Weather-Based Prediction Strategy inside the Proactive Historian with Application in Wastewater Treatment Plants



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Materials and Methods
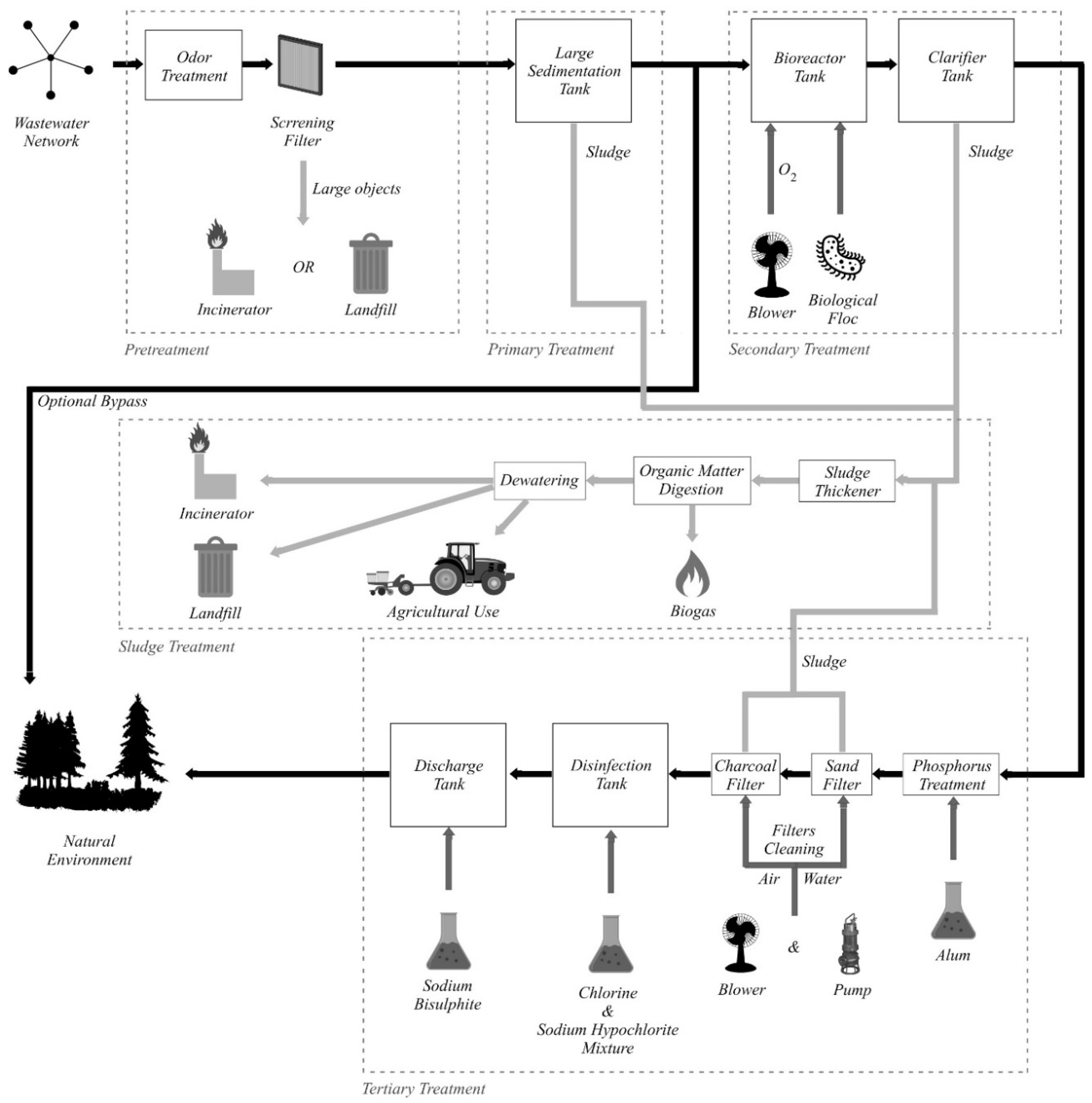
2.1. Wastewater Treatment Plant Typical Processes
2.2. Wastewater Treatment Plant Defining Problems and Weather Dependency
- Overloading of the plant: This can cause overheating of the blowers, which, in turn, causes a low-oxygen level in the bioreactor tank, thus reducing the efficiency of the secondary treatment stage. Plant overloading can also lead to sludge leakage from the settling tank.
- High substances consumption: For instance, the odor treatment process requires continuous adjustment of the used substances, depending on the input wastewater concentration and content. The wastewater content is highly dependent on the weather conditions.
- High energy costs: Around 30% of the annual WWTP operation costs is represented by the electricity consumption. Considering a developed country, an estimate of about 2–3% of the entire nation’s electrical power is consumed for wastewater treatment. This can be significantly improved by optimizing the biological treatment processes.
- Equipment and/or algorithmic faults that can lead to various problems.
