
Comparative Study of Various Neural Network Types for Direct Inverse Material Parameter Identification in Numerical Simulations



Abstract
:1. Introduction
2. Materials and Methods
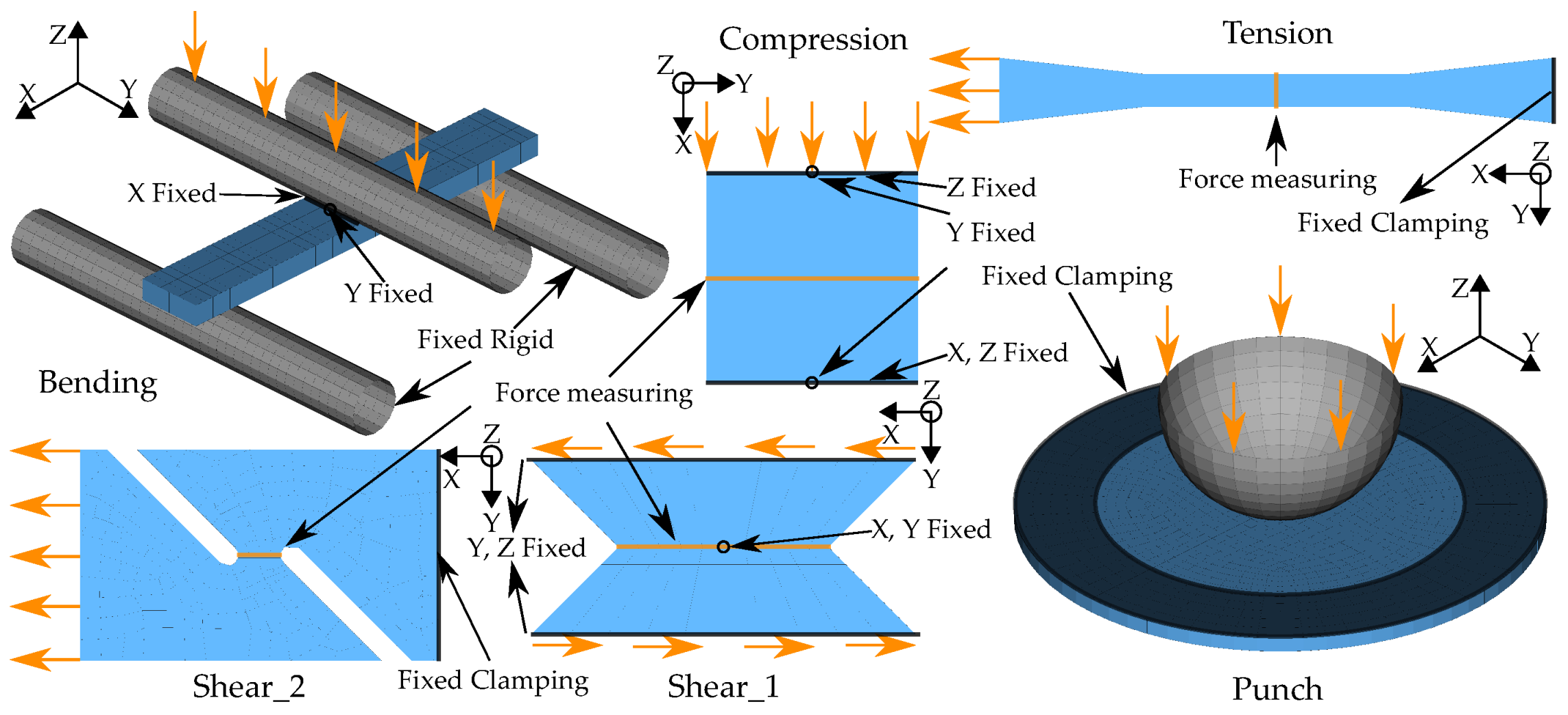
2.1. Virtual Dataset under Investigation
- a quasi-static tensile test;
- four strain rate dependent tensile tests (velocity 1–4);
- a compression test;
- a three-point bending test;
- a punch test;
- and two different shear tests.
2.2. Direct, Inverse Neural Network-Based Material Parameter Identification Process
2.2.1. Multilayer Perceptron
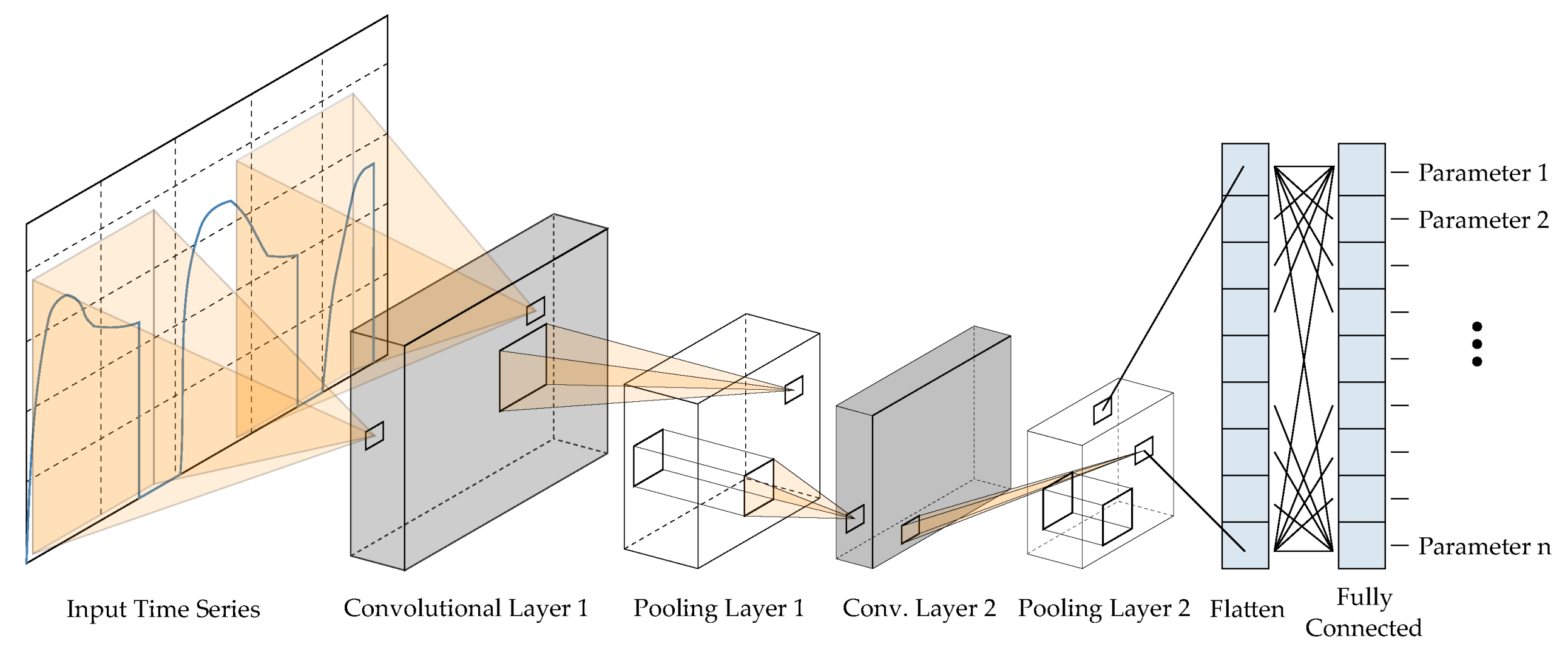
2.2.2. Convolutional Neural Networks
2.2.3. Bayesian Neural Networks
2.3. Experimental Plan for Comparative Study
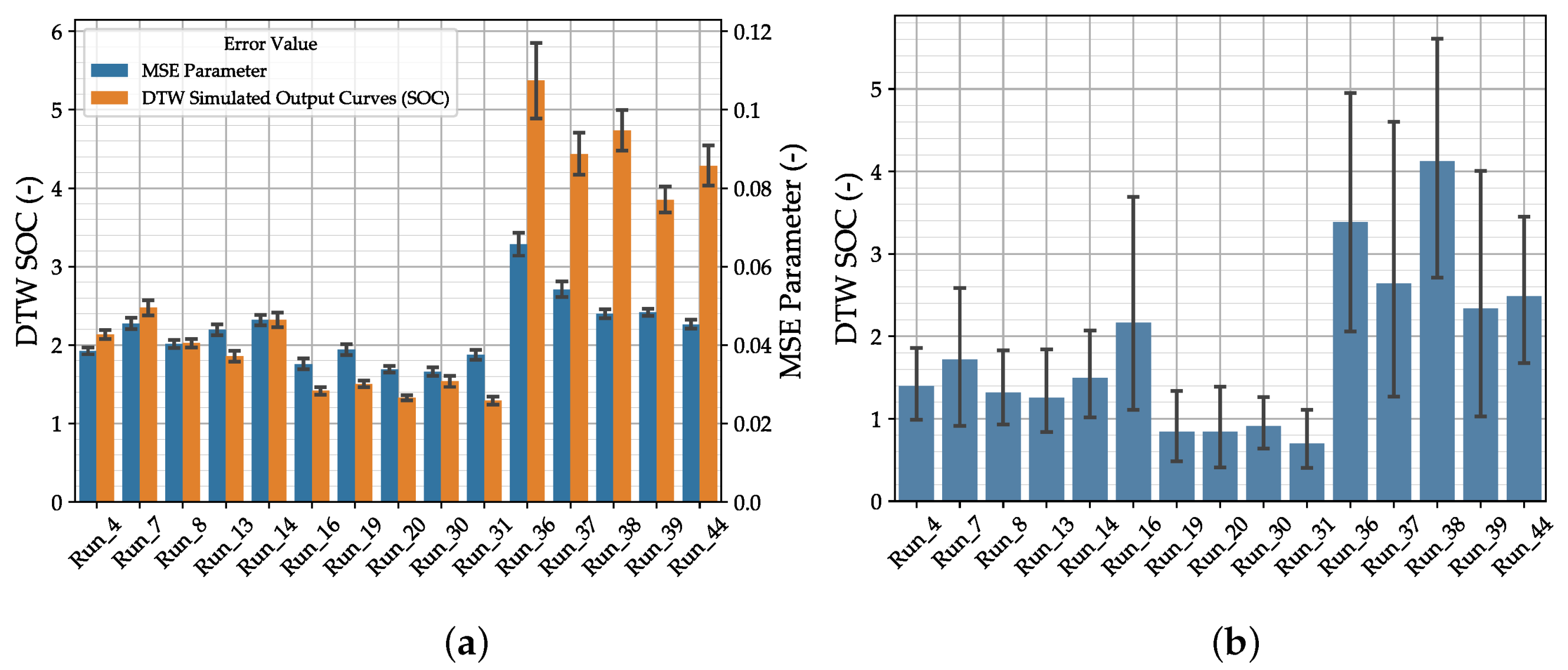
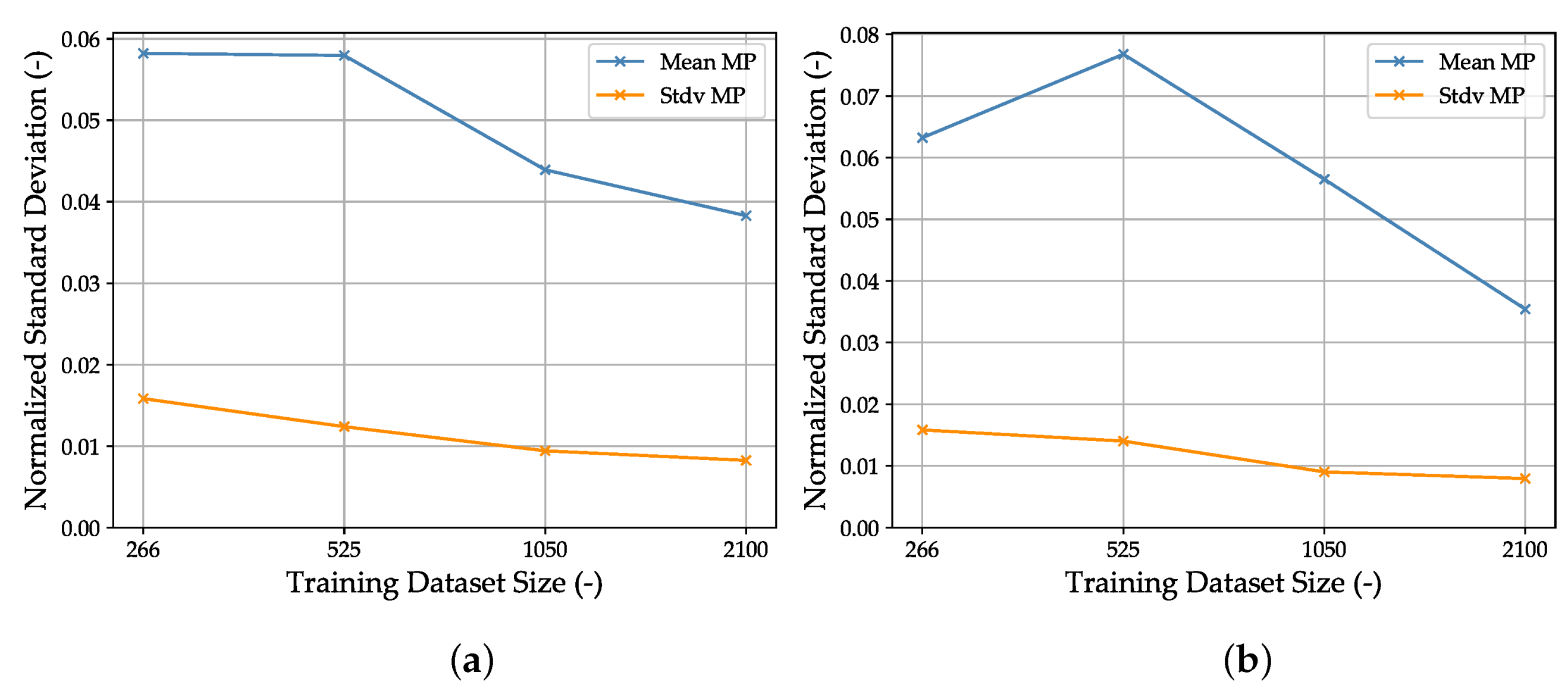
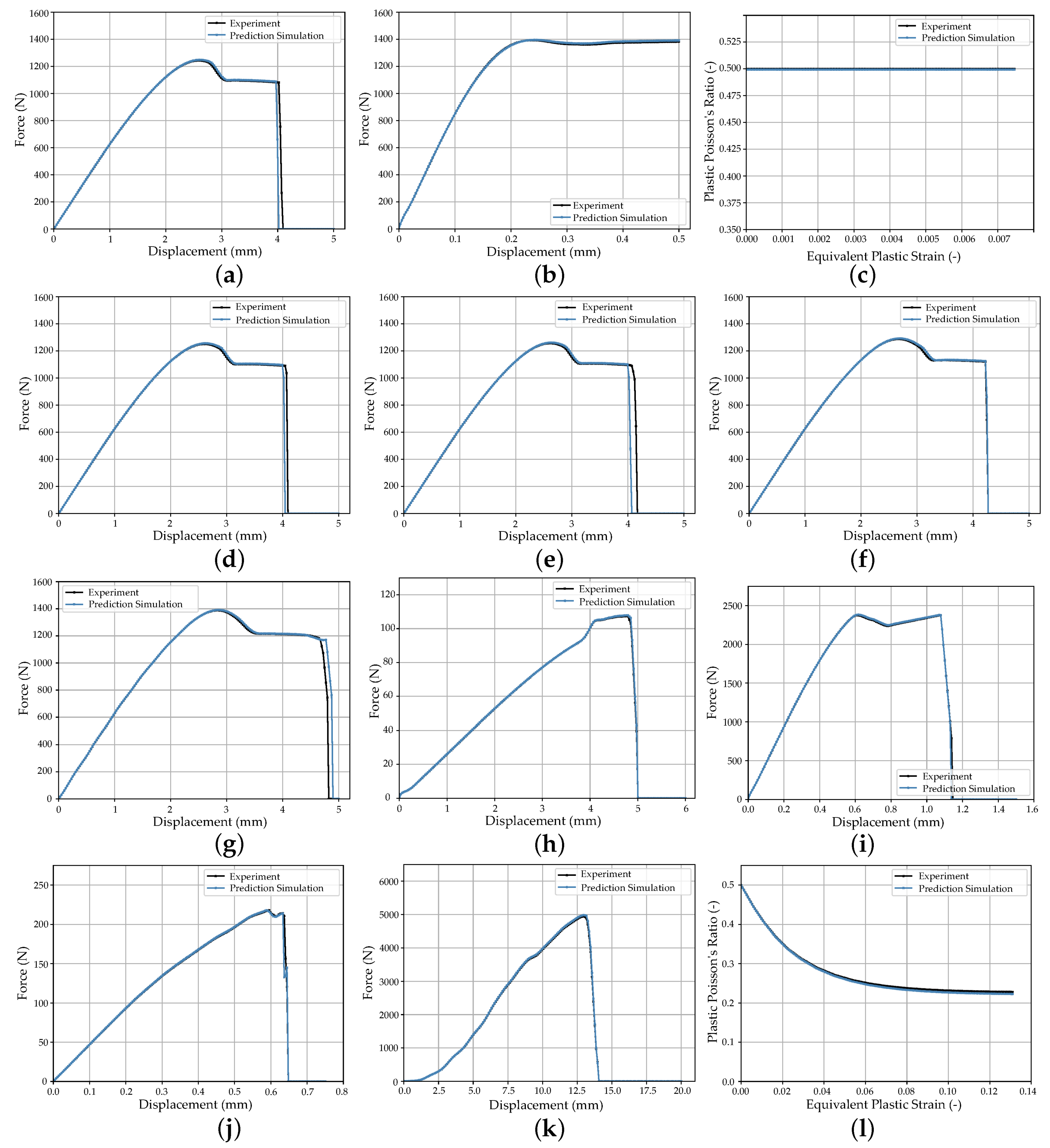
3. Results and Discussion
4. Conclusions and Outlook
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| ABS | Acrylonitrile Butadiene Styrene |
| AI | Artificial Intelligence |
| AUG | Augmentation |
| BNN | Bayesian Neural Network(s) |
| BCNN | Bayesian Convolution Neural Network(s) |
| CAE | Computer Aided Engineering |
| CNN | Convolutional Neural Network |
| CL | Custom Loss |
| CLF | Custom Loss Function |
| COL | Combined Loss Function |
| DA | Data Augmentation |
| DTW | Dynamic Time Warping |
| DVL | DenseVariational Layer |
| EMD | Empirical Mode Decomposition |
| EPS | Equivalent Plastic Strain |
| EPSF | Equivalent Plastic Strain at Failure |
| FCL | Fully Connected Layer |
| FCN | Fully Convolutional Neural Network |
| FDC | Force–Displacement Curve(s) |
| FE | Finite Element |
| FFANN | FeedForward Artificial Neural Network |
| GAP | Global Average Pooling |
| GD | Gradient Descent |
| GISSMO | Generalized Incremental Stress State-Dependent Damage Model |
| HL | Hidden Layer(s) |
| HP | Hyperparameter(s) |
| HPO | Hyperparameter Optimization |
| IMF | Intrinsic Mode Function |
| LHS | Latin Hypercube Sampling |
| MCDCNN | Multi-Channel Deep Convolutional Neural Network |
| MCIC | Material Card Input Curve(s) |
| ML | Machine Learning |
| MLP | Multilayer Perceptron |
| MP | Material Parameter(s) |
| MPI | Material Parameter Identification |
| MSE | Mean Squared Error |
| MTS | Multivariate Time Series |
| NLL | Negative Log-Likelihood |
| Probability Density Function | |
| PEC | Plastic Poisson’s Ratio – Equivalent Plastic Strain Curve(s) |
| PI | Parameter Identification |
| PPR | Plastic Poisson’s Ratio |
| SANN | Stochastic Artificial Neural Networks |
| SOC | Simulation Output Curve(s) |
| STDV | Standard Deviation |
| TFP | TensorFlow Probability |
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Input Name | Value |
|---|---|
| ro | |
| nue | |
| dtyp | |
| ecrit | |
| dmgexp | |
| dcrit |
| MP Name | MPexp | MPMin | MPMax | MCIC |
|---|---|---|---|---|
| emod (MPa) | - | |||
| at (-) | 43,416.1 | 40,000.0 | 46,000.0 | lcid-t; lcid-t1–lcid-t4 |
| bt (-) | lcid-t; lcid-t1–lcid-t4 | |||
| ct (-) | lcid-t; lcid-t1–lcid-t4 | |||
| dt (-) | lcid-t; lcid-t1–lcid-t4 | |||
| ac (-) | 51,000.0 | 47,000.0 | 52,000.0 | lcid-c |
| bc (-) | lcid-c | |||
| cc (-) | lcid-c | |||
| dc (-) | lcid-c | |||
| p,plat (-) | lcid-p | |||
| p,press (-) | lcid-p | |||
| p,plat (-) | lcid-p | |||
| C () | 27,572.1 | 15,000.0 | 50,000.0 | lcid-t1–lcid-t4 |
| P (-) | lcid-t1–lcid-t4 | |||
| epsf0 (-) | lcsdg | |||
| epsf1 (-) | lcsdg | |||
| epsf2 (-) | lcsdg | |||
| epsf3 (-) | lcsdg |
| (Hyper-)Parameter | Default_MLP | MLPHPO |
|---|---|---|
| Batch Size | 25 | 40 |
| Maximum Epochs * | 500 | 500 |
