
A Sample Balance-Based Regression Module for Object Detection in Construction Sites



Abstract
:1. Introduction
- Considering the redundancy problem of bounding boxes in the construction site, it is caused by the imbalance of hard and easy samples in the BBR process. The strategy of balancing hard and easy samples is introduced into the IOU-based loss to help the BBR as much as possible by segmenting the hard and easy samples.
- The strategy of balancing hard and easy samples is also introduced into the -norm loss by controlling the regression gradient to obtain better regression results.
- Compared with the previous object detection loss function, this loss function introduces the hard-versus-easy sample balancing strategy and combines the IOU-based loss and the -norm loss as a new loss function to obtain better performance.
2. Related Work
2.1. Imbalance of Hard and Easy Sample
2.2. Object Detection in Construction Sites
3. Materials and Methods
3.1. Experiments Details
3.1.1. Dataset and Evaluation Metric
3.1.2. Implementation Details
3.1.3. Network Architecture
3.2. Limitations of IOU-Based Losses
3.2.1. Limitations of IOU Loss
3.2.2. Limitations of Generalized IOU Loss
3.2.3. Limitations of Complete IOU Loss
3.2.4. Limitations of Efficient IOU Loss
3.3. EfocalL1-SEIOU Loss for BBR
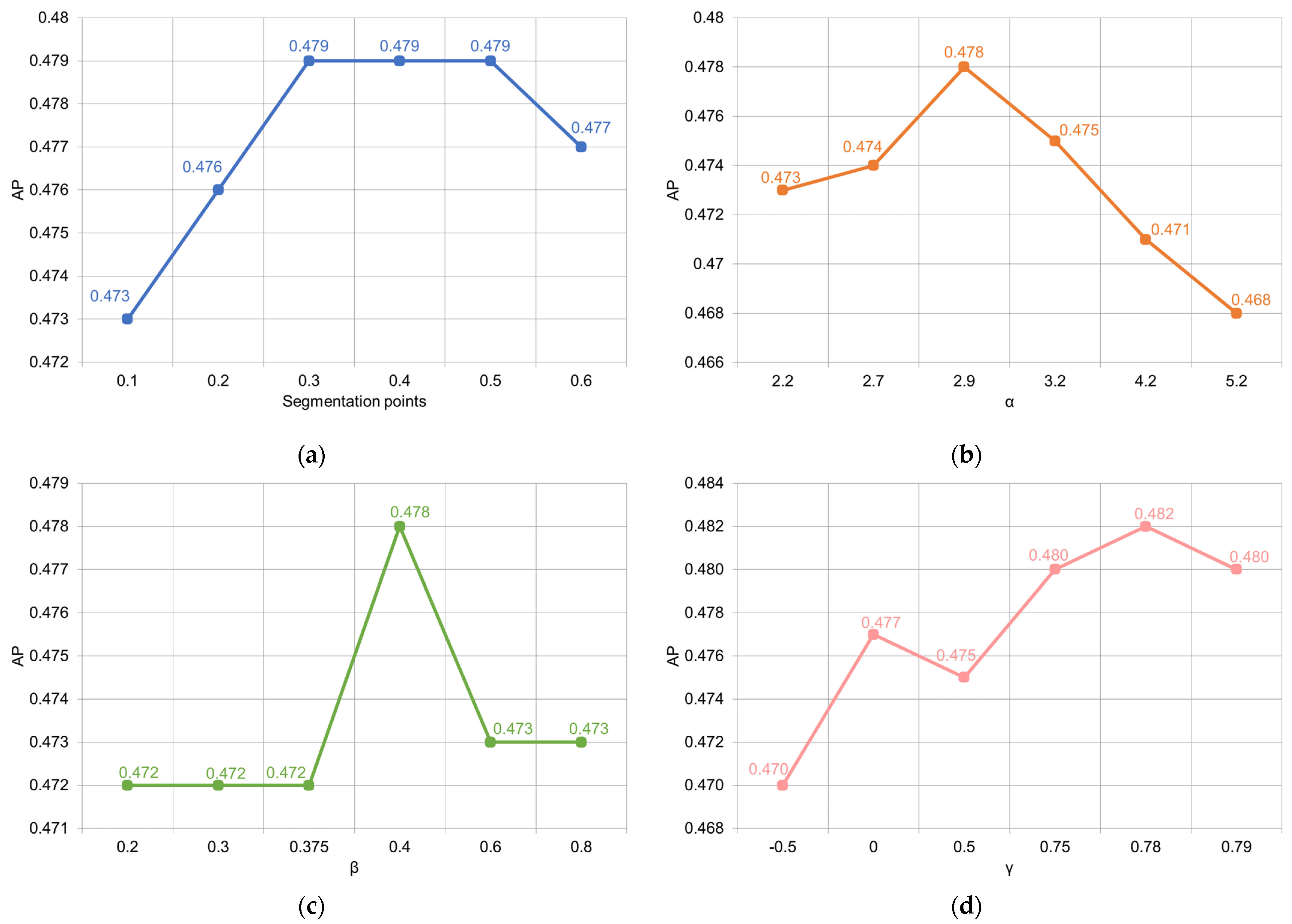
3.3.1. Segmented Efficient Intersection over Union Loss
3.3.2. Efficient FocalL1 Loss
3.3.3. EfocalL1-SEIOU Loss
4. Results
4.1. Ablation Studies on SEIOU Loss
4.2. Ablation Studies on EfocalL1 Loss
4.3. Ablation Studies on EfocalL1-SEIOU Loss
4.4. Overall Ablation Studies
4.5. Incorporations with State-of-the-Arts
5. Limitation and Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Sacks, R.; Radosavljevic, M.; Barak, R. Requirements for building information modeling based lean production management systems for construction. Autom. Constr. 2010, 19, 641–655. [Google Scholar] [CrossRef] [Green Version]
- Su, Y.Y.; Liu, L.Y. Real-time tracking and analysis of construction operations. In Proceedings of the 2007 ASCE/CIB Construction Research Congress, Grand Bahama Island, Bahamas, 6–8 May 2007. [Google Scholar]
- Mukhiddinov, M.; Cho, J. Smart Glass System Using Deep Learning for the Blind and Visually Impaired. Electronics 2021, 10, 2756. [Google Scholar] [CrossRef]
- Mukhiddinov, M.; Abdusalomov, A.B.; Cho, J. Automatic Fire Detection and Notification System Based on Improved YOLOv4 for the Blind and Visually Impaired. Sensors 2022, 22, 3307. [Google Scholar] [CrossRef] [PubMed]
- Park, M.W.; Elsafty, N.; Zhu, Z.H. Hardhat-wearing detection for enhancing on-site safety of construction workers. J. Constr. Eng. Manag. 2015, 141, 04015024. [Google Scholar] [CrossRef]
- Kim, D.; Liu, M.Y.; Lee, S.H.; Kamat, V.R. Remote proximity monitoring between mobile construction resources using camera-mounted UAVs. Autom. Constr. 2019, 99, 168–182. [Google Scholar] [CrossRef]
- Roberts, D.; Golparvar-Fard, M. End-to-end vision-based detection, tracking and activity analysis of earthmoving equipment filmed at ground level. Autom. Constr. 2019, 105, 102811. [Google Scholar] [CrossRef]
