A Novel Indoor Localization Method Based on Image Retrieval and Dead Reckoning

Abstract
:1. Introduction
2. Related Works
2.1. PDR Improvements with Visual Information
2.2. Visual Position Recognition
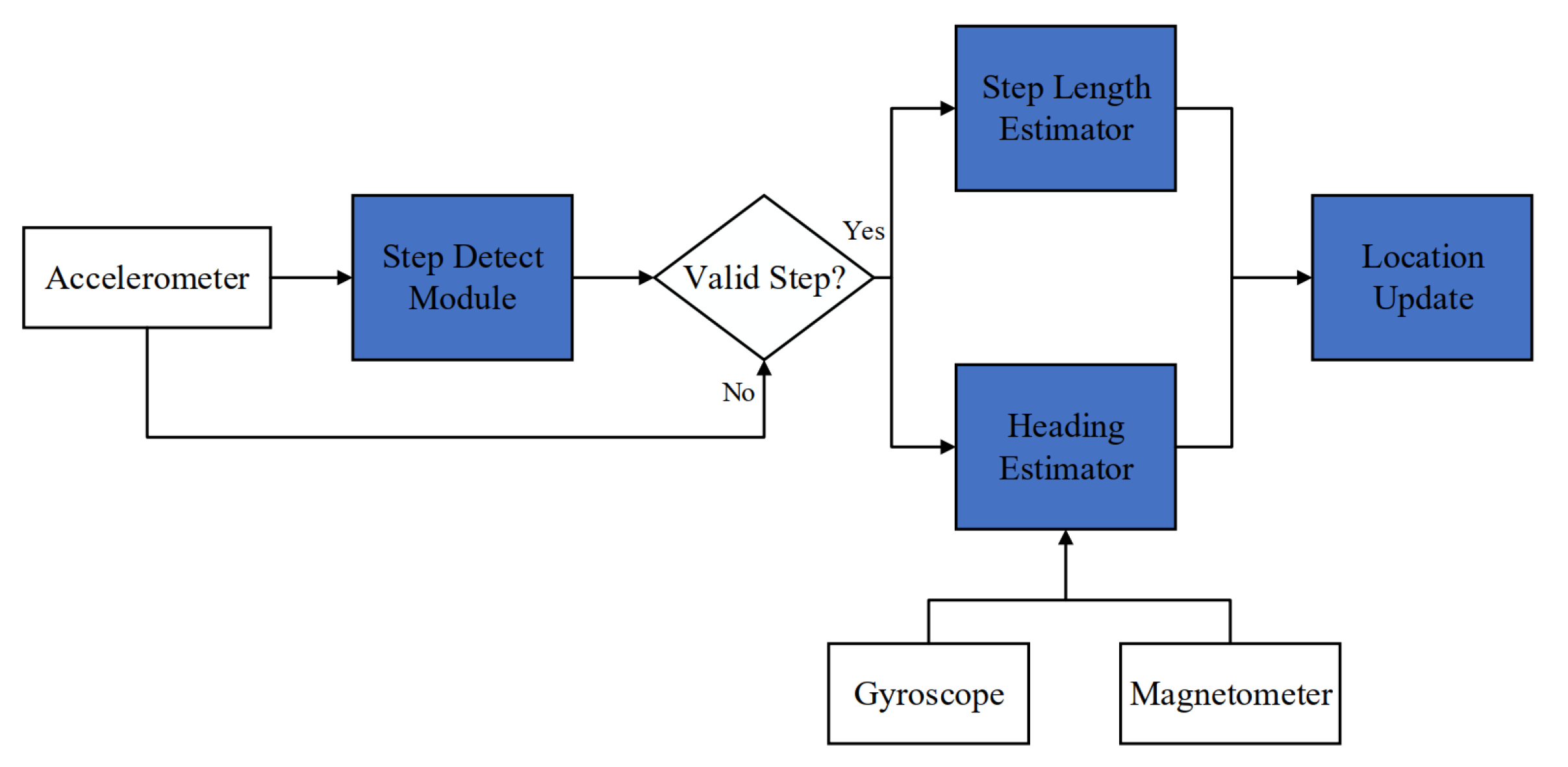
3. Pedestrian Dead Reckoning
3.1. Step Detection
- The peak value of acceleration amplitude is greater than the threshold, and the valley value is less than the threshold during the period of step k.
- The difference between the peak value of acceleration amplitude and the threshold in step k is within the restricted range. In addition, the difference between the threshold and the valley value of acceleration amplitude in step k is within the restricted range.
- The duration of step k is within the restricted range, which can be determined by the walking frequency.
