1. Introduction
Computed Tomography (CT) is one of the most adopted imaging methodologies to accomplish different medical tasks. If combined with intelligent systems based on artificial intelligence, its range of applicability includes, but is not limited to, Computer-Aided Diagnosis (CAD) systems and intelligent applications supporting surgical procedures [
1,
2].
Liver segmentation is a pivotal task in abdominal radiology, as it is essential for several clinical tasks, including surgery, radiotherapy, and objective quantification [
3]. In addition, several pieces of clinical evidence over the last few decades have demonstrated the necessity to go beyond the conception of the liver as a single object (from a morphological perspective), but rather to consider the liver as formed by functional segments [
4]. Couinaud’s classification [
5] of liver segments is the most widely adopted system for this purpose, since it is especially useful in surgery setups. The separation of these anatomical areas can be exploited for tumor resections in Computer-Assisted Surgery (CAS) systems [
6], allowing surgeons to focus on different segments. In this way, a surgeon can avoid removing healthy liver parenchyma, by performing a segmentectomy, also reducing the risk of complications for the patient [
7].
However, different other tissues and organs, such as the kidney and spleen, are in the abdominal area. Since the tissues in such an area are characterized by similar intensity levels when acquired by CT or other imaging systems in general, their segmentation with automatic methods is not a simple task. In fact, the segmentation of organs in the abdominal area is mostly tackled by employing manual or semi-automatic approaches [
8,
9]. To do this, there is a multitude of traditional image processing algorithms for biomedical image segmentation, including thresholding algorithms, Region-Growing (RG) algorithms, level sets, and graph cuts.
Deep Learning (DL) is an emerging paradigm that is changing the world of medical imaging. DL consists of the application of hierarchical computational models that can directly learn from data, creating representations with multiple levels of abstraction [
10]. Thanks to the natural proneness of DL architectures to process grid-like data, such as images or multi-dimensional signals, they are extensively investigated in image classification and segmentation tasks; in fact, several works have already demonstrated their capabilities to outperform the state-of-the-art in such tasks, making them valid systems to be applied also in the medical domain [
1,
11,
12,
13,
14].
DL architectures may be employed for both classification and segmentation tasks, i.e., the delineation of areas or Regions of Interest (ROIs) within images or volumes. In this regard, it is necessary to distinguish between semantic segmentation [
15,
16] and object detection [
17,
18] approaches implemented using DL methodologies. The first aims at producing a dense, pixel- (or voxel-) level segmentation mask, whereas the latter aims at individuating the bounding boxes of the regions of interest [
19,
20]. In many contexts, precise segmentation masks are more useful than bounding boxes, especially in the medical domain, but they require more human effort for labeling the ground-truth dataset required to train and validate the models (since a domain expert must manually produce precise voxel-level masks to create the dataset themselves).
In this work, we performed the segmentation of the liver segments. This task may be performed directly or by performing a prior segmentation of the liver parenchyma. Although literature exists for both approaches, our experiments revealed that liver parenchyma segmentation is not needed to train a multi-class classification DL model on liver segments, since applying liver masks to the volumes reduces the context. Nonetheless, other authors found this step useful [
21].
1.1. Deep Learning in Radiology
Radiology involves the exploitation of 3D images that result from non-invasive techniques such as Magnetic Resonance Imaging (MRI) or CT, allowing studying the anatomical structures inside the body. When there is the need to delineate the boundary of organs or lesions, e.g., in CAS or radiomics [
22] workflows, the manual delineation of boundaries performed by trained radiologists is considered the gold standard. Unfortunately, this operation is tedious and can lead to errors, since it involves the annotation of a volume composed of many slices. Lastly, inter- and intra-observer variability are well-known problems in the medical imaging landscape, further showing the limitations of the classical workflow [
23].
In this context, the design and implementation of automatic systems, often based on DL architectures, capable of performing organ and lesion segmentation are very appreciated, since they can reduce the workload of radiologists and also increase the robustness of the findings [
24]. The application of artificial intelligence methodologies in the radiological workflow is leading to a huge impact in the field, with a special regard for oncological applications [
25].
