
CoreBug: Improving Effort-Aware Bug Prediction in Software Systems Using Generalized k-Core Decomposition in Class Dependency Networks


Abstract
:1. Introduction
- The work of Qu et al. [3] used unweighted undirected software networks to represent software structure at the class level. Worse still, their software networks only considered five coupling types between classes, neglecting many important couplings such as “instantiates”, “access”, and “method call”. It is a primitive representation that cannot precisely capture the couplings between classes. In this work, we propose a WDCDN that captures nine coupling types between classes, uses link weight to denote coupling strength and uses link direction to denote the coupling direction. In this sense, our WDCDN is a more accurate representation of the software structure when compared with the software network used in [3].
- The work of Qu et al. [3] used k-core decomposition to compute the coreness of classes in the software network. This k-core decomposition can only be used in unweighted undirected networks. In this work, we apply a generalized k-core decomposition that can be used in weighted directed networks.
- We perform a comprehensive set of experiments to validate the effectiveness of CoreBug.
2. Related Work
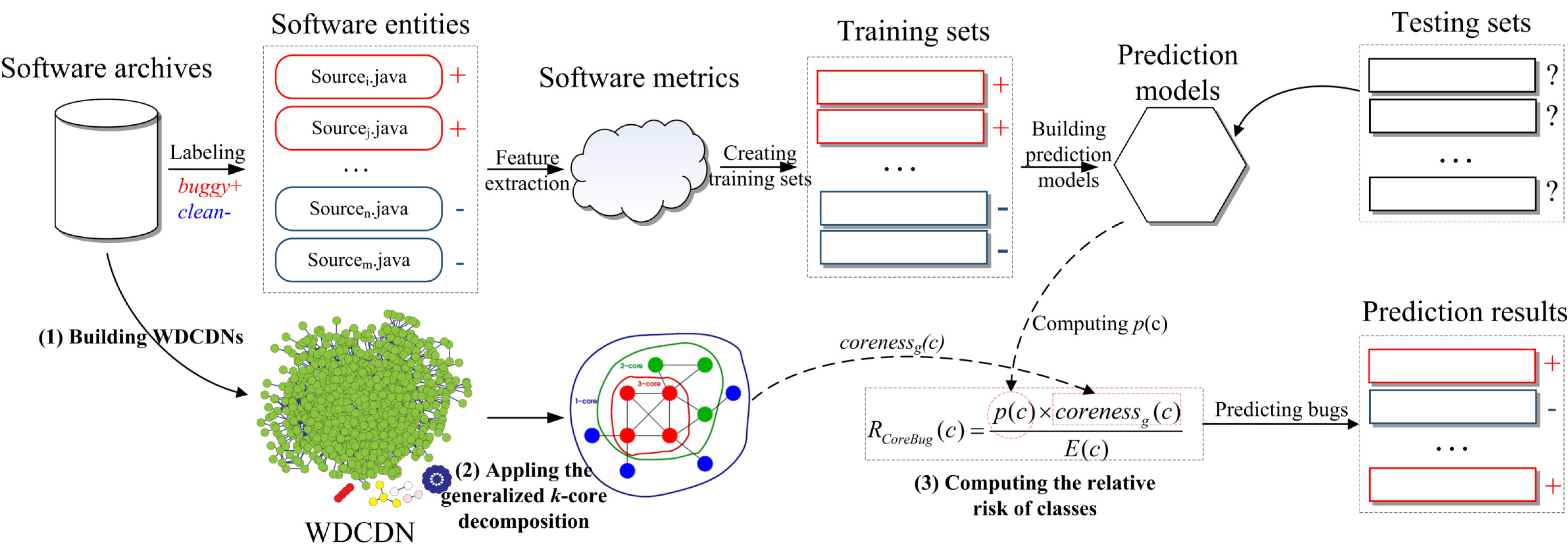
