Generative Adversarial Network for Image Super-Resolution Combining Texture Loss


Abstract
:1. Introduction
2. Related Work
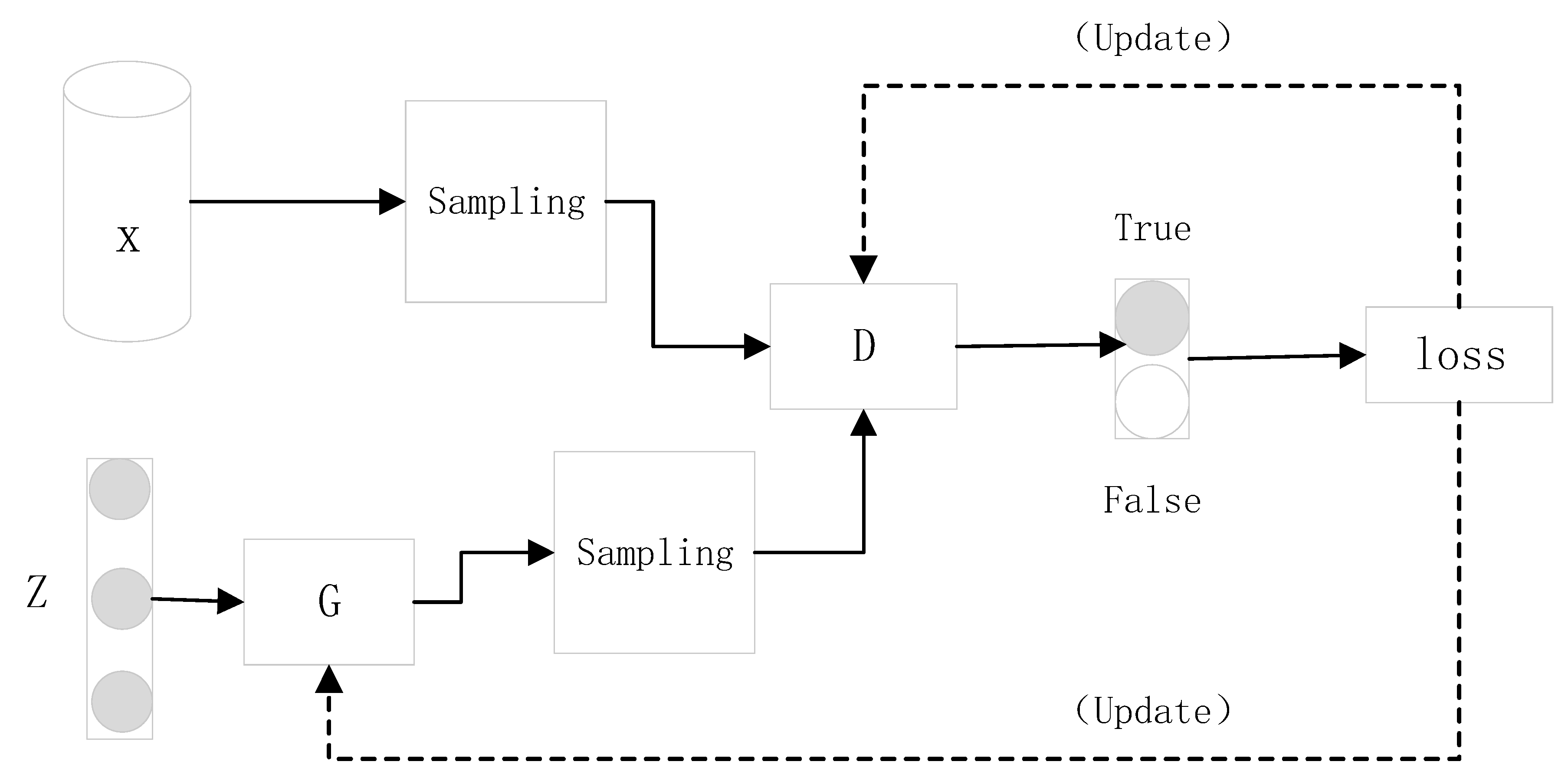
2.1. Generative Adversarial Networks
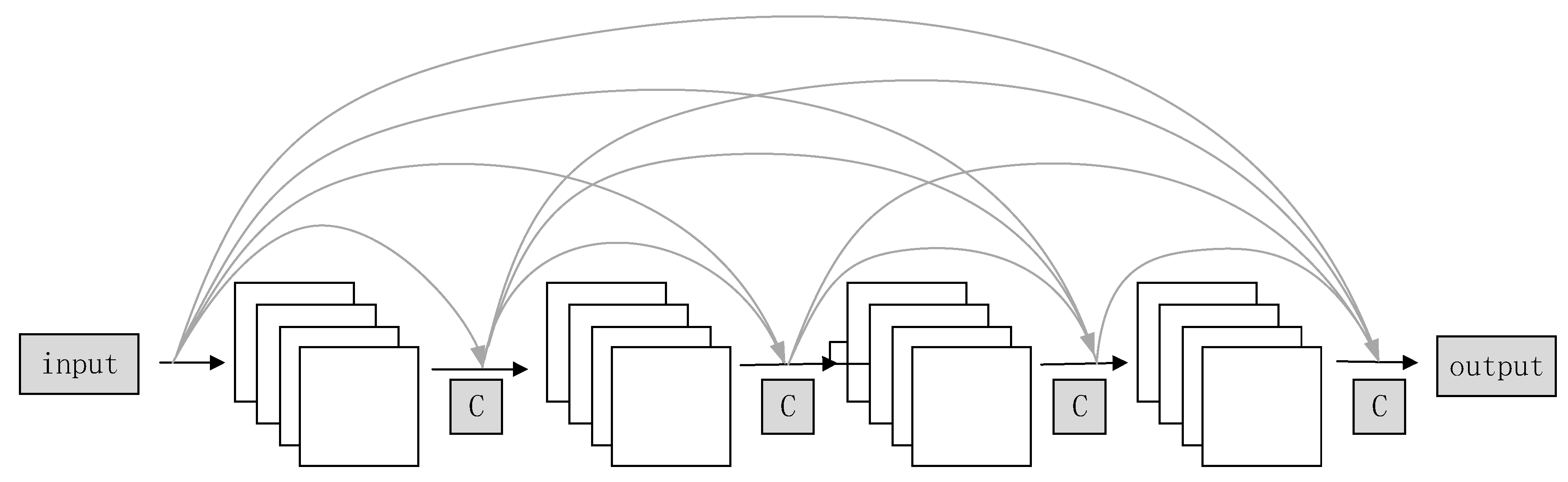
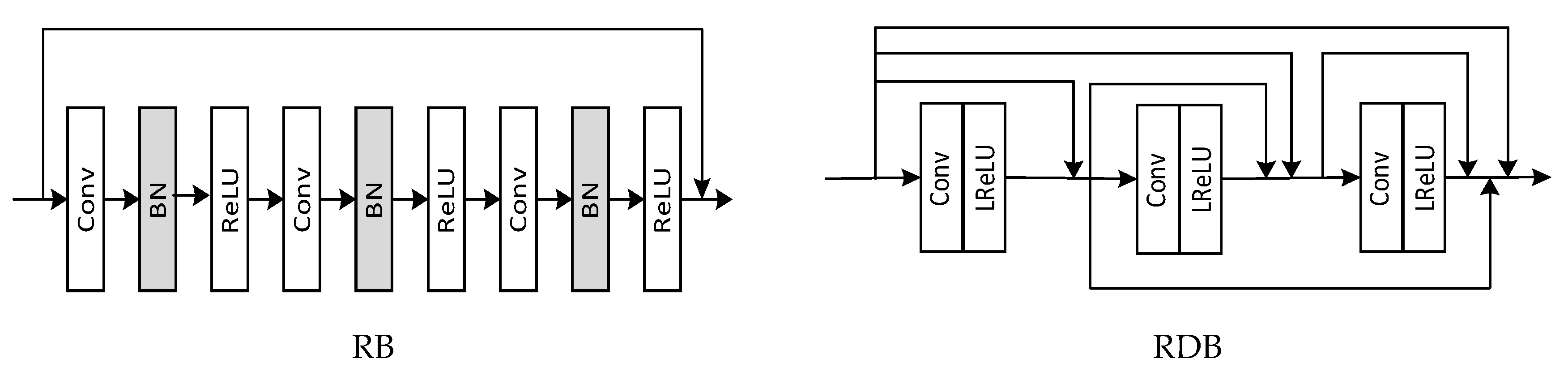
2.2. Dense Convolutional Network
3. Proposed Methods
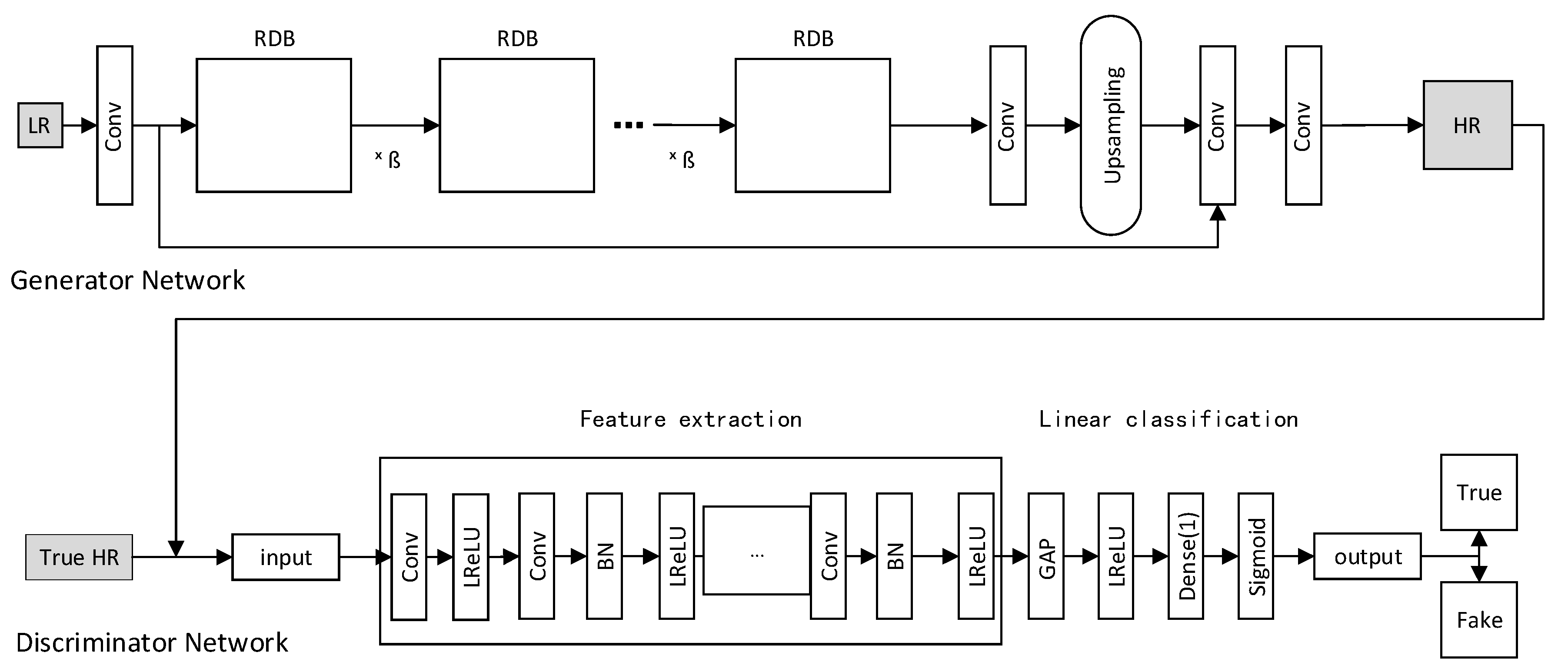
3.1. Network Architecture
3.1.1. Generator Network
3.1.2. Discriminator Network
3.2. Loss Functions
3.2.1. Content Loss
3.2.2. Adversarial Loss
3.2.3. Perceptual Loss
3.2.4. Texture Loss
4. Experiments and Results
4.1. Experimental Details
4.2. Experimental Results
4.2.1. Quantitative Evaluation
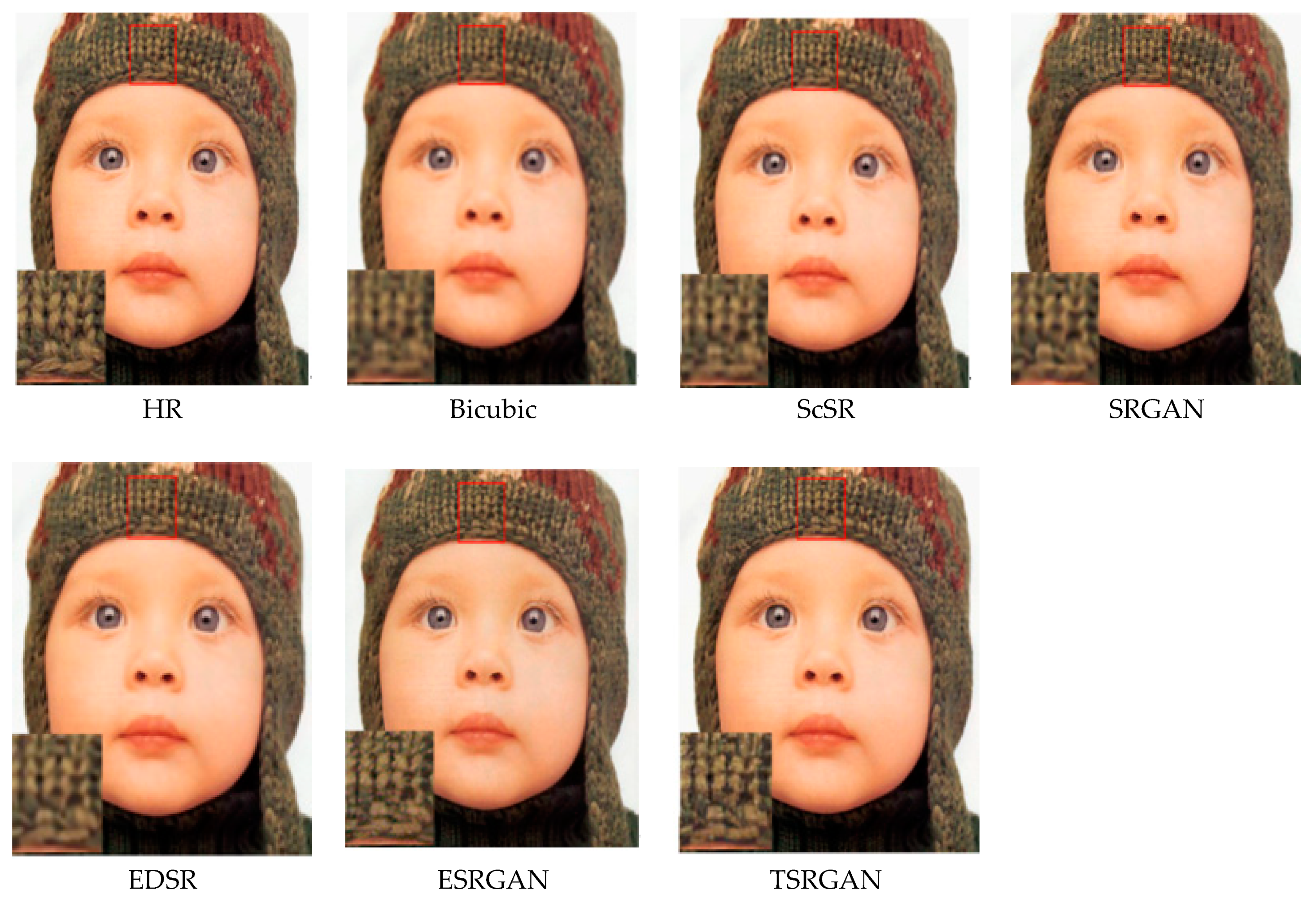
4.2.2. Qualitative Evaluation
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Gonzalez, R.; Woods, R.E. Digital Image Processing. Up. Saddle River Nj Pearson Hall. 2002, 28, 290–291. [Google Scholar]
- Schultz, R.R.; Stevenson, R.L. A Bayesian approach to image expansion for improved definition. IEEE Trans. Image Process. 1994, 3, 233–242. [Google Scholar] [CrossRef] [PubMed]
- Gribbon, K.T.; Bailey, D.G. A novel approach to real-time bilinear interpolation. In Proceedings of the DELTA, Second IEEE International Workshop on Electronic Design, Test and Applications, Perth, WA, Australia, 28–30 January 2004; pp. 126–131. [Google Scholar]