3.2. Stride Length Estimation
3.3. Heading Calculation
3.4. The Uncertainty of PDR
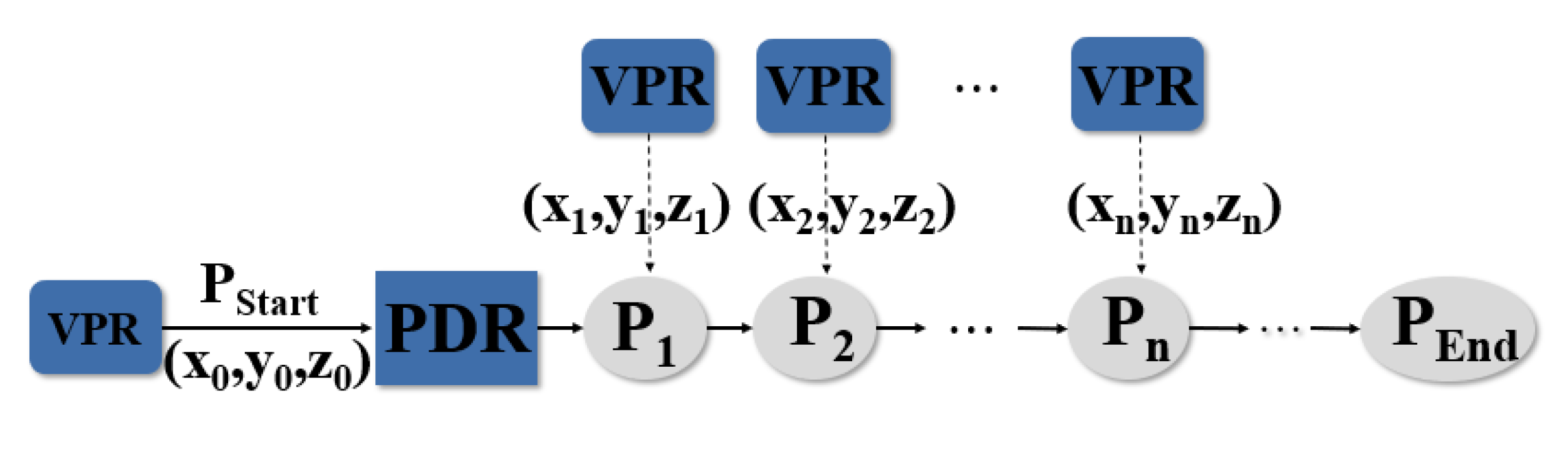
4. Vision-Aided PDR System Design
4.1. Visual Place Recognition
- Extract features from the location image in the original map library, and establish a feature vector dataset.
- Extract the feature vector of the image to be predicted in the same way.
- Compare the feature vectors in the dataset and the feature of the image to be predicted by the method and select the location corresponding to the most similar feature vector as the predicted value.
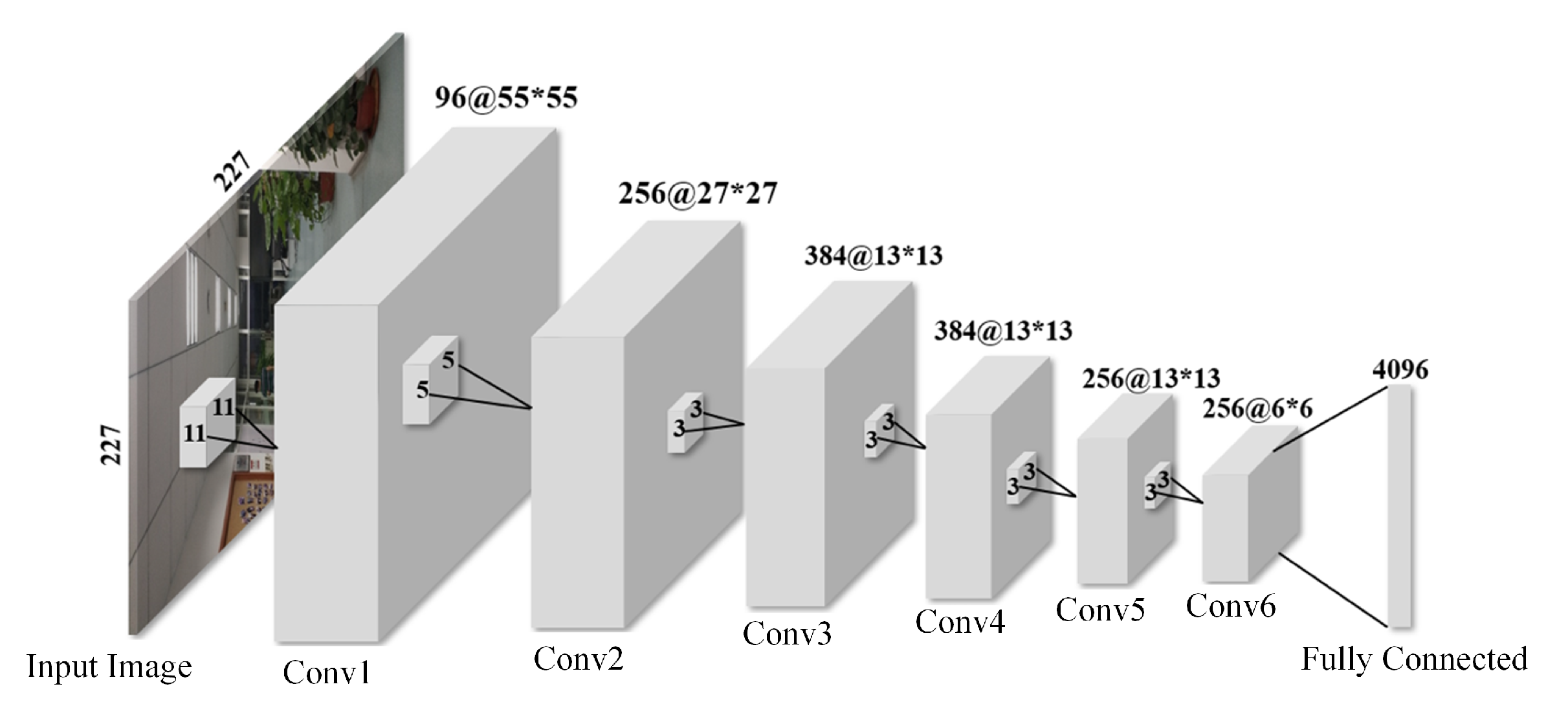
4.1.1. Design of VPR Network and Training
4.1.2. Ranking Search
4.1.3. Location of VPR
4.2. Vision-Aided PDR Fusing
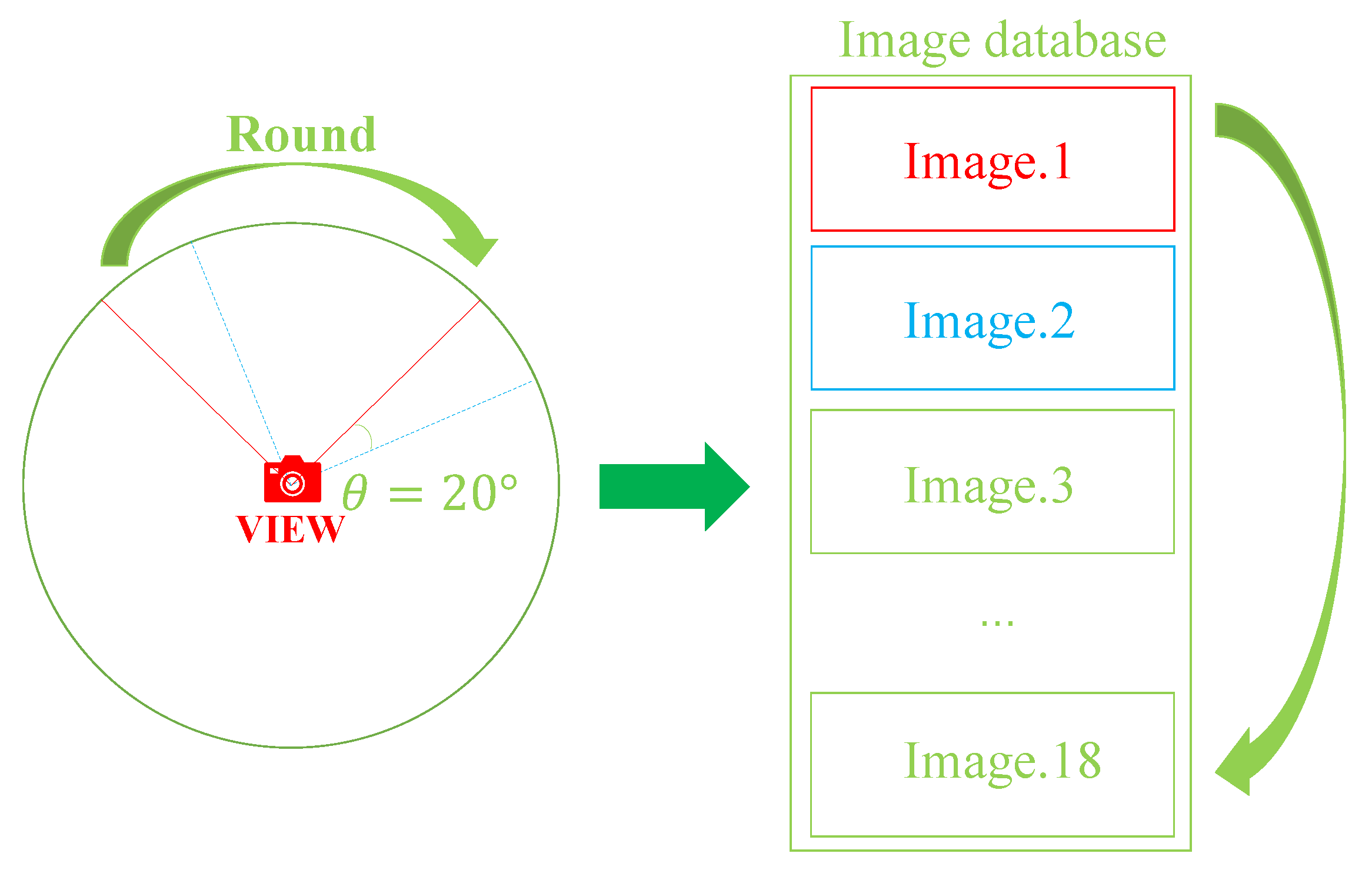
| Algorithm 1 Measure the location at time t |
| Require: Picture in the facing direction |
| = |
| while do |
| Turn right for 20 degrees and get new picture |
| = |
| end while |
| while do |
| Get a new picture in the facing direction |
| = |
| if then |
| end if |
| end while |
| return |
5. Experiments and Results
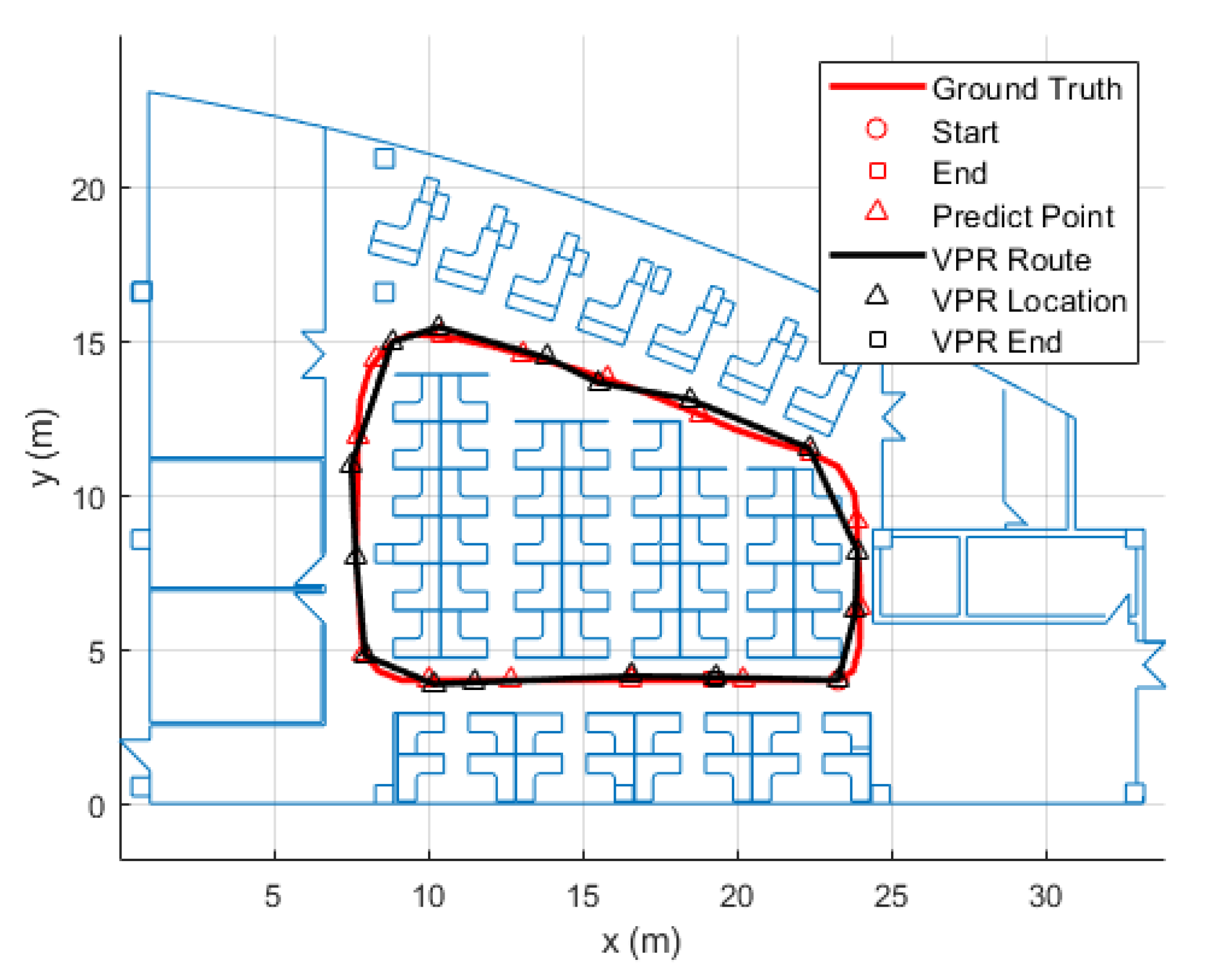
5.1. VPR Test Result
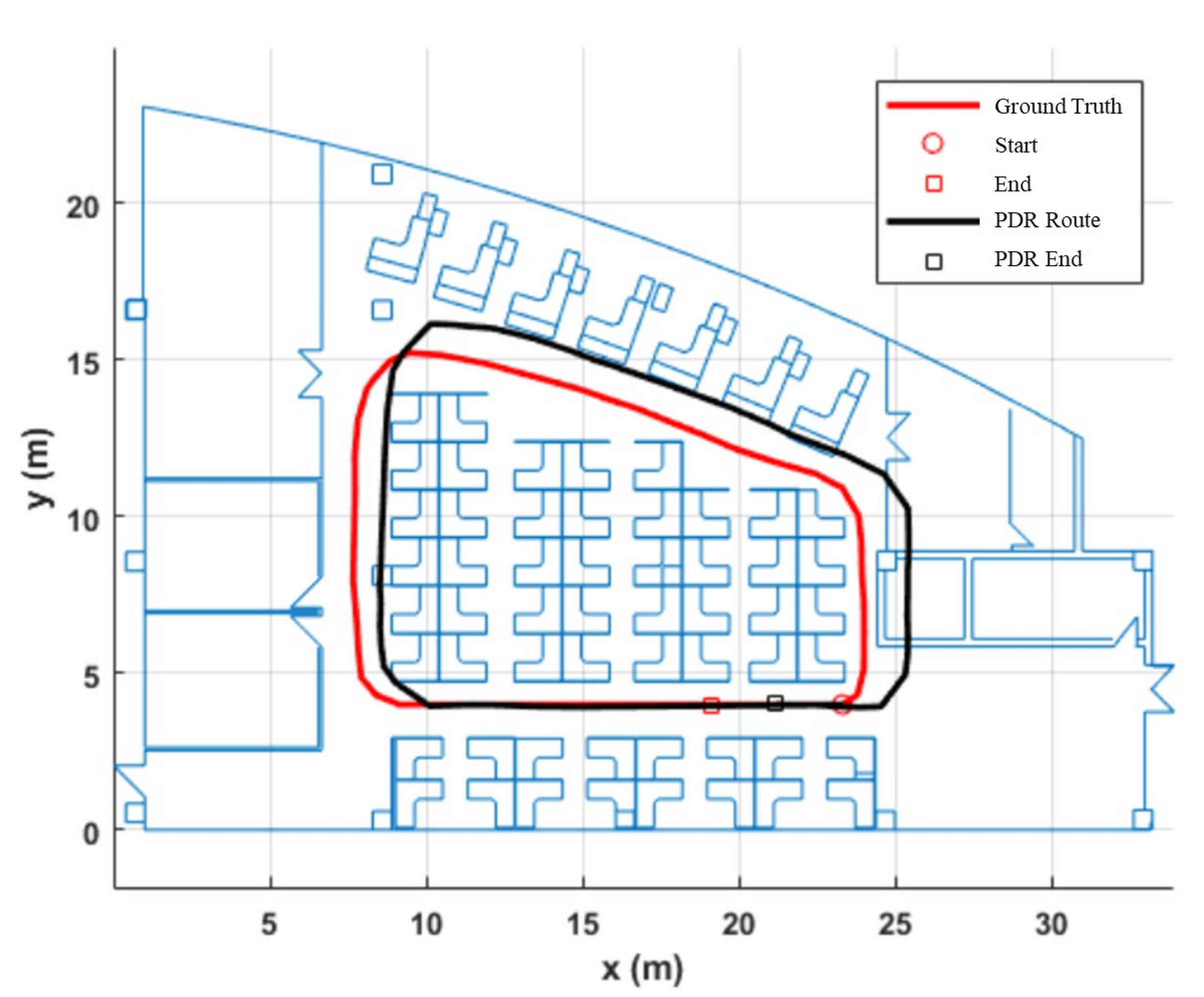
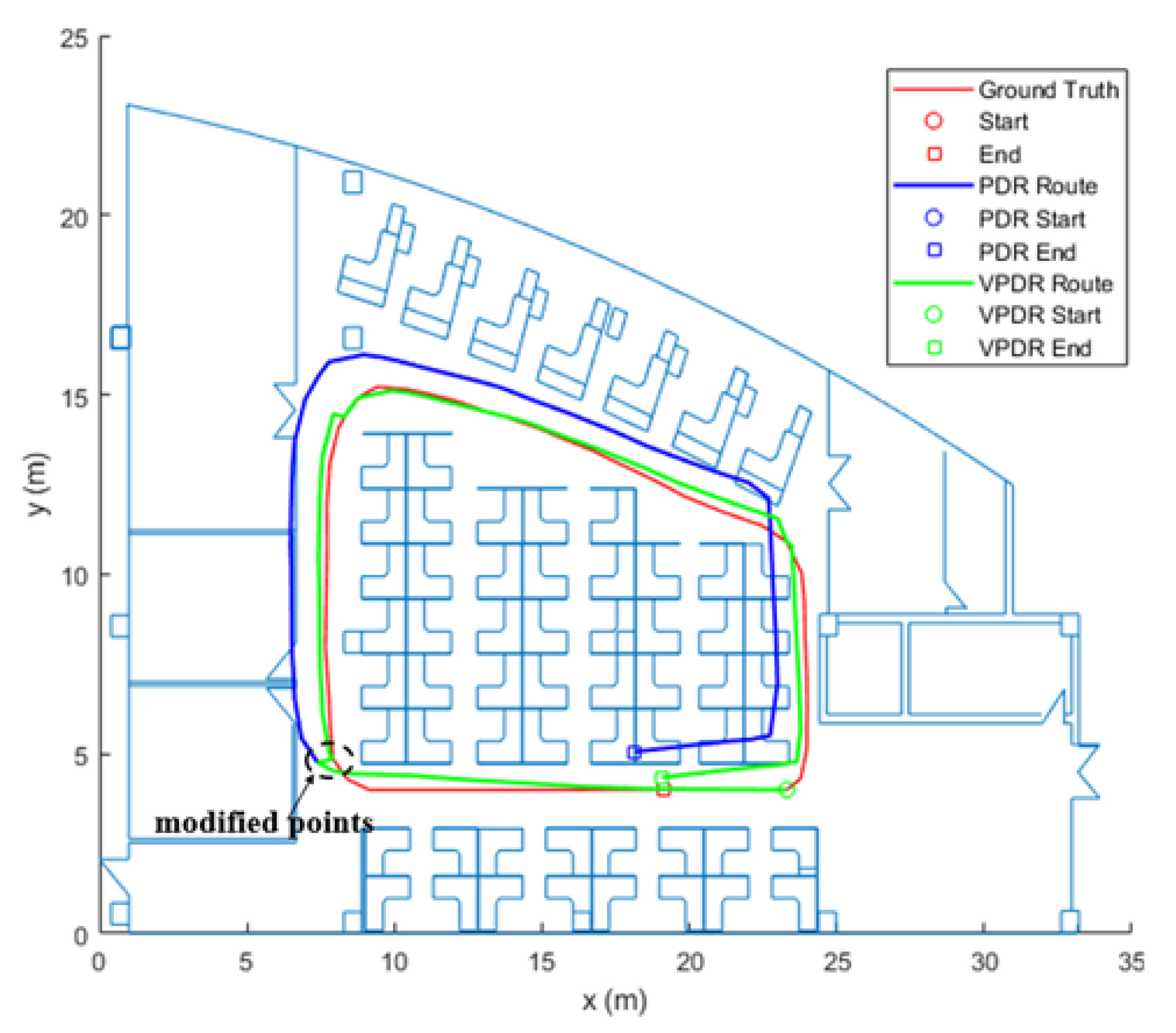
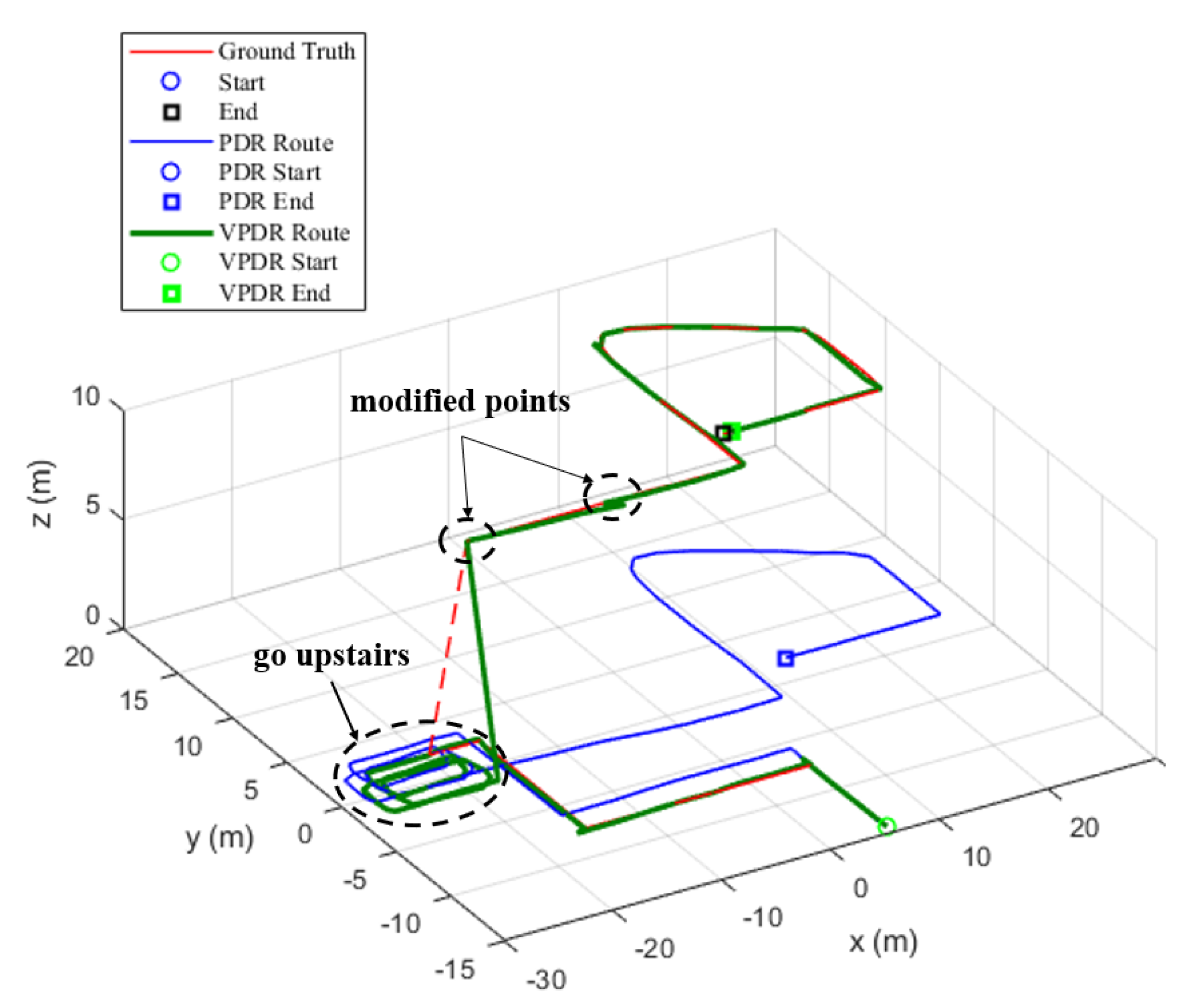
5.2. V-PDR Testing Result
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| PDR | Pedestrian Dead Reckoning |
| VPR | Visual Place Recognition |
| GNSS | Global Navigation Satellite System |
| RFID | Radio Frequency Identification |
| IR | Infrared Ray |
| WLAN | Wireless Local Area Network |
| MEMS | Micro Electro Mechanical System |
