
Multi-Scale Feature Learning for Language Identification of Overlapped Speech


Abstract
:1. Introduction
2. Related Work
3. Algorithm Model Structure
3.1. Algorithm Module
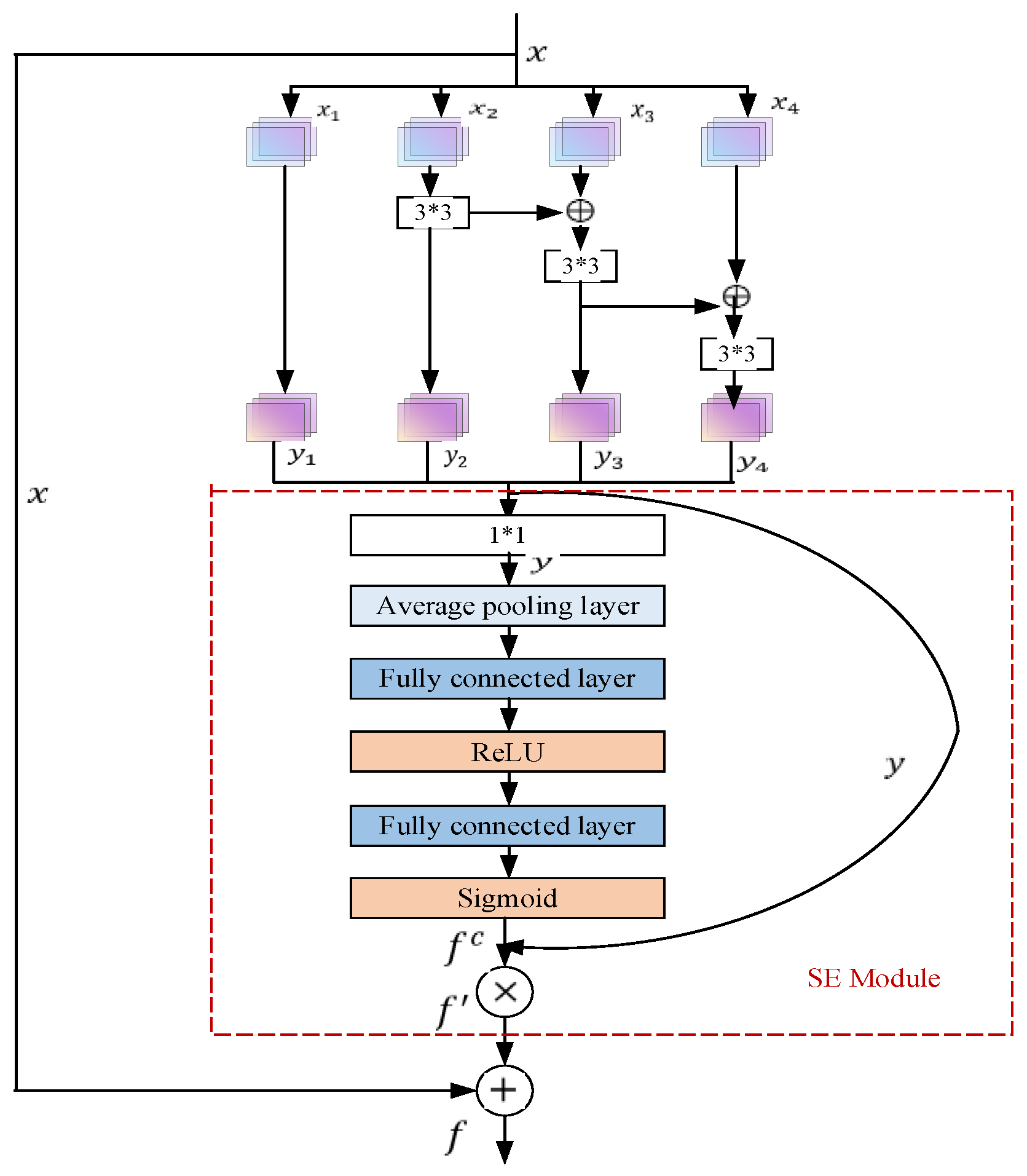
3.1.1. SE-Res2Net-CBAM-BiLSTM Network
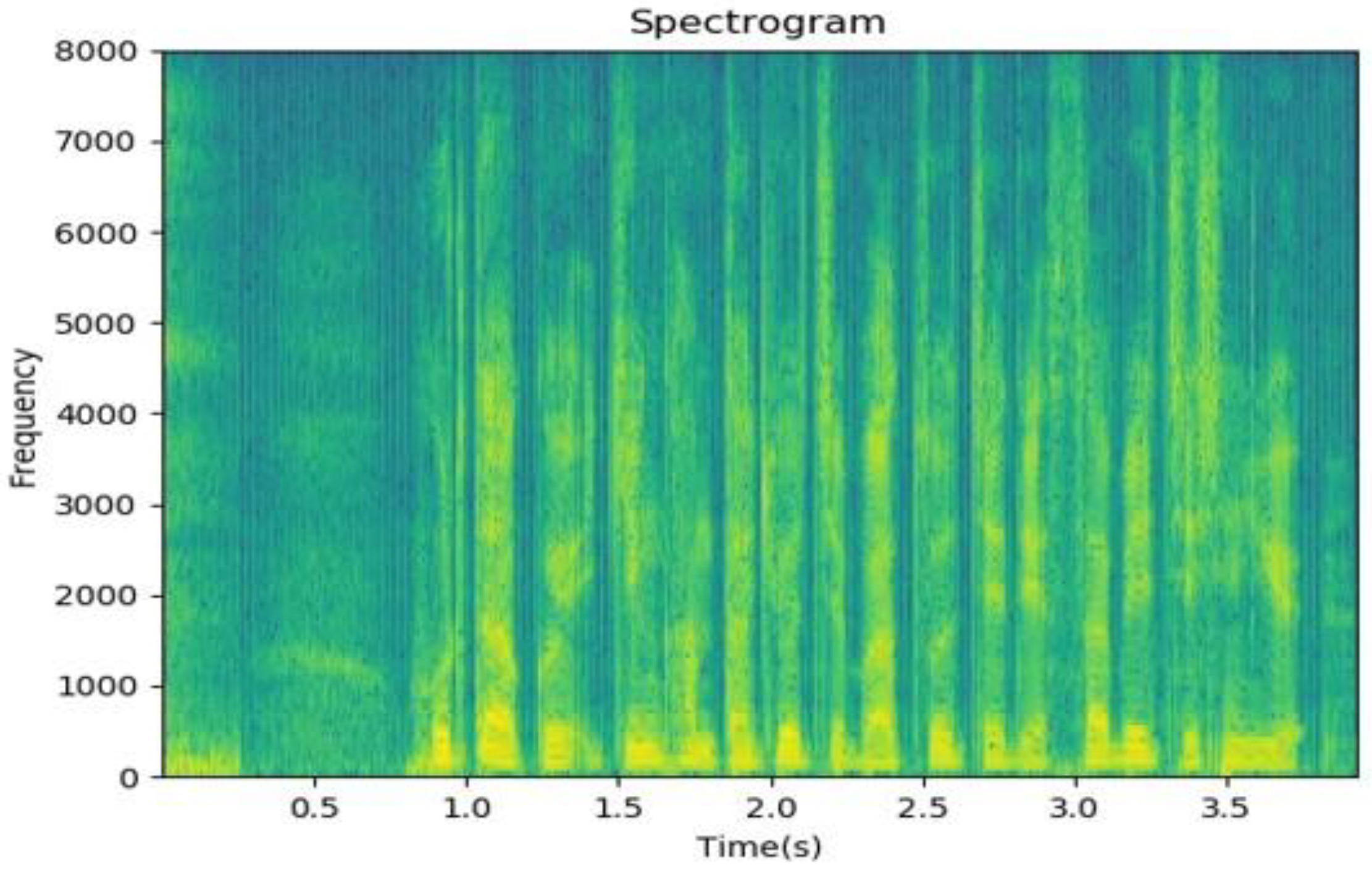
3.1.2. Feature Extraction
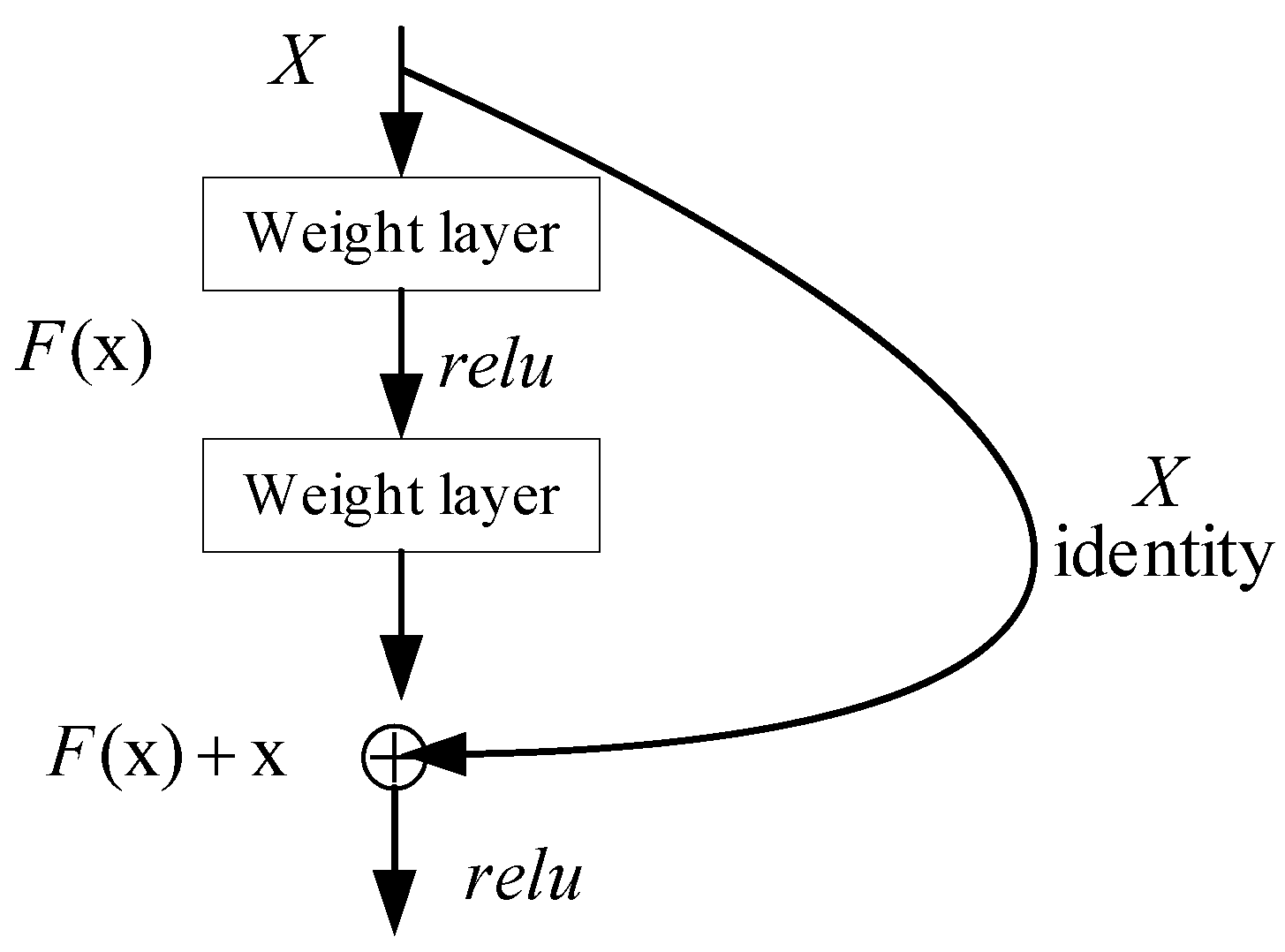
3.1.3. Residual Network
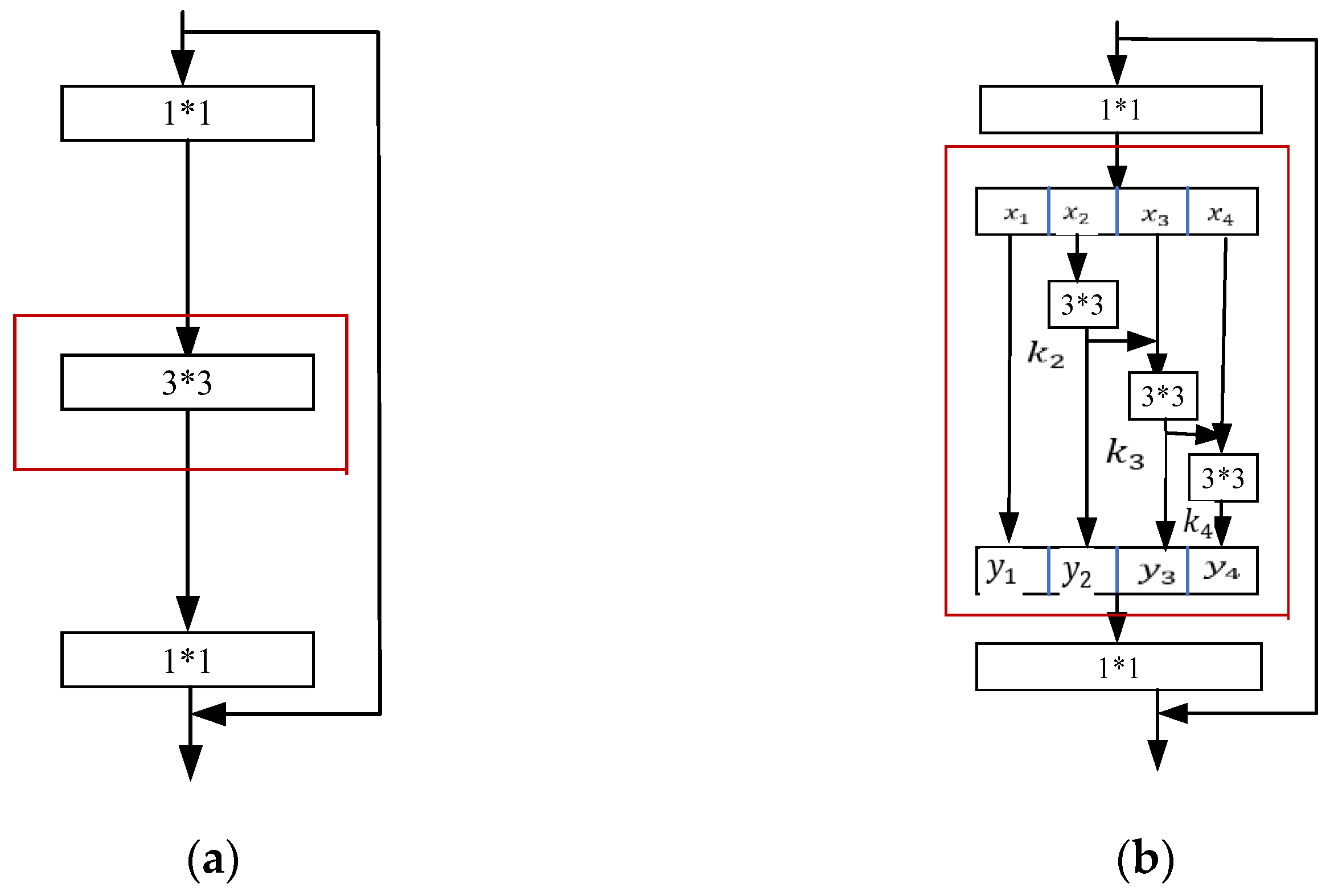
3.1.4. Res2Net Module
3.1.5. SE-Res2Net Module
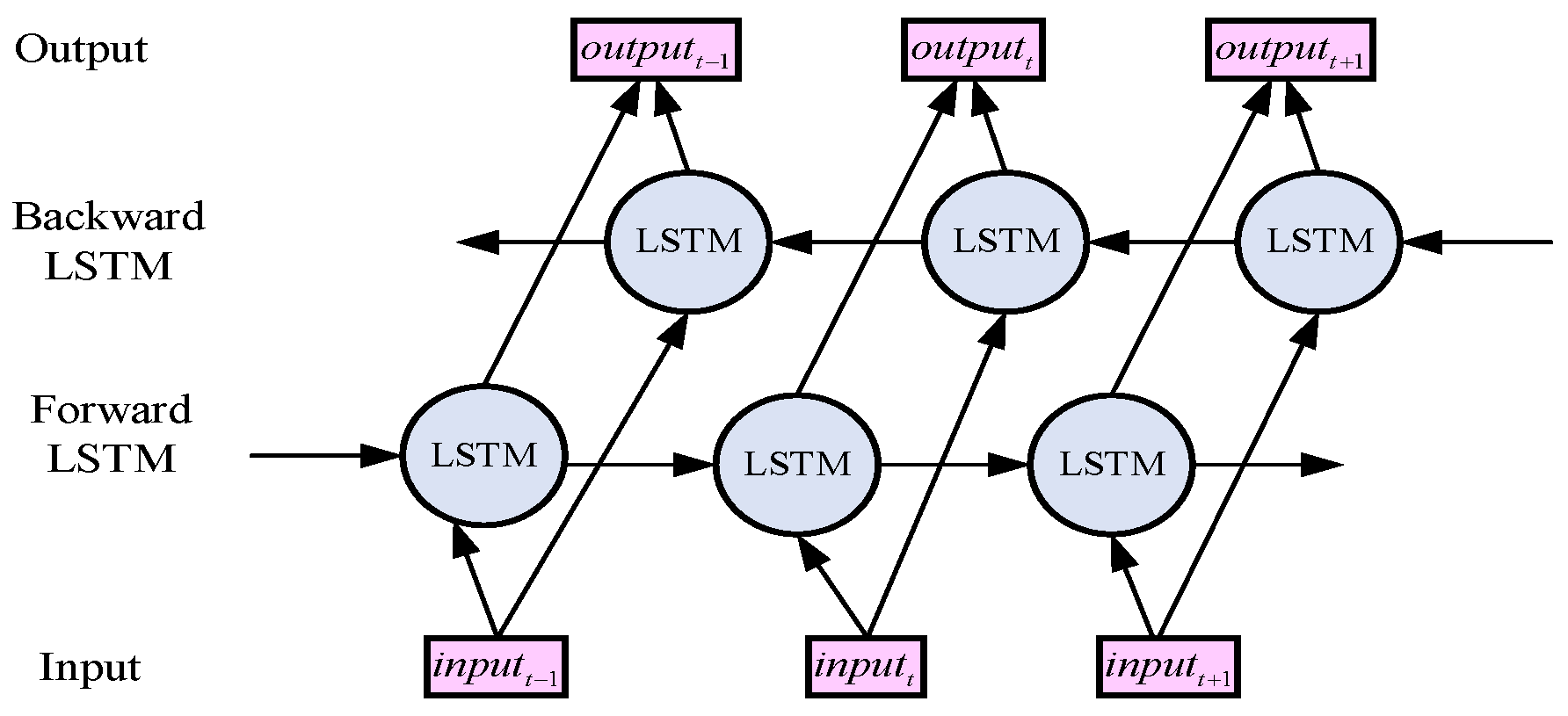
3.1.6. Bidirectional Long- and Short-Term Memory Network (BiLSTM)
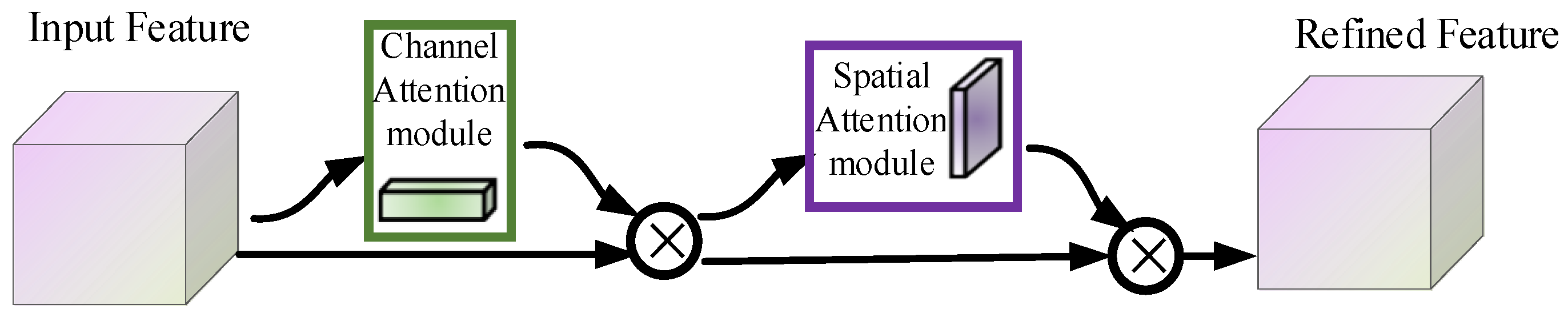
3.1.7. Convolutional Block Attention Module (CBAM)
3.2. Loss Function
4. Experiments and Discussion
4.1. Dataset
4.2. Network Parameters
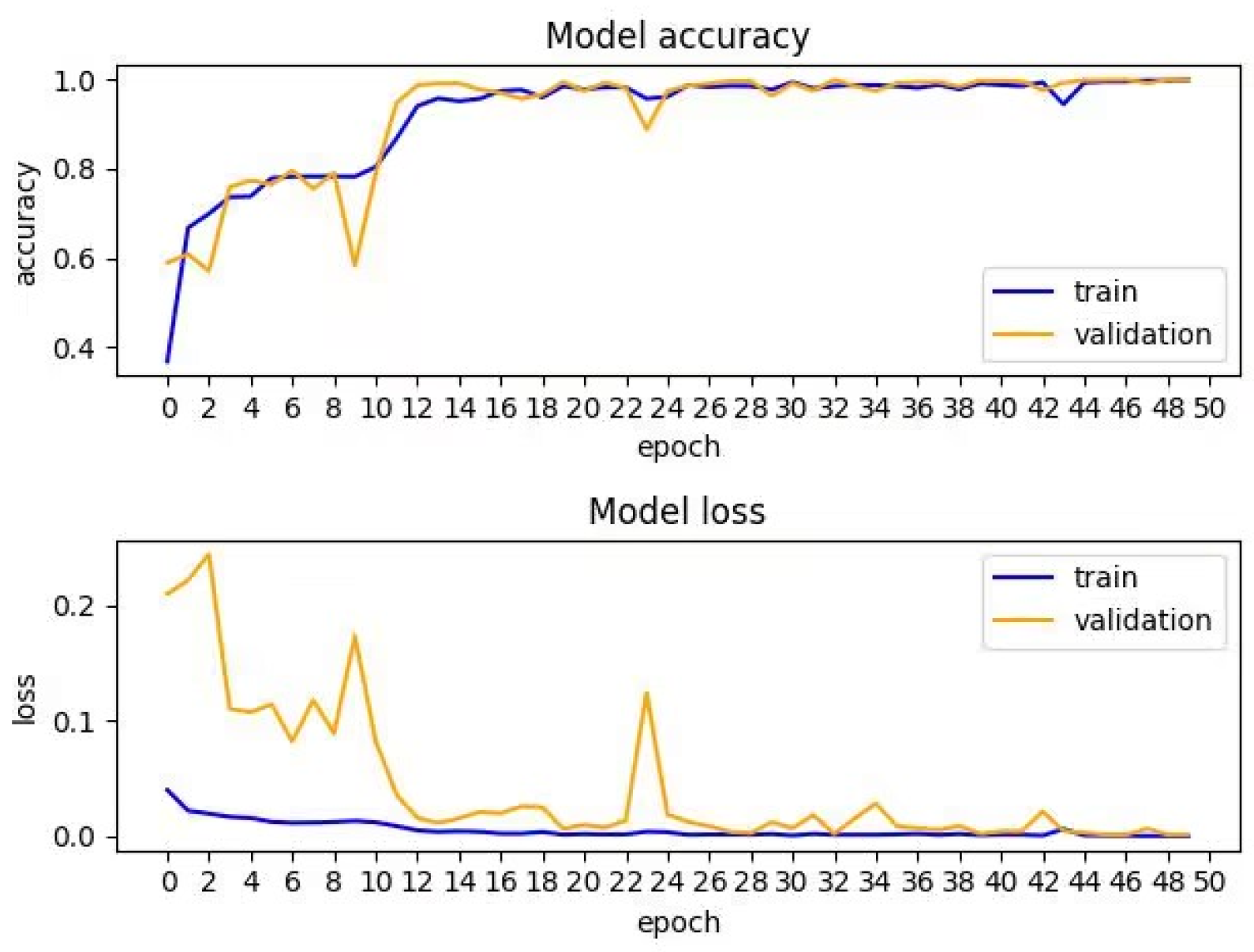
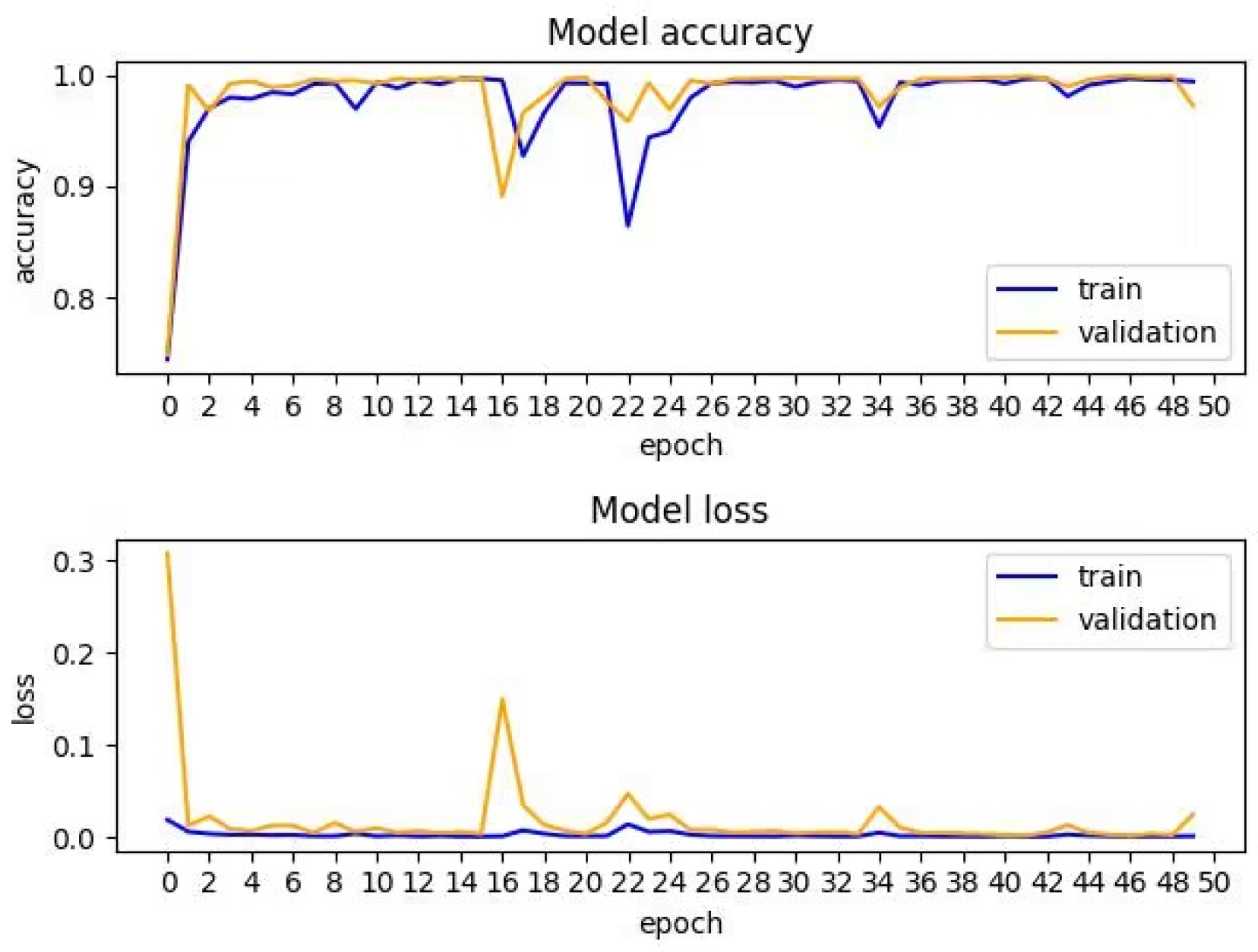
4.3. Performance Evaluation
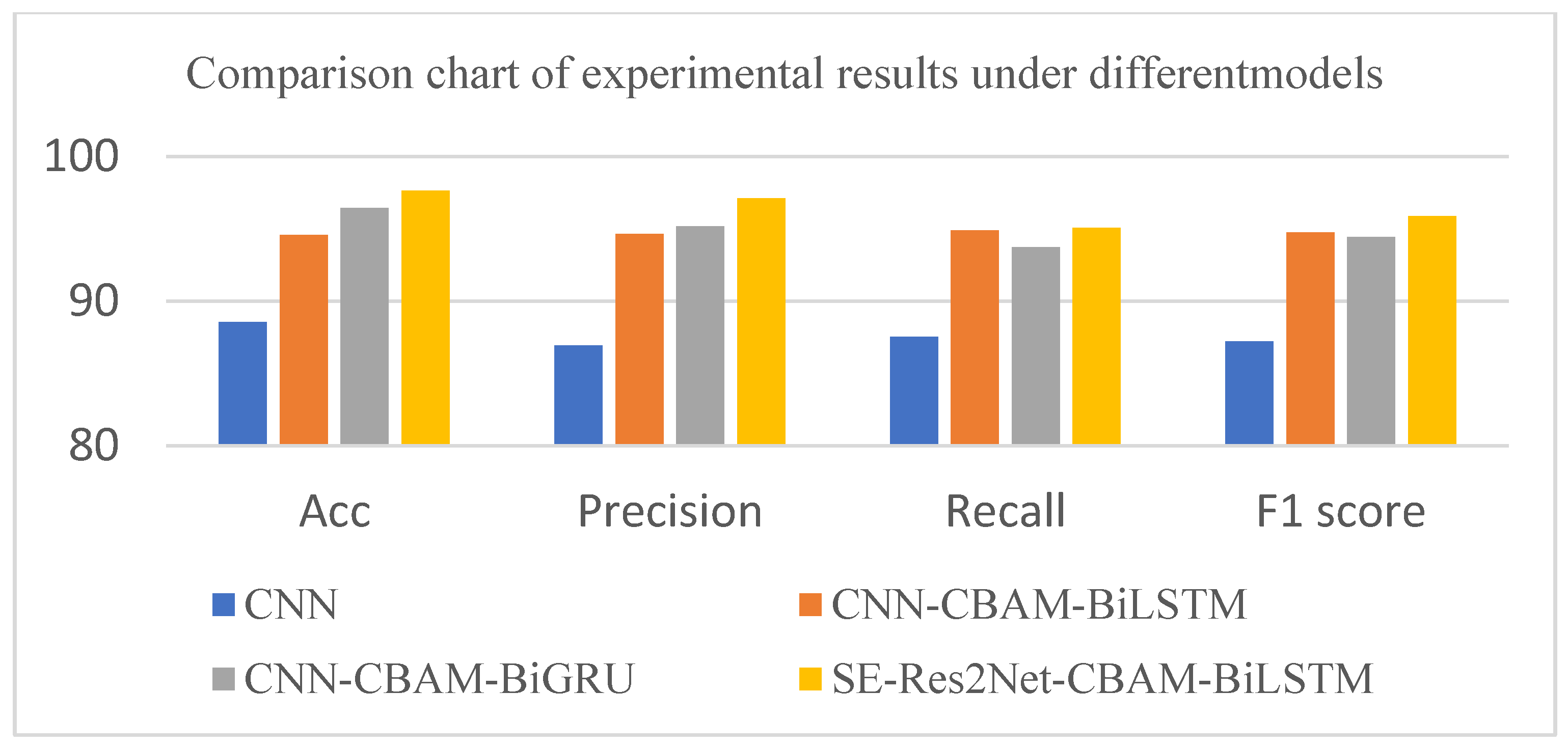
4.4. Experimental Results and Analysis
4.5. Limitation
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Hazen, T.J.; Zue, V.W. Recent improvements in an approach to segment-based automatic language identification. In Proceedings of the 3rd International Conference on Spoken Language Processing (ICSLP 1994), Yokohama, Japan, 18–22 September 1994; pp. 1883–1886. [Google Scholar]
- Navratil, J. Spoken language identification-a step toward multilinguality in speech processing. IEEE Trans. Speech Audio Process. 2001, 9, 678–685. [Google Scholar] [CrossRef]
- Chen, S.; Wang, C.; Chen, Z.; Wu, Y.; Liu, S.; Chen, Z.; Li, J.; Kanda, N.; Yoshioka, T.; Xiao, X.; et al. Wavlm: Large-scale self-supervised pre-training for full stack speech processing. IEEE J. Sel. Top. Signal Process. 2022, 16, 1505–1518. [Google Scholar] [CrossRef]
