
U-Net-Based Models towards Optimal MR Brain Image Segmentation

 ,
,  , , , ,
, , , , 
Abstract
:1. Introduction
- Addressing the recent techniques focused on brain tumor segmentation based on U-Net architecture as the backbone, along with its variants.
- Highlighting the major trends and patterns in the research that may help to guide future work in the field by summarizing the cutting-edge techniques in one place.
- Providing a comparative analysis of the most recent relevant literature results and other experimental results to observe the improvements achieved by the incremental research.
1.1. Brain MRI Segmentation
1.2. Before U-Net
- Architecture: traditional deep learning models, such as fully convolutional networks (FCNs) or convolutional neural networks (CNNs), typically have a simpler architecture compared to U-Net-based models.
- Training Data: U-Net-based models are specifically designed to work well with medical imaging data, which often have higher resolutions and more complex structures than natural images. Meanwhile, traditional deep learning models may struggle to handle complex data and may need to be fine-tuned to work well with medical imaging data.
- Performance: U-Net-based models have been shown to perform better than traditional deep learning models on brain tumor segmentation tasks, particularly on datasets with limited training data.
- Small objects segmentation: U-Net-based models have the capacity to handle small structural objects in the image, which is an important aspect in brain tumor segmentation where small tumors need to be segmented.
2. U-Net and U-Net Expansions towards Optimized DL Models for Segmentations
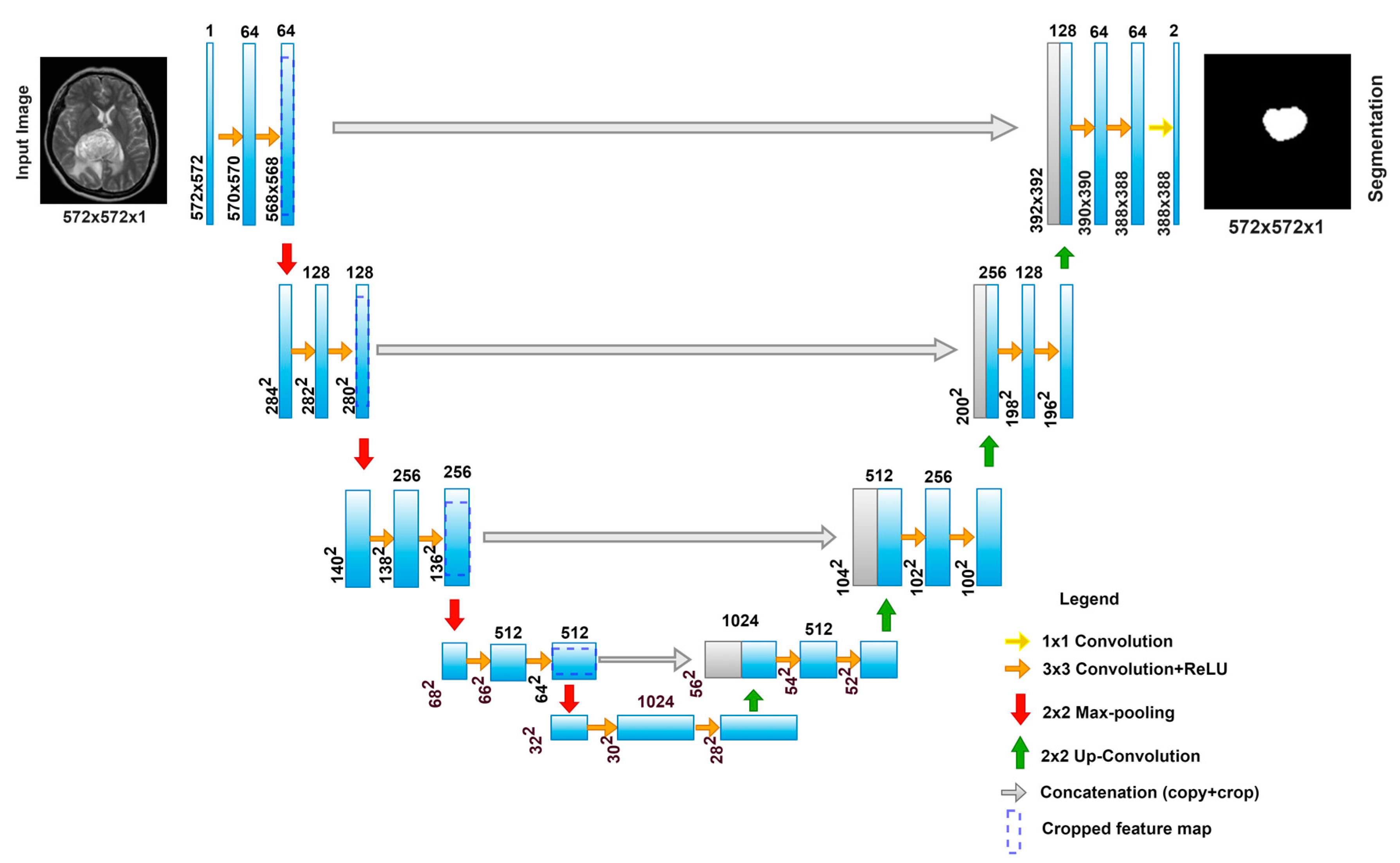
2.1. U-Net
U-Net Workflow
- The Contracting Path
- The Expansion Path
- Training
2.2. 3D U-Net
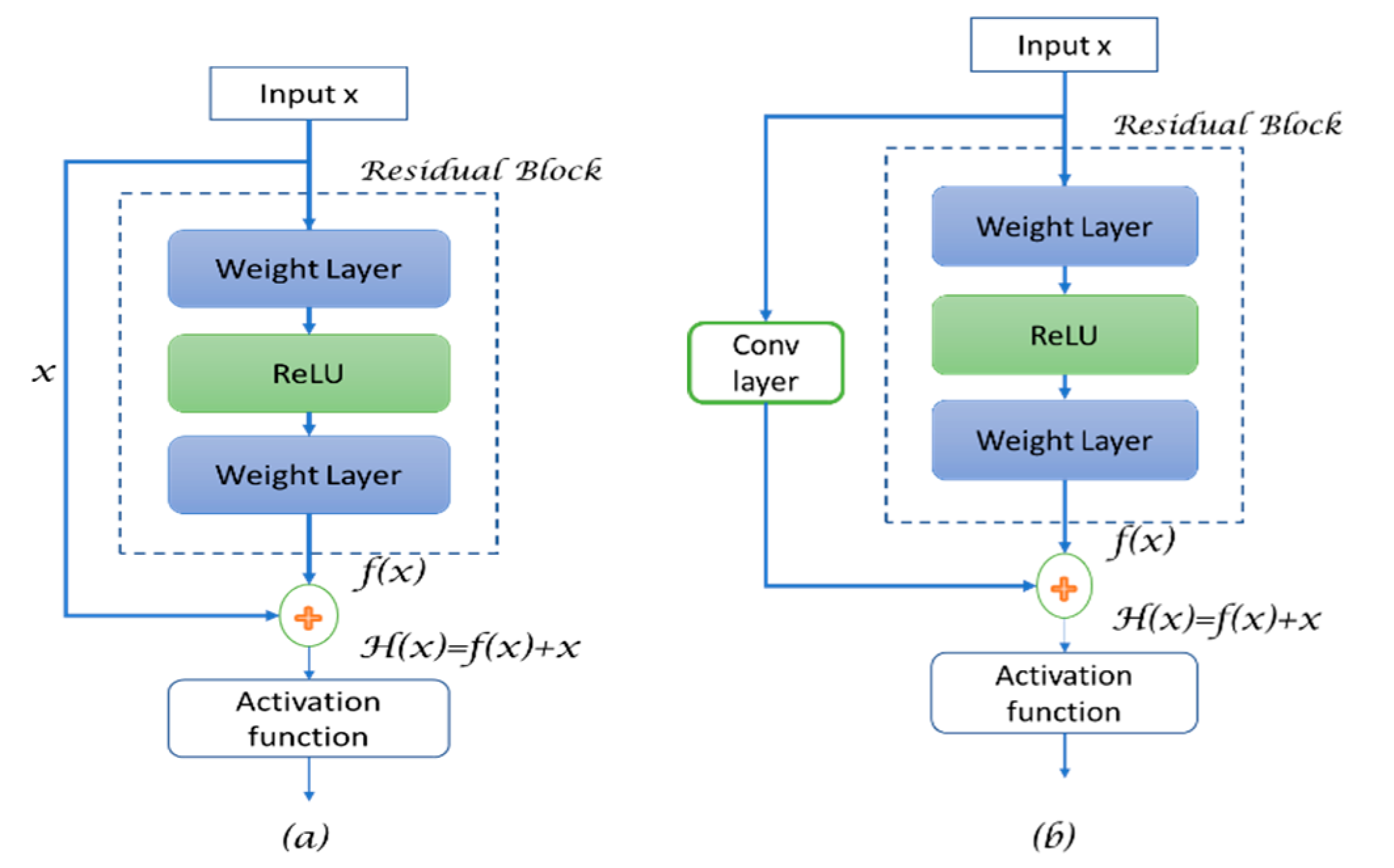
2.3. Residual U-Net
- R(X) refers to the residual mapping,
- h(x) is referred to as the identity map function after applying the convolution operation,
- x+1 is the input for the next layer, and
- f(.) is the activation function.
