
Classifying Malicious Documents on the Basis of Plain-Text Features: Problem, Solution, and Experiences



Abstract
:1. Introduction
- We propose a malicious-document classification framework that only exploits plaintext data. Our proposed framework extracts plaintext features from given malicious or benign electronic documents and builds vector representations of the documents (i.e., vectorization). After that, it trains a classification model by using the vector representations of all documents. By applying the trained model to an unseen (new) document, our framework predicts whether the target document is malicious.
- We designed our proposed framework to be capable of adopting various vectorization strategies and classification methods. We adopted three well-known vectorization strategies (i.e., bag of words (BoW), term frequency-inverse document frequency (TF-IDF), and Word2Vec) and three popular classification methods (i.e., deep neural networks (DNNs), support vector machines (SVMs), and decision trees) in this paper.
- We show that the proposed framework works well in practice. We carefully evaluate the effectiveness of our framework equipped with different combinations of vectorization strategies and classification methods by conducting extensive experiments on five types of electronic documents. Experimental results demonstrate that our framework provides accuracy higher than 98% in detecting malicious documents.
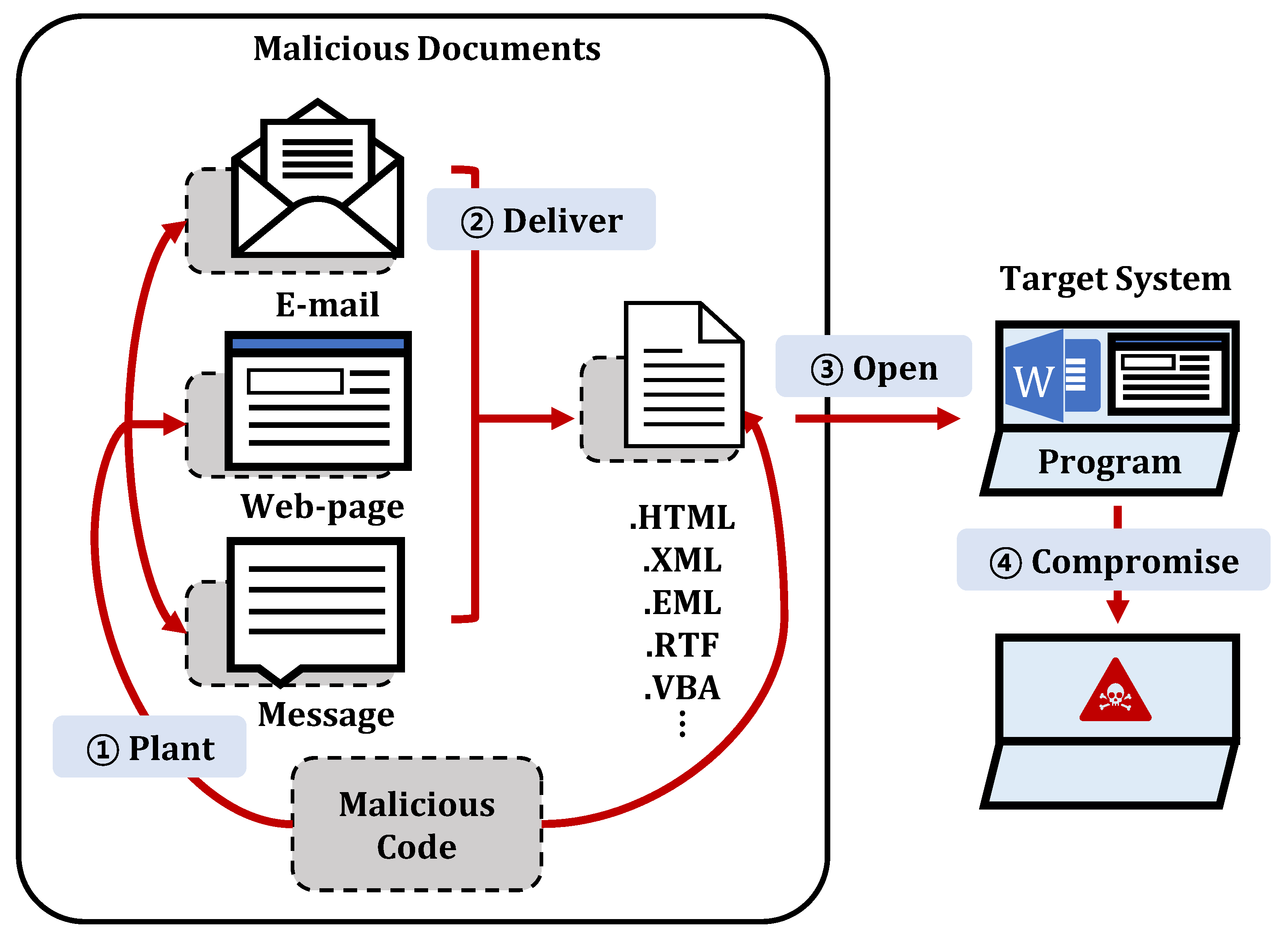
2. Malicious Code and Malicious Documents
3. Malicious Document Classification
3.1. Overview
3.2. Electronic Documents
3.2.1. HTML and XML
3.2.2. EML
3.2.3. RTF
3.2.4. VBA
3.3. Feature Extraction
3.3.1. Preprocessing
3.3.2. Tokenization
3.3.3. Vectorization
3.4. Model Construction
3.4.1. Decision Tree
3.4.2. SVM
3.4.3. DNN
4. Evaluation
4.1. Experimental Setup
4.1.1. Datasets
4.1.2. Model Parameters in Classification
- Decision tree: we used the classification and regression trees (CART) algorithm [44] and built a decision tree on the basis of Gini impurity. We employ multiple class weight settings of (100:1, 10:1, 1:1, 1:10, and 1:100).
- DNN: the model in our case uses five layers having 64 units for the document vector obtained from BoW and TF-IDF and 4096 units for the document vector obtained from Word2Vec. The activation function in the intermediate layer uses a rectified linear unit (ReLU) [45], and the sigmoid function was used in the last layer. We used AdaGrad and Adam optimizers [46,47]. We added the batch normalization, drop out, and early stop as improvement tactics [48,49,50]. We set patience parameters to 20, 30, and 40 for early stop.
4.1.3. Evaluation Metrics
4.2. Results
