1. Introduction
Closed-circuit television (CCTV) systems are composed of one or more surveillance cameras connected to one or more video monitors [
1]. This type of security system tries to prevent dangerous situations such as intrusions or armed robberies. Usually, human operators observe these events and activate action protocols when a dangerous situation occurs. However, these systems have the disadvantage that they depend on human detection to activate alarms or action protocols. In [
2] it is shown that an operator’s ability to accurately observe activity on a screen is reduced by up to 45% after 12 min of constant monitoring. The failure rate increases to 95% after 22 min. Normally, the high cost of surveillance systems with additional monitoring services is a deterrent to their wide-scale use. In many cases, businesses only implement surveillance cameras without additional monitoring services for their protection. One way to reduce or avoid this type of crime could be the real-time detection of firearms in dangerous situations such as armed robberies. This would provide a faster reaction from security forces, because the detection would be made at the same time that the gun is first detected on the scene. This would allow security forces to be notified simultaneously with the activation of alarms in incidents involving a firearm, thus having a deterrent effect on the attackers. This system could also work as a support system, notifying those observing the monitors.
The problem with firearms detection in CCTV videos has been addressed in many different ways, firstly using classic machine learning algorithms like K-means to make color-based segmentation, combining it with algorithms like SURF (speeded up robust features), Harris interest point detector, and FREAK (fast retina keypoint) to make the detection and localization of the gun [
2,
3]. In [
4] the authors use algorithms like SIFT (scale-invariant feature transform) to extract different features of the image, combining it with K-means clustering and support vector machines to decide whether an image has a gun or not. The authors in [