- Zhang, L.; Wu, X. An edge-guided image interpolation algorithm via directional filtering and data fusion. IEEE Trans. Image Process. 2006, 15, 2226–2238. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Jung, S.W.; Kim, T.H.; Ko, S.J. A novel multiple image deblurring technique using fuzzy projection onto convex sets. IEEE Signal Process. Lett. 2009, 16, 192–195. [Google Scholar] [CrossRef]
- Nayak, R.; Harshavardhan, S.; Patra, D. Morphology based iterative back-projection for super-resolution reconstruction of image. In Proceedings of the 2014 2nd International Conference on Emerging Technology Trends in Electronics, Communication and Networking, Surat, India, 26–27 December 2014; pp. 1–6. [Google Scholar]
- Sun, D.; Gao, Q.; Lu, Y.; Huang, Z.; Li, T. A novel image denoising algorithm using linear Bayesian MAP estimation based on sparse representation. Signal Process. 2014, 100, 132–145. [Google Scholar] [CrossRef]
- Yang, J.; Wright, J.; Huang, T.; Ma, Y. Image super-resolution via sparse representation. IEEE Process. IEEE Trans. Image Process. 2010, 19, 2861–2873. [Google Scholar] [CrossRef] [PubMed]
- Tang, S.; Xiao, L.; Liu, P. Single image super-resolution method via refined local learning. J. Shanghai Jiaotong Univ. (Sci.) 2015, 20, 26–31. [Google Scholar] [CrossRef]
- He, L.; Qi, H.; Zaretzki, R. Beta process joint dictionary learning for coupled feature spaces with application to single image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern recognition, Portland, ON, USA, 23–28 June 2013; pp. 345–352. [Google Scholar]
- Peleg, T.; Elad, M. A statistical prediction model based on sparse representations for single image super-resolution. IEEE Trans. Image Process. 2014, 23, 2569–2582. [Google Scholar] [CrossRef] [PubMed]