5. Conclusions and Further Studies
Author Contributions
Funding
Conflicts of Interest
References
- Ye, Y.; Li, T.; Adjeroh, D.; Iyengar, S.S. A Survey on Malware Detection Using Data Mining Techniques. ACM Comput. Surv. 2017, 50, 1–40. [Google Scholar] [CrossRef]
- Or-Meir, O.; Nissim, N.; Elovici, Y.; Rokach, L. Dynamic Malware Analysis in the Modern Era—A State of the Art Survey. ACM Comput. Surv. 2019, 52, 1–48. [Google Scholar] [CrossRef] [Green Version]
- Sihwail, R.; Omar, K.; Ariffin, K.A.Z. A Survey on Malware Analysis Techniques: Static, Dynamic, Hybrid and Memory Analysis. Int. J. Adv. Sci. Eng. Inf. Technol. 2018, 8, 1662. [Google Scholar] [CrossRef] [Green Version]
- Kim, E.; Park, S.J.; Choi, S.; Chae, D.K.; Kim, S.W. MANIAC: A man-machine collaborative system for classifying malware author groups. In Proceedings of the 2021 ACM SIGSAC Conference on Computer and Communications Security (CCS), Virtual, 15–19 November 2021; pp. 2441–2443. [Google Scholar]
- Pinhero, A.; Anupama, M.; Vinod, P.; Visaggio, C.A.; Aneesh, N.; Abhijith, S.; AnanthaKrishnan, S. Malware Detection Employed by Visualization and Deep Neural Network. Comput. Secur. 2021, 105, 102247. [Google Scholar] [CrossRef]
- Bott, E. Introducing Windows 10 for IT Professionals; Microsoft Press: Redmond, WA, USA, 2016. [Google Scholar]
- Singh, J.; Singh, J. A Survey on Machine Learning-Based Malware Detection in Executable Files. J. Syst. Archit. 2021, 112, 101861. [Google Scholar] [CrossRef]
- Sudhakar; Kumar, S. An Emerging Threat Fileless Malware: A Survey and Research Challenges. Cybersecurity 2020, 3, 1–12. [Google Scholar] [CrossRef] [Green Version]
- Mimura, M.; Tajiri, Y. Static Detection of Malicious PowerShell Based on Word Embeddings. Internet Things 2021, 15, 100404. [Google Scholar] [CrossRef]
- Afreen, A.; Aslam, M.; Ahmed, S. Analysis of fileless malware and its evasive behavior. In Proceedings of the 2020 International Conference on Cyber Warfare and Security (ICCWS), Islamabad, Pakistan, 20–21 October 2020; pp. 1–8. [Google Scholar]
- Mansfield-Devine, S. Fileless Attacks: Compromising Targets without Malware. Netw. Secur. 2017, 2017, 7–11. [Google Scholar] [CrossRef]
- Smutz, C.; Stavrou, A. Malicious PDF detection using metadata and structural features. In Proceedings of the 28th Annual Computer Security Applications Conference (ACSAC), Orlando, FL, USA, 3–7 December 2012; pp. 239–248. [Google Scholar]
- Ye, Y.; Wang, D.; Li, T.; Ye, D. IMDS: Intelligent malware detection system. In Proceedings of the 13th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (SIGKDD), San Jose, CA, USA, 12–15 August 2007; pp. 1043–1047. [Google Scholar]
