Machine Learning Methods for Pipeline Surveillance Systems Based on Distributed Acoustic Sensing: A Review


 ,
,
Abstract
:1. Introduction
- Present the first extensive review of the machine learning techniques applied on DAS-based surveillance systems.
- Provide meaningful recommendations for a methodology that aims to build a DAS-based surveillance system based on machine learning techniques.
2. Related Work
2.1. Distributed Acoustic Sensing and Pattern Recognition Systems (DAS+PRS)
- The rigorous application of machine learning methods and methodologies to the area of pipeline integrity surveillance, using distributed acoustic sensing.
- The generation of extensive, varied, and realistic field data, using real machinery carrying out real activities sensed by state-of-the-art DAS systems on optical fibers deployed along active gas pipelines.
- The application of objective evaluation metrics on the realistic data, so that the results could provide a real perspective on the actual capabilities of the DAS+PRS in the real world.
2.2. Machine/Vehicle Classification from Other Sensing Systems
2.3. Summary
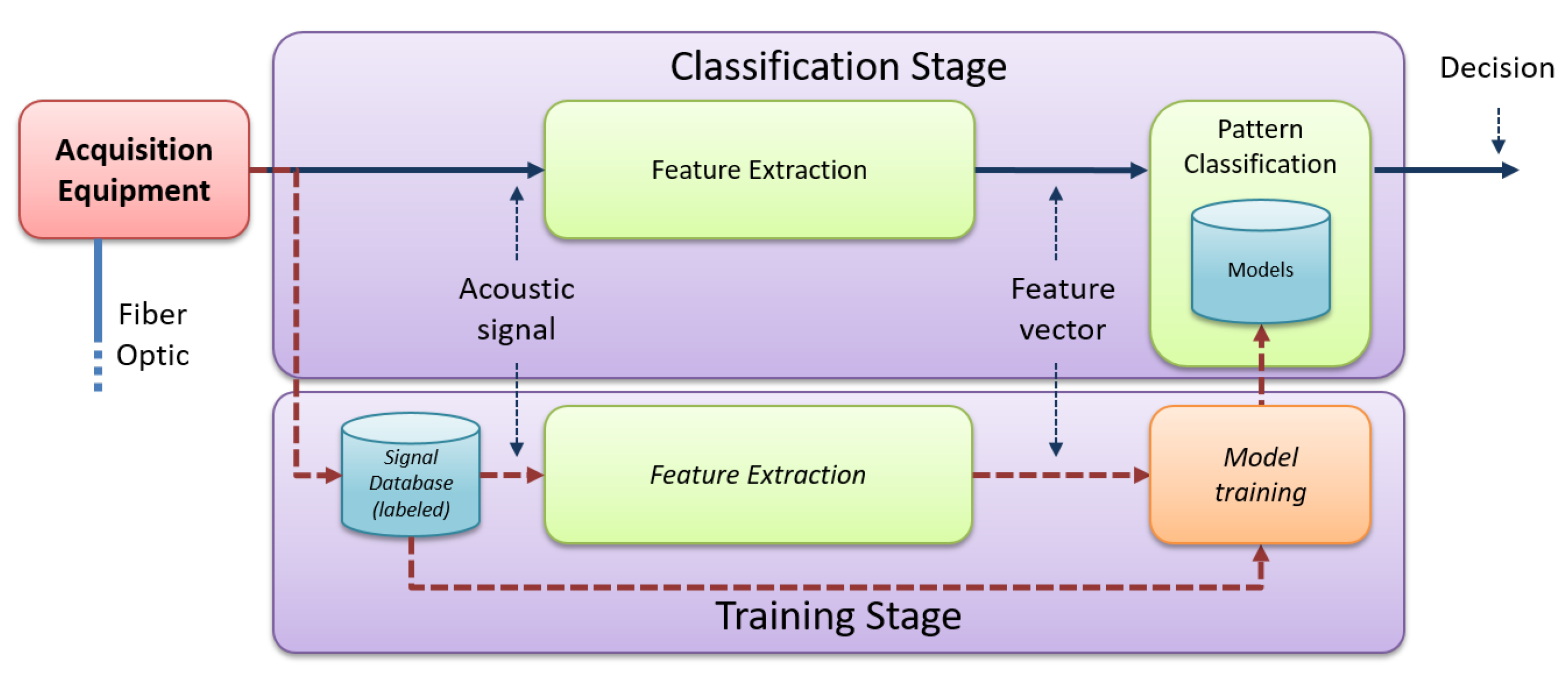
3. Principles of Machine Learning for DAS
3.1. Introduction
3.2. Feature Extraction
3.3. Pattern Classification
- A generative model is able to randomly generate observable data values given some hidden parameters. This can be seen as a full probabilistic model of all variables, can be used to simulate values of any variable in the model, and typically trains a model for each event to identify. Some examples of generative models are Gaussian Mixture Model (GMM), Hidden Markov Model (HMM), Naive Bayes (NB), and Restricted Boltzmann Machine (RBM), among others.
- A discriminative model is used in machine learning to model the dependence of an unobserved variable y on an observed variable x. Contrary to the generative model, the discriminative model only allows sampling of the target variables conditional on the observed values. The discriminative model typically builds a single model (contrary to the generative model) from all the data with some parameters learned that make predictions possible. Some discriminative models are Logistic Regression (LR), Artificial Neural Network (ANN), Support Vector Machine (SVM), Decision Tree (DT), and Conditional Random Field (CRF), among others.
