
A Novel Principal Component Analysis Integrating Long Short-Term Memory Network and Its Application in Productivity Prediction of Cutter Suction Dredgers



Abstract
:1. Introduction
2. Preliminaries
2.1. Principal Components Analysis (PCA)
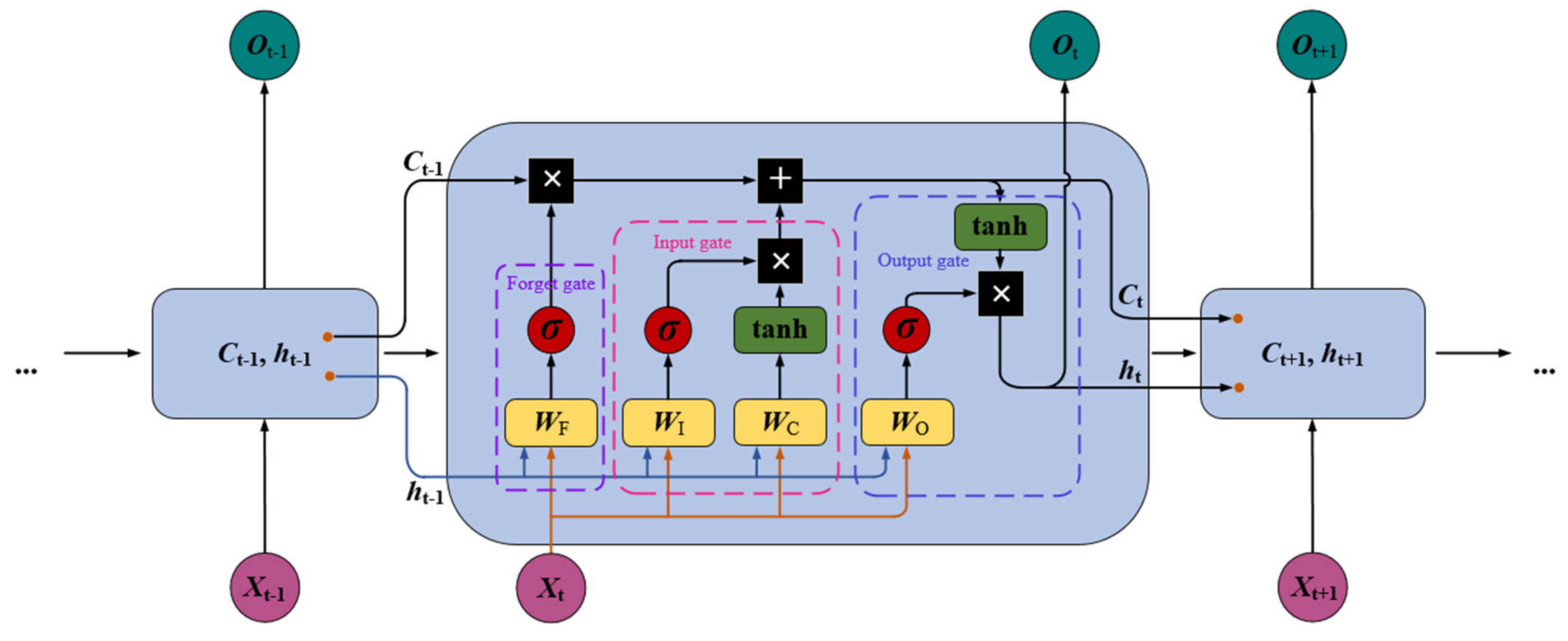
2.2. Long Short-Term Memory Network (LSTM)
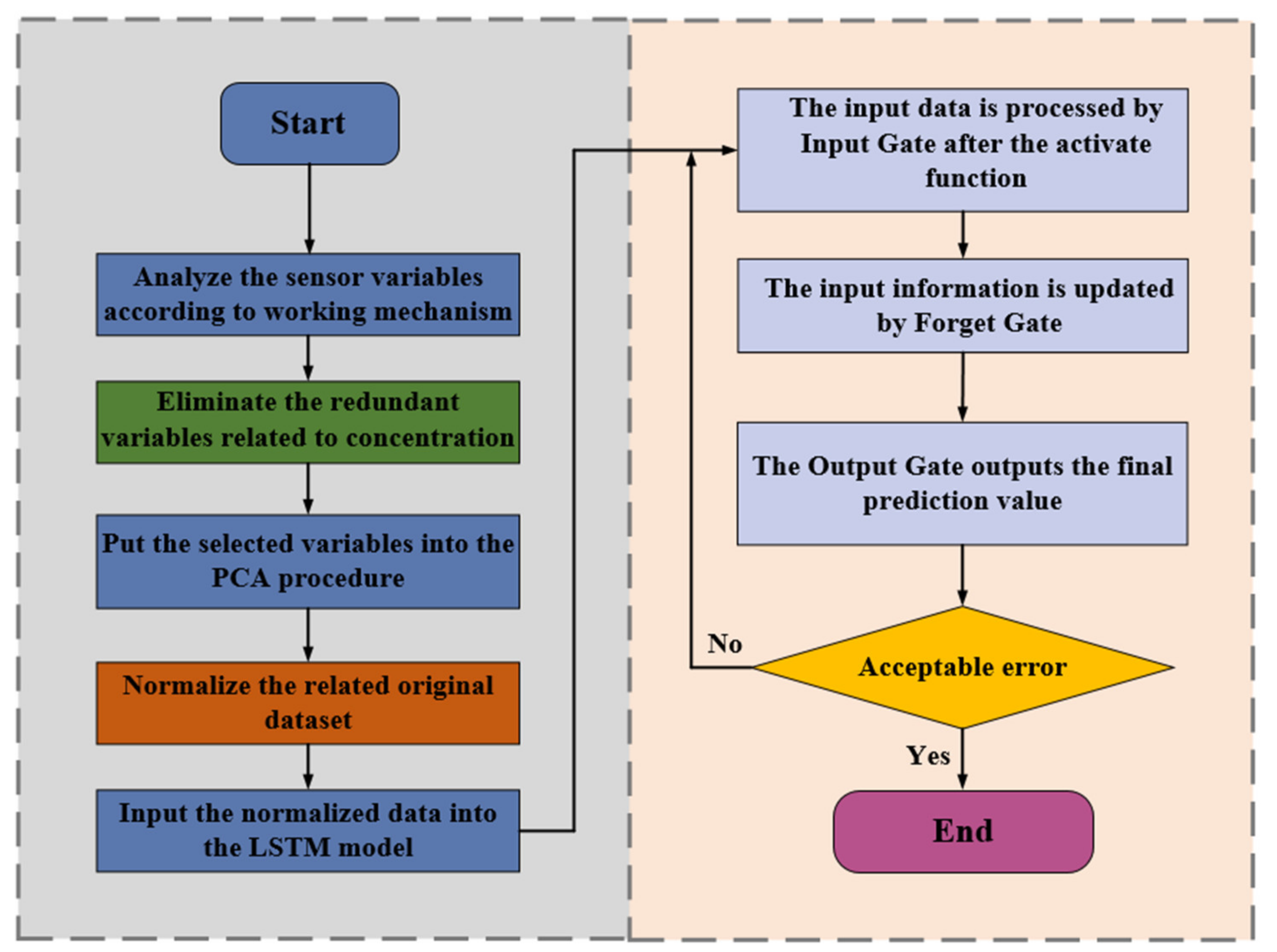
3. The Proposed PCA-LSTM Model
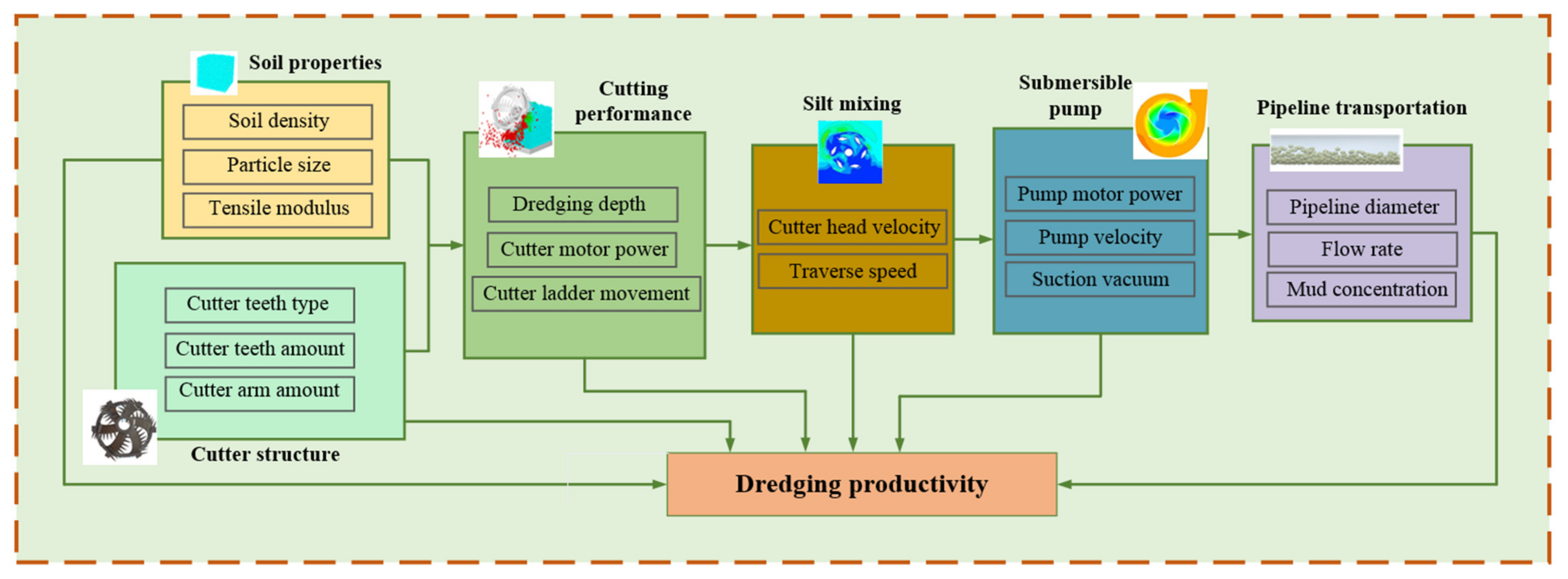
3.1. PCA Based on Mechanism
3.2. The Proposed Methodology
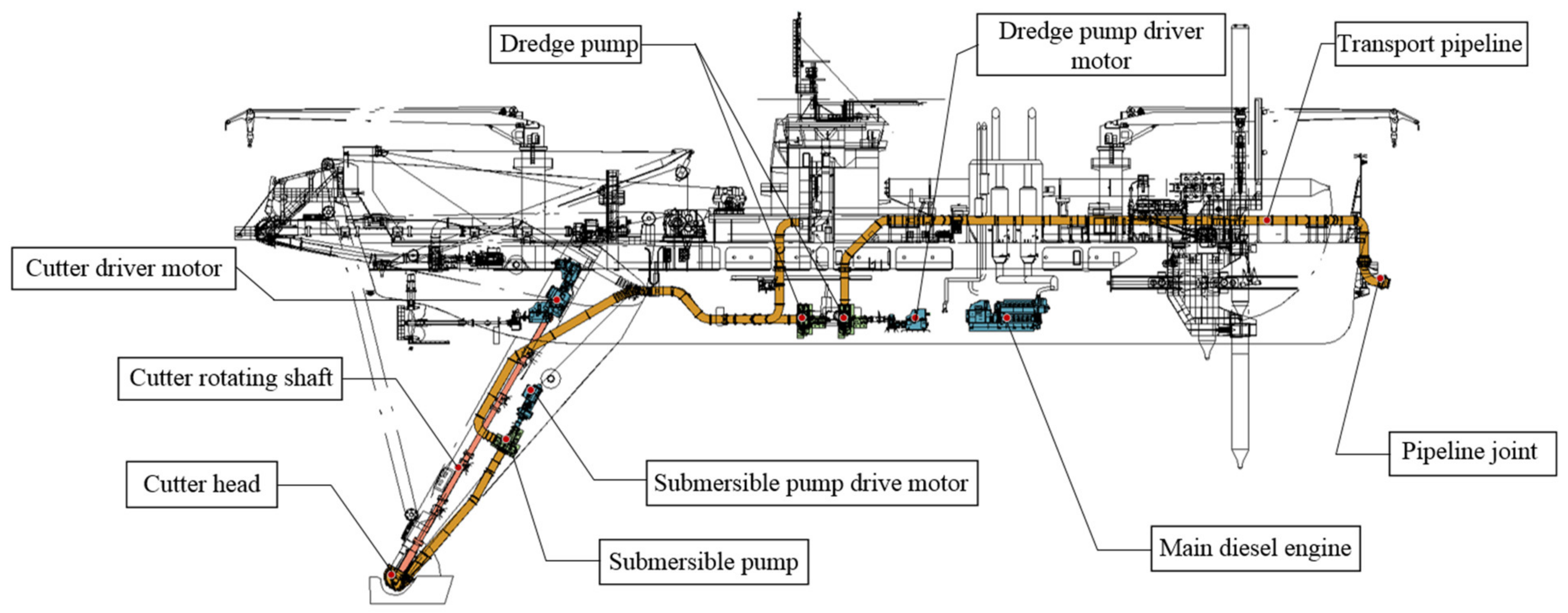
4. Case Study
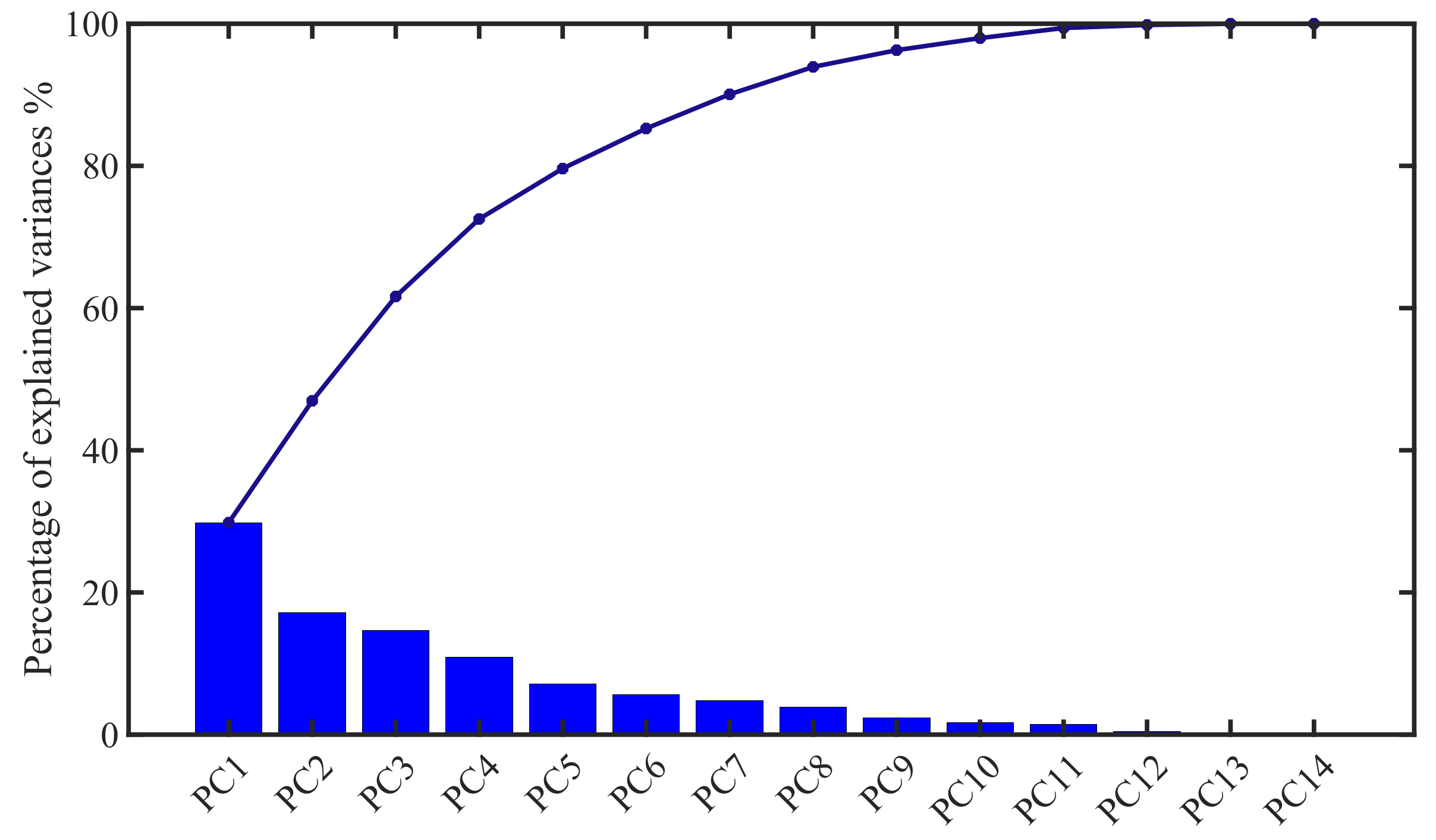
4.1. Principal Components Analysis Based on Mechanism and Knowledge
4.2. Modeling Prediction Analysis
4.2.1. Learning Results Analysis
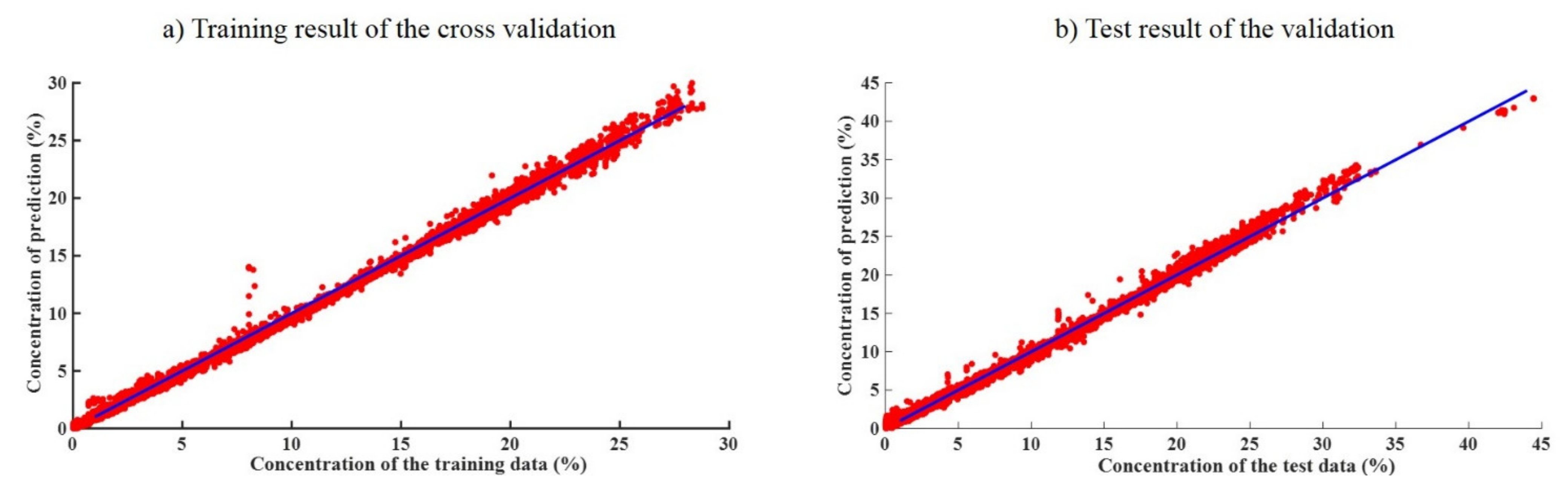
4.2.2. Cross Validation
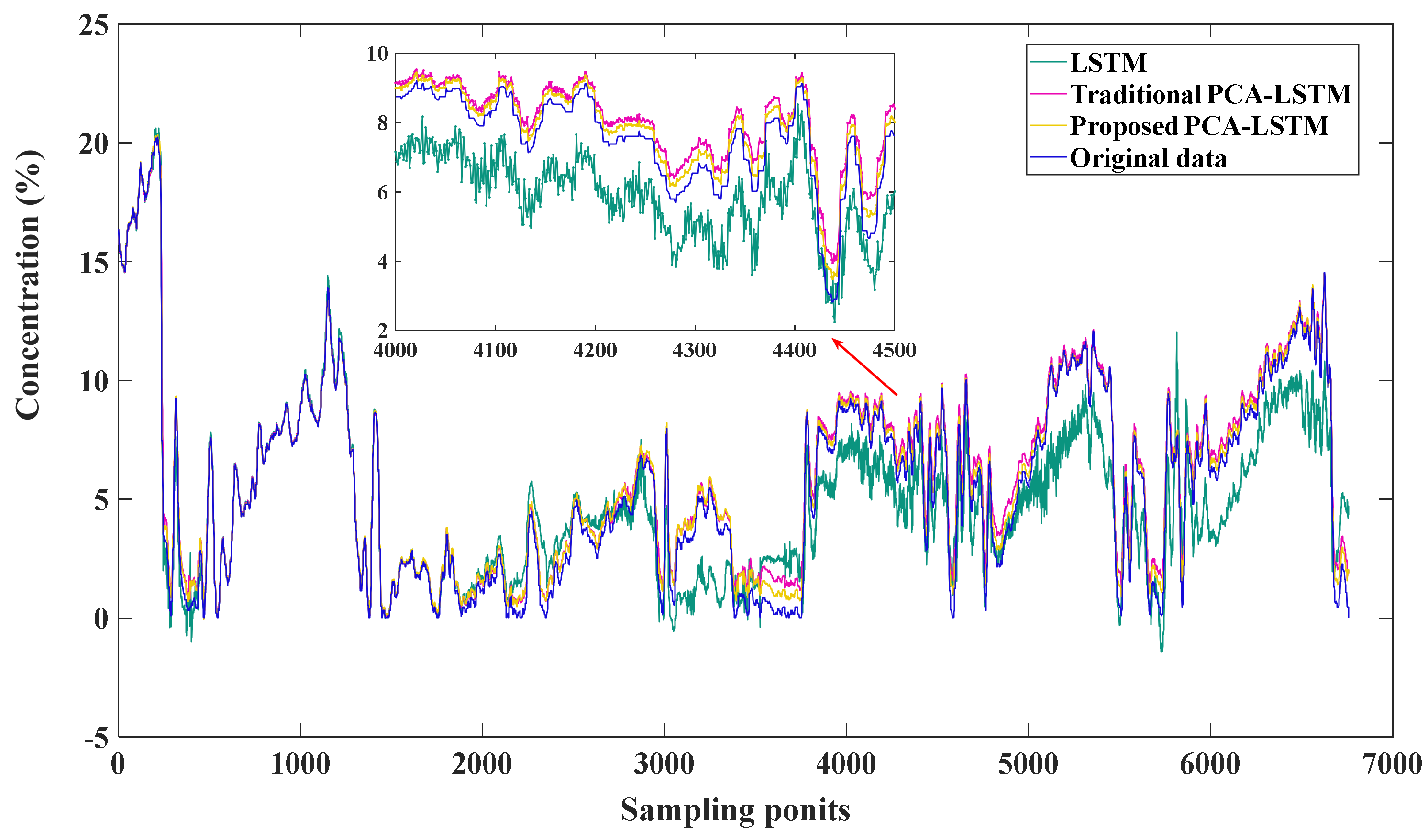
4.3. Comparative Study
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Kawakatsu, H.; Watada, S. Seismic evidence for deep-water transportation in the mantle. Science 2007, 316, 1468–1471. [Google Scholar] [CrossRef]
