Multi-Robot Exploration Based on Multi-Objective Grey Wolf Optimizer


Abstract
:1. Introduction
2. Related Work
3. Single and Multi-Objective Grey Wolf Optimizer
3.1. Grey Wolf Optimizer
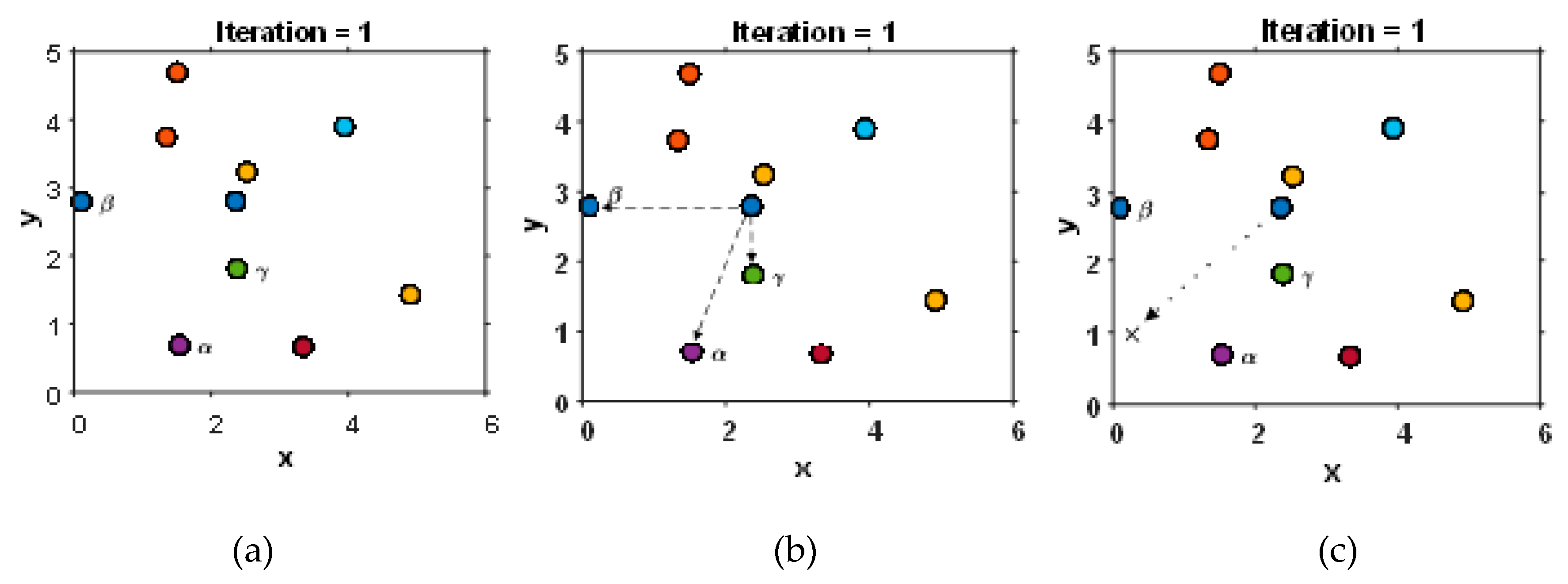
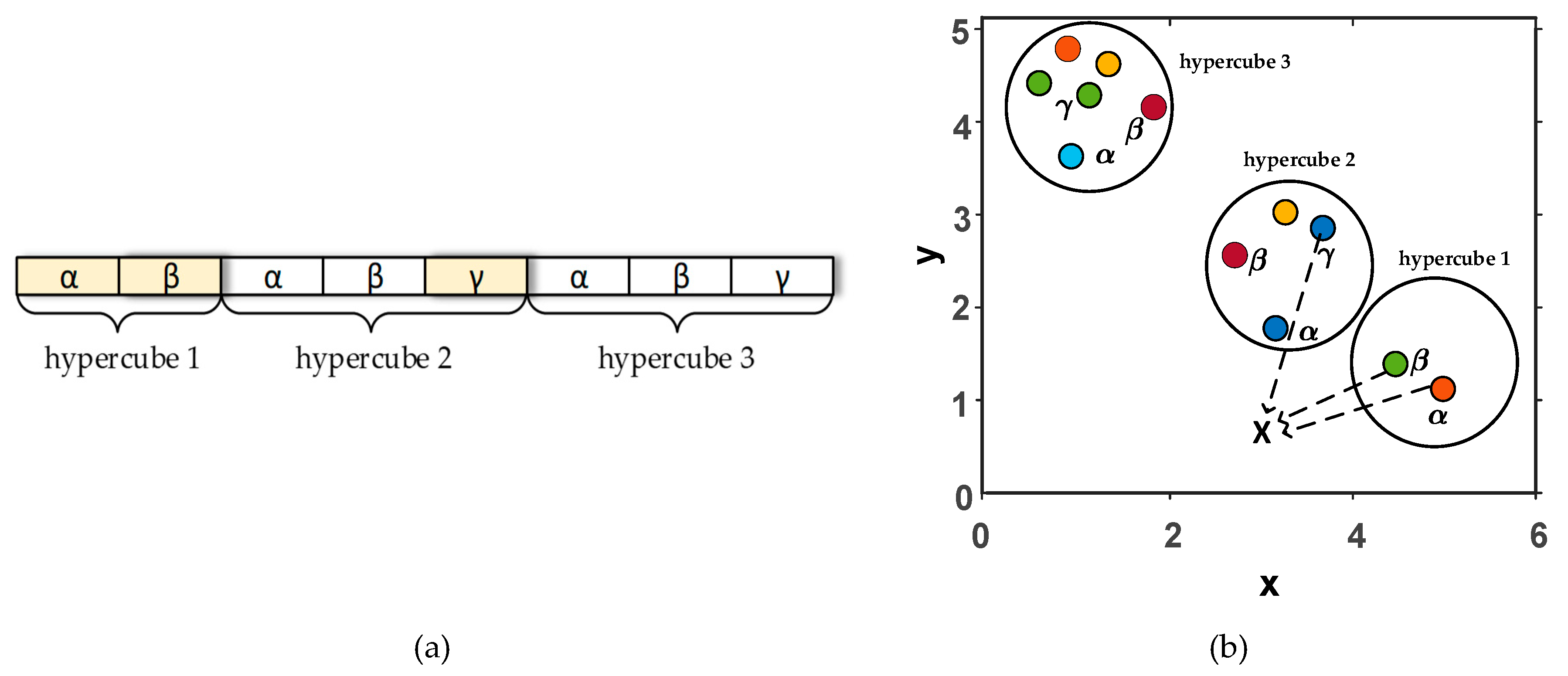
3.2. Multi-Objective Grey Wolf Optimizer
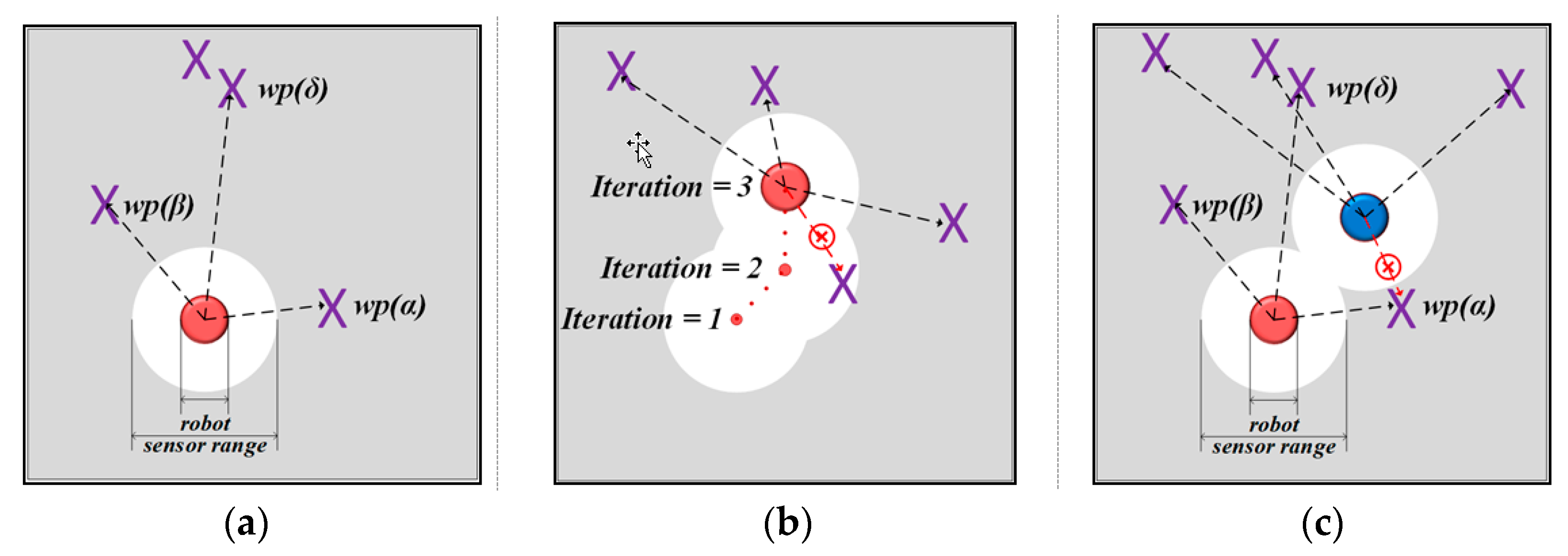
4. MOGWO Exploration for Multi-Robot System
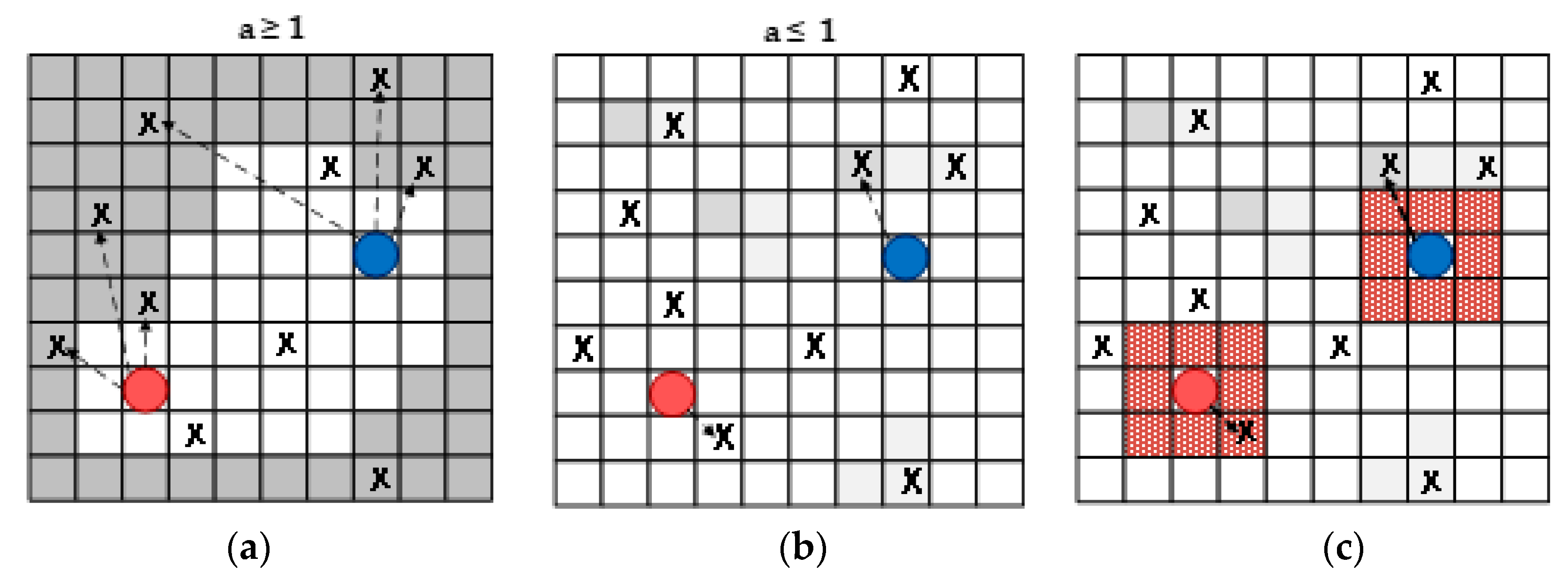
4.1. Mathematical Formulation of MOOPs in the Multi-Robot Exploration
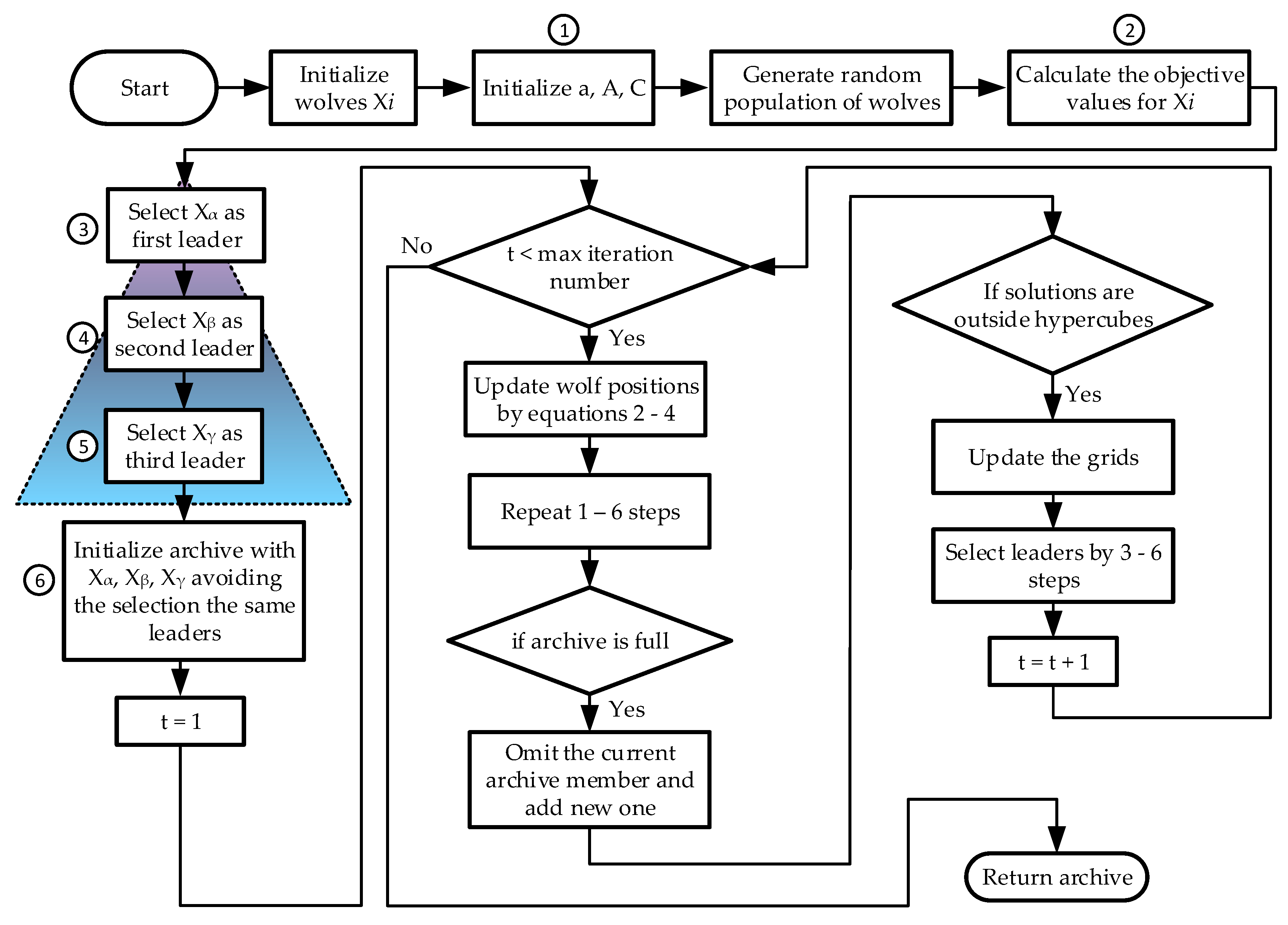
4.2. The Proposed MOGWO Exploration Algorithm
| Algorithm 1. The pseudocode of the proposed MOGWO exploration 1: Set waypoints randomly in unknown space ( 2: Set the archive is empty 3: Set initial robot position ( 4: Initialize a, A, C 5: while t is not over 6: Update A, C 7: Set the archive is empty 8: for j = 1: nRbt 9: Find current position of 10: Find frontier point (n = 1,…,8) of 11: Insert rays to the map from position 12: Calculate the distances by the objective function () 13: Calculate the probability values by objective function () for 14: if a ≥ 1 15: if is explored 16: Then, to increase cost 17: if else is unexplored 18: Then, cost 19: end if 20: Find minimum costs and save in archive 21: Find of by Equation (2) 22: Find and by Equations (3) and (4) 23: Find 24: end if 25: if a ≤ 1 26: Divide probability cost by distance cost 27: Find maximum costs and save in archive 28: Find 29: end if 30: end for 31: Reduce a 32: show map 33: end while |
5. Simulation Results and Analysis
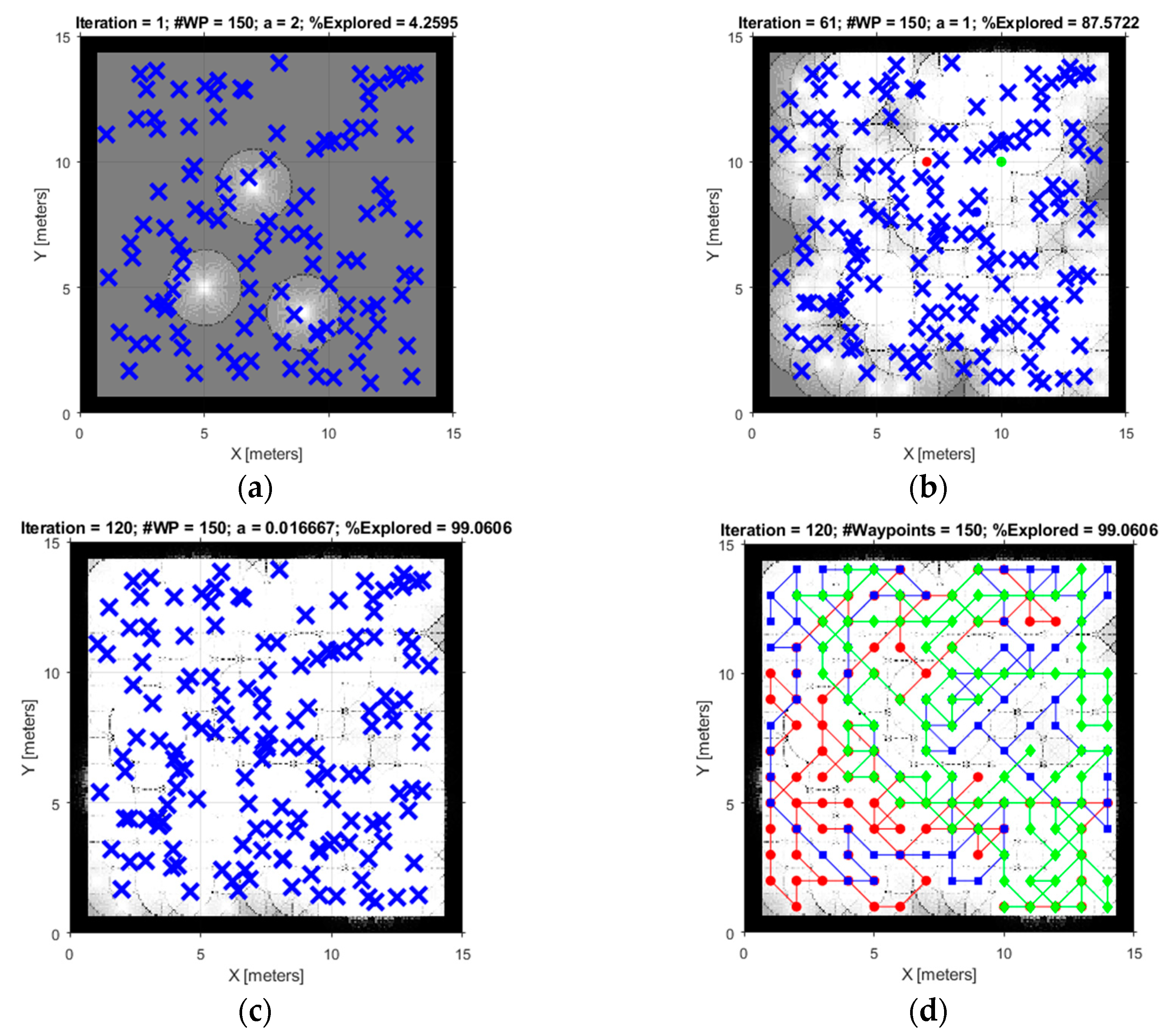
5.1. Simulation Results
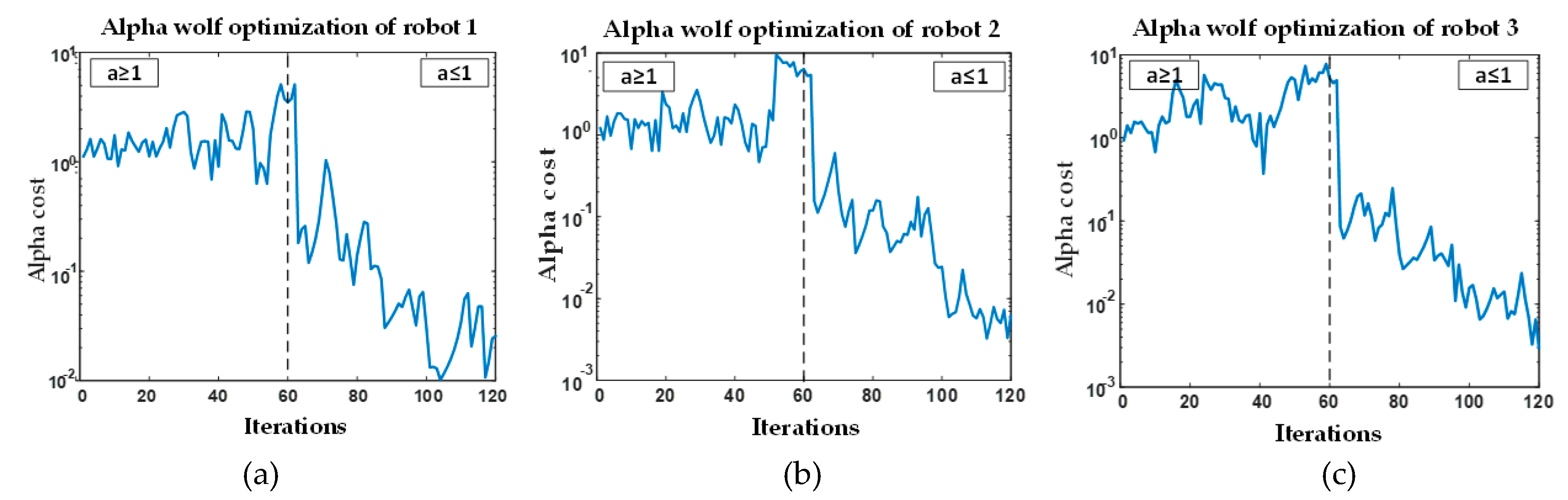
5.2. The Pareto Optimality Analysis for MOGWO Exploration Algorithm