3.4. Experimental Procedure
3.4.1. Database Generation
3.4.2. Evaluation Metrics
3.4.3. System Configuration
- The signal processing conditions, which are related to the definition of the signal analysis window.
- The division of the database to rigorously carry out the training, validation, and testing processes.
- Training subset, which will be used to generate the system trained models.
- Validation subset (if required) which, if available, is used to estimate how well the models actually represent the events to be classified, and possibly to do further fine tuning or adaptation in the training procedures.
- Testing subset, which will provide assessment on the actual system performance, and on which the selected evaluation metrics will be calculated.
4. Literature Review on DAS+PRS
4.1. Feature Extraction
4.1.1. Time Domain-Based Feature Extraction Methods
4.1.2. Frequency Domain-Based Feature Extraction Methods
4.1.3. Time-Frequency Domain-Based Feature Extraction Methods
4.1.4. Other Feature Extraction Methods
4.2. Pattern Classification
4.2.1. No Pattern Classification
4.2.2. Rule-Based Methods
4.2.3. Generative Model-Based Methods
4.2.4. Discriminative Model-Based Methods
4.3. Experimental Procedure
4.3.1. 2-Class Classification
4.3.2. Multi-Class Classification
5. Discussion
6. Real Field Deployment of Systems Based on DAS+PRS
6.1. Data Acquisition and Processing in a Field Deployed System
6.2. System Evaluation in a Field Deployed System
- There may be defects in the correct labeling of the blind field test activities, which in some cases is not as precise as required to have meaningful comparisons with the PRS output results.
- There may be events for which no model exists in the system. These events will generate a classification error, which must also be considered to properly assess the real system performance.
7. Recommended Practices
- The database recordings must cover the broadest possible range of acoustic conditions, which are influenced by:
- -
- Environmental and soil conditions (that will have an impact in the characteristics of the generated signals),
- -
- Geographical conditions (in what respect to the distance to the sensing equipment, which will have an impact in the SNR of the generated signals).
This is due to the need of generating robust models that are able to properly generalize when the system faces unseen data (that can be obtained at any location along the fiber trajectory). - The database labeling must be accurate enough to provide precise time alignment between the labels and the actual activities being recorded. On the one hand, this is important to generate models that actually correspond to the desired activity (otherwise, the models will also contain information of wrong activities). On the other hand, that is also important to provide accurate labels for system evaluation (a wrong label will generate a classification error).
- The database size should be large enough to provide enough data for generating robust models and also to ensure the statistical significance of the results. It is very difficult to provide a recommendation on the actual database size, but according to the experience acquired in the PIT-STOP project [23,24], and for initial system development purposes, we may initially recommend 30 min per event, per day, with at least five recording days and locations. Also, precise information on the actual duration of the recordings must be provided.
- The training subset must be completely independent of the validation/testing subsets to ensure that the obtained results are not biased due to over-training issues. If the database size is not large enough, cross-validation techniques must be applied.
- Regarding the feature extraction module, we recommend the use of frequency domain-based features, since these have provided good results in the systems presented in the literature review, and they can actually integrate all the meaningful behavior of the analyzed signals.
- The acquired signals must be properly normalized (either at the signal or feature levels) to deal with the signal degradation due to the distance to the sensing equipment.
- Regarding the pattern classification algorithm, it is not possible to propose any of the alternatives as being superior to the others. The choice is affected by multiple factors: database size (discriminative models typically need larger datasets than generative ones), signal variability and number of classes (for more complex signals and more classes, more complex models are needed, thus demanding larger datasets), signal properties (those generated by linear processes may, in general, be handled by less complex models), etc. Therefore, the best approach would be to select different pattern classification techniques, and make a thorough evaluation of their performance.
- The evaluation metrics must be precisely described, so that there is no doubt about how these are being calculated.
- The evaluation process should provide details on the statistical significance of the results to properly assess their impact. As stated above, this also requires precise information of the experimental procedure (training/validation/testing subset partition, recording durations, etc.).
8. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- European Gas Pipline Incident Data Group (EGIG). 7th EGIG-Report on Gas Pipeline Incidents (1970–2007); Technical Report; EGIG Secretariat: Groningen, The Netherlands, 2008. [Google Scholar]
- Trust, P.S. Nationwide Data on Reported Incidents by Pipeline Type (Gas Transmission, Gas Distribution, Hazardous Liquid). 2004. Available online: http://pstrust.org/about-pipelines1/stats/accident/ (accessed on 1 July 2017).
