
A Chinese Few-Shot Text Classification Method Utilizing Improved Prompt Learning and Unlabeled Data


Abstract
:1. Introduction
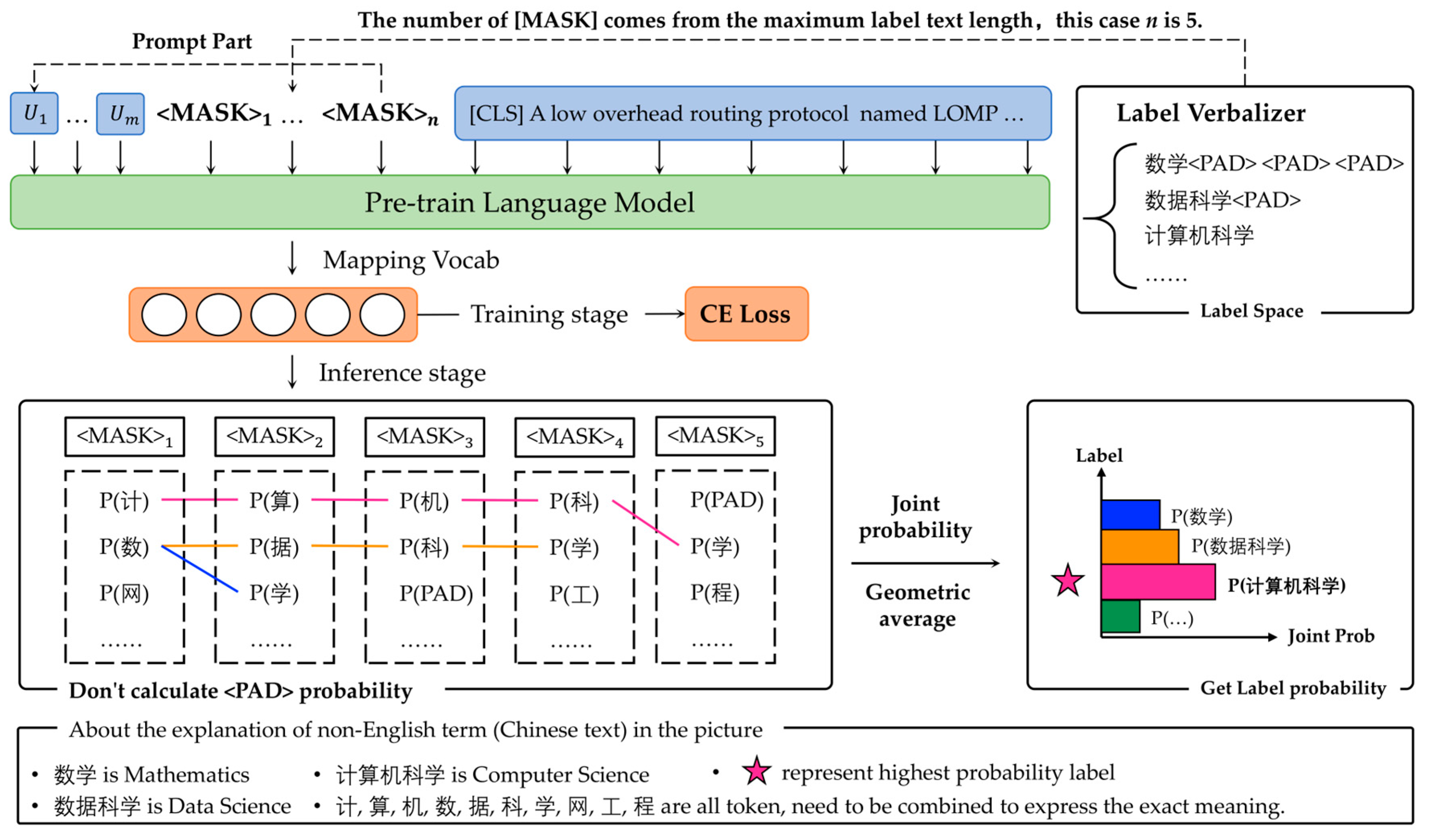
- According to our best knowledge, this is the first study to combine the prompt learn-ing method and unlabeled data for Chinese FSTC. The proposed CIPLUD model de-signs a universal prompt template for different Chinese FSTC tasks. It uses the joint probability and length-constrained decoding method to solve the random token composition problem caused by the multiple masks’ prompt templates;
