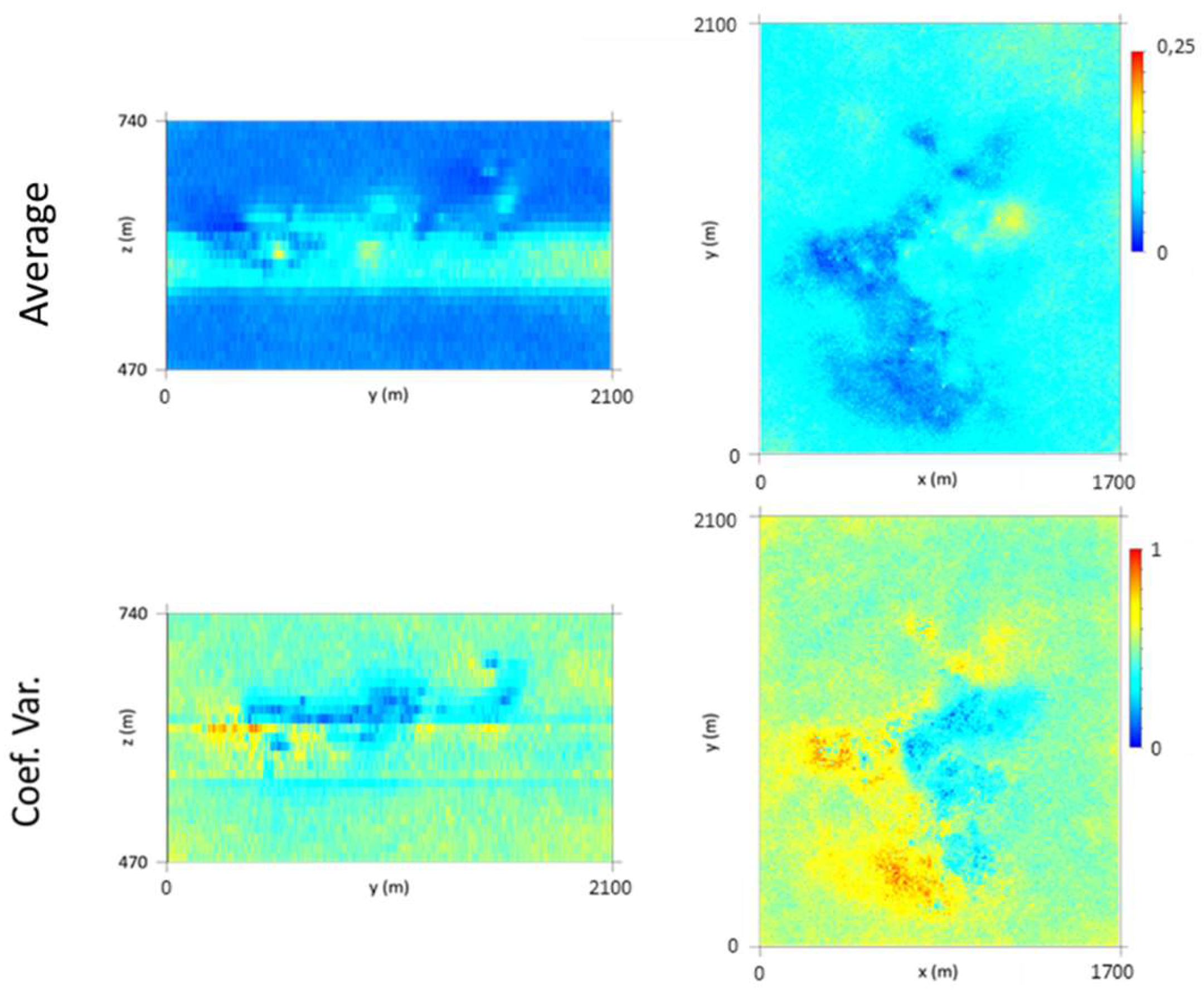
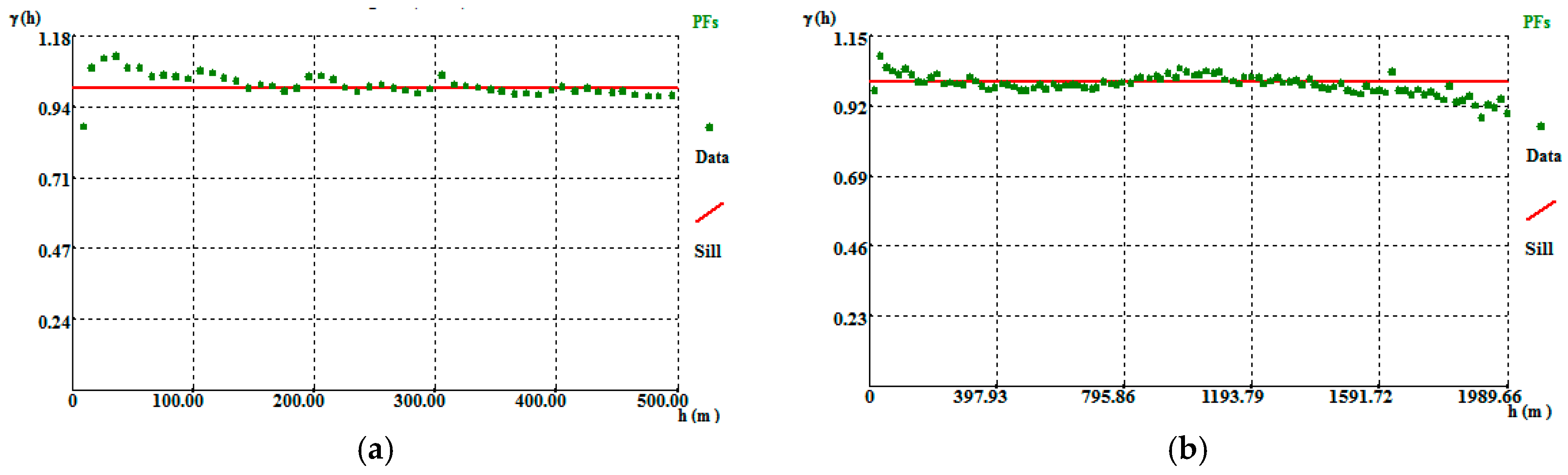
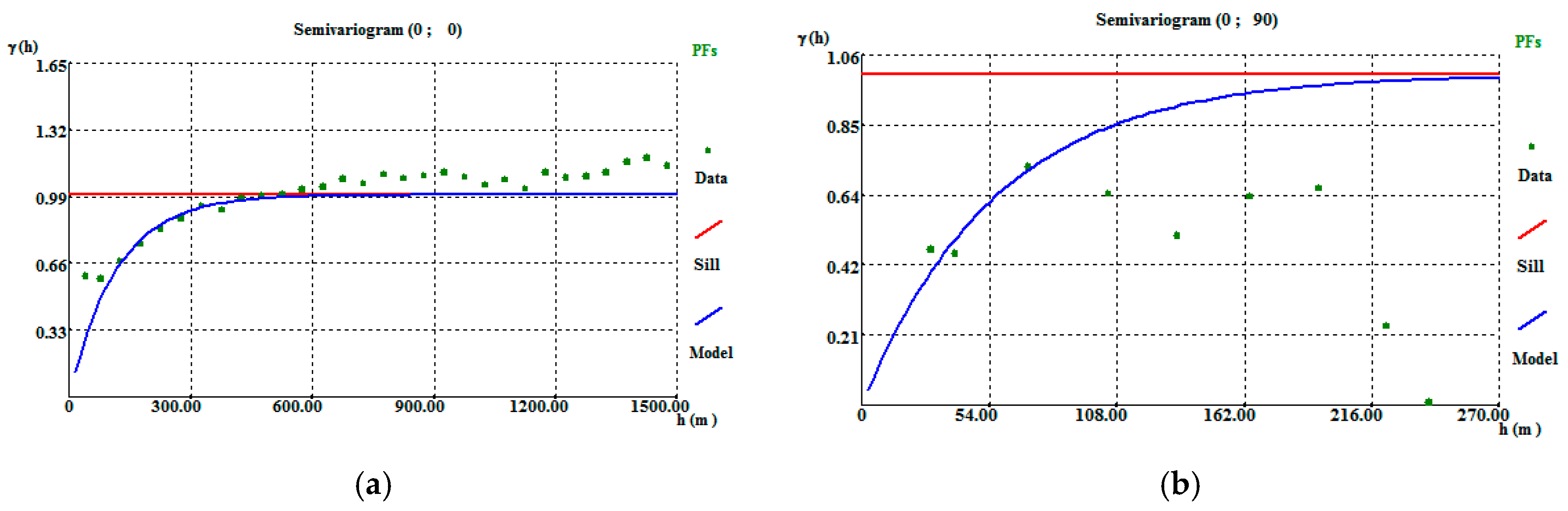
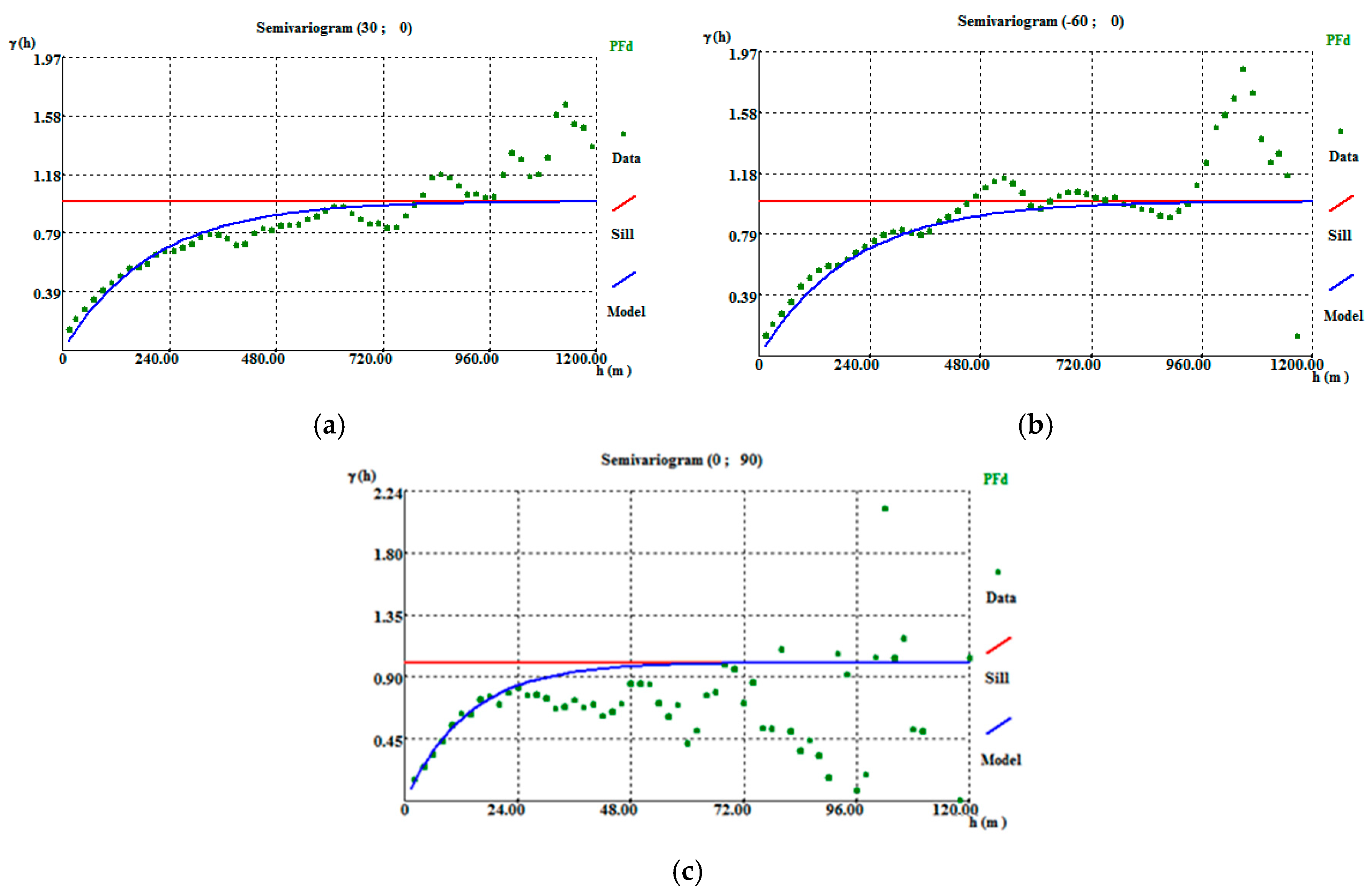
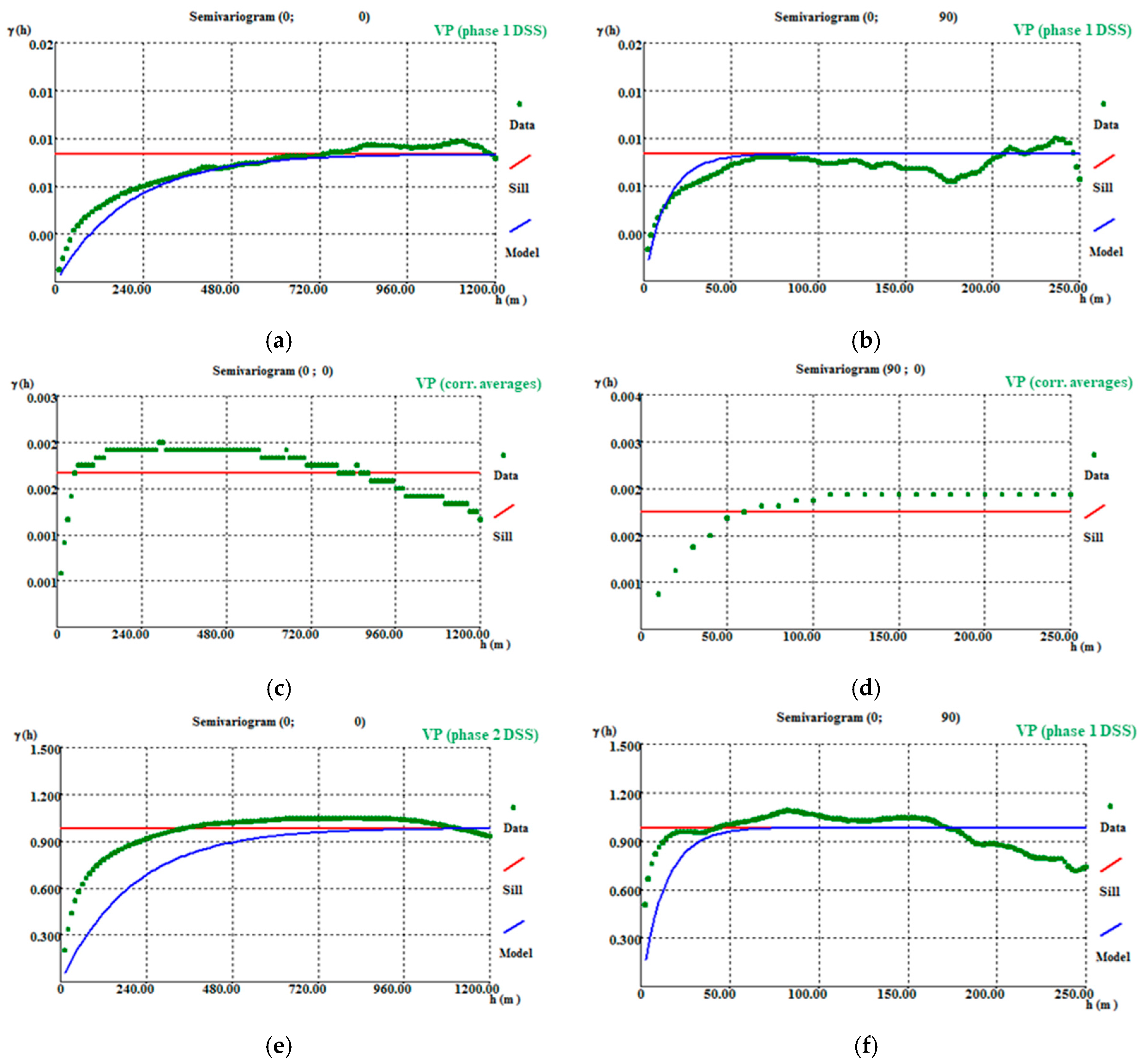
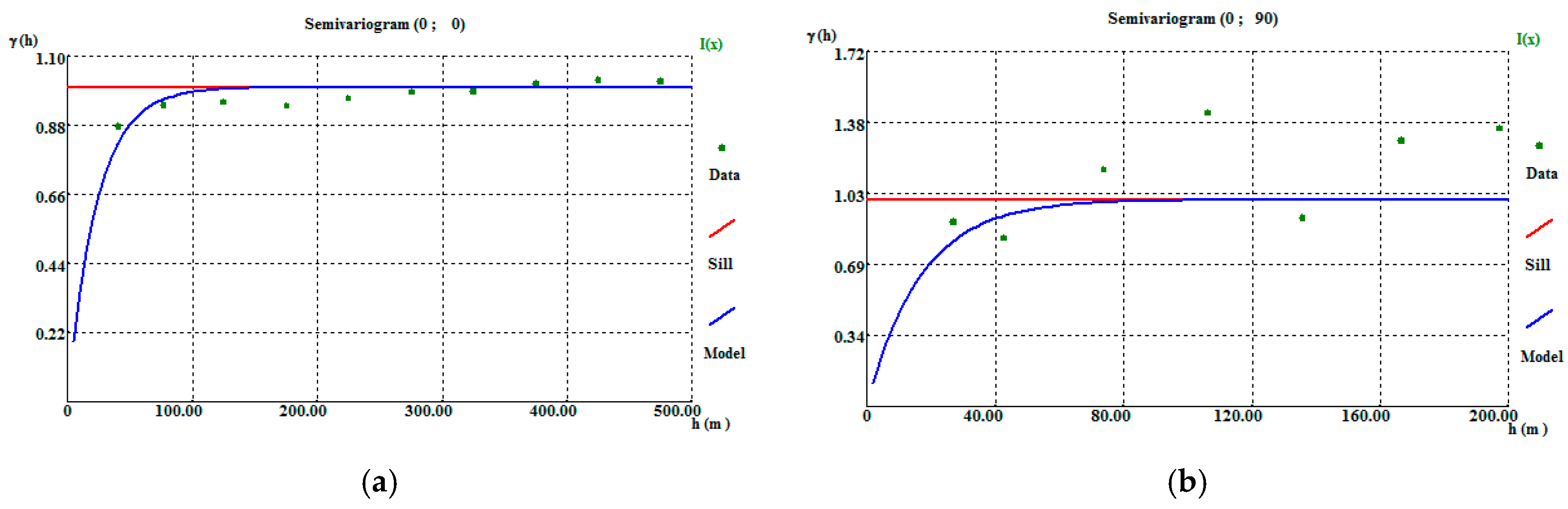
The final morphology model allows the following conclusions to be made: (i) The thickest zone of the deposit is found in the central part of the modelled region, corresponding to levels L1 and L2; (ii) The local uncertainty is higher in the peripheral parts of the modelled deposit, as expected, and zero in the stope location. There are some local high values of CV, explained in terms of the occurrence of very dissimilar values in close proximity within zones of high sampling density; and (iii) The adjustments to output variograms in the different phases of the methodology present a discrepancy because the application of the correction of averages (in step 3) increases the data variance, distorting the variograms.
