1. Introduction
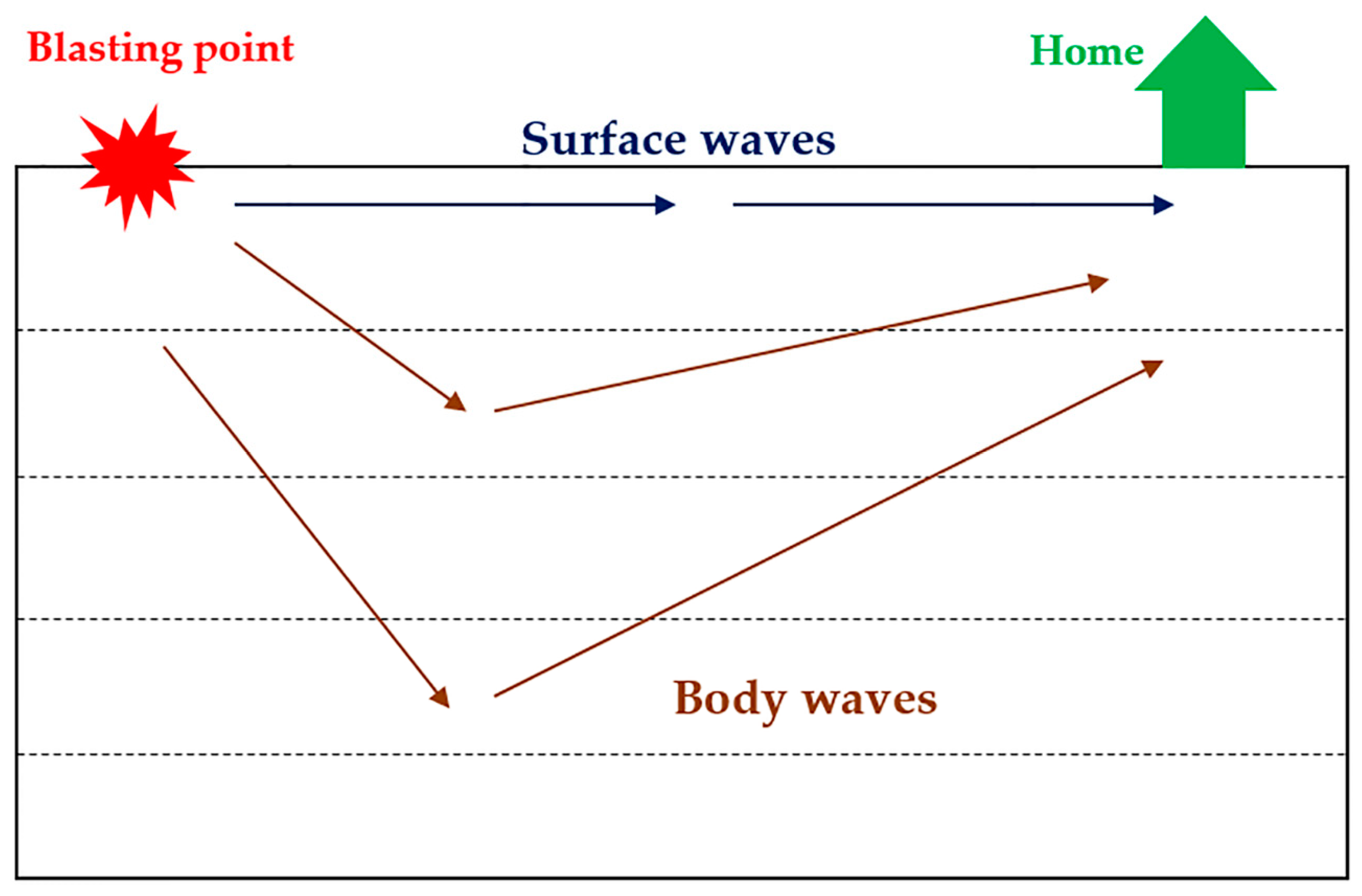
Drilling and blasting are important parts of an effective method to excavate the hard rock in the mining industry. One of the fundamental problems induced by blasting is the ground vibration (see
Figure 1). Therefore, the ability to make accurate predictions of the ground vibration is a crucial need in this field. As shown in
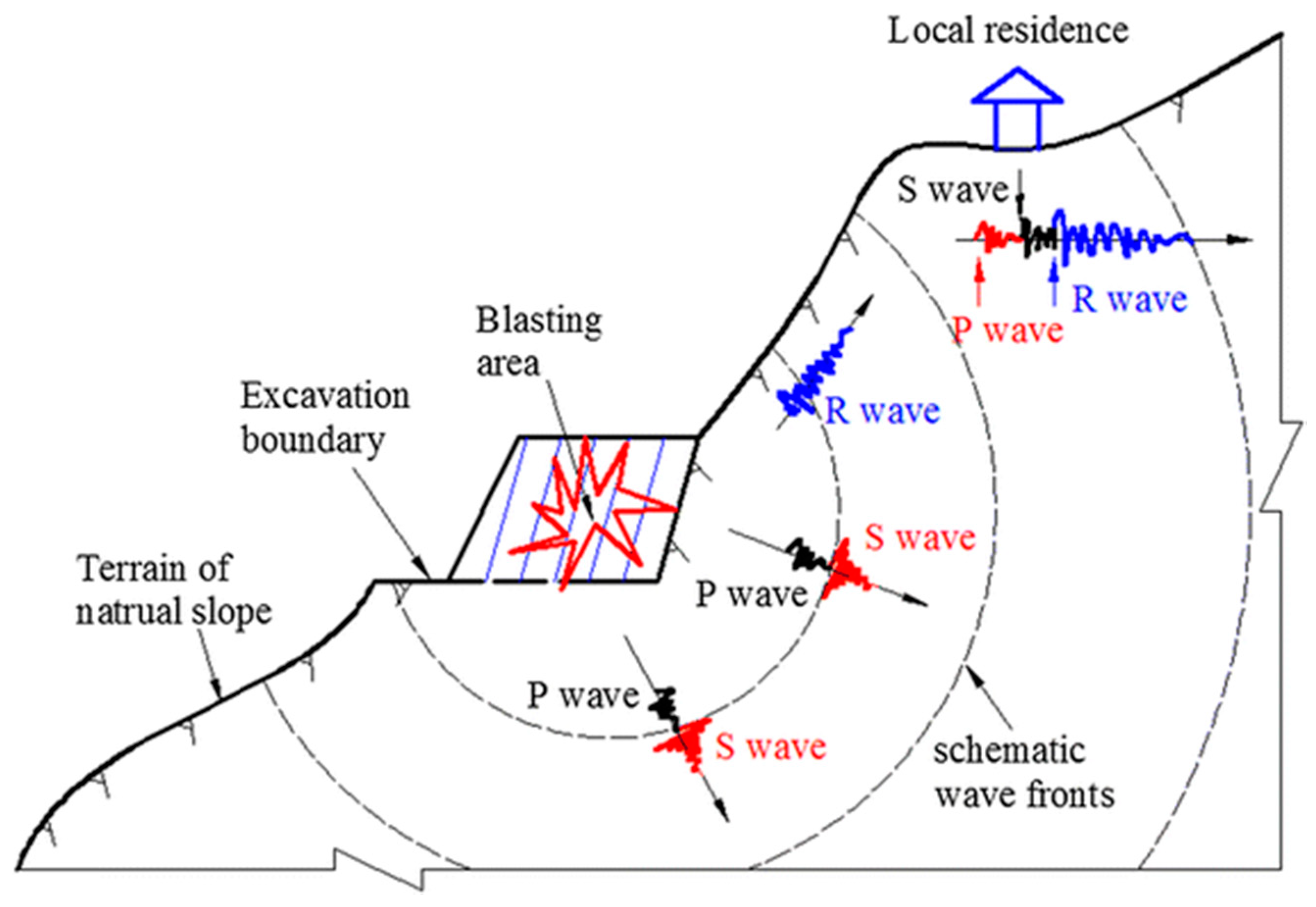
Figure 2, body waves including the compressional P-wave, transverse S-wave, and surface waves including the Love wave (Q-wave) and the Rayleigh wave (R-wave) are generated by blasting. It is worth mentioning that the majority of the energy is transmitted by the R-wave, and the P-wave has the fastest speed.
