A Hybrid CFS Filter and RF-RFE Wrapper-Based Feature Extraction for Enhanced Agricultural Crop Yield Prediction Modeling




Abstract
:1. Introduction
1.1. Background
- Enhancing forecasting precision
- Lowering the dimensions
- Removing superfluous or insignificant features
- Improving the data interpretability
- Enhancing the model interpretability
- Decreasing the volume of the required information.
1.2. Literature Review
1.3. Aim of the Paper
2. Materials and Methods
2.1. Proposed Hybrid Feature Selection Methodology
- The initial phase utilizes the filter method to minimize the size of the feature set by discarding the noisy insignificant features.
- The final phase utilizes the wrapper method to identify the ideal characteristic feature subgroup from the reserved feature set.
2.1.1. Filter Stage—Correlation Based Feature Selector (CFS)
| Algorithm 1 CFS filter-based feature selection method |
| SELECT FEATURES |
| INPUT: |
| Dtrain—Training dataset |
| P—The predictor |
| n—Number of features to select |
| OUTPUT: |
| —Selected feature set |
| BEGIN: |
| = Ø |
| x = 1 |
| while do |
| if then |
| = CFS () |
| else |
| Add the best-ranked feature to |
| end if |
| x = x + 1 |
| end while |
| END |
- The higher the correlation among the individual and the extrinsic variable, the higher is the correlation among the combination and external variables.
- The lower the inter-correlation among the individual and the extrinsic variable, the lower is the correlation among the combination and extrinsic variable.
2.1.2. Wrapper Stage—Random Forest Recursive Feature Elimination (RF-RFE)
- In all iterations, each feature is shuffled, and over this shuffled data set, an out-of-bag estimation of the forecasting error is made.
- Naturally, when trying to alter this way, the insignificant features will not change the prediction error, inverse to the significant features.
- The corresponding loss in efficiency among the actual and the shuffled datasets is accordingly associated with the efficiency of the shuffled features.
| Algorithm 2 RF-RFE wrapper-based feature selection method |
| INPUT: |
| = []—Training dataset |
| F = []—Set of n features |
| Ranking Method M(D, F) |
| S = [1, 2 … m]—Subset of features |
| OUTPUT: |
| Final ordered feature set |
| BEGIN: |
| S = [1, 2 … m] |
| = [] |
| while S ≠ [] do |
| Repeat for x in |
| Ranking feature set utilizing M(D, F) |
| ← F’s last ranked feature |
| (n − x + 1) ← |
| S (Fs) ← S (Fs) − |
| end while |
| END |
2.2. Significant Agrarian Parameters and Dataset Description
2.2.1. Agronomical Variables Impacting Yield of Crops
Climate
Soil Productivity
Groundwater Characteristics and Availability
2.2.2. Crop Dataset and Study Area Description
2.3. Machine Learning Models and Evaluation Metrics
- Random forest
- Decision tree
- Gradient boosting.
2.3.1. Machine Learning
- Mean Square Error (MSE),
- Mean Absolute Error (MAE),
- Root Mean Squared Error (RMSE),
- Determination Coefficient (R2),
- Mean Absolute Percentage Error (MAPE).
2.3.2. Metrics of Evaluation
2.3.3. Cross-Validation
3. Results
- Random forest
- Decision tree
- Gradient boosting.
- In the first phase, the models are constructed using all the features or variables in the dataset, and the prediction results are validated using various statistical evaluation measures.
- In the second phase, models are constructed using the algorithm inbuilt ‘feature_importances’ methods, where only significant features alone are selected, and the prediction results are evaluated.
- In the third phase, the models are built utilizing the developed hybrid feature extraction method. The most significant features as per the proposed approach are selected, and the prediction results are evaluated.
3.1. Machine Learning Algorithms Performance Estimation in Terms of Evaluation Metrics
- All the features,
- Selective features obtained through inbuilt feature importance method and
- Features obtained through proposed hybrid feature selection methods.
