

Development of a General Prediction Model of Moisture Content in Maize Seeds Based on LW-NIR Hyperspectral Imaging



Abstract
:1. Introduction
2. Materials and Methods
2.1. Samples Preparation
2.2. Hyperspectral Image Acquisition and Spectra Pretreatment
2.3. Moisture Content Measurement
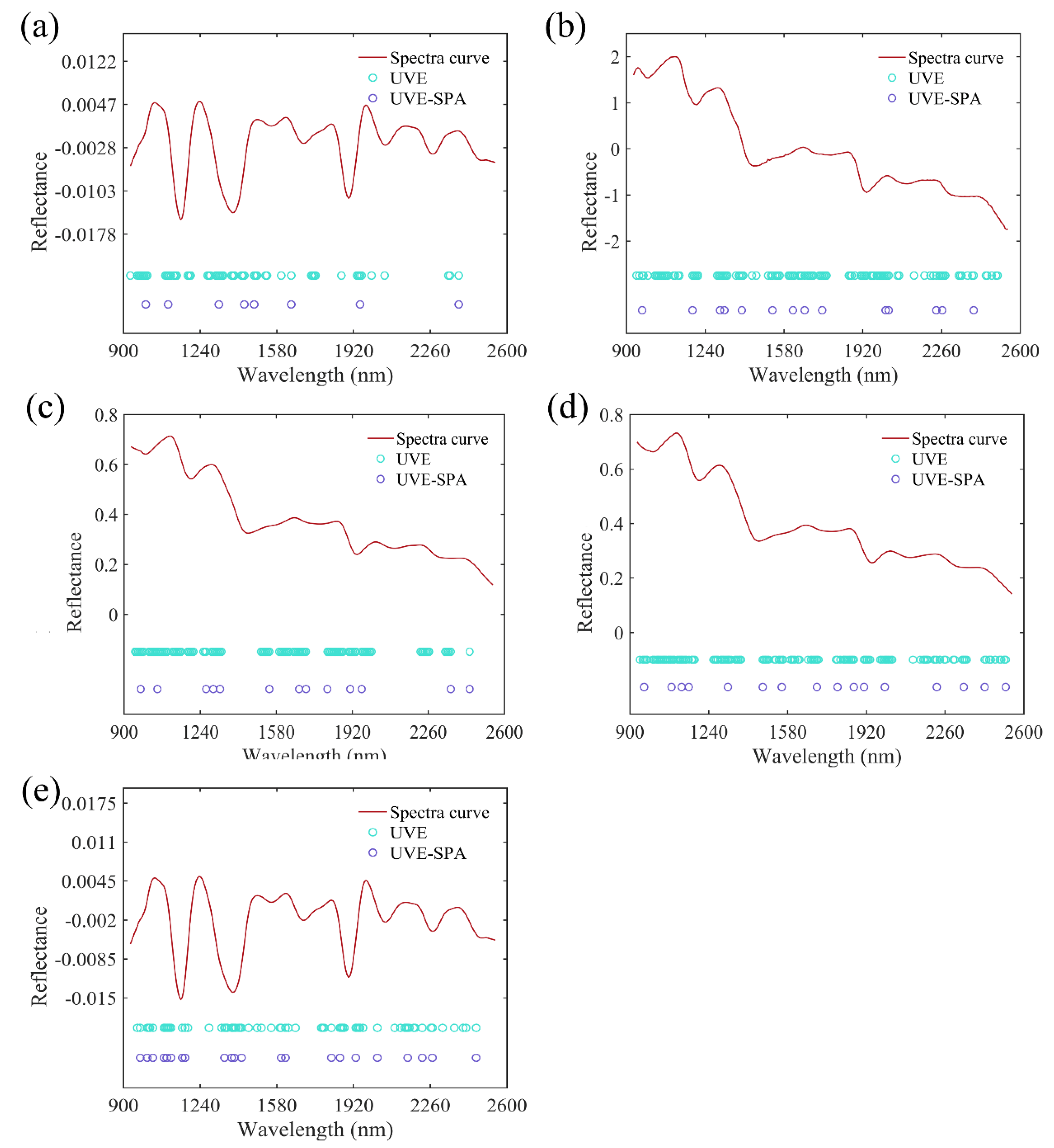
2.4. Variable Selection Methods
2.5. Model Establishment for Quantitative Analysis
2.6. The Performance Evaluation of Models
3. Results and Discussion
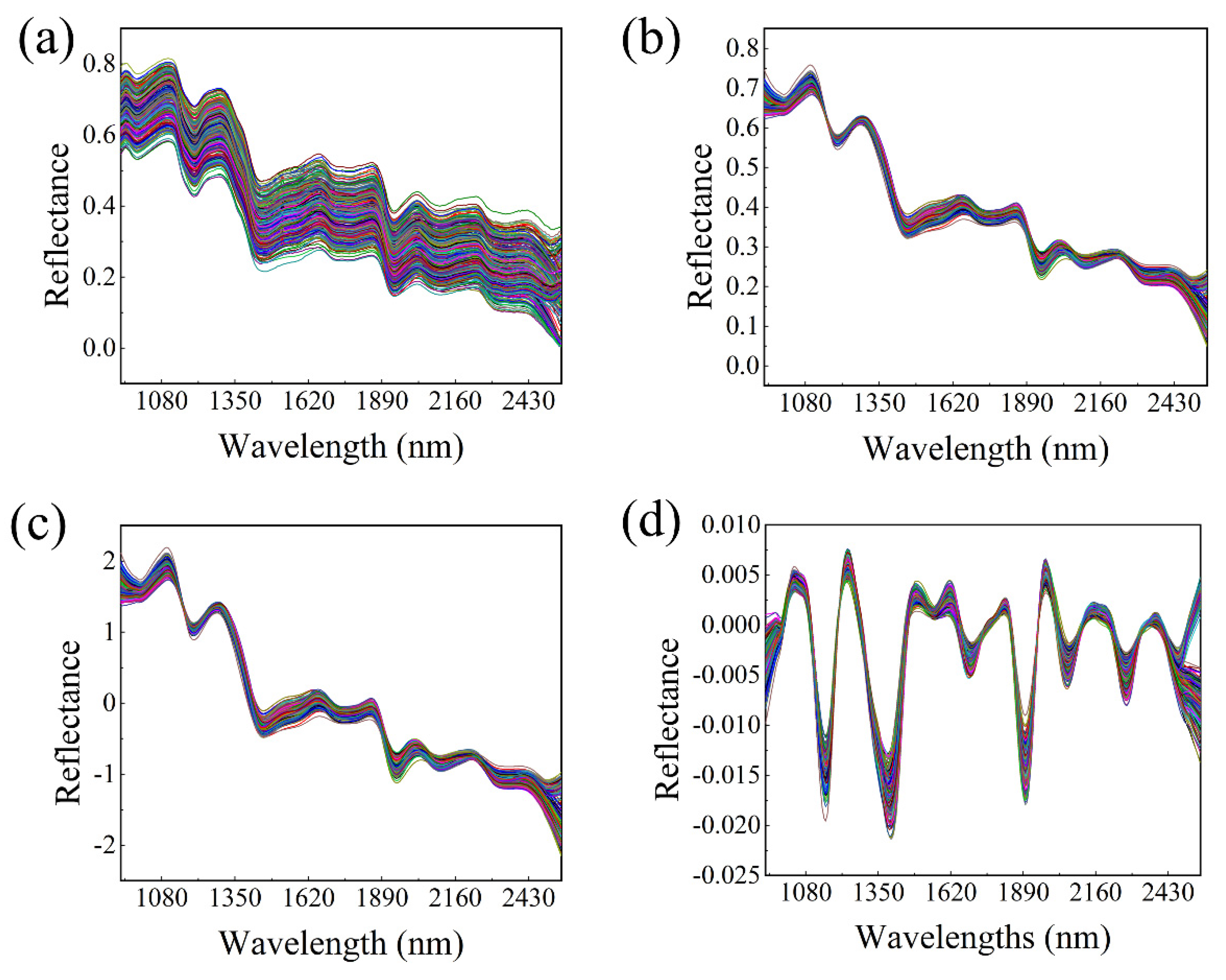
3.1. Spectra Analysis
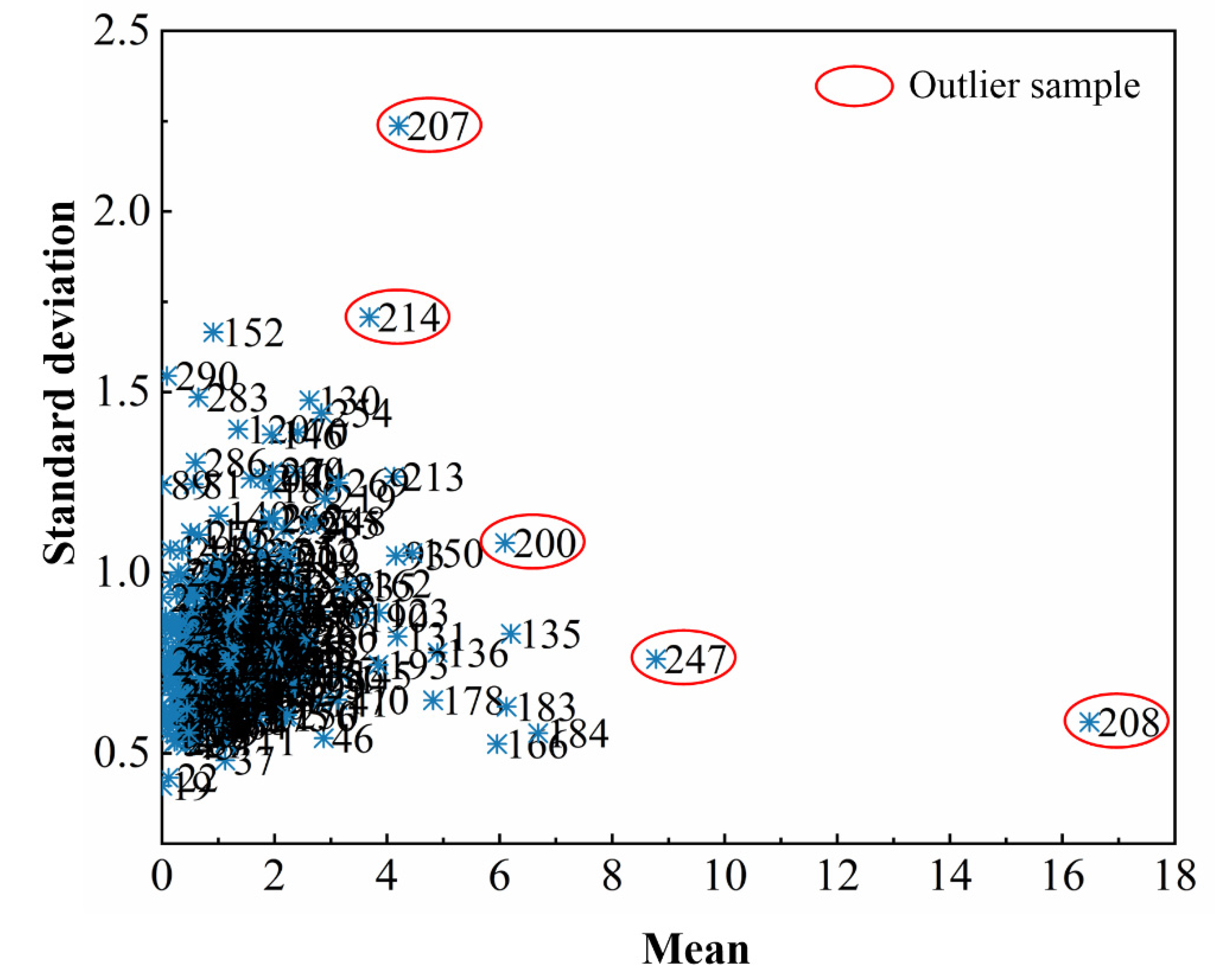
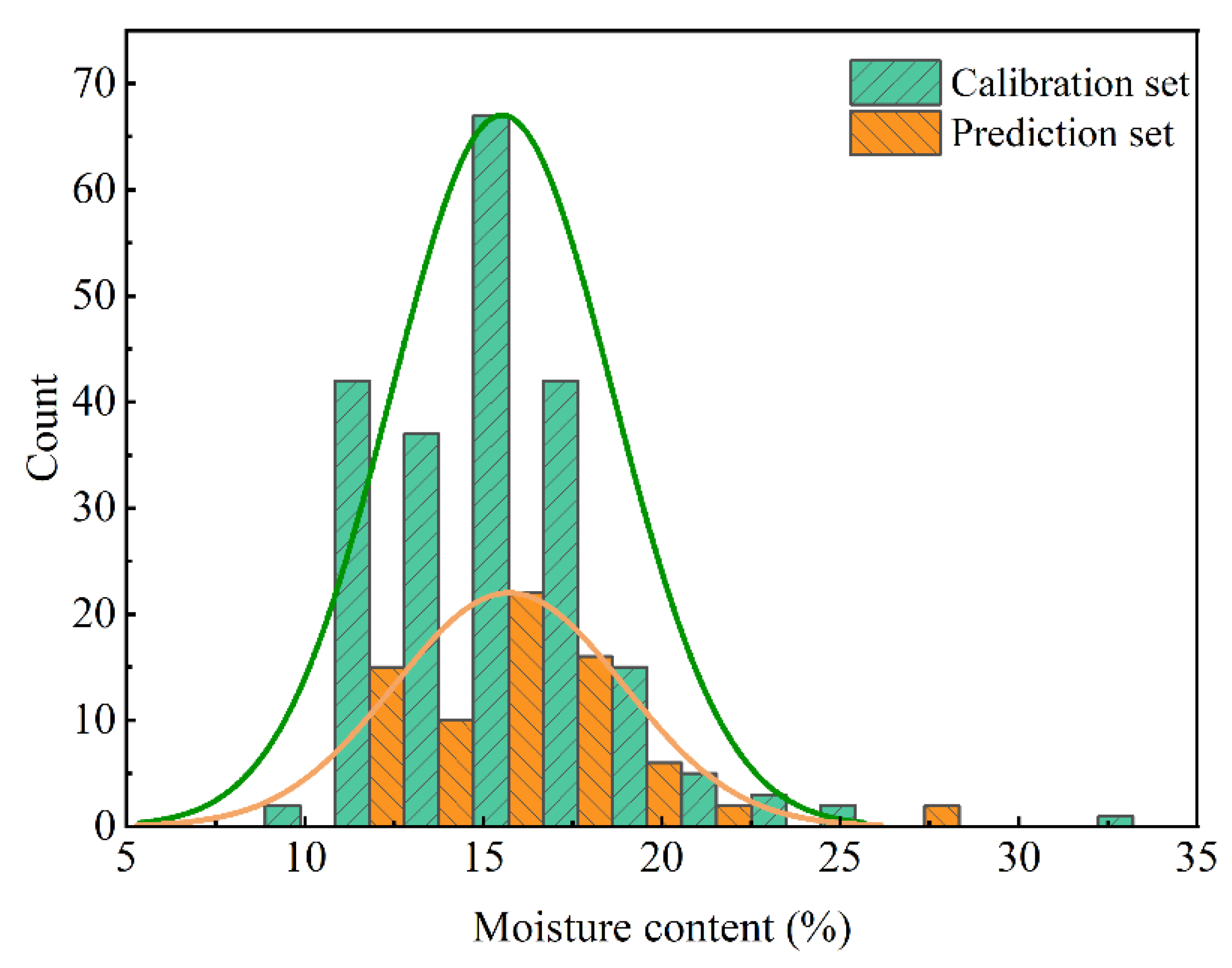
3.2. Abnormal Sample Elimination and Sample Division
3.3. Pretreatment Method Selection
3.4. The Prediction Results of Models Established Based on Feature Wavelengths
3.5. Discussion on Model Practicability
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Green, D.I.G.; Agu, R.C.; Bringhurst, T.A.; Brosnan, J.M.; Jack, F.R.; Walker, G.M. Maximizing alcohol yields from wheat and maize and their co-products for distilling or bioethanol production. J. Inst. Brew. 2015, 121, 332–337. [Google Scholar] [CrossRef]
- Li, Z.F.; Wang, D.H.; Shi, Y.C. High-Solids Bio-Conversion of Maize Starch to Sugars and Ethanol. Starch-Starke 2019, 71, 7. [Google Scholar] [CrossRef]
- Kljak, K.; Duvnjak, M.; Grbesa, D. Contribution of zein content and starch characteristics to vitreousness of commercial maize hybrids. J. Cereal Sci. 2018, 80, 57–62. [Google Scholar] [CrossRef]
- Niaz, I.; Dawar, S.; Sitara, U. Effect of different moisture and storage temperature on seed borne mycoflora of maize. Pak. J. Bot. 2011, 43, 2639–2643. [Google Scholar]