- Wong, E. Automatic Spoken Language Identification Utilizing Acoustic and Phonetic Speech Information. Ph.D. Thesis, Queensland University of Technology, Brisbane City, Australia, 2004. [Google Scholar]
- Lopez-Moreno, I.; Gonzalez-Dominguez, J.; Plchot, O.; Martinez, D.; Gonzalez-Rodriguez, J.; Moreno, P. Automatic language identification using deep neural networks. In Proceedings of the 2014 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Florence, Italy, 4–9 May 2014; pp. 5337–5341. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Gao, S.-H.; Cheng, M.-M.; Zhao, K.; Zhang, X.-Y.; Yang, M.-H.; Torr, P. Res2net: A new multi-scale backbone architecture. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 43, 652–662. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tang, Z.; Wang, D.; Chen, Y.; Chen, Q. AP17-OLR Challenge: Data, Plan, and Baseline. In Proceedings of the 2017 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), Kuala Lumpur, Malaysia, 12–15 December 2017; pp. 1–5. [Google Scholar]
- Baldwin, T.; Lui, M. Language identification: The long and the short of the matter. In Proceedings of the Human Language Technologies: The 2010 Annual Conference of the North American Chapter of the ACL, Los Angeles, CA, USA, 1–6 June 2010; pp. 229–237. [Google Scholar]
- Singh, G.; Sharma, S.; Kumar, V.; Kaur, M.; Baz, M.; Masud, M. Spoken language identification using deep learning. Comput. Intell. Neurosci. 2021, 2021, 5123671. [Google Scholar] [CrossRef] [PubMed]
- Toshniwal, S.; Sainath, T.N.; Weiss, R.J. Multilingual Speech Recognition with a Single End-to-End Model. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 4904–4908. [Google Scholar]
