1. Introduction
Air pollution is a major problem in public health that increases health impacts on both the cardiovascular and respiratory systems in humans [
1]. There are many important air pollutants, including ground-level ozone (O
3), carbon monoxide (CO), nitrogen dioxide (NO
2), sulfur dioxide (SO
2), and particulate matter (PM), announced by the World Health Organization. However, PM exceeds both the national and international standards to the greatest extent compared with others [
2]. The PM is a mixture of particles that it compounds and four types of components, namely, organic, inorganic, biological, and carbonaceous materials. The proportion of each component is different in each area [
3]. Most of the PM is classified into two categories by size, which are based on health-related effects [
4]. The size of PM affecting human health has an aerodynamic diameter of less than 10 μm, which can only be detected by an electron microscope. There are two major sizes of PM. First, coarse particulate matter called PM
10 is PM with an aerodynamic diameter smaller than 10 μm. Another type is fine particulate matter called PM
2.5, which is PM with an aerodynamic diameter smaller than 2.5 μm [
5,
6]. However, there are other types of PM, such as PM
1 [
7], which are excluded from this research due to air pollution standards.
Every year during the dry season, which begins in February, the upper northern region of Thailand is affected by air pollution problems from both types of PM and this problem ends when the rainy season begins [
8]. Anthropogenic activities, both garbage and agricultural burning, are important sources that contribute to air pollution. After the harvest periods, farmers prepare their area for the next crop period by burning their crop residues [
9]. Another source is wildfire from natural and human-made occurrences as this area is mostly covered with forests and mountains. Fire management is difficult due to many limitations, such as a lack of effective equipment [
10]. There are many policies from the government to protect and prohibit burning. However, the air pollution problem does not seem to be improved.
In recent years, researchers have been focused on both processes and methods in data science to apply it in various applications, such as daily cattle health classification [
11], tomography image analysis [
12], and student dropout prediction [
13]. For the air pollution problem, data science techniques can implement notification systems to alert people by predicting the upcoming air pollution level. Numerous research articles are interested in applying data science to the air pollution problem, especially both types of PM. They try to find both appropriate processes and methods to create prediction models with high model performance or computation time reduction for their desired output, such as PM concentrations, PM levels, or classes [
14,
15,
16]. The popular models are multiple linear regression (MLR), autoregressive integrated moving average (ARIMA), and various types of artificial neural networks (ANNs).
MLR is a popular statistical model for comparing the model performance with the ANN, but the results showed that MLR is less effective than ANN [
17,
18,
19,
20]. ARIMA is a common model for time-series data. There are two interesting examples. The first example, a combination of MLR and ARIMA proposed by [
21] was used to predict daily and monthly average PM
10 concentrations in Delhi, India. The second example, using the output data from ARIMA as input features for MLR, was presented by [
22]. In the article, ARIMA is used with the dataset, including seasonal features and the period of seasonal patterns, to predict hourly PM
10 concentrations in Negeri Sembilan, Malaysia.
The ANN is the most popular model selected by many researchers as it outperforms other models. The presentation in [
23] focusing on three cities of China proposed a combination of the rolling mechanism and gray model in the data preparation process and the ANN model was used in the prediction process. The result was a prediction of the daily average values of PM
10 concentrations and PM
10 classes, calculated from the China air quality index. A research article presented in [
24] applied ANN to predict the highest daily PM
10 concentration in Santiago, Chile. The rule-based classification is used from a combination of two models, ANN and K-nearest neighbor (K-NN), to improve model performance in the minor classes. There is another type of ANN, long short-term memory (LSTM), used by [
25]. The research presented an appropriate LSTM structure to predict the daily average PM
10 concentration in Seoul, South Korea.
Another type of ANN is a combination of ANN and fuzzy logic called neuro-fuzzy. Two research articles used neuro-fuzzy with the Tagaki-Sugeno system to predict daily average PM
10 concentrations in Turkey. The output data from fuzzy logic was used as an input feature for ANN. In the fuzzy logic part, in [
26], a bell-shaped membership function was selected, while in [
27], the Gaussian membership function was selected. Moreover, neuro-fuzzy is more effective than the other classifiers, such as NN and the support vector machine, when using the standard datasets from UCI reported by [
28,
29,
30]. Neuro-fuzzy was selected to be applied in various applications, such as the diffuse large B-cell lymphomas classification [
31]. In addition, in [
32], it was reported that the positions for changing slope in the fuzzy membership function are very important, so the minimum entropy principle (MEP) is applied to find these values.