- Juarez, J.C.; Maier, E.W.; Choi, K.N.; Taylor, H.F. Distributed Fiber-Optic Intrusion Sensor System. J. Lightwave Technol. 2005, 23, 2081–2087. [Google Scholar] [CrossRef]
- Martins, H.F.; Martín-López, S.; Corredera, P.; Filograno, M.L.; Frazão, O.; González-Herráez, M. Phase-sensitive Optical Time Domain Reflectometer Assisted by First-order Raman Amplification for Distributed Vibration Sensing Over >100 km. J. Lightwave Technol. 2014, 32, 1510–1518. [Google Scholar] [CrossRef]
- Wang, Z.; Zeng, J.; Li, J.; Fan, M.; Wu, H.; Peng, F.; Zhang, L.; Zhou, Y.; Rao, Y. Ultra-long phase-sensitive OTDR with hybrid distributed amplification. Opt. Lett. 2014, 39, 5866–5869. [Google Scholar] [CrossRef] [PubMed]
- Kirkendall, C. Distributed Acoustic and Seismic Sensing. In Proceedings of the Conference on Optical Fiber Communication and the National Fiber Optic Engineers Conference, Anaheim, CA, USA, 25–29 March 2007; pp. 1–3. [Google Scholar]
- Lumens, P. Fibre-Optic Sensing for Application in Oil and Gas Wells. Ph.D. Thesis, Eindhoven University of Technology, Eindhoven, The Netherlands, 2014. [Google Scholar]
- Guo, T.; Yuan, W.; Wu, L. Experimental research on distributed fiber sensor for sliding damage monitoring. Opt. Lasers Eng. 2009, 47, 156–160. [Google Scholar]
- Buerck, J.; Roth, S.; Kraemer, K.; Mathieu, H. OTDR fiber-optical chemical sensor system for detection and location of hydrocarbon leakage. J. Hazard. Mater. 2003, 102, 13–28. [Google Scholar] [CrossRef]
- Li, H.N.; Li, D.S.; Song, G.B. Recent applications of fiber optic sensors to health monitoring in civil engineering. Eng. Struct. 2004, 26, 1647–1657. [Google Scholar] [CrossRef]
- Hill, D. Distributed Acoustic Sensing (DAS): Theory and Applications. In Proceedings of the Frontiers in Optic 2015, San Jose, CA, USA, 18–22 October 2015; pp. 1–2. [Google Scholar]
- Lyons, W.; Ewald, H.; Lewis, E. An optical fibre distributed sensor based on pattern recognition. J. Mater. Process. Technol. 2002, 127, 23–30. [Google Scholar] [CrossRef]
- Lyons, W.; Ewald, H.; Flanagan, C.; Lewis, E. A multi-point optical fibre sensor for condition monitoring in process water systems based on pattern recognition. Measurement 2003, 34, 301–312. [Google Scholar] [CrossRef]
- Lyons, W.; Flanagan, C.; Lewis, E.; Ewald, H.; Lochmann, S. Interrogation of multipoint optical fibre sensor signals based on artificial neural network pattern recognition techniques. Sens. Actuators 2004, 114, 7–12. [Google Scholar] [CrossRef]
- King, D.; Lyons, W.; Flanagan, C.; Lewis, E. A multipoint optical fibre sensor system for use in process water systems based on artificial neural network pattern recognition techniques. Sens. Actuators 2004, 115, 293–302. [Google Scholar] [CrossRef]
- Lewis, E.; Sheridan, C.; O’Farrell, M.; King, D.; Flanagan, C.; Lyons, W.; Fitzpatrick, C. Principal component analysis and artificial neural network based approach to analysing optical fibre sensors signals. Sens. Actuators 2007, 136, 28–38. [Google Scholar] [CrossRef]
- Madsen, C.; Baea, T.; Snider, T. Intruder Signature Analysis from a Phase-sensitive Distributed Fiber-optic Perimeter Sensor. Proc. SPIE 2007, 6770, 67700K-1–67700K-8. [Google Scholar]
- Zhu, H.; Pan, C.; Sun, X. Vibration Pattern Recognition and Classification in OTDR Based Distributed Optical-Fiber Vibration Sensing System. Proc. SPIE 2014, 9062, 906205-1–906205-6. [Google Scholar]
- Wu, H.; Li, X.; Peng, Z.; Rao, Y. A novel intrusion signal processing method for phase-sensitive optical time-domain reflectometry (ϕ-OTDR). Proc. SPIE 2014, 9157, 9157O-1–9157O-4. [Google Scholar]
- Qu, Z.; Feng, H.; Zeng, Z.; Zhuge, J.; Jin, S. A SVM-based pipeline leakage detection and pre-warning system. Measurement 2010, 43, 513–519. [Google Scholar] [CrossRef]
- Sun, Q.; Feng, H.; Yan, X.; Zeng, Z. Recognition of a Phase-Sensitivity OTDR Sensing System Based on Morphologic Feature Extraction. Sensors 2015, 15, 15179–15197. [Google Scholar] [CrossRef] [PubMed]
- Martins, H.; Piote, D.; Tejedor, J.; Macias, J.; Pastor, J.; Martin, S.; Corredera, P.; Smet, F.D.; Postvoll, W.; Ahlen, C.; et al. Early detection of pipeline integrity threats using a smart fiber-optic surveillance system: The PIT-STOP project. In Proceedings of the International Conference on Optical Fibre Sensors 2015, Curitiba, Brazil, 28 September–2 October 2015; pp. 96347X:1–96347X:4. [Google Scholar]
