
Comparison of Machine Learning Tree-Based Algorithms to Predict Future Paratuberculosis ELISA Results Using Repeat Milk Tests

 , , and
, , and
Abstract
:Simple Summary
Abstract
1. Introduction
2. Objective and Hypothesis
3. Material and Methods
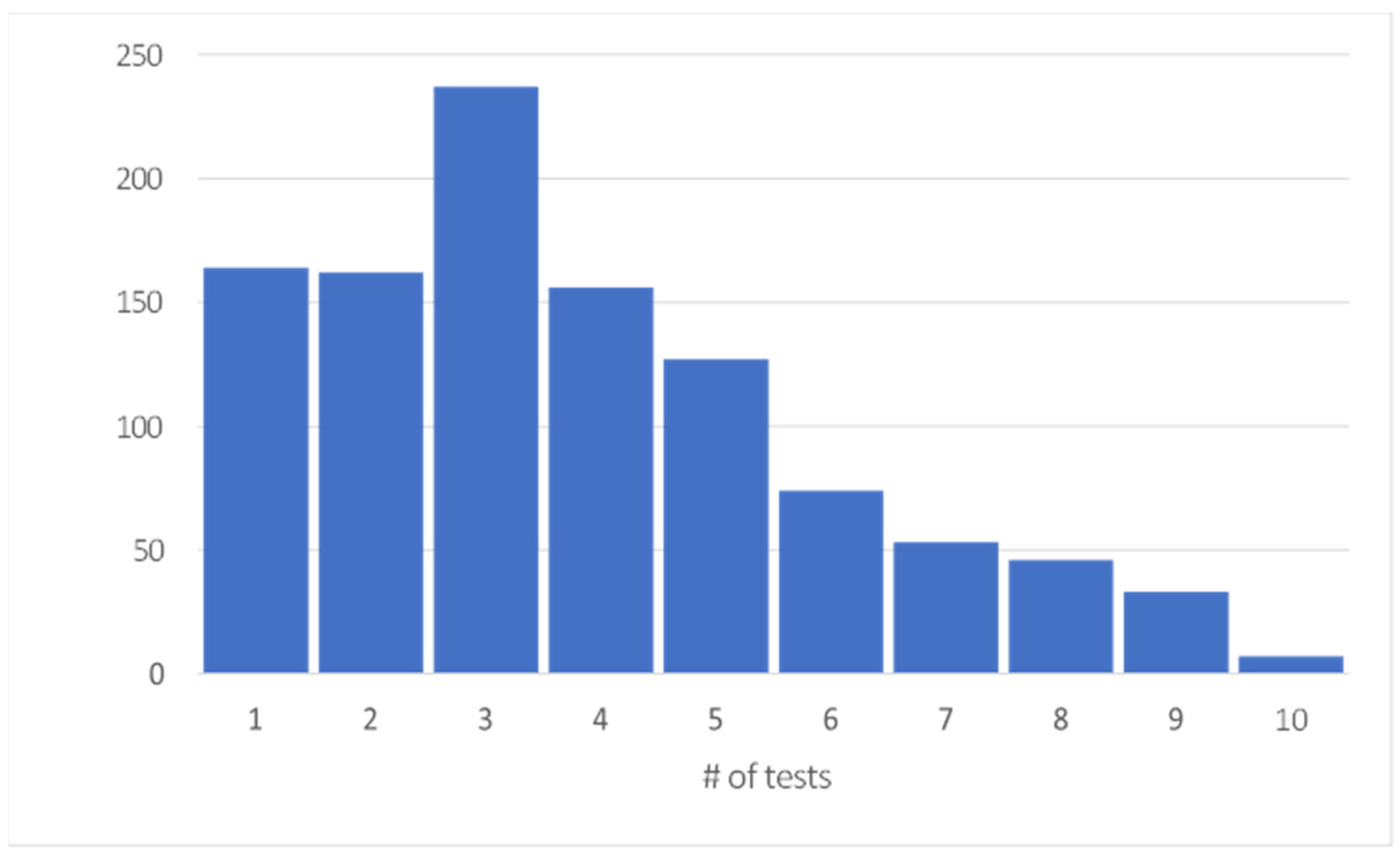
3.1. Data Preparation
3.2. Model Building
4. Results
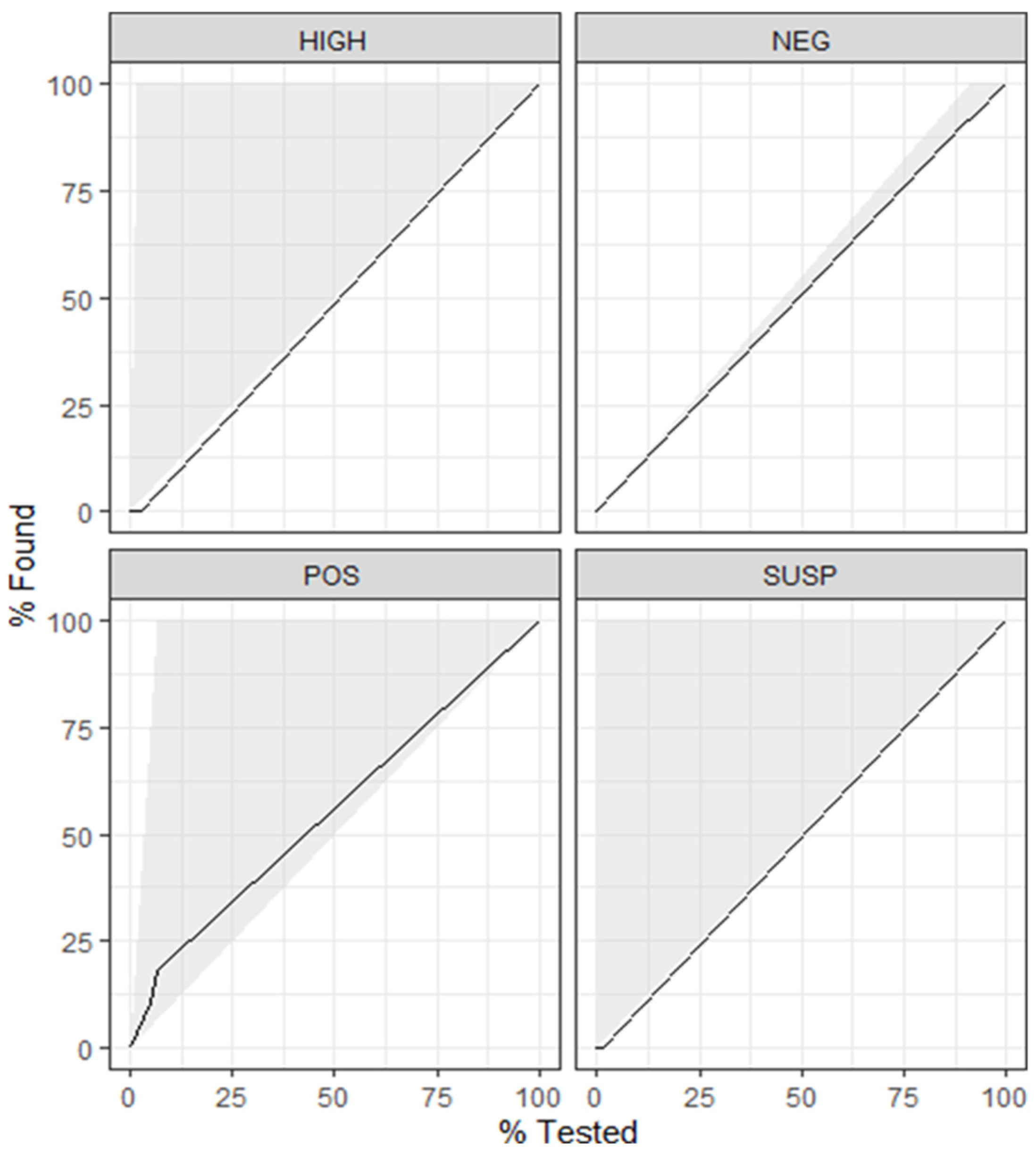
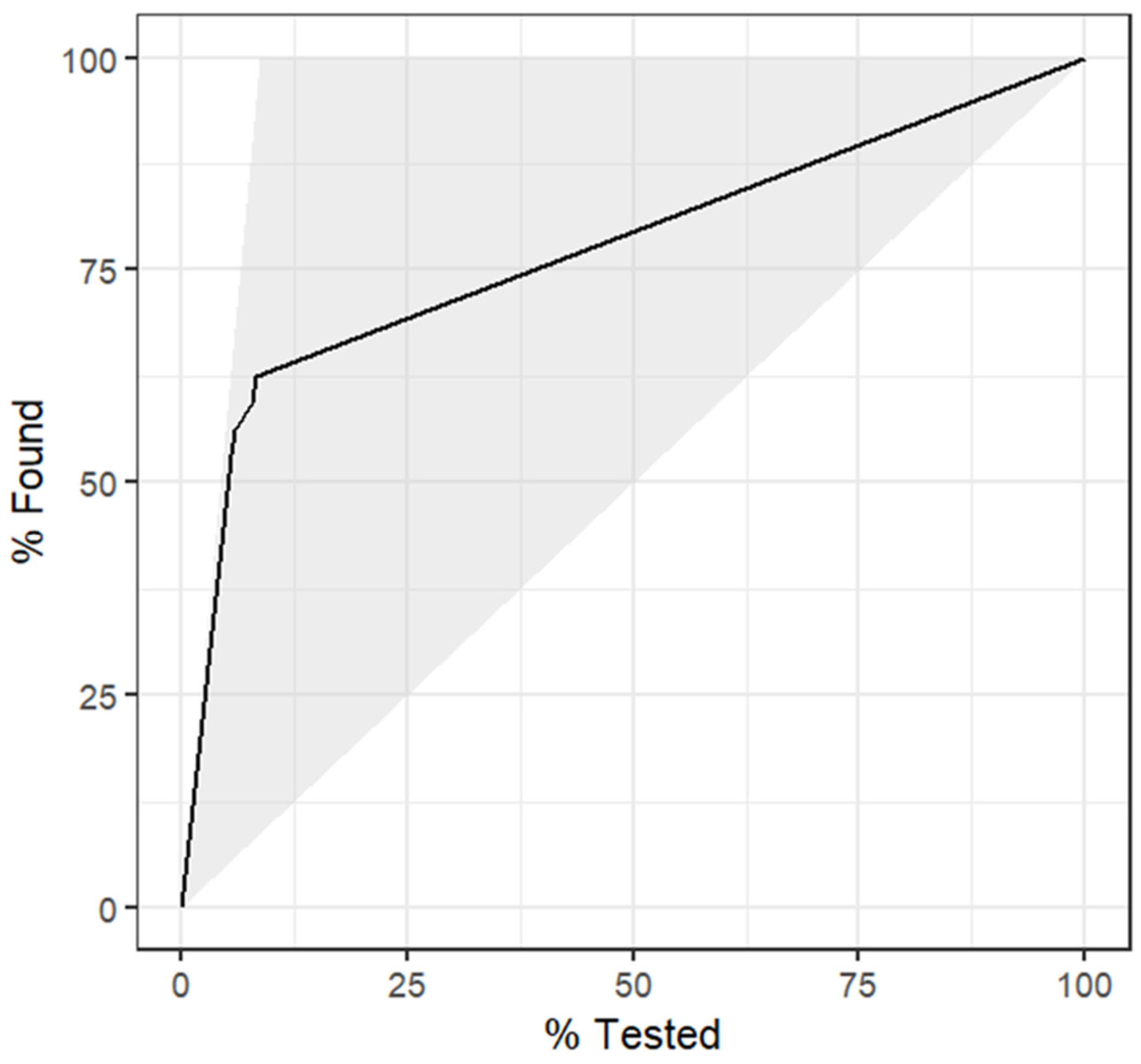
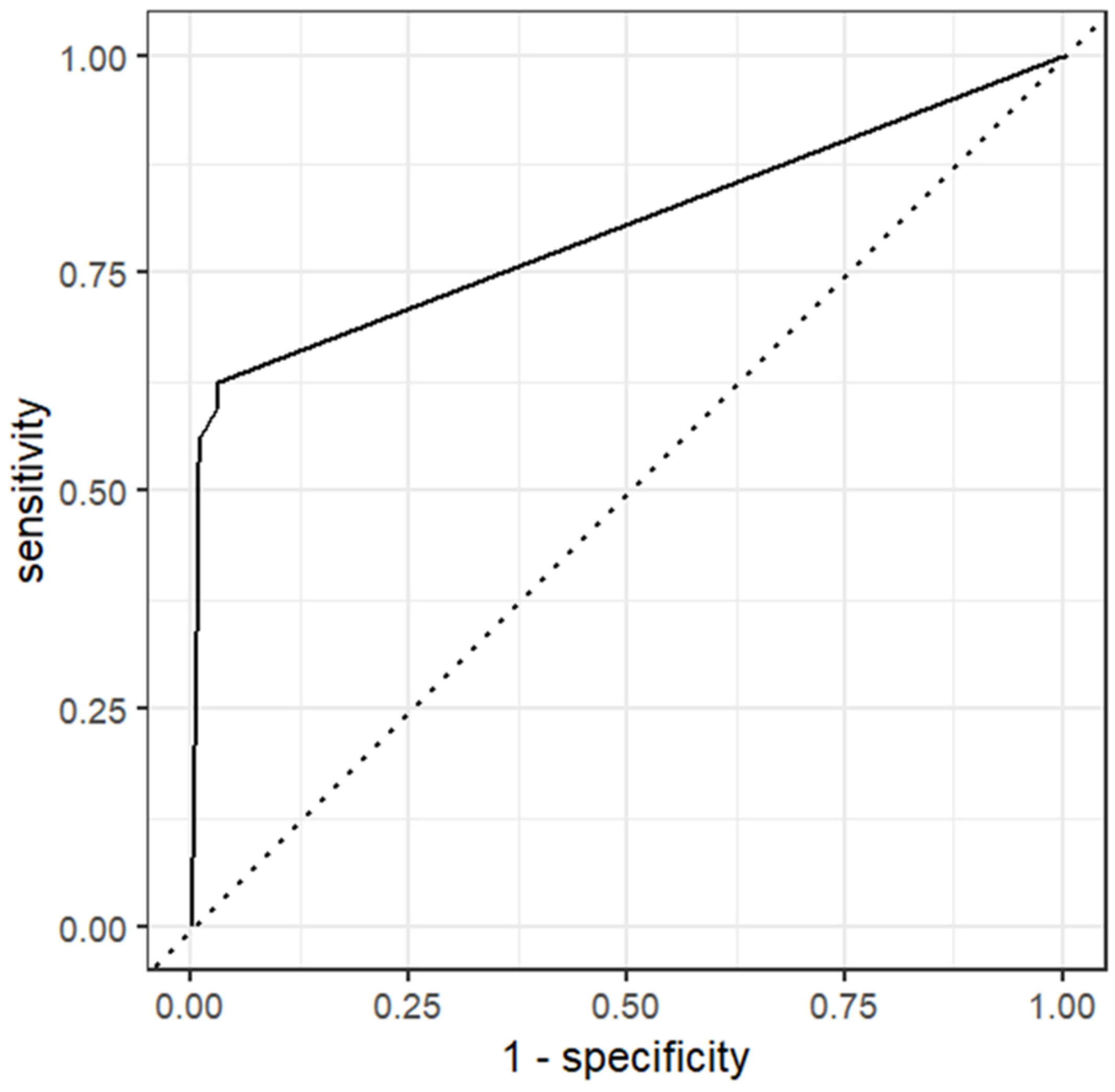
4.1. Model 1
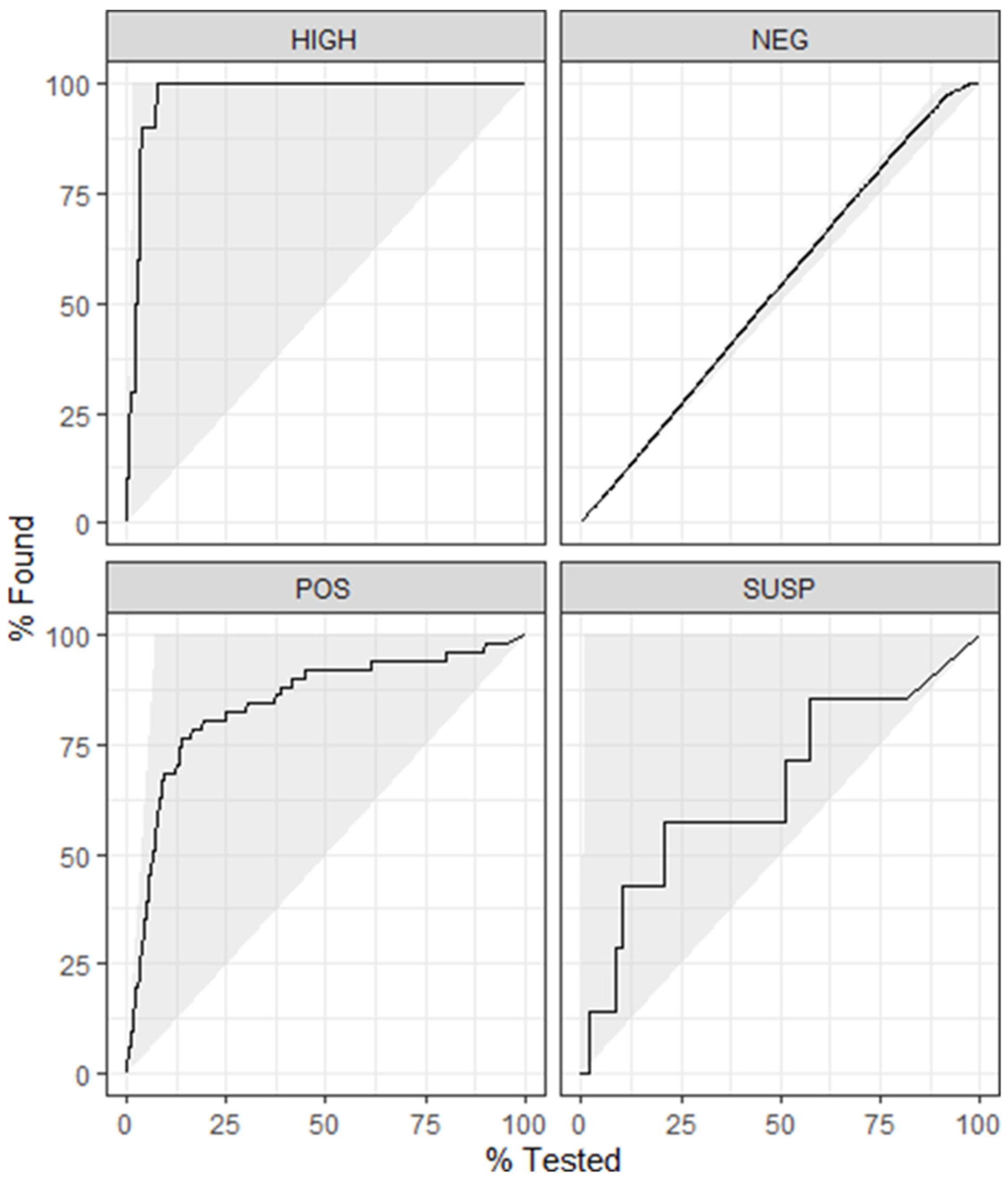
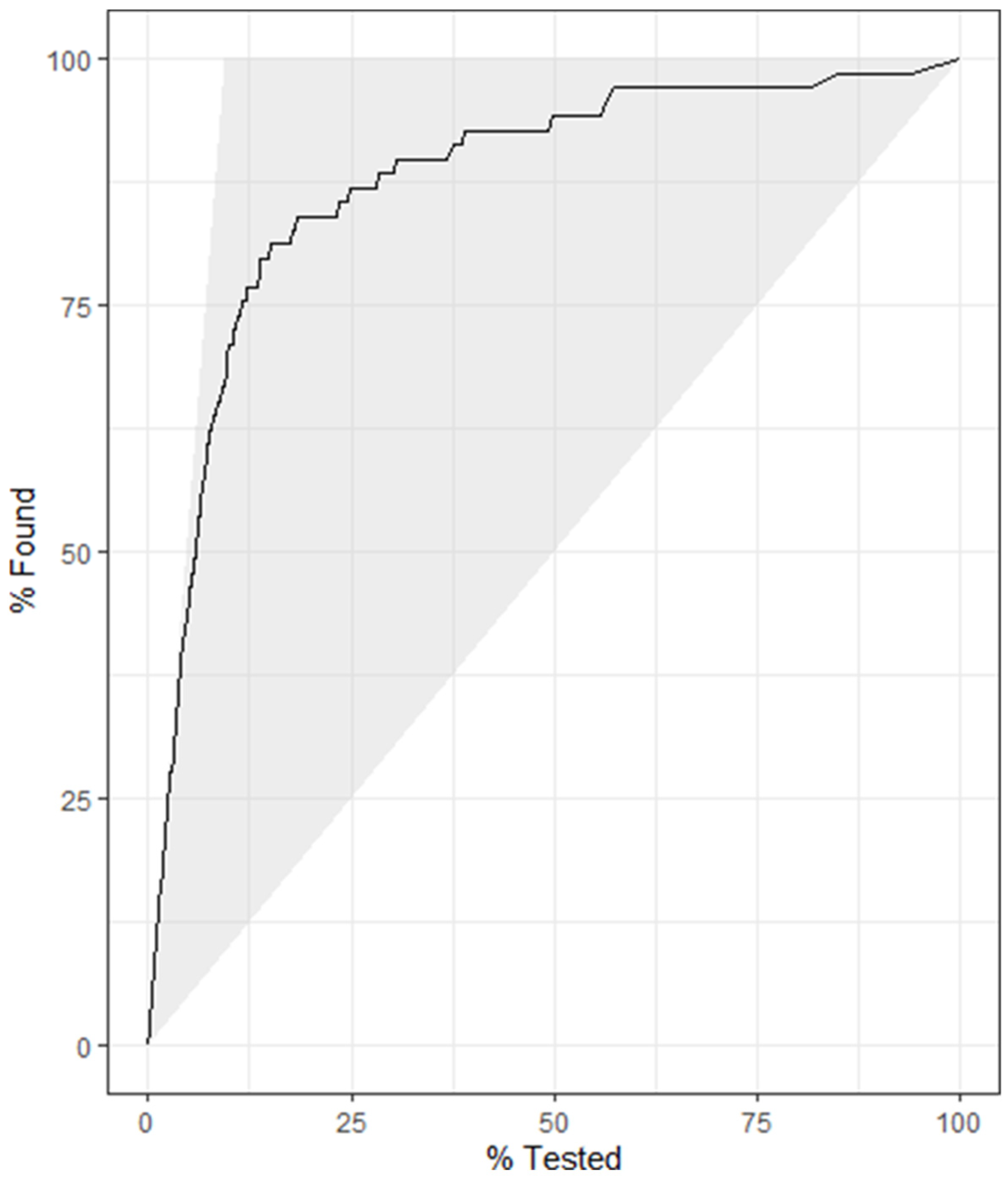
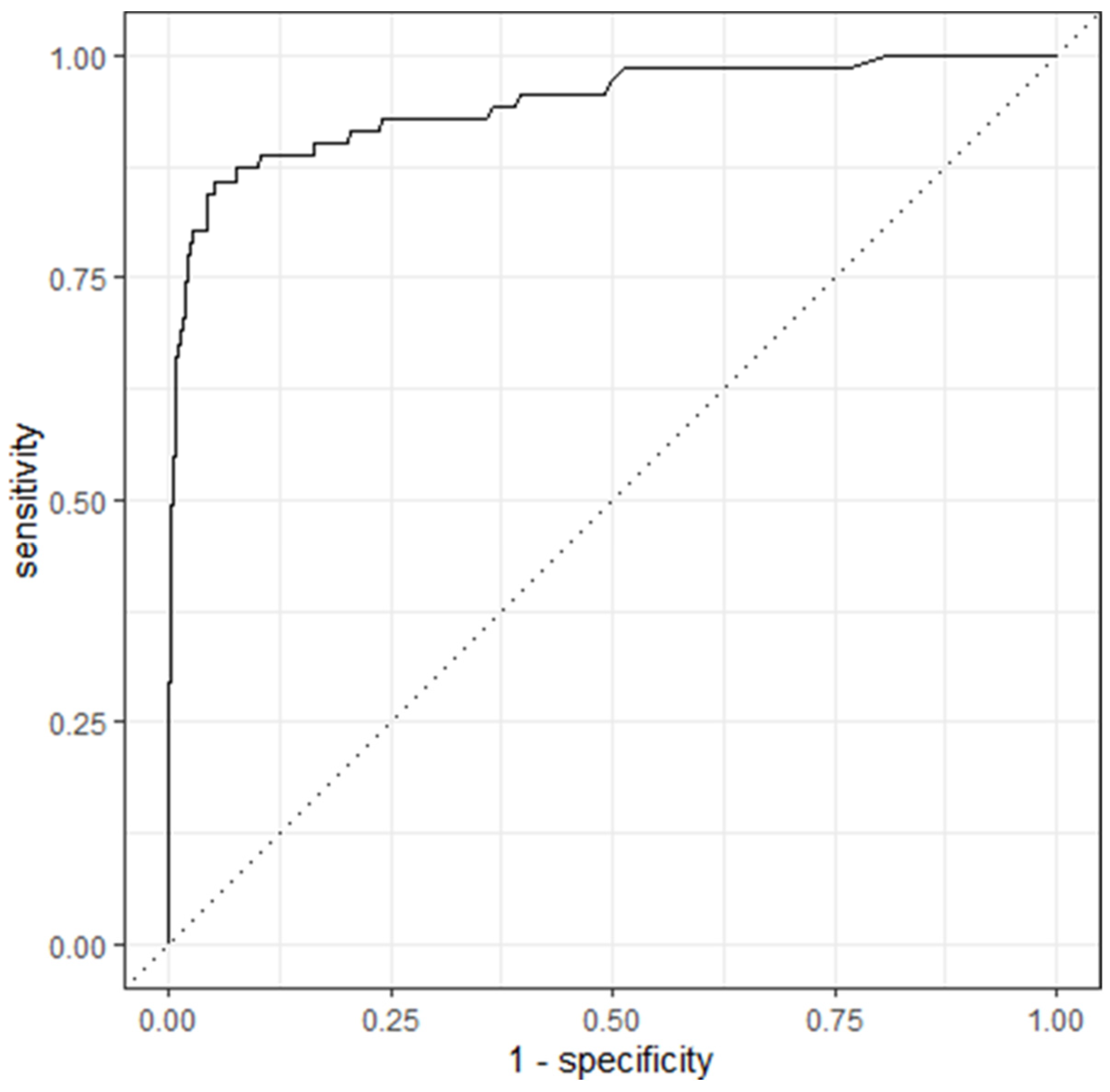
4.2. Model 2
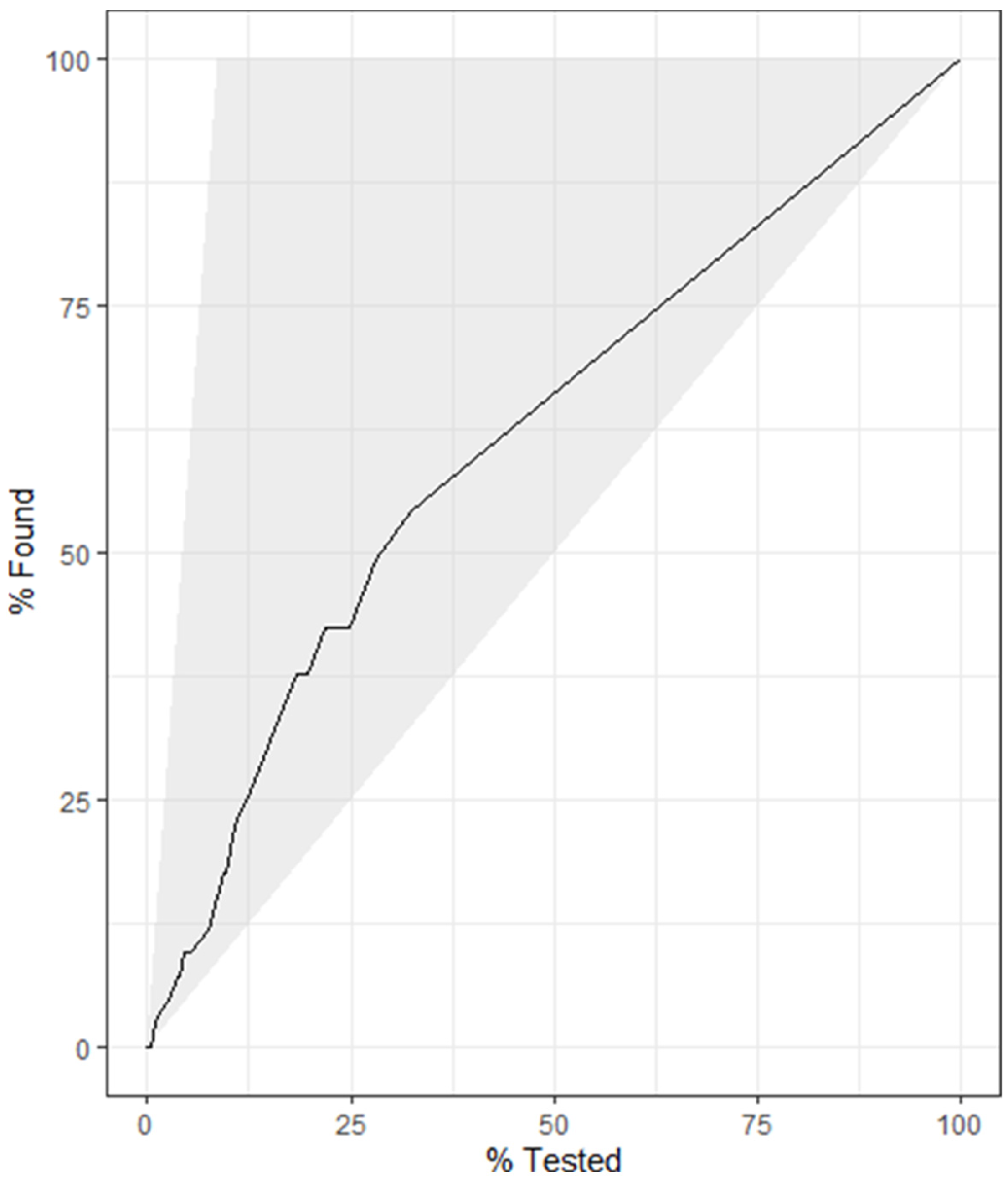
4.3. Model 3
4.4. Model 4
4.5. Decision Tree
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Rasmussen, P.; Barkema, H.W.; Mason, S.; Beaulieu, E.; Hall, D.C. Economic losses due to Johne’s disease (paratuberculosis) in dairy cattle. J. Dairy Sci. 2021, 104, 3123–3143. [Google Scholar] [CrossRef] [PubMed]
- Whittington, R.; Donat, K.; Weber, M.F.; Kelton, D.F.; Nielsen, S.S.; Eisenberg, S.; Arrigoni, N.; Juste, R.; Sáez, J.L.; Dhand, N.K.; et al. Control of paratuberculosis: Who, why and how. A review of 48 countries. BMC Vet. Res. 2019, 15, 1–29. [Google Scholar] [CrossRef] [PubMed]
- McAloon, C.G.; Roche, S.; Ritter, C.; Barkema, H.W.; Whyte, P.; More, S.J.; O’Grady, L.; Green, M.J.; Doherty, M.L. A review of paratuberculosis in dairy herds–Part 1: Epidemiology. Vet. J. 2019, 246, 59–65. [Google Scholar] [CrossRef] [PubMed]
- McAloon, C.G.; Roche, S.; Ritter, C.; Barkema, H.W.; Whyte, P.; More, S.J.; O’Grady, L.; Green, M.J.; Doherty, M.L. A review of paratuberculosis in dairy herds–Part 2: On-farm control. Vet. J. 2019, 246, 54–58. [Google Scholar] [CrossRef] [PubMed]
- Eisenberg SW, F.; Veldman, E.; Rutten, V.P.; Koets, A.P. A longitudinal study of factors influencing the result of a Mycobacterium avium ssp. paratuberculosis antibody ELISA in milk of dairy cows. J. Dairy Sci. 2015, 98, 2345–2355. [Google Scholar] [CrossRef] [PubMed]
- McAloon, C.G.; O’Grady, L.; Botaro, B.; More, S.J.; Doherty, M.; Whyte, P.; Saxmose Nielsen, S.; Citer, L.; Kenny, K.; Graham, D.; et al. Individual and herd-level milk ELISA test status for Johne’s disease in Ireland after correcting for non-disease-associated variables. J. Dairy Sci. 2020, 103, 9345–9354. [Google Scholar] [CrossRef] [PubMed]
- Fecteau, M.E.; Whitlock, R.H.; Buergelt, C.D.; Sweeney, R.W. Exposure of young dairy cattle to Mycobacterium avium subsp. paratuberculosis (MAP) through intensive grazing of contaminated pastures in a herd positive for Johne’s disease. Can. Vet. J. 2010, 51, 198. [Google Scholar] [PubMed]
