The Influence of the Activation Function in a Convolution Neural Network Model of Facial Expression Recognition


Abstract
:1. Introduction
2. Activation Functions
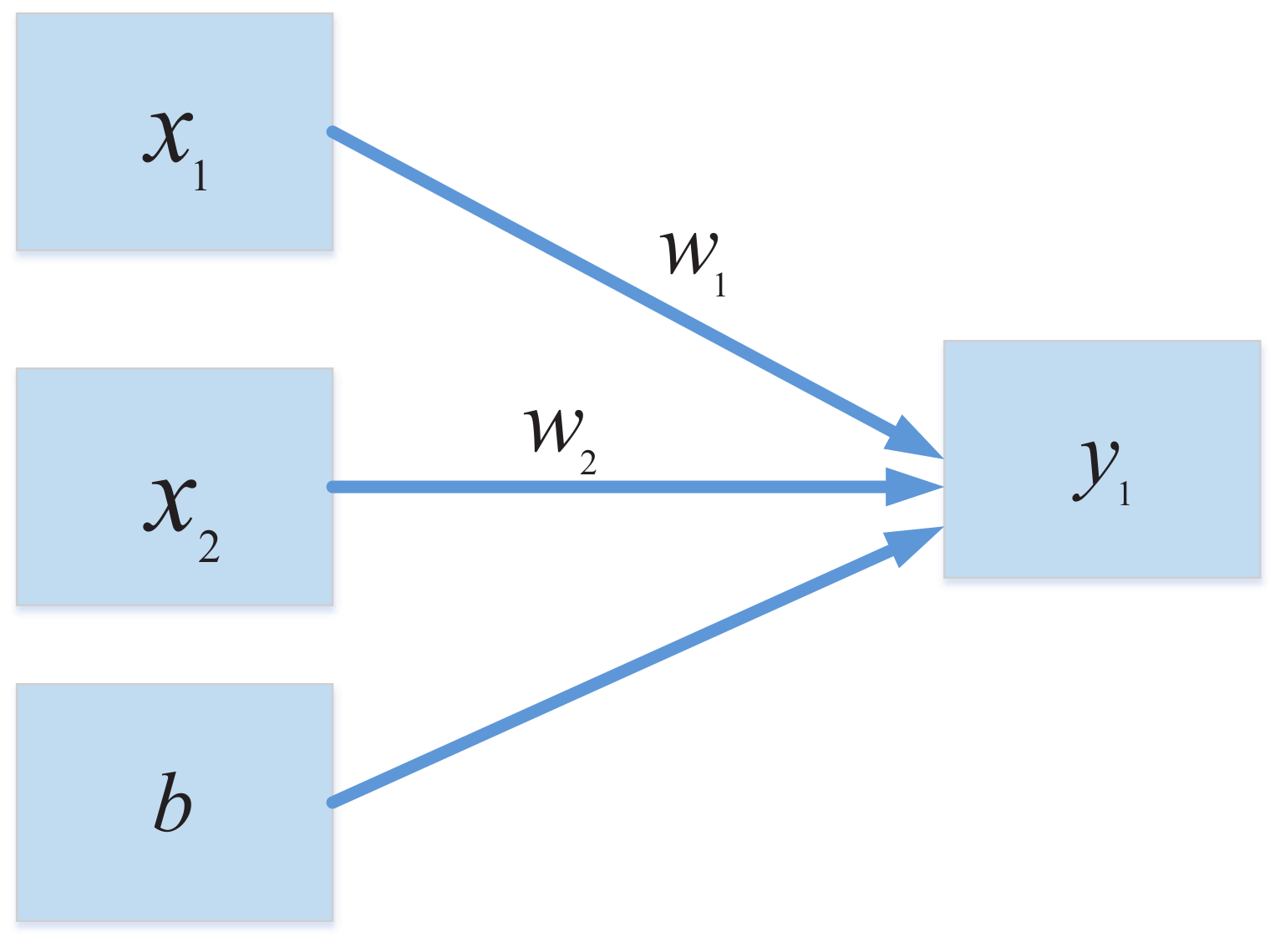
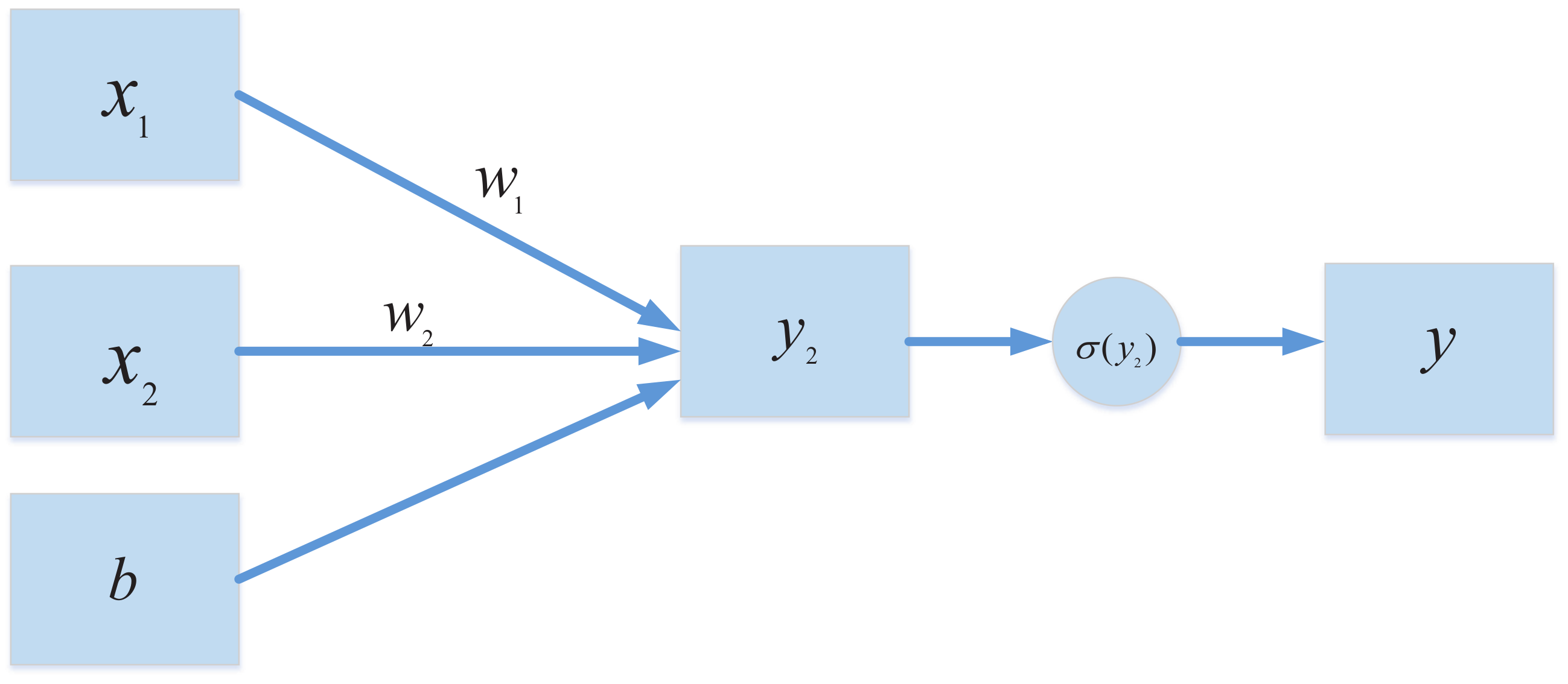
2.1. The Significance of the Activation Function
2.2. The Comparison and Study of Traditional Activation Functions
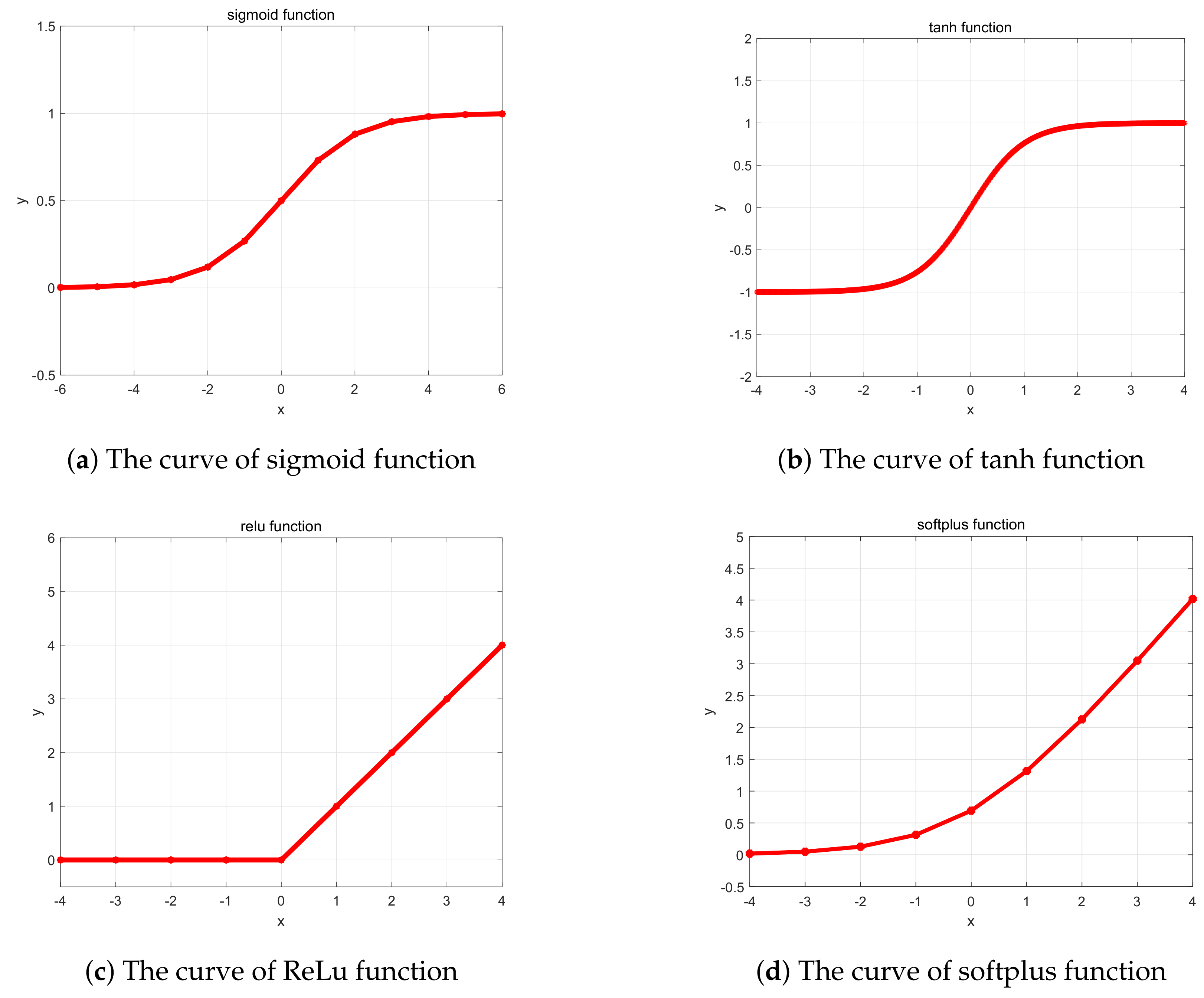
2.2.1. Common Activation Functions
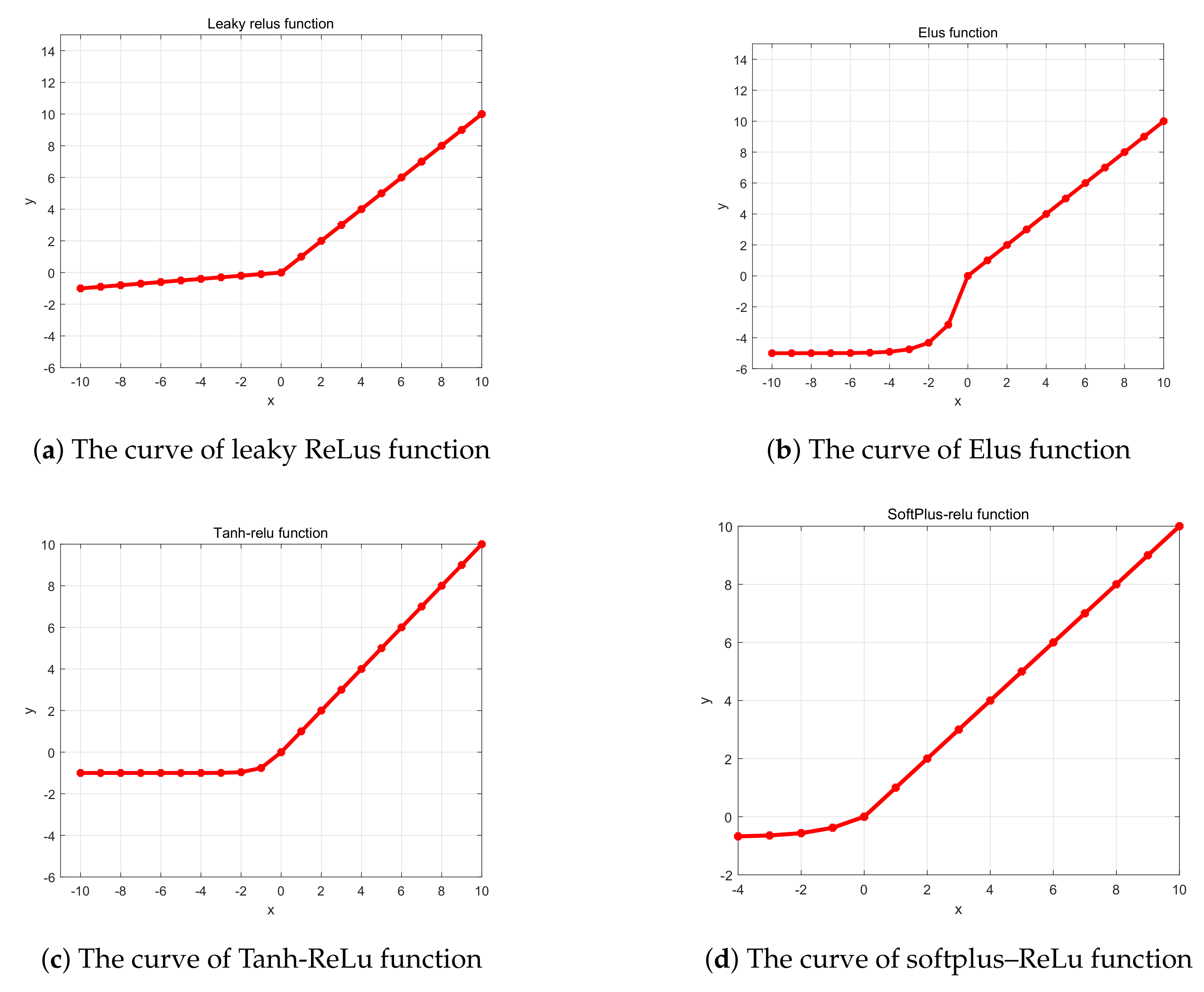
2.2.2. Common Variations of ReLu Function
2.2.3. Analysis and Research on the Design Method of Activation Function in the Convolution Neural Network Model
- (a)
- Calculate the loss function E; the squared error loss function is selected in this paper.
- (b)
- Calculate the sensitivity of the l layer. The sensitivity of the convolution layer l can be gotten by the sensitivity of the next sample layer :where is the sensitivity of the j channel in l layer, is the weight of the sample layer, is the derivative of the activation function, o refers to make multiply operation for each function and stands for the up-sampling operation.
