
Phase Prediction and Visualized Design Process of High Entropy Alloys via Machine Learned Methodology

 , ,
, , 
Abstract
:1. Introduction
2. Methods
2.1. Data Collection and Descriptor Construction
2.2. Data Preprocessing and Features Selection
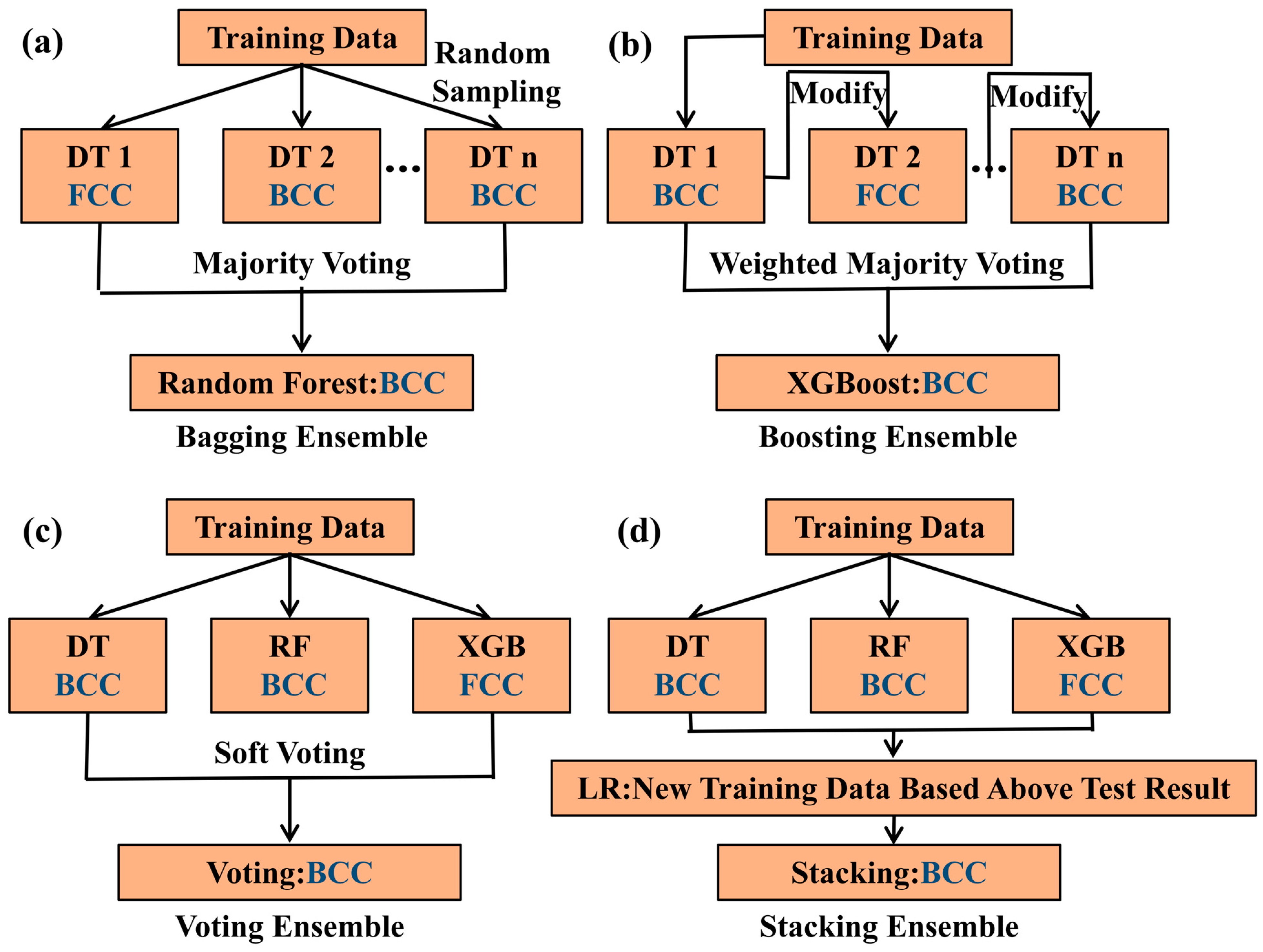
2.3. Machine Learning Algorithm
2.4. Evaluation Criteria of the ML Model
3. Results and Discussion
3.1. Feature Selection
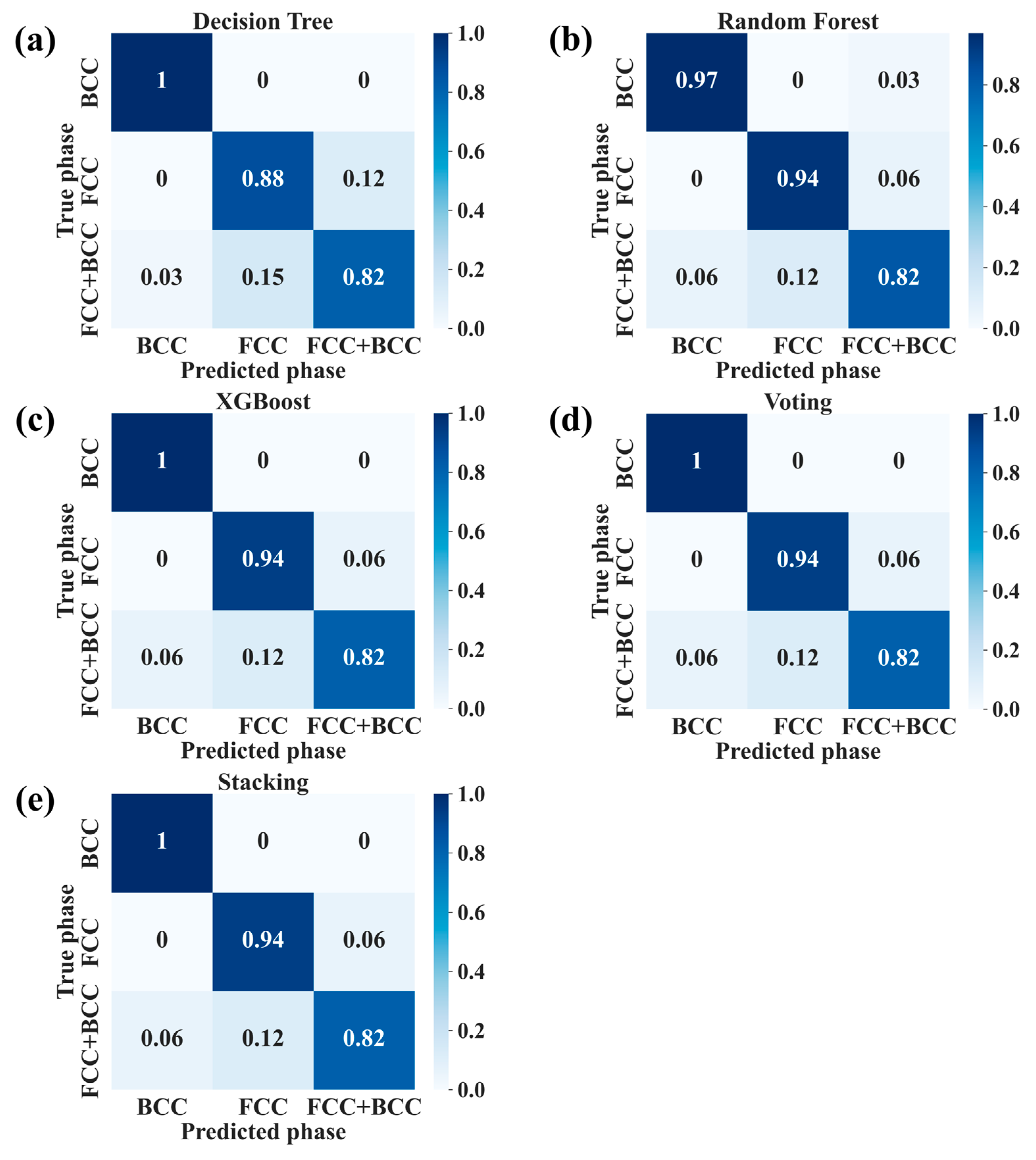
3.2. Prediction Performance of Different ML Models
3.3. HEAs Designing Process Visualized by Decision Tree
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zhang, D.Y.; Qiu, D.; Fraser, H.L. Easton Additive manufacturing of ultrafine-grained high-strength titanium alloys. Nature 2019, 576, 91–95. [Google Scholar] [CrossRef] [PubMed]
- Wu, Z.X.; Ahmad, R.; Yin, B.; Curtin, W. Mechanistic origin and prediction of enhanced ductility in magnesium alloys. Science 2018, 359, 447–452. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yeh, J.W.; Chen, S.K.; Lin, S.J.; Gan, J.Y. Nanostructured High-Entropy Alloys with Multiple Principal Element: Novel Alloy Design Concepts and Outcomes. Adv. Eng. Mater. 2004, 6, 299–303. [Google Scholar] [CrossRef]
- Lilensten, L.; Couzinie, J.-P. Study of a bcc multi-principal element alloy: Tensile and simple shear properties and underlying deformation mechanisms. Acta Mater. 2018, 142, 131–141. [Google Scholar] [CrossRef]
- Senkov, O.N.; Wilks, G.B.; Miracle, D.B. Mechanical properties of Nb25Mo25Ta25W25 and V20Nb20Mo20Ta20W20 refractory high entropy alloys. Intermetallics 2011, 19, 698–706. [Google Scholar] [CrossRef]
- Müller, F.; Gorr, B. On the oxidation mechanism of refractory high entropy alloys. Corros. Sci. 2019, 159, 108161. [Google Scholar] [CrossRef]
- Rajendrachari, S.; Adimule, V.; Gulen, M. Synthesis and Characterization of High Entropy Alloy 23Fe-21Cr-18Ni-20Ti-18Mn for Electrochemical Sensor Applications. Materials 2022, 15, 7591. [Google Scholar] [CrossRef]
- Rajendrachari, S. An Overview of High-Entropy Alloys Prepared by Mechanical Alloying Followed by the Characterization of Their Microstructure and Various Properties. Alloys 2022, 1, 116–132. [Google Scholar] [CrossRef]
- Song, H.; Tian, F.; Wang, Y. Local lattice distortion in high-entropy alloys. Phys. Rev. Mater. 2017, 1, 023404. [Google Scholar] [CrossRef] [Green Version]
