1. Introduction
Optical coherence tomography angiography (OCTA) is a non-invasive imaging method that images the three-dimensional retinal microvasculature by detecting the motion contrast of blood flow in the retina without intravenous dye injections [
1]. OCTA visualizes the retinal microvasculature with higher contrast and better resolution than fluorescein angiography (FA) [
2]. The high contrast and resolution in OCTA images make it possible to evaluate the retinal microvasculature quantitatively, including vessel density and nonperfusion areas, more effectively than in FA images [
3,
4].
OCTA artifacts [
5] (i.e., motion artifacts) and OCTA scanning protocols [
6] (i.e., wide-angle scanning or small A-scan sampling density) easily degrade OCTA image quality, which prevents accurate interpretation and quantitative analysis of OCTA images even in normal populations [
7]. Therefore, methods for improving OCTA image quality are important. Uji et al. [
8,
9,
10] and Maloca et al. [
11] reported that averaging multiple en face OCTA images improved the OCTA image quality, removing background noise and enhancing the continuity of the vessel, and affected the OCTA data quantitatively and qualitatively. However, substantial image recording time with multiple image acquisitions is a major problem.
Deep learning, which is one of the most common artificial intelligence techniques, reportedly provides a promising solution in image-based medical diagnoses, such as glaucoma and diabetic retinopathy [
12,
13]. Previous studies have shown that deep learning can enhance the quality of various medical images including ultrasound [
14], magnetic resonance imaging [
15,
16], and optical coherence tomography B-scan images [
17]. Since deep learning has the potential to generate a high-quality OCTA image from a single shot image without multiple image acquisition, the application of deep learning to en face OCTA imaging is expected to provide high-quality retinal microvasculature images in a short time. However, to date, OCTA image quality enhancement via deep learning has never been reported.
In this study, we developed a novel deep learning-based algorithm for noise reduction (denoising) in en face OCTA imaging and evaluated the effects of deep learning denoising on the image quality and image acquisition time.
2. Materials and Methods
This was a prospective, observational, cross-sectional case series study. The Institutional Review Board of Kyoto University Graduate School of Medicine (Kyoto, Japan) approved this study (000028853), which was conducted according to the tenets of the Declaration of Helsinki. Written informed consent from each subject was obtained before performing any study procedures or examinations.
2.1. Participants
Patients with various retinal vascular diseases examined at the Department of Ophthalmology of Kyoto University Hospital between June 2018 and September 2018 were enrolled in the study. All patients underwent a comprehensive ophthalmic examination including measurement of best-corrected visual acuity, slit-lamp biomicroscopy, color fundus photography, and OCTA.
Eyes with keratoconus, high myopia (more severe than -6 diopters or longer than 26.5 mm), or high astigmatism (more severe than ±3 diopters) were excluded. Eyes with OCTA images of poor quality were excluded if significant media opacity was present, if the signal strength was less than 7, or if there were severe motion artifacts (e.g., motion lines).
2.2. OCTA Imaging
Each subject was scanned using a spectral-domain OCTA instrument (OCT HS-100; Canon, Inc., Tokyo, Japan). The OCT HS-100 has a scanning rate of 70,000 A-scans/s; a central wavelength of 855 nm; a full-width at half maximum of 100 nm, which enables 3 μm axial resolution in tissue; and a lateral resolution at the retinal surface of 15 μm. The OCT HS-100 scanned the macular area centered on the fovea and measured an area of 3 × 3 mm2 (232 × 232 pixels) 10 times with pupil dilation. Then, the 10-frame-averaged en face OCTA images for each subject were created using built-in software in OCT HS-100. The superficial capillary plexus (SCP) was obtained and analyzed using the commercial default automated segmentation boundaries.
Intelligent Denoise (Canon, Inc., Tokyo, Japan), which is a deep learning denoising method developed by Canon, Inc., was utilized to create the denoised en face OCTA image (denoised image). The first en face OCTA image acquisition obtained from 10 scanning sequences was defined as the original image. The original image was processed as the input image, and then the denoised image was automatically output. The system exported three images (original, averaged, and denoised) for further analyses.
The image acquisition time of each image was measured, i.e., the time from when the image acquisition start button was pressed until the viewer displayed the OCTA image.