- (c)
- The partial derivative of the parameter can be obtained by the sensitivity:
- (d)
- Update the parameters in the convolution layerwhere is the learning rate.
- (1)
- The derivative of the first half of the activation function should be large enough to enable the parameters to be rapidly updated to the vicinity of the optimal value.
- (2)
- The derivative of the second half gradually reduces to a value close to zero, so as to realise fine-tuning of parameters.
- (1)
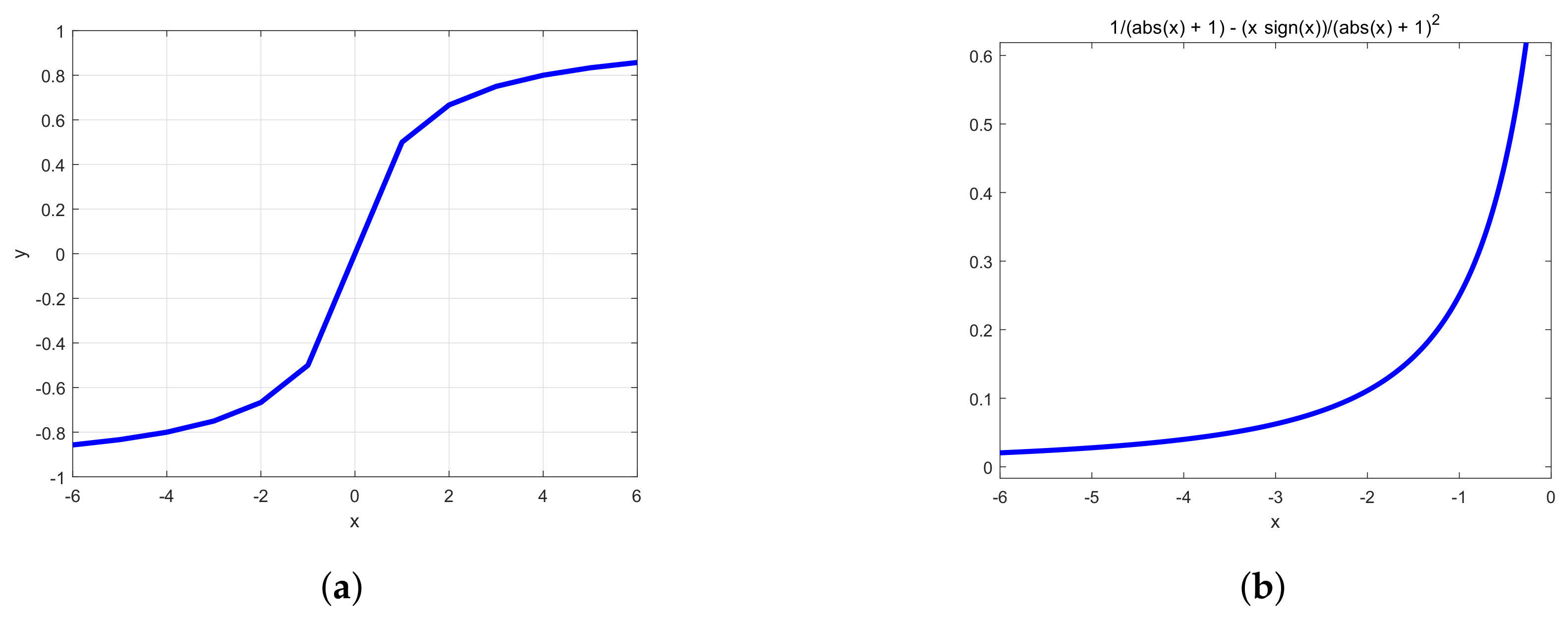
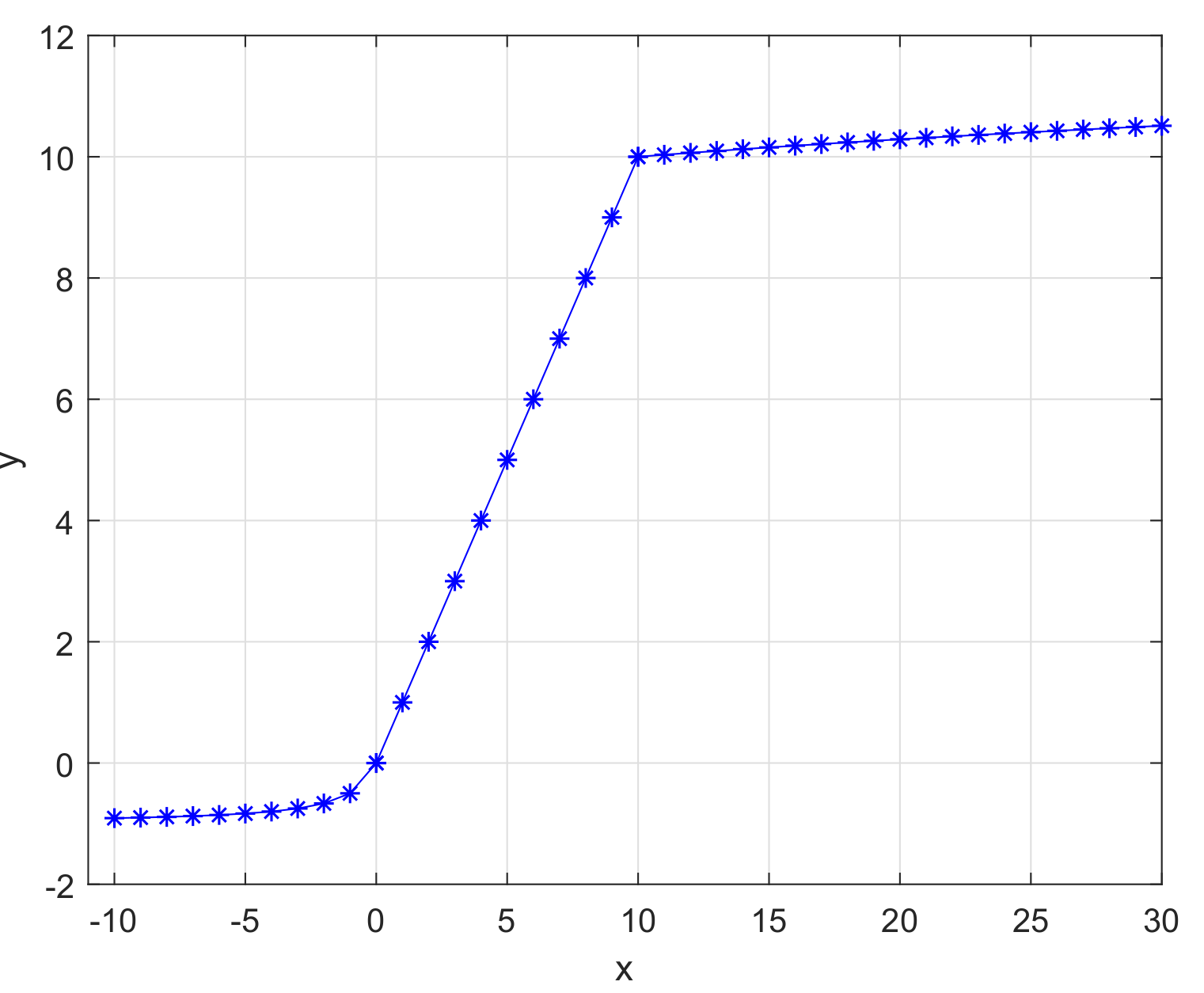
- With the gradual deepening of training, it is possible to bring about the problem of neuron death, which will make the weight fail to be updated normally. In order to solve the problem, the softsign function has been used in the region of . The addition of the new function can avoid the problem of mass neuronal death, because the new function is designed to selectively activate many negative values, not mask a large number of signals in the negative half of the shaft. From the trend of the derivative curve in Figure 6b, the derivative of the softsign function changes faster in the region near zero. This characteristic indicates that this function is more sensitive to data, and it is more beneficial to solve the gradient disappearance problem that is caused by the derivative at both ends being zero. In addition, in the negative axis, the derivative of softsign function keeps changing, and decreases slowly, which can effectively reduce the occurrence of the phenomenon of non-convergence of the training model.