- Senkov, O.N.; Senkova, S.V.; Woodward, C. Effect of aluminum on the microstructure and properties of two refractory high-entropy alloys. Acta Mater. 2014, 68, 214–228. [Google Scholar] [CrossRef]
- Zhang, Y.; Wen, C.; Su, Y.J. Phase prediction in high entropy alloys with a rational selection of materials descriptors and machine learning models. Acta Mater. 2020, 185, 528–539. [Google Scholar] [CrossRef]
- Zhang, Y.; Zuo, T.T.; Tang, Z.; Lu, Z.P. Microstructures and properties of high-entropy alloys. Prog. Mater. Sci. 2014, 61, 1–93. [Google Scholar] [CrossRef]
- Takeuchi, A.; Inoue, A. Classification of Bulk Metallic Glasses by Atomic Size Difference, Heat of mixing and period of constituent elements and its application to characterization of the main alloying element. Mater. Trans. 2005, 46, 2817–2829. [Google Scholar] [CrossRef] [Green Version]
- Yang, X.; Zhang, Y. Prediction of high-entropy stabilized solid-solution in multicomponent alloys. Mater. Chem. Phys. 2012, 132, 233–238. [Google Scholar] [CrossRef]
- Guo, S.; Liu, C.T. Phase stability in high entropy alloys: Formation of solid-solution phase or amorphous phase. Prog. Nat. Sci. Mater. Int. 2011, 21, 433–446. [Google Scholar] [CrossRef] [Green Version]
- Guo, S.; Liu, C.T. Effect of valence electron concentration on stability of fcc or bcc phase in high entropy alloys. J. Appl. Phys. 2011, 109, 103505. [Google Scholar] [CrossRef] [Green Version]
- Yang, S.G.; Lu, J.; Zhong, Y. Revisit the VEC rule in high entropy alloys (HEAs) with high-throughput CALPHAD approach and its applications for material design-A case study with AlCoCrFeNi system. Acta Mater. 2020, 192, 11–19. [Google Scholar] [CrossRef]
- Tang, L.X.; Meng, Y. Data analytics and optimization for smart industry. Front. Eng. Manag. 2021, 8, 157–171. [Google Scholar] [CrossRef]
- Han, Q.A.; Lu, Z.L.; Cui, H.T. Data-driven based phase constitution prediction in high entropy alloys. Comput. Mater. Sci. 2022, 215, 111774. [Google Scholar] [CrossRef]
- Beniwal, D.; Ray, P.K. Learning phase selection and assemblages in High-Entropy Alloys through a stochastic ensemble-averaging model. Comput. Mater. Sci. 2021, 197, 110647. [Google Scholar] [CrossRef]
