1. Introduction
Human activity and behavior recognition (HABR) is an area of research to gain a high level of knowledge about human activities from raw sensor inputs, and it is regarded as an essential component to realize the 4th industrial revolution. Technologies of the 4th Industrial Revolution society will primarily comprise IoT sensors broadly deployed almost everywhere and intelligent software technologies such as artificial intelligence, machine learning, and so on. These technologies are collectively used to make our daily lives better by making various useful applications viable, which include healthcare, surveillance, location-based services, silver-care services, etc. Let alone several of these interesting applications, environmental issues, including the air pollution problem, have drawn lots of attention, especially in most Asian countries where the economy is growing very rapidly. Many countries have made efforts to develop technologies to predict the level and impact of air pollution in our daily life so that people can avoid air pollution and protect themselves. Related research efforts have focused on predicting the level of air pollution based on data collected from the sensors deployed broadly with the aim of alerting the untargeted majority of people. This kind of service needs to be advanced to provide a personal care type of service so that each individual can have different environmental information. If this kind of service is desired, it is essential to track the precise movement of individuals so that it is possible to let people know of their level of pollution in advance. Thus, it is important to predict the activities or behaviors of humans in a very reliable manner. This paper strived to develop deep learning prediction models to predict the activities of humans, using datasets collected from body-worn sensors designed to obtain personal environmental data during daily life. Related studies have presented online and offline predictive technologies for human activities, primarily in outdoor or indoor environments. However, our daily life is composed of lots of diverse indoor and outdoor activities; therefore, research efforts should develop into working in any environment afterward. In this study, we developed two machine-learning-based activity prediction models applicable to our daily lives and evaluated the performance of the models to weigh up the possibility of their practical use.
Lots of technologies have been proposed to predict human behaviors and activities. Most of them are classified into two different categories depending on the type of data collected [
1]. We can predict human behaviors using image or video data (image-based technologies) or sensor data (sensor-type technologies) collected from mobile devices or from stationary sensors deployed at home or in any target area. For the literature review, we excluded image-based studies and focused primarily on those using non-image data, collected especially from mobile devices. Sensor data can be classified into two different categories, mobile or stationary. Mobile-type sensors are, in general, worn by the subject person and generate data associated with the movements of the subject person, so it is highly likely to contain a significant amount of missing data or noise caused by the movements [
2,
3,
4,
5]. Stationary sensors are, in general, installed in places of interest, and the collected data contains relatively fewer missing values and noise compared to those of mobiles [
6,
7,
8,
9,
10]. It is also important to differentiate whether the activity recognition is performed in online or offline environments. Online recognition, in general, refers to approaches in which the recognition tasks occur mostly in local devices and are executed in real time. Offline recognition, on the other hand, works in client–server computing environments and does not require real-time processing.
Our designed classifiers are developed to apply to both environments and to work online as well as offline. Further, there are lots of classifiers to realize the prediction tasks using the collected data. Those classifiers include classic machine-learning-type classifiers as well as modern deep-learning-type classifiers. The classic machine learning types of classifiers include the naïve Bayes classifiers [
2,
11,
12], decision trees [
13], hidden Markov models [
3,
14,
15], support vector machines [
16] and etc. Modern machine learning algorithms include well-known convolutional neural networks (CNN) [
17], recurrent neural networks (RNN) [
18,
19], long short-term memory (LSTM) [
20,
21,
22,
23,
24,
25,
26,
27,
28,
29], etc. These classifiers are data-driven classifiers that require labeled data to train the classifiers themselves.