According to the literature [
1,
2,
3,
4] the intensity of ground vibration can be measured based on some descriptors, including the frequency and peak particle velocity (PPV). Among them, PPV is accepted globally and is used in many studies to evaluate the blast-induced ground vibration [
5,
6]. In the production cycle of mines, PPV plays a significant role during blasting operations and may result in undesirable effects in terms of anthropogenic hazards. Thus, a precise prediction of PPV is very crucial in terms of process and health safety. This key parameter is highly dynamic and non-linear because it depends upon various process attributes. Therefore, the estimation of PPV through modeling is a challenging and haphazard task.
A review of previous studies [
7,
8] revealed that two categories of parameters significantly affect PPV: the blasting design and rock properties. As can be guessed, the blasting design parameters such as burden, weight charge per delay, stemming, and powder factor are controllable, while the rock properties parameters such as the tensile strength of the rock mass are uncontrollable and cannot be changed by engineers. In the past, various physical-based models have been used to study the blasting operations and simulations in order to minimize environmental damage. These types of physical models made use of governing formulations to account for blasting parameters. However, these governing equations have some limitations. The main limitation is that they consider ideal conditions rather than the conditions which exist in real-life situations. Additionally, the physical-based studies are typically costlier since they require a more experimental set-up as well as experts who understand complex mathematical formulations. In such circumstances, when the number of variables is limited and forecasting is more crucial than understanding the underlying causative mechanism, pattern recognition-based models are a viable tool. In order to overcome the problem stated above and establish the relationship between the blasting process through pattern recognition, the researchers used different ML techniques that can mimic and establish relationships to obtain a higher prediction accuracy.
A literature review showed that a wide range of recently-published papers have demonstrated soft computing methods for predicting aims in different fields [
9,
10,
11,
12,
13,
14,
15,
16,
17,
18], especially for predicting the PPV, such as an artificial neural network (ANN), support vector machine (SVM), and adaptive neuro-fuzzy inference system (ANFIS). Khandelwal [
19] compared SVM and empirical models to predict the PPV, with a better result for the former. In another study, Mohamadnejad et al. [
20] predicted the blast-induced PPV using SVM and a general regression neural network (GRNN) with the conclusion that SVM is a promising alternative tool for both empirical and GRNN models. On the other hand, Ghasemi et al. [
21] explored the potential application of fuzzy system (FIS) and empirical models using 120 samples. The result showed that FIS predicts PPV more accurately than the empirical models. Jahed Armaghani et al. [
22] compared ANFIS, and ANN, as two well-known soft computing models, to predict PPV, then the result was compared to that of empirical models. The results confirmed that ANFIS and ANN outperformed the empirical models in terms of providing a prediction, while ANFIS was found to be more feasible than ANN in this regard. Amiri et al. [
8] predicted the PPV using ANN combined with the K-nearest neighbords (KNN) method. In their study, a common empirical model introduced by United States Bureau of Mines (USBM) was also applied. Based on their results, the hybrid of ANN and KNN predicted PPV with higher accuracy compared to the ANN and USBM models. Nguyen et al. [
23] used an extreme gradient boosting (XGBoost) model to predict ground vibration. For comparison aims, SVM, random forest (RF), and KNN models were also used in their study. Based on the results, it was found that the XGBoost model was more accurate than SVM, RF, and KNN models in predicting ground vibration. In another study, a Gaussian process regression (GPR) model was employed to predict ground vibration by Arthur et al. [
24]. They showed the superiority of the GPR for predicting the blast-induced ground vibration compared to empirical models. Recently, Nguyen et al. [
25] predicted blast-induced ground vibration using a hybrid model of ANN and the k-means clustering algorithm (HKM). Their results were then compared with support vector regression (SVR) results. They showed that the HKM–ANN model can predict ground vibration more effectively than ANN and SVR models. Overall, it could be seen that machine learning models are capable of producing better prediction results.
However, there are some disadvantages to ML techniques such as ANN. One of them is slow convergence and the other is the trap in local minima. Generally, the optimization algorithm is used to improve the convergence rate and isolation from the local optimum phenomenon. The two categories of optimization algorithms can be defined as global optimization methods which do not follow the derivative. They are the stochastic metaheuristic algorithm and the deterministic optimization algorithm. Stochastic metaheuristic algorithms are interpreted using simplicity stating and are therefore used for many engineering problems, while the deterministic optimization algorithm guarantees convergence in complexity problems due to its theoretical features. However, deterministic methods, such as the DIRECT method [
26], obtain superiority in the analytical approach, while heuristic methods have presented more flexible and efficient approaches [
27,
28]. In this paper, both metaheuristic and deterministic algorithms are used to improve the ANN results.
The aim of the present study is to develop two stochastic metaheuristic algorithms, namely PSO and biogeography-based optimization (BBO), as well as one deterministic optimization algorithm, namely the DIRECT method, to improve the performance of the ANN model in predicting the PPV. For comparison aims, minimax probability machine regression (MPMR), the extreme learning machine (ELM), and three common empirical methods were also employed. It is worth mentioning that this was the first time that BBO-ANN and DIRECT-ANN models were applied to predict PPV, which can be a contribution of the present paper to the body of knowledge in this field of study.
2. Methods
2.1. DIRECT-ANN
One of the important deterministic optimization algorithms called DIRECT was developed by Joens et al. [
26]. The DIRECT optimization algorithm can discover the global optimum of the objective function for complex problems, which has an extremely robust direct search approach. The DIRECT algorithm evaluates the objective function without needing any extra information. Although the DIRECT algorithm is based on a very powerful search, it needs a certain number of iterations to obtain a global minimum, especially when target points are at certain boundaries.
In real-world problems, there is no understanding of the global solution, thus the quality of the solution cannot be checked. Therefore finding different approaches that are close to the global solution is very important for improving the optimization algorithm. In the complexity problem, the objective function
f(
x) can touch many local optima. In global optimization, it is essential to gain the global optimum
x* and in accordance with it, a value of
f* such that
where
D is a search space so the profound minimum
f* is the global optimum and the objective function
f(
x) meets the Lipschitz condition
where
L is an unknown Lipschitz constant. This condition implies that any restricted variation in the parameters yields some constrained variation in the values of the objective function. The global optimization problem (1) where
f(
x) satisfies (2) and can be non-differentiable, multi-extremum, hard to measure, and given as a “black box” is considered for combining with ANN in this paper.
In this algorithm, the weights and biases in the ANN are demonstrated by the initial solution set. In the next step, the initial solution is optimized by many iterations in the DIRECT algorithm to fix the weights of ANN as well as to converge the lowest error.
