



EnsembleVehicleDet: Detection of Faraway Vehicles with Real-Time Consideration

 ,
, 
Abstract
:Featured Application
Abstract
1. Introduction
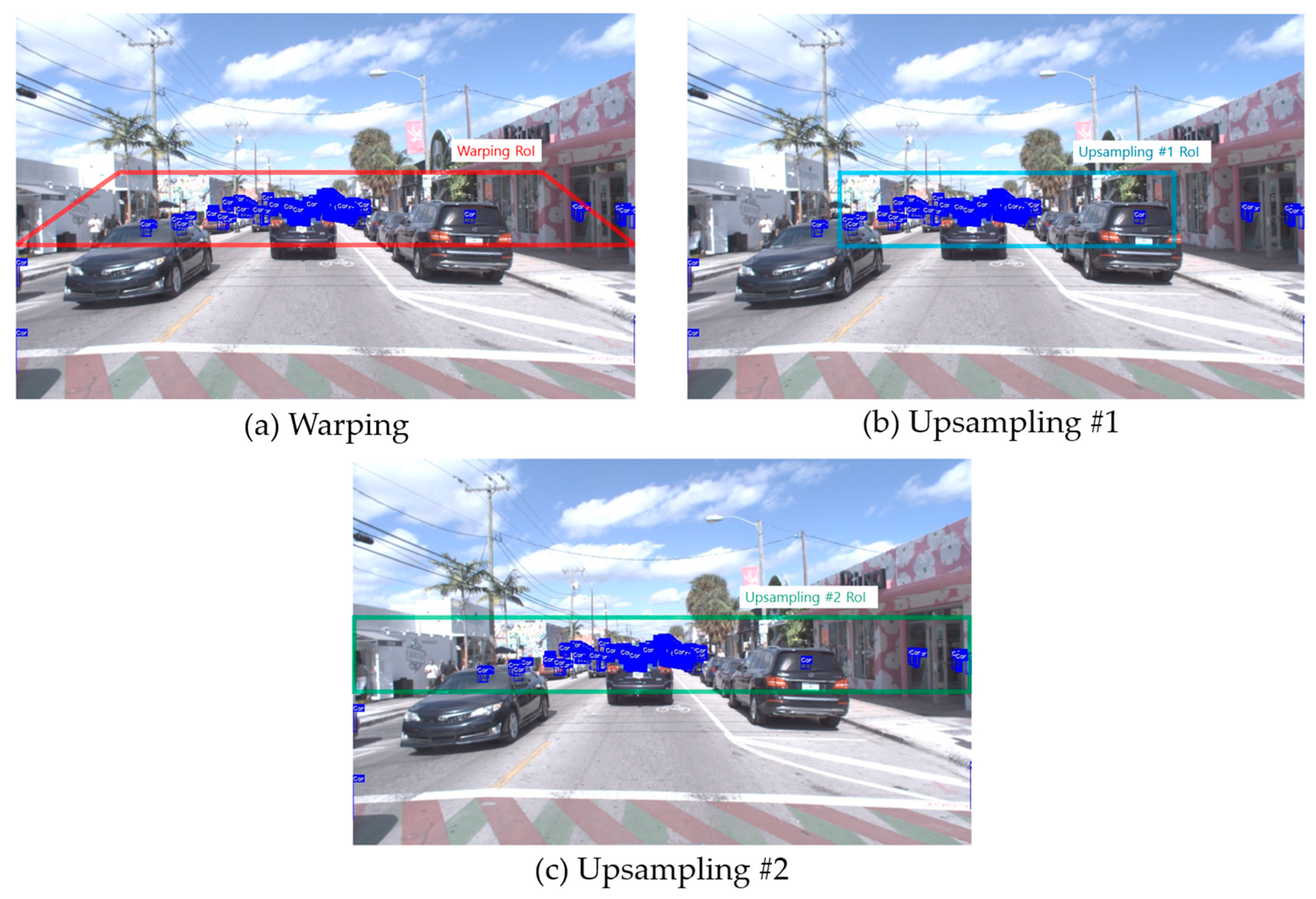
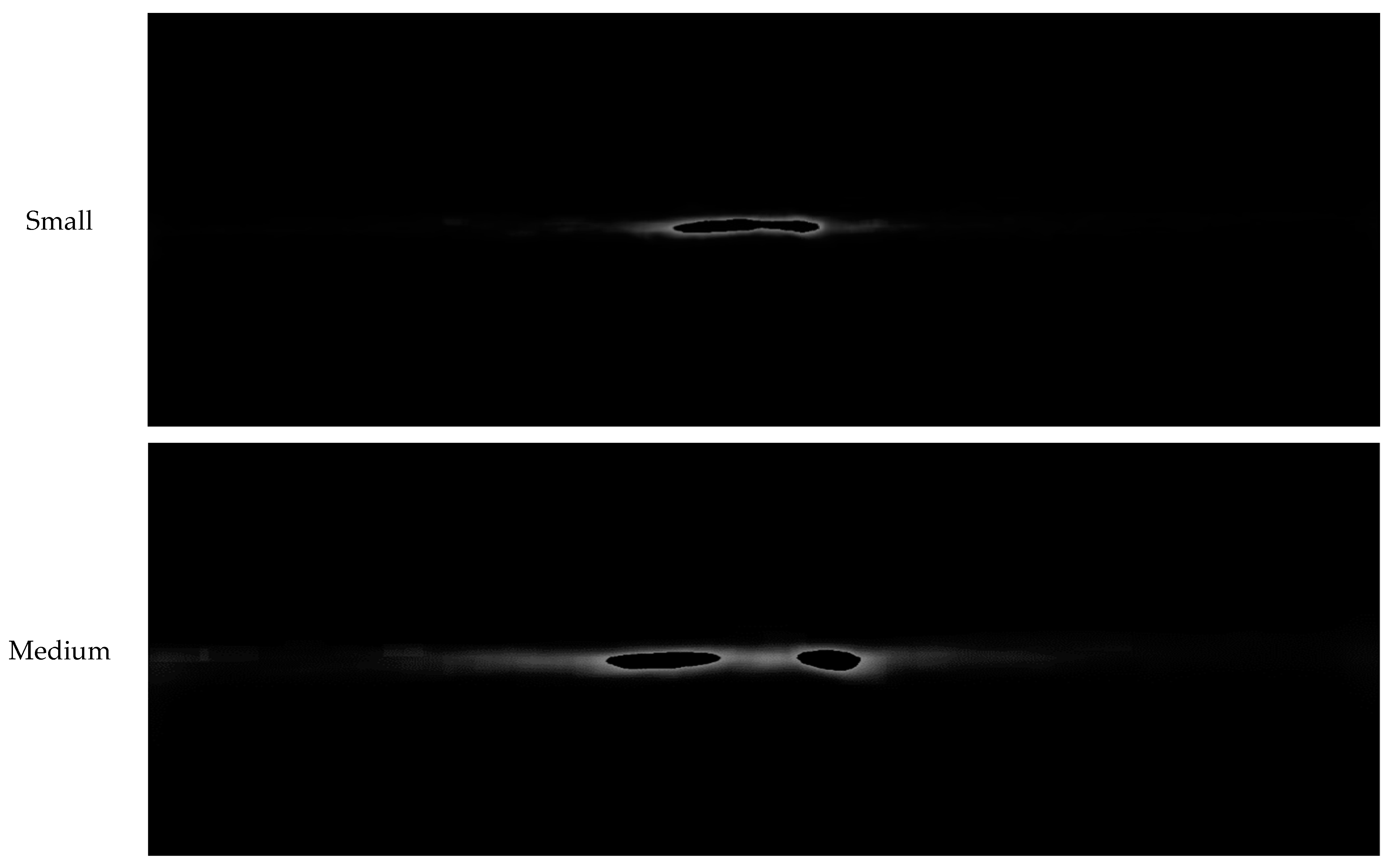
- Since the location of the camera in autonomous vehicles is fixed, we assume no height difference is present for the perspective view with either the training or test data. Therefore, we propose acquiring AccumulateImage, which distributes the location of small vehicles from the training dataset, and configuring the RoI with this distribution.