5] use algorithms like background and canny edge detection in combination with the sliding window approach and neural networks to detect and localize the gun. The disadvantage of these systems is that they use a database where the gun occupies most of the image, which does not represent authentic scenarios in which a firearm is involved. Therefore, these systems are not optimal for continuous monitoring where the images extracted from CCTV videos have a high complexity due to the multiple factors involved or where there are open areas with many objects around.
This problem has also been addressed with more complex algorithms like deep convolutional neural networks (CNNs). In [
6] the authors used transfer learning, utilizing faster R-CNN trained in a database with only high-quality and low-complexity images. The authors show that the best system that was evaluated in well-known films garnered a low recall produced by the frames with very low contrast and luminosity. It also obtained false positives in the detection produced by the objects in the background of the image, which could be produced because multiple areas of the image are analyzed with the sliding window and region proposals approaches to detect and localize the gun. The authors in [
7] face this problem using a symmetric dual camera system and CNNs, using a database made by the authors. However, the most common cameras in CCTV systems are not dual cameras [
8], and therefore the use of this system would not apply to most retail businesses.
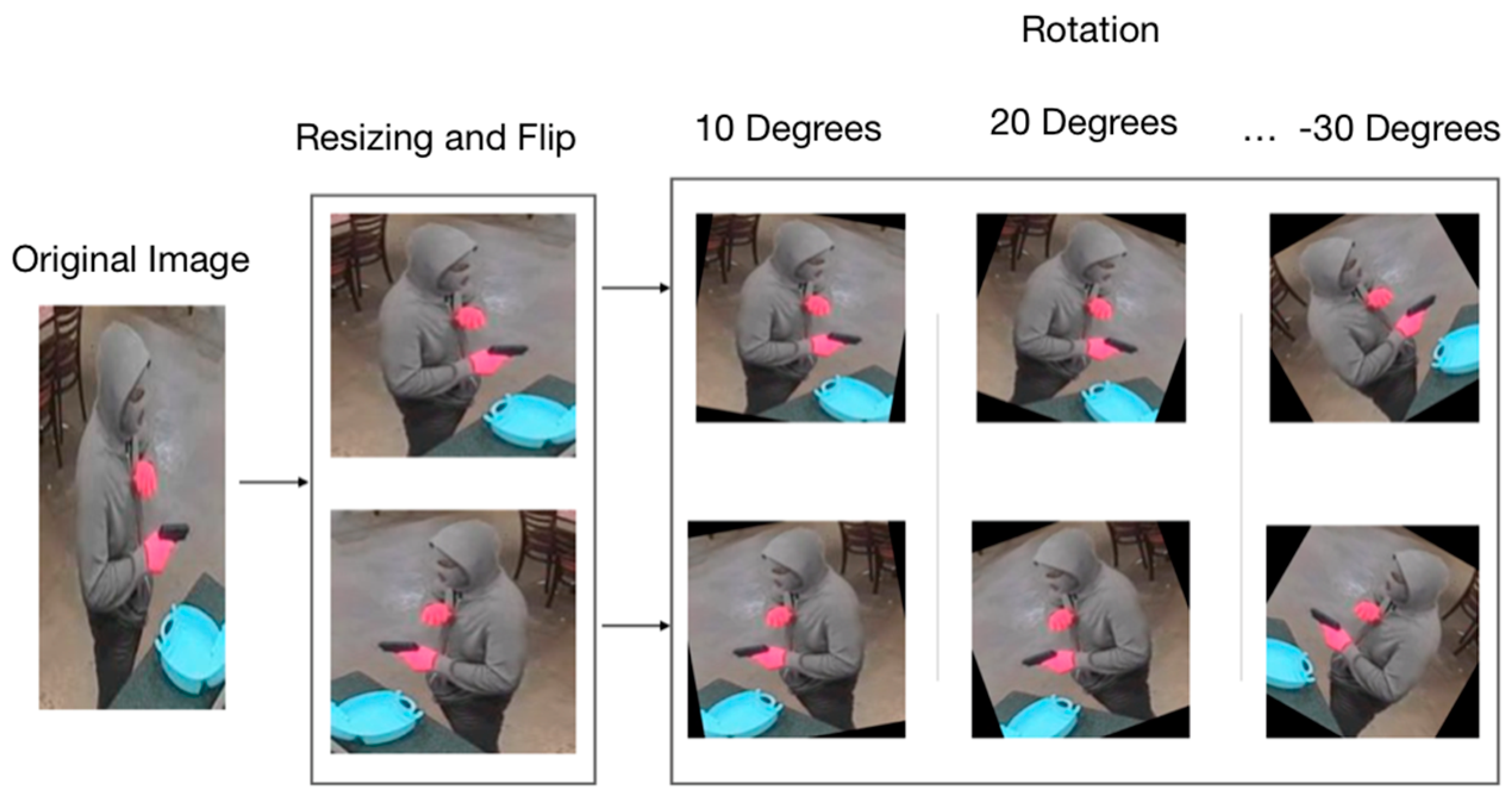
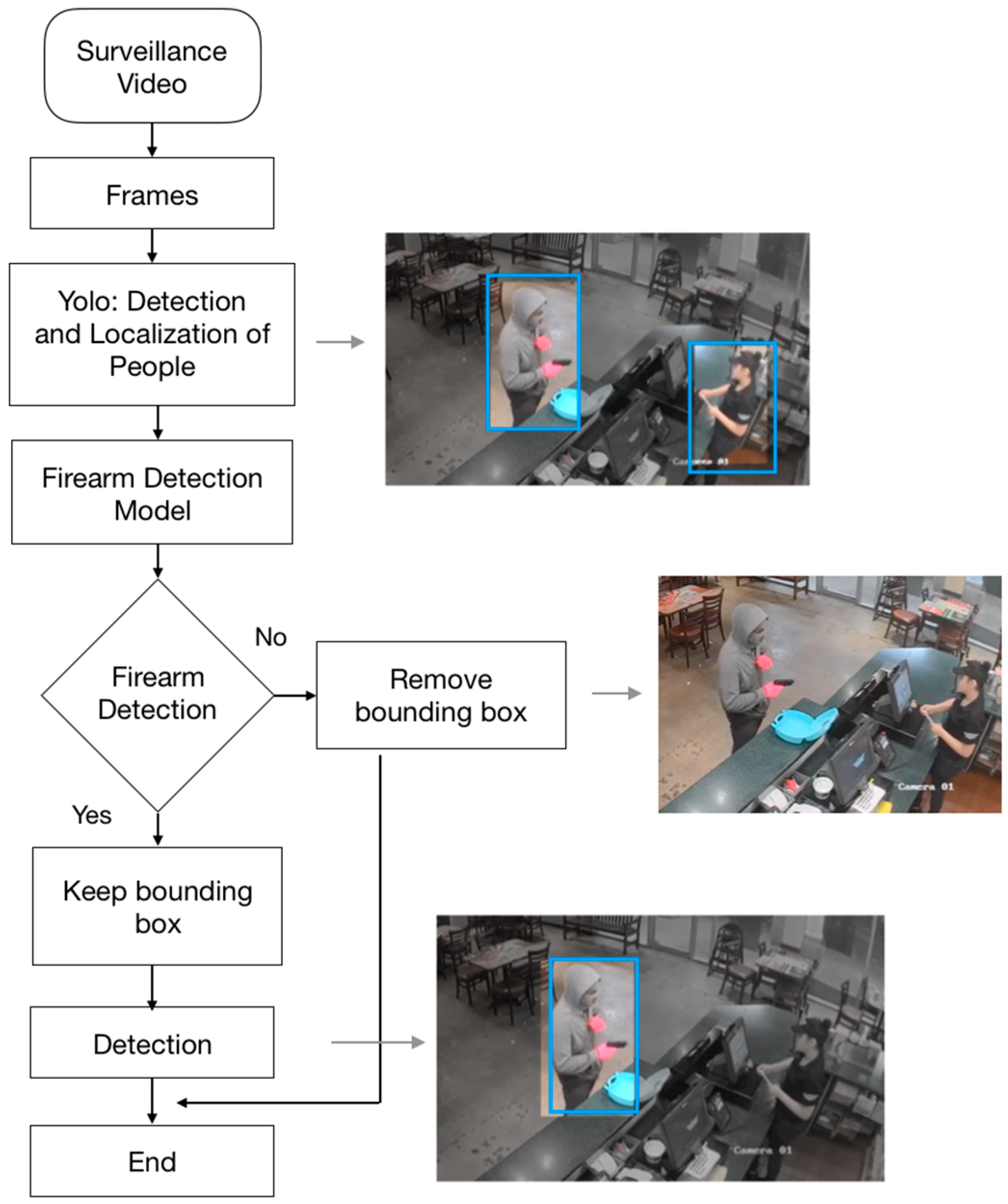
The most common problems that we found were first that the developed systems use small databases that do not represent authentic robbery scenarios, where many factors are involved. Small and medium markets and businesses use low-cost cameras that capture low-quality video. Luminosity is a risk factor in firearm detection; robberies can be done at any time of the day. Additionally, firearm position is an important factor; the gun can be shown in multiple positions. Second, the sliding window and region proposals approaches that are used for detection and localization of the gun analyze multiple places in the image where a gun could never be found. This could contribute to obtaining a large number of false positives, because the system could easily confuse a number of harmless objects with a gun. Once it is established that a firearm is most likely only to be found next to people, then the close monitoring of any image needs to be in and around the people in the image. To overcome the limitations of the described developed systems, we propose a firearm detection system made up of two convolutional models, in order to focus the detection system only in the part of the image where people are located. It uses the YOLO object detection and localization system [
