
MNCF: Prediction Method for Reliable Blockchain Services under a BaaS Environment


Abstract
:1. Introduction
- Reliability Prediction. We herein propose a general framework for predicting the reliability of blockchain peers. By predicting unknown QoS values, we can calculate the reliability of each peer.
- Global and Local Information Introduction. In the prediction part of the framework, we propose a context-sensitive collaborative model that supports various side information, including country, autonomous systems, IP address, and time zone. Experimental result shows that the model implicitly identifies specific context from inputs to improve the prediction accuracy.
- Multi-Task Learning. We endow our model with a multi-task learning technique. Since our predicted target (Success Rate, SR) is calculated using three other QoS values, the model can enrich the training samples and average out the noise on the main task by introducing three other tasks related to the main task. Furthermore, the experimental result shows that multi-task learning can improve the performance of our model.
- Extensive experiments conducted on a public blockchain dataset shows that our model performs better than the other methods, thereby proving the effectiveness of our method.
2. Related Work
2.1. Traditional Reliability Prediction Research
2.2. Blockchain Reliability Research
3. The Model
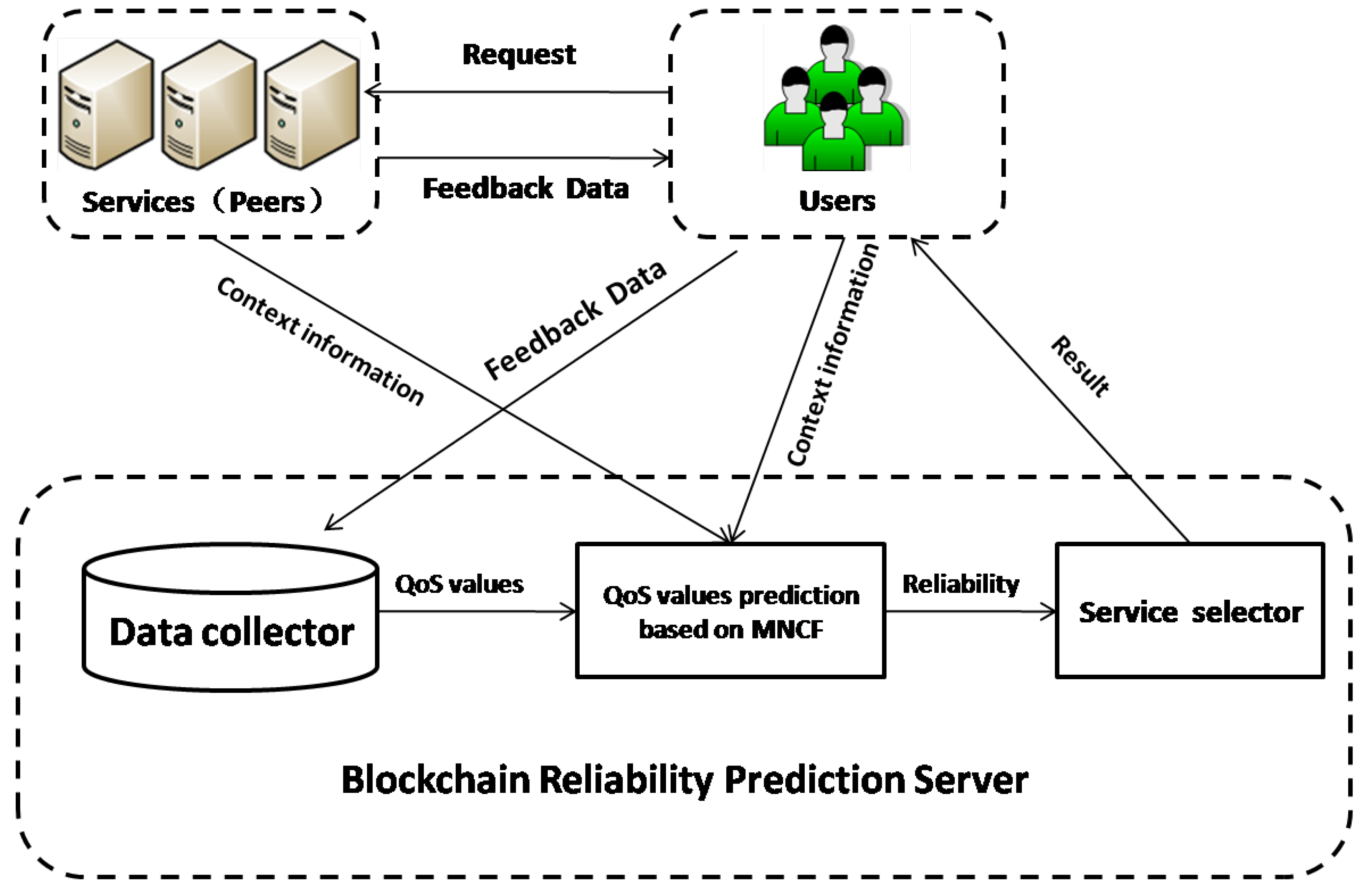
3.1. Reliability Prediction Framework for Blockchain Services
- Users send requests to the peers; subsequently, the blockchain services (peers) respond to the requests and return the feedback QoS data. The complete feedback data contain seven items: the peer IP, user IP, request time cost, response time cost, bulk request time cost, block height, and block hash.
- In the prediction server, after feedback data are received, the success rate based on the submitted data is calculated. The calculation results are used to form the user–service matrix of the success rate for MNCF.
- The matrix will be extremely sparse as users cannot request all services. With these known values, we can predict the unknown values with the input context information based on MNCF.
- After MNCF is performed, the request success rates of all the users for all the services are obtained, and the reliability of each blockchain service can be calculated using the service selector.