| CNN | Convolutional Neural Network |
References
- Liu, P.; Liu, D.; Qian, J. A Survey of Indoor Positioning Technology and Application. Navig. Position. Timing 2017, 4. [Google Scholar] [CrossRef]
- Fallah, N.; Apostolopoulos, I.; Bekris, K. Indoor Human Navigation Systems: A Survey. Interact. Comput. 2013, 25, 21–33. [Google Scholar]
- Kang, W.; Han, Y. Smartpdr: Smartphone-based pedestrian dead reckoning for indoor localization. IEEE Sens. J. 2015, 5, 2906–2916. [Google Scholar] [CrossRef]
- Hsu, L.T.; Gu, Y.; Huang, Y.; Kamijo, S. Urban pedestrian navigation using smartphone-based dead reckoning and 3-d map-aided gnss. Sens. J. IEEE 2016, 5, 1281–1293. [Google Scholar] [CrossRef]
- Bidder, O.R.; Walker, J.; Jones, M.W.; Holton, M.D.; Urge, P.; Scantlebury, D.; Wilson, R.P. Step by step: Reconstruction of terrestrial animal movement paths by dead-reckoning. Mov. Ecol. 2015, 3, 23. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Thong, H.; Filippo, S.; Vinh, T. A Hybrid Algorithm Based on WiFi for Robust and Effective Indoor Positioning. In Proceedings of the 19th International Symposium on Communications and Information Technologies (ISCIT), Ho Chi Minh City, Vietnam, 25–27 September 2019; pp. 416–421. [Google Scholar]
- Wu, J.; Zhu, M.; Xiao, B.; Qiu, Y. The Improved Fingerprint-Based Indoor Localization with RFID/PDR/MM Technologies. In Proceedings of the 2018 IEEE 24th International Conference on Parallel and Distributed Systems (ICPADS), Singapore, 11–13 December 2018; pp. 878–885. [Google Scholar] [CrossRef]