- Hou, Y.T.; Chang, Y.; Chen, T.; Laih, C.S.; Chen, C.M. Malicious Web Content Detection by Machine Learning. Expert Syst. Appl. 2010, 37, 55–60. [Google Scholar] [CrossRef]
- Saad, G.; Raggi, M.A. Attribution is in the object: Using RTF object dimensions to track APT phishing weaponizers. Virus Bull. 2020, 12, 1–2. [Google Scholar]
- Yadav, N.; Panda, S.P. Feature selection for email phishing detection using machine learning. In Proceedings of the International Conference on Innovative Computing and Communications (ICICC), New Delhi, India, 19–20 February 2022; pp. 365–378. [Google Scholar]
- Yang, S.; Chen, W.; Li, S.; Xu, Q. Approach using transforming structural data into image for detection of malicious MS-DOC files based on deep learning models. In Proceedings of the 2019 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), Lanzhou, China, 18–21 November 2019; pp. 28–32. [Google Scholar]
- Tzermias, Z.; Sykiotakis, G.; Polychronakis, M.; Markatos, E.P. Combining static and dynamic analysis for the detection of malicious documents. In Proceedings of the Fourth European Workshop on System Security (EUROSEC), Salzburg, Austria, 10 April 2011; pp. 1–6. [Google Scholar]
- Kowsari, K.; Jafari Meimandi, K.; Heidarysafa, M.; Mendu, S.; Barnes, L.; Brown, D. Text Classification Algorithms: A Survey. Information 2019, 10, 150. [Google Scholar] [CrossRef] [Green Version]
- Kowsari, K.; Brown, D.E.; Heidarysafa, M.; Meimandi, K.J.; Gerber, M.S.; Barnes, L.E. Hdltex: Hierarchical deep learning for text classification. In Proceedings of the 2017 16th IEEE International Conference on Machine Learning and Applications (ICMLA), Cancun, Mexico, 18–21 December 2017; pp. 364–371. [Google Scholar]
- Kowsari, K.; Heidarysafa, M.; Brown, D.E.; Meimandi, K.J.; Barnes, L.E. Rmdl: Random multimodel deep learning for classification. In Proceedings of the 2nd International Conference on Information System and Data Mining (ICISDM), Lakeland, FL, USA, 9–11 April 2018; pp. 19–28. [Google Scholar]
- Aggarwal, C.C.; Zhai, C. A Survey of Text Classification Algorithms. In Mining Text Data; Springer: Berlin/Heidelberg, Germany, 2012; pp. 163–222. [Google Scholar]
- Gupta, G.; Malhotra, S. Text Document Tokenization for Word Frequency Count Using Rapid Miner. Int. J. Comput. Appl. 2015, 975, 8887. [Google Scholar]
- Verma, T.; Renu, R.; Gaur, D. Tokenization and Filtering Process in RapidMiner. Int. J. Appl. Inf. Syst. 2014, 7, 16–18. [Google Scholar] [CrossRef]
- Friedl, J.E. Mastering Regular Expressions; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2006. [Google Scholar]
- Pahwa, B.; Taruna, S.; Kasliwal, N. Sentiment Analysis-Strategy for Text Pre-Processing. Int. J. Comput. Appl. 2018, 180, 15–18. [Google Scholar] [CrossRef]