9] and the convolutional model to detect firearms that is developed in this work. The development of this model was done with a new large database of images extracted from surveillance videos and other situations that simulate for the most part a real robbery, considering factors like luminosity in the image, image quality, firearm position, and camera position.
This paper is organized as follows. In
Section 2, we describe the database and the system architecture. In
Section 3, we present the experiments and the final results. Finally, in
Section 4, the conclusions are presented.
4. Conclusions
This paper addressed the development of a firearm detection system. Two convolutional models were used in order to discard areas of the image that are irrelevant for the detection and to focus the firearm detection model only on the areas of the image where people are located. The results showed that with this configuration we were able to reduce the complex environment of real robbery scenarios, taking only the segments of the image where there were people, since these segments are the most important areas of the image to make a detection. Using a convolutional network architecture in the firearm detection model based on VGG Net allowed us to obtain a relative improvement in this application of 21.4% in loss and 3.33% in accuracy, compared to a convolutional network architecture based on ZF Net. The use of grayscale images allowed us to obtain a better performance, having an improvement of 0.22% in accuracy and 34.3% in loss in the evaluation phase of the network, compared to the results obtained with RGB images. In the final performance of the detection system, we obtained 86% precision and 86% recall, which are not the best results. However, to improve this performance, as future research lines it would be interesting to use the same architecture with the two convolutional models to focus the detection system only in the important parts of the image, but using a new model to detect firearms either by training the model on a larger database or using other models and adapting it to this problem with transfer learning.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}