
An Advanced Decision Making Framework via Joint Utilization of Context-Dependent Data Envelopment Analysis and Sentimental Messages



Abstract
:1. Introduction
2. Literature Review
2.1. Applications of Numerical Information
2.2. Applications of Textual Information
3. Methodologies
3.1. Fuzzy Robust Principal Component Analysis: FRPCA
3.2. Stochastic Gradient Twin Support Vector Machine: SGTSVM
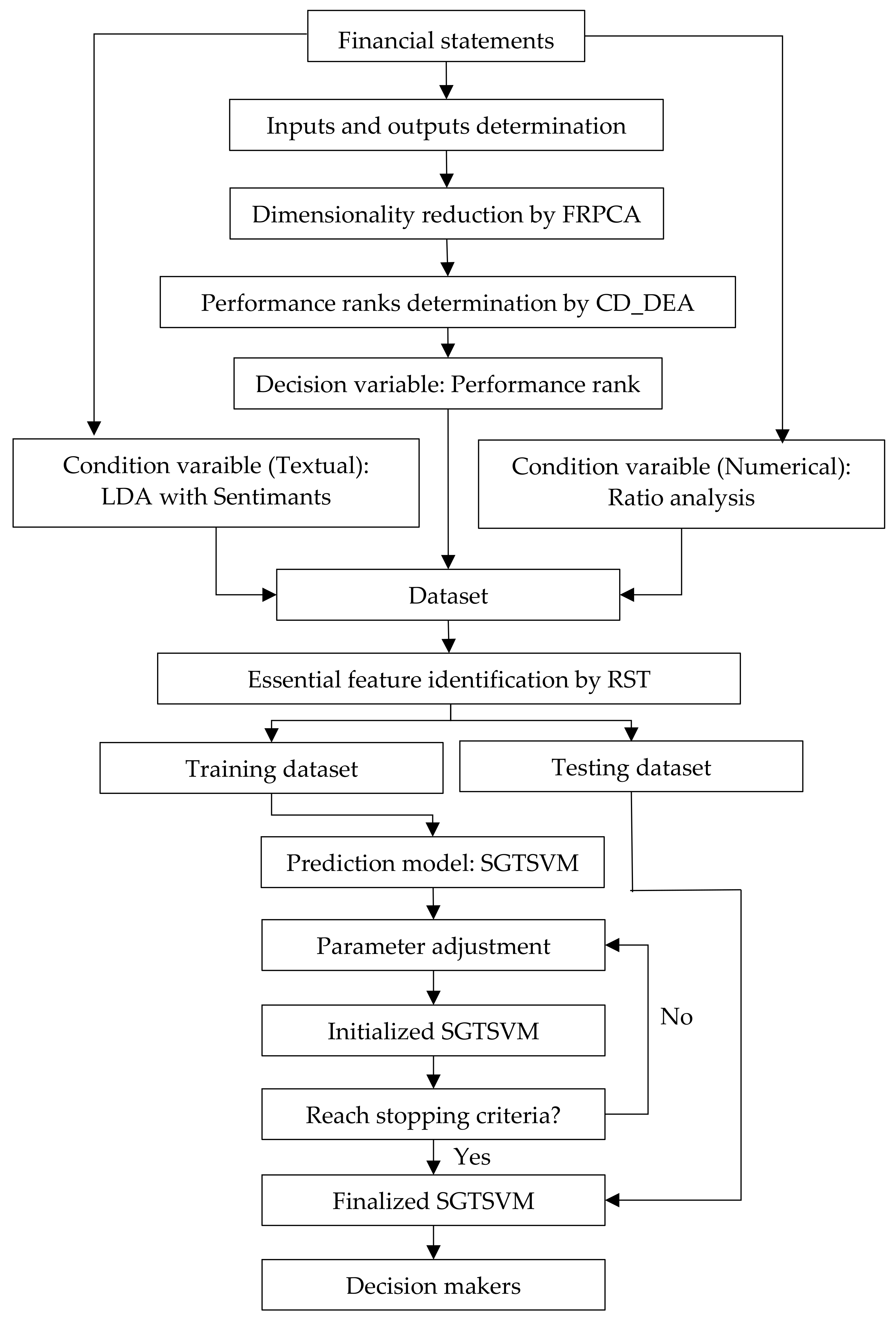
3.3. An Advanced Decision Making Framework: FRPCA_CD-DEA + SGTSVM
4. Empirical Analysis and Outcome
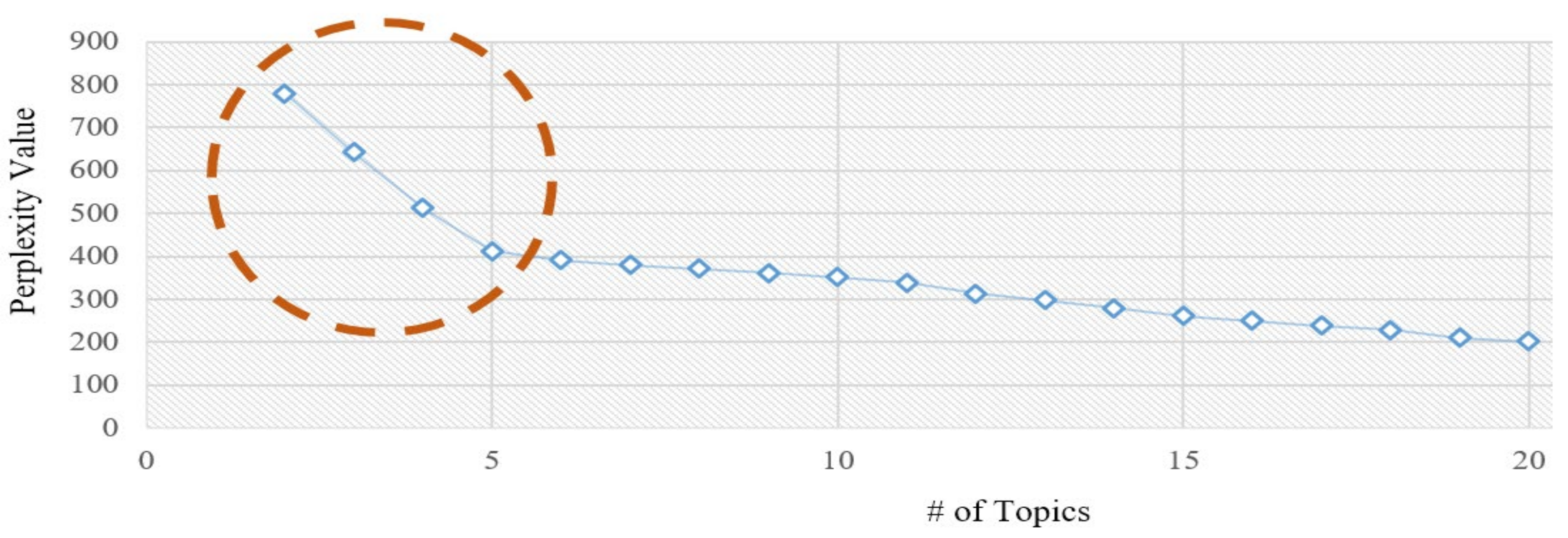
4.1. The Data and Decision Variables
4.2. The Results
5. Conclusions and Future Works
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Mian, A.; Sufi, A. The Consequences of Mortgage Credit Expansion: Evidence from the U.S. Mortgage Default Crisis. Q. J. Econ. 2009, 124, 1449–1496. [Google Scholar] [CrossRef]
- Ko, Y.C.; Fujita, H.; Li, T. An evidential analysis of Altman Z-score for financial predictions: Case study on solar energy companies. Appl. Soft Comput. 2017, 52, 748–759. [Google Scholar] [CrossRef]
- Lin, S.J. Integrated artificial intelligence and visualization technique for enhanced management decision in today’s turbulent business environments. Cybern. Syst. 2021, 52, 274–292. [Google Scholar] [CrossRef]
- Peters, M.D.; Wieder, B.; Sutton, S.G.; Wakefield, J. Business intelligence systems use in performance measurement capabilities: Implications for enhanced competitive advantage. Int. J. Account. Inf. Syst. 2016, 21, 1–17. [Google Scholar] [CrossRef]
- Altman, E.J. Financial ratios, discriminant analysis and the prediction of corporate bankruptcy. J. Financ. 1968, 23, 589–609. [Google Scholar] [CrossRef]
- Beaver, W.H. Financial ratios as predictors of failures. J. Account. Res. 1966, 4, 71–111. [Google Scholar] [CrossRef]
- Charnes, A.; Cooper, W.; Rhodes, E. Measuring the efficiency of decision making units. Eur. J. Oper. Res. 1978, 2, 429–444. [Google Scholar] [CrossRef]
- Wang, C.N.; Nguyen, N.A.T.; Fu, H.P.; Hsu, H.P.; Dang, T.T. Efficiency Assessment of Seaport Terminal Operators Using DEA Malmquist and Epsilon-Based Measure Models. Axioms 2021, 10, 48. [Google Scholar] [CrossRef]
- Adler, N.; Golany, B. Evaluation of deregulated airline networks using data envelopment analysis combined with principal component analysis with an application to Western Europe. Eur. J. Oper. Res. 2001, 132, 260–273. [Google Scholar] [CrossRef]
- Luukka, P. Classification based on fuzzy robust PCA algorithms and similarity classifier. Expert Syst. Appl. 2009, 36, 7463–7468. [Google Scholar] [CrossRef]
- He, Z.; Wu, J.; Han, N. Flexible robust principal component analysis. Int. J. Mach. Learn. Cyber. 2020, 11, 603–613. [Google Scholar] [CrossRef]