- Undersized treatment plants: Most plants were developed 10–20 years ago, becoming undersized for the current loads since then, leading to the choice of increasing the load and costs in order to maintain a thorough cleaning process or discharging the partially treated wastewater to the environment and keeping the costs lower.
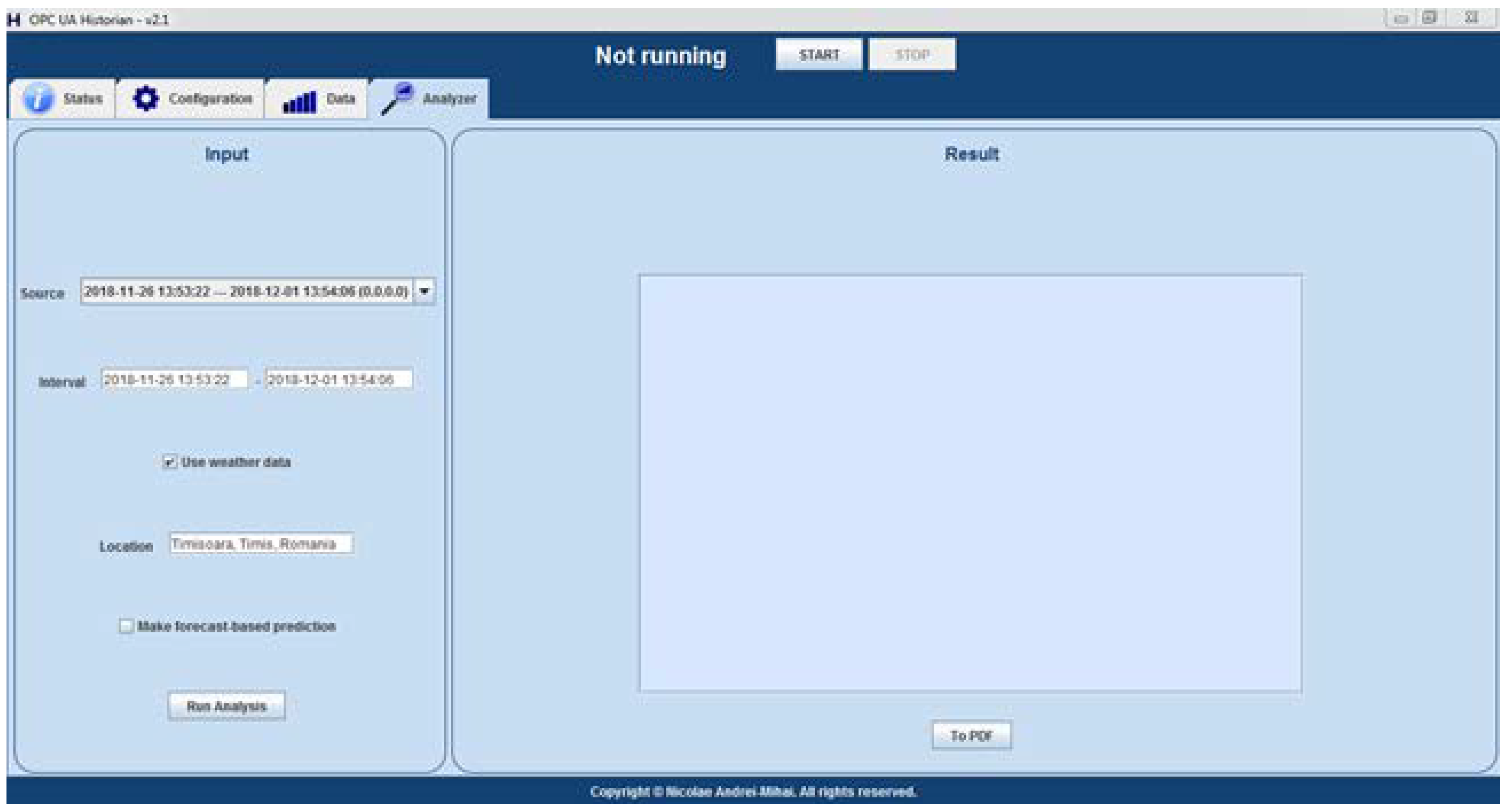
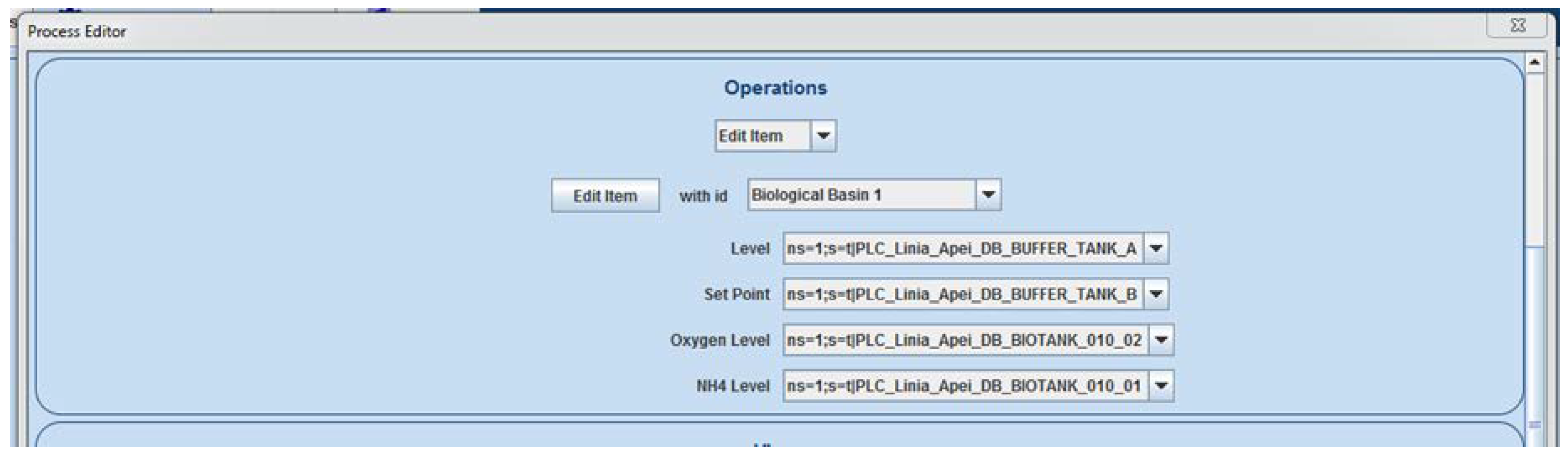
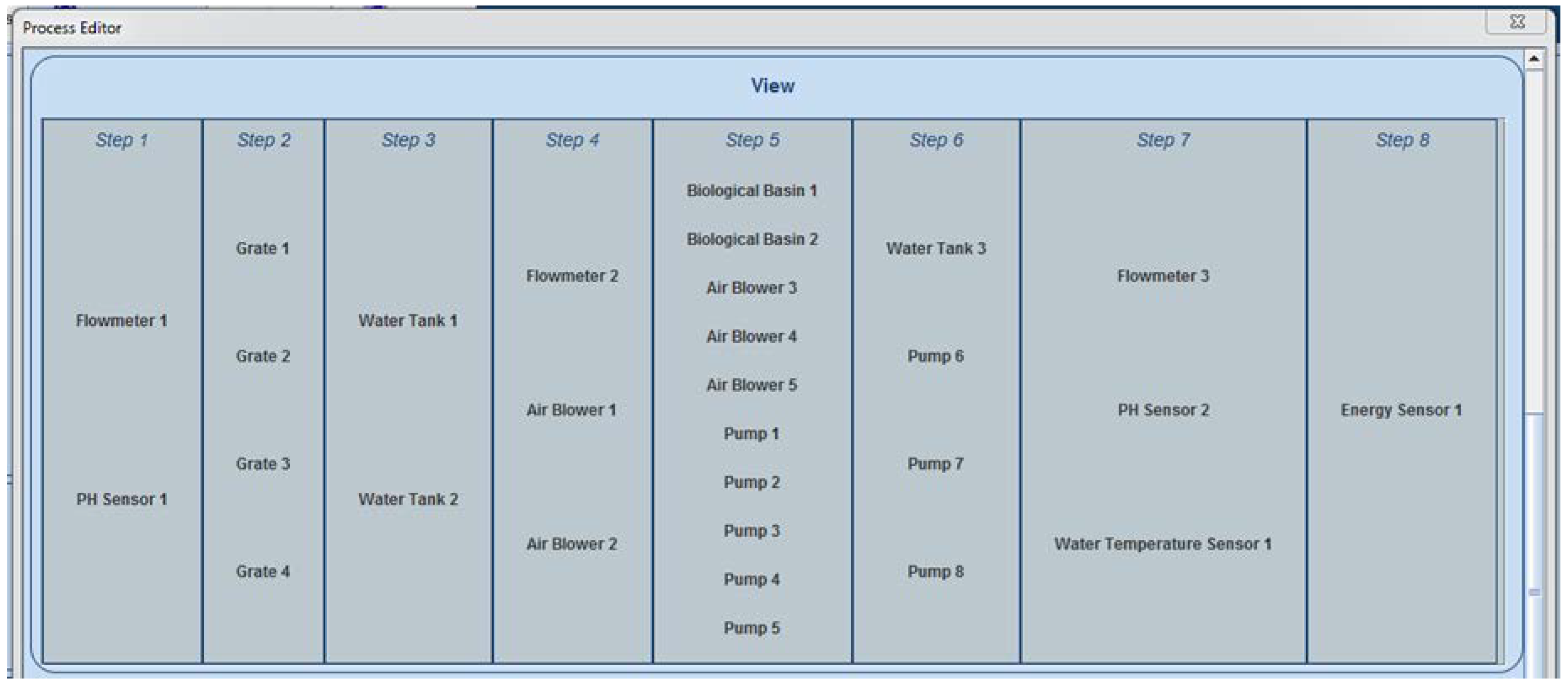
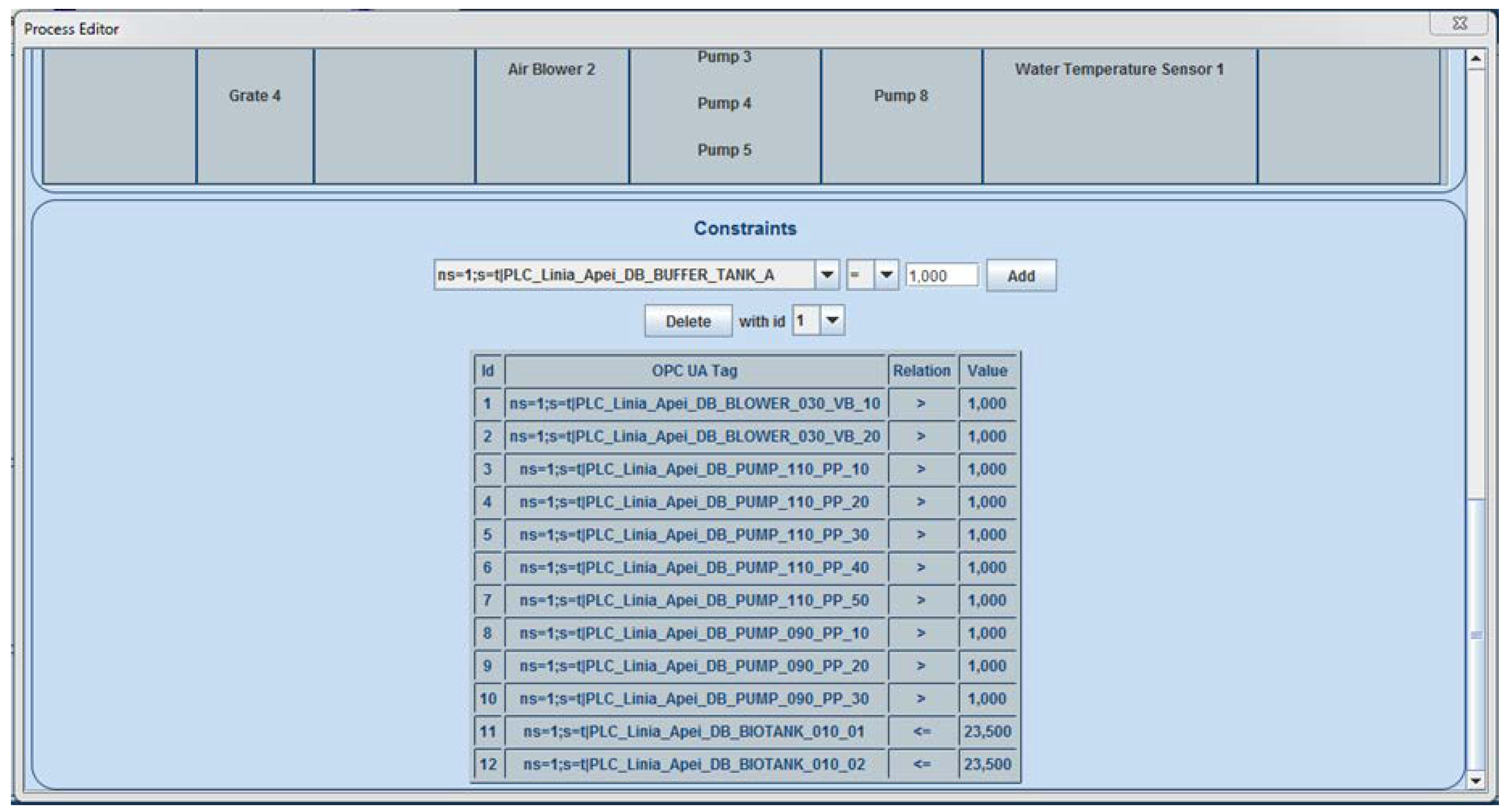
2.3. The Implemented Solution
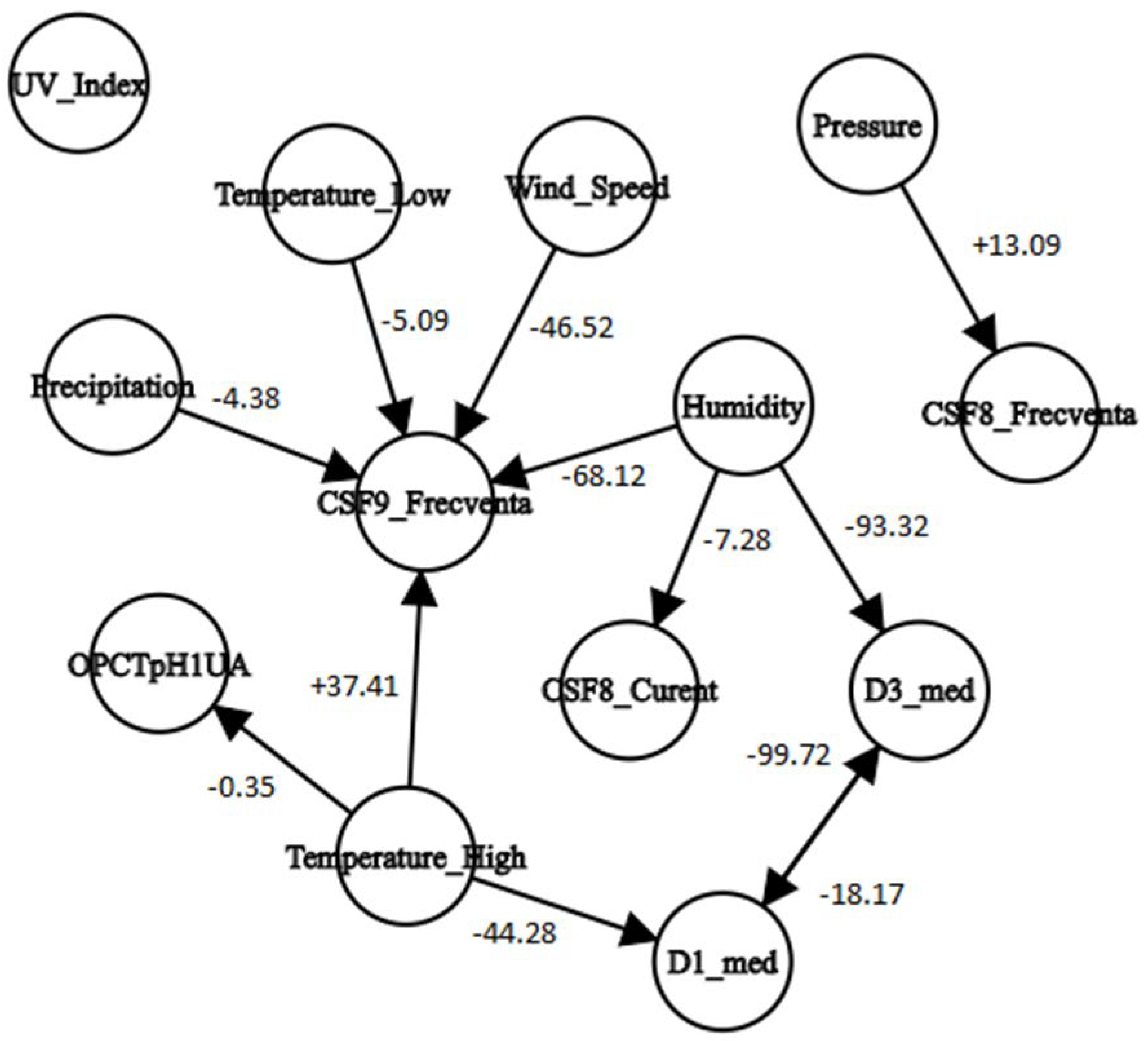
- An arc from node i to node j with weight -N signifies when node i was set as the reference,
- A dependency of node j on node i was identified,
- The measured values of node j evolving inversely proportional (minus sign) to the node i values, in a quantitative proportion of N% (this percent represents the quantitative result identified by the analysis; more details regarding this percent is available in [26]).
- the dependencies graph generated by the first-level algorithms must be available;
- weather forecast data must be obtained from [28];
- the most recent values of the monitored tags (which are used as initial values in the prediction process) must be extracted from the database (it is not necessary that they represent the current values; if the current values are not available, then the most recent ones are used);
- computing the percent of change in the previous node (the node from which the arc leading to the current node starts), by comparing the previous node’s current value and the node’s previous day value.
- computing the sign of change (if the previous node’s value increased or decreased from the previous day).
- using the percent of change in the previous node and the dependency from the graph, the predictive algorithm computes the percent of change for the current node (more details regarding the value of dependency in the graph can be found in [26]).
- the percent of change for the current node is further used alongside the current value of the current node in order to identify the value of change (in units) for the current node. The value of change is onwards used together with the current value of the current node, the corresponding dependency from the graph, and the sign of change for the previous node, in order to compute the new value of the current node.
