
A Real-Time Dual-Task Defect Segmentation Network for Grinding Wheels with Coordinate Attentioned-ASP and Masked Autoencoder

Abstract
:1. Introduction
- Our scientific contributions include two aspects:
- We have filled in the blanks in research on grinding wheel defect segmentation by providing thorough analysis on the grinding wheel datasets, and a comprehensive deep learning-based solutions with both network designs and training strategies.
- Based on our finding of the similarity between Coordinate Attention and ASPP, we have proposed the novel Coordinate Attentioned—Atrous Spatial Pyramid (CA–ASP) module, which achieves higher segmentation accuracy compared to the ASPP, with highly reduced parameters size and computational complexity. It has shown great potential for replacing the classic ASPP according to the experimental results.
- Furthermore, we have made application contributions by addressing imbalance through self-supervised pretraining with our developed Hybrid MAE network, which would significantly reduce the raw data wastage on the production line.
2. Experimental Materials and Methods
2.1. Defects of Grinding Wheels
2.2. Characteristics in the Materials
2.2.1. Class Imbalance
2.2.2. Spatial Patterns
2.2.3. More Complex Segmentation Scenes in the Reverse Set
2.2.4. Similarity between the Dual-Sided Tasks
2.2.5. Related Work
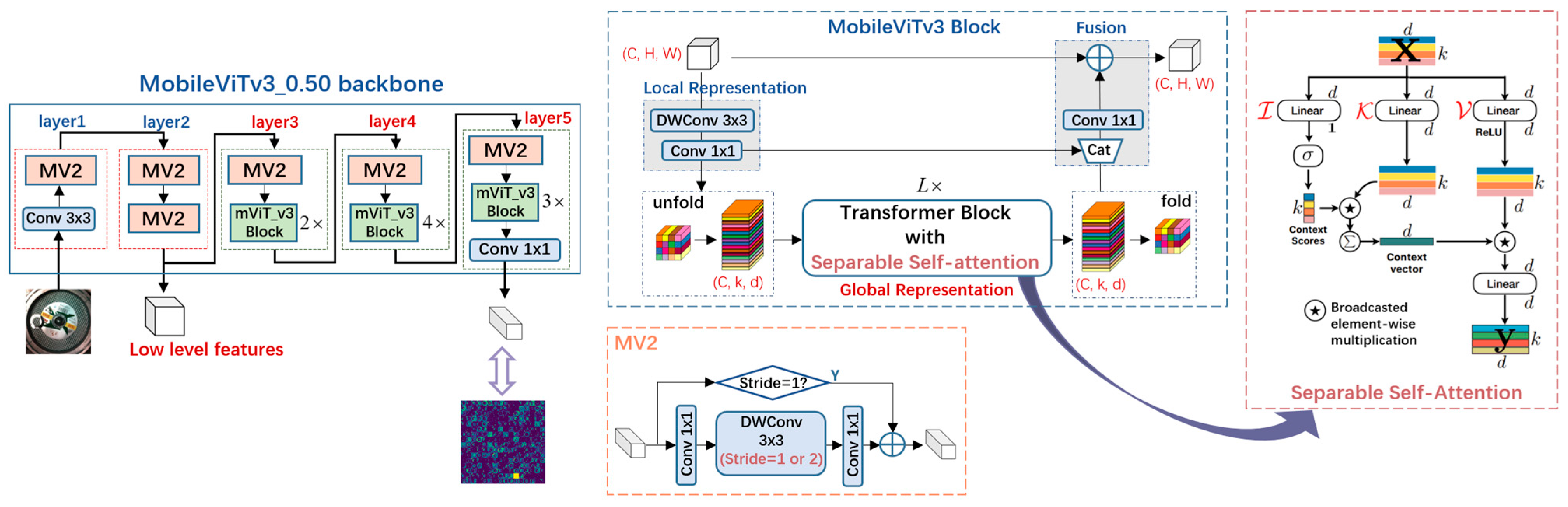
3. DeeplabV3+ Based on Coordinate Attentioned-ASP (CA-ASP)
- Adopting the lightweight MobileViTv3_0.50 as the backbone.
- Replacing ASPP with the proposed lightweight CA-ASP module.
3.1. Analysis on the Computational Complexity of ASPP
- A 1 × 1 convolution for the smallest receptive field (single pixel) projection;
- Three atrous-separable-convolution branches extracting features with 3 different receptive fields, which produce multi-scale features;
- A pooling branch aimed at transforming the feature map into global statistical information and then regenerating them as features with the maximum receptive field, helping the network better understand overall semantics and improve its understanding of object context.
3.2. Coordinate Attentioned-Atrous Spatial Pyramid (CA-ASP)
3.2.1. ASP: A Slimmed-Down ASPP without Pooling
- 1 × 1 Conv as Pre-Mapping Unit.
- Fusion to the features from four different receptive fields.
- ASPP with no Pooling (Based on similarity between CA and ASPP).