- Harris, Z.S. Distributional Structure. Word 1954, 10, 146–162. [Google Scholar] [CrossRef]
- Salton, G.; Buckley, C. Term-Weighting Approaches in Automatic Text Retrieval. Inf. Process. Manag. 1988, 24, 513–523. [Google Scholar] [CrossRef] [Green Version]
- Jones, K.S. A Statistical Interpretation of Term Specificity and Its Application in Retrieval. J. Doc. 1972, 28, 11–21. [Google Scholar] [CrossRef]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. In Proceedings of the International Conference on Learning Representations Workshop Track (ICLR Workshop), Scottsdale, AZ, USA, 2–4 May 2013; pp. 1301–3781. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed representations of words and phrases and their compositionality. In Proceedings of the Advances in Neural Information Processing Systems (NIPS), Lake Tahoe, NV, USA, 5–8 December 2013; pp. 3111–3119. [Google Scholar]
- Goldberg, Y.; Levy, O. Word2vec explained: Deriving Mikolov et al.’s negative-sampling word-embedding method. arXiv 2014, arXiv:1402.3722. [Google Scholar]
- Morgan, J.N.; Sonquist, J.A. Problems in the Analysis of Survey Data, and a Proposal. J. Am. Stat. Assoc. 1963, 58, 415–434. [Google Scholar] [CrossRef]
- Safavian, S.R.; Landgrebe, D. A Survey of Decision Tree Classifier Methodology. IEEE Trans. Syst. Man Cybern. Syst. 1991, 21, 660–674. [Google Scholar] [CrossRef] [Green Version]
- Magerman, D.M. Statistical decision-tree models for parsing. In Proceedings of the 33rd Annual Meeting of the Association for Computational Linguistics (ACL), Cambridge, MA, USA, 26–30 June 1995; pp. 276–283. [Google Scholar]
- Quinlan, J.R. Induction of Decision Trees. Mach. Learn. 1986, 1, 81–106. [Google Scholar] [CrossRef] [Green Version]
- De Mántaras, R.L. A Distance-Based Attribute Selection Measure for Decision Tree Induction. Mach. Learn. 1991, 6, 81–92. [Google Scholar] [CrossRef]
- Manevitz, L.M.; Yousef, M. One-Class SVMs for Document Classification. J. Mach. Learn. Res. 2001, 2, 139–154. [Google Scholar]
- Han, E.H.S.; Karypis, G. Centroid-based document classification: Analysis and experimental results. In Proceedings of the European Conference on Principles of Data Mining and Knowledge Discovery (PKDD), Lyon, France, 13–16 September 2000; pp. 424–431. [Google Scholar]
- Bengio, Y.; Courville, A.; Vincent, P. Representation Learning: A Review and New Perspectives. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 1798–1828. [Google Scholar] [CrossRef] [PubMed]
- Schmidhuber, J. Deep Learning in Neural Networks: An Overview. Neural Netw. 2015, 61, 85–117. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Virustotal. Available online: https://www.virustotal.com/ (accessed on 9 January 2019).
