1. Introduction
The human brain is the management center and the central organ of the human nervous system, which is responsible for performing daily life activities. The brain receives stimuli or signals from sensory organs of the body, performs processing and sends final decisions and output information to the muscles. Uncontrolled cell division or mutations generate an abnormal group of cells in the brain, resulting in a brain tumor. This type of cell has the ability to affect normal brain function as well as damage healthy cells [
1,
2]. Headaches, cognitive issues, vomiting, personality changes, eyesight and speech are some of the most prevalent symptoms of brain tumors. The growth of a brain tumor affects the personality, way of thinking and all other essential functions of patients.
Usually, brain tumors are of two types: non-cancerous tumors, which are called benign, and cancerous tumors, which are called malignant. Benign tumors are non-progressive and originate in the brain. This kind of tumor is less aggressive and cannot expand in the body. On the other hand, malignant tumors are cancerous tumors that spread rapidly throughout the body. Furthermore, there are two categories of malignant tumors: primary malignant tumors that originate in the brain and transfer to other body parts, and secondary malignant tumors that initiate in other body regions and spread to the brain [
3]. Meningioma, pituitary and glioma tumors are common types of brain tumors. Meningioma arises in the thin membranes, i.e., tissues surrounding the spinal cord and brain. Gliomas arise within the glial cells of the brain. Pituitary tumors grow when cells in the pituitary gland near the brain grow in an abnormal pattern. One of the most life-threatening disorders is a brain tumor. As a result, the timely treatment and identification of brain tumors are required to preserve patients’ lives. One possible solution is to use machine learning (ML) algorithms to identify brain tumors and their types in patients automatically. However, because of brain tumors’ wide range of sizes, shapes and intensities, classifying them into meningioma, pituitary and glioma tumors is a more difficult task [
4]. Moreover, among all brain tumors, meningioma, pituitary and glioma tumors have the highest occurrence rate [
5].
Furthermore, brain magnetic resonance imaging (MRI) provides detailed information about the brain’s structure due to its high resolution. Hence, MRI images significantly impact automatic medical image analysis [
6,
7,
8,
9]. To detect and analyze brain tumors, researchers mostly rely on MRI techniques. Recently, many automated brain tumor detection and classification approaches have been proposed by researchers using MRI images. For the detection of brain tumors, traditional ML algorithms, particularly Multi-Layer Perceptron (MLP) and SVM classifiers, are widely used [
10]. DL is a ML subfield in which low-level features aid in the construction of high-level features, producing a hierarchy of features [
11]. The DL structure adds more hidden layers between the input and output layers to extend the traditional neural network framework. Researchers are now using DL techniques to solve various medical image analysis challenges, such as image denoising, segmentation, registration and classification [
8,
12,
13,
14,
15]. CNNs, which use convolutional filters to accomplish complex tasks, have become the most extensively used DL framework in recent years. Feedforward layers with convolutional filters, pooling layers and fully connected (FC) layers make up the CNN framework. A CNN-based classifier can provide a fully automated classifier considered for brain tumor classification [
11]. Pashaei et al. [
16] suggested a CNN-based model to efficiently extract features from brain MRI. Since CNN-based models do not require manual feature extraction, they are faster than standard ML algorithms. However, training a CNN classifier from scratch is difficult and time-consuming and requires an extensive labeled dataset.
Additionally, there are a lot of irregularities in the sizes and positions of brain tumors, which makes the natural understanding of brain tumors problematic. Generally, for the classification of brain tumors, T1-weighted contrast-enhanced (with gadolinium-enhanced) MRI images (T1c) are used because tumors are considerably better visualized on T1c due to the stimulation of 0.150 mMol/kg of contrast material (gadolinium) in patients [
17]. Diffusion-weighted imaging (DWI) is also considered vital for detecting brain tumors because it can visualize restrictions to the free diffusion of water caused by tissue microstructures [
18].
The different features extracted from MRI images are key sources for tumor classification. DL makes predictions and decisions on data by learning data representation. DL practices are most widely used for medical imaging classification. However, DL-based methods have shown satisfactory results in various applications across a wide range of domains in various fields [
19,
20,
21,
22]. However, DL approaches are starving data approaches, i.e., they require a lot of training data. Recently, DL approaches, particularly the CNN model, have been attracting more and more attention. CNN outperforms other classifiers on larger datasets, such as ImageNet, consisting of millions of images. However, it is challenging to employ CNNs in the field of medical imaging. Firstly, medical image datasets contain limited data because expert radiologists are required to label the dataset’s images, which is a tedious and time-consuming task. Secondly, CNN training is difficult for a small dataset because of overfitting. Thirdly, hyperparameters of CNN classifiers need to be adjusted to achieve better performance that requires domain expertise. Therefore, using pre-trained models on TL and fine tuning are viable solutions to address these challenges. In TL approaches, DL models are trained on a large dataset (base dataset) and transfer learned knowledge to the target dataset (small dataset) [
23]. This paper proposes an automatic brain tumor classification approach intended for three-class classification. Several approaches utilize manually defined tumor regions to detect and classify brain tumors, preventing them from being fully automated [
1,
2,
19]. However, the proposed new approach does not involve any segmentation or feature extraction and selection in the pre-processing step, in contrast to some previous methods [
1,
2,
19], which require prior segmentation and feature extraction of tumors from MRI images. We use a standard Kaggle brain tumor classification (MRI) dataset, including three types of brain tumors: meningioma, pituitary and glioma. We perform extensive experiments based on this dataset to compare the performance of nine DL models for the classification of brain tumor MRI images using TL. We used Inceptionresnetv2, Inceptionv3, Xception, Resnet18, Resnet50, Resnet101, Shufflenet, Densenet201 and Mobilenetv2 for the automatic detection and classification of brain tumors using a fine-grained classification approach. Furthermore, several approaches utilize the manually defined tumor regions
to detect and classify brain tumors that prevent them from being fully automated. The aim is to identify the most effective and efficient deep TL model for brain tumor classification. We report the overall accuracy, precision, recall, f-measure and elapsed time of the nine pre-trained frameworks in this paper.
The key contributions of our research include the following:
Proposing a DL-based framework for automatically detecting and classifying brain tumors into meningioma, pituitary and glioma tumors.
Analyzing and validating the TL concept for nine different deep neural networks.
Analyzing the performance of each TL model in classifying brain MRI images correctly and efficiently.
Comparing the performance of TL approaches with hybrid approaches (DL + SVM).
The remainder of the paper is organized into the following subsections.
Section 2 provides details about the existing literature on brain MRI classification.
Section 3 describes the proposed methodology and details of TL algorithms.
