Characterizing Situations of Dock Overload in Bicycle Sharing Stations


 ,
, 
 ,
,
Abstract
:1. Introduction
2. Literature Review
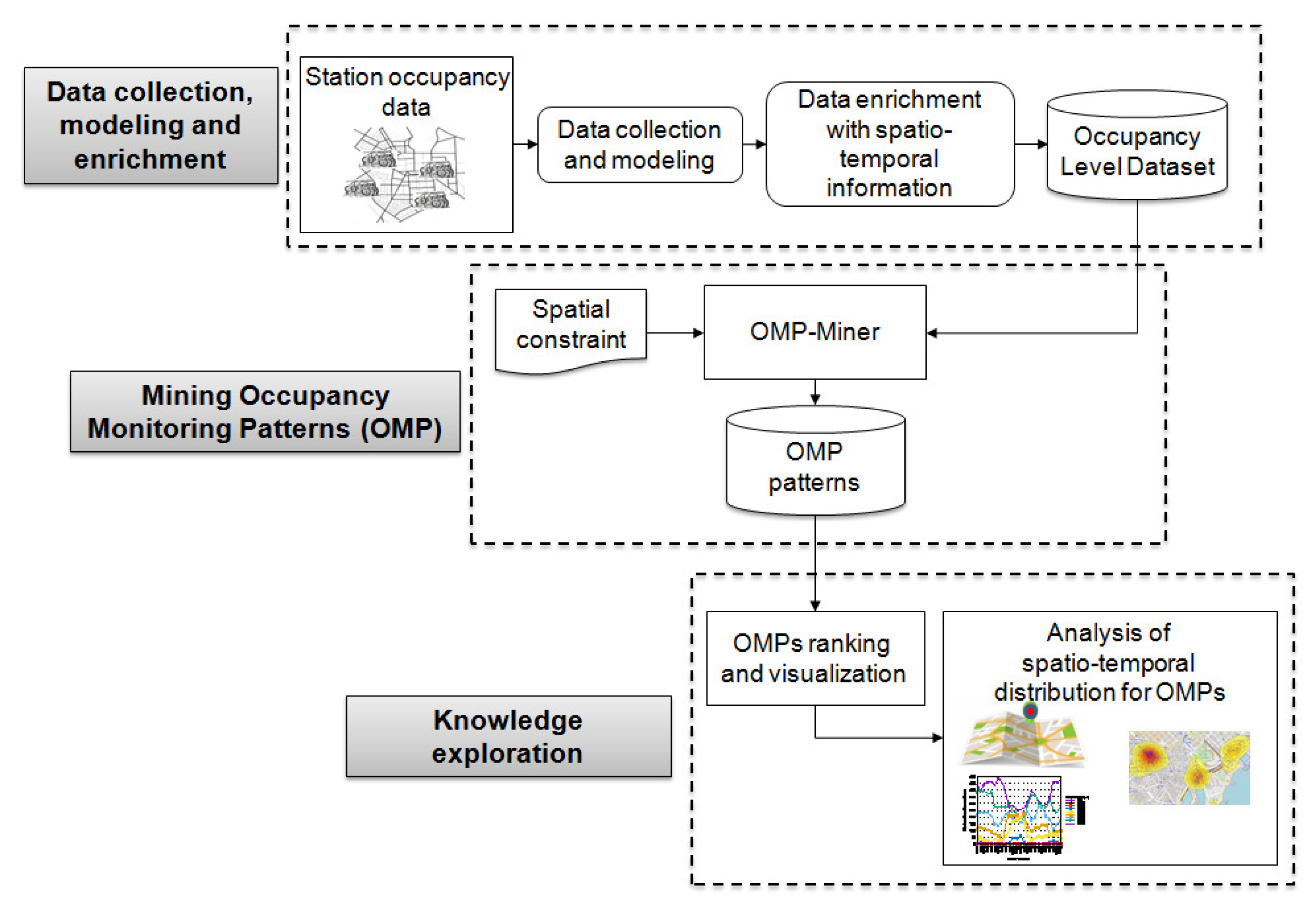
3. Methodology
3.1. Data Collection, Modeling and Enrichment
3.2. Mining Occupancy Monitoring Patterns
3.2.1. OMP Characterization
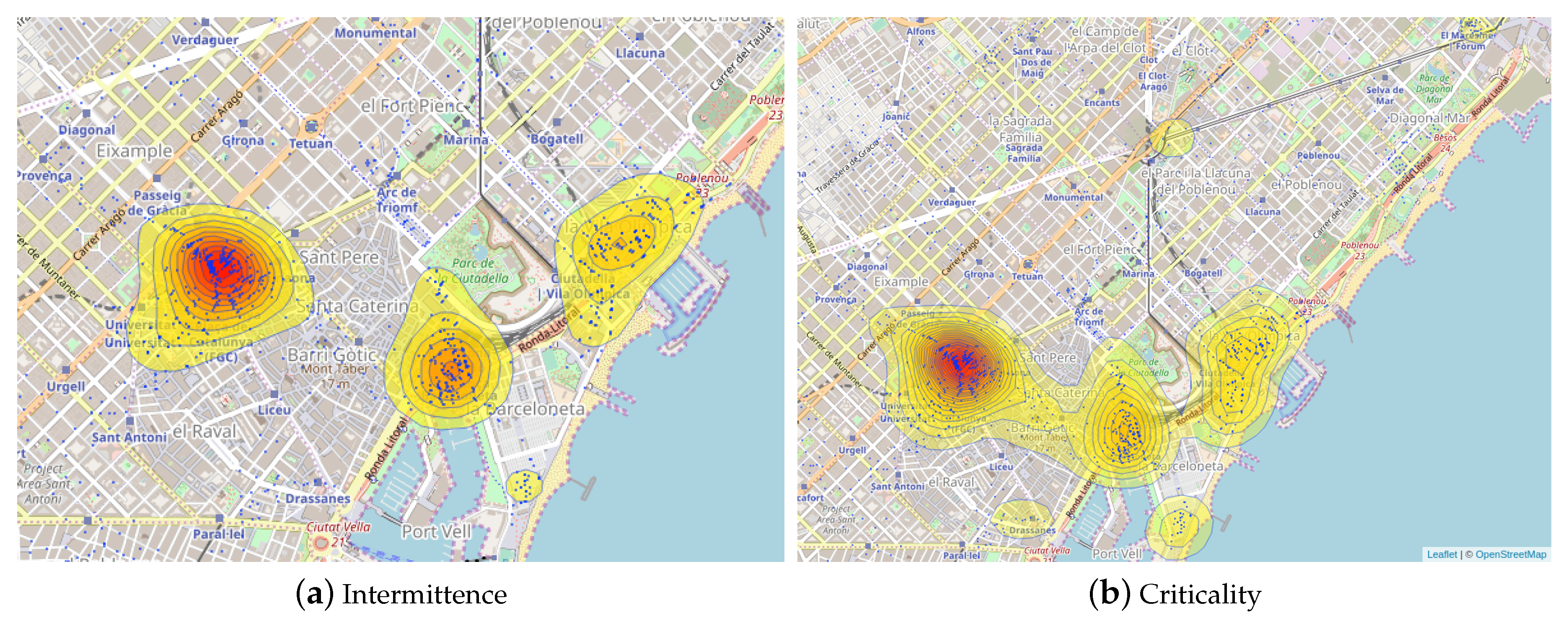
- Critical situation. The occupancy levels of a group of stations are frequently overloaded at the same time. In this case, simultaneously, all the stations in the group are fully occupied.