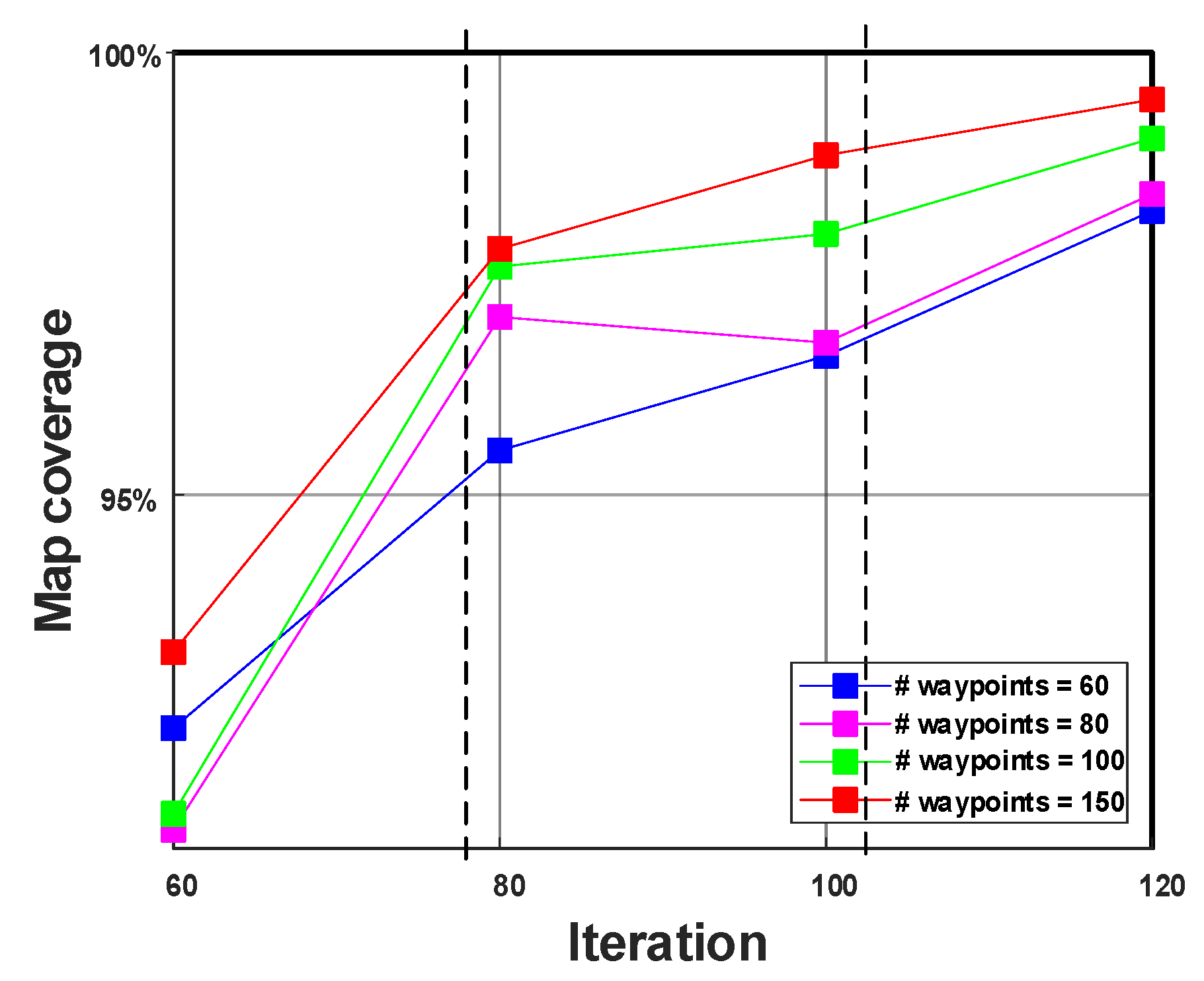
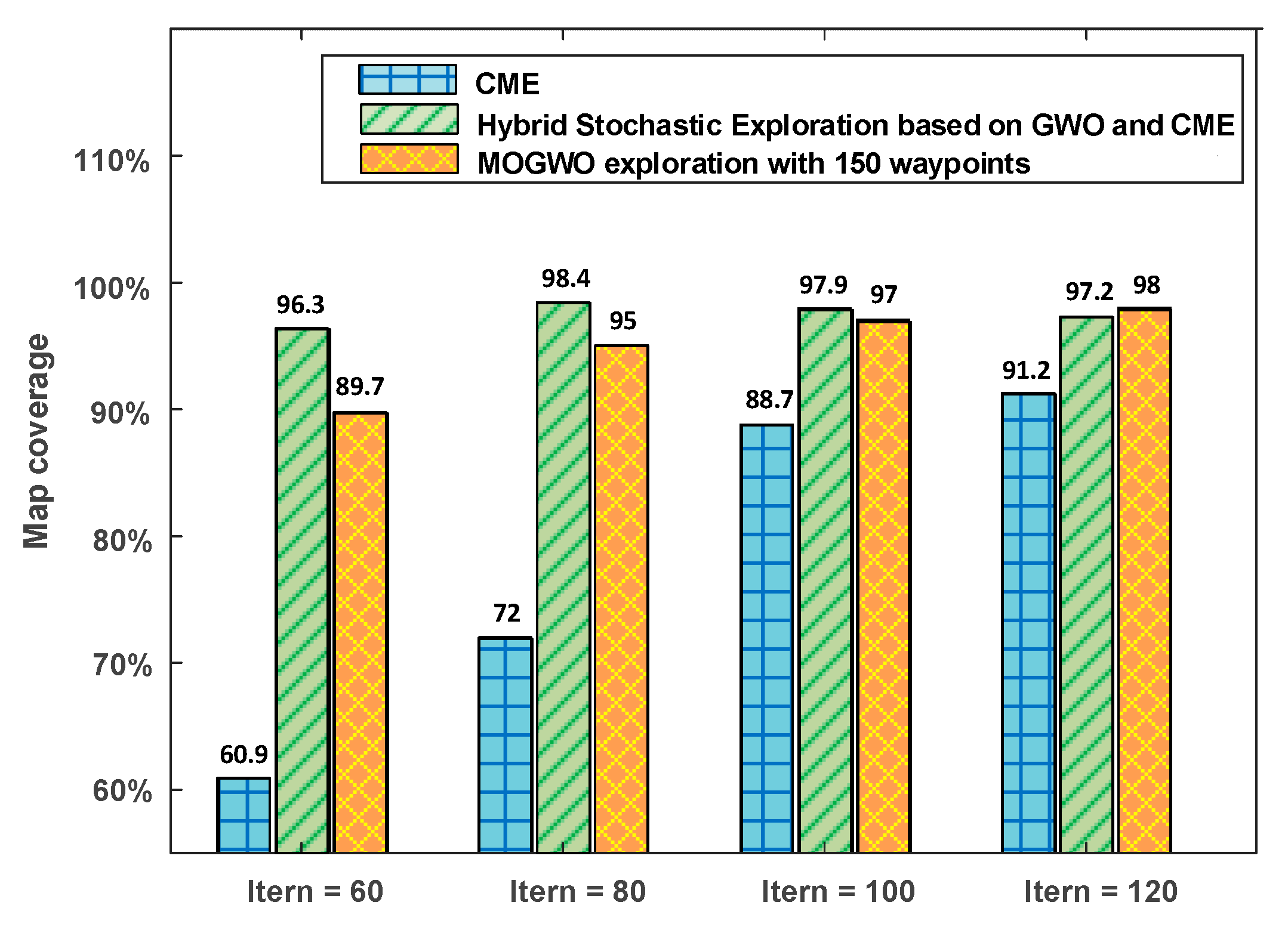
5.3. Comparison
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Limosani, R.; Esposito, R.; Manzi, A.; Teti, G.; Cavallo, F.; Dario, P. Robotic delivery service in combined outdoor–indoor environments: Technical analysis and user evaluation. Robot. Auton. Syst. 2018, 103, 56–67. [Google Scholar] [CrossRef]
- Vidal, E.; Hernández, J.D.; Palomeras, N.; Carreras, M. Online Robotic Exploration for Autonomous Underwater Vehicles in Unstructured Environments. In Proceedings of the IEEE 2018 OCEANS-MTS/IEEE Kobe Techno-Oceans (OTO), Kobe, Japan, 28–31 May 2018; pp. 1–4. [Google Scholar]
- Deb, K. Multi-objective optimization. In Search Methodologies; Springer: Boston, MA, USA, 2014; pp. 403–449. [Google Scholar]
- Amorós, F.; Payá, L.; Marín, J.M.; Reinoso, O. Trajectory estimation and optimization through loop closure detection, using omnidirectional imaging and global-appearance descriptors. Expert Syst. Appl. 2018, 102, 273–290. [Google Scholar] [CrossRef]
- Rizk, Y.; Mariette, A.; Edward, W.T. Cooperative Heterogeneous Multi-Robot Systems: A Survey. ACM Comput. Surv. (CSUR) 2019, 52. [Google Scholar]
- Zhang, Y.; Gong, D.W.; Zhang, J.H. Robot path planning in uncertain environment using multi-objective particle swarm optimization. Neurocomputing 2013, 103, 172–185. [Google Scholar] [CrossRef]
- Pang, B.; Song, Y.; Zhang, C.; Wang, H.; Yang, R. A Swarm Robotic Exploration Strategy Based on an Improved Random Walk Method. J. Robot. 2019, 2019. [Google Scholar] [CrossRef]
- Kamalova, A.; Lee, S.G. Hybrid Stochastic Exploration Using Grey Wolf Optimizer and Coordinated Multi-Robot Exploration Algorithms. IEEE Access 2019, 7, 14246–14255. [Google Scholar]