- Norby, B.; Fosgate, G.T.; Manning, E.J.; Collins, M.T.; Roussel, A.J. Environmental mycobacteria in soil and water on beef ranches: Association between presence of cultivable mycobacteria and soil and water physicochemical characteristics. Vet. Microbiol. 2007, 124, 153–159. [Google Scholar] [CrossRef] [PubMed]
- Hirst, H.L.; Garry, F.B.; Salman, M.D. Assessment of test results when using a commercial enzyme-linked immunosorbent assay for diagnosis of paratuberculosis in repeated samples collected from adult dairy cattle. J. Am. Vet. Med. Assoc. 2002, 220, 1685–1689. [Google Scholar] [CrossRef] [PubMed]
- Awaysheh, A.; Wilcke, J.; Elvinger, F.; Rees, L.; Fan, W.; Zimmerman, K.L. Review of medical decision support and machine-learning methods. Vet. Pathol. 2019, 56, 512–525. [Google Scholar] [CrossRef] [PubMed]
- Aguilar-Lazcano, C.A.; Espinosa-Curiel, I.E.; Ríos-Martínez, J.A.; Madera-Ramírez, F.A.; Pérez-Espinosa, H. Machine Learning-Based Sensor Data Fusion for Animal Monitoring: Scoping Review. Sensors 2023, 23, 5732. [Google Scholar] [CrossRef] [PubMed]
- Bao, J.; Xie, Q. Artificial intelligence in animal farming: A systematic literature review. J. Clean. Prod. 2022, 331, 129956. [Google Scholar] [CrossRef]
- Basran, P.S.; Appleby, R.B. The unmet potential of artificial intelligence in veterinary medicine. Am. J. Vet. Res. 2022, 83, 385–392. [Google Scholar] [CrossRef] [PubMed]
- Gunakala, A.; Shahid, A.H. A comparative study on performance of basic and ensemble classifiers with various datasets. Appl. Comput. Sci. 2023, 19, 107–132. [Google Scholar] [CrossRef]
- Osisanwo, F.Y.; Akinsola, J.E.; Awodele, O.; Hinmikaiye, J.O.; Olakanmi, O.; Akinjobi, J. Supervised Machine Learning Algorithms: Classification and Comparison. Int. J. Comput. Trends Technol. 2017, 48, 128–138. [Google Scholar] [CrossRef]
- Matvieiev, M.; Romasevych, Y.; Getya, A. The Use of Artificial Neural Networks for Prediction of Milk Productivity of Cows in Ukraine. Kafkas Üniversitesi Veteriner Fakültesi Dergisi 2023, 29, 289. [Google Scholar]
- Awaysheh, A.; Wilcke, J.; Elvinger, F.; Rees, L.; Fan, W.; Zimmerman, K. Identifying free-text features to improve automated classification of structured histopathology reports for feline small intestinal disease. J. Vet. Diagn. Investig. 2018, 30, 211–217. [Google Scholar] [CrossRef] [PubMed]