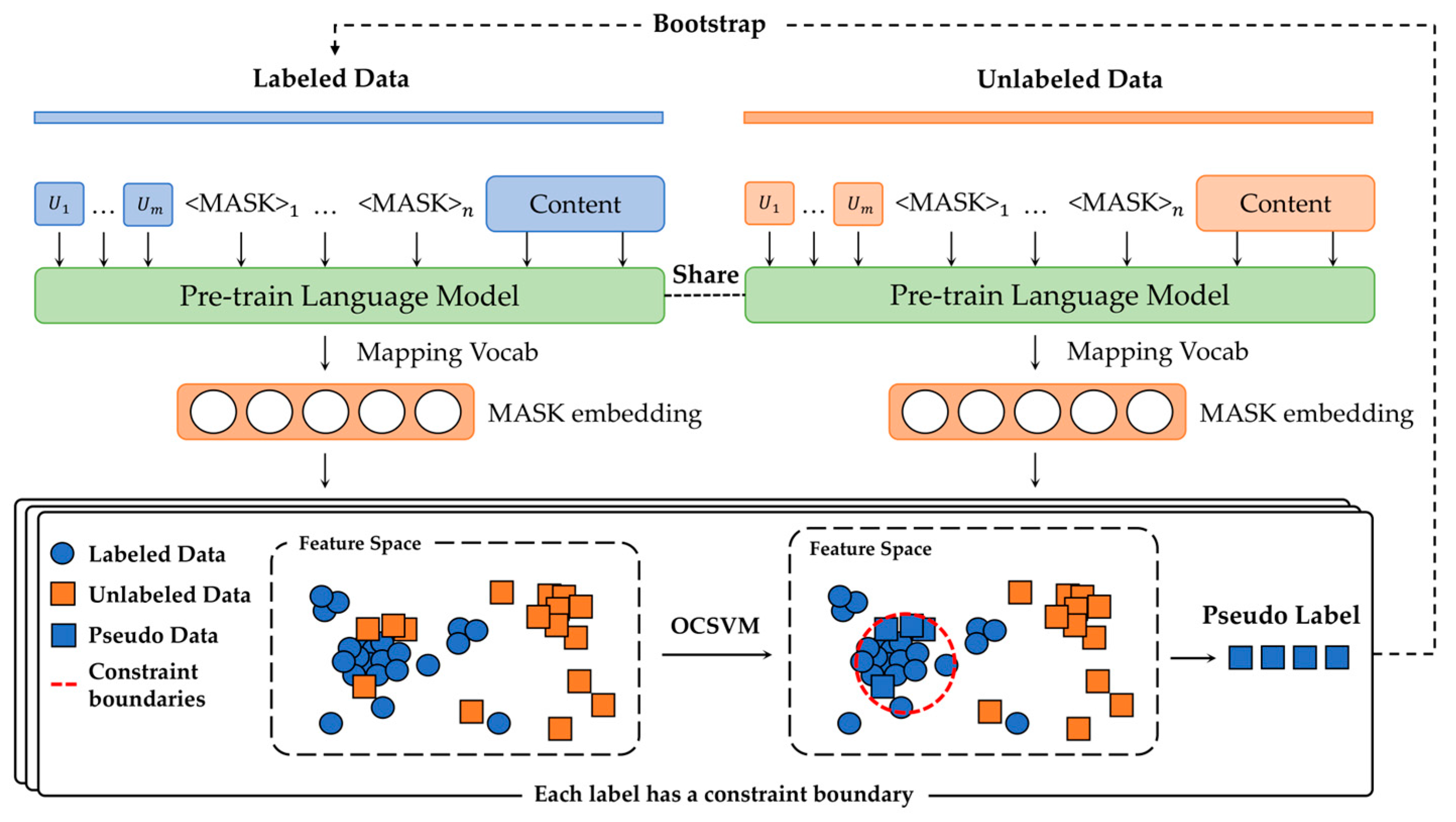
- To design a pseudo-label candidate method using the OCSVM model and conduct semi-supervised training using the pseudo-labels, resulting in improved performance;
- We conducted experiments and evaluated a series of Chinese FSTC datasets. The experimental results demonstrate that the proposed CIPLUD model can gain signifi-cant improvement over other prompt learning methods.