- We acquired the transformed images by either using perspective transformation on the configured RoI or performing upsampling and then identifying the locations of the small vehicles in the box regions. Thus, we propose a method to convert the detection boxes to the coordinates of the RoI region using an inverse perspective transformation.
- Furthermore, we propose an ensemble-based vehicle detection method that considers the requirements of real-time processing. The comparison of the detection results of the two deep learning-based models used in the ensemble method with the baseline reveals that the execution speed of vehicle detection can be improved without degrading the accuracy. To the best of our knowledge, this is the first report of improving the execution speed without degrading the detection accuracy with an ensemble-based vehicle detection method.
2. Background
3. Proposed Method
3.1. Setting RoI Configuration for Model B
| Algorithm 1 RoI Set |
| Input: AccumulateImage_S = Pixel information representing the frequency of small box appearances accumulated in video. Frame = Pixel information for the current frame from the video Output: RoIImage = Pixel information for RoI region through AccumulateImage_S from the original image |
| AccumulateImage_S.rows = rows from AccumulateImage_S AccumulateImage_S.cols = columns from AccumulateImage_S Frame.rows = rows from Frame Frame.cols = columns from Frame Max_sum = 0 RoI_cols = 0 X_Range_1 = AccumulateImage_S.rows/4 X_Range_2 = AccumulateImage_S.rows ∗ 3/4 i = 0 while i < (AccumulateImage_S.cols-160) sum = 0 for x = X_Range_1 to X_Range_2 do for y = i to (i + 160) do sum += AccumulateImage_S[Frame.cols ∗ y ∗ 3 + x ∗ 3] sum += AccumulateImage_S[Frame.cols ∗ y ∗ 3 + x ∗ 3 + 1] sum += AccumulateImage_S[Frame.cols ∗ y ∗ 3 + x ∗ 3 + 2] if Max_sum < sum then Max_sum = sum RoI_cols = i i = i + 160 for x = 0 to Frame.rows/2 do for y = 0 to 160 do RoIImage[160 ∗ y ∗ 3 + x ∗ 3] = Frame[Frame.cols ∗ (y + RoI_cols) ∗ 3 + (x + AccumulateImage_S.rows/2) ∗ 3] RoIImage[160 ∗ y ∗ 3 + x ∗ 3 + 1] = Frame[Frame.cols ∗ (y + RoI_cols) ∗ 3 + (x + AccumulateImage_S.rows/2) ∗ 3 + 1] RoIImage[160 ∗ y ∗ 3 + x ∗ 3 + 2] = Frame[Frame.cols ∗ (y + RoI_cols) ∗ 3 + (x + AccumulateImage_S.rows/2) ∗ 3 + 2] return RoIImage |
3.2. Obtaining Detection Results from Transformed Image
| Algorithm 2 Re-coordinate the detections |
| Input: Frame = Pixel information for the current frame from the video Model B = Network Modified Model Warping_Coordinates = Two coordinates on the image to apply Perspective Transformation on: [y1, y2] Checking the pre-processing method = 0(upsampling#1 or upsampling#2), 1(warping) RoIImage = Pixel information for RoI region through AccumulateImage_S from the original image Output: Re-coordinate_Detections = Box list readjusted from Model B to the original image |