| Early Stopping Patience * | 60 | 60 |
| Neurons (IL) * | 2400 | 2400 |
| Hidden Layers | 1 | 2 |
| Neurons (HL1) | 100 | 330 |
| Kernel Initializer (HL1) | He Uniform | He Uniform |
| Activation (HL1) | Hard Sigmoid | Hard Sigmoid |
| Dropout (HL1) | ||
| Neurons (HL2) | - | 400 |
| Kernel Initializer (HL2) | - | Normal |
| Activation (HL2) | - | Softsign |
| Dropout (HL2) | - | |
| Neurons (Output Layer) * | 19 | |
| Kernel Initializer (OL) | He Uniform | He Uniform |
| Activation (OL) * | Linear | Linear |
| Gradient Descent Optimizer | Adam | Adamax |
| HP Optimizer | - | Bayesian |
| HPO max. Trials | - | 500 |
| (Hyper-)Parameter | Search Range |
|---|---|
| Batch Size | 20; 25 *; 30; …; 150 |
| Number HL | 1 *; 2; 3 |
| Neurons (HL1) | 30; 40; 50 *; …; 500 |
| Kernel Initializer (HL) | Normal *; Uniform; Glorot Uniform; Lecun Uniform; Glorot Normal; He Normal; He Uniform |
| Activation (HL1) | Softmax; Softplus; Softsign; Relu *; Sigmoid; Hard Sigmoid |
| Dropout (HL1) | ; ; *; …; |
| Neurons (HL2) | 30; 40; 50 *; …; 500 |
| Kernel Initializer (HL2) | Normal *; Uniform; Glorot Uniform; Lecun Uniform; Glorot Normal; He Normal; He Uniform |
| Activation (HL2) | Softmax; Softplus; Softsign; Relu *; Sigmoid; Hard Sigmoid |
| Dropout (HL2) | ; ; *; …; |
| Neurons (HL3) | 30; 40; 50*; …; 500 |
| Kernel Initializer (HL3) | Normal *; Uniform; Glorot Uniform; Lecun Uniform; Glorot Normal; He Normal; He Uniform |
| Activation (HL3) | Softmax; Softplus; Softsign; Relu *; Sigmoid; Hard Sigmoid |
| Dropout (HL3) | ; ; *; …; |
| Kernel Initializer (OL) | Normal *; Uniform; Lecun Uniform; Glorot Normal; He Normal; He Uniform |
| GD Optimizer | Adam *; Adagrad; Adamax; Nadam |
| (Hyper-)Parameter | Default_CNN | CNNHPO | FCN2 | FCN3 |
|---|---|---|---|---|
| Batch Size | 16 | 16 | 16 | 16 |
| Maximum Epochs | 1000 | 1000 | 1000 | 2000 |
| Early Stopping Patience | 100 | 100 | none | 100 |
| Layer 1 | Conv1D | Conv1D | Conv1D | Conv1D |
| Layer 1 Filters | 6 | 12 | 12 | 12 |
| Layer 1 Kernel Size | 7 | 2 | 8 | 8 |
| Layer 1 Activation | Sigmoid | Tanh | Relu | Relu |
| Layer 1 Batch Normalization | no | no | no | yes |
| Layer 1 Pooling | Average Pooling1D | Average Pooling1D | no | no |
| Layer 1 Pooling Size | 3 | 7 | - | - |
| Layer 2 | Conv1D | Conv1D | Conv1D | Conv1D |
| Layer 2 Filters | 12 | 128 | 24 | 24 |
| Layer 2 Kernel Size | 7 | 2 | 5 | 5 |
| Layer 2 Activation | Sigmoid | Tanh | Relu | Relu |
| Layer 2 Batch Normalization | no | no | no | yes |
| Layer 2 Pooling | Average Pooling1D | Average Pooling1D | no | no |
| Layer 2 Pooling Size | 3 | 5 | - | - |
| Layer 3 | - | - | Conv1D | Conv1D |
| Layer 3 Filters | - | - | 24 | 24 |
| Layer 3 Kernel Size | - | - | 3 | 3 |
| Layer 3 Activation | - | - | Relu | Relu |
| Layer 3 Batch Normalization | - | - | no | yes |
| Layer 3 Pooling | - | - | no | no |
| Layer 4 | Flatten | Flatten | Global Average Pooling1D | Global Average Pooling1D |
| Dense Output Layer Neurons | 18 | 18 | 18 | 18 |
| Gradient Descent Optimizer | Adam | Adam | Adam | Adam |
| HP Optimizer | - | Bayesian | - | - |
| HPO max. Trials | - | 250 | - | - |
| (Hyper-)Parameter | Search Range |
|---|---|
| Layer 1 Filters | 3; 6; 12; 16; 32; 64; 128 |
| Layer 1 Kernel Size | 2; 3; 5; 7; 9 |
| Layer 1 Pooling Size | 2; 3; 5; 7 |
| Layer 2 Filters | 3; 6; 12; 16; 32; 64; 128 |
| Layer 2 Kernel Size | 2; 3; 5; 7; 9 |
| Layer 2 Pooling Size | 2; 3; 5; 7 |
| Activation Function | Relu; Sigmoid; Tanh |
| GD Optimizer | Adam; Adamax; Nadam |
| (Hyper-)Parameter | BNN1 | BNN2 | BNN3 |
|---|---|---|---|
| Batch Size | 25 | 25 | 25 |
