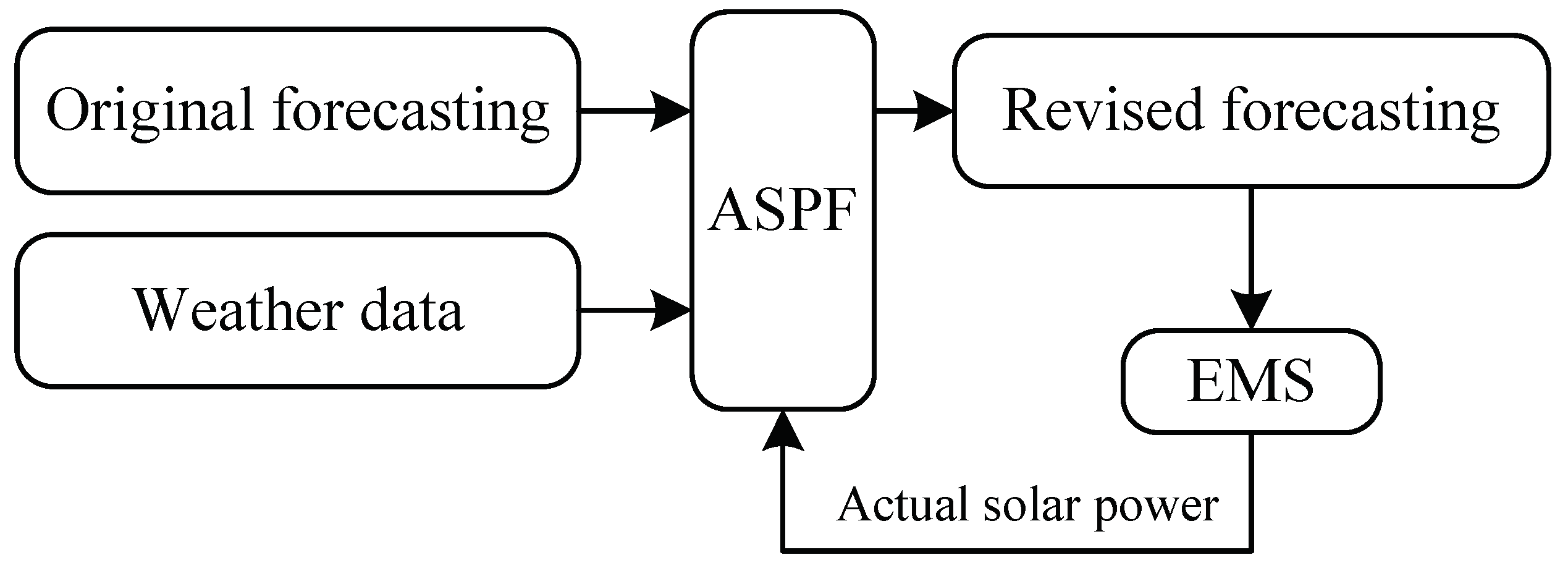
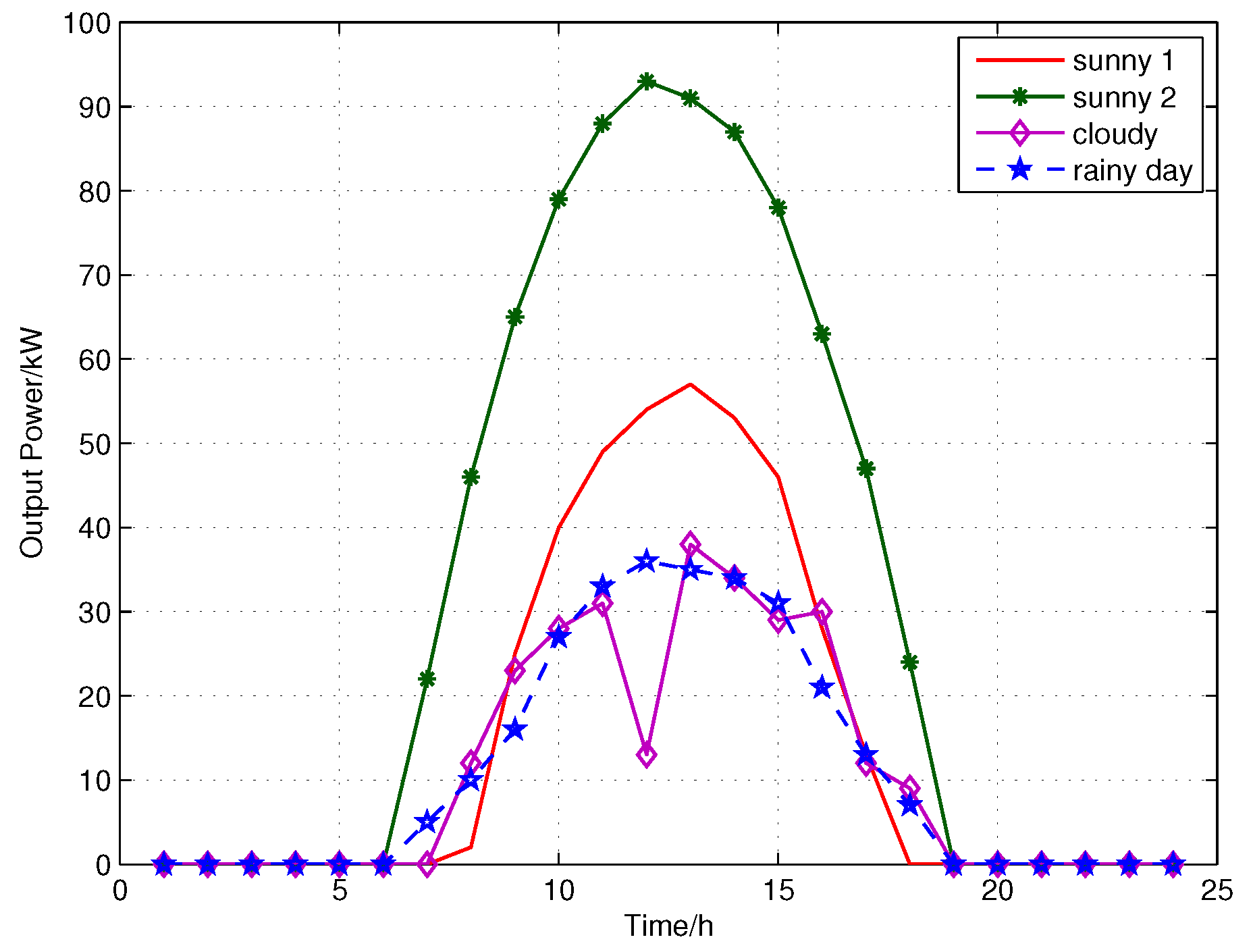
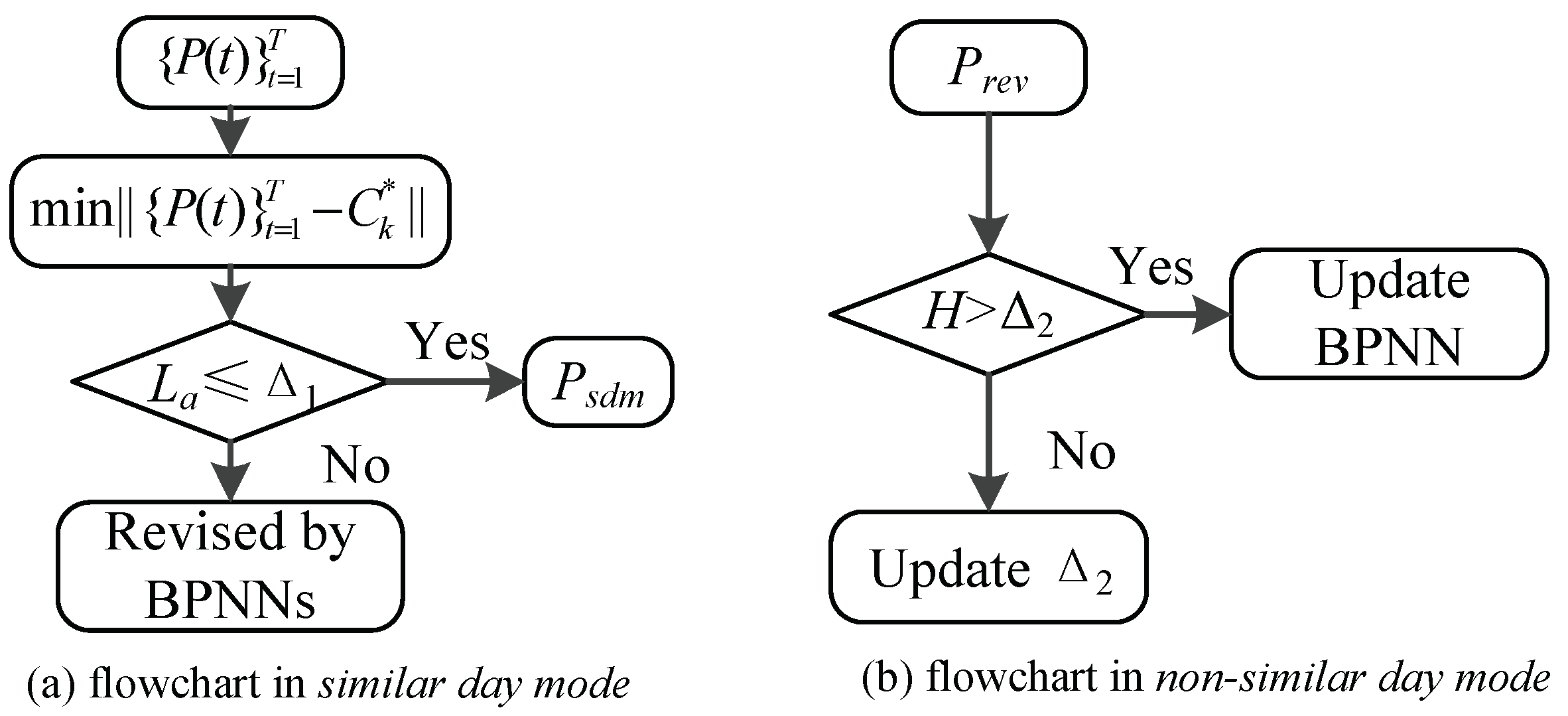
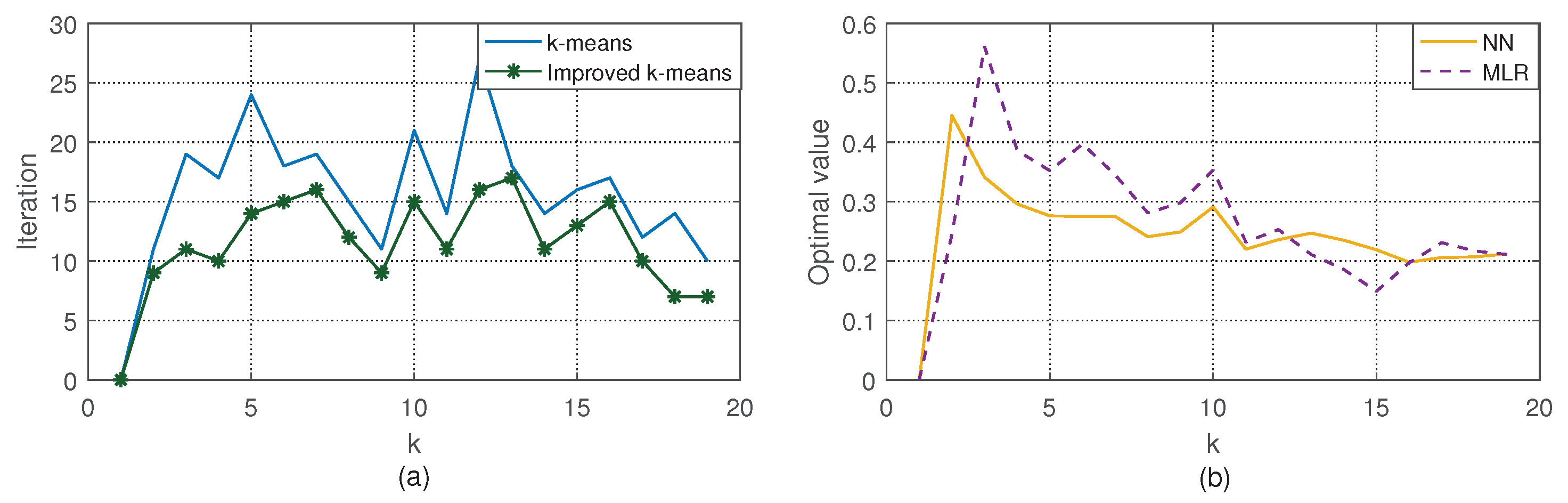
In this section, we test the performance of ASPF based on the trace obtained from a small power system in China. In order to validate the proposed algorithm, we apply it in the original forecasting PV power which is predicted by radial basis function NN and Multiple Linear Regression (MLR). The algorithms including the improved k-means, LARS, BPNN and ASPF are verified via simulations and comparisons.