- Hu, Y.; Wang, N.; Tao, D.; Gao, X.; Li, X. SERF: A simple, effective, robust, and fast image super-resolver from cascaded linear regression. IEEE Trans. Image Process. 2016, 25, 4091–4102. [Google Scholar] [CrossRef] [PubMed]
- Hatvani, J.; Basarab, A.; Tourneret, J.Y.; Gyöngy, M.; Kouamé, D. A Tensor Factorization Method for 3-D Super Resolution with Application to Dental CT. IEEE Trans. Med. Imaging 2018, 38, 1524–1531. [Google Scholar] [CrossRef] [PubMed]
- Zdunek, R.; Sadowski, T. Image Completion with Hybrid Interpolation in Tensor Representation. Appl. Sci. 2020, 10, 797. [Google Scholar] [CrossRef] [Green Version]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Image Super-Resolution Using Deep Convolutional Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 295–307. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kim, J.; Kwon Lee, J.; Mu Lee, K. Accurate image super-resolution using very deep convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1646–1654. [Google Scholar]
- Ledig, C.; Theis, L.; Huszar, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z.H.; et al. Photo-realistic single image super-resolution using a generative adversarial network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4681–4690. [Google Scholar]
- Lai, W.S.; Huang, J.B.; Ahuja, N.; Yang, M. Deep laplacian pyramid networks for fast and accurate super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 624–632. [Google Scholar]
