


An Efficient Subspace Minimization Conjugate Gradient Method for Solving Nonlinear Monotone Equations with Convex Constraints

Abstract
:1. Introduction
2. The SMCG Method for Solving Nonlinear Monotone Equations with Convex Constraints
2.1. The SMCG Method for Unconstrained Optimization
2.2. The SMCG Method for Solving (1) and Its Some Important Properties
| Algorithm 1 Subspace Minimization Conjugate Gradient Method for Solving (1) |
|
3. Convergence Analysis
3.1. Global Convergence
3.2. R-Linear Convergence Rate
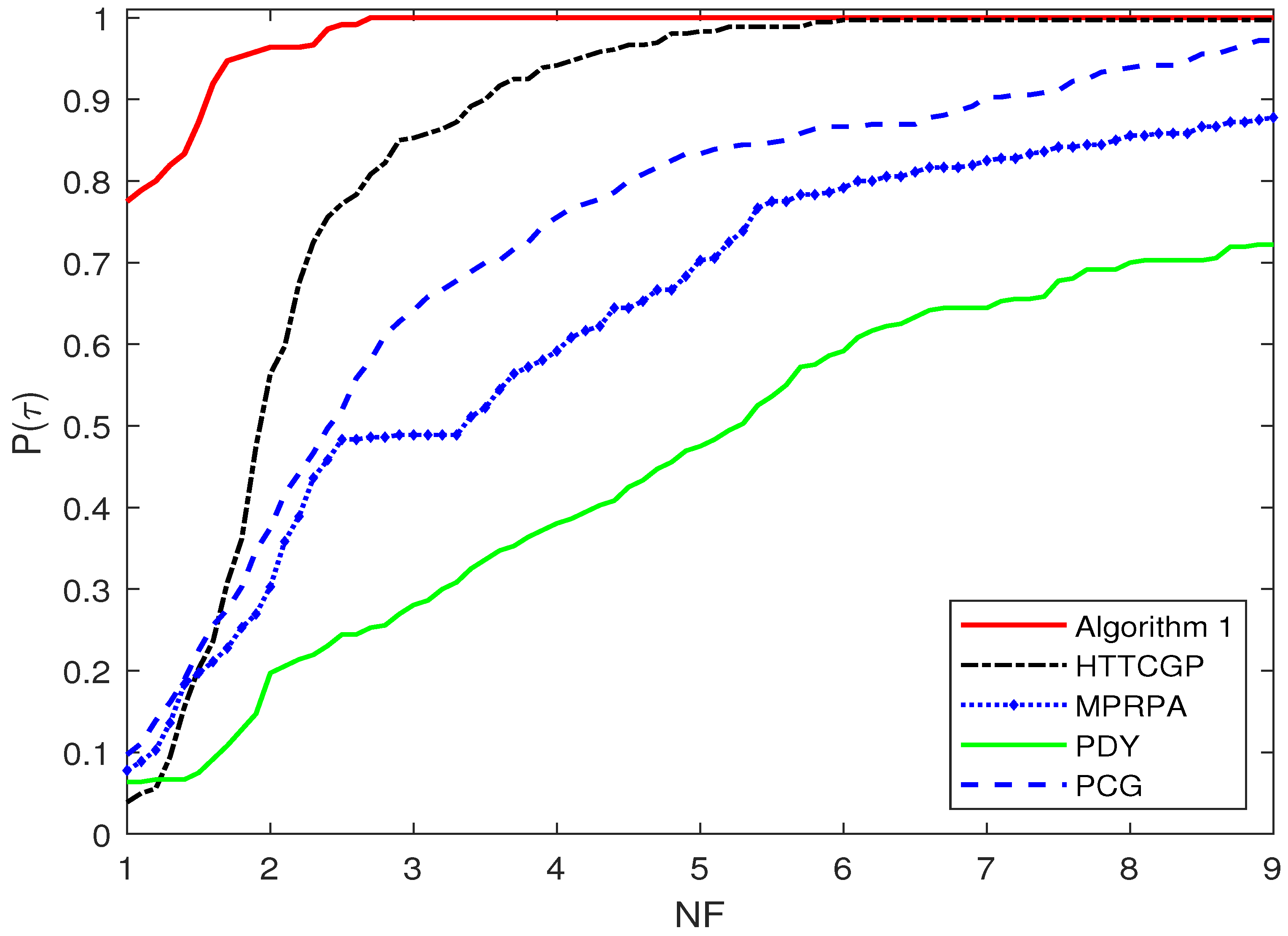
4. Numerical Experiments
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Guo, D.S.; Nie, Z.Y.; Yan, L.C. The application of noise-tolerant ZD design formula to robots’ kinematic control via time-varying nonlinear equations solving. IEEE Trans. Syst. Man Cybern. Syst. 2017, 48, 2188–2197. [Google Scholar] [CrossRef]
- Shi, Y.; Zhang, Y. New discrete-time models of zeroing neural network solving systems of time-variant linear and nonlinear inequalities. IEEE Trans. Syst. Man Cybern. Syst. 2017, 50, 565–576. [Google Scholar] [CrossRef]
- Dirkse, S.P.; Ferris, M.C. MCPLIB: A collection of nonlinear mixed complementarity problems. Optim. Methods Softw. 1995, 5, 319–345. [Google Scholar] [CrossRef]
- Xiao, Y.H.; Wang, Q.Y.; Hu, Q.J. Non-smooth equations based methods for l1-norm problems with applications to compressed sensing. Nonlinear Anal. 2011, 74, 3570–3577. [Google Scholar] [CrossRef]
- Yuan, Y.X. Subspace methods for large scale nonlinear equations and nonlinear least squares. Optim. Eng. 2009, 10, 207–218. [Google Scholar] [CrossRef]
- Ahmad, F.; Tohidi, E.; Carrasco, J.A. A parameterized multi-step Newton method for solving systems of nonlinear equations. Numer. Algorithms 2016, 71, 631–653. [Google Scholar] [CrossRef]
- Lukšan, L.; Vlček, J. New quasi-Newton method for solving systems of nonlinear equations. Appl. Math. 2017, 62, 121–134. [Google Scholar] [CrossRef]
- Yu, Z. On the global convergence of a Levenberg-Marquardt method for constrained nonlinear equations. JAMC 2004, 16, 183–194. [Google Scholar] [CrossRef]
- Zhang, J.L.; Wang, Y. A new trust region method for nonlinear equations. Math. Methods Oper. Res. 2003, 58, 283–298. [Google Scholar] [CrossRef]
- Solodov, M.V.; Svaiter, B.F. A globally convergent inexact Newton method for systems of monotone equations. In Reformulation: Nonsmooth, Piecewise Smooth, Semismooth and Smoothing Methods; Fukushima, M., Qi, L., Eds.; Kluwer Academic: Boston, MA, USA, 1998; pp. 355–369. [Google Scholar]
