1. Introduction
Tomography is a powerful technique for reconstructing an image of the interior of an object from a series of its projections, acquired from a range of angles. In computed tomography (CT), a 3D volumetric representation of the object is computed from a set of projections using a tomographic reconstruction algorithm. A broad range of imaging modalities can be used for acquiring the projection images, including X-ray imaging [
1], electron imaging [
2], neutron imaging [
3], and optical imaging [
4], all resulting in similar computational reconstruction problems.
Improving the resolution of tomographic 3D volumes is an important goal in the development of new tomographic scanners and their accompanying software. Improvements in resolution enable new developments in materials science [
5], geology [
1], and other fields of inquiry [
6]. In some cases, the resolution of the acquired projections is limited by the effective pixel size of the detector, which imposes a discretization on the measured data that is carried over into the reconstructed 3D volume. For certain tomographic scanners, this limit can be overcome by zooming into a region of interest, decreasing the effective pixel size of the detector [
1]. Often, other properties of the imaging process also limit the resolution, such as the spot-size of the radiation source or pixel cross-talk on the detector. In such cases, the actual resolution at which a 3D image can be reconstructed is lower than the theoretical maximum based on the detector resolution [
7]. When using standard reconstruction algorithms, such as the well-known Filtered Backprojection method (FBP) or Algebraic Reconstruction Technique (ART), the resolution of the reconstructed volume is inherently limited by the resolution and signal-to-noise ratio of the acquired projection data [
8,
9].
Various tomographic techniques permit zooming in to a specific parts of an object, leading to magnified projection images. At synchrotron light sources, X-ray images are acquired by converting the high energy photons transmitted through the object into visible light using a scintillator. The visible light is converted into digital images by a conventional high-resolution image sensor. Magnification of the region of interest is achieved by magnifying the visible light using optical instruments placed between the scintillator and image sensor [
6]. Laboratory CT systems, on the other hand, have a natural zooming ability, since the X-rays emanate from a point source and are projected onto a linear (fan beam) or planar detector (cone beam). Therefore, moving the object closer to the source magnifies the projected image on the detector. In this paper, we will focus on the 3D cone-beam setup, although the proposed approach is applicable to other tomographic techniques as well, including synchrotron tomography.
A variety of strategies have been proposed for increasing the resolution of tomographic volumes, either by changing the scanning process, or by changing the reconstruction method. When changing the scanning process, several strategies are commonly used:
High-resolution 3D images can be obtained if a small section can be physically extracted from the object and then scanned at a higher magnification. This provides only information on the particular section, and involves the destruction of the full sample [
10].
Region-of-interest tomography focuses the imaging system on a sub-region of the object, obtaining a set of projections in which that region is always visible, but also superimposed on the surrounding structures. This only recovers high-quality 3D information of the region of interest and leads to challenging image reconstruction problems, as truncation artifacts can hamper the reconstruction quality [
11].
In some cases, it is possible to move the detector while performing a scan, creating a large projection by stitching the images for several detector positions [
12]. This permits capturing the full object at a high zoom factor, yet at the cost of a strong increase in radiation dose, scanning time, and computation time.
The resolution of the reconstruction can also be increased by incorporating certain prior knowledge about the scanned object into the reconstruction algorithm, resulting in super-resolution reconstruction. In CT, such prior knowledge comes in many forms, e.g., sparsity of the reconstructed image [
13], sparsity of its gradient [
14,
15], or knowledge of the materials constituting the object and their attenuation coefficients [
16]. However, such prior knowledge is often not available in practice and introduces the risk of making assumptions that are not in good agreement with the actual scanned object, which can decrease the quality of the reconstructed image.
In recent years, machine learning has shown the ability to improve resolution in a range of imaging applications [
17,
18]. In particular, convolutional neural networks (CNN) have been applied successfully to attain super-resolution for a wide range of imaging modalities [
17]. By training the CNN to compute the mapping between low-resolution data and specially obtained high-resolution training data, the characteristics of the datasets can be learned, removing the need for manually choosing a model. However, this approach relies on the availability of high quality training data for a series of similar objects, which for tomography would consist of high- and low-resolution scans of these objects. Such data are often difficult to obtain in practice for two main reasons:
when the objects under investigation are unique (i.e., no batches of similar objects are available), it is not possible to obtain the training data;
creating high-resolution scans requires long scanning time and may also require high radiation dose, which can be unacceptable for dose-sensitive objects.
Therefore, applying existing machine learning approaches to achieve super-resolution in tomographic imaging is often infeasible in practice.