- Awaysheh, A.; Wilcke, J.; Elvinger, F.; Rees, L.; Fan, W.; Zimmerman, K.L. Evaluation of supervised machine-learning algorithms to distinguish between inflammatory bowel disease and alimentary lymphoma in cats. J. Vet. Diagn. Investig. 2016, 28, 679–687. [Google Scholar] [CrossRef] [PubMed]
- Flory, A.; Kruglyak, K.M.; Tynan, J.A.; McLennan, L.M.; Rafalko, J.M.; Fiaux, P.C.; Hernandez, G.E.; Marass, F.; Nakashe, P.; Ruiz-Perez, C.A.; et al. Clinical validation of a next-generation sequencing-based multi-cancer early detection “liquid biopsy” blood test in over 1,000 dogs using an independent testing set: The CANcer Detection in Dogs (CANDiD) study. PLoS ONE 2022, 17, e0266623. [Google Scholar] [CrossRef] [PubMed]
- Renard, J.; Faucher, M.R.; Combes, A.; Concordet, D.; Reynolds, B.S. Machine-learning algorithm as a prognostic tool in non-obstructive acute-on-chronic kidney disease in the cat. J. Feline Med. Surg. 2021, 23, 1140–1148. [Google Scholar] [CrossRef] [PubMed]
- Reagan, K.L.; Deng, S.; Sheng, J.; Sebastian, J.; Wang, Z.; Huebner, S.N.; Wenke, L.A.; Michalak, S.R.; Strohmer, T.; Sykes, J.E. Use of machine-learning algorithms to aid in the early detection of leptospirosis in dogs. J. Vet. Diagn. Investig. 2022, 34, 612–621. [Google Scholar] [CrossRef] [PubMed]
- Biourge, V.; Delmotte, S.; Feugier, A.; Bradley, R.; McAllister, M.; Elliott, J. An artificial neural network-based model to predict chronic kidney disease in aged cats. J. Vet. Intern. Med. 2020, 34, 1920–1931. [Google Scholar] [CrossRef] [PubMed]
- Ferreira, T.S.; Santana, E.E.C.; Junior, A.F.L.J.; Junior, P.F.S.; Bastos, L.S.; Silva, A.L.A.; Melo, S.A.; Cruz, C.A.M.; Aquino, V.S.; Castro, L.S.O.; et al. Diagnostic Classification of Cases of Canine Leishmaniasis Using Machine Learning. Sensors 2022, 22, 3128. [Google Scholar] [CrossRef] [PubMed]
- De Vries, A.; Bliznyuk, N.; Pinedo, P. Invited Review: Examples and opportunities for artificial intelligence (AI) in dairy farms. Appl. Anim. Sci. 2023, 39, 14–22. [Google Scholar] [CrossRef]
- Lokhorst, C.; De Mol, R.M.; Kamphuis, C. Invited review: Big Data in precision dairy farming. Animal 2019, 13, 1519–1528. [Google Scholar] [CrossRef] [PubMed]
- Slob, N.; Catal, C.; Kassahun, A. Application of machine learning to improve dairy farm management: A systematic literature review. Prev. Vet. Med. 2021, 187, 105237. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Li, Q.; Chu, M.; Kang, X.; Liu, G. Application of infrared thermography and machine learning techniques in cattle health assessments: A review. Biosyst. Eng. 2023, 230, 361–387. [Google Scholar] [CrossRef]
