
Potato Surface Defect Detection Based on Deep Transfer Learning



Abstract
:1. Introduction
- # classes. Half of the listed studies classify the target samples into two categories: healthy and defective. One study, by Hasan et al. [39], considered a fine-grained classification problem with twenty categories, which describe the different types of potato diseases. Our study considers three potato classes: normal, scratch, and sprout. Based on an experiment conducted by Al-Dosary et al. [40], 2–3% of potato tubers are superficially or deeply scratched, accounting for over 70% of the total damaged potatoes during harvesting. Our review reveals that the scratched type is rarely considered in surface defect detection models by prior efforts. Furthermore, sprouted potatoes can be toxic to human being due to the higher level of glycoalkaloids [41]. The two defective types we consider are crucial and meaningful, as they represent the major defects caused during and post-harvesting.
- Learning task. We have seen both classification [42] and object detection [43] used in the literature to build a detection model. The former takes an input image and outputs a predicted class, meaning that there is only one object in the image. On the other hand, the latter allows an input image to contain objects of different classes and outputs bounding boxes and classes of the predicted objects. Apparently, object detection is a more powerful model with more practical value, suitable for large-scale and real-time detection systems [44]. Our investigation shows that classification is mainly adopted by most existing studies, and we develop detection models based on object detection algorithms in this study.
- Transfer learning. Training a robust DCNN model requires a large amount of data, which is usually not available for the surface defect detection task. Transfer learning [45] addresses the low-resource issue by transferring knowledge from a source domain, where a base model can be trained with sufficient data, to a target domain. We find that most existing studies have adopted transfer learning, i.e., a pretrained DCNN model is only fine tuned on the target dataset for surface defect detection.
- OOS testing. OOS testing is essential to evaluate how robust a model is by testing it on a different batch of sample and potentially in a different environment [46]. A grading system can be installed and utilized in various scenarios. It is thus crucial to simulate the image variance caused by environment change via an OOS test set gathered in a different scenario than the one where the original dataset is developed. We did not find another related study using an OOS test set.
- We develop a dataset for potato surface defect detection with three categories and a total of 2770 images. Compared to the existing studies, we treat the potato surface defect task as an object detection problem and consider the scratched and sprouted potatoes, which are rarely seen in prior efforts.
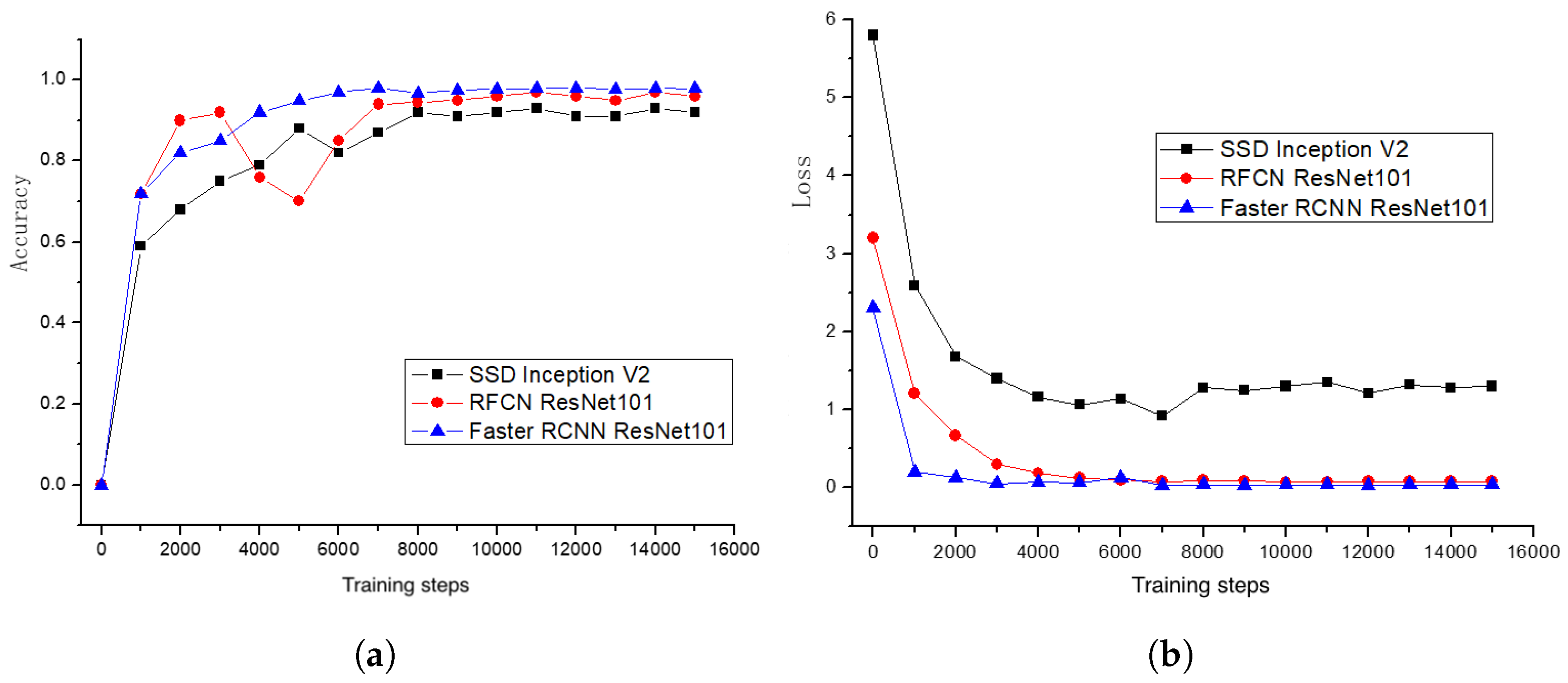
- Three pretrained DCNN models—SSD Inception V2, Faster RCNN ResNet101, and RFCN ResNet101—have been fine-tuned on our dataset and achieved an accruacy of 92.5%, 95.6%, and 98.7%, respectively. In addition, we develop an OOS test set to evaluate the best model, namely, RFCN ResNet101, in three scenarios. Results show that the RFCN ResNet101 model demonstrates robust performance with moderate inference speed. To our best knowledge, this is the first time DCNN-based transfer learning is employed for potato surface detect detection, with three object detection algorithms evaluated on both original and OOS test sets. Our work can serve as a credible baseline for future research.
2. Material and Methods
2.1. Potato Surface Defect
- Normal: Potatoes that are yellow without sprouts, damage, scratch, rot, etc. and are ready for everyday human consumption.
- Scratch: The potatoes were artificially scratched to simulate damage at the time of harvesting. In our experiment, we keep the number of scratches to one to three.
- Sprout: Potatoes germinate in the temperature range of 15 to 20 °C. Below 10 °C, germination is slow; above 25 °C, germination is rapid, but the shoot roots are small. Therefore, potatoes are placed in a room with a room temperature of 18 to 25 °C and high humidity.
2.2. Dataset
2.2.1. Potato Samples Acquisition
2.2.2. Image Data Collection
2.2.3. Out-of-Sample Test Set
- Scenario one. We took one image per sample at different sites within the campus, with the camera directly facing down to the potato sample, creating 214 sample images per category.
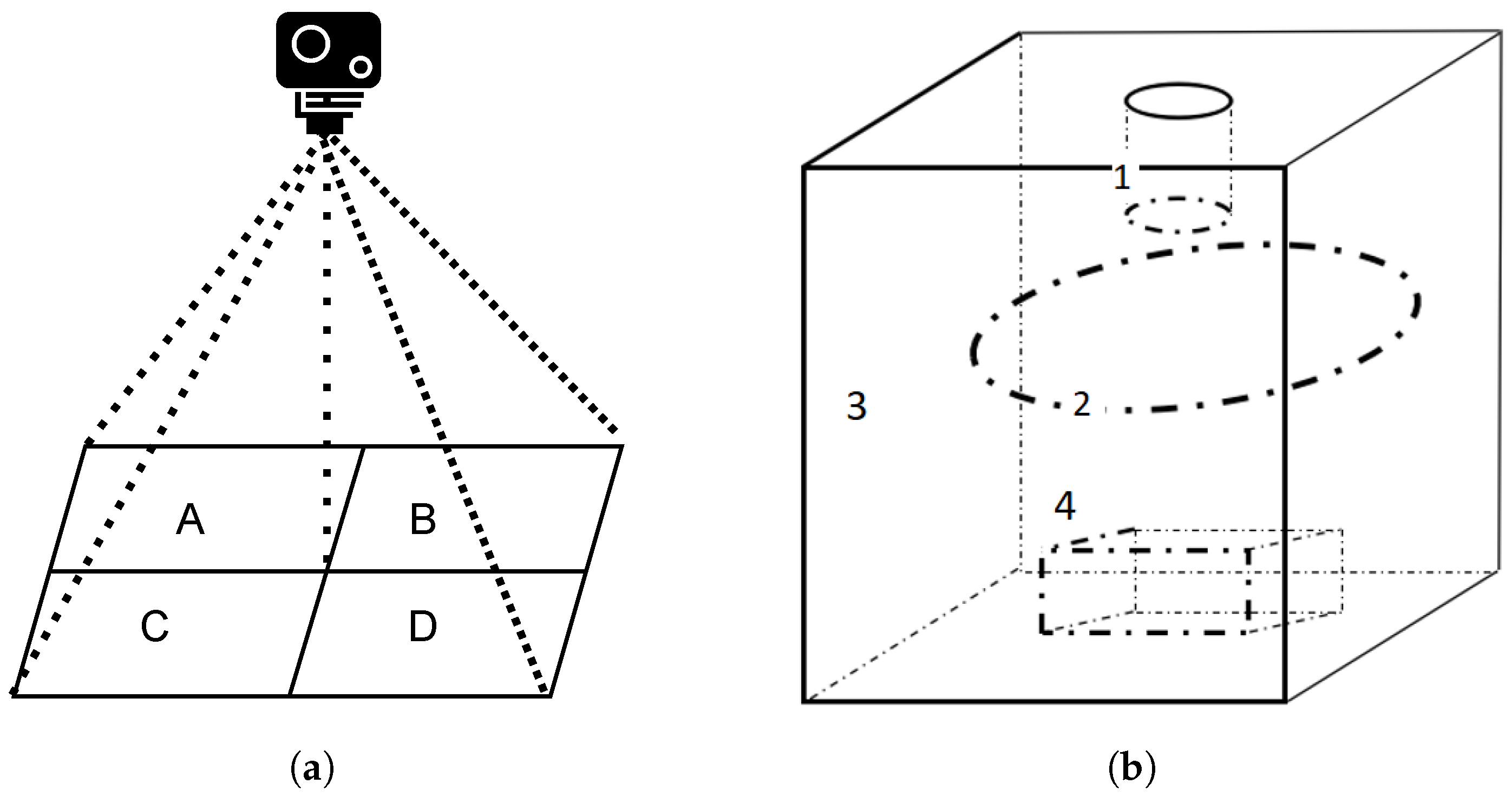
- Scenario two. This experiment was conducted indoor. We set up a clean desktop. The camera was placed 30 cm above the desktop. Taking the point where the camera was facing the desktop as the center position, we divided the shooting range equally into four areas A, B, C, and D, as shown in Figure 3a. The potatoes were put into A, B, C, and D areas in turn for testing. Scenario two also created 214 × 4 sample images per category.
- Scenario three. Our last experiment aims to study the impact of different light intensities on model performance. We moved the test platform into a closed dark box, within which the light intensity can be changed by a ring-shaped adjustable light source, as shown in Figure 3b. The adjustable light source has four levels of brightness. At each brightness level, we placed a potato sample on the platform with the feature parts (if any) of the potato facing up to the camera. We obtained 214 × 4 images for each category.
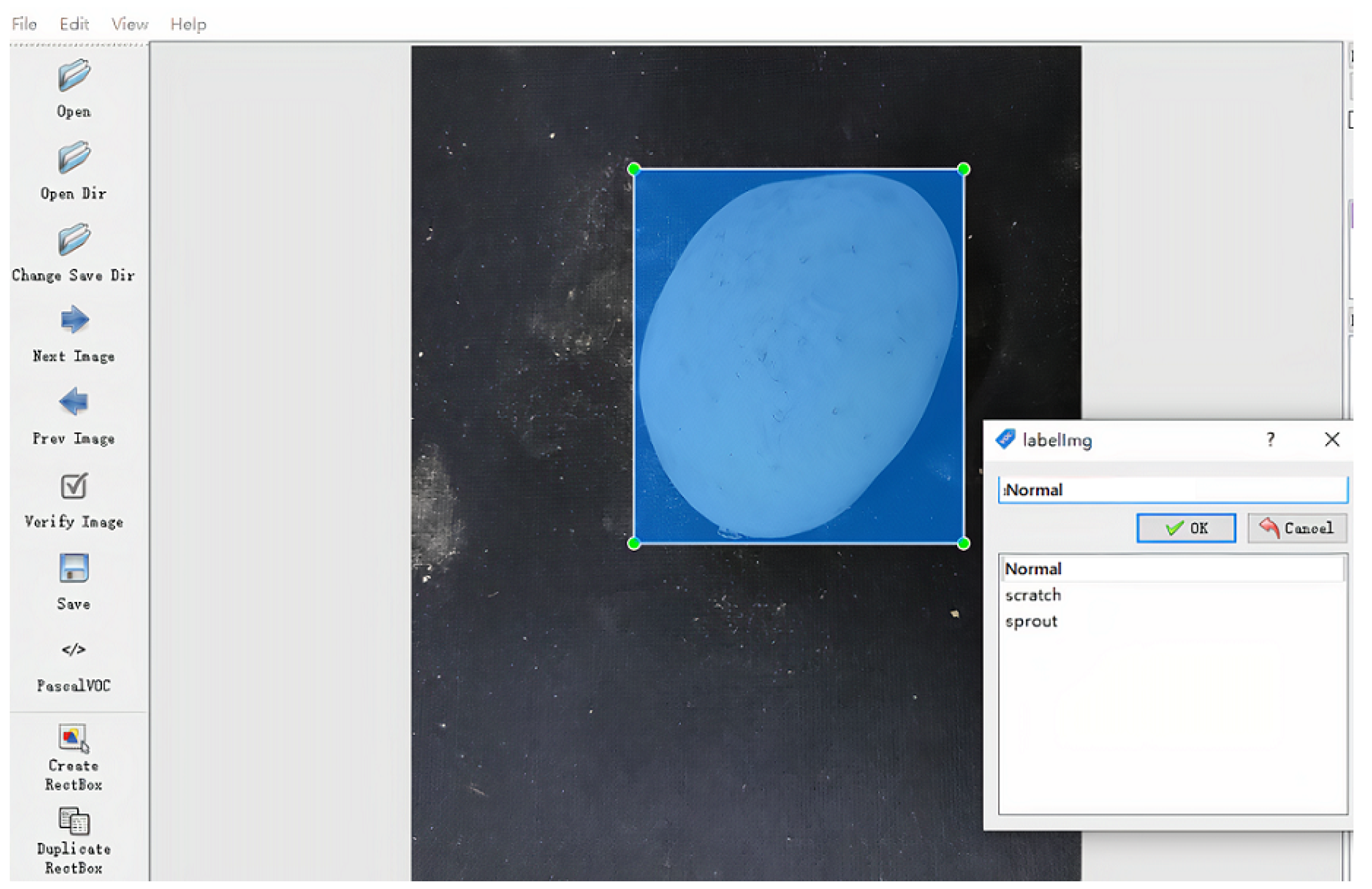
2.2.4. Data Labeling
2.3. DCNN Models for Object Detection
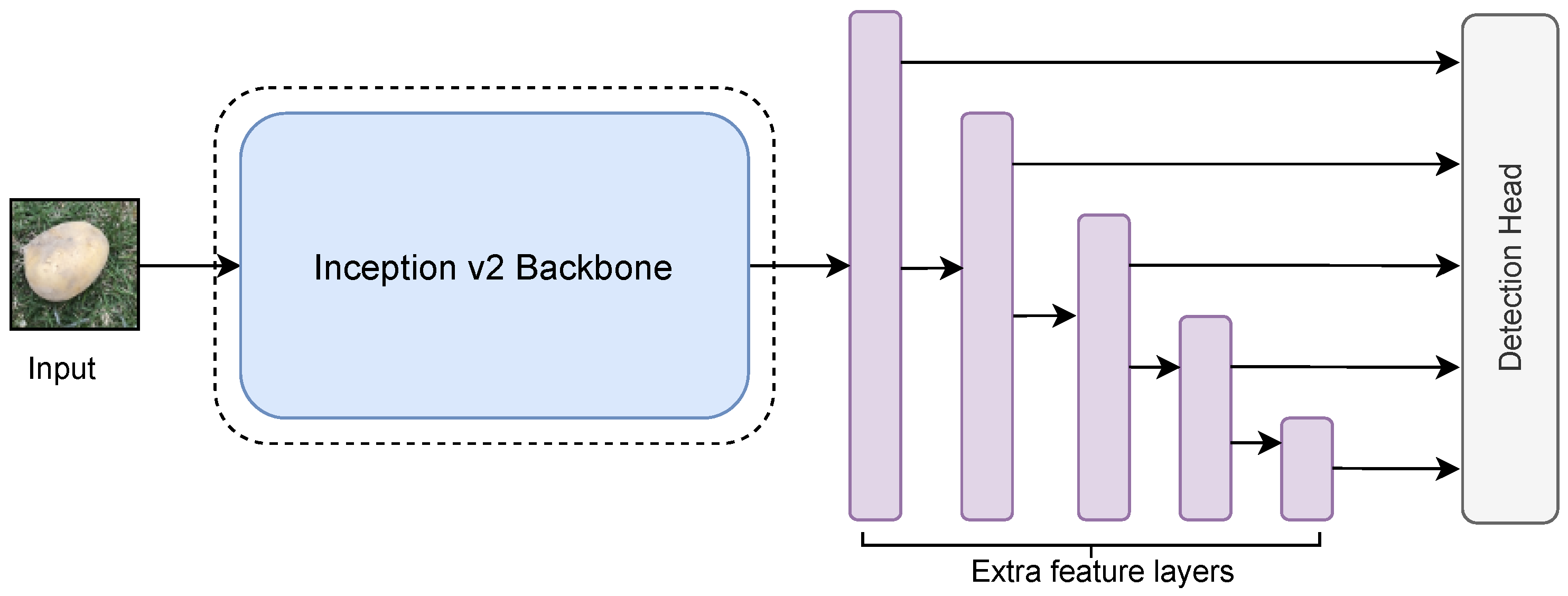
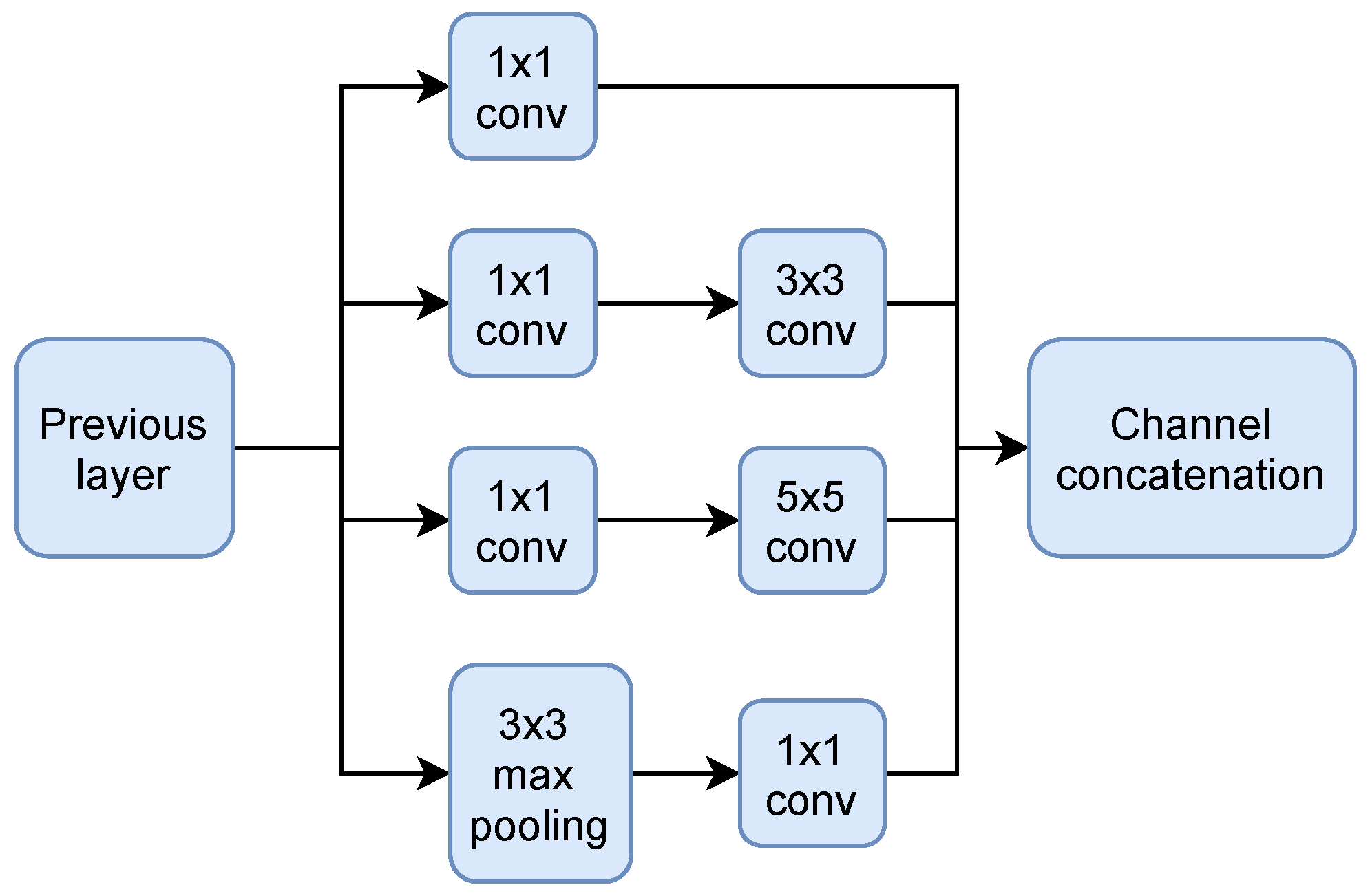
2.3.1. Model 1: SSD Inception V2
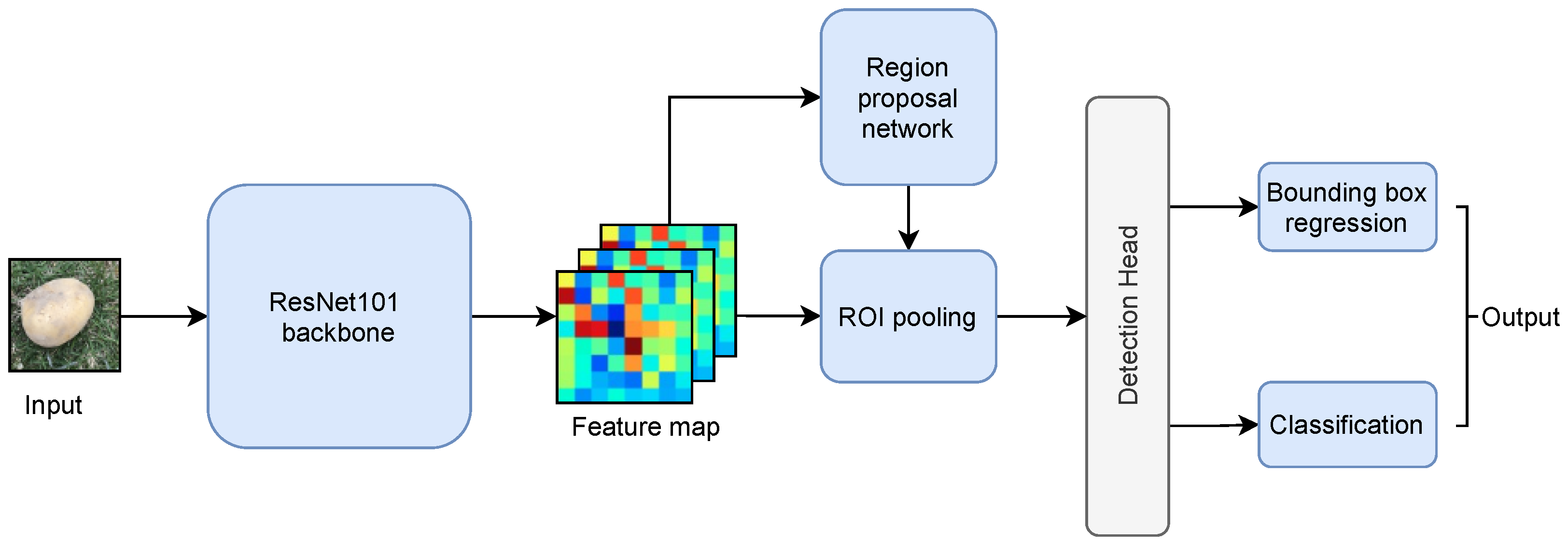
2.3.2. Model 2: Faster RCNN ResNet101
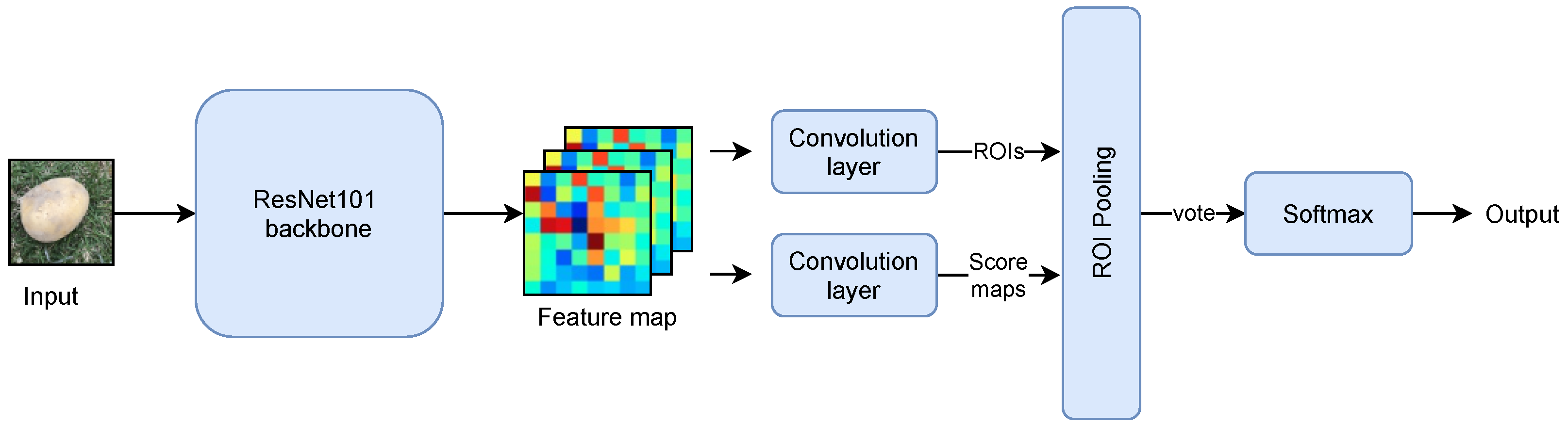
2.3.3. Model 3: RFCN ResNet101
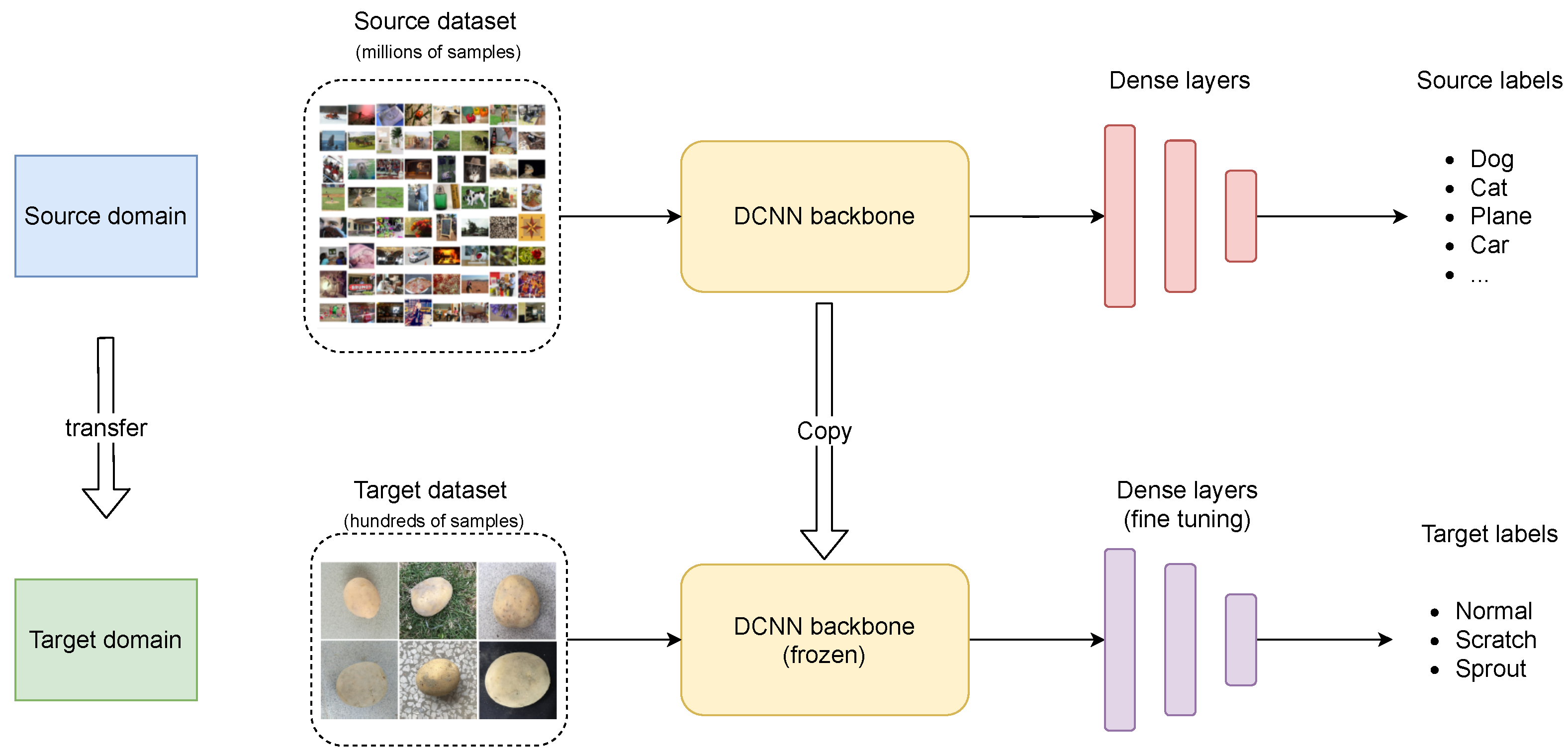
2.4. Transfer Learning for Potato Surface Defect Detection
2.5. Performance Metrics
3. Results
3.1. Experimental Setting
3.2. Implementation Details
- SSD Inception V2. The loss function of SSD is a weighted combination of localization and confidence loss. The former is defined as the smooth L1 loss with the offset from the predicted bounding box to the ground truth bounding box, and the latter is calculated as the softmax over the confidences of multiple classes. We adopt a learning rate of 0.001, 0.9 momentum, 0.0005 weight decay, and batch size 32. The model is trained using a stochastic gradient decent (SGD) optimizer. The used model in this study is offered by supervise.ly at https://supervise.ly/explore/models/ssd-inception-v-2-coco-1861/overview (accessed on 6 February 2021).
- RFCN ResNet101. The loss function of RFCN on each RoI is the sum of cross-entropy loss and the box regression loss, which correspond to the confidence and localization loss defined in SSD, respectively. We adopt a learning rate of 0.001, a weight decay of 0.0005, and a momentum of 0.9, with an Adam optimizer, also used by the original authors of RFCN in [57]. In addition, the batch size is 32. The released model used in this study is at https://supervise.ly/explore/models/rfcn-res-net-101-coco-1862/overview (accessed on 6 February 2021).
- Faster RCNN ResNet101. Faster RCNN uses the same loss function as SSD and RFCN. For training, we adopt similar settings as [55], with a learning rate of 0.003, a batch size of 16, a momentum of 0.9, a weight decay of 0.0005, and an optimizer of SGD. We used the released model at https://supervise.ly/explore/models/faster-r-cnn-res-net-101-coco-1866/overview (accessed on 6 February 2021) for our experiment.
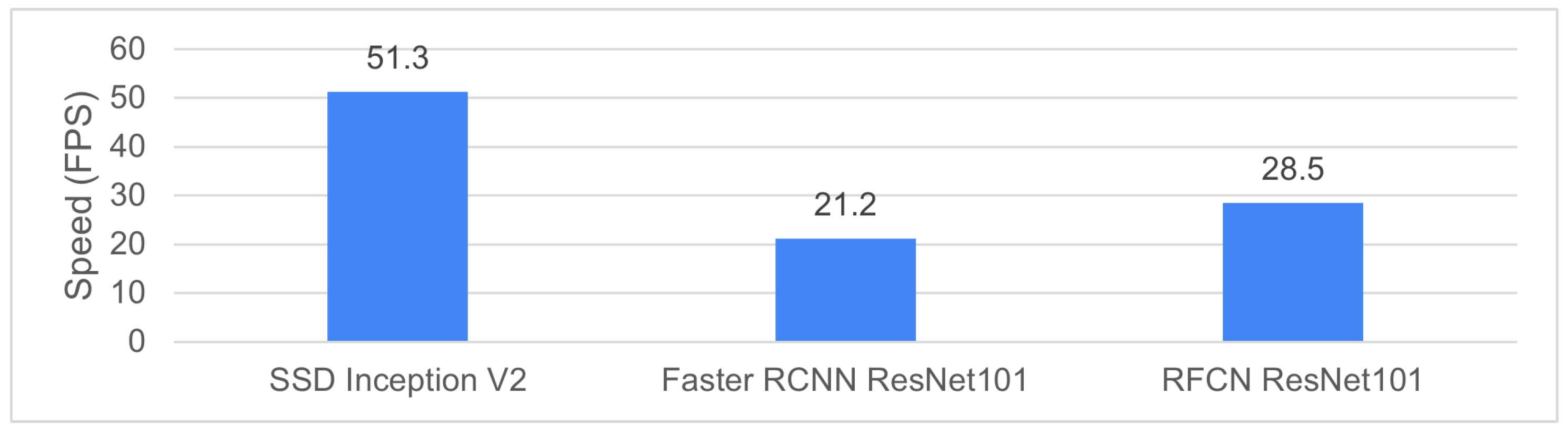
3.3. Model Evaluation and Selection
3.4. Out-of-Sample Testing
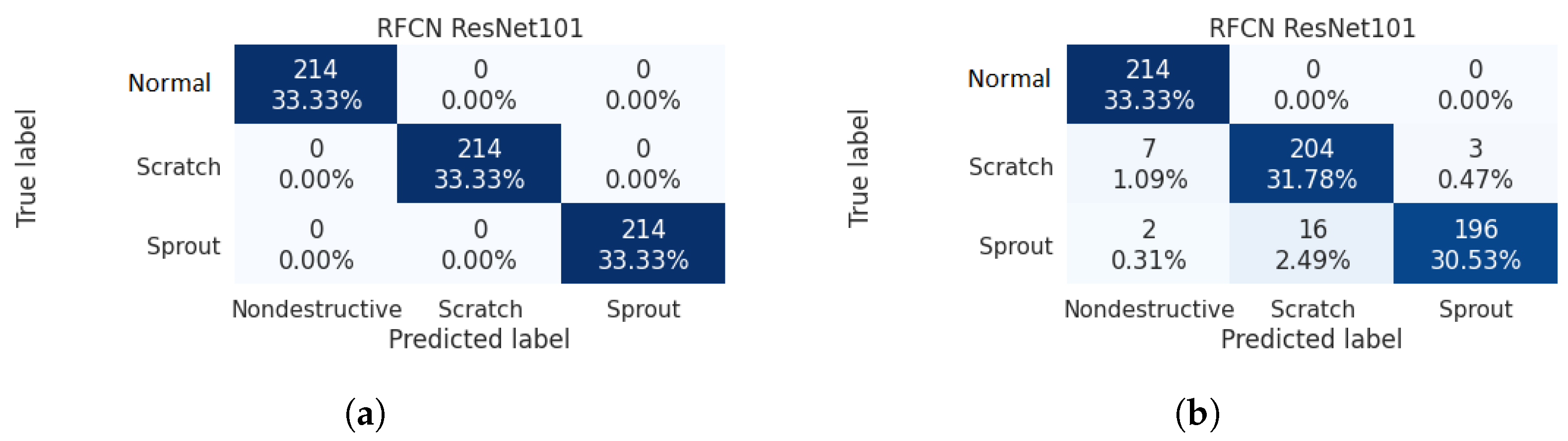
3.4.1. Scenario One: Effect of Different Batches
3.4.2. Scenario Two: Effect of Different Detection Regions
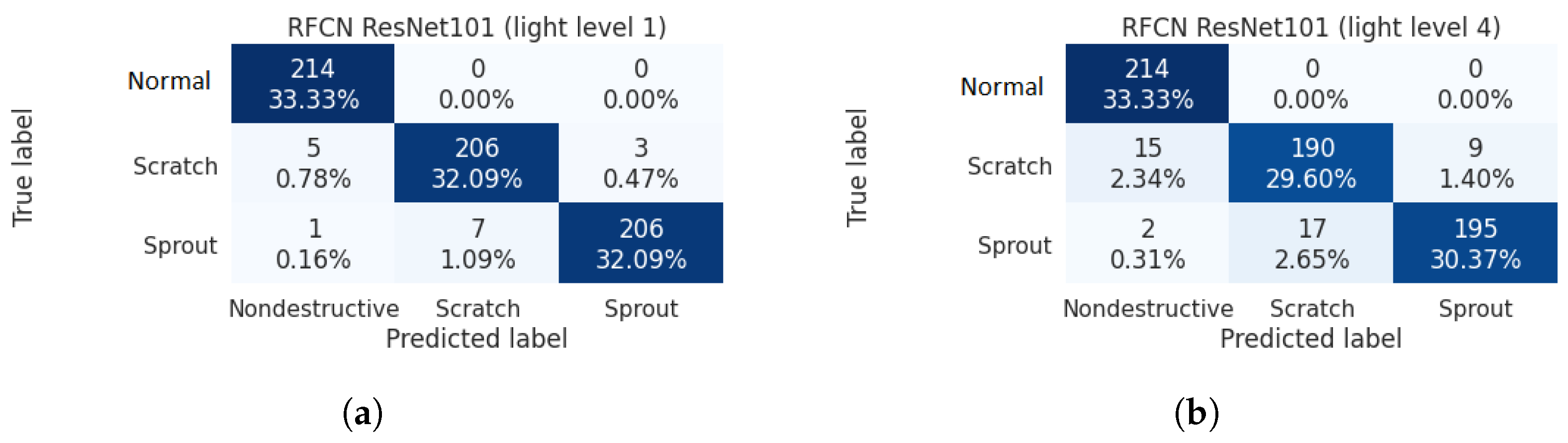
3.4.3. Scenario Three: Effect of Different Light Intensities
4. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- FAO. Food and Agriculture Organization Statistics; FAO: Rome, Italy, 2013. [Google Scholar]
- Gao, B.; Huang, W.; Xue, X.; Hu, Y.; Huang, Y.; Wang, L.; Ding, S.; Cui, S. Comprehensive environmental assessment of potato as staple food policy in China. Int. J. Environ. Res. Public Health 2019, 16, 2700. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Su, Q.; Kondo, N.; Al Riza, D.F.; Habaragamuwa, H. Potato Quality Grading Based on Depth Imaging and Convolutional Neural Network. J. Food Qual. 2020, 2020, 8815896. [Google Scholar] [CrossRef]
- ElMasry, G.; Cubero, S.; Moltó, E.; Blasco, J. In-line sorting of irregular potatoes by using automated computer-based machine vision system. J. Food Eng. 2012, 112, 60–68. [Google Scholar] [CrossRef]
- Narvankar, D.S.; Jha, S.; Singh, A. Development of rotating screen grader for selected orchard crops. J. Agric. Eng. 2005, 42, 60–64. [Google Scholar]
- Razmjooy, N.; Mousavi, B.S.; Soleymani, F. A real-time mathematical computer method for potato inspection using machine vision. Comput. Math. Appl. 2012, 63, 268–279. [Google Scholar] [CrossRef] [Green Version]
- Zhou, Z.; Huang, Y.; Li, X.; Wen, D.; Wang, C.; Tao, H. Automatic detecting and grading method of potatoes based on machine vision. Trans. Chin. Soc. Agric. Eng. 2012, 28, 178–183. [Google Scholar]
- Wang, C.; Li, X.; Wu, Z.; Zhou, Z.; Feng, Y. Machine vision detecting potato mechanical damage based on manifold learning algorithm. Trans. Chin. Soc. Agric. Eng. 2014, 30, 245–252. [Google Scholar]
- Yao, L.; Lu, L.; Zheng, R. Study on Detection Method of External Defects of Potato Image in Visible Light Environment. In Proceedings of the 2017 10th International Conference on Intelligent Computation Technology and Automation (ICICTA), Changsha, China, 9–10 October 2017; pp. 118–122. [Google Scholar]
- Moallem, P.; Razmjooy, N.; Ashourian, M. Computer vision-based potato defect detection using neural networks and support vector machine. Int. J. Robot. Autom. 2013, 28, 137–145. [Google Scholar] [CrossRef]
- Wang, Z.; Hu, M.; Zhai, G. Application of deep learning architectures for accurate and rapid detection of internal mechanical damage of blueberry using hyperspectral transmittance data. Sensors 2018, 18, 1126. [Google Scholar] [CrossRef] [Green Version]
- Suykens, J.A. Support vector machines: A nonlinear modelling and control perspective. Eur. J. Control 2001, 7, 311–327. [Google Scholar] [CrossRef]
- Duarte-Carvajalino, J.M.; Yu, G.; Carin, L.; Sapiro, G. Task-driven adaptive statistical compressive sensing of Gaussian mixture models. IEEE Trans. Signal Process. 2012, 61, 585–600. [Google Scholar] [CrossRef] [Green Version]
- Kleinbaum, D.G.; Dietz, K.; Gail, M.; Klein, M.; Klein, M. Logistic Regression; Springer: Berlin/Heidelberg, Germany, 2002. [Google Scholar]
- Yang, L.; Chen, L.; Tian, F.; Li, S.; Liu, X.; Tan, Y. Automatic Recognition of Potato Germ Based on AdaBoost Algorithm. In Proceedings of the 2019 ASABE Annual International Meeting, Boston, MA, USA, 7–10 July 2019. [Google Scholar]
- Xu, H.; Mannor, S. Robustness and generalization. Mach. Learn. 2012, 86, 391–423. [Google Scholar] [CrossRef] [Green Version]
- Brown, C.R. The contribution of traditional potato breeding to scientific potato improvement. Potato Res. 2011, 54, 287–300. [Google Scholar] [CrossRef]
- Heinemann, P.H.; Pathare, N.P.; Morrow, C.T. An automated inspection station for machine-vision grading of potatoes. Mach. Vis. Appl. 1996, 9, 14–19. [Google Scholar] [CrossRef]
- Zhou, L.; Chalana, V.; Kim, Y. PC-based machine vision system for real-time computer-aided potato inspection. Int. J. Imaging Syst. Technol. 1998, 9, 423–433. [Google Scholar] [CrossRef]
- Noordam, J.C.; Otten, G.W.; Timmermans, T.J.; van Zwol, B.H. High-speed potato grading and quality inspection based on a color vision system. In Proceedings of the Machine Vision Applications in Industrial Inspection VIII, San Jose, CA, USA, 24–26 January 2000; Volume 3966, pp. 206–217. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Khan, A.; Sohail, A.; Zahoora, U.; Qureshi, A.S. A survey of the recent architectures of deep convolutional neural networks. Artif. Intell. Rev. 2020, 53, 5455–5516. [Google Scholar] [CrossRef] [Green Version]
- Zhu, L.; Spachos, P.; Pensini, E.; Plataniotis, K.N. Deep learning and machine vision for food processing: A survey. Curr. Res. Food Sci. 2021, 4, 233–249. [Google Scholar] [CrossRef]
- Biswas, S.; Barma, S. A large-scale optical microscopy image dataset of potato tuber for deep learning based plant cell assessment. Sci. Data 2020, 7, 1–11. [Google Scholar] [CrossRef] [PubMed]
- Pandey, N.; Kumar, S.; Pandey, R. Grading and Defect Detection in Potatoes Using Deep Learning. In Proceedings of the International Conference on Communication, Networks and Computing, Gwalior, India, 22–24 March 2018; pp. 329–339. [Google Scholar]
- Pouyanfar, S.; Sadiq, S.; Yan, Y.; Tian, H.; Tao, Y.; Reyes, M.P.; Shyu, M.L.; Chen, S.C.; Iyengar, S. A survey on deep learning: Algorithms, techniques, and applications. ACM Comput. Surv. (CSUR) 2018, 51, 1–36. [Google Scholar] [CrossRef]
- Siddiqi, R. Automated apple defect detection using state-of-the-art object detection techniques. SN Appl. Sci. 2019, 1, 1–12. [Google Scholar] [CrossRef] [Green Version]
- Kayaalp, K.; Metlek, S. Classification of robust and rotten apples by deep learning algorithm. Sak. Univ. J. Comput. Inf. Sci. 2020, 3, 112–120. [Google Scholar] [CrossRef]
- Alam, M.N.; Saugat, S.; Santosh, D.; Sarkar, M.I.; Al-Absi, A.A. Apple Defect Detection Based on Deep Convolutional Neural Network. In International Conference on Smart Computing and Cyber Security: Strategic Foresight, Security Challenges and Innovation; Springer: Berlin/Heidelberg, Germany, 2020; pp. 215–223. [Google Scholar]
- Fan, S.; Li, J.; Zhang, Y.; Tian, X.; Wang, Q.; He, X.; Zhang, C.; Huang, W. On line detection of defective apples using computer vision system combined with deep learning methods. J. Food Eng. 2020, 286, 110102. [Google Scholar] [CrossRef]
- Valdez, P. Apple defect detection using deep learning based object detection for better post harvest handling. arXiv 2020, arXiv:2005.06089. [Google Scholar]
- Xie, W.; Wei, S.; Zheng, Z.; Yang, D. A CNN-based lightweight ensemble model for detecting defective carrots. Biosyst. Eng. 2021, 208, 287–299. [Google Scholar] [CrossRef]
- Deng, L.; Li, J.; Han, Z. Online defect detection and automatic grading of carrots using computer vision combined with deep learning methods. LWT 2021, 149, 111832. [Google Scholar] [CrossRef]
- Azizah, L.M.; Umayah, S.F.; Riyadi, S.; Damarjati, C.; Utama, N.A. Deep learning implementation using convolutional neural network in mangosteen surface defect detection. In Proceedings of the 2017 7th IEEE International Conference on Control System, Computing and Engineering (ICCSCE), Penang, Malaysia, 24–26 November 2017; pp. 242–246. [Google Scholar]
- Shi, X.; Wu, X. Tomato processing defect detection using deep learning. In Proceedings of the 2019 2nd World Conference on Mechanical Engineering and Intelligent Manufacturing (WCMEIM), Shanghai, China, 22–24 November 2019; pp. 728–732. [Google Scholar]
- Da Costa, A.Z.; Figueroa, H.E.; Fracarolli, J.A. Computer vision based detection of external defects on tomatoes using deep learning. Biosyst. Eng. 2020, 190, 131–144. [Google Scholar] [CrossRef]
- Turaev, S.; Abd Almisreb, A.; Saleh, M.A. Application of Transfer Learning for Fruits and Vegetable Quality Assessment. In Proceedings of the 2020 14th International Conference on Innovations in Information Technology (IIT), Al Ain, United Arab Emirates, 17–18 November 2020; pp. 7–12. [Google Scholar]
- Casaño, C.D.L.C.; Sánchez, M.C.; Chavez, F.R.; Ramos, W.V. Defect Detection on Andean Potatoes using Deep Learning and Adaptive Learning. In Proceedings of the 2020 IEEE Engineering International Research Conference (EIRCON), Lima, Peru, 21–23 October 2020; pp. 1–4. [Google Scholar]
- Hasan, M.Z.; Zahan, N.; Zeba, N.; Khatun, A.; Haque, M.R. A Deep Learning-Based Approach for Potato Disease Classification. In Computer Vision and Machine Learning in Agriculture; Springer: Berlin/Heidelberg, Germany, 2021; pp. 113–126. [Google Scholar]
- Al-Dosary, N.M.N. Potato harvester performance on tuber damage at the eastern of Saudi Arabia. Agric. Eng. Int. CIGR J. 2016, 18, 32–42. [Google Scholar]
- Friedman, M.; McDonald, G.M.; Filadelfi-Keszi, M. Potato glycoalkaloids: Chemistry, analysis, safety, and plant physiology. Crit. Rev. Plant Sci. 1997, 16, 55–132. [Google Scholar] [CrossRef]
- Wang, W.; Yang, Y.; Wang, X.; Wang, W.; Li, J. Development of convolutional neural network and its application in image classification: A survey. Opt. Eng. 2019, 58, 040901. [Google Scholar] [CrossRef] [Green Version]
- Liu, L.; Ouyang, W.; Wang, X.; Fieguth, P.; Chen, J.; Liu, X.; Pietikäinen, M. Deep learning for generic object detection: A survey. Int. J. Comput. Vis. 2020, 128, 261–318. [Google Scholar] [CrossRef] [Green Version]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar]
- Tan, C.; Sun, F.; Kong, T.; Zhang, W.; Yang, C.; Liu, C. A survey on deep transfer learning. In International Conference on Artificial Neural Networks; Springer: Berlin/Heidelberg, Germany, 2018; pp. 270–279. [Google Scholar]
- Fang, J.; Jacobsen, B.; Qin, Y. Predictability of the simple technical trading rules: An out-of-sample test. Rev. Financ. Econ. 2014, 23, 30–45. [Google Scholar] [CrossRef] [Green Version]
- Jiang, L.; Wang, Z.; Jin, G.; Lu, D.; Li, X. Responses of Favorita Potato Plantlets Cultured in Vitro under Fluorescent and Light-Emitting Diode (LED) Light Sources. Am. J. Potato Res. 2019, 96, 396–402. [Google Scholar] [CrossRef]
- Aksenova, N.; Sergeeva, L.; Konstantinova, T.; Golyanovskaya, S.; Kolachevskaya, O.; Romanov, G. Regulation of potato tuber dormancy and sprouting. Russ. J. Plant Physiol. 2013, 60, 301–312. [Google Scholar] [CrossRef]
- Turnbull, C.; Hanke, D. The control of bud dormancy in potato tubers. Planta 1985, 165, 359–365. [Google Scholar] [CrossRef] [PubMed]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2014; pp. 740–755. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-FCN: Object detection via region-based fully convolutional networks. In Proceedings of the 30th International Conference on Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 379–387. [Google Scholar]
- Guo, J.; Chen, P.; Jiang, Y.; Yokoi, H.; Togo, S. Real-time Object Detection with Deep Learning for Robot Vision on Mixed Reality Device. In Proceedings of the 2021 IEEE 3rd Global Conference on Life Sciences and Technologies (LifeTech), Nara, Japan, 9–11 March 2021; pp. 82–83. [Google Scholar]
- Cheng, Y.; Liu, W.; Xing, W. Weighted feature fusion and attention mechanism for object detection. J. Electron. Imaging 2021, 30, 023015. [Google Scholar] [CrossRef]
- Liu, Z.; Zheng, T.; Xu, G.; Yang, Z.; Liu, H.; Cai, D. TTFNeXt for real-time object detection. Neurocomputing 2021, 433, 59–70. [Google Scholar] [CrossRef]
- Huang, S.W.; Lin, C.T.; Chen, S.P.; Wu, Y.Y.; Hsu, P.H.; Lai, S.H. Auggan: Cross domain adaptation with gan-based data augmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 718–731. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ref | Product | # Classes | Task | T.L. | OOS T. |
|---|---|---|---|---|---|
| Fan et al. (2020) [30] | Apple | Two | Cls. | ✗ | ✗ |
| Valdez et al. (2020) [31] | Apple | Two | O.D. | ✓ | ✗ |
| Xie et al. (2021) [32] | Carrot | Six | Cls. | ✓ | ✗ |
| Deng et al. (2021) [33] | Carrot | Six | Cls. | ✓ | ✗ |
| Azizah et al. (2017) [34] | Mangosteen | Two | Cls. | ✗ | ✗ |
| Shi et al. (2019) [35] | Tomato | Two | O.D. | ✓ | ✗ |
| da Costa et al. (2020) [36] | Tomato | Two | Cls. | ✓ | ✗ |
| Turaev et al. (2020) [37] | 12 types | Five | Cls. | ✓ | ✗ |
| Casano et al. (2020) [38] | Potato | Two | Cls. | ✗ | ✗ |
| Su et al. (2020) [3] | Potato | Six | Cls. | ✗ | ✗ |
| Hasan et al. (2021) [39] | Potato | Twenty | Cls. | ✓ | ✗ |
| Ours | Potato | Three | O.D. | ✓ | ✓ |
| Category | Samples | Images | Percentage | Training | Test |
|---|---|---|---|---|---|
| Normal | 428 | 813 | 29.4% | 610 | 203 |
| Scratch | 214 | 841 | 30.4% | 631 | 210 |
| Sprout | 428 | 1116 | 40.2% | 837 | 279 |
| Total | 1070 | 2770 | 100% | 2078 | 693 |
| Model | Category | Acc | Pre | Rec | Spe | F1 |
|---|---|---|---|---|---|---|
| S.I.V2 | Normal | 92.5% | 91.7% | 92.6% | 92.4% | 92.2% |
| Scratch | 92.5% | 89.4% | 92.9% | 92.3% | 91.1% | |
| Sprout | 92.5% | 95.5% | 92.1% | 92.7% | 93.8% | |
| Macro avg. | 92.5% | 92.2% | 92.5% | 92.5% | 92.4% | |
| F.R.R.N.101 | Normal | 95.7% | 95.1% | 96.1% | 95.5% | 95.6% |
| Scratch | 95.7% | 93.9% | 94.8% | 96.1% | 94.3% | |
| Sprout | 95.7% | 97.5% | 96.1% | 95.4% | 96.8% | |
| Macro avg. | 95.7% | 95.5% | 95.6% | 95.7% | 95.6% | |
| R.R.N.101 | Normal | 98.7% | 99.0% | 98.5% | 98.8% | 98.8% |
| Scratch | 98.7% | 98.1% | 99.0% | 98.5% | 98.6% | |
| Sprout | 98.7% | 98.9% | 98.6% | 98.8% | 98.7% | |
| Macro avg. | 98.7% | 98.7% | 98.7% | 98.7% | 98.7% |
| Category | Acc | Pre | Rec | Spe | F1 |
|---|---|---|---|---|---|
| Normal | 95.60% | 96.00% | 100.00% | 93.50% | 97.90% |
| Scratch | 95.60% | 92.70% | 95.30% | 95.80% | 94.00% |
| Sprout | 95.60% | 98.50% | 91.60% | 97.70% | 94.90% |
| Macro avg. | 95.60% | 95.70% | 95.60% | 95.60% | 95.70% |
| Light Level | Category | Acc | Pre | Rec | Spe | F1 |
|---|---|---|---|---|---|---|
| One | Normal | 97.50% | 97.30% | 100.00% | 96.30% | 98.60% |
| Scratch | 97.50% | 96.70% | 96.30% | 98.10% | 96.50% | |
| Sprout | 97.50% | 98.60% | 96.30% | 98.10% | 97.40% | |
| Macro avg. | 97.50% | 97.50% | 97.50% | 97.50% | 97.50% | |
| Four | Normal | 93.30% | 93.00% | 100.00% | 90.00% | 96.40% |
| Scratch | 93.30% | 91.30% | 88.80% | 95.60% | 90.00% | |
| Sprout | 93.30% | 95.60% | 91.10% | 94.40% | 93.30% | |
| Macro avg. | 93.30% | 93.30% | 93.30% | 93.30% | 93.30% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, C.; Xiao, Z. Potato Surface Defect Detection Based on Deep Transfer Learning. Agriculture 2021, 11, 863. https://doi.org/10.3390/agriculture11090863
Wang C, Xiao Z. Potato Surface Defect Detection Based on Deep Transfer Learning. Agriculture. 2021; 11(9):863. https://doi.org/10.3390/agriculture11090863
Chicago/Turabian StyleWang, Chenglong, and Zhifeng Xiao. 2021. "Potato Surface Defect Detection Based on Deep Transfer Learning" Agriculture 11, no. 9: 863. https://doi.org/10.3390/agriculture11090863
APA StyleWang, C., & Xiao, Z. (2021). Potato Surface Defect Detection Based on Deep Transfer Learning. Agriculture, 11(9), 863. https://doi.org/10.3390/agriculture11090863