
Important Trading Point Prediction Using a Hybrid Convolutional Recurrent Neural Network



Abstract
:1. Introduction
- Focus on high-margin opportunities: Even experienced human investors do not predict the stock price or trend at every time point; instead, they focus on the important trading points that are more likely to represent high-margin opportunities. This is not only because of the uncertainty and difficulty of the stock price forecasting task but also because the considerable transaction costs make slight price fluctuations meaningless.
- Keep track for some time: A signal at a single time point is very likely not to be sufficiently informative. Furthermore, it may have different meanings in different contexts. Human traders usually comprehensively consider a sequence of recent data and consequently make a more reliable prediction of the subsequent stock trend. Within a sequential context, human traders can give different levels of attention to various parts according to their respective importance and influence.
- Diversify the investment portfolio: Diversification is a management strategy that integrates different investments into a single portfolio. This is because diversified investments produce higher returns and face lower risks [33,34]. To diversify portfolios, human investors typically look for asset classes that are less relevant to each other or negatively correlated so that if one asset class moves down, the other will counteract it.
- A summary of principles for imitating the process of human stock traders looking for trading opportunities, which is of great help in developing better prediction models;
- A deep learning framework based on a hybrid convolutional recurrent neural network to predict the important trading points, which is driven by the principles of the human investment process;
- Experimental studies on real-world data with simulated investment performance based on real-world stock data.
2. Related Works
3. Empirical Analysis
3.1. Focus on High-Margin Opportunities
3.2. Keep Track for Some Time
3.3. Diversify the Investment Portfolio
4. Deep Learning Framework for Important Trading Point Prediction
4.1. Problem Statement
4.2. Hybrid Convolutional Recurrent Neural Network
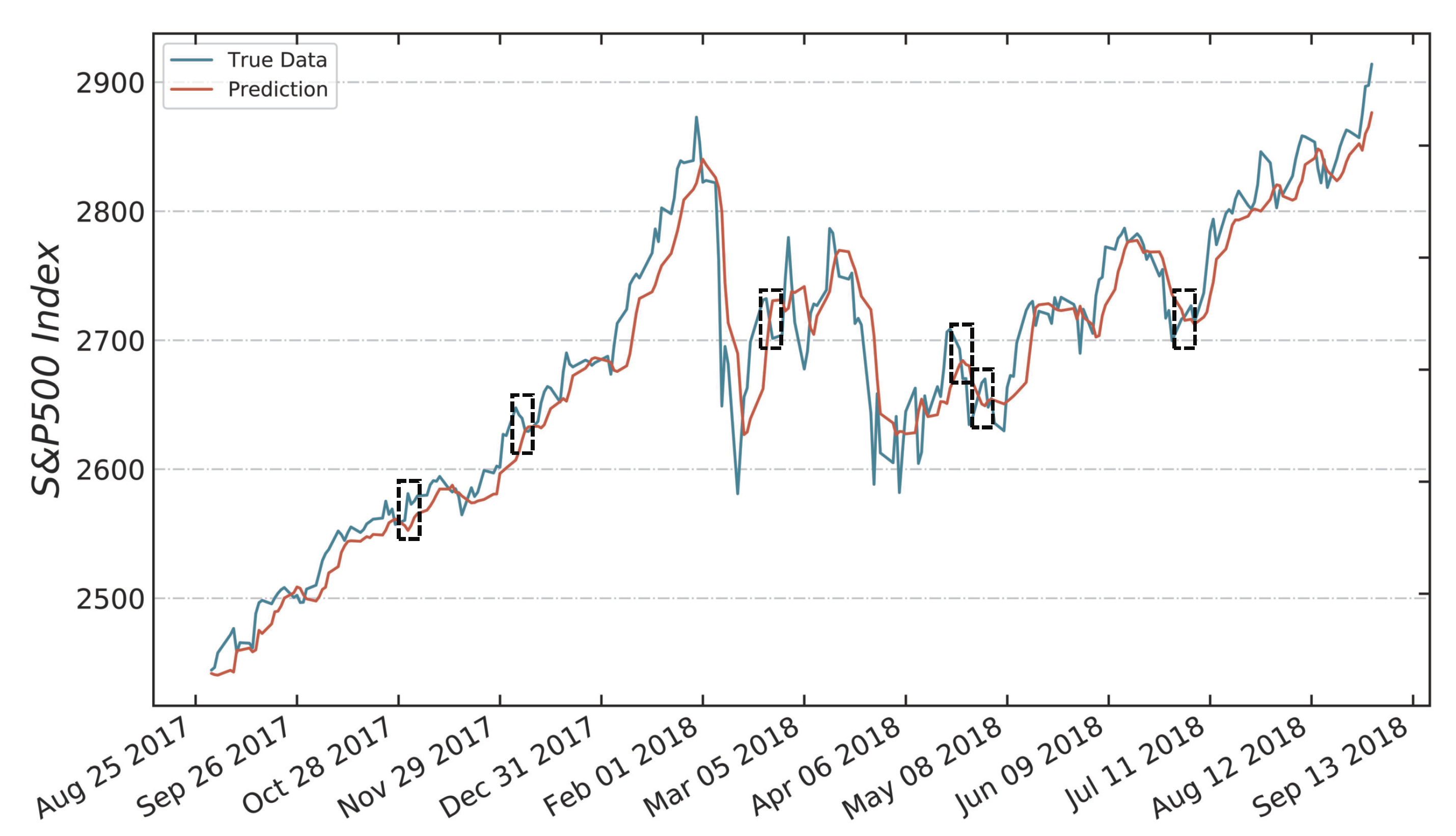
4.3. Threshold Search Mechanism
- Obtain the output of the validation set, where , and then sort from largest to smallest as , where denotes the reordered output.
- Count the number of “1” values (belonging to a SIP) on the training set ; then, calculate the estimated number of “1” values (belonging to a SIP) on the validation set in proportion to the lengths of these two sets. Formally,
- According to the experience of professional human investors, the actual number of “1” values (belonging to a SIP) in the validation set is approximately . Considering the situation of stock market changes over time, we multiply by a coefficient ranging from 1/2 to 2 (based on the statistical results shown in Section 5.1.2) as an estimate of , denoted by