- Schmeling, L.; Elmamooz, G.; Hoang, P.T.; Kozar, A.; Nicklas, D.; Sünkel, M.; Thurner, S.; Rauch, E. Training and validating a machine learning model for the sensor-based monitoring of lying behavior in dairy cows on pasture and in the barn. Animals 2021, 11, 2660. [Google Scholar] [CrossRef] [PubMed]
- Zhou, X.; Xu, C.; Wang, H.; Xu, W.; Zhao, Z.; Chen, M.; Jia, B.; Huang, B. The Early Prediction of Common Disorders in Dairy Cows Monitored by Automatic Systems with Machine Learning Algorithms. Animals 2022, 12, 1251. [Google Scholar] [CrossRef]
- Hernandez Brenda Contla Lopez-Villalobos, N.; Vignes, M. Identifying Health Status in Grazing Dairy Cows from Milk Mid-Infrared Spectroscopy by Using Machine Learning Methods. Animals 2021, 11, 2154. [Google Scholar] [CrossRef] [PubMed]
- Sykes, A.L.; Silva, G.S.; Holtkamp, D.J.; Mauch, B.W.; Osemeke, O.; Linhares, D.C.; Machado, G. Interpretable machine learning applied to on-farm biosecurity and porcine reproductive and respiratory syndrome virus. Transbound. Emerg. Dis. 2022, 69, e916–e930. [Google Scholar] [CrossRef] [PubMed]
- Pereira, L.E.C.; Ferraudo, A.S.; Panosso, A.R.; Carvalho AA, B.; Mathias, L.A.; Saches, A.C.; Hellwig, K.S.; Ancêncio, R.A. Machine Learning to predict tuberculosis in cattle from the state of Sao Paulo, Brazil. Eur. J. Public Health 2020, 30 (Suppl. 5), ckaa166.849. [Google Scholar] [CrossRef]
- Stański, K.; Lycett, S.; Porphyre, T.; Bronsvoort, B.D.C. Using machine learning improves predictions of herd-level bovine tuberculosis breakdowns in Great Britain. Sci. Rep. 2021, 11, 2208. [Google Scholar] [CrossRef] [PubMed]
- Ebrahimie, E.; Ebrahimi, F.; Ebrahimi, M.; Tomlinson, S.; Petrovski, K.R. Hierarchical pattern recognition in milking parameters predicts mastitis prevalence. Comput. Electron. Agric. 2018, 147, 6–11. [Google Scholar] [CrossRef]
- Dhoble, A.S.; Ryan, K.T.; Lahiri, P.; Chen, M.; Pang, X.; Cardoso, F.C.; Bhalerao, K.D. Cytometric fingerprinting and machine learning (CFML): A novel label-free, objective method for routine mastitis screening. Comput. Electron. Agric. 2019, 162, 505–513. [Google Scholar] [CrossRef]
- Bobbo, T.; Biffani, S.; Taccioli, C.; Penasa, M.; Cassandro, M. Comparison of machine learning methods to predict udder health status based on somatic cell counts in dairy cows. Sci. Rep. 2021, 11, 13642. [Google Scholar] [CrossRef] [PubMed]
- Heald, C.W.; Kim, T.; Sischo, W.M.; Cooper, J.B.; Wolfgang, D.R. A computerized mastitis decision aid using farm-based records: An artificial neural network approach. J. Dairy Sci. 2000, 83, 711–720. [Google Scholar] [CrossRef] [PubMed]