2.3. Network Architecture of Deep Learning Denoising Method and Training Protocol
The U-Net architecture was employed to Intelligent Denoise (Canon, Inc., Tokyo, Japan), which is an encoder–decoder-style neural network that solves semantic segmentation tasks [
18]. This network consisted of two parts. Firstly, an encoder took an image tile as input and successively computed feature maps on multiple scales. Secondly, a decoder took the feature representation and classified all pixels/voxels at the original image resolution in parallel. The layers in the decoder synthesized the image, starting at low-resolution feature maps and moving to full-resolution feature maps.
For training, 23,744 datapoints were selected from a set of 742 patients (disease: 595, healthy: 147), which included subjects who received OCTA imaging (OCT HS-100, Canon, Inc., Tokyo, Japan) at Kyoto University Hospital. We labeled the single-shot en face OCTA images as noise patches and the images based on averaged en face OCTA images as denoised patches. Training was performed using a computer with 64 GB of RAM, 4TB HDD, and an NVIDIA 1080Ti 11GB Graphics Processing Unit. The Intelligent Denoise software converted the noisy input en face OCTA images into denoised images.
2.4. Quantitative Image Analyses
For objective image quality comparison, the contrast-to-noise ratio (CNR) was calculated as described previously [
9,
19], using the following equation:
where
and
are the mean gray values of the foreground and background, respectively; and
and
are the standard deviations from the mean values of
and
, respectively. For this calculation, a circular area within the foveal avascular zone (FAZ) was selected as the background region of interest (ROI) and four circular areas at four corners of OCTA image as the foreground ROIs (
Supplementary Figure S1). The diameters of these ROIs were 20 pixels (corresponding to areas of about 314 pixels
2). To match the ROIs among three images (the original, averaged, and denoised images), an ROI manager (
https://imagej.nih.gov/ij/developer/api/ij/plugin/frame/RoiManager.html), which recorded the exact locations of the ROIs, was used. The CNR was calculated by automatic execution of ImageJ version 1.52b (National Institutes of Health, Bethesda, MD;
https://imagej.nih.gov/ij/index.html) by using a macro that automates a series of ImageJ commands.
Because Intelligent Denoise generated the denoised image using averaged images as training data, the peak signal-to-noise ratio (PSNR), which represents image structural similarity [
20], was calculated in the original and denoised images by setting the averaged images as the reference images (ground truths). The definition of the PSNR is
where
stands for mean square error and
stands for the greatest potential pixel intensity in image
, which is 255 in the case of an 8-bit grey scale image. A higher PSNR of the sample image indicates good similarity between the ground truth (averaged image) and sample image (original or denoised image). ImageJ calculated the PSNR automatically via the SNR plug-in (
http://bigwww.epfl.ch/sage/soft/snr/).
The vessel density (VD), vessel length density (VLD), vessel diameter index (VDI), and fractal dimension (FD) were measured for quantitative analysis of the microvascular density and morphology comparison among the original, averaged, and denoised images in SCP by automatic execution of ImageJ by using a macro. The built-in software in the OCT HS-100 automatically created binarized and skeletonized images and exported them with dimensions of 500 × 500 pixels.
The VD was assessed on the binarized image, defined as the ratio of the area occupied by vessels (white pixels) divided by the total area. The VLD, which represents the length of blood vessels per unit area, was evaluated as described previously [
3,
9]. The VDI, which represents the average vessel caliber, was calculated by dividing the total vessel area in the binarized image by the total vessel length in the skeletonized image. The FD, which represents the vascular complexity [
21,
22], was determined on the skeletonized image by using the Box Counting plug-in (
https://imagej.nih.gov/ij/plugins/fraclac/FLHelp/BoxCounting.htm). The FD can range from 0 to 2, and images with more complex vessel branching patterns have higher FDs [
21].
2.5. Expert Comparison of Image Quality
Two experienced ophthalmologists (A.U. and Y.M.) masked to the image information performed independent expert comparisons of original and averaged image pairs or original and denoised image pairs. The ophthalmologists graded 112 pairs of en face OCTA images in total. We arranged the images in two panels (left and right) to facilitate comparison with random assignment of the original versus averaged or original versus denoised images to the left and right panels. The graders assigned scores for comparative image quality between image pairs based on the following three parameters, in line with previous research [
9]: (1) vessel quality (contrast and continuity), (2) nonvascular area quality (background noise level), and (3) overall image quality score (overall clarity) to each pair of images. A comparative image quality score was assigned to each image pair as follows: 2 = the left image is definitely better; 1 = the left image is slightly better; 0 = the two images are equal; −1 = the right image is slightly better; and −2 = the right image is definitely better. If the graders disagreed in a particular case, they made an open decision to produce a single determination.