- Zheng, Y.; Zheng, B. Two new Dai–Liao-type conjugate gradient methods for unconstrained optimization problems. J. Optim. Theory Appl. 2017, 175, 502–509. [Google Scholar] [CrossRef]
- Li, M.; Liu, H.W.; Liu, Z.X. A new family of conjugate gradient methods for unconstrained optimization. J. Appl. Math. Comput. 2018, 58, 219–234. [Google Scholar] [CrossRef]
- Xiao, Y.H.; Zhu, H. A conjugate gradient method to solve convex constrained monotone equations with applications in compressive sensing. J. Math. Anal. Appl. 2013, 405, 310–319. [Google Scholar] [CrossRef]
- Hager, H.H.; Zhang, H. A new conjugate gradient method with guaranteed descent and an efficient line search. SIAM J. Optim. 2005, 16, 170–192. [Google Scholar] [CrossRef]
- Liu, J.K.; Li, S.J. A projection method for convex constrained monotone nonlinear equations with applications. Comput. Math. Appl. 2015, 70, 2442–2453. [Google Scholar] [CrossRef]
- Dai, Y.H.; Yuan, Y.X. A nonlinear conjugate gradient with a strong global convergence property. SIAM J. Optim. 1999, 10, 177–182. [Google Scholar] [CrossRef]
- Liu, J.K.; Feng, Y.M. A derivative-free iterative method for nonlinear monotone equations with convex constraints. Numer. Algorithms 2019, 82, 245–262. [Google Scholar] [CrossRef]
- Gao, P.T.; He, C.J.; Liu, Y. An adaptive family of projection methods for constrained monotone nonlinear equations with applications. Appl. Math. Comput. 2019, 359, 1–16. [Google Scholar] [CrossRef]
- Bojari, S.; Eslahchi, M.R. Two families of scaled three-term conjugate gradient methods with sufficient descent property for nonconvex optimization. Numer. Algorithms 2020, 83, 901–933. [Google Scholar] [CrossRef]
- Li, Q.; Zheng, B. Scaled three-term derivative-free methods for solving large-scale nonlinear monotone equations. Numer. Algorithms 2021, 87, 1343–1367. [Google Scholar] [CrossRef]
- Waziri, M.Y.; Ahmed, K. Two Descent Dai-Yuan Conjugate Gradient Methods for Systems of Monotone Nonlinear Equations. J. Sci. Comput. 2022, 90, 36. [Google Scholar] [CrossRef]
- Ibrahim, A.H.; Alshahrani, M.; Al-Homidan, S. Two classes of spectral three-term derivative-free method for solving nonlinear equations with application. Numer. Algorithms 2023. [Google Scholar] [CrossRef]
- Yuan, Y.X.; Stoer, J. A subspace study on conjugate gradient algorithms. Z. Angew. Math. Mech. 1995, 75, 69–77. [Google Scholar] [CrossRef]
- Dai, Y.H.; Kou, C.X. A Barzilai-Borwein conjugate gradient method. Sci. China Math. 2016, 59, 1511–1524. [Google Scholar] [CrossRef]