- Torres-Carrasquillo, P.A.; Singer, E.; Kohler, M.A.; Greene, R.J. Approaches to language identification using Gaussian mixture models and shifted delta cepstral features. In Proceedings of the 7th International Conference on Spoken Language Processing, ICSLP2002—INTERSPEECH 2002, Denver, CO, USA, 16–20 September 2002. [Google Scholar]
- Zissman, M.A. Automatic language identification using Gaussian mixture and hidden Markov models. In Proceedings of the 1993 IEEE International Conference on Acoustics, Speech, and Signal Processing, Minneapolis, MN, USA, 27–30 April 1993; Volume 2, pp. 399–402. [Google Scholar]
- Wang, X.L.; Wu, Z.G.; Zhou, R.H.; Yan, Y.H. Language-Pair Scoring Method Based on SVM for Language Recognition. Appl. Mech. Mater. 2013, 333, 737–741. [Google Scholar] [CrossRef]
- Dehak, N.; Pedro, A.; Torres-Carrasquillo; Reynolds, D.; Dehak, R. Language identification via i-vectors and dimensionality reduction. In Proceedings of the 12th Annual Conference of the International Speech Communication Association, Interspeech 2011, Florence, Italy, 28–31 August 2011; pp. 857–860. [Google Scholar]
- Jiang, B.; Song, Y.; Wei, S.; Liu, J.-H.; McLoughlin, I.V.; Dai, L.-R. Deep bottleneck features for spoken language identification. PLoS ONE 2014, 9, e100795. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gonzalez-Dominguez, J.; Lopez-Moreno, I.; Sak, H.; Gonzalez-Rodriguez, J.; Moreno, P.J. Automatic language identification using long short-term memory recurrent neural networks. In Proceedings of the 15th Annual Conference of the International Speech Communication Association, Singapore, 14–18 September 2014; pp. 2155–2159. [Google Scholar]
- Fernando, S.; Sethu, V.; Ambikairajah, E. Factorized hidden variability learning for adaptation of short duration language identification models. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 5204–5208. [Google Scholar]