- Tai, Y.; Yang, J.; Liu, X. Image super-resolution via deep recursive residual network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3147–3155. [Google Scholar]
- Johnson, J.; Alahi, A.; Fei-Fei, L. Perceptual losses for real-time style transfer and super-resolution. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherland, 8–16 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 694–711. [Google Scholar]
- Sajjadi, M.S.M.; Scholkopf, B.; Hirsch, M. Enhancenet: Single image super-resolution through automated texture synthesis. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4491–4500. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 2672–2680. [Google Scholar]
- Lim, B.; Son, S.; Kim, H.; Nah, S.; Lee, K.M. Enhanced deep residual networks for single image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 136–144. [Google Scholar]
- Wang, X.; Yu, K.; Wu, S.; Gu, J.; Liu, Y.; Dong, C.; Loy, C.C.; Qiao, Y.; Tang, X. Esrgan: Enhanced super-resolution generative adversarial networks. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Ratliff, L.J.; Burden, S.A.; Sastry, S.S. Characterization and computation of local nash equilibria in continuous games. In Proceedings of the 2013 51st Annual Allerton Conference on Communication, Control, and Computing (Allerton), Monticello, IL, USA, 2–4 October 2013; IEEE: Piscataway, NJ, USA, 2013; pp. 917–924. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Identity mappings in deep residual networks. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherland, 8–16 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 630–645. [Google Scholar]