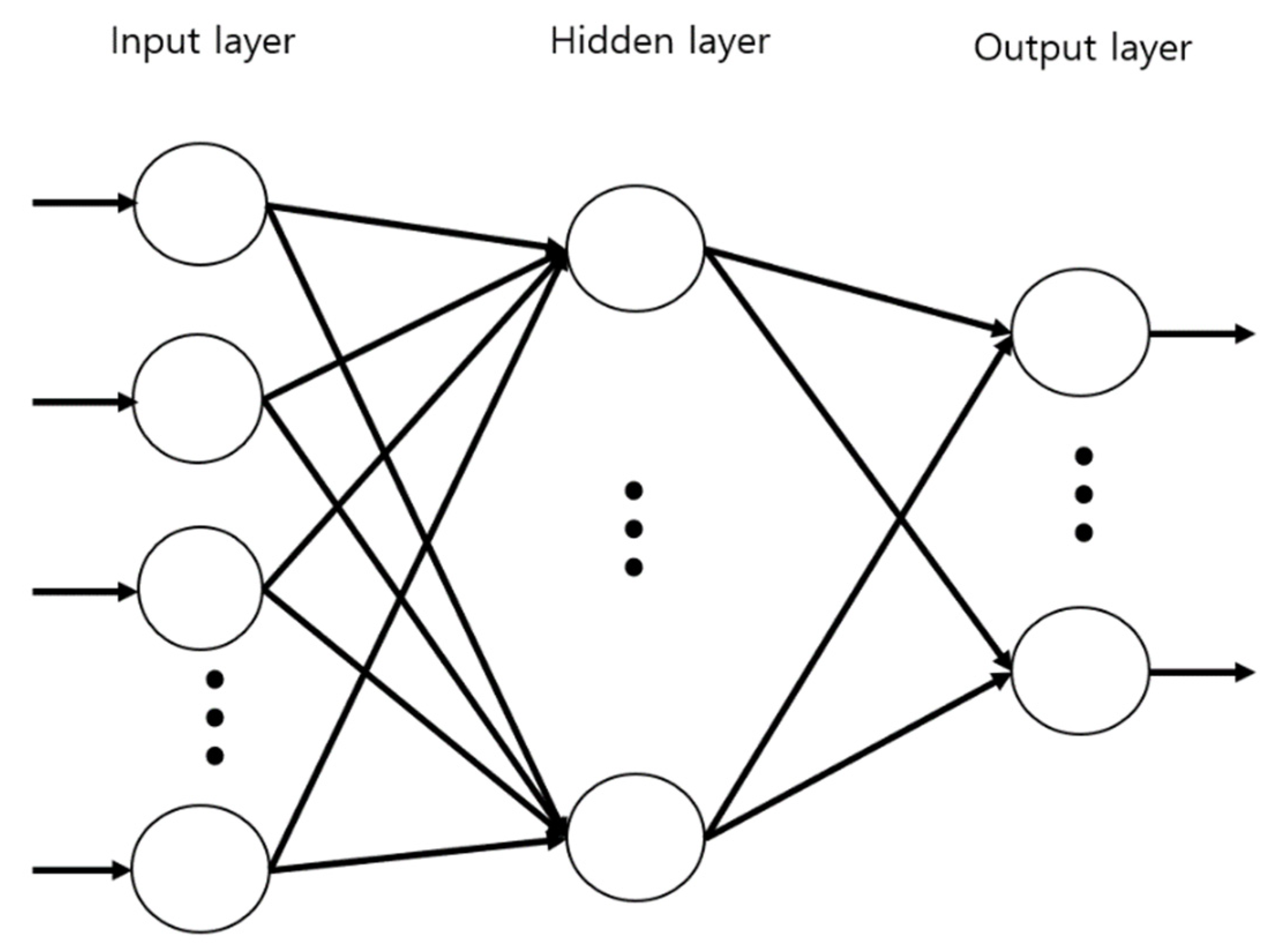
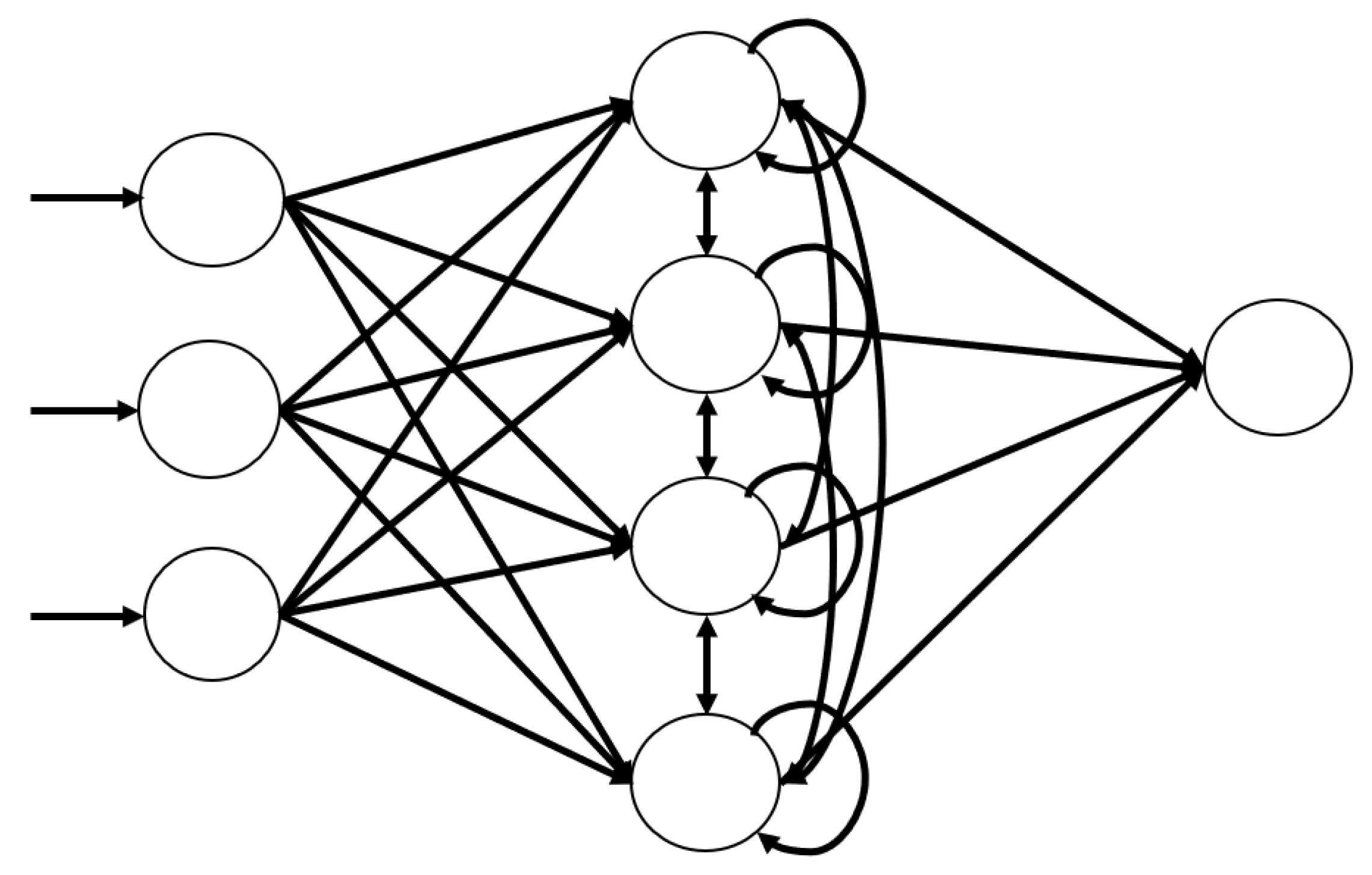
As we described previously, we implement two classifiers for activity recognition using data collected from portable body-worn sensors to obtain personal environmental information. Most previous research primarily addressed activity recognition in either indoor or outdoor environments. However, our research attempted to predict activities in more heterogeneous environments, reflecting our various daily life in diverse environments. We assumed 13 different activities that are typical to Korean families and tried to predict the activities using well-known MLP and LSTM models. Simulation results showed that the LSTM model has higher accuracy compared to that of the MLP model.