- Wang, A.D.; Jin, Z.; Yang, J.Y. A faster tensor robust PCA via tensor factorization. Int. J. Mach. Learn. Cyber. 2020, 11, 2771–2791. [Google Scholar] [CrossRef]
- Luukka, P. A New Nonlinear Fuzzy Robust PCA Algorithm and Similarity Classifier in Classification of Medical Data Sets. Int. J. Fuzzy Syst. 2011, 13, 153–162. [Google Scholar]
- Li, Y.; Chai, Y.; Yin, H.; Chen, B. A novel feature learning framework for high-dimensional data classification. Int. J. Mach. Learn. Cyber. 2021, 12, 555–569. [Google Scholar] [CrossRef]
- Farnè, M.; Vouldis, A.T. Banks’ business models in the euro area: A cluster analysis in high dimensions. Ann. Oper. Res. 2021. [Google Scholar] [CrossRef]
- Jie, T. Parallel processing of the Build Hull algorithm to address the large-scale DEA problem. Ann. Oper. Res. 2020, 295, 453–481. [Google Scholar] [CrossRef]
- Hsu, M.F.; Lin, S.J. A BSC-based network DEA model equipped with computational linguistics for performance assessment and improvement. Int. J. Mach. Learn. Cyber. 2021. [Google Scholar] [CrossRef]
- Seiford, L.M.; Zhu, J. Context-dependent data envelopment analysis-Measuring attractiveness and progress. Omega 2003, 31, 397–408. [Google Scholar] [CrossRef]
- Lim, S. Context-dependent data envelopment analysis with cross-efficiency evaluation. J. Oper. Res. Soc. 2012, 63, 38–46. [Google Scholar] [CrossRef]
- Ulucan, A.; Atıcı, K.B. Efficiency evaluations with context-dependent and measure-specific data envelopment approaches: An application in a World Bank supported project. Omega 2010, 38, 68–83. [Google Scholar] [CrossRef]
- Morita, H.; Hirokawa, K.; Zhu, J. A slack-based measure of efficiency in context-dependent data envelopment analysis. Omega 2005, 33, 357–362. [Google Scholar] [CrossRef]
- Akeb, H.; Lévy, A.; Rdali, M. A quantitative method for opinion ratings and analysis: An event study. Ann. Oper. Res. 2021. [Google Scholar] [CrossRef]
- Chen, X.; Qi, J.; Zhu, X.; Wang, X.; Wang, Z. Unlabelled text mining methods based on two extension models of concept lattices. Int. J. Mach. Learn. Cyber. 2020, 11, 475–490. [Google Scholar] [CrossRef]
- Yu, C.; Zuo, Y.; Feng, B.; Au, L.; Chen, B. An individual-group-merchant relation model for identifying fake online reviews: An empirical study on a Chinese e-commerce platform. Inf. Technol. Manag. 2019, 20, 123–138. [Google Scholar] [CrossRef]
- Hajek, P.; Olej, V.; Myskova, R. Forecasting corporate financial performance using sentiment in annual reports for stakeholders’ decision-making. Technol. Econ. Dev. Econ. 2014, 20, 721–738. [Google Scholar] [CrossRef]
