
Advanced Control by Reinforcement Learning for Wastewater Treatment Plants: A Comparison with Traditional Approaches

 , ,
, ,  ,
,  and
and
Abstract
:1. Introduction
2. Materials and Methods
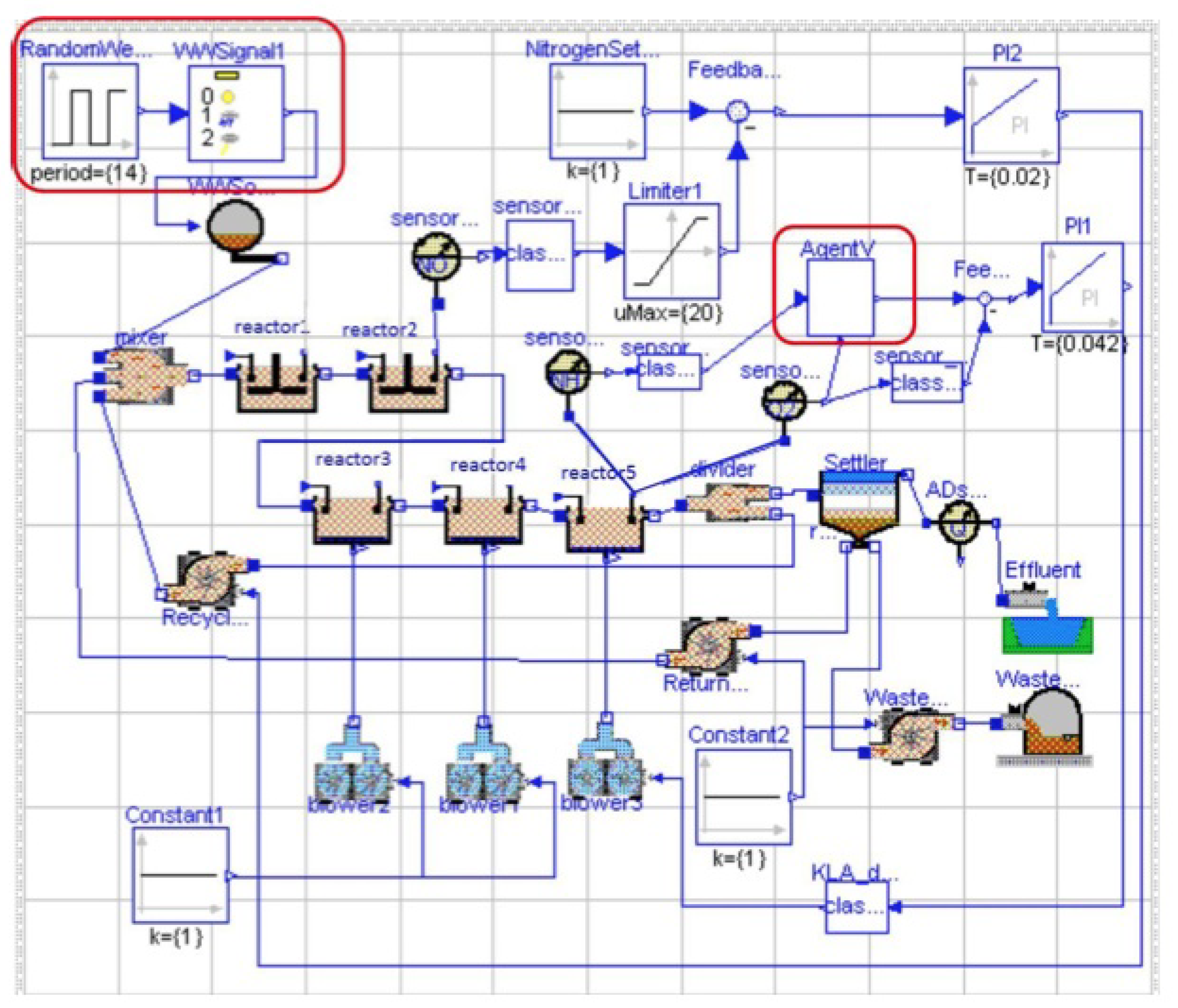
2.1. WWTP Simulation Model
2.2. Control Structures
2.2.1. PI Cascade Control Structure
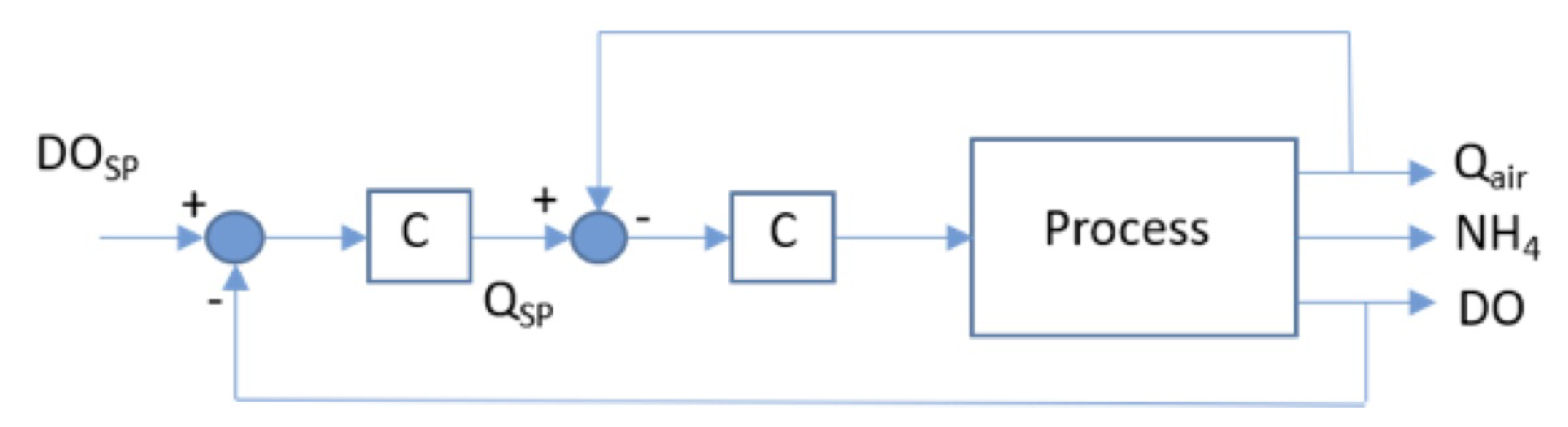
2.2.2. Ammonium-Based Control: Feedback Control
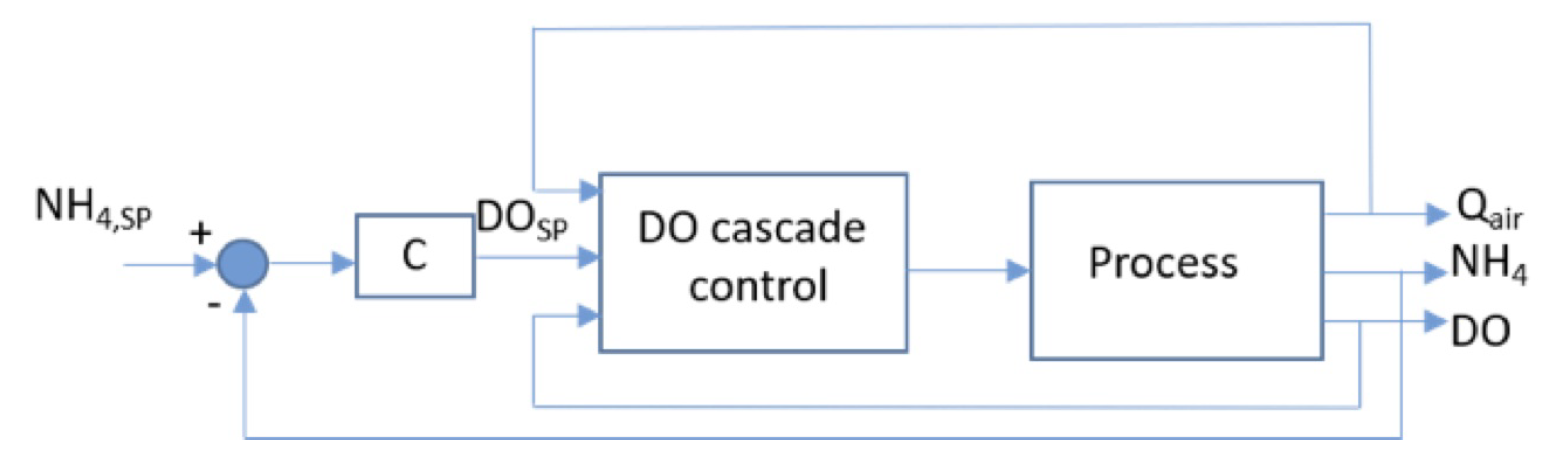
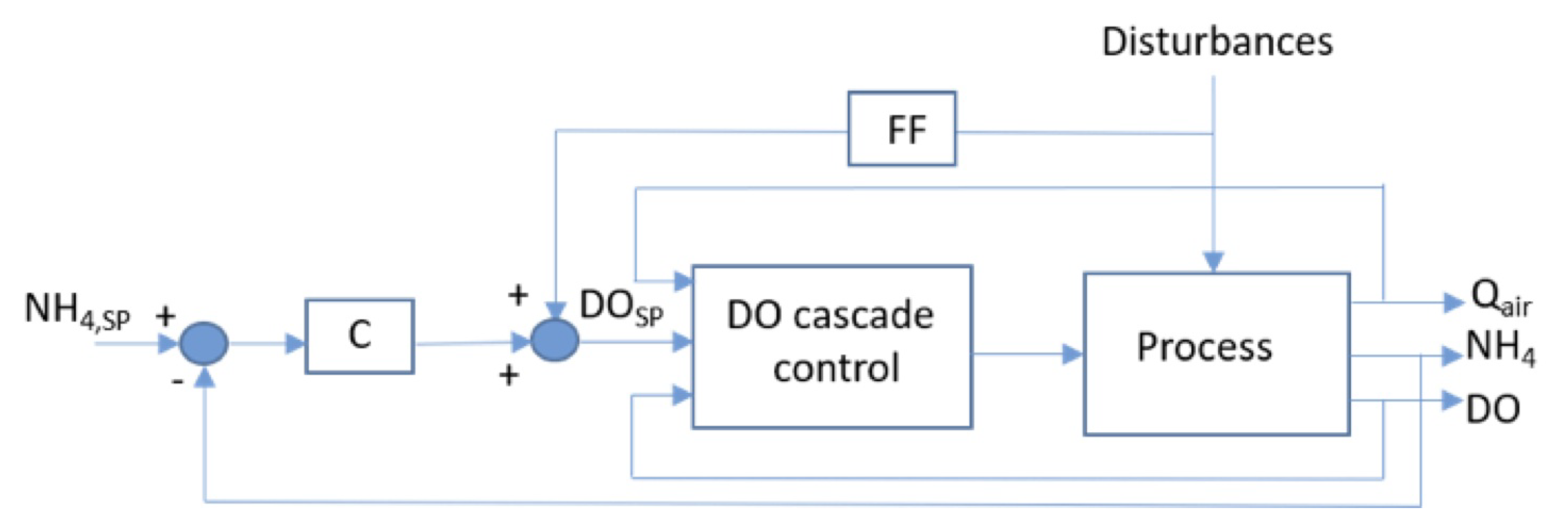
2.2.3. Ammonium-Based Control: Feedforward–Feedback Control
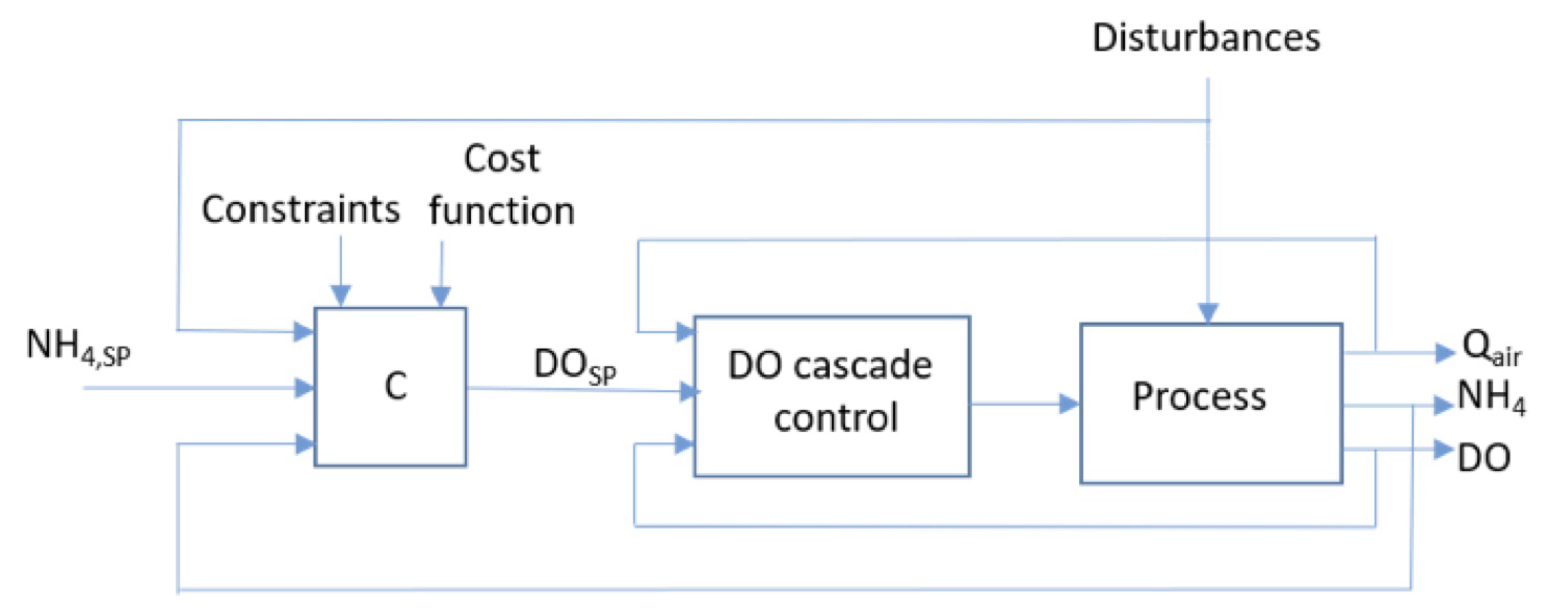
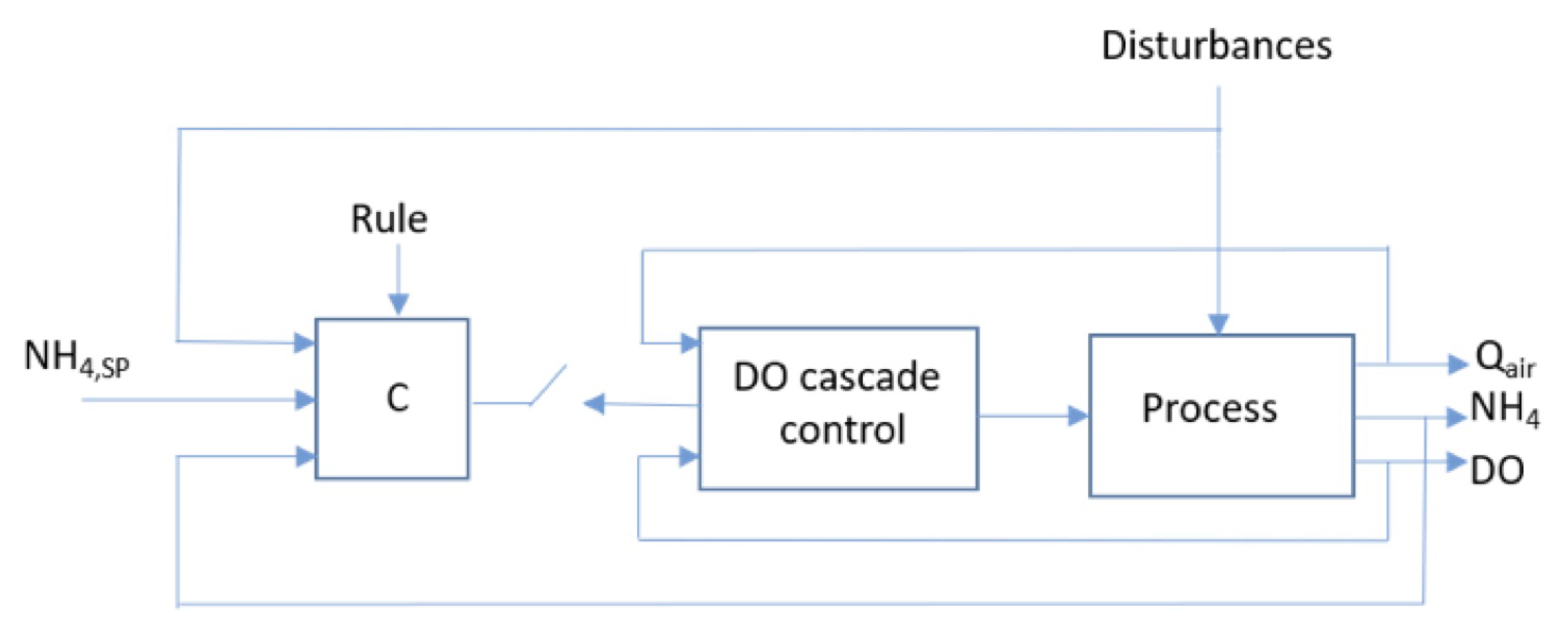
2.2.4. Advanced SISO and MIMO Controllers
2.2.5. Control of the Aerobic Volume
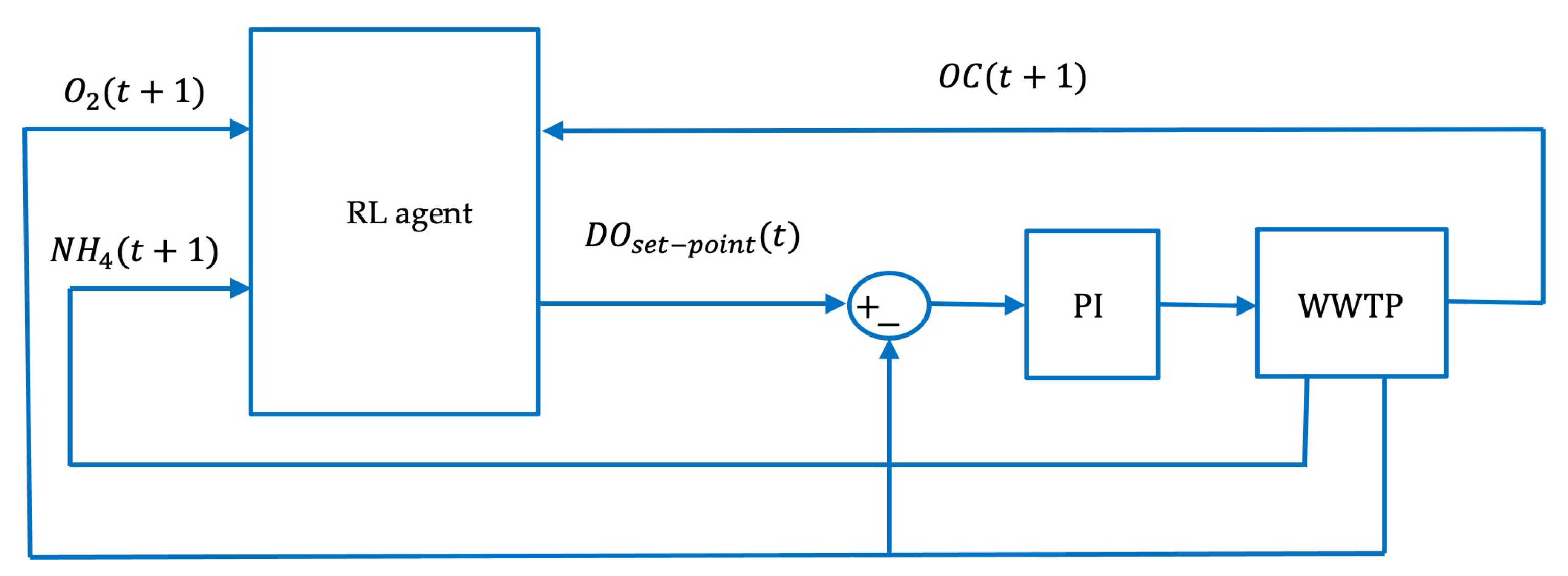
2.3. Reinforcement Learning
2.3.1. Reinforcement Learning Elements
2.3.2. Reinforcement Learning Agent
| Algorithm 1: RL agent pseudocode. |
 |
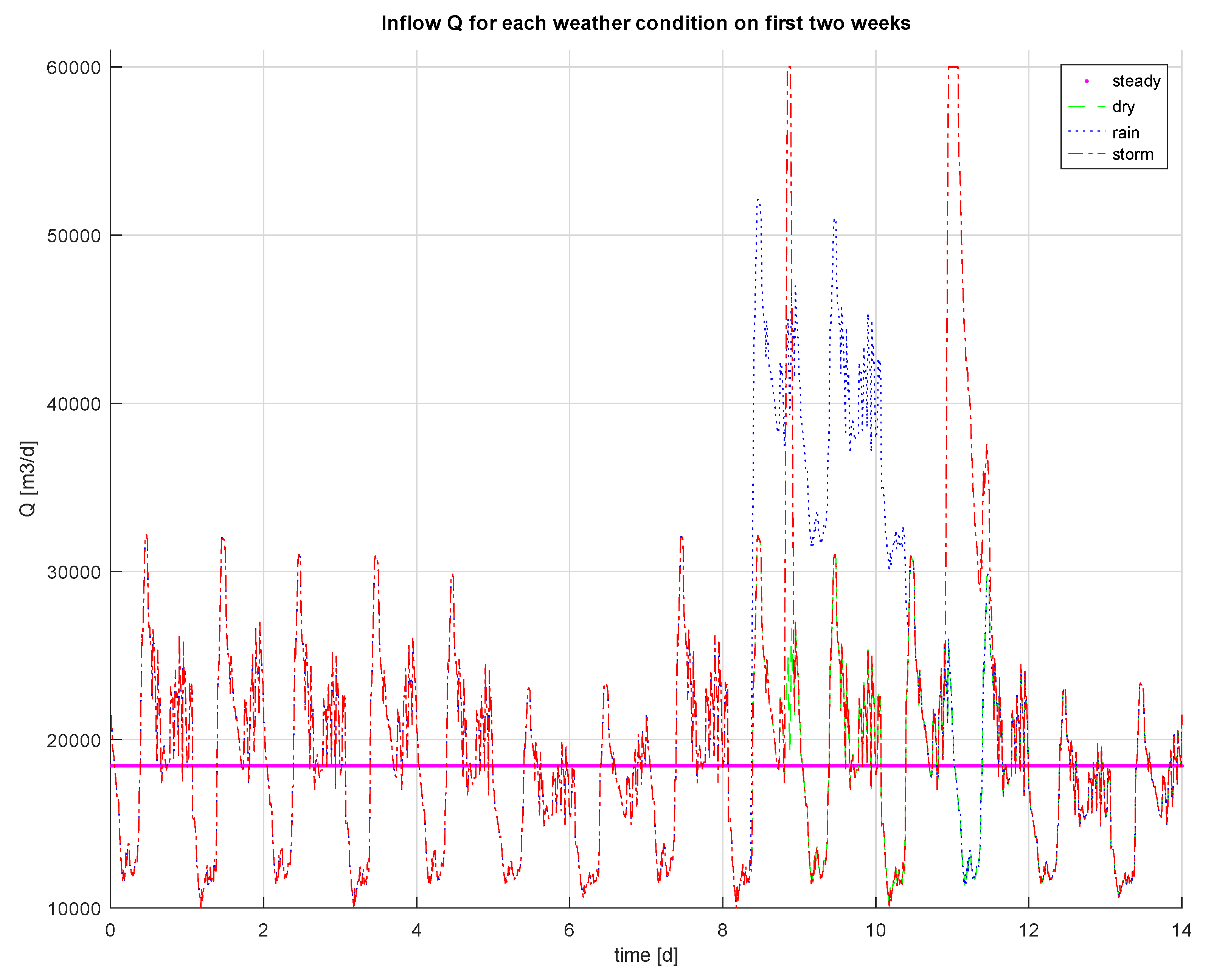
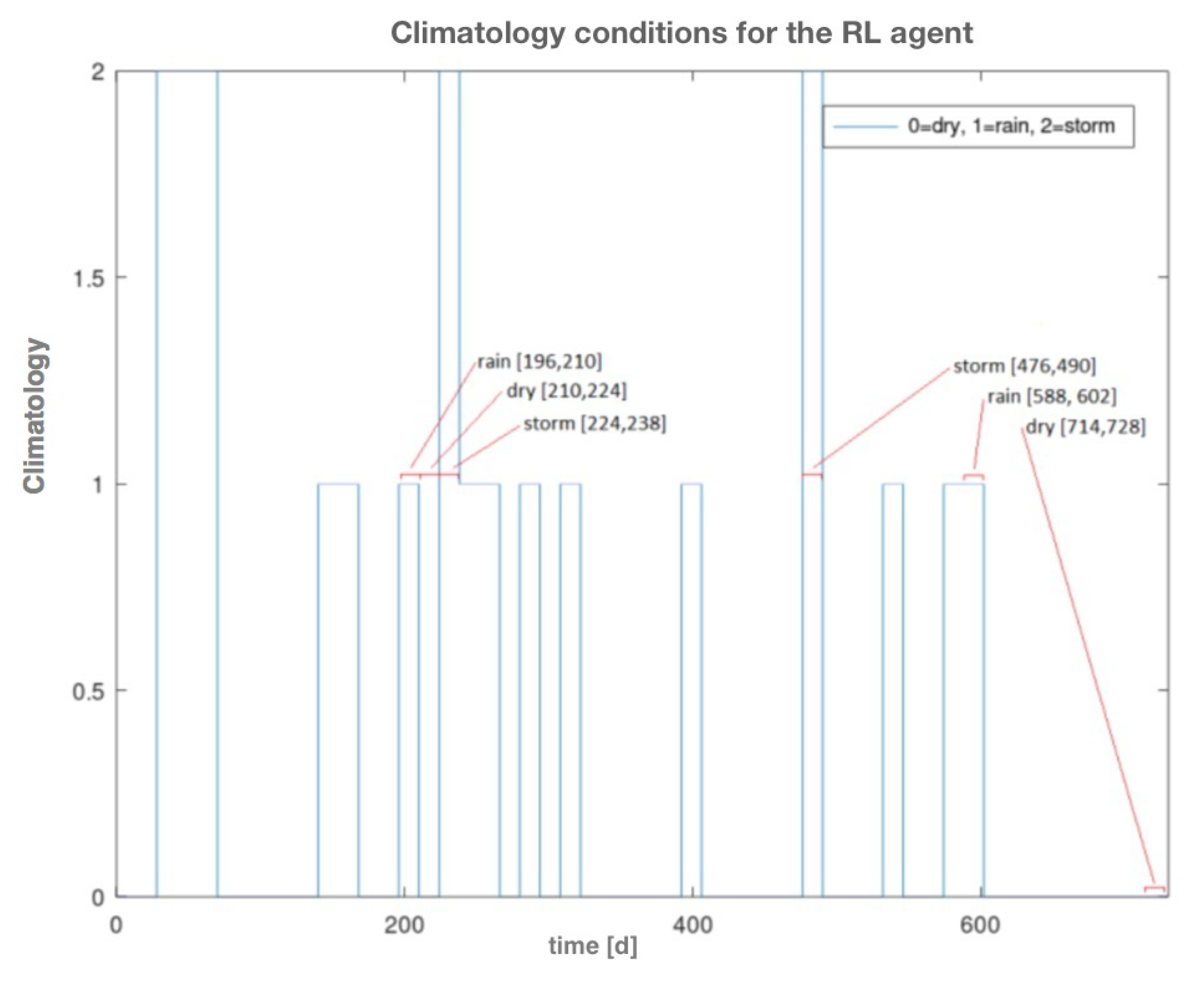
2.4. Conditions of the Simulation
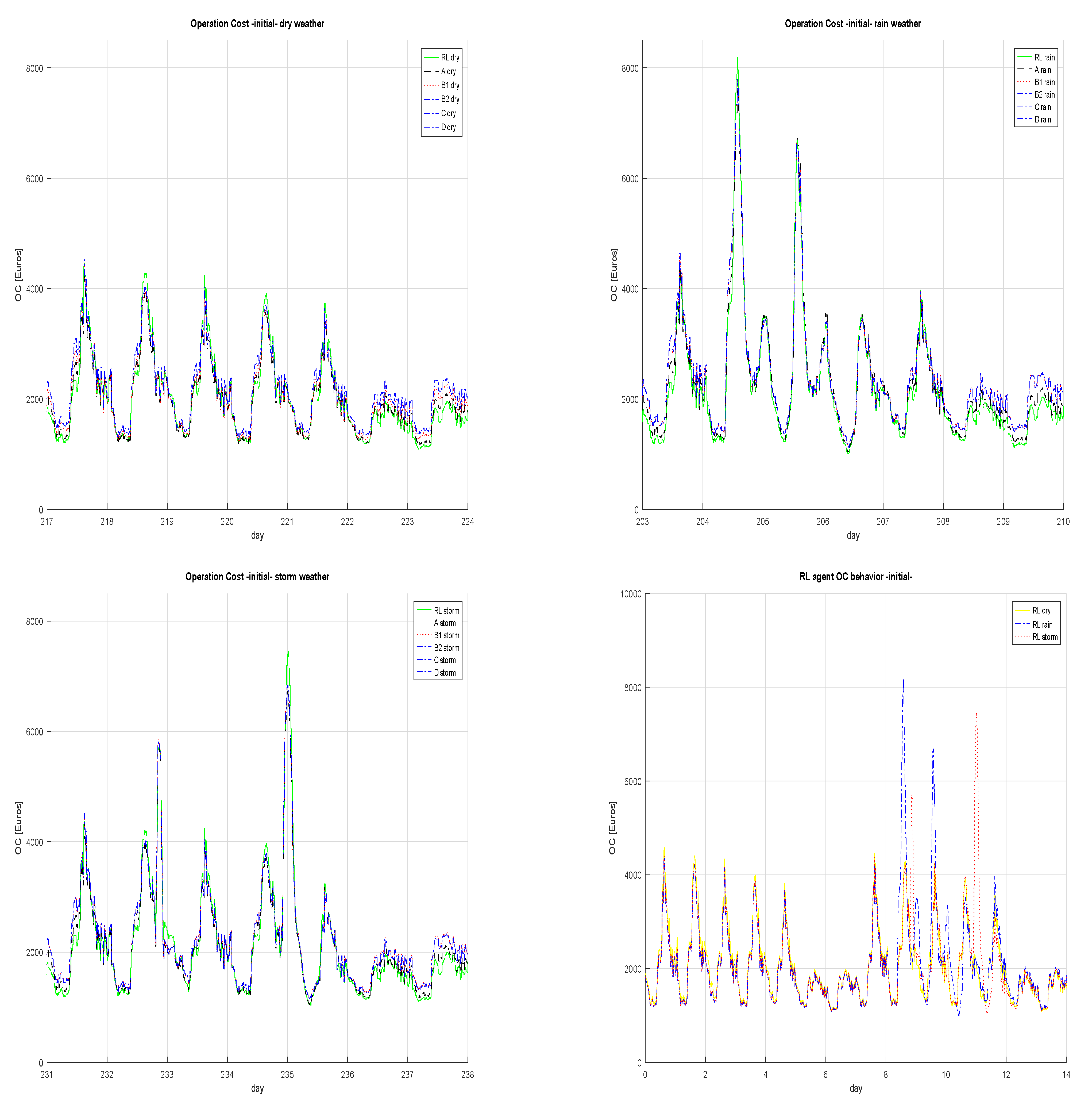
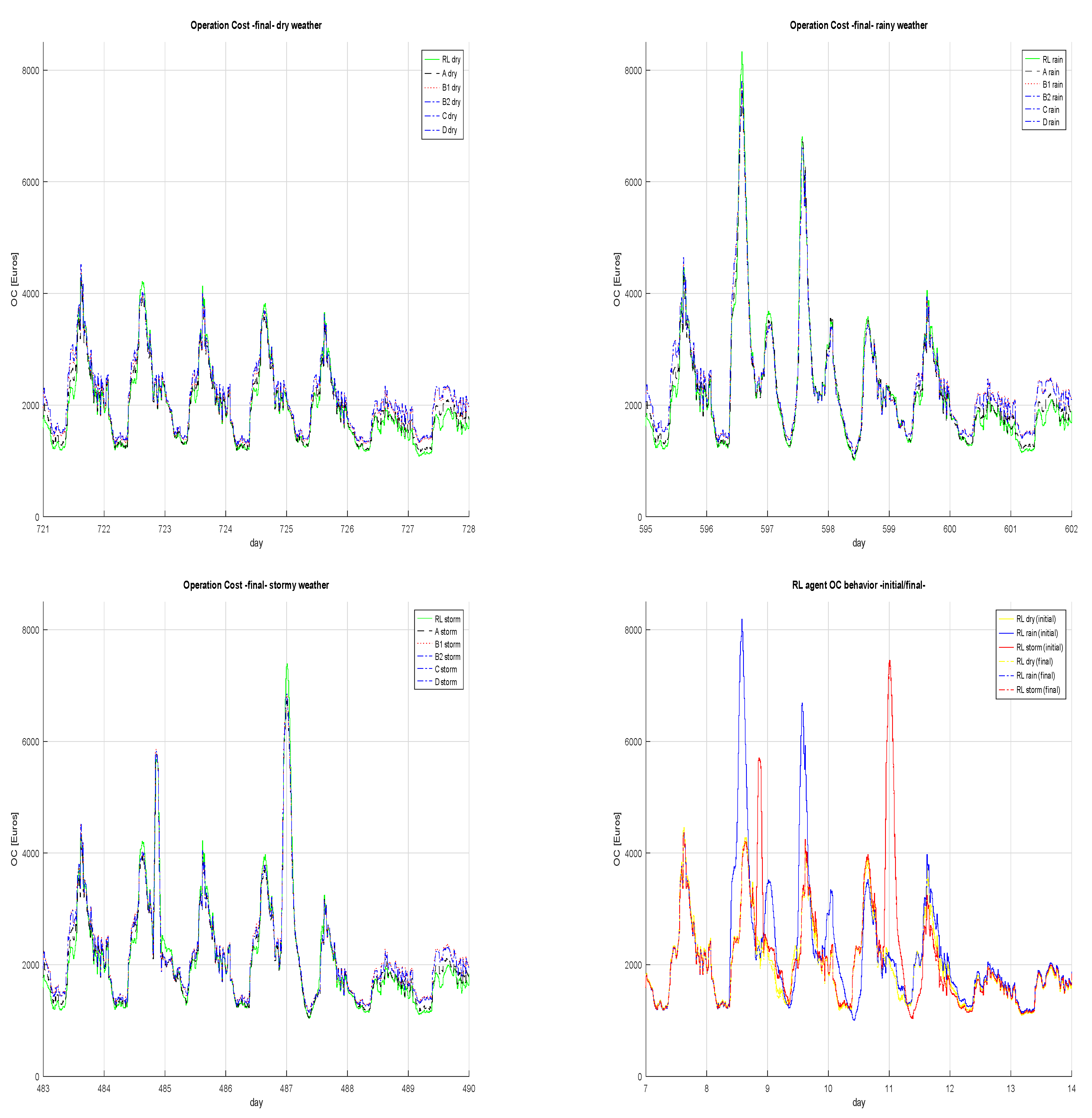
3. Results
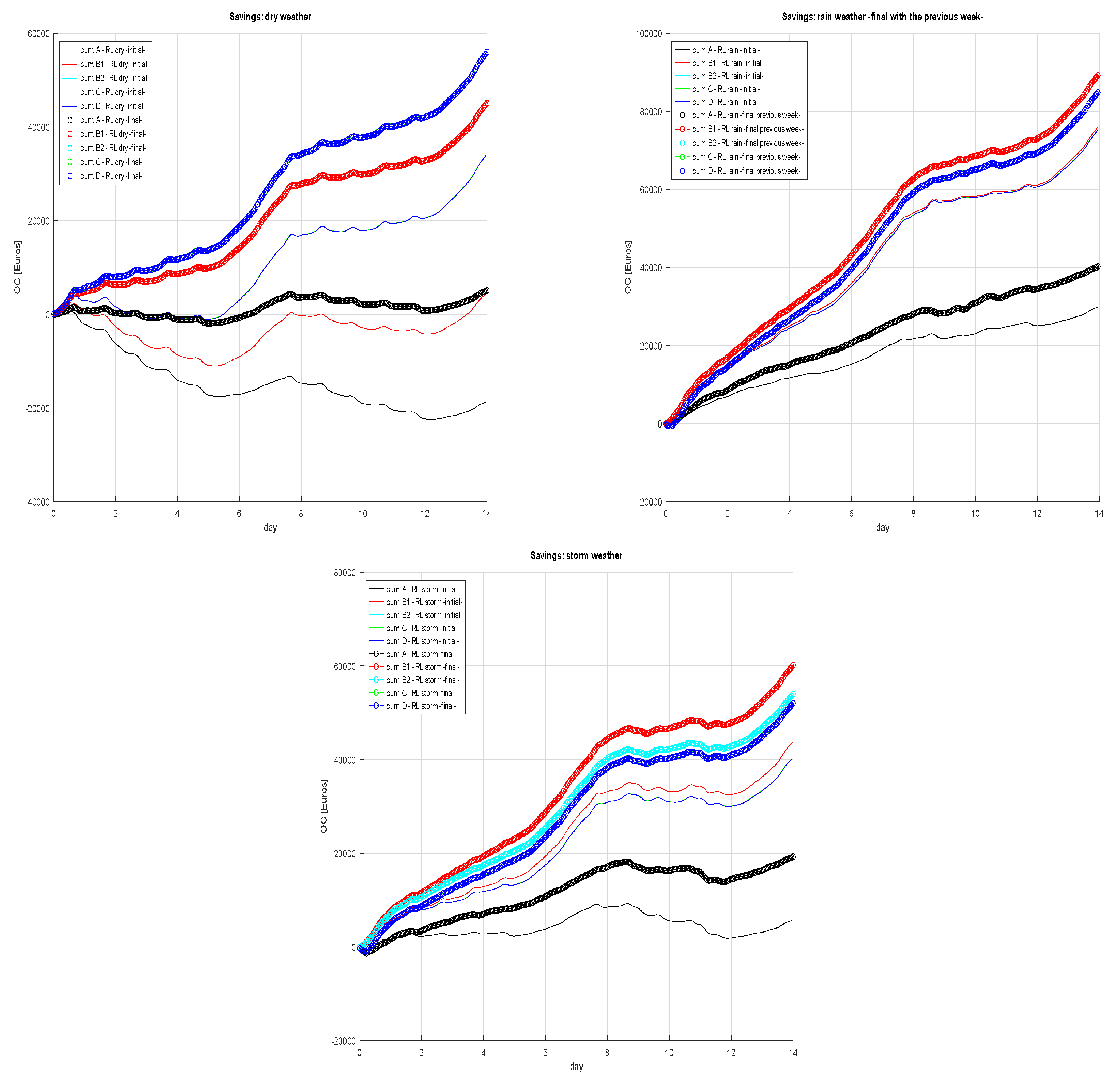
3.1. Operation Cost Savings
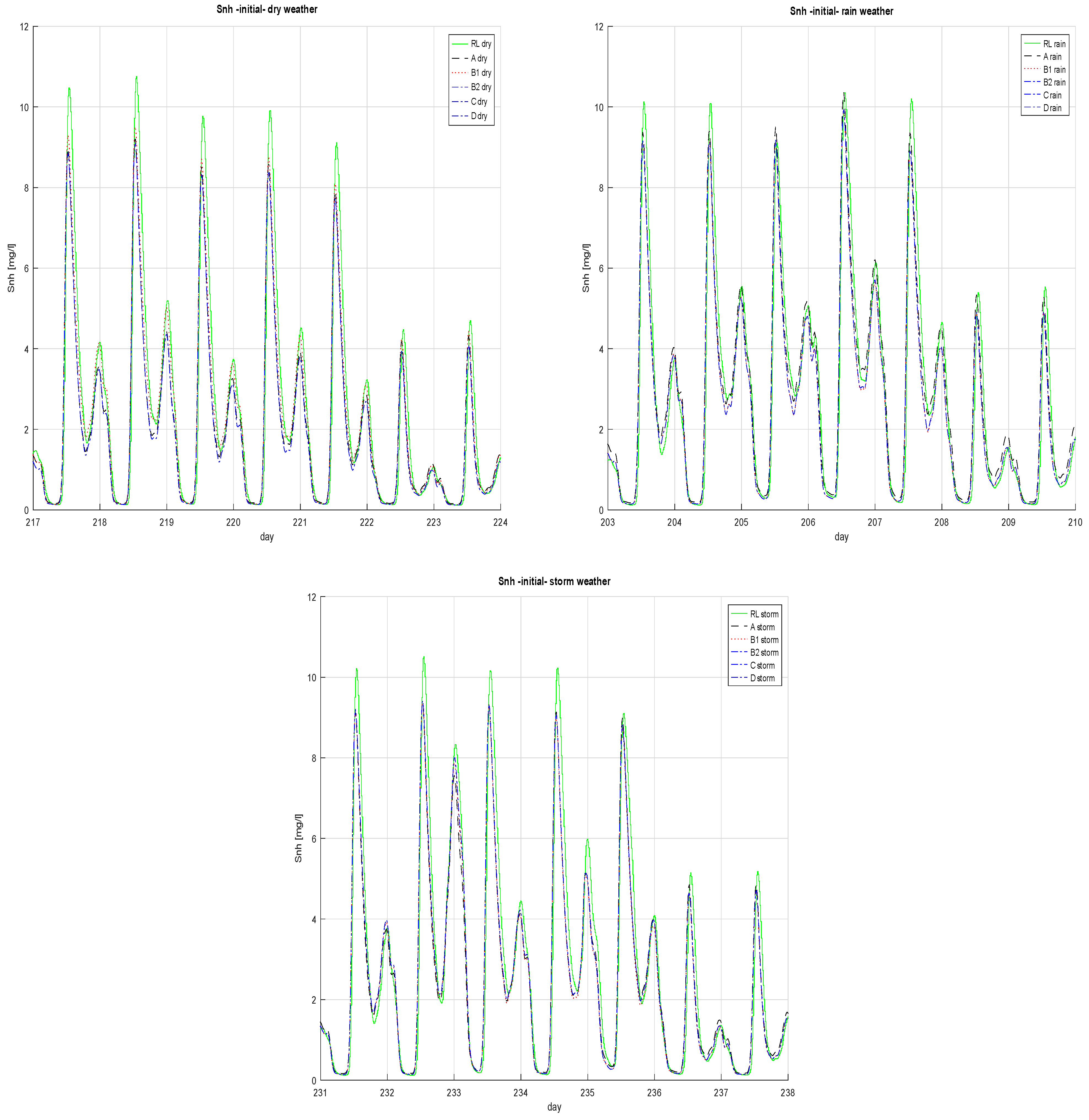
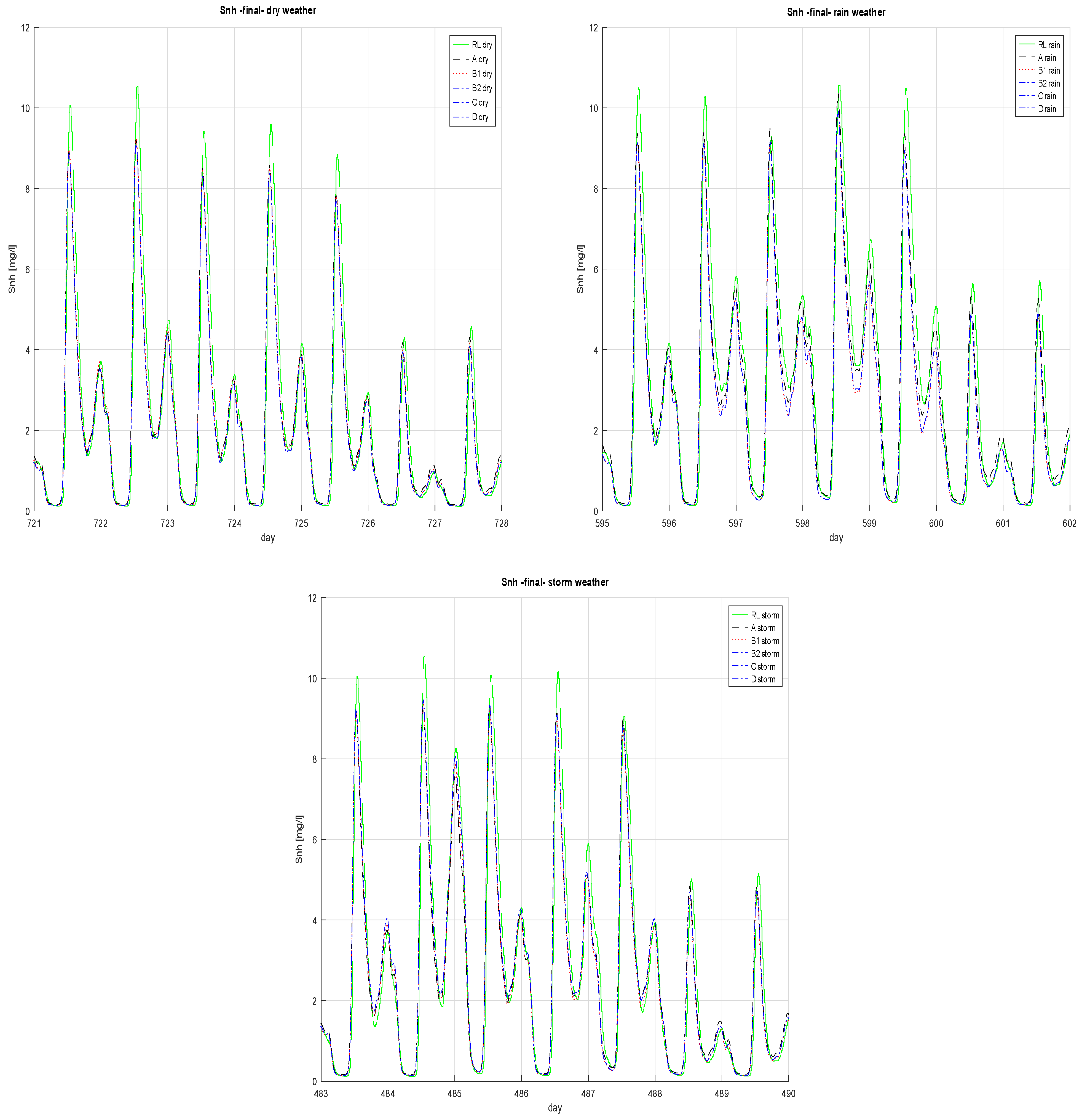
3.2. N-Ammonia Concentration
3.3. Operation Cost
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Dochain, D.; Vanrolleghem, P. Dynamical Modelling & Estimation in Wastewater Treatment Processes; IWA Publishing: London, UK, 2001. [Google Scholar]