Section 4 elaborates on the experimental work in comparison with existing state-of-the-art TL approaches and hybrid DL approaches. Finally,
Section 5 concludes the research paper and discusses future directions.
2. Related Work
Recently, there has been a lot of work on brain tumor detection and classification [
24,
25,
26,
27,
28,
29,
30,
31,
32]. For the detection and categorization of brain tumors, various techniques have been presented. These methods include traditional ML methods and DL methods. This section includes the investigation of existing brain tumor detection and classification approaches.
Ismael et al. introduced an approach that integrates statistical features and neural network techniques [
24] to detect and classify brain tumor MRI images. Region of interest (ROI) is used in this method, defined as the tumor segment detected using any ROI segmentation technique. Moreover, 2D Discrete Wavelet Transform (DWT) and 2D Gabor filter techniques were used to determine features for the classifier. To create the feature set, they used many transform domain statistical features. For classification, a backpropagation neural network classifier was used. A Figshare dataset of 3064 slices of T1-weighted MRI images of three forms of brain tumors, meningioma, glioma, and pituitary, was used to evaluate the model. The authors achieved a maximum accuracy of 91.9%. A Deep Neural Network classifier, one of the DL frameworks, was used by Mohsen et al. to classify a dataset of 66 brain MRIs into four categories: normal, glioblastoma, sarcoma and metastatic bronchogenic carcinoma tumors [
25]. The classifier was combined with the discrete wavelet transform (DWT), a powerful feature extraction approach, and principal component analysis (PCA), with promising results across all performance metrics. The authors achieved a maximum accuracy of 98.4% by combining DNN with DWT. Deepak et al. classified medical images using a combination of CNN features and SVM [
26]. To analyze and validate their proposed approach, they used publicly available MRI images of brain tumors from Figshare that comprised three types of brain tumors. They extracted characteristics from MRI scans of the brain using the CNN classifier. For increased performance, a multiclass SVM was paired with CNN features. They also tested and evaluated an integrated system using a five-fold cross-validation technique. The proposed model surpassed the current techniques with respect to total classification accuracy by achieving a classification accuracy of 95.82%. When there is limited training data, the SVM classifier outperforms the softmax classifier for CNN feature extraction. They employed the CNN–SVM approach, which requires fewer computations and less memory than TL-based classification. For brain tumor identification, the authors of [
27] presented a multi-level attention mechanism network (MANet). The suggested MANet incorporates both spatial and cross-channel attention, focusing on tumor region prioritization while also preserving cross-channel temporal relationships found in the Xception backbone’s semantic feature sequence. The proposed method was tested using the Figshare and BraTS benchmark datasets. Experiments show that combining cross-channel and spatial attention blocks improves generalizations and results with improved performance with fewer model parameters. The suggested MANet outperforms various current models for tumor recognition, with a maximum accuracy of 96.51 percent on Figshare and 94.91 percent on BraTS’2018 datasets.
In image detection and recognition challenges, CNN plays a significant role. To extract features automatically from brain images, CNN filters are convolved with the input image. Most research methodologies use CNN-based approaches for brain tumor detection and classification. Afshar et al. used capsule networks for brain tumor classification and investigated the overfitting problem of CapsNets using a real collection of MRI data [
28]. CapsNets require far less training data, making them perfect for medical imaging datasets such as brain MRI scans. They built a visualization paradigm for CapsNet’s output to better illustrate the learned features. The achieved accuracy of 86.56% demonstrates that the presented method for brain tumor classification could successfully overcome CNNs. MR images are used to diagnose a brain tumor [
29]. The use of CNN classification for automatic brain tumor detection was proposed by the authors. Small kernels were used to create deeper architecture. The neuron’s weight is described as tiny. When compared to all other state-of-the-art methodologies, the experimental results demonstrate that CNN archives have a rate of 97.5% accuracy with little complexity.
Rai et al. adopted a Less Layered and Less Complex U-Net (LeU-Net) framework for brain tumor detection [
30]. The LeU-Net idea was influenced by both the Le-Net and U-Net frameworks; however, it differs significantly from both architectural approaches. The performance of LeU-Net was compared to the existing basic CNN frameworks Le-Net, U-Net and VGG-16. Accuracy, precision, F-score, recall and specificity were used to assess CNN performance. The experiment was conducted on an MR dataset with cropped (removed unwanted area) and uncropped images. Moreover, the results were compared to all three models. The LeU-Net model has a much faster processing (simulation) time; training the network with 100 epochs achieved 98% accuracy on cropped images and achieved 94% accuracy on uncropped images, which took 252.36 s and 244.42 s, respectively. Kader et al. proposed a new hybrid model for brain tumor identification and classification based on MR brain images [
31], intending to assist doctors in the early diagnosis and classification of brain tumors with maximum accuracy and performance. The approach was developed using a hybrid deep CNN and a deep watershed auto-encoder (CNN–DWA) model. The technique can be broken down into six steps: input MR images, preprocessing with a filter and morphological operation, generating a matrix that represents MR brain images, using the hybrid CNN–DWA framework, brain tumor detection and classification and model performance evaluation. The model was validated using five databases: BRATS2012, BRATS2013, BRATS2014, ISLES-SISS 2015 and BRATS2015. Based on the RCNN technique [
32], Kesav et al. developed a new framework for brain tumor classification and tumor type object recognition, tested using two publicly available datasets from Figshare and Kaggle. The goal was to design a basic framework that would allow the classic RCNN framework to run faster. Glioma and healthy tumor MRI images were initially classified using a two-channel CNN. Later, a feature extractor in an RCNN was used to locate tumor locations in a glioma MRI sample categorized from a previous stage using the same framework. Bounding boxes were used to define the tumor region. Meningioma and pituitary tumors are two more malignancies that have been treated with this method. The proposed method achieved an average confidence level of 98.83% for two-class tumor classification, i.e., meningioma and pituitary tumors.
Existing works on brain tumor detection and classification have some limitations. Most of the approaches are validated with the figshare dataset, which is an imbalanced dataset and affects the performances of classification approaches. Hence, there is a need to validate brain tumor classification approaches on another balanced dataset. ML, in its traditional form, necessitates domain knowledge and experience. Manual feature extraction necessitates time and effort, reducing the system’s efficiency. On the other hand, employing DL, particularly CNN, in medical imaging is challenging, as it requires a significant amount of data for training. In contrast, deep TL-based algorithms can avoid these drawbacks by using automatic feature extraction and robust classification applications based on convolutional layers. This study proposes an automatic classification system for multiclass brain tumor MR images, which is a more complex and difficult assignment than simple binary classification. However, our dataset is very small, and it is difficult to train CNN from scratch using small datasets without suffering from overfitting and with appropriate convergence. Inspired by the success of TL techniques [
5,
19,
33,
34], we adopted the concept of TL in this work. For this purpose, we employed various TL models in this research work, including Inceptionresnetv2, Inceptionv3, Xception, Resnet18, Resnet50, Resnet101, Shufflenet, Densenet201 and Mobilenetv2 to achieve brain tumor detection and classification on the target dataset. Furthermore, we compared the best model with other methods to show its efficacy in identifying brain tumors.