- Kuehl, S.; DeMaster, D.; Nittrouer, C. Nature of sediment accumulation on the Amazon continental shelf. Cont. Shelf Res. 1986, 6, 209–225. [Google Scholar] [CrossRef]
- Walsh, J.; Nittrouer, C. Contrasting styles of off-shelf sediment accumulation in New Guinea. Mar. Geol. 2003, 196, 105–125. [Google Scholar] [CrossRef]
- Tang, H.; Wang, Q.; Bi, Z. Expert system for operation optimization and control of cutter suction dredger. Expert Syst. Appl. 2008, 34, 2180–2192. [Google Scholar] [CrossRef]
- Wang, B.; Fan, S.; Jiang, P.; Xing, T.; Fang, Z.; Wen, Q. Research on predicting the productivity of cutter suction dredgers based on data mining with model stacked generalization. Ocean. Eng. 2020, 217, 108001. [Google Scholar] [CrossRef]
- Sierhuis, M.; Clancey, W.; Seah, C.; Trimble, J.; Sims, M. Modeling and simulation for mission operations work system design. J. Manag. Inf. Syst. 2003, 19, 85–128. [Google Scholar]
- Blazquez, C.; Adams, T.; Keillor, P. Optimization of mechanical dredging operations for sediment remediation. J. Waterw. Port Coast. Ocean. Eng.-ASCE 2001, 127, 229–307. [Google Scholar] [CrossRef]