- Padi, B.; Mohan, A.; Ganapathy, S. End-to-end language identification using attention based hierarchical gated recurrent unit models. In Proceedings of the ICASSP 2019—2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 5966–5970. [Google Scholar]
- Lei, Y.; Ferrer, L.; Lawson, A.; McLaren, M.; Scheffer, N. Application of convolutional neural networks to language identification in noisy conditions. In Proceedings of the Odyssey 2014: The Speaker and Language Recognition Workshop, Joensuu, Finland, 16–19 June 2014; pp. 287–292. [Google Scholar]
- Geng, W.; Wang, W.; Zhao, Y.; Cai, X.; Xu, B. End-to-end language identification using attention based recurrent neural networks. In Proceedings of the 17th Annual Conference of the International Speech and Communication Association, San Francisco, CA, USA, 8–12 September 2016; pp. 2944–2948. [Google Scholar]
- Bartz, C.; Herold, T.; Yang, H.; Meinel, C. Language identification using deep convolutional recurrent neural networks. In Proceedings of the Neural Information Processing: 24th International Conference, ICONIP 2017, Guangzhou, China, 14–18 November 2017; pp. 880–889. [Google Scholar]
- Cai, W.; Cai, D.; Huang, S.; Li, M. Utterance-level end-to-end language identification using attention-based CNN-BLSTM. In Proceedings of the ICASSP 2019—2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 5991–5995. [Google Scholar]
- Romero, D.; D’Haro, L.F.; Salamea, C. Exploring transformer-based language identification using phonotactic information. In Proceedings of the Fifth International Conference IberSPEECH 2021, Valladolid, Spain, 24–25 March 2021; pp. 250–254. [Google Scholar]