3.2. QoS Values Calculation
- RightBlock (RB): The block hash is at the corresponding block height on the blockchain.
- RecentHeight (RH): The block height subtracted from the highest one in the batch.
- RoundTripTime (RTT): The round trip time from the request to the peer.
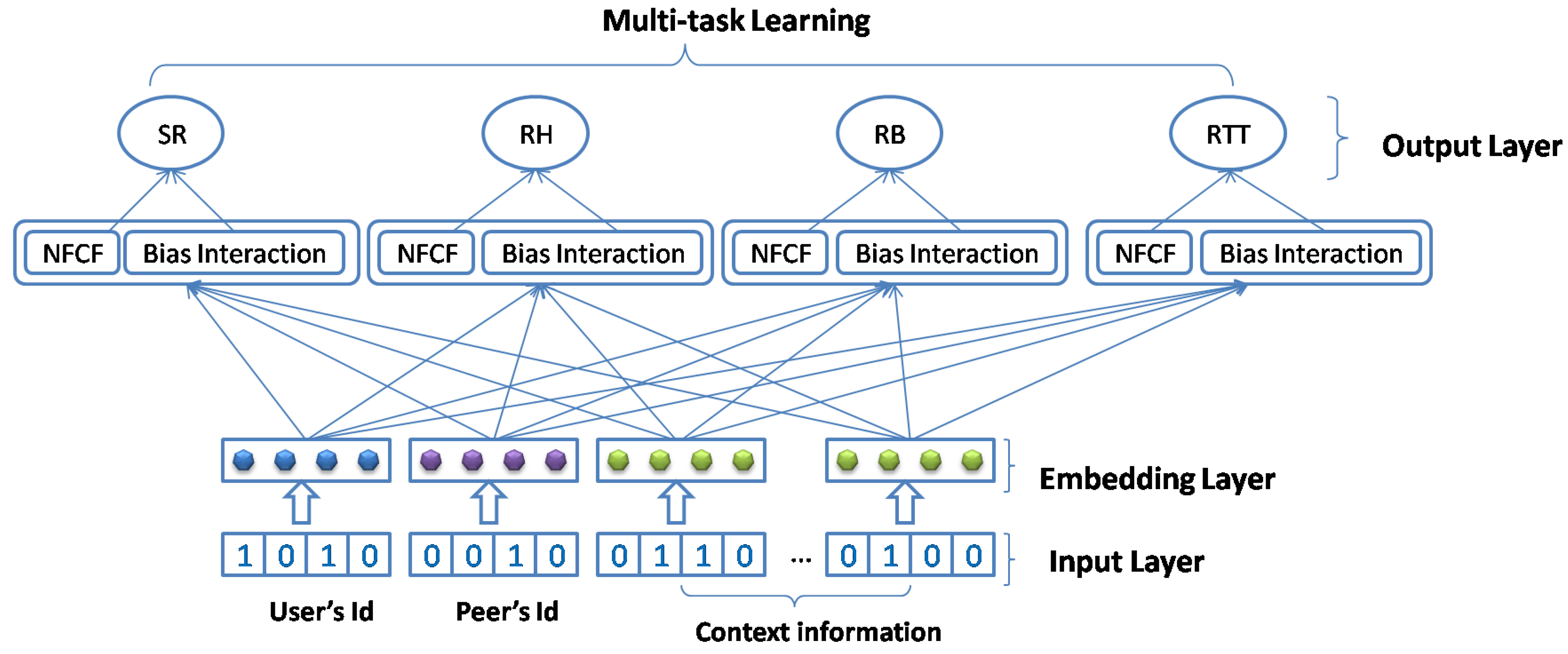
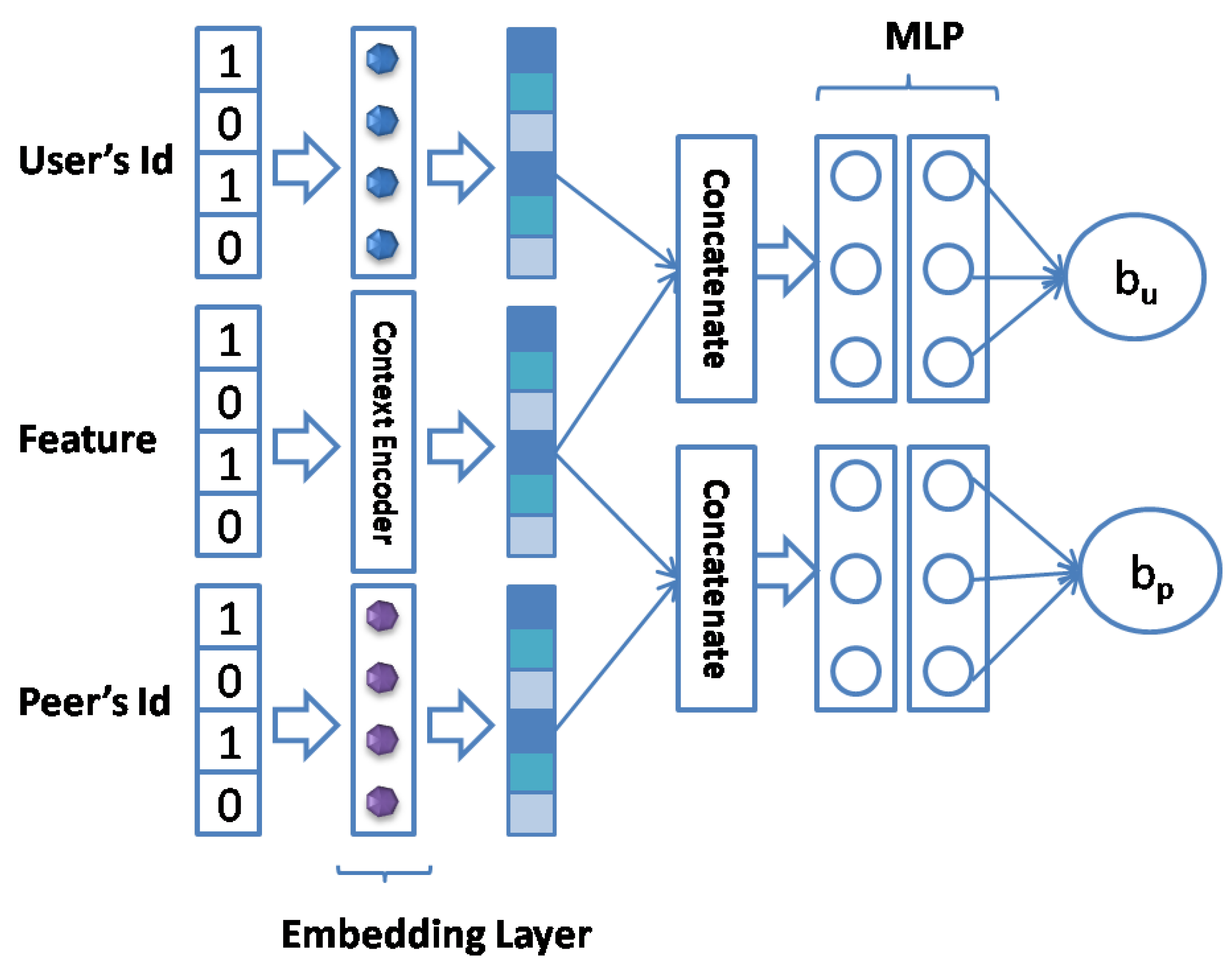
3.3. The Overall Architecture of MNCF
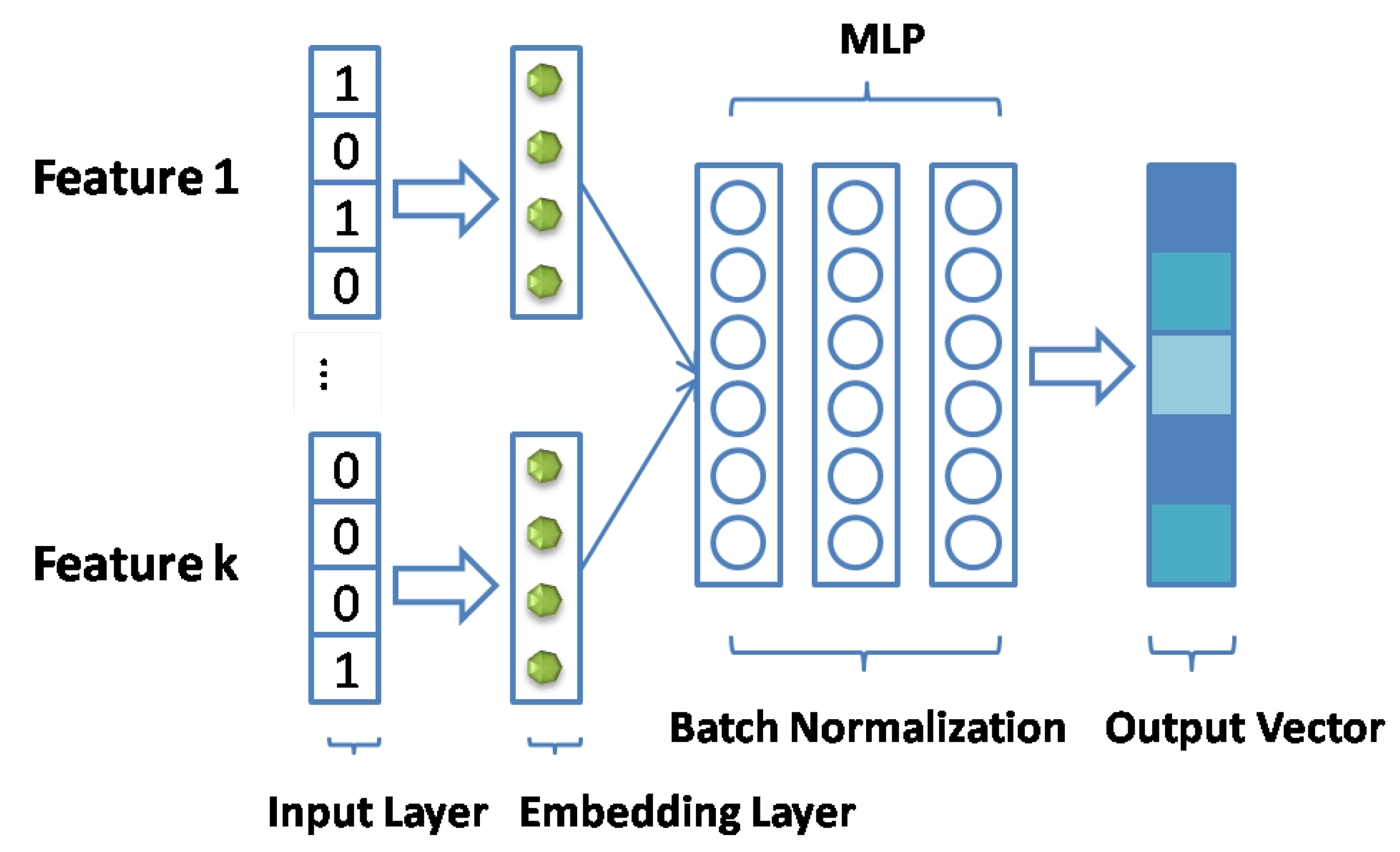
3.4. Input Layer
3.5. Embedding Layer
3.6. Task-Specific Layers
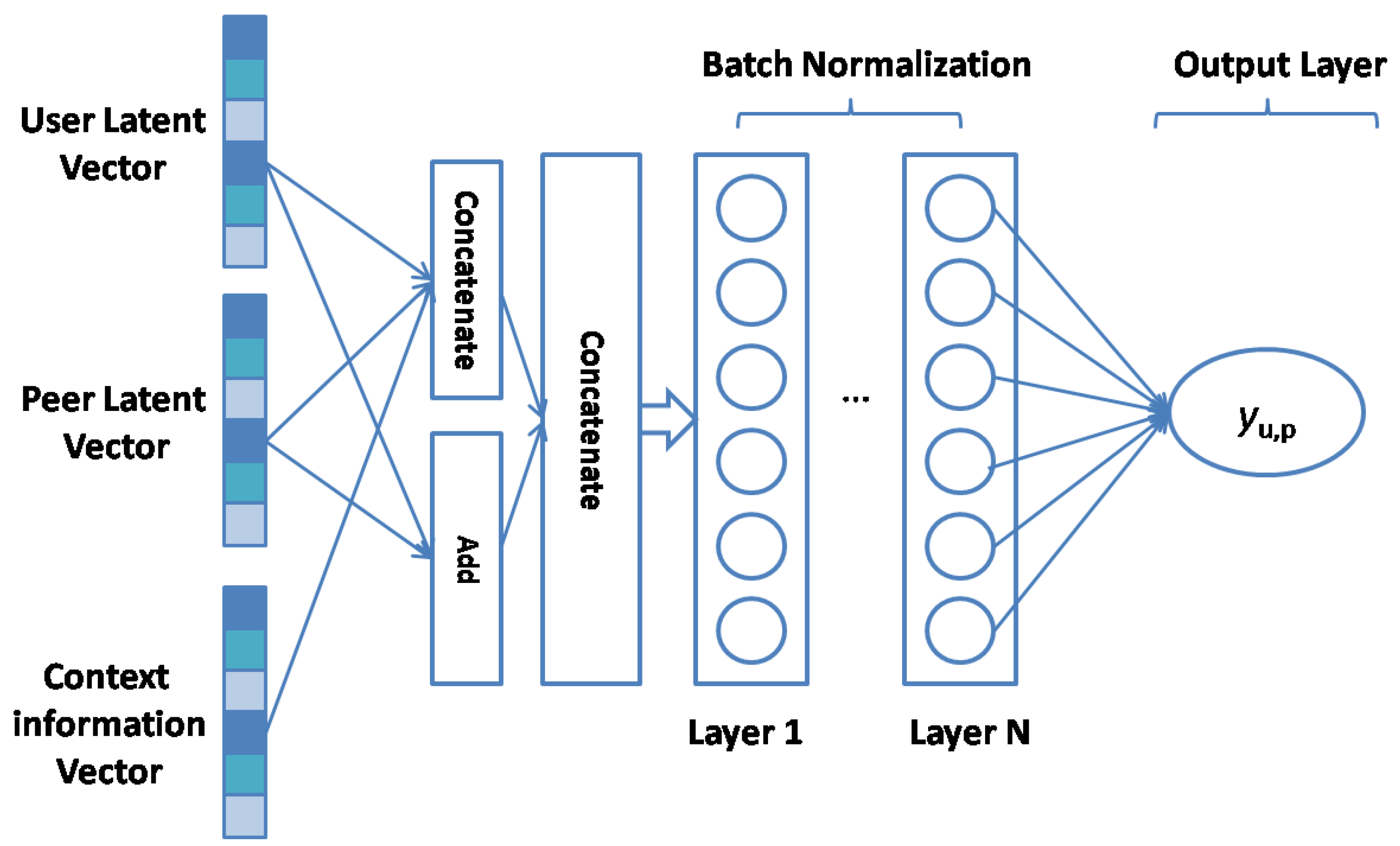
3.6.1. Neural Fusion Collaborative Filtering
3.6.2. Bias Interaction Module
3.6.3. Multi-Task Learning
3.6.4. Batch Normalization
3.7. MNCF Algorithm
| Algorithm 1 MNCF Algorithm |
| Require: User ID, Peer ID, Context Information, model parameters Ensure: Prediction Result: 1: Randomly remove entries to make the density reach the required density. 2: 3: while in the training round do 4: = , = 5: = , = 6: 7: 8: 9: 10: 11: 12: 13: 14: 15: 16: 17: 18: 19: 20: Update by 21: Loss Back Propagation 22: end while |
4. Experiment
- : Can deep learning improve blockchain reliability prediction performance?