- Liu, H.W.; Liu, Z.X. An efficient Barzilai–Borwein conjugate gradient method for unconstrained optimization. J. Optim. Theory Appl. 2019, 180, 879–906. [Google Scholar] [CrossRef]
- Li, Y.F.; Liu, Z.X.; Liu, H.W. A subspace minimization conjugate gradient method based on conic model for unconstrained optimization. Comput. Appl. Math. 2019, 38, 16. [Google Scholar] [CrossRef]
- Zhao, T.; Liu, H.W.; Liu, Z.X. New subspace minimization conjugate gradient methods based on regularization model for unconstrained optimization. Numer. Algorithms 2021, 87, 1501–1534. [Google Scholar] [CrossRef]
- Wang, T.; Liu, Z.; Liu, H. A new subspace minimization conjugate gradient method based on tensor model for unconstrained optimization. Int. J. Comput. Math. 2019, 96, 1924–1942. [Google Scholar] [CrossRef]
- Ortega, J.M.; Rheinboldt, W.C. Iterative Solution of Nonlinear Equation in Several Variables; Academic Press: New York, NY, USA; London, UK, 1970. [Google Scholar]
- Yin, J.H.; Jian, J.B.; Jiang, X.Z.; Liu, M. X; Wang, L.Z. A hybrid three-term conjugate gradient projection method for constrained nonlinear monotone equations with applications. Numer. Algorithms 2021, 88, 389–418. [Google Scholar] [CrossRef]
- Ou, Y.G.; Li, J.Y. A new derivative-free SCG-type projection method for nonlinear monotone equations with convex constraints. J. Appl. Math. Comput. 2018, 56, 195–216. [Google Scholar] [CrossRef]
- Ma, G.D.; Jin, J.C.; Jian, J.B.; Yin, J.H.; Han, D.L. A modified inertial three-term conjugate gradient projection method for constrained nonlinear equations with applications in compressed sensing. Numer. Algorithms 2023, 92, 1621–1653. [Google Scholar] [CrossRef]
- Dolan, E.D.; More, J.J. Benchmarking optimization software with performance profiles. Math. Program 2002, 91, 201–213. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
| P | Al | PDY | HTTCGP | MPRPA | PCG | Al | HTTCGP | PDY | MPRPA | PCG | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Ni/NF | Ni/NF | Ni/NF | Ni/NF | Ni/NF | Ni/NF | Ni/NF | Ni/NF | Ni/NF | Ni/NF | |||
| P1 | 0.1 m | 4\9 | 14\31 | 3\7 | 28\57 | 9\23 | 1.2 m | 8\17 | 14\31 | 5\11 | 34\69 | 11\27 |
| 0.2 m | 5\11 | 14\31 | 3\7 | 29\59 | 8\20 | 1.5 m | 8\17 | 20\42 | 5\11 | 35\71 | 9\22 | |
| 0.5 m | 6\13 | 18\39 | 4\9 | 31\63 | 10\25 | 2.0 m | 8\17 | 15\33 | 6\14 | 36\73 | 11\27 | |
| P2 | 0.1 m | 4\10 | 7\23 | 6\19 | 12\25 | 10\36 | 1.2 m | 5\11 | 8\25 | 7\22 | 13\27 | 9\32 |