- Xu, Y.F.; Zhang, H.J.; Zhang, C.; Wu, P.; Li, J.B.; Xia, Y.; Fan, S.X. Rapid prediction and visualization of moisture content in single cucumber (Cucumis sativus L.) seed using hyperspectral imaging technology. Infrared Phys. Technol. 2019, 102, 9. [Google Scholar] [CrossRef]
- An, D.; Zhang, L.; Liu, Z.; Liu, J.; Wei, Y. Advances in infrared spectroscopy and hyperspectral imaging combined with artificial intelligence for the detection of cereals quality. Crit. Rev. Food Sci. Nutr. 2022, 20, 1–31. [Google Scholar] [CrossRef]
- Wang, Y.L.; Peng, Y.K.; Zhuang, Q.B.; Zhao, X.L. Feasibility analysis of NIR for detecting sweet corn seeds vigor. J. Cereal Sci. 2020, 93, 7. [Google Scholar] [CrossRef]
- Fan, Y.M.; Ma, S.C.; Wu, T.T. Individual wheat kernels vigor assessment based on NIR spectroscopy coupled with machine learning methodologies. Infrared Phys. Technol. 2020, 105, 7. [Google Scholar] [CrossRef]
- Ma, T.; Tsuchikawa, S.; Inagaki, T. Rapid and non-destructive seed viability prediction using near-infrared hyperspectral imaging coupled with a deep learning approach. Comput. Electron. Agric. 2020, 177, 105683. [Google Scholar] [CrossRef]
- Appeltans, S.; Pieters, J.G.; Mouazen, A.M. Potential of laboratory hyperspectral data for in-field detection of Phytophthora infestans on potato. Precis. Agric. 2021, 23, 876–893. [Google Scholar] [CrossRef]
- Ruett, M.; Junker-Frohn, L.V.; Siegmann, B.; Ellenberger, J.; Jaenicke, H.; Whitney, C.; Luedeling, E.; Tiede-Arlt, P.; Rascher, U. Hyperspectral imaging for high-throughput vitality monitoring in ornamental plant production. Sci. Hortic. 2022, 291, 10. [Google Scholar] [CrossRef]