- (2)
- ReLu function is used in the region of . Combined with the curve in the positive half axis of ReLu function, the combined activation function can have some characteristics of ReLu function. The new combined function accelerates the convergence speed of the model, and greatly reduces the possibility of gradient disappearance.
- (3)
- Meanwhile, in order to reduce the problem of gradient explosion produced by a large amount of data in deep network, an adjustable log function is applied in the region of . The aim of the log function is to slow the upward trend to prevent the gradient explosion problem that is brought about by the large amount of data in a deep network.
3. The Design of the CNN Model Based on the Transfer Learning Method
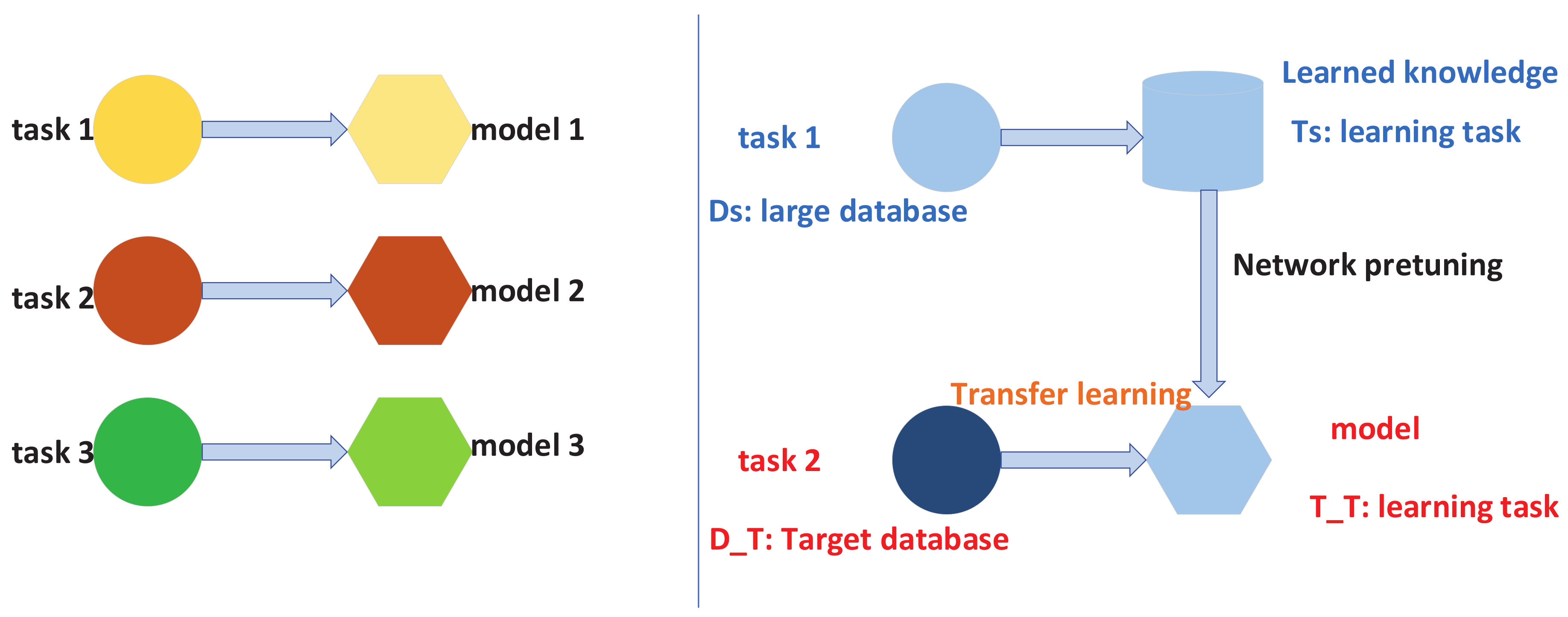
3.1. The Introduction of the Transfer Learning Method
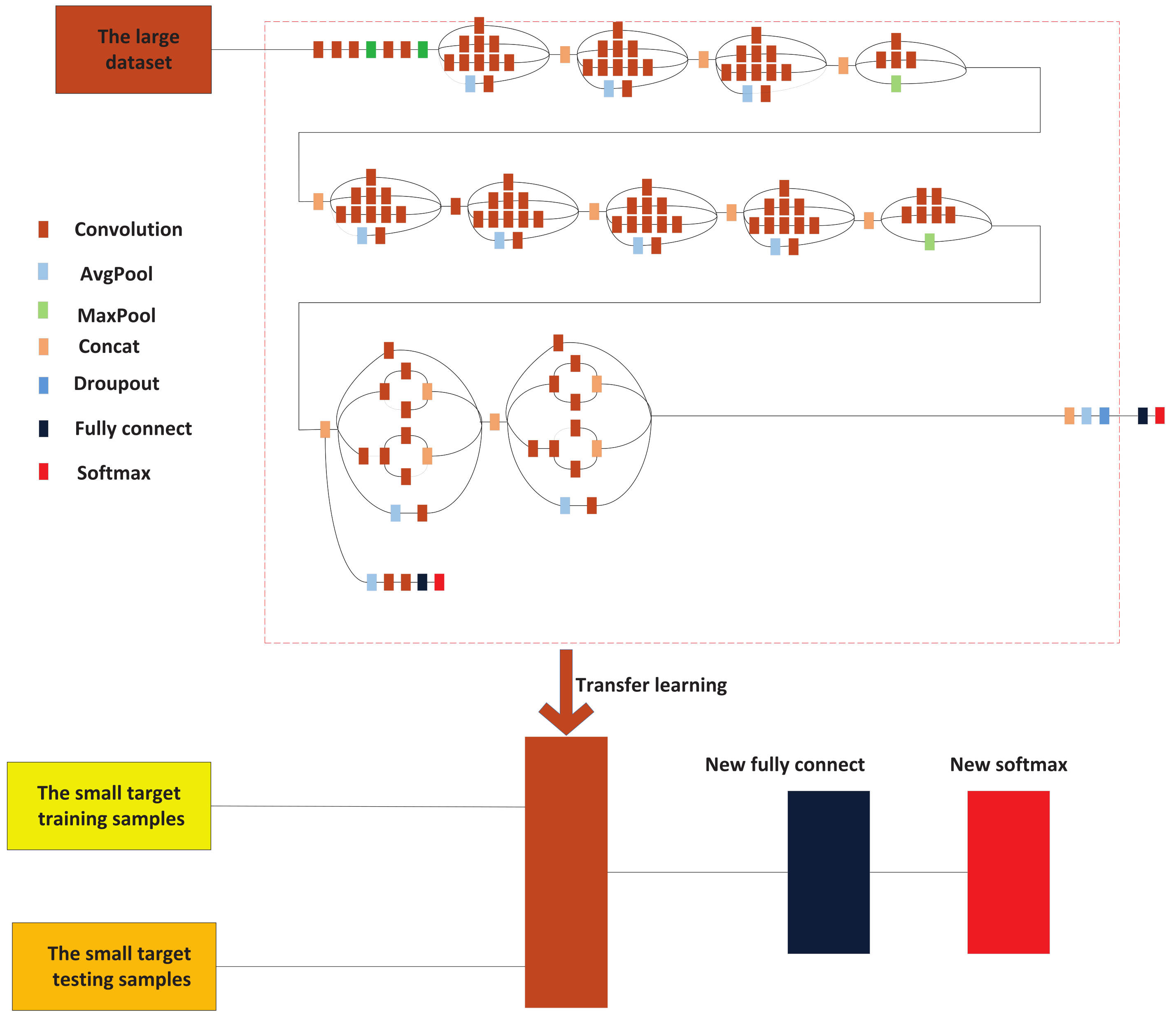
3.2. The CNN Model Based on the Transfer Learning Method
4. Experiments and Results
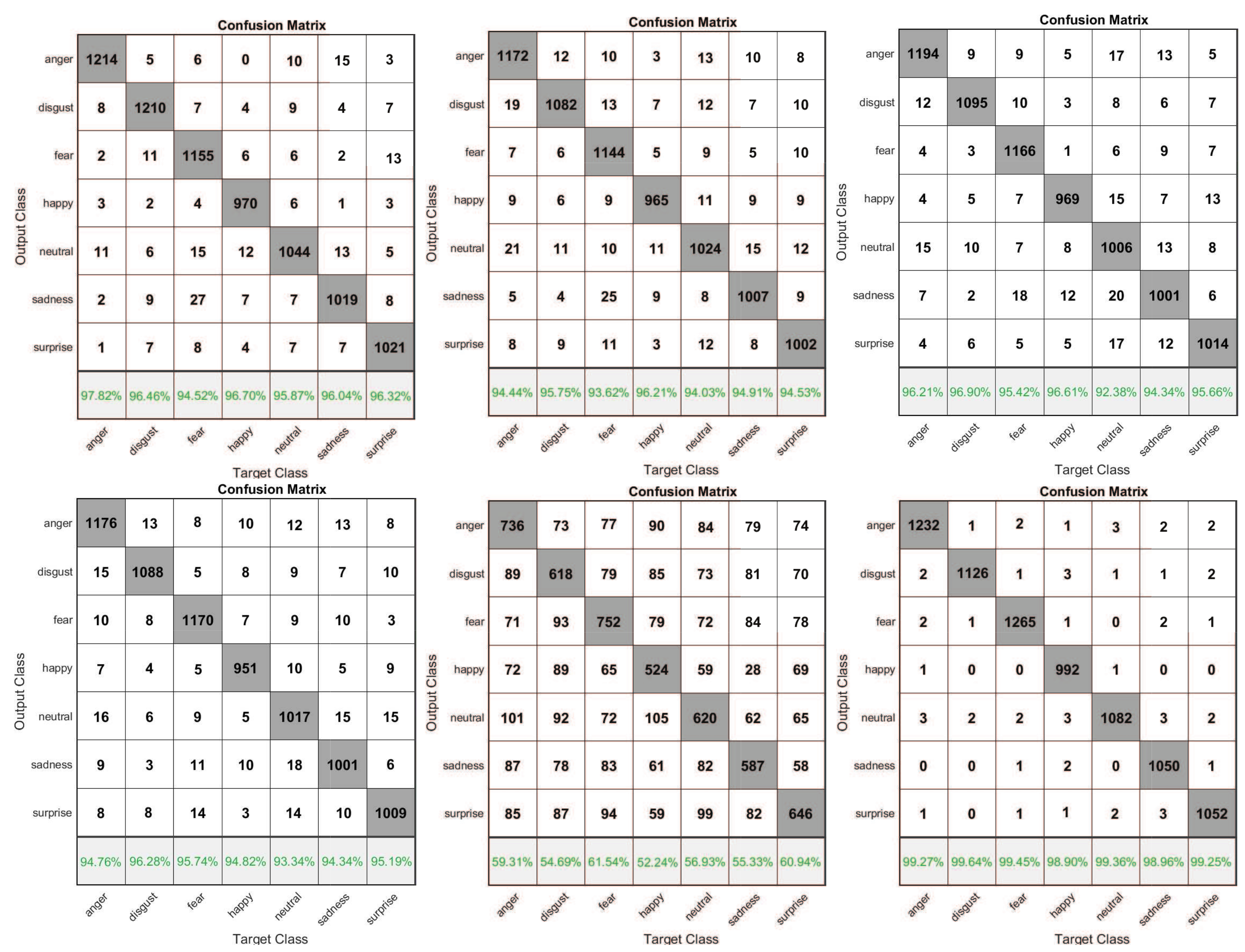
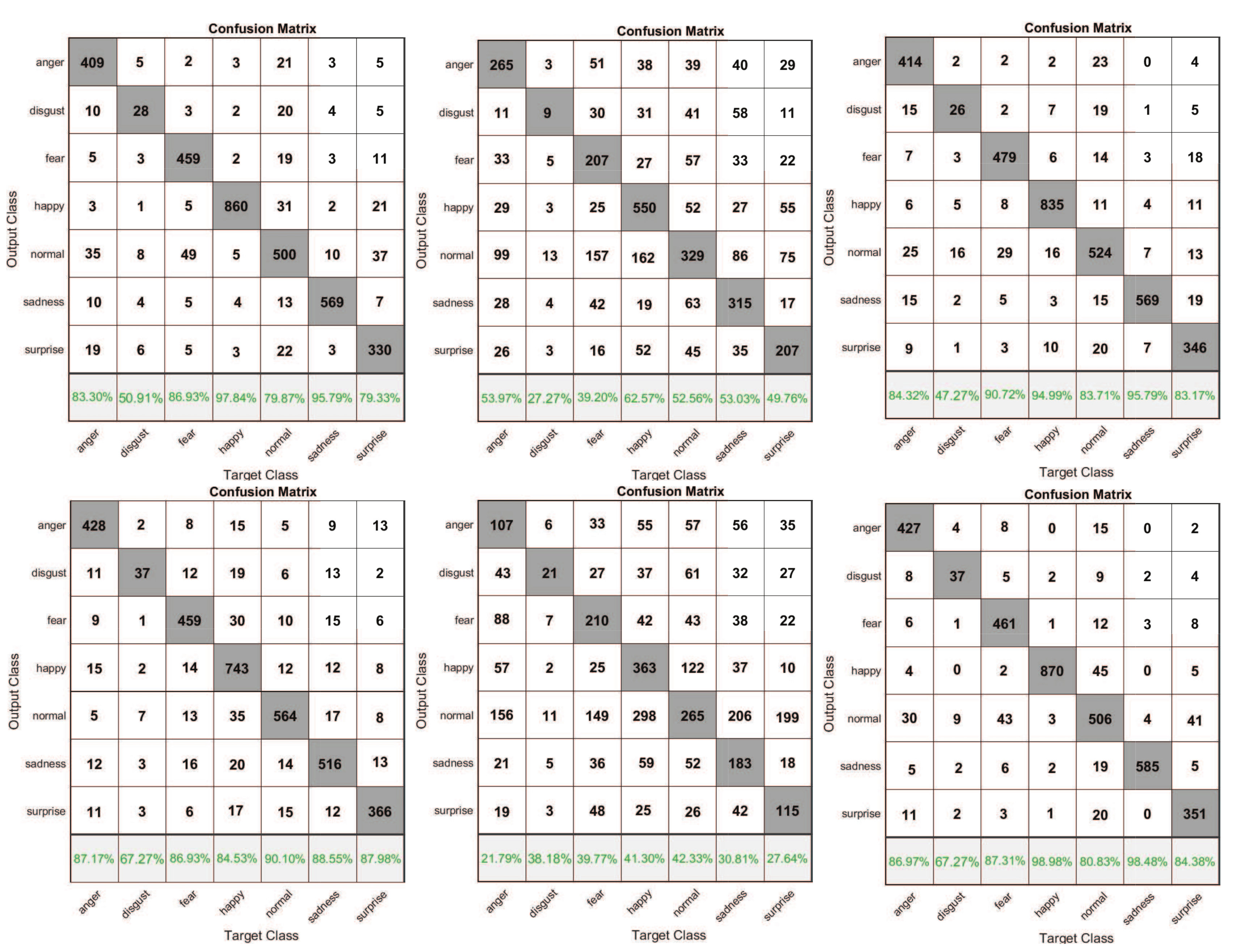
4.1. Databases
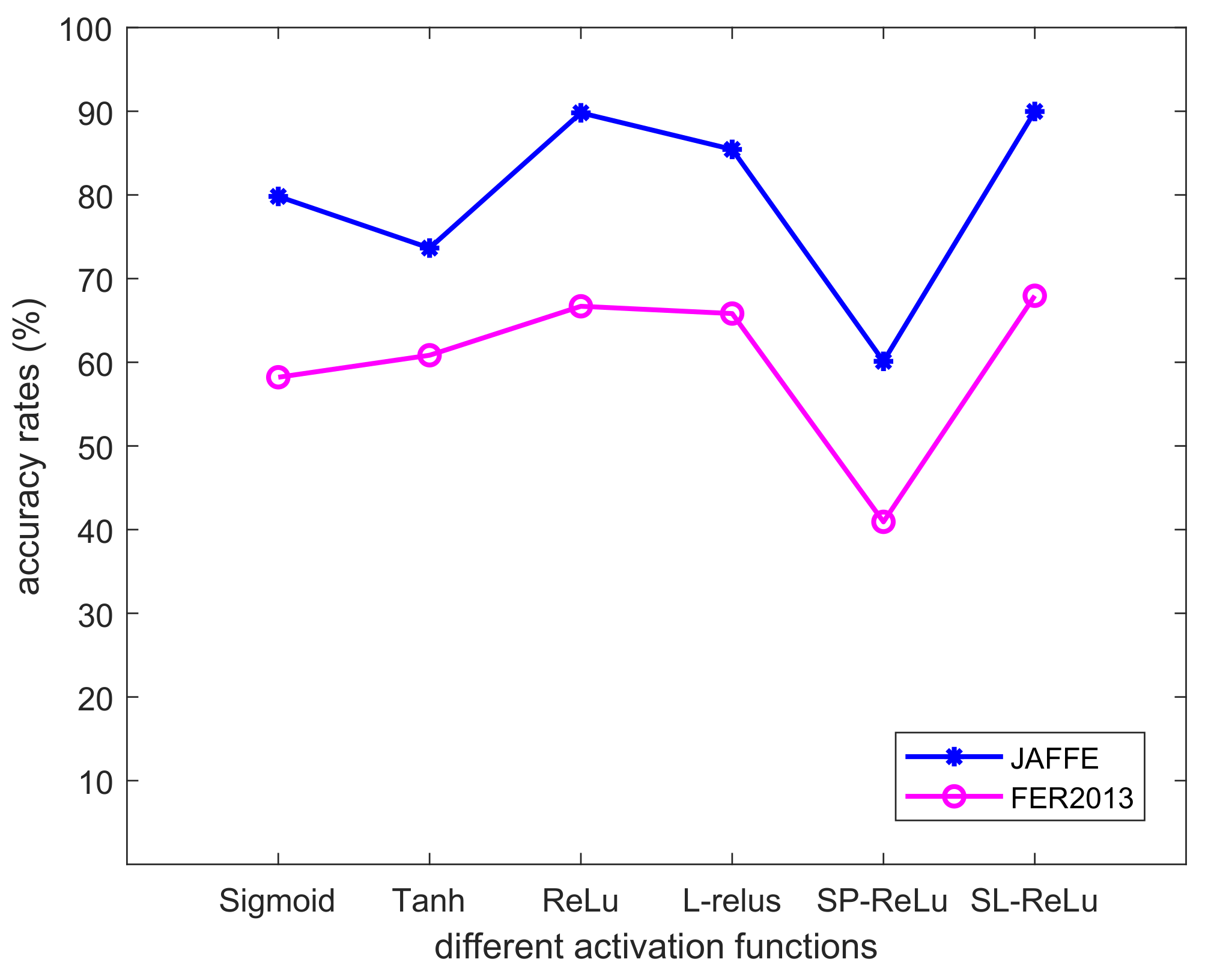
4.2. Results
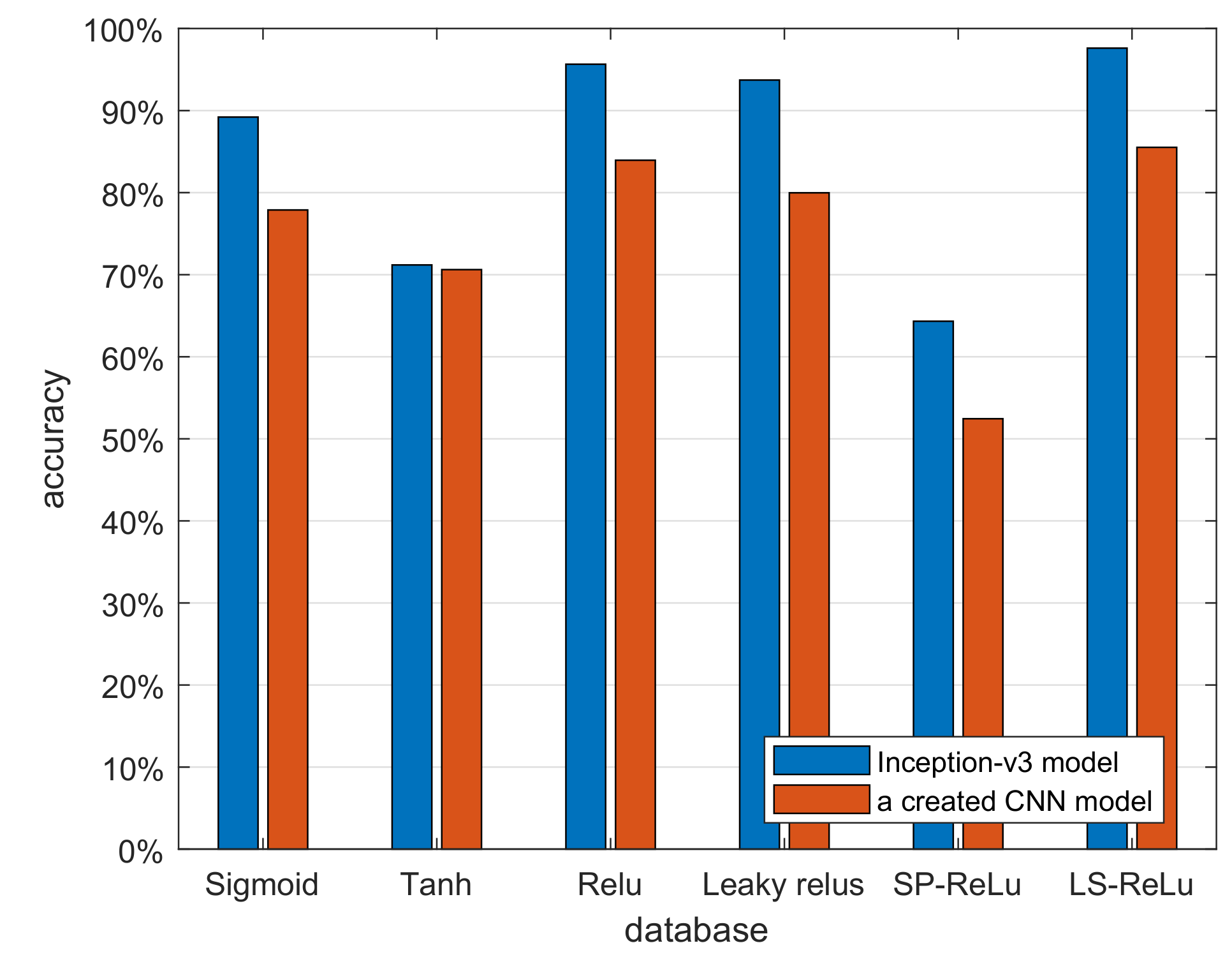
4.3. Extensibility
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Mehrabian, A.; Russell, J.A. An Approach to Environmental Psychology; The MIT Press: Cambridge, MA, USA, 1974. [Google Scholar]
- Wang, K.; Peng, X.; Yang, J. Region attention networks for pose and occlusion robust facial expression recognition. IEEE Trans. Image Process. 2020, 29, 4057–4069. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wood, A.; Rychlowska, M.; Korb, S.; Niedenthal, P. Fashioning the face: Sensorimotor simulation contributes to facial expression recognition. Trends Cogn. Sci. 2016, 20, 227–240. [Google Scholar] [CrossRef] [PubMed]
- Otwell, K. Facial Expression Recognition in Educational Learning Systems. U.S. Patent 10,319,249, 11 June 2019. [Google Scholar]
- Cambria, E. Affective computing and sentiment analysis. IEEE Intell. Syst. 2016, 31, 102–107. [Google Scholar] [CrossRef]
- Poria, S.; Cambria, E.; Howard, N.; Huang, G.B.; Hussain, A. Fusing audio, visual and textual clues for sentiment analysis from multimodal content. Neurocomputing 2016, 174, 50–59. [Google Scholar] [CrossRef]
- Chaturvedi, I.; Satapathy, R.; Cavallari, S.; Cambria, E. Fuzzy commonsense reasoning for multimodal sentiment analysis. Pattern Recognit. Lett. 2019, 125. [Google Scholar] [CrossRef]
- Charniak, E. Introduction to Deep Learning; The MIT Press: Cambridge, MA, USA, 2019. [Google Scholar]
- Howard, A.G. Some improvements on deep convolutional neural network based image classification. arXiv 2013, arXiv:1312.5402. [Google Scholar]
- Greenspan, H.; Van Ginneken, B.; Summers, R.M. Guest editorial deep learning in medical imaging: Overview and future promise of an exciting new technique. IEEE Trans. Med Imaging 2016, 35, 1153–1159. [Google Scholar] [CrossRef]
