1. Introduction
Tea is a popular beverage consumed worldwide and also a vital economic crop for many countries. In comparison to the high demand and output of tea, the traditional method of harvesting tea leaves remains quite rudimentary, particularly for famous teas, which are often picked manually. This picking process is labor-intensive, time-consuming, and physically demanding, which may result in strains and injuries among laborers. Instead of picking manually, an automatic tea picking system has the potential to lower the requirement of labor and ease labor intensity [
1]. In order to develop this automatic system, detecting and positioning the tea leaves in 3D space is an essential process, which allows the system to accurately perceive the leaves in the field for picking. Moreover, the algorithm for detecting and positioning tea leaves can be used to enhance production, facilitate research, and monitor and preserve the environment. Research into tea detection and positioning algorithms plays a crucial role in automatic picking systems, which have the potential to significantly improve the efficiency and productivity of tea production in the future [
2].
The development of tea bud detectors has been sustained for several years. Researchers have extracted and combined various features, such as shape, color, and texture, from tea bud images to design advanced features using complicated processes. For example, Zhang et al. utilized R-B factors to convert the image to grayscale and performed threshold segmentation using the Otsu method. They applied area filtering, erosion, and expansion algorithms to generate a binary image of the tea buds. Finally, the center of mass method was employed to determine the position of the tea buds within the binary image [
3]. Zhang et al. applied a Gaussian filter to reduce image noise and split the images into their respective R, G, and B components. Image operations were performed to obtain G-B’ components. The minimum error method was utilized to determine the most suitable adaptation thresholds, which underwent a piecewise linear transformation to enhance the distinction between the tea buds and the background. Binarization and the application of the Canny operator were then employed to detect edges in the binary image. Finally, the unknown area was calculated and marked, and the segmentation process was completed using the watershed function [
4]. Wu et al. analyzed the color information of G and G-B components of tea buds and leaves. They calculated segmentation thresholds using an improved Otsu method to recognize tea buds [
5]. While these methods have demonstrated effectiveness under specific conditions, their limited generalizability and lack of intelligence restrict their applicability in production scenarios.
With the progression of deep learning methods, the object detection field has shifted the focus toward acquiring larger labeled datasets and refining the network architecture, rather than emphasizing image features. Many studies on object detection have used large public datasets to train and test detectors based on convolutional networks, with subjects such as cars [
6], traffic signs [
7] and pedestrians [
8]. Similarly, many studies on object detection based on deep learning in agriculture have also been conducted [
9]. Zeng et al. proposed using a lightweight YOLOv5 model to efficiently detect the location and ripeness of tomato fruits in real time, and the improvement reduced the model size by 51.1% while maintaining a 93% true detection rate [
10]. Ma et al. integrated a coordinate attention (CA) module with YOLOv5 and trained and tested a YOLOv5-lotus model to effectively detect overripe lotus seedpods in a natural environment [
11]. Wang et al. introduced an apple fruitlet detection method that utilizes a channel-pruned YOLOv5s deep learning algorithm, achieving rapid and accurate detection, and the compact model size of 1.4 MB facilitated the development of portable mobile fruit thinning terminals [
12]. Sozzi et al. evaluated six versions of YOLO (YOLOv3, YOLOv3-tiny, YOLOv4, YOLOv4-tiny, YOLOv5x, and YOLOv5s) for real-time bunch detection and counting in grapes. Finally, YOLOv4-tiny emerged as the best choice due to its optimal balance between accuracy and speed. This study provided valuable insights into the performance of different YOLO versions and their applicability in the grape industry [
13]. Cardellicchio et al. used single-stage detectors based on YOLOv5 to effectively identify nodes, fruit, and flowers on a challenging dataset acquired during a stress experiment conducted on multiple tomato genotypes, and achieved relatively high scores [
14].
In particular, studies on the detection of tea buds based on deep learning have also made some significant advancements. Murthi and Thangavel employed the active contour model to identify potential tea bud targets in images, then utilized a DCNN for recognition [
15]. Chen et al. introduced a new fresh tea sprout detection method, FTSD-IEFSSD, which integrates image enhancement and a fusion single-shot detector. This method separately inputs the original and enhanced images into a ResNet50 subnetwork and improves detection accuracy through score fusion. This method achieved an AP of 92.8% [
16]. Xu et al. combined YOLOv3 with DenseNet201 to quickly and accurately detect and classify tea buds, achieving 82.58% precision on the top-shot dataset and 99.28% precision on the side-shot dataset [
17]. Gui et al. enhanced and reduced the weight of the YOLOv5 network for tea bud detection by replacing the standard convolution with a Ghost_conv module, adding a BAM into the backbone, applying MS-WFF in the neck, and switching to a CIOU loss function. After training and testing on a dataset of 1000 samples, the model achieved a frame rate of 29,509 FPS, an mAP of 92.66%, and a model size of 90 M [
18]. Moreover, tea buds can also be segmented using deep learning. Hu et al. presented a discriminative pyramid (DP) network-based method with exceptional accuracy for the semantic segmentation of tea geometrids in natural scene images [
19], while TS-SegNet, a novel deep convolutional encoder-decoder network method for tea sprout segmentation proposed by Qian et al., produced a good segmentation result [
20].