3.2.2. Integrate CA into ASP
3.2.3. Mathematical Description and Effects
3.3. Loss Function: Weighted Cross-Entropy
4. Training Strategies: Self-Supervised Pre-Training and Transfer Learning
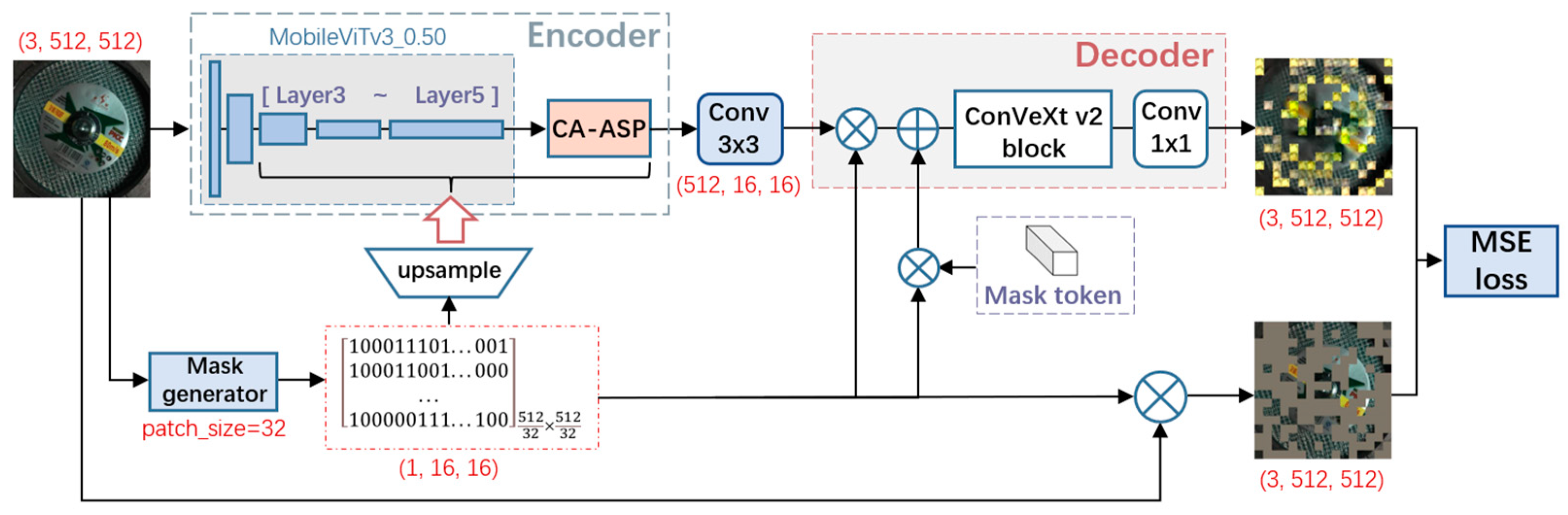
4.1. Self-Supervised Pre-Training Based on the Hybrid MAE
4.1.1. Mask Generation
4.1.2. Encoder
- Layers for masking:
- Masking strategies:
4.1.3. Decoder
- Adjustment for the output stride of the encoder in semantic segmentation:
- ConvNeXtV2 block in FCMAE:
- Prediction Layer:
4.1.4. Loss Function
4.2. Transfer Learning for the Reverse Task
5. Results
5.1. Experimental Setup
5.1.1. Dataset and Loss Function
5.1.2. Evaluation Indicators
- Metrics of overall segmentation accuracy: Two metrics were used to verify the overall segmentation accuracy.
- Mean Pixel Accuracy (MPA): MPA calculates the average pixel-level segmentation accuracy, but it does not consider the spatial relationships between categories, and it is insensitive to segmentation boundaries;
- Mean Intersection over Union (mIoU): mIoU measures the average overlap between predicted masks and ground truth masks across all classes in a dataset. It is the most widely accepted and primary metric among all the other metrics to evaluate the overall segmentation accuracy as it considers not only pixel-level accuracy but also the accuracy of segmentation boundaries;
- Metrics for class imbalance: Due to the significant class imbalance, we adopt two auxiliary metrics to assess the model’s ability to address this issue.
- Intersection over the Union (IoU) of the minority classes: IoU measures the overlap between predicted masks and ground truth masks for a certain class. We will provide extra attention to the IoU of the minority classes in the results;
- Frequency Weighted Intersection over the Union (FWIoU): FWIoU computes a weighted sum of IoU for each category, with the weights being the frequency of occurrence of each category.
- Metrics for measuring lightweighting and computational complexity: The three metrics below are calculated on the obverse set, as it contains more categories which result in larger number of parameters compared to the reverse set. Metrics in this part will determine whether the network meets the real-time requirements of Grinding Wheel defect segmentation.