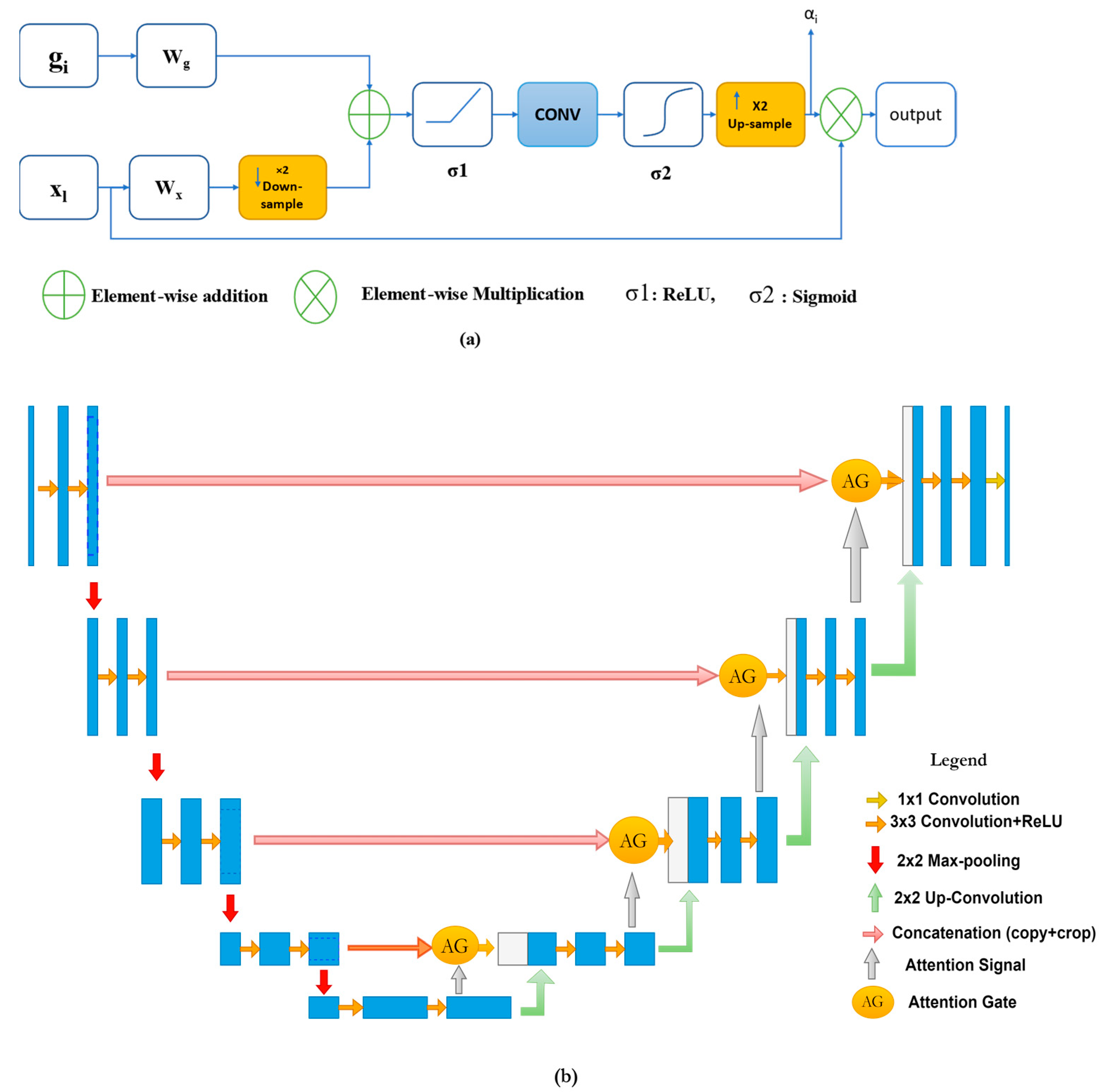
2.4. Attention U-Net
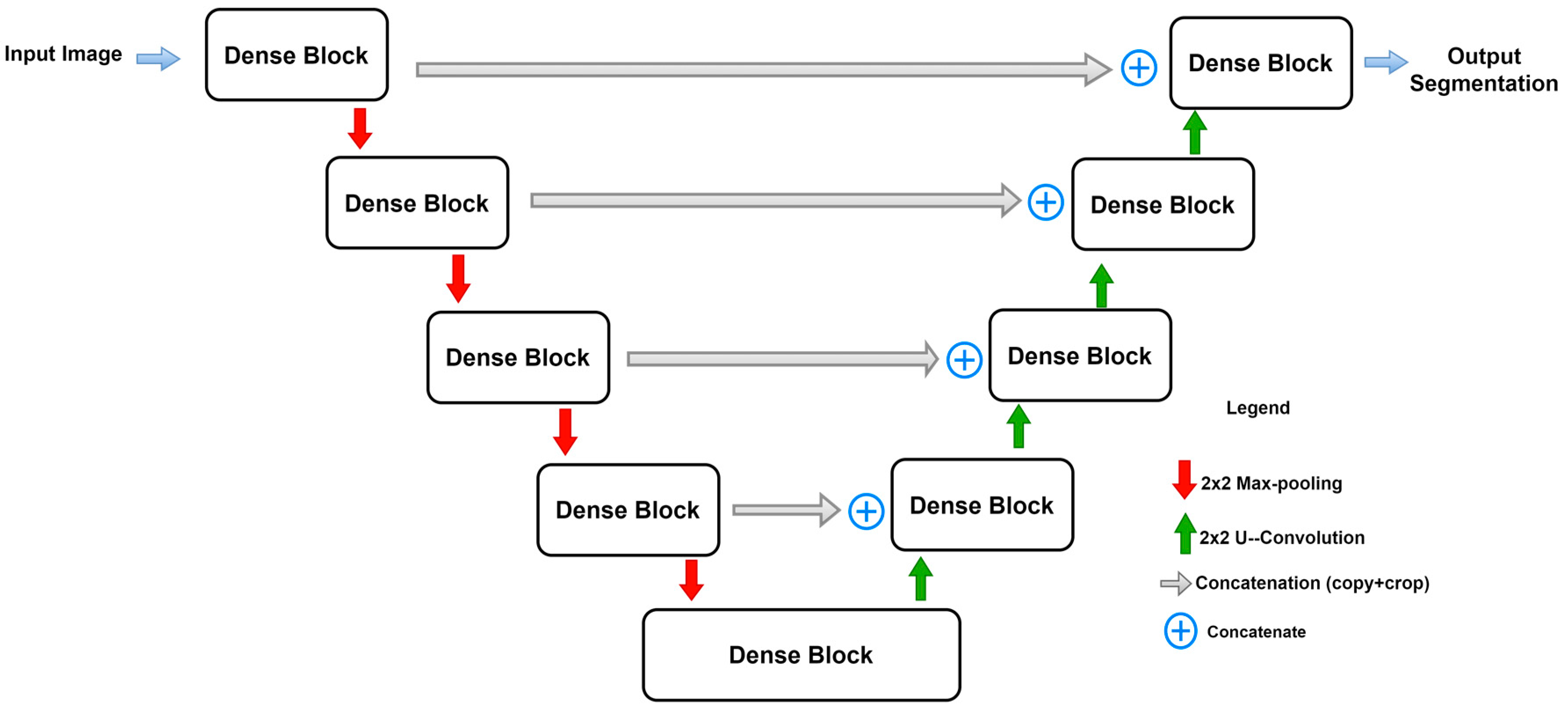
2.5. Dense U-Net
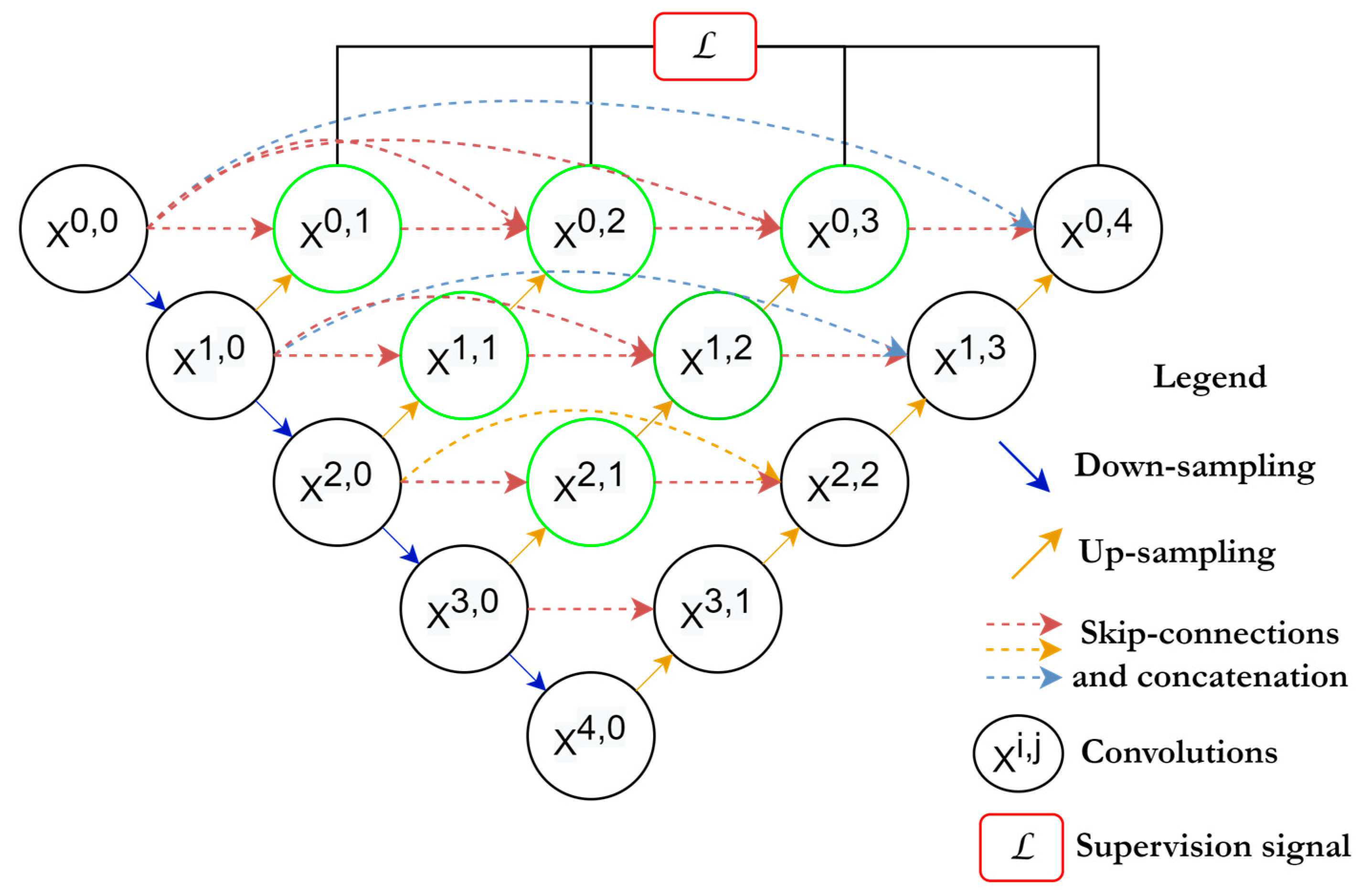
2.6. U-Net++
2.7. U-Net 3+
2.8. Adversarial U-Net
2.9. Other Well-Known Architectures Based on U-Net
3. Materials and Methods
3.1. Loss Functions
3.1.1. Cross-Entropy Loss
3.1.2. Dice Loss Function
3.1.3. IoU Loss
3.1.4. Tversky Loss
3.1.5. Hausdorff Distance Loss
3.2. Evaluation Metrics
3.2.1. Dice Coefficient
3.2.2. Jaccard Index/Intersection over Union (IoU)
3.2.3. Hausdorff Distance (HD)
3.2.4. Sensitivity and Specificity
3.3. Comparison and Analysis
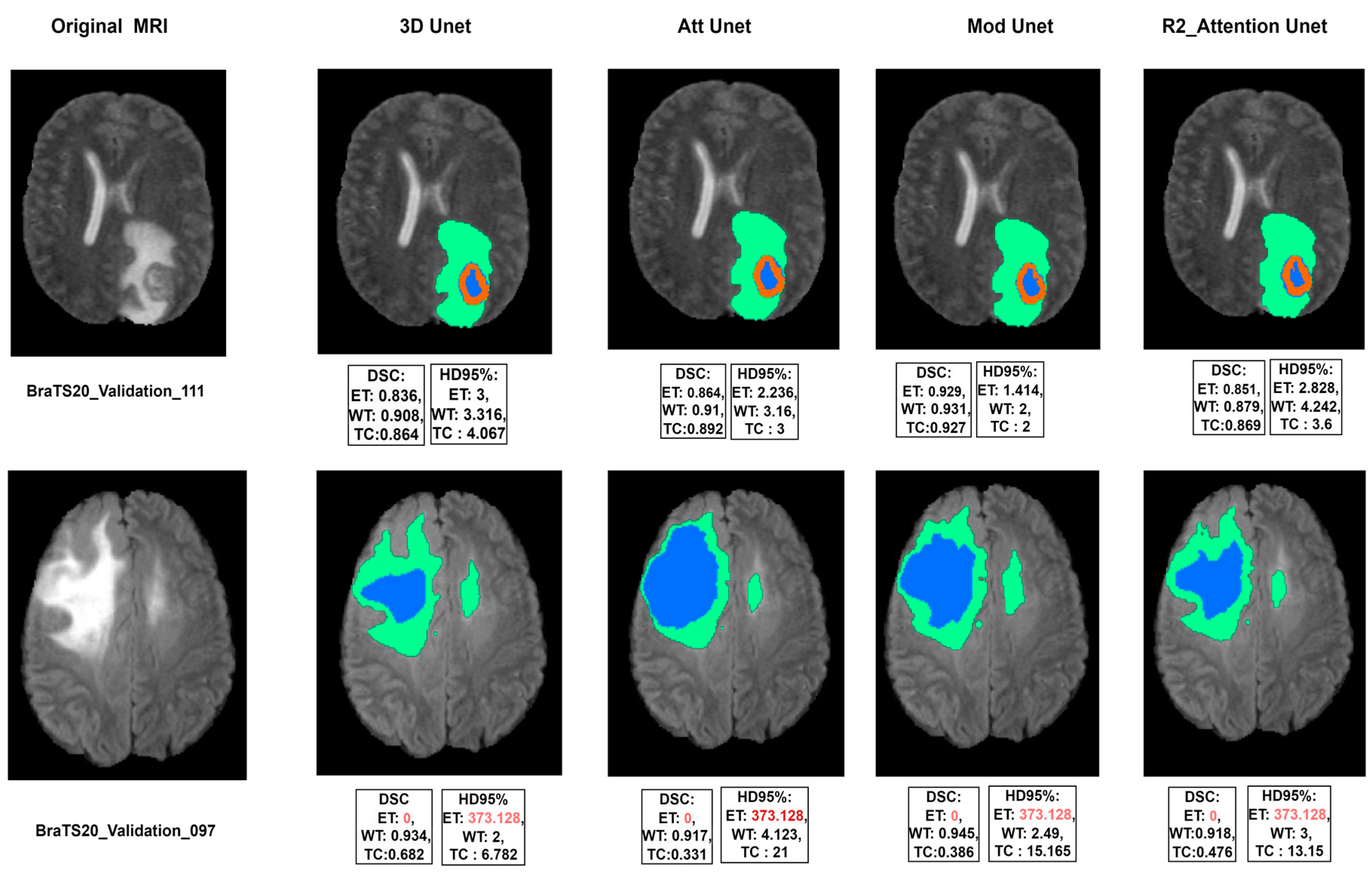
4. Experimental Results
Experimental Training Layout
- 3D U-Net: This architecture consists of four levels of convolutions in both the encoder and decoder. It was proposed in [96].
- Modified 3D U-Net: follows the same attributes as the previous model, but an extra level is added, so the encoder–decoder network uses five levels of convolutions.
- R2 Attention U-Net: Recurrent Residual Attention U-Net was proposed in [97], which adds the recurrent and residual blocks to the first 3D model.
5. Discussion
5.1. Limitations of this Research
5.2. Challenges
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Munsif, M.; Ullah, M.; Ahmad, B.; Sajjad, M.; Cheikh, F.A. Monitoring Neurological Disorder Patients via Deep Learning Based Facial Expressions Analysis. In Artificial Intelligence Applications and Innovations. AIAI 2022 IFIP WG 12.5 International Workshops; Springer International Publishing: Cham, Switzerland, 2022; pp. 412–423. [Google Scholar]
- Hussain, A.; Khan, A.; Yar, H. Efficient Deep learning Approach for Classification of Pneumonia using Resources Constraint Devices in Healthcare. In Proceedings of the 5th International Conference on Next Generation Computing, Bidholi Via-Prem Nagar, India, 20–21 December 2019; pp. 20–21. [Google Scholar]
- Li, J.P.; Khan, S.; Alshara, M.A.; Alotaibi, R.M.; Mawuli, C. DACBT: Deep learning approach for classification of brain tumors using MRI data in IoT healthcare environment. Sci. Rep. 2022, 12, 15331. [Google Scholar]
- Chopra, P.; Junath, N.; Singh, S.K.; Khan, S.; Sugumar, R.; Bhowmick, M. Cyclic GAN Model to Classify Breast Cancer Data for Pathological Healthcare Task. Biomed Res. Int. 2022, 2022, 6336700. [Google Scholar] [CrossRef] [PubMed]
- Haq, A.U.; Li, J.P.; Khan, I.; Agbley, B.L.Y.; Ahmad, S.; Uddin, M.I.; Zhou, W.; Khan, S.; Alam, I. DEBCM: Deep Learning-Based Enhanced Breast Invasive Ductal Carcinoma Classification Model in IoMT Healthcare Systems. IEEE J. Biomed. Health Inform. 2022, 1–12. [Google Scholar] [CrossRef] [PubMed]
- Agbley, B.L.Y.; Li, J.P.; Haq, A.U.; Bankas, E.K.; Mawuli, C.B.; Ahmad, S.; Khan, S.; Khan, A.R. Federated Fusion of Magnified Histopathological Images for Breast Tumor Classification in the Internet of Medical Things. IEEE J. Biomed. Health Inform. 2023, 1–12. [Google Scholar] [CrossRef]
- Haq, A.U.; Li, J.P.; Ahmad, S.; Khan, S.; Alshara, M.A.; Alotaibi, R.M. Diagnostic approach for accurate diagnosis of COVID-19 employing deep learning and transfer learning techniques through chest X-ray images clinical data in E-healthcare. Sensors 2021, 21, 8219. [Google Scholar] [CrossRef]