- : What are the effects of the selected parameters on the blockchain reliability prediction?
- : How important is selecting contextual information?
- : How important is the Bias Interaction Module?
4.1. Dataset
4.2. Evaluation Metrics
4.3. Data Preprocessing
4.4. Parameter Settings
4.5. Performance Comparison (RQ1)
- UPCC [42] is a memory-based CF approach which uses the similars users’ information.
- IPCC [43] is a memory-based CF approach which uses the similars peers’ information.
- UIPCC [44] is a memory-based CF approach which combines UPCC and IPCC.
- PMF [26] employs a user-item matrix for the service selecion based on probabilistic matrix factorization method
- HBRP [36] employs the relationship between similar users and peers to do the collaborative prediction with hybrid linear regression.
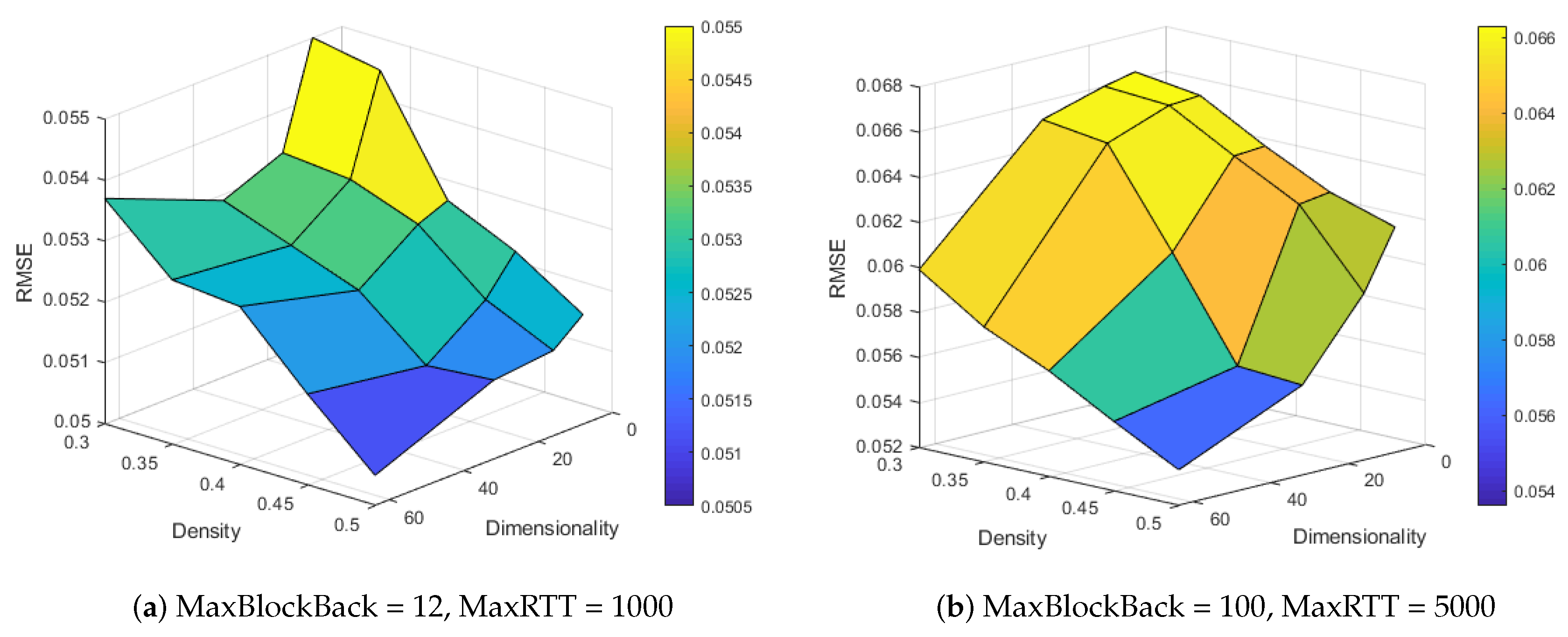
4.6. Impact of Dimensionality and Density (RQ2)
- Generally, model performance increases with dimensionality and density rise.
- When dimensionality is set to 32 or 64, model get optimum performance with MaxBlockBack set to 12 and MaxRTT set to 1000 while when Max