3.2. ML Algorithms Performance Estimation in Terms of Accuracy
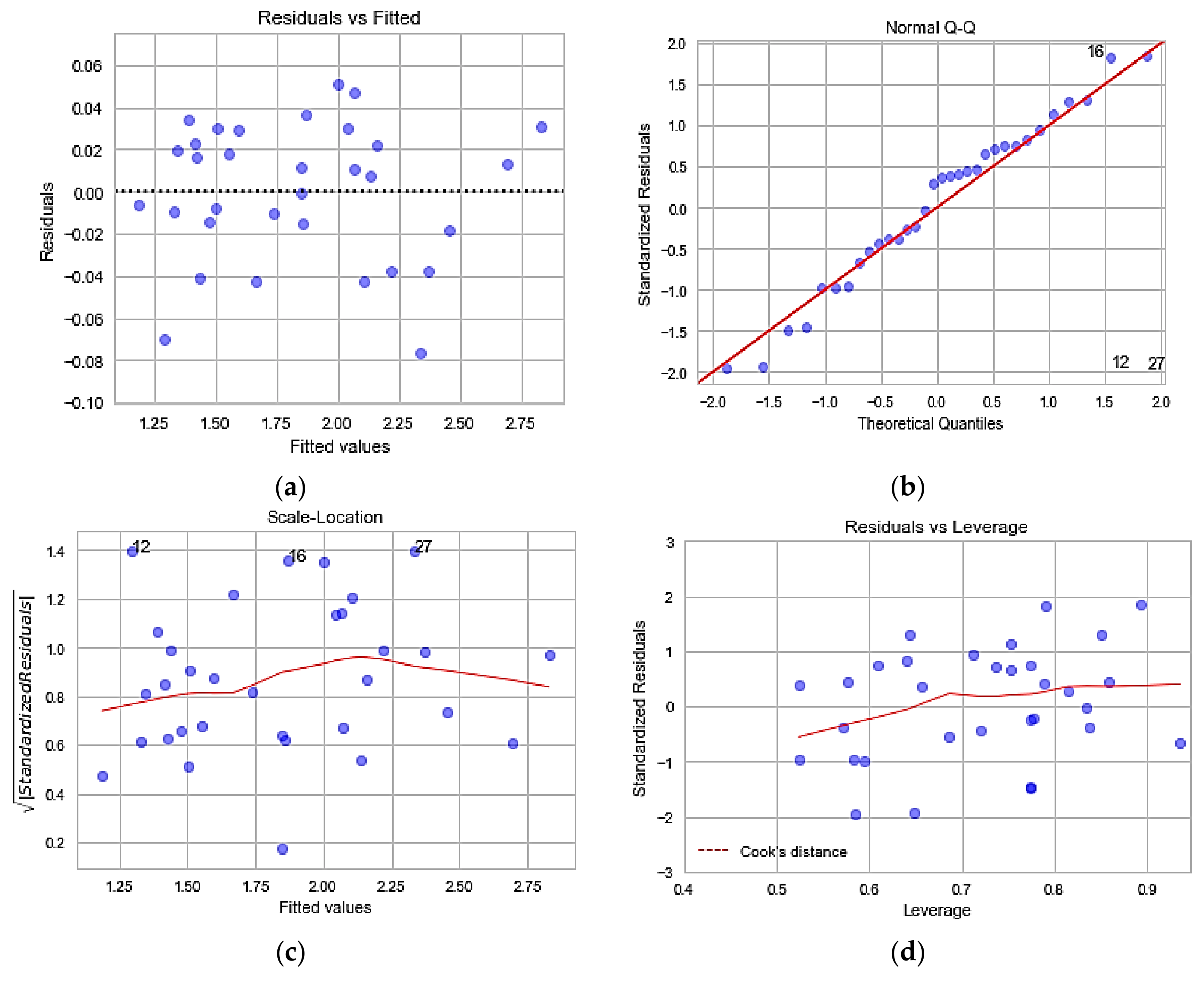
3.3. Regression Performance Analyses—Diagnostic Plots
4. Discussion
Future Scope
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Hamzeh, S.; Mokarram, M.; Haratian, A.; Bartholomeus, H.; Ligtenberg, A.; Bregt, A.K. Feature selection as a time and cost-saving approach for land suitability classification (Case Study of Shavur Plain, Iran). Agriculture 2016, 6, 52. [Google Scholar] [CrossRef] [Green Version]
- Monzon, J.P.; Calviño, P.A.; Sadras, V.O.; Zubiaurre, J.B.; Andrade, F.H. Precision agriculture based on crop physiological principles improves whole-farm yield and profit: A case study. Eur. J. Agron. 2018, 99, 62–71. [Google Scholar] [CrossRef]
- Rehman, T.U.; Mahmud, M.S.; Chang, Y.K.; Jin, J.; Shin, J. Current and future applications of statistical machine learning algorithms for agricultural machine vision systems. Comput. Electron. Agric. 2019, 156, 585–605. [Google Scholar] [CrossRef]
- Chlingaryan, A.; Sukkarieh, S.; Whelan, B. Machine learning approaches for crop yield prediction and nitrogen status estimation in precision agriculture: A review. Comput. Electron. Agric. 2018, 151, 61–69. [Google Scholar] [CrossRef]
- Elavarasan, D.; Vincent, D.R.; Sharma, V.; Zomaya, A.Y.; Srinivasan, K. Forecasting yield by integrating agrarian factors and machine learning models: A survey. Comput. Electron. Agric. 2018, 155, 257–282. [Google Scholar] [CrossRef]
- Cisternas, I.; Velásquez, I.; Caro, A.; Rodríguez, A. Systematic literature review of implementations of precision agriculture. Comput. Electron. Agric. 2020, 176, 105626. [Google Scholar] [CrossRef]
- Saikai, Y.; Patel, V.; Mitchell, P.D. Machine learning for optimizing complex site-specific management. Comput. Electron. Agric. 2020, 174, 105381. [Google Scholar] [CrossRef]
- Guyon, I.; Elisseeff, A. An introduction to variable and feature selection. J. Mach. Learn. Res. 2003, 3, 1157–1182. [Google Scholar]
- Liu, J.; Lin, Y.; Lin, M.; Wu, S.; Zhang, J. Feature selection based on quality of information. Neurocomputing 2017, 225, 11–22. [Google Scholar] [CrossRef]
- Chandrashekar, G.; Sahin, F. A survey on feature selection methods. Comput. Electr. Eng. 2014, 40, 16–28. [Google Scholar] [CrossRef]
- Cai, J.; Luo, J.; Wang, S.; Yang, S. Feature selection in machine learning: A new perspective. Neurocomputing 2018, 300, 70–79. [Google Scholar] [CrossRef]
- Bommert, A.; Sun, X.; Bischl, B.; Rahnenführer, J.; Lang, M. Benchmark for filter methods for feature selection in high-dimensional classification data. Comput. Stat. Data. Anal. 2020, 143, 106839. [Google Scholar] [CrossRef]
- Macedo, F.; Oliveira, M.R.; Pacheco, A.; Valadas, R. Theoretical foundations of forward feature selection methods based on mutual information. Neurocomputing 2019, 325, 67–89. [Google Scholar] [CrossRef] [Green Version]
- Mielniczuk, J.; Teisseyre, P. Stopping rules for mutual information-based feature selection. Neurocomputing 2019, 358, 255–274. [Google Scholar] [CrossRef]
- Kohavi, R.; John, G.H. Wrappers for feature subset selection. Artif. Intell. 1997, 97, 273–324. [Google Scholar] [CrossRef] [Green Version]
- Chen, G.; Chen, J. A novel wrapper method for feature selection and its applications. Neurocomputing 2015, 159, 219–226. [Google Scholar] [CrossRef]
