
A Method for Visualizing Posterior Probit Model Uncertainty in the Early Prediction of Fraud for Sustainability Development



Abstract
:1. Introduction
2. Literature Review
2.1. Related Studies of Fraud Detection
2.2. Comparing the Bayesian Probit Model to the Standard Logistic Model
3. Methods
3.1. Notations
3.2. MCMC Parameter Estimation
3.3. Creating the Fraud Detection Model
3.4. Description of Variables
- Dependent Variables:
- Independent Variables:
- Control Variables
4. Bayesian Modeling
4.1. Sample Data
4.2. Prior Distributions
4.3. Sampling and Modeling
4.4. Prediction Results from the Standard Logistic and Bayesian Probit Models
4.5. Comparison of the One-Time Model and the Interaction Term Model
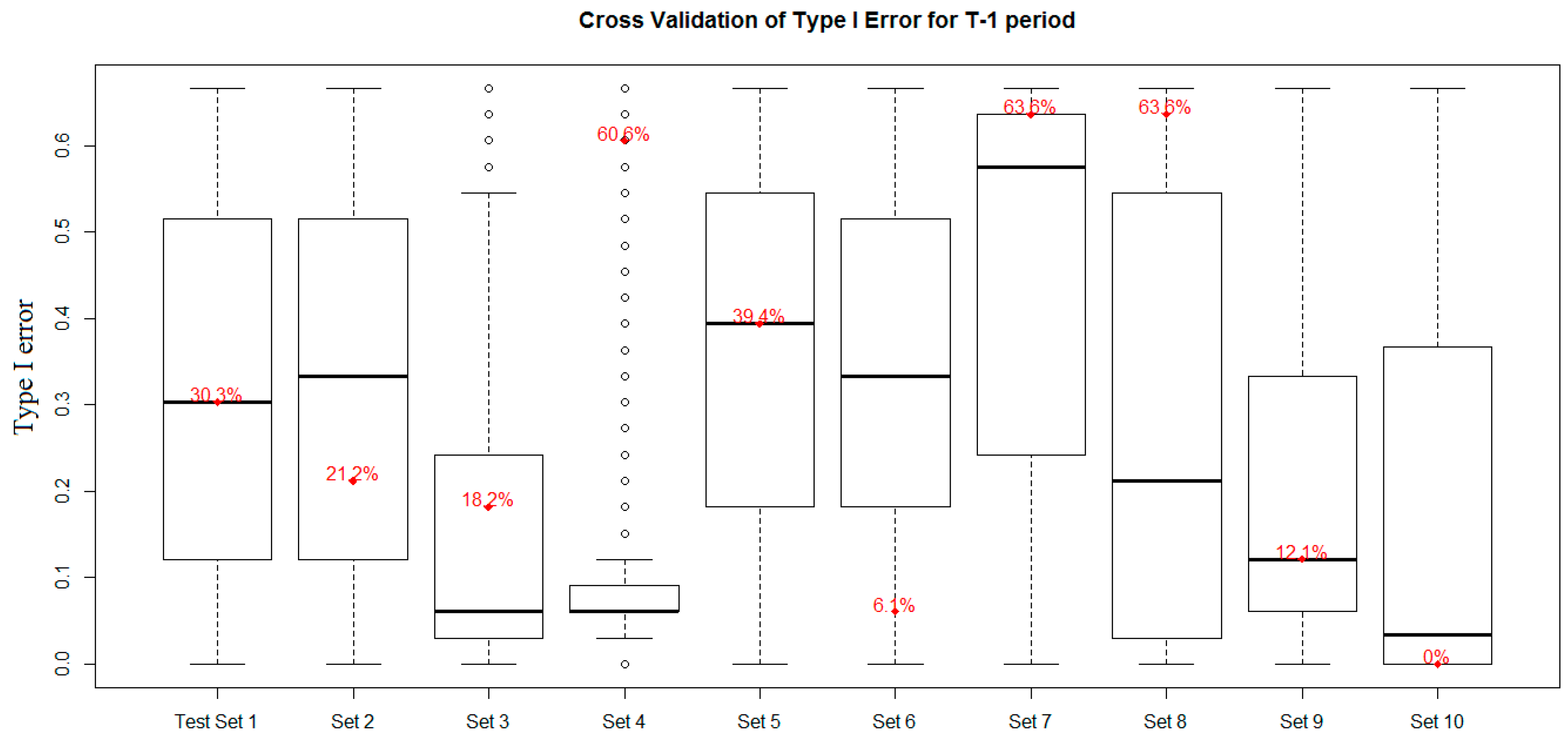