- Mishra, A.; Kompella, L.; Varam, S. Ensemble-based machine learning models for phase prediction in high entropy alloys. Comput. Mater. Sci. 2022, 210, 111025. [Google Scholar] [CrossRef]
- Jaiswal, U.K.; Krishna, Y.V.; Phanikumar, G. Machine learning-enabled identification of new medium to high entropy alloys with solid solution phases. Comput. Mater. Sci. 2021, 197, 110623. [Google Scholar] [CrossRef]
- Singh, A.K.; Kumar, N.; Subramaniam, A. A geometrical parameter for the formation of disordered solid solutions in multi-component alloys. Intermetallics 2014, 53, 112–119. [Google Scholar] [CrossRef]
- Senkov, O.N.; Miracle, D.B. A new thermodynamic parameter to predict formation of solid solution or intermetallic phases in high entropy alloys. J. Alloy. Compd. 2016, 658, 603–607. [Google Scholar] [CrossRef] [Green Version]
- Couzinié, J.P.; Senkov, O.N.; Dirras, G. Comprehensive data compilation on the mechanical properties of refractory high-entropy alloys. Data Brief 2018, 21, 622–1641. [Google Scholar] [CrossRef]
- Chen, J.; Zhou, X.Y. A review on fundamental of high entropy alloys with promising high temperature properties. J. Alloy. Compd. 2018, 760, 15–30. [Google Scholar] [CrossRef]
- Gorsse, S.; Nguyen, M.H.; Miracle, D.B. Database on the mechanical properties of high entropy alloys and complex concentrated alloys. Data Brief 2018, 21, 2664–2678. [Google Scholar] [CrossRef] [PubMed]
- Tang, Z.W.; Zhang, S.; Wang, H.F. Designing High Entropy Alloys with Dual fcc and bcc Solid-Solution Phases: Structures and Mechanical Properties. Met. Mater. Trans. A 2019, 50, 1888–1901. [Google Scholar] [CrossRef]
- Senkov, O.N.; Miracle, D.B. Development and exploration of refractory high entropy alloys—A review. J. Mater. Res. 2018, 33, 3092–3128. [Google Scholar] [CrossRef] [Green Version]
- Ye, Y.F.; Wang, Q.; Yang, Y. High-entropy alloy: Challenges and prospects. Mater. Today 2016, 19, 349–362. [Google Scholar] [CrossRef]
- Tsai, M.H.; Tsai, R.C.; Huang, W.F. Intermetallic Phases in High-Entropy Alloys: Statistical Analysis of their Prevalence and Structural Inheritance. Metals 2019, 9, 247. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Y.; Zhou, Y.J.; Lin, J.P. Solid-Solution Phase Formation Rules for Multi-component Alloys. Adv. Eng. Mater. 2008, 10, 534–538. [Google Scholar] [CrossRef]