3. The CoreBug Approach
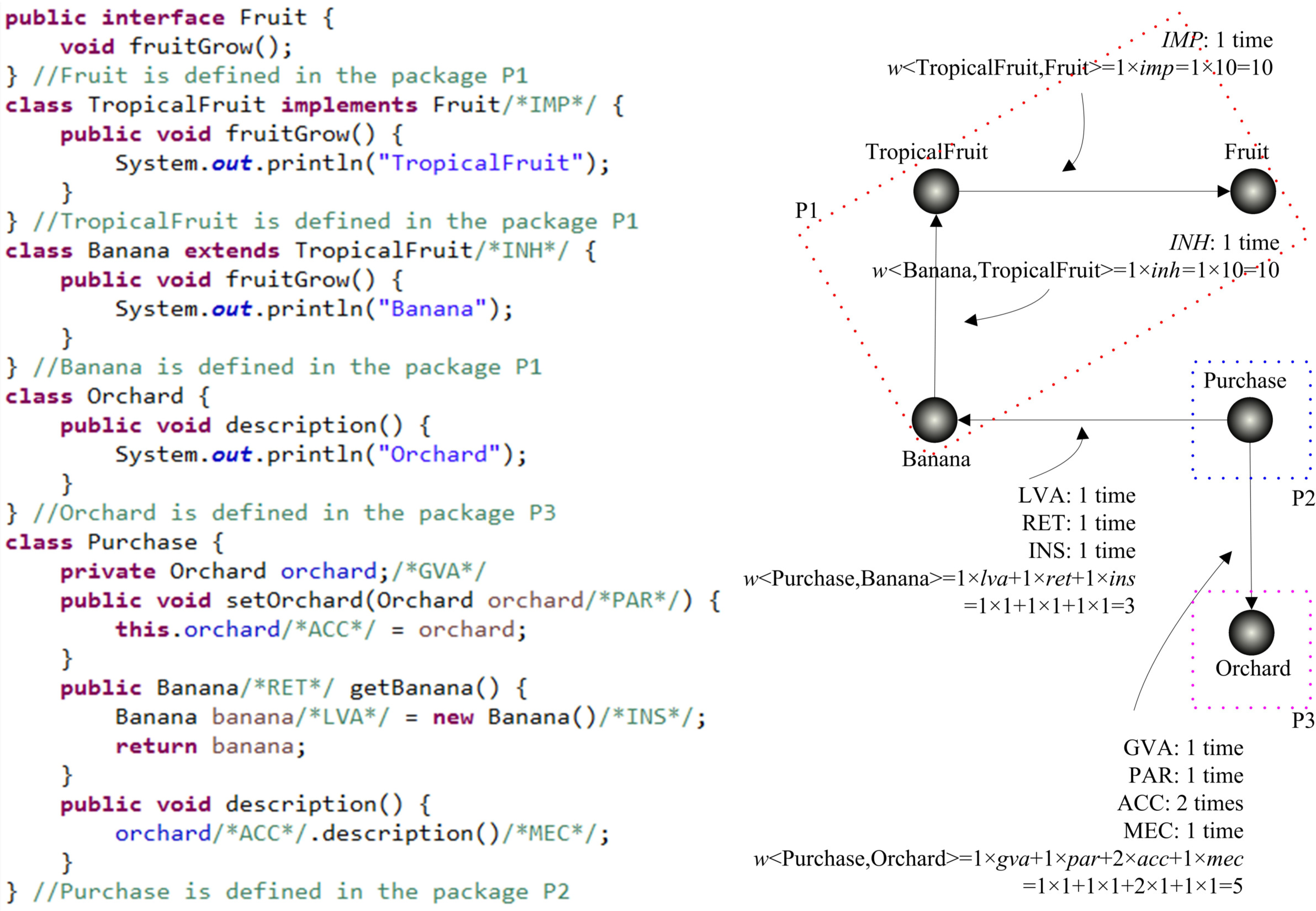
3.1. Weighted Directed Class Dependency Network
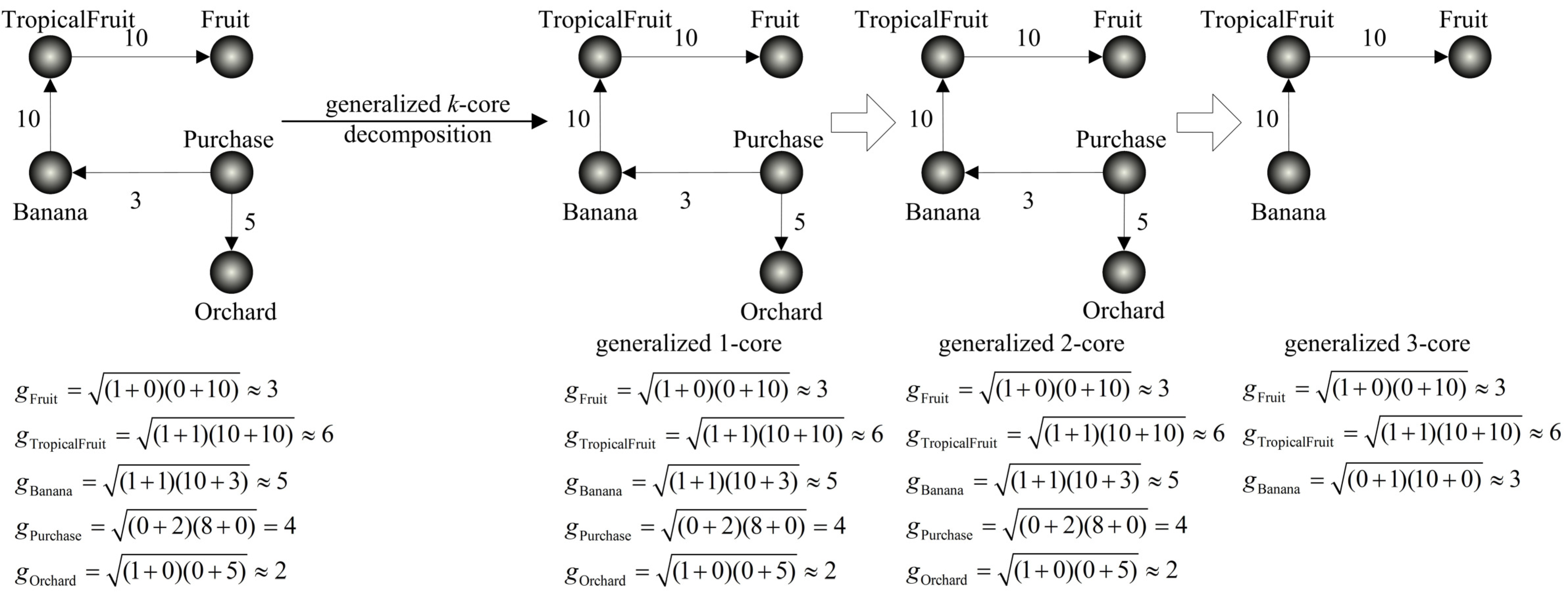
3.2. Generalized k-Core Decomposition
3.3. The Relative Risk of Classes
4. Empirical Evaluation
4.1. Research Questions
- RQ:
- Does CoreBug perform better than the baseline approaches? CoreBug improved on top-core in two aspects, that is, a much more accurate representation of the software structure (i.e., WDCDN) and the generalized k-core decomposition to compute the coreness of classes in the WDCDN. Thus, we want to examine whether our CoreBug approach performs better than the baseline approaches in Section 4.3.