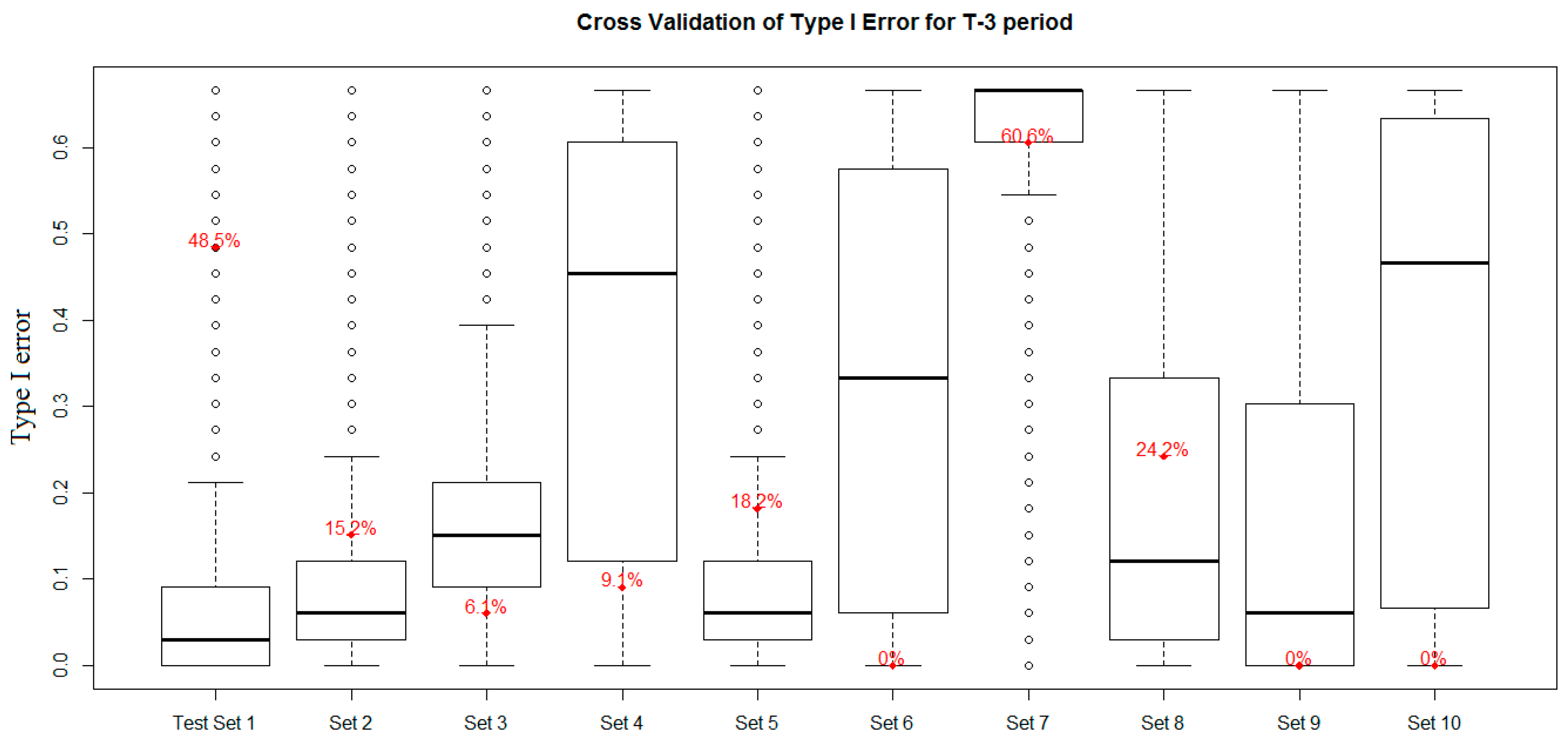
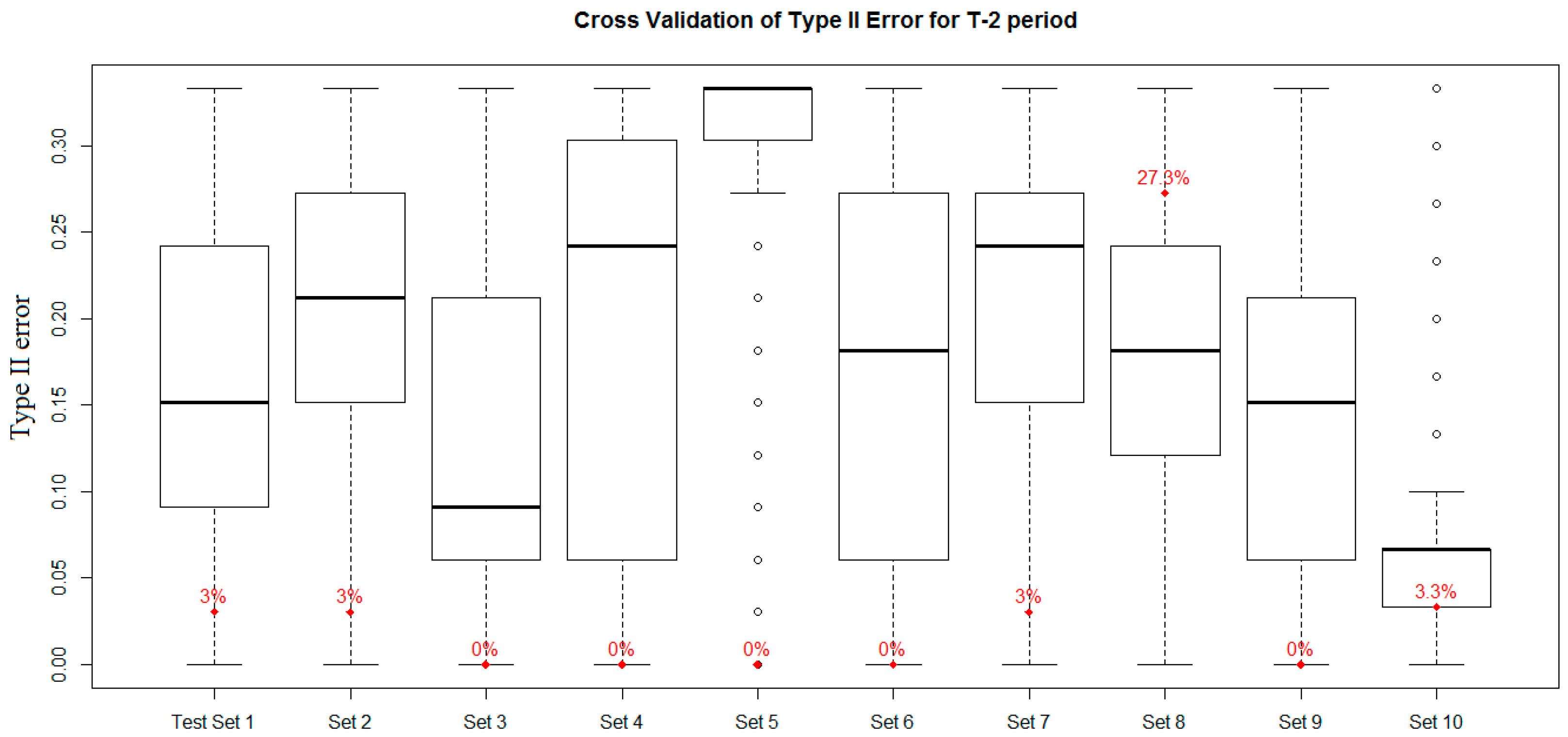
4.6. Model Error Analysis
5. Conclusions and Recommendations
5.1. Theoretical Implications
5.2. Implications for Managers
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Persons, O.S. Using financial statement data to identify factors associated with fraudulent financial reporting. J. Appl. Bus. Res. 1995, 11, 38–46. [Google Scholar] [CrossRef]
- Kaminski, K.A.; Wetzel, T.S.; Guan, L. Can financial ratios detect fraudulent financial reporting? Manag. Audit. J. 2004, 19, 15–28. [Google Scholar] [CrossRef]
- ACFE. Report to the Nations on Occupational Fraud and Abuse. Available online: https://www.acfe.com/report-to-the-nations/2020/ (accessed on 20 June 2021).