2. Related Work
2.1. Few-Shot Text Classification
2.2. Pre-Trained Language Model
2.3. Prompt Learning
3. Chinese Few-Shot Text Classification Method with Improved Prompt Learning and Unlabeled Data
3.1. Multiple Masks Optimization-Based Prompt Learning Module
3.2. One-Class Support Vector Machine-based Unlabeled Data Leveraging Module
| Algorithm 1 The iterative training process of the OCSVM-UDL |
| Input: Training set D, validation set D’, Unlabeled set U, Mixed Training set F, MMOPL model M1, OCSVM model M2. 1: Initialize F = D // Mixed Training set equal Training set 2: repeat |
| 3: repeat 4: Load a batch size of instances B belong F and add a prompt template 5: Generate input embedding vector using the M1 for each instance in B 6: Update parameter by minimizing 7: Save the best model M1′ according to the average performance on D’ |
| 8: until no more batches 9: Load a batch size of instances B belong F and add a prompt template 10: Generate input embedding vector using the M1′ for each instance in B 11: Generate a constrained boundary for each label using the M2. 12: Filtering a batch size of instances u belong U and get pseudo-label data P 13: Update mixed training set F = D + P and duplicate removal 14: until M1 convergence |
4. Experiments
4.1. Experiment Datasets
- EPRSTMT, an e-commerce product review dataset for sentiment analysis, with the task of predicting whether the user of the reviews is positive or negative;
- CSLDCP, a Chinese scientific literature subject classification dataset, includes 67 categories of literature labels. There are 13 broad categories, ranging from the social sciences to the natural sciences, and the task is to assign a separate category to each piece of literature through Chinese abstracts;
- TNEWS, a Toutiao short text categorized news dataset, comes from the news section of Today of Headlines. There are 15 news categories, and it is the goal of this task to categorize news titles based on their headlines;
- IFLYTEK, a long text classification dataset that collects descriptive information on various application topics related to daily life, with 119 categories. The task is to pre-dict application categories from application description information.
4.2. Baseline Models
- Fine-tuning is a Chinese pre-trained language model that adopts;
- Pattern-Exploiting Training (PET) employs hand-crafted templates and label words to form the prompt, along with an ensemble model to annotate an unlabeled dataset, which can be considered as a text augmentation;
- EFL uses the T5 model to generate the best discrete prompt template, eliminating the need for a manual search;
- P-tuning proposes to learn continuous prompts by inserting trainable variables into the embedded input.