- Fong, S.; Suash, D.; Ankit, C. A review of metaheuristics in robotics. Comput. Electr. Eng. 2015, 43, 278–291. [Google Scholar] [CrossRef]
- Wadood, A.; Khurshaid, T.; Farkoush, S.G.; Yu, J.; Kim, C.-H.; Rhee, S.-B. Nature-Inspired Whale Optimization Algorithm for Optimal Coordination of Directional Overcurrent Relays in Power Systems. Energies 2019, 12, 2297. [Google Scholar] [CrossRef]
- Kim, C.H.; Khurshaid, T.; Wadood, A.; Farkoush, S.G.; Rhee, S.B. Gray wolf optimizer for the optimal coordination of directional overcurrent relay. J. Electr. Eng. Technol. 2018, 13, 1043–1051. [Google Scholar]
- Wolpert, D.H.; Macready, W.G. No free lunch theorems for optimization. IEEE Trans. Evolut. Comput. 1997, 1, 67–82. [Google Scholar] [CrossRef] [Green Version]
- Kennedy, J. Particle swarm optimization. Encycl. Mach. Learn. 2010, 760–766. [Google Scholar]
- Gen, M.; Lin, L. Genetic Algorithms. Wiley Encyc. Comput. Sci. Eng. 2007, 1–15. [Google Scholar]
- Dorigo, M.; Di Caro, G. Ant colony optimization: A new meta-heuristic. In Proceedings of the 1999 Congress on Evolutionary Computation-CEC99, Washington, DC, USA, 6–9 July 1999. [Google Scholar]
- Seyedali, M.; Lewis, A. Grey wolf optimizer. Adv. Eng. Softw. 2014, 69, 46–61. [Google Scholar]
- Mirjalili, S.; Aljarah, I.; Mafarja, M.; Heidari, A.A.; Faris, H. Grey Wolf Optimizer: Theory, Literature Review, and Application in Computational Fluid Dynamics Problems. In Nature-Inspired Optimizers; Springer: Cham, Switzerland, 2020; pp. 87–105. [Google Scholar]
- Coello, C.A.; Lechuga, M. MOPSO: A proposal for multiple objective particle swarm optimization. In Proceedings of the 2002 Congress on Evolutionary Computation. CEC’02 (Cat. No. 02TH8600), Washington, DC, USA, 12–17 May 2002. [Google Scholar]