- Gajzler, M. Text and data mining techniques in aspect of knowledge acquisition for decision sup-port system in construction industry. Technol. Econ. Dev. Econ. 2010, 16, 219–232. [Google Scholar] [CrossRef] [Green Version]
- Rönnqvist, S.; Sarlin, P. Bank distress in the news: Describing events through deep learning. Neurocomputing 2017, 264, 57–70. [Google Scholar] [CrossRef] [Green Version]
- Huotari, T.; Savolainen, J.; Collan, M. Deep Reinforcement Learning Agent for S&P 500 Stock Selection. Axioms 2020, 9, 130. [Google Scholar]
- Too, J.; Abdullah, A.R.; Mohd Saad, N. Hybrid Binary Particle Swarm Optimization Differential Evolution-Based Feature Selection for EMG Signals Classification. Axioms 2019, 8, 79. [Google Scholar] [CrossRef] [Green Version]
- Vijayarani, J.; Geetha, T.V. Joint learning of author and citation contexts for computing drift in scholarly documents. Int. J. Mach. Learn. Cyber. 2021, 12, 1667–1686. [Google Scholar] [CrossRef]
- Cambria, E.; White, B. Jumping NLP curves: A review of natural language processing research. IEEE Comput. Intell. Mag. 2014, 9, 48–57. [Google Scholar] [CrossRef]
- Gross, A.; Murthy, D. Modeling virtual organizations with Latent Dirichlet Allocation: A case for natural language processing. Neural Netw. 2014, 58, 38–49. [Google Scholar] [CrossRef]
- Tetlock, P.C. Giving Content to Investor Sentiment: The Role of Media in the Stock Market. J. Financ. 2007, 62, 1139–1168. [Google Scholar] [CrossRef]
- Tetlock, P.C.; Saar-Tsechansky, M.; Macskassy, S. More than Words: Quantifying Language to Measure Firms’ Fundamentals. J. Financ. 2008, 63, 1437–1467. [Google Scholar] [CrossRef]
- Wang, Z.; Shao, Y.H.; Bai, L.; Li, C.N.; Liu, L.M.; Deng, N.Y. Insensitive stochastic gradient twin support vector machines for large scale problems. Inf. Sci. 2018, 462, 114–131. [Google Scholar] [CrossRef] [Green Version]
- Liu, L.; Li, P.; Chu, M.; Cai, H. Stochastic gradient support vector machine with local structural information for pattern recognition. Int. J. Mach. Learn. Cyber. 2021. [Google Scholar] [CrossRef]
- Hu, K.H.; Lin, S.J.; Hsu, M.F.; Chen, F.H. A dynamic network-based decision architecture for performance evaluation and improvement. J. Intell. Fuzzy Syst. 2020, 39, 4299–4311. [Google Scholar] [CrossRef]
- Hu, K.-H.; Chen, F.-H.; Hsu, M.-F.; Yao, S.; Hung, M.-C. Identification of the Critical Factors for Global Supply Chain Management under the COVID-19 Outbreak via a Fusion Intelligent Decision Support System. Axioms 2021, 10, 61. [Google Scholar] [CrossRef]
- Hua, Z.; Wang, Y.; Xu, X.; Zhang, B.; Liang, L. Predicting corporate financial distress based on integration of support vector machine and logistic regression. Expert Syst. Appl. 2007, 33, 434–440. [Google Scholar] [CrossRef]