- Parameter Size (in Million, M): Parameter size refers to the total number of learnable parameters in a model, measured in millions (M), which intuitively reflect the scale of the network. Additionally, it is important to note that parameter size is not equivalent to memory usage (in MB). Typically, each parameter is stored using a precision floating-point format (float32). Hence, the memory usage of a network can be estimated by multiplying the parameter size by 4;
- Floating-point Operations (FLOPs) (in Million times, M): FLOPs are the most commonly used and intuitive metric for measuring model computational complexity;
- Latency (in ms): Latency is measured as the average speed of 50 consecutive inferences of an input with a shape of , verifying the inference speed.
5.2. Experiments on the Obverse Task
5.2.1. Ablation Experiments of the CA-ASP
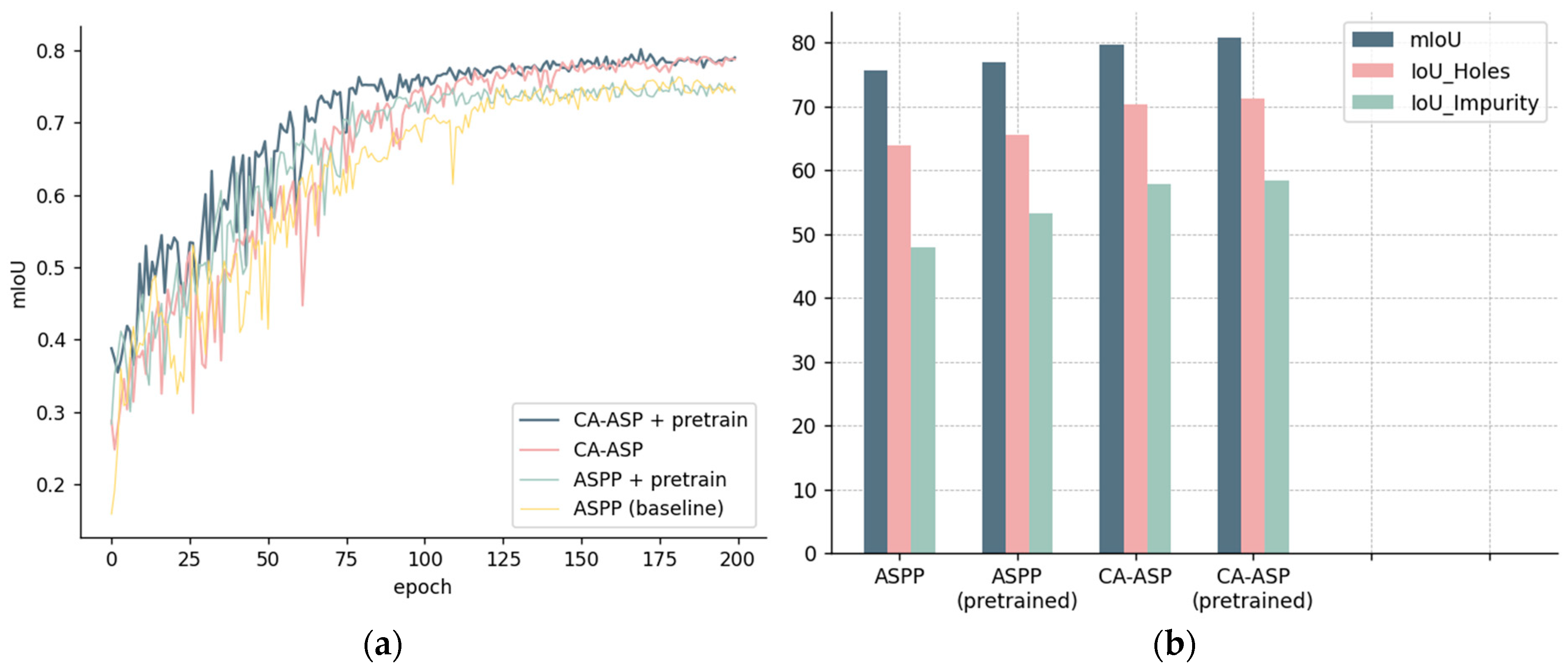
5.2.2. Ablation Experiments of MAE Self-Supervised Pretraining
- Changes in the metrics.
- mIoU-over-epoch curves.
- IoU-over-epoch curves.
- Improved Quality of Features from the Encoder.