| Maximum Epochs | 20,000 | 20,000 | 5000 |
| Early Stopping | none | none | none |
| Batch- Normalization- Layer | yes | yes | yes |
| Not Stochastic- Hidden FCL | no | no | yes |
| Not Stochastic- FCL Neurons | - | - | 100 |
| Not Stochastic- FCL Activation | - | - | Sigmoid |
| Not Stochastic- FCL Kernel- Initializer | - | - | Glorot Uniform |
| DVL Neurons | 30 | 20 | 25 |
| DVL Activation | Sigmoid | Sigmoid | Sigmoid |
| TFP Prior | Multivariate- NormalDiag | Multivariate- NormalDiag | Multivariate- NormalDiag |
| TFP Posterior | Multivariate- NormalTriL | Multivariate- NormalTriL | Multivariate- NormalTriL |
| kl_use_exact | True | True | True |
| TFP Output Layer | IndependentNormal | IndependentNormal | IndependentNormal |
| GD Optimizer | RMSprop | RMSprop | RMSprop |
| Run | NN | Dataset | Loss | Noise AUG | EMD AUG | Eval. Point Number SOC | Prior Mean | Prior SDV |
|---|---|---|---|---|---|---|---|---|
| 1 | Default_MLP | 1 | MSE | No | No | 200 | - | - |
| 2 | Default_MLP | 2 | MSE | No | No | 200 | - | - |
| 3 | Default_MLP | 3 | MSE | No | No | 200 | - | - |
| 4 | Default_MLP | 4 | MSE | No | No | 200 | - | - |
| 5 | Default_MLP | 1 | COL | No | No | 200 | - | - |
| 6 | Default_MLP | 2 | COL | No | No | 200 | - | - |
| 7 | Default_MLP | 3 | COL | No | No | 200 | - | - |
| 8 | Default_MLP | 4 | COL | No | No | 200 | - | - |
| 9 | Default_MLP | 5 | COL | No | No | 200 | - | - |
| 10 | Default_MLP | 6 | COL | No | No | 200 | - | - |
| 11 | Default_MLP | 7 | COL | No | No | 200 | - | - |
| 12 | Default_MLP | 8 | COL | No | No | 200 | - | - |
| 13 | MLPHPO | 3 | COL | No | No | 200 | - | - |
| 14 | Default_MLP | 3 | COL | Yes | No | 200 | - | - |
| 15 | Default_MLP | 3 | COL | No | Yes | 200 | - | - |
| 16 | Default_CNN | 3 | MSE | No | No | 200 | - | - |
| 17 | Default_CNN | 1 | COL | No | No | 200 | - | - |
| 18 | Default_CNN | 2 | COL | No | No | 200 | - | - |
| 19 | Default_CNN | 3 | COL | No | No | 200 | - | - |
| 20 | Default_CNN | 4 | COL | No | No | 200 | - | - |
| 21 | CNN_Yang | 3 | COL | No | No | 200 | - | - |
| 22 | CNN_Azizjon | 3 | COL | No | No | 200 | - | - |
| 23 | CNN_Rautela | 3 | COL | No | No | 200 | - | - |
| 24 | MCDCNN | 3 | COL | No | No | 200 | - | - |
| 25 | Resnet | 3 | COL | No | No | 200 | - | - |
| 26 | FCN | 3 | COL | No | No | 200 | - | - |
| 27 | Encoder | 3 | COL | No | No | 200 | - | - |
| 28 | FCN2 | 3 | COL | No | No | 200 | - | - |
| 29 | FCN3 | 3 | COL | No | No | 200 | - | - |
| 30 | CNNHPO | 3 | COL | No | No | 200 | - | - |
| 31 | Default_CNN | 3 | COL | Yes | No | 200 | - | - |
| 32 | Default_CNN | 3 | COL | No | Yes | 200 | - | - |
| 33 | BNN1 | 3 | NLL | No | No | 50 | 0 | 1 |
| 34 | BNN2 | 3 | NLL | No | No | 50 | 0 | 1 |
| 35 | BNN1 | 3 | NLL | No | No | 30 | 0 | 1 |
| 36 | BNN3 | 1 | NLL | No | No | 200 | 0 | 1 |
| 37 | BNN3 | 2 | NLL | No | No | 200 | 0 | 1 |
| 38 | BNN3 | 3 | NLL | No | No | 200 | 0 | 1 |
| 39 | BNN3 | 4 | NLL | No | No | 200 | 0 | 1 |
| 40 | BNN3 | 3 | NLL | No | No | 200 | 0 | |
| 41 | BNN3 | 3 | NLL | No | No | 200 | 0 | 2 |
| 42 | BNN3 | 3 | NLL | No | No | 200 | 2 | 1 |
| 43 | BNN3 | 3 | NLL | No | No | 200 | 1 | |
| 44 | BNN3 | 3 | NLL | Yes | No | 200 | 0 | 1 |
| 45 | BNN3 | 3 | NLL | No | Yes | 200 | 0 | 1 |
| SOC Type | SDV1 | SDV2 | SDV3 | SDV4 |
|---|---|---|---|---|
| FOC | 0.001 | 0.002 | 0.003 | 0.004 |
| PEC | 0.0005 | 0.0006 | 0.0007 | 0.0008 |
| Normalized Uncertainty (-) | Uncertainty Type | Run36 | Run37 | Run38 | Run39 | Run44 |
|---|---|---|---|---|---|---|
| STDV | aleatoric | |||||
| STDV of Mean | epistemic | |||||
| STDV of STDV | epistemic |



References