| Perspect_Mat // 3 × 3 array used when warp transforming, saved only once in the first frame. if Checking the pre-processing method = 0 then // Image transformation is performed using the RoI image obtained from Algorithm 1. Upsampling1_Frame = Upsampling1_Transform(Frame, RoIImage) // Box list for the present Upsampling1_Frame from Model B Detections_B_U_1 = GetBoxList(Upsampling1_Frame, Model_B) // The box information detected through image conversion is readjusted to match the original image. Re-coordinate_Detections = Upsampling1Re-adjustment(Detections_B_U_1, Frame) return Re-coordinate_Detections else if Checking the pre-processing method == 1 then // Image transformation is performed using the RoI image obtained from Algorithm 1. Upsampling2_Frame = Upsampling2_Transform(Frame, RoIImage) // Box list for the present Upsampling2_Frame from Model B Detections_B_U_2 = GetBoxList(Upsampling2_Frame, Model_B) // The box information detected through image conversion is readjusted to match the original image. Re-coordinate_Detections = Upsampling2Re-adjustment(Detections_B_U_2, Frame) return Re-coordinate_Detections else if Perspect_Mat.data = 0 then // When there is no value of Inverse_Perspect_Mat Frame_p[0] = [W/3, Warping_Coordinates[y1]] Frame_p[1] = [W * 2/3, Warping_Coordinates[y1]] Frame_p[2] = [0, Warping_Coordinates[y2]] Frame_p[3] = [W, Warping_Coordinates[y2]] dst_p[0] = [0, 0] dst_p[1] = [W, 0] dst_p[2] = [0, H ∗ 4/5] dst_p[3] = [W, H ∗ 4/5] Perspect_Mat = getPerspectiveTransform(Frame_p, dst_p) // Image transformation is performed using the RoI image obtained from Algorithm 1. Warping_Frame = Warping_Transform(Frame, RoIImage, Perspect_Mat) // Box list for the present Warping_Frame from Model B Detections_B_W = GetBoxList(Warping_Frame, Model_B) // The box information detected through image conversion is readjusted to match the original image. Re-coordinate_Detections = WarpingRe-adjustment(Detections_B_W, Frame, Perspect_Mat) return Re-coordinate_Detections |
3.3. Merging Detection Results from First and Second Detectors
| Algorithm 3 Merging Detection Results |
| Input: Frame = Pixel information for the current frame from the video Original_Detections = Box list for the current frame from Model A Re-coordinate_Detections = Box list readjusted from Model B to the original image DIoU_Thresh = Variables to determine the degree to which DIoU overlaps the detection results of both models Output: Final_Detections = Final detection results for the current frame |
| //sort first_box and second_box in descending order of confidence value Sort_Descending(Original_Detections) Sort_Descending(Re-coordinate_Detections) matched_boxes = 0 for i = 0 to size of Re-coordinate_Detections do for j = 0 to size of Original_Detections do max_DIoU = largest DIoU of Re-coordinate_Detections[i] and Original_Detections[j] if max_DIoU > DIoU_Thresh do Final_Detections[matched_boxes] = Re-coordinate_Detections[i] Final_Detections[matched_boxes].confidence = Re-coordinate_Detections[i].confidence > Original_Detections[j].con fidence ? Re-coordinate_Detections[i].confidence: Original_Detections[j].confidence matched_boxes++ Original_Detections[j] = 0 for j = 0 to size of Original_Detections do if Original_Detections[j] == 0 then continue Final_Detections[matched_boxes] = Original_Detections[j] matched_boxes++ return Final_Detections |
4. Experimental Results
4.1. Experimental Setup
- Precision, defined as TP/(TP + FP), means the false detection rate of the proposed method;
- Recall, defined as TP/(TP + FN), means the missed detection rate of the proposed method;
- AP0.5, defined as the average precision (AP) evaluated for vehicle class, means the target accuracy of the proposed method when the IoU of the detection box and the GT is more than 0.5.