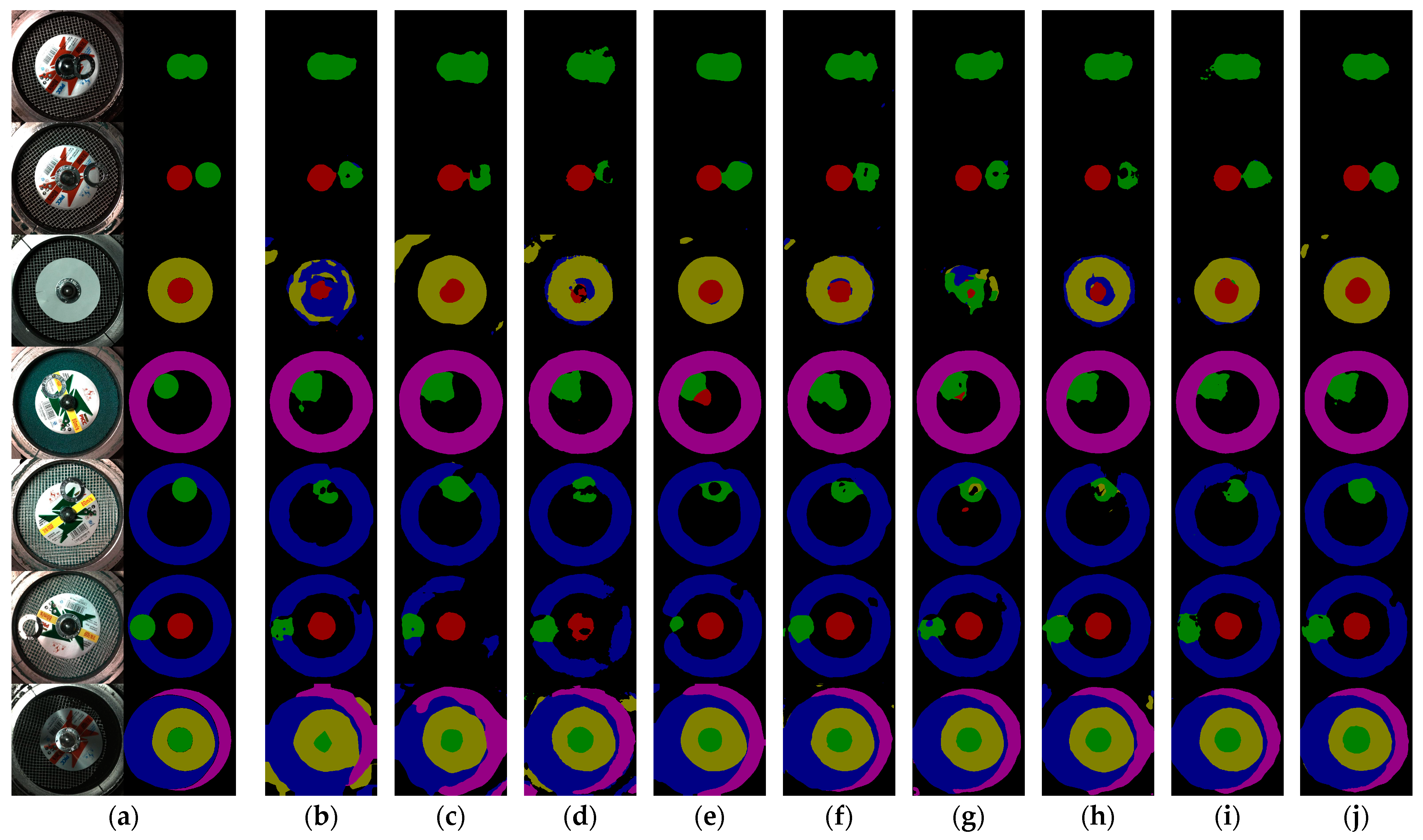
5.2.3. Comparative Experiments with State-of-the-Art Methods
- DeeplabV3+ is slower than other simple architecture, but better in segmentation precision: FCN, PSPNet, and Segformer are typical asymmetric encoder–decoder structures, where the decoder is considerably simpler than the encoder. Hence, when given a light-weight encoder, it would exhibit faster inference speeds. However, when we compare Methods (1)–(3) and (6), it becomes evident that models of such structure all suffer from one issue: they attain an excellent MPA but struggle to achieve a sufficient mIoU, which means that the model is capable of accurately predicting most areas (profit for MPA) but fails to produce precise mask boundaries (adverse to mIoU).
- In the perspective of latency, our method bridges the gap between CNNs and hybrid transformers: Experimental results in other research [46,47,48] have shown that lightweight CNNs are still faster than lightweight hybrid transformers. When we refer to Methods (4)–(8), it is evident that the models based on MobileViTv3 contain fewer parameters but obtain lager FLOPs, which stem from the mechanism of self-attention, optimizing the limited parameters to perform denser computations to achieve superior segmentation precision.Among the DeeplabV3+ models, our method contains the fewest parameters, which is 45.2% smaller than models with the MobileNetV3_large, and 41.4% smaller than the one using the MobileViTv3_0.75. The FLOPs of our method is between the above two models and is closely comparable to the one using the MobileNetV3_large (+1,789.88 M), which on the GPU device will provide minimal differences in the latency (+0.146 ms).All in all, the latency of 9.512 ms in our method can meet the real-time requirement. Moreover, this result can provide valuable insights for improving real-time transformer-based semantic segmentation models: if the computational complexity of self-attention cannot be further reduced, then improvements can be made to the ASPP module to achieve faster inference speeds.