- Machineni, L. Review on biological wastewater treatment and resources recovery: Attached and suspended growth systems. Water Sci. Technol. 2020, 80, 2013–2026. [Google Scholar] [CrossRef] [PubMed]
- Alex, J.; Benedetti, L.; Copp, J.; Gernaey, K.; Jeppsson, U.; Nopens, I.; Pons, M.; Rieger, L.; Rosen, C.; Steyer, J.; et al. Benchmark Simulation Model no. 1 (BSM1). Scientific and Technical Report, IWA Taskgroup on Benchmarking of Control Stategies for WWTPs, Department of Industrial Electrical Engineering and Automation. Lund University. 2008. Available online: https://www.iea.lth.se/publications/Reports/LTH-IEA-7229.pdf (accessed on 4 April 2023).
- Metcalf, E.; Eddy, H. Wastewater Engineering: Treatment and Reuse, 4th ed.; McGraw-Hill Publishing: New York, NY, USA, 2003. [Google Scholar]
- Olsson, G.; Nielsen, M.; Yuan, Z.; Lynggaard-Jensen, A.; Steyer, J. Instrumentation, Control and Automation in Wastewater Systems; IWA Publishing: London, UK, 2005. [Google Scholar]
- Yang, T.; Qiu, W.; Ma, Y.; Chadli, M.; Zhang, L. Fuzzy model-based predictive control of dissolved oxygen in activated sludge processes. Neurocomputing 2014, 136, 88–95. [Google Scholar] [CrossRef]
- Holenda, B.; Domokos, E.; Redey, A.; Fazakas, J. Dissolved oxygen control of the activated sludge wastewater treatment process using model predictive control. Comput. Chem. Eng. 2008, 32, 1270–1278. [Google Scholar] [CrossRef]