- Konak, A.; Coit, D.W.; Smith, A. Multi-objective optimization using genetic algorithms: A tutorial. Reliab. Eng. Syst. Saf. 2006, 91, 992–1007. [Google Scholar] [CrossRef]
- Alaya, I.; Solnon, C.; Khaled, G. Ant colony optimization for multi-objective optimization problems. In Proceedings of the 19th IEEE International Conference on Tools with Artificial Intelligence (ICTAI 2007), Washington, DC, USA, 29–31 October 2007. [Google Scholar]
- Mirjalili, S.; Saremi, S.; Mirjalili, S.M.; Coelho, L.D.S. Multi-objective grey wolf optimizer: A novel algorithm for multi-criterion optimization. Expert Syst. Appl. 2016, 47, 106–119. [Google Scholar] [CrossRef]
- Burgard, W.; Moors, M.; Stachniss, C.; Schneider, F.E. Coordinated multi-robot exploration. IEEE Trans. Robot. 2005, 21, 376–386. [Google Scholar] [CrossRef] [Green Version]
- Thrun, S. A probabilistic on-line mapping algorithm for teams of mobile robots. Int. J. Robot. Res. 2001, 20, 335–363. [Google Scholar] [CrossRef]
- Mirjalili, S.; Dong, J.S.; Lewis, A. Ant Colony Optimizer: Theory, Literature Review, and Application in AUV Path Planning. In Nature-Inspired Optimizers; Springer: Cham, Switzerland, 2020; pp. 7–21. [Google Scholar]
- Kulich, M.; Kubalík, J.; Přeučil, L. An Integrated Approach to Goal Selection in Mobile Robot Exploration. Sensors 2019, 19, 1400. [Google Scholar] [CrossRef]
- Yamauchi, B. A frontier-based approach for autonomous exploration. Cira 1997, 97. [Google Scholar]
- Franchi, A.; Freda, L.; Oriolo, G.; Vendittelli, M. A randomized strategy for cooperative robot exploration. In Proceedings of the 2007 IEEE International Conference on Robotics and Automation, Roma, Italy, 10–14 April 2007. [Google Scholar]