In this paper, we propose a novel technique for computationally improving image resolution in tomography. The technique integrates a specially designed scheme for acquiring the scan data and a machine learning method for super-resolution imaging. The data acquisition protocol ensures that certain sub-regions of the scanned object can be reconstructed at high resolution, while still keeping the total scanning time and dose relatively low. By using these high-resolution sub-regions as a training target for creating a super-resolution version of the full object, key morphological properties of the scanned object can be captured even if the scanned object is unique and no similar objects are available.
Rather than exploiting similarity between a large batch of objects, our approach exploits self-similarity within a single object. As such, it is expected to perform properly if the object has high self-similarity, meaning that the local structure of the material is consistent throughout the entire object. Objects with such self-similar structures are abundantly available in nature, and are investigated in detail specifically for their structure. Examples include the crystallization of rare fossils and meteorites, or the porosity and texture of rocks and soils in geology [
10]. Furthermore, in materials science, investigations are conducted on the micro-structure of metal foams, batteries, and other materials to improve their physical properties [
5,
19]. The goal of this paper is to present an approach for improving the resolution of tomographic reconstructions of these type of objects. We show visual and quantitative results for simulated and experimentally acquired cone-beam CT datasets.
This paper is structured as follows.
Section 2 introduces necessary notation. In
Section 3, we present our method. In
Section 4, we describe the experiments that were performed to evaluate the accuracy of the proposed approach. Results are presented on simulated and experimentally acquired data. In
Section 5, we discuss these results and provide possibilities for further research. Finally, our conclusions are presented in
Section 6.
3. Method
In this section, we describe the main contribution of this paper: an integrated data acquisition and machine learning approach for improving resolution in cone-beam tomography. Our approach consists of several steps. First, we perform a standard CT scan of the object under study. In addition to a standard CT scan, we acquire additional projection images with the object moved closer to the radiation source. Second, we reconstruct the entire volume at low resolution. Next, using both projection datasets, we reconstruct a region of interest at high resolution. These two reconstructions are used to train a neural network to compute a mapping between the low-resolution volume in the region of interest and its high-resolution counterpart. The trained neural network is then applied to the entire low-resolution volume to obtain a final high-resolution volume representation. This process is illustrated in
Figure 2. In the next subsections, we describe the steps of our data acquisition and reconstruction strategy in detail.
3.1. Data Acquisition
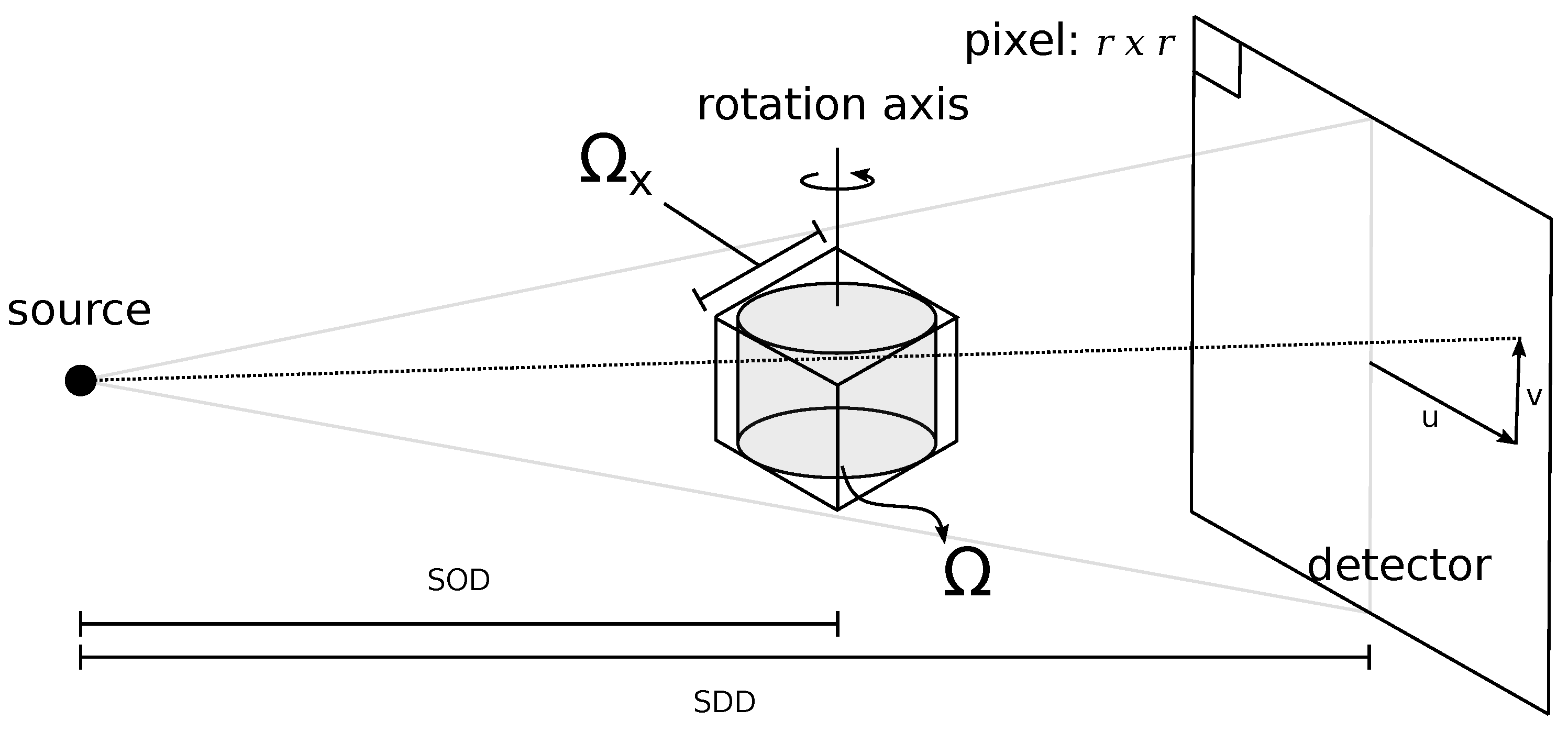
Our data acquisition protocol consists of two scans. The first scan with magnification factor
is a standard circular cone beam scan and yields projection dataset
, as shown in
Figure 1. In addition to the standard acquisition, we propose to acquire an additional projection dataset