- Fang, Q.; Li, H.; Luo, X.C.; Ding, L.Y.; Luo, H.B.; Rose, T.M.; An, W.P. Detecting non-hardhat-use by a deep learning method from far-field surveillance videos. Autom. Constr. 2018, 85, 1–9. [Google Scholar] [CrossRef]
- Fang, Q.; Li, H.; Luo, X.C.; Ding, L.Y.; Rose, T.M.; An, W.P.; Yu, Y.T. A deep learning-based method for detecting non-certified work on construction sites. Adv. Eng. Inform. 2018, 35, 56–68. [Google Scholar] [CrossRef]
- Luo, X.C.; Li, H.; Cao, D.P.; Dai, F.; Seo, J.; Lee, S.H. Recognizing diverse construction activities in site images via relevance networks of construction-related objects detected by convolutional neural networks. J. Comput. Civ. Eng. 2018, 32, 04018012. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. NeurIPS 2012, 25, 1106–1114. [Google Scholar] [CrossRef]
- Sermanet, P.; Eigen, D.; Zhang, X.; Mathieu, M.; Fergus, R.; LeCun, Y. Overfeat: Integrated recognition, localization and detection using convolutional networks. arXiv 2013, arXiv:1312.6229. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7 June 2015; pp. 1–9. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26–30 June 2016; pp. 770–778. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer vision and Pattern Recognition, Honolulu, HI, USA, 16–21 July 2017; pp. 2117–2125. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]
- Guo, C.; Fan, B.; Zhang, Q.; Xiang, S.; Pan, C. Augfpn: Improving multi-scale feature learning for object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 12595–12604. [Google Scholar]
- Ghiasi, G.; Lin, T.Y.; Le, Q.V. Nas-fpn: Learning scalable feature pyramid architecture for object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–21 June 2019; pp. 7036–7045. [Google Scholar]
- Xu, H.; Yao, L.; Zhang, W.; Liang, X.; Li, Z. Auto-fpn: Automatic network architecture adaptation for object detection beyond classification. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–3 November 2019; pp. 6649–6658. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the European Conference on Computervision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 21–37. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Ren, S.Q.; He, K.M.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 91–99. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.M.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Shenzhen, China, 22–29 October 2017; pp. 2999–3007. [Google Scholar]
- Cui, Y.; Jia, M.; Lin, T.Y.; Song, Y.; Belongie, S. Class balanced loss based on effective number of samples. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–21 June 2019; pp. 9260–9269. [Google Scholar]
- Pang, J.M.; Chen, K.; Shi, J.P.; Feng, H.J.; Ouyang, W.L.; Lin, D.H. Libra R-CNN: Towards balanced learning for object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–21 June 2019; pp. 821–830. [Google Scholar]