- Lai, H.; Chang, K.; Lin, C. A Novel Method for Evaluating Dredging Productivity Using a Data Envelopment Analysis-Based Technique. Math. Probl. Eng. 2019, 2019, 5130835. [Google Scholar] [CrossRef]
- Pei, H.; Hu, C.; Si, X.; Zhang, J.; Pang, Z.; Zhang, P. Review of machine learning based remaining useful life prediction methods for equipment. J. Mech. Eng. 2019, 8, 1–13. [Google Scholar] [CrossRef] [Green Version]
- Wang, L.; Chen, X.; Wang, W. Research and analysis on construction output prediction of cutter suction dredger based on RBF neural network. China Harb. Eng. 2019, 39, 64–68. [Google Scholar]
- Guan, F.; Wang, W. Application of extreme learning machines in productivity prediction of trailing suction hopper dredger. Sci. Technol. Innov. 2020, 8, 58–61. [Google Scholar]
- Yang, J.; Ni, F.; Wei, C. Prediction of cutter suction dredger production based on double hidden layer BP neural network. Comput. Digit. Eng. 2016, 44, 1234–1237. [Google Scholar]
- Ren, L.; Sun, Y.; Cui, J.; Zhang, L. Bearing remaining useful life prediction based on deep autoencoder and deep neural networks. J. Manuf. Syst. 2018, 48, 71–77. [Google Scholar] [CrossRef]
- Wang, S.; Chen, Z.; Chen, S. Applicability of deep neural networks on production forecasting in bakken shale reservoirs. J. Pet. Sci. Eng. 2019, 179, 112–125. [Google Scholar] [CrossRef]
- Xu, W.; Peng, H.; Tian, X.; Peng, X. DBN based SD-ARX model for nonlinear time series prediction and analysis. Appl. Intell. 2020, 50, 4586–4601. [Google Scholar] [CrossRef]
- Hu, C.; Pei, H.; Si, X.; Du, D.; Wang, X. A prognostic model based on DBN and diffusion process for degrading bearing. IEEE Trans. Ind. Electron. 2019, 67, 8767–8777. [Google Scholar] [CrossRef]
- Deutsch, J.; He, D. Using deep learning-based approach to predict remaining useful life of rotating components. IEEE Trans. Syst. Man Cybern. Syst. 2017, 48, 11–20. [Google Scholar] [CrossRef]