- Franchi, A.; Freda, L.; Oriolo, G.; Vendittelli, M. The sensor-based random graph method for cooperative robot exploration. IEEE/ASME Trans. Mechatron. 2009, 14, 163–175. [Google Scholar] [CrossRef]
- Palacios, A.T.; Sánchez, L.A.; Bedolla Cordero, J.M.E. The random exploration graph for optimal exploration of unknown environments. Int. J. Adv. Robot. Syst. 2017, 14, 1729881416687110. [Google Scholar] [CrossRef]
- Tai, L.; Liu, M. Mobile robots exploration through cnn-based reinforcement learning. Robot. Biomim. 2016, 3, 24. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tai, L.; Li, S.; Liu, M. Autonomous exploration of mobile robots through deep neural networks. Int. J. Adv. Robot. Syst. 2017, 14. [Google Scholar] [CrossRef]
- Caley, J.A.; Lawrance, N.R.; Hollinger, G.A. Deep learning of structured environments for robot search. In Proceedings of the 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Daejeon, South Korea, 9–14 October 2016. [Google Scholar]
- Papoutsidakis, M.; Kalovrektis, K.; Drosos, C.; Stamoulis, G. Design of an Autonomous Robotic Vehicle for Area Mapping and Remote Monitoring. Int. J. Comput. Appl. 2017, 167, 36–41. [Google Scholar] [CrossRef]
- Tai, L.; Liu, M. Deep-learning in mobile robotics-from perception to control systems: A survey on why and why not. arXiv 2016, arXiv:1612.07139. [Google Scholar]
- Sharma, S.; Shukla, A.; Tiwari, R. Multi robot area exploration using nature inspired algorithm. Biol. Inspir. Cognit. Archit. 2016, 18, 80–94. [Google Scholar] [CrossRef]
- Wang, D.; Wang, H.; Liu, L. Unknown environment exploration of multi-robot system with the FORDPSO. Swarm Evolut. Comput. 2016, 26, 157–174. [Google Scholar] [CrossRef]