2.6. Evaluation of Artifacts in Denoised Images
Deep learning denoising generated two major artifacts in the denoised images. One was “capillary over-dropped out” and the other was “capillary over-generation (pseudo-vessel)”. We arranged the images in two panels (left and right) to facilitate comparison with assignment of the averaged and denoised images to the left and right panels (we set the averaged images as the reference images and placed them on the left side). The two graders (A.U and Y.M) scored the degrees of these two artifacts in the denoised images as follows: 0 = there are no artifacts; −1 = the denoised image has slight artifacts; and −2 = the denoised image definitely has artifacts. If the graders disagreed, they made an open decision to produce a single determination.
2.7. Statistical Analyses
Statistical analyses were performed using JMP® 14 (SAS Institute Inc., Cary, NC, USA), presenting all values as the mean ± standard deviation. We compared the differences in the VD, VLD, VDI, FD, and CNR values and image acquisition times for the original, averaged, and denoised images using one-way analysis of variance with the Tukey HSD test for multiple comparison. We assessed the PSNR values obtained from the original and denoised images with paired t-tests and analyzed the scores that the two graders provided by performing paired t-tests as well. We evaluated the interobserver reproducibility between the two graders by using the kappa statistic . We considered P values less than 0.05 to be statistically significant.
3. Results
Four eyes from five patients that did not meet the inclusion criteria in image quality (signal strength greater than 7) using the 3 × 3 mm2 OCTA scan protocol were excluded, leaving 112 eyes from 108 patients for further analyses. The patients had a mean age of 64.2 ± 13.1 years (range: 33–84 years). Among the patients, 60 were male and 48 were female.
The image acquisition times for the original, averaged, and denoised images were 16.6 ± 2.4, 285 ± 38, and 22.1 ± 2.4 s, respectively. The denoised image had a significantly shorter acquisition time than the averaged image (P < 0.0001). The ratio between the image acquisition times of the denoised and averaged images was 0.08 ± 0.01, and that between the acquisition times of the denoised and original images was 1.35 ± 0.06.
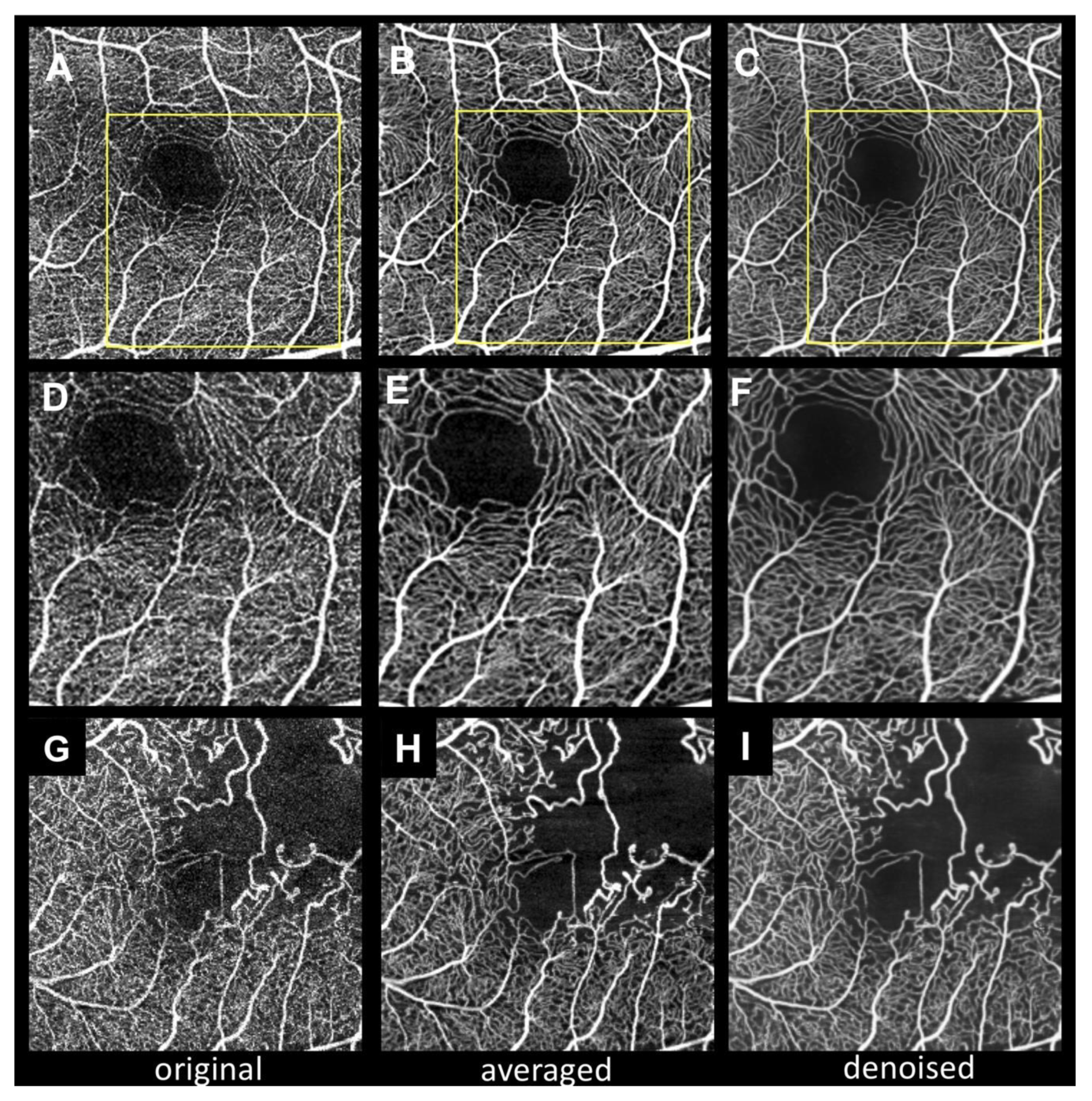
Figure 1 shows representative cases of 3 × 3 mm
2 SCP OCTA with three different images (original, averaged, and denoised). The averaged image shows more continuous vessels and less background noise than the original image. Notably, the denoised image also shows a high-contrast capillary structure and capillary-free zone around the arteriole, as previous reports have described [
23,
24]. In contrast, the original image shows fragmented FAZ and noisy capillaries. In the branch retinal vein occlusion case (
Figure 1G–I), the averaged and denoised images show well-denoised dots within nonperfusion areas.
As
Table 1 demonstrates, the CNR of the denoised image is significantly higher than those of the other two images (