- Set the threshold as the th value of , expressed asThen, this threshold is used to classify the output of the validation set into two types, and the number of time points classified as “1” (belonging to a SIP) will be . We can obtain a trading module based on this classification and calculate the profit on the validation set with this threshold.
- Increase by a step size of 0.1 and calculate the profit of each threshold. Finally, output the threshold that achieves the highest profit on the validation set as the threshold used for the model test.
5. Evaluation
5.1. Experimental Setup
5.1.1. Data Collection
5.1.2. Learning Settings
5.1.3. Evaluation Metric
5.1.4. Compared Methods
- ITPP-LSTM: We use a long short-term memory neural network to construct the proposed important trading point prediction framework (ITPP-LSTM) to evaluate the effectiveness of this method. The LSTM model takes training sequences with the length of the training set and corresponding targets as input.
- FSPD-LSTM: Forecasting stock prices directly is a common method in stock performance prediction, and we use an LSTM model that is the same as ITPP-LSTM to carry out this method (FSPD-LSTM). When the ratio of the forecasting price to the current price is above a certain threshold, the fund simulation performs a purchase operation. The optimal threshold is also obtained by backtesting on the validation set.
- FSPD-SFM: Zhang et al. proposed the state frequency memory (SFM) and applied it to the stock prediction task [15]. Compared to LSTM, SFM decomposes the hidden states of memory cells into multiple frequency components, each of which models a particular frequency of latent trading patterns underlying the fluctuation of the stock price. This method is based on the same dataset as ours and can also be viewed as a specification of the method of forecasting stock prices directly.
- FSPD-HCRNN: This method uses our proposed HCRNN model to forecast stock price directly. We use FSPD-HCRNN to compare with ITPP-HCRNN to evaluate the effectiveness of the proposed method of important trading point prediction. This method can also be viewed as a specification of the method of forecasting stock prices directly.
- FSTD-LSTM: Nelson et al. proposed the usage of an LSTM network for predicting future trends of stock prices, i.e., predicting if the price of a particular stock is going to increase or not in the near future [18]. When the predicted class is “1”—in other words, in the case that the network predicts that the stock price will go up—a “buy” operation will be triggered; then, the trading strategy is to open a “buy” position on the current day and close it on the next day. This method can be viewed as a specification of the method of forecasting stock trends directly.
- Random Forest: The Random Forest (RF) is a fundamental and commonly used machine learning classification approach, and we use an RF classifier with the number of trees in the forest set as 200 to construct the proposed framework.