- Porter, I.R.; Wieland, M.; Basran, P.S. Feasibility of the use of deep learning classification of teat-end condition in Holstein cattle. J. Dairy Sci. 2021, 104, 4529–4536. [Google Scholar] [CrossRef] [PubMed]
- Machado, G.; Mendoza, M.R.; Corbellini, L.G. What variables are important in predicting bovine viral diarrhea virus? A random forest approach. Vet. Res. 2015, 46, 1–15. [Google Scholar] [CrossRef] [PubMed]
- Punyapornwithaya, V.; Klaharn, K.; Arjkumpa, O.; Sansamur, C. Exploring the predictive capability of machine learning models in identifying foot and mouth disease outbreak occurrences in cattle farms in an endemic setting of Thailand. Prev. Vet. Med. 2022, 207, 105706. [Google Scholar] [CrossRef] [PubMed]
- Camanes, G.; Joly, A.; Fourichon, C.; Ben Romdhane, R.; Ezanno, P. Control measures to prevent the increase of paratuberculosis prevalence in dairy cattle herds: An individual-based modelling approach. Vet. Res. 2018, 49, 1–13. [Google Scholar] [CrossRef] [PubMed]
- Vitense, P.; Kasbohm, E.; Klassen, A.; Gierschner, P.; Trefz, P.; Weber, M.; Miekisch, W.; Schubert, J.K.; Möbius, P.; Reinhold, P.; et al. Detection of Mycobacterium avium ssp. paratuberculosis in cultures from fecal and tissue samples using VOC analysis and machine learning tools. Front. Vet. Sci. 2021, 8, 620327. [Google Scholar] [CrossRef] [PubMed]
- Weber, M.; Gierschner, P.; Klassen, A.; Kasbohm, E.; Schubert, J.K.; Miekisch, W.; Reinhold, P.; Köhler, H. Detection of paratuberculosis in dairy herds by analyzing the scent of feces, alveolar gas, and stable air. Molecules 2021, 26, 2854. [Google Scholar] [CrossRef] [PubMed]
- Lee, S.M.; Park, H.T.; Park, S.; Lee, J.H.; Kim, D.; Yoo, H.S.; Kim, D. A Machine Learning Approach Reveals a Microbiota Signature for Infection with Mycobacterium avium subsp. paratuberculosis in Cattle. Microbiol. Spectr. 2023, 11, e03134-22. [Google Scholar] [CrossRef] [PubMed]
- Umanets, A.; Dinkla, A.; Vastenhouw, S.; Ravesloot, L.; Koets, A.P. Classification and prediction of Mycobacterium avium subsp. Paratuberculosis (MAP) shedding severity in cattle based on young stock heifer faecal microbiota composition using random forest algorithms. Anim. Microbiome 2021, 3, 1–13. [Google Scholar] [CrossRef] [PubMed]
- Capewell, P.; Lowe, A.; Athanasiadou, S.; Wilson, D.; Hanks, E.; Coultous, R.; Hutchings, M.R.; Palarea-Albaladejo, J. A microRNA-based Johne’s disease diagnostic predictive system: Preliminary results. bioRxiv 2023. [Google Scholar] [CrossRef]