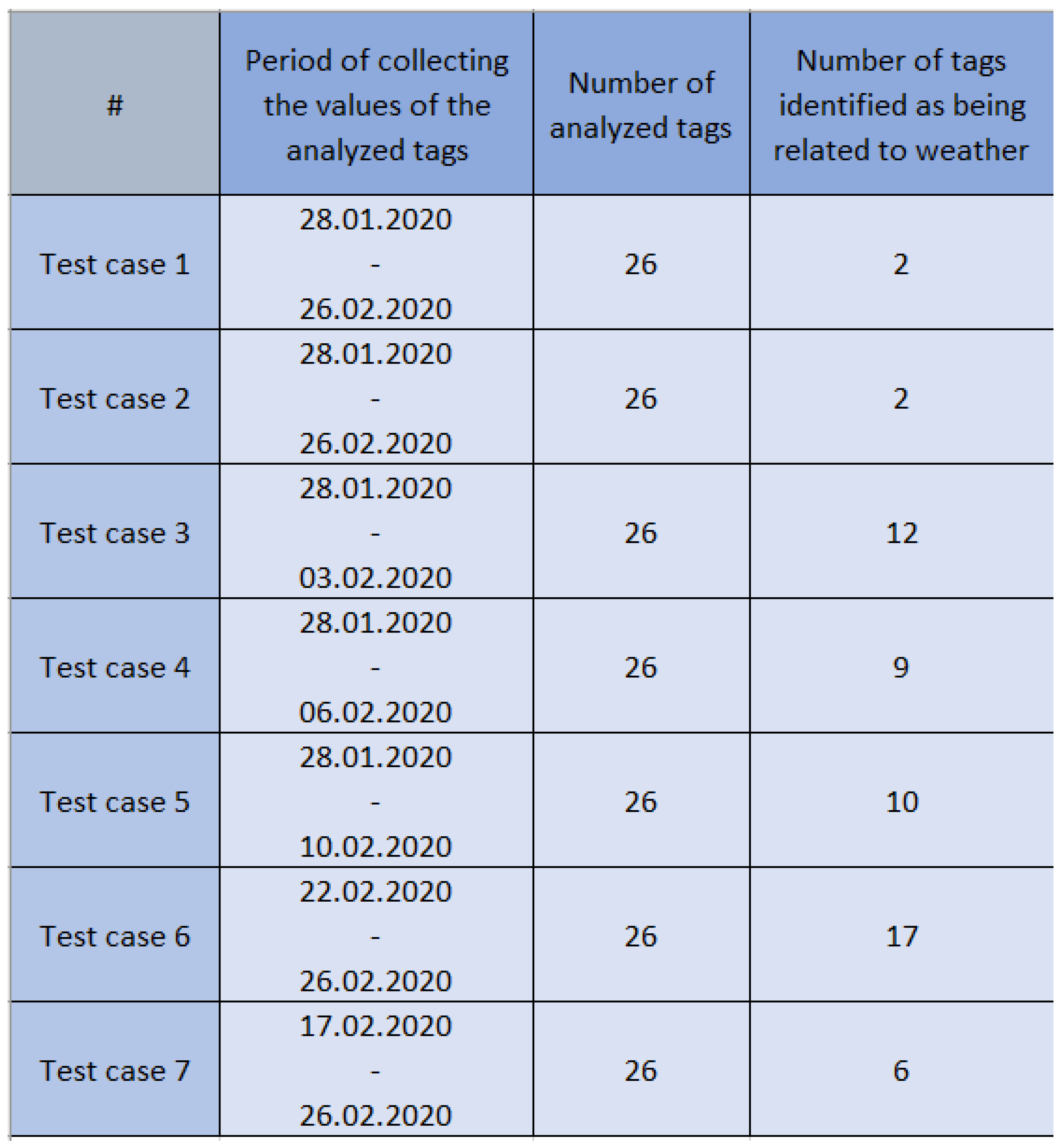
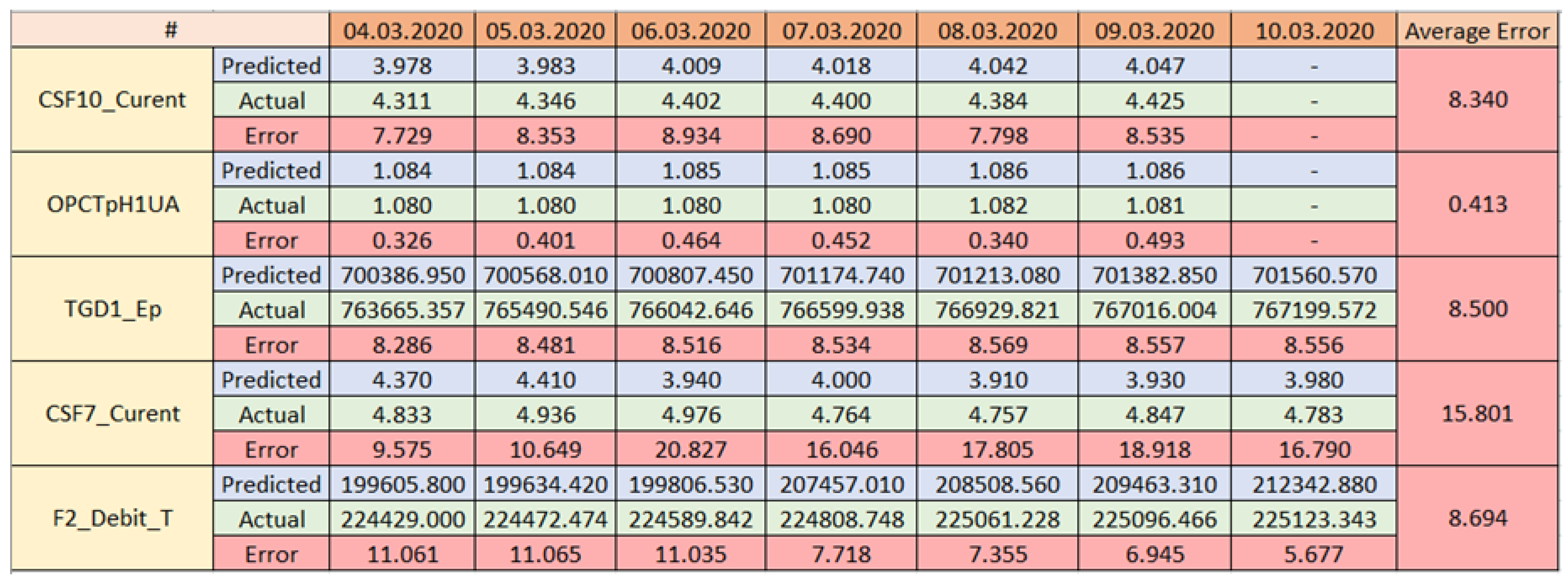
3. Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Yury, S.; Samoylova, E. The internet of things as socio-technological institution of civil society in post-informational era. In Proceedings of the 2nd International Conference on Computer and Communication Systems (ICCCS), Krakow, Poland, 11–14 July 2017. [Google Scholar]
- Sisinni, E.; Saifullah, A.; Han, S.; Jennehag, U.; Gidlund, M. Industrial Internet of Things: Challenges, Opportunities, and Directions. IEEE Trans. Ind. Inf. 2018, 99, 4724–4734. [Google Scholar] [CrossRef]
- Perera, C.; Liu, C.H.; Jayawardena, S.; Chen, M. A Survey on Internet of Things From Industrial Market Perspective. IEEE Access 2014, 2, 1660–1679. [Google Scholar] [CrossRef]
- Nicolae, A.; Korodi, A.; Silea, I. An Overview of Industry 4.0 Development Directions in the Industrial Internet of Things Context. Rom. J. Inf. Sci. Tech. 2019, 22, 183–201. [Google Scholar]
- Strasser, T.I.; Andrén, F.P.; Vrba, P.; Šuhada, R.; Moulis, V.; Farid, A.M.; Rohjans, S. An Overview of Trends and Developments of Internet of Things Applied to Industrial Systems. In Proceedings of the 44th Annual Conference of the IEEE Industrial Electronics Society (IECON), Washington, DC, USA, 21–23 October 2018. [Google Scholar]
- Xu, H.; Yu, W.; Griffith, D.; Golmie, N. A Survey on Industrial Internet of Things: A Cyber-Physical Systems Perspective. IEEE Access 2018, 6, 78238–78259. [Google Scholar] [CrossRef]
- Vandikas, K.; Tsiatsis, V. Performance evaluation of an IoT platform. In Proceedings of the IEEE Eighth International Conference on Next Generation Mobile Apps, Services and Technologies (NGMAST), Oxford, UK, 10–12 September 2014. [Google Scholar]
- Khan, W.A.; Wisniewski, L.; Lang, D.; Jasperneite, J. Analysis of the requirements for offering industrie 4.0 applications as a cloud service. In Proceedings of the 26th IEEE International Symposium on Industrial Electronics (ISIE), Edinburgh, UK, 19–21 June 2017. [Google Scholar]
- Eliasson, J.; Delsing, J.; Derhamy, H.; Salcic, Z.; Wang, K. Towards industrial Internet of Things: An efficient and interoperable communication framework. In Proceedings of the IEEE International Conference on Industrial Technology (ICIT), Seville, Spain, 17–19 March 2015. [Google Scholar]
- Aazam, M.; Zeadally, S.; Harras, K.A. Deploying Fog Computing in Industrial Internet of Things and Industry 4.0. IEEE Trans. Ind. Inf. 2018, 14, 4674–5682. [Google Scholar] [CrossRef]
- Gazis, V.; Leonardi, A.; Mathioudakis, K.; Sasloglou, K.; Kikiras, P.; Sudhaakar, R. Components of fog computing in an industrial internet of things context. In Proceedings of the 12th Annual IEEE International Conference on Sensing, Communication, and Networking - Workshops (SECON Workshops), Seattle, WA, USA, 22–25 June 2015. [Google Scholar]