- Mahdianpari, M.; Salehi, B.; Rezaee, M.; Mohammadimanesh, F.; Zhang, Y. Very deep convolutional neural networks for complex land cover mapping using multispectral remote sensing imagery. Remote Sens. 2018, 10, 1119. [Google Scholar] [CrossRef] [Green Version]
- Baccouche, M.; Mamalet, F.; Wolf, C.; Garcia, C.; Baskurt, A. Sequential deep learning for human action recognition. In International Workshop on Human Behavior Understanding; Springer: Berlin/Heidelberg, Germany, 2011; pp. 29–39. [Google Scholar]
- Ng, W.; Minasny, B.; Montazerolghaem, M.; Padarian, J.; Ferguson, R.; Bailey, S.; McBratney, A.B. Convolutional neural network for simultaneous prediction of several soil properties using visible/near-infrared, mid-infrared, and their combined spectra. Geoderma 2019, 352, 251–267. [Google Scholar] [CrossRef]
- Savvides, M.; Luu, K.; Zheng, Y.; Zhu, C. Methods and Software for Detecting Objects in Images Using a Multiscale Fast Region-Based Convolutional Neural Network. U.S. Patent 10,354,362, 16 July 2019. [Google Scholar]
- Zhao, H.; Liu, F.; Zhang, H.; Liang, Z. Research on a learning rate with energy index in deep learning. Neural Netw. 2019, 110, 225–231. [Google Scholar] [CrossRef]
- Luo, L.; Xiong, Y.; Liu, Y.; Sun, X. Adaptive gradient methods with dynamic bound of learning rate. arXiv 2019, arXiv:1902.09843. [Google Scholar]
- Yedida, R.; Saha, S. A novel adaptive learning rate scheduler for deep neural networks. arXiv 2019, arXiv:1902.07399. [Google Scholar]
- Cai, S.; Gao, J.; Zhang, M.; Wang, W.; Chen, G.; Ooi, B.C. Effective and efficient dropout for deep convolutional neural networks. arXiv 2019, arXiv:1904.03392. [Google Scholar]
- Labach, A.; Salehinejad, H.; Valaee, S. Survey of Dropout Methods for Deep Neural Networks. arXiv 2019, arXiv:1904.13310. [Google Scholar]
- Hou, S.; Wang, Z. Weighted channel dropout for regularization of deep convolutional neural network. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019. [Google Scholar]
- Maguolo, G.; Nanni, L.; Ghidoni, S. Ensemble of Convolutional Neural Networks Trained with Different Activation Functions. arXiv 2019, arXiv:1905.02473. [Google Scholar]
- Dubey, A.K.; Jain, V. Comparative Study of Convolution Neural Network’s ReLu and Leaky-ReLu Activation Functions. In Applications of Computing, Automation and Wireless Systems in Electrical Engineering; Springer: Singapore, 2019; pp. 873–880. [Google Scholar]
- Bawa, V.S.; Kumar, V. Linearized sigmoidal activation: A novel activation function with tractable non-linear characteristics to boost representation capability. Expert Syst. Appl. 2019, 120, 346–356. [Google Scholar] [CrossRef]
- Lohani, H.K.; Dhanalakshmi, S.; Hemalatha, V. Performance Analysis of Extreme Learning Machine Variants with Varying Intermediate Nodes and Different Activation Functions. In Cognitive Informatics and Soft Computing; Springer: Singapore, 2019; pp. 613–623. [Google Scholar]