4.2. Detection Performance
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A


References
- Bengio, Y.; Lecun, Y.; Hinton, G. Deep Learning for AI. Commun. ACM 2021, 64, 58–65. [Google Scholar] [CrossRef]
- Li, Z.; Liu, F.; Yang, W.; Peng, S.; Zhou, J. A Survey of Convolutional Neural Networks: Analysis, Applications, and Prospects. IEEE Trans. Neural Netw. Learn. Syst. 2022, 33, 6999–7019. [Google Scholar] [CrossRef]
- Bhatt, D.; Patel, C.; Talsania, H.; Patel, J.; Vaghela, R.; Pandya, S.; Modi, K.; Ghayvat, H. CNN Variants for Computer Vision: History, Architecture, Application, Challenges and Future Scope. Electronics 2021, 10, 2470. [Google Scholar] [CrossRef]
- Dai, H.; Huang, G.; Zeng, H.; Zhou, F. PM2.5 Volatility Prediction by XGBoost-MLP Based on GARCH Models. J. Clean. Prod. 2022, 356, 131898. [Google Scholar] [CrossRef]
- Dai, H.; Huang, G.; Zeng, H.; Yu, R. Haze Risk Assessment Based on Improved PCA-MEE and ISPO-LightGBM Model. Systems 2022, 10, 263. [Google Scholar] [CrossRef]
- Zhao, Z.; Zheng, P.; Xu, S.; Wu, X. Object Detection with Deep Learning: A Review. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 3212–3232. [Google Scholar] [CrossRef] [Green Version]
- Wang, Z.; Zhan, J.; Duan, C.; Guan, X.; Lu, P. A Review of Vehicle Detection Techniques for Intelligent Vehicles. IEEE Trans. Neural Netw. Learn. Syst. 2022, 23, 1–21. [Google Scholar] [CrossRef]
- Li, M.; Wang, Y.; Ramanan, D. Towards Streaming Perception. In Proceedings of the ECCV, Glasgow, UK, 23–28 August 2020. [Google Scholar]
- Casado-García, Á.; Heras, J. Ensemble Methods for Object Detection. In Proceedings of the ECAI, Santiago de Compostela, Spain, 29 August–8 September 2020. [Google Scholar]
- Ahn, H.; Son, S.; Kim, H.; Lee, S.; Chung, Y.; Park, D. EnsemblePigDet: Ensemble Deep Learning for Accurate Pig Detection. Appl. Sci. 2021, 11, 5577. [Google Scholar] [CrossRef]
- Mittal, U.; Chawla, P.; Tiwari, R. EnsembleNet: A Hybrid Approach for Vehicle Detection and Estimation of Traffic Density based on Faster R-CNN and YOLO Models. Neural Comput. Appl. 2023, 35, 4755–4774. [Google Scholar] [CrossRef]
- Mittal, U.; Chawla, P. Vehicle Detection and Traffic Density Estimation using Ensemble of Deep Learning Models. Multimed. Tools Appl. 2022, 82, 10397–10419. [Google Scholar] [CrossRef]
- Hai, W.; Yijie, Y.; Yingfeng, C.; Xiaobo, C.; Long, C.; Yicheng, L. Soft-Weighted-Average Ensemble Vehicle Detection Method Based on Single-Stage and Two-Stage Deep Learning Models. IEEE Trans. Intell. Veh. 2021, 6, 100–109. [Google Scholar]
- Sommer, L.; Acatay, O.; Schumann, A.; Beyerer, J. Ensemble of Two-Stage Regression Based Detectors for Accurate Vehicle Detection in Traffic Surveillance Data. In Proceedings of the AVSS, Auckland, New Zealand, 27–30 November 2018. [Google Scholar]
- Darehnaei, Z.; Fatemi, S.; Mirhassani, S.; Fouladian, M. Ensemble Deep Learning Using Faster R-CNN and Genetic Algorithm for Vehicle Detection in UAV Images. IETE J. Res. 2021, 29, 1–10. [Google Scholar] [CrossRef]
- Darehnaei, Z.; Fatemi, S.; Mirhassani, S.; Fouladian, M. Two-level Ensemble Deep Learning for Traffic Management using Multiple Vehicle Detection in UAV Images. Int. J. Smart Electr. Eng. 2021, 10, 127–133. [Google Scholar]
- Jagannathan, P.; Rajkumar, S.; Frnda, J.; Divakarachari, P.; Subramani, P. Moving Vehicle Detection and Classification using Gaussian Mixture Model and Ensemble Deep Learning Technique. Wirel. Commun. Mob. Comput. 2021, 2021, 5590894. [Google Scholar] [CrossRef]
- Walambe, R.; Marathe, A.; Kotecha, K.; Ghinea, G. Lightweight Object Detection Ensemble Framework for Autonomous Vehicles in Challenging Weather Conditions. Comput. Intell. Neurosci. 2021, 2021, 5278820. [Google Scholar] [CrossRef]
- Rong, Z.; Wang, S.; Kong, D.; Yin, B. A Cascaded Ensemble of Sparse-and-Dense Dictionaries for Vehicle Detection. Appl. Sci. 2021, 11, 1861. [Google Scholar] [CrossRef]
- Darehnaei, Z.; Shokouhifar, M.; Yazdanjouei, H.; Fatemi, S. SI-EDTL Swarm Intelligence Ensemble Deep Transfer Learning for Multiple Vehicle Detection in UAV Images. Concurr. Comput. Pract. Exp. 2022, 34, e6726. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the CVPR, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the CVPR, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.; Liao, H. Yolov4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Ultralytics/Yolov5. Available online: https://github.com/ultralytics/yolov5 (accessed on 25 June 2020).