- Wilson, R.; Sharda, R. Bankruptcy prediction using neural networks. Decis. Support Syst. 1994, 11, 545–557. [Google Scholar] [CrossRef]
- Ross, S.A.; Westerfield, R.W.; Jordan, B.D. Corporate Finance; McGraw-Hill-Irwin: New York, NY, USA, 2002. [Google Scholar]
- Geng, R.; Bose, I.; Chen, X. Prediction of financial distress: An empirical study of listed Chinese companies using data mining. Eur. J. Oper. Res. 2015, 241, 236–247. [Google Scholar] [CrossRef]
- Martin, D. Early warning of bank failure: A logit regression approach. J. Bank. Financ. 1977, 1, 249–276. [Google Scholar] [CrossRef]
- Ohlson, J.A. Financial ratios and the probabilistic prediction of bankruptcy. J. Account. Res. 1980, 18, 109–131. [Google Scholar] [CrossRef] [Green Version]
- Kolari, J.; Glennon, D.; Shin, H.; Caputo, M. Predicting large US commercial bank failures. J. Econ. Bus. 2002, 54, 361–387. [Google Scholar] [CrossRef]
- Shirata, C.Y.; Takeuchi, H.; Ogino, S.; Watanabe, H. Extracting key phrases as predictors of corporate bankruptcy: Empirical analysis of annual reports by text mining. J. Emerg. Technol. Account. 2011, 8, 31–44. [Google Scholar] [CrossRef] [Green Version]
- Henry, E. Are investors influenced by how earnings press releases are written? Int. J. Bus. Commun. 2008, 45, 363–407. [Google Scholar] [CrossRef]
- Holsti, O.R. Content Analysis for the Social Sciences and Humanities; Addison Wesley: Reading, MA, USA, 1969. [Google Scholar]
- Fisher, I.E.; Garnsey, M.R.; Goel, S.; Tam, K. The role of text analytics and information retrieval in the accounting domain. J. Emerg. Technol. Account. 2010, 7, 1–24. [Google Scholar] [CrossRef] [Green Version]
- Smith, J.E.; Smith, N.P. Readability: A measure of performance of the communication function of financial reporting. Account. Rev. 1971, 46, 552–556. [Google Scholar]
- Healy, P. Can you understand the footnotes to financial statements? Account. J. 1977, 56, 219–222. [Google Scholar]
- Li, F. Annual report readability, current earnings, and earnings persistence. J. Account. Econ. 2008, 45, 221–247. [Google Scholar] [CrossRef]
- Goel, S.; Gangolly, J.; Faerman, S.R.; Uzuner, O. Can linguistic predictors detect fraudulent financial filings? J. Emerg. Technol. Account. 2010, 7, 25–46. [Google Scholar] [CrossRef]
- Bowman, E.H. Content analysis of annual reports for corporate strategy and risk. Interfaces 1984, 14, 61–71. [Google Scholar] [CrossRef]
- Bodnaruk, A.; Loughran, T.; McDonald, B. Using 10-K text to gauge financial constraints. J. Financ. Quant. Anal. 2015, 50, 623–646. [Google Scholar] [CrossRef] [Green Version]
- Yang, T.N.; Wang, S.D. Robust algorithms for principal component analysis. Pattern Recognit. Lett. 1999, 20, 927–933. [Google Scholar] [CrossRef]