- Jin, C.; Jin, S.W.; Qin, L.N. Attribute selection method based on a hybrid BPNN and PSO algorithms. Appl. Soft Comput. 2012, 12, 2147–2155. [Google Scholar] [CrossRef]
- Wang, F.; Liang, J. An efficient feature selection algorithm for hybrid data. Neurocomputing 2016, 193, 33–41. [Google Scholar] [CrossRef]
- Pourpanah, F.; Lim, C.P.; Wang, X.; Tan, C.J.; Seera, M.; Shi, Y. A hybrid model of fuzzy min–max and brain storm optimization for feature selection and data classification. Neurocomputing 2019, 333, 440–451. [Google Scholar] [CrossRef]
- Holzman, M.E.; Carmona, F.; Rivas, R.; Niclòs, R. Early assessment of crop yield from remotely sensed water stress and solar radiation data. ISPRS J. Photogramm. Remote. Sens. 2018, 145, 297–308. [Google Scholar] [CrossRef]
- Helman, D.; Lensky, I.M.; Bonfil, D.J. Early prediction of wheat grain yield production from root-zone soil water content at heading using Crop RS-Met. Field Crop. Res. 2019, 232, 11–23. [Google Scholar] [CrossRef]
- Ogutu, G.E.O.; Franssen, W.H.P.; Supit, I.; Omondi, P.; Hutjes, R.W.A. Probabilistic maize yield prediction over East Africa using dynamic ensemble seasonal climate forecasts. Agric. Meteorol. 2018, 250–251, 243–261. [Google Scholar] [CrossRef]
- Chatterjee, S.; Dey, N.; Sen, S. Soil moisture quantity prediction using optimized neural supported model for sustainable agricultural applications. Sustain. Comput. Inform. Syst. 2018. [Google Scholar] [CrossRef]
- Dash, Y.; Mishra, S.K.; Panigrahi, B.K. Rainfall prediction for the Kerala state of India using artificial intelligence approaches. Comput. Electr. Eng. 2018, 70, 66–73. [Google Scholar] [CrossRef]
- Sharif, M.; Khan, M.A.; Iqbal, Z.; Azam, M.F.; Lali, M.I.U.; Javed, M.Y. Detection and classification of citrus diseases in agriculture based on optimized weighted segmentation and feature selection. Comput. Electron. Agric. 2018, 150, 220–234. [Google Scholar] [CrossRef]
- Jiang, Y.; Li, C. mRMR-based feature selection for classification of cotton foreign matter using hyperspectral imaging. Comput. Electron. Agric. 2015, 119, 191–200. [Google Scholar] [CrossRef]
- Daassi-Gnaba, H.; Oussar, Y.; Merlan, M.; Ditchi, T.; Géron, E.; Holé, S. Wood moisture content prediction using feature selection techniques and a kernel method. Neurocomputing 2017, 237, 79–91. [Google Scholar] [CrossRef] [Green Version]
- Qian, W.; Shu, W. Mutual information criterion for feature selection from incomplete data. Neurocomputing 2015, 168, 210–220. [Google Scholar] [CrossRef]
- Shekofteh, H.; Ramazani, F.; Shirani, H. Optimal feature selection for predicting soil CEC: Comparing the hybrid of ant colony organization algorithm and adaptive network-based fuzzy system with multiple linear regression. Geoderma 2017, 298, 27–34. [Google Scholar] [CrossRef]
- Ghosh, A.; Datta, A.; Ghosh, S. Self-adaptive differential evolution for feature selection in hyperspectral image data. Appl. Soft. Comput. 2013, 13, 1969–1977. [Google Scholar] [CrossRef]
- Sadr, S.; Mozafari, V.; Shirani, H.; Alaei, H.; Pour, A.T. Selection of the most important features affecting pistachio endocarp lesion problem using artificial intelligence techniques. Sci. Hortic. 2019, 246, 797–804. [Google Scholar] [CrossRef]