- Among the Deeplabs, our method obtains the best mIoU, with the smallest parameter size: It is apparent that our method, with the best mIoU of 70.796%, surpasses other Deeplabs ranging from +2.463% to +0.597%. Furthermore, this improvement is achieved with the parameters reduced to a minimum.
- Ability for dealing with imbalance: It can be observed from the FWIoU and IoU that our method presents notable advantages in addressing imbalance. In terms of FWIoU, our method gains the highest score of 89.133%. For the IoU of the challenging classes, other methods encounter difficulty in balancing the segmentation precision across both classes. However, this phenomenon is effectively addressed by our method as there is a significant improvement in the IoU of the two classes.
- Smoother boundaries brought by lager parameters: PSPNet and the DeeplabV3+ with the MobileNetV3_large are constructed by the largest parameters compared to other models, and thus they have provided smoother mask boundaries.However, smoothness is not equivalent to precision. In the relatively simpler scenes (Row 1~3), Methods (c), along with (b) and (d), present insufficient segmentation accuracy. As the scenes become increasingly complex, Methods (c) and (e) exhibit more pronounced misclassifications (Method (c) in Row 5~6, Method (e) in Row 4~6), some of which is caused by its shortcomings in segmenting the challenging Ring_NG and correctly predicting the category of a moderately sized region.
- The stability of segmentation accuracy unaffected by scene complexity: Segmentation in complex scenes not only tests the overall segmentation accuracy of the model but also requires the model to sensitively discern precise boundaries. Additionally, it poses high demands on how the model balances different categories. When multiple segmentation categories coexist, the model may expand the regions of majority classes (including the Background) and engulf those of minority classes. This reflects the model’s ability in addressing class imbalance. Methods (b)-(e) and (g)-(h) show discrepancies as the scene becomes more complex, especially in the challenging classes of Ring_NG and Logo.When we observe Row 7, another phenomenon emerges: as the scene becomes sufficiently complex, some methods, including (c), (e) and (h), tend to expand the segmented regions outwards. This could be a contributing factor to the lack of improvement in the mIoU metric: the denominator, represented by the Union, becomes larger.Overall, compared to the best-performing methods (e), (f), and (h), our approach demonstrates the fewest misclassifications and ensures the most precise boundaries of Ring_NG and Logo, and thus maintains solid stability and better generalizability as the scene complexity increases, thanks to the enhanced attention capability of CA-ASP on spatially salient regions, which significantly improves the accuracy of the baseline (g) with fewer parameters, and the improvement in addressing imbalance through MAE self-supervised pretraining.
5.3. Experiments on the Reverse Task
5.3.1. Ablation Experiments of Transfer Learning
5.3.2. Comparative Experiments with State-of-the-Art Methods
- Achieving the best performance on overall precision and dealing with imbalance.
- Magnified gaps between different methods caused by the more complex scenes.
6. Conclusions and Discussion
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Tulbure, A.; Tulbure, A.; Dulf, E. A review on modern defect detection models using DCNNs–Deep convolutional neural networks. J. Adv. Res. 2022, 35, 33–48. [Google Scholar] [CrossRef] [PubMed]
- Bhatt, P.M.; Malhan, R.K.; Rajendran, P.; Shah, B.C.; Thakar, S.; Yoon, Y.J.; Gupta, S.K. Image-Based Surface Defect Detection Using Deep Learning: A Review. J. Comput. Inf. Sci. Eng. Comput. Inf. Sci. Eng. 2021, 21, 040801. [Google Scholar] [CrossRef]
- Yang, J.; Li, S.; Wang, Z.; Dong, H.; Wang, J.; Tang, S. Using deep learning to detect defects in manufacturing: A comprehensive survey and current challenges. Materials 2020, 13, 5755. [Google Scholar] [CrossRef] [PubMed]