- Lu, S.-Y.; Zhang, Z.; Zhang, Y.-D.; Wang, S.-H. CGENet: A Deep Graph Model for COVID-19 Detection Based on Chest CT. Biology 2022, 11, 33. [Google Scholar] [CrossRef] [PubMed]
- Khan, J.; Khan, G.A.; Li, J.P.; AlAjmi, M.F.; Haq, A.U.; Khan, S.; Ahmad, N.; Parveen, S.; Shahid, M.; Ahmad, S. Secure smart healthcare monitoring in industrial internet of things (iiot) ecosystem with cosine function hybrid chaotic map encryption. Sci. Program 2022, 2022, 8853448. [Google Scholar] [CrossRef]
- Fazil, M.; Khan, S.; Albahlal, B.M.; Alotaibi, R.M.; Siddiqui, T.; Shah, M.A. Attentional Multi-Channel Convolution With Bidirectional LSTM Cell Toward Hate Speech Prediction. IEEE Access 2023, 11, 16801–16811. [Google Scholar] [CrossRef]
- Khan, S.; Fazil, M.; Sejwal, V.K.; Alshara, M.A.; Alotaibi, R.M.; Kamal, A.; Baig, A.R. BiCHAT: BiLSTM with deep CNN and hierarchical attention for hate speech detection. J. King Saud Univ. Inf. Sci. 2022, 34, 4335–4344. [Google Scholar] [CrossRef]
- Khan, S.; Kamal, A.; Fazil, M.; Alshara, M.A.; Sejwal, V.K.; Alotaibi, R.M.; Baig, A.R.; Alqahtani, S. HCovBi-Caps: Hate Speech Detection Using Convolutional and Bi-Directional Gated Recurrent Unit With Capsule Network. IEEE Access 2022, 10, 7881–7894. [Google Scholar] [CrossRef]
- Morrow, M.; Waters, J.; Morris, E. MRI for breast cancer screening, diagnosis, and treatment. Lancet 2011, 378, 1804–1811. [Google Scholar] [CrossRef]
- Zhao, M.; Cao, X.; Zhou, M.; Feng, J.; Xia, L.; Pogue, B.W.; Paulsen, K.D.; Jiang, S. MRI-Guided Near-Infrared Spectroscopic Tomography (MRg-NIRST): System Development for Wearable, Simultaneous NIRS and MRI Imaging. In Multimodal Biomedical Imaging XVII; SPIE: Bellingham, DC, USA, 2022; Volume 11952, p. 119520E. [Google Scholar]
- Kirkham, A.P.S.; Emberton, M.; Allen, C. How Good is MRI at Detecting and Characterising Cancer within the Prostate? Eur. Urol. 2006, 50, 1163–1175. [Google Scholar] [CrossRef] [PubMed]
- Kasivisvanathan, V.; Rannikko, A.S.; Borghi, M.; Panebianco, V.; Mynderse, L.A.; Vaarala, M.H.; Briganti, A.; Budäus, L.; Hellawell, G.; Hindley, R.G.; et al. MRI-Targeted or Standard Biopsy for Prostate-Cancer Diagnosis. N. Engl. J. Med. 2018, 378, 1767–1777. [Google Scholar] [CrossRef] [PubMed]
- Singh, A.K.; Khan, I.R.; Khan, S.; Pant, K.; Debnath, S.; Miah, S. Multichannel CNN model for biomedical entity reorganization. BioMed Res. Int. 2022, 2022, 5765629. [Google Scholar] [CrossRef]
- Prasoon, A.; Petersen, K.; Igel, C.; Lauze, F.; Dam, E.; Nielsen, M. Deep Feature Learning for Knee Cartilage Segmentation Using a Triplanar Convolutional Neural Network. In Medical Image Computing and Computer-Assisted Intervention—MICCAI 2013; Springer: Berlin/Heidelberg, Germany, 2013; pp. 246–253. [Google Scholar]
- Siddique, N.; Paheding, S.; Elkin, C.P.; Devabhaktuni, V. U-Net and Its Variants for Medical Image Segmentation: A Review of Theory and Applications. IEEE Access 2021, 9, 82031–82057. [Google Scholar] [CrossRef]
- Lu, S.; Wang, S.-H.; Zhang, Y.-D. Detection of abnormal brain in MRI via improved AlexNet and ELM optimized by chaotic bat algorithm. Neural Comput. Appl. 2021, 33, 10799–10811. [Google Scholar] [CrossRef]
- Gordillo, N.; Montseny, E.; Sobrevilla, P. State of the art survey on MRI brain tumor segmentation. Magn. Reson. Imaging 2013, 31, 1426–1438. [Google Scholar] [CrossRef]