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. Yolox: Exceeding Yolo Series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Wang, C.; Bochkovskiy, A.; Liao, H. YOLOv7: Trainable Bag-of-Freebies Sets New State-of-the-Art for Real-Time Object Detectors. arXiv 2022, arXiv:2207.02696. [Google Scholar]
- Zhang, Y.; Song, X.; Bai, B.; Xing, T.; Liu, C.; Gao, X.; Wang, Z.; Wen, Y.; Liao, H.; Zhang, G.; et al. 2nd Place Solution for Waymo Open Dataset Challenge—Real-Time 2D Object Detection. In Proceedings of the CVPRW, Nashville, TN, USA, 19–25 June 2021. [Google Scholar]
- Nikolay, S. 3rd Place Waymo Real-Time 2D Object Detection: YOLOv5 Self-Ensemble. In Proceedings of the CVPRW, Nashville, TN, USA, 19–25 June 2021. [Google Scholar]
- Jeon, H.; Tran, D.; Pham, L.; Nguyen, H.; Tran, T.; Jeon, J. Object Detection with Camera-Wise Training. In Proceedings of the CVPRW, Nashville, TN, USA, 19–25 June 2021. [Google Scholar]
- Balasubramaniam, A.; Pasricha, S. Object Detection in Autonomous Vehicles: Status and Open Challenges. arXiv 2022, arXiv:2201.07706. [Google Scholar]
- Argoverse-HD. Available online: https://www.kaggle.com/datasets/mtlics/argoversehd (accessed on 23 September 2022).
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.; Berg, A. SSD: Single Shot Multibox Detector. In Proceedings of the ECCV, Amsterdam, Netherlands, 8–16 October 2016. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. In Proceedings of the NeurIPS, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Cai, Z.; Vasconcelos, N. Cascade R-CNN: Delving into High Quality Object Detection. In Proceedings of the CVPR, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- NVIDIA 2020. Jetson AGX Xavier Series: Thermal Design Guide. Available online: https://tinyurl.com/r7zeehya (accessed on 23 September 2022).