- Eckle, K.; Schmidt-Hieber, J. A comparison of deep networks with ReLu activation function and linear spline-type methods. Neural Netw. 2019, 110, 232–242. [Google Scholar] [CrossRef]
- Freire-Obregón, D.; Narducci, F.; Barra, S.; Castrillón-Santana, M. Deep learning for source camera identification on mobile devices. Pattern Recognit. Lett. 2019, 126, 86–91. [Google Scholar] [CrossRef] [Green Version]
- Liu, Y.; Wang, X.; Wang, L.; Liu, D. A modified leaky ReLu scheme (MLRS) for topology optimization with multiple materials. Appl. Math. Comput. 2019, 352, 188–204. [Google Scholar] [CrossRef]
- Zuo, Z.; Li, J.; Wei, B.; Yang, L.; Fei, C.; Naik, N. Adaptive Activation Function Generation Through Fuzzy Inference for Grooming Text Categorisation. In Proceedings of the 2019 IEEE International Conference on Fuzzy Systems, New Orleans, LA, USA, 23–26 June 2019. [Google Scholar]
- Tsai, Y.H.; Jheng, Y.J.; Tsaih, R.H. The Cramming, Softening and Integrating Learning Algorithm with Parametric ReLu Activation Function for Binary Input/Output Problems. In Proceedings of the 2019 International Joint Conference on Neural Networks (IJCNN), Budapest, Hungary, 14–19 July 2019; pp. 1–7. [Google Scholar]
- Yang, J.; Duan, A.; Li, K.; Yin, Z. Prediction of vehicle casualties in major traffic accidents based on neural network. In AIP Conference Proceedings; AIP Publishing: Chongqing, China, 2019; Volume 2073, p. 020098. [Google Scholar]
- Shynk, J.J. Performance surfaces of a single-layer perceptron. IEEE Trans. Neural Netw. 1990, 1, 268–274. [Google Scholar] [CrossRef]
- Tang, J.; Deng, C.; Huang, G.B. Extreme learning machine for multilayer perceptron. IEEE Trans. Neural Networks Learn. Syst. 2015, 27, 809–821. [Google Scholar] [CrossRef] [PubMed]
- Akçay, S.; Kundegorski, M.E.; Devereux, M.; Breckon, T.P. Transfer learning using convolutional neural networks for object classification within x-ray baggage security imagery. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 1057–1061. [Google Scholar]
- Lyons, M.J.; Akamatsu, S.; Kamachi, M.; Gyoba, J.; Budynek, J. The Japanese female facial expression (JAFFE) database. In Proceedings of the Third International Conference on Automatic Face and Gesture Recognition, Nara, Japan, 14–16 April 1998; pp. 14–16. [Google Scholar]
- Carrier, P.L.; Courville, A.; Goodfellow, I.J.; Mirza, M.; Bengio, Y. FER-2013 Face Database; Technical report; Universit de Montral: Montral, QC, Canada, 2013. [Google Scholar]
- Abdullah, A.I. Facial Expression Identification System Using fisher linear discriminant analysis and K-Nearest Neighbor Methods. ZANCO J. Pure Appl. Sci. 2019, 31, 9–13. [Google Scholar]
- Alif, M.M.F.; Syafeeza, A.; Marzuki, P.; Alisa, A.N. Fused convolutional neural network for facial expression recognition. In Proceedings of the Symposium on Electrical, Mechatronics and Applied Science 2018, Melaka, Malaysia, 8 November 2018; pp. 73–74. [Google Scholar]