3. Research Methodology
This section elaborates on the proposed research methodology for fine-grained brain tumor classification. We thoroughly explain the proposed TL-based approach, its framework and the different pre-trained TL classifiers employed to detect and classify brain MRI images into meningioma, pituitary and glioma.
3.1. Proposed Approach
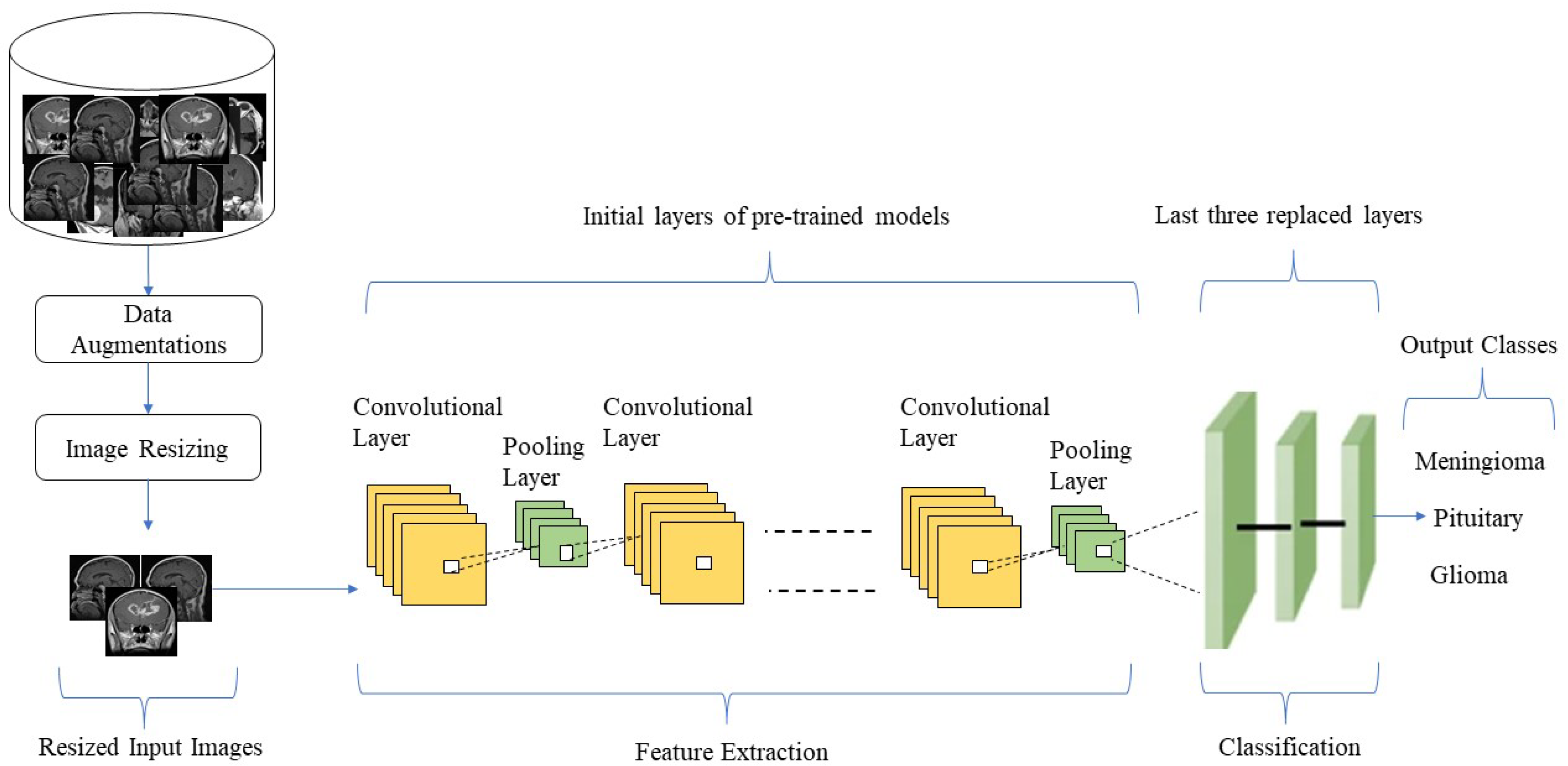
The proposed research methodology is depicted in
Figure 1, which demonstrates an abstract view of the proposed TL-based approach for brain tumor classification using MRI images. The proposed TL-based brain tumor classification comprises the following steps. Firstly, we downloaded the freely available Kaggle MR image dataset [
35], including glioma, meningioma and pituitary MR images, and we placed the dataset into the training directory. Secondly, we employed imageDataStore to read the MR images of the dataset from the training directory.
In the third step, we applied a data augmentation technique to test the generalizability of the TL models. Data augmentation, or increasing the amount of available data without acquiring new data by applying multiple processes to the current data, has been proven to be advantageous in image classification. Due to the limited number of images in the dataset, we applied the data augmentation technique in this study. The images in the training set were rotated at a random angle between −20 and 20 degrees, and were arbitrarily translated up to thirty pixels vertically and horizontally to create additional images. It is also worth noting that the imageDataAugmenter function was utilized to dynamically create sets of augmented images during each training phase. The number of images in the training set was significantly expanded using this data augmentation method, enabling more effective use of our DL model by training with a much higher number of training images. Furthermore, the augmented images were only used to train the proposed framework, not to test it; hence, only real images from the dataset were utilized to test the learned framework.
In the fourth step, the input MRI images of the dataset were resized according to the pre-trained CNN model’s input image requirements. The images in the dataset were of various sizes, and different models required input images of various sizes, such as the TL mobilenetv2 classifier, accepting 224 × 224 input images, and the inceptionv3 classifier, requiring 229 × 229 input images. Therefore, before being inserted into the DL network, the training and testing images were automatically scaled utilizing augmented image data stores of TL.