. Here, the object is moved closer to the source such that the resulting projection on the detector has a magnification factor of
. Now, only a region of interest
is in full view on the detector at all times, as is depicted in
Figure 3. The addition of the second projection dataset
permits the high-resolution reconstruction of a rectangular sub-region of the region of interest. This is described below.
3.2. Reconstruction
From the acquired datasets, two reconstructions are computed. The first reconstruction contains the entire object at low resolution, and the second reconstruction describes the region of interest at high resolution. Because these reconstructions are later used for the training of a neural network, we ensure that their voxel grids are aligned.
The dimensions of the low-resolution reconstruction grid are determined using the pixel size
r and the physical dimensions
of the object. We calculate the effective voxel size
using Equations (
4) and (
5). Given the voxel size, the shape of the voxel grid
,
, is established such that its real-world volume
covers the object, i.e.,
. On this grid, the low-resolution reconstruction is computed using the FDK algorithm
Next, we determine the shape and voxel size
of the high-resolution voxel grid
. We set the voxel size to equal
, where
k equals
rounded to the nearest integer. In practice, magnification factors
and
can be carefully chosen to avoid the need for rounding. The voxel size
is close to the limit defined by Equation (
4), since, by Equation (
5), we have
We fix the physical volume of the high-resolution grid, , to be contained in the region of interest, i.e., , and set its shape, , such that is divisible by k. Now, voxels from relate to cubes of voxels in . This assists in modeling the forward projection of the second scan.
As shown in
Figure 3, the rays forming the projection data,
, have been transmitted through both
and
. This is modeled by the discrete linear equation
where
is a matrix that masks all voxels in
that are contained in
. In other words,
is a diagonal matrix where the diagonal is 0 on row
i if voxel
i of the large grid
overlaps
, and is 1 elsewhere. The matrix
is defined such that
represents the contribution of the low-resolution volume voxel
to detector pixel
at magnification
. The matrix
similarly defines the projection of the high-resolution volume
at magnification
.
To reconstruct
, we subtract the reprojection of the masked reconstruction
from the acquired high-resolution projection data
Next, we apply the FDK algorithm to the processed projection data to obtain the reconstruction
In a conventional FDK reconstruction, the outside contributions of
to the projection data
cause truncation artifacts. Because we have approximately removed these contributions, we can apply the FDK algorithm to obtain a high-resolution reconstruction of the region of interest. Note that similar subtraction methods have been proposed before to remove truncation artifacts in region-of-interest tomography [
25,
27,
28]. Some artifacts may occur on the border of the region of interest, which may be due to the specifics of the interpolation kernel that is used in the forward projection
or due to discontinuity at the image borders enhanced by the FDK filter kernel. Water cylinder extrapolation or truncation robust FBP methods like [
29] may alleviate these artifacts. These artifacts are not a problem in practice, as the affected border voxels may be ignored.