Important radiological tasks that can be efficiently met by DL methodologies include classification, the detection of diseases or lesions, the quantification of radiographic characteristics, and image segmentation [
11,
14,
26,
27].
In this work, the possibility to automatically delineate the boundaries of liver segments can be effectively exploited by radiologists and surgeons to improve the surgery workflow with CASs for liver tumor resections.
The interested reader is referred to the works of Liu et al. [
28] and Litjens et al. [
29] for a wider perspective on the architectures that can be exploited to solve clinical problems in radiology with deep learning.
1.2. Liver Parenchyma Segmentation
Prencipe et al. developed an RG algorithm for liver and spleen segmentation [
30]. The crucial point of segmentation algorithms based on RG is the individuation of a suitable criterion for growing the segmentation mask including only those pixels belonging to the area of interest. In particular, the authors devised an algorithm that, starting from an initial seed point, created a tridimensional segmentation mask adopting two utility data structures, namely the Moving Average Seed Heat map (MASH) and the Area Union Map (AUM), with the positive effect of avoiding the choice of the subsequent seeds from unsuitable locations while propagating the mask.
There is a realm of other techniques proposed for liver segmentation. Contrast enhancement and cropping were used for pre-processing by Bevilacqua et al. [
11]. Then, local thresholding, the extraction of the largest connected component, and the adoption of operators from a mathematical morphology were applied to obtain the 2D segmentation. Finally, the obtained mask was broadcast upward and downward to process the entire volume.
In [
31], an automatic 3D segmentation approach was presented, where the seed was chosen via the minimization of an objective function and the homogeneity criteria based on the Euclidean distance of the texture features related to the voxels. The homogeneity criteria can also depend on the difference between the currently segmented area and the pixel intensity [
32,
33,
34] or pixel gradient [
35,
36]. There exist also other approaches based on the adoption of a suitable homogeneity criteria [
37,
38].
As useful pre-processing techniques, it is worth noting the adoption of the Non-Sub-sampled Contourlet Transform (NSCT) to enhance the liver’s edges [
39] and the implementation of a contrast stretch algorithm and an atlas intensity distribution to create voxel probability maps [
40]. For the post-processing step, we note the adoption of an entropy filter for finding the best structural element [
41] or the adoption of the GrowCut algorithm [
42,
43]. Other approaches that involve image processing techniques both for pre- and post-processing can be found in [
12,
44].
1.3. Liver Segments’ Classification
There are some approaches proposed in the literature for liver segments’ classification. Most of the published research tries to obtain the segments from an accurate modeling of the liver vessels.
Oliveira et al. employed a geometric fit algorithm, based on the least-squares method, to generate planes for separating the liver into its segments [
45].
Yang et al. exploited a semi-automatic approach for calculating the segments [
6]. The user has to input the root points for the branches of the portal vein and the hepatic veins, and then, a Nearest Neighbor Approximation (NNA) algorithm is implemented to assign each liver voxel to a specific segment. The classification was very straightforward: the voxel belonged to the segment whose branch was nearest to that voxel.
Among the approaches that aim to directly classify liver segments, it is worth noting the work of Tian et al. [
21], who offered the first publicly available dataset for liver segments’ classification. They realized an architecture based on U-Net [
46], but with considerations for the Global and Local Context (GLC), resulting in a model that they referred to as GLC U-Net.
Yan et al. collected a huge CT dataset, composed of 500 cases, to realize CAD systems targeted at the liver region [
47]. The ComLiver datasets include labels for liver parenchyma, vessels, and Couinaud segments. For the task of performing Couinaud segmentation, the authors compared only 3D CNN models, namely Fully Convolutional Networks (FCNs) [
48], U-Net [
46,
49], U-Net++ [
50], nnU-Net [
51], Attention U-Net (AU-Net) [
52], and Parallel Reverse Attention Network (PraNet) [
53].
In this work, we introduce two possible definitions of the Focal Dice Loss (
), and we compare them with a definition already provided by Wang et al. [
54]. One of the proposed
definitions is similar to that of Wang et al., whereas the other one is more adherent to the original formulation provided by Lin et al. [
55], considering the modulating factor on the single voxel and not on the whole Dice loss. In particular, we trained a 2.5D CNN model, the V-Net architecture, originally proposed for 3D segmentation by Milletari et al. [
56], but in a multi-class classification fashion. We also implemented and tested a rule-based post-processing to correct the segmentation errors.