- Tejedor, J.; Martins, H.F.; Piote, D.; Macias-Guarasa, J.; Pastor-Graells, J.; Martin-Lopez, S.; Corredera, P.; Smet, F.D.; Postvoll, W.; Gonzalez-Herraez, M. Towards Prevention of Pipeline Integrity Threats using a Smart Fiber Optic Surveillance System. J. Lightwave Technol. 2016, 34, 4445–4453. [Google Scholar] [CrossRef]
- Tejedor, J.; Macias-Guarasa, J.; Martins, H.F.; Pastor-Graells, J.; Martin-Lopez, S.; Corredera, P.; Gonzalez-Herraez, M. A novel fiber optic based surveillance system for prevention of pipeline integrity threats. Sensors 2017, 17, 355. [Google Scholar] [CrossRef] [PubMed]
- Martins, H.; Piote, D.; Tejedor, J.; Macias, J.; Pastor, J.; Martin, S.; Corredera, P.; Smet, F.D.; Postvoll, W.; Ahlen, C.; et al. Towards detection of Pipeline Integrity Threats using a SmarT fiber-OPtic surveillance system: PIT-STOP project Blind Field Test results. In Proceedings of the International Conference on Optical Fibre Sensors 2015, Curitiba, Brazil, 28 September–2 October 2015; p. 103231K:4. [Google Scholar]
- Wu, H.; Wang, Z.; Peng, F.; Peng, Z.; Li, X.; Wu, Y.; Rao, Y. Field test of a fully distributed fiber optic intrusion detection system for long-distance security monitoring of national borderline. Proc. SPIE 2014, 91579, 915790-1–915790-4. [Google Scholar]
- Wu, H.; Xiao, S.; Li, X.; Wang, Z.; Xu, J.; Rao, Y. Separation and Determination of the Disturbing Signals in Phase-Sensitive Optical Time Domain Reflectometry (ϕ-OTDR). J. Lightwave Technol. 2015, 33, 3156–3162. [Google Scholar] [CrossRef]
- Choi, K.N.; Juarez, J.C.; Taylor, H.F. Distributed fiber optic pressure/seismic sensor for low-cost monitoring of long perimeters. Proc. SPIE 2003, 134–141. [Google Scholar] [CrossRef]
- Juarez, J.C.; Taylor, H.F. Field test of a distributed fiber-optic intrusion sensor system for long perimeters. Appl. Opt. 2007, 46, 1968–1971. [Google Scholar] [CrossRef] [PubMed]
- Rao, Y.J.; Luo, J.; Ran, Z.L.; Yue, J.F.; Luo, X.D.; Zhou, Z. Long-distance fiber-optic ψ-OTDR intrusion sensing system. Proc. SPIE 2009, 7503, 75031O-1–75031O-4. [Google Scholar]
- Juarez, J.C.; Taylor, H.F. Polarization discrimination in a phase-sensitive optical time-domain reflectometer intrusion-sensor system. Opt. Lett. 2005, 30, 3284–3286. [Google Scholar] [CrossRef] [PubMed]
- Chao, P.; Hui, Z.; Bin, Y.; Zhu, Z.; Xiahoan, S. Distributed optical-fiber vibration sensing system based on differential detection of differential coherent-OTDR. In Proceedings of the IEEE Sensors 2012, Taipei, Taiwan, 28–31 October 2012; pp. 1–3. [Google Scholar]
- Quin, Z.G.; Chen, L.; Bao, X.Y. Wavelet denoising method for improving detection performance of distributed vibration sensor. IEEE Photonics Technol. Lett. 2012, 24, 542–544. [Google Scholar] [CrossRef]
- Wang, Z.N.; Li, J.; Fan, M.Q.; Zhang, L.; Peng, F.; Wu, H.; Zeng, J.J.; Zhou, Y.; Rao, Y.J. Phase-sensitive optical time-domain reflectometry with Brillouin amplification. Opt. Lett. 2014, 39, 4313–4316. [Google Scholar] [CrossRef] [PubMed]
- Peng, F.; Wu, H.; Jia, X.H.; Rao, Y.J.; Wang, Z.N.; Peng, Z.P. Ultra-long high-sensitivity ϕ-OTDR for high spatial resolution intrusion detection of pipelines. Opt. Express 2014, 22, 13804–13810. [Google Scholar] [CrossRef] [PubMed]
- Li, J.; Wang, Z.; Zhang, L.; Peng, F.; Xiao, S.; Wu, H.; Rao, Y. 124km Phase-sensitive OTDR with Brillouin Amplification. Proc. SPIE 2014, 9157, 91575Z-1–91575Z-4. [Google Scholar]
- Wang, Z.; Zeng, J.; Li, J.; Peng, F.; Zhang, L.; Zhou, Y.; Wu, H.; Rao, Y. 175km Phase-sensitive OTDR with Hybrid Distributed Amplification. Proc. SPIE 2014, 9157, 9157D5-1–9157D5-4. [Google Scholar]
- Pan, Z.; Wang, Z.; Ye, Q.; Cai, H.; Qu, R.; Fang, Z. High sampling rate multi-pulse phase-sensitive OTDR employing frequency division multiplexing. Proc. SPIE 2014, 9157, 91576X-1–91576X-4. [Google Scholar]
- Shi, Y.; Feng, H.; Zeng, Z. A Long Distance Phase-Sensitive Optical Time Domain Reflectometer with Simple Structure and High Locating Accuracy. Sensors 2015, 15, 21957–21970. [Google Scholar] [CrossRef] [PubMed]