- Hernández-del Olmo, F.; Gaudioso, E.; Dormido, R.; Duro, N. Energy and Environmental Efficiency for the N-Ammonia Removal Process in Wastewater Treatment Plants by Means of Reinforcement Learning. Energies 2016, 9, 755. [Google Scholar] [CrossRef] [Green Version]
- Åmand, L.; Olsson, G.; Carlsson, B. Aeration control—A review. Water Sci. Technol. 2013, 67, 2374–2398. [Google Scholar] [CrossRef] [Green Version]
- Du, S.; Yan, Q.; Qiao, J. Event-triggered PID control for wastewater treatment plants. J. Water Process. Eng. 2020, 38, 101659. [Google Scholar] [CrossRef]
- Meneses, M.; Concepción, H.; Vilanova, R. Joint Environmental and Economical Analysis of Wastewater Treatment Plants Control Strategies: A Benchmark Scenario Analysis. Sustainability 2016, 8, 360. [Google Scholar] [CrossRef] [Green Version]
- Lozano, A.B.; Del Cerro, F.; Lloréns, M. Methodology for Energy Optimization in Wastewater Treatment Plants. Phase III: Implementation of an Integral Control System for the Aeration Stage in the Biological Process of Activated Sludge and the Membrane Biological Reactor. Sensors 2020, 20, 4342. [Google Scholar] [CrossRef]
- Iratni, A.; Chang, N. Advances in control technologies for wastewater treatment processes: Status, challenges, and perspectives. IEEE/CAA J. Autom. Sin. 2019, 6, 337–363. [Google Scholar] [CrossRef]
- Wang, D.; Thunéll, S.; Lindberg, U.; Jiang, L.; Trygg, J.; Tysklind, M.; Souihi, N. A machine learning framework to improve effluent quality control in wastewater treatment plants. Sci. Total Environ. 2021, 784, 147138. [Google Scholar] [CrossRef]