- Benhur, S.; Sivanraju, K. Pretrained Transformers for Offensive Language Identification in Tanglish. arXiv 2021, arXiv:2110.02852. [Google Scholar]
- Nie, Y.; Zhao, J.; Zhang, W.-Q.; Bai, J. BERT-LID: Leveraging BERT to Improve Spoken Language Identification. arXiv 2022, arXiv:2203.00328. [Google Scholar]
- Borsdorf, M.; Li, H.; Schultz, T. Target Language Extraction at Multilingual Cocktail Parties. In Proceedings of the 2021 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), Cartagena, Colombia, 13–17 December 2021; pp. 717–724. [Google Scholar]
- Borsdorf, M.; Scheck, K.; Li, H.; Schultz, T. Experts Versus All-Rounders: Target Language Extraction for Multiple Target Lan-guages. In Proceedings of the ICASSP 2022—2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 23–27 May 2022; pp. 846–850. [Google Scholar]
- Borsdorf, M.; Scheck, K.; Li, H.; Schultz, T. Blind Language Separation: Disentangling Multilingual Cocktail Party Voices by Language. In Proceedings of the 23rd INTERSPEECH Conference, Incheon, Republic of Korea, 18–22 September 2022; pp. 256–260. [Google Scholar]
- Ablimit, M.; Xueli, M.; Hamdulla, A. Language Identification Research Based on Dual Attention Mechanism. In Proceedings of the 2021 IEEE 2nd International Conference on Pattern Recognition and Machine Learning (PRML), Chengdu, China, 16–18 July 2021; pp. 241–246. [Google Scholar]
- Revathi, A.; Jeyalakshmi, C. Robust speech recognition in noisy environment using perceptual features and adaptive filters. In Proceedings of the 2017 2nd International Conference on Communication and Electronics Systems (ICCES), Coimbatore, India, 19–20 October 2017; pp. 692–696. [Google Scholar]