| 0.2 m | 4\10 | 7\23 | 6\19 | 12\25 | 10\36 | 1.5 m | 6\13 | 8\25 | 7\22 | 13\27 | 9\32 | |
| 0.5 m | 3\8 | 6\20 | 5\16 | 9\19 | 8\29 | 2.0 m | 6\13 | 8\25 | 8\25 | 14\29 | 10\35 | |
| P3 | 0.1 m | 19\39 | 16\42 | 26\72 | 42\85 | 16\39 | 1.2 m | 17\35 | 27\81 | 49\126 | 37\75 | 18\52 |
| 0.2 m | 19\39 | 19\49 | 31\83 | 42\85 | 16\39 | 1.5 m | 19\40 | 20\58 | 41\109 | 33\67 | 17\46 | |
| 0.5 m | 19\39 | 22\57 | 28\80 | 41\83 | 18\48 | 2.0 m | 18\38 | 32\148 | 46\121 | 34\70 | 19\59 | |
| P4 | 0.1 m | 22\46 | 24\97 | 50\172 | 77\170 | 19\77 | 1.2 m | 29\60 | 32\129 | 53\185 | 92\205 | 22\89 |
| 0.2 m | 24\50 | 26\105 | 52\179 | 83\184 | 20\81 | 1.5 m | 30\62 | 33\133 | 53\185 | 92\205 | 22\89 | |
| 0.5 m | 26\54 | 30\121 | 59\202 | 86\191 | 21\85 | 2.0 m | 31\64 | 34\137 | 54\189 | 95\212 | 23\93 | |
| P5 | 0.1 m | 1\3 | 1\4 | 20\61 | 27\55 | 9\24 | 1.2 m | 1\4 | 1\5 | 23\71 | 30\61 | 11\31 |
| 0.2 m | 1\3 | 1\4 | 21\64 | 29\59 | 9\24 | 1.5 m | 1\4 | 1\5 | 23\71 | 29\59 | 11\31 | |
| 0.5 m | 1\3 | 1\4 | 22\67 | 30\61 | 10\27 | 2.0 m | 1\4 | 1\6 | 24\76 | 31\64 | 10\28 | |
| P6 | 0.1 m | 5\11 | 6\20 | 7\22 | 12\25 | 9\32 | 1.2 m | 6\13 | 7\22 | 7\22 | 13\27 | 9\32 |
| 0.2 m | 5\11 | 6\20 | 6\19 | 12\25 | 8\29 | 1.5 m | 5\11 | 6\20 | 7\22 | 13\27 | 10\35 | |
| 0.5 m | 3\8 | 6\20 | 5\16 | 9\19 | 8\29 | 2.0 m | 6\14 | 7\22 | 8\25 | 14\29 | 10\34 | |
| P7 | 0.1 m | 8\18 | 11\36 | 16\57 | 17\35 | 17\65 | 1.2 m | 6\13 | 10\31 | 18\70 | 12\25 | 11\42 |
| 0.2 m | 8\20 | 10\33 | 15\54 | 16\33 | 20\78 | 1.5 m | 6\13 | 10\31 | 20\79 | 11\23 | 15\59 | |
| 0.5 m | 7\15 | 11\33 | 18\68 | 14\29 | 18\69 | 2.0 m | 3\8 | 7\23 | 17\69 | 8\17 | 15\61 | |
| P8 | 0.1 m | 5\11 | 7\19 | 20\61 | 28\57 | 10\26 | 1.2 m | 7\15 | 13\31 | 24\73 | 32\65 | 10\26 |
| 0.2 m | 5\11 | 7\19 | 21\64 | 29\59 | 10\26 | 1.5 m | 7\15 | 14\33 | 24\74 | 32\65 | 10\26 | |
| 0.5 m | 6\13 | 6\16 | 23\70 | 31\63 | 10\26 | 2.0 m | 8\17 | 14\33 | 25\77 | 32\65 | 11\29 | |
| P9 | 0.1 m | 6\13 | 9\24 | 26\80 | 34\69 | 12\31 | 1.2 m | 6\13 | 9\24 | 24\73 | 33\67 | 11\29 |
| 0.2 m | 6\13 | 9\24 | 26\80 | 34\69 | 12\31 | 1.5 m | 6\13 | 9\24 | 24\73 | 32\65 | 11\29 | |
| 0.5 m | 6\13 | 9\24 | 25\77 | 34\69 | 12\31 | 2.0 m | 6\13 | 9\24 | 23\70 | 31\63 | 10\26 | |
| P10 | 0.1 m | 51\105 | 40\192 | 197\816 | 13\40 | 68\311 | 1.2 m | 27\57 | 26\143 | 147\617 | 14\43 | 52\241 |
| 0.2 m | 51\105 | 31\159 | 187\774 | 13\40 | 71\324 | 1.5 m | 31\65 | 36\180 | 121\512 | 14\43 | 43\201 | |
| 0.5 m | 29\61 | 26\131 | 181\752 | 14\43 | 62\285 | 2.0 m | 34\71 | 35\174 | 132\557 | 16\49 | 43\201 | |