- Katsuhiko, K.; Keisuke, I.; Tsubasa, T. Step Recognition Method Using Air Pressure Sensor. In Proceedings of the International Conference on Indoor Positioning and Indoor Navigation (IPIN), Pisa, Italy, 30 September–3 October 2019; pp. 1–8. [Google Scholar]
- Wang, G.; Wang, X.; Nie, J.; Lin, L. Magnetic-Based Indoor Localization Using Smartphone via a Fusion Algorithm. IEEE Sens. J. 2019, 19, 6477–6485. [Google Scholar] [CrossRef]
- Lowe, D.G. Object Recognition from Local Scale-Invariant Features. In Proceedings of the Seventh IEEE International Conference on Computer Vision, Kerkyra, Greece, 20–27 September 1999; Volume 2, pp. 1150–1157. [Google Scholar]
- Bay, H. Surf: Speeded up robust features. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2006; Volume 110, pp. 404–417. [Google Scholar]
- Agrawal, M.; Konolige, K.; Blas, M.R. CenSurE: Center Surround Extremas for Realtime Feature Detection and Matching. In European Conference on Computer Vision; Proceedings, Part IV. DBLP; Springer: Berlin/Heidelberg, Germany, 2008. [Google Scholar]
- Oliva, A. Building the gist of a scene: The role of global image features in recognition. Prog. Brain Res. 2006, 155, 23–36. [Google Scholar] [PubMed]
- Wen, F.; Ying, R.; Gong, Z.; Liu, P. Efficient Algorithms for Maximum Consensus Robust Fitting. IEEE Trans. Robot. 2020, 36, 92–106. [Google Scholar] [CrossRef]
- Lowry, S.; Sunderhauf, N.; Newman, P.; Leonard, J.J.; Milford, M.J. Visual place recognition: A survey. IEEE Trans. Robot. 2016, 32, 1–19. [Google Scholar] [CrossRef] [Green Version]
- Zhou, B.; Lapedriza, A.; Xiao, J.; Torralba, A.; Oliva, A. Learning deep features for scene recognition using places database. Adv. Neural Inf. Process. Syst. 2014, 1, 487–495. [Google Scholar]