- Intermittent situation. The occupancy levels of a group of stations are frequently overloaded in an alternate fashion. At a given point of time, some stations are fully occupied whereas the other ones are almost empty. At another point of time, the occupancy level of the same stations could be the opposite.
3.2.2. Proposed Approach for OMP Mining
- (i)
- Pattern P contains all the stations appearing in the critical o-itemset (or equivalently in the normal o-itemset ), i.e., P = {}.
- (ii)
- According to Definition 5, the criticality of pattern P in time period is the number of times all the stations in P are overloaded in . It follows that that criticality of P in period is equal to the number of transactions in including the o-itemset . Thus,
- (iii)
- According to Definition 5, the intermittence of pattern P in a time period is the number of times at least one station in P (but not all stations at the same time) is overloaded in . It follows that the intermittence of P in period is equal to the total frequency of all o-itemsets with the same stations as P, such that at least one station (but not all them at the same time) is overloaded in . For the sake of efficiency, our approach avoids generating all these o-itemsets, but instead it proceeds as follows. Let us denote as the total number of transactions in period in the analyzed dataset. It easily follows that is equal to the sum of the following three terms: the frequency of the critical o-itemset (), the frequency of the normal o-itemset () and the total frequency of all o-itemsets with the same stations as P, such as at least one station (but not all them at the same time) is overloaded at time . Therefore, we compute the intermittence of P in period as
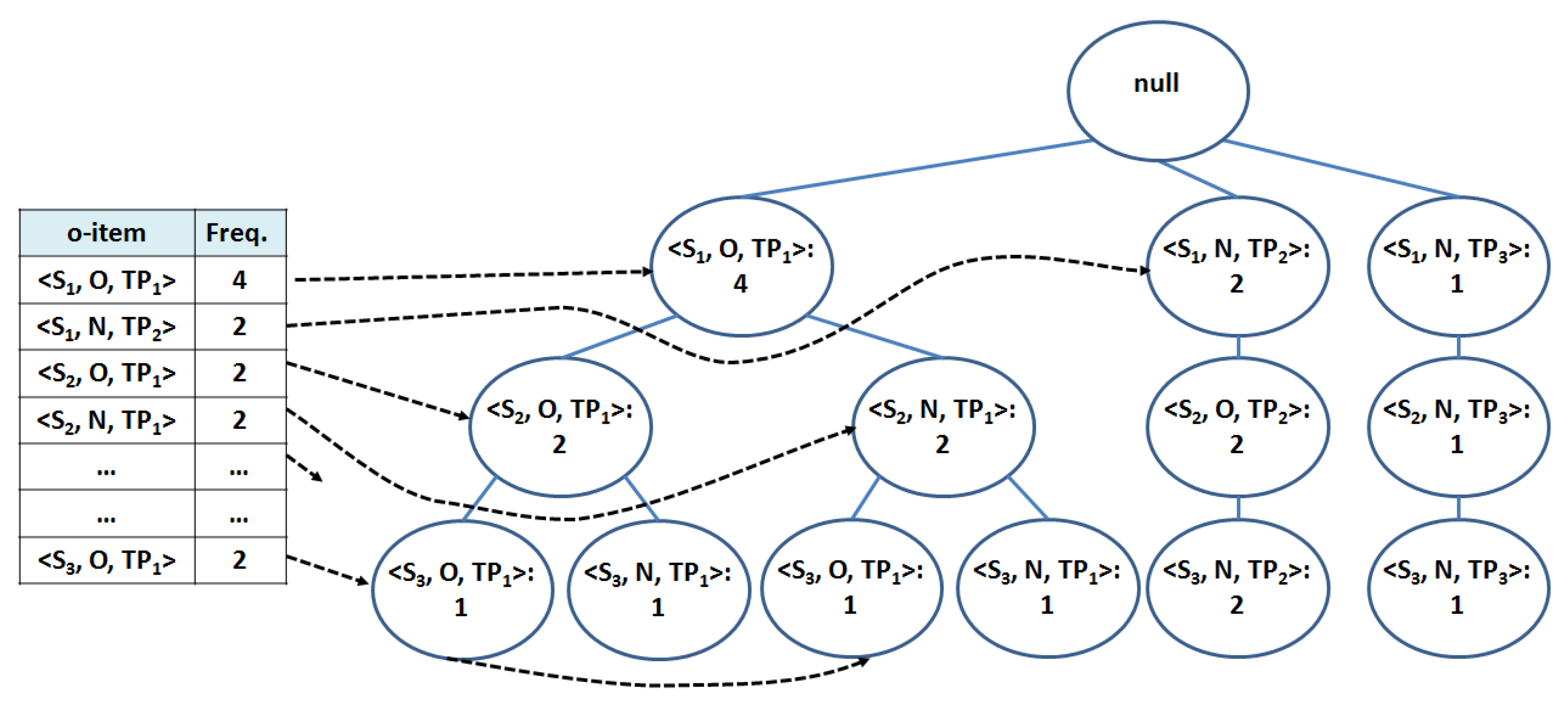
3.2.3. The OMP-Miner Algorithm
- Phase 1: Creation of a compact in-memory representation of the occupancy level transactional dataset (Algorithm 1, line 1).