The VP data are concentrated in the central part of the model. The simulation extends beyond the stope data where the borehole-derived data exhibit low or null values, so the methodology simulates values that, in these peripheral parts of the model, tend to be lower.
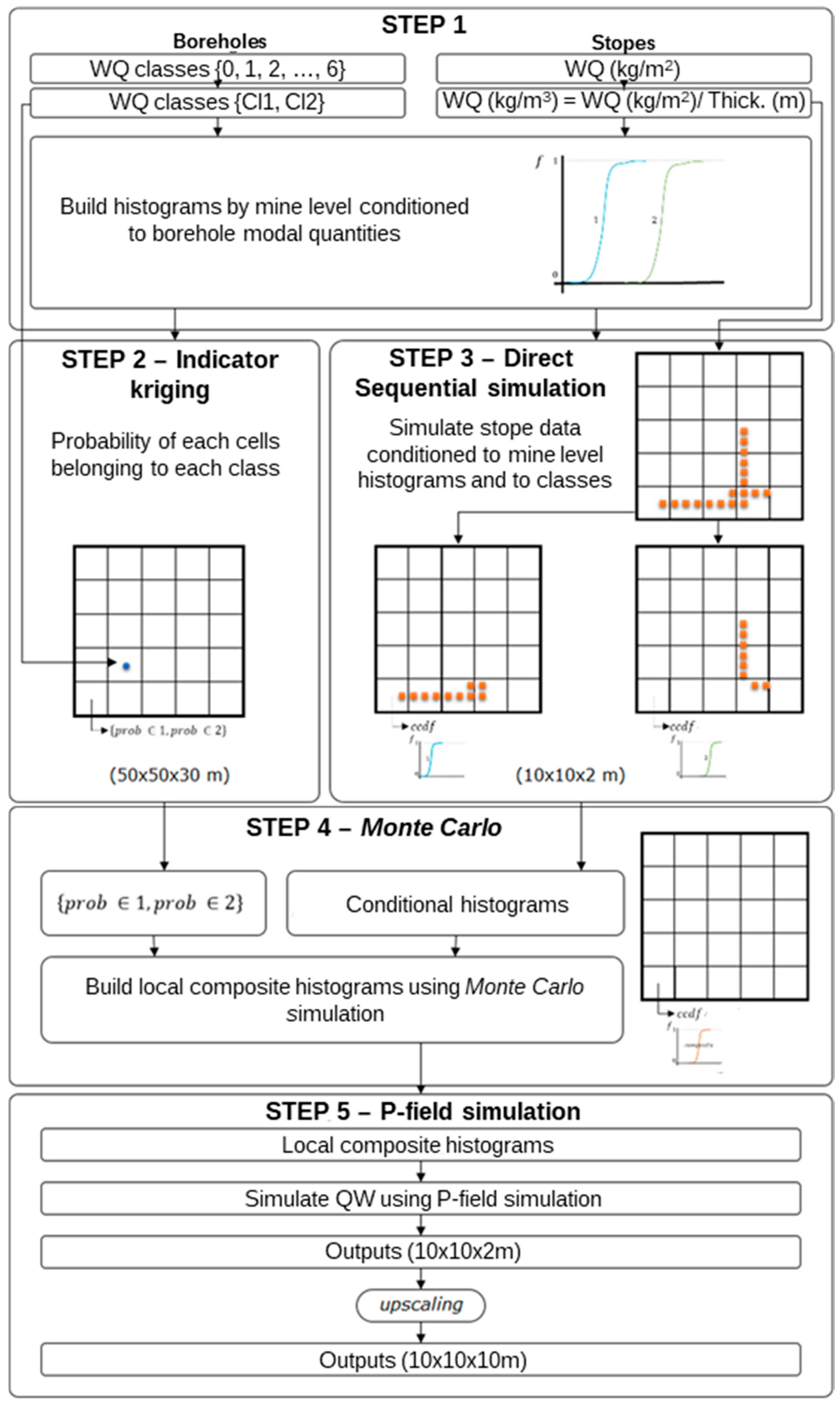
Contrary to the initial information of the morphology model, the WQ variables are distinct, being continuous in stopes and modal in boreholes, and it was necessary to formulate an appropriate methodology, establishing the objective of simulating WQ conditioned to the data measured in stopes (hard data) and to the wolframite classes reported in boreholes (soft data).