- Xiao, J.; Hays, J.; Ehinger, K.A.; Oliva, A.; Torralba, A. SUN database: Large-scale scene recognition from abbey to zoo. In Proceedings of the Twenty-Third IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2010, San Francisco, CA, USA, 13–18 June 2010; pp. 3485–3492. [Google Scholar] [CrossRef]
- Razavian, A.S.; Azizpour, H.; Sullivan, J.; Carlsson, S. CNN Features Off-the-Shelf: An Astounding Baseline for Recognition. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition Workshops, Columbus, OH, USA, 23–28 June 2014; pp. 512–519. [Google Scholar]
- Li, D.; Lu, Y.; Xu, J.; Ma, Q.; Liu, Z. iPAC: Integrate Pedestrian Dead Reckoning and Computer Vision for Indoor Localization and Tracking. IEEE Access 2019, 183514–183523. [Google Scholar] [CrossRef]
- Roggen, D.; Jenny, R.; Hamette, P.D.L.; Tröster, G. Mapping by Seeing—Wearable Vision-Based Dead-Reckoning, and Closing the Loop. In Smart Sensing and Context, Second European Conference, Eurossc, Kendal, England, October; Springer: Berlin/Heidelberg, Germany, 2007. [Google Scholar]
- Fu, W.; Peng, A.; Tang, B.; Zheng, L. Inertial sensor aided visual indoor positioning. In Proceedings of the International Conference on Electronics Technology (ICET), Chengdu, China, 23–27 May 2018; pp. 106–110. [Google Scholar]
- Yan, J.; He, G.; Basiri, A.; Hancock, C. 3D Passive-Vision-Aided Pedestrian Dead Reckoning for Indoor Positioning. IEEE Trans. Instrum. Meas. 2020, 1370–1386. [Google Scholar] [CrossRef]
- Yan, Z.; Xianwei, Z.; Ruizhi, C.; Hanjiang, X.; Sheng, G. Image-based localization aided indoor pedestrian trajectory estimation using smartphones. Sensors 2018, 18, 258. [Google Scholar]