- Phase 2: Mining of all the critical and normal o-itemsets including nearby stations according to the spatial constraint maxdist (Algorithm 1, line 2).
- Phase 3: Generation of the OMPs on top of the mined o-itemsets and computation of their criticality and intermittence levels (Algorithm 1, lines 3–7).
| Algorithm 1 OMP-Miner(, maxdist, ) |
| Require:: occupancy level dataset in transactional format |
| Require:maxdist: maximum distance between two stations in the same OMP |
| Require:: set of time periods , …, |
| Ensure:: the set of OMPs for each time period in |
| 1: ← FP-tree() {Create the initial FP-tree from } |
| 2: O-ITEMSETMining(, maxdist, ∅) {Recursive projection-based o-itemset mining function} {Generate OMPs on top of the mined o-itemsets in } |
| 3: : normal o-itemsets in |
| 4: : critical o-itemsets in |
| 5: : Hash map with keys storing the criticality values of each normal o-itemset ∈ for each period |
| 6: card_value[]: vector storing in the k-th element the number of transactions in associated with period |
| 7: = ComputeOMPintermittence(,card_value) |
| 8: return |
| Algorithm 2 O-ITEMSETMining(, maxdist, ) |
| Require:, an FP-tree |
| Require:maxdist: maximum distance between two stations in the same o-itemset |
| Require:, the set of o-items with respect to which FPTree has been generated |
| Ensure:, the set of o-itemsets extending |
| 1: |
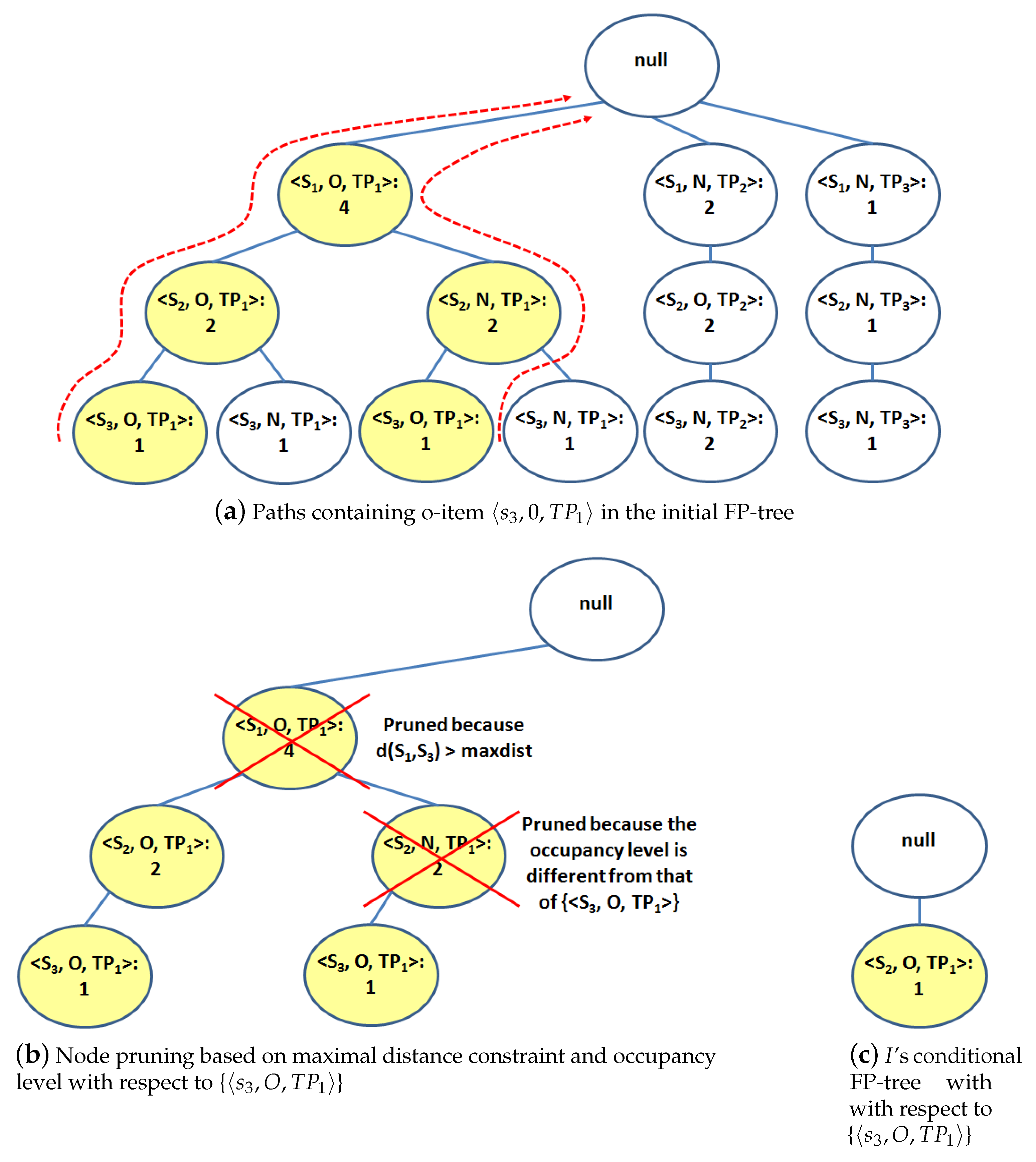
| 2: for all o-item = in the header table of do |
| 3: {Generate a new o-itemset I by joining o-itemset and o-item } |
| 4: |