2.2. PSO-ANN
Particle swarm optimization (PSO) is a bird simulation metaheuristic approach developed by Kennedy and Eberhart [
29]. The PSO approach is a decision-making process using the populated swarm. In this research, PSO was used to search and optimize the weights of the model, and once the ANN model was configured, its input weights, biases, and output weights were transformed into the coordinates of each particle in the swarm. Herein, each particle is a solution for the ANN model. Consequently, all particles are searching in a defined search space to find the best position in which the difference of the measured PPV and the predicted PPV is the lowest possible. Theoretically, each swarm makes a decision depending on the following factors:
The best results are obtained through the personal experience of each individual during the search completed in each iteration.
Experienced individuals in the swarm help the others to achieve the best results in the generated entire swarm population.
During the initialization phase, a certain number of individuals (i.e., the particles each of which contains feasible solution) are placed in a random pattern within the search domain. The optimization of the objective function is determined with the help of pre-defined coefficients:
C1 and
C2 signify the personal best position (
) of each individual particle and global best position (
) among the populated particles, respectively [
30].
The hybrid PSO-ANN ensemble method starts with initialization of random particles. In this process, the ANN connection factors (weights and biases) are represented by positions of the particles. In the subsequent step, the initial particles (bias and weights) are trained followed by different iterations to stabilize the weights as well as to converge the computing error (using different statistical indices). The convergence of the computing error is achieved by updating the positions of particles through the velocity equation (Equation (1)). The value of (the lowest computing error achieved until that moment) of (the lowest computing error by particle at current time) was updated in each iteration using Equation (1) to obtain the best solution of the problem until the relevant condition was satisfied (the lowest error).
2.3. MPMR
The basic aim of the MPMR model is to maximize the minimum probability of future data points in the classification process. The advantage of this model is that it considers a minimal assumption of underlying distribution for true functions in the trivial regression problem within its bounds [
31]. MPMR maximizes the minimum probability of future predictions within some bound of the true regression function. Hence, it has control over future predictions. It uses only two tuning parameters (the width of the radial basis function and the error insensitive zone). It also reduces the chance of over-fitting. MPMR provides an alternative justification for discriminative approaches. Furthermore, this model closely works on the formulation of classification as proposed by Marshall and Olkin [
32], which was later improved by Bertsimas and Popescu [
33].
2.4. ELM
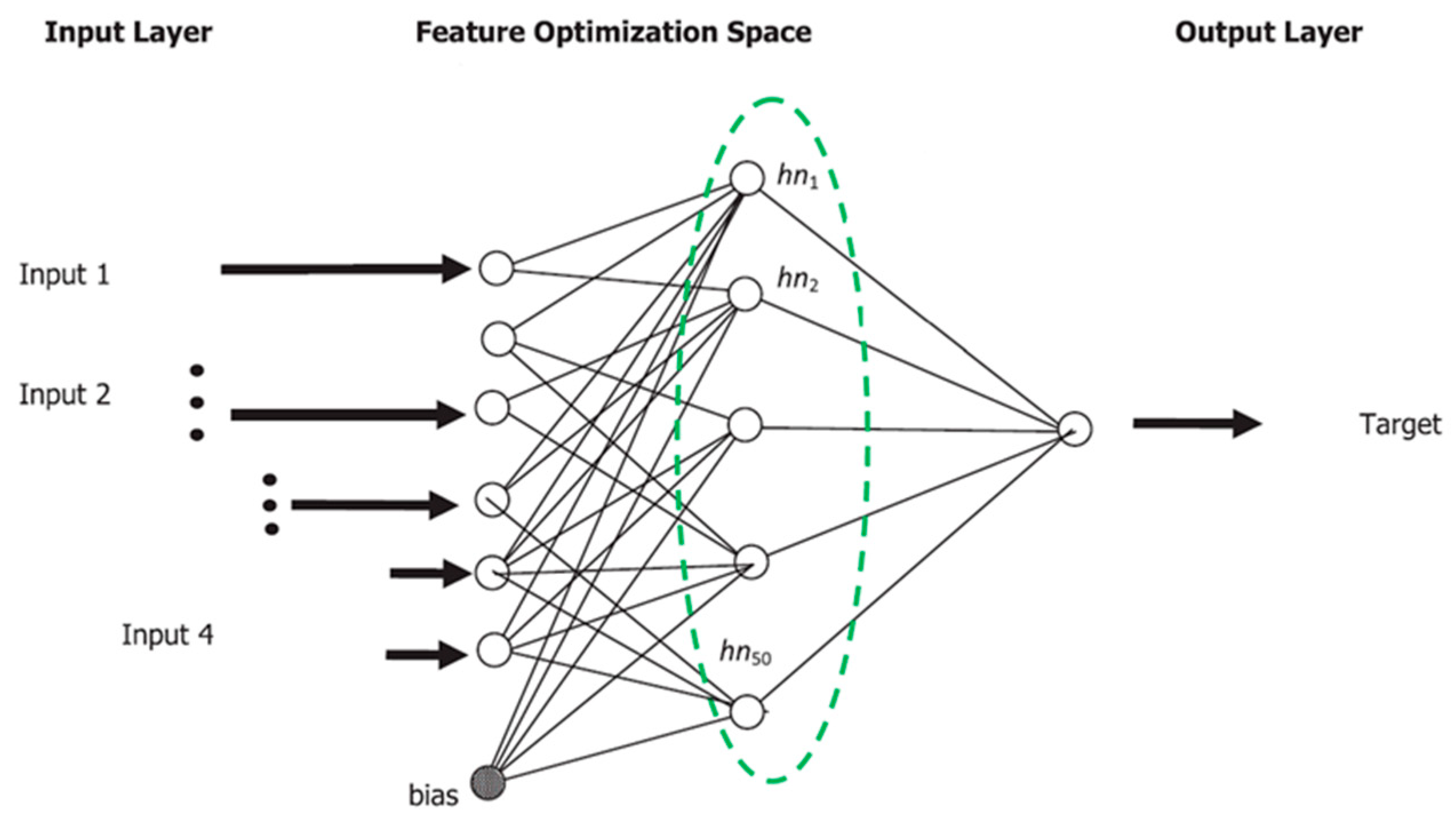
ELM is an advancement of a single layer feed-forward Network (SLFNs) developed by Huang et al. [
34]. ELM with a fast learning speed and smallest training error make it a non-linear model at the cost of linear model. ELM is able to initialize weights analytically, meaning it is semi-random, and the weights are not tuned through back-propagation. The background theory of ELM shows that although the presented neurons in the hidden layer are important, it is not necessary for them to be turned, and the learning process can be done simply without tuning the hidden neurons [
34]. The brief topological structure of ELM is presented in
Figure 3, including an input layer, feature optimization space, and an output layer. To find a detailed discussion on this issue, you can refer to the studies conducted by Huang et al. [
35].
2.5. BB0-ANN
The evolutionary algorithm BBO was proposed by Simon [
36]. The basic idea of BBO is based on biogeography concepts: (i) migration of habitants (species) from a habitat (island) to another habitat, (ii) arising of habitants, and (iii) extinction of habitants. BBO is the most popular optimization algorithm used to solve complex, non-linear real-world problems [
37]. In this paper, BBO is used to optimize the network weights and biases of ANN. Each habitat contains network weights and biases as the number of features or habitants.