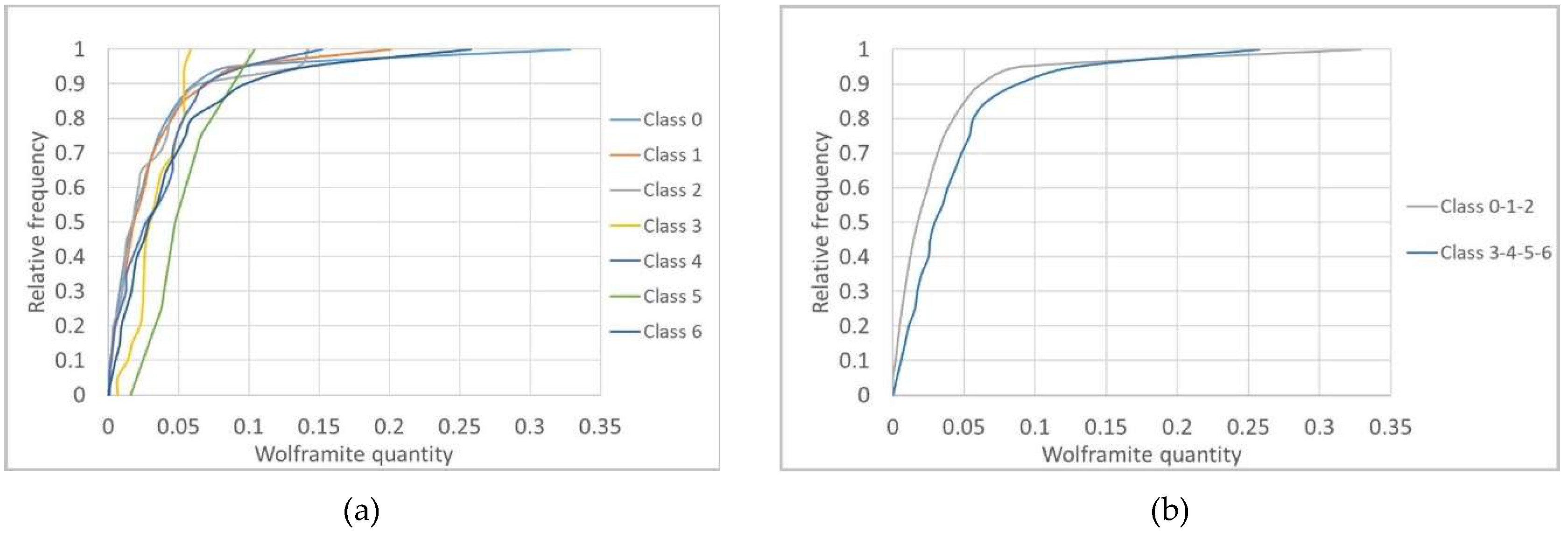
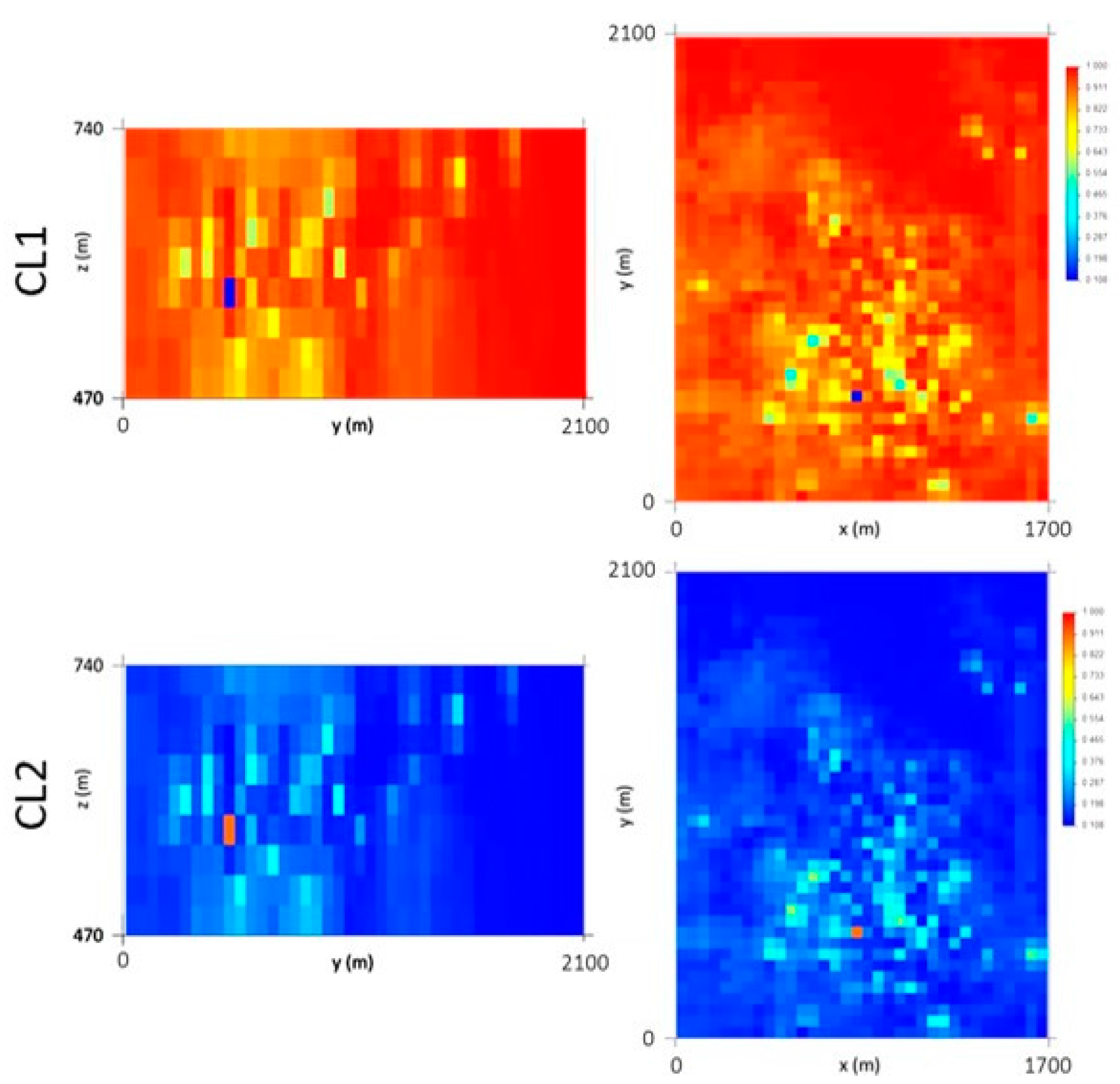
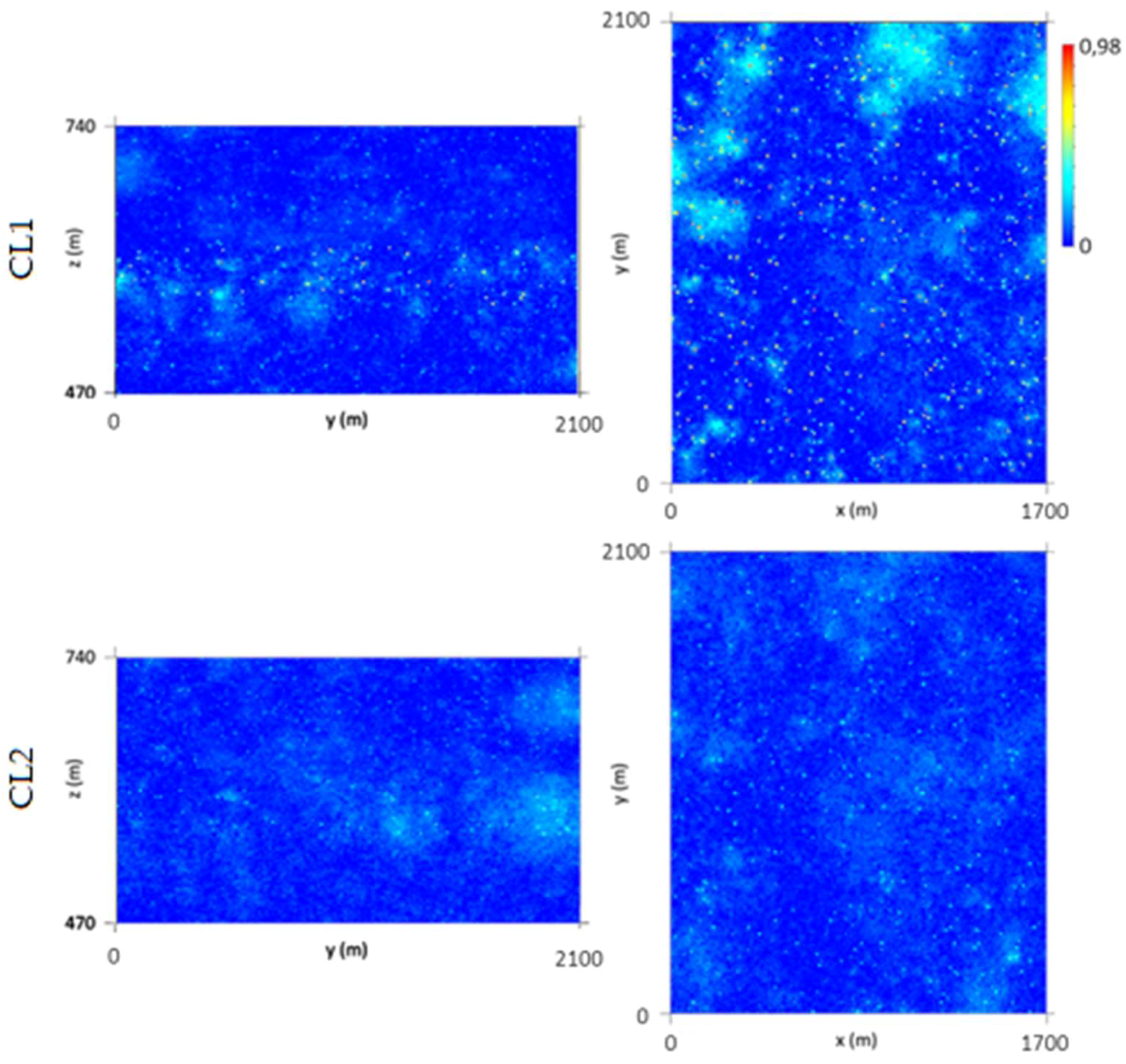
The primary and secondary data are not co-located, so it was necessary to cross the information by proximity. As there were too many borehole wolframite classes with poor discrimination, the seven classes were grouped into two classes, corresponding to low quantity, CL1 {0, 1, 2}, and to high quantity, CL2 {3, 4, 5, 6}, for each of the four mine levels. The discrimination of the classes is reasonable in levels L0 and L3 and non-existent in levels L1 and L2.