- Li, B.; Liu, Y.; Wang, X. Gradient harmonized single-stage detector. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 24 January–1 February 2019; Volume 33, pp. 8577–8584. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- He, K.M.; Zhang, X.Y.; Ren, S.Q.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 13–16 December 2015; pp. 1440–1448. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26–30 June 2016; pp. 779–788. [Google Scholar]
- Zhang, H.K.; Chang, H.; Ma, B.P.; Wang, N.Y.; Chen, X.L. Dynamic R-CNN: Towards high quality object detection via dy-namic training. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2020; pp. 260–275. [Google Scholar]
- Zhang, Y.F.; Ren, W.Q.; Zhang, Z.; Jia, Z.; Wang, L.; Tan, T.N. Focal and efficient IOU loss for accurate bounding box regression. arXiv 2021, arXiv:2101.08158. [Google Scholar]
- Yu, J.H.; Jiang, Y.N.; Wang, Z.Y.; Cao, Z.M.; Huang, T. Unitbox: An advanced object detection network. In Proceedings of the 24th ACM International Conference on Multimedia, New York, NY, USA, 15–19 October 2016; pp. 516–520. [Google Scholar]
- Rezatofighi, H.; Tsoi, N.; Gwak, J.Y.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized intersection over union: A metric and a loss for bounding box regression. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 658–666. [Google Scholar]
- Zheng, Z.H.; Wang, P.; Liu, W.; Li, J.Z.; Ye, R.G.; Ren, D.W. Distance-iou loss: Faster and better learning for bounding box regression. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–16 February 2020; pp. 12993–13000. [Google Scholar]
- Chen, Z.M.; Chen, K.A.; Lin, W.Y.; See, J.; Yu, H.; Ke, Y.; Yang, C. Piou loss: Towards accurate oriented object detection in complex environments. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2020; pp. 195–211. [Google Scholar]
- He, J.B.; Erfani, S.; Ma, X.J.; Bailey, J.; Chi, Y.; Hua, X.S. Alpha-IoU: A Family of Power Intersection over Union Losses for Bounding Box Regression. Proc. Adv. Neural Inf. Process. Syst. 2021, 34, 20230–20242. [Google Scholar]
- He, K.M.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Shenzhen, China, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Cai, Z.W.; Vasconcelos, N. Cascade R-CNN: Delving into high quality object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6154–6162. [Google Scholar]
- Chen, Q.; Wang, Y.M.; Yang, T.; Zhang, X.Y.; Cheng, J.; Sun, J. You only look one-level feature. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 13 November 2021; pp. 13034–13043. [Google Scholar]
- An, X.H.; Zhou, L.; Liu, Z.G.; Wang, C.Z.; Li, P.F.; Li, Z.W. Dataset and benchmark for detecting moving objects in construction sites. Autom. Constr. 2021, 122, 103482. [Google Scholar]
- Shrivastava, A.; Gupta, A.; Girshick, R. Training region-based object detectors with online hard example mining. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26–30 June 2016; pp. 761–769. [Google Scholar]
- Roberts, D.; Bretl, T.; Golparvar-Fard, M. Detecting and classifying cranes using camera-equipped UAVs for monitoring crane-related safety hazards. J. Comput. Civ. Eng. 2017, 2017, 442–449. [Google Scholar]