- De Almeida, J.P.L.S.; Nakashima, R.T.; Neves-Jr, F.; de Arruda, L.V.R. Bio-inspired on-line path planner for cooperative exploration of unknown environment by a Multi-Robot System. Robot. Auton. Syst. 2019, 112, 32–48. [Google Scholar] [CrossRef]
- Puig, D.; García, M.A.; Wu, L. A new global optimization strategy for coordinated multi-robot exploration: Development and comparative evaluation. Robot. Auton. Syst. 2011, 59, 635–653. [Google Scholar] [CrossRef]
- Benavides, F.; Ponzoni Carvalho Chanel, C.; Monzón, P.; Grampín, E. An Auto-Adaptive Multi-Objective Strategy for Multi-Robot Exploration of Constrained-Communication Environments. Appl. Sci. 2019, 9, 573. [Google Scholar] [CrossRef]
- Thabit, S.; Mohades, A. Multi-Robot Path Planning Based on Multi-Objective Particle Swarm Optimization. IEEE Access 2019, 7, 2138–2147. [Google Scholar] [CrossRef]
- Chen, X.; Zhang, P.; Du, G.; Li, F. Ant colony optimization based memetic algorithm to solve bi-objective multiple traveling salesmen problem for multi-robot systems. IEEE Access 2018, 6, 21745–21757. [Google Scholar] [CrossRef]
- Hu, P.; Chen, S.; Huang, H.; Zhang, G.; Liu, L. Improved alpha-guided Grey wolf optimizer. IEEE Access 2018, 7, 5421–5437. [Google Scholar] [CrossRef]
- Long, W.; Wu, T.; Cai, S.; Liang, X.; Jiao, J.; Xu, M. A Novel Grey Wolf Optimizer Algorithm with Refraction Learning. IEEE Access 2019, 7, 57805–57819. [Google Scholar] [CrossRef]
- Han, T.; Wang, X.; Liang, Y.; Wei, Z.; Cai, Y. A Novel Grey Wolf Optimizer with Random Walk Strategies for Constrained Engineering Design. In Proceedings of the International Conference on Information Technology and Electrical Engineering, Bandung, Padang, Indonesia, 22–25 October 2018. [Google Scholar]