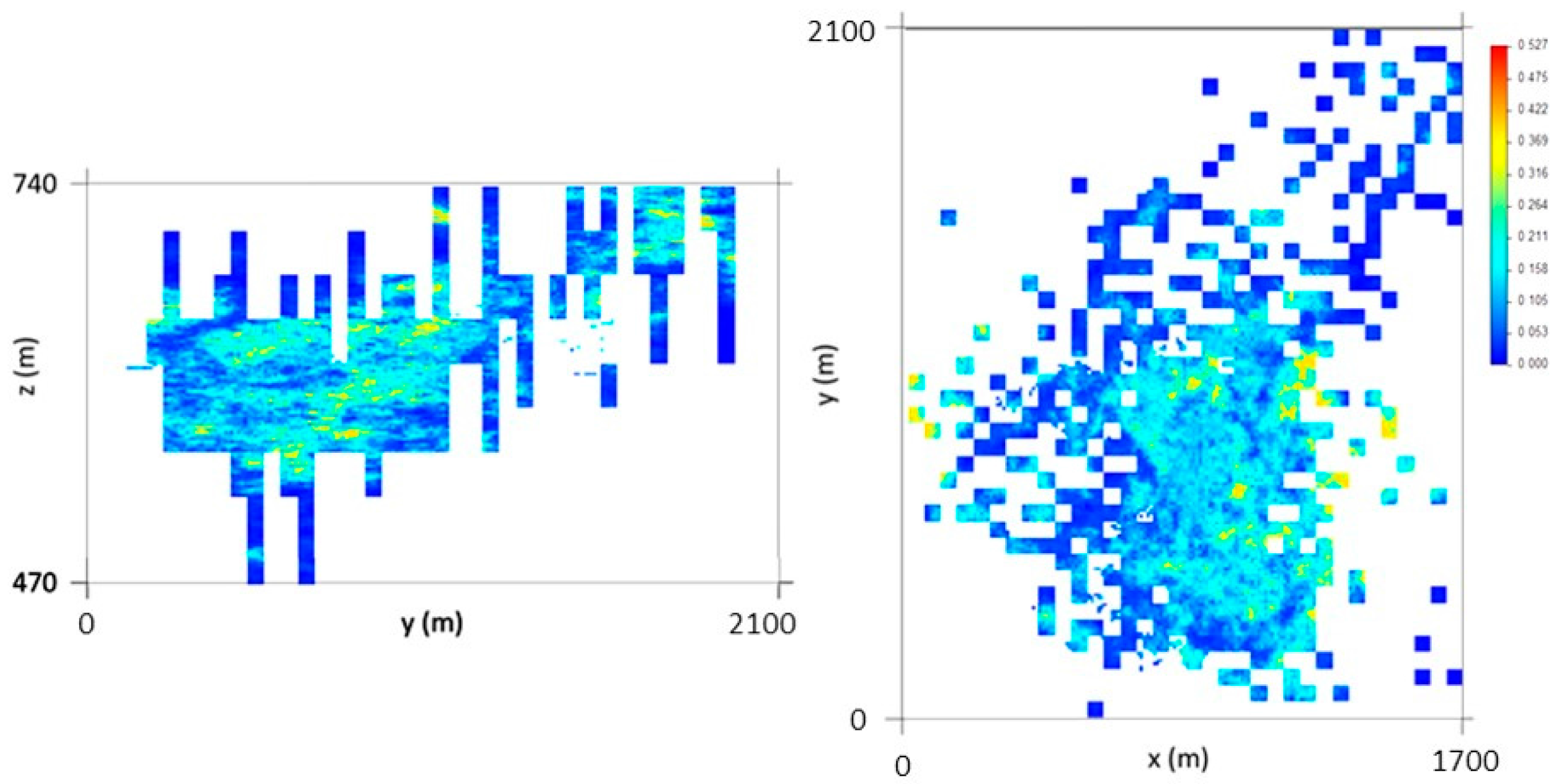
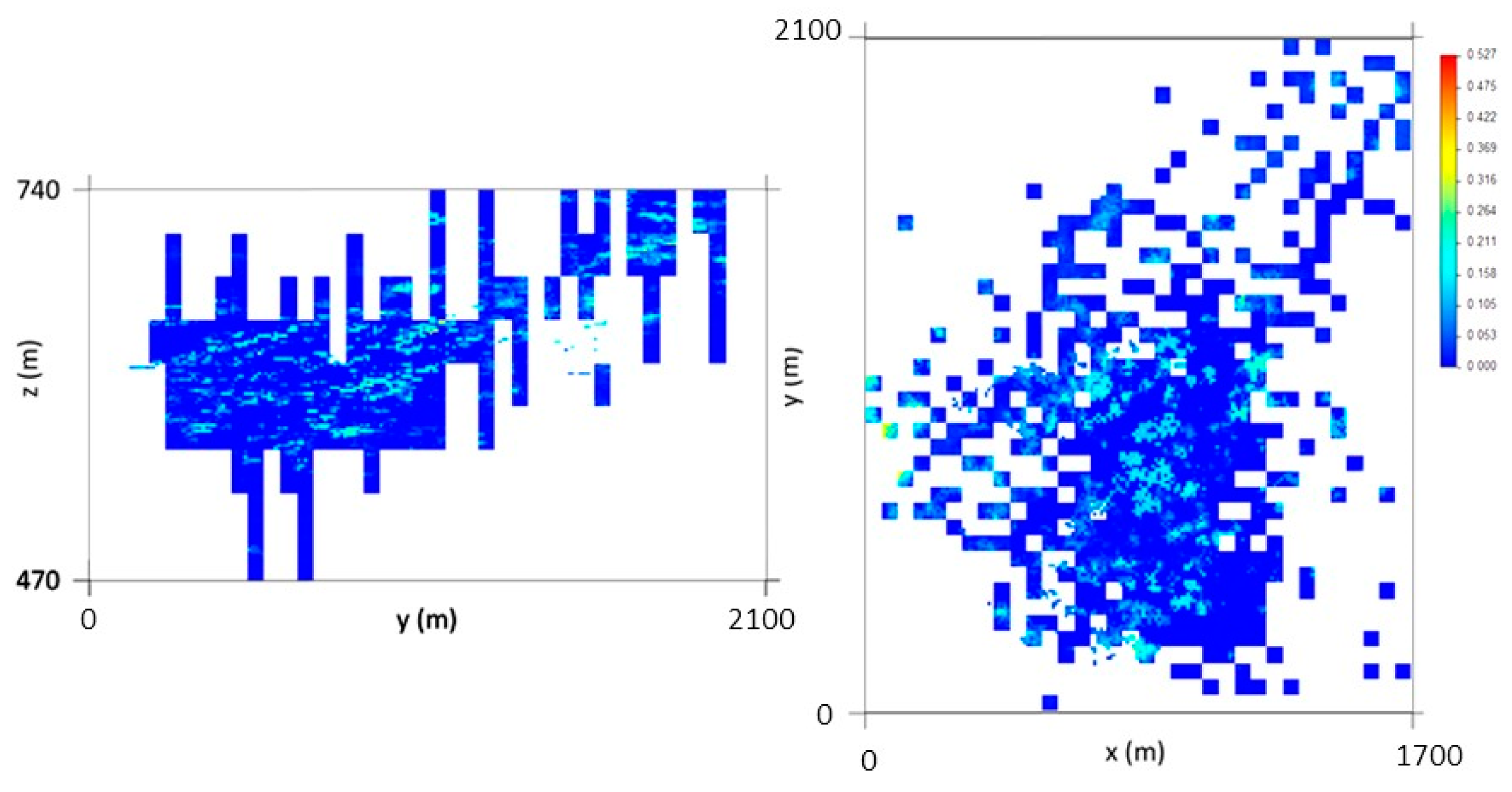
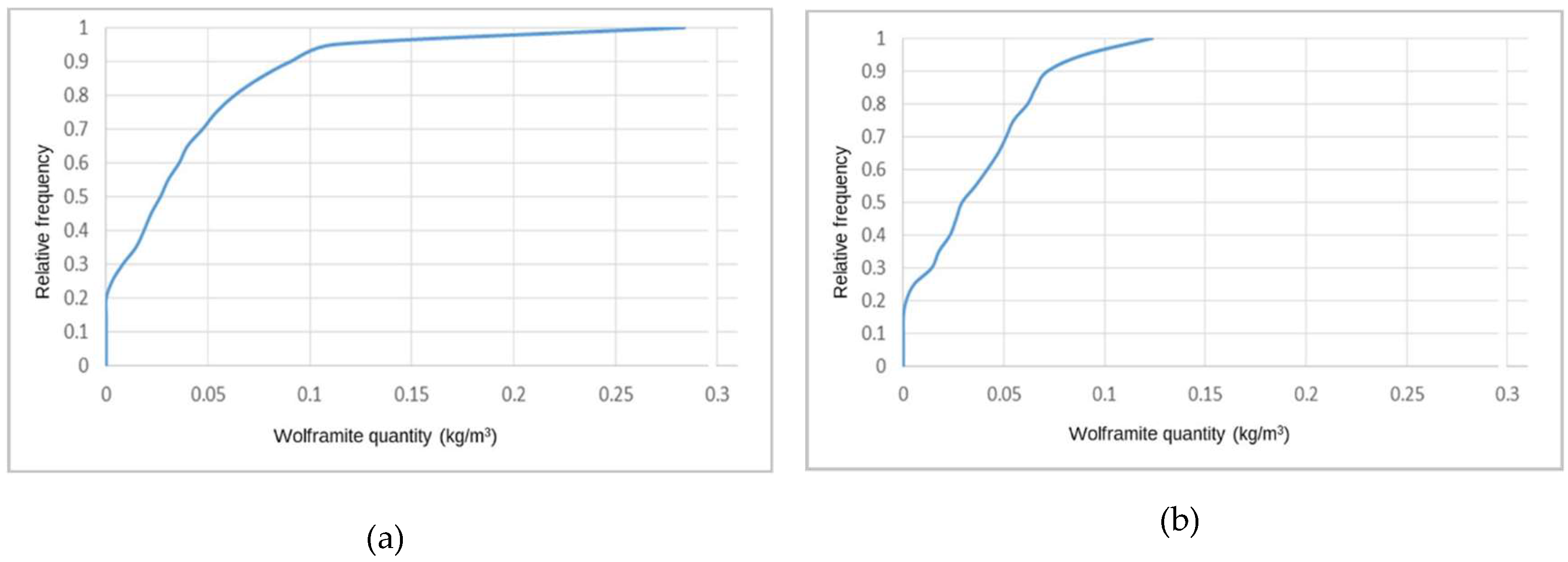
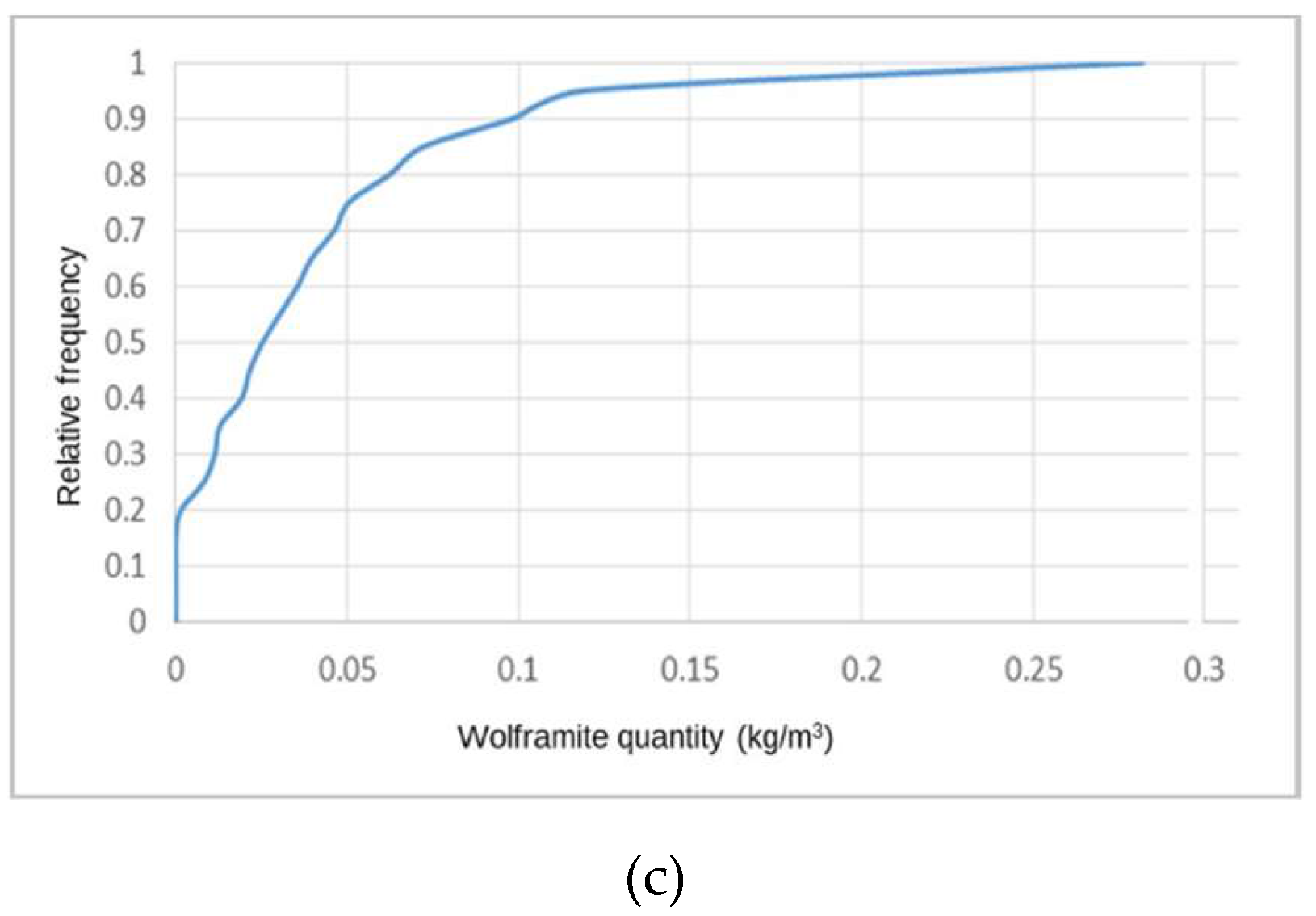
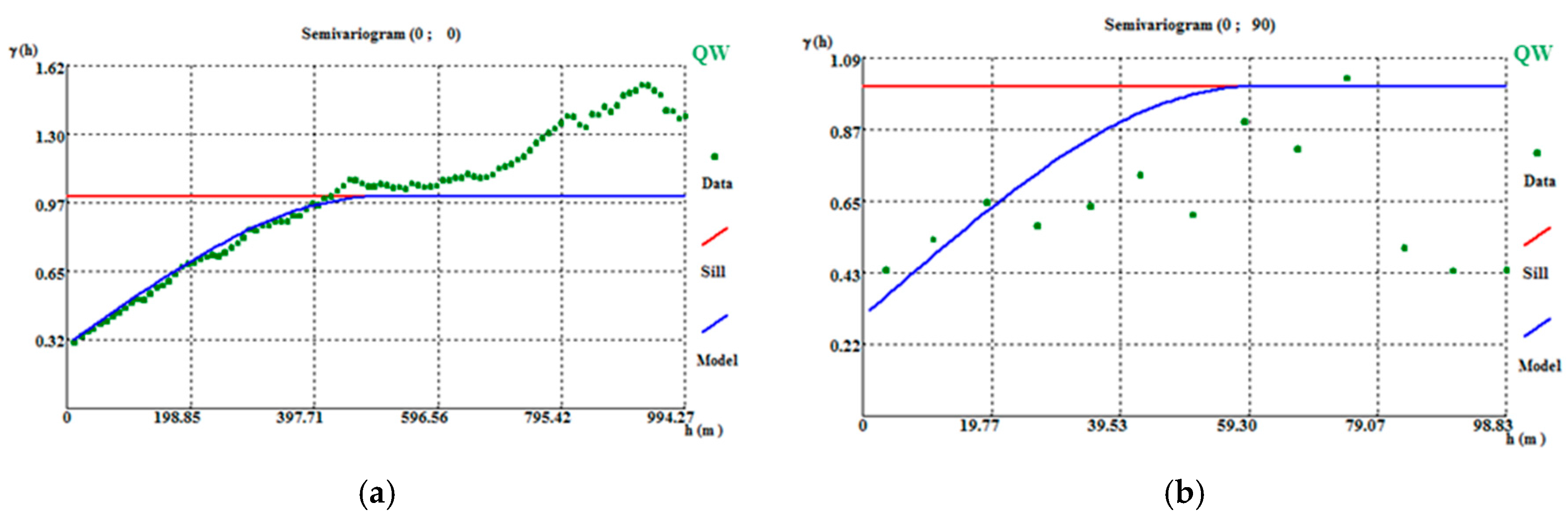
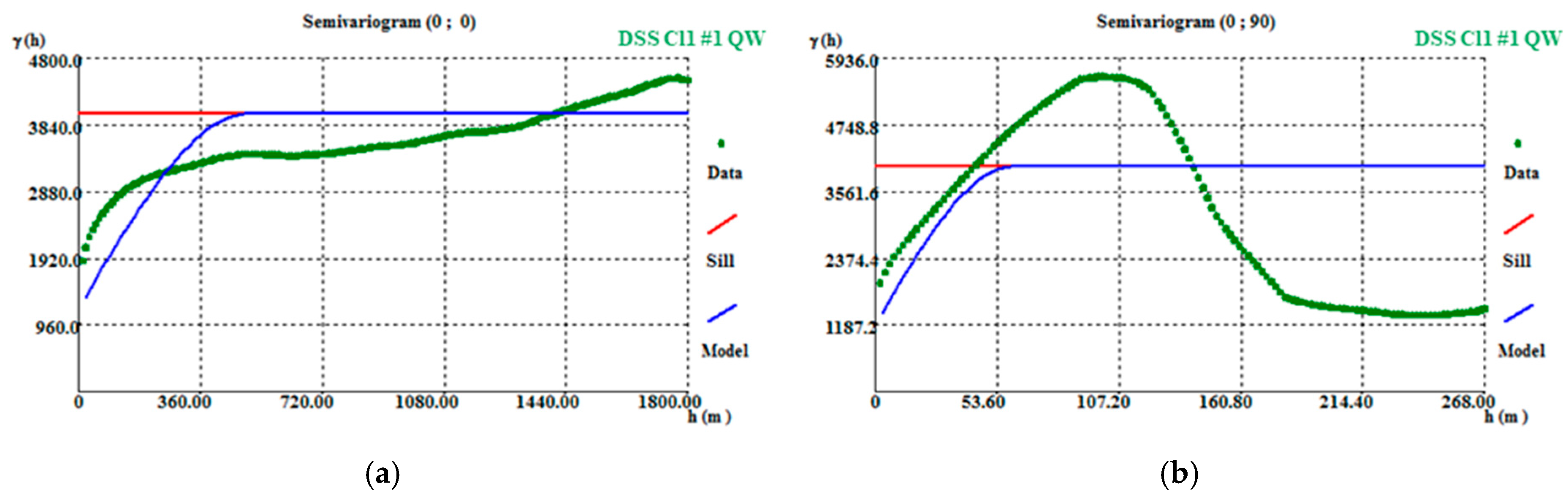
The simulated WQ variograms are similar to the variograms for the initial data, with small discrepancies because the WQ variograms are calculated and adjusted for the total data set and the WQ simulation is conditional to CL1 and CL2 and uses split data sets. The simulation also influences the final statistics, as the probability of belonging to each class estimation has a degradational effect in the data that is more pronounced in the peripheral zones of the model, where the stope wolframite quantities are lower, generating more accentuated left-skewed distribution laws.