- Xu, L.; Yuille, A.L. Robust principal component analysis by self-organizing rules based on statistical physics approach. IEEE Trans. Neural Netw. 1995, 6, 131–143. [Google Scholar]
- Bezdek, J.C. Pattern Recognition with Fuzzy Objective Function Algoritms; Plenum Press: New York, NY, USA, 1981. [Google Scholar]
- Ren, L.H.; Ye, Z.F.; Zhao, Y.P. A modeling method for aero-engine by combining stochastic gradient descent with support vector regression. Aerosp. Sci. Technol. 2020, 99, 105775. [Google Scholar] [CrossRef]
- Roy, J.; Pamučar, D.; Kar, S. Evaluation and selection of third party logistics provider under sustainability perspectives: An interval valued fuzzy-rough approach. Ann. Oper. Res. 2020, 293, 669–714. [Google Scholar] [CrossRef]
- Rajesh, R. Sustainability performance predictions in supply chains: Grey and rough set theoretical approaches. Ann. Oper. Res. 2020. [Google Scholar] [CrossRef]
- Banker, R.D.; Charnes, A.; Cooper, W.W. Some Models for Estimating Technical and Scale Inefficiencies in Data Envelopment Analysis. Manag. Sci. 1984, 30, 1078–1092. [Google Scholar] [CrossRef] [Green Version]
- Tone, K.; Tsutsui, M. Network DEA: A slacks-based measure approach. Eur. J. Oper. Res. 2009, 197, 243–252. [Google Scholar] [CrossRef] [Green Version]
- Xu, X.; Wang, Y. Financial failure prediction using efficiency as a predictor. Expert Syst. Appl. 2009, 36, 366–373. [Google Scholar] [CrossRef]
- Cook, W.D.; Tone, K.; Zhu, J. Data envelopment analysis: Prior to choosing a model. Omega 2014, 44, 1–4. [Google Scholar] [CrossRef]
- Golany, B.; Roll, Y. An Application Procedure for DEA. Omega 1989, 1, 237–250. [Google Scholar] [CrossRef]
- Chen, X.; Dai, Q.; Na, C. The value of enterprise information systems under different corporate governance aspects. Inf. Technol. Manag. 2019, 20, 223–247. [Google Scholar] [CrossRef]
- Lucanera, J.P.; Fabregat-Aibar, L.; Scherger, V.; Vigier, H. Can the SOM Analysis Predict Business Failure Using Capital Structure Theory? Evidence from the Subprime Crisis in Spain. Axioms 2020, 9, 46. [Google Scholar] [CrossRef]
- Hsu, M.F. A fusion mechanism for management decision and risk analysis. Cybern. Syst. 2019, 50, 497–515. [Google Scholar] [CrossRef]
- Mario, I.T.; Brenda, V.; Julia, G. Organizational Diseases. Cybern. Syst. 2020, 51, 615–630. [Google Scholar]
- Blei, D.; Ng, A.; Jordan, M. Latent Dirichlet allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]
- Skowron, A.; Rauszer, C. The Discernibility Matrices and Functions in Information Systems. In Intelligent Decision Support. Theory and Decision Library; Series D: System Theory, Knowledge Engineering and Problem Solving; Słowiński, R., Ed.; Springer: Dordrecht, The Netherlands, 1992; Volume 11, pp. 331–362. [Google Scholar]