- Lopes, A.T.; de Aguiar, E.; De Souza, A.F.; Oliveira-Santos, T. Facial expression recognition with convolutional neural networks: Coping with few data and the training sample order. Pattern Recognit. 2017, 61, 610–628. [Google Scholar] [CrossRef]
- Liu, P.; Han, S.; Meng, Z.; Tong, Y. Facial expression recognition via a boosted deep belief network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, America, 24–27 June 2014; pp. 1805–1812. [Google Scholar]
- Shan, C.; Gong, S.; McOwan, P.W. Facial expression recognition based on local binary patterns: A comprehensive study. Image Vis. Comput. 2009, 27, 803–816. [Google Scholar] [CrossRef] [Green Version]
- Selitskaya, N.; Sielicki, S.; Jakaite, L.; Schetinin, V.; Evans, F.; Conrad, M.; Sant, P. Deep Learning for Biometric Face Recognition: Experimental Study on Benchmark Data Sets. In Deep Biometrics; Springer: Cham, Switzerland, 2020; pp. 71–97. [Google Scholar]
- Yee, S.Y.; Rassem, T.H.; Mohammed, M.F.; Awang, S. Face Recognition Using Laplacian Completed Local Ternary Pattern (LapCLTP). In Advances in Electronics Engineering; Springer: Singapore, 2020; pp. 315–327. [Google Scholar]
- Nandi, A.; Dutta, P.; Nasir, M. Recognizing Human Emotions from Facial Images by Landmark Triangulation: A Combined Circumcenter-Incenter-Centroid Trio Feature-Based Method. In Algorithms in Machine Learning Paradigms; Springer: Singapore, 2020; pp. 147–164. [Google Scholar]
- Shin, M.; Kim, M.; Kwon, D.S. Baseline CNN structure analysis for facial expression recognition. In Proceedings of the 2016 25th IEEE International Symposium on Robot and Human Interactive Communication (RO-MAN), New York, NY, USA, 26–31 August 2016; pp. 724–729. [Google Scholar]
- Alfakih, A.; Yang, S.; Hu, T. Multi-view Cooperative Deep Convolutional Network for Facial Recognition with Small Samples Learning. In International Symposium on Distributed Computing and Artificial Intelligence; Springer: Cham, Switzerland, 2019; pp. 207–216. [Google Scholar]
- Yar, H.; Jan, T.; Hussain, A.; Din, S.U. Real-Time Facial Emotion Recognition and Gender Classification for Human Robot Interaction Using CNN. Available online: https://www.academia.edu/41996316/Real-Time_Facial_Emotion_Recognition_and_Gender_Classification_for_Human_Robot_Interaction_using_CNN (accessed on 9 March 2020).
- Agrawal, A.; Mittal, N. Using CNN for facial expression recognition: A study of the effects of kernel size and number of filters on accuracy. Vis. Comput. 2020, 36, 405–412. [Google Scholar] [CrossRef]
- Vishwakarma, V.P.; Dalal, S. A novel non-linear modifier for adaptive illumination normalization for robust face recognition. Multimed. Tools Appl. 2020, 1–27. [Google Scholar] [CrossRef]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| JAFFE Dataset | |
|---|---|
| Expression Labels | Samples |
| angry | 6031 |
| disgust | 5264 |
| fear | 5911 |
| happy | 4640 |
| neutral | 5391 |
| sad | 5873 |
| surprise | 5907 |
| FER2013 Dataset | ||
|---|---|---|
| Expression Labels | Training Samples | Testing Samples |