- Kim, H.; Kim, H.; Hong, Y.W.; Byun, H. Detecting construction equipment using a region-based fully convolutional network and transfer learning. J. Comput. Civ. Eng. 2018, 32, 04017082. [Google Scholar] [CrossRef]
- Paszke, A.; Gross, S.; Chintala, S.; Chanan, G.; Yang, E.; DeVito, Z.; Lin, Z.M.; Desmaison, A.; Antiga, L.; Lerer, A. Automatic differentiation in pytorch. In Proceedings of the 31st Conference on Neural Information Processing Systems, Long Beach, CA, USA, 3–9 December 2017. [Google Scholar]
- Oksuz, K.; Cam, B.C.; Kalkan, S.; Akbas, E. Imbalance problems in object detection: A Review. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 3388–3415. [Google Scholar] [CrossRef] [PubMed] [Green Version]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | AP | |||||
|---|---|---|---|---|---|---|
| Baseline | 0.458 | 0.730 | 0.501 | 0.171 | 0.364 | 0.564 |
| IOU | 0.476 | 0.728 | 0.520 | 0.179 | 0.373 | 0.590 |
| GIOU | 0.476 | 0.729 | 0.521 | 0.174 | 0.376 | 0.589 |
| CIOU | 0.476 | 0.731 | 0.519 | 0.178 | 0.376 | 0.589 |
| EIOU | 0.472 | 0.723 | 0.514 | 0.167 | 0.374 | 0.585 |
| EfocalL1 | 0.478 | 0.724 | 0.522 | 0.174 | 0.372 | 0.597 |
| SEIOU | 0.479 | 0.736 | 0.522 | 0.174 | 0.376 | 0.594 |
| EfocalL1-SEIOU | 0.482 | 0.728 | 0.524 | 0.189 | 0.374 | 0.594 |
| Setting | AP | |||||
|---|---|---|---|---|---|---|
| Baseline | 0.458 | 0.730 | 0.501 | 0.171 | 0.364 | 0.564 |
| BalancedL1 | 0.473 | 0.723 | 0.520 | 0.171 | 0.368 | 0.587 |
| FocalL1 | 0.469 | 0.729 | 0.515 | 0.179 | 0.371 | 0.580 |
| EfocalL1 | 0.478 | 0.724 | 0.522 | 0.174 | 0.372 | 0.597 |
| Method | Backbone | AP | |||||
|---|---|---|---|---|---|---|---|
| Faster R-CNN | ResNet-50-FPN | 0.458 | 0.730 | 0.501 | 0.171 | 0.364 | 0.564 |
| Faster R-CNN * | ResNet-50-FPN | 0.482 | 0.728 | 0.524 | 0.189 | 0.374 | 0.594 |
| Mask R-CNN | ResNet-50-FPN | 0.477 | 0.727 | 0.527 | 0.176 | 0.374 | 0.593 |
| Mask R-CNN * | ResNet-50-FPN | 0.486 | 0.727 | 0.526 | 0.172 | 0.385 | 0.602 |
| Cascade R-CNN | ResNet-50-FPN | 0.514 | 0.736 | 0.561 | 0.176 | 0.396 | 0.632 |
| Cascade R-CNN * | ResNet-50-FPN | 0.520 | 0.733 | 0.566 | 0.184 | 0.400 | 0.636 |
| YOLOF | ResNet-50 | 0.376 | 0.620 | 0.397 | 0.073 | 0.232 | 0.524 |
| YOLOF * | ResNet-50 | 0.389 | 0.622 | 0.409 | 0.061 | 0.254 | 0.541 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, X.; Wang, H.; Zhang, C.; He, Q.; Huo, L. A Sample Balance-Based Regression Module for Object Detection in Construction Sites. Appl. Sci. 2022, 12, 6752. https://doi.org/10.3390/app12136752
Wang X, Wang H, Zhang C, He Q, Huo L. A Sample Balance-Based Regression Module for Object Detection in Construction Sites. Applied Sciences. 2022; 12(13):6752. https://doi.org/10.3390/app12136752
Chicago/Turabian StyleWang, Xiaoyu, Hengyou Wang, Changlun Zhang, Qiang He, and Lianzhi Huo. 2022. "A Sample Balance-Based Regression Module for Object Detection in Construction Sites" Applied Sciences 12, no. 13: 6752. https://doi.org/10.3390/app12136752
APA StyleWang, X., Wang, H., Zhang, C., He, Q., & Huo, L. (2022). A Sample Balance-Based Regression Module for Object Detection in Construction Sites. Applied Sciences, 12(13), 6752. https://doi.org/10.3390/app12136752