- Kohar, C.P.; Greve, L.; Eller, T.K.; Connolly, D.S.; Inal, K. A machine learning framework for accelerating the design process using CAE simulations: An application to finite element analysis in structural crashworthiness. Comput. Methods Appl. Mech. Eng. 2021, 385, 114008. [Google Scholar] [CrossRef]
- Jones, E.; Carroll, J.; Karlson, K.; Kramer, S.; Lehoucq, R.; Reu, P.; Turner, D. Parameter covariance and non-uniqueness in material model calibration using the Virtual Fields Method. Comput. Mater. Sci. 2018, 152, 268–290. [Google Scholar] [CrossRef]
- Mahnken, R. Identification of Material Parameters for Constitutive Equations. In Encyclopedia of Computational Mechanics Second Edition; Stein, E., Borst, R., Hughes, T.J.R., Eds.; John Wiley & Sons: Hoboken, NJ, USA, 2018. [Google Scholar] [CrossRef]
- Grabski, J.K.; Mrozek, A. Identification of elastoplastic properties of rods from torsion test using meshless methods and a metaheuristic. Comput. Math. Appl. 2021, 92, 149–158. [Google Scholar] [CrossRef]
- Kolodziej, J.A.; Jankowska, M.A.; Mierzwiczak, M. Meshless methods for the inverse problem related to the determination of elastoplastic properties from the torsional experiment. Int. J. Solids Struct. 2013, 50, 4217–4225. [Google Scholar] [CrossRef] [Green Version]
- Asaadi, E.; Wilke, D.N.; Heyns, P.S.; Kok, S. The use of direct inverse maps to solve material identification problems: Pitfalls and solutions. Struct. Multidiscip. Optim. 2016, 55, 613–632. [Google Scholar] [CrossRef] [Green Version]
- Meißner, P.; Winter, J.; Vietor, T. Methodology for Neural Network-Based Material Card Calibration Using LS-DYNA MAT_187_SAMP-1 Considering Failure with GISSMO. Materials 2022, 15, 643. [Google Scholar] [CrossRef]
- Morand, L.; Helm, D. A mixture of experts approach to handle ambiguities in parameter identification problems in material modeling. Comput. Mater. Sci. 2019, 167, 85–91. [Google Scholar] [CrossRef]
- Yagawa, G.; Okuda, H. Neural networks in computational mechanics. Arch. Comput. Methods Eng. 1996, 3, 435–512. [Google Scholar] [CrossRef]
- Abendroth, M.; Kuna, M. Determination of deformation and failure properties of ductile materials by means of the small punch test and neural networks. Comput. Mater. Sci. 2003, 28, 633–644. [Google Scholar] [CrossRef]
- Chamekh, A.; Salah, H.B.H.; Hambli, R. Inverse technique identification of material parameters using finite element and neural network computation. Int. J. Adv. Manuf. Technol. 2008, 44, 173–179. [Google Scholar] [CrossRef]
- Ktari, Z.; Leitão, C.; Prates, P.A.; Khalfallah, A. Mechanical design of ring tensile specimen via surrogate modelling for inverse material parameter identification. Mech. Mater. 2021, 153, 103673. [Google Scholar] [CrossRef]
- Rappel, H.; Beex, L.A.A.; Hale, J.S.; Noels, L.; Bordas, S.P.A. A Tutorial on Bayesian Inference to Identify Material Parameters in Solid Mechanics. Arch. Comput. Methods Eng. 2019, 27, 361–385. [Google Scholar] [CrossRef] [Green Version]
- Shridhar, K.; Laumann, F.; Liwicki, M. A Comprehensive guide to Bayesian Convolutional Neural Network with Variational Inference. arXiv 2019, arXiv:1901.02731. [Google Scholar] [CrossRef]
- Gundersen, K.; Alendal, G.; Oleynik, A.; Blaser, N. Binary Time Series Classification with Bayesian Convolutional Neural Networks When Monitoring for Marine Gas Discharges. Algorithms 2020, 13, 145. [Google Scholar] [CrossRef]
- MacKay, D.J.C. A Practical Bayesian Framework for Backpropagation Networks. Neural Comput. 1992, 4, 448–472. [Google Scholar] [CrossRef] [Green Version]