5.3. Performance Evaluation of ASPF
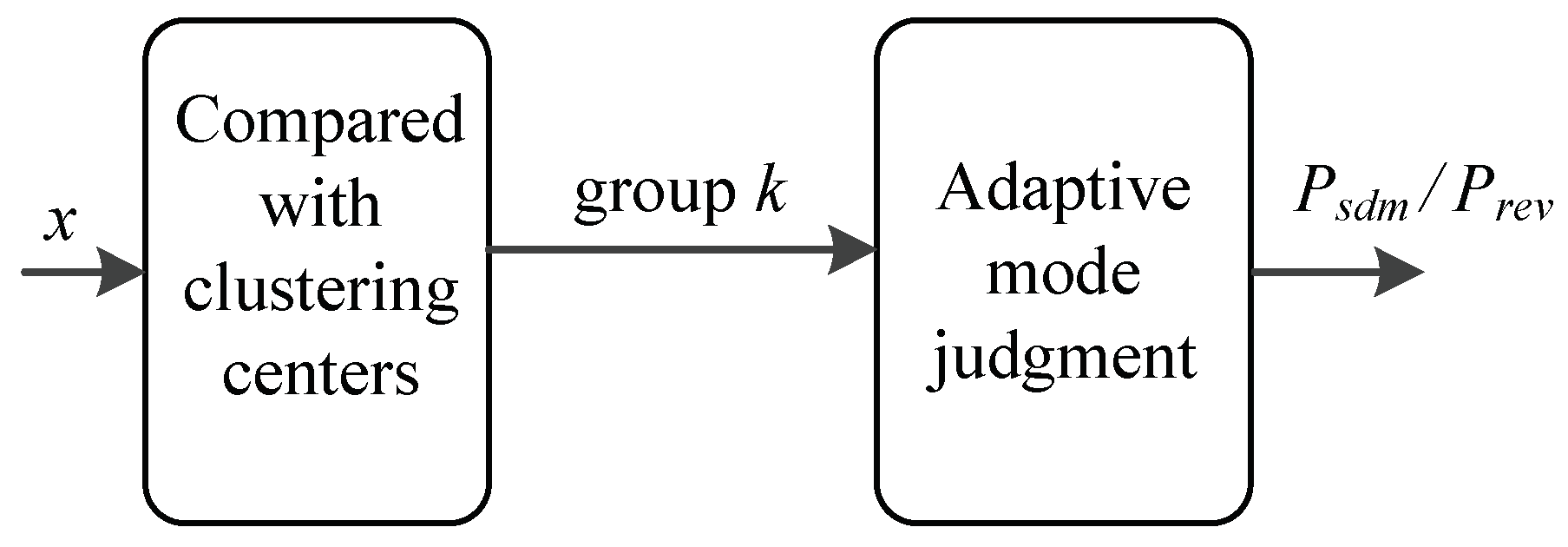
We now validate that our ASPF can adaptively revise the solar power which is predicted by NN. We randomly select 100 days of data from 1 January to 31 October 2016, and store the data as the initial database, which includes both predictive information and PV actual power. The data in the database gradually accumulates as the number of days increases in this system. Data from 1 November to 30 December 2016 are used to test the effectiveness of the ASPF. By comparing with the cluster centers and , 1 has 23 data points, and 2 has 37. Here, , .
For these 60 testing days, the ASPF results are in
Table 6.
NL is the number of days whose MxAE is smaller than
, and
NB denotes the number of days whose MxAE is larger than
. Through
Table 6, it can be observed that there are 8 times with similar day, and 15 times with no similar day in
1. Due to the stored data in
1 is less than in
2, there are only 4 times that the historical actual value can be accepted as revised solar power. The non-similar day data are revised by our proposed BPNN, and the results are ideal as their MxAEs are less than
. Moreover, the similar day number of
group 2 is more than that in group 1 because there are more data in
2 in the database. There is also one non-similar day’s result predicted by BPNN over the
, because the weather changes are more complex in non-sunny circumstances which lead to larger errors. However, the overall performance of our proposed methods is very stable and reliable.