- Fusco, G.; Coughlan, J.M. Indoor localization using computer vision and visual-inertial odometry. In International Conference on Computers Helping People with Special Needs; Springer: Cham, Switzerland, 2018. [Google Scholar]
- Chen, Z.; Lam, O.; Jacobson, A.; Milford, M. Convolutional Neural Network-based Place Recognition. arXiv 2014, arXiv:1411.1509. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. Neural information processing systems. In Proceedings of the Advances in Neural Information Processing Systems 25, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1106–1114. [Google Scholar]
- Arandjelovic, R.; Gronat, P.; Torii, A.; Pajdla, T.; Sivic, J. NetVLAD: CNN Architecture for Weakly Supervised Place Recognition. Computer vision and pattern recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 1437–1451. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chen, Z.; Jacobson, A.; Sunderhauf, N.; Upcroft, B.; Liu, L.; Shen, C. Deep learning features at scale for visual place recognition. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 3223–3230. [Google Scholar]
- Harle, R. A Survey of Indoor Inertial Positioning Systems for Pedestrians. IEEE Commun. Surv. Tutor. 2013, 15, 1281–1293. [Google Scholar] [CrossRef]
- Beauregard, S. A Helmet-Mounted Pedestrian Dead Reckoning System. In Proceedings of the 3rd International Forum on Applied Wearable Computing 2006, Bremen, Germany, 15–16 March 2006; pp. 1–11. [Google Scholar]