- Jospin, L.V.; Laga, H.; Boussaid, F.; Buntine, W.; Bennamoun, M. Hands-On Bayesian Neural Networks—A Tutorial for Deep Learning Users. IEEE Comput. Intell. Mag. 2022, 17, 29–48. [Google Scholar] [CrossRef]
- Unger, J.F.; Könke, C. An inverse parameter identification procedure assessing the quality of the estimates using Bayesian neural networks. Appl. Soft Comput. 2011, 11, 3357–3367. [Google Scholar] [CrossRef]
- Bagnall, A.; Lines, J.; Bostrom, A.; Large, J.; Keogh, E. The great time series classification bake off: A review and experimental evaluation of recent algorithmic advances. Data Min. Knowl. Discov. 2016, 31, 606–660. [Google Scholar] [CrossRef] [Green Version]
- Kiranyaz, S.; Avci, O.; Abdeljaber, O.; Ince, T.; Gabbouj, M.; Inman, D.J. 1D convolutional neural networks and applications: A survey. Mech. Syst. Signal Process. 2021, 151, 107398. [Google Scholar] [CrossRef]
- Munir, M.; Siddiqui, S.A.; Dengel, A.; Ahmed, S. DeepAnT: A Deep Learning Approach for Unsupervised Anomaly Detection in Time Series. IEEE Access 2019, 7, 1991–2005. [Google Scholar] [CrossRef]
- Demir, S.; Mincev, K.; Kok, K.; Paterakis, N.G. Data augmentation for time series regression: Applying transformations, autoencoders and adversarial networks to electricity price forecasting. Appl. Energy 2021, 304, 117695. [Google Scholar] [CrossRef]
- Liu, B.; Zhang, Z.; Cui, R. Efficient Time Series Augmentation Methods. In Proceedings of the 2020 13th International Congress on Image and Signal Processing, BioMedical Engineering and Informatics (CISP—BMEI), Chengdu, China, 17–19 October 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1004–1009. [Google Scholar] [CrossRef]
- Iwana, B.K.; Uchida, S. An empirical survey of data augmentation for time series classification with neural networks. PLoS ONE 2021, 16, e0254841. [Google Scholar] [CrossRef] [PubMed]
- Winkler, P.; Koch, N.; Hornig, A.; Gerritzen, J. OmniOpt – A Tool for Hyperparameter Optimization on HPC. In Lecture Notes in Computer Science; Springer International Publishing: Berlin/Heidelberg, Germany, 2021; pp. 285–296. [Google Scholar]
- Meißner, P.; Watschke, H.; Winter, J.; Vietor, T. Artificial Neural Networks-Based Material Parameter Identification for Numerical Simulations of Additively Manufactured Parts by Material Extrusion. Polymers 2020, 12, 2949. [Google Scholar] [CrossRef] [PubMed]
- Kolling, S.; Haufe, A.; Feucht, M.; Bois, P.A.D. SAMP-1: A Semi-Analytical Model for the Simulation of Polymers. In Proceedings of the 4th LS-DYNA Anwenderforum, Bamberg, Germany, 20–21 October 2005. [Google Scholar]
- Livermore Software Technology Corporation (LSTC). LS-DYNA Keyword User’s Manual Volume II Material Models LS-DYNA, 11th ed.; LSTC: Livermore, CA, USA, 2018. [Google Scholar]
- Andrade, F.X.C.; Feucht, M.; Haufe, A.; Neukamm, F. An incremental stress state dependent damage model for ductile failure prediction. Int. J. Fract. 2016, 200, 127–150. [Google Scholar] [CrossRef]
- Hallquist, J.O. LS-DYNA Theory Manual; Livermore Software Technology Corporation (LSTC): Livermore, CA, USA, 2006. [Google Scholar]
- Neukamm, F.; Feucht, M.; Haufe, A.D. Considering damage history in crashworthiness simulations. In Proceedings of the 7th European LS-DYNA Conference, Salzburg, Austria, 14–15 May 2009. [Google Scholar]
- Basaran, M.; Wölkerling, S.D.; Feucht, M.; Neukamm, F.; Weichert, D. An Extension of the GISSMO Damage Model Based on Lode Angle Dependence. In Proceedings of the 9th LS-DYNA FORUM 2010, Stuttgart, Germany, 12–13 October 2010; DYNAmore: Stuttgart, Germany, 2010; pp. 3–17. [Google Scholar]