- Srivastava, R.K.; Greff, K.; Schmidhuber, J. Training very deep networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 2377–2385. [Google Scholar]
- Huang, G.; Sun, Y.; Liu, Z.; Sedra, D.; Weinberger, K. Deep networks with stochastic depth. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherland, 8–16 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 646–661. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Jégou, S.; Drozdzal, M.; Vazquez, D.; Romero, A.; Bengio, Y. The one hundred layers tiramisu: Fully convolutional densenets for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 11–19. [Google Scholar]
- Park, S.; Jeong, Y.; Kim, H.S. Multi-resolution DenseNet based acoustic models for reverberant speech recognition. Phon. Speech Sci. 2018, 10, 33–38. [Google Scholar] [CrossRef]
- Nah, S.; Hyun Kim, T.; Mu Lee, K. Deep multi-scale convolutional neural network for dynamic scene deblurring. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3883–3891. [Google Scholar]
- Zhang, Y.; Tian, Y.; Kong, Y.; Zhong, B.; Fu, Y. Residual densenet work for image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2472–2481. [Google Scholar]
- Zhang, Y.; Li, K.; Li, K.; Wang, L.; Zhong, B.; Fu, Y. Image super-resolution using very deep residual channel attention networks. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 286–301. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Gulrajani, I.; Ahmed, F.; Arjovsky, M.; Dumoulin, V.; Courville, A. Improved training of wasserstein gans. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5767–5777. [Google Scholar]