- Martins, H.F.; Martin-Lopez, S.; Corredera, P.; Ania-Castañon, J.D.; Frazão, O.; Gonzalez-Herraez, M. Distributed vibration sensing over 125 km with enhanced SNR using ϕ-OTDR over a URFL cavity. J. Lightwave Technol. 2015, 33, 2628–2632. [Google Scholar] [CrossRef]
- Quin, Z.G.; Chen, L.; Bao, X.Y. Continuous wavelet transform for nonstationary vibration detection with phase-OTDR. Opt. Express 2012, 20, 20459–20465. [Google Scholar] [CrossRef] [PubMed]
- Zhu, T.; Xiao, X.; He, Q.; Diao, D. Enhancement of SNR and Spatial Resolution in ψ-OTDR System by Using Two-Dimensional Edge Detection Method. J. Lightwave Technol. 2013, 31, 2851–2856. [Google Scholar] [CrossRef]
- Conway, C.; Mondanos, M. An introduction to fibre optic Intelligent Distributed Acoustic Sensing (iDAS) technology for power industry applications. In Proceedings of the International Conference on Insulated Power Cables 2015, Paris, France, 21–25 June 2015; Volume A3.4, pp. 1–6. [Google Scholar]
- Martins, H.F.; Martín-López, S.; Corredera, P.; Filograno, M.L.; Frazão, O.; González-Herráez, M. Coherent noise reduction in high visibility phase sensitive optical time domain reflectometer for distributed sensing of ultrasonic waves. J. Lightwave Technol. 2013, 31, 3631–3637. [Google Scholar] [CrossRef]
- Papp, A.; Wiesmeyr, C.; Litzenberger, M.; Garn, H.; Kropatsch, W. A real-time algorithm for train position monitoring using optical time-domain reflectometry. In Proceedings of the IEEE International Conference on Intelligent Rail Transportation 2016, Birmingham, UK, 23–25 August 2016; pp. 1–5. [Google Scholar]
- Cao, C.; Fan, X.Y.; Liu, Q.W.; He, Z.Y. Practical Pattern Recognition System for Distributed Optical Fiber Intrusion Monitoring System Based on Phase-Sensitive Coherent OTDR. In Proceedings of the Asia Communications and Photonics Conference 2015, Hong Kong, 19–23 November 2015; p. ASu2A.145. [Google Scholar]
- Kim, Y.; Jeong, S.; Kim, D. A GMM-based Target Classification Scheme for a Node in Wireless Sensor Networks. IEICE Trans. Commun. 2008, E91-B, 3544–3551. [Google Scholar] [CrossRef]
- Kandpa, M.; Kakar, V.K.; Verma, G. Classification of Ground Vehicles Using Acoustic Signal Processing and Neural Network Classifier. In Proceedings of the International Conference on Signal Processing and Communication 2013, Noida, India, 12–14 December 2013; pp. 512–518. [Google Scholar]
- Li, J.; Zhang, C.; Li, Z. Battlefield Target Identification Based on Improved Grid-search SVM Classifier. In Proceedings of the International Conference on Computational Intelligence and Software Engineering 2009, Wuhan, China, 11–13 December 2009; pp. 1–4. [Google Scholar]
- Qi, X.; Ji, J.; Han, X.; Yuan, Z. An Approach of Passive Vehicle Type Recognition by Acoustic Signal Based on SVM. In Proceedings of the International Conference on Genetic and Evolutionary Computing 2009, Guilin, China, 14–17 October 2009; pp. 545–548. [Google Scholar]
- Shen, X.; Wan, S.C.; Huo, H.; Fang, T. An Improvement on Discrete Wavelet Transform-based Algorithm for Vehicle Classification in Wireless Sensor Networks. In Proceedings of the IEEE Conference on Industrial Electronics and Applications 2006, Singapore, 24–26 May 2006; pp. 1–4. [Google Scholar]
- Huang, J.; Zhou, Q.; Zhang, X.; Song, E.; Li, B.; Yuan, X. Seismic Target Classification Using a Wavelet Packet Manifold in Unattended Ground Sensors Systems. Sensors 2013, 13, 8534–8550. [Google Scholar] [CrossRef] [PubMed]
- Wang, X.; Qi, H.; Iyengar, S.S. Collaborative multi-modality target classification in distributed sensor networks. In Proceedings of the International Conference on Information Fusion 2002, Annapolis, MD, USA, 8–11 July 2002; pp. 285–290. [Google Scholar]
- Zhang, X.; Yang, X.; Song, E.; Li, B.; Yuan, X. A Distance Segmented Classification Algorithm for Ground Moving Targets Based on Seismic-acoustic Sensor Arrays and Parallel Fuzzy Classifier. J. Comput. Inf. Syst. 2012, 8, 2789–2798. [Google Scholar]
- Meesookho, C.; Narayanan, S.; Raghavendra, C. Collaborative classification applications in sensor networks. In Proceedings of the Sensor Array and Multichannel Signal Processing Workshop 2002, Rosslyn, VA, USA, 6–6 August 2002; pp. 370–374. [Google Scholar]