Currently, research is primarily focused on detecting and segmenting tea buds, with very few studies proposing methods for identifying the specific points for picking. However, identifying the position of the picking point is crucial for efficient and effective tea bud harvesting. The Faster R-CNN was used to locate tea shoot picking points in the field, achieving a precision of 79% [
21], and the Mask-RCNN was utilized to create a recognition model for tea buds, leaves, and picking points. The results showed an average detection accuracy of 93.95% and a recall rate of 92.48% [
22]. Although these algorithms position the picking point of tea buds in the image, the lack of a depth sensor limits the acquisition of spatial coordinates for picking points. Thus, the robot would be unable to determine the target position in robot coordinates for end-effector movement. Li et al. used the YOLO network to detect the tea buds and acquired the position of the target in the 3D space by using an RGB-D camera [
23]. This method calculates the center point of all points and represents the grab position using a vertical minimum circumscribed cylinder. Then, they inclined the minimum circumscribed cylinder according to the growth direction of tea buds calculated via the PCA method [
24]. Chen et al. developed a robotics system for the intelligent picking of tea buds, training the YOLOv3 model to detect the tea buds from images and proposing an image algorithm to locate the picking point. While their system has a successful picking rate of 80%, the detection precision of this system could be improved, and the importance of addressing measurement errors and motion errors in the picking process should not be overlooked [
25].
In conclusion, tea bud detection research has experienced good development, but some datasets are still quite simple and small-sized. Moreover, the pose of tea buds within a 3D space is important for the robot to grasp the target accurately, yet there are few studies that have talked about this issue. Therefore, the aim of this study is to detect tea buds using an improved YOLOv5 network and determine their 3D pose through the OPVSM. The contributions of this study are as follows:
3. Results and Discussion
3.1. Experiments with Improved YOLOv5
3.1.1. Preparation
The deep learning method utilizes a known dataset with a homologous pattern to build an approximate model for predicting unknown data. The deep neural network can be considered as an approximation of the feature distribution. Therefore, the foundation of deep learning is the quality of the dataset, as only high-quality data can ensure the reliability of the model. There are three important properties that determine the quality of data, namely authenticity, multiplicity, and correctness. The authenticity of the data requires that the samples accurately reflect the application scenarios in the real world. The multiplicity of the data requires that the dataset contains different samples under varying conditions such as weather, illumination, shooting angle, camera parameters, and background. The correctness of the data requires that the labels of the dataset are accurate and precise for labeling the objects in the images. Moreover, a larger volume of data typically leads to better model performance.
As mentioned above, a large tea bud image dataset was established over a period of three years, from 2020 to 2022. It includes tens of thousands of samples acquired with different cameras, during different seasons and weather conditions and from different tea plant varieties. A selection of these samples can be seen in
Figure 10.
In this paper, tea buds from longjing43 tea plants were selected as the detection object. All of the images in the dataset were of the longjing43 variety. The variations in plantation, seasons, and shooting time account for the distinct appearances observed in these samples. A total of 20,859 samples of the longjing43 variety were acquired, and the remaining samples were excluded. From these samples, we randomly selected 16,000 samples for both the training and validation datasets. In each training epoch, the 16,000 samples were split randomly into training and validation datasets in a 7:3 ratio. The remaining 4859 samples formed the test set, which was not used during the training stage, but rather only for testing after training to eliminate any potential bias.
This study aimed to detect tea buds that conform to the “one bud and one leaf” (BL1) standard specified in the tea industry guidelines. They were labeled into two different classes, namely ST (Spring Tea) and AT (Autumn Tea), due to their significant differences. The dataset included a total of 198,227 objects, out of which 122,762 were Spring Tea and 75,465 were Autumn Tea. The labeling process employed the Labelimg software, where tea buds in the images were selected using rectangular frames and assigned corresponding class labels. The resulting labeling data were saved in a .txt file format, adhering to the specified format (c, xcenter, ycenter, w, h). Here, c represents the class number, (xcenter, ycenter) represents the normalized central coordinates of the rectangle, and (w, h) indicates the normalized length and width of the rectangle.