- Recht, M.P.; Dewey, M.; Dreyer, K.; Langlotz, C.; Niessen, W.; Prainsack, B.; Smith, J.J. Integrating artificial intelligence into the clinical practice of radiology: Challenges and recommendations. Eur. Radiol. 2020, 30, 3576–3584. [Google Scholar] [CrossRef] [PubMed]
- Ahmad, S.; Khan, S.; AlAjmi, M.F.; Dutta, A.K.; Dang, L.M.; Joshi, G.P.; Moon, H. Deep Learning Enabled Disease Diagnosis for Secure Internet of Medical Things. Comput. Mater. Contin. 2022, 73, 965–979. [Google Scholar] [CrossRef]
- Ciresan, D.; Giusti, A.; Gambardella, L.; Schmidhuber, J. Deep Neural Networks Segment Neuronal Membranes in Electron Microscopy Images. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: Red Hook, NY, USA, 2012; Volume 25, Available online: https://proceedings.neurips.cc/paper/2012/file/459a4ddcb586f24efd9395aa7662bc7c-Paper.pdf (accessed on 18 November 2022).
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional Networks for Biomedical Image Segmentation. In Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015; Springer International Publishing: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Haq, A.U.; Li, J.P.; Agbley, B.L.Y.; Khan, A.; Khan, I.; Uddin, M.I.; Khan, S. IIMFCBM: Intelligent integrated model for feature extraction and classification of brain tumors using MRI clinical imaging data in IoT-healthcare. IEEE J. Biomed. Health Inform. 2022, 26, 5004–5012. [Google Scholar] [CrossRef]
- Çiçek, Ö.; Abdulkadir, A.; Lienkamp, S.S.; Brox, T.; Ronneberger, O. 3D U-Net: Learning Dense Volumetric Segmentation from Sparse Annotation. In Medical Image Computing and Computer-Assisted Intervention—MICCAI 2016; Springer International Publishing: Cham, Switzerland, 2016; pp. 424–432. [Google Scholar]
- Tong, Q.; Ning, M.; Si, W.; Liao, X.; Qin, J. 3D Deeply-Supervised U-Net Based Whole Heart Segmentation. In Statistical Atlases and Computational Models of the Heart. ACDC and MMWHS Challenges; Springer International Publishing: Cham, Switzerland, 2018; pp. 224–232. [Google Scholar]
- Chen, W.; Liu, B.; Peng, S.; Sun, J.; Qiao, X. S3D-UNet: Separable 3D U-Net for Brain Tumor Segmentation. In Brainlesion: Glioma, Multiple Sclerosis, Stroke and Traumatic Brain Injuries; Springer International Publishing: Cham, Switzerland, 2019; pp. 358–368. [Google Scholar]
- Kolarik, M.; Burget, R.; Uher, V.; Povoda, L. Superresolution of MRI brain images using unbalanced 3D Dense-U-Net network. In Proceedings of the 2019 42nd International Conference on Telecommunications and Signal Processing (TSP), Budapest, Hungary, 1–3 July 2019; pp. 643–646. [Google Scholar] [CrossRef]
- Gamal, A.; Bedda, K.; Ashraf, N.; Ayman, S.; AbdAllah, M.; Rushdi, M.A. Brain Tumor Segmentation using 3D U-Net with Hyperparameter Optimization. In Proceedings of the 2021 3rd Novel Intelligent and Leading Emerging Sciences Conference (NILES), Giza, Egypt, 23–25 October 2021; pp. 269–272. [Google Scholar] [CrossRef]
- Yu, W.; Fang, B.; Liu, Y.; Gao, M.; Zheng, S.; Wang, Y. Liver Vessels Segmentation Based on 3d Residual U-NET. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 250–254. [Google Scholar] [CrossRef]
- Owler, J.; Irving, B.; Ridgeway, G.; Wojciechowska, M.; McGonigle, J.; Brady, S.M. Comparison of Multi-atlas Segmentation and U-Net Approaches for Automated 3D Liver Delineation in MRI. In Medical Image Understanding and Analysis; Springer International Publishing: Cham, Switzerland, 2020; pp. 478–488. [Google Scholar]