- Lu, W.M.; Kweh, Q.L.; Wang, C.W. Integration and application of rough sets and data envelopment analysis for assessments of the investment trusts industry. Ann. Oper. Res. 2021, 296, 163–194. [Google Scholar] [CrossRef]
- Huang, A.; Zang, A.; Zheng, R. Evidence on the information content of text in analyst reports. Account. Rev. 2014, 89, 2151–2180. [Google Scholar] [CrossRef] [Green Version]
- Cai, Y.; Yang, K.; Huang, D.; Zhou, Z.; Lei, X.; Xie, H.; Wong, T.L. A hybrid model for opinion mining based on domain sentiment dictionary. Int. J. Mach. Learn. Cybern. 2019, 10, 2131–2142. [Google Scholar] [CrossRef]
- Dridi, A.; Atzeni, M.; Reforgiato Recupero, D. FineNews: Fine-grained semantic sentiment analysis on financial microblogs and news. Int. J. Mach. Learn. Cyber. 2019, 10, 2199–2207. [Google Scholar] [CrossRef]
- Ibtihel, B.L.; Lobna, H.; Lotfi, B.R. Hybrid Deep Neural Network-Based Text Representation Model to Improve Microblog Retrieval. Cybern. Syst. 2020, 51, 115–139. [Google Scholar]
- Du Jardin, P. Forecasting bankruptcy using biclustering and neural network-based ensembles. Ann. Oper. Res. 2021, 299, 531–566. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
| Input Variables | Output Variables | ||
|---|---|---|---|
| Symbol | Description | Symbol | Description |
| Input (1): TA | Total assets | Output (1): TS | Total sales |
| Input (2): NOE | Number of employees | Output (2): GM | Gross margin |
| Input (3): FA | Fixed assets | Output (3): NI | Net income |
| Input (4): COGS | Cost of goods sold | Output (4): EPS | Earnings per share |
| Input (5): TD | Total debts | ||
| Symbol | TA | NOE | FA | COGS | TD | TS | GM | NI | EPS |
|---|---|---|---|---|---|---|---|---|---|
| TA | 1 | 0.829 ** | 0.870 ** | 0.856 ** | 0.962 ** | 0.908 ** | 0.862 ** | 0.765 ** | 0.105 |
| NOE | 0.829 ** | 1 | 0.490 ** | 0.946 ** | 0.922 ** | 0.939 ** | 0.461 ** | 0.313 ** | 0.033 |
| FA | 0.870 ** | 0.490 ** | 1 | 0.501 ** | 0.713 ** | 0.593 ** | 0.969 ** | 0.940 ** | 0.109 * |
| COGS | 0.856 ** | 0.946 ** | 0.501 ** | 1 | 0.959 ** | 0.993 ** | 0.498 ** | 0.354 ** | 0.034 |
| TD | 0.962 ** | 0.922 ** | 0.713 ** | 0.959 ** | 1 | 0.983 ** | 0.705 ** | 0.579 ** | 0.065 |
| TS | 0.908 ** | 0.939 ** | 0.593 ** | 0.993 ** | 0.983 ** | 1 | 0.594 ** | 0.458 ** | 0.051 |
| GM | 0.862 ** | 0.461 ** | 0.969 ** | 0.498 ** | 0.705 ** | 0.594 ** | 1 | 0.979 ** | 0.151 ** |
| NI | 0.765 ** | 0.313 ** | 0.940 ** | 0.354 ** | 0.579 ** | 0.458 ** | 0.979 ** | 1 | 0.147 ** |
| EPS | 0.105 | 0.033 | 0.109 * | 0.034 | 0.065 | 0.051 | 0.151 ** | 0.147 ** | 1 |
| Condition | CD-DEA | FRPCA + CD-DEA |
|---|---|---|
| Total number of DMUs | 400 | 400 |