Data augmentation is a technique that enhances the diversity and variability of the training set, resulting in a more robust model with reduced possibility of overfitting. It promotes better generalization by exposing the model to various variations of the same data points. Data augmentation expands the dataset without the need for additional labeled examples, thereby providing the model with more instances to learn from and reducing the risk of overfitting to noise or outliers. It also serves as a regularization technique by imposing constraints and introducing random perturbations to mitigate the model’s sensitivity to individual training examples. By applying data augmentation with other techniques, such as dropout, batch normalization and weight decay, the model can avoid overfitting and achieve optimal results [
31].
Therefore, some of the images in the dataset were pre-processed before training. This process may involve various techniques such as translation, rotation, cropping, noise addition, mirroring, contrast, color, and brightness transformation. All of these augmentation methods are shown in
Figure 11.
This research applied specific constraints to the parameters of various data augmentation methods to strike a balance between introducing meaningful variations and avoiding excessive distortions. The translation distance was limited to a maximum of 0.1 times the image width horizontally and 0.1 times the image height vertically. Rotation augmentation was constrained to a maximum angle of 30 degrees in both clockwise and counterclockwise directions. For cropping augmentation, the cropping parameter was set to 0.8, indicating that the cropped region covered 80% of the original image size. Gaussian noise augmentation employed a variance parameter of 0.02. Mirroring augmentation involved horizontal flipping with a 50% chance. Contrast, color, and brightness transformations were limited to a magnitude range of −0.2 to 0.2. These specific parameter constraints were selected based on empirical observations and domain knowledge to ensure reasonable variations while preserving image quality and information integrity.
In addition, the mosaic [
32] process was used to improve the robustness and generalization of the model in this study. As shown in
Figure 12, the mosaic image was created by randomly selecting four images from the training dataset and placing them together in a square. The images were resized and padded to fit into the square, with random flips and rotations applied to each individual image. This technique exposes the model to a wide range of object arrangements and backgrounds in a single image, which helps to improve the performance of object detection models.
3.1.2. Results
To evaluate the performance of the improved YOLOv5, the improved model was compared with the original YOLOv5 using several evaluation metrics, including P (precision), R (recall), mAP (mean average precision), Params (parameters), FLOPs (floating point operations) and speed (FPS). Precision is defined as the ratio of true positive predictions to the total number of positive predictions made by the model. It is calculated as follows:
where
TP represents the number of correctly predicted positive instances and
FP represents the number of instances that were predicted as positive but are actually negative. Recall is defined as the ratio of true positive predictions to the total number of positive instances in the dataset. It can be expressed as:
where
FN represents the number of instances that were predicted as negative but are actually positive. Recall measures the ability of the model to correctly identify positive instances. AP is a measure of the precision–recall curve for a given class, where precision represents the fraction of true positive detections among all predicted detections at a certain recall level. mAP is calculated by computing the average precision (AP) for each class in the dataset and then taking the mean of all AP values, defined as follows:
where
k is the number of classes of detection object; in this dataset,
k is equal to 2. mAP is widely used to evaluate detectors because it can consider both precision and recall, providing a more comprehensive evaluation of the model’s performance. Params refers to the number of learnable weights and biases in a neural network model. The number of parameters in the model determines its complexity and capacity to learn from the data. Models with a large number of parameters require more computational resources and longer training times, but may also achieve higher accuracy. The FLOPs value represents the number of floating-point arithmetic operations that the model performs during inference or training. A large FLOPs value directly reflects the massive computational resources required by the model. The speed measures the processing speed of a deep learning model during inference. It is usually represented by FPS (frames per second), which indicates how many frames or data samples the model can process per second.
To ensure optimal performance of the proposed model, it was essential to determine its depth and width prior to training. In order to accomplish this, various YOLOv5 models with differing depths (number of bottlenecks) and widths (number of channels) of the backbone were trained using the training data, and subsequently evaluated using the testing data. The evaluation metrics obtained from this process are presented in
Table 1.
Despite YOLOv5l having only 75% of the depth and 80% of the width of YOLOv5x, it achieved the highest mAP of 82.2%, which is even better than YOLOv5x’s 81.1% mAP due to the overfitting problem. However, the large number of parameters in YOLOv5l makes its size much larger than models with shallower and narrower networks. Additionally, the FLOPs value, which represents the magnitude of computation, is also very high in YOLOv5l compared to smaller models, which limits the detection speed of the model. Therefore, the proposed model should be implemented based on the YOLOv5l to reduce its size and FLOPs without compromising its detection effectiveness.