- RNN: We use a standard RNN as a comparison with ITPP-LSTM to evaluate the effectiveness of the LSTM setting. This method has the same structure as ITPP-LSTM except that the LSTM is replaced with the RNN.
- Stacked LSTM: We use a double-layer LSTM to evaluate the effectiveness of the stacked LSTM setting. The other parameter settings are the same as for ITPP-LSTM.
- ITPP-HCRNN: This is the important trading point prediction framework based on our proposed hybrid convolutional RNN.
- Simplistic: This method directly takes the previous day’s trend in the historical stock price series as the future trend.
- Random: This method determines whether to perform a purchase operation based on the hypothesis that the probabilities of prices increasing or decreasing are both 50%.
5.2. Overall Performance Experiments
5.2.1. Classification Results
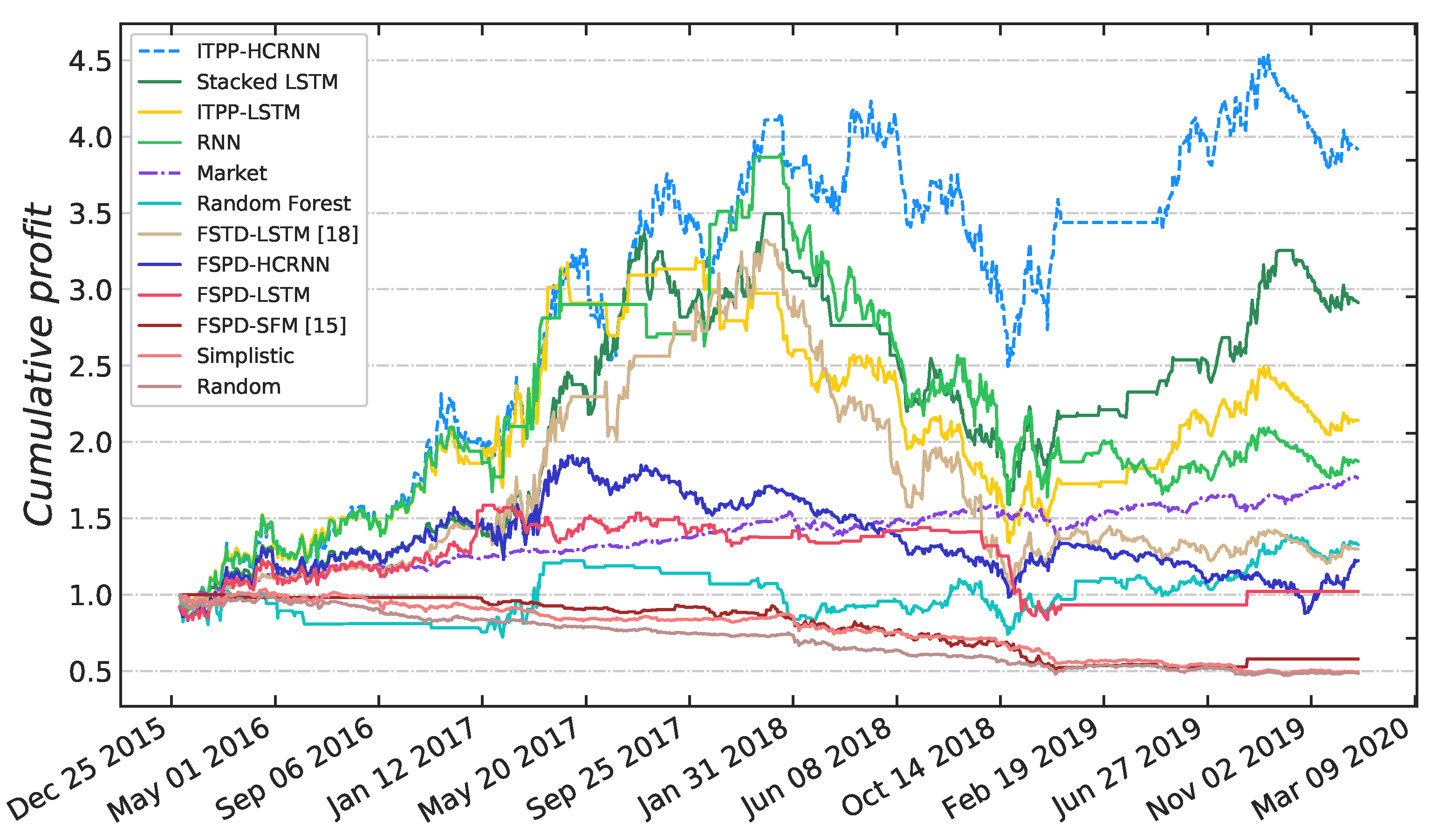
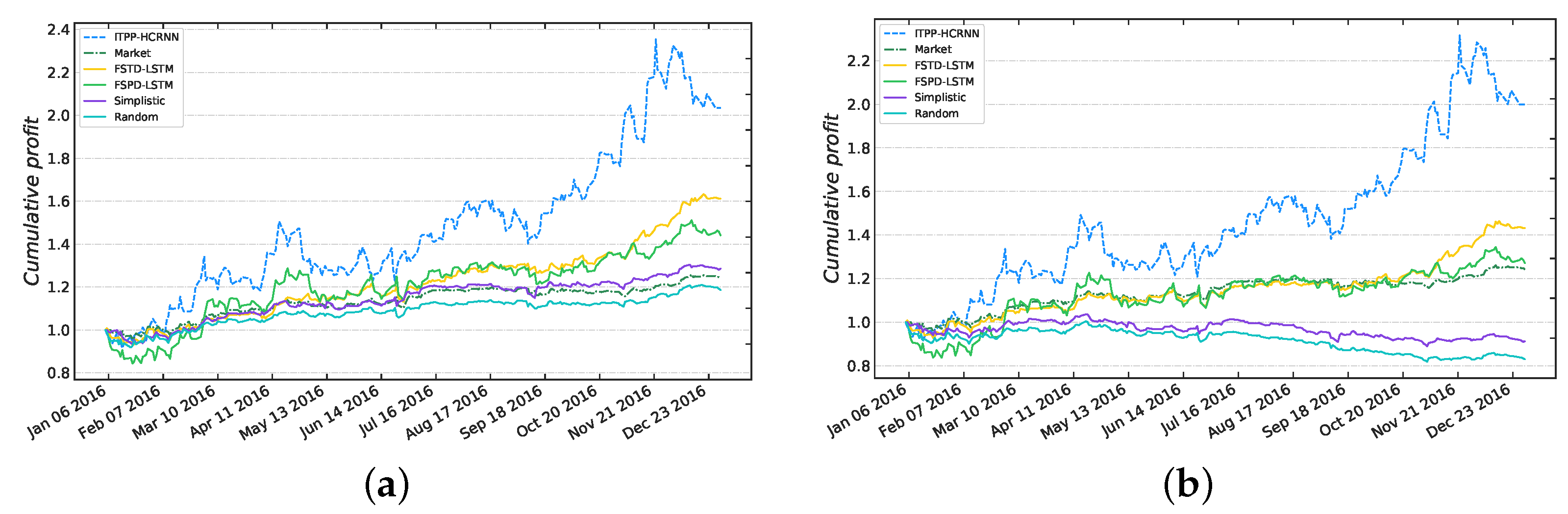
5.2.2. Market Trading Simulation
5.2.3. Performance Discussion
- Discussion of effectiveness: Compared to the performance of simplistic and random methods, all of the other methods show an improvement, suggesting that these methods have a certain predictive ability and are capable of extracting profitable information. Although the performances of FSPD-SFM, FSPD-LSTM, FSPD-HCRNN, FSTD-LSTM, and Random Forest are worse than that of the market (18.99%), an important factor is that the transaction cost offsets the profits. The other four methods earn more profit than the market, and they are all based on our proposed important trading point prediction framework. In terms of the comparison of FSPD-LSTM, FSTD-LSTM, and ITPP-LSTM, the improvement of ITPP-LSTM is indicated by both the annualized return and the Sharpe ratio. It can be concluded that the proposed important trading point prediction framework is indeed effective in stock performance prediction tasks; moreover, it has great advantages over the traditional method of forecasting stock prices directly and forecasting stock trends directly.
- Discussion of the RNN setting: Although Random Forest could obtain some profit, the performance of Random Forest is clearly worse than that of the other RNN-based methods, which is probably because the RNN networks can extract temporal information effectively, but Random Forest does not have this ability. This result indicates the significance of using RNNs for sequential modeling in the context of our research.
- Discussion of the stacked LSTM setting: In contrast to the RNN, LSTM has the ability to maintain the long-term memory of the trading patterns from the historical sequence data; thus, IPTT-LSTM outperforms the RNN. In addition, as stacking LSTM layers can enable the characteristics of raw temporal data to be learned from diverse perspectives at each time step, we can see that stacked LSTM shows certain improvements in the experimental results.