- Davis, S.; Mermelstein, P. Comparison of parametric representations for monosyllabic word recognition in continuously spoken sentences. IEEE Trans. Acoust. Speech Signal Process. 1980, 28, 357–366. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Identity mappings in deep residual networks. In Proceedings of the Computer Vision—ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; pp. 630–645. [Google Scholar]
- Bizzoni, Y.; Ghanimifard, M. Bigrams and BLSTMs two neural networks for sequential metaphor detection. In Proceedings of the Workshop on Figurative Language Processing, New Orleans, LA, USA, 6 June 2018. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. CBAM: Convolutional block attention module. In Proceedings of the 15th European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollar, P. Focal loss for dense object detection. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
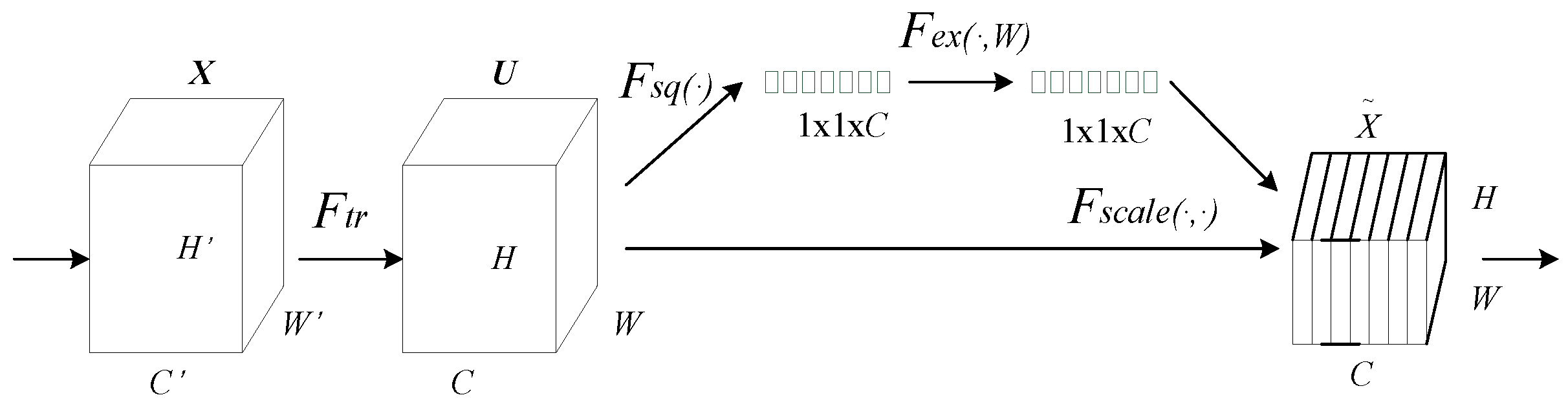{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Proposed Algorithm | Features |
|---|---|
| GMM-UBM [12] | The method of combining SDC features with a Gaussian mixture model–general background model is proposed, but it requires a large number of parameters, and the training data are usually insufficient. |
| GMM-SVM [14] | SVM algorithm is proposed to classify the GMM mean super-vector of speech. |
| i-Vector [15] | Language identification using i-vector obtained from speech combined with a back-end discrimination algorithm |
| DBF [16] | Replaces the traditional GMM-UBM combined with acoustic features, which can effectively characterize linguistic information and make language more easily distinguishable. |
| DNN [5] | First proposed application of deep neural networks to language identification tasks. |
| LSTM-RNN [17] | This method effectively solved the problem of gradient disappearance in RNNs. |