- Zhou, Z.; Zhou, Y.; He, Q.; Ding, Z.; Li, F.; Yang, Y. Machine learning guided appraisal and exploration of phase design for high entropy alloys. Npj Comput. Mater. 2019, 5, 128. [Google Scholar] [CrossRef] [Green Version]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A. Scikit-learn: Machine learning in python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar] [CrossRef]
- Moshkov, M. Decision trees for regular factorial languages. Array 2022, 15, 203. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Chen, T.Q.; Cuestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM Sigkdd International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar] [CrossRef] [Green Version]
- Gao, J.W.; Lin, Z.P. Voting based extreme learning machine. Inf. Sci. 2012, 185, 66–77. [Google Scholar] [CrossRef]
- Zenko, B.; Dzeroski, S. Stacking with an Extended Set of Meta-Level Attributes and MLR. In Machine Learning: ECML 2002; Springer: Berlin/Heidelberg, Germany, 2002; pp. 493–504. [Google Scholar] [CrossRef] [Green Version]
- Roy, A.; Babuska, T.; Krick, B. Machine learned feature identification for predicting phase and Young’s modulus of low-, medium- and high-entropy alloys. Scr. Mater. 2020, 185, 152–158. [Google Scholar] [CrossRef]
- Mangal, A.; Holm, E.A. A comparative study of feature selection methods for stress hotspot classifification in materials. Integr. Mater. Manuf. Innov. 2018, 7, 87–95. [Google Scholar] [CrossRef] [Green Version]
- He, Q.F.; Ye, Y.F.; Yang, Y. The configurational entropy of mixing of metastable random solid solution in complex multi-component alloys. J. Appl. Phys. 2016, 120, 154902. [Google Scholar] [CrossRef]
- Hawkins, D.M. The problem of overfitting. J. Chem. Inf. Comput. Sci. 2004, 44, 1–12. [Google Scholar] [CrossRef] [PubMed]
- Islam, N.; Huang, W.J.; Zhuang, H.L. Machine learning for phase selection in multi-principal element alloys. Comput. Mater. Sci. 2018, 150, 230–235. [Google Scholar] [CrossRef]
- Risal, S.; Zhu, W.H.; Guillen, P.; Sun, L. Improving phase prediction accuracy for high entropy alloys with Machine learning. Comput. Mater. Sci. 2021, 192, 110389. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Formula | Definition | Reference |
|---|---|---|
| Mixing entropy | [32] | |
| Mixing enthalpy | [32] | |
| Melting point | [14] | |
| Parameter for predicting the SS formation | [14] | |