- Discussion of our proposed HCRNN model: Unlike the traditional method, which only utilizes RNNs to learn sequential information, the hybrid neural network we propose combines an RNN and CNN to capture both long-term temporal dependencies and local fluctuation features simultaneously during the training process, as they can complement each other. As we can see from Figure 7, our ITPP-HCRNN significantly outperforms all the above-mentioned models for all the test times. Therefore, we can conclude that such a hybrid neural network can indeed enhance the prediction capability of the method, and utilizing a CNN to extract implicit local fluctuation features can promote accurate prediction.
5.3. Impact of Transaction Costs
5.4. Impact of Hyperparameters
6. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
References
- Li, L.; Leng, S.; Yang, J.; Yu, M. Stock Market Autoregressive Dynamics: A Multinational Comparative Study with Quantile Regression. Math. Probl. Eng. 2016, 2016, 1285768. [Google Scholar] [CrossRef] [Green Version]
- Zhang, M.; Jiang, X.; Fang, Z.; Zeng, Y.; Xu, K. High-order Hidden Markov Model for trend prediction in financial time series. Phys. A Stat. Mech. Appl. 2019, 517, 1–12. [Google Scholar] [CrossRef]
- Song, Y.; Lee, J. Importance of Event Binary Features in Stock Price Prediction. Appl. Sci. 2020, 10, 1597. [Google Scholar] [CrossRef] [Green Version]
- Akita, R.; Yoshihara, A.; Matsubara, T.; Uehara, K. Deep learning for stock prediction using numerical and textual information. In Proceedings of the 2016 IEEE/ACIS 15th International Conference on Computer and Information Science (ICIS), Okayama, Japan, 26–29 June 2016; pp. 1–6. [Google Scholar]
- Gao, Q. Stock Market Forecasting Using Recurrent Neural Network. Ph.D. Thesis, University of Missouri–Columbia, Columbia, MO, USA, 2016. [Google Scholar]
- Rather, A.M.; Agarwal, A.; Sastry, V. Recurrent neural network and a hybrid model for prediction of stock returns. Expert Syst. Appl. 2015, 42, 3234–3241. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Li, H.; Shen, Y.; Zhu, Y. Stock price prediction using attention-based multi-input LSTM. In Proceedings of the Asian Conference on Machine Learning, Beijing, China, 14–16 November 2018; pp. 454–469. [Google Scholar]
- Fischer, T.; Krauss, C. Deep learning with long short-term memory networks for financial market predictions. Eur. J. Oper. Res. 2018, 270, 654–669. [Google Scholar] [CrossRef] [Green Version]
- Gu, Y.; Shibukawa, T.; Kondo, Y.; Nagao, S.; Kamijo, S. Prediction of Stock Performance Using Deep Neural Networks. Appl. Sci. 2020, 10, 8142. [Google Scholar] [CrossRef]
- Bao, W.; Yue, J.; Rao, Y. A deep learning framework for financial time series using stacked autoencoders and long-short term memory. PLoS ONE 2017, 12, e0180944. [Google Scholar] [CrossRef] [Green Version]
- Sirignano, J.; Cont, R. Universal features of price formation in financial markets: Perspectives from deep learning. Quant. Financ. 2019, 19, 1449–1459. [Google Scholar] [CrossRef]
- Tsantekidis, A.; Passalis, N.; Tefas, A.; Kanniainen, J.; Gabbouj, M.; Iosifidis, A. Using deep learning to detect price change indications in financial markets. In Proceedings of the 2017 25th European Signal Processing Conference (EUSIPCO), Kos Island, Greece, 28 August–2 September 2017; pp. 2511–2515. [Google Scholar]