The main operation of BBO is a migration process which involves an immigration (I) and emigration (E) rate. The exploration and exploitation tasks of BBO depend on migration operators. It is a successful technique for bringing local search and good convergence capability to a global optimum. The BBO algorithm modifies features of a selected habitat based on the immigration rate. Then the algorithm choses other habitats based on their emigration rate for migration of an inhabitant of a habitat to another selected habitat. Initially, BBO generates number of problem solutions (ANN generations) based on the size of the habitats. After each of the run of the main algorithm best fitness (minimum) the valued habitat is stored and this process is continued for a maximum number of iterations run or until the accepted level of the fitness score is reached. Mean-square error (MSE) is used as the fitness function for BBO algorithm. A more detailed review of BBO algorithm can be found in reference [
37,
38]. The Algorithm 1 shows a rudimentary structure of BBO-ANN.
| Algorithm 1: Basic structure of the BBO-ANN for prediction of blast-induced ground vibration, rand function produces a random number which is uniformly distributed in [0, 1], the jth dimensional lower and upper bound are lj and uj, respectively. |
Select calibration and validation dataset Begin ANN calibration period Get ANN learning operators in BBO (decision variables (N)); Set objective/fitness function (MSE); Initialize habitats (say S); Set mutation probability (mk); Calculate E and I. Evaluate the fitness measure for every habitat; Sort habitats (ascending order) according to the fitness value; B = best so far habitat (least fitness valued habitat); for it = 1 to maximum iteration do for i = 1 to S do for j =1 to N do if rand() < I of ith habitat then choose an emigrating habitat with a probability proportional to E; Replace jth habitant of the immigrating habitat with a corresponding value of the emigrating habitat; end if for j = 1 to N do if rand() < mk then Update jth habitant with ; end if end for Evaluate fitness value of the ith habitat; end for Elitism Sort habitats. B = Keep the good solution; end for End Acquire the optimal parameter set for ANN using B; ANN test
|
3. Field Investigation
Two quarry mines in the Shur river dam region, located in the southwest of Iran, were investigated in this study. Andesite and tuff were the types of bed rock in these mines. The blasting method was performed to fragment rock mass in the monitored mines. Controlling blasting environmental issues like flyrock and ground vibration was considered to be an important task there.
Lots of equipment was used for construction purposes and to assist workers in mine sites. In addition, a residential area is very close to the mines and some local people live there. As a result, there is a need for the blasting engineers to predict, monitor and control the effects of ground vibrations on nearby residents and building structures. There was always a high risk of causing blast-induced ground vibration damage affecting nearby residents and buildings.
Based on the recommendations of mining engineers in the site, the measurement of ground vibration was conducted for every single blasting operation. For the mentioned descriptions, the amount of environmental risk due to ground vibration at blasting mines in the study area was high and because of this, the development of any models or techniques that can minimize the risk is useful. To this end, a research program was carried out to predict blast-induced ground vibration in these quarry mines. A total of 80 blasting events were monitored and 80 sets of data were prepared. In this database, several effective parameters affecting the PPV, including burden (B), spacing (S), stemming (ST), powder factor (PF), maximum weight charge per delay (W), rock mass rating (RMR), and distance from the blasting-point (D) were provided. These parameters were used as the input parameters in the modeling process of the predictive models. Additionally, PPV was used as the output parameter.
To measure the PPV values, a MR2002-CE SYSCOM seismograph was installed on the site. This instrument can measure PPV values in the range of 0.001 to 115 mm/s. Also, the values of B, S, ST, PF, and W were measured by controlling the blast-hole charge.
To measure
D, GPS (global positioning system) was also used. The ranges of the model inputs and outputs together with some other information are provided in
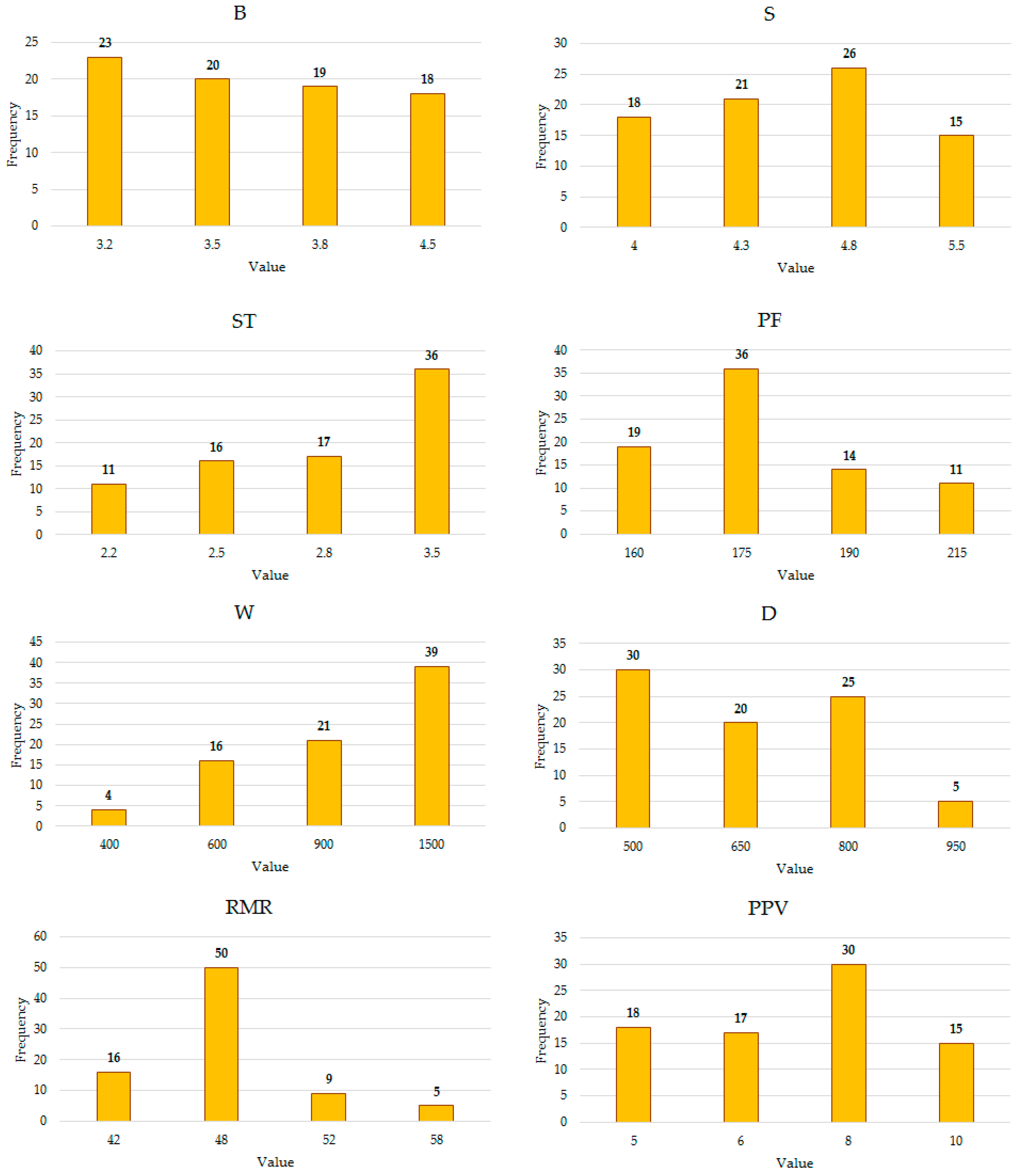
Table 1. Furthermore, the histograms of the input and output parameters are shown in
Figure 4. According to this figure, for the B parameter, 23, 20, 19, and 18 data values were varied in the ranges of 0–3.2 m, 3.2–3.5 m, 3.5–3.8 m, and 3.8–4.5 m, respectively.