- Bologna, J.; Lindquist, R.J.; Wells, J.T. The Accountant’s Handbook of Fraud and Commercial Crime; Wiley: New York, NY, USA, 1993. [Google Scholar]
- Mitnick, B.M. The theory of agency. Public Choice 1975, 24, 27–42. [Google Scholar] [CrossRef]
- Song, J.; Wang, R.; Cavusgil, S.T. State ownership and market orientation in China’s public firms: An agency theory perspective. Int. Bus. Rev. 2015, 24, 690–699. [Google Scholar] [CrossRef]
- Schipper, K. Earnings management. Account. Horiz. 1989, 3, 91. [Google Scholar]
- Healy, P.M.; Wahlen, J.M. A review of the earnings management literature and its implications for standard setting. Account. Horiz. 1999, 13, 365–383. [Google Scholar] [CrossRef]
- Cressey, D.R. Other People’s Money: A Study of the Social Psychology of Embezzlement; Free Press: Glencoe, IL, USA, 1953. [Google Scholar]
- Vousinas, G.L. Advancing theory of fraud: The SCORE model. J. Financ. Crime 2019, 26, 372–381. [Google Scholar] [CrossRef]
- Brennan, N.M.; McGrath, M. Financial statement fraud: Some lessons from US and European case studies. Aust. Account. Rev. 2007, 17, 49–61. [Google Scholar] [CrossRef]
- Skousen, C.J.; Smith, K.R.; Wright, C.J. Detecting and predicting financial statement fraud: The effectiveness of the fraud triangle and SAS No. 99. In Corporate Governance and Firm Performance; Hirschey, M., John, K., Makhija, A.K., Eds.; Emerald Group Publishing Limited: Bingley, UK, 2009; pp. 53–81. [Google Scholar]
- Hollow, M. Money, morals and motives: An exploratory study into why bank managers and employees commit fraud at work. J. Financ. Crime 2014, 21, 174–190. [Google Scholar] [CrossRef] [Green Version]
- Altman, E.I. Financial ratios, discriminant analysis and the prediction of corporate bankruptcy. J. Financ. 1968, 23, 589–609. [Google Scholar] [CrossRef]
- Beasley, M.S. An empirical analysis of the relation between the board of director composition and financial statement fraud. Account. Rev. 1996, 71, 443–465. [Google Scholar]
- Persons, O.S. The relation between the new corporate governance rules and the likelihood of financial statement fraud. Rev. Account. Financ. 2005, 4, 125–148. [Google Scholar] [CrossRef]
- Tan, D.T.; Chapple, L.; Walsh, K.D. Corporate fraud culture: Re-examining the corporate governance and performance relation. Account. Financ. 2017, 57, 597–620. [Google Scholar] [CrossRef]
- Xie, B.; Davidson, W.N., III; DaDalt, P.J. Earnings management and corporate governance: The role of the board and the audit committee. J. Corp. Financ. 2003, 9, 295–316. [Google Scholar] [CrossRef]
- Francis, J.R. What do we know about audit quality? Br. Account. Rev. 2004, 36, 345–368. [Google Scholar] [CrossRef] [Green Version]
- Hribar, P.; Kravet, T.; Wilson, R. A new measure of accounting quality. Rev. Account. Stud. 2014, 19, 506–538. [Google Scholar] [CrossRef]
- Givoly, D.; Hayn, C. The changing time-series properties of earnings, cash flows and accruals: Has financial reporting become more conservative? J. Account. Econ. 2000, 29, 287–320. [Google Scholar] [CrossRef]
- Kamarudin, K.A.; Ismail, W.A.W.; Mustapha, W.A.H.W. Aggressive financial reporting and corporate fraud. Procedia Soc. Behav. Sci. 2012, 65, 638–643. [Google Scholar] [CrossRef] [Green Version]
- Lin, Y.-J. A Study of the Corporate Fraud Early Warning Models. Master’s Thesis, National Chung Hsing University, Taichung, Taiwan, 2014. [Google Scholar]
- Leith, C. Theoretical skill of Monte Carlo forecasts. Mon. Weather Rev. 1974, 102, 409–418. [Google Scholar] [CrossRef] [Green Version]