| P11 | 0.1 m | 1\5 | 1\7 | 16\81 | 23\93 | 10\51 | 1.2 m | 1\4 | 1\4 | 18\92 | 24\97 | 1\5 |
| 0.2 m | 1\5 | 1\7 | 17\86 | 24\97 | 10\51 | 1.5 m | 1\7 | 1\3 | 18\93 | 1\4 | 1\3 | |
| 0.5 m | 1\5 | 1\3 | 17\86 | 25\101 | 1\3 | 2.0 m | 1\6 | 1\8 | 19\100 | 1\4 | 2\11 | |
| P12 | 0.1 m | 20\41 | 18\75 | 95\306 | 25\51 | 44\152 | 1.2 m | 21\43 | 15\60 | 73\233 | 28\57 | 43\149 |
| 0.2 m | 20\41 | 15\59 | 95\306 | 24\49 | 44\152 | 1.5 m | 21\43 | 15\61 | 65\210 | 26\53 | 24\85 | |
| 0.5 m | 20\41 | 17\67 | 98\315 | 25\51 | 44\152 | 2.0 m | 18\37 | 20\76 | 92\293 | 23\47 | 38\131 | |
| P13 | 0.1 m | 30\62 | 24\119 | 182\741 | 83\246 | 99\442 | 1.2 m | 37\76 | 27\136 | 216\880 | 104\333 | 127\641 |
| 0.2 m | 34\70 | 25\124 | 188\761 | 88\261 | 98\440 | 1.5 m | 37\77 | 28\157 | 226\963 | 85\284 | 79\389 | |
| 0.5 m | 34\71 | 26\133 | 191\786 | 96\288 | 101\458 | 2.0 m | 3\80 | 25\127 | 210\872 | 120\454 | 3\48 | |
| P14 | 0.1 m | 54\111 | 31\163 | 101\430 | 129\416 | 14\70 | 1.2 m | 47\99 | 28\152 | 61\269 | 167\533 | 18\94 |
| 0.2 m | 40\82 | 42\260 | 125\530 | 184\582 | 17\85 | 1.5 m | 55\120 | 27\158 | 91\393 | 157\505 | 18\96 | |
| 0.5 m | 49\101 | 31\159 | 123\522 | 177\563 | 17\86 | 2.0 m | 52\115 | 34\177 | 138\588 | 147\473 | 22\119 | |
| P15 | 0.1 m | 34\72 | 22\177 | 39\245 | 16\80 | 20\140 | 1.2 m | 21\47 | 20\165 | 48\306 | 15\76 | 16\113 |
| 0.2 m | 31\66 | 23\185 | 35\218 | 16\80 | 18\126 | 1.5 m | 31\67 | 22\184 | 48\311 | 18\91 | 43\291 | |
| 0.5 m | 28\60 | 23\162 | 42\262 | 17\86 | 18\127 | 2.0 m | 24\54 | 19\155 | 58\361 | 16\82 | 17\121 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Song, T.; Liu, Z. An Efficient Subspace Minimization Conjugate Gradient Method for Solving Nonlinear Monotone Equations with Convex Constraints. Axioms 2024, 13, 170. https://doi.org/10.3390/axioms13030170
Song T, Liu Z. An Efficient Subspace Minimization Conjugate Gradient Method for Solving Nonlinear Monotone Equations with Convex Constraints. Axioms. 2024; 13(3):170. https://doi.org/10.3390/axioms13030170
Chicago/Turabian StyleSong, Taiyong, and Zexian Liu. 2024. "An Efficient Subspace Minimization Conjugate Gradient Method for Solving Nonlinear Monotone Equations with Convex Constraints" Axioms 13, no. 3: 170. https://doi.org/10.3390/axioms13030170
APA StyleSong, T., & Liu, Z. (2024). An Efficient Subspace Minimization Conjugate Gradient Method for Solving Nonlinear Monotone Equations with Convex Constraints. Axioms, 13(3), 170. https://doi.org/10.3390/axioms13030170