4. Empirical Methods to Predict PPV
In this study, three well-known empirical methods, namely the US Bureau of Mines (USBM, Washington, DC, USA) [
39], Indian Standard [
40], and Ambraseys–Hendron [
41] models, were used to predict PPV. These methods are only related to
W and
D parameters, and are formulated as:
Equations (3)–(5) show the USBM, Indian Standard, and Ambraseys–Hendron methods. In these equations,
Q and
z are the site constants, and can be computed using the SPSS software. Using the database and our analysis, Equations (6)–(8) are updated as follows:
Note that to construct the empirical methods, firstly, the datasets used were normalized, as well as the same AI models. In other words, Equations (6)–(8) are based on normalized datasets. The performance of these empirical methods is evaluated in
Section 6.
5. Development of BBO-ANN, PSO-ANN, MPMR, and ELM to Predict PPV
The algorithm for the prediction of PPV was developed with the help of MATLAB sub-routines. The structure of the models drew on an input matrix (x) defined by x = (B, S, ST, PF, W, RMR, and D) which provided the predictor variables, while PPV induced by blasting was denoted as the target variable (y). In any modeling process, the most important task is to find the appropriate size of the training data and testing dataset. Therefore, in this research, 70% of the total dataset was randomly selected and used to develop the models and the developed models was tested on the remaining dataset. In other words, 56 and 24 datasets were used to develop and test the models, respectively. Prior to model development, the whole dataset was normalized to the range of zero to one. All the models (DIRECT-ANN, PSO-ANN, BBO-ANN, MPMR, and ELM) were tuned based on the trial and error method in order to optimize the PPV prediction. The values for tuning parameters of models were selected initially and thereafter varied in trials until the best fitness measures were achieved.
As stated in the literature [
5,
6,
13], the most important work in ANN modeling is to choose a proper number of neurons in the hidden layer. In this study, different ANN models were constructed using 2–12 hidden neurons of, as shown in
Table 2, and according to the results, the best performance (highest R
2) was for the 7 × 5 × 1 architecture (seven inputs, one hidden layer with five neurons and one output layer). Additionally, the sigmoid activation function was used in the ANN modeling. It is worth mentioning that the mentioned architecture was employed in the DIRECT-ANN, PSO-ANN, and BBO-ANN modeling of this study.
For the DIRECT-ANN algorithm, the DIRECT uses an initial solution set that is assigned as a qualified n-dimensional vector (set of simplex vertices) between the upper and lower boundaries. DIRECT is driven by a set of operations that depend on the cost function value. The termination condition of this algorithm occurs when the simplex vertices are close enough to each other. Note that the value of the generic iterations and the mesh size were reported to be 1724 and 4096, respectively.
The most important work in PSO-ANN modeling is to select the appropriate values for the PSO parameters. By reviewing the literature, it was found that the cognitive acceleration (C1), social acceleration (C2), number of particles, number of iterations, and inertia weight are the most important parameters in PSO-ANN. The first step was to determine the most appropriate values of C1 and C2. For this work, different values of C1 and C2 were tested and their performances were evaluated based on R
2, as shown in
Table 3. Note that the values of 1.333, 2.667, 1.5, 2, and 1.75 were selected as the values of C1 and C2 in some studies. Hence, these values were tested in the present study. From
Table 3, it can be seen that model number 5 has the best
R2, therefore the values of 1.75 and 1.75 are selected as the C1 and C2 values, respectively.
In order to select the appropriate value of inertia weight, some previous studies were reviewed. Based on the literature, the value of 0.75 was used as the inertia weight. In this step, the number of particles (swarm size) was determined. For this work, different values for the number of particles were tested and their performances were checked based on
R2, as shown in
Table 4. According to
Table 4, model number 4 with the number of particles = 350 had the best performance. Hence, the value of 350 was selected as the number of particles of this study. In the next step, the number of iterations was determined. In the literature, different values such as 400 and 450 were selected as the number of iterations. To determine the maximum number of iterations of this study, a 7 × 5 × 1 structure of ANN, C1 = 1.75, C2 = 1.75, inertia weight = 0.75 and an iteration number of 1000 were used. According to the obtained results, after an iteration number of 400, there were no significant changes in the network results. Therefore, the value of 400 was selected as the maximum number of iterations of this study.
Regarding the modeling process of BBO-ANN, the BBO has a number of parameters to initially set for a better ANN model performance. After an initial trial and error process for BBO parameters, the final parameter values were as follows: (i) Elitism rate: 0.3, (ii) Mutation probability: 0.015, (iii) Maximum value of immigration and emigration rate: 1.
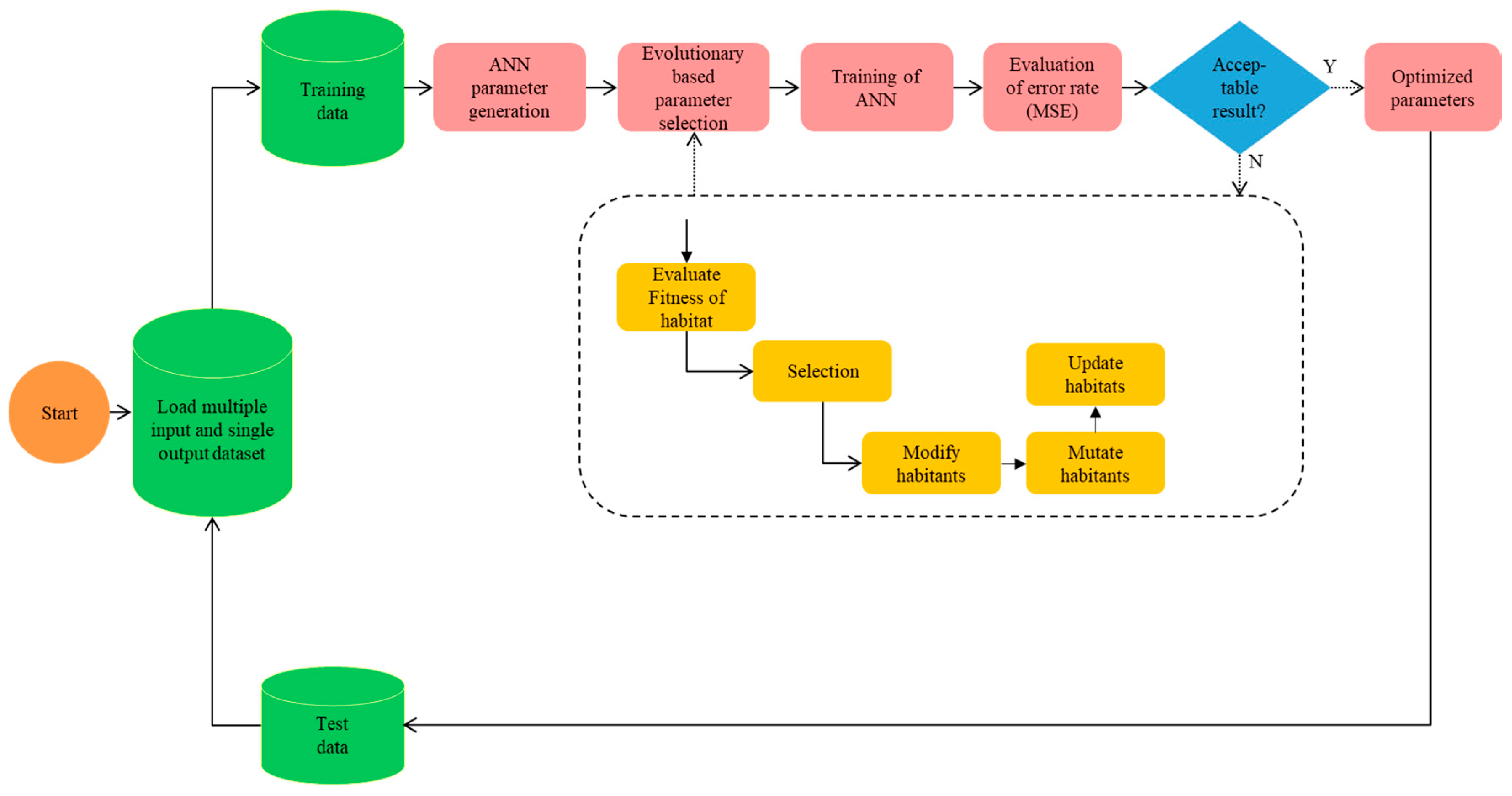
Figure 5 shows the process flow chart of the proposed BBO-ANN. Note that the different values for the number of habitats were tested in this study, as shown in
Table 5. Based on this Table, model number 8 had the best performance with the highest R
2 value. Hence, 350 was selected as the number of habitats in the BBO-ANN modeling for this study.