- Li, H.; Zhang, L.; Sun, H.; Rao, Z.; Ji, H. Discrimination of unsound wheat kernels based on deep convolutional generative adversarial network and near-infrared hyperspectral imaging technology. Spectrochim. Acta Part A Mol. Biomol. Spectrosc. 2022, 268, 120722. [Google Scholar] [CrossRef] [PubMed]
- Wakholi, C.; Kandpal, L.M.; Lee, H.; Bae, H.; Park, E.; Kim, M.S.; Mo, C.; Lee, W.H.; Cho, B.K. Rapid assessment of corn seed viability using short wave infrared line-scan hyperspectral imaging and chemometrics. Sens. Actuators B-Chem. 2018, 255, 498–507. [Google Scholar] [CrossRef]
- Jiang, H.Z.; Cheng, F.N.; Shi, M.H. Rapid Identification and Visualization of Jowl Meat Adulteration in Pork Using Hyperspectral Imaging. Foods 2020, 9, 154. [Google Scholar] [CrossRef] [PubMed]
- Shao, Y.; Shi, Y.; Qin, Y.; Xuan, G.; Li, J.; Li, Q.; Yang, F.; Hu, Z. A new quantitative index for the assessment of tomato quality using Vis-NIR hyperspectral imaging. Food Chem. 2022, 386, 132864. [Google Scholar] [CrossRef]
- Fan, S.X.; Huang, W.Q.; Guo, Z.M.; Zhang, B.H.; Zhao, C.J. Prediction of Soluble Solids Content and Firmness of Pears Using Hyperspectral Reflectance Imaging. Food Anal. Methods 2015, 8, 1936–1946. [Google Scholar] [CrossRef]
- Qiao, M.M.; Xu, Y.; Xia, G.Y.; Su, Y.; Lu, B.; Gao, X.J.; Fan, H.F. Determination of hardness for maize kernels based on hyperspectral imaging. Food Chem. 2022, 366, 8. [Google Scholar] [CrossRef]
- Zhang, L.; Wang, Y.; Wei, Y.; An, D. Near-infrared hyperspectral imaging technology combined with deep convolutional generative adversarial network to predict oil content of single maize kernel. Food Chem. 2022, 370, 131047. [Google Scholar] [CrossRef]