- Kohavi, R.; John, G.H. Wrapper Approach. In Feature Extraction, Construction and Selection; Liu, H., Motoda, H., Eds.; Springer US: New York, NY, USA, 1998; Volume 453. [Google Scholar]
- Robert, H.M. Methods for aggregating opinions. In Decision Making and Change in Human Affairs; Jungermann, H., De Zeeuw, G., Eds.; Springer: Dordrecht, The Netherlands, 1977; Volume 16. [Google Scholar]
- Isabelle, G.; Jason, W.; Stephen, B. Vladimir vapnik gene selection for cancer classification using support vector machines. Mach. Learn. 2002, 46, 389–422. [Google Scholar] [CrossRef]
- Elavarasan, D.; Vincent, P.M.D. Crop Yield Prediction Using Deep Reinforcement Learning Model for Sustainable Agrarian Applications. IEEE Access 2020, 8, 86886–86901. [Google Scholar] [CrossRef]
- Park, S.; Im, J.; Jang, E.; Rhee, J. Drought assessment and monitoring through blending of multi-sensor indices using machine learning approaches for different climate regions. Agric. Meteorol. 2016, 216, 157–169. [Google Scholar] [CrossRef]
- Elavarasan, D.; Vincent, D.R. Reinforced XGBoost machine learning model for sustainable intelligent agrarian applications. J. Intell. Fuzzy. Syst. 2020. pre-press. [Google Scholar] [CrossRef]
- Vanli, N.D.; Sayin, M.O.; Mohaghegh, M.; Ozkan, H.; Kozat, S.S. Nonlinear regression via incremental decision trees. Pattern Recognit. 2019, 86, 1–13. [Google Scholar] [CrossRef]
- Prasad, R.; Deo, R.C.; Li, Y.; Maraseni, T. Soil moisture forecasting by a hybrid machine learning technique: ELM integrated with ensemble empirical mode decomposition. Geoderma 2018, 330, 136–161. [Google Scholar] [CrossRef]
- Fratello, M.; Tagliaferri, R. Decision trees and random forests. In Encyclopedia of Bioinformatics and Computational Biology; Academic Press: Cambridge, MA, USA, 2019; pp. 374–383. [Google Scholar]
- Herold, N.; Ekström, M.; Kala, J.; Goldie, J.; Evans, J.P. Australian climate extremes in the 21st century according to a regional climate model ensemble: Implications for health and agriculture. Weather Clim. Extrem. 2018, 20, 54–68. [Google Scholar] [CrossRef]
- Kari, D.; Mirza, A.H.; Khan, F.; Ozkan, H.; Kozat, S.S. Boosted adaptive filters. Digit. Signal Process. 2018, 81, 61–78. [Google Scholar] [CrossRef] [Green Version]
- Friedman, J.H. Stochastic gradient boosting. Comput. Stat. Data Anal. 2002, 38, 367–378. [Google Scholar] [CrossRef]
- Ali, M.; Deo, R.C.; Downs, N.J.; Maraseni, T. Multi-stage committee based extreme learning machine model incorporating the influence of climate parameters and seasonality on drought forecasting. Comput. Electron. Agric. 2018, 152, 149–165. [Google Scholar] [CrossRef]
- Deepa, N.; Ganesan, K. Hybrid Rough Fuzzy Soft classifier based Multi-Class classification model for Agriculture crop selection. Soft Comput. 2019, 23, 10793–10809. [Google Scholar] [CrossRef]
- Torres, A.F.; Walker, W.R.; McKee, M. Forecasting daily potential evapotranspiration using machine learning and limited climatic data. Agric. Water Manag. 2011, 98, 553–562. [Google Scholar] [CrossRef]
- Rousson, V.; Goşoniu, N.F. An R-square coefficient based on final prediction error. Stat. Methodol. 2007, 4, 331–340. [Google Scholar] [CrossRef]
- Ferré, J. Regression diagnostics. In Comprehensive Chemometrics; Tauler, R., Walczak, B., Eds.; Elsevier: Amsterdam, The Netherlands, 2009; pp. 33–89. [Google Scholar]