After the trial process, the final architecture of ELM consisted of 15 hidden neurons with the sigmoid activation function for training and validation. Meanwhile, the MPMR model had an error tube width of ε = 0.002 and C = 0.9.
To investigate the performance of the models, the root mean square error (RMSE),
R2, Ratio of RMSE to the standard deviation of the observations (RSR), mean absolute error (MAE), and degree of agreement (
d) were taken into account, which are shown in Equations (9)–(12) [
42,
43,
44,
45,
46,
47,
48,
49,
50,
51,
52,
53,
54,
55,
56]:
where
is the predicted PPV obtained using the proposed models;
signifies the actual PPV;
represents the average of the PPV data; and
n stands for the number of data values.
6. Results and Discussion
The predicted PPV values obtained from all predictive models for only the testing phase is given in
Table 6. In this Table, k is ratio of the actual PPV to the predicted PPV values for each dataset (
. According to the predicted values,
Table 7 and
Table 8 show the values of different statistical indices of the models for both training and testing phases. Additionally,
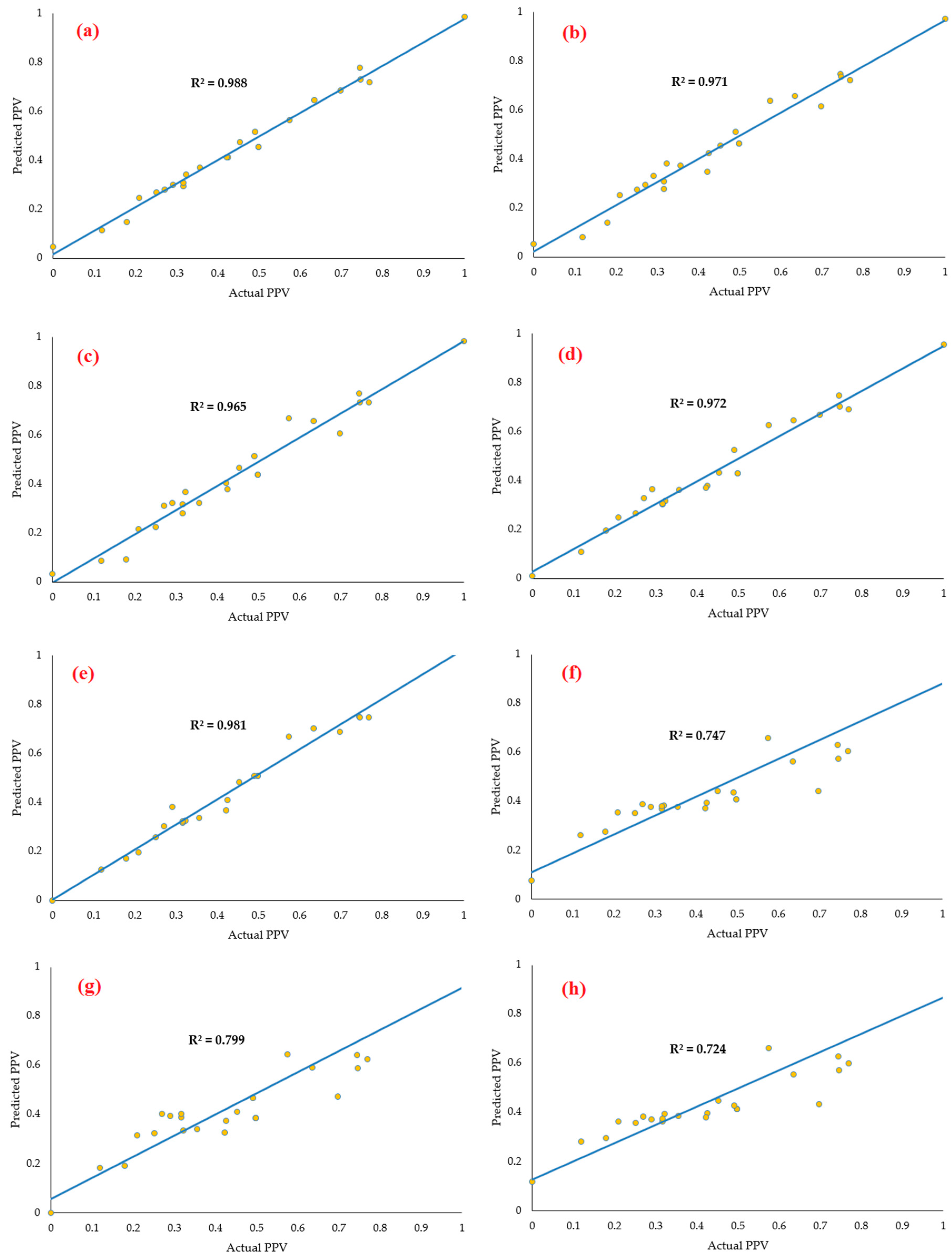
Figure 6 shows the scatter plot of the actual and the predicted PPV involving four soft computing techniques and empirical methods only for the testing phase. From these results, it is evident that all the models performed efficiently in predicting PPV in terms of statistical indices. Regarding the prediction accuracy, the
R2 was found to be higher in the case of BBO-ANN (
R2 = 0.988) compared to the other seven models: DIRECT-ANN (
R2 = 0.981), PSO-ANN (
R2 = 0.972), MPMR (
R2 = 0.971), ELM (
R2 = 0.965), USBM (
R2 = 0.747), Indian standard (
R2 = 0.799), and Ambraseys–Hendron (
R2 = 0.724).
Furthermore, in terms of the prediction error (i.e., the lower the error, the better the model), the lowest value was found for BBO-ANN (MAE = 0.022, RMSE = 0.026, RSR = 0.109) compared to DIRECT-ANN (MAE = 0.024, RMSE = 0.036, RSR = 0.151), PSO-ANN (MAE = 0.034, RMSE = 0.041, RSR = 0.174), MPMR (MAE = 0.034, RMSE = 0.040, RSR = 0.169), ELM (MAE = 0.037, RMSE = 0.045, RSR = 0.188), USBM (MAE = 0.100, RMSE = 0.117, RSR = 0.494), Indian standard (MAE = 0.087, RMSE = 0.105, RSR = 0.444), and Ambraseys–Hendron (MAE = 0.105, RMSE = 0.123, RSR = 0.517).