- Taylor, E.N.; Beckmann, M.; Hewinson, G.; Rooke, D.; Mur, L.A.; Koets, A.P. Metabolomic changes in polyunsaturated fatty acids and eicosanoids as diagnostic biomarkers in Mycobacterium avium ssp. paratuberculosis (MAP)-inoculated Holstein–Friesian heifers. Vet. Res. 2022, 53, 1–13. [Google Scholar] [CrossRef] [PubMed]
- Ezanno, P.; Picault, S.; Beaunée, G.; Bailly, X.; Muñoz, F.; Duboz, R.; Monod, H.; Guégan, J.F. Research perspectives on animal health in the era of artificial intelligence. Vet. Res. 2021, 52, 1–15. [Google Scholar] [CrossRef] [PubMed]
- Hennessey, E.; DiFazio, M.; Hennessey, R.; Cassel, N. Artificial intelligence in veterinary diagnostic imaging: A literature review. Vet. Radiol. Ultrasound 2022, 63, 851–870. [Google Scholar] [CrossRef] [PubMed]
- Kour, S.; Agrawal, R.; Sharma, N.; Tikoo, A.; Pande, N.; Sawhney, A. Artificial Intelligence and its Application in Animal Disease Diagnosis. J. Anim. Res. 2022, 12, 1–10. [Google Scholar]
- Guitian, J.; Arnold, M.; Chang, Y.; Snary, E.L. Applications of machine learning in animal and veterinary public health surveillance. Rev. Sci. Tech. (Int. Off. Epizoot.) 2023, 42, 230–241. [Google Scholar] [CrossRef]
- Hassan, F.A.; Moawed, S.A.; El-Araby, I.E.; Gouda, H.F. Machine Learning Based Prediction for Solving Veterinary Data Problems: A Review. J. Adv. Vet. Res. 2022, 12, 798–802. [Google Scholar]
- Fuentes, S.; Viejo, C.G.; Tongson, E.; Dunshea, F.R. The livestock farming digital transformation: Implementation of new and emerging technologies using artificial intelligence. Anim. Health Res. Rev. 2022, 23, 59–71. [Google Scholar] [CrossRef]
- Kelton, D.F.; Von Konigslow, T.E.; Perkins, N.; Godkin, A.; MacNaughton, G.; Cantin, R. Quantifying the cost of removing fecals shedders in a voluntary Johne’s disease control program. In Proceedings of the 12th International Colloquium on Paratuberculosis, Parma, Italy, 22–26 June 2014; p. 120. [Google Scholar]
- Sweeney, R.W.; Whitlock, R.H.; McAdams, S.; Fyock, T. Longitudinal study of ELISA seroreactivity to Mycobacterium avium subsp. paratuberculosis in infected cattle and culture-negative herd mates. J. Vet. Diagn. Investig. 2006, 18, 2–6. [Google Scholar] [CrossRef] [PubMed]
- Roche, S.M.; Jones-Bitton, A.; Meehan, M.; Von Massow, M.; Kelton, D.F. Evaluating the effect of Focus Farms on Ontario dairy producers’ knowledge, attitudes, and behavior toward control of Johne’s disease. J. Dairy Sci. 2015, 98, 5222–5240. [Google Scholar] [CrossRef] [PubMed]