- Kohavi, R. A study of cross-validation and bootstrap for accuracy estimation and model selection. In Proceedings of the 14th International Joint Conference on Artificial Intelligence (IJCAI), Montreal, QC, Canada, 20–25 August 1995; Volume 2, pp. 1137–1143. [Google Scholar]
- Hastie, T.; Tibshirani, R.; Friedman, J.H.; Friedman, J.H. The Elements of Statistical Learning: Data Mining, Inference, and Prediction; Springer: Berlin/Heidelberg, Germany, 2009; Volume 2. [Google Scholar]
- Brownlee, J. A Gentle Introduction to the Rectified Linear Unit (ReLU). 2019. Available online: https://machinelearningmastery.com/rectified-linear-activation-function-for-deep-learning-neural-networks/ (accessed on 9 January 2019).
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. In Proceedings of the International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Freund, Y.; Schapire, R.E. A Decision-Theoretic Generalization of On-Line Learning and an Application to Boosting. J. Comput. Syst. Sci. 1997, 55, 119–139. [Google Scholar] [CrossRef] [Green Version]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning (PMLR), Lille, France, 7–9 July 2015; pp. 448–456. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A Simple Way to Prevent Neural Networks from Overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Yao, Y.; Rosasco, L.; Caponnetto, A. On Early Stopping in Gradient Descent Learning. Constr. Approx. 2007, 26, 289–315. [Google Scholar] [CrossRef]
- Powers, D. Evaluation: From Precision, Recall and F-Measure to ROC, Informedness, Markedness & Correlation. J. Mach. Learn. Technol. 2011, 2, 37–63. [Google Scholar]
- Breiman, L. Bagging Predictors. Mach. Learn. 1996, 24, 123–140. [Google Scholar] [CrossRef] [Green Version]
- Freund, Y.; Schapire, R.E. Experiments with a new boosting algorithm. In Proceedings of the International Conference on Machine Learning (ICML), Bari, Italy, 3–6 July 1996; Volume 96, pp. 148–156. [Google Scholar]



{kind=link}
{kind=link}
| File Type | Plaintext Examples |
|---|---|
| HTML & XML | … <div style=“border: 1 px solid #f90; margin: 0–15 px; padding: 10 px;”> <h2>Big Size Clothing for Men</h2> <strong>Clothes sizes from 2XL to 8XL</strong>with <strong>chest and waist sizes</strong>up to 72 inches. </div><section class=’home_page_links’> … |
| EML | … Content-Type: text/plain; charset=“utf-8” Content-Transfer-Encoding: quoted-printable Content-Disposition: inline Hallo. Im Anhang finden Sie eine Zahlungskopie. … |
| RTF | … {\f0\fswiss\fcharset0 Arial;} {\f1\fmodern Courier New;} {\colortbl\red0\green0\blue0;\red0\green0\blue255;} \uc1\pard\plain\deftab360 \f0\fs20 Invio file invoice.xml, con identificativo 123456789. In allegato il file contenente la fattura ed il file contenente i metadati.\par … |
| VBA | … Set SomeDoc = App.OpenDocumentByCode(“DOC”) Set rsSomeDoc = SomeDoc.DataSets(“MAIN”) For i = 0 To rsSomeDoc.Fields.Count − 1 Fld_Name = rsSomeDoc.Fields.Item(i).Name If Left(Fld_Name, 1) = “A” Then FldVal(Fld_Name) = rsSomeDoc.FldVal(Fld_Name) End if Next … |