By conditioning the WQ simulation to histograms by mine level, the results are more consistent, mainly because many of the simulated regions are located far from stopes and there is a clear segregation of WQ with depth.
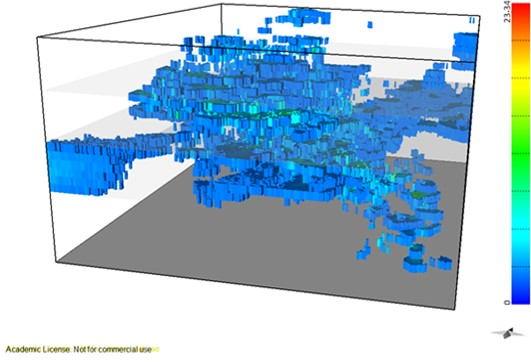
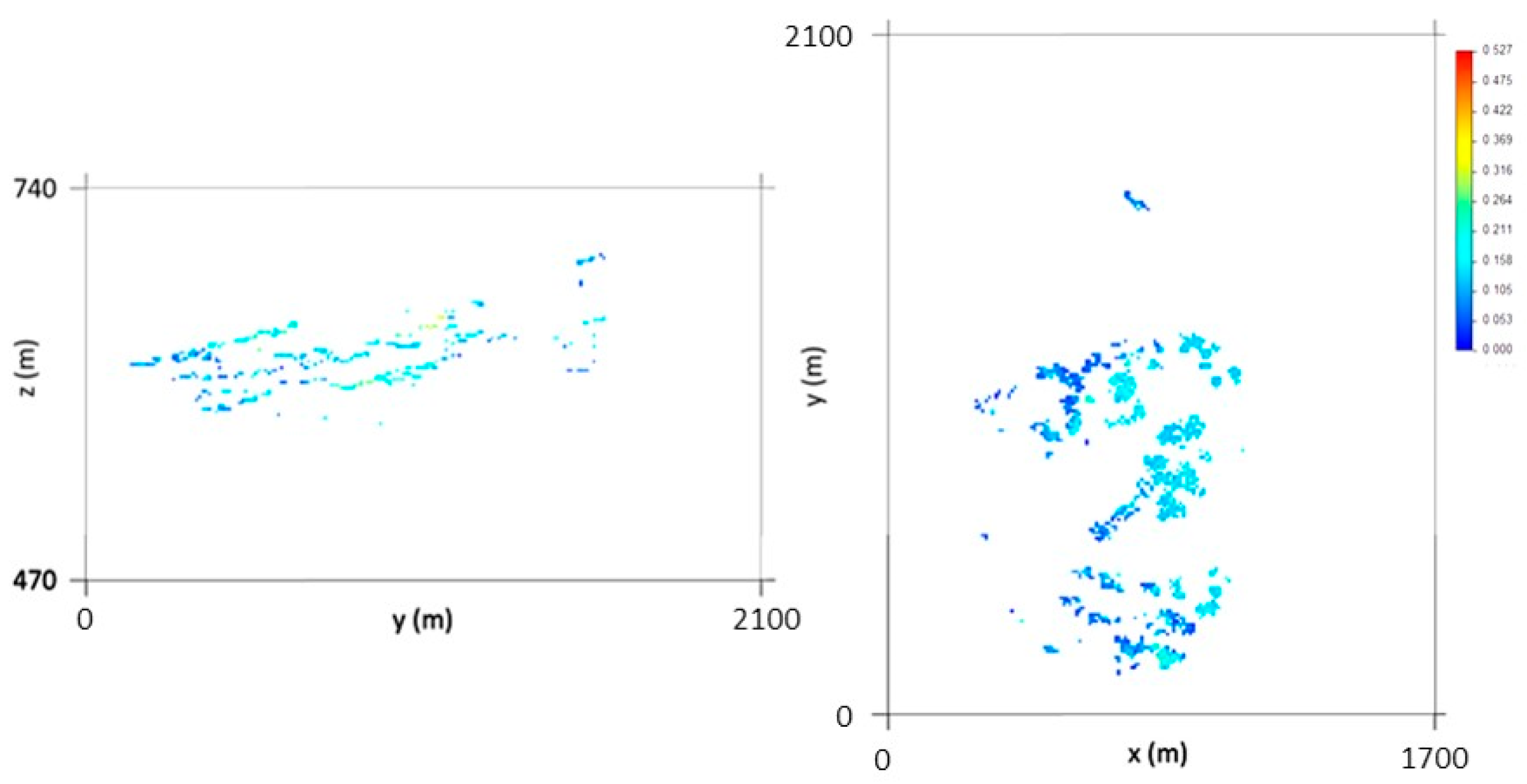
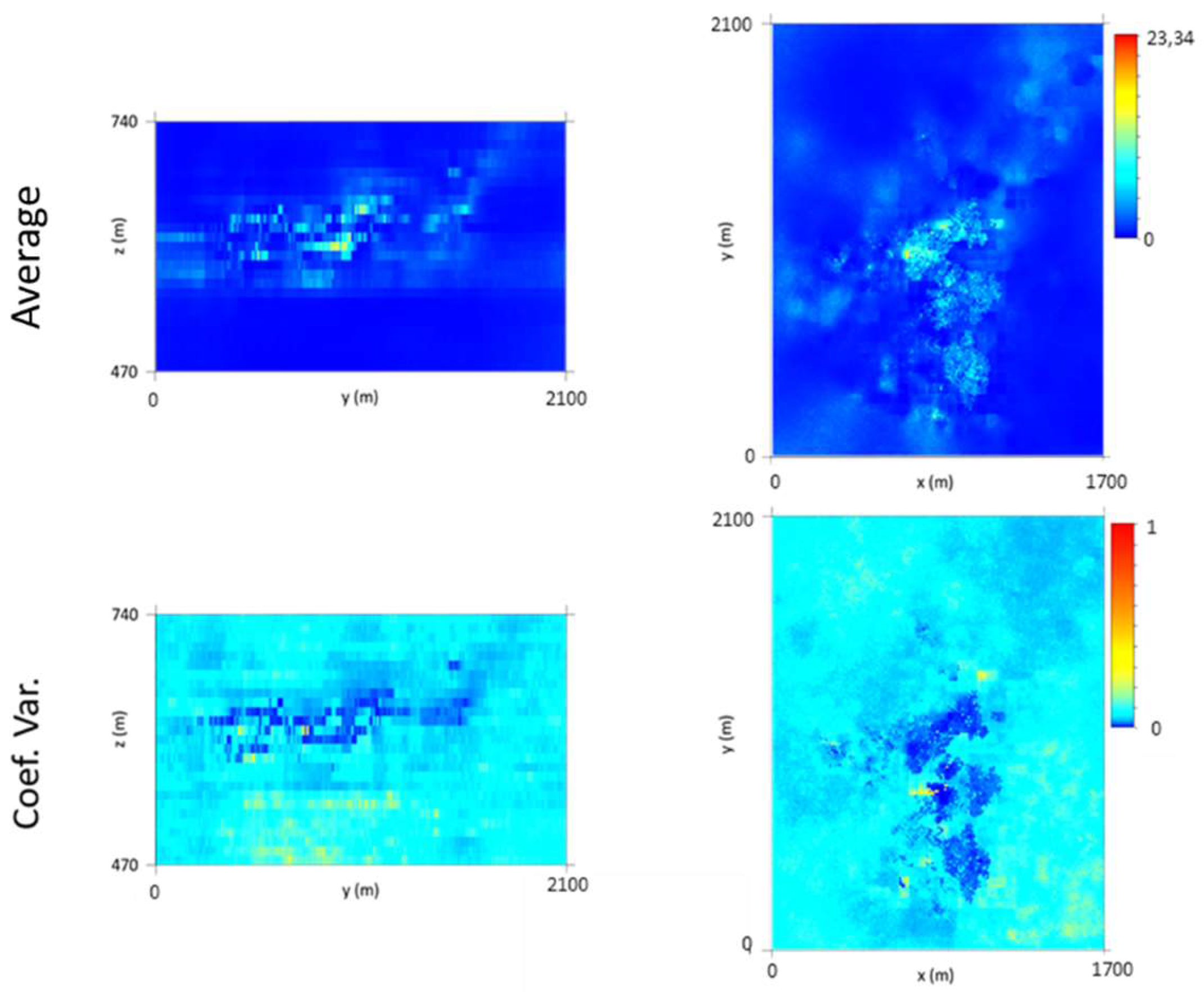
The final wolframite content model allows the following conclusions to be made: (i) The richest part of the modelled deposit corresponds to level L2, followed by L1. (ii) The model uncertainty behavior is similar to that of the morphology model. However, a region of high dispersion is evident in level L2 (in the southwestern part of the deposit), where wide discrepancies exist between neighboring values, forcing the simulation to generate different values between each scenario.
