
Replay Speech Detection Based on Dual-Input Hierarchical Fusion Network


Abstract
:1. Introduction
- 1.
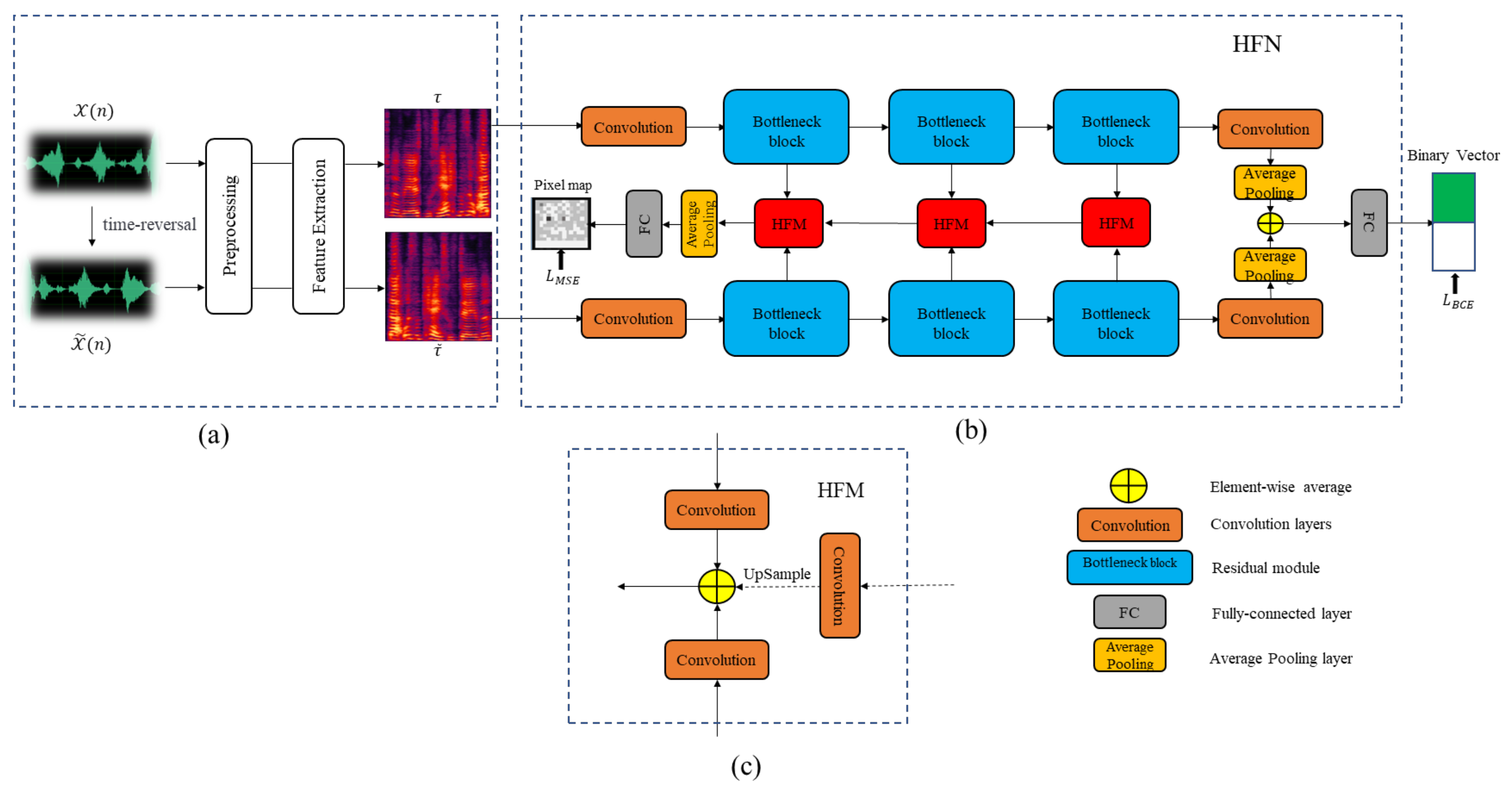
- We first introduce the HFN model into the replay attack detection system. The HFM in the model can more thoroughly fuse information from inputs at different levels, thereby improving the robustness of the system.