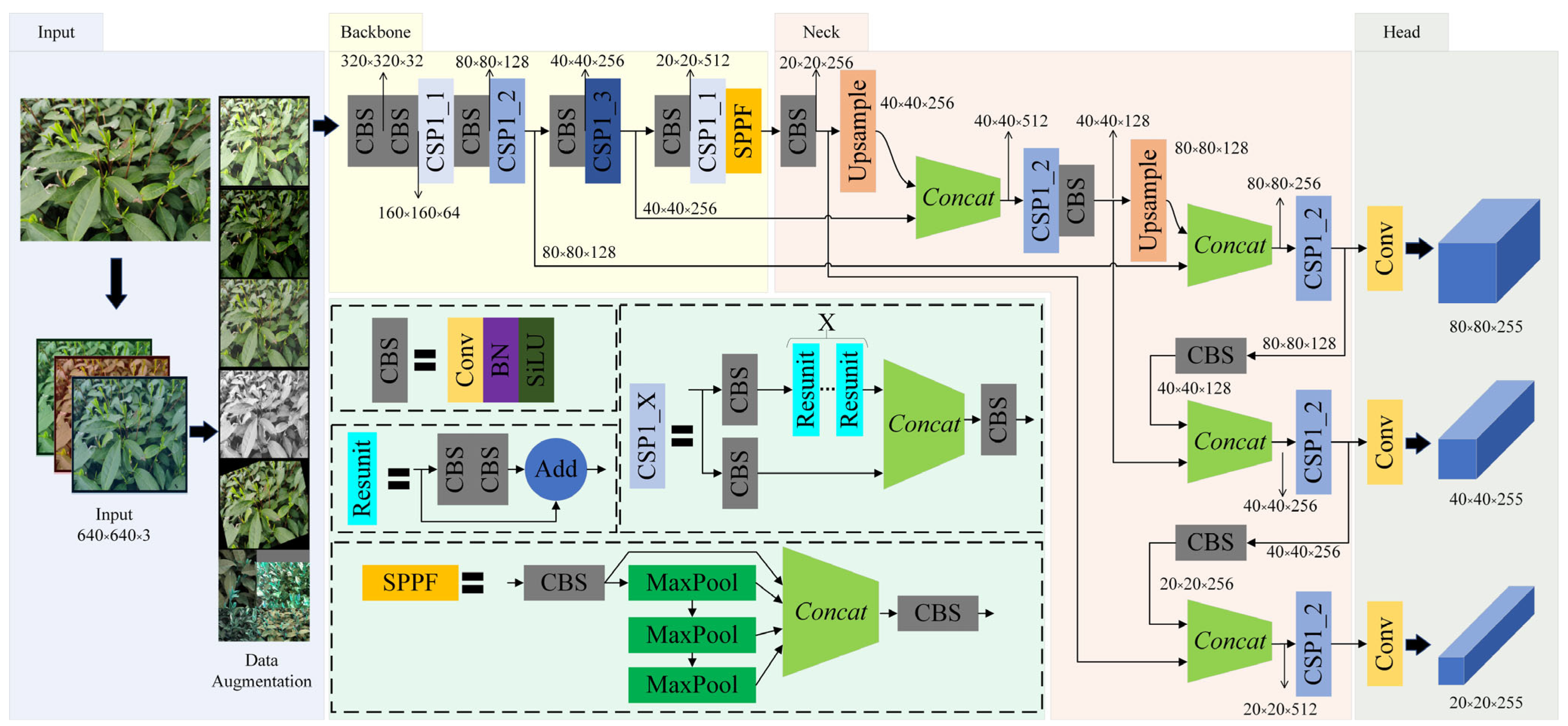
The improved YOLOv5 was developed using Python and based on the original YOLOv5l architecture. The model was trained and tested on Ubuntu 18.04 LTS using an Intel i7-10700 processor, an NVIDIA GeForce RTX 3090, CUDA Version 11.7, PyTorch version 1.8.0, and Python version 3.8. The training process consisted of 700 epochs with a batch size of 64 and an SGD optimizer. The training results are shown in
Figure 13. The proposed model achieved its best performance in epoch 473, with a precision of 76.2%, a recall of 77.6%, and an mAP of 82%.
Furthermore, the model was tested on a previously unseen test dataset. The results for precision, recall, and mAP at different confidence levels are shown in
Figure 14, with the best mAP of 85.2% achieved at a class ST of 84.8% and a class AT of 85.6%.