3. Experimental Results
In order to assess the performances of the different classifiers obtained by varying the
formulation and the associated modulation factor
, we assessed the “hard” Dice coefficient
for each class
t, the average
Dice coefficient across all classes, the mean accuracy
, and the confusion matrix, in order to see the relationships of the errors from different segments. We compared the
presented by Wang et al. with the ones presented in this paper. We considered five values for the modulation parameter:
. The case
is equivalent to using the Dice coefficient as defined in Equation (
7). For each experiment, we checked if the application of the post-processing was beneficial or not.
Experimental results are reported in
Table 3,
Table 4,
Table 5 and
Table 6, for models trained with
,
,
, and
, respectively.
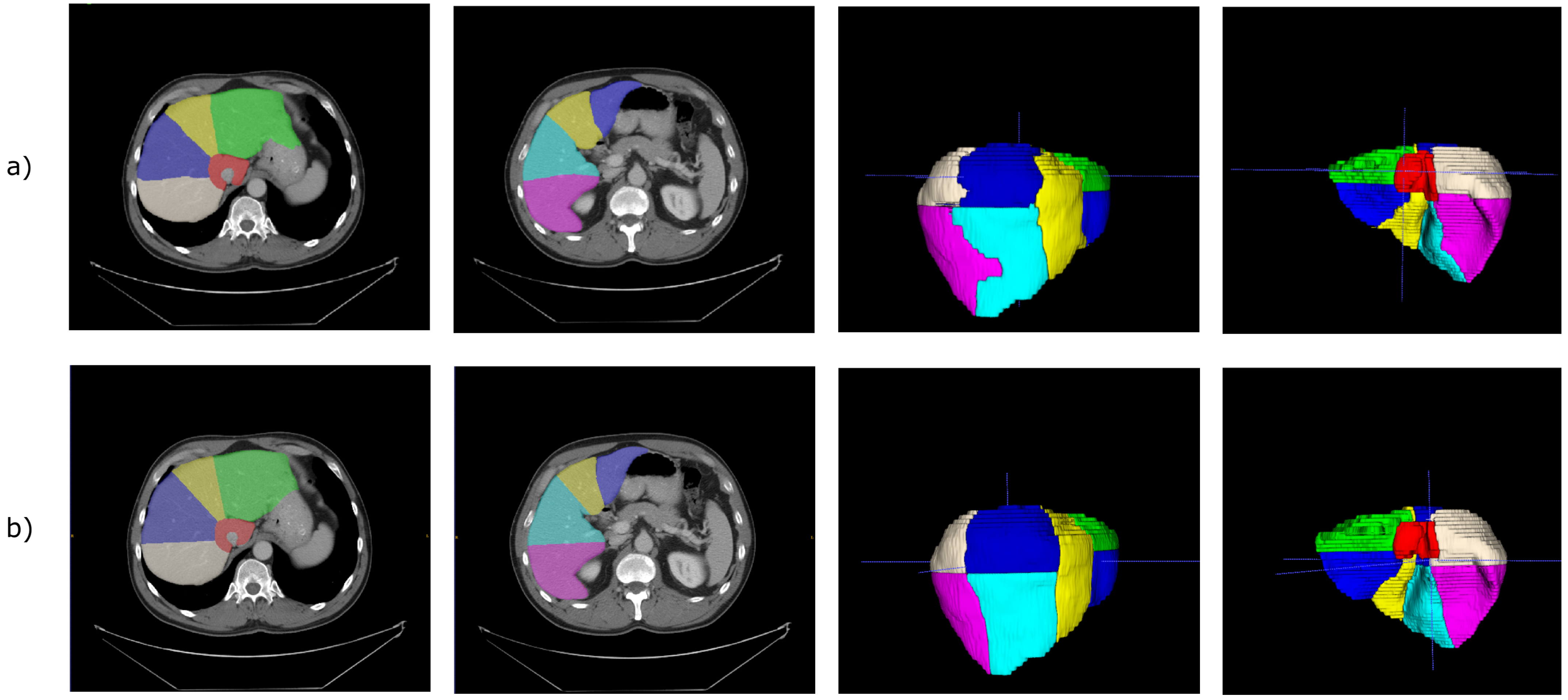
Figure 5 shows the segmentation obtained for a single CT scan, adopting
with
.