- Usamentiaga, R.; Lema, D.G.; Pedrayes, O.D.; Garcia, D.F. Automated surface defect detection in metals: A comparative review of object detection and semantic segmentation using deep learning. IEEE Trans. Ind. Appl. 2022, 58, 4203–4213. [Google Scholar] [CrossRef]
- Zhang, H.; Liu, H.; Kim, C. Semantic and Instance Segmentation in Coastal Urban Spatial Perception: A Multi-Task Learning Framework with an Attention Mechanism. Sustainability 2024, 16, 833. [Google Scholar] [CrossRef]
- Guo, M.H.; Lu, C.Z.; Hou, Q.; Liu, Z.; Cheng, M.M.; Hu, S.M. SegNeXt: Rethinking Convolutional Attention Design for Semantic Segmentation. Adv. Neural Inf. Process. Syst. 2022, 35, 1140–1156. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Cumbajin, E.; Rodrigues, N.; Costa, P.; Miragaia, R.; Frazão, L.; Costa, N.; Fernández-Caballero, A.; Carneiro, J.; Buruberri, L.H.; Pereira, A. A Systematic Review on Deep Learning with CNNs Applied to Surface Defect Detection. J. Imaging 2023, 9, 193. [Google Scholar] [CrossRef]
- Chen, L.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Semantic image segmentation with deep convolutional nets and fully connected crfs. arXiv 2014, arXiv:1412.7062. [Google Scholar]
- Chen, L.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef]
- Chen, L.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Chen, L.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual attention network for scene segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–17 June 2019; pp. 3146–3154. [Google Scholar]
- Pan, Y.; Zhang, L. Dual attention deep learning network for automatic steel surface defect segmentation. Comput. Civ. Infrastruct. Eng. 2022, 37, 1468–1487. [Google Scholar] [CrossRef]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]
- Liu, Q.; El-Khamy, M. Panoptic-Deeplab-DVA: Improving Panoptic Deeplab with Dual Value Attention and Instance Boundary Aware Regression. In Proceedings of the 2022 IEEE International Conference on Image Processing (ICIP), Bordeaux, France, 16–19 October 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 3888–3892. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate attention for efficient mobile network design. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13713–13722. [Google Scholar]
- Liu, R.; Tao, F.; Liu, X.; Na, J.; Leng, H.; Wu, J.; Zhou, T. RAANet: A Residual ASPP with Attention Framework for Semantic Segmentation of High-Resolution Remote Sensing Images. Remote Sens. 2022, 14, 3109. [Google Scholar] [CrossRef]
- Li, Y.; Cheng, Z.; Wang, C.; Zhao, J.; Huang, L. RCCT-ASPPNet: Dual-Encoder Remote Image Segmentation Based on Transformer and ASPP. Remote Sens. 2023, 15, 379. [Google Scholar] [CrossRef]
- Zhang, J.; Zhu, W. Research on Algorithm for Improving Infrared Image Defect Segmentation of Power Equipment. Electronics 2023, 12, 1588. [Google Scholar] [CrossRef]
- Yang, Z.; Wu, Q.; Zhang, F.; Zhang, X.; Chen, X.; Gao, Y. A New Semantic Segmentation Method for Remote Sensing Images Integrating Coordinate Attention and SPD-Conv. Symmetry 2023, 15, 1037. [Google Scholar] [CrossRef]
- Li, Q.; Kong, Y. An Improved SAR Image Semantic Segmentation Deeplabv3+ Network Based on the Feature Post-Processing Module. Remote Sens. 2023, 15, 2153. [Google Scholar] [CrossRef]
- Wang, J.; Zhang, X.; Yan, T.; Tan, A. DPNet: Dual-Pyramid Semantic Segmentation Network Based on Improved Deeplabv3 Plus. Electronics 2023, 12, 3161. [Google Scholar] [CrossRef]
- Xie, J.; Jing, T.; Chen, B.; Peng, J.; Zhang, X.; He, P.; Yin, H.; Sun, D.; Wang, W.; Xiao, A. Method for Segmentation of Litchi Branches Based on the Improved DeepLabv3+. Agronomy 2022, 12, 2812. [Google Scholar] [CrossRef]
- He, L.; Liu, W.; Li, Y.; Wang, H.; Cao, S.; Zhou, C. A Crack Defect Detection and Segmentation Method That Incorporates Attention Mechanism and Dimensional Decoupling. Machines 2023, 11, 169. [Google Scholar] [CrossRef]
- Chen, X.; Fu, C.; Tie, M.; Sham, C.; Ma, H. AFFNet: An Attention-Based Feature-Fused Network for Surface Defect Segmentation. Appl. Sci. 2023, 13, 6428. [Google Scholar] [CrossRef]