- Kimuli, D.; Wang, W.; Wang, W.; Jiang, H.; Zhao, X.; Chu, X. Application of SWIR hyperspectral imaging and chemometrics for identification of aflatoxin B1 contaminated maize kernels. Infrared Phys. Technol. 2018, 89, 351–362. [Google Scholar] [CrossRef]
- Zhang, T.; Fan, S.; Xiang, Y.; Zhang, S.; Wang, J.; Sun, Q. Non-destructive analysis of germination percentage, germination energy and simple vigour index on wheat seeds during storage by Vis/NIR and SWIR hyperspectral imaging. Spectrochim. Acta Part A Mol. Biomol. Spectrosc. 2020, 239, 118488. [Google Scholar] [CrossRef]
- Zhang, L.; Wang, D.; Liu, J.; An, D. Vis-NIR hyperspectral imaging combined with incremental learning for open world maize seed varieties identification. Comput. Electron. Agric. 2022, 199, 107153. [Google Scholar] [CrossRef]
- Zhou, Q.; Huang, W.; Fan, S.; Zhao, F.; Liang, D.; Tian, X. Non-destructive discrimination of the variety of sweet maize seeds based on hyperspectral image coupled with wavelength selection algorithm. Infrared Phys. Technol. 2020, 109, 103418. [Google Scholar] [CrossRef]
- Nie, P.; Zhang, J.; Feng, X.; Yu, C.; He, Y. Classification of hybrid seeds using near-infrared hyperspectral imaging technology combined with deep learning. Sens. Actuators B Chem. 2019, 296, 126630. [Google Scholar] [CrossRef]
- Zhang, L.; Sun, H.; Rao, Z.; Ji, H. Hyperspectral imaging technology combined with deep forest model to identify frost-damaged rice seeds. Spectrochim. Acta Part A-Mol. Biomol. Spectrosc. 2020, 229, 117973. [Google Scholar] [CrossRef] [PubMed]