Next, we employed different pre-trained deep neural networks, i.e., Inceptionresnetv2, Inceptionv3, Xception, Resnet18, Resnet50, Resnet101, Shufflenet Densenet201 and Mobilenetv2, to identify their performance in identifying and classifying different kinds of brain tumors. The proposed TL models consisted of layers from the pre-trained networks and three new layers, i.e., the last three layers modified to suit the new image categories (meningioma, pituitary and glioma). The transfer learned models had a softmax layer, classifying images into meningioma, pituitary and glioma. For example, for “Inceptionv3” and “InceptionResNetV2”, we replaced “predictions”, “predictions_softmax” and “ClassificationLayer_predictions” with a “fully connected layer”, a “softmax layer” and a “classification output” layer. We connected the additional layers to the network’s last remaining transferred layer, i.e., “avg pool”. We replaced the network’s last three layers, i.e., “fc1000”, “fc1000_softmax” and “ClassificationLayer_fc1000”, with a “completely connected layer”, a “softmax layer” and “classification output” layers for “ResNet50” and connected the additional layers to the network’s last remaining transferred layer (“avg pool”). Similarly, we replaced the “fc1000”, “prob” and “ClassificationLayer_predictions” layers of the network with a “fully connected layer”, a “softmax layer” and a “classification output” layer for “ResNet101” and connected the new layers to the network’s last remaining transferred layer (“pool5”).
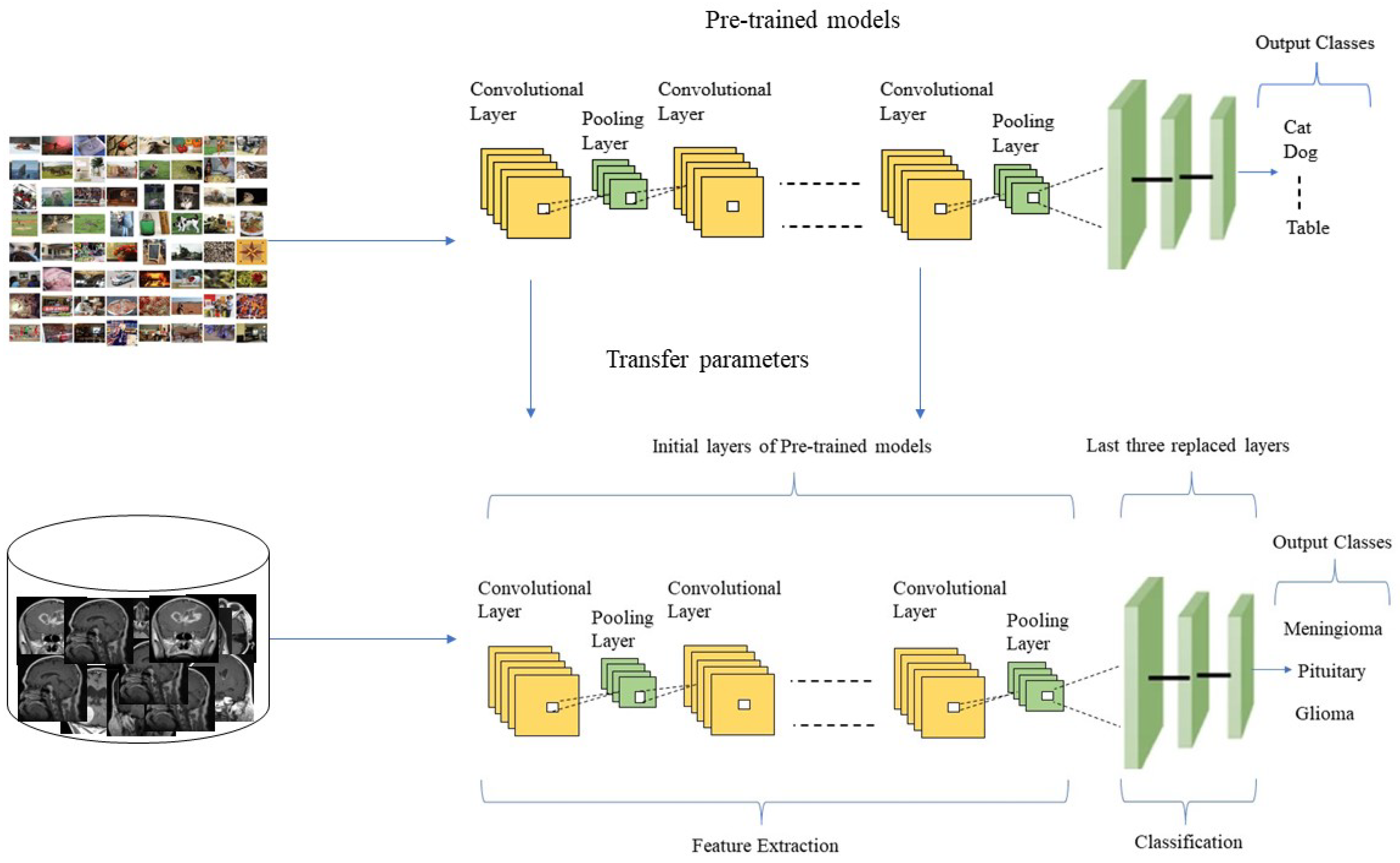
The detailed structure of the proposed DL framework is shown in
Figure 2, extended from the concept of TL. Furthermore, we evaluated and validated each model to assess the performance of different pre-trained TL algorithms in identifying brain tumor types. For this purpose, we divided the dataset into training and testing sets to obtain accurate and reliable results; more specifically, we used 80% of the data for model training and the remaining 20% for testing. The overall process of pre-trained TL classification for brain tumor identification and classification is shown in
Figure 1.
3.2. Transfer Learning in an Inductive Setting
To train and validate a classifier that can achieve accuracy on image classification tasks near or above the human level, a lot of training data, heavy computational power, time and resources are required. It becomes challenging to train and validate an image classifier from scratch until having a large data set. In contrast, TL is a method that uses the gained knowledge of a trained model and applies it to solve other related problems [
19]. The aim is to employ a wide training dataset provided to the model with more image feature information before adapting it to a new data field. TL networks are intended to acquire spatial features using convolutional, pooling and FC layers. Moreover, traditional CNN requires a lot of training data, time and computation resources for training. Therefore, in the case of limited data (such as brain tumor recognition, where training image samples are scarce, then classifier performance suffers significantly) and computational resources, the TL of pre-trained deep neural networks is a faster and more cost-effective approach for classification tasks. When there are limited data to learn from, common information is transferred from old tasks to new ones, and some specialized knowledge is produced throughout the problem-solving process. The model learns high-level features specific to the target domain, e.g., brain tumor classification, whereas the pre-trained layers learns low-level features of the original networks. Depending on the type of task and the nature of the data accessible at the source and destination domains, several parameters for TL are offered [
36]. The TL approach is known as inductive TL [
37] when labeled data are available in the source and target domains for a classification task. TL algorithms enhance classification performance even with limited data available for training and validation. The key task in TL is selecting a pre-trained deep neural network among the available TL algorithms. This selection is based on the related problem relevant to the target problem. The chances of overfitting are high in the case of limited target data, similar to the source training dataset. In contrast, the chances of overfitting are low if the target dataset is larger and similar to the source dataset, and then it only needs fine tuning of the pre-trained deep neural network. For this purpose, we selected nine pre-trained TL algorithms to identify their performance in detecting and identifying meningioma, pituitary and glioma brain tumors.