- Várhelyi, S.; Tomoiagă, C.; Brehar, M.; Cristea, V. Dairy wastewater processing and automatic control for waste recovery at the municipal wastewater treatment plant based on modelling investigations. J. Environ. Manag. 2021, 287, 112316. [Google Scholar] [CrossRef]
- Santín, I.; Vilanova, R.; Pedret, C.; Barbu, M. New approach for regulation of the internal recirculation flow rate by fuzzy logic in biological wastewater treatments. ISA Trans. 2022, 120, 167–189. [Google Scholar] [CrossRef]
- Pisa, I.; Morell, A.; Vilanova, R.; Vicario, J.L. Transfer Learning in Wastewater Treatment Plant Control Design: From Conventional to Long Short-Term Memory-Based Controllers. Sensors 2021, 21, 6315. [Google Scholar] [CrossRef]
- Hansen, L.D.; Stokholm-Bjerregaard, M.; Durdevic, P. Modeling phosphorous dynamics in a wastewater treatment process using Bayesian optimized LSTM. Comput. Chem. Eng. 2022, 160, 107738. [Google Scholar] [CrossRef]
- Meng, X.; Zhang, Y.; Qiao, J. An adaptive task-oriented RBF network for key water quality parameters prediction in wastewater treatment process. Neural Comput. Appl. 2021, 33, 11401–11414. [Google Scholar] [CrossRef]
- Chen, Y.; Song, L.; Liu, Y.; Yang, L.; Li, D. A Review of the Artificial Neural Network Models for Water Quality Prediction. Appl. Sci. 2020, 10, 5776. [Google Scholar] [CrossRef]
- Cao, W.; Yang, Q. Online sequential extreme learning machine based adaptive control for wastewater treatment plant. Neurocomputing 2020, 408, 169–175. [Google Scholar] [CrossRef]