4.2. Subject Systems
4.3. Baseline Approaches
4.4. Evaluation Metrics
4.5. Experiment Results and Analysis
4.6. Threats to Validity
4.6.1. Threats to Internal Validity
4.6.2. Threats to External Validity
5. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- He, P.; Li, B.; Liu, X.; Chen, J.; Ma, Y. An empirical study on software defect prediction with a simplified metric set. Inf. Softw. Technol. 2015, 59, 170–190. [Google Scholar] [CrossRef] [Green Version]
- Yang, Y.; Zhou, Y.; Lu, H.; Chen, L.; Chen, Z.; Xu, B.; Leung, H.K.N.; Zhang, Z. Are Slice-Based Cohesion Metrics Actually Useful in Effort-Aware Post-Release Fault-Proneness Prediction? An Empirical Study. IEEE Trans. Softw. Eng. 2015, 41, 331–357. [Google Scholar] [CrossRef]
- Qu, Y.; Zheng, Q.; Chi, J.; Jin, Y.; He, A.; Cui, D.; Zhang, H.; Liu, T. Using K-core Decomposition on Class Dependency Networks to Improve Bug Prediction Model’s Practical Performance. IEEE Trans. Softw. Eng. 2021, 47, 348–366. [Google Scholar] [CrossRef]
- Pan, W.; Li, B.; Liu, J.; Ma, Y.; Hu, B. Analyzing the structure of Java software systems by weighted K-core decomposition. Future Gener. Comput. Syst. 2018, 83, 431–444. [Google Scholar] [CrossRef]
- Li, H.; Wang, T.; Pan, W.; Wang, M.; Chai, C.; Chen, P.; Wang, J.; Wang, J. Mining Key Classes in Java Projects by Examining a Very Small Number of Classes: A Complex Network-Based Approach. IEEE Access 2021, 9, 28076–28088. [Google Scholar] [CrossRef]
- Meneely, A.; Williams, L.A.; Snipes, W.; Osborne, J.A. Predicting failures with developer networks and social network analysis. In Proceedings of the 16th ACM SIGSOFT International Symposium on Foundations of Software Engineering, Atlanta, GA, USA, 9–14 November 2008; Harrold, M.J., Murphy, G.C., Eds.; pp. 13–23. [Google Scholar] [CrossRef] [Green Version]
- Pinzger, M.; Nagappan, N.; Murphy, B. Can developer-module networks predict failures? In Proceedings of the 16th ACM SIGSOFT International Symposium on Foundations of Software Engineering, Atlanta, GA, USA, 9–14 November 2008; Harrold, M.J., Murphy, G.C., Eds.; pp. 2–12. [Google Scholar] [CrossRef] [Green Version]
- Chen, L.; Ma, W.; Zhou, Y.; Xu, L.; Wang, Z.; Chen, Z.; Xu, B. Empirical analysis of network measures for predicting high severity software faults. Sci. China Inf. Sci. 2016, 59, 122901:1–122901:18. [Google Scholar] [CrossRef] [Green Version]
- Ma, W.; Chen, L.; Yang, Y.; Zhou, Y.; Xu, B. Empirical analysis of network measures for effort-aware fault-proneness prediction. Inf. Softw. Technol. 2016, 69, 50–70. [Google Scholar] [CrossRef]
- Pan, W.; Ming, H.; Yang, Z.; Wang, T. Comments on “using k-core decomposition on class dependency networks to improve bug prediction model’s practical performance”. IEEE Trans. Softw. Eng. 2022. [Google Scholar] [CrossRef]