3.3. Machine Learning
At this point in the process, the tomographic reconstruction method yields a low-resolution voxel grid and a high-resolution voxel grid . For the neural network to match the low-resolution input to the high-resolution target, it is necessary that both input and target relate to the same physical space, and have the same voxel size. In this section, we outline how and are processed to match in physical space and voxel size. We also describe the training procedure, and motivate the choice of neural network architecture.
The voxel grid
corresponds to the physical space
and
corresponds to
. To serve as input data for neural network training, we use the voxels from
that are contained in
. We denote this restriction operation by
. The resulting voxel grid
corresponds to the physical volume
, and each of its voxels can thus be matched with voxels from
.
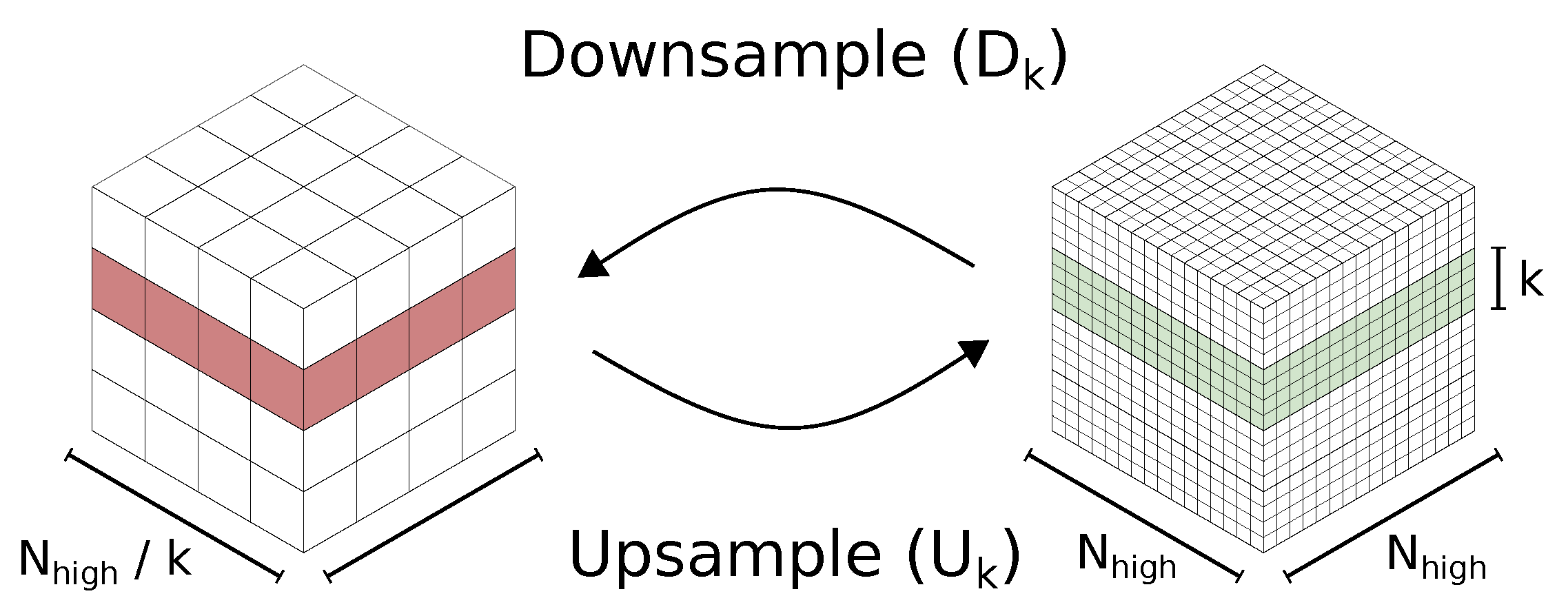
The voxel sizes of
and
can be equalized by either up-sampling the input data
or down-sampling the target data
. We present both options, which we designate as method A and method B, respectively. By up-sampling the input data by a factor
k with an interpolation method
with
, we obtain training data on a fine grid
By down-sampling the target data by a factor
k with an interpolation method
with
, we obtain training data on a coarse grid
The interpolation methods
and
are open to choice. Various methods can be used, including, for instance, cubic interpolation. The up- and down-sampling operations are illustrated in
Figure 4.
The properties of the acquired projection data can be used to inform the choice whether to up-sample the input (method A), or down-sample the target (method B). When optical blurring on the detector is negligible, the small-scale features that can be seen in
will be hard to visualize on the coarse grid of
. Therefore, it is recommended to use method A where
is defined on a fine grid. If, on the other hand, optical blurring limits the effective resolution of
, and its resolution can be improved without reducing the voxel size, then it is recommended to use method B, where the grid size is smaller, and training and applying the network is thus computationally faster. The differences between the input and target grids are summarized in the first three columns of
Table 1.