- Amerstorfer, T.; Hinterreiter, J.; Reiss, M.A.; Möstl, C.; Davies, J.A.; Bailey, R.L.; Weiss, A.J.; Dumbović, M.; Bauer, M.; Amerstorfer, U.V.; et al. Evaluation of CME Arrival Prediction Using Ensemble Modeling Based on Heliospheric Imaging Observations. Space Weather 2021, 19, e2020SW002553. [Google Scholar] [CrossRef]
- Buonaguidi, B.; Mira, A.; Bucheli, H.; Vitanis, V. Bayesian Quickest Detection of Credit Card Fraud. Bayesian Anal. 2021, 1, 1–30. [Google Scholar] [CrossRef]
- Tseng, S.-H.; Kang, H.-Y.; Chen, H.-Y. A Test-Bed to Compare Alternative Bayesian Regression Formulations And An Application Of Cnc Milling Roughness Minimization. J. Qual. 2018, 25, 241–257. [Google Scholar]
- Perols, J. Financial statement fraud detection: An analysis of statistical and machine learning algorithms. Audit. J. Pract. Theory 2011, 30, 19–50. [Google Scholar] [CrossRef]
- Fanning, K.M.; Cogger, K.O. Neural network detection of management fraud using published financial data. Intell. Syst. Account. Financ. Manag. 1998, 7, 21–41. [Google Scholar] [CrossRef]
- Kirkos, E.; Spathis, C.; Manolopoulos, Y. Data mining techniques for the detection of fraudulent financial statements. Expert Syst. Appl. 2007, 32, 995–1003. [Google Scholar] [CrossRef]
- Dong, W.; Liao, S.; Zhang, Z. Leveraging financial social media data for corporate fraud detection. J. Manag. Inf. Syst. 2018, 35, 461–487. [Google Scholar] [CrossRef]
- Liu, C.; Chan, Y.; Kazmi, S.H.A.; Fu, H. Financial fraud detection model: Based on random forest. Int. J. Econ. Financ. 2015, 7. [Google Scholar] [CrossRef] [Green Version]
- Baesens, B.; Höppner, S.; Verdonck, T. Data engineering for fraud detection. Decis. Support Syst. 2021, 113492, in press. [Google Scholar]
- Altman, E.I.; Iwanicz-Drozdowska, M.; Laitinen, E.K.; Suvas, A. Financial distress prediction in an international context: A review and empirical analysis of Altman’s Z-score model. J. Int. Financ. Manag. Account. 2017, 28, 131–171. [Google Scholar] [CrossRef]
- Summers, S.L.; Sweeney, J.T. Fraudulently misstated financial statements and insider trading: An empirical analysis. Account. Rev. 1998, 73, 131–146. [Google Scholar]
- Imhoff, G. Accounting quality, auditing and corporate governance. Audit. Corp. Gov. 2003. [Google Scholar] [CrossRef] [Green Version]
- Desai, M.A. The degradation of reported corporate profits. J. Econ. Perspect. 2005, 19, 171–192. [Google Scholar] [CrossRef] [Green Version]
- Davidson, R.; Goodwin-Stewart, J.; Kent, P. Internal governance structures and earnings management. Account. Financ. 2005, 45, 241–267. [Google Scholar] [CrossRef]
- Perols, J.L.; Lougee, B.A. The relation between earnings management and financial statement fraud. Adv. Account. 2011, 27, 39–53. [Google Scholar] [CrossRef]
- Lennox, C.; Pittman, J.A. Big Five audits and accounting fraud. Contemp. Account. Res. 2010, 27, 209–247. [Google Scholar] [CrossRef]
- Nusinovici, S.; Tham, Y.C.; Yan, M.Y.C.; Ting, D.S.W.; Li, J.; Sabanayagam, C.; Wong, T.Y.; Cheng, C.-Y. Logistic regression was as good as machine learning for predicting major chronic diseases. J. Clin. Epidemiol. 2020, 122, 56–69. [Google Scholar] [CrossRef] [PubMed]
- O’brien, S.M.; Dunson, D.B. Bayesian multivariate logistic regression. Biometrics 2004, 60, 739–746. [Google Scholar] [CrossRef] [PubMed]
- Polson, N.G.; Scott, J.G.; Windle, J. Bayesian inference for logistic models using Pólya–Gamma latent variables. J. Am. Stat. Assoc. 2013, 108, 1339–1349. [Google Scholar] [CrossRef] [Green Version]
- Sanchez-Lengeling, B.; Roch, L.M.; Perea, J.D.; Langner, S.; Brabec, C.J.; Aspuru-Guzik, A. A Bayesian approach to predict solubility parameters. Adv. Theory Simul. 2019, 2, 1800069. [Google Scholar] [CrossRef]
- Ghosh, J.; Li, Y.; Mitra, R. On the use of Cauchy prior distributions for Bayesian logistic regression. Bayesian Anal. 2018, 13, 359–383. [Google Scholar] [CrossRef]