| BiLSTM [18] | This method effectively takes into account the past and future information of speech. |
| GRU [19] | GRU has a more straightforward structure and improved recognition rate compared to the Bi-LSTM network. |
| CNN [20] | CNN extracts local features of speech signals and effectively improves language identification. |
| Attention mechanism [21] | Through the attention mechanism, the more valuable information for language identification in speech features is obtained, and the effect of language identification is improved. |
| CRNN [22] | The combined network extracts richer speech feature information, thus improving the accuracy of language identification. |
| Transformer [24] | Transformer architecture can perform parallel computation and extract deeper and richer feature information. |
| Pre-trained [25] | The pre-trained model can obtain better discriminative representation and make full use of unsupervised data. |
| BERT-based [26] | The study extended the original BERT model by taking the phonetic posterior grams (PPGs) derived from the front-end phone recognizer as input. |
| Language | Train | Validation | Test | Total |
|---|---|---|---|---|
| zh-cn | 1260 | 360 | 180 | 1800 |
| id-id | 1260 | 360 | 180 | 1800 |
| ja-jp | 1260 | 360 | 180 | 1800 |
| ko-kr | 1260 | 360 | 180 | 1800 |
| vi-vn | 1260 | 360 | 180 | 1800 |
| Confusion Matrix for Target and Non-Target Languages | Predicted Value | Total | ||
|---|---|---|---|---|
| Target Languages | Non-Target Languages | |||
| True value | Target languages | |||
| Non-target languages | ||||
| Total | - | |||
| Languages | Acc (%) | Precision (%) | Recall (%) | F1 Score |
|---|---|---|---|---|
| zh-cn (Mandarin) | 61.51 | 63.71 | 60.62 | 62.12 |