- Srinivasan, R.; Lohith, C.P. Main study—Detailed statistical analysis by multiple regression. In Strategic Marketing and Innovation for Indian MSMEs; India Studies in Business and Economics; Springer: Berlin/Heidelberg, Germany, 2017; pp. 69–92. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| S. No | Parameter Name | Description | Units |
|---|---|---|---|
| 1 | Net cropped area | The total geographic area on which the crop has been planted at least once during a year | Integer (hectare) |
| 2 | Gross cropped area | Total area planted to crops during all growing seasons of the year | Integer (hectare) |
| 3 | Net irrigated area | The total geographic area that has acquired irrigation throughout the year | Integer (hectare) |
| 4 | Gross irrigated area | The total area under crops that have received irrigation during all the growing seasons of the year. | Integer (hectare) |
| 5 | Area rice | Total area in which the rice crop is planted | Integer (hectare) |
| 6 | Quantity rice | Total rice production in the study area | Integer (ton) |
| 7 | Yield rice | The total quantity of rice acquired | Integer (ton) |
| 8 | Soil type | Type of the soil in the study area considered | Integer |
| 1—Medium black soil type | |||
| 2—Red soil type | |||
| 9 | Land slope | A rise or fall of the land surface | Integer (meters) |
| 10 | Soil pH | Acidity and alkalinity measure in the soil. | Integer |
| 11 | Topsoil depth | The outermost soil layer rich in microorganisms and organic matter | Integer (meters) |
| 12 | N soil | The nitrogen amount present in the soil | Integer (kilogram/hectare) |
| 13 | P soil | The phosphorus amount present in the soil | Integer (kilogram/hectare) |
| 14 | K soil | The potassium amount present in the soil | Integer (kilogram/hectare) |
| 15 | QNitro | Amount of nitrogen fertilizers utilized | Integer (kilogram) |
| 16 | QP2O5 | Amount of phosphorus fertilizers utilized | Integer (kilogram) |
| 17 | QK2O | Amount of potassium fertilizers utilized | Integer (kilogram) |
| 18 | Precipitation | Rain or water vapor condensation from the atmosphere | Integer (millimeter) |
| 19 | Potential evapotranspiration | Quantity of evaporation occurring in an area in the presence of a sufficient water source | Integer (millimeter/day) |
| 20 | Reference crop evapotranspiration | The evapotranspiration rate from a crop reference surface that is not short of water | Integer (millimeter/day) |
| 21 | Ground frost frequency | Number of days referring to the condition when the upper layer soil temperature falls below the water freezing point | Integer (number of days) |
| 22 | Diurnal temperature range | Difference between the daily maximum and minimum temperature | Integer (°C) |
| 23 | Wet day frequency | The number of days in which a quantity of 0.2 mm or more of rain is observed. | Integer (number of days) |
| 24 | Vapor pressure | The pressure administered by water vapor with its condensed phase in thermodynamic equilibrium | Integer (hectopascal) |
| 25 | Maximum temperature | The highest temperature of air recorded | Integer (°C) |
| 26 | Minimum temperature | The lowest temperature of air recorded | Integer (°C) |
| 27 | Average temperature | The average temperature of air recorded | Integer (°C) |