- Necioglu, B.F.; Christou, C.T.; George, E.B.; Jacyna, G.M. Vehicle Acoustic Classification in Netted Sensor Systems Using Gaussian Mixture Models; Technical Report; The MITRE Corporation: McLean, VA, USA, 2005. [Google Scholar]
- Li, D.; Wong, K.D.; Hu, Y.H.; Sayeed, A.M. Detection, Classification and Tracking of Targets in Distributed Sensor Networks. IEEE Signal Process. Mag. 2002, 19, 17–29. [Google Scholar]
- Xing, H.; Li, F.; Xiao, H.; Wang, Y.; Liu, Y. Ground Target Detection, Classification and Sensor Fusion in Distributed Fiber Seismic Sensor Network. Proc. SPIE 2007, 1–10. [Google Scholar] [CrossRef]
- Ji, J.; Qi, X.; Han, X.; Yuan, Z. An Approach of Automatic Vehicle Classification by Acoustic Wave based on PCA-RBF. In Proceedings of the International Conference on Information Engineering and Computer Science 2009, Wuhan, China, 19–20 December 2009; pp. 1–4. [Google Scholar]
- Brooks, R.R.; Ramanathan, P.; Sayeed, A.M. Distributed Target Classification and Tracking in Sensor Networks. Proc. IEEE 2003, 91, 1163–1171. [Google Scholar] [CrossRef]
- Jobin, G.; Leena, M.; Riyas, K.S. Vehicle Detection and Classification from Acoustic Signal Using ANN and KNN. In Proceedings of the International Conference on Control Communication and Computing 2013, Thiruvananthapuram, India, 13–15 December 2013; pp. 436–439. [Google Scholar]
- Samanta, B.; Al-Balushi, K.R. Artificial neural network based fault diagnostics of rolling element bearings using time-domain features. Mech. Syst. Signal Process. 2003, 17, 317–328. [Google Scholar] [CrossRef]
- Kreucher, C.; Lakshman, S. LANA: A Lane Extraction Algorithm that Uses Frequency Domain Features. IEEE Trans. Robot. Autom. 1999, 15, 343–350. [Google Scholar] [CrossRef]
- Hlawatsch, F.; Boudreaux-Bartels, G.F. Linear and quadratic time-frequency signal representations. IEEE Signal Process. Mag. 1992, 9, 21–67. [Google Scholar] [CrossRef]
- Murphy, K.P. Machine Learning: A Probabilistic Perspective; The MIT Press: Cambridge, MA, USA, 2012. [Google Scholar]
- Bishop, C.M.; Lasserre, J. Generative or Discriminative? Getting the Best of Both Worlds; Bayesian Statistics; Oxford University Press: Oxford, UK, 2007; pp. 3–24. [Google Scholar]
- Ng, A.Y.; Jordan, M.I. On Discriminative vs. Generative Classifiers: A comparison of logistic regression and naive Bayes. In Proceedings of the Advances in Neural Information Processing Systems (NIPS) 2001, Vancouver, BC, Canada, 3–8 December 2001; pp. 841–848. [Google Scholar]
- Babic, B.; Nesic, N.; Miljkovic, Z. A review of automated feature recognition with rule-based pattern recognition. Comput. Ind. 2008, 59, 321–337. [Google Scholar] [CrossRef]
- Kohavi, R. A Study of Cross-validation and Bootstrap for Accuracy Estimation and Model Selection. In Proceedings of the International Joint Conference on Artificial Intelligence 1995, Montreal, QC, Canada, 20–25 August 1995; Volume 2, pp. 1137–1143. [Google Scholar]
- Zhu, Q.; Chen, B.; Morgan, N.; Stolcke, A. On using MLP features in LVCSR. In Proceedings of the Interspeech 2004, Jeju Island, Korea, 4–8 September 2004; pp. 921–924. [Google Scholar]
- FOCUS, S.L. Fiber Network Distributed Acoustic Sensor (FINDAS) Datasheet. 2015. Available online: http://www.focustech.eu/docs/FINDAS-MR-datasheet.pdf (accessed on 1 July 2017).
- Pastor-Graells, J.; Martins, H.F.; Garcia-Ruiz, A.; Martin-Lopez, S.; Gonzalez-Herraez, M. Single-shot distributed temperature and strain tracking using direct detection phase-sensitive OTDR with chirped pulses. Opt. Express 2016, 24, 13121–13133. [Google Scholar] [CrossRef] [PubMed]
- Wang, Z.; Zhang, L.; Wang, S.; Xue, N.; Peng, F.; Fan, M.; Sun, W.; Qian, X.; Rao, J.; Rao, Y. Coherent ϕ-OTDR based on I/Q demodulation and homodyne detection. Opt. Express 2016, 24, 853–858. [Google Scholar] [CrossRef] [PubMed]
- Martins, H.F.; Shi, K.; Thomsen, B.C.; Martin-Lopez, S.; Gonzalez-Herraez, M.; Savory, S.J. Real time dynamic strain monitoring of optical links using the backreflection of live PSK data. Opt. Express 2016, 24, 22303–22318. [Google Scholar] [CrossRef] [PubMed]
- Stodden, V.; Leisch, F.; Peng, R.D. Implementing Reproducible Research; CRC Press: Taylor & Francis Group, Boca Raton, FL, USA, 2014. [Google Scholar]


{kind=link}