- González Sánchez, J.C.; Magnusson, M.; Sandborg, M.; Carlsson Tedgren, Å.; Malusek, A. Segmentation of bones in medical dual-energy computed tomography volumes using the 3D U-Net. Phys. Medica 2020, 69, 241–247. [Google Scholar] [CrossRef] [PubMed]
- Yang, Z. A Novel Brain Image Segmentation Method Using an Improved 3D U-Net Model. Sci. Program 2021, 2021, 4801077. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; Volume 2016-Decem, pp. 770–778. [Google Scholar] [CrossRef]
- Abdelaziz Ismael, S.A.; Mohammed, A.; Hefny, H. An enhanced deep learning approach for brain cancer MRI images classification using residual networks. Artif. Intell. Med. 2020, 102, 101779. [Google Scholar] [CrossRef] [PubMed]
- Li, H.; Chen, D.; Nailon, W.H.; Davies, M.E.; Laurenson, D. Improved Breast Mass Segmentation in Mammograms with Conditional Residual U-Net. In Image Analysis for Moving Organ, Breast, and Thoracic Images; Springer International Publishing: Cham, Switzerland, 2018; pp. 81–89. [Google Scholar]
- Wang, G.; Li, W.; Ourselin, S.; Vercauteren, T. Automatic brain tumor segmentation using convolutional neural networks with test-time augmentation. Lect. Notes Comput. Sci. (Incl. Subser. Lect. Notes Artif. Intell. Lect. Notes Bioinform.) 2019, 11384 LNCS, 61–72. [Google Scholar] [CrossRef]
- Zhang, J.; Lv, X.; Sun, Q.; Zhang, Q.; Wei, X.; Liu, B. SDResU-Net: Separable and Dilated Residual U-Net for MRI Brain Tumor Segmentation. Curr. Med. Imaging 2019, 16, 720–728. [Google Scholar] [CrossRef]
- Saeed, M.U.; Ali, G.; Bin, W.; Almotiri, S.H.; AlGhamdi, M.A.; Nagra, A.A.; Masood, K.; Amin, R. ul RMU-Net: A Novel Residual Mobile U-Net Model for Brain Tumor Segmentation from MR Images. Electronics 2021, 10, 1962. [Google Scholar] [CrossRef]
- Abd-Ellah, M.K.; Khalaf, A.A.M.; Awad, A.I.; Hamed, H.F.A. TPUAR-Net: Two Parallel U-Net with Asymmetric Residual-Based Deep Convolutional Neural Network for Brain Tumor Segmentation. In Image Analysis and Recognition; Springer International Publishing: Cham, Switzerland, 2019; pp. 106–116. [Google Scholar]
- Nguyen, P.X.; Lu, Z.; Huang, W.; Huang, S.; Katsuki, A.; Lin, Z. Medical Image Segmentation with Stochastic Aggregated Loss in a Unified U-Net. In Proceedings of the 2019 IEEE EMBS International Conference on Biomedical Health Informatics (BHI), Chicago, IL, USA, 19–22 May 2019; pp. 1–4. [Google Scholar] [CrossRef]
- Oktay, O.; Schlemper, J.; Folgoc, L.L.; Lee, M.; Heinrich, M.; Misawa, K.; Mori, K.; McDonagh, S.; Hammerla, N.Y.; Kainz, B.; et al. Attention U-Net: Learning Where to Look for the Pancreas. arXiv 2018, arXiv:1804.03999. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is All you Need. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: Red Hook, NY, USA, 2017; Volume 30, Available online: https://proceedings.neurips.cc/paper/2017/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf (accessed on 20 November 2022).
- Schlemper, J.; Oktay, O.; Schaap, M.; Heinrich, M.; Kainz, B.; Glocker, B.; Rueckert, D. Attention gated networks: Learning to leverage salient regions in medical images. Med. Image Anal. 2019, 53, 197–207. [Google Scholar] [CrossRef]