- Al-Gumaei, K.; Schuba, K.; Friesen, A.; Heymann, S.; Pieper, C.; Pethig, F.; Schriegel, S. A Survey of Internet of Things and Big Data Integrated Solutions for Industrie 4.0. In Proceedings of the 23rd International Conference on Emerging Technologies and Factory Automation (ETFA), Turin, Italy, 4–7 September 2018. [Google Scholar]
- Geng, D.; Zhang, C.; Xia, C.; Xia, X.; Liu, Q.; Fu, X. Big Data-Based Improved Data Acquisition and Storage System for Designing Industrial Data Platform. IEEE Access 2019, 7, 44574–44582. [Google Scholar] [CrossRef]
- Eren, H. Assessing the health of sensors using data historians. In Proceedings of the IEEE Sensors Applications Symposium (SAS), Brescia, Italy, 7–9 February 2012. [Google Scholar]
- Mazur, D.C.; Entzminger, R.A.; Kay, J.A. Enhancing Traditional Process SCADA and Historians for Industrial and Commercial Power Systems With Energy (Via IEC 61850). In Proceedings of the IEEE/IAS 50th Industrial & Commercial Power Systems Technical Conference (I&CPS), Fort Worth, TX, USA, 20–23 May 2014. [Google Scholar]
- Fras, A.; Dang, T. Improving industrial application’s performances with an Historian. In Proceedings of the IEEE International Conference on Industrial Technology (ICIT), Hammamet, Tunisia, 8–10 December 2004. [Google Scholar]
- Jankowski, T.; Davis, G.; Holmes, J.; Kemper, G. Increasing data historian efficiency. In Proceedings of the IEEE-IAS/PCA 53rd Cement Industry Technical Conference, St. Louis, MO, USA, 22–26 May 2011. [Google Scholar]
- Kefalakis, N.; Roukounaki, A.; Soldatos, J. A Configurable Distributed Data Analytics Infrastructure for the Industrial Internet of things. In Proceedings of the 15th International Conference on Distributed Computing in Sensor Systems (DCOSS), Santorini Island, Greece, 29–31 May 2019. [Google Scholar]
- Mateev, V.; Marinova, I. Distributed Internet of Things System for Wireless Monitoring of Electrical Grids. In Proceedings of the 20th International Symposium on Electrical Apparatus and Technologies (SIELA), Bourgas, Bulgaria, 3–6 June 2018. [Google Scholar]
- Prakash, C.; Thakur, S. Smart Shut-Down and Recovery Mechanism for Industrial Machines Using Internet of Things. In Proceedings of the 8th International Conference on Cloud Computing, Data Science & Engineering (Confluence), Noida, India, 11–12 January 2018. [Google Scholar]
- Kulkarni, P.H.; Kute, P.D.; More, V.N. IoT based data processing for automated industrial meter reader using Raspberry Pi. In Proceedings of the 2016 International Conference on Internet of Things and Applications (IOTA), Pune, India, 22–24 January 2016. [Google Scholar]