- 2.
- We propose using both the original speech signal and the time-reversed speech signal as inputs to the network, which increases the amount of information provided to the model and facilitates the learning and classification of the model.
- 3.
- Our proposed method achieves an EER of 24.46% and a min t-DCF of 0.6708 on the ASVspoof 2021 PA test set. Compared to the four baseline systems of the ASVspoof 2021 PA task, the min t-DCF values are reduced by 28.9%, 31.0%, 32.6%, and 32.9%, and the EER values are reduced by 35.7%, 38.1%, 45.4%, and 49.7%, respectively.
2. Methods
2.1. Hierarchical Fusion Network
2.2. Different Input Methods of Models
3. Research Process
3.1. Datasets and Evaluation Metrics
3.2. Feature Extraction
3.3. Training Details
3.4. Test Details
4. Results
4.1. The System Performance of Different Input Methods
4.2. The System Performance of Different Acoustic Features
4.3. The System Performance Compared with State-of-the-Art Systems

{kind=link}
| Teams | Min t-DCF | EER (%) |
|---|---|---|
| T07 [39] | 0.6824 | 24.25 |
| T16 | 0.7122 | 27.59 |
| T23 [42] | 0.7296 | 26.42 |
| T01 | 0.7446 | 28.36 |
| T04 | 0.7462 | 29.00 |
| Proposed method | 0.6708 | 24.46 |
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Delac, K.; Grgic, M. A survey of biometric recognition methods. In Proceedings of the Elmar-2004, 46th International Symposium on Electronics in Marine, Zadar, Croatia, 18 June 2004; IEEE: New York, NY, USA; pp. 184–193. [Google Scholar]
- Kinnunen, T.; Evans, N.; Yamagishi, J.; Lee, K.A.; Sahidullah, M.; Todisco, M.; Delgado, H. Asvspoof 2017: Automatic speaker verification spoofing and countermeasures challenge evaluation plan. Training 2017, 10, 1508. [Google Scholar]
- Juvela, L.; Bollepalli, B.; Wang, X.; Kameoka, H.; Airaksinen, M.; Yamagishi, J.; Alku, P. Speech waveform synthesis from MFCC sequences with generative adversarial networks. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 1–20 April 2018; IEEE: New York, NY, USA; pp. 5679–5683. [Google Scholar]
- Oord, A.V.D.; Dieleman, S.; Zen, H.; Simonyan, K.; Vinyals, O.; Graves, A.; Kalchbrenner, N.; Senior, A.; Kavukcuoglu, K. Wavenet: A generative model for raw audio. arXiv 2016, arXiv:1609.03499. [Google Scholar]
- Toda, T.; Chen, L.H.; Saito, D.; Villavicencio, F.; Wester, M.; Wu, Z.; Yamagishi, J. The Voice Conversion Challenge 2016. In Proceedings of the Interspeech 2016, San Francisco, CA, USA, 8–12 September 2016; pp. 1632–1636. [Google Scholar]
- Huang, W.C.; Lo, C.C.; Hwang, H.T.; Tsao, Y.; Wang, H.M. Wavenet vocoder and its applications in voice conversion. In Proceedings of the 30th ROCLING Conference on Computational Linguistics and Speech Processing (ROCLING), Hsinchu, Taiwan, 4–5 October 2018. [Google Scholar]
- Yamagishi, J.; Wang, X.; Todisco, M.; Sahidullah, M.; Patino, J.; Nautsch, A.; Liu, X.; Lee, K.A.; Kinnunen, T.; Delgado, H.; et al. ASVspoof 2021: Accelerating progress in spoofed and deepfake speech detection. arXiv 2021, arXiv:2109.00537. [Google Scholar]