- Zimmermann, T.; Nagappan, N. Predicting defects using network analysis on dependency graphs. In Proceedings of the 30th International Conference on Software Engineering (ICSE 2008), Leipzig, Germany, 10–18 May 2008; Schäfer, W., Dwyer, M.B., Gruhn, V., Eds.; pp. 531–540. [Google Scholar] [CrossRef] [Green Version]
- Tosun, A.; Turhan, B.; Bener, A.B. Validation of network measures as indicators of defective modules in software systems. In Proceedings of the 5th International Workshop on Predictive Models in Software Engineering, PROMISE, Vancouver, BC, Canada, 18–19 May 2009; Ostrand, T.J., Ed.; p. 5. [Google Scholar] [CrossRef]
- Premraj, R.; Herzig, K. Network Versus Code Metrics to Predict Defects: A Replication Study. In Proceedings of the 5th International Symposium on Empirical Software Engineering and Measurement, ESEM, Banff, AB, Canada, 22–23 September 2011; pp. 215–224. [Google Scholar] [CrossRef]
- Qu, Y.; Liu, T.; Chi, J.; Jin, Y.; Cui, D.; He, A.; Zheng, Q. node2defect: Using network embedding to improve software defect prediction. In Proceedings of the 33rd ACM/IEEE International Conference on Automated Software Engineering, ASE, Montpellier, France, 3–7 September 2018; Huchard, M., Kästner, C., Fraser, G., Eds.; pp. 844–849. [Google Scholar] [CrossRef]
- Guo, S.; Dong, J.; Li, H.; Wang, J. Software defect prediction with imbalanced distribution by radius-synthetic minority over-sampling technique. J. Softw. Evol. Process 2021, 33, e2362. [Google Scholar] [CrossRef]
- Eken, B.; Palma, F.; Basar, A.; Tosun, A. An empirical study on the effect of community smells on bug prediction. Softw. Qual. J. 2021, 29, 159–194. [Google Scholar] [CrossRef]
- Brito e Abreu, F.; Goulao, M. Coupling and cohesion as modularization drivers: Are we being over-persuaded? In Proceedings of the Proceedings Fifth European Conference on Software Maintenance and Reengineering, Lisbon, Portugal, 14–16 March 2001; pp. 47–57. [Google Scholar] [CrossRef]
- Pan, W.; Song, B.; Li, K.; Zhang, K. Identifying key classes in object-oriented software using generalized k-core decomposition. Future Gener. Comput. Syst. 2018, 81, 188–202. [Google Scholar] [CrossRef]
- Hall, T.; Beecham, S.; Bowes, D.; Gray, D.; Counsell, S. A Systematic Literature Review on Fault Prediction Performance in Software Engineering. IEEE Trans. Softw. Eng. 2012, 38, 1276–1304. [Google Scholar] [CrossRef]
- Lessmann, S.; Baesens, B.; Mues, C.; Pietsch, S. Benchmarking Classification Models for Software Defect Prediction: A Proposed Framework and Novel Findings. IEEE Trans. Softw. Eng. 2008, 34, 485–496. [Google Scholar] [CrossRef] [Green Version]
- Menzies, T.; Caglayan, B.; Kocaguneli, E.; Krall, J.; Peters, F.; Turhan, B. The Promise Repository of Empirical Software Engineering Data; West Virginia University, Department of Computer Science: Morgantown, WV, USA, 2012. [Google Scholar]