- Gerlach, R.; Bird, R.; Hall, A.D. A Bayesian Approach to Variable Selection in Logistic Regression with Application to Predicting Earnings Direction from Accounting Information; School of Finance and Economics, University of Technology Sydney: Sydney, Australia, 2000. [Google Scholar]
- Jackman, S. Bayesian Analysis for the Social Sciences; John Wiley & Sons: New York, NY, USA, 2009; Volume 846. [Google Scholar]
- Rossi, P.E.; Allenby, G.M.; McCulloch, R. Bayesian Statistics and Marketing; John Wiley & Sons: New York, NY, USA, 2012. [Google Scholar]
- Hosmer, D.W., Jr.; Lemeshow, S.; Sturdivant, R.X. Applied Logistic Regression; John Wiley & Sons: New York, NY, USA, 2013; Volume 398. [Google Scholar]
- Peduzzi, P.; Concato, J.; Kemper, E.; Holford, T.R.; Feinstein, A.R. A simulation study of the number of events per variable in logistic regression analysis. J. Clin. Epidemiol. 1996, 49, 1373–1379. [Google Scholar] [CrossRef]
- Gilks, W.R.; Richardson, S.; Spiegelhalter, D. Markov Chain Monte Carlo in Practice; Chapman and Hall/CRC: Boca Raton, FL, USA, 1995. [Google Scholar]
- Geman, S.; Geman, D. Stochastic relaxation, Gibbs distributions, and the Bayesian restoration of images. In Readings in Computer Vision; Elsevier: Amsterdam, The Netherlands, 1987; pp. 564–584. [Google Scholar]
- Von Toussaint, U. Bayesian inference in physics. Rev. Mod. Phys. 2011, 83, 943. [Google Scholar] [CrossRef] [Green Version]
- Bernstein, L.A. Analysis of Financial Statements; Irwin Professional Publishing: Chicago, IL, USA, 1993. [Google Scholar]
- Allen, T.T.; Tseng, S.H. Variance plus bias optimal response surface designs with qualitative factors applied to stem choice modeling. Qual. Reliab. Eng. Int. 2011, 27, 1199–1210. [Google Scholar] [CrossRef]
- Joseph, V.R.; Wang, D.; Gu, L.; Lyu, S.; Tuo, R. Deterministic sampling of expensive posteriors using minimum energy designs. Technometrics 2019, 61, 297–308. [Google Scholar] [CrossRef] [Green Version]
- Fielding, M.; Nott, D.J.; Liong, S.-Y. Efficient MCMC schemes for computationally expensive posterior distributions. Technometrics 2011, 53, 16–28. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| 5 Financial Ratios | Equation | Index | Index Equation |
|---|---|---|---|
| Profitability (β1) | Revenue growth ratio | Revenue growth ratio | (Net income of T period–Net income of T-1 period)/(Net income of T-1 period) |
| Liquidity (β2) | (Current ratio + Working capital ratio)/2 | Current ratio | Current assets/Current liabilities |
| Working capital ratio | (current assets—current liabilities)/Total assets | ||
| Growth (β3) | (Ratio of return on assets + Net profit rate + Net operating profit ratio)/3 | Return on assets ratio | Income after taxes/Total assets |
| Net profit ratio | Income after taxes/Sales revenue | ||
| Net operating profit ratio | Net operating income/Sales revenue | ||
| Utility (β4) | (Accounts receivable to total assets ratio + Sales to total assets ratio)/2 | Accounts receivable to total assets ratio | Accounts receivable/Total assets |
| Sales to total assets ratio | Sales revenue/Total assets | ||
| Structure (β5) | Debt ratio + Net liabilities ratio)/2 | Debt ratio | Total liabilities/Total assets |
| Equity Ratio | Total liabilities/Shareholders’ equity |
| Corporate Governance Variable | Equation/Explanation |
|---|---|
| Number of board members (β6) | Number of directors |
| Ratio of external directors (β7) | The ratio of the number of external directors to total director’s seats |
| The chairman also holds the position of general manager (β8) | Dummy variable, chairman who also holds the position of general manager is represented by 1. If not, it is represented by 0. |