| Model | HTML | XML | EML | ||||||||
| Acc. | Prec. | Rec. | Acc. | Prec. | Rec. | Acc. | Prec. | Rec. | |||
| Vectorization | BoW | SVM | 0.979 | 0.965 | 0.994 | 0.997 | 1.000 | 0.994 | 0.900 | 0.899 | 0.886 |
| DT | 0.975 | 0.986 | 0.970 | 0.996 | 0.992 | 1.000 | 0.836 | 0.845 | 0.829 | ||
| DNN | 0.987 | 0.998 | 0.980 | 1.000 | 1.000 | 1.000 | 0.965 | 0.964 | 1.000 | ||
| TF-IDF | SVM | 0.934 | 0.952 | 0.914 | 0.991 | 0.990 | 0.992 | 0.875 | 0.889 | 0.838 | |
| DT | 0.973 | 0.982 | 0.964 | 0.995 | 0.996 | 0.998 | 0.829 | 0.858 | 0.831 | ||
| DNN | 0.982 | 0.994 | 0.970 | 0.997 | 1.000 | 0.998 | 0.946 | 0.975 | 0.920 | ||
| W2VSum | SVM | 0.936 | 0.954 | 0.916 | 0.990 | 0.988 | 0.992 | 0.831 | 0.828 | 0.826 | |
| DT | 0.920 | 0.920 | 0.920 | 0.988 | 0.992 | 0.992 | 0.798 | 0.791 | 0.810 | ||
| DNN | 0.973 | 0.996 | 0.950 | 0.980 | 1.000 | 0.992 | 0.770 | 0.919 | 0.962 | ||
| W2VAvg | SVM | 0.936 | 0.950 | 0.948 | 0.990 | 0.988 | 0.992 | 0.842 | 0.834 | 0.826 | |
| DT | 0.915 | 0.912 | 0.920 | 0.988 | 0.984 | 0.992 | 0.809 | 0.791 | 0.773 | ||
| DNN | 0.995 | 1.000 | 0.992 | 1.000 | 1.000 | 1.000 | 0.885 | 1.000 | 0.784 | ||
| Model | RTF | VBA | |||||||||
| Acc. | Prec. | Rec. | Acc. | Prec. | Rec. | ||||||
| Vectorization | BoW | SVM | 0.998 | 0.998 | 0.998 | 0.996 | 0.996 | 0.996 | |||
| DT | 0.997 | 0.998 | 0.996 | 0.991 | 0.992 | 0.992 | |||||
| DNN | 0.998 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | |||||
| TF-IDF | SVM | 0.991 | 0.990 | 0.992 | 0.985 | 0.974 | 0.996 | ||||
| DT | 0.996 | 0.996 | 0.996 | 0.984 | 0.984 | 0.984 | |||||
| DNN | 0.993 | 1.000 | 0.992 | 0.993 | 1.000 | 0.992 | |||||
| W2VSum | SVM | 0.966 | 0.972 | 0.960 | 0.982 | 0.984 | 0.980 | ||||
| DT | 0.966 | 0.970 | 0.974 | 0.979 | 0.973 | 0.986 | |||||
| DNN | 0.952 | 0.952 | 0.958 | 0.924 | 1.000 | 0.968 | |||||
| W2VAvg | SVM | 0.955 | 0.976 | 0.984 | 0.990 | 0.990 | 0.990 | ||||
| DT | 0.974 | 0.966 | 0.960 | 0.987 | 0.980 | 0.998 | |||||
| DNN | 0.985 | 0.990 | 0.982 | 0.996 | 0.996 | 0.996 | |||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hong, J.; Jeong, D.; Kim, S.-W. Classifying Malicious Documents on the Basis of Plain-Text Features: Problem, Solution, and Experiences. Appl. Sci. 2022, 12, 4088. https://doi.org/10.3390/app12084088
Hong J, Jeong D, Kim S-W. Classifying Malicious Documents on the Basis of Plain-Text Features: Problem, Solution, and Experiences. Applied Sciences. 2022; 12(8):4088. https://doi.org/10.3390/app12084088
Chicago/Turabian StyleHong, Jiwon, Dongho Jeong, and Sang-Wook Kim. 2022. "Classifying Malicious Documents on the Basis of Plain-Text Features: Problem, Solution, and Experiences" Applied Sciences 12, no. 8: 4088. https://doi.org/10.3390/app12084088
APA StyleHong, J., Jeong, D., & Kim, S. -W. (2022). Classifying Malicious Documents on the Basis of Plain-Text Features: Problem, Solution, and Experiences. Applied Sciences, 12(8), 4088. https://doi.org/10.3390/app12084088