In the case of , the best model was the one with after post-processing. A possible justification is that larger values of result in flattening too much the loss of the volumetric predictions, so that those having a good Dice coefficient are too penalized.
For the FDLs defined in this paper, the model trained achieved the best performance also in the case , after post-processing, while the one trained with obtained the best performance in the configuration .
Concerning
, in our experiments, we found that the model trained with
could not generalize, and the
for at least a class remained one (worst case) during the training. A possible explanation could be similar to the one provided for the
from the paper of Wang et al. [
54]. When you increase the value of
, even the high values of
are penalized, as we can see from
Figure 3.
We tested if was better than the other formulations. To do this, we performed the Wilcoxon signed-rank test, obtaining that showed superior performances to with , to with , and to with . Considering, as usual, the significance threshold , the obtained results were statistically significant.
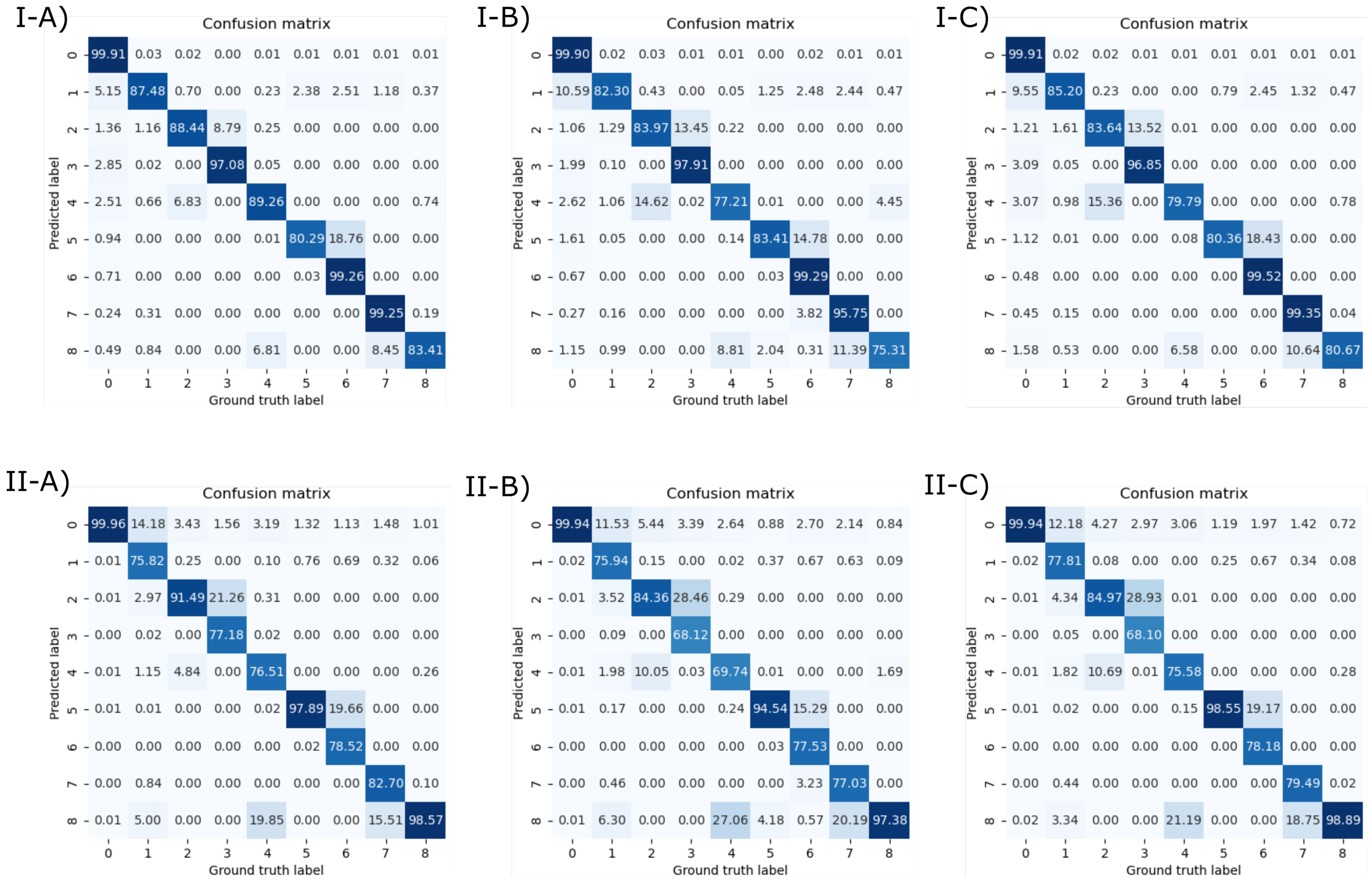
We also report the normalized confusion matrices in
Figure 6. Elements in the main diagonal of the row-normalized and column-normalized confusion matrices are the
precision(s) and
recall(s) of the corresponding classes, respectively. From the confusion matrices, we can see that the most frequent errors arose between (in all the list here, the notation is predicted segment and ground-truth segment): Segment I and the background (this could be due to the fact that the CNN classifies the vena cava as Segment I, instead of background), Segment II and Segment III (this depends on the fact that the LB is predicted in a lower position than the real one), Segment IV and Segment II (they are adjacent on the axial plane), Segment VIII and Segment IV (they are adjacent on the axial plane), Segment V and Segment VI (they are adjacent on the axial plane), and Segment VIII and Segment VII (they are adjacent on the axial plane).
Existing approaches are compared in
Table 7. We note that existing works did not provide results (as
) for each segment. Different papers, such as [
6,
45], only proposed a qualitative assessment of the obtained results via expert radiologists, whereas Tian et al. [
21] and Yan et al. [
47] only reported the aggregated Dice coefficientper case across all classes.
4. Conclusions and Future Works