- Zhang, C.; Lim, P.; Qin, A.K.; Tan, K.C. Multiobjective deep belief networks ensemble for remaining useful life estimation in prognostics. IEEE Trans. Neural Netw. Learn. Syst. 2016, 28, 2306–2318. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Zhang, Y.; Wu, Z.; Li, H.; Christofides, P. Operational Trend Prediction and Classification for Chemical Processes: A Novel Convolutional Neural Network Method Based on Symbolic Hierarchical Clustering. Chem. Eng. Sci. 2020, 225, 115796. [Google Scholar] [CrossRef]
- Chow, T.; Fang, Y. A recurrent neural-network-based real-time learning control strategy applying to nonlinear systems with unknown dynamics. IEEE Trans. Ind. Electron. 1998, 45, 151–161. [Google Scholar] [CrossRef]
- Malhi, A.; Yan, R.; Gao, R. Prognosis of defect propagation based on recurrent neural networks. IEEE Trans. Instrum. Meas. 2011, 60, 703–711. [Google Scholar] [CrossRef]
- Li, D.; Huang, D.; Yu, G.; Liu, Y. Learning Adaptive Semi-Supervised Multi-Output Soft-Sensors with Co-Training of Heterogeneous Models. IEEE Access 2020, 8, 46493–46504. [Google Scholar] [CrossRef]