- Li, J.; Bu, H.; Wu, J. Sentiment-aware stock market prediction: A deep learning method. In Proceedings of the 2017 International Conference on Service Systems and Service Management, Dalian, China, 16–18 June 2017; pp. 1–6. [Google Scholar]
- Zhang, L.; Aggarwal, C.; Qi, G.J. Stock price prediction via discovering multi-frequency trading patterns. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Halifax, NS, Canada, 13–17 August 2017; pp. 2141–2149. [Google Scholar]
- Si, W.; Li, J.; Ding, P.; Rao, R. A multi-objective deep reinforcement learning approach for stock index future’s intraday trading. In Proceedings of the 2017 10th International Symposium on Computational Intelligence and Design (ISCID), Hangzhou, China, 9–10 December 2017; Volume 2, pp. 431–436. [Google Scholar]
- Hao, Y.; Gao, Q. Predicting the Trend of Stock Market Index Using the Hybrid Neural Network Based on Multiple Time Scale Feature Learning. Appl. Sci. 2020, 10, 3961. [Google Scholar] [CrossRef]
- Nelson, D.M.; Pereira, A.C.; de Oliveira, R.A. Stock market’s price movement prediction with LSTM neural networks. In Proceedings of the 2017 International Joint Conference on Neural Networks (IJCNN), Anchorage, AK, USA, 14–19 May 2017; pp. 1419–1426. [Google Scholar]
- JuHyok, U.; Lu, P.; Kim, C.; Ryu, U.; Pak, K. A new LSTM based reversal point prediction method using upward/downward reversal point feature sets. Chaos Solitons Fractals 2020, 132, 109559. [Google Scholar]
- Chang, P.C.; Fan, C.Y.; Liu, C.H. Integrating a piecewise linear representation method and a neural network model for stock trading points prediction. IEEE Trans. Syst. Man Cybern. Part C (Appl. Rev.) 2008, 39, 80–92. [Google Scholar] [CrossRef] [Green Version]
- Yin, J.; Si, Y.W.; Gong, Z. Financial time series segmentation based on Turning Points. In Proceedings of the 2011 International Conference on System Science and Engineering, Macau, China, 8–10 June 2011; pp. 394–399. [Google Scholar]
- Huang, Q.; Yang, J.; Feng, X.; Liew, A.W.-C.; Li, X. Automated trading point forecasting based on bicluster mining and fuzzy inference. IEEE Trans. Fuzzy Syst. 2019, 28, 259–272. [Google Scholar] [CrossRef]
- Liu, S.; Zhang, C.; Ma, J. CNN-LSTM neural network model for quantitative strategy analysis in stock markets. In Proceedings of the International Conference on Neural Information Processing, Guangzhou, China, 14–18 November 2017; pp. 198–206. [Google Scholar]
- Dospinescu, N.; Dospinescu, O. A profitability regression model in financial communication of Romanian stock exchange’s companies. Ecoforum J. 2019, 8, 1–4. [Google Scholar]
- Dospinescu, O.; Dospinescu, N. A profitability regression model of romanian stock exchange’s energy companies. In Proceedings of the IE 2018 17th International Conference on Informatics in Economy Education, Research & Business Technologies, lasi, Romania, 17–20 May 2018; pp. 169–174. [Google Scholar]
- Atsalakis, G.S.; Dimitrakakis, E.M.; Zopounidis, C.D. Elliott Wave Theory and neuro-fuzzy systems, in stock market prediction: The WASP system. Expert Syst. Appl. 2011, 38, 9196–9206. [Google Scholar] [CrossRef]
- Hyerczyk, J.A. Pattern, Price and Time: Using Gann Theory in Technical Analysis; John Wiley & Sons: Hoboken, NJ, USA, 2009; Volume 408. [Google Scholar]
- Sykes, T. The Golden Ratio of Stock Trading. Available online: https://www.wallstreetdaily.com/2019/10/03/the-golden-ratio-of-stock-trading/ (accessed on 26 February 2021).