P < 0.0001). There is no significant difference between the original and averaged images (
P = 0.0648), although the PSNR of the denoised image is significantly higher than that of the original image (
P < 0.0001).
Table 2 summarizes the average scores for the subjective image quality assessment. The denoised image scores are significantly higher than those of the averaged images (
P < 0.0001).
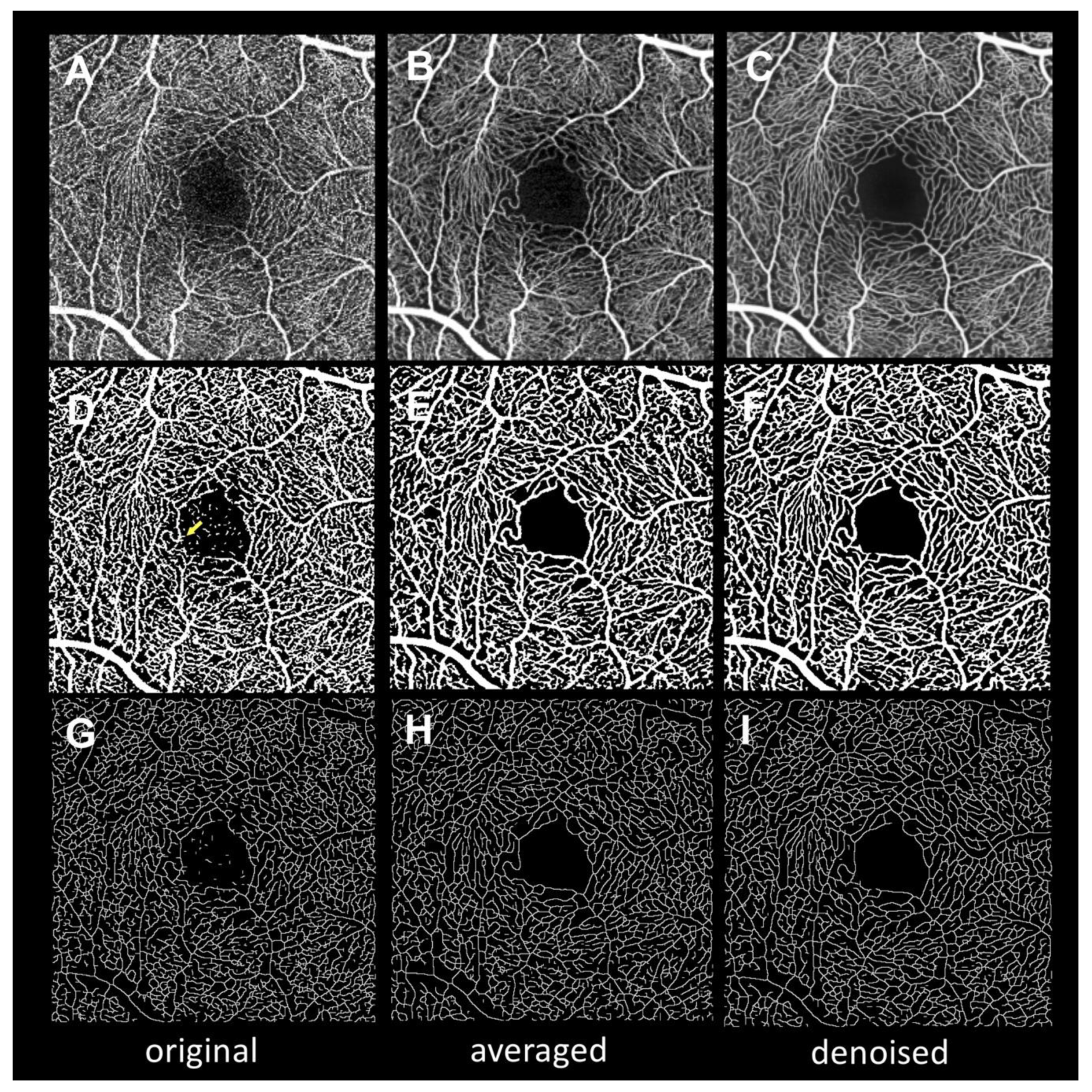
Figure 2 presents the images after binarization and skeletonization for use in quantitative measurements. Both the averaged and denoised binarized images show less background noise in FAZ and more continuous vessels than the original binarized images. These findings are also observable in the skeletonized images.
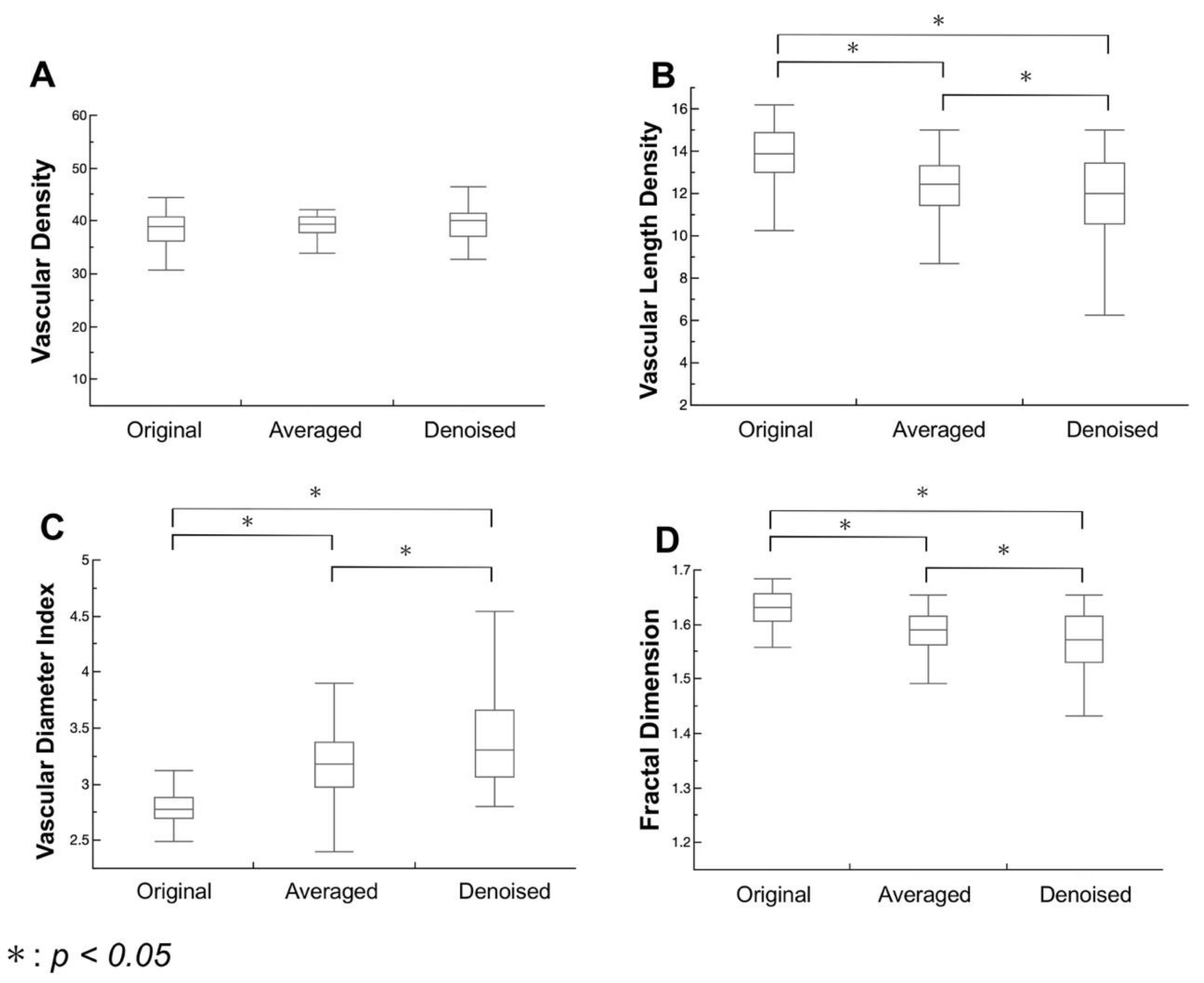
Figure 3 summarizes the results of quantitative microvascular density and morphology analysis from the binarized and skeletonized images. The three images do not differ significantly in VD (
P = 0.9199,
P = 0.4247, and
P = 0.2307, respectively). The VLD in the denoised image is significantly lower than those in the original and averaged images (
P < 0.0001,
P < 0.0001, and
P = 0.0049, respectively), while the VDI in the denoised image is significantly higher than those in the original and averaged images (
P < 0.0001). The FD in the denoised image is significantly lower than those in the original and averaged images (
P < 0.0001).
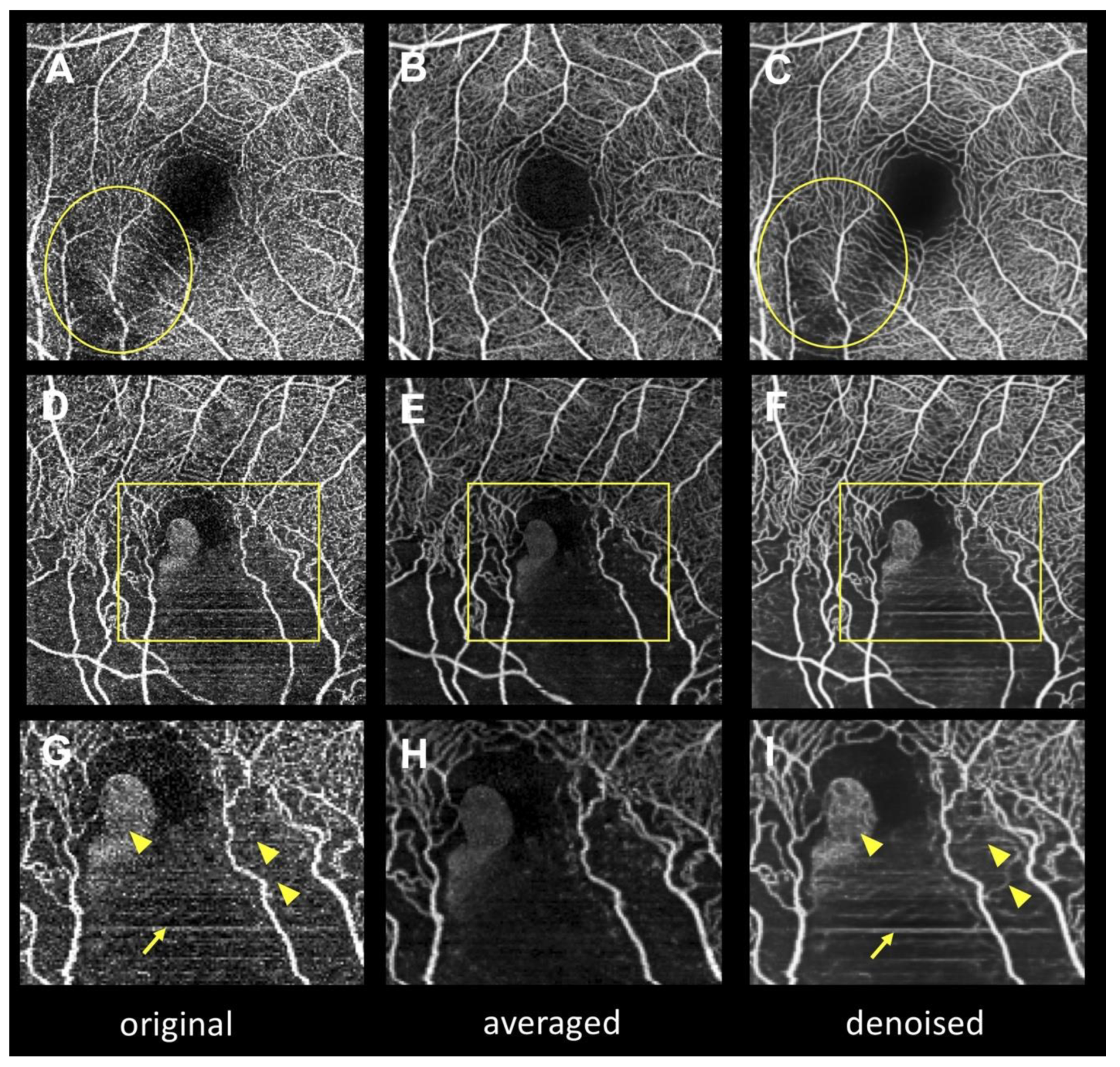