- Delgado, H.; Evans, N.; Kinnunen, T.; Lee, K.A.; Liu, X.; Nautsch, A.; Patino, J.; Sahidullah, M.; Todisco, M.; Yamagishi, J.; et al. Asvspoof 2021: Automatic speaker verification spoofing and countermeasures challenge evaluation plan. arXiv 2021, arXiv:2109.00535. [Google Scholar]
- Li, X.; Li, N.; Zhong, J.; Wu, X.; Liu, X.; Su, D.; Yu, D.; Meng, H. Investigating robustness of adversarial samples detection for automatic speaker verification. arXiv 2020, arXiv:2006.06186. [Google Scholar]
- Cheng, X.; Xu, M.; Zheng, T.F. Replay detection using CQT-based modified group delay feature and ResNeWt network in ASVspoof 2019. In Proceedings of the 2019 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), Lanzhou, China, 18–21 November 2019; pp. 540–545. [Google Scholar]
- Wu, Z.; Chng, E.S.; Li, H. Detecting converted speech and natural speech for anti-spoofing attack in speaker recognition. In Proceedings of the Thirteenth Annual Conference of the International Speech Communication Association, Portland, OR, USA, 9–13 September 2012. [Google Scholar]
- Alzantot, M.; Wang, Z.; Srivastava, M.B. Deep residual neural networks for audio spoofing detection. arXiv 2019, arXiv:1907.00501. [Google Scholar]
- Cai, W.; Wu, H.; Cai, D.; Li, M. The DKU replay detection system for the ASVspoof 2019 challenge: On data augmentation, feature representation, classification, and fusion. arXiv 2019, arXiv:1907.02663. [Google Scholar]
- Zhang, Y.; Jiang, F.; Duan, Z. One-class learning towards synthetic voice spoofing detection. IEEE Signal Process. Lett. 2021, 28, 937–941. [Google Scholar] [CrossRef]
- Lavrentyeva, G.; Novoselov, S.; Malykh, E.; Kozlov, A.; Kudashev, O.; Shchemelinin, V. Audio Replay Attack Detection with Deep Learning Frameworks. In Proceedings of the Interspeech 2017, Stockholm, Sweden, 20–24 August 2017; pp. 82–86. [Google Scholar]
- Garcia-Romero, D.; Espy-Wilson, C.Y. Analysis of i-vector length normalization in speaker recognition systems. In Proceedings of the Twelfth Annual Conference of the International Speech Communication Association, Florence, Italy, 27–31 August 2011. [Google Scholar]
- Huang, L.; Pun, C.M. Audio replay spoof attack detection by joint segment-based linear filter bank feature extraction and attention-enhanced DenseNet-BiLSTM network. IEEE/ACM Trans. Audio Speech Lang. Process. 2020, 28, 1813–1825. [Google Scholar] [CrossRef]
- Todisco, M.; Wang, X.; Vestman, V.; Sahidullah, M.; Delgado, H.; Nautsch, A.; Yamagishi, J.; Evans, N.; Kinnunen, T.; Lee, K.A.; et al. ASVspoof 2019: Future horizons in spoofed and fake audio detection. arXiv 2019, arXiv:1904.05441. [Google Scholar]
- Zeinali, H.; Stafylakis, T.; Athanasopoulou, G.; Rohdin, J.; Gkinis, I.; Burget, L.; Černocký, J. Detecting spoofing attacks using vgg and sincnet: But-omilia submission to asvspoof 2019 challenge. arXiv 2019, arXiv:1907.12908. [Google Scholar]
- Monteiro, J.; Alam, J.; Falk, T.H. Generalized end-to-end detection of spoofing attacks to automatic speaker recognizers. Comput. Speech Lang. 2020, 63, 101096. [Google Scholar] [CrossRef]
- Lavrentyeva, G.; Novoselov, S.; Tseren, A.; Volkova, M.; Gorlanov, A.; Kozlov, A. STC antispoofing systems for the ASVspoof2019 challenge. arXiv 2019, arXiv:1904.05576. [Google Scholar]