| STATE selectConditionalPaths(, I) {Select I’s conditional paths} |
| 5: applyConstraints(, I) {Prune o-items = such that |
| distance(, ) > maxdist or } |
| 6: createFP-tree(, I) {Build I’s conditional FP-tree} |
| 7: if then |
| 8: O-ITEMSETMining(, maxdist, I) {Recursive mining} |
| 9: end if |
| 10: end for |
| 11: return |
Complexity Analysis
3.3. Knowledge Exploration
4. Experimental Results
4.1. Reference Use Case Datasets
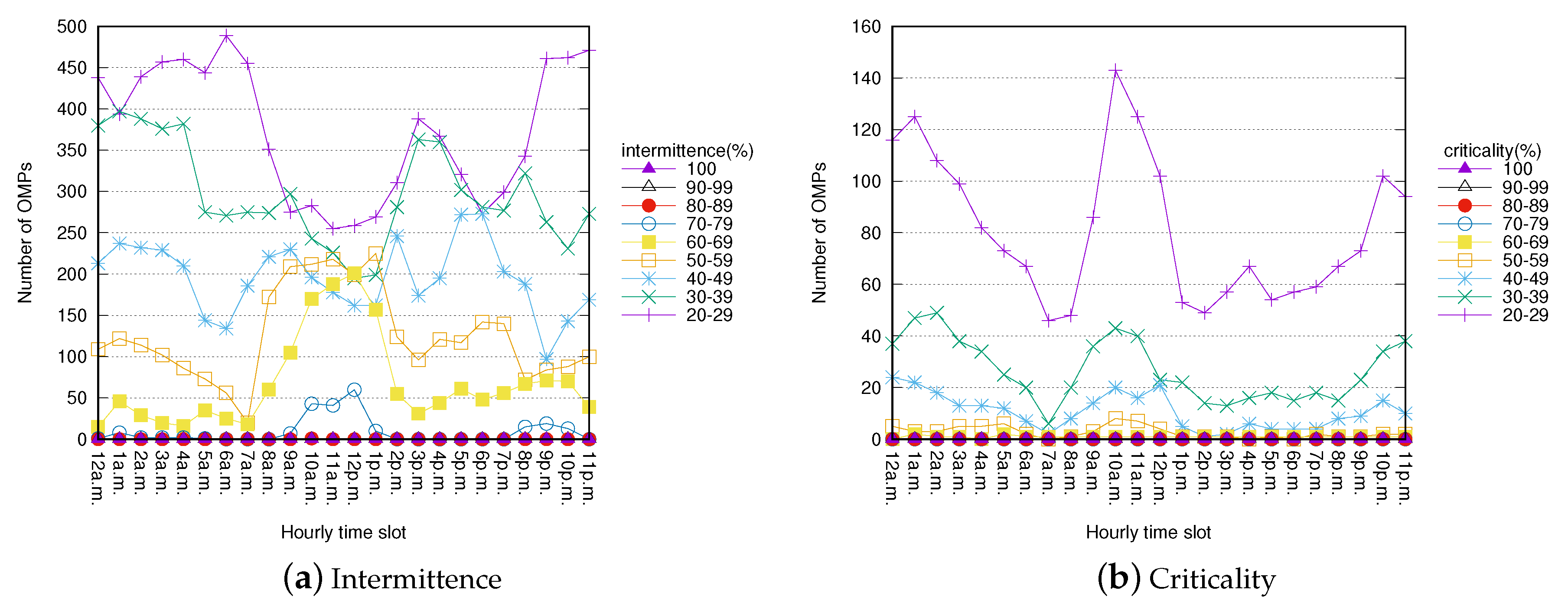
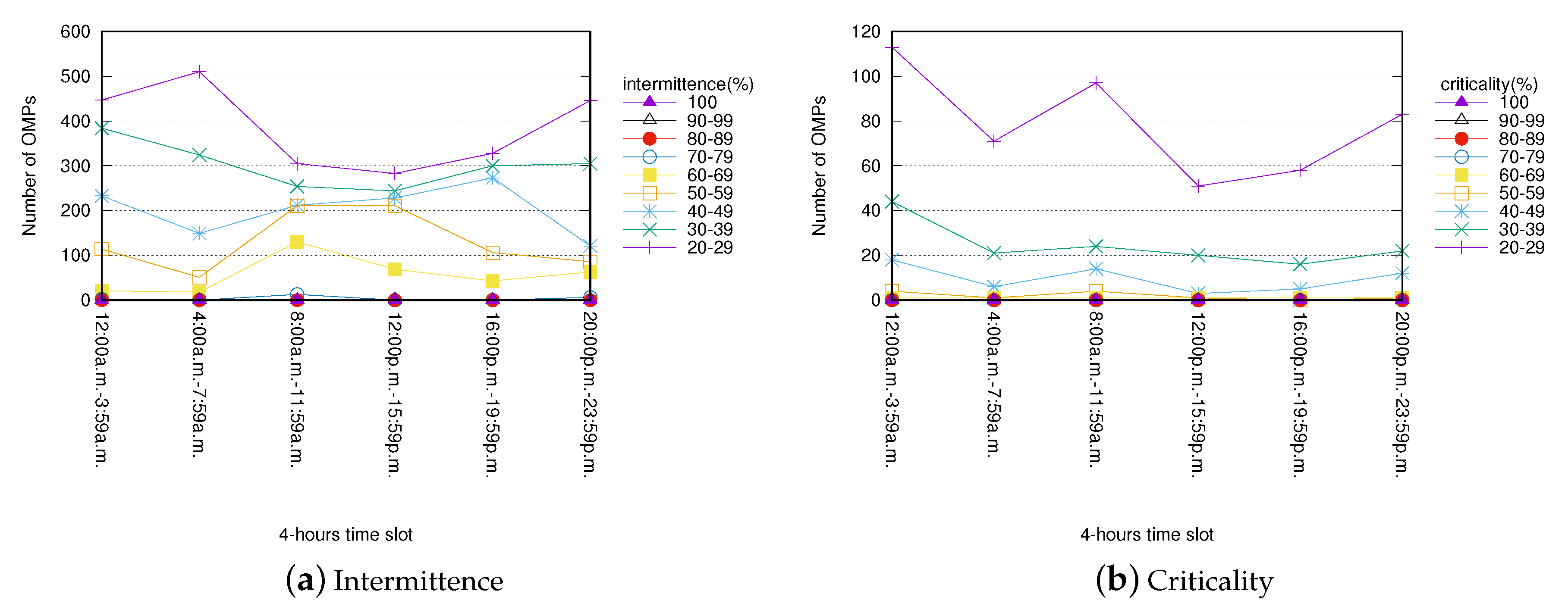
4.2. OMP Characterization
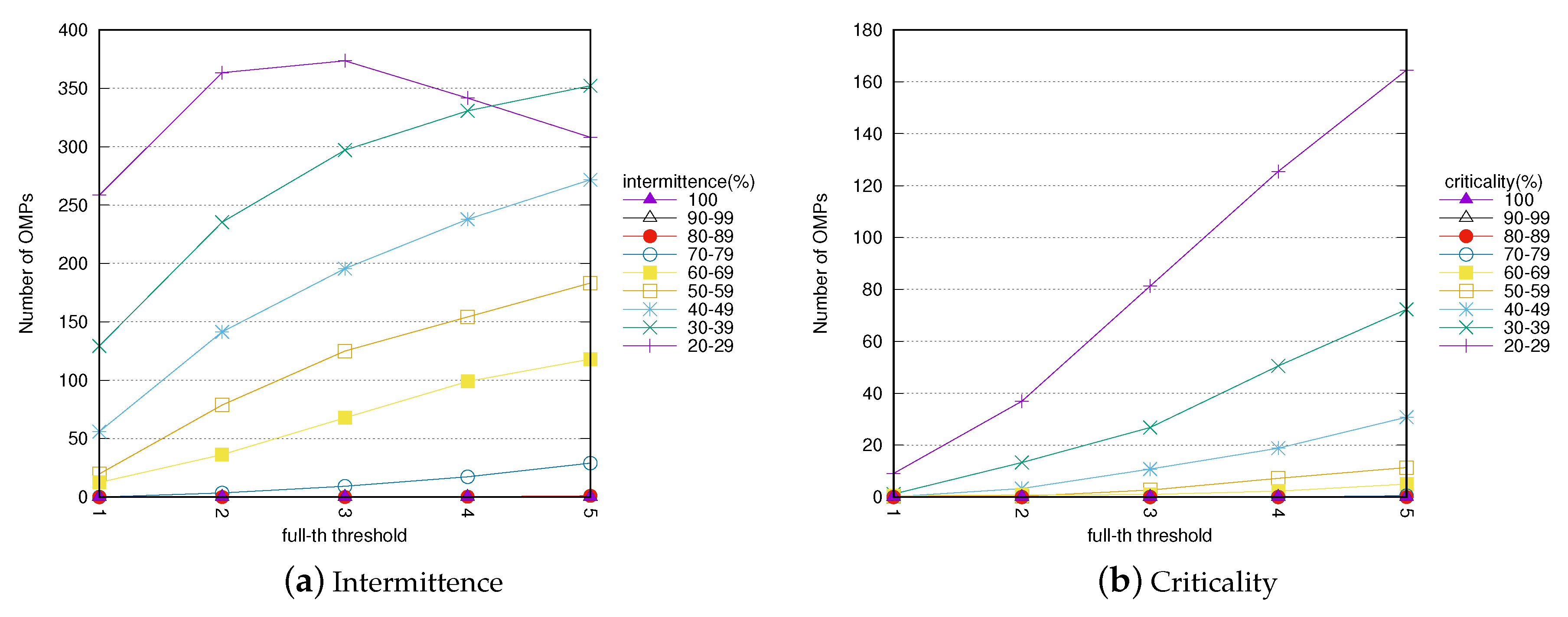
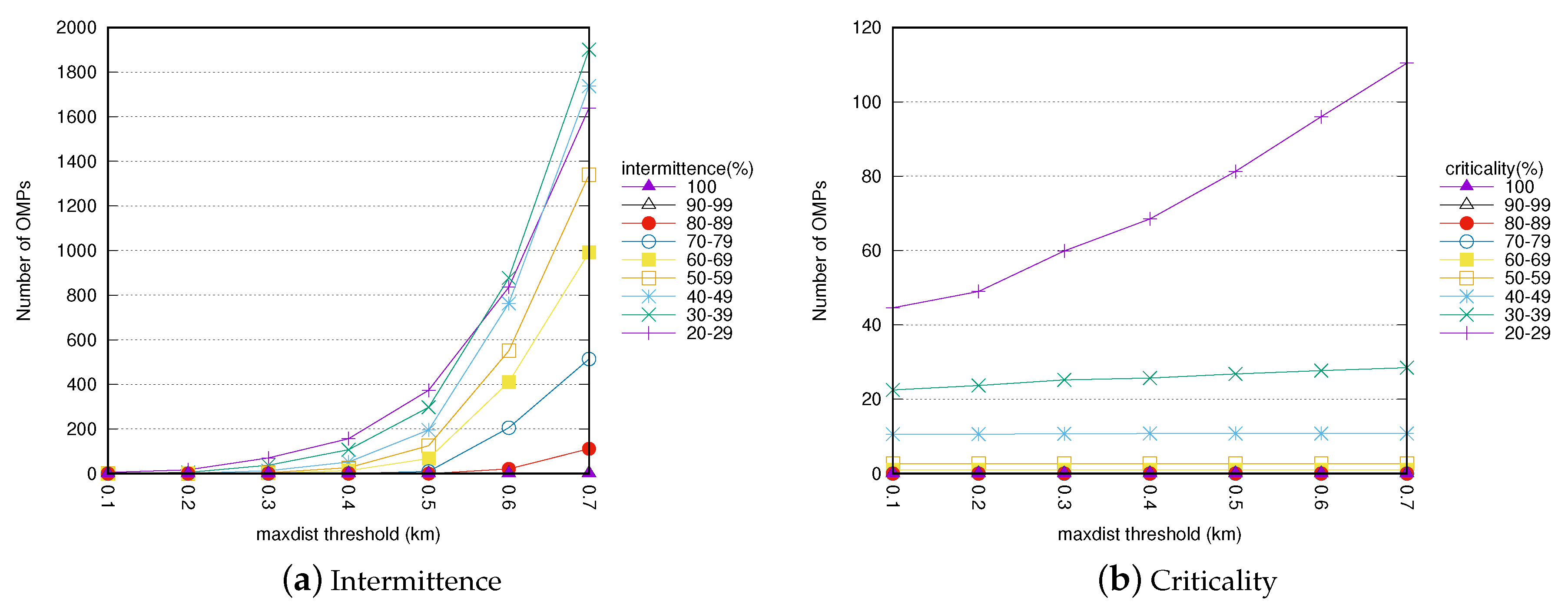
4.3. Parameter analysis
4.4. Algorithm Performance
5. Discussion
- The use of data mining tools to analyze bicycle sharing system data has become more and more attractive.