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| YOLOv7-Tiny | AP0.5 | AP0.5-Small | AP0.5-Medium | AP0.5-Large |
|---|---|---|---|---|
| 1920 × 1216 | 0.81 | 0.67 | 0.76 | 0.86 |
| 960 × 608 | 0.79 | 0.63 | 0.75 | 0.86 |
| 480 × 320 | 0.68 | 0.51 | 0.66 | 0.83 |
| Execution Time Per Image (CPU or GPU) | Execution Speed Improvement | Reference |
|---|---|---|
| 18,500 ms (not specified) | NO | [11] |
| 22,300 ms (GTX GPU) | NO | [12] |
| 131 ms (1080 GPU) | NO | [13] |
| 1000 ms (TitanX GPU) | NO | [14] |
| 1300 ms (not specified) | NO | [15] |
| Not specified (not specified) | NO | [16] |
| 1400 ms (CPU) | NO | [17] |
| Not specified (not specified) | NO | [18] |
| Not specified (not specified) | NO | [19] |
| 1500 ms (TitanX GPU) | NO | [20] |
| 11 ms (AGX Embedded GPU) | YES | Proposed Method |
| Model | TP ↑ | FP ↓ | FN ↓ | Precision ↑ | Recall ↑ | AP0.5 ↑ | FPS ↑ | AP0.5 × FPS ↑ |
|---|---|---|---|---|---|---|---|---|
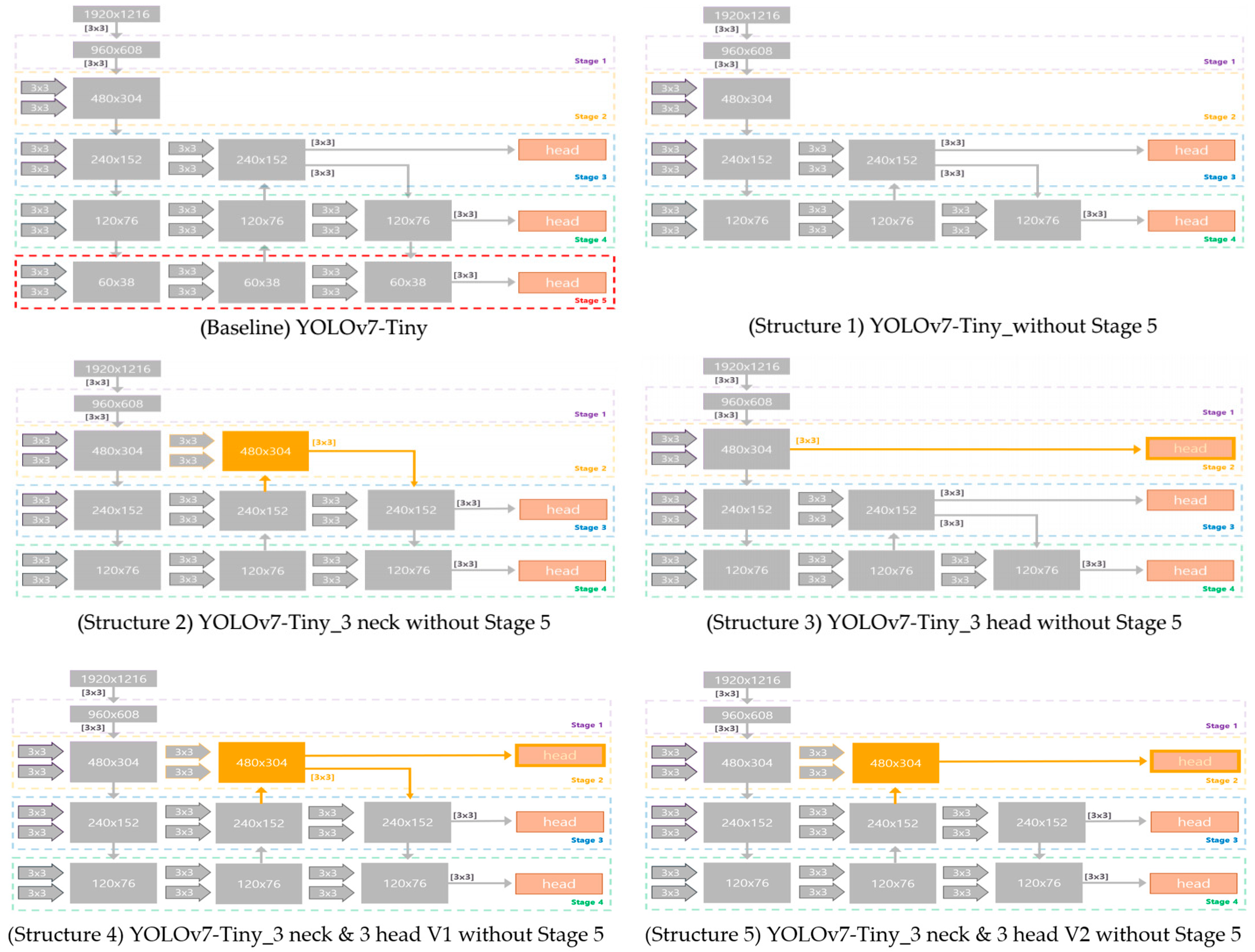
| YOLOv7-Tiny (Baseline) | 112,372 | 28,092 | 60,960 | 0.80 | 0.65 | 0.81 | 28.80 | 23.32 |
| YOLOv7-Tiny _without Stage 5 (Structure 1) | 99,564 | 22,134 | 73,768 | 0.82 | 0.57 | 0.75 | 35.10 | 26.32 |
| YOLOv7-Tiny _3 neck and without Stage 5 (Structure 2) | 103,307 | 33,139 | 70,025 | 0.78 | 0.60 | 0.80 | 28.80 | 23.04 |
| YOLOv7-Tiny _3 neck and without Stage 5 (Structure 3) | 91,161 | 17,641 | 82,171 | 0.84 | 0.53 | 0.68 | 27.98 | 18.97 |
| YOLOv7-Tiny _3 neck and 3 head and without Stage 5 V1 (Structure 4) | 112,358 | 31,348 | 60,974 | 0.78 | 0.65 | 0.84 | 24.50 | 20.58 |
| YOLOv7-Tiny _3 neck and 3 head and without Stage 5 V2 (Structure 5) | 113,499 | 30,573 | 59,833 | 0.79 | 0.65 | 0.84 | 25.60 | 21.50 |
| Model | Resolution 1 (Model A) | Resolution 2 (Model B) | AP0.5 | FPS | AP0.5 × FPS | |