To check the consistency of the developed models, the degree of agreement (d) was calculated using Equation (12) and the higher value was recorded for the BBO-ANN model. Therefore, it can be concluded that the BBO-ANN model (d = 0.997) had the best performance, followed by DIRECT-ANN (d = 0.994), PSO-ANN (d = 0.991), MPMR (d = 0.992), ELM (d = 0.991), USBM (d = 0.924), Indian standard (d = 0.943), and Ambraseys–Hendron (d = 0.914).
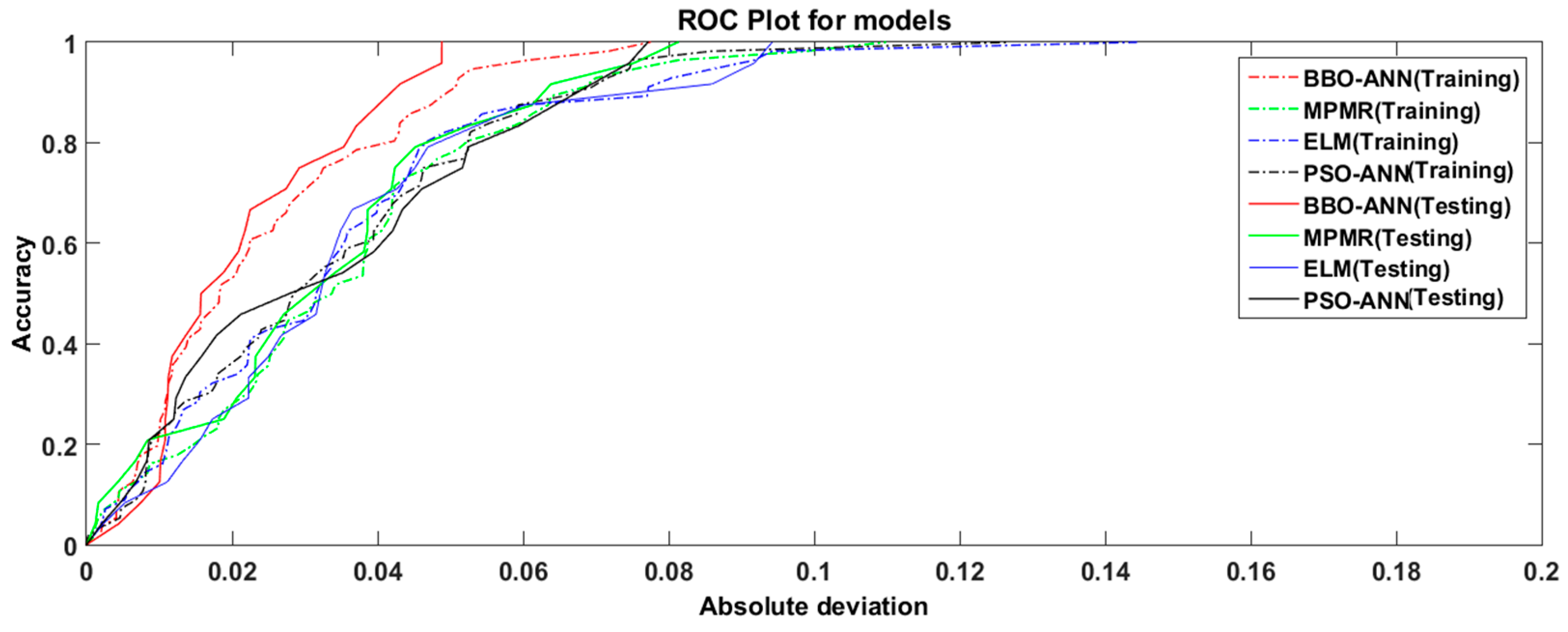
Moreover, for a better representation in terms of model deviations, the receiver operating characteristic (ROC) curve was plotted (
Figure 7). It is evident that all the models captured a good relationship when determining the PPV during training, and the lowest deviation was recorded for BBO-ANN followed by DIRECT-ANN, PSO-ANN, MPMR, and ELM. During the testing period, the BBO-ANN model outperformed the rivals in terms of all the fitness parameters. The results analyzed showed a consistent performance of BBO-ANN during both training and testing periods.
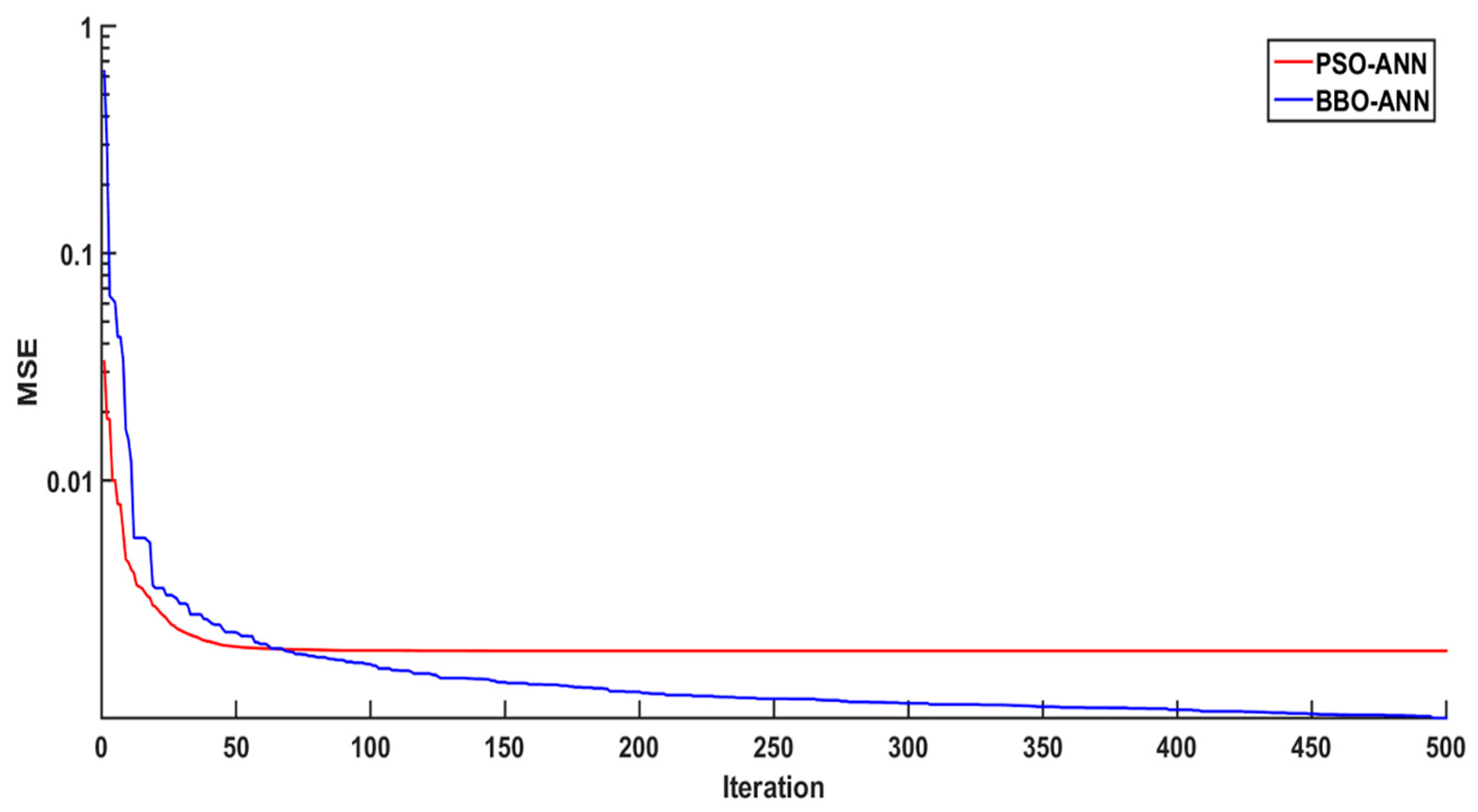
Furthermore, during the training period, the convergence curve of two metaheuristic based optimized ANN models (
Figure 8) showed that the BBO has a lower MSE (0.000899) compared to PSO (0.001777).