| Maximum efficiency | 1 | 1 |
| Number of efficiency DMUs | 38 | 17 |
| Percent of efficient DMUs | 9.5 | 4.25 |
| Average performance score | 0.63 | 0.47 |
| Standard deviation (S.D.) | 0.11 | 0.15 |
| Model | CD-DEA | FRPCA + CD-DEA | ||
|---|---|---|---|---|
| Mean | S.D. | Mean | S.D. | |
| Eliminating 20% of the data | 0.67 | 0.11 | 0.49 | 0.14 |
| Eliminating 40% of the data | 0.71 | 0.08 | 0.53 | 0.13 |
| Eliminating 60% of the data | 0.76 | 0.07 | 0.59 | 0.11 |
| Eliminating 80% of the data | 0.78 | 0.06 | 0.61 | 0.10 |
| Symbol | Description |
|---|---|
| X1: TL/TA | Total liabilities to total assets |
| X2: CA/CL | Current assets to current liabilities |
| X3: EBIT/IE | Earnings before interest and tax to interest expense |
| X4: NP/TS | Net profit to total sales |
| X5: GM/TS | Gross margin to total sales |
| X6: TS/TA | Total sales to total assets |
| X7: NP/SE | Net profit to shareholders’ equity |
| X8: FA/TA | Fixed assets to total assets |
| X9: NP/OS | Net profit to outstanding shares |
| X10: NPGR | Net profit growth rate |
| Topic | ||||
|---|---|---|---|---|
| Operation Related | Business Strategy-Related | Stock Market-Related | Environmental Protection-Related | Corporate Governance-Related |
| profit | development | growth | protection | responsibility |
| gain | efficiency | decline | continue | dividend policy |
| reduce | prospect | decrease | sustainability | capital expenditure |
| efficiency | Lay off | profitability | emission | Remuneration committee |
| promote | performance | profit | lawsuit | audit |
| reduce | creative | reduce | risk | governance |
| growth | risk | promote | penalty | internal control |
| decline | uncertainty | modification | safe | duality |
| shock | liquidity | volume | energy save | disclosure |
| loss | severance | uncertainty | reduce | transparency |
| Symbol | ■: Selected; □: Unselected |
|---|---|
| Numerical messages | |
| PC1 | ■: Selected |
| PC2 | ■: Selected |
| PC3 | ■: Selected |
| PC4 | ■: Selected |
| PC5 | ■: Selected |
| Topic-based sentimental messages | |
| S1: Operation related | ■: Selected |
| S2: Business strategy-related | ■: Selected |
| S3: Stock market-related | ■: Selected |
| S4: Environmental protection-related | □: Unselected |
| S5: Corporate governance-related | □: Unselected |
| Condition | 1: With Topic-Based Sentimental Messages | 2: Without Topic-Based Sentimental Messages |
|---|---|---|
| CV-1 | (83.75) (10.67) (19.60) | (76.25) (14.67) (29.20) |
| CV-2 | (86.50) (11.33) (14.80) | (68.00) (24.00) (36.80) |
| CV-3 | (85.00) (12.00) (16.80) | (70.00) (20.00) (36.00) |
| CV-4 | (85.50) (13.33) (15.20) | (66.75) (21.33) (40.40) |