Figure 2 represents the basic framework of the TL method employed in our work. We changed the last three models’ layers to adapt them to the brain tumor classification domain.
3.3. Transfer-Learning-Based Networks
This section provides in depth details about the nine TL algorithms, i.e., Inceptionresnetv2, Inceptionv3, Xception, Resnet18, Resnet50, Resnet101, Shufflenet, Densenet201 and Mobilenetv2, selected for the purpose of brain tumor classification. The algorithms were selected based on their popularity and good performance for image classification. Below, we elaborate on each TL algorithm.
3.3.1. Inceptionresnetv2
Inceptionresnetv2 [
37] is a deep CNN made from the family of Inception frameworks, and it incorporates residual connections. Inceptionresnetv2 uses inexpensive Inception blocks instead of the original Inception and a filter expansion layer after each Inception block, having 1 × 1 convolution without activation. Batch normalization (BN) is only employed on top of traditional layers, not on summations, to increase the number of inception blocks. This network takes a 299 × 299-pixel image as input for processing.
3.3.2. Inceptionv3
Inceptionv3 [
38] is 48 layers deep, and it requires an input image of a size of 229 × 299. Inceptionv3 is a deep neural network that belongs to the Inception family, and it makes numerous improvements, such as Factorized 7 × 7 convolutions and label smoothing. The available pre-trained version of Inceptionv3 is trained on the ImageNet database and can classify images of 1000 objects into different categories.
3.3.3. Xception
The Xception [
39] TL algorithm is 71 layers deep. The Xception network has 36 convolutional layers used as a base for feature extraction. Each convolutional layer has linear residual connections around it. Moreover, the Xception network is completely based on depth-wise separable convolutional layers. The framework of the Xception model can easily be modified. The pre-trained version of the Xception TL algorithm can classify new related tasks after being trained on millions of images from the ImageNet dataset.
3.3.4. Resnet101, Resnet50 and Resnet18
The residual networks [
40] Resnet101, Resnet50 and Resnet18 are 101 layers, 50 layers and 18 layers deep, respectively. Residual deep neural networks use shortcut connections to skip some layers; skipping is used to compress the network, thus enabling faster learning. All three models are trained on the ImageNet database, and the pre-trained versions are available to classify new image-related tasks. Resnet101 provides more accurate results than Resnet18 and Resnet50 because of the increased depth of the TL algorithm.
3.3.5. Shufflenet
Shufflenet [
41] is 50-layer-deep TL classifier. Shufflenet is computationally efficient and is designed for devices with limited computation power (i.e., mobile devices). Channel shuffle and pointwise group convolution are the core operations used by the Shufflenet model to reduce computational costs. Shufflenet accepts an input image of size 224 × 224. The pre-trained version of Shufflenet can be used to classify new image-related tasks.
3.3.6. Densenet201
Densenet201 [
42] is 201-layer-deep TL classifier. In the Densenet201 model, all preceding layers’ feature maps are utilized as inputs in subsequent layers; hence, the model encourages feature reuse and decreases feature redundancy. The Densenet’s classifier reduces the vanishing gradient problem and boosts feature reuse. The Densenet’s TL algorithm is a good feature extractor for numerous computer vision tasks because of its compact internal representations.
3.3.7. Mobilenetv2
The Mobilenetv2 [
43] framework is a 53-layer-deep TL classifier used to classify image-related tasks. The image input size of Mobilenetv2 is 224 × 224. The Mobilenetv2 model is computationally efficient; therefore, this model is more suitable for real-time and mobile applications. The high speed of the Mobilenetv2 model is a result of point-wise and depth-wise convolution concepts used by the model. Residual connections between bottleneck layers are used in the network. An initial convolutional layer (with 32 filters) is followed by 19 residual bottleneck layers in the Mobilenetv2 network.
4. Results and Discussion
This section contains thorough information on the research dataset adopted for the fine-grained brain tumor classification experimental setup, i.e., the TL setting, and it provides an in-depth discussion of the findings of numerous experiments designed to assess the performance of our model. The experimental setup contains information regarding training the TL models and the software platform used in this study.