- Montesinos López, O.A.; Montesinos López, A.; Crossa, J. Multivariate Statistical Machine Learning Methods for Genomic Prediction. In Multivariate Statistical Machine Learning Methods for Genomic Prediction; Springer Nature: Cham, Switzerland, 2022. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Nielsen, S.S.; Enevoldsen, C.; Gröhn, Y.T. The Mycobacterium avium subsp. paratuberculosis ELISA response by parity and stage of lactation. Prev. Vet. Med. 2002, 54, 1–10. [Google Scholar] [CrossRef] [PubMed]
- Nielsen, S.S.; Toft, N. Effect of days in milk and milk yield on testing positive in milk antibody ELISA to Mycobacterium avium subsp. paratuberculosis in dairy cattle. Vet. Immunol. Immunopathol. 2012, 149, 6–10. [Google Scholar] [CrossRef] [PubMed]
- Viazzi, S.; Bahr, C.; Schlageter-Tello, A.; Van Hertem, T.; Romanini, C.; Pluk, A.; Halachmi, I.; Lokhorst, C.; Berckmans, D. Analysis of individual classification of lameness using automatic measurement of back posture in dairy cattle. J. Dairy Sci. 2013, 96, 257–266. [Google Scholar] [CrossRef] [PubMed]
- Wagner, N.; Antoine, V.; Mialon, M.M.; Lardy, R.; Silberberg, M.; Koko, J.; Veissier, I. Machine learning to detect behavioural anomalies in dairy cows under subacute ruminal acidosis. Comput. Electron. Agric. 2020, 170, 105233. [Google Scholar] [CrossRef]
- Naqvi, S.A.; King, M.T.; DeVries, T.J.; Barkema, H.W.; Deardon, R. Data considerations for developing deep learning models for dairy applications: A simulation study on mastitis detection. Comput. Electron. Agric. 2022, 196, 106895. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Number of Observations | Number of Cows 1 | Outcome (Levels) | # of Predictors | Model Performance |
|---|---|---|---|---|---|
| Subset 1 | 4008 | 1059 | Interpretation (negative, suspect, positive, high) | 10 | κ: 0.054, AUC: 0.514 |
| Subset 2 | 2949 | 895 | Interpretation (negative, suspect, positive, high) | 18 | κ: 0.518, AUC: 0.763 |
| Subset 3 | 4008 | 1059 | Interpretation (negative, positive) | 10 | κ: 0.038, AUC: 0.372 |
| Subset 4 | 2949 | 895 | Interpretation (negative, positive) | 16 | κ: 0.626, AUC: 0.915 |
| Training Dataset | Test Dataset | |||||||
|---|---|---|---|---|---|---|---|---|
| Data Subset | 1 | 2 | 3 | 4 | 1 | 2 | 3 | 4 |
| Number of observations | 3006 | 2211 | 3006 | 2211 | 1002 | 738 | 1002 | 738 |
| Proportion of negative results | 0.92 | 0.9 | 0.93 | 0.92 | 0.91 | 0.91 | 0.92 | 0.91 |
| Proportion of suspect results | 0.01 | 0.01 | NA 1 | NA1 | 0.01 | 0.01 | NA 1 | NA 1 |