- Unsupervised approaches, like the BELL methodology presented in this study, characterize system usage in the medium and long-term. They identify contexts in which user experience could worsen due to recurrent system inefficiencies.
- System users may take advantage of the data-driven approaches to system monitoring because potentially critical situations can be automatically detected and managed without the need for explicit notification.
- Urban policymakers can exploit the BELL methodology to periodically monitor the dock overload situations detected in specific city areas at different time slots.
- Based on the knowledge extracted by the BELL methodology, policymakers could put in place medium-term actions, such as rebalancing actions triggered by the extraction of OMPs with high intermittence value, and long-term actions, such as station resizing or new station placement triggered by the extraction of OMPs with high criticality value.
- The results in the real case studies demonstrated the quality of the proposed methodology in supporting system managers under various aspects.
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbol | Description |
|---|---|
| Reference time window | |
| Set of points of time in | |
| Station of the bicycle sharing system | |
| occupancy level of station at any timestamp | |
| Set of stations | |
| Occupancy level dataset in relational format | |
| Dataset record corresponding to timestamp | |
| Occupancy level dataset in transactional format | |
| Record identifier | |
| Transaction identifier | |
| P | Occupancy Monitoring Pattern |
| maxdist | Spatial constraint |
References
- Shaheen, S.; Martin, E. Unraveling the modal impacts of Bikesharing. Access Magazine, 2009; 8–15. [Google Scholar]
- Martin, E.; Chan, N.; Cohen, A.; Pogodzinski, M. Public Bike sharing in North America During A Period of Rapid Expansion: Understanding Business Models, Industry Trends and User Impacts; Technical Report; Mineta Transportation Institute: San Jose, CA, USA, 2014. [Google Scholar]
- Susan, S.; Martin, E.; Cohen, A. Bikesharing and Modal Shift Behavior: A Comparative Study of Early Bikesharing Systems in North America. Int. J. Sustain. Transp. 2013, 1, 35–54. [Google Scholar] [CrossRef]
- Natalie, B.; Buck, D.; Chung, P.; Happ, P.; Kushner, N.; Maher, T.; Rawls, B.; Reyes, P.; Steenhoek, M.; Studhalter, C.; Watkins, A.; Buehler, R. Virginia Tech Capital Bikeshare Study; Technical Report; Virginia Tech: Blacksburg, VA, USA, 2012. [Google Scholar]
- Gleason, R.; Miskimins, L. Options for Federal Lands: Bike Sharing, Rentals and Employee Fleets; Technical Report; Western Transportation Institute: Bozeman, MT, USA, 2012. [Google Scholar]
- Wang, S.; Zhang, J.; Liu, L.; Duan, Z.Y. Bike-Sharing-A new public transportation mode: State of the practice and prospects. In Proceedings of the 2010 IEEE International Conference on Emergency Management and Management Sciences (ICEMMS), Beijing, China, 8–10 August 2010; pp. 222–225. [Google Scholar]
- Shaheen, S.; Guzman, S.; Zhang, H. Bikesharing in Europe, the Americas, and Asia: Past, Present, and Future; UC Davis: Institute of Transportation Studies (UCD): Davis, CA, USA, 2010; pp. 8–15. [Google Scholar]
- Zheng, Y.; Capra, L.; Wolfson, O.; Yang, H. Urban Computing: Concepts, Methodologies, and Applications. ACM Trans. Intell. Syst. Technol. 2014, 5, 38:1–38:55. [Google Scholar] [CrossRef]
- Etienne, C.; Latifa, O. Model-Based Count Series Clustering for Bike Sharing System Usage Mining: A Case Study with the Velib System of Paris. ACM Trans. Intell. Syst. Technol. 2014, 5, 39:1–39:21. [Google Scholar] [CrossRef]
- Sarkar, A.; Lathia, N.; Mascolo, C. Comparing cities’ cycling patterns using online shared bicycle maps. Transportation 2015, 42, 541–559. [Google Scholar] [CrossRef]
- Ciancia, V.; Latella, D.; Massink, M.; Pakauskas, R. Exploring Spatio-temporal Properties of Bike-Sharing Systems. In Proceedings of the 2015 IEEE International Conference on Self-Adaptive and Self-Organizing Systems Workshops (SASOW), Cambridge, MA, USA, 21–25 September 2015; pp. 74–79. [Google Scholar]
- Nair, R.; Miller-Hooks, E.; Hampshire, R.C.; Bušić, A. Large-Scale Vehicle Sharing Systems: Analysis of Vélib’. Int. J. Sustain. Transp. 2013, 7, 85–106. [Google Scholar] [CrossRef]
- Kaltenbrunner, A.; Meza, R.; Grivolla, J.; Codina, J.; Banchs, R. Urban Cycles and Mobility Patterns: Exploring and Predicting Trends in a Bicycle-based Public Transport System. Pervasive Mob. Comput. 2010, 6, 455–466. [Google Scholar] [CrossRef]