- Yang, L.; Song, S.; Fan, J.; Huo, B.; Li, E.; Liu, Y. An Automatic Deep Segmentation Network for Pixel-Level Welding Defect Detection. IEEE Trans. Instrum. Meas. 2022, 71, 5003510. [Google Scholar] [CrossRef]
- Song, Y.; Xia, W.; Li, Y.; Li, H.; Yuan, M.; Zhang, Q. AnomalySeg: Deep Learning-Based Fast Anomaly Segmentation Approach for Surface Defect Detection. Electronics 2024, 13, 284. [Google Scholar] [CrossRef]
- Augustauskas, R.; Lipnickas, A. Improved Pixel-Level Pavement-Defect Segmentation Using a Deep Autoencoder. Sensors 2020, 20, 2557. [Google Scholar] [CrossRef]
- Liu, T.; He, Z. TAS 2-Net: Triple-attention semantic segmentation network for small surface defect detection. IEEE Trans. Instrum. Meas. 2022, 71, 5004512. [Google Scholar]
- Wei, Y.; Wei, W.; Zhang, Y. EfferDeepNet: An Efficient Semantic Segmentation Method for Outdoor Terrain. Machines 2023, 11, 256. [Google Scholar] [CrossRef]
- Feng, H.; Song, K.; Cui, W.; Zhang, Y.; Yan, Y. Cross Position Aggregation Network for Few-Shot Strip Steel Surface Defect Segmentation. IEEE Trans. Instrum. Meas. 2023, 72, 5007410. [Google Scholar] [CrossRef]
- Niu, S.; Li, B.; Wang, X.; Lin, H. Defect image sample generation with GAN for improving defect recognition. IEEE Trans. Autom. Sci. Eng. 2020, 17, 1611–1622. [Google Scholar] [CrossRef]
- Zhang, G.; Cui, K.; Hung, T.; Lu, S. Defect-GAN: High-fidelity defect synthesis for automated defect inspection. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Virtual Conference, 5–9 January 2021; pp. 2524–2534. [Google Scholar]
- Bird, J.J.; Barnes, C.M.; Manso, L.J.; Ekárt, A.; Faria, D.R. Fruit quality and defect image classification with conditional GAN data augmentation. Sci. Hortic. Amst. 2022, 293, 110684. [Google Scholar] [CrossRef]
- Wang, C.; Xiao, Z. Lychee surface defect detection based on deep convolutional neural networks with gan-based data augmentation. Agronomy 2021, 11, 1500. [Google Scholar] [CrossRef]
- He, K.; Chen, X.; Xie, S.; Li, Y.; Dollár, P.; Girshick, R. Masked autoencoders are scalable vision learners. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 16000–16009. [Google Scholar]
- Li, G.; Zheng, H.; Liu, D.; Wang, C.; Su, B.; Zheng, C. Semmae: Semantic-guided masking for learning masked autoencoders. Adv. Neural Inf. Process. Syst. 2022, 35, 14290–14302. [Google Scholar]
- Woo, S.; Debnath, S.; Hu, R.; Chen, X.; Liu, Z.; Kweon, I.S.; Xie, S. Convnext v2: Co-designing and scaling convnets with masked autoencoders. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 16133–16142. [Google Scholar]
- Zhuang, F.; Qi, Z.; Duan, K.; Xi, D.; Zhu, Y.; Zhu, H.; Xiong, H.; He, Q. A comprehensive survey on transfer learning. Proc. IEEE 2020, 109, 43–76. [Google Scholar] [CrossRef]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V. Searching for mobilenetv3. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27–28 October 2019; pp. 1314–1324. [Google Scholar]
- Wadekar, S.N.; Chaurasia, A. Mobilevitv3: Mobile-friendly vision transformer with simple and effective fusion of local, global and input features. arXiv 2022, arXiv:2209.15159. [Google Scholar]
- Mehta, S.; Rastegari, M. Separable Self-attention for Mobile Vision Transformers. arXiv 2022, arXiv:2206.02680. [Google Scholar]
- Mehta, S.; Rastegari, M. MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer. arXiv 2021, arXiv:2110.02178. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Xie, E.; Wang, W.; Yu, Z.; Anandkumar, A.; Alvarez, J.M.; Luo, P. SegFormer: Simple and efficient design for semantic segmentation with transformers. Adv. Neural Inf. Process. Syst. 2021, 34, 12077–12090. [Google Scholar]

























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Obverse Set | Reverse Set | ||
|---|---|---|---|
| Defect Type | Category | Defect Type | Category |
| None | Background | None | Background |
| Missing Metal Ring | Ring_OK | Holes | Holes |
| Abnormal Metal Ring | Ring_NG | Abnormal Mesh | Mesh |