4.3. Implementation Details
5. Discussion
5.1. Overall Performance
5.2. Ablation Experiment
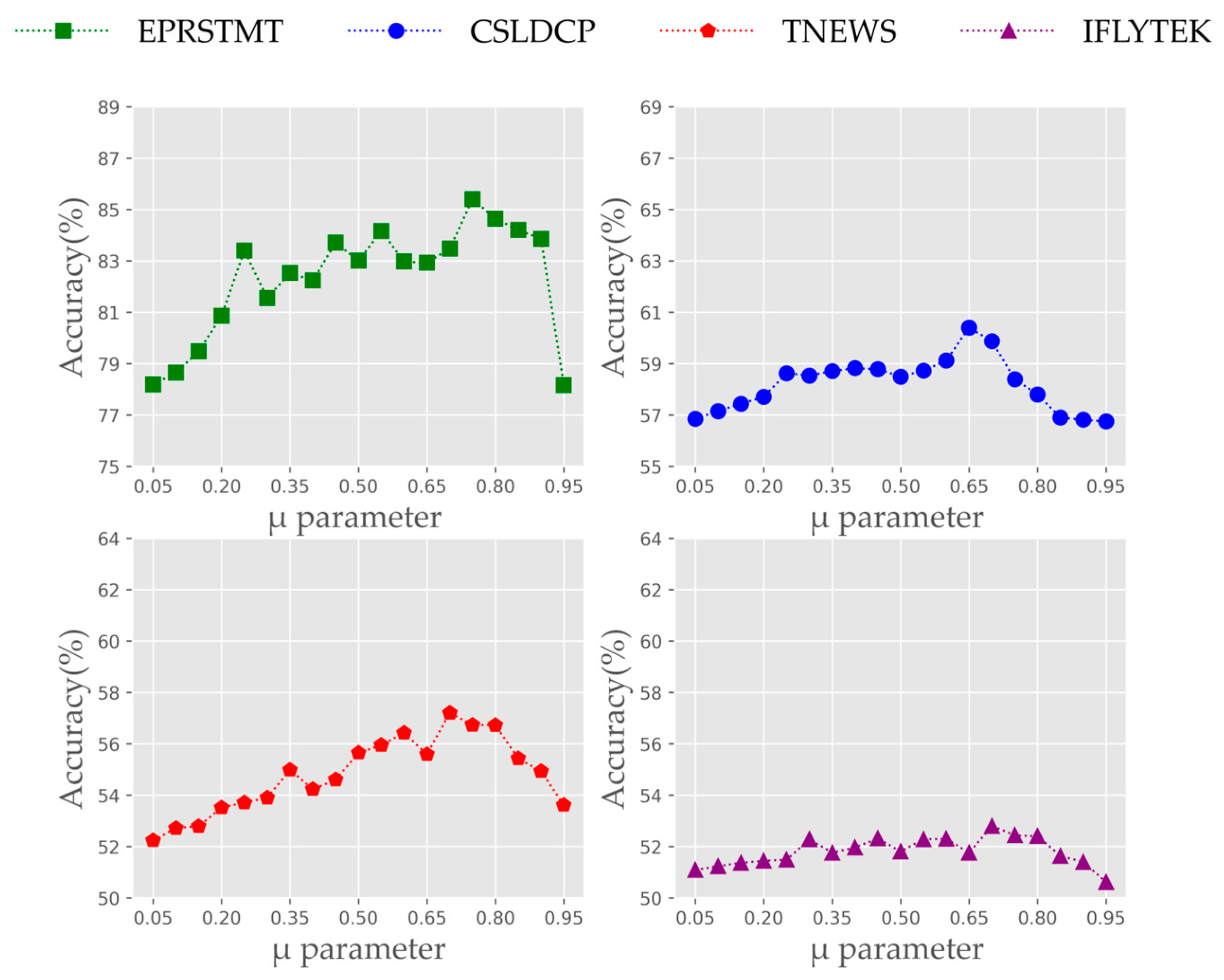
5.3. Impact of Hyper-Parameter on Constraint Boundary
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Kadhim, A.I. Survey on supervised machine learning techniques for automatic text classification. Artif. Intell. Rev. 2019, 52, 273–292. [Google Scholar] [CrossRef]
- Chen, W.; Xu, Z.; Zheng, X.; Yu, Q.; Luo, Y. Research on Sentiment Classification of Online Travel Review Text. Appl. Sci. 2020, 10, 5275. [Google Scholar] [CrossRef]
- Xu, G.; Liu, P.; Zhu, Z.; Liu, J.; Xu, F. Attention-Enhanced Graph Convolutional Networks for Aspect-Based Sentiment Classification with Multi-Head Attention. Appl. Sci. 2021, 11, 3640. [Google Scholar] [CrossRef]
- Wang, Y.; Guo, J.; Yuan, C.; Li, B. Sentiment Analysis of Twitter Data. Appl. Sci. 2022, 12, 11775. [Google Scholar] [CrossRef]
- Eminagaoglu, M. A new similarity measure for vector space models in text classification and information retrieval. J. Inf. Sci. 2022, 48, 463–476. [Google Scholar] [CrossRef]
- Khan, S.U.R.; Islam, M.A.; Aleem, M.; Iqbal, M.A. Temporal specificity-based text classification for information retrieval. Turk. J. Electr. Eng. Comput. Sci. 2018, 26, 2915–2926. [Google Scholar] [CrossRef] [Green Version]
- Ebadi, N.; Jozani, M.; Choo, K.K.R.; Rad, P. A memory network information retrieval model for identification of news misinformation. IEEE Trans. Big Data 2021, 8, 1358–1370. [Google Scholar] [CrossRef]
- Duan, K.; Du, S.; Zhang, Y.; Lin, Y.; Wu, H.; Zhang, Q. Enhancement of Question Answering System Accuracy via Transfer Learning and BERT. Appl. Sci. 2022, 12, 11522. [Google Scholar] [CrossRef]
- Wei, J.; Bosma, M.; Zhao, V.; Guu, K.; Yu, A.W.; Lester, B.; Du, N.; Dai, A.M.; Le, Q.V. Finetuned Language Models are Zero-Shot Learners. arXiv 2021, arXiv:2109.01652. [Google Scholar]
- Zhong, R.; Lee, K.; Zhang, Z.; Klein, D. Adapting Language Models for Zero-shot Learning by Meta-tuning on Dataset and Prompt Collections. In Findings of the Association for Computational Linguistics: EMNLP 2021; Association for Computational Linguistics: Punta Cana, Dominican Republic, 2021; pp. 2856–2878. [Google Scholar]
- Qin, G.; Eisner, J. Learning How to Ask: Querying LMs with Mixtures of Soft Prompts. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Online, 6–11 June 2021; Association for Computational Linguistics: Punta Cana, Dominican Republic, 2021; pp. 5203–5212. [Google Scholar]
- Schick, T.; Schütze, H. Exploiting Cloze-Questions for Few-Shot Text Classification and Natural Language Inference. In Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume, Online, 19–23 April 2021; pp. 255–269. [Google Scholar]