The input and target voxel grids
and
serve to train the convolutional neural network. The voxel grids
and
are divided into slices
as illustrated in
Figure 4. In this article,
denotes both a single voxel at position
i and a horizontal slice
i of a voxel grid
. The surrounding text always distinguishes between a voxel and a slice.
The input slices are combined into slabs
containing the input slice and the
s slices above and below. The target slices are not combined into slabs. The training procedure now minimizes
which yields the set of parameters,
. Other norms, such as the L1 norm, could also be used.
Multiple deep network architectures can be used to improve the quality of reconstructions [
30,
31,
32,
33]. One of these is the mixed-scale dense (MS-D) network, which is a neural network architecture specifically developed for scientific settings. The mixed-scale dense network has several properties that make it well-suited for our method. The MS-D network has relatively few parameters compared to other neural network structures, making it easier to train and less likely to overfit. This is especially useful if a small training set is available, and no part of the training set is sacrificed to serve as a validation set, as is the case in this paper. Another advantage is that the MS-D network maximally reuses the intermediate images in each layer, thus requiring fewer intermediate images compared to other deep convolutional neural network architectures. Therefore, the MS-D network can transform large images using less memory and computation time compared to other popular convolutional neural network architectures [
33]. Finally, the network has shown good results for removing noise and other artifacts from tomographic images when a large training set of similar objects scanned at high dose is available. This is described in [
34], where the network was applied to tomographic images reconstructed from a dataset of parallel beam projections, rather than cone beam projections.
3.4. Improving Resolution
After training the network, a set of network parameters
is obtained. The trained neural network
is applied to the initially reconstructed low-resolution volume
to obtain a final volume representation
. This process consists of several steps. If the training input has been up-sampled using method A, then the reconstruction
must likewise be up-sampled to
, which is
k times larger in every dimension. If method B has been used, no up-sampling of the reconstruction is necessary. The resulting voxel grid is processed by the network slice by slice. These slices must be collected in slabs containing
s slices above and below the input slice. This influences the output size, since the top and bottom
s slices of
do not have enough surrounding slices to be processed by the network. This is usually not a problem because
s is small (
) and the low-resolution grid can be chosen large enough that any important features are at some distance from the top and bottom. Finally, the network can be applied to each of these slabs in turn, the result of which we collect into
. In summary, this process results in the final volume representation
For both methods, the size of the final grid
is summarized in
Table 1.
4. Results
We evaluate the accuracy of our method on simulated and experimental data, which is described below. Before going through the specifics of each experiment, we first provide details on the steps that all experiments have in common.
Data acquisition For each experiment, three projection datasets are acquired. The first projection dataset has the entire object in the field of view and has a low magnification factor
. The second and third projection datasets are acquired of a central and upper region of interest and have a higher magnification factor
. This is illustrated in
Figure 5.
Reconstruction In all experiments, high-resolution reconstructions are computed of a central and upper region of interest to serve as target data for the
training set and
test set, respectively. A low-resolution reconstruction is computed of the entire object, which serves as input data for both training and testing. In all experiments, the low-resolution voxels are
times as large as the high-resolution voxels. FDK reconstructions were computed using the ASTRA toolbox [
35].
Up- and down-sampling The up- and down-sampling of the reconstructed volumes can be performed in various ways. In the experiments, up-sampling in method A is carried out by nearest-neighbor up-sampling, where each voxel is repeated k times in each direction. Empirically, we found this to be sufficient, as cubic up-sampling did not improve the quality of the network output. Down-sampling of the target voxel grid in method B is carried out using three-dimensional cubic interpolation, where the image is interpolated to a coarser grid using polynomials of degree at most 3 determined by a window of voxels.
Neural network implementation For each experiment, three separate networks are trained using: (i) method A and a single input slice, (ii) method A and a slab of nine input slices, (iii) method B and a single input slice. The MS-D network is implemented in PyTorch [
36]. Each trained network has 100 single-channel intermediate layers, and the convolution in layer
i is dilated by
, as is described in [
33]. The network has 45,652 parameters when there is a single input slice, and it has 52,948 parameters when the input is a slab of nine slices.
Training procedure The network is trained on the central region of interest. Because we chose not to use a validation set, a criterion was set for early stopping. In all experiments, training finished after two days or 1000 epochs, whichever came first. All networks are trained from scratch in each experiment. The training procedure minimizes the mean square error between the output and target images, and the networks are trained using the ADAM algorithm [
37] with a mini-batch size of one. The network output is evaluated on a test set containing the low- and high-resolution reconstructions of the upper region of interest. The training and test set are thus non-overlapping.