- Haufe, A.; DuBois, P.; Neukamm, F.; Feucht, M. GISSMO – Material Modeling with a sophisticated Failure Criteria. In Proceedings of the Conference LS-DYNA Info Day, Filderstadt, Germany, 13 October 2011. [Google Scholar] [CrossRef]
- Lemaitre, J. A Continuous Damage Mechanics Model for Ductile Fracture. J. Eng. Mater. Technol. 1985, 107, 83–89. [Google Scholar] [CrossRef]
- Lemaitre, J. A Course on Damage Mechanics; Springer: Berlin/Heidelberg, Germany, 1996. [Google Scholar] [CrossRef]
- Škrlec, A.; Klemenc, J. Estimating the Strain-Rate-Dependent Parameters of the Cowper-Symonds and Johnson-Cook Material Models using Taguchi Arrays. Strojniški Vestn. J. Mech. Eng. 2016, 62, 220–230. [Google Scholar] [CrossRef]
- Hayashi, S. Prediction of Failure Behavior in Polymers Under Multiaxial Stress State. Seikei-Kakou 2013, 25, 476–482. [Google Scholar] [CrossRef] [Green Version]
- Stavroulakis, G.; Bolzon, G.; Waszczyszyn, Z.; Ziemianski, L. Inverse Analysis. In Comprehensive Structural Integrity; Elsevier: Amsterdam, The Netherlands, 2003; pp. 685–718. [Google Scholar] [CrossRef]
- Goldberg, D.E. Genetic algorithms in search, optimization, and machine learning. Comput. Sci. 1989, 27, 27-0936. [Google Scholar] [CrossRef]
- Stander, N.; Craig, K.; Müllerschön, H.; Reichert, R. Material identification in structural optimization using response surfaces. Struct. Multidiscip. Optim. 2005, 29, 93–102. [Google Scholar] [CrossRef]
- Kučerová, A. Identification of Nonlinear Mechanical Model Parameters Based on Softcomputing Methods. Ph.D. Thesis, Czech Technical University, Prague, Czech Republic, 2007. [Google Scholar]
- Aguir, H.; BelHadjSalah, H.; Hambli, R. Parameter identification of an elasto-plastic behaviour using artificial neural networks–genetic algorithm method. Mater. Des. 2011, 32, 48–53. [Google Scholar] [CrossRef]
- Wen, Q.; Sun, L.; Yang, F.; Song, X.; Gao, J.; Wang, X.; Xu, H. Time Series Data Augmentation for Deep Learning: A Survey. In Proceedings of the Thirtieth International Joint Conference on Artificial Intelligence. International Joint Conferences on Artificial Intelligence Organization, Montreal, Canada, 19–27 August 2021; pp. 4653–4660. [Google Scholar] [CrossRef]
- Shorten, C.; Khoshgoftaar, T.M. A survey on Image Data Augmentation for Deep Learning. J. Big Data 2019, 6, 1–48. [Google Scholar] [CrossRef]
- Huang, N.E.; Shen, Z.; Long, S.R.; Wu, M.C.; Shih, H.H.; Zheng, Q.; Yen, N.C.; Tung, C.C.; Liu, H.H. The empirical mode decomposition and the Hilbert spectrum for nonlinear and non-stationary time series analysis. Proc. R. Soc. London Ser. A Math. Phys. Eng. Sci. 1998, 454, 903–995. [Google Scholar] [CrossRef]
- Stander, K.W.N. Modified Dynamic Time Warping for Utilizing Partial Curve Data to Calibrate Material Models. In Proceedings of the 16th International LS-DYNA Users Conference, Virtual Event, 31 May–2 June 2020. [Google Scholar]
- Petitjean, F.; Ketterlin, A.; Gançarski, P. A global averaging method for dynamic time warping, with applications to clustering. Pattern Recognit. 2011, 44, 678–693. [Google Scholar] [CrossRef]
- Giorgino, T. Computing and Visualizing Dynamic Time Warping Alignments inR: ThedtwPackage. J. Stat. Softw. 2009, 31, 1–24. [Google Scholar] [CrossRef]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016; Available online: http://www.deeplearningbook.org (accessed on 23 June 2022).
- Haykin, S. Number Bd. 10. In Neural Networks and Learning Machines; Prentice Hall: Hoboken, NJ, USA, 2009. [Google Scholar]
- da Silva, I.N.; Spatti, D.H.; Flauzino, R.A.; Liboni, L.H.B.; dos Reis Alves, S.F. Artificial Neural Networks; Springer International Publishing: Berlin/Heidelberg, Germany, 2017. [Google Scholar] [CrossRef]