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A. Inception-v4, inception-resnet and the impact of residual connections on learning. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; Volume 31. [Google Scholar]
- Li, H. Deep learning for natural language processing: Advantages and challenges. Natl. Sci. Rev. 2018, 5, 24–26. [Google Scholar] [CrossRef]
- Khan, M.A.; Kim, J. Toward Developing Efficient Conv-AE-Based Intrusion Detection System Using Heterogeneous Dataset. Electronics 2020, 9, 1771. [Google Scholar] [CrossRef]
- Hu, Z.; Zhao, Y.; Khushi, M. A Survey of Forex and Stock Price Prediction Using Deep Learning. Appl. Syst. Innov. 2021, 4, 9. [Google Scholar] [CrossRef]
- Yahaya, A.; Abubakar, A.H.; Garba, J. Statistical analysis on the advantages of portfolio diversification. Int. J. Pure Appl. Sci. Technol. 2011, 7, 98–106. [Google Scholar]
- Goetzmann, W.N.; Kumar, A. Equity portfolio diversification. Rev. Financ. 2008, 12, 433–463. [Google Scholar] [CrossRef] [Green Version]
- Thakkar, A.; Chaudhari, K. Fusion in stock market prediction: A decade survey on the necessity, recent developments, and potential future directions. Inf. Fusion 2021, 65, 95–107. [Google Scholar] [CrossRef]
- Zhan, X.; Li, Y.; Li, R.; Gu, X.; Habimana, O.; Wang, H. Stock Price Prediction Using Time Convolution Long Short-Term Memory Network. In Proceedings of the International Conference on Knowledge Science, Engineering and Management, Changchun, China, 17–19 August 2018; pp. 461–468. [Google Scholar]
- Kim, T.; Kim, H.Y. Forecasting stock prices with a feature fusion LSTM-CNN model using different representations of the same data. PLoS ONE 2019, 14, e0212320. [Google Scholar] [CrossRef] [PubMed]
- Chen, C.T.; Chen, A.P.; Huang, S.H. Cloning strategies from trading records using agent-based reinforcement learning algorithm. In Proceedings of the 2018 IEEE International Conference on Agents (ICA), Singapore, 28–31 July 2018; pp. 34–37. [Google Scholar]
- Siripurapu, A. Convolutional networks for stock trading. Stanf. Univ. Dep. Comput. Sci. 2014, 1, 1–6. [Google Scholar]
- Gunduz, H.; Yaslan, Y.; Cataltepe, Z. Intraday prediction of Borsa Istanbul using convolutional neural networks and feature correlations. Knowl. Based Syst. 2017, 137, 138–148. [Google Scholar] [CrossRef]
- Wang, Y.; Zhang, C.; Wang, S.; Yu, P.; Bai, L.; Cui, L. Deep Co-Investment Network Learning for Financial Assets. In Proceedings of the 2018 IEEE International Conference on Big Knowledge (ICBK), Singapore, 17–18 November 2018; pp. 41–48. [Google Scholar]
- Eapen, J.; Bein, D.; Verma, A. Novel deep learning model with CNN and bi-directional LSTM for improved stock market index prediction. In Proceedings of the 2019 IEEE 9th Annual Computing and Communication Workshop and Conference (CCWC), Las Vegas, NV, USA, 7–9 January2019; pp. 264–270. [Google Scholar]
- Long, W.; Lu, Z.; Cui, L. Deep learning-based feature engineering for stock price movement prediction. Knowl. Based Syst. 2019, 164, 163–173. [Google Scholar] [CrossRef]
- Chen, J.F.; Chen, W.L.; Huang, C.P.; Huang, S.H.; Chen, A.P. Financial time-series data analysis using deep convolutional neural networks. In Proceedings of the 2016 7th International Conference on Cloud Computing and Big Data (CCBD), Macau, China, 16–18 November 2016; pp. 87–92. [Google Scholar]
- Sezer, O.B.; Ozbayoglu, A.M. Algorithmic financial trading with deep convolutional neural networks: Time series to image conversion approach. Appl. Soft Comput. 2018, 70, 525–538. [Google Scholar] [CrossRef]
- Zhou, X.; Pan, Z.; Hu, G.; Tang, S.; Zhao, C. Stock market prediction on high-frequency data using generative adversarial nets. Math. Probl. Eng. 2018, 2018. [Google Scholar] [CrossRef] [Green Version]
- Bowman, R. Fundamental vs. Technical Analysis—Beginner’s Guide with Pros and Cons of Each Investment Analysis Method. Available online: https://catanacapital.com/blog/fundamental-vs-technical-analysis-beginners-guide/ (accessed on 26 February 2021).
- Pratt, K.B. Locating Patterns in Discrete Time-Series. Master’s Thesis, University of South Florida, Tampa, FL, USA, 2001. [Google Scholar]
- Fu, T.c.; Chung, F.l.; Luk, R.; Ng, C.m. Representing financial time series based on data point importance. Eng. Appl. Artif. Intell. 2008, 21, 277–300. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Widiastuti, N. Convolution Neural Network for Text Mining and Natural Language Processing. In IOP Conference Series: Materials Science and Engineering; IOP Publishing: Bristol, UK, 2019; Volume 662, p. 052010. [Google Scholar]
- Khand, S.; Anand, V.; Qureshi, M.N. The Predictability and Profitability of Simple Moving Averages and Trading Range Breakout Rules in the Pakistan Stock Market. Rev. Pac. Basin Financ. Mark. Policies 2020, 23, 2050001. [Google Scholar] [CrossRef]
- Chang, E.J.; Lima, E.J.A.; Tabak, B.M. Testing for predictability in emerging equity markets. Emerg. Mark. Rev. 2004, 5, 295–316. [Google Scholar] [CrossRef]
- Chen, J. The Anatomy of Trading Breakouts. Available online: https://www.investopedia.com/articles/trading/08/trading-breakouts.asp (accessed on 26 February 2021).