Following the training of the proposed model, a comparison was made between its testing results and those of the YOLOv5l model, as detailed in
Table 2. The proposed model showed improved performance over YOLOv5l, with higher precision, recall, and mAP scores. Specifically, the mAP of all classes in the proposed model was found to be 3.2% higher than that of YOLOv5l. The ST class of the proposed model showed a 3.7% increase in mAP compared to YOLOv5l, while the AT class of the proposed model showed a 2.7% increase. Moreover, the proposed model had only 60% of the parameters and size of YOLOv5l. The number of FLOPs in the proposed model was only 55% that in YOLOv5l. Furthermore, despite our model having more layers than YOLOv5l, which could limit its performance, the speed of our model on GPU and CPU devices was higher than that of YOLOv5l, and was close to that of YOLOv5m.
Some sample detections performed using both the original and improved models are shown in
Figure 15. A yellow circle indicates that the detector missed this target, while a red circle indicates that the detector detected this non-target. It is shown that both the proposed and original methods rarely detected non-targets, and the improved model could detect more small targets in the same scene, demonstrating higher recall.
3.1.3. Ablation Study
An ablation study was conducted to investigate the contribution of individual components or features to the overall performance of the improved model. By systematically removing or disabling different parts of the model and evaluating the resulting performance, insights into the relative importance of each component can be gained, including CAM, BiFPN and GhostConv.
The results of the ablation study are presented and compared in
Table 3. The Coordinate Attention Mechanism was found to improve the mAP of the model without significantly increasing the number of parameters and FLOPs. The BiFPN improved the mAP of the model by utilizing multi-scale feature fusion, but it also increased the number of layers and FLOPs. GhostConv reduced the number of parameters and model size to 63% that of the previous version, as well as reducing the number of FLOPs to 55% that of the original. Despite the increase in the number of layers due to DWConv in the GhostConv block, it improved the speed of the model when running on both GPU and CPU devices.
3.1.4. Experimental Comparison with Different Detection Methods
The improved model presented in this paper is compared with other state-of-the-art detection models in