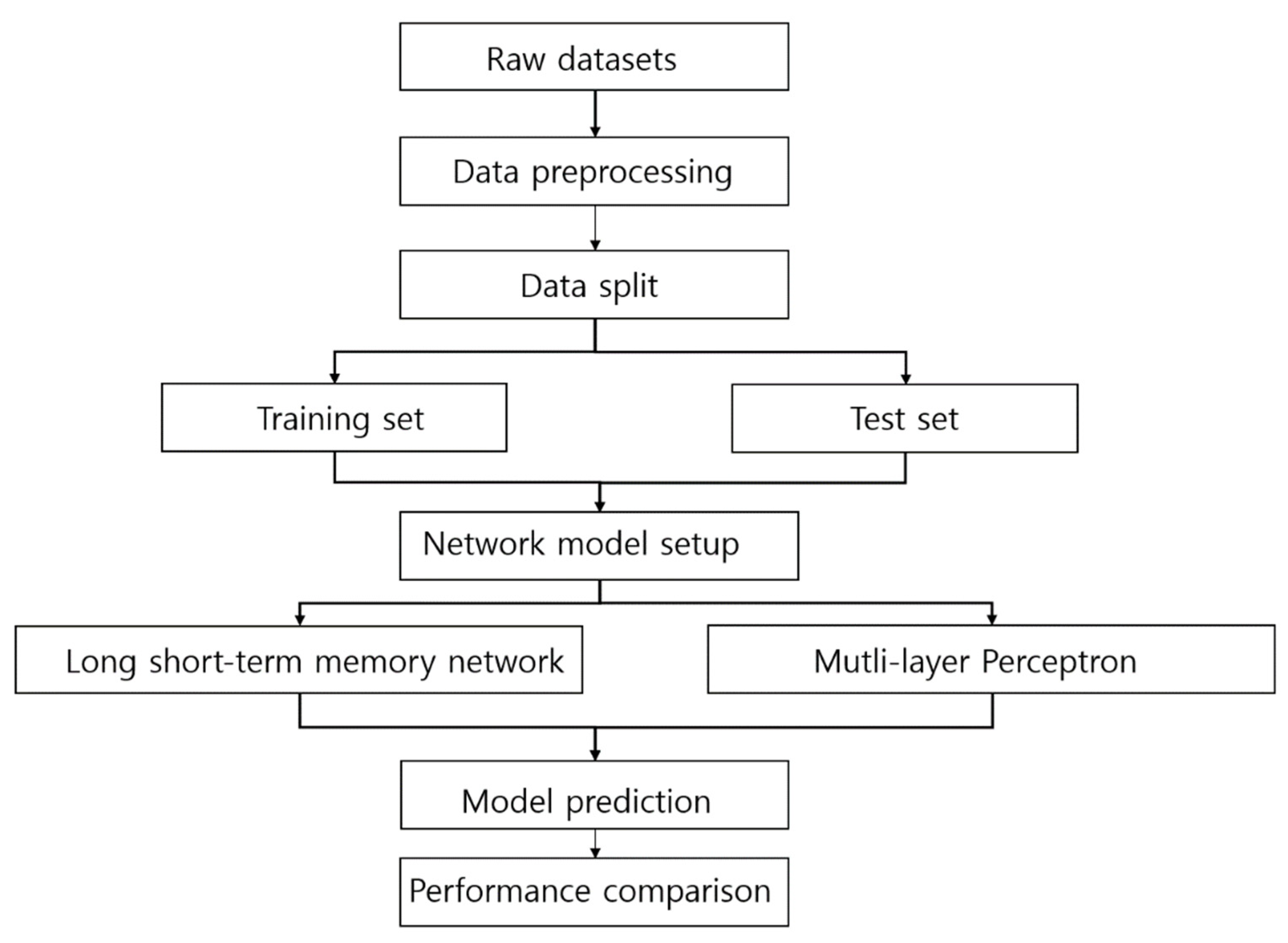
This paper is organized as follows. The first section provides in-depth details on the collection of raw data, including the place where the data were collected and the subject persons who volunteered for the collection task. The second section provides technical details on the deep learning models used. The third section describes simulation results comparing the performance of the two deep learning models. Finally, the fourth section provides conclusions and insights from the results.