- Liu, C.; Huang, W.; Yang, G.; Wang, Q.; Li, J.; Chen, L. Determination of Starch Content in Single Kernel Using Near-infrared Hyperspectral Images from Two Sides of Corn Seeds. Infrared Phys. Technol. 2020, 110, 103462. [Google Scholar] [CrossRef]
- Zhang, Y.M.; Guo, W.C. Moisture content detection of maize seed based on visible/near-infrared and near-infrared hyperspectral imaging technology. Int. J. Food Sci. Technol. 2019, 55, 631–664. [Google Scholar] [CrossRef]
- Wang, Z.; Fan, S.; Wu, J.; Zhang, C.; Xu, F.; Yang, X.; Li, J. Application of long-wave near infrared hyperspectral imaging for determination of moisture content of single maize seed. Spectrochim. Acta Part A Mol. Biomol. Spectrosc. 2021, 254, 119666. [Google Scholar] [CrossRef]
- Liu, C.; Wang, Q.; Lin, W.; Yu, C. Origins classification of egg with different storage durations using FT-NIR: A characteristic wavelength selection approach based on information entropy. Biosyst. Eng. 2022, 222, 82–92. [Google Scholar] [CrossRef]
- Mansuri, S.M.; Chakraborty, S.K.; Mahanti, N.K.; Pandiselvam, R. Effect of germ orientation during Vis-NIR hyperspectral imaging for the detection of fungal contamination in maize kernel using PLS-DA, ANN and 1D-CNN modelling. Food Control 2022, 139, 109077. [Google Scholar] [CrossRef]
- Pereira, E.V.d.S.; Fernandes, D.D.d.S.; de Araújo, M.C.U.; Diniz, P.H.G.D.; Maciel, M.I.S. Simultaneous determination of goat milk adulteration with cow milk and their fat and protein contents using NIR spectroscopy and PLS algorithms. LWT 2020, 127, 109427. [Google Scholar] [CrossRef]