| Sensing System | Feature Extraction | Pattern Classification | Classification Task | Accuracy |
|---|---|---|---|---|
| Acoustic and Seismic [47] | MFCC | GMM | Heavy wheeled truck, tracked vehicle, and noise | 94% |
| Microphone [48] | Energy | NN | Car, truck, and bike | 67% |
| Acoustic [49] | Wavelet | k-NN, SVM, NN | Helicopter, vehicle, fighter, UAV, tank, and cruise missile | 90% |
| Acoustic [50] | PSD+PCA | SVM | Truck, tractor, and car | 89% |
| Acoustic [51] | Wavelet | NN | Two types of vehicles | 90% |
| Seismic [52] | Wavelet | k-NN | Pedestrian, tracked vehicle, wheeled vehicle, and helicopter | 95% |
| Acoustic and Seismic [53] | PSD, wavelet+PCA | k-NN | Three types of military vehicles | 85% |
| Acoustic and Seismic [54] | Wavelet+LDB | Fuzzy logic | Person, wheeled vehicle, and tracked vehicle | 95% |
| Acoustic and Seismic [55] | Energy | k-NN, ML | Three types of military vehicles | 90% |
| Acoustic [56] | Energy | GMM | Light and heavy vehicles | 93% |
| Acoustic and Seismic [57] | PSD | k-NN, SVM, GMM | Wheeled and tracked vehicles | 95% |
| Quasi-Distributed Fiber Seismic [58] | PSD, Wavelet | SVM, NN, GMM | Wheeled and tracked vehicles | 90% |
| Acoustic [59] | PSD+PCA | NN | Truck, tractor, and car | 93% |
| Acoustic [60] | FFT-based | GMM | Wheeled and tracked vehicles | 84% |
| Microphone [61] | MFCC | NN, k-NN | Light, medium, and heavy cars | 73% |
| LOC1 | LOC2 | LOC3 | LOC4 | LOC5 | LOC6 | |
|---|---|---|---|---|---|---|
| Distance from sensor (km) | 22.24 | 22.49 | 23.75 | 27.43 | 27.53 | 34.27 |
| Soil condition | Grass & clay | Grass | Concrete, grass & clay | Wet clay | Clay | Grass in forest |
| Location type | Agricultural field | Next to public street. Private house nearby | Agricultural field | Forest. Country road nearby | ||
| Expected normal activity | Agricultural | Road traffic | Agricultural | Agricultural. Country road traffic | ||
| Weather condition | Sunny/cloudy | Sunny | Rainy | Cloudy | Sunny | |
| Machine | Activity | Duration (in Seconds) | Threat Non-Threat | ||||||
|---|---|---|---|---|---|---|---|---|---|
| LOC1 | LOC2 | LOC3 | LOC4 | LOC5 | LOC6 | Total | |||
| Big excavator | Moving along the ground | 1100 | 1100 | 3540 | 1740 | 1620 | 4160 | 13,260 | Non-threat |
| Hitting the ground | 120 | 140 | 240 | 220 | 80 | 260 | 1060 | Threat | |
| Scrapping the ground | 460 | 460 | 920 | 620 | 200 | 580 | 3240 | Threat | |
| Small excavator | Moving along the ground | 600 | 500 | 1700 | 820 | 820 | 1660 | 6100 | Non-threat |
| Hitting the ground | 200 | 180 | 220 | 220 | 80 | 240 | 1140 | Threat | |
| Scrapping the ground | 420 | 340 | 780 | 360 | 180 | 520 | 2600 | Threat | |
| Pneumatic hammer | Compacting ground | 660 | 0 | 580 | 1320 | 0 | 1320 | 3880 | Non-threat |
| Plate compactor | 740 | 0 | 740 | 1240 | 0 | 1680 | 4400 | ||
| Machine+Activity Identification | Threat Detection | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Big Excavator | Small Excavator | Pneumatic Hammer | Plate Compactor | Acc. | TDR | FAR | Acc. | |||||
| Window Size | Mov. | Hit. | Scrap. | Mov. | Hit. | Scrap. | Compact. | Compact. | ||||
| Baseline [23] | ||||||||||||
| Short | ||||||||||||
| Medium | ||||||||||||
| Long | ||||||||||||
| Recognized Class | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Big Excavator | Small Excavator | Pneumatic Hammer | Plate Compactor | |||||||||
| Moving | Hitting | Scrapping | Moving | Hitting | Scrapping | Compacting | Compacting | |||||
| Real class | Big excavator | Moving | 66.09 |  | ||||||||
| Hitting | 30.60 | 22.15 | 19.21 | |||||||||
| Scrapping | 24.64 | 33.74 | 18.39 | |||||||||
| Small excavator | Moving | 57.91 | 16.92 | |||||||||
| Hitting | 17.03 | 14.01 | 14.32 | 29.55 | ||||||||
| Scrapping | 15.55 | 12.62 | 36.57 | |||||||||
| Pneu. hamm. | Compacting | 78.38 | ||||||||||
| Plate compact. | Compacting | 14.24 | 16.29 | 41.28 | ||||||||
| Big Excavator | Small Excavator | Pneumatic Hammer | Plate Compactor | Averages | |||||
|---|---|---|---|---|---|---|---|---|---|
| Moving | Hitting | Scrapping | Moving | Hitting | Scrapping | Compacting | Compacting | ||
| Baseline | |||||||||
| Novel Proposal | |||||||||
| Relative improvement | 34.74% | 10.14% | 29.62% | 12.89% | 3.92% | 21.01% | 9.10% | 4.48% | 21.30% |