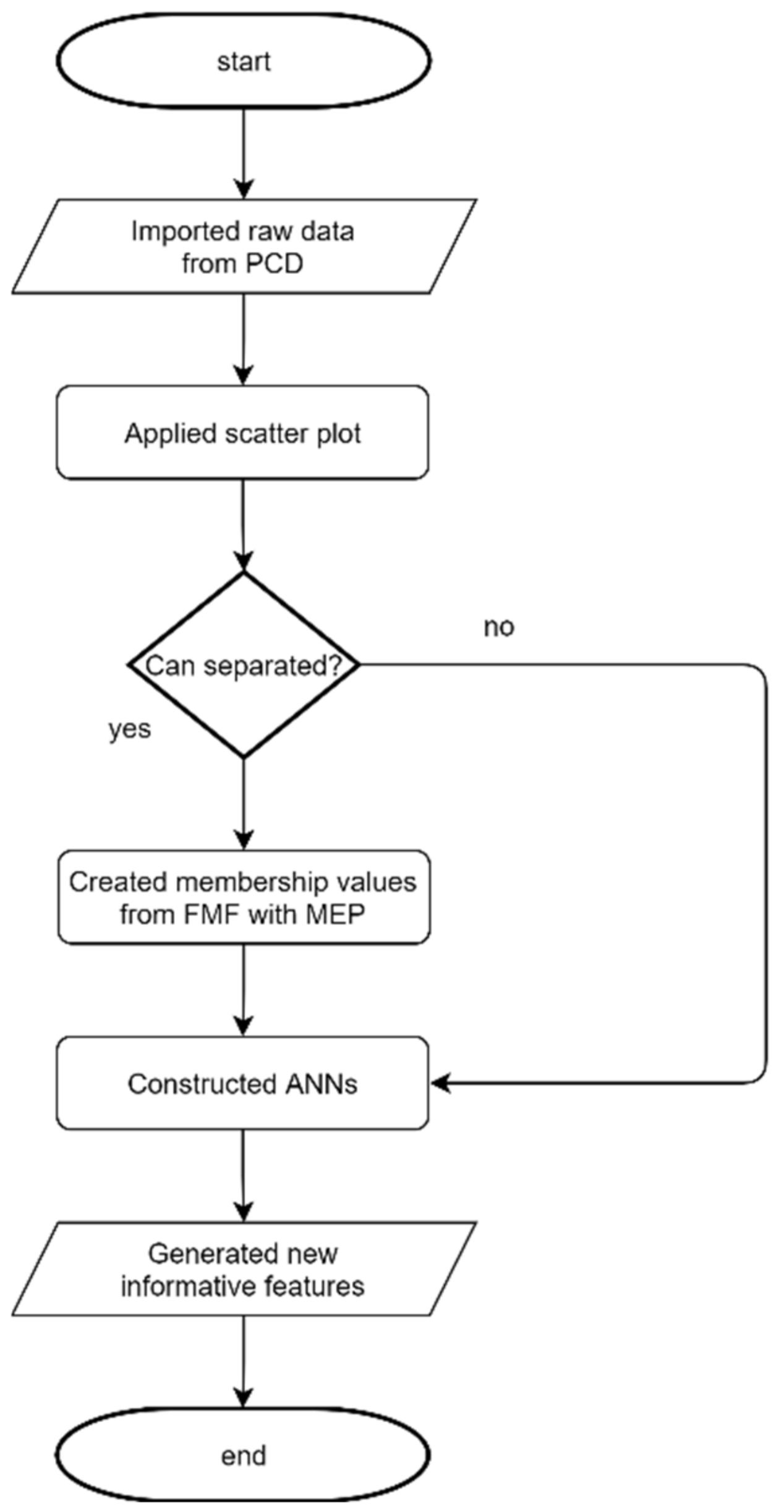
This research proposes the neuro-fuzzy with the minimum entropy principle model for data transformation to create new informative features that are used to represent historical data. Moreover, the proposed transformation model can reduce concerns about bias in raw data. Finally, an ANN model is created for new informative features. The three- and five-class output data of this model are the hourly PM10 and PM2.5 classes associated with the Thailand standard. The results of the model can be an application implemented to alert people and for short-term outdoor activity planning up to three hours in advance.