Figure 4 depicts the artifacts in the denoised images. When there was excessive signal attenuation (i.e., due to the opacity of the medium) in the original en face OCTA image (
Figure 4A), capillary over-dropped out artifacts (
Figure 4B) occurred in the denoised image. Moreover, deep learning turned aggregated dots into capillary-like structures, producing capillary over-generation (pseudo-vessel,
Figure 4H).
Table 3 summarizes the average scores for subjective assessment of artifacts in the denoised images. The average scores in the capillary over-dropped out and capillary over-generation cases are −0.11 ± 0.45 and −0.09 ± 0.41, respectively. Capillary over-dropped out and capillary over-generation artifacts were observed in six and five eyes out of 112 eyes, respectively (5.4% and 4.5%, respectively). The total number of eyes with artifacts (containing either capillary over-dropped out or capillary over-generation artifacts) was 10 out of 112 (8.9%).
4. Discussion
In this study, deep learning denoising and multiple image averaging were applied to en face OCTA images. The impact of deep learning denoising on OCTA quantitative parameters and en face OCTA image acquisition times were evaluated and the results were compared with those obtained using the averaging technique. Although there was a significant improvement in the quality in both the denoised and averaged images, deep learning denoising yielded a significantly shorter OCTA image acquisition time than the averaging technique. However, unique deep learning-derived artifacts were observed in the denoised images.
Computed tomography (CT) imaging requires a high radiation dose to obtain high-contrast images, which takes substantial image acquisition time and causes high radiation exposure to patients. Applying deep learning in low-dose-radiation CT imaging [
25] can reduce the image acquisition time and radiation exposure. Although OCTA imaging is not an invasive imaging modality, the enormous image acquisition time imposes a certain physical burden on patients and could degrade the image quality, as fatigue resulting from long examination times can cause poor eye fixation and dry eyes. Previous studies have demonstrated that multiple image averaging improves the image quality of en face OCTA by reducing the background noise and enhancing the image contrast [
8,
10]. However, this approach requires multiple image acquisitions and substantial time. In this study, the image acquisition time with deep learning denoising was observed to be significantly shorter than that with the averaging technique (12.8 ± 1.5 times shorter), and the denoised image acquisition time was statistically determined to be significantly different from the original image (22.1 s vs. 16.6 s
P < 0.0001). However, this acquisition time in denoising is nominally small and insignificant from a practical standpoint (6 s longer for denoising vs 269 s longer for averaging), suggesting that deep learning has the potential to alleviate the burden on patients of acquiring high-quality OCTA images in patients.