- Zhang, C.; Yu, C.; Hansen, J.H.L. An Investigation of Deep-Learning Frameworks for Speaker Verification Antispoofing. IEEE J. Sel. Top. Signal Process. 2017, 11, 684–694. [Google Scholar] [CrossRef]
- Li, X.; Li, N.; Weng, C.; Liu, X.; Su, D.; Yu, D.; Meng, H. Replay and synthetic speech detection with res2net architecture. In Proceedings of the ICASSP 2021–2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 6354–6358. [Google Scholar]
- Tak, H.; Patino, J.; Todisco, M.; Nautsch, A.; Evans, N.; Larcher, A. End-to-end anti-spoofing with rawnet2. In Proceedings of the ICASSP 2021–2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 6369–6373. [Google Scholar]
- Yoon, S.H.; Yu, H.J. Multiple points input for convolutional neural networks in replay attack detection. In Proceedings of the ICASSP 2020–2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 6444–6448. [Google Scholar]
- Lai, C.I.; Chen, N.; Villalba, J.; Dehak, N. ASSERT: Anti-spoofing with squeeze-excitation and residual networks. arXiv 2019, arXiv:1904.01120. [Google Scholar]
- Cai, R.; Li, Z.; Wan, R.; Li, H.; Hu, Y.; Kot, A.C. Learning meta pattern for face anti-spoofing. IEEE Trans. Inf. Forensics Secur. 2022, 17, 1201–1213. [Google Scholar] [CrossRef]
- Chao, F.A.; Jiang SW, F.; Yan, B.C.; Hung, J.W.; Chen, B. TENET: A time-reversal enhancement network for noise-robust ASR. In Proceedings of the 2021 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), Cartagena, Colombia, 13–17 December 2021; pp. 55–61. [Google Scholar]
- Yoon, S.H.; Koh, M.S.; Yu, H.J. Phase Spectrum of Time-Flipped Speech Signals for Robust Spoofing Detection. In Proceedings of the Speaker and Language Recognition Workshop (Odyssey 2020), Tokyo, Japan, 1–5 November 2020; pp. 319–325. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Sun, W.; Song, Y.; Chen, C.; Huang, J.; Kot, A.C. Face spoofing detection based on local ternary label supervision in fully convolutional networks. IEEE Trans. Inf. Forensics Secur. 2020, 15, 3181–3196. [Google Scholar] [CrossRef]
- Chen, B.; Yang, W.; Li, H.; Wang, S.; Kwong, S. Camera Invariant Feature Learning for Generalized Face Anti-Spoofing. IEEE Trans. Inf. Forensics Secur. 2021, 16, 2477–2492. [Google Scholar] [CrossRef]
- Yoon, S.; Yu, H.J. Multiple-point input and time-inverted speech signal for the ASVspoof 2021 challenge. In Proceedings of the 2021 Edition of the Automatic Speaker Verification and Spoofing Countermeasures Challenge, Online, 16 September 2021; pp. 37–41. [Google Scholar]
- Kinnunen, T.; Lee, K.A.; Delgado, H.; Evans, N.; Todisco, M.; Sahidullah, M.; Yamagishi, J.; Reynolds, D.A. t-DCF: A detection cost function for the tandem assessment of spoofing countermeasures and automatic speaker verification. arXiv 2018, arXiv:1804.09618. [Google Scholar]
- Griffin, D.; Lim, J. Signal estimation from modified short-time Fourier transform. IEEE Trans. Acoust. Speech Signal Process. 1984, 32, 236–243. [Google Scholar] [CrossRef]
- Hueber, T.; Chollet, G.; Denby, B.; Stone, M. Acquisition of ultrasound, video and acoustic speech data for a silent-speech interface application. Proc. ISSP 2008, 24, 365–369. [Google Scholar]