| angry | 3995 | 491 |
| disgust | 436 | 55 |
| fear | 4097 | 528 |
| happy | 7215 | 879 |
| normal | 4965 | 626 |
| sad | 4830 | 594 |
| surprise | 3171 | 416 |
| JAFFE Dataset | ||||||
|---|---|---|---|---|---|---|
| Learning Rate | Sigmoid | Tanh | ReLu | LeakyReLus | Softplus-ReLu | New (LS–ReLu) |
| learning rate = 0.001 | 96.25 | 94.75 | 95.38 | 94.95 | 57.43 | 99.91 |
| JAFFE Dataset | ||
|---|---|---|
| Author | Method | Acuuuracy (%) |
| AI Abdullah [36] | FLDA+KNN | 95.09 |
| M.K.Mohd Fitri Alif [37] | Fused CNN | 83.72 |
| André TeixeiraLopes [38] | CNN+preprocessing | 82.10 |
| Ping Liu [39] | BDBN | 68.00 |
| CaifengShan [40] | LBP+SVM | 41.30 |
| Shan [41] | deep learning | 99.3 |
| Yee [42] | LapCLTP | 98.78 |
| Nandi [43] | Circumcenter-Incenter-Centroid Trio Feature | 97.18 |
| This paper | new method | 99.66 |
| FER2013 Dataset | ||||||
|---|---|---|---|---|---|---|
| Learning Rate | Sigmoid | Tanh | ReLu | LeakyReLus | Softplus-ReLu | New (LS–ReLu) |
| learning rate = 0.001 | 87.91 | 44.52 | 80.33 | 86.74 | 35.22 | 90.16 |
| FER2013 Dataset | ||
|---|---|---|
| Author | Method | Acuuuracy (%) |
| Liu [39] | ECNN | 69.96 |
| Minchul Shin [44] | Raw+CNN | 62.2 |
| Minchul Shin [44] | Hist+CNN | 66.67 |
| Minchul Shin [44] | Is+CNN | 62.16 |
| Minchul Shin [44] | DCT+CNN | 56.09 |
| Minchul Shin [44] | DOG+CNN | 58.96 |
| Amani Alfakih [45] | multi-view DCNN | 72.27 |
| YAR H [46] | Gender+CNN | 94 |
| Agrawal [47] | CNN+kernel size and number of filters | 65 |
| this paper | new method | 90.16 |
| Layer | Input | Kernel Size | Output |
|---|---|---|---|
| Conv | 96 × 96 | 5 × 5 | 92 × 92 |
| Conv | 92 × 92 | 5 × 5 | 88 × 88 |
| Pool | 88 × 88 | 2 × 2 | 44 × 44 |
| Conv | 44 × 44 | 3 × 3 | 42 × 42 |
| Pool | 42 × 42 | 2 × 2 | 21 × 21 |
| Conv | 21 × 21 | 3 × 3 | 19 × 19 |
| Conv | 19 × 19 | 3 × 3 | 17 × 17 |
| Conv | 17 × 17 | 5 × 5 | 13 × 13 |
| Conv | 13 × 13 | 3 × 3 | 11 × 11 |
| Conv | 11 × 11 | 2 × 2 | 5 × 5 |
| FC | |||
| Softmax |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Y.; Li, Y.; Song, Y.; Rong, X. The Influence of the Activation Function in a Convolution Neural Network Model of Facial Expression Recognition. Appl. Sci. 2020, 10, 1897. https://doi.org/10.3390/app10051897
Wang Y, Li Y, Song Y, Rong X. The Influence of the Activation Function in a Convolution Neural Network Model of Facial Expression Recognition. Applied Sciences. 2020; 10(5):1897. https://doi.org/10.3390/app10051897
Chicago/Turabian StyleWang, Yingying, Yibin Li, Yong Song, and Xuewen Rong. 2020. "The Influence of the Activation Function in a Convolution Neural Network Model of Facial Expression Recognition" Applied Sciences 10, no. 5: 1897. https://doi.org/10.3390/app10051897
APA StyleWang, Y., Li, Y., Song, Y., & Rong, X. (2020). The Influence of the Activation Function in a Convolution Neural Network Model of Facial Expression Recognition. Applied Sciences, 10(5), 1897. https://doi.org/10.3390/app10051897