- When the number of training samples is insufficient, increasing the dimensionality will reduce the prediction accuracy in some cases. This phenomenon is primarily caused by overfitting. Compared with the number of training samples, MNCF has a significantly high number of parameters [45], which will overreact to small fluctuations in the training data.
4.7. Impact of Context Information (RQ3)
4.8. Impact of the Bias Interaction Module (RQ4)
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zheng, P.; Zheng, Z.; Luo, X.; Chen, X.; Liu, X. A Detailed and Real-Time Performance Monitoring Framework for Blockchain Systems. In Proceedings of the 2018 IEEE/ACM 40th International Conference on Software Engineering: Software Engineering in Practice Track (ICSE-SEIP), Gothenburg, Sweden, 30 May–1 June 2018; pp. 134–143. [Google Scholar] [CrossRef]
- Zhang, Y.; Kasahara, S.; Shen, Y.; Jiang, X.; Wan, J. Smart Contract-Based Access Control for the Internet of Things. IEEE Internet Things J. 2019, 6, 1594–1605. [Google Scholar] [CrossRef] [Green Version]
- Wang, S.; Ouyang, L.; Yuan, Y.; Ni, X.; Han, X.; Wang, F. Blockchain-Enabled Smart Contracts: Architecture, Applications, and Future Trends. IEEE Trans. Syst. Man Cybern. Syst. 2019, 49, 2266–2277. [Google Scholar] [CrossRef]