4.1. Dataset
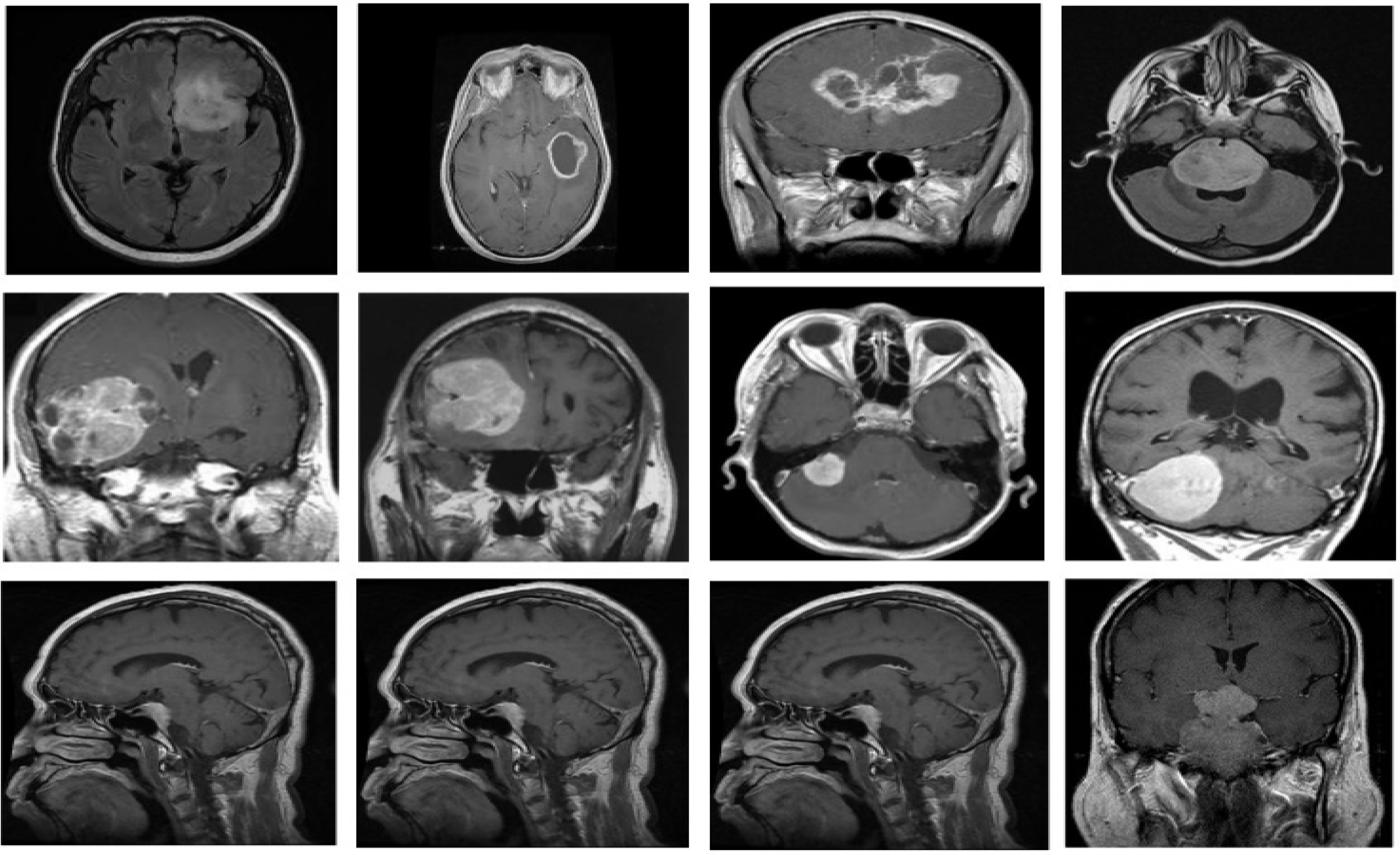
For the proposed fine-grained classification approach, we employed the brain tumor classification (MRI) dataset [
35] to test, train and validate the different TL-based approaches, with the intention of identifying the best DL classifier. The dataset is freely available as a standard Kaggle dataset. The dataset comprises two brain tumor MRI image collections, i.e., testing and training. Each collection contains four types of brain tumor MRI images, i.e., no tumor, meningioma tumors, pituitary tumors and glioma tumors. However, we only used the meningioma, pituitary and glioma tumor MRI images. The latest version of the research dataset contains 822 MRI images of meningioma, 827 MRI images of pituitary tumors and 826 MRI images of glioma brain tumors in the training folder. The samples from each brain tumor category are shown in
Figure 3. Moreover, the testing folder contains 115 images of meningioma, 72 images of pituitary tumors and 100 images of glioma brain tumors. We combined images from both folders. Then, 80% of the data was used for training, and the remaining 20% was used for testing. The dataset comprises grayscale images of different resolutions. In the preprocessing stage, the MRI images of the dataset were resized by using the augmented image data store according to the image input size requirements of different DL models; for example, for mobilenetv2, MRI images were resized to 224 × 224, and for darknet19, images were resized to 256 × 256. The details of the research dataset adopted for brain image classification are shown in
Table 1, which describes the number of images against each tumor type, image format and brain image type.
4.2. Transfer Learning Setting
The pre-trained TL network classifiers adopted for this research study, i.e., Inceptionresnetv2, Inceptionv3, Xception, Resnet18, Resnet50, Resnet101, Shufflenet, Densenet201 and Mobilenetv2, can categorize images into 1000 different item classes and are trained on 1.28 million images of ImageNet database. The focus of this study is a three-class classification of brain tumors using the brain tumor classification (MRI) dataset. Furthermore, we employed a trial-and-error strategy. Experiments were carried out by assigning different values to the parameters to determine the optimum values for each parameter. We used stochastic gradient descent (SGD) to train pre-trained DL models through TL. We utilized a 0.01 learning rate and a 10-image minibatch size. In addition, each DL model was trained for 14 epochs to conduct the TL experiments for detecting and categorizing brain tumor types, accounting for the possibility of overfitting. We performed all experimentations on a machine equipped with Intel (R) Core (TM) i5-5200U CPU and 8GB of RAM. For implementation, we used the R2020a version of MATLAB. The optimized parameters used for the classification experiment are shown in
Table 2.
4.3. Evaluation Metrics
In this study, we employed the accuracy, precision, recall and
F1-score [
44] to assess the performance of all deep neural networks. All the performance metrics were computed as follows:
TN stands for true negative, TP for true positive, FP for false positive and FN for false negative, and TS denotes the whole number of samples.
4.4. Results
This section discusses the performance of different pre-trained TL classifiers used to classify brain MRI images from the brain tumor classification (MRI) dataset into meningioma, pituitary and glioma. The main advantage of TL classifiers and fine tuning is decreasing overfitting issues that frequently occur in DL algorithms when experimenting with a smaller sample of training and testing images. All the TL models were trained and validated on the same TL settings indicated in
Table 2 for the classification of brain tumors. We used 2762 brain tumor classification (MRI) images to classify brain tumors.
Table 3 represents the detailed results of various TL algorithms in classifying brain tumor images and shows that each TL classifier achieved satisfactory results. We analyzed and evaluated the TL algorithms using accuracy, precision, recall and f-measure evaluation metrics. The results show that the inceptionresnetv2 DL model achieved the best average accuracy of 98.91%, and resnet50 achieved the lowest average accuracy of 67.03%. In contrast, the TL of the remaining seven deep neural networks achieved average classification accuracy. It is essential to mention that variants of the Resnet framework achieved different results. Resnet18 achieved a minimum accuracy of 67.03%, and Resnet50 attained an accuracy of 67.03%, whereas Resnet101 achieved an accuracy of 74.09%, which is the highest among all variants.