- Pang, J.; Yang, S.; He, L.; Chen, Y.; Ren, N. Intelligent Control/Operational Strategies in WWTPs through an Integrated Q-Learning Algorithm with ASM2d- Guided Reward. Water 2019, 11, 927. [Google Scholar] [CrossRef] [Green Version]
- Bahramian, M.; Dereli, R.K.; Zhao, W.; Giberti, M.; Casey, E. Data to intelligence: The role of data-driven models in wastewater treatment. Expert Syst. Appl. 2023, 217, 119453. [Google Scholar] [CrossRef]
- Qambar, A.S.; Al Khalidy, M.M. Optimizing dissolved oxygen requirement and energy consumption in wastewater treatment plant aeration tanks using machine learning. J. Water Process. Eng. 2022, 50, 103237. [Google Scholar] [CrossRef]
- Dairi, A.; Cheng, T.; Harrou, F.; Sun, Y.; Leiknes, T. Deep learning approach for sustainable WWTP operation: A case study on data-driven influent conditions monitoring. Sustain. Cities Soc. 2019, 50, 101670. [Google Scholar] [CrossRef]
- Jiang, Y.; Li, C.; Sun, L.; Guo, D.; Zhang, Y.; Wang, W. A deep learning algorithm for multi-source data fusion to predict water quality of urban sewer networks. J. Clean. Prod. 2021, 318, 128533. [Google Scholar] [CrossRef]
- Ching, P.; So, R.H.; Morck, T. Advances in soft sensors for wastewater treatment plants: A systematic review. J. Water Process. Eng. 2021, 44, 102367. [Google Scholar] [CrossRef]