- Liu, Y.; Wang, K.; Qian, K.; Du, M.; Guo, S. Tornado: Enabling Blockchain in Heterogeneous Internet of Things Through a Space-Structured Approach. IEEE Internet Things J. 2020, 7, 1273–1286. [Google Scholar] [CrossRef]
- Liang, W.; Huang, W.; Long, J.; Zhang, K.; Li, K.; Zhang, D. Deep Reinforcement Learning for Resource Protection and Real-Time Detection in IoT Environment. IEEE Internet Things J. 2020, 7, 6392–6401. [Google Scholar] [CrossRef]
- White, B.S.; King, C.G.; Holladay, J. Blockchain security risk assessment and the auditor. J. Corp. Account. Financ. 2020, 31, 47–53. [Google Scholar] [CrossRef]
- Liang, W.; Fan, Y.; Li, K.; Zhang, D.; Gaudiot, J. Secure Data Storage and Recovery in Industrial Blockchain Network Environments. IEEE Trans. Ind. Inform. 2020, 16, 6543–6552. [Google Scholar] [CrossRef]
- Lu, Q.; Xu, X.; Liu, Y.; Weber, I.; Zhu, L.; Zhang, W. uBaaS: A unified blockchain as a service platform. Future Gener. Comput. Syst. 2019, 101, 564–575. [Google Scholar] [CrossRef] [Green Version]
- Liu, J.; Chen, Y. HAP: A Hybrid QoS Prediction Approach in Cloud Manufacturing combining Local Collaborative Filtering and Global Case-based Reasoning. IEEE Trans. Serv. Comput. 2019. [Google Scholar] [CrossRef]