- Yang, K.; Liu, Y.; Yao, Y.; Fan, S.; Ali, M. Operational time-series data modeling via LSTM network integrating principal component analysis based on human experience. J. Manuf. Syst. 2021, in press. [Google Scholar] [CrossRef]
- D’Agostino, R.B. Principal Components Analysis. In Handbook of Disease Burdens and Quality of Life Measures; Preedy, V.R., Watson, R.R., Eds.; Springer: New York, NY, USA, 2020. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Jafari, H.; Alipoor, A. A New Method for Calculating General Lagrange Multiplier in the Variational Iteration Method. Numer. Methods Partial. Differ. Equ. 2011, 27, 996–1001. [Google Scholar] [CrossRef]
- Bai, S.; Li, M.; Kong, R.; Han, S.; Li, H.; Qin, L. Data mining approach to construction productivity prediction for cutter suction dredgers. Autom. Constr. 2019, 105, 102833. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable | Description | Unit |
|---|---|---|
| S8 | Angle of the cutter ladder | |
| S9 | Depth of the dredging | m |
| S12 | Rotation speed of the submersible pump | rpm |
| S13 | Rotation speed of the cutter | rpm |
| S20 | Flow | m3/h |
| S23 | Soil density | kg/m3 |
| S79 | Distance of the swing movement | m |
| S80 | Angle of the swing | |
| S100 | Rotation speed of the No.1 dredge pump | rpm |
| S101 | Rotation speed of the No.2 dredge pump | rpm |
| S108 | Power of the cutter | kw |
| S164 | Mud density | kg/m3 |
| S165 | Flow rate | m/s |
| S182 | Trolley trip | m |
| S198 | Discharge pressure of the submersible pump | kPa |
| S199 | Discharge pressure of the No.1 dredge pump | kPa |
| S200 | Discharge pressure of the No.2 dredge pump | kPa |
| S201 | Vacuum | kPa |
| S223 | Water density | kg/m3 |
| S21 | Mud concentration | % |
| MAE | R2 | RMSE | |
|---|---|---|---|
| Proposed PCA-LSTM | 0.0424 | 0.9999 | 0.0925 |
| Traditional PCA-LSTM | 0.3063 | 0.9863 | 0.4054 |
| LSTM | 0.3352 | 0.9828 | 0.5010 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, K.; Yuan, J.-L.; Xiong, T.; Wang, B.; Fan, S.-D. A Novel Principal Component Analysis Integrating Long Short-Term Memory Network and Its Application in Productivity Prediction of Cutter Suction Dredgers. Appl. Sci. 2021, 11, 8159. https://doi.org/10.3390/app11178159
Yang K, Yuan J-L, Xiong T, Wang B, Fan S-D. A Novel Principal Component Analysis Integrating Long Short-Term Memory Network and Its Application in Productivity Prediction of Cutter Suction Dredgers. Applied Sciences. 2021; 11(17):8159. https://doi.org/10.3390/app11178159
Chicago/Turabian StyleYang, Ke, Jun-Lang Yuan, Ting Xiong, Bin Wang, and Shi-Dong Fan. 2021. "A Novel Principal Component Analysis Integrating Long Short-Term Memory Network and Its Application in Productivity Prediction of Cutter Suction Dredgers" Applied Sciences 11, no. 17: 8159. https://doi.org/10.3390/app11178159
APA StyleYang, K., Yuan, J. -L., Xiong, T., Wang, B., & Fan, S. -D. (2021). A Novel Principal Component Analysis Integrating Long Short-Term Memory Network and Its Application in Productivity Prediction of Cutter Suction Dredgers. Applied Sciences, 11(17), 8159. https://doi.org/10.3390/app11178159