Table 4. The results show that the proposed algorithm performed extremely well in terms of detection speed, model size, and computational amount while ensuring the highest mAP. The SSD model, which uses Vgg16 as the backbone network, had a fast detection speed, low computational complexity, and small model size, but low precision. The Faster-RCNN model, which uses Resnet50 as the backbone network, had higher accuracy, but the largest model size and computational amount, and the slowest detection speed. The YOLO series models, including YOLOv3, YOLOv4, YOLOv5, YOLOv6, YOLO7, and YOLOv8l, performed worse than the proposed improved model in terms of mAP, model size, and detection speed. The YOLOv8m and YOLOX models have a model size similar to the proposed algorithm, and these two models performed well in GPU detection speed, both above 90 FPS, but their performance on CPU devices was worse, and their precision scores were lower than that of the proposed model. Overall, the proposed improved object detection model for tea buds had the best performance among those state-of-the-art detection models.
3.2. Experiments on OPVSM
3.2.1. Preparation
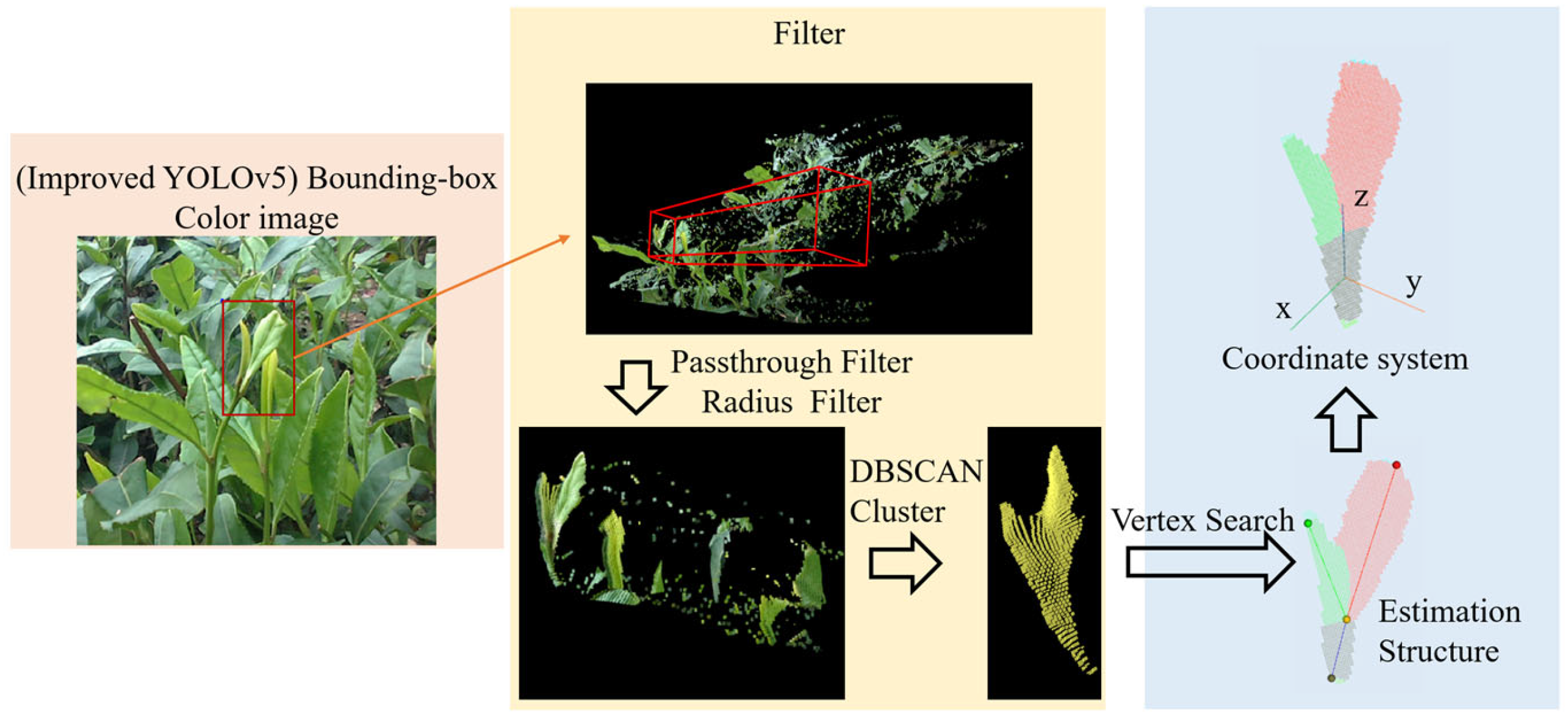
In this paper, the target was set as BL1 (one bud and one leaf). A total of 50 pointclouds including the BL1 target were acquired from the field using a depth camera. As shown in
Figure 16, according to the method in
Section 2.2.1, each pointcloud was detected using the improved model, filtered by a passthrough filter and a radius filter, clustered using the DBSCAN algorithm, and finally estimated via the OPVSM to build the coordinate system of tea buds.
3.2.2. Results
All pointclouds collected in the field for testing were processed, and the results of the model construction were examined and analyzed. Some of the test results are shown in
Figure 17.
After testing, the OPVSM successfully fitted the actual poses of 45 tea buds out of the total samples. The accuracy of this method was around 90%. The wrong results were primarily due to the bad pointclouds and local optima. As shown in
Figure 17, the imprecise bounding boxes and measurement instability of the depth camera led to the acquisition of bad pointclouds. Additionally, the search process may have been affected by the initial parameters of the algorithm, resulting in local optima.