- Tom, J. A Personal Dead Reckoning Module. In Proceedings of the 10th International Technical Meeting of the Satellite Division of The Institute of Navigation (ION GPS 1997), Kansas City, MO, USA, 16–19 September 1997; pp. 47–51. [Google Scholar]
- Ying, H.; Silex, C.; Schnitzer, A.; Leonhardt, S.; Schiek, M. Automatic Step Detection in the Accelerometer Signal. In Wearable and Implantable Body Sensor Networks; Springer: Berlin/Heidelberg, Germany, 2007. [Google Scholar]
- Nozawa, M.; Hagiwara, Y.; Choi, Y. Indoor human navigation system on smartphones using view-based navigation. In Proceedings of the 2012 12th International Conference on Control, Automation and Systems, JeJu Island, Korea, 17–21 October 2012; pp. 1916–1919. [Google Scholar]
- Robert, R.; Thomas, J. Dead Reckoning Navigational System Using Accelerometer to Measure Foot Impacts. U.S. Patent 5,583,776, 10 December 1996. [Google Scholar]
- Qian, J.; Pei, L.; Zou, D.; Liu, P. Optical Flow-Based Gait Modeling Algorithm for Pedestrian Navigation Using Smartphone Sensors. IEEE Sens. J. 2015, 12, 6797–6804. [Google Scholar] [CrossRef]
- Kim, J.W.; Jang, H.J.; Hwang, D.; Park, C. A Step, Stride and Heading Determination for the Pedestrian Navigation System. J. Glob. Position. Syst. 2004, 3, 273–279. [Google Scholar] [CrossRef] [Green Version]
- Qian, J.; Pei, L.; Ma, J.; Ying, R.; Liu, P. Vector graph assisted pedestrian dead reckoning using an unconstrained smartphone. Sensors 2015, 3, 5032–5057. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, T.; Huang, H.; Lin, J.; Hu, C.; Zeng, K.; Sun, M. Omnidirectional CNN for Visual Place Recognition and Navigation. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018; pp. 2341–2348. [Google Scholar] [CrossRef] [Green Version]