- Schölkopf, B.; Williamson, R.C.; Smola, A.; Shawe-Taylor, J.; Platt, J.C. Support vector method for novelty detection. Adv. Neural Inf. Process. Syst. 2000, 12, 582–588. [Google Scholar]
- Xu, L.; Lu, X.; Yuan, C.; Zhang, X.; Xu, H.; Yuan, H.; Wei, G.; Pan, X.; Tian, X.; Qin, L.; et al. Fewclue: A chinese few-shot learning evaluation benchmark. arXiv 2021, arXiv:2107.07498. [Google Scholar]
- Yan, L.; Zheng, Y.; Cao, J. Few-shot learning for short text classification. Multimed. Tools. Appl. 2018, 77, 29799–29810. [Google Scholar] [CrossRef]
- Xu, J.; Du, Q. Learning transferable features in meta-learning for few-shot text classification. Pattern. Recogn. Lett. 2020, 135, 271–278. [Google Scholar] [CrossRef]
- Pang, N.; Zhao, X.; Wang, W.; Xiao, W.; Guo, D. Few-shot text classification by leveraging bi-directional attention and cross-class knowledge. Sci. China. Inform. Sci. 2021, 64, 130103. [Google Scholar] [CrossRef]
- Wang, D.; Wang, Z.; Cheng, L.; Zhang, W. Few-Shot Text Classification with Global–Local Feature Information. Sensors 2022, 22, 4420. [Google Scholar] [CrossRef]
- Pan, C.; Huang, J.; Gong, J.; Yuan, X. Few-shot transfer learning for text classification with lightweight word embedding based models. IEEE Access 2019, 7, 53296–53304. [Google Scholar] [CrossRef]
- Zheng, J.; Cai, F.; Chen, W.; Lei, W.; Chen, H. Taxonomy-aware learning for few-shot event detection. In Proceedings of the Web Conference 2021, Ljubljana, Slovenia, 19–23 April 2021; pp. 3546–3557. [Google Scholar]
- Huisman, M.; van Rijn, J.N.; Plaat, A. A survey of deep meta-learning. Artif. Intell. Rev. 2021, 54, 4483–4541. [Google Scholar] [CrossRef]
- Koch, G.; Zemel, R.; Salakhutdinov, R. Siamese neural networks for one-shot image recognition. In Proceedings of the 32nd International Conference on Machine Learning, ICML 2015, Lille, France, 6–11 July 2015. [Google Scholar]
- Vinyals, O.; Blundell, C.; Lillicrap, T.; Wierstra, D. Matching networks for one shot learning. Adv. Neural Inf. Process. Syst. 2016, 29, 3630–3638. [Google Scholar]
- Snell, J.; Swersky, K.; Zemel, R. Prototypical networks for few-shot learning. Adv. Neural Inf. Process. Syst. 2017, 30, 4077–4087. [Google Scholar]
- Sung, F.; Yang, Y.; Zhang, L.; Xiang, T.; Torr, P.H.; Hospedales, T.M. Learning to compare: Relation network for few-shot learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1199–1208. [Google Scholar]
- Zhang, N.; Li, L.; Chen, X.; Deng, S.; Bi, Z.; Tan, C.; Huang, F.; Chen, H. Differentiable Prompt Makes Pre-trained Language Models Better Few-shot Learners. In Proceedings of the 9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, 3–7 May 2021. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019; Volume 1, pp. 4171–4186. [Google Scholar]