| id-id (Indonesian) | 58.72 | 58.42 | 59.43 | 58.92 |
| ja-jp (Japanese) | 67.91 | 66.31 | 70.02 | 68.11 |
| ko-kr (Korean) | 56.12 | 43.83 | 73.34 | 54.87 |
| vi-vn (Vietnamese) | 66.23 | 68.41 | 64.45 | 66.37 |
| Languages | Acc (%) | Precision (%) | Recall (%) | F1 Score |
|---|---|---|---|---|
| zh-cn (Mandarin) | 71.45 | 73.14 | 69.91 | 71.57 |
| id-id (Indonesian) | 69.42 | 68.52 | 70.13 | 69.32 |
| ja-jp (Japanese) | 79.14 | 77.41 | 81.24 | 79.37 |
| ko-kr (Korean) | 68.91 | 59.63 | 83.16 | 69.46 |
| vi-vn (Vietnamese) | 76.82 | 79.12 | 75.24 | 77.13 |
| Loss Function | Model | Acc (%) | Precision (%) | Recall (%) | F1 Score |
|---|---|---|---|---|---|
| Cross-entropy loss | CNN-CBAM-BiLSTM | 94.57 | 94.64 | 94.91 | 94.77 |
| Focal loss | 95.65 | 95.68 | 94.95 | 95.31 | |
| Cross-entropy loss | SE-Res2Net-CBAM-BiLSTM | 96.26 | 96.11 | 95.07 | 95.59 |
| Focal loss | 97.31 | 96.97 | 96.86 | 96.91 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Aysa, Z.; Ablimit, M.; Hamdulla, A. Multi-Scale Feature Learning for Language Identification of Overlapped Speech. Appl. Sci. 2023, 13, 4235. https://doi.org/10.3390/app13074235
Aysa Z, Ablimit M, Hamdulla A. Multi-Scale Feature Learning for Language Identification of Overlapped Speech. Applied Sciences. 2023; 13(7):4235. https://doi.org/10.3390/app13074235
Chicago/Turabian StyleAysa, Zuhragvl, Mijit Ablimit, and Askar Hamdulla. 2023. "Multi-Scale Feature Learning for Language Identification of Overlapped Speech" Applied Sciences 13, no. 7: 4235. https://doi.org/10.3390/app13074235
APA StyleAysa, Z., Ablimit, M., & Hamdulla, A. (2023). Multi-Scale Feature Learning for Language Identification of Overlapped Speech. Applied Sciences, 13(7), 4235. https://doi.org/10.3390/app13074235