| Proportion of positive results | 0.06 | 0.07 | 0.07 | 0.08 | 0.07 | 0.07 | 0.08 | 0.09 |
| Proportion of high results | 0.01 | 0.01 | NA 1 | NA 1 | 0.01 | 0.01 | NA 1 | NA 1 |
| Model 1 | |||||||||
| (mtry = 5, min_n = 2, and trees = 1) | |||||||||
| m305 | dim | m24 | f305 | p305 | f24 | sccls | p24 | lact | breed |
| 72.77 | 66.52 | 62.21 | 58.38 | 52.01 | 48.93 | 43.69 | 41.22 | 10.04 | 5.71 |
| Model 2 | |||||||||
| (mtry = 18, min_n = 21, and trees = 1000) | |||||||||
| proppos | avELISA | f24 | p24 | m305 | dim | m24 | f305 | p305 | sccls |
| 82.27 | 78.94 | 16.26 | 15.42 | 14.04 | 12.03 | 11.55 | 11.54 | 11.12 | 9.43 |
| Model 3 | |||||||||
| (mtry = 1, min_n = 21, and trees = 1) | |||||||||
| f305 | dim | p24 | m305 | sccls | p305 | lact | m24 | f24 | breed |
| 31.36 | 28.37 | 16.92 | 15.82 | 15.72 | 13.88 | 12.71 | 11.64 | 9.69 | 2.92 |
| Model 4 | |||||||||
| (mtry = 8, min_n = 2, and trees = 2000) | |||||||||
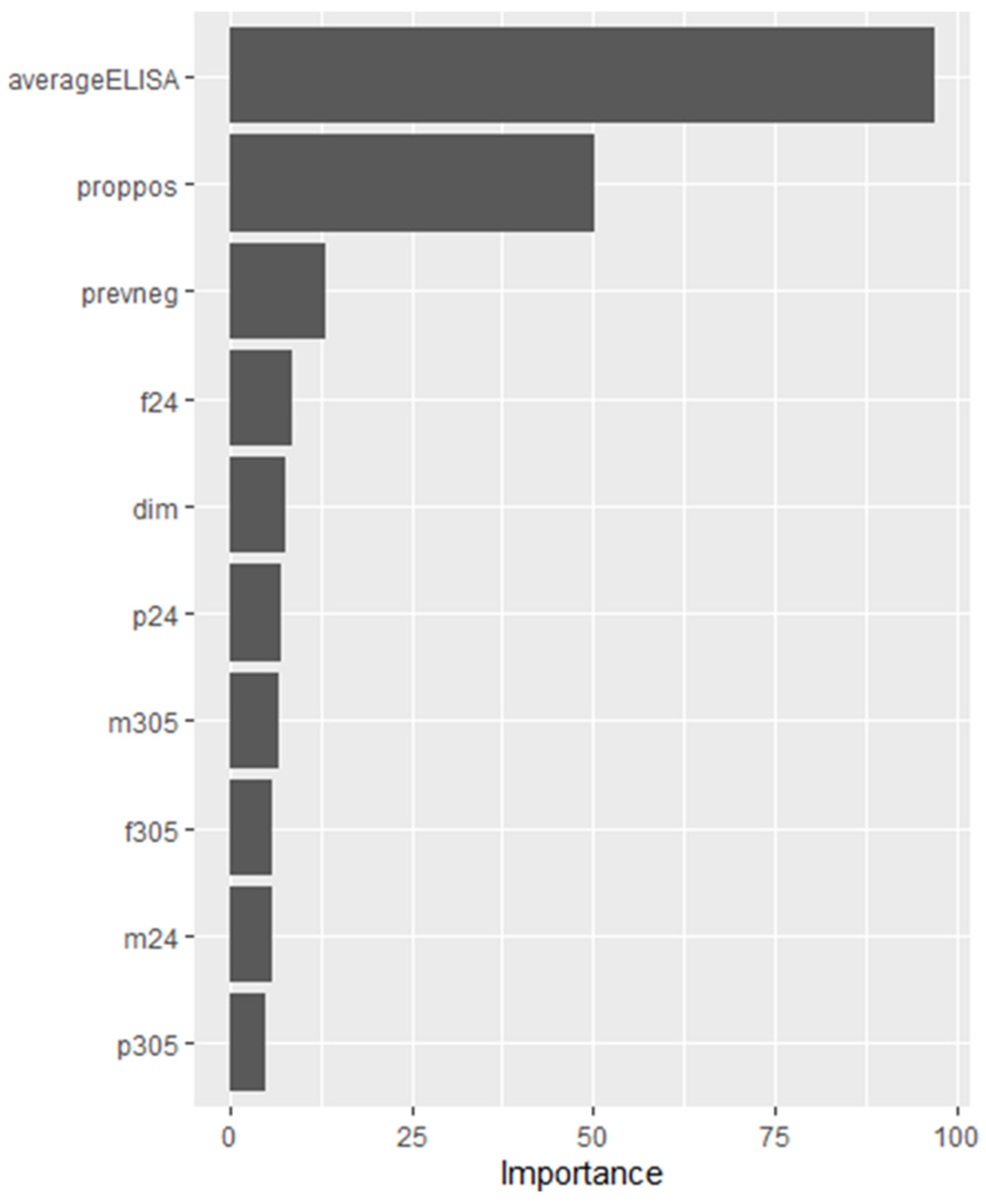
| avELISA | proppos | prevneg | f24 | dim | p24 | m305 | f305 | m24 | p305 |
| 97.15 | 50.25 | 13.15 | 8.47 | 7.80 | 7.19 | 6.82 | 5.96 | 5.94 | 4.83 |
| Model | Mtry | Trees | Min_n | Kappa | Out-of-Bag Error |
|---|---|---|---|---|---|
| 4-A 1 | 8 | 2000 | 2 | 0.727 | 0.042 |
| 4-B | 16 | 2000 | 2 | 0.724 | 0.043 |
| 4-C | 8 | 2000 | 21 | 0.737 | 0.041 |
| 4-D | 8 | 1000 | 2 | 0.737 | 0.042 |
| 4-E | 8 | 1000 | 40 | 0.717 | 0.041 |
| 4-F | 16 | 1000 | 40 | 0.727 | 0.042 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Imada, J.; Arango-Sabogal, J.C.; Bauman, C.; Roche, S.; Kelton, D. Comparison of Machine Learning Tree-Based Algorithms to Predict Future Paratuberculosis ELISA Results Using Repeat Milk Tests. Animals 2024, 14, 1113. https://doi.org/10.3390/ani14071113
Imada J, Arango-Sabogal JC, Bauman C, Roche S, Kelton D. Comparison of Machine Learning Tree-Based Algorithms to Predict Future Paratuberculosis ELISA Results Using Repeat Milk Tests. Animals. 2024; 14(7):1113. https://doi.org/10.3390/ani14071113
Chicago/Turabian StyleImada, Jamie, Juan Carlos Arango-Sabogal, Cathy Bauman, Steven Roche, and David Kelton. 2024. "Comparison of Machine Learning Tree-Based Algorithms to Predict Future Paratuberculosis ELISA Results Using Repeat Milk Tests" Animals 14, no. 7: 1113. https://doi.org/10.3390/ani14071113
APA StyleImada, J., Arango-Sabogal, J. C., Bauman, C., Roche, S., & Kelton, D. (2024). Comparison of Machine Learning Tree-Based Algorithms to Predict Future Paratuberculosis ELISA Results Using Repeat Milk Tests. Animals, 14(7), 1113. https://doi.org/10.3390/ani14071113