Figure 8 shows the convergence plot of both hybridized ANN models. From analysis, it became evident that the BBO-ANN model reduces the fitness parameter MSE significantly compared to PSO-ANN for the same number of iterations. Therefore, based on the above analysis, it was found that BBO-ANN can be a new reliable technique for PPV analysis. In the present study, a sensitivity analysis was also performed using Yang and Zang’s [
57] method to assess the impact of input parameters on PPV. This method has been used in some studies [
58,
59,
60], and is formulated as:
where
n is the number of data values (this study used 80 data values),
and
are the input and output parameters. The value of
for each input parameter varied between zero and one, and the highest
values indicated the most effective output parameter (which was PPV in this study).
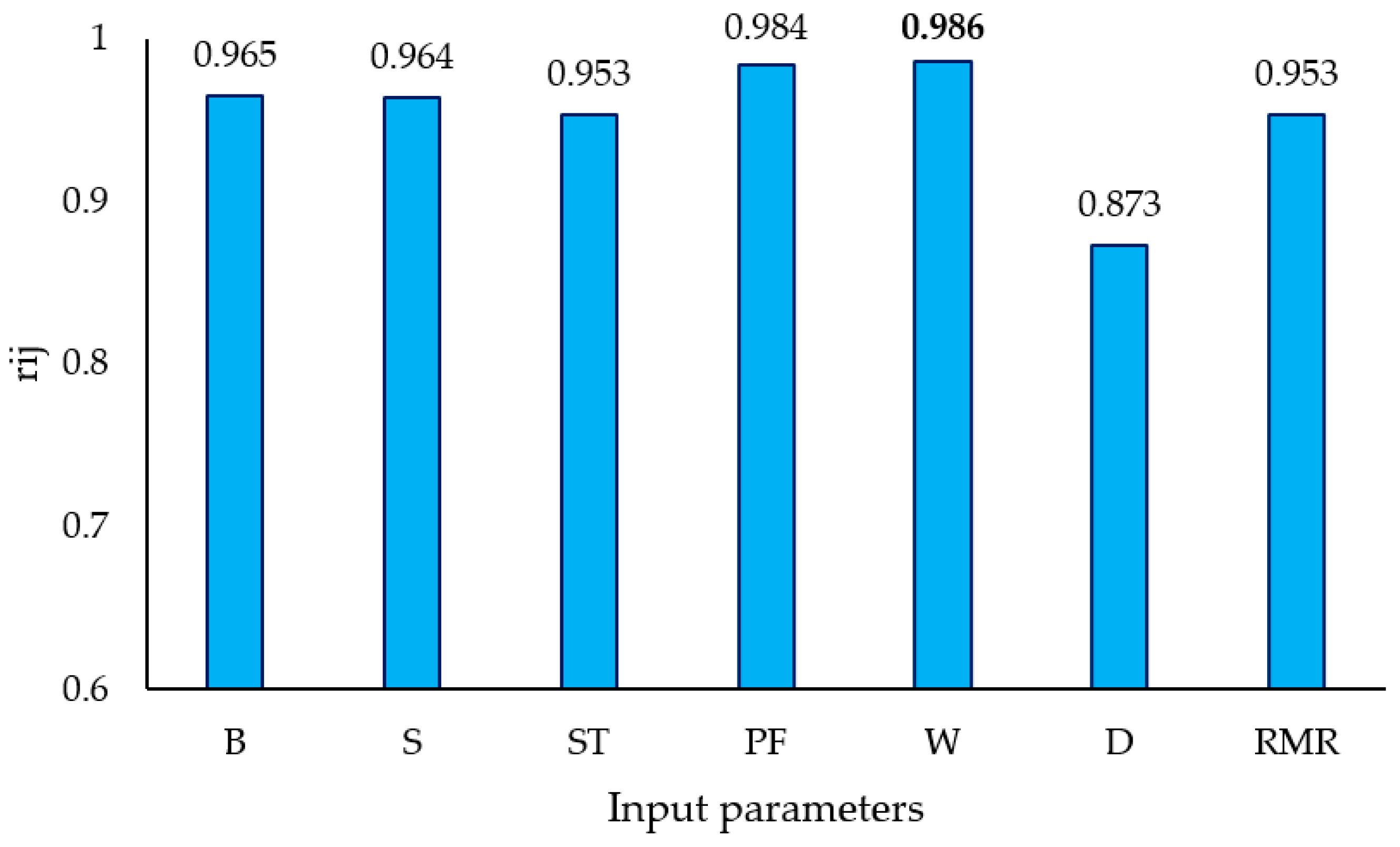
Figure 9 shows the
values for all input parameters. From
Figure 9, it can be seen that the W with
of 0.986 was the main parameter influencing PPV.
7. Conclusions
Ground vibration is considered to be the most adverse result induced by blasting. Accordingly, predictions of ground vibration are necessary, and this issue requires the application of appropriate prediction models. In this study, PPV was used as a descriptor to evaluate ground vibration. To predict the blast-induced PPV, this study proposed two novel hybrid AI models, namely the BBO-ANN and DIRECT-ANN models. In other words, one stochastic metaheuristic algorithm, namely BBO, and one deterministic optimization algorithm, namely DIRECT, were combined with the ANN model. To the best of our knowledge, this is the first work that predicted a blast-induced PPV using the DIRECT-ANN and BBO-ANN models. To demonstrate model reliability and effectiveness, the PSO-ANN, MPMR, ELM, and three empirical models, namely USBM, Indian Standard and Ambraseys–Hendron were also employed. In the first step, the empirical models were used to predict PPV, and according to the results, their performances were not good enough. The R2 values of 0.799, 0.747, and 0.724 obtained from Indian Standard, USBM and Ambraseys–Hendron models indicated that we need more accurate predictions. To consider all the attributes needed to predict the PPV, seven input parameters, namely B, S, ST, PF, W, RMR, and D were used in the modeling. Although the ELM, MPMR and PSO-ANN models, with the R2 of 0.963, 0.971 and 0.972, respectively, were capable of predicting PPV with reasonable performances, the accuracy of DIRECT-ANN and BBO-ANN models were the best. Based on the results, the DIRECT-ANN with R2 of 0.981 and the BBO-ANN with R2 of 0.988 possessed superior predictive ability compared to the other models. In other words, the effectiveness of the BBO and DIRECT methods for improving the ANN model’s performance was confirmed. Additionally, sensitivity analysis showed that the W was the main parameter influencing PPV.
These findings confirm that the BBO-ANN and DIRECT-ANN models are significant and reliable artificial intelligence techniques for producing precise predictions of PPV and can be used in various fields. Additionally, the use of deterministic optimization algorithms, such as the DIRECT method, to improve the ANN performance and other soft computing methods can be recommended.

 ,
, 












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}