- Quattoni, A.; Torralba, A. Recognizing indoor scenes computer vision and pattern recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 413–420. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Localization Method | Maximum Error (m) | Mean Error (m) | 95% Situation Error (m) | Step Counting Accuracy |
|---|---|---|---|---|
| PDR | 1.52 | 0.91 | 1.43 | 98.8% |
| Localization Method | Maximum Error (m) | Mean Error (m) | 95% Situation Error (m) |
|---|---|---|---|
| PDR | 1.74 | 1.04 | 1.66 |
| V-PDR | 0.91 | 0.44 | 0.81 |
| Localization Method | Maximum Error (m) | Mean Error (m) | 95% Situation Error (m) |
|---|---|---|---|
| PDR | 14.96 | 4.29 | 10.30 |
| V-PDR | 1.68 | 0.46 | 0.90 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qian, J.; Cheng, Y.; Ying, R.; Liu, P. A Novel Indoor Localization Method Based on Image Retrieval and Dead Reckoning. Appl. Sci. 2020, 10, 3803. https://doi.org/10.3390/app10113803
Qian J, Cheng Y, Ying R, Liu P. A Novel Indoor Localization Method Based on Image Retrieval and Dead Reckoning. Applied Sciences. 2020; 10(11):3803. https://doi.org/10.3390/app10113803
Chicago/Turabian StyleQian, Jiuchao, Yuhao Cheng, Rendong Ying, and Peilin Liu. 2020. "A Novel Indoor Localization Method Based on Image Retrieval and Dead Reckoning" Applied Sciences 10, no. 11: 3803. https://doi.org/10.3390/app10113803
APA StyleQian, J., Cheng, Y., Ying, R., & Liu, P. (2020). A Novel Indoor Localization Method Based on Image Retrieval and Dead Reckoning. Applied Sciences, 10(11), 3803. https://doi.org/10.3390/app10113803