- Zhong, W.; Yin, X.; Zhang, X.; Li, S.; Dou, W.; Wang, R.; Qi, L. Multi-dimensional quality-driven service recommendation with privacy-preservation in mobile edge environment. Comput. Commun. 2020, 157, 116–123. [Google Scholar] [CrossRef]
- Yakubu, I.Z.; Malathy, C. Priority Based Delay Time Scheduling for Quality of Service in Cloud Computing Networks. In Proceedings of the 2020 International Conference on Emerging Trends in Information Technology and Engineering (ic-ETITE), Vellore, India, 24–25 February 2020; pp. 1–5. [Google Scholar] [CrossRef]
- Syu, Y.; Kuo, J.Y.; Fanjiang, Y.Y. Time series forecasting for dynamic quality of web services: An empirical study. J. Syst. Softw. 2017, 134, 279–303. [Google Scholar] [CrossRef]
- Guo, L.; Mu, D.; Cai, X.; Tian, G.; Hao, F. Personalized QoS Prediction for Service Recommendation With a Service-Oriented Tensor Model. IEEE Access 2019, 7, 55721–55731. [Google Scholar] [CrossRef]
- Yang, Y.; Zheng, Z.; Niu, X.; Tang, M.; Lu, Y.; Liao, X. A Location-Based Factorization Machine Model for Web Service QoS Prediction. IEEE Trans. Serv. Comput. 2018. [Google Scholar] [CrossRef]