- Bevilacqua, M.; Roumy, A.; Guillemot, C.; Alberi Morel, M.-L. Low-Complexity Single-Image Super-Resolution based on Nonnegative Neighbor Embedding. In Proceedings of the Acoustics, Speech and Signal Processing (ICASSP), Kyoto, Japan, 25–30 March 2012. [Google Scholar]
- Zeyde, R.; Elad, M.; Protter, M. On single image scale-up using sparse-representations. In Proceedings of the International Conference on Curves and Surfaces, Avignon, France, 24–30 June 2010; Springer: Berlin/Heidelberg, Germany, 2010; pp. 711–730. [Google Scholar]
- Martin, D.; Fowlkes, C.; Tal, D.; Malik, J. A database of human segmented natural images and its application to evaluating segmentation algorithms and measuring ecological statistics. In Proceedings of the Eighth IEEE International Conference on Computer Vision, ICCV, Vancouver, BC, Canada, 7–14 July 2001; Volume 2, pp. 416–423. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A. Inception-v4, inception-resnet and the impact of residual connections on learning. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| RDB | Set5 | Set14 | |||
|---|---|---|---|---|---|
| × | × | × | × | 30.37 | 27.02 |
| √ | × | × | × | 31.22 | 27.98 |
| √ | √ | × | × | 31.54 | 28.27 |
| √ | √ | √ | × | 31.83 | 28.39 |
| √ | √ | √ | √ | 32.38 | 28.73 |
| λ | 1 × 10−3 | 2 × 10−3 | 3 × 10−3 | 4 × 10−3 | 5 × 10−3 | |
|---|---|---|---|---|---|---|
| η | ||||||
| 1× 10−2 | 32.31 | 32.34 | 32.36 | 32.35 | 32.36 | |