Next, in order to evaluate the performance of the OPVSM, various metrics were recorded during the process, including the pointcloud size, number of iterations, and processing time. To increase the size of test samples, each pointcloud was downsampled multiple times, resulting in a total of 619 test samples, as shown in
Figure 18.
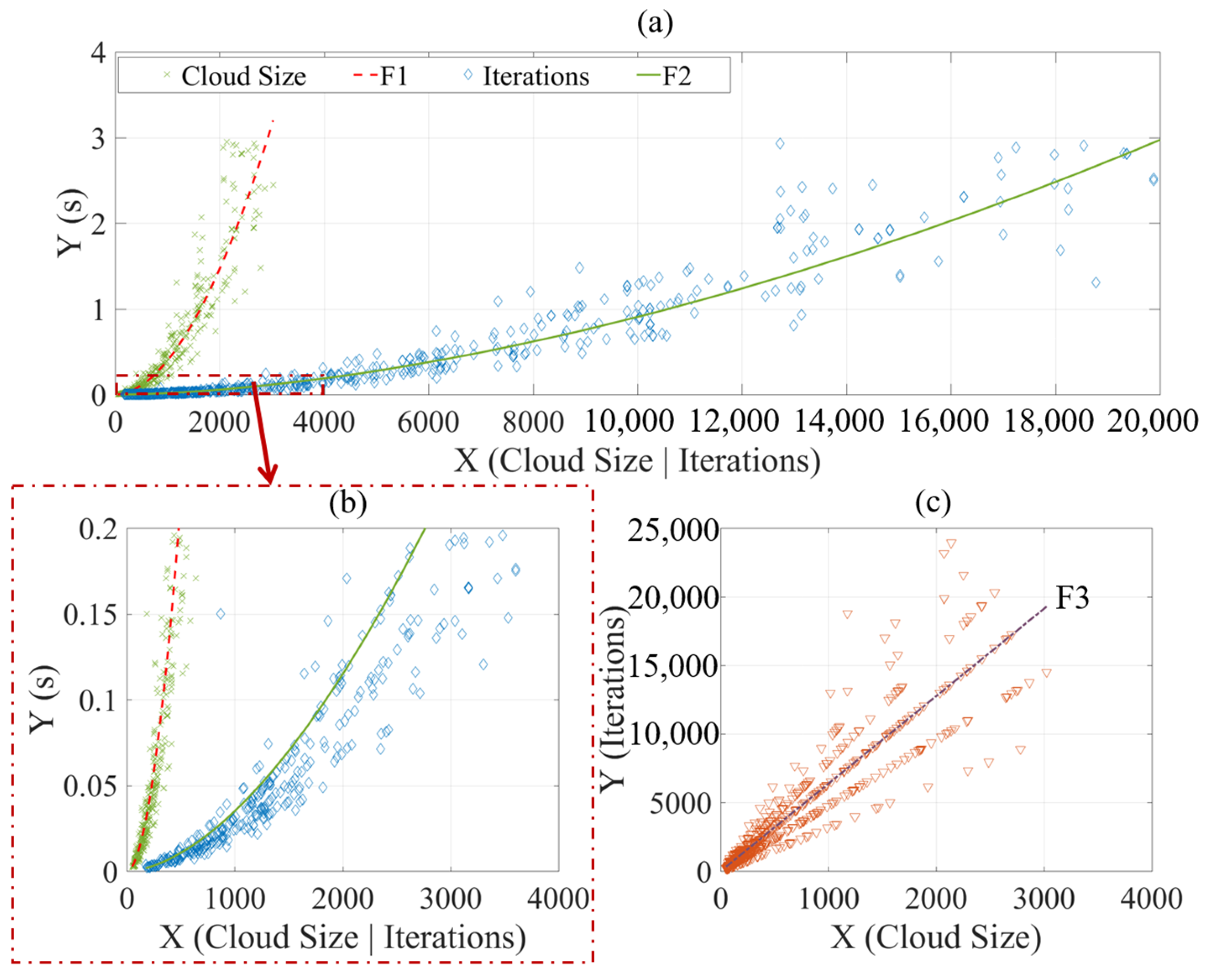
As the pointcloud size and number of iterations increase, the processing time also increases exponentially. F1 in
Figure 18a represents the fitting curve between pointcloud size and processing times, built using the Levenberg–Marquardt method with a function of
f(
x) =
axb. Similarly, F2 in
Figure 18b represents the fitting curve between number of iterations and processing times, built using the same method and function as F1.
Furthermore,
Figure 18c shows the proportional relationship between pointcloud size and number of iterations, which could be fitted as a proportional curve (F3). The parameters and evaluation metrics of these fitting curves are shown in
Table 5.
The primary independent variable is the cloud size. As the cloud size increases, the number of iterations also increases proportionally, while the processing time increases exponentially. The proportional function (F3) was identified between the cloud size and number of iterations, with a coefficient
a of 6.375. Although the SSE and RMSE of this fitting curve were large, indicating that the data points in
Figure 18c were scattered, the fitting curve had strong explanatory power and a good fitting result due to a high R-square value of 0.9995.
Notably, the two exponent coefficients, b, in F1 and F2 were close to each other. Additionally, the difference between the two coefficients a in F1 and F2 was 6.98 times, which was close to the coefficient a in F3. The time complexity O(n) of this algorithm is was nearly equal to n1.7~1.9, where n is the size of the pointcloud.
To achieve real-time processing, the process of the proposed algorithm had to be completed within 0.2 s. Thus, in
Figure 18b, the plot with processing times of 0 s to 0.2 s was examined. The cloud size should be no larger than 800, and the number of iterations should be no greater than 4000, allowing for a processing time of less than 0.2 s. To reduce the pointcloud size, the voxel filter was used to down-sample the pointcloud to a size of 800. The voxel filter replaced all points within a voxel grid cell with the point closest to the center of the cell, effectively reducing the number of 3D points in the pointcloud while preserving the overall shape of the object being represented. The algorithm results after filtering are shown in
Figure 19.