- Sun, Y.; Wang, S.; Li, Y.; Feng, S.; Chen, X.; Zhang, H.; Tian, X.; Zhu, D.; Tian, H.; Wu, H. Ernie: Enhanced representation through knowledge integration. arXiv 2019, arXiv:1904.09223. [Google Scholar]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language models are few-shot learners. Adv. Neural Inf. Process. Syst. 2020, 33, 1877–1901. [Google Scholar]
- Liu, P.; Yuan, W.; Fu, J.; Jiang, Z.; Hayashi, H.; Neubig, G. Pre-train, prompt, and predict: A systematic survey of prompting methods in natural language processing. arXiv 2021, arXiv:2107.13586. [Google Scholar] [CrossRef]
- Schick, T.; Schütze, H. It’s Not Just Size That Matters: Small Language Models Are Also Few-Shot Learners. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Online, 6–11 June 2021; pp. 2339–2352. [Google Scholar]
- Tam, D.; Menon, R.R.; Bansal, M.; Srivastava, S.; Raffel, C. Improving and Simplifying Pattern Exploiting Training. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, Punta Cana, Dominican Republic, 7–11 November 2021; pp. 4980–4991. [Google Scholar]
- Wang, S.; Fang, H.; Khabsa, M.; Mao, H.; Ma, H. Entailment as few-shot learner. arXiv 2021, arXiv:2104.14690. [Google Scholar]
- Liu, X.; Zheng, Y.; Du, Z.; Ding, M.; Qian, Y.; Yang, Z.; Tang, J. GPT understands, too. arXiv 2021, arXiv:2103.10385. [Google Scholar]
- Jiang, Z.; Xu, F.F.; Araki, J.; Neubig, G. How can we know what language models know? Trans. Assoc. Comput. Linguist. 2020, 8, 423–438. [Google Scholar] [CrossRef]
- Lester, B.; Al-Rfou, R.; Constant, N. The Power of Scale for Parameter-Efficient Prompt Tuning. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, Online and Punta Cana, Dominican Republic, 7–11 November 2021; pp. 3045–3059. [Google Scholar]
- Vu, T.; Barua, A.; Lester, B.; Cer, D.; Iyyer, M.; Constant, N. Overcoming Catastrophic Forgetting in Zero-Shot Cross-Lingual Generation. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, Abu Dhabi, United Arab Emirates, 7–11 December 2022; pp. 9279–9300. [Google Scholar]
- Domingues, R.; Filippone, M.; Michiardi, P. A comparative evaluation of outlier detection algorithms: Experiments and analyses. Pattern. Recogn. 2018, 74, 406–421. [Google Scholar] [CrossRef]
- Schölkopf, B.; Platt, J.C.; Shawe-Taylor, J.; Smola, A.J.; Williamson, R.C. Estimating the support of a high-dimensional distribution. Neural Comput. 2001, 13, 1443–1471. [Google Scholar] [CrossRef]
- Fei, G.; Liu, B. Breaking the Closed World Assumption in Text Classification. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, San Diego, CA, USA, 12–17 June 2016; pp. 506–514. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