- Wang, Y.J.; Ren, Z.Y.; Li, M.Y.; Yuan, W.X.; Zhang, Z.Z.; Ning, J.M. pH indicator-based sensor array in combination with hyperspectral imaging for intelligent evaluation of withering degree during processing of black tea. Spectrochim. Acta Part A-Mol. Biomol. Spectrosc. 2022, 271, 120959. [Google Scholar] [CrossRef] [PubMed]
- Noroozi, R.; Sohrabi, M.R.; Davallo, M. A simple and rapid spectrophotometric method coupled with intelligent approaches for the simultaneous determination of antiepileptic drugs in pharmaceutical formulations, biological, serological, and breast milk samples. Chemom. Intell. Lab. Syst. 2022, 228, 104633. [Google Scholar] [CrossRef]
- Qin, C.; Shi, G.; Tao, J.; Yu, H.; Jin, Y.; Xiao, D.; Zhang, Z.; Liu, C. An adaptive hierarchical decomposition-based method for multi-step cutterhead torque forecast of shield machine. Mech. Syst. Signal Process. 2022, 175, 109148. [Google Scholar] [CrossRef]
- Guo, W.C.; Zhao, F.; Dong, J.L. Nondestructive Measurement of Soluble Solids Content of Kiwifruits Using Near-Infrared Hyperspectral Imaging. Food Anal. Methods 2016, 9, 38–47. [Google Scholar] [CrossRef]
- Dong, G.; Guo, J.; Wang, C.; Liang, K.; Lu, L.; Wang, J.; Zhu, D. Differentiation of storage time of wheat seed based on near infrared hyperspectral imaging. Int. J. Agric. Biol. Eng. 2017, 10, 251–258. [Google Scholar] [CrossRef]
- Dong, J.L.; Guo, W.C. Nondestructive Determination of Apple Internal Qualities Using Near-Infrared Hyperspectral Reflectance Imaging. Food Anal. Methods 2015, 8, 2635–2646. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. of Samples | R cv | RMSECV/% |
|---|---|---|
| 294 | 0.84 | 1.77 |
| 289 | 0.91 | 1.32 |