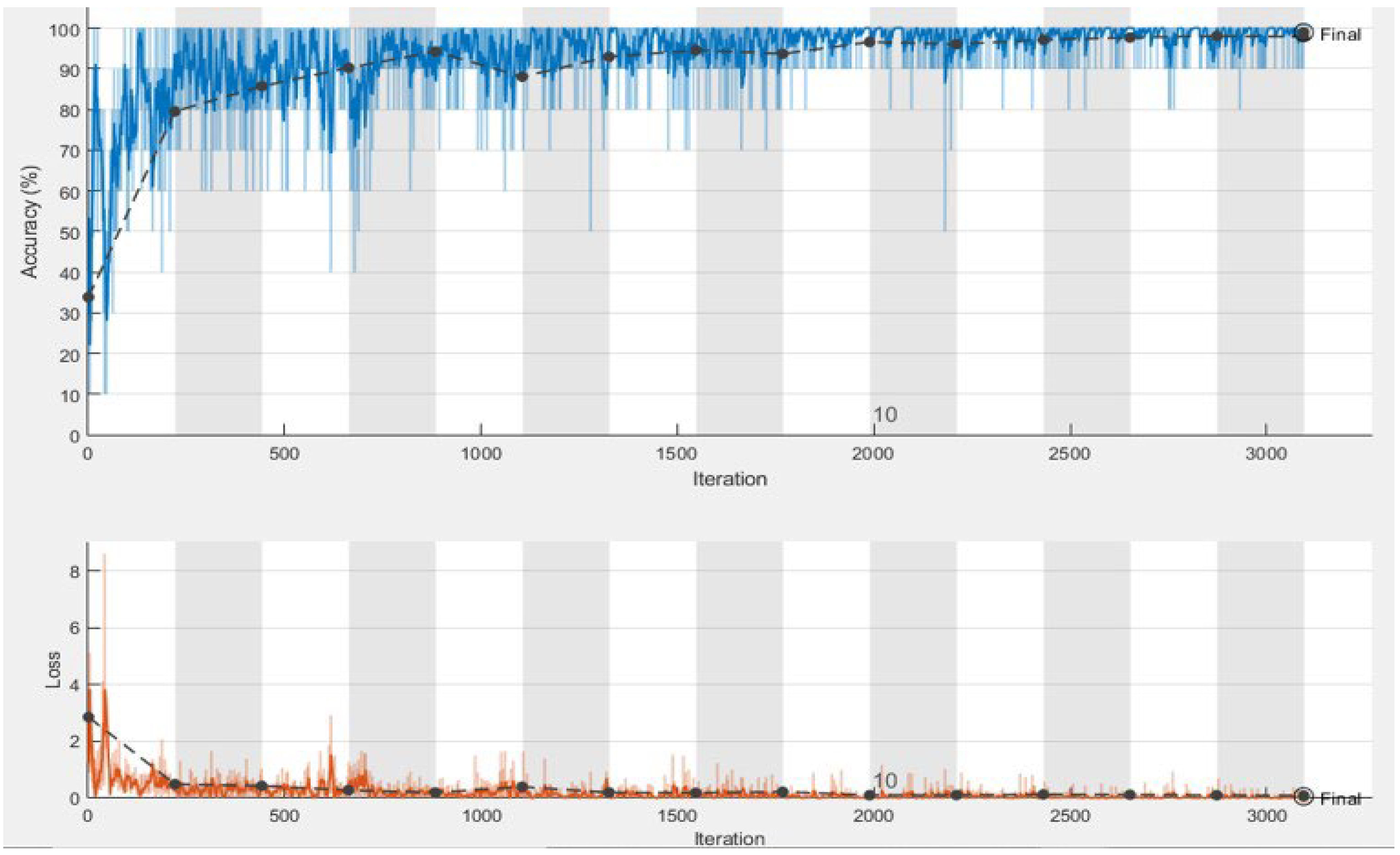
The training and validation process of our best performing deep neural network, i.e., Inceptionresnetv2, is shown in
Figure 4. The elapsed time returns the total CPU time used by the DL model since it was started, which is the time taken by the model to process (classify) all images of the dataset. Since we used the data augmentation technique, which significantly increased the dataset’s size, all models took considerable time for classification. This time also depended on the depth and architectural design of the models. The elapsed time is expressed in seconds. The Shufflenet TL model was the most efficient elapsed time classifier, achieving satisfactory classification results and taking the shortest time, 159 min, for brain tumor classification. In contrast, the Xception TL model took a maximum time of 1730 min 25 sec to identify and classify brain tumor MRI images into different types. The Shufflenet model is fast because it uses two new operations, i.e., channel shuffle and pointwise group convolution, significantly reducing computation costs while retaining accuracy. It should be noted that the classification time for different variants of the Resnet TL classifiers increases with the number of framework layers. For example, Renset18 took a minimum time of 187 min 47 sec, and Resnet50 took 525 min 14 sec. Additionally, Resnet101 took the maximum time of 801 min 36 sec to classify brain tumors into meningioma, pituitary and glioma. Resnet18 achieved the lowest classification accuracy because of the ReLU activation function. The ReLU function outputs the positive input directly, whereas it outputs zero for negative inputs (x < 0). Therefore, the ReLU activation function fails to activate the neuron when it receives negative inputs, leaving no guarantee that all of the neurons would be active at all times, resulting in the dying ReLU problem. In this case, the network cannot learn using the optimization approach. The dying ReLU problem is undesirable because it causes a large percentage of the network to become idle over time. We can observe in
Table 3 that, in the case of different variants of Resnet, accuracy improves with increasing depths of the networks because a deeper DL-based model captures more complicated and essential deep features and increases the network’s classification performance. However, as the depth of the network expands, computational complexity increases, which ultimately affects the efficiency of the network. Furthermore, we can conclude from
Table 3 that the inceptionresnetv2 TL algorithm is identified as the best classification method for detecting and classifying brain tumors.
Inceptionresnetv2 achieved effective results for several reasons. Inceptionresnetv2 achieved the best classification results because of its capability to extract more discriminative, detailed and robust deep features. Inceptionresnetv2 possesses the features of both Resnet and Inception such as wider networks, hyperparameters, kernel filters, etc. The two DL models, i.e., Inception and Resnet, were combined to achieve high-performance results at lower epochs. Each Inception block in Inceptionresnetv2 is followed by 1 × 1 convolution without activation, i.e., a filter expansion layer to compensate for the dimensionality reduction caused by the inception block. To better utilize computing resources for the classification experiment, the number of inception blocks was increased by adding BN only on top of traditional layers, not on summations.
The benefits of using pre-trained DL frameworks with TL for the detection and classification of brain tumors into meningioma, pituitary and glioma are numerous; for example, the classification method is completely automated, and it removes the traditional stages of noise filtering, ROI delineation, feature extraction and selection. Moreover, the results achieved by the pre-trained DL frameworks are reproducible, and, in contrast to [
4,
5,
6,
7], the highest level of accuracy is attained. Furthermore, running pre-trained frameworks with TL on a single CPU computer is computationally expensive. For all pre-trained frameworks, the computation times for the TLs are approximately 159 min, 187 min, 318 min s, 525 min, 667 min, 801 min, 950 min, 1252 min and 1730 min. Even the most efficient model, shufflenet, took 159 min for brain tumor classification. Longer computation times were a result of all models being developed using the MATLAB 2020a platform and running on a PC with an Intel (R) Core (TM) i5-5200U CPU and 8GB of RAM. The computation times were long because we ran the code in a MATLAB environment with a single CPU.