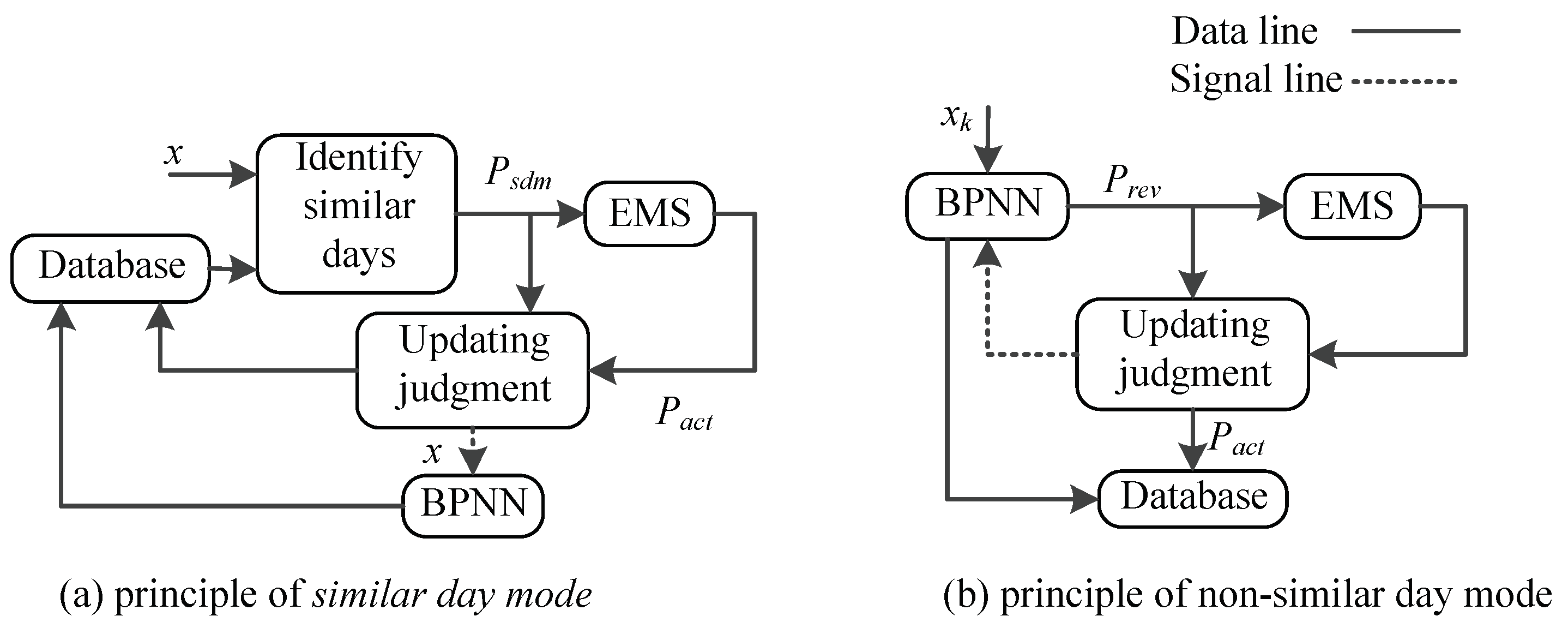
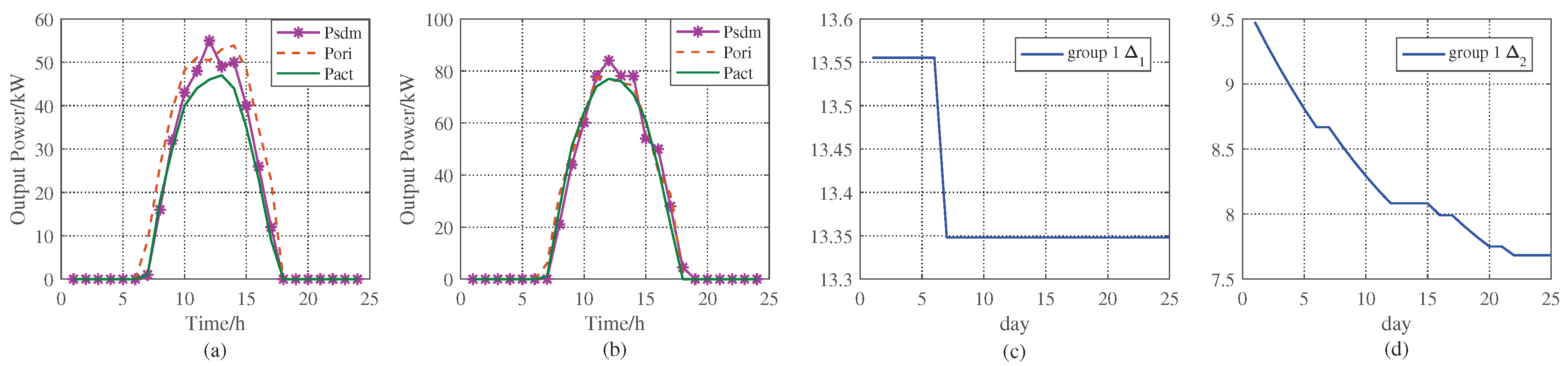
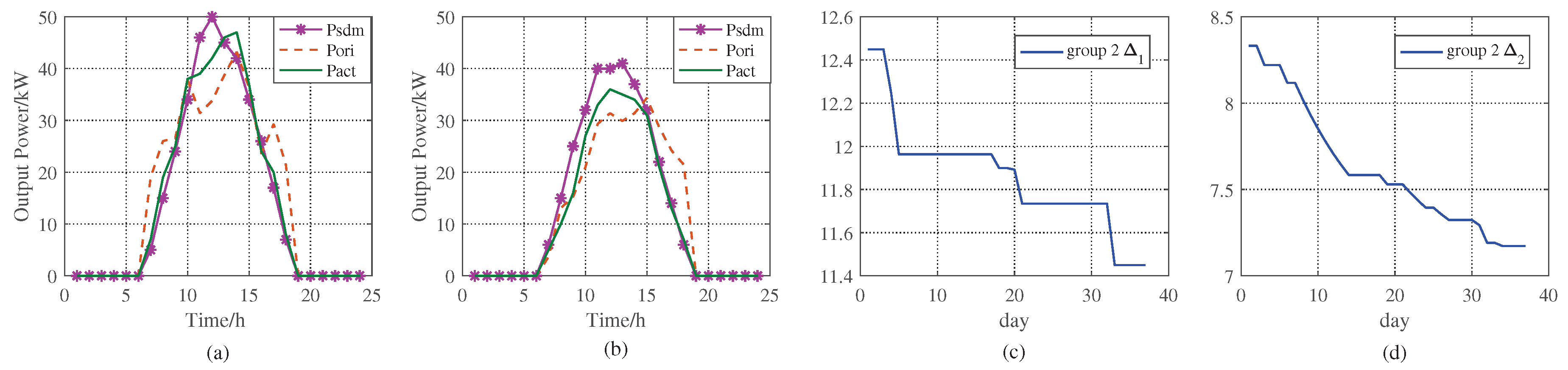
The comparisons between the proposed method and the historical data are shown in
Figure 9 and
Figure 10. Here,
denotes the corresponding historical actual solar power if similar days exist.
is the predicted solar power by original method.
represents the actual solar power of the day.
Figure 9a shows the result when there is a similar day in
1 and when
,
is used as the revised PV power. In addition, at the night of the day, we can know the actual solar power
by EMS, the MxAE between the
and
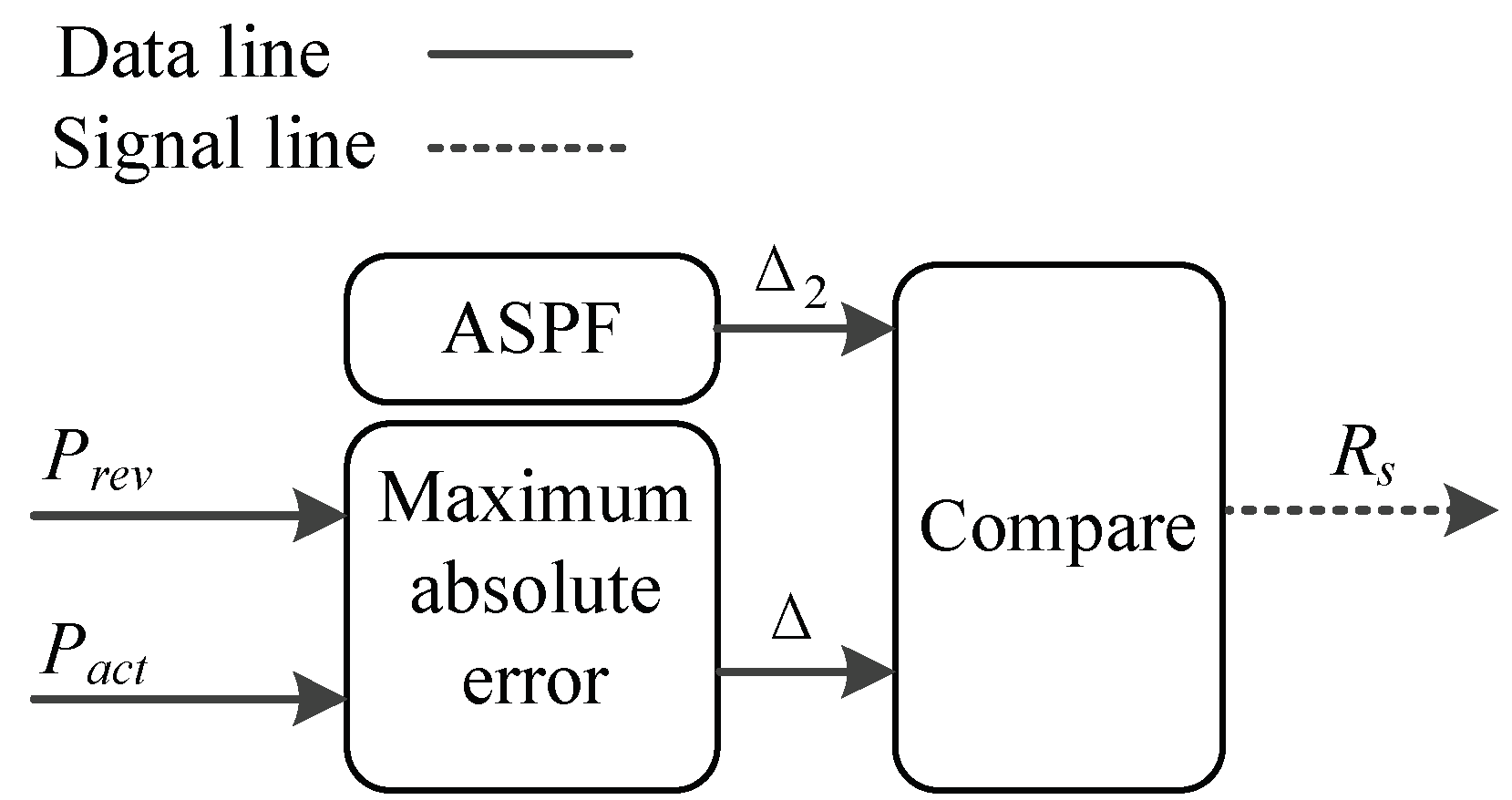
will be gotten, here MxAE is 9.112, less than initial
, which is 9.476. In
Figure 9b, there are 3 similar days, and the actual MxAE between
and
is 8.351, larger than the current
. In
Figure 9d, the data of the 13rd day are used to retrain the BP neural network. When
, there is no similar day, so BPNN is used to get the day-ahead revised solar power as shown in
Table 7. And the MxAEs in these days are less than 9.476, so
gradually reduces.
does not update when BPNN is not working as shown in
Figure 9d for the 6th and the 7th day.
Figure 9c illustrates the
in EMS, and if there is no similar day or the number of similar days is 1,