The CNR for image quality assessment was used because distinguishing high bright areas (especially capillaries) from low brightness areas (especially FAZ) is important in OCTA imaging, in which quantitative assessments are based on image binarization [
9]. After deep learning denoising, the CNR significantly increased, suggesting the highest image contrast among the original, averaged, and denoised images. In addition, the PSNR, which is one of the most straightforward objective measurements used to compare the similarity between two images, showed higher values in the denoised images than in the original images, suggesting that deep learning denoising can produce high-quality images closer to averaged images. The subjective assessments support these results (overall impression: 1.83 vs. 1.22). In this study, the quantitative parameters describing the microvascular density and morphology (VLD, VDI, and FD) significantly changed after denoising, as previously reported when using the multiple averaging technique [
8], suggesting that deep learning denoising could remove the background noise and smooth the rough vessel surface. According to the above results, deep learning denoising can significantly improve the quality of the original OCTA images by reducing background noise and annealing fragmented vessels.
Interestingly, although we developed the deep learning denoising method by using averaged en face OCTA images for training, the CNR and subjective assessments of the denoised images were superior to those of the averaged images. On the contrary, there was no significant difference in CNR between original and averaged images, although a previous study with a small sample size showed a significant difference in CNR between the original and averaged images, where all of the subjects were among the normal population [
9]. These findings suggest the possibility that the quality of the averaged images was actually worse than the theoretical estimate (unsuccessful averaging). One possible explanation for this characteristic may be the lower successful image registration rate for multiple image averaging in this study because this study included not only healthy subjects, but also subjects with various retinal diseases, which made it difficult to register each OCTA image due to poor eye fixation (
Supplementary Figure S2).
Surprisingly, our study showed no significant difference in VD. Binarization strongly affects the quantification of VD [
26]. In this study, the binarization and skeletonized images produced by built-in hardware were used. It could be suggested that the noisy signals and fragmented vessel gaps compensated each other in the original images, as if the process smoothed the pixel counts.
The distributions of each metric in the denoised images were wider than those in the averaged images (
Figure 3). Averaging the en face OCTA images facilitated the removal of background noise by equalizing uneven signal distributions. Meanwhile, the denoising method removed background noise by subtracting those pixels that the deep learning denoising method considered as noise even if they were actual flow signals. This result suggested that the denoising method might strongly remove background noise compared with the averaging technique.
We found that two major artifacts occurred in the denoised images: capillary over-dropped out (
Figure 4B) and capillary over-generation (pseudo-vessel) artifacts (
Figure 4E,H). Ten eyes (8.9%) had artifacts when there was focal signal attenuation or noise accumulation in the original images. Since the purposes of Intelligent Denoise are to reduce background noise and to anneal fragmented vessels, unnatural signal distribution in en face OCTA images (i.e., media opacity shadow or motion artifacts) may be falsely converted into capillary over-dropped out or capillary over-generation artifacts. Although these artifacts always occurred only in small areas of the OCTA images, it is recommended to refer to both original and denoised images for proper interpretation of OCTA images.
This study has several limitations. First, it was not possible to interpret how deep learning enhanced the OCTA image quality because the deep learning algorithm automatically obtained the parameters from learning experience. Second, the sample size of patients was small, which could have made small differences between the groups less detectable. Third, since this study did not evaluate wide-field images exceeding 3 × 3 mm2 because the training datasets were based on 3 × 3 mm2 en face averaged OCTA images, it is not known whether it would be possible to obtain similar image enhancement in wide-field OCTA images. Fourth, this study only evaluated the superficial vasculature slab because implementing a similar strategy for deeper vessels would be limited by the projection artifact.
In this study, we proposed a novel deep learning denoising method that achieved high-quality OCTA imaging comparable to that provided by multiple image averaging in almost as short of an acquisition time as for a single shot. This deep learning denoising method has the potential to facilitate studies of retinal microvasculature.







{kind=link}
{kind=link}
{kind=link}
{kind=link}