3. Experimental Methods and Results
In this section, various experiments are presented to find the appropriate structure of the proposed model or to confirm model performance. The details of the experimental design consist of four subsections. The first three subsections are experiments to predict the class of PM one hour in advance. The first one found the best time interval for the new informative features. The second one was used to confirm that the new informative features created from FMF with MEP can increase the prediction performance. These experiments used four out of eight stations. The first two data monitoring stations were the CHM-Yup and NAN-Hos stations, due to the availability of the PM2.5 data. The other two stations were the LPA-Met and PHY-Kno stations. The third subsection implemented the proposed model to all data monitoring stations and the overall model performances were reported. In addition, other popular prediction models in this problem were selected to compare the model performance with the proposed model. The last subsection was the reported model performance of the proposed model to predict an additional period of output data up to three hours in advance.
To obtain accurate prediction results, a specific data set for the dry season from 1 February to 31 May of each year, during which air pollution levels in Thailand are high, was the focus of this research. The dataset during the crisis of the last two years was defined as the testing data. The first set was raw data between 1 February 2018, and 30 April 2018. The second set was raw data between 1 February 2017, and 31 May 2017, while the remaining years were selected as the training data.
3.1. Experimental Method and Results for the New Informative Features with Different Number of Historical Data
This experiment aimed to determine an appropriate number of hours before the generation of the new informative features, as described in
Section 2.2.4. The dataset of the five different time periods, 1, 6, 12, 18, and 24 h, was used in the experiments. Therefore, each dataset had a different number of features that varied from 1 to 12 depending on the number of hours prior. The experiments in this subsection used three classes that were defined per the T-AQI standard, as detailed in
Table 2. The hourly PM
10 class prediction was used in four stations, while the hourly PM
2.5 class prediction was used in two stations, due to the reason described earlier.
Table 3 shows the results of the class prediction of PM
10 with the F-Score separated by class and the average overall and average accuracy of the two testing datasets. In addition, the PHY-Kno station had no experimental result from 24 h prior due to a lack of continuity data. The results shown in
Table 3 in the last column show that the usage of 6 h usage had the highest F-score in three out of the four stations, CHM-Yup, NAN-Hos, and PHY-Kno stations. In the LPA-Met Station, there was no clear F-score result for any time period as with the other stations. In addition, 6 h prior had the highest average accuracy in every station.
The same conditions were applied to experiments of the PM
2.5 datasets.
Table 4 shows that the transformed dataset of 6 h prior had the highest average F-score in the CHM-Yup station, but this period had an inferior average F-score in the NAN-Hos station. The transformed dataset of 12 h prior had the highest average F-score in the NAN-Hos station. Considering the average accuracy, the transformed dataset of 6 h prior had the highest value in both stations. The results of the transformed dataset of 6 h prior showed that the average accuracy was 76.51% and 72.59% and the average F-score was 0.7194 and 0.5846 for CHM-Yup and NAN-Hos stations, respectively.
3.2. Experimental Method and Results of the Neuro-Fuzzy Transformation with and without MEP
The aim of the experiments in this section was to investigate whether adding FMF with MEP to the process and using those new informative features can improve prediction accuracy. The dataset of PM
10 from the four stations was selected for this experiment. The 6 h prior dataset was built on the new features of NFT-MEP. Moreover, the structure from
Section 2.2, which excludes FMF with MEP as the neural network transformation (NT), was used in the experiment.
The comparison results of the NT model and the NFT-MEP model to predict hourly PM
10 with three classes of output data are reported in
Table 5, where all results were the averaged value between the two testing datasets. The results in
Table 5 revealed that the NFT-MEP model had higher statistical indicators than the NT model in every station, which indicates that the neuro-fuzzy transformation gives better results than the one that is not used. Considering the performance of the model in each station, the NFT-MEP model had much better performance than the NT model in the CHM-Yup and NAN-Hos stations. On the other hand, this model slightly improved efficiency on the other two stations.