- Froehlich, J.; Neumann, J.; Oliver, N. Measuring the Pulse of the City through Shared Bicycle Programs. In Proceedings of the International Workshop on Urban, Community, and Social Applications of Networked Sensing Systems (UrbanSense08), Raleigh, NC, USA, 4 November 2008. [Google Scholar]
- Girardin, F.; Calabrese, F.; Fiore, F.D.; Ratti, C.; Blat, J. Digital Footprinting: Uncovering Tourists with User-Generated Content. IEEE Pervasive Comput. 2008, 7, 36–43. [Google Scholar] [CrossRef] [Green Version]
- Hasan, S.; Zhan, X.; Ukkusuri, S.V. Understanding Urban Human Activity and Mobility Patterns Using Large-scale Location-based Data from Online Social Media. In Proceedings of the 2nd ACM SIGKDD International Workshop on Urban Computing, Chicago, IL, USA, 11 August 2013; ACM: New York, NY, USA, 2013; pp. 6:1–6:8. [Google Scholar]
- ter Hofte, H.; Jensen, K.L.; Nurmi, P.; Froehlich, J. Mobile Living Labs 09: Methods and Tools for Evaluation in the Wild: Http://Mll09.Novay.Nl. In Proceedings of the 11th International Conference on Human-Computer Interaction with Mobile Devices and Services, MobileHCI’09, Bonn, Germany, 15–18 September 2009; ACM: New York, NY, USA, 2009; pp. 107:1–107:2. [Google Scholar] [CrossRef]
- Wang, I.L.; Wang, C.W. Analyzing Bike Repositioning Strategies Based on Simulations for Public Bike Sharing Systems: Simulating Bike Repositioning Strategies for Bike Sharing Systems. In Proceedings of the 2013 IIAI International Conference on Advanced Applied Informatics (IIAIAAI), Los Alamitos, CA, USA, 31 August–4 September 2013; pp. 306–311. [Google Scholar]
- Raviv, T.; Tzur, M.; Forma, I.A. Static repositioning in a bike-sharing system: Models and solution approaches. EURO J. Transp. Logist. 2013, 2, 187–229. [Google Scholar] [CrossRef]
- Vogel, P.; Greiser, T.; Mattfeld, D.C. Understanding Bike-Sharing Systems using Data Mining: Exploring Activity Patterns. Procedia Soc. Behav. Sci. 2011, 20, 514–523. [Google Scholar] [CrossRef]
- Schuijbroek, J.; Hampshire, R.; van Hoeve, W.J. Inventory rebalancing and vehicle routing in bike sharing systems. Eur. J. Oper. Res. 2017, 257, 992–1004. [Google Scholar] [CrossRef] [Green Version]
- Singla, A.; Santoni, M.; Bartók, G.; Mukerji, P.; Meenen, M.; Krause, A. Incentivizing Users for Balancing Bike Sharing Systems. In Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence, AAAI’15, Austin, TX, USA, 25–30 January 2015; AAAI Press: Palo Alto, CA, USA, 2015; pp. 723–729. [Google Scholar]
- O’Mahony, E.; Shmoys, D.B. Data Analysis and Optimization for (Citi)Bike Sharing. In Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence, AAAI’15, Austin, TX, USA, 25–30 January 2015; AAAI Press: Palo Alto, CA, USA, 2015; pp. 687–694. [Google Scholar]
- Lozano, A.; De Paz, J.F.; Villarrubia Gonzalez, G.; Iglesia, D.H.D.L.; Bajo, J. Multi-Agent System for Demand Prediction and Trip Visualization in Bike Sharing Systems. Appl. Sci. 2018, 8. [Google Scholar] [CrossRef]
- Pang-Ning, T.; Michael, S.; Vipin, K. Introduction to Data Mining; Pearson India: Uttar Pradesh, India, 2005. [Google Scholar]
- O’Brien, O.; Cheshire, J.; Batty, M. Mining bicycle sharing data for generating insights into sustainable transport systems. J. Transp. Geogr. 2014, 34, 262–273. [Google Scholar] [CrossRef]
- Formentin, S.; Bianchessi, A.G.; Savaresi, S.M. On the prediction of future vehicle locations in free-floating car sharing systems. In Proceedings of the 2015 IEEE Intelligent Vehicles Symposium (IV), Seoul, Korea, 28 June–1 July 2015; pp. 1006–1011. [Google Scholar] [CrossRef]
- Agrawal, R.; Imielinski, T.; Swami, A. Mining association rules between sets of items in large databases. In Proceedings of the 1993 ACM SIGMOD International Conference on Management of Data, Washington, DC, USA, 25–28 May 1993; pp. 207–216. [Google Scholar]
- Han, J.; Pei, J.; Yin, Y. Mining Frequent Patterns without Candidate Generation. In Proceedings of the 2000 ACM SIGMOD International Conference on Management of Data, Dallas, TX, USA, 15–18 May 2000. [Google Scholar]
- Agrawal, R.; Srikant, R. Fast Algorithms for Mining Association Rules in Large Databases. In Proceedings of the 20th International Conference on VLDB, Santiago, Chile, 12–15 September 1994; pp. 487–499. [Google Scholar]