- Yaqub, M.; Asif, H.; Kim, S.; Lee, W. Modeling of a full-scale sewage treatment plant to predict the nutrient removal efficiency using a long short-term memory (LSTM) neural network. J. Water Process. Eng. 2020, 37, 101388. [Google Scholar] [CrossRef]
- Shi, S.; Xu, G. Novel performance prediction model of a biofilm system treating domestic wastewater based on stacked denoising auto-encoders deep learning network. Chem. Eng. J. 2018, 347, 280–290. [Google Scholar] [CrossRef]
- Hernández-del Olmo, F.; Gaudioso, E.; Duro, N.; Dormido, R. Machine Learning Weather Soft-Sensor for Advanced Control of Wastewater Treatment Plants. Sensors 2019, 19, 3139. [Google Scholar] [CrossRef] [Green Version]
- Hernández-del Olmo, F.; Gaudioso, E.; Dormido, R.; Duro, N. Tackling the start-up of a reinforcement learning agent for the control of wastewater treatment plants. Knowl. Based Syst. 2018, 144, 9–15. [Google Scholar] [CrossRef]
- Copp, J. The COST Simulation Benchmark: Description and Simulator Manual; Scientific and Technical Report; Office for Official Publications of the European Community: Luxembourg, 2002. [Google Scholar]
- Dorf, R.; Bishop, R.H. Modern Control Systems, 13th ed.; Pearson: London, UK, 2017. [Google Scholar]
- Buşoniu, L.; Babuška, R.; De Schutter, B.; Ernst, D. Reinforcement Learning and Dynamic Programming Using Function Approximators; CRC Press: Boca Raton, FL, USA, 2010. [Google Scholar]
- Stare, A.; Vrečko, D.; Hvala, N.; Strmčnik, S. Comparison of control strategies for nitrogen removal in an activated sludge process in terms of operating costs: A simulation study. Water Res. 2007, 41, 2004–2014. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | Techniques | Goal |