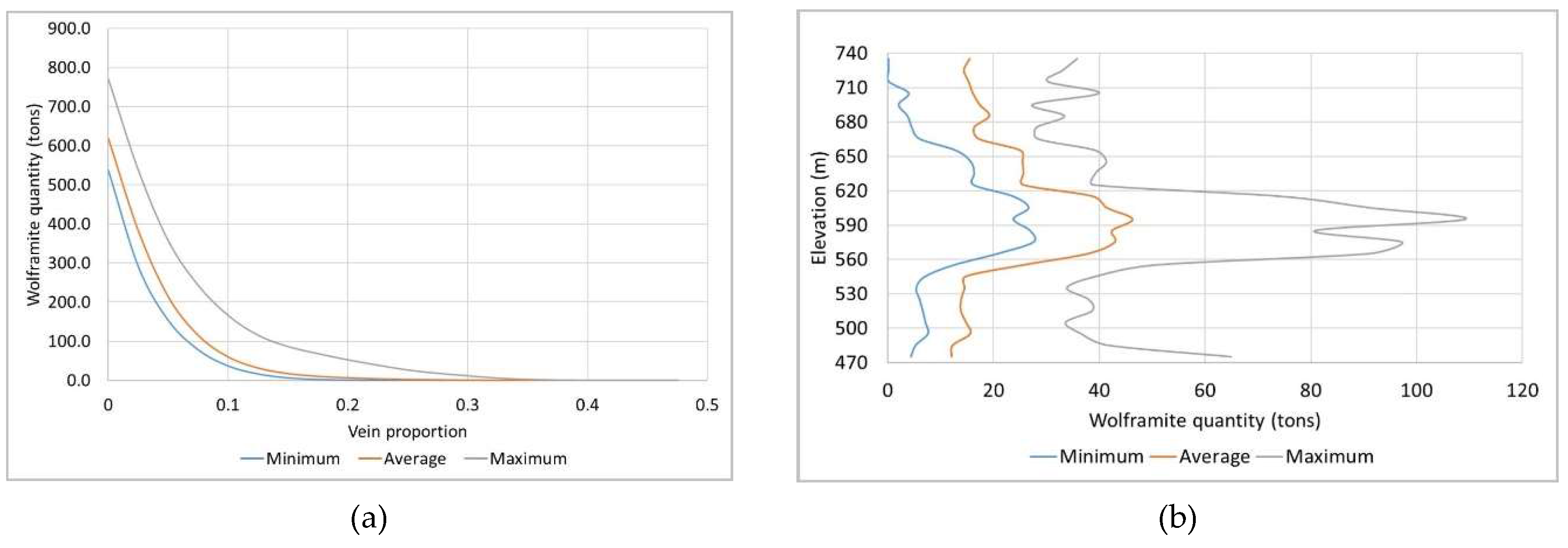
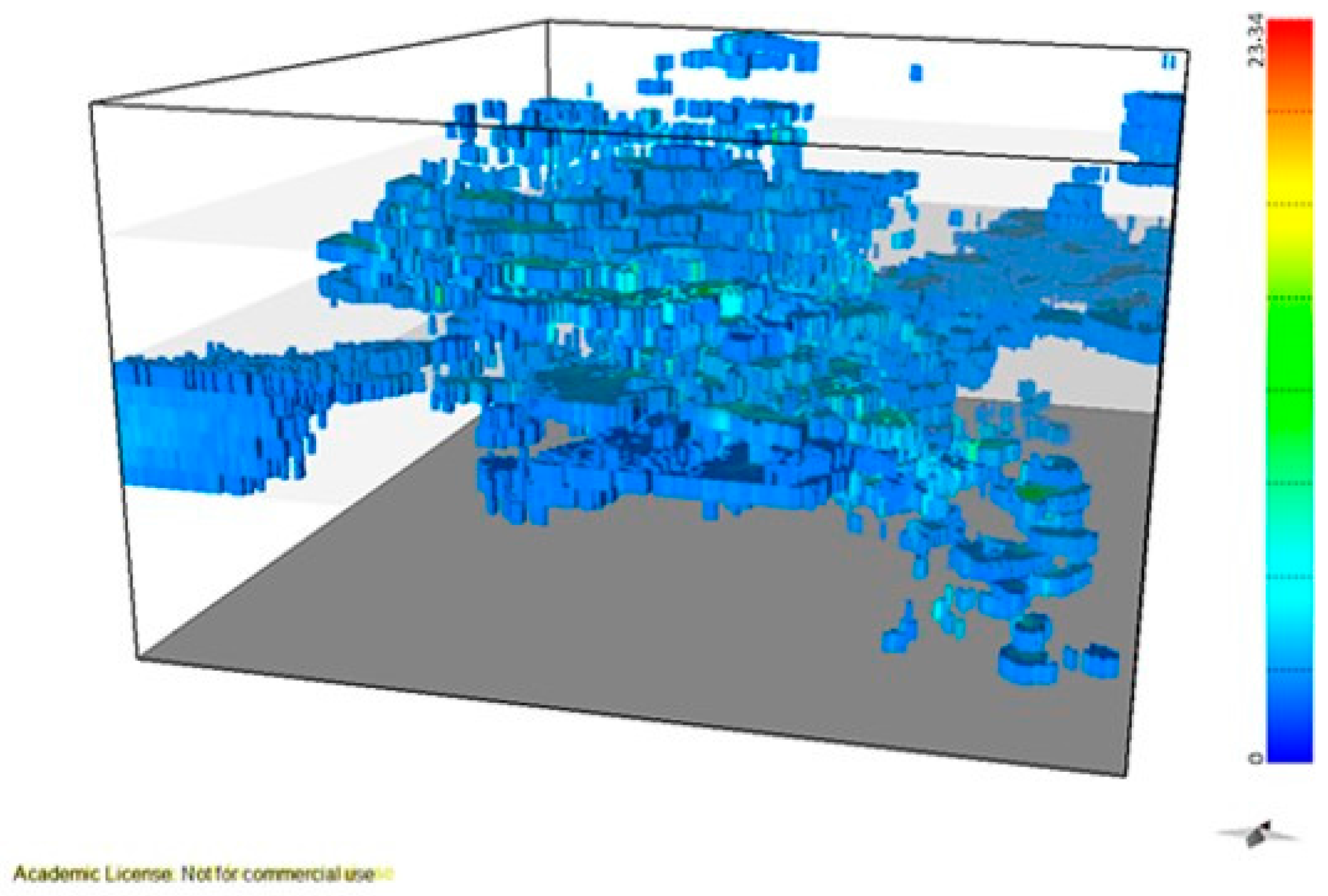
Finally, crossing the two independent models allowed the wolframite resource to be quantified. The results show that: (i) The richest part of the modelled deposit corresponds to levels L1 and L2 (the central part of the model); (ii) the estimated mineral potential of the deposit is 618.47 tons, with the optimistic scenario being 769.73 tons and the pessimistic scenario being 537.19 tons; and (iii) the variation in WQ by elevation indicates that the richest level is L2, supporting the interpretations of the wolframite content model.
Although the proposed methodology involves many steps and combinations of results, this study has shown that the implementation of the methodology to a deposit being mined is feasible and does not require huge computational effort, if the proposed procedures are chained as scripts. DSS simulations are quick procedures and depend only on the total number of cells of the model and the amount of available data. To give an idea of the computational effort, the DSS of a variable in the higher-resolution grid used in this study, involving almost 5 million blocks, represents about two minutes of computation per realization using a computer with an Intel® I7 processor.
5. Conclusions
This study is based on a decades-long exploited mineral vein deposit, with a unique pattern of sampling and data collection, where the problem is how to appropriately handle and analyze a large volume of data according to their various characteristics. The objective of this study was to establish a methodology for building a 3D geological model of a mineral vein deposit, combining stope data (vein thickness and wolframite quantity, WQ) and borehole data (vein thickness and wolframite modal classes).
The approach formulated here considered the initially identified sampling and data issues, allowing two independent models to be created, namely, a morphology model and a wolframite content model. All available information, comprising hard data (from stopes) and soft data (from boreholes), was used to build the models. As a final outcome, the potential of the mineral deposit was quantified by integrating the results of the two methodologies.
In the morphological model, the application of two-phase DSS is an innovative approach. Although the stope variograms are of high quality, the borehole data had to be declustered on a 50 m × 50 m × 30 m grid, being used as local means. The application of the methodology allowed us to conclude that zones of thicker mineral veins coincide with mine levels L1 and L2. In the model of wolframite quantity, the information from stopes and boreholes is not co-located, so a proximity study had to be conducted. The poor discrimination of WQ by borehole modal quantity classes revealed the need to group the classes. By crossing the two independent models, it was possible to quantify the mineral potential of the deposit, revealing that the richest zone corresponds to the central parts of the deposit.
The methodology proved to be very suitable for integrating data from different sources, namely, stopes and boreholes, and with distinct spatial biases. However, future work could include reviewing the borehole database, incorporating the local means correction into the DSS algorithm, and studying WQ in a more closely defined and smaller part of the deposit.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}






