| Abnormal Logo | Logo | Sand Leakage | Sand |
| Abnormal Mesh | Mesh | Impurity | Impurity |
| Sand Leakage | Sand | - | - |
| Method | Params (M) | FLOPs (M) |
|---|---|---|
| ASPP (Baseline) | 1.59 | 1386.99 |
| ASPP + CBAM | 1.60 | 1387.37 |
| ASPP + Separable Self-Attention | 1.79 | 1588.58 |
| CA + ASPP | 1.68 | 1392.71 |
| ASPP + CA | 1.60 | 1387.79 |
| CA-ASP (Ours) | 0.72 | 737.69 |
| Method | Params (M) | FLOPs (M) | Latency (ms) | MPA (%) | mIoU (%) | FWIoU (%) | IoU (%) | |
|---|---|---|---|---|---|---|---|---|
| Ring_NG | Logo | |||||||
| ASPP (baseline) | 4.31 | 25,282.92 | 9.978 | 78.346 | 68.333 | 88.583 | 36.123 | 46.058 |
| ASPP + CBAM | 4.32 | 25,283.30 | 10.682 | 78.681 | 68.252 | 88.698 | 33.741 | 44.602 |
| ASPP+ Separable Self-Attention | 4.51 | 25,484.51 | 10.841 | 78.018 | 68.680 | 88.584 | 30.790 | 52.274 |
| CA + ASPP | 4.40 | 25,288.65 | 10.031 | 78.110 | 67.212 | 87.857 | 33.907 | 48.333 |
| ASPP + CA | 4.31 | 25,283.73 | 9.836 | 80.238 | 69.359 | 89.019 | 35.357 | 52.626 |
| CA-ASP (Ours) | 3.44 | 24,633.63 | 9.512 | 80.821 | 70.208 | 89.090 | 37.075 | 50.944 |
| CA-ASP + MAE (Ours) | 81.315 | 70.796 | 89.133 | 41.727 | 53.355 | |||
| Method | Params(M) | FLOPs (M) | Latency (ms) | MPA (%) | mIoU (%) | FWIoU (%) | IoU (%) | ||
|---|---|---|---|---|---|---|---|---|---|
| Ring_NG | Logo | ||||||||
| (1) | mViTv3_0.50 1 + FCN | 3.49 | 4770.27 | 6.330 | 78.110 | 66.672 | 86.933 | 37.602 | 44.518 |
| (2) | mViTv3_0.50 + PSPNet | 11.2 | 11,724.93 | 7.890 | 80.772 | 67.661 | 87.042 | 37.406 | 48.618 |
| (3) | mViTv3_0.50 + Segformer | 2.03 | 6960.19 | 7.440 | 79.895 | 68.021 | 87.651 | 33.563 | 53.222 |
| (4) | MobileNetv3_large + DV3+ 2 | 6.28 | 22,843.75 | 9.366 | 81.303 | 69.003 | 88.410 | 41.698 | 43.607 |
| (5) | mViTv3_0.75 + DV3+ | 5.87 | 28,268.60 | 10.519 | 83.094 | 70.199 | 88.869 | 37.975 | 53.338 |
| (6) | mViTv3_0.50 + DV3+ (baseline) | 4.31 | 25,282.92 | 9.978 | 78.346 | 68.333 | 88.583 | 36.123 | 46.058 |
| (7) | mViTv3_0.50 + CA-ASP + DV3+ (Ours) | 3.44 | 24,633.63 | 9.512 | 80.821 | 70.208 | 89.090 | 37.075 | 50.944 |
| (8) | mViTv3_0.50 + CA-ASP + DV3+ + MAE (Ours) | 81.315 | 70.796 | 89.133 | 41.727 | 53.355 | |||
| Method | MPA (%) | mIoU (%) | FWIoU (%) | IoU (%) | ||
|---|---|---|---|---|---|---|
| Holes | Impurity | |||||
| (1) | mViTv3_0.50 1 + PSPNet | 85.321 | 72.015 | 93.613 | 60.346 | 36.660 |
| (2) | mViTv3_0.50 + Segformer | 91.818 | 74.683 | 93.852 | 66.919 | 42.226 |
| (3) | MobileNetV3_large + DV3+ 2 | 93.895 | 75.216 | 94.184 | 59.336 | 49.121 |
| (4) | mViTv3_0.75 + DV3+ | 93.552 | 76.961 | 94.394 | 65.948 | 51.713 |
| (5) | mViTv3_0.50 + DV3+ (baseline) | 92.896 | 75.541 | 94.143 | 63.881 | 47.939 |
| (6) | mViTv3_0.50 + DV3+ (pre) 3 | 93.558 | 76.967 | 94.267 | 65.442 | 53.257 |
| (7) | mViTv3_0.50 + (ASPP+CA) + DV3+ | 92.402 | 77.119 | 94.634 | 65.839 | 53.228 |
| (8) | mViTv3_0.50 + CA-ASP + DV3+ (Ours) | 93.908 | 79.507 | 95.485 | 69.028 | 55.164 |
| (9) | mViTv3_0.50 + CA-ASP + DV3+ (pre) (Ours) | 94.215 | 80.757 | 95.645 | 71.152 | 58.398 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Y.; Li, C.; Zhang, P.; Wang, H. A Real-Time Dual-Task Defect Segmentation Network for Grinding Wheels with Coordinate Attentioned-ASP and Masked Autoencoder. Machines 2024, 12, 276. https://doi.org/10.3390/machines12040276
Li Y, Li C, Zhang P, Wang H. A Real-Time Dual-Task Defect Segmentation Network for Grinding Wheels with Coordinate Attentioned-ASP and Masked Autoencoder. Machines. 2024; 12(4):276. https://doi.org/10.3390/machines12040276
Chicago/Turabian StyleLi, Yifan, Chuanbao Li, Ping Zhang, and Han Wang. 2024. "A Real-Time Dual-Task Defect Segmentation Network for Grinding Wheels with Coordinate Attentioned-ASP and Masked Autoencoder" Machines 12, no. 4: 276. https://doi.org/10.3390/machines12040276
APA StyleLi, Y., Li, C., Zhang, P., & Wang, H. (2024). A Real-Time Dual-Task Defect Segmentation Network for Grinding Wheels with Coordinate Attentioned-ASP and Masked Autoencoder. Machines, 12(4), 276. https://doi.org/10.3390/machines12040276