- Heidari, A.A.; Pahlavani, P. An efficient modified grey wolf optimizer with Lévy flight for optimization tasks. Appl. Soft Comput. 2017, 60, 115–134. [Google Scholar] [CrossRef]
- Gupta, S.; Deep, K. A novel random walk grey wolf optimizer. Swarm Evolut. Comput. 2019, 44, 101–112. [Google Scholar] [CrossRef]
- Fatima, A.; Javaid, N.; Anjum Butt, A.; Sultana, T.; Hussain, W.; Bilal, M.; Ilahi, M. An Enhanced Multi-Objective Gray Wolf Optimization for Virtual Machine Placement in Cloud Data Centers. Electronics 2019, 8, 218. [Google Scholar] [CrossRef]
- Sahoo, A.; Chandra, S. Multi-objective grey wolf optimizer for improved cervix lesion classification. Appl. Soft Comput. 2017, 52, 64–80. [Google Scholar] [CrossRef]
- Wu, C.; Wang, J.; Chen, X.; Du, P.; Yang, W. A novel hybrid system based on multi-objective optimization for wind speed forecasting. Renew. Energy 2020, 146, 149–165. [Google Scholar] [CrossRef]
- Qin, H.; Fan, P.; Tang, H.; Huang, P.; Fang, B.; Pan, S. An effective hybrid discrete grey wolf optimizer for the casting production scheduling problem with multi-objective and multi-constraint. Comput. Ind. Eng. 2019, 128, 458–476. [Google Scholar] [CrossRef]
- Available online: https://www.mathworks.com/help/robotics/ref/robotics.occupancygrid-class.htmlU30T (accessed on 20 July 2019).
- Kumar, N.; Vámossy, Z.; Szabó-Resch, Z.M. Robot path pursuit using probabilistic roadmap. In Proceedings of the 2016 IEEE 17th International Symposium on Computational Intelligence and Informatics (CINTI), Budapest, Hungary, 17–19 November 2016; pp. 139–144. [Google Scholar]
- Available online: https://youtu.be/b_IiUjwM-bQ (accessed on 15 July 2019).