- Fang, Z.; Chen, Y.; Nie, D.; Lin, W.; Shen, D. RCA-U-Net: Residual Channel Attention U-Net for Fast Tissue Quantification in Magnetic Resonance Fingerprinting. In Medical Image Computing and Computer Assisted Intervention—MICCAI 2019; Springer International Publishing: Cham, Switzerland, 2019; pp. 101–109. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the 30th IEEE Conf. Comput. Vis. Pattern Recognition, CVPR 2017, Honolulu, HI, USA, 21–26 July 2017; Volume 2017-Janua, pp. 2261–2269. [Google Scholar] [CrossRef]
- Yang, Z.; Xu, P.; Yang, Y.; Bao, B.K. A Densely Connected Network Based on U-Net for Medical Image Segmentation. ACM Trans. Multimed. Comput. Commun. Appl. 2021, 17, 1–14. [Google Scholar] [CrossRef]
- Li, S.; Dong, M.; Du, G.; Mu, X. Attention Dense-U-Net for Automatic Breast Mass Segmentation in Digital Mammogram. IEEE Access 2019, 7, 59037–59047. [Google Scholar] [CrossRef]
- Ji, Z.; Han, X.; Lin, T.; Wang, W. A Dense-Gated U-Net for Brain Lesion Segmentation. In Proceedings of the International Conference on Visual Communications and Image Processing (VCIP), Macau, China, 1–4 December 2020; pp. 104–107. [Google Scholar] [CrossRef]
- Kolařík, M.; Burget, R.; Uher, V.; Dutta, M.K. 3D Dense-U-Net for MRI Brain Tissue Segmentation. In Proceedings of the 2018 41ST international conference on telecommunications and signal processing (TSP), Athens, Greece, 4–6 July 2018; pp. 237–240. [Google Scholar] [CrossRef]
- Kolařík, M.; Burget, R.; Uher, V.; Říha, K.; Dutta, M.K. Optimized high resolution 3D dense-U-Net network for brain and spine segmentation. Appl. Sci. 2019, 9, 404. [Google Scholar] [CrossRef]
- Zhou, Z.; Rahman Siddiquee, M.M.; Tajbakhsh, N.; Liang, J. Unet++: A nested u-net architecture for medical image segmentation. In Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support; Springer International Publishing: Cham, Switzerland, 2018; Volume 11045 LNCS, pp. 3–11. [Google Scholar]
- Hou, A.; Wu, L.; Sun, H.; Yang, Q.; Ji, H.; Cui, B.; Ji, P. Brain Segmentation Based on UNet++ with Weighted Parameters and Convolutional Neural Network. In Proceedings of the 2021 IEEE International Conference on Advances in Electrical Engineering and Computer Applications (AEECA), Dalian, China, 27–28 August 2021; pp. 644–648. [Google Scholar]
- Micallef, N.; Seychell, D.; Bajada, C.J. A Nested U-Net Approach for Brain Tumour Segmentation. In Proceedings of the 2020 IEEE 20th Mediterranean Electrotechnical Conference (MELECON 2020)—Proceedings, Palermo, Italy, 16–18 June 2020; pp. 376–381. [Google Scholar] [CrossRef]
- Micallef, N.; Seychell, D.; Bajada, C.J. Exploring the U-Net++ Model for Automatic Brain Tumor Segmentation. IEEE Access 2021, 9, 125523–125539. [Google Scholar] [CrossRef]
- Li, C.; Tan, Y.; Chen, W.; Luo, X.; He, Y.; Gao, Y.; Li, F. ANU-Net: Attention-based nested U-Net to exploit full resolution features for medical image segmentation. Comput. Graph. 2020, 90, 11–20. [Google Scholar] [CrossRef]
- Huang, H.; Lin, L.; Tong, R.; Hu, H.; Zhang, Q.; Iwamoto, Y.; Han, X.; Chen, Y.W.; Wu, J. UNet 3+: A Full-Scale Connected UNet for Medical Image Segmentation. In Proceedings of the ICASSP 2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 1055–1059. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: Red Hook, NY, USA, 2014; Volume 27, Available online: https://proceedings.neurips.cc/paper/2014/file/5ca3e9b122f61f8f06494c97b1afccf3-Paper.pdf (accessed on 20 November 2022).