- Fausett, L.; Fausett, L. Fundamentals of Neural Networks: Architectures, Algorithms, and Applications; Prentice-Hall: Hoboken, NJ, USA, 1994. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; IEEE: Piscataway, NJ, USA, 2015. [Google Scholar] [CrossRef] [Green Version]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural Machine Translation by Jointly Learning to Align and Translate. arXiv 2014, arXiv:1409.0473. [Google Scholar] [CrossRef]
- Gamboa, J.C.B. Deep Learning for Time-Series Analysis. arXiv 2017, arXiv:1701.01887. [Google Scholar] [CrossRef]
- Fawaz, H.I.; Forestier, G.; Weber, J.; Idoumghar, L.; Muller, P.A. Deep learning for time series classification: A review. Data Min. Knowl. Discov. 2019, 33, 917–963. [Google Scholar] [CrossRef] [Green Version]
- Zhao, B.; Lu, H.; Chen, S.; Liu, J.; Wu, D. Convolutional neural networks for time series classification. J. Syst. Eng. Electron. 2017, 28, 162–169. [Google Scholar] [CrossRef]
- Wang, Z.; Yan, W.; Oates, T. Time series classification from scratch with deep neural networks: A strong baseline. In Proceedings of the 2017 International Joint Conference on Neural Networks (IJCNN), Anchorage, AK, USA, 14–19 May 2017; IEEE: Piscataway, NJ, USA, 2017. [Google Scholar] [CrossRef] [Green Version]
- Yang, H.; Meng, C.; Wang, C. Data-Driven Feature Extraction for Analog Circuit Fault Diagnosis Using 1-D Convolutional Neural Network. IEEE Access 2020, 8, 18305–18315. [Google Scholar] [CrossRef]
- Azizjon, M.; Jumabek, A.; Kim, W. 1D CNN based network intrusion detection with normalization on imbalanced data. In Proceedings of the 2020 International Conference on Artificial Intelligence in Information and Communication (ICAIIC), Fukuoka, Japan, 19–21 February 2020; IEEE: Piscataway, NJ, USA, 2020. [Google Scholar] [CrossRef]
- Rautela, M.; Gopalakrishnan, S. Deep Learning frameworks for wave propagation-based damage detection in 1D-waveguides. In Proceedings of the 11th International Symposium on NDT in Aerospace, Paris, France, 13–15 November 2020. [Google Scholar]
- Zheng, Y.; Liu, Q.; Chen, E.; Ge, Y.; Zhao, J.L. Exploiting multi-channels deep convolutional neural networks for multivariate time series classification. Front. Comput. Sci. 2015, 10, 96–112. [Google Scholar] [CrossRef]
- Serrà, J.; Pascual, S.; Karatzoglou, A. Towards a universal neural network encoder for time series. arXiv 2018, arXiv:1805.03908. [Google Scholar] [CrossRef]
- Abdar, M.; Pourpanah, F.; Hussain, S.; Rezazadegan, D.; Liu, L.; Ghavamzadeh, M.; Fieguth, P.; Cao, X.; Khosravi, A.; Acharya, U.R.; et al. A review of uncertainty quantification in deep learning: Techniques, applications and challenges. Inf. Fusion 2021, 76, 243–297. [Google Scholar] [CrossRef]











| Reference Point | Stress Triaxiality (-) | Equivalent Plastic Strain at Failure (EPSF) (-) |
|---|---|---|
| 1 | epsf0 | |
| 2 | epsf0 | |
| 3 | epsf1 | |
| 4 | epsf2 | |
| 5 | epsf2 | |
| 6 | epsf3 | |
| 7 | epsf3 |
| V1 | V2 | V3 | V4 | |
|---|---|---|---|---|
| Velocity () | ||||
| Strain Rate () |
| Dataset | Sampling Method | Sampling Type | Training Set Size | Validation Set Size | Complete Set Size |
|---|---|---|---|---|---|
| 1 | LHS | individually | 266 | 114 | 380 |
| 2 | LHS | individually | 525 | 225 | 750 |
| 3 | LHS | individually | 1050 | 450 | 1500 |
| 4 | LHS | individually | 2100 | 900 | 3000 |
| 5 | LHS | complete | 266 | 114 | 380 |
| 6 | LHS | complete | 525 | 225 | 750 |
| 7 | LHS | complete | 1050 | 450 | 1500 |
| 8 | LHS | complete | 2100 | 900 | 3000 |