- Babicki, S.; Arndt, D.; Marcu, A.; Liang, Y.; Grant, J.R.; Maciejewski, A.; Wishart, D.S. Heatmapper: web-enabled heat mapping for all. Nucleic Acids Res. 2016, 44, W147–W153. [Google Scholar] [CrossRef] [PubMed] [Green Version]











| Record IDentifier (RID) | Stations | Time | |||
|---|---|---|---|---|---|
| Timestamp | Time Period | ||||
| RID | Overloaded | Overloaded | Overloaded | ||
| RID | Overloaded | Normal | Overloaded | ||
| RID | Overloaded | Overloaded | Normal | ||
| RID | Overloaded | Normal | Normal | ||
| RID | Normal | Overloaded | Normal | ||
| RID | Normal | Overloaded | Normal | ||
| RID | Normal | Normal | Normal | ||
| Transaction IDentifier (TID) | Transaction |
|---|---|
| TID | , , |
| TID | , , |
| TID | , , |
| TID | , , |
| TID | , , |
| TID | , , |
| TID | , , |
| OMP IDentifier (ID) | OMP | Time Slot | Crit. % | Interm. % |
|---|---|---|---|---|
| 1 | {Vilamara davant, Mallorca, Calabria} | [4:00 a.m., 5:00 a.m.] | 8.29 | 73.84 |
| 2 | {Vilamara davant, Mallorca, Calabria} | [2:00 a.m., 3:00 a.m.] | 8.58 | 73.53 |
| 3 | {Sant Pere Mas Alt, Pl. Carles Sunyer, Pl. Catalunya, Pl. Urquinaona} | [10:00 a.m., 11:00 a.m.] | 1.86 | 71.28 |
| 4 | {Pl. Catalunya A, Pl. Catalunya B, Pl. Catalunya C, Pl. Urquinaona} | [11:00 a.m., 12:00 a.m.] | 4.31 | 70.72 |
| 5 | {Carrer de Bonavista, Pl. del Poble Romaní} | [7:00 a.m., 8:00 a.m.] | 1.56 | 63.05 |
| 6 | {Carrer del Cana, Pl. del Poble Romaní} | [5:00 a.m., 6:00 a.m.] | 0.13 | 62.69 |
| 7 | {Pl. del Poble Romaní, Montmany} | [6:00 a.m., 7:00 a.m.] | 0.13 | 62.41 |
| OMP IDentifier (ID) | OMP | Time Slot | Crit. % | Interm. % |
|---|---|---|---|---|
| 1 | {W 42 St & 8 Ave, PABT Valet} | [7:00 p.m., 8:00 p.m.] | 0 | 100 |
| PABT Valet} | ||||
| 2 | {W 33 St & 8 Ave, W 29 St & 9 Ave, W 31 St & 8 Ave, Penn Station Valet} | [8:00 p.m., 9:00 p.m.] | 0 | 100 |
| 3 | {W 41 St & 8 Ave, W 45 St & 9 Ave, W 42 St & 8 Ave, PABT Valet} | [7:00 p.m., 8:00 p.m.] | 0 | 100 |
| 4 | {W 42 St & 8 Ave, PABT Valet} | [6:00 p.m., 7:00 p.m.] | 0 | 93.7 |
| 5 | {E 22 St & Broadway, E 24 St & Park Ave} | [11:00 a.m., 12:00 a.m.] | 0 | 90 |
| OMP IDentifier (ID) | OMP | Time Slot | Crit. % | Interm. % |
|---|---|---|---|---|
| 1 | {Marquas de l’Argentera, Avinguda del Marques Argentera} | [10:00 a.m., 11:00 a.m.] | 37.96 | 19.23 |
| 2 | {Gran Via, Rocafort} | [11:00 a.m., 12:00 a.m.] | 35.94 | 19.91 |
| 3 | {Gran Via, Rocafort} | [10:00 a.m., 11:00 a.m.] | 34.48 | 19.84 |
| 4 | {Marquas de l’Argentera Avinguda del Marques Argentera} | [11:00 a.m., 12:00 a.m.] | 33.52 | 21.15 |
| 5 | {Paralà lel, Pl. Jean Genet} | [1:00 a.m., 2:00 a.m.] | 32.64 | 25.42 |
| 6 | {Paralà lel, Sant Oleguer, Pl. Jean Genet} | [1:00 a.m., 2:00 a.m.] | 23.41 | 41.91 |
| 7 | {Marquas de l’Argentera, Avinguda del Marques Argentera, Pl. Comercial} | [10:00 p.m., 11:00 p.m.] | 22.99 | 37.16 |
| 8 | {Marquas de l’Argentera Avinguda del Marques Argentera, Pl. Comercial} | [12:00 p.m., 1:00 a.m.] | 22.48 | 32.55 |
| OMP IDentifier (ID) | OMP | Time Slot | Crit. % | Interm. % |
|---|---|---|---|---|
| 1 | {E 85 St & 3 Ave, E 84 St & 1 Ave} | [8:00 p.m., 9:00 p.m.] | 51.15 | 29.01 |
| 2 | {E 53 St & Madison Ave, E 48 St & 5 Ave} | [9:00 a.m., 10:00 a.m.] | 49.76 | 20.53 |
| 3 | {E 84 St & 1 Ave, E 82 st & 2 Ave} | [9:00 p.m., 10:00 p.m.] | 49.26 | 27.53 |
| 4 | {E 85 St & 3 Ave, E 84 St & 1 Ave} | [7:00 p.m., 8:00 p.m.] | 45.01 | 31.13 |
| 5 | {W 51 St & 6 Ave, E 48 St & 5 Ave} | [9:00 a.m., 10:00 a.m.] | 44.93 | 16.91 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cagliero, L.; Cerquitelli, T.; Chiusano, S.; Garza, P.; Ricupero, G.; Baralis, E. Characterizing Situations of Dock Overload in Bicycle Sharing Stations. Appl. Sci. 2018, 8, 2521. https://doi.org/10.3390/app8122521
Cagliero L, Cerquitelli T, Chiusano S, Garza P, Ricupero G, Baralis E. Characterizing Situations of Dock Overload in Bicycle Sharing Stations. Applied Sciences. 2018; 8(12):2521. https://doi.org/10.3390/app8122521
Chicago/Turabian StyleCagliero, Luca, Tania Cerquitelli, Silvia Chiusano, Paolo Garza, Giuseppe Ricupero, and Elena Baralis. 2018. "Characterizing Situations of Dock Overload in Bicycle Sharing Stations" Applied Sciences 8, no. 12: 2521. https://doi.org/10.3390/app8122521
APA StyleCagliero, L., Cerquitelli, T., Chiusano, S., Garza, P., Ricupero, G., & Baralis, E. (2018). Characterizing Situations of Dock Overload in Bicycle Sharing Stations. Applied Sciences, 8(12), 2521. https://doi.org/10.3390/app8122521