4.5. Comparison with the Hybrid Approach
In this section, another hybrid experiment is performed to classify brain tumors into meningioma, pituitary and glioma to assess the efficacy of the identified best TL model, i.e., Inceptionresnetv2. It has been claimed that using an SVM classifier instead of typical deep neural networks at the top of the net significantly improves classification performance [
32]. Hence, we designed a hybrid approach in which we used the twelve most famous deep neural networks for in-depth feature extraction and used these features as inputs to train SVM with a linear kernel. We used Mobilnetv2, Densenet201, Squeeznet, Alexnet, Googlenet, Inceptionv3, Resnet50, Resnet18, Resnet101, Xception, Inceptionresnetv3, VGG19 and Shufflenet in the proposed work. The dataset images were resized differently according to the image input requirements of the deep neural networks by using augmented image data stores before inserting them into the DL network for feature extraction. We applied activations on the last global average pooling layer (a deeper layer) to extract high-level features. The classification results of deep features and the SVM approach are presented in
Table 4. This experiment shows that the deep features of all twelve networks and the SVM approach achieved lower accuracy results compared to the TL of Inceptionresnetv2. An accuracy of 98.91% signifies the effectiveness of the Inceptionresnetv2 deep neural network for reliable tumor classification.
4.6. Comparison with State-of-the-Art Related Work
We compared the classification performance of the best deep neural network, i.e., Inceptionresnetv2, with existing methods for classifying brain tumors into meningioma, pituitary and glioma tumors. More specifically, we compared the proposed work with state-of-the-art DL approaches [
4,
11,
16,
17,
24,
26,
28,
45]. Deepak et al. and Swati et al. used the same TL techniques for brain tumor classification [
17,
26]. Deepak et al. suggested a three-class classification approach based on deep TL [
26]. A pre-trained GoogLeNet model was used for the feature extraction of brain MRI scans to distinguish between glioma, meningioma and pituitary cancers. Proven classification models were employed to classify the collected features. The experiment used a five-fold cross-validation strategy on an MRI dataset from figshare. With an average accuracy of 98 %, the suggested method exceeds all current state-of-the-art approaches. The performance metrics used were the area under the curve (AUC), precision, recall, F-score and specificity. According to the study results, TL appears to be a valuable method when the availability of medical images is limited.
Researchers have used TL techniques and have succeeded in achieving the best results. Using a pre-trained VGG19 deep CNN model, Swati et al. developed a block-wise fine-tuning technique based on TL [
45]. A benchmark dataset of T1-weighted contrast-enhanced magnetic resonance imaging (CE-MRI) was used to test the proposed method. When validated in a five-fold cross-validation setting, the method achieved an average accuracy of 94.82% for the classification of meningioma, pituitary and glioma brain tumors. The proposed technique outperformed state-of-the-art classification on the CE-MRI dataset, according to experimental findings. Arshia Rehman et al. [
17] proposed a framework and performed three studies to classify brain malignancies such as meningioma, glioma, and pituitary tumors utilizing three convolutional neural networks architectures (AlexNet, GoogLeNet, and VGGNet). Each study then investigated TL approaches, such as fine tuning and freezing, utilizing MRI slices from a brain tumor dataset (Figshare). Data augmentation techniques were used on MRI slices to help generalize results, increase dataset samples and reduce the risk of overfitting. In the presented studies, the fine-tuned VGG16 architecture achieved the greatest classification and detection accuracy of 98.69%.
Table 5 shows a comprehensive comparison of different approaches based on accuracy. Only accuracy is included in
Table 5 as a performance parameter because it is the most prevalent metric used in all relevant studies. According to our current knowledge, Inceptionresnetv2’s TL beats all current state-of-the-art approaches in the literature. The proposed approach attains the best results because of its capability to extract more robust and distinctive deep features for classification. Moreover, we used a balanced dataset (
brain tumor classification (MRI) dataset). In contrast, the datasets (CE-MRI) used in previous approaches such as [
17,
26] and other approaches (mentioned in
Table 5) were unbalanced, comprising 1426, 708, and 930 MRI images of glioma, meningioma, and pituitary brain tumors, respectively. The third column of
Table 5 defines the percentage of the whole dataset used for training. We used 80% of the data for training all nine deep neural networks.
5. Conclusions
This paper presents a comparative analysis of nine DL models for the classification of brain tumors through TL. The aim of this effort was to automate the process of detecting brain tumors by finding the best DL classifier for brain tumor classification. We applied TL to nine deep neural networks, i.e., Inceptionresnetv2, Inceptionv3, Xception, Resnet18, Resnet50, Resnet101, Shufflenet, Densenet201, and Mobilenetv2, and classified brain tumors into glioma, meningioma, and pituitary using a brain tumor classification (MRI) dataset. Our experimental findings validate that the Inceptionresnetv2 model achieved the most effective results for the classification of brain tumors. An accuracy of 98.71% signifies the effectiveness of Inceptionresnetv2 for reliable brain tumor classification. An accuracy of 98.91% for brain tumor classification has confirmed the superiority of the best model (Inceptionresnetv2) over other hybrid approaches in which we used DL models for deep features extraction and SVM for the classification of brain tumors. Although this paper explored TL of nine DL models for the classification of brain tumor MRI images, other models remain to be explored. Despite the limited data in our dataset, we have achieved satisfactory results. We applied data augmentation techniques to increase the size of the training dataset. However, the results can be further improved in the future by training the model with a larger dataset.
Moreover, despite the accomplishments of this study, some improvements are still possible: firstly, the comparatively weak performance of the pre-trained DL models as stand-alone classifiers; secondly, significant training time elapsed by the transfer of learned deep neural networks; and thirdly, because of limited training data, the phenomenon of overfitting was observed. Future exploration in this domain can address these issues, possibly utilizing larger datasets for training and further tuning the transfer of learned deep neural networks. In the future, we will explore the TL of the remaining powerful deep neural networks for brain tumor detection and classification with less time complexity. Furthermore, we will also apply image segmentation techniques to improve the performance of our best performing model.



 ,
, 




{kind=link}
{kind=link}
{kind=link}
{kind=link}