- Mirza, M.; Osindero, S. Conditional Generative Adversarial Nets. arXiv 2014, arXiv:1411.1784. [Google Scholar]
- Chen, X.; Li, Y.; Yao, L.; Adeli, E.; Zhang, Y. Generative Adversarial U-Net for Domain-free Medical Image Augmentation. arXiv 2021, arXiv:2101.04793. [Google Scholar]
- Li, G.; Zhang, L.; Hu, S.; Fu, D.; Liu, M. Adversarial Network with Dual U-net Model and Multiresolution Loss Computation for Medical Images Registration. In Proceedings of the 2019 12th International Congress on Image and Signal Processing, BioMedical Engineering and Informatics (CISP-BMEI), Suzhou, China, 19–21 October 2019; pp. 1–5. [Google Scholar]
- Yang, G.; Yu, S.; Dong, H.; Slabaugh, G.; Dragotti, P.L.; Ye, X.; Liu, F.; Arridge, S.; Keegan, J.; Guo, Y.; et al. DAGAN: Deep De-Aliasing Generative Adversarial Networks for Fast Compressed Sensing MRI Reconstruction. IEEE Trans. Med. Imaging 2018, 37, 1310–1321. [Google Scholar] [CrossRef] [PubMed]
- Chen, Y.; Jakary, A.; Avadiappan, S.; Hess, C.P.; Lupo, J.M. QSMGAN: Improved Quantitative Susceptibility Mapping using 3D Generative Adversarial Networks with increased receptive field. Neuroimage 2020, 207, 116389. [Google Scholar] [CrossRef] [PubMed]
- Teki, S.M.; Varma, M.K.; Yadav, A.K. Brain tumour segmentation using U-net based adversarial networks. Trait. Du Signal 2019, 36, 353–359. [Google Scholar] [CrossRef]
- Chen, J.; Lu, Y.; Yu, Q.; Luo, X.; Adeli, E.; Wang, Y.; Lu, L.; Yuille, A.L.; Zhou, Y. TransUNet: Transformers Make Strong Encoders for Medical Image Segmentation. arXiv 2021, arXiv:2102.04306. [Google Scholar]
- Milletari, F.; Navab, N.; Ahmadi, S.-A. V-Net: Fully Convolutional Neural Networks for Volumetric Medical Image Segmentation. In Proceedings of the 2016 Fourth International Conference on 3D Vision (3DV), Stanford, CA, USA, 5–28 October 2016; pp. 565–571. [Google Scholar]
- Alom, M.Z.; Yakopcic, C.; Hasan, M.; Taha, T.M.; Asari, V.K. Recurrent residual U-Net for medical image segmentation. J. Med. Imaging 2019, 6, 014006. [Google Scholar] [CrossRef]
- Fatemeh, Z.; Nicola, S.; Satheesh, K.; Eranga, U. Ensemble U-net-based method for fully automated detection and segmentation of renal masses on computed tomography images. Med. Phys. 2020, 47, 4032–4044. [Google Scholar] [CrossRef] [PubMed]
- Feng, X.; Wang, C.; Cheng, S.; Guo, L. Automatic Liver and Tumor Segmentation of CT Based on Cascaded U-Net. In Proceedings of 2018 Chinese Intelligent Systems Conference; Springer: Singapore, 2019; pp. 155–164. [Google Scholar]
- Valanarasu, J.M.J.; Sindagi, V.A.; Hacihaliloglu, I.; Patel, V.M. KiU-Net: Overcomplete Convolutional Architectures for Biomedical Image and Volumetric Segmentation. IEEE Trans. Med. Imaging 2021, 41, 965–976. [Google Scholar] [CrossRef]
- Zhang, J.; Lv, X.; Zhang, H.; Liu, B. AResU-Net: Attention residual U-Net for brain tumor segmentation. Symmetry 2020, 12, 721. [Google Scholar] [CrossRef]
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Dice, L.R. Measures of the Amount of Ecologic Association Between Species. Ecology 1945, 26, 297–302. [Google Scholar] [CrossRef]
- Fidon, L.; Li, W.; Garcia-Peraza-Herrera, L.C.; Ekanayake, J.; Kitchen, N.; Ourselin, S.; Vercauteren, T. Generalised Wasserstein Dice Score for Imbalanced Multi-class Segmentation Using Holistic Convolutional Networks. In Brainlesion: Glioma, Multiple Sclerosis, Stroke and Traumatic Brain Injuries; Springer International Publishing: Cham, Switzerland, 2018; pp. 64–76. [Google Scholar]
- Jaccard, P. The distribution of the flora in the alpine zone.1. New Phytol. 1912, 11, 37–50. [Google Scholar] [CrossRef]
- Abraham, N.; Khan, N.M. A Novel Focal Tversky Loss Function With Improved Attention U-Net for Lesion Segmentation. In Proceedings of the 2019 IEEE 16th International Symposium on Biomedical Imaging (ISBI 2019), Venice, Italy, 8–11 April 2019; pp. 683–687. [Google Scholar]
- Kervadec, H.; Bouchtiba, J.; Desrosiers, C.; Granger, E.; Dolz, J.; Ben Ayed, I. Boundary loss for highly unbalanced segmentation. In Proceedings of the 2nd International Conference on Medical Imaging with Deep Learning, London, UK, 8–10 July 2019; Volume 102, pp. 285–296. Available online: https://proceedings.mlr.press/v102/kervadec19a.html (accessed on 20 November 2022).
- Gerig, G.; Jomier, M.; Chakos, M. Valmet: A New Validation Tool for Assessing and Improving 3D Object Segmentation. In Medical Image Computing and Computer-Assisted Intervention—MICCAI 2001; Springer: Berlin/Heidelberg, Germany, 2001; pp. 516–523. [Google Scholar]
- Nai, Y.H.; Teo, B.W.; Tan, N.L.; O’Doherty, S.; Stephenson, M.C.; Thian, Y.L.; Chiong, E.; Reilhac, A. Comparison of metrics for the evaluation of medical segmentations using prostate MRI dataset. Comput. Biol. Med. 2021, 134, 104497. [Google Scholar] [CrossRef]
- Taha, A.A.; Hanbury, A. Metrics for evaluating 3D medical image segmentation: Analysis, selection, and tool. BMC Med. Imaging 2015, 15, 29. [Google Scholar] [CrossRef]
- Menze, B.H.; Jakab, A.; Bauer, S.; Kalpathy-Cramer, J.; Farahani, K.; Kirby, J.; Burren, Y.; Porz, N.; Slotboom, J.; Wiest, R. The multimodal brain tumor image segmentation benchmark (BRATS). IEEE Trans. Med. Imaging 2014, 34, 1993–2024. [Google Scholar] [CrossRef]
- Isensee, F.; Jäger, P.F.; Full, P.M.; Vollmuth, P.; Maier-Hein, K.H. nnU-Net for brain tumor segmentation. In International MICCAI Brainlesion Workshop; Springer: Berlin/Heidelberg, Germany, 2020; pp. 118–132. [Google Scholar]
- Sahayam, S.; Nenavath, R.; Jayaraman, U.; Prakash, S. Brain tumor segmentation using a hybrid multi resolution U-Net with residual dual attention and deep supervision on MR images. Biomed. Signal Process. Control 2022, 78, 103939. [Google Scholar] [CrossRef]
- Maji, D.; Sigedar, P.; Singh, M. Attention Res-UNet with Guided Decoder for semantic segmentation of brain tumors. Biomed. Signal Process. Control 2022, 71, 103077. [Google Scholar] [CrossRef]