- Meiappane, A.; Prabavadhi, J.; Dharani, R.; Kaviya, R.; Malathy, R. Web Service Recommendation and QoS Prediction via Matrix Factorization. In Proceedings of the 2020 International Conference on System, Computation, Automation and Networking (ICSCAN), Pondicherry, India, 3–4 July 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Manju, K.; David Peter, S.; Idicula, S.M. A Framework for Generating Extractive Summary from Multiple Malayalam Documents. Information 2021, 12, 41. [Google Scholar] [CrossRef]
- Semenkov, A.; Bragin, D.; Usoltsev, Y.; Konev, A.; Kostuchenko, E. Generation of an EDS Key Based on a Graphic Image of a Subject’s Face Using the RC4 Algorithm. Information 2021, 12, 19. [Google Scholar] [CrossRef]
- Chen, J.; Wu, Y.; Fan, L.; Lin, X.; Zheng, H.; Yu, S.; Xuan, Q. N2VSCDNNR: A Local Recommender System Based on Node2vec and Rich Information Network. IEEE Trans. Comput. Soc. Syst. 2019, 6, 456–466. [Google Scholar] [CrossRef] [Green Version]
- Hassan, H.; El-Desouky, A.I.; Ibrahim, A.; El-Kenawy, E.S.M.; Arnous, R. Enhanced QoS-Based Model for Trust Assessment in Cloud Computing Environment. IEEE Access 2020, 8, 43752–43763. [