|---|---|---|
| [10,11] | PIDs | Control of DO concentration |
| [12] | PIDs and fuzzy logic techniques | Control of DO and ammonium/nitrate concentration |
| [15] | Genetic algorithm optimization | Control of nitrogen and ammonia concentration |
| [16] | Fuzzy control | Control of nitrogen and ammonia concentration |
| [17,21] | Artificial Neural Networks | Control of nitrogen and/or DO concentration |
| [18] | Recurrent Neural Networks | Control of phosphorus concentration |
| [19] | Artificial Neural Networks | Prediction of effluent biochemical oxygen demand and the effluent total nitrogen |
| [22] | Reinforcement Learning | Optimal control of hydraulic retention time and internal recycling ratio in an naerobic–anoxic–aerobic system |
| [25] | Recurrent neural networks | detect anomalies in influent conditions |
| [26] | Recurrent neural network, long-short term memory | analyze and predict water quality |
| [28,29] | recurrent neural networks deep learning network | predict the ammonium, total nitrogen, and total deep learning network efficiency |
| [30] | Machine learning techniques (Support Vector Machine, Decision Trees, Random Forest and Gaussian Naive Bayes, k-nearest neighbors) | Predict weather conditions |
| [31] | Reinforcement learning | Control DO concentration |
| Weather Condition | Initial Phase Days | Final Phase Days |