| CNN Number | Internal Denotation | Author | Source |
|---|---|---|---|
| 1 | Default_CNN | B. Zhao et al. | [58] |
| 2 | CNN Yang | H. Yang et al. | [60] |
| 3 | CNN Azizjon | M. Azizjon et al. | [61] |
| 4 | CNN Rautela | M. Rautela et al. | [62] |
| 5 | MCDCNN | Y. Zheng et al. | [63] |
| 6 | Resnet | Z. Wang et al. | [59] |
| 7 | FCN | Z. Wang et al. | [59] |
| 8 | Encoder | J. P. Serrà et al. | [64] |
| 9 | FCN2 | Meißner et al. | - |
| 10 | FCN3 | Meißner et al. | - |
| Run | NN | Dataset | Loss | Stopped Epoch | Best Val. Loss (-) | Cor. Training Loss (-) | MSE MP Val. Set (-) | Mean DTW SOC Val. Set (-) | Mean DTW SOC Exp. Set (-) |
|---|---|---|---|---|---|---|---|---|---|
| 1 | Default_MLP | 1 | MSE | 180 | |||||
| 2 | Default_MLP | 2 | MSE | 184 | |||||
| 3 | Default_MLP | 3 | MSE | 193 | |||||
| 4 | Default_MLP | 4 | MSE | 254 | |||||
| 5 | Default_MLP | 1 | COL | 245 | |||||
| 6 | Default_MLP | 2 | COL | 450 | |||||
| 7 | Default_MLP | 3 | COL | 333 | |||||
| 8 | Default_MLP | 4 | COL | 441 | |||||
| 9 | Default_MLP | 5 | COL | 265 | - | - | |||
| 10 | Default_MLP | 6 | COL | 168 | - | - | |||
| 11 | Default_MLP | 7 | COL | 310 | - | - | |||
| 12 | Default_MLP | 8 | COL | 339 | - | - | |||
| 13 | MLPHPO | 3 | COL | 316 | |||||
| 14 | Default_MLP | 3 | COL | 96 | |||||
| 15 | Default_MLP | 3 | COL | 340 | |||||
| 16 | Default_CNN | 3 | MSE | 922 | |||||
| 17 | Default_CNN | 1 | COL | 927 | |||||
| 18 | Default_CNN | 2 | COL | 736 | |||||
| 19 | Default_CNN | 3 | COL | 1000 | |||||
| 20 | Default_CNN | 4 | COL | 946 | |||||
| 21 | CNN_Yang | 3 | COL | 668 | |||||
| 22 | CNN_Azizjon | 3 | COL | 132 | |||||
| 23 | CNN_Rautela | 3 | COL | 152 | - | - | |||
| 24 | MCDCNN | 3 | COL | 142 | |||||
| 25 | Resnet | 3 | COL | 238 | |||||
| 26 | FCN | 3 | COL | 174 | |||||
| 27 | Encoder | 3 | COL | 136 | |||||
| 28 | FCN2 | 3 | COL | 2000 | |||||
| 29 | FCN3 | 3 | COL | 594 | |||||
| 30 | CNNHPO | 3 | COL | 614 | |||||
| 31 | Default_CNN | 3 | COL | 408 | |||||
| 32 | Default_CNN | 3 | COL | 1000 | |||||
| 33 | BNN1 | 3 | NLL | 20,000 | - | - | |||
| 34 | BNN2 | 3 | NLL | 20,000 | - | - | |||
| 35 | BNN1 | 3 | NLL | 20,000 | * | * | |||
| 36 | BNN3 | 1 | NLL | 5000 | |||||
| 37 | BNN3 | 2 | NLL | 5000 | |||||
| 38 | BNN3 | 3 | NLL | 5000 | |||||
| 39 | BNN3 | 4 | NLL | 5000 | |||||
| 40 | BNN3 | 3 | NLL | 5000 | - | - | |||
| 41 | BNN3 | 3 | NLL | 5000 | - | - | |||
| 42 | BNN3 | 3 | NLL | 5000 | - | - | |||
| 43 | BNN3 | 3 | NLL | 5000 | - | - | |||
| 44 | BNN3 | 3 | NLL | 5000 | |||||
| 45 | BNN3 | 3 | NLL | 5000 | - | - |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Meißner, P.; Hoppe, T.; Vietor, T. Comparative Study of Various Neural Network Types for Direct Inverse Material Parameter Identification in Numerical Simulations. Appl. Sci. 2022, 12, 12793. https://doi.org/10.3390/app122412793
Meißner P, Hoppe T, Vietor T. Comparative Study of Various Neural Network Types for Direct Inverse Material Parameter Identification in Numerical Simulations. Applied Sciences. 2022; 12(24):12793. https://doi.org/10.3390/app122412793
Chicago/Turabian StyleMeißner, Paul, Tom Hoppe, and Thomas Vietor. 2022. "Comparative Study of Various Neural Network Types for Direct Inverse Material Parameter Identification in Numerical Simulations" Applied Sciences 12, no. 24: 12793. https://doi.org/10.3390/app122412793
APA StyleMeißner, P., Hoppe, T., & Vietor, T. (2022). Comparative Study of Various Neural Network Types for Direct Inverse Material Parameter Identification in Numerical Simulations. Applied Sciences, 12(24), 12793. https://doi.org/10.3390/app122412793