In this paper, we proposed two novel focal Dice loss formulations for liver segments’ classification and compared them with the previous one presented in the literature. The problem of correctly identifying liver segments is pivotal in surgical planning, since it can allow more precise surgery, as performing segmentectomies. In fact, according to the Couinaud model [
5], hepatic vessels are the anatomic boundaries of the liver segments. Therefore, in current hepatic surgery, the identification of the liver vessel tree can avoid the unnecessary removal of healthy liver parenchyma, thus lowering the risk of complications that can arise from larger resections [
7]. Despite this, in the literature, many authors that focused on liver segments’ classification methods usually only provided visual assessment (as [
6,
45]), making it difficult to benchmark different algorithms for this task. Thanks to the work of Tian et al. [
21], a huge dataset composed of CT scans with liver segments’ annotation is now publicly available, easing the development and evaluation of algorithms suited for the task. Our CNN-based approach allowed us to obtain reliable results, with the best formulation,
with
, obtaining an average Dice coefficient higher than 83% and an average accuracy higher than 98%. The adoption of a rule-based post-processing, which implements a mechanism for detecting and resolving inconsistencies across axial slice images, allowed slightly improving the obtained results for different models. Given that the difference between the models was exiguous, it may be necessary to exploit a different model to assess a clearer difference between these loss functions.
A limitation of this work is the absence of an external validation dataset, which is due to the facts that there is a lack of annotated datasets with liver segments and it is very expensive to create a local one labeled by radiologists. Furthermore, with more GPU memory available, more complex 3D architectures capable of handling a larger context can be exploited, whereas in this work, we limited this to five slices at once.
As future work, we note that another possible way to approach this task consists of determining regression planes using a 3D CNN. Even if there are classical approaches (as Oliveira et al. [
45]) devoted to the estimation of these cutting planes, there are actually no DL-based approaches in this direction (Tian et al. [
21] and Yan et al. [
47], as us, developed a semantic segmentation model), which can be more resilient to overfitting and to the prediction of inconsistent segments’ classification.


 ,
, 









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}