is constant. When the number of similar days is larger than 1, it means several similar days are in the database, and
should be lowered in order to find possible similar days as the data increases. In this way, the efficiency of ASPF keeps improving. Please note that, we plot the results for sunny day in
Figure 9 and
Figure 10, however, our simulation results are not only effective for sunny days, but also for PV power revision in other weather types, such as cloudy, rainy day. It can be seen in
Table 7 and
Table 8, because the data in
1 or
2 can be any weather types.
The results from
2 are shown in
Figure 10. The number of similar days increase, the change in
and
are even more apparent than
1. This change depends on the number of operation days.
Table 7 and
Table 8 record the detailed steps in
1 and
2. Here, SI is an indicator of the existence of similar days: 1 indicates similar days exist, while 0 means no similar day. TS represents the number of similar days when SI
. WD is the MxAE in
, and
is less than
. In contrast, BD indicates that the MxAE is greater than
. NS is the opposite of SI, and NS = 1 means no similar day.
and
are used to record the states of our revised prediction performance after updating.
In
Table 7, BD is 1 in the 13th day, which means the similar day’s actual value has a large deviation from the 13th day’s actual solar power. In addition, then, ASPF retrains the network using the 13th day’s data at the end of the 13th day. When there is similar day close to the 13th day at the 18th day, the 13th day’s actual solar power is adopted as day-ahead revised power and the MxAE is less than
. The same situation also happens in
2, as shown in
Table 8. In
2, at the 3rd day, there is no similar day, solar power is revised by BPNN and then stored in database as shown in
Table 8. In addition, the 25th day is similar to the 3rd day’s information, so the 3rd day’s actual solar power is used as the 25th day’s revised power, and the result is acceptable as shown in
Figure 10d. This reveals that as the number of data increases, the results of adopting similar day’s actual power become more accurate, and the predictive input message can be identified and compensated adaptively.
Through the above simulations, it is reasonable to use the similar day’s actual value as the solar forecast power if the forecasting data satisfies the certain condition, which limits the deviation of the predicted data be less than . Also, because BPNN updates the network when MxAE exceeds , this also ensures that BPNN can effectively predict the data in different situations. In the case of 98%, BPNN can get satisfactory results in this system.