| Spectra Types | Modeling Methods | Pretreatment Methods | Rcv | RMSECV/% |
|---|---|---|---|---|
| S1 | PLSR | None | 0.90 | 1.33 |
| SG-MSC | 0.90 | 1.36 | ||
| SG-D1 | 0.91 | 1.31 | ||
| SG-SNV | 0.90 | 1.35 | ||
| LS-SVM | None | 0.89 | 1.30 | |
| SG-MSC | 0.88 | 1.33 | ||
| SG-D1 | 0.91 | 1.21 | ||
| SG-SNV | 0.91 | 1.31 | ||
| S2 | PLSR | None | 0.92 | 1.16 |
| SG-MSC | 0.93 | 1.12 | ||
| SG-D1 | 0.93 | 1.16 | ||
| SG-SNV | 0.93 | 1.11 | ||
| LS-SVM | None | 0.92 | 1.10 | |
| SG-MSC | 0.92 | 1.05 | ||
| SG-D1 | 0.92 | 1.12 | ||
| SG-SNV | 0.93 | 1.01 | ||
| S3 | PLSR | None | 0.95 | 1.06 |
| SG-MSC | 0.94 | 1.05 | ||
| SG-D1 | 0.93 | 1.07 | ||
| SG-SNV | 0.94 | 1.07 | ||
| LS-SVM | None | 0.93 | 1.07 | |
| SG-MSC | 0.94 | 0.98 | ||
| SG-D1 | 0.93 | 1.03 | ||
| SG-SNV | 0.93 | 1.05 |
| Spectra Types | Modeling Methods | Variable Selection Methods | No. of Variables | Calibration Set | Prediction Set | ||
|---|---|---|---|---|---|---|---|
| Rcal | RMSEC/% | Rpre | RMSEP/% | ||||
| S1 | PLSR | None | 256 | 0.92 | 1.18 | 0.89 | 1.38 |
| UVE | 56 | 0.92 | 1.26 | 0.90 | 1.38 | ||
| UVE-SPA | 8 | 0.92 | 1.21 | 0.89 | 1.39 | ||
| LS-SVM | None | 256 | 0.94 | 1.04 | 0.91 | 1.30 | |
| UVE | 56 | 0.94 | 1.03 | 0.91 | 1.29 | ||
| UVE-SPA | 8 | 0.93 | 1.08 | 0.91 | 1.31 | ||
| S2 | PLSR | None | 256 | 0.95 | 0.93 | 0.91 | 1.30 |
| UVE | 110 | 0.95 | 0.94 | 0.91 | 1.28 | ||
| UVE-SPA | 14 | 0.94 | 1.03 | 0.88 | 1.48 | ||
| LS-SVM | None | 256 | 0.98 | 0.67 | 0.92 | 1.32 | |
| UVE | 110 | 0.97 | 0.72 | 0.92 | 1.27 | ||
| UVE-SPA | 14 | 0.97 | 0.73 | 0.91 | 1.38 | ||
| S3 | PLSR | None | 256 | 0.95 | 0.94 | 0.93 | 1.18 |