| 28 | Humidity | The quantity of water vapor in the atmosphere | Integer (percentage) |
| 29 | Wind speed | The rate at which the air blows | Integer (miles/hour) |
| 30 | Aquifer area percentage | Percentage of an area enclosed by a body of permeable rock that can transmit or contain groundwater. | Integer (percentage) |
| 31 | Aquifer well yield | Amount of water pumped from a well in an aquifer area | Integer (liters/minute) |
| 32 | Aquifer transmissivity | The water quantity that can be disseminated horizontally by a full saturated thickness of the aquifer | Integer (meter2/day) |
| 33 | Aquifer permeability | A measure of the rock property, which defines how fluids can flow through it. | Integer (meter/day) |
| 34 | Pre–electrical conductivity | Average pre-monsoon electrical conductivity of groundwater | Integer (siemens/meter) |
| 35 | Post-electrical conductivity | Average post-monsoon electrical conductivity of groundwater | Integer (siemens/meter) |
| 36 | Groundwater pre-calcium | Average pre-monsoon calcium level in groundwater | Integer (milligram/Liters) |
| 37 | Groundwater post-calcium | Average post-monsoon calcium level in groundwater | Integer (milligram/Liters) |
| 38 | Groundwater pre-magnesium | Average pre-monsoon magnesium level in groundwater | Integer (milligram/Liters) |
| 39 | Groundwater post-magnesium | Average post-monsoon magnesium level in groundwater | Integer (milligram/Liters) |
| 40 | Groundwater pre-sodium | Average pre-monsoon sodium level in groundwater | Integer (milligram/Liters) |
| 41 | Groundwater post-sodium | Average post-monsoon sodium level in groundwater | Integer (milligram/Liters) |
| 42 | Groundwater pre-potassium | Average pre-monsoon potassium level in groundwater | Integer (milligram/Liters) |
| 43 | Groundwater post-potassium | Average post-monsoon potassium level in groundwater | Integer (milligram/Liters) |
| 44 | Groundwater pre-chloride | Average pre-monsoon chloride level in groundwater | Integer (milligram/Liters) |
| 45 | Groundwater post-chloride | Average post-monsoon chloride level in groundwater | Integer (milligram/Liters) |
| Model Data Subset | Training Data (In Years) | Test Data (In Years) | Correlation Measure Value | R2 Score |
|---|---|---|---|---|
| 1 | 1996–2000 | 2001–2003 | 0.77 | 0.82 |
| 2 | 1996–2003 | 2004–2006 | 0.84 | 0.86 |
| 3 | 1996–2006 | 2007–2009 | 0.61 | 0.70 |
| 4 | 1996–2009 | 2010–2012 | 0.76 | 0.84 |
| 5 | 1996–2012 | 2013–2016 | 0.86 | 0.89 |
| Algorithm Name | The Performance Measure with All Features in the Dataset | ||||
|---|---|---|---|---|---|
| MAE | MSE | RMSE | R2 | MAPE (%) | |
| Random Forest | 0.203 | 0.082 | 0.286 | 0.53 | 21.3 |
| Decision Tree | 0.481 | 0.378 | 0.614 | 0.48 | 48 |
| Gradient Boosting | 0.334 | 0.208 | 0.456 | 0.41 | 33 |
| Algorithm Name | The Performance Measure with Algorithm Inbuilt Feature Importance Method | ||||
|---|---|---|---|---|---|
| MAE | MSE | RMSE | R2 | MAPE (%) | |
| Random Forest | 0.202 | 0.08 | 0.284 | 0.59 | 20 |
| Decision Tree | 0.356 | 0.225 | 0.474 | 0.50 | 35 |
| Gradient Boosting | 0.323 | 0.196 | 0.443 | 0.45 | 31 |
| Algorithm Name | Performance Measure with CFS Filter and RF-RFE Wrapper Feature Selection Method | ||||
|---|---|---|---|---|---|
| MAE | MSE | RMSE | R2 | MAPE (%) | |
| Random Forest | 0.194 | 0.07 | 0.265 | 0.67 | 19 |
| Decision Tree | 0.341 | 0.182 | 0.426 | 0.55 | 33 |
| Gradient Boosting | 0.306 | 0.187 | 0.433 | 0.48 | 29 |
| Algorithm Name | Model Accuracy with All Features in the Dataset (%) | Model Accuracy with Algorithm Inbuilt Feature Importance Method (%) | Model Accuracy with CFS Filter and RF-RFE Wrapper Feature Selection Method (%) |
|---|---|---|---|
| Random Forest | 90.84 | 90.94 | 91.23 |
| Decision Tree | 77.05 | 80.75 | 82.58 |
| Gradient Boosting | 83.71 | 84.4 | 85.41 |
| S. No | Final Set of Parameters | Description | Normal Acceptable Level | Units |
|---|---|---|---|---|
| 1 | QK2O | Amount of potassium fertilizers utilized | 15–20 | Integer (kilogram/hectare) |
| 2 | Quantity rice | Total production of rice in the study area | 2.37–2.5 | Integer (ton/hectare) |
| 3 | QNitro | Amount of nitrogen fertilizers utilized | 15–20 | Integer (kilogram/hectare) |
| 4 | QP2O5 | Amount of phosphorus fertilizers utilized | 2–3 | Integer (kilogram/hectare) |
| 5 | Vapor pressure | The pressure administered by water vapor with its condensed phase in thermodynamic equilibrium | 23.8–41.2 | Integer (hectopascal) |
| 6 | Gross cropped area | Total area planted to crops during all growing seasons of the year | 195–220 | Integer (hectare) |
| 7 | Net irrigated area | Total geographic area that has acquired irrigation throughout the year | 80–110 | Integer (hectare) |
| 8 | Ground frost frequency | Number of days referring to the condition when the upper layer soil temperature falls below the water freezing point | 5–7 | Integer (number of days) |
| 9 | Diurnal temperature range | Difference between the daily maximum and minimum temperature | 90–130 | Integer (°C) |
| 10 | Net cropped area | Total geographic area on which the crop has been planted at least once during a year | 175–200 | Integer (hectare) |
| 11 | Precipitation | Rain or water vapor condensation from the atmosphere | 1400–1800 | Integer (millimeter/year) |
| 12 | Gross irrigated area | Total area under crops that have received irrigation during all the growing seasons of the year. | 90–116 | Integer (hectare) |
| 13 | Average temperature | The average air temperature recorded in a particular location | 21–25 | Integer (°C) |
| 14 | Wet day frequency | The number of days in which a quantity of 0.2 mm or more of rain is observed. | 45–55 | Integer (number of days) |
| 15 | Area rice | Total area planted for rice crop | 35–40 | Integer (hectare) |
| 16 | Potential evapotranspiration | Quantity of evaporation occurring in an area in the presence of a sufficient water source | 27–35 | Integer (millimeter/day) |
| 17 | Reference crop Evapotranspiration | The evapotranspiration rate from a crop reference surface that is not short of water | 25–30 | Integer (millimeter/day) |
| 18 | Maximum temperature | The highest temperature of air recorded | 21–37 | Integer (°C) |
| 19 | Humidity | The quantity of water vapor in the atmosphere | 60–80 | Integer (percentage) |
| 20 | Wind speed | The rate at which the air blows | 40–50 | Integer (miles/hour) |
| 21 | Minimum temperature | The lowest temperature of air recorded | 16–20 | Integer (°C) |
| 22 | K soil | The potassium amount present in the soil | ≥42 | Integer (ton/hectare) |
| 23 | N soil | The nitrogen amount present in the soil | ≥48 | Integer (kilogram/hectare) |
| 24 | P soil | The phosphorus amount present in the soil | ≥30 | Integer (kilogram/hectare) |
| 25 | Aquifer area percentage | Percentage of the area covered by the aquifer. An aquifer is a body of permeable rock that can contain or transmit groundwater. | 55–60 | Integer (percentage) |
| 26 | Aquifer permeability | A measure of the rock property which determines how easily water and other fluids can flow through it. Permeability depends on the extent to which pores are interconnected. | 25–30 | Integer (meter/day) |
| 27 | Pre–electrical conductivity | Average pre-monsoon electrical conductivity of groundwater | 55–60 | Integer (siemens/meter) |
| 28 | Post-electrical conductivity | Average post-monsoon electrical conductivity of groundwater | 65–70 | Integer (siemens/meter) |
| 29 | Groundwater pre-magnesium | Average pre-monsoon magnesium level in groundwater | 68–73 | Integer (milligram/litres) |
| 30 | Groundwater post-magnesium | Average post-monsoon magnesium level in groundwater | 60–65 | Integer (milligram/litres) |
| 31 | Groundwater pre-sodium | The average pre-monsoon sodium level in groundwater | 150–170 | Integer (milligram/litres) |
| 32 | Groundwater Post-Sodium | Average post-monsoon sodium level in groundwater | 190–200 | Integer (milligram/litres) |
| 33 | Groundwater pre-potassium | Average pre-monsoon potassium level in groundwater | 15–20 | Integer (milligram/litres) |
| 34 | Groundwater post-potassium | Average post-monsoon potassium level in groundwater | 20–25 | Integer (milligram/litres) |
| 35 | Groundwater pre-chloride | Average pre-monsoon chloride level in groundwater | 320–325 | Integer (milligram/litres) |
| 36 | Groundwater post-chloride | Average post-monsoon chloride level in groundwater | 330–340 | Integer (milligram/litres) |
| 37 | Yield rice | The total quantity of rice acquired | 2.0–2.5 | Integer (ton) |
| 38 | Soil PH | Acidity and alkalinity measure in the soil. | 6–7 | Integer |
| 39 | Topsoil depth | The outermost soil layer rich in microorganisms and organic matter | 0.5–0.75 | Integer (meters) |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Elavarasan, D.; Vincent P M, D.R.; Srinivasan, K.; Chang, C.-Y. A Hybrid CFS Filter and RF-RFE Wrapper-Based Feature Extraction for Enhanced Agricultural Crop Yield Prediction Modeling. Agriculture 2020, 10, 400. https://doi.org/10.3390/agriculture10090400
Elavarasan D, Vincent P M DR, Srinivasan K, Chang C-Y. A Hybrid CFS Filter and RF-RFE Wrapper-Based Feature Extraction for Enhanced Agricultural Crop Yield Prediction Modeling. Agriculture. 2020; 10(9):400. https://doi.org/10.3390/agriculture10090400
Chicago/Turabian StyleElavarasan, Dhivya, Durai Raj Vincent P M, Kathiravan Srinivasan, and Chuan-Yu Chang. 2020. "A Hybrid CFS Filter and RF-RFE Wrapper-Based Feature Extraction for Enhanced Agricultural Crop Yield Prediction Modeling" Agriculture 10, no. 9: 400. https://doi.org/10.3390/agriculture10090400
APA StyleElavarasan, D., Vincent P M, D. R., Srinivasan, K., & Chang, C. -Y. (2020). A Hybrid CFS Filter and RF-RFE Wrapper-Based Feature Extraction for Enhanced Agricultural Crop Yield Prediction Modeling. Agriculture, 10(9), 400. https://doi.org/10.3390/agriculture10090400