Furthermore, in order to verify the wide applicability of our proposed ASPF algorithm, we run similar simulation for the PV power predicted by MLR, and compare the result. Firstly, 150 days data from 1 January 2016 to 31 August 2016 are randomly selected as the initial database to get the MLR predictive PV power. Then, we select 120 days from 1 September, to 31 December 2016 as testing data. According to the results of
k-means, the data of the testing days is classified into three groups, which contain 43, 51, and 26 days, respectively. In addition, the ASPF simulation results are shown in
Figure 11. In
Figure 11a,
gradually decreases as the number of days increases, because the data in
1 has more accurate predictions than
2 from
Table 5. As
decreases in
Figure 11b, the network updates continuously, and the number of similar days increases so that
becomes smaller correspondingly. For
Figure 11c,e,
does not change, because in
2 and
3, the number of the similar days are less than in
1.
in
Figure 11d,f decrease gradually, and thus the accuracy of our method improves continuously. In summary, the proposed ASPF obtains high-precision prediction values in both
non-similar days and
similar day mode under different predicting methods.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
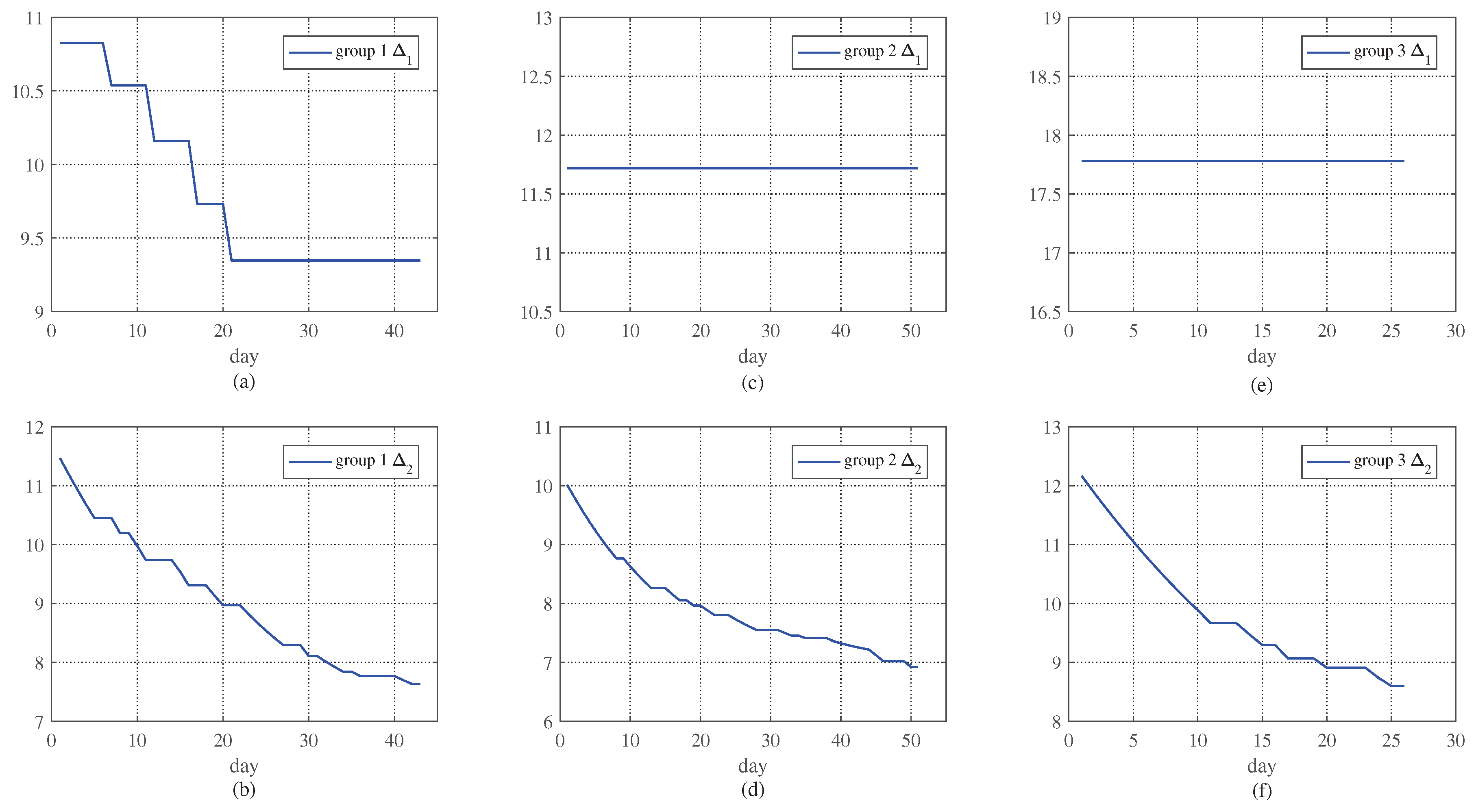{kind=link}