- D’Ambros, M.; Lanza, M.; Robbes, R. An extensive comparison of bug prediction approaches. In Proceedings of the 7th International Working Conference on Mining Software Repositories, MSR 2010 (Co-Located with ICSE), Cape Town, South Africa, 2–3 May 2010; Whitehead, J., Zimmermann, T., Eds.; pp. 31–41. [Google Scholar] [CrossRef]
- Shippey, T.; Hall, T.; Counsell, S.; Bowes, D. So You Need More Method Level Datasets for Your Software Defect Prediction?: Voilà! In Proceedings of the 10th ACM/IEEE International Symposium on Empirical Software Engineering and Measurement, ESEM, Ciudad Real, Spain, 8–9 September 2016; p. 12. [Google Scholar] [CrossRef] [Green Version]
- García, S.; Fernández, A.; Luengo, J.; Herrera, F. Advanced nonparametric tests for multiple comparisons in the design of experiments in computational intelligence and data mining: Experimental analysis of power. Inf. Sci. 2010, 180, 2044–2064. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
| System | Version | LOC | #Class | Website (Accessed on 16 January 2022) | |
|---|---|---|---|---|---|
| Camel | 1.6.0 | 98,125 | 2158 | 8.73% | camel.apache.org |
| lvy | 2 | 37,020 | 570 | 7.04% | ant.apache.org/ivy |
| Log4j | 1.1.3 | 12,407 | 210 | 17.70% | logging.apache.org |
| Poi | 3 | 138,585 | 1457 | 19.20% | poi.apache.org |
| Synapse | 1.2 | 45,674 | 554 | 15.37% | synapse.apache.org |
| Tomcat | 6.0.38 | 173,064 | 1583 | 4.85% | tomcat.apache.org |
| Velocity | 1.6.1 | 37,274 | 463 | 16.83% | velocity.apache.org |
| Xalan | 2.6.0 | 151,984 | 1081 | 36.30% | xalan.apache.org |
| Eclipse JDT Core | 3.4 | 264,271 | 1294 | 15.89% | www.eclipse.org/jdt/core |
| Equinox framework | 3.4 | 59,074 | 611 | 21.08% | www.eclipse.org/jdt/core/equinox |
| Lucene | 2.4.0 | 123,333 | 1295 | 4.02% | lucene.apache.org |
| DrJava | 20080106 | 65,274 | 1797 | 7.40% | drjava.org |
| Genoviz | 6.3 | 108,108 | 853 | 8.46% | sourceforge.net/projects/genoviz |
| HtmlUnit | 2.7 | 87,308 | 805 | 13.37% | htmlunit.sourceforge.net |
| Jmol | 6 | 31,576 | 1816 | 4.30% | jmol.sourceforge.net |
| Jikes RVM | 3.0.0 | 189,351 | 1657 | 7.48% | www.jikesrvm.org |
| Jppf | 5 | 78,668 | 1555 | 10.26% | jppf.org |
| Jump | 1.9.0 | 182,703 | 1966 | 3.68% | openjump.org |
| System | Top-Core | CoreBug | |
|---|---|---|---|
| Camel | 0.5252 | 0.5367 | 0.5411 |
| Ivy | 0.2084 | 0.1871 | 0.2137 |
| Log4j | 0.3824 | 0.5369 | 0.4801 |
| Poi | 0.7394 | 0.6565 | 0.7308 |
| Synapse | 0.4627 | 0.3949 | 0.4191 |
| Tomcat | 0.2401 | 0.2908 | 0.2925 |
| Velocity | 0.6461 | 0.6584 | 0.6137 |
| Xalan | 0.6898 | 0.5804 | 0.5844 |
| Eclipse JDT Core | 0.4586 | 0.4362 | 0.4283 |
| Equinox framework | 0.68 | 0.6308 | 0.6083 |
| Lucene | 0.4454 | 0.4763 | 0.4754 |
| DrJava | 0.3726 | 0.3087 | 0.2493 |
| GenoViz | 0.2677 | 0.2839 | 0.2883 |
| HtmlUnit | 0.3693 | 0.4068 | 0.4094 |
| Jmol | 0.3781 | 0.4831 | 0.4988 |
| Jikes RVM | 0.2079 | 0.3605 | 0.382 |
| Jppf | 0.2755 | 0.3307 | 0.361 |
| Jump | 0.1842 | 0.1985 | 0.1835 |
| Win/Tie/Loss | CoreBug vs. | 10/0/8 | |
| CoreBug vs. top-core | 11/0/7 | ||