- Brown, J.C. Computer identification of musical instruments using pattern recognition with cepstral coefficients as features. J. Acoust. Soc. Am. 1999, 105, 1933–1941. [Google Scholar] [CrossRef] [PubMed]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Wang, X.; Qin, X.; Zhu, T.; Wang, C.; Zhang, S.; Li, M. The DKU-CMRI system for the ASVspoof 2021 challenge: Vocoder based replay channel response estimation. In Proceedings of the 2021 Edition of the Automatic Speaker Verification and Spoofing Countermeasures Challenge, Online, 16 September 2021; pp. 16–21. [Google Scholar]
- Morise, M.; Yokomori, F.; Ozawa, K. WORLD: A Vocoder-Based High-Quality Speech Synthesis System for Real-Time Applications. IEICE Trans. Inf. Syst. 2016, 99, 1877–1884. [Google Scholar] [CrossRef]
- Kumar, K.; Kumar, R.; de Boissiere, T.; Gestin, L.; Teoh, W.Z.; Sotelo, J.; de Brébisson, A.; Bengio, Y.; Courville, A.C. MelGAN: Generative Adversarial Networks for Conditional Waveform Synthesis. In Proceedings of the Advances in Neural Information Processing Systems; Curran Associates, Inc.: Red Hook, NY, USA, 2019; Volume 32. [Google Scholar]
- Tomilov, A.; Svishchev, A.; Volkova, M.; Chirkovskiy, A.; Kondratev, A.; Lavrentyeva, G. STC antispoofing systems for the ASVspoof2021 challenge. In Proceedings of the ASVspoof 2021 Workshop, Online, 16 September 2021; pp. 61–67. [Google Scholar]

| Dataset | Bona Fide | Spoofed |
|---|---|---|
| Utterance | Utterance | |
| Train | 5400 | 48,600 |
| Dev | 5400 | 24,300 |
| Evaluation | 94,068 | 627,264 |
| Input Methods | Acoustic Features | Models | Min t-DCF | EER (%) |
|---|---|---|---|---|
| Single-input | CQT | ResNet-50 | 0.9913 | 38.17 |
| CQT (invert) | 0.9848 | 41.12 | ||
| Overlay-input | CQT + CQT (invert) | ResNet-50 | 0.9826 | 38.84 |
| Dual-input | CQT + CQT (invert) | HFN | 0.7572 | 28.51 |
| Double CQT | 0.7741 | 29.33 | ||
| Double CQT (invert) | 0.7709 | 29.63 |
| System | Min t-DCF | EER (%) | |
|---|---|---|---|
| Baseline | CQCC + GMM | 0.9434 | 38.07 |
| LFCC + GMM | 0.9724 | 39.54 | |
| LFCC + LCNN | 0.9958 | 44.77 | |
| RawNet2 | 0.9997 | 48.60 | |
| Proposed | HFN + Spec | 0.9453 | 45.15 |
| HFN + LFCC | 0.8945 | 36.25 | |
| HFN + CQT | 0.7572 | 28.51 | |
| Fusion | 0.6708 | 24.46 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hu, C.; Zhou, R.; Yuan, Q. Replay Speech Detection Based on Dual-Input Hierarchical Fusion Network. Appl. Sci. 2023, 13, 5350. https://doi.org/10.3390/app13095350
Hu C, Zhou R, Yuan Q. Replay Speech Detection Based on Dual-Input Hierarchical Fusion Network. Applied Sciences. 2023; 13(9):5350. https://doi.org/10.3390/app13095350
Chicago/Turabian StyleHu, Chenlei, Ruohua Zhou, and Qingsheng Yuan. 2023. "Replay Speech Detection Based on Dual-Input Hierarchical Fusion Network" Applied Sciences 13, no. 9: 5350. https://doi.org/10.3390/app13095350
APA StyleHu, C., Zhou, R., & Yuan, Q. (2023). Replay Speech Detection Based on Dual-Input Hierarchical Fusion Network. Applied Sciences, 13(9), 5350. https://doi.org/10.3390/app13095350