| Subtask | Task | Train | Dev | Test Public | Unlabeled Num | Num Labels |
|---|---|---|---|---|---|---|
| EPRSTMT | SentimentAnalysis | 32 | 32 | 610 | 19565 | 2 |
| CSLDCP | LongTextClassify | 536 | 536 | 1784 | 18111 | 67 |
| TNEWS | ShortTextClassify | 240 | 240 | 2010 | 20000 | 15 |
| IFLYTEK | ShortTextClassify | 928 | 690 | 1749 | 7558 | 119 |
| Method | Prompt Designing | Prompt Style | Use Unlabeled | |
|---|---|---|---|---|
| Templates | Mask Number | |||
| Fine-tuning | — | — | — | No |
| PET | Hand-craft | Single | Discrete | YES |
| P-tuning | Auto | Single | Continuous | No |
| EFL | Hand-craft | Single | Discrete | No |
| Ours | Auto | Multiple | Continuous | YES |
| Task | Hyper-Parameters | Value | Task | Hyper-Parameters | Value |
|---|---|---|---|---|---|
| EPRSTMT | Max length | 88 | TNEWS | Max length | 33 |
| Learning rate | 3 × 10−4 | Learning rate | 4 × 10−5 | ||
| μ | 0.75 | μ | 0.65 | ||
| CSLDCP | Max length | 278 | IFLYTEK | Max length | 215 |
| Learning rate | 5 × 10−4 | Learning rate | 7 × 10−4 | ||
| μ | 0.70 | μ | 0.70 |
| Method | EPRSTMT (Acc. %) | CSLDCP (Acc. %) | TNEWS (Acc. %) | IFLYTEK (Acc. %) | Avg (Acc. %) |
|---|---|---|---|---|---|
| Human | 90.0 | 68.0 | 71.0 | 66.0 | 73.6 |
| Fine-Tuning | 66.5 | 57.0 | 51.6 | 42.1 | 54.3 |
| PET | 84.0 | 59.9 | 56.4 | 50.3 | 62.7 |
| P-tuning | 80.6 | 56.6 | 55.9 | 52.6 | 61.4 |
| EFL | 76.7 | 47.9 | 56.3 | 52.1 | 58.3 |
| MMOPL | 82.1 | 59.8 | 56.4 | 52.2 | 62.6 |
| CIPLUD | 85.4 | 60.4 | 57.2 | 52.8 | 64.0 |
| Method | EPRSTMT (Acc. %) | CSLDCP (Acc. %) | TNEWS (Acc. %) | IFLYTEK (Acc. %) |
|---|---|---|---|---|
| w/o MMOPL | 77.8 | 56.7 | 52.0 | 50.6 |
| w/o OCSVM-UDL | 82.1 | 59.8 | 56.4 | 52.2 |
| CIPLUD | 85.4 | 60.4 | 57.2 | 52.8 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hu, T.; Chen, Z.; Ge, J.; Yang, Z.; Xu, J. A Chinese Few-Shot Text Classification Method Utilizing Improved Prompt Learning and Unlabeled Data. Appl. Sci. 2023, 13, 3334. https://doi.org/10.3390/app13053334
Hu T, Chen Z, Ge J, Yang Z, Xu J. A Chinese Few-Shot Text Classification Method Utilizing Improved Prompt Learning and Unlabeled Data. Applied Sciences. 2023; 13(5):3334. https://doi.org/10.3390/app13053334
Chicago/Turabian StyleHu, Tingkai, Zuqin Chen, Jike Ge, Zhaoxu Yang, and Jichao Xu. 2023. "A Chinese Few-Shot Text Classification Method Utilizing Improved Prompt Learning and Unlabeled Data" Applied Sciences 13, no. 5: 3334. https://doi.org/10.3390/app13053334
APA StyleHu, T., Chen, Z., Ge, J., Yang, Z., & Xu, J. (2023). A Chinese Few-Shot Text Classification Method Utilizing Improved Prompt Learning and Unlabeled Data. Applied Sciences, 13(5), 3334. https://doi.org/10.3390/app13053334