Metrics and evaluation On both datasets, the on-the-fly machine learning approach is evaluated using the structural similarity index (SSIM) [
38] and the mean square error (MSE) metrics. These metrics are used to compare the output slices of the networks to target slices from the upper ROI reconstruction. To compare methods A and B on the same grid, the output volume of method B is cubically up-sampled before computing the MSE and SSIM metrics. The output slices of method A are not processed, since they are the same size as the target slices of the test set. Both metrics are computed slice by slice and averaged. To prevent the influence of reconstruction artifacts at the boundaries of the high-resolution reconstructions, all metrics are calculated on pixels that are at least eight pixels from the boundary of the volume. Likewise, all displayed images are cropped to remove eight pixels from all sides. The error metrics of our approach are compared to a baseline: a full-volume three-dimensional cubic up-sampling of the low-resolution input volume. We visually compare all methods on the central slice of the upper ROI reconstruction on both the simulated and the experimental data.
All computations were performed on a server with 192 GB of RAM and four Nvidia GeForce GTX 1080 Ti GPUs (Nvidia, Santa Clara, CA, USA) or on a workstation with 64 GB of RAM and one Nvidia GeForce GTX 1070.
4.1. Simulations
First, we investigated the performance of the proposed on-the-fly machine learning technique on simulated tomographic data.
Simulation phantom A foam ball simulation phantom was generated by removing 90,000 randomly-placed non-overlapping spheres from a large sphere made of one material. The foam ball has diameter 1. All other dimensions in the simulation are relative to this unit length. The radius of the random spheres ranges between
and
. The central slice of this phantom is displayed in
Figure 6.
Data simulation Using the foam phantom, three projection datasets were computed. For the first projection dataset, which has the entire foam ball in the field of view, the source-object distance is equal to the source-detector distance, yielding a magnification factor of . In practice, having an equal source-object and source-detector distance is not possible, since the detector and object would share the same physical space. In simulations, however, this is both possible and natural, since it results in a minimal voxel size that is equal to the detector pixel size. The second and third projection dataset were acquired at a magnification factor of .
To simulate how our method copes with optical phenomena, another set of projections was created by post-processing the projections using a Gaussian blur with standard deviation of two pixels. The Gaussian blur convolves the projection images with a 2D filter defined by , where is the chosen standard deviation. We refer to the blurred data as optics-limited, and to the non-blurred data as pixel-limited.
The projections were carried out using the GPU-accelerated
cone_balls software package, which we have made available as an open source package [
39]. This package analytically computes the linear cone beam projection of solid spheres of constant density. For each dataset, 1500 projections were acquired over 360 degrees on a virtual detector with
pixels. For each detector pixel, four rays were cast through the phantom, and their projection values were averaged.
Processing The reconstruction and training of the foam phantom was performed as described before in
Section 4. The details are summarized in
Table 2. Methods A and B are evaluated on the upper ROI reconstruction, and compared below for both the pixel-limited and optics-limited case.
Evaluation For the simulated data, the MSE and SSIM metrics are computed between the network outputs and the original phantom data, rather than the high-resolution reconstruction. As the SSIM metric is designed to operate on images with a fixed intensity interval, we clip the network outputs such that all images have the same minimum and maximum intensity as the phantom data. Similarly, the images displayed in
Figure 7 are clipped to the range
. The MSE metrics are calculated on the unclipped data.
The quantitative results for the foam phantom are given in
Table 3. Both variants of method A significantly outperform cubic up-sampling on both MSE and SSIM metrics. On the pixel-limited dataset, the SSIM score of method B is lower than the methods A but higher than cubic up-sampling. The fine scale features in the pixel-limited high-resolution image can simply not be represented on the coarser grid that method B operates on. On the optics-limited dataset, on the other hand, the SSIM score of method B is comparable to the SSIM scores of methods A, and is significantly higher than that of cubic up-sampling.
In
Figure 7, the methods are visually compared on both the pixel-limited dataset and the optics-limited dataset. In the pixel-limited dataset, the low-resolution input suffers from partial volume effects, where some voxels contain more than one material. In this case, the foam and void contributions to a voxel are averaged, which leads to jagged edges. The high-resolution data are significantly sharper, but still has some non-smooth texture in the foam and voids. The output of method A with nine input slices makes the edges as sharp as in the high-resolution image, and removes the non-smooth texture in the foam and voids. Moreover, it does not introduce any voids where there are none in the target data. Method A with one input slice performs similarly, but has some difficulty with features that are rapidly introduced in the vertical direction. This is apparent in the magnified image in
Figure 7, where the top or bottom of one void in the input data are not correctly removed. As discussed before, method B performs worse than method A when the high-resolution features cannot be represented on the coarse grid.