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Value |
|---|---|
| Initial poses | r1 = (5,5), r2 = (7,9), r3 = (4,9) |
| Map size | 15 × 15 |
| Obstacle Width | 0.5 |
| Ray Length | 1.5 |
| Probabilities of occupancy cells | P(robotRx,yR) = 0.0010 |
| P(obstacleRx,yR) = 0.9990 | |
| P(unexploredRx,yR) = 0.5000 | |
| P(unexploredRx,yR) > P(exploredRx,yR) ≥ P(robotRx,yR) |
| Number of Waypoints | Number of Iterations | |||
|---|---|---|---|---|
| 60 | 80 | 100 | 120 | |
| 60 | 90.17 92.36 82.08 85.55 89.10 85.36 86.58 85.52 90.62 86.79 90.01 82.14 87.78 88.84 88.00 86.03 87.62 89.68 81.42 88.60 92.15 88.48 85.58 84.89 84.16 86.74 86.61 83.59 91.63 84.70 | 92.42 91.16 88.27 90.20 87.91 87.90 90.72 91.70 94.03 91.11 89.21 88.30 93.94 88.85 93.18 90.65 85.15 92.61 94.39 89.23 93.05 90.43 91.99 89.39 93.40 94.95 95.50 93.14 92.40 95.23 | 91.51 85.93 93.54 95.92 96.07 93.47 92.07 92.30 190.33 87.92 95.22 91.70 95.30 88.25 95.76 88.89 93.60 93.46 92.21 90.34 92.77 92.81 91.31 94.86 93.50 88.99 91.83 96.57 94.61 92.46 | 98.21 95.81 95.38 89.61 89.62 89.03 94.26 98.02 96.59 92.89 95.22 93.38 96.33 91.68 94.10 95.99 91.63 93.65 91.60 91.22 97.20 94.28 91.69 95.57 95.84 92.64 95.48 94.63 97.47 97.33 |
| 80 | 90.53 89.00 89.24 90.01 90.24 89.59 88.92 88.62 86.90 87.66 84.95 91.15 89.38 87.89 88.41 88.39 90.47 87.61 82.78 87.21 82.00 82.86 91.21 84.37 89.07 89.44 88.21 89.54 87.64 89.23 | 96.28 93.19 94.32 93.73 94.72 92.70 95.38 96.69 91.98 89.37 90.90 92.56 92.05 93.81 92.11 90.56 97.01 94.86 95.15 94.39 90.49 93.43 91.49 95.56 93.47 90.93 91.19 94.18 92.93 88.49 | 90.16 95.48 94.30 90.94 96.16 86.94 96.42 96.67 94.17 94.85 93.84 95.92 96.61 94.65 94.66 96.51 95.20 92.80 94.89 93.81 96.76 93.81 96.72 95.43 92.19 95.63 91.21 94.38 93.71 92.50 | 96.68 94.28 86.57 97.28 95.38 94.13 98.40 94.95 97.86 94.07 95.16 96.54 96.14 95.16 97.52 94.90 94.76 97.84 96.92 95.63 94.72 92.89 95.91 96.74 94.38 94.67 98.01 97.78 98.45 92.14 |
| 100 | 90.12 87.49 90.16 88.19 87.59 90.10 89.32 92.26 88.19 88.81 87.18 89.89 80.68 87.74 89.14 89.01 89.23 91.39 84.98 88.36 90.95 90.45 87.77 89.86 88.52 86.66 88.18 91.14 86.81 89.48 | 95.34 89.59 93.45 92.88 95.47 95.37 97.58 96.16 91.33 93.93 93.17 95.23 93.77 93.65 95.73 95.55 93.25 94.18 94.71 95.08 92.78 92.91 91.44 86.62 92.31 93.42 92.71 92.62 94.45 94.70 | 95.11 94.45 96.69 97.29 95.81 96.48 93.90 96.97 96.57 96.03 94.61 97.52 92.49 97.32 95.99 96.97 97.49 97.72 97.27 95.42 95.84 94.40 97.11 92.47 94.00 93.77 95.49 97.95 95.40 97.09 | 97.78 97.05 95.14 97.48 95.13 97.11 96.86 98.48 96.17 97.07 96.51 98.17 93.09 96.31 97.09 96.16 98.40 96.43 97.24 96.49 96.67 96.23 95.15 97.56 95.75 95.89 96.38 99.03 94.30 98.03 |
| 150 | 91.15 92.52 92.83 91.41 91.97 86.52 92.14 85.72 92.02 87.60 89.30 91.56 89.73 91.20 84.98 88.67 90.40 88.26 90.52 80.15 88.25 88.63 92.41 93.22 93.22 92.24 88.31 90.85 91.21 86.41 | 96.26 90.48 94.41 95.21 96.27 95.72 95.38 93.91 96.80 95.70 95.75 94.94 95.82 93.62 96.76 91.84 95.58 95.02 96.50 95.98 93.46 96.55 95.52 95.62 95.38 97.78 94.24 93.77 95.94 91.67 | 98.48 98.06 98.41 96.60 98.84 97.24 95.91 95.21 96.83 97.53 97.71 97.34 98.52 95.53 98.54 96.67 97.64 97.26 93.97 96.51 95.28 97.56 96.43 96.52 96.97 95.96 98.27 98.78 96.67 97.27 | 99.06 98.94 98.96 95.48 98.97 97.40 98.21 98.15 97.13 98.33 98.11 97.54 98.31 97.61 96.17 98.19 98.69 98.11 97.26 98.63 94.85 98.13 98.26 98.92 98.49 98.52 97.71 99.47 98.94 98.04 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kamalova, A.; Navruzov, S.; Qian, D.; Lee, S.G. Multi-Robot Exploration Based on Multi-Objective Grey Wolf Optimizer. Appl. Sci. 2019, 9, 2931. https://doi.org/10.3390/app9142931
Kamalova A, Navruzov S, Qian D, Lee SG. Multi-Robot Exploration Based on Multi-Objective Grey Wolf Optimizer. Applied Sciences. 2019; 9(14):2931. https://doi.org/10.3390/app9142931
Chicago/Turabian StyleKamalova, Albina, Sergey Navruzov, Dianwei Qian, and Suk Gyu Lee. 2019. "Multi-Robot Exploration Based on Multi-Objective Grey Wolf Optimizer" Applied Sciences 9, no. 14: 2931. https://doi.org/10.3390/app9142931
APA StyleKamalova, A., Navruzov, S., Qian, D., & Lee, S. G. (2019). Multi-Robot Exploration Based on Multi-Objective Grey Wolf Optimizer. Applied Sciences, 9(14), 2931. https://doi.org/10.3390/app9142931