| CV-5 | (86.25) (10.00) (16.00) | (77.25) (12.67) (28.80) |
| Average | (85.40) (11.47) (16.48) | (71.65) (18.53) (34.24) |
| Performance Measure: Accuracy (Rank) | Friedman Test |
|---|---|
| Benchmark (85.40) (1) >> RVM (78.25) (2) >> ELM (72.20) (3) >> BPNN (67.45) (4) | 0.000 |
| Performance measure: 100-Type I error (Rank) | |
| Benchmark (88.53) (1) >> RVM (82.13) (2) >> ELM (72.27) (3) >> BPNN (69.87) (4) | 0.003 |
| Performance measure: 100-Type II error (Rank) | |
| Benchmark (83.52) (1) >> RVM (75.92) (2) >> ELM (72.16) (3) >> BPNN (66) (4) | 0.000 |
| Situation 1: Eliminating 20% of the data |
|---|
| Accuracy: Benchmark (81.50) >> RVM (78.75) >> ELM (77.05) >> BPNN (75.75) 100-Type I error: Benchmark (81.00) >> RVM (80.05) >> ELM (78.00) >> BPNN (77.00) 100-Type II error: Benchmark (82.00) >> RVM (77.00) = ELM (77.00) >> BPNN (74.50) |
| Situation 2: Eliminating 40% of the data |
| Accuracy: Benchmark (77.75) >> ELM (75.75) >> RVM (71.75) >> BPNN (69.75) 100-Type I error: Benchmark (78.00) >> ELM (77.50) >> RVM (74.50) >> BPNN (72.00) 100-Type II error: Benchmark (77.50) >> ELM (74.00) >> RVM (69.00) >> BPNN (67.50) |
| Situation 3: Eliminating 60% of the data |
| Accuracy: Benchmark (73.75) >> ELM (70.75) >> RVM (67.75) >> BPNN (65.75) 100-Type I error: Benchmark (74.00) >> ELM (72.50) >> RVM (70.50) >> BPNN (69.00) 100-Type II error: Benchmark (73.50) >> ELM (69.00) >> RVM (65.00) >> BPNN (62.50) |
| Situation 4: Eliminating 80% of the data |
| Accuracy: Benchmark (68.00) >> ELM (67.50) >> RVM (62.00) >> BPNN (60.50) 100-Type I error: Benchmark (65.00) >> ELM (64.00) >> RVM (59.00) >> BPNN (57.00) 100-Type II error: Benchmark (71.00) = ELM (71.00) >> RVM (65.00) >> BPNN (64.00) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, H.-L.; Lin, S.-J.; Hsu, M.-F. An Advanced Decision Making Framework via Joint Utilization of Context-Dependent Data Envelopment Analysis and Sentimental Messages. Axioms 2021, 10, 179. https://doi.org/10.3390/axioms10030179
Huang H-L, Lin S-J, Hsu M-F. An Advanced Decision Making Framework via Joint Utilization of Context-Dependent Data Envelopment Analysis and Sentimental Messages. Axioms. 2021; 10(3):179. https://doi.org/10.3390/axioms10030179
Chicago/Turabian StyleHuang, Hsueh-Li, Sin-Jin Lin, and Ming-Fu Hsu. 2021. "An Advanced Decision Making Framework via Joint Utilization of Context-Dependent Data Envelopment Analysis and Sentimental Messages" Axioms 10, no. 3: 179. https://doi.org/10.3390/axioms10030179
APA StyleHuang, H. -L., Lin, S. -J., & Hsu, M. -F. (2021). An Advanced Decision Making Framework via Joint Utilization of Context-Dependent Data Envelopment Analysis and Sentimental Messages. Axioms, 10(3), 179. https://doi.org/10.3390/axioms10030179