Next, the NFT-MEP model was used to predict hourly PM2.5 with three classes of output data. The results found that the NFT-MEP model had higher statistical indicators than the NT model in every station similar to the PM10 model. The results of the NFT-MEP model were 81.45% and 85.29% for average accuracy and 0.7851 and 0.7824 for average F-score for CHM-Yup and NAN-Hos stations, respectively. The NFT-MEP model had a much-improved efficiency of the NT model, especially in the NAN-Hos station.
Finally, the results in this section showed that the NFT-MEP model had a higher model performance to predict hourly classes for both types of PM in every selected station than the NT model. Therefore, applying FMF with MEP to the NT model could improve the efficiency of the model. The average accuracy of the prediction model was more than 80% of both types of PM. In addition, the average F-scores of the prediction model was mostly greater than 0.7 for both types of PM, except the NAN-Hos station.
3.3. Comparison Results between the NFT-MEP Model and Other Popular Models
To verify the performance of the proposed NFT-MEP model, the other popular models in this problem were selected, including LSTM [
15], ARIMA [
12], and ARIMAX [
34], for comparison. Every other model adjusted the structures to find appropriate parameters. The experimental design in this section differed from the previous section. Four additional stations, namely, CHR-Env, MHS-Env, LPH-Sta, and PHA-Met stations, were selected, so there were eight stations in this experiment. Moreover, the five classes of output data, for which the details are shown in
Table 2, were selected to create a prediction model. Finally, each station was applied to four prediction models, namely, NFT-MEP, LSTM, ARIMA, and ARIMAX, and two different output data, including three and five classes. To compare model performance, three statistical indicators, namely, accuracy, F-score, and MCC, were used in this subsection.
The comparison results of the four models to predict hourly PM
10 with three and five classes of output data are reported in
Table 6. All results were an average value between two testing datasets from all stations. The results for the three classes of output data showed that the NFT-MEP model had the highest average accuracy with a value between 79.40% and 90.83%. In addition, the NFT-MEP model had the highest average F-score with a value between 0.6253 and 0.8183 and the highest average MCC between 0.5318 and 0.7395. The LSTM showed an inferior model performance to the NFT-MEP model, while the ARIMA and ARIMAX showed the lowest model performance mainly because they cannot classify Class 2 and Class 3. In addition, the results for the five classes of output data were similar to those of the three classes of output data. The results showed that the NFT-MEP model had the highest statistic indicators. The average accuracy of the NFT-MEP model was between 67.40% and 83.31%. In addition, the average F-score was between 0.5001 and 0.7255, and the average MCC was between 0.6778 and 0.4983. The LSTM had a higher model performance than the other two models.
The four models were used to predict hourly PM
2.5 with three and five classes of output data similar to PM
10, which are reported in
Table 7. The results showed that the NFT-MEP model had the highest three statistic indicators compared to the three other models similar to the PM
10 model. The average accuracy of the NFT-MEP model for the three classes of output data was between 81.45 and 85.28%. In addition, the average F-score was between 0.7824 and 0.7851, and the average MCC was between 0.6847 and 0.6920. The average accuracy of the NFT-MEP model for five classes of output data was between 73.76% and 76.16%. In addition, the average F-score was between 0.7229 and 0.7285 and the average MCC was between 0.6515 and 0.6632. For both types of output data, the LSTM had an inferior model performance and the other two models had the lowest model performance.
As evidenced by the experimental results, the NFT-MEP model had the highest model performance. The LSTM had an inferior model performance, while ARIMA and ARIMAX had the lowest model performance. Based on the experimental results, it can be concluded that the NFT-MEP model outperformed both types of PM for prediction with two different amounts of output data when compared with the three other popular PM prediction models.
3.4. Implementation Results of the NFT-MEP Model to Predict Additional Periods of Output Data
From the previous experiment, the NFT-MEP model outperformed the other popular PM prediction models. However, this model predicts only one hour ahead of both types of PM. To implement the NFT-MEP model in real-world applications, information about PM one hour in advance was not sufficient for outdoor activity planning. This subsection implemented the NFT-MEP model to predict additional periods: two and three hours in advance. The implementation results are reported in
Table 8. The results showed that as the length of the time periods increased, the model performance of the proposed model decreased for both types of PM and output data. However, the overall accuracy was more than 70 and 60% for three and five classes of output data, respectively. In addition, the F-score was more than 0.6 and MCC was approximately 0.5 for both types of PM.




{kind=link}
{kind=link}
{kind=link}
{kind=link}