| Reference | Feature Extraction Category | Feature Extraction Method |
|---|---|---|
| [3] | Frequency domain | Signal Phase |
| [28] | ||
| [29] | ||
| [31] | ||
| [24] | Tandem features (MLP from Energy in Frequency Bands) + normalization | |
| [17] | STFFT | |
| [18] | Time domain | LCR |
| [26] | Time-Frequency domain | DWT (low + high freq. decomposition) |
| [19] | Frequency domain | Singular Spectrum Analysis |
| [21] | Other | Morphology from image processing |
| [46] | Frequency domain | Energy related from FFT |
| [27] | Time-Frequency domain | DWT (low + high freq. decomposition) |
| [23] | Frequency domain | Energy in Frequency Bands + normalization |
| [12] | Time domain | Raw signal |
| [13] | ||
| [14] | Normalized Raw Signal | |
| [15] | Frequency domain | FFT + PSD |
| [16] | ||
| [22] | Energy in Frequency Bands | |
| [25] | Energy in Frequency Bands + normalization | |
| [45] | Energy based from FFT + PCA | |
| [20] | Time-Frequency domain | Energy in Frequency Bands from DWT |
| Reference | Pattern Classification Category | Pattern Classification Method |
|---|---|---|
| [3] | Rule-based | Threshold |
| [28] | ||
| [29] | ||
| [31] | ||
| [24] | Generative model-based | GMM + system combination |
| [17] | - | None: just visual analysis of FE |
| [18] | ||
| [26] | Rule-based | Threshold |
| [19] | Discriminative model-based | BP ANN |
| [21] | RVM | |
| [46] | SVM (RBF) | |
| [27] | BP ANN | |
| [23] | Generative model-based | GMM |
| [12] | Discriminative model-based | BP + momentum ANN |
| [13] | ||
| [14] | FF ANN | |
| [15] | ||
| [16] | ||
| [22] | Generative model-based | GMM |
| [25] | GMM + postprocessing | |
| [45] | Discriminative model-based | SVM (RBF) |
| [20] | SVM |
| Reference | Number of Classes | Fiber Optic Length | Distance to the Sensor | Acc. | TDR | FAR | |
|---|---|---|---|---|---|---|---|
| 2 | More Than 2 | ||||||
| [3] | 2 | 44 m | 0 m | 100% | - | - | |
| [28] | 2 | 5 m | 0 m | 100% | - | - | |
| [29] | 2 | 8.5 km | 3.3–8.4 km | 59% | - | - | |
| [31] | 2 | 12 km (sensed segment 44 m) | 2 km | 100% | - | - | |
| [24] | 2 | 8 | 45 km | 22–34 km | 55% | 81% | 35% |
| [17] | 3 | 12 km (sensed segment 44 m) | 50 f | - | - | - | |
| [18] | 3 | - | - | - | - | - | |
| [26] | 3 | 220 km | - | 96% | - | - | |
| [19] | 3 | 20.6 km (sensed segment 20 m) | 14.1 km | - | 94% | 6% | |
| [21] | 3 | 20 km | - | 98% | - | - | |
| [46] | 3 | 50 km | 20 km | 93% | - | - | |
| [27] | 3 | 23.7 km (sensed segment 1 km) | 13 km | 89% | 86% | 1.75% | |
| [23] | 2 | 8 | 45 km | 22–34 km | 45% | 80% | 40% |
| [12] | 2 | 200 m | 0 m | 100% | - | - | |
| [13] | 2 | 200 m | 0 m | 100% | - | - | |
| [14] | 6 | 1 km | - | 100% | - | - | |
| [15] | 9 | 1 km | - | 95% | - | - | |
| [16] | 9 | 500 m | - | 92% | - | - | |
| [22] | 2 | 45 km | 22–34 km | - | 68% | 56% | |
| [25] | 2 | 45 | 45 km | 22–34 km | 46% | 80% | 10% |
| [45] | 2 | 15 km (sensed segment 1 km) | - | 99.6% | - | - | |
| [20] | 3 | 150 m | 0 m | 97% | - | - | |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tejedor, J.; Macias-Guarasa, J.; Martins, H.F.; Pastor-Graells, J.; Corredera, P.; Martin-Lopez, S. Machine Learning Methods for Pipeline Surveillance Systems Based on Distributed Acoustic Sensing: A Review. Appl. Sci. 2017, 7, 841. https://doi.org/10.3390/app7080841
Tejedor J, Macias-Guarasa J, Martins HF, Pastor-Graells J, Corredera P, Martin-Lopez S. Machine Learning Methods for Pipeline Surveillance Systems Based on Distributed Acoustic Sensing: A Review. Applied Sciences. 2017; 7(8):841. https://doi.org/10.3390/app7080841
Chicago/Turabian StyleTejedor, Javier, Javier Macias-Guarasa, Hugo F. Martins, Juan Pastor-Graells, Pedro Corredera, and Sonia Martin-Lopez. 2017. "Machine Learning Methods for Pipeline Surveillance Systems Based on Distributed Acoustic Sensing: A Review" Applied Sciences 7, no. 8: 841. https://doi.org/10.3390/app7080841
APA StyleTejedor, J., Macias-Guarasa, J., Martins, H. F., Pastor-Graells, J., Corredera, P., & Martin-Lopez, S. (2017). Machine Learning Methods for Pipeline Surveillance Systems Based on Distributed Acoustic Sensing: A Review. Applied Sciences, 7(8), 841. https://doi.org/10.3390/app7080841