| System | Top-Core | CoreBug | |
|---|---|---|---|
| Camel | 0.5549 | 0.5747 | 0.578 |
| Ivy | 0.2644 | 0.2264 | 0.2494 |
| Log4j | 0.4539 | 0.5618 | 0.5346 |
| Poi | 0.7873 | 0.7071 | 0.7643 |
| Synapse | 0.4887 | 0.4421 | 0.4578 |
| Tomcat | 0.2975 | 0.3474 | 0.3423 |
| Velocity | 0.6935 | 0.692 | 0.6548 |
| Xalan | 0.73 | 0.6331 | 0.6379 |
| Eclipse JDT Core | 0.51 | 0.4892 | 0.4906 |
| Equinox framework | 0.7091 | 0.6652 | 0.645 |
| Lucene | 0.5109 | 0.5478 | 0.5415 |
| DrJava | 0.4373 | 0.3994 | 0.3091 |
| GenoViz | 0.3269 | 0.3591 | 0.3711 |
| HtmlUnit | 0.4213 | 0.4845 | 0.5002 |
| Jmol | 0.4697 | 0.5407 | 0.5556 |
| Jikes RVM | 0.292 | 0.4522 | 0.5041 |
| Jppf | 0.3434 | 0.4073 | 0.4184 |
| Jump | 0.2422 | 0.2441 | 0.2333 |
| Win/Tie/Loss | CoreBug vs. | 9/0/9 | |
| CoreBug vs. top-core | 11/0/7 | ||
| System | Top-Core | CoreBug | |
|---|---|---|---|
| Camel | 0.592 | 0.6156 | 0.6217 |
| Ivy | 0.3228 | 0.2723 | 0.2938 |
| Log4j | 0.4955 | 0.5837 | 0.5689 |
| Poi | 0.817 | 0.7434 | 0.7887 |
| Synapse | 0.5212 | 0.4811 | 0.4985 |
| Tomcat | 0.3578 | 0.39 | 0.3869 |
| Velocity | 0.7309 | 0.7321 | 0.6934 |
| Xalan | 0.758 | 0.674 | 0.6689 |
| Eclipse JDT Core | 0.5579 | 0.5349 | 0.5383 |
| Equinox framework | 0.7344 | 0.6981 | 0.6825 |
| Lucene | 0.5778 | 0.61 | 0.6032 |
| DrJava | 0.4941 | 0.4779 | 0.3648 |
| GenoViz | 0.3859 | 0.4342 | 0.4413 |
| HtmlUnit | 0.4742 | 0.5404 | 0.5686 |
| Jmol | 0.5399 | 0.5877 | 0.605 |
| Jikes RVM | 0.373 | 0.5298 | 0.5939 |
| Jppf | 0.4024 | 0.4797 | 0.4701 |
| Jump | 0.2992 | 0.2978 | 0.2871 |
| Win/Tie/Loss | CoreBug vs. | 9/0/9 | |
| CoreBug vs. top-core | 9/0/9 | ||
| Approach | Ranking |
|---|---|
| CoreBug | 1.9074074074074072 |
| top-core | 2.0 |
| 2.092592592592594 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Du, X.; Wang, T.; Wang, L.; Pan, W.; Chai, C.; Xu, X.; Jiang, B.; Wang, J. CoreBug: Improving Effort-Aware Bug Prediction in Software Systems Using Generalized k-Core Decomposition in Class Dependency Networks. Axioms 2022, 11, 205. https://doi.org/10.3390/axioms11050205
Du X, Wang T, Wang L, Pan W, Chai C, Xu X, Jiang B, Wang J. CoreBug: Improving Effort-Aware Bug Prediction in Software Systems Using Generalized k-Core Decomposition in Class Dependency Networks. Axioms. 2022; 11(5):205. https://doi.org/10.3390/axioms11050205
Chicago/Turabian StyleDu, Xin, Tian Wang, Liuhai Wang, Weifeng Pan, Chunlai Chai, Xinxin Xu, Bo Jiang, and Jiale Wang. 2022. "CoreBug: Improving Effort-Aware Bug Prediction in Software Systems Using Generalized k-Core Decomposition in Class Dependency Networks" Axioms 11, no. 5: 205. https://doi.org/10.3390/axioms11050205
APA StyleDu, X., Wang, T., Wang, L., Pan, W., Chai, C., Xu, X., Jiang, B., & Wang, J. (2022). CoreBug: Improving Effort-Aware Bug Prediction in Software Systems Using Generalized k-Core Decomposition in Class Dependency Networks. Axioms, 11(5), 205. https://doi.org/10.3390/axioms11050205