- Ellis, D.G.; Aizenberg, M.R. Trialing u-Net Training Modifications for Segmenting Gliomas Using Open Source Deep Learning Framework. In International MICCAI Brainlesion Workshop; Springer: Berlin/Heidelberg, Germany, 2020; pp. 40–49. [Google Scholar]
- Qamar, S.; Ahmad, P.; Shen, L. Hi-net: Hyperdense Inception 3d Unet for Brain Tumor Segmentation. In International MICCAI Brainlesion Workshop; Springer: Berlin/Heidelberg, Germany, 2020; pp. 50–57. [Google Scholar]
- Cirillo, M.D.; Abramian, D.; Eklund, A. Vox2Vox: 3D-GAN for Brain Tumour Segmentation. In International MICCAI Brainlesion Workshop; Springer: Berlin/Heidelberg, Germany, 2020; pp. 274–284. [Google Scholar]
- Ahmad, P.; Qamar, S.; Shen, L.; Saeed, A. Context aware 3D UNet for Brain Tumor Segmentation. In International MICCAI Brainlesion Workshop; Springer: Berlin/Heidelberg, Germany, 2020; pp. 207–218. [Google Scholar]
- Agarwala, S.; Sharma, S.; Uma Shankar, B. A-UNet: Attention 3D UNet architecture for multiclass segmentation of Brain Tumor. In Proceedings of the 2022 IEEE Region 10 Symposium (TENSYMP), Mumbai, India, 1–3 July 2022; pp. 1–5. [Google Scholar]
- Raza, R.; Bajwa, U.I.; Mehmood, Y.; Anwar, M.W.; Jamal, M.H. dResU-Net: 3D deep residual U-Net based brain tumor segmentation from multimodal MRI. Biomed. Signal Process. Control 2023, 79, 103861. [Google Scholar] [CrossRef]
- AboElenein, N.M.; Songhao, P.; Afifi, A. IRDNU-Net: Inception residual dense nested u-net for brain tumor segmentation. Multimed. Tools Appl. 2022, 81, 24041–24057. [Google Scholar] [CrossRef]
- Ghaffari, M.; Sowmya, A.; Oliver, R. Automated Brain Tumour Segmentation Using Cascaded 3D Densely-Connected U-Net BT—Brainlesion: Glioma, Multiple Sclerosis, Stroke and Traumatic Brain Injuries; Springer International Publishing: Cham, Switzerland, 2021; pp. 481–491. [Google Scholar]
- Wang, W.; Chen, C.; Ding, M.; Yu, H.; Zha, S.; Li, J. Transbts: Multimodal brain tumor segmentation using transformer. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Strasbourg, France, 27 September 2021; pp. 109–119. [Google Scholar]
- Henry, T.; Carré, A.; Lerousseau, M.; Estienne, T.; Robert, C.; Paragios, N.; Deutsch, E. Brain Tumor Segmentation with Self-Ensembled, Deeply-Supervised 3D U-Net Neural Networks: A BraTS 2020 Challenge Solution. In International MICCAI Brainlesion Workshop; Springer: Berlin/Heidelberg, Germany, 2020; pp. 327–339. [Google Scholar]
- Zuo, Q.; Chen, S.; Wang, Z. R2AU-Net: Attention recurrent residual convolutional neural network for multimodal medical image segmentation. Secur. Commun. Netw. 2021, 2021, 6625688. [Google Scholar] [CrossRef]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef]
- Peiris, H.; Chen, Z.; Egan, G.; Harandi, M. Reciprocal adversarial learning for brain tumor segmentation: A solution to BraTS challenge 2021 segmentation task. arXiv 2022, arXiv:2201.03777. [Google Scholar]
- Hussain, Z.; Gimenez, F.; Yi, D.; Rubin, D. Differential Data Augmentation Techniques for Medical Imaging Classification Tasks. AMIA Annu. Symp. Proc. AMIA Symp. 2017, 2017, 979–984. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning? Nature 2016, 29, 1–73. [Google Scholar]
- Yi, X.; Walia, E.; Babyn, P. Generative adversarial network in medical imaging: A review. Med. Image Anal. 2019, 58, 101552. [Google Scholar] [CrossRef]
- Papernot, N.; McDaniel, P.; Goodfellow, I.; Jha, S.; Celik, Z.B.; Swami, A. Practical Black-Box Attacks against Machine Learning. In Proceedings of the 2017 ACM on Asia Conference on Computer and Communications Security, Abu Dhabi, United Arab Emirates, 2–6 April 2017; pp. 506–519. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ref. | Model | DSC | ||
|---|---|---|---|---|
| ET | WT | TC | ||
| [87] | Modified U-Net | 0.7412 | 0.8988 | 0.8086 |
| [88] | HI-Net | 0.741 | 0.906 | 0.842 |
| [89] | Vox-to-vox | 0.75 | 0.892 | 0.791 |
| [41] | Residual Mobile U-Net | 0.832 | 0.913 | 0.881 |
| [84] | nnU-Net architecture with augmentation and modification | 0.82 | 0.889 | 0.85 |
| [90] | Dense U-Net | 0.791 | 0.891 | 0.847 |
| [91] | Attention 3D U-Net | 0.78 | 0.92 | 0.87 |
| [92] | Residual U-Net | 0.82 | 0.86 | 0.84 |
| [93] | Inception Residual Dense Nested U-Net | 0.819 | 0.88 | 0.876 |
| [94] | Cascaded 3D Dense U-Net | 0.78 | 0.901 | 0.83 |
| [95] | Trans U-Net (TransBTS) | 0.787 | 0.909 | 0.817 |
| [68] | Deep V-Net | 0.689 | 0.861 | 0.779 |
| Activation Function | Leaky-ReLU |
|---|---|
| Epochs | 200 |
| Loss function | Dice loss |
| Optimizer | Adam |
| Model | DSC | HD95% | Parameters | Time | ||||
|---|---|---|---|---|---|---|---|---|
| ET | WT | TC | ET | WT | TC | |||
| 3D U-Net [96] | 0.779 | 0.881 | 0.827 | 27.23 | 7.788 | 8.278 | 23 M | 6 h (1.2 s/sample) |
| Modified U-Net | 0.781 | 0.905 | 0.807 | 26.607 | 5.785 | 18.545 | 26 M | 10 h (3.8 s/sample) |
| Attention U-Net [44] | 0.778 | 0.878 | 0.827 | 26.662 | 7.794 | 8.305 | 23.2 M | 6.2 h (1.7 s/sample) |
| R2 Attention U-Net [97] | 0.7426 | 0.8784 | 0.7993 | 36.653 | 9.228 | 9.95 | 22 M | 5.8 h (0.8 s/sample) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yousef, R.; Khan, S.; Gupta, G.; Siddiqui, T.; Albahlal, B.M.; Alajlan, S.A.; Haq, M.A. U-Net-Based Models towards Optimal MR Brain Image Segmentation. Diagnostics 2023, 13, 1624. https://doi.org/10.3390/diagnostics13091624
Yousef R, Khan S, Gupta G, Siddiqui T, Albahlal BM, Alajlan SA, Haq MA. U-Net-Based Models towards Optimal MR Brain Image Segmentation. Diagnostics. 2023; 13(9):1624. https://doi.org/10.3390/diagnostics13091624
Chicago/Turabian StyleYousef, Rammah, Shakir Khan, Gaurav Gupta, Tamanna Siddiqui, Bader M. Albahlal, Saad Abdullah Alajlan, and Mohd Anul Haq. 2023. "U-Net-Based Models towards Optimal MR Brain Image Segmentation" Diagnostics 13, no. 9: 1624. https://doi.org/10.3390/diagnostics13091624
APA StyleYousef, R., Khan, S., Gupta, G., Siddiqui, T., Albahlal, B. M., Alajlan, S. A., & Haq, M. A. (2023). U-Net-Based Models towards Optimal MR Brain Image Segmentation. Diagnostics, 13(9), 1624. https://doi.org/10.3390/diagnostics13091624