5. Conclusions
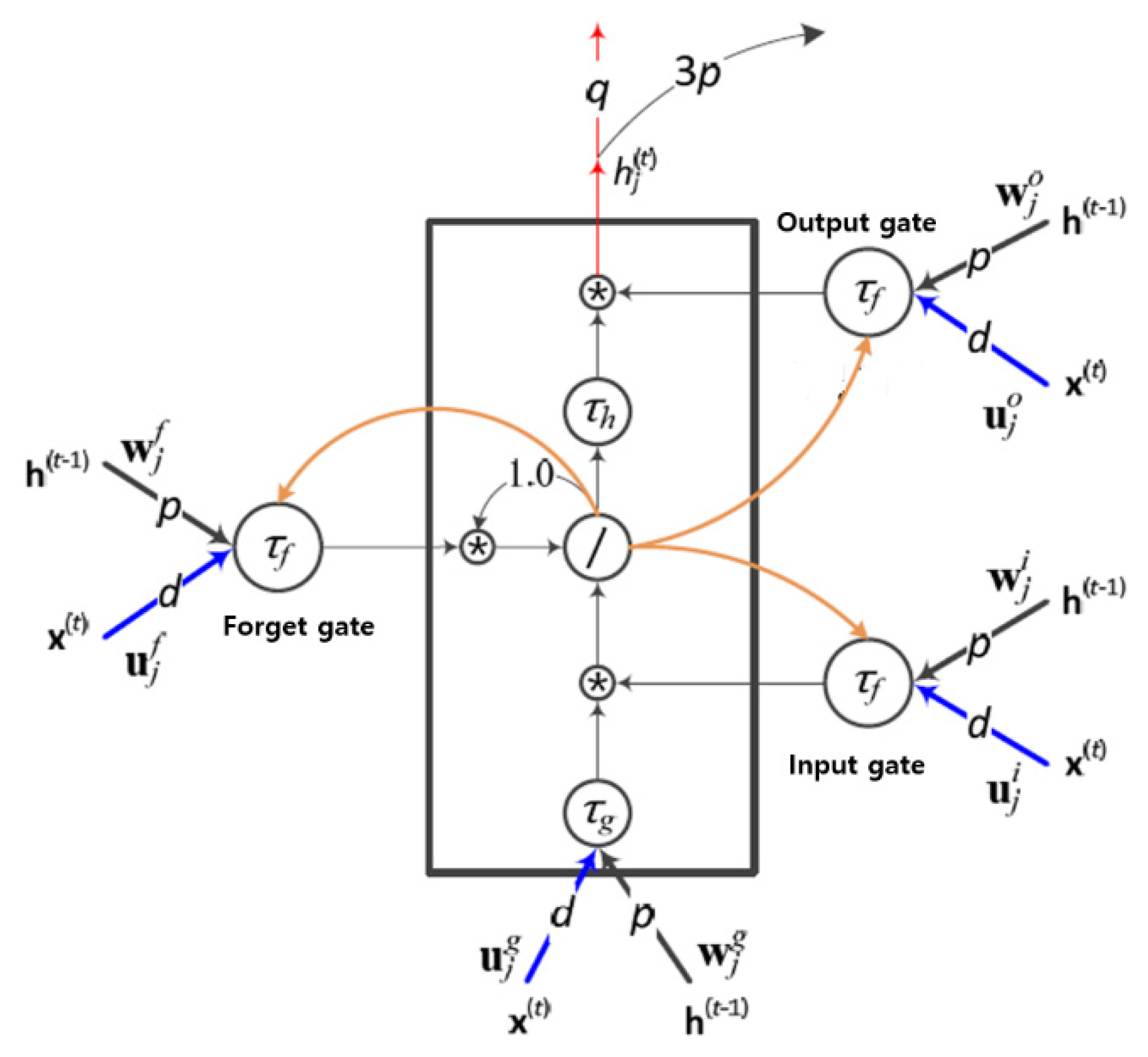
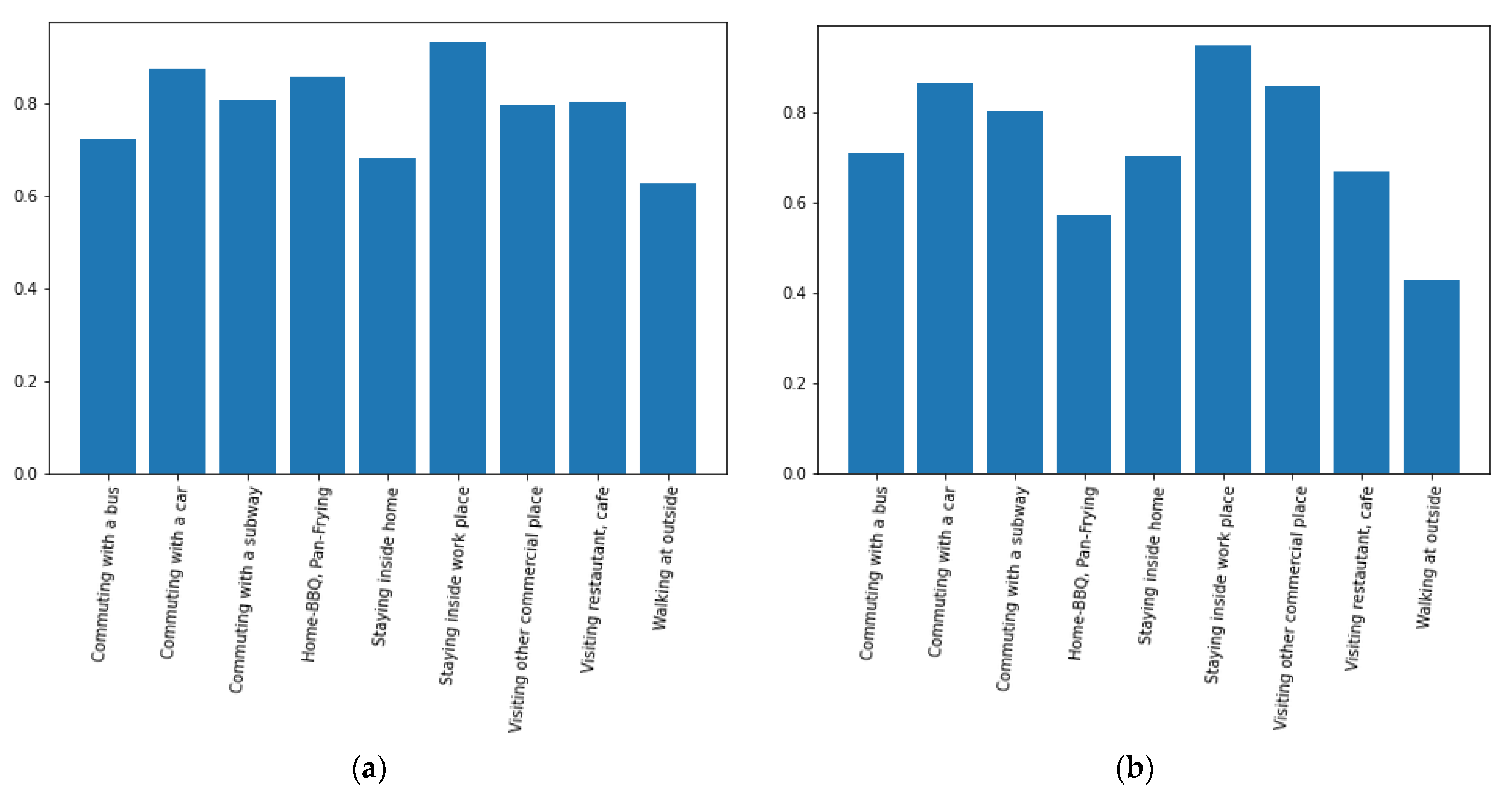
This paper strived to infer activity patterns in both indoor and outdoor environments using environmental information, which distinguishes it from most previous studies that focus on the levels of PM2.5 concentration affecting human health. We used a commercial multipurpose sensor to collect the raw data and designed deep learning models to infer the activity patterns using the collected raw data. We chose both MLP and LSTM network models for this research. MLP, a popular model in the 1980s, has recently gained interest again today due to the success of deep learning techniques in various applications, including speech recognition, image recognition, machine translation, etc. LSTM is a deep learning model that characterizes itself to handle a time-series type of data and has proved its characteristic adaptability for various applications such as voice recognition, stock index prediction, weather forecast, etc. During the performance comparison, we found that LSTM outperformed MLP in terms of prediction accuracy, which was expected considering the nature of the LSTM. More specifically, the accuracy was higher in the indoor-like environments than in the outdoor-like environments in both training and test simulations, except for the case of indoor cooking activities. Moreover, considering that all four features used for this research could be unstable under outdoor environments compared to indoor environments, we believe that the test accuracy of around 90% is very high. However, LSTM took significant amounts of computation time compared to MLP due to the complexity of network architecture, especially when the number of hidden layers is more than two. Therefore, we aimed to reduce the number of hidden layers to make the model more practical.
In the current study, we acknowledge the lack of large differences in lifestyles of subjects for various reasons, which could have led to degradation of performance. This issue will be included in our next research. Additionally, we will try to apply our model to more diverse heterogeneous environments based on the results of this research and enhance the performance of the current models. For this purpose, it is worth building a conceptual model as in [
21] and collecting datasets corresponding to the model for more precise activity prediction. In addition, one of the ways to enhance the performance of the models is to incorporate other deep learning architectures, such as CNNs, into current LSTM architectures. Certain parts of the time series data show very frequent local and temporal changes of movements, which may be suitable for CNN to capture. If CNN is used together with LSTM, the current performance can be further improved.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}