|---|---|---|
| dry | 210–224 | 714–728 |
| rain | 196–210 | 588–602 |
| storm | 224–238 | 476–490 |
| Control Method | Dry | Rain | Storm |
|---|---|---|---|
| A | 126.29% | 34.61% | 235.6% |
| B1 | 937.97% | 17.50% | 37.45% |
| B2 | 64.38% | 12.80% | 33.64% |
| C | 64.18% | 12.76% | 28.68% |
| D | 64.32% | 12.84% | 28.77% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hernández-del-Olmo, F.; Gaudioso, E.; Duro, N.; Dormido, R.; Gorrotxategi, M. Advanced Control by Reinforcement Learning for Wastewater Treatment Plants: A Comparison with Traditional Approaches. Appl. Sci. 2023, 13, 4752. https://doi.org/10.3390/app13084752
Hernández-del-Olmo F, Gaudioso E, Duro N, Dormido R, Gorrotxategi M. Advanced Control by Reinforcement Learning for Wastewater Treatment Plants: A Comparison with Traditional Approaches. Applied Sciences. 2023; 13(8):4752. https://doi.org/10.3390/app13084752
Chicago/Turabian StyleHernández-del-Olmo, Félix, Elena Gaudioso, Natividad Duro, Raquel Dormido, and Mikel Gorrotxategi. 2023. "Advanced Control by Reinforcement Learning for Wastewater Treatment Plants: A Comparison with Traditional Approaches" Applied Sciences 13, no. 8: 4752. https://doi.org/10.3390/app13084752
APA StyleHernández-del-Olmo, F., Gaudioso, E., Duro, N., Dormido, R., & Gorrotxategi, M. (2023). Advanced Control by Reinforcement Learning for Wastewater Treatment Plants: A Comparison with Traditional Approaches. Applied Sciences, 13(8), 4752. https://doi.org/10.3390/app13084752