In the optics-limited dataset, both low- and high-resolution slices are less sharp than in the pixel-limited case. Due to the additional blur on the projection data, some of the smaller features in the low-resolution image cannot easily be distinguished. Nonetheless, the output of both methods A has significantly improved resolution and is visually similar to the target slice. With few exceptions, all voids in the output are round, and, without exception, all voids in the output are also present in the target. Method B produces output that looks similar to the output of methods A, although it fuses some voids that can still be distinguished in the output of methods A.
4.2. Experimental Data
To verify the practical applicability of our approach, we have investigated the performance of our method on experimentally acquired cone-beam CT data.
Sample A plastic jar filled with oatmeal was scanned. The oatmeal was specifically chosen for its structure, which is consistent throughout the entire object. A package of oatmeal contains thousands of flakes, which all have roughly the same dimensions and shape, but still exhibit fine-scale features, requiring high-resolution tomography to accurately capture. Projection and reconstruction images of the oatmeal are displayed in
Figure 8.
Data acquisition The projection images were acquired using the custom-built and flexible CT scanner, FleX-ray Laboratory, developed by XRE NV and located at CWI [
40]. The apparatus consists of a cone-beam microfocus X-ray point source that projects polychromatic X-rays onto a
pixels, 14-bit, flat detector panel. The data was acquired over 360 degrees in circular motion with 2000 projections distributed evenly over the full circle. The projections were collected with 250 ms exposure time and the total scanning time was 11 minutes per acquisition. The tube voltage was 70 kV and the tube power was 42 W. This acquisition strategy was performed three times with magnification factors
and
. Examples of the acquired projection images are displayed in
Figure 8 and an overview of scanning time and emitted beam energy is given in
Table 4. The object was centered on the detector for the first two scans, and the object was moved down to capture a region of interest above the center of the object for the final scan. These data are publicly available via [
41].
Processing Reconstructions were computed of the full object, a central region of interest (serving as training set), and an upper region of interest (serving as test set). An example of the central slice of the oatmeal is displayed in
Figure 8d. The voxels in the full-object reconstruction are four times larger in each dimension than the voxels in the region-of-interest reconstructions. The training step was also performed in the same way as for the simulated data. The details are summarized in
Table 2. Up-sampling the low-resolution region-of-interest slices to
pixels takes roughly
s per slice and 13 min in total using method A with one input slice. Using method B, up-sampling a single slice takes
s, and the entire region of interest can be up-sampled in less than a minute.
Evaluation The attenuation coefficients of the voxels in the high-resolution reconstruction are contained in the range
. To enable comparison of the MSE and SSIM metrics of the experimental data with the simulated data, we rescaled the attenuation coefficients of the target volume to the range
, and used the same scaling factors to rescale the values of all other volumes. In addition, before calculating the SSIM, all volumes are clipped to the range
, similar to the simulated data. Likewise, the slices displayed in
Figure 9 are rescaled and clipped to the unit range.
The experimental results on the oatmeal dataset are visually compared on the central slice of the upper region of interest. This low-resolution input slice, which is displayed in
Figure 9, is thus not part of the training set. The low- and high-resolution slices of the oatmeal both suffer from some noise. The high-resolution slice contains significantly more visible fine-scale features. The output of the three methods is virtually indistinguishable in the non-magnified images. In the magnified images, we see that not all fine details can be retrieved: some small features are removed and others are slightly deformed compared to the target. In the red ellipse, a large flake is visible in the low-resolution slice that appears larger than it really is due to partial volume effects. The high-resolution slice, on the other hand, shows only a small fragment of the large flake. All three networks are able to filter away a large part of the flake and retain the ridge that is visible in the high-resolution slice. The three methods significantly reduce the background noise that is present in the high-resolution target beyond what can be achieved using cubic up-sampling. Overall, all three methods sharpen features that are hard to distinguish in the input, significantly reduce the background noise, and do not introduce new features that are not present in the high-resolution slice. The quantitative results paint a similar picture, and are displayed in
Table 5. The difference between the three proposed methods in terms of MSE and SSIM is small, whereas the cubic up-sampling performs worse on both metrics.
Comparing method A and method B, we observe a difference between simulation and experimental data. For the pixel-limited dataset, method A performs better on the MSE and SSIM metrics, and it outputs visually more appealing and accurate results. For the real-world data, however, there appears to be qualitatively little difference between method B and method A. In this case, the coarse voxel grid seems fine enough to represent almost all details that can be reconstructed.