- Nicolae, A.; Korodi, A. Node-Red and OPC UA Based Lightweight and Low-Cost Historian with Application in the Water Industry. In Proceedings of the IEEE 16th International Conference on Industrial Informatics (INDIN), Porto, Portugal, 18–20 July 2018; pp. 1012–1017. [Google Scholar]
- Salvador, J.R.; de la Peña, D.M.; Ramirez, D.R.; Alamo, T. Historian Data Based Predictive Control of a Water Distribution Network. In Proceedings of the European Control Conference (ECC), Limassol, Cyprus, 12–15 June 2018. [Google Scholar]
- Weyrich, M.; Ebert, C. Reference Architectures for the Internet of Things. IEEE Softw. 2016, 33, 112–116. [Google Scholar] [CrossRef]
- Bloom, G.; Alsulami, B.; Nwafor, E.; Bertolotti, I.C. Design patterns for the industrial Internet of Things. In Proceedings of the 14th IEEE International Workshop on Factory Communication Systems (WFCS), Imperia, Italy, 13–15 June 2018. [Google Scholar]
- Nicolae, A.; Korodi, A.; Silea, I. Identifying Data Dependencies as First Step to Obtain a Proactive Historian: Test Scenario in the Water Industry 4.0. Water 2019, 11, 1144. [Google Scholar] [CrossRef] [Green Version]
- Korodi, A.; Crisan, R.; Nicolae, A.; Silea, I. Industrial Internet of Things and Fog Computing to Reduce Energy Consumption in Drinking Water Facilities. Processes 2020, 8, 282. [Google Scholar] [CrossRef] [Green Version]
- Dark Sky API Weather Service. Available online: https://darksky.net/dev (accessed on 12 April 2020).
- OpenStreetMap Nominatim Service for Converting an Address to Longitude and Latitude. Available online: https://nominatim.openstreetmap.org/ (accessed on 12 April 2020).










© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nicolae, A.; Korodi, A.; Silea, I. Weather-Based Prediction Strategy inside the Proactive Historian with Application in Wastewater Treatment Plants. Appl. Sci. 2020, 10, 3015. https://doi.org/10.3390/app10093015
Nicolae A, Korodi A, Silea I. Weather-Based Prediction Strategy inside the Proactive Historian with Application in Wastewater Treatment Plants. Applied Sciences. 2020; 10(9):3015. https://doi.org/10.3390/app10093015
Chicago/Turabian StyleNicolae, Andrei, Adrian Korodi, and Ioan Silea. 2020. "Weather-Based Prediction Strategy inside the Proactive Historian with Application in Wastewater Treatment Plants" Applied Sciences 10, no. 9: 3015. https://doi.org/10.3390/app10093015
APA StyleNicolae, A., Korodi, A., & Silea, I. (2020). Weather-Based Prediction Strategy inside the Proactive Historian with Application in Wastewater Treatment Plants. Applied Sciences, 10(9), 3015. https://doi.org/10.3390/app10093015