| Valence electron concentration | [16] | |
| Average atom radius | [32] | |
| Atom radius difference | [32] | |
| Electronegativity | [11] | |
| Standard deviation of electronegativity | [11] | |
| Mean bulk modulus | [33] | |
| Standard deviation of bulk modulus | [19] | |
| Mean cohesive energy | [33] | |
| Standard deviation of cohesive energy | [20] |
| Alloy (Phase) | AlCuCoCNi (FCC + BCC) | HfNbTTiZr (BCC) | MoNbTaW (BCC) | CoCrMnNi (FCC) |
|---|---|---|---|---|
| 13.38 | 13.38 | 11.53 | 11.53 | |
| −6.56 | 2.72 | −6.5 | −5.5 | |
| 1583 | 2513 | 3145 | 1786 | |
| 3.23 | 12.36 | 5.58 | 3.74 | |
| 7.8 | 4.4 | 5.3 | 8 | |
| 0.13 | 0.15 | 0.14 | 0.13 | |
| 0.0552 | 0.0498 | 0.0232 | 0.0345 | |
| 1.79 | 1.45 | 1.91 | 1.75 | |
| 0.13 | 0.12 | 0.36 | 0.15 | |
| 147.2 | 135.4 | 200 | 160 | |
| 38.57 | 42.43 | 21.21 | 24.49 | |
| 381.6 | 638.2 | 749 | 384 | |
| 43.68 | 56.49 | 54.74 | 39.19 |
| Algorithms | Mean CV Accuracy (%) | Accuracy (%) | Precision (%) | Recall (%) | F1 Score (%) |
|---|---|---|---|---|---|
| Decision Tree | 83.76 (±3.35) | 90.10 | 90 | 90 | 90 |
| Random Forest | 87.13 (±2.50) | 91.09 | 91 | 91 | 91 |
| XGBoost | 86.93 (±4.03) | 92.08 | 92 | 92 | 92 |
| Voting | 86.73 (±2.84) | 92.08 | 92 | 92 | 92 |
| Stacking | 86.53 (±2.77) | 92.08 | 92 | 92 | 92 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gao, J.; Wang, Y.; Hou, J.; You, J.; Qiu, K.; Zhang, S.; Wang, J. Phase Prediction and Visualized Design Process of High Entropy Alloys via Machine Learned Methodology. Metals 2023, 13, 283. https://doi.org/10.3390/met13020283
Gao J, Wang Y, Hou J, You J, Qiu K, Zhang S, Wang J. Phase Prediction and Visualized Design Process of High Entropy Alloys via Machine Learned Methodology. Metals. 2023; 13(2):283. https://doi.org/10.3390/met13020283
Chicago/Turabian StyleGao, Jin, Yifan Wang, Jianxin Hou, Junhua You, Keqiang Qiu, Suode Zhang, and Jianqiang Wang. 2023. "Phase Prediction and Visualized Design Process of High Entropy Alloys via Machine Learned Methodology" Metals 13, no. 2: 283. https://doi.org/10.3390/met13020283
APA StyleGao, J., Wang, Y., Hou, J., You, J., Qiu, K., Zhang, S., & Wang, J. (2023). Phase Prediction and Visualized Design Process of High Entropy Alloys via Machine Learned Methodology. Metals, 13(2), 283. https://doi.org/10.3390/met13020283