- Mitchell, C. Breakout Definition and Example. Available online: https://www.investopedia.com/terms/b/breakout.asp (accessed on 26 February 2021).









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Training Set | Validation Set | Test Set |
|---|---|---|
| 1 January 2007–31 December 2014 | 1 January 2015–31 December 2015 | 1 January 2016–31 December 2016 |
| 1 January 2008–31 December 2015 | 1 January 2016–31 December 2016 | 1 January 2017–31 December 2017 |
| 1 January 2009–31 December 2016 | 1 January 2017–31 December 2017 | 1 January 2018–31 December 2018 |
| 1 January 2010–31 December 2017 | 1 January 2018–31 December 2018 | 1 January 2019–31 December 2019 |
| 2016 | 2017 | 2018 | 2019 | |
|---|---|---|---|---|
| 6462 | 3388 | 3438 | 3671 | |
| 808 | 424 | 430 | 459 | |
| 461 | 568 | 616 | 836 | |
| 0.57 | 1.34 | 1.43 | 1.82 |
| Parameter | Parameter Description | Value |
|---|---|---|
| lr | Learning rate | 0.01 |
| optimizer | Optimization method | RMSprop |
| Iteration | Training rounds | 10,000 |
| batch_size | Batch size | 50 |
| lstm_unit | Neuron number in LSTM | 50 |
| cnn_kernel_size | Length of filters in CNN | 100 |
| cnn_filters | Number of filters in CNN | 1 |
| padding | Padding mode of Conv1D | causal |
| lstm_activation | Activation function of LSTM | Tanh |
| cnn_activation | Activation function of CNN | Relu |
| dense_activation | Activation function of Dense | Linear |
| kernel_initializer | Method of weight initialization | Uniform |
| Methods | Annualized Return | Sharpe Ratio |
|---|---|---|
| Random | −12.89% | −1.63 |
| Simplistic | −12.65% | −1.44 |
| FSPD-SFM [15] | −11.92% | −0.64 |
| FSPD-LSTM | 0.51% | 0.01 |
| FSPD-HCRNN | 5.54% | 0.17 |
| FSTD-LSTM [18] | 7.46% | 0.31 |
| Random Forest | 8.17% | 0.25 |
| RNN | 21.82% | 0.44 |
| ITPP-LSTM | 28.51% | 0.52 |
| Stacked LSTM | 47.82% | 0.58 |
| ITPP-HCRNN | 72.87% | 0.78 |
| (L, W) | (3, 1.05) | (4, 1.05) | (5, 1.05) | (6, 1.05) | (7, 1.05) |
| Profit ratio | 94.30% | 105.00% | 72.90% | 80.90% | 92.10% |
| (L, W) | (4, 1.03) | (4, 1.04) | (4, 1.05) | (4, 1.06) | (4, 1.07) |
| Profit ratio | 44.30% | 86.20% | 105.00% | 104.00% | 48.80% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yu, X.; Li, D. Important Trading Point Prediction Using a Hybrid Convolutional Recurrent Neural Network. Appl. Sci. 2021, 11, 3984. https://doi.org/10.3390/app11093984
Yu X, Li D. Important Trading Point Prediction Using a Hybrid Convolutional Recurrent Neural Network. Applied Sciences. 2021; 11(9):3984. https://doi.org/10.3390/app11093984
Chicago/Turabian StyleYu, Xinpeng, and Dagang Li. 2021. "Important Trading Point Prediction Using a Hybrid Convolutional Recurrent Neural Network" Applied Sciences 11, no. 9: 3984. https://doi.org/10.3390/app11093984
APA StyleYu, X., & Li, D. (2021). Important Trading Point Prediction Using a Hybrid Convolutional Recurrent Neural Network. Applied Sciences, 11(9), 3984. https://doi.org/10.3390/app11093984