| 2 × 10−2 | 32.32 | 32.35 | 32.38 | 32.36 | 32.35 | |
| 3× 10−2 | 32.31 | 32.33 | 32.36 | 32.34 | 32.32 | |
| Algorithm | Set5 | Set14 | BSD100 |
|---|---|---|---|
| Bicubic | 30.07/0.862 | 27.18/0.786 | 26.68/0.729 |
| ScSR | 30.29/0.868 | 27.69/0.790 | 26.94/0.730 |
| SRGAN | 30.36/0.873 | 27.02/0.772 | 26.51/0.724 |
| EDSR | 31.53/0.882 | 28.02/0.793 | 27.23/0.732 |
| ESRGAN | 32.05/0.895 | 28.49/0.819 | 27.58/0.747 |
| TSRGAN | 32.38/0.967 | 28.73/0.810 | 27.67/0.764 |
| Algorithm | Bicubic/s | ScSR/s | SRGAN/s | EDSR/s | ESRGAN/s | TSRGAN/s |
|---|---|---|---|---|---|---|
| Set5 | 1.725 | 2.376 | 3.763 | 3.005 | 3.247 | 3.750 |
| Set14 | 1.816 | 2.693 | 4.098 | 3.729 | 3.862 | 3.899 |
| BSD100 | 12.519 | 20.067 | 28.686 | 26.103 | 27.034 | 27.935 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jiang, Y.; Li, J. Generative Adversarial Network for Image Super-Resolution Combining Texture Loss. Appl. Sci. 2020, 10, 1729. https://doi.org/10.3390/app10051729
Jiang Y, Li J. Generative Adversarial Network for Image Super-Resolution Combining Texture Loss. Applied Sciences. 2020; 10(5):1729. https://doi.org/10.3390/app10051729
Chicago/Turabian StyleJiang, Yuning, and Jinhua Li. 2020. "Generative Adversarial Network for Image Super-Resolution Combining Texture Loss" Applied Sciences 10, no. 5: 1729. https://doi.org/10.3390/app10051729
APA StyleJiang, Y., & Li, J. (2020). Generative Adversarial Network for Image Super-Resolution Combining Texture Loss. Applied Sciences, 10(5), 1729. https://doi.org/10.3390/app10051729