The processing time in
Figure 19 includes the voxel filtering process. After voxel filtering with a voxel grid 1 mm × 1 mm × 1 mm in size, the cloud size was reduced to 1/6, the number of iterations was reduced to 1/10, and the processing time was reduced to 1/78, while the pose of the tea buds was correctly built. Furthermore, considering the sparse distribution of the pointcloud along the z axis due to the acquisition principle of the depth camera, we set the voxel grid with a size of 2 mm × 2 mm × 1 mm as the voxel filter, and the cloud size was reduced to 1/17, the number of iterations was reduced to 1/35, the processing time was reduced to 1/618, and the pose of the tea bud was correctly built. This test demonstrated that this method can be applied in real time.
3.3. Discussion
After analyzing the errors in the test dataset, it was found that blurred objects in the image often confused the detector. This was especially true when the camera captured tea buds from a side angle, as the distant buds were also captured in the image. Due to the limited depth of field of the camera, these tea buds were often blurred, making it difficult to manually label all tea buds accurately. As a result, the model was more prone to errors when it encountered these blurred targets. Additionally, the occlusion between the tea buds and illumination (especially overexposure) also led to some mistakes in these detection results. All of these possible factors reduced the precision and recall of this detection model.
There are several ways to address these problems. Firstly, improving the image quality can be achieved by using a better camera or adjusting the illumination conditions to avoid overexposure. Secondly, developing an image processing algorithm combined with a depth camera to segment the distant background and remove blurred targets far away from the camera can be helpful. Additionally, training the model on datasets with images captured from multiple angles may improve its ability to detect objects from different perspectives, thereby reducing the impact of occlusions and improving detection accuracy.
The OPVSM’s performance is affected by bad pointclouds and local optima. The imprecise bounding boxes and measurement instability of the depth camera result in incomplete pointclouds for the tea buds. While some of these incomplete pointclouds still retain the shape of the tea buds, others have their shapes destroyed, making it difficult for the algorithm to operate effectively and increasing the likelihood of it getting stuck in local minima. Combining multiple sensors to fill in missing data or preprocessing the pointclouds to classify and remove low-quality pointclouds may help to solve this problem.
Overall, this research work has several limitations that need to be acknowledged. Firstly, the dataset used in our research, although extensively acquired, annotated, and curated over a period of three years, may not fully capture the diversity of tea buds in real-world scenarios. This limitation could potentially impact the generalizability of our results to unseen data or different settings. To overcome this limitation, future studies could focus on incorporating larger and more diverse datasets to enhance the robustness and applicability of the proposed methods. Secondly, while OPSVM is based on breadth-first search and does not require learning from big data, it is important to validate the method on a larger and more diverse test set to enhance the generalizability of our results. This validation will be conducted in future studies. Furthermore, the proposed methodology and algorithms are subject to computational constraints, and the scalability and computational efficiency of the model may pose challenges when applied in real time or in resource-constrained environments. Addressing these limitations could involve exploring optimization techniques or alternative architectures that improve efficiency without compromising performance. Lastly, this study primarily focused on tea bud detection in the field as a specific application domain. The effectiveness of the proposed approach in other locations, such as laboratory or greenhouse settings, or for detecting other small targets, remains an open question. Further investigations and experiments are necessary to evaluate the generalizability of our findings and determine the suitability of the proposed approach in diverse contexts.
4. Conclusions
In conclusion, an algorithm for detecting and estimating the pose of tea buds using a depth camera was proposed in this paper. The improved YOLOv5l model with CAM, BiFPN and GhostConv components demonstrated superior performance in detecting tea buds, achieving a higher mAP of 85.2%, a faster speed of 87.71 FPS on GPU devices and 6.88 FPS on CPU devices, a lower parameter value of 29.25 M, and a lower FLOP value of 59.8 G compared with other models. Moreover, the datasets were collected under different conditions and were augmented to enhance the model’s generalization ability under complex scenes. The OPVSM achieved results with 90% accuracy during testing. It builds a graph model that fits the tea buds by iteratively searching for the best vertices from the point cloud guided by a loss function. The algorithm gradually improves the fitness of the model until it reaches a local minimum. The optimal vertex set V acquired could build a graph model that accurately represents the pose of the tea bud. This approach is adaptive to variations in size, color, and shape features. The algorithm’s time complexity O(n) is n1.7~1.9, and it can be completed within 0.2 s by using voxel filtering to compress the pointcloud to around 800.
The combination of the proposed detection model and the OPVSM resulted in a reliable and efficient approach for tea bud detection and pose estimation. This study has the potential to be used in tea picking automation and can be extended to other crops and objects for precision agriculture and robotic applications. Future work will aim to improve the model performance and inference speed via data cleaning and expansion, model pruning and compression, and other methods, and parallel processing will be used to accelerate the OPVSM.


























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}