| Percentage of shareholding by directors (β9) | The quantity of shares held by the directors/Total outstanding shares at the end of the period. |
| Percentage of shareholding by institutional investors (β10) | The ratio of institutional investors in the company. |
| Deviation between one’s voting rights and earnings (β11) | Voting rights minus earnings distribution rights |
| Definition of Fraud | According to Statements on Auditing Standards (SAS) No. 43: One or more managers, those in governance, or employee level personnel have deliberately used deception to obtain improper or illegal gains. | ||
| Fraud Sample Screening Methods | Announcements by the Securities and Futures Investors Protection Center Court Judgments | ||
| Fraud Sample Years | 1999–2017 | ||
| Fraud Sample Types | Type 1 | Stock Price Manipulation | 42 |
| Type 2 | Falsifying Financial Statements | 32 | |
| Type 3 | Insider Trading | 35 | |
| Total 109 | |||
| 1999 | 2001 | 2002 | 2003 | 2004 | 2005 | 2006 | 2007 | 2008 | 2009 | 2010 | 2011 | 2012 | 2013 | 2014 | 2015 | 2016 | 2017 | Total | Percentage | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Hardware and Furniture | 1 | 1 | 2 | 1.8% | ||||||||||||||||
| Motherboards | 1 | 2 | 2 | 1 | 2 | 8 | 7.3% | |||||||||||||
| Semiconductors | 3 | 2 | 1 | 1 | 1 | 1 | 2 | 11 | 10.1% | |||||||||||
| Petrochemicals | 1 | 1 | 1 | 3 | 2.8% | |||||||||||||||
| Optoelectronics | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 7 | 6.4% | |||||||||||
| Garments | 1 | 1 | 2 | 1.8% | ||||||||||||||||
| Bicycles | 1 | 1 | 2 | 1.8% | ||||||||||||||||
| Automotive Components | 1 | 1 | 1 | 3 | 2.8% | |||||||||||||||
| Textiles | 1 | 1 | 1 | 1 | 4 | 3.7% | ||||||||||||||
| Basic Metals | 1 | 1 | 1 | 1 | 4 | 3.7% | ||||||||||||||
| Metal Products | 1 | 1 | 2 | 1.8% | ||||||||||||||||
| Construction | 1 | 1 | 1 | 1 | 1 | 1 | 6 | 5.5% | ||||||||||||
| Glass Ceramics | 1 | 1 | 0.9% | |||||||||||||||||
| Ocean Freight | 1 | 1 | 0.9% | |||||||||||||||||
| Freight Warehousing | 1 | 1 | 0.9% | |||||||||||||||||
| Software Services | 1 | 2 | 1 | 4 | 3.7% | |||||||||||||||
| Communication equipment | 1 | 1 | 0.9% | |||||||||||||||||
| Weaving | 1 | 1 | 0.9% | |||||||||||||||||
| Dairy | 1 | 1 | 2 | 1.8% | ||||||||||||||||
| Information Channels | 1 | 1 | 1 | 2 | 5 | 4.6% | ||||||||||||||
| Electronics Equipment | 1 | 1 | 1 | 1 | 4 | 3.7% | ||||||||||||||
| Electronic Components | 3 | 1 | 1 | 2 | 1 | 2 | 1 | 1 | 12 | 11% | ||||||||||
| Electrical Wires | 1 | 1 | 0.9% | |||||||||||||||||
| Electrical Products | 1 | 1 | 2 | 1.8% | ||||||||||||||||
| Network Equipment | 1 | 1 | 1 | 3 | 2.8% | |||||||||||||||
| Shoes and Suitcases | 1 | 1 | 0.9% | |||||||||||||||||
| Resin | 1 | 1 | 2 | 1.8% | ||||||||||||||||
| Machinery Industry | 1 | 1 | 1 | 1 | 4 | 3.7% | ||||||||||||||
| Medical Supplies | 1 | 1 | 2 | 1.8% | ||||||||||||||||
| Medical Pharmaceuticals | 1 | 1 | 2 | 1.8% | ||||||||||||||||
| Chemical Material Products | 2 | 2 | 1.8% | |||||||||||||||||
| Other Electronics | 1 | 1 | 0.9% | |||||||||||||||||
| Tourism and Dining | 1 | 1 | 0.9% | |||||||||||||||||
| Foods and Animal Feed | 1 | 1 | 0.9% | |||||||||||||||||
| Cement Products | 1 | 1 | 0.9% | |||||||||||||||||
| Total | 1 | 4 | 3 | 2 | 2 | 9 | 13 | 13 | 10 | 9 | 4 | 5 | 4 | 7 | 9 | 5 | 5 | 4 | 109 | 100% |
| Test Set | Summary | First Order Correct Rate (Mean) | Interaction Term Correct Rate (Mean) | T-Test | |
|---|---|---|---|---|---|
| Period | |||||
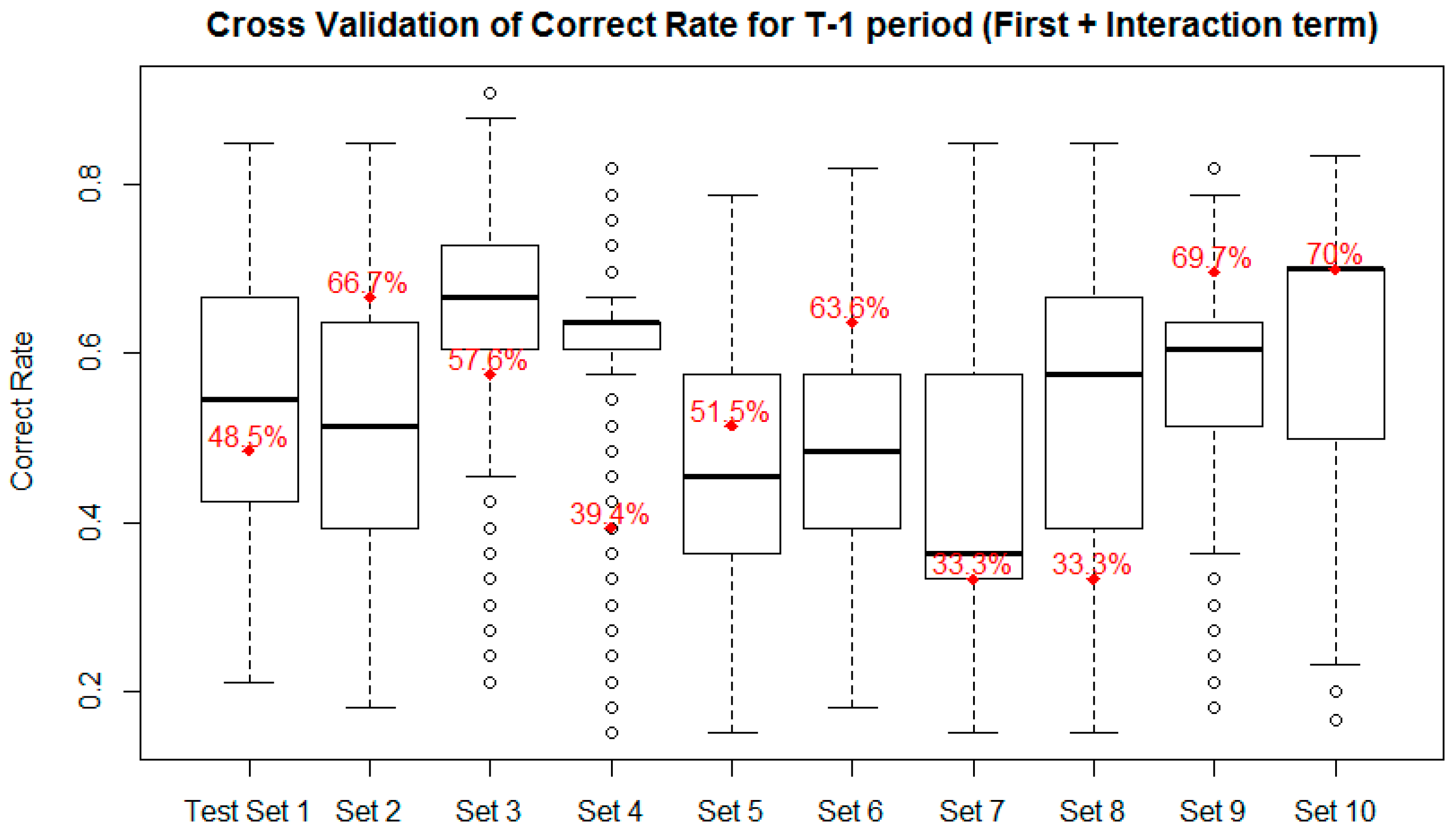
| Set 1 | T-1 | 45.5% | 53.3% | −146.1 *** | |
| T-2 | 48.6% | 54.9% | −121.4 *** | ||
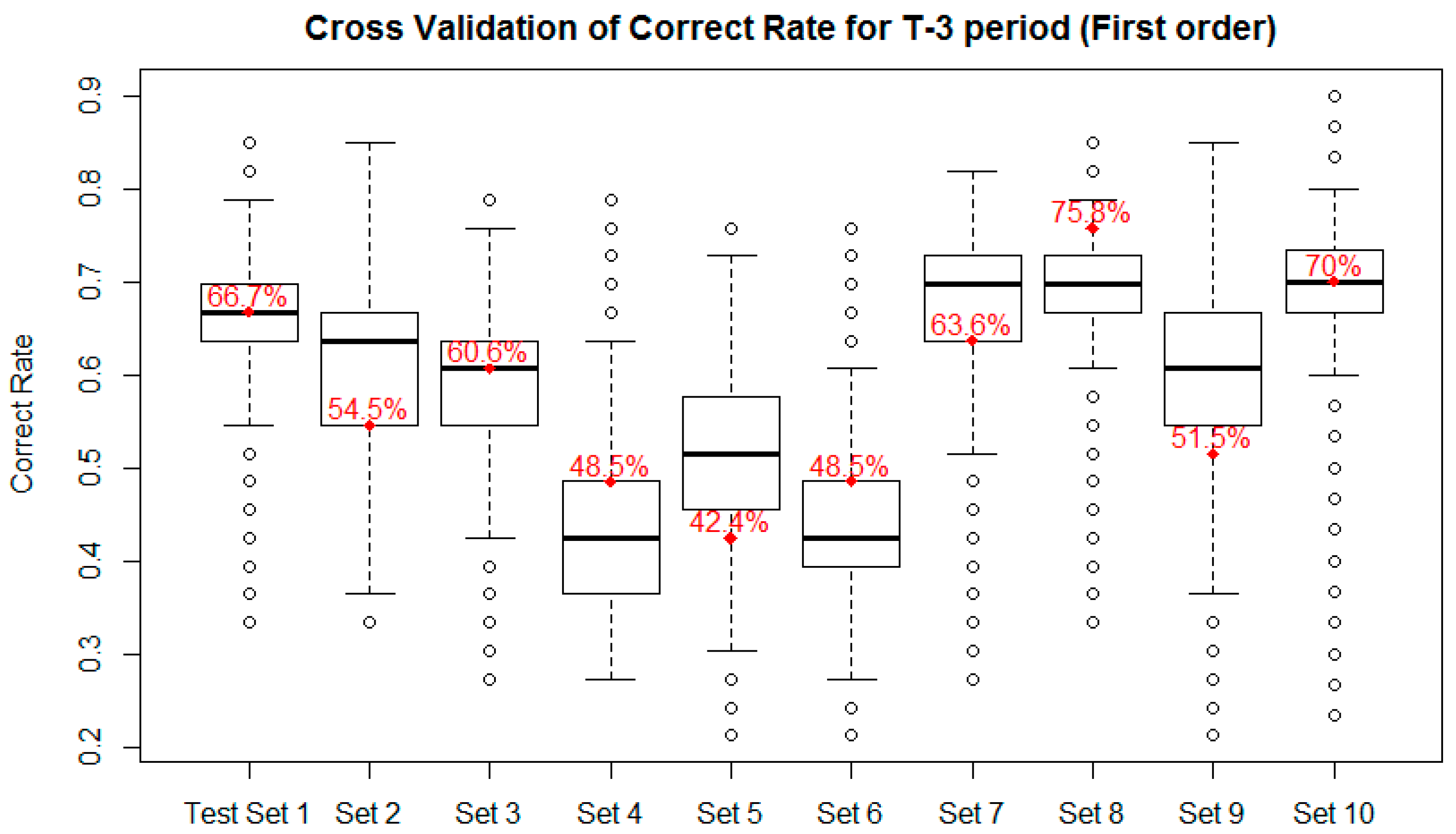
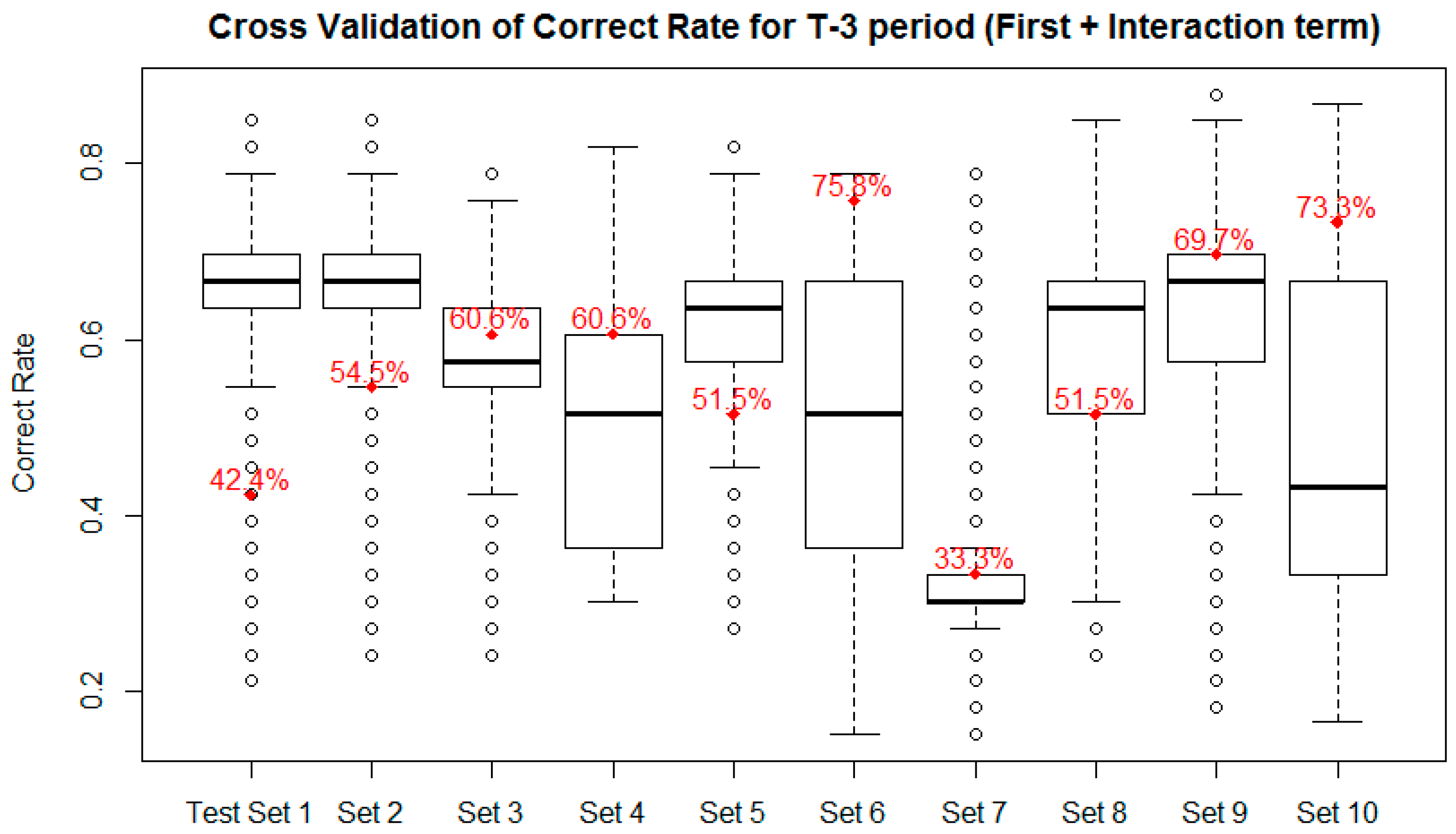