|---|---|---|---|---|---|---|
| Baseline | YOLOv7-Tiny | 1920 × 1216 | 0.81 | 28.80 | 23.32 | |
| Proposed Method | Ensemble-Warping | 960 × 608 | 1920 × 320 | 0.80 | 44.60 | 35.68 |
| Ensemble-Upsampling #1 | 960 × 608 | 1920 × 320 | 0.81 | 44.80 | 36.28 | |
| Ensemble-Upsampling #2 | 960 × 608 | 3840 × 320 | 0.81 | 30.60 | 24.78 | |
| Model | Resolution 1 (Model A) | Resolution 2 (Model B) | AP0.5 ↑ | FPS ↑ | AP0.5 × FPS ↑ | |
|---|---|---|---|---|---|---|
| Baseline | YOLOv7-Tiny | 960 × 608 | 0.79 | 46.00 | 36.34 | |
| Proposed Method | Ensemble-Warping | 480 × 320 | 960 × 320 | 0.77 | 85.20 | 65.60 |
| Ensemble-Upsampling #1 | 480 × 320 | 960 × 320 | 0.80 | 85.30 | 68.24 | |
| Ensemble-Upsampling #2 | 480 × 320 | 1920 × 320 | 0.79 | 62.10 | 49.05 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yu, S.; Son, S.; Ahn, H.; Baek, H.; Nam, K.; Chung, Y.; Park, D. EnsembleVehicleDet: Detection of Faraway Vehicles with Real-Time Consideration. Appl. Sci. 2023, 13, 3939. https://doi.org/10.3390/app13063939
Yu S, Son S, Ahn H, Baek H, Nam K, Chung Y, Park D. EnsembleVehicleDet: Detection of Faraway Vehicles with Real-Time Consideration. Applied Sciences. 2023; 13(6):3939. https://doi.org/10.3390/app13063939
Chicago/Turabian StyleYu, Seunghyun, Seungwook Son, Hanse Ahn, Hwapyeong Baek, Kijeong Nam, Yongwha Chung, and Daihee Park. 2023. "EnsembleVehicleDet: Detection of Faraway Vehicles with Real-Time Consideration" Applied Sciences 13, no. 6: 3939. https://doi.org/10.3390/app13063939
APA StyleYu, S., Son, S., Ahn, H., Baek, H., Nam, K., Chung, Y., & Park, D. (2023). EnsembleVehicleDet: Detection of Faraway Vehicles with Real-Time Consideration. Applied Sciences, 13(6), 3939. https://doi.org/10.3390/app13063939