4.3. Comparison with Other Network Structures
In this section, we compare the results of the MS-D network to the widely used U-net approach described in [
30] on both the simulated and experimental data. The data acquisition and reconstruction procedures remain unchanged, and the U-net is trained on the low- and high-resolution data for two days or 1000 epochs, whichever comes first. As before, the metrics on the simulated data are computed based on the original phantom and the output of the network, and the metrics on the experimental data are computed based on the high-resolution target and the output of the network.
Neural network implementation The U-net network is implemented in PyTorch, and is based on a widely available open source implementation. We have provided our code as an open source package [
42]. This implementation of the U-net architecture is almost identical to that described in [
30]: the images are down-sampled four times using
max-pooling, the “up-convolutions” have trainable parameters, and the convolutions have
kernels. Like [
43], this implementation uses batch normalization before each ReLU. Moreover, the smallest image layers are 512 channels instead of 1024 channels, and zero-padding is used instead of reflection-padding. An adaptation was made to allow the network to process images whose width or height was not divisible by 16: these images were padded to the right dimensions using reflection padding. All U-net networks are trained from scratch in each experiment.
Metrics and evaluation The quantitative results are given in
Table 6, and the network outputs are visually compared in
Figure 10. On the whole, the output of the U-net is visually similar to the MS-D network, and apart from a few negative outliers, the metrics of U-net are similar to those of the MS-D network. The lower SSIM metrics of the U-net could be explained by the fact that, on the pixel-limited dataset, the U-net appears to introduce the same non-smooth texture in the foam (method A—9 slices) and in the voids (method B) that is present in the high-resolution image. Likewise, the oatmeal flakes in the U-net outputs appear to have a distinct texture, especially for method B. It appears that some care must be taken to prevent the U-net from overfitting to the training data. In
Figure 11, we compare the training and test error of the U-net and MS-D networks as training progresses. The mean square error metric is computed on the central slice of the training and test set of the oatmeal dataset. For both networks, the MSE decreases on the training slice. On the test slice, however, the MSE metric of the MS-D network remains consistently low, but the MSE of the U-net increases as training progresses, indicating that the network overfits to the training data.
5. Discussion
The experimental results demonstrate the feasibility of applying our combined acquisition scheme and on-the-fly machine learning technique to improve the resolution of tomographic reconstructions. Although our approach already achieves substantial improvement in image resolution, we believe our approach can still be improved. In this section, we discuss improvements for the training and architecture of the neural network, and how the acquisition geometry may be adapted to less self-similar objects.
We believe that training the neural network can be accomplished faster and that the training procedure can be made less sensitive to small changes in alignment. In its current form, the computations of the learning step take considerably longer than the reconstruction step. In fact, the reconstruction for both the simulated data and the experimental data took less than fifteen minutes, while the learning step took up to two days. By using a validation set, for instance, the training can be cut short when the validation error does not improve. Sacrificing part of the training set for validation appears possible without making the training set too small for the network to learn a useful transformation from low- to high-resolution data. Based on the results in
Figure 11, we expect that training for a considerably shorter period is possible, and will lead to results comparable to those reported in this paper. The neural networks were trained using the mean square error, which is sensitive to small changes in alignment. Hence, the alignment of the low-resolution and high-resolution reconstructions is critical, but can in practice not always be guaranteed. Therefore, using an error metric that does not depend on the exact alignment of the input and target data could improve robustness. Resolving this problem has received considerable attention, for instance by learning the loss function in an adversarial setting [
17,
44]. Finally, training time could be further improved in batch settings by pre-training the network with an object that is similar to the object under investigation.
The MS-D network architecture could be changed to obtain better results. Since we have not found the MS-D network to overfit to the training data, a deeper MS-D network with the capacity to exploit more input features might be able to increase resolution even more. Furthermore, we believe that a fully three-dimensional convolutional neural network might be able to achieve even better results on this task. In the synthetic data, we have found some qualitative visual difference in the output of the networks with a single input slice and those with nine input slices. This suggests that three-dimensional information can be useful for transforming low-resolution data to high-resolution data.
The experimental results indicate that, if objects are self-similar, super-resolution can be obtained using our method, thus providing a super-resolution approach that does not rely on a training set of similar objects. There are cases, however, where not all parts of the object have similar structure. For example, an object may consist of multiple parts with different characteristics. In that case, the network may be trained on multiple ROI reconstructions in these parts to ensure that it is able to improve the resolution of the various structures within the object. The areas where the local structure are different can usually be identified using just the low-resolution reconstruction.

 ,
, 











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}