| T-3 | 66.8% | 63.6% | 84.1 *** | ||
| Set 2 | T-1 | 51.4% | 52.1% | −11.5 *** | |
| T-2 | 50.2% | 68.4% | −372.6 *** | ||
| T-3 | 60.7% | 64.8% | −101.1 *** | ||
| Set 3 | T-1 | 54.8% | 64.1% | −173.4 *** | |
| T-2 | 47.7% | 51.5% | −89.0 *** | ||
| T-3 | 59.8% | 58.0% | 55.3 *** | ||
| Set 4 | T-1 | 65.2% | 61.0% | 160.9 *** | |
| T-2 | 55.7% | 56.5% | −17.5 *** | ||
| T-3 | 43.2% | 49.2% | −118.8 *** | ||
| Set 5 | T-1 | 40.1% | 46.1% | −101.3 *** | |
| T-2 | 34.6% | 62.4% | −1068.5 *** | ||
| T-3 | 51.4% | 61.8% | −252.0 *** | ||
| Set 6 | T-1 | 60.4% | 48.4% | 236.2 *** | |
| T-2 | 66.6% | 55.0% | 235.8 *** | ||
| T-3 | 43.7% | 50.6% | −113.5 *** | ||
| Set 7 | T-1 | 50.5% | 43.4% | 107.4 *** | |
| T-2 | 48.5% | 55.2% | −90.0 *** | ||
| T-3 | 66.3% | 33.1% | 928.0 *** | ||
| Set 8 | T-1 | 34.1% | 54.6% | −361.2 *** | |
| T-2 | 37.9% | 53.4% | −246.4 *** | ||
| T-3 | 69.4% | 59.2% | 253.0 *** | ||
| Set 9 | T-1 | 54.2% | 55.8% | −31.8 *** | |
| T-2 | 36.6% | 52.8% | −379.4 *** | ||
| T-3 | 59.8% | 61.1% | −22.3 *** | ||
| Set 10 | T-1 | 42.2% | 60.6% | −269.5 *** | |
| T-2 | 38.4% | 33.2% | 103.9 *** | ||
| T-3 | 69.7% | 47.7% | 329.4 *** | ||
| Total | T-1 | 49.8% | 53.9% | −191.4 *** | |
| T-2 | 46.5% | 54.3% | −369.4 *** | ||
| T-3 | 59.1% | 54.9% | 199.1 *** | ||
| Test Set | Sample | T-1 | T-2 | T-3 | |||
|---|---|---|---|---|---|---|---|
| Logistic | MCMC | Logistic | MCMC | Logistic | MCMC | ||
| Set 1 | 1 | 1 | 78.6% | 1 | 53.7% | 0 | 18.0% |
| 4 | 1 | 42.1% | 1 | 4.9% | 0 | 5.8% | |
| 7 | 0 | 80.2% | 0 | 15.9% | 0 | 54.4% | |
| 10 | 0 | 29.8% | 1 | 99.2% | 1 | 7.0% | |
| 13 | 0 | 49.5% | 1 | 38.1% | 1 | 8.6% | |
| 16 | 0 | 30.4% | 1 | 60.1% | 1 | 14.7% | |
| 19 | 1 | 76.5% | 1 | 40.2% | 1 | 11.7% | |
| 22 | 0 | 55.7% | 1 | 43.1% | 1 | 23.4% | |
| 25 | 0 | 38.5% | 1 | 73.5% | 1 | 21.9% | |
| 28 | 0 | 24.3% | 1 | 71.5% | 1 | 32.8% | |
| 31 | 1 | 96.7% | 1 | 62.9% | 1 | 32.5% | |
| Set 2 | 34 | 0 | 58.8% | 1 | 61.2% | 0 | 23.5% |
| 37 | 0 | 37.0% | 1 | 87.2% | 0 | 77.1% | |
| 40 | 1 | 78.0% | 1 | 33.3% | 0 | 7.2% | |
| 43 | 1 | 56.0% | 1 | 24.3% | 1 | 5.7% | |
| 46 | 1 | 66.8% | 1 | 15.7% | 0 | 0.6% | |
| 49 | 1 | 43.0% | 1 | 23.3% | 0 | 16.6% | |
| 52 | 1 | 42.7% | 1 | 10.7% | 0 | 4.5% | |
| 55 | 1 | 39.4% | 1 | 35.0% | 0 | 11.5% | |
| 58 | 0 | 90.3% | 1 | 46.2% | 0 | 17.8% | |
| 61 | 0 | 59.4% | 1 | 9.0% | 0 | 82.3% | |
| 64 | 1 | 16.1% | 0 | 84.5% | 0 | 54.7% | |
| Set 3 | 67 | 0 | 15.1% | 1 | 40. 7% | 0 | 13.6% |
| 70 | 0 | 22.8% | 1 | 82.2% | 0 | 10.3% | |
| 73 | 1 | 62.8% | 1 | 98. 8% | 0 | 24.6% | |
| 76 | 0 | 4.6% | 1 | 16.2% | 0 | 25.9% | |
| 79 | 1 | 85.9% | 1 | 21.7% | 0 | 1.7% | |
| 82 | 0 | 25.4% | 1 | 74.7% | 0 | 28.7% | |
| 85 | 0 | 21.1% | 1 | 61.6% | 0 | 79.8% | |
| 88 | 1 | 68.8% | 1 | 79.3% | 0 | 26.0% | |
| 91 | 0 | 23.7% | 1 | 63.1% | 0 | 28.8% | |
| 94 | 0 | 62.1% | 1 | 79.3% | 0 | 13.0% | |
| 97 | 0 | 42.2% | 1 | 66.1% | 0 | 18.8% | |
| Set 4 | 100 | 1 | 15.8% | 1 | 44.1% | 0 | 71.4% |
| 103 | 1 | 5.3% | 1 | 44.1% | 0 | 70.5% | |
| 106 | 1 | 5.2% | 1 | 41.3% | 0 | 69.3% | |
| 109 | 1 | 1.6% | 1 | 42.4% | 0 | 62.9% | |
| 112 | 1 | 4.4% | 1 | 29.7% | 0 | 63.3% | |
| 115 | 1 | 21.9% | 1 | 43. 5% | 1 | 72.8% | |
| 118 | 1 | 48.4% | 1 | 85.4% | 0 | 62.9% | |
| 121 | 1 | 6.6% | 1 | 26. 5% | 0 | 51.5% | |
| 124 | 1 | 4.1% | 1 | 26.7% | 0 | 36.3% | |
| 127 | 1 | 12.7% | 1 | 33.1% | 0 | 59.9% | |
| 130 | 1 | 10.9% | 1 | 45.0% | 0 | 62.5% | |
| Set 5 | 133 | 1 | 69.4% | 1 | 6.7% | 0 | 24.8% |
| 136 | 1 | 38.1% | 1 | 4.0% | 0 | 11.4% | |
| 139 | 0 | 76.3% | 1 | 1.7% | 0 | 13.8% | |
| 142 | 1 | 19.9% | 1 | 0.8% | 0 | 6.8% | |
| 145 | 1 | 81.2% | 1 | 19.4% | 0 | 5.8% | |
| 148 | 0 | 9.0% | 1 | 6.6% | 0 | 17.7% | |
| 151 | 1 | 69.4% | 1 | 4.9% | 1 | 46.2% | |
| 154 | 1 | 47.0% | 1 | 22.3% | 0 | 6.0% | |
| 157 | 0 | 20.6% | 1 | 0.1% | 0 | 8.1% | |
| 160 | 1 | 48.5% | 1 | 2.1% | 0 | 11.2% | |
| 163 | 1 | 56.0% | 1 | 28.5% | 0 | 71.1% | |
| Set 6 | 166 | 1 | 70.2% | 1 | 59.6% | 1 | 74.3% |
| 169 | 0 | 78.2% | 1 | 41.0% | 0 | 42.0% | |
| 172 | 0 | 50.8% | 1 | 54.8% | 0 | 66.0% | |
| 175 | 0 | 40.1% | 1 | 17.9% | 0 | 48.2% | |
| 178 | 0 | 54.1% | 1 | 39.8% | 0 | 58.5% | |
| 181 | 0 | 16.3% | 1 | 75.4% | 1 | 34.3% | |
| 184 | 0 | 56.3% | 1 | 24.5% | 0 | 48.3% | |
| 187 | 0 | 17.0% | 1 | 89.3% | 0 | 58.1% | |
| 190 | 0 | 54.3% | 1 | 69.6% | 0 | 41.8% | |
| 193 | 0 | 38.9% | 1 | 38.1% | 1 | 39.2% | |
| 196 | 0 | 65.9% | 1 | 34.7% | 0 | 46.6% | |
| Set 7 | 199 | 1 | 87.3% | 1 | 13.0% | 1 | 81.3% |
| 202 | 0 | 29.7% | 0 | 13.5% | 0 | 82.9% | |
| 205 | 1 | 67.7% | 1 | 33.3% | 1 | 92.4% | |
| 208 | 1 | 43.7% | 1 | 15.6% | 1 | 75.5% | |
| 211 | 1 | 90.5% | 1 | 61.0% | 1 | 97.9% | |
| 214 | 1 | 60.9% | 1 | 4.1% | 0 | 2.7% | |
| 217 | 1 | 60.0% | 1 | 44.5% | 1 | 89.5% | |
| 220 | 1 | 75.4% | 1 | 62.3% | 1 | 95.5% | |
| 223 | 1 | 54.8% | 1 | 28.3% | 1 | 83.5% | |
| 226 | 1 | 92.3% | 1 | 43.2% | 1 | 91.9% | |
| 229 | 1 | 79.7% | 1 | 97.0% | 1 | 99.6% | |
| Set 8 | 232 | 1 | 39.8% | 0 | 45.1% | 1 | 76.5% |
| 235 | 1 | 51.9% | 0 | 16.3% | 0 | 38.3% | |
| 238 | 1 | 47.3% | 0 | 96.1% | 1 | 61.3% | |
| 241 | 1 | 50.6% | 0 | 19.4% | 0 | 32.0% | |
| 244 | 1 | 32.4% | 1 | 55.5% | 0 | 30.4% | |
| 247 | 1 | 72.7% | 1 | 68. 5% | 0 | 22.2% | |
| 250 | 0 | 53.8% | 0 | 71.5% | 1 | 42.7% | |
| 253 | 1 | 32.1% | 0 | 30.2% | 0 | 16.5% | |
| 256 | 1 | 84.2% | 0 | 98.8% | 0 | 37.1% | |
| 259 | 1 | 33.9% | 0 | 19.0% | 0 | 16.3% | |
| 262 | 1 | 29.0% | 0 | 9.8% | 0 | 10.3% | |
| Set 9 | 265 | 0 | 56.1% | 1 | 71. 7% | 0 | 31.4% |
| 268 | 0 | 19.9% | 1 | 32.4% | 0 | 46.0% | |
| 271 | 0 | 31.4% | 1 | 87.3% | 0 | 29.5% | |
| 274 | 0 | 19.4% | 1 | 8.7% | 0 | 59.1% | |
| 277 | 1 | 50.8% | 1 | 70.1% | 0 | 52.1% | |
| 280 | 1 | 32.8% | 1 | 33.7% | 0 | 33.4% | |
| 283 | 0 | 10.8% | 1 | 84.1% | 1 | 37.7% | |
| 286 | 1 | 51.5% | 1 | 61.4% | 0 | 33.8% | |
| 289 | 1 | 29.1% | 1 | 52.0% | 0 | 37.9% | |
| 292 | 0 | 20.5% | 1 | 35.0% | 0 | 21.4% | |
| 295 | 1 | 16.7% | 1 | 77.7% | 0 | 42.2% | |
| Set 10 | 298 | 0 | 21.5% | 1 | 98. 7% | 1 | 83.4% |
| 301 | 0 | 37.7% | 1 | 96.9% | 0 | 67.4% | |
| 304 | 0 | 35.2% | 1 | 72.2% | 0 | 51.5% | |
| 307 | 1 | 51.6% | 1 | 38.0% | 0 | 45.8% | |
| 310 | 0 | 27.1% | 1 | 96.8% | 0 | 43.6% | |
| 313 | 0 | 22.1% | 1 | 97.4% | 0 | 66.1% | |
| 316 | 0 | 17.8% | 0 | 31.9% | 1 | 3.4% | |
| 319 | 0 | 25.7% | 1 | 97.7% | 0 | 48.1% | |
| 322 | 0 | 88.8% | 1 | 99.4% | 0 | 88.0% | |
| 325 | 0 | 35.7% | 1 | 95.3% | 0 | 56.2% | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tseng, S.-H.; Nguyen, T.S. A Method for Visualizing Posterior Probit Model Uncertainty in the Early Prediction of Fraud for Sustainability Development. Axioms 2021, 10, 178. https://doi.org/10.3390/axioms10030178
Tseng S-H, Nguyen TS. A Method for Visualizing Posterior Probit Model Uncertainty in the Early Prediction of Fraud for Sustainability Development. Axioms. 2021; 10(3):178. https://doi.org/10.3390/axioms10030178
Chicago/Turabian StyleTseng, Shih-Hsien, and Tien Son Nguyen. 2021. "A Method for Visualizing Posterior Probit Model Uncertainty in the Early Prediction of Fraud for Sustainability Development" Axioms 10, no. 3: 178. https://doi.org/10.3390/axioms10030178
APA StyleTseng, S. -H., & Nguyen, T. S. (2021). A Method for Visualizing Posterior Probit Model Uncertainty in the Early Prediction of Fraud for Sustainability Development. Axioms, 10(3), 178. https://doi.org/10.3390/axioms10030178