| UVE | 108 | 0.95 | 0.95 | 0.93 | 1.20 | ||
| UVE-SPA | 13 | 0.95 | 0.97 | 0.92 | 1.22 | ||
| LS-SVM | None | 256 | 0.96 | 0.91 | 0.93 | 1.21 | |
| UVE | 108 | 0.96 | 0.91 | 0.93 | 1.19 | ||
| UVE-SPA | 13 | 0.95 | 0.92 | 0.94 | 1.20 | ||
| Models | Spectra Types | No. of Variables | Rpre | RMSEP/% |
|---|---|---|---|---|
| S1-UVE-SPA-LS-SVM | S1+S2 | 8 | 0.58 | 3.40 |
| S2-UVE-SPA-LS-SVM | 14 | 0.79 | 2.33 | |
| S1+S2-PLSR | 256 | 0.91 | 1.34 | |
| S1+S2-LS-SVM | 256 | 0.92 | 1.30 | |
| S1+S2-UVE-PLSR | 125 | 0.91 | 1.35 | |
| S1+S2-UVE-LS-SVM | 66 | 0.92 | 1.30 | |
| S1+S2-UVE-SPA-PLSR | 16 | 0.90 | 1.37 | |
| S1+S2-UVE-SPA-LS-SVM | 22 | 0.91 | 1.32 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Z.; Li, J.; Zhang, C.; Fan, S. Development of a General Prediction Model of Moisture Content in Maize Seeds Based on LW-NIR Hyperspectral Imaging. Agriculture 2023, 13, 359. https://doi.org/10.3390/agriculture13020359
Wang Z, Li J, Zhang C, Fan S. Development of a General Prediction Model of Moisture Content in Maize Seeds Based on LW-NIR Hyperspectral Imaging. Agriculture. 2023; 13(2):359. https://doi.org/10.3390/agriculture13020359
Chicago/Turabian StyleWang, Zheli, Jiangbo Li, Chi Zhang, and Shuxiang Fan. 2023. "Development of a General Prediction Model of Moisture Content in Maize Seeds Based on LW-NIR Hyperspectral Imaging" Agriculture 13, no. 2: 359. https://doi.org/10.3390/agriculture13020359
APA StyleWang, Z., Li, J., Zhang, C., & Fan, S. (2023). Development of a General Prediction Model of Moisture Content in Maize Seeds Based on LW-NIR Hyperspectral Imaging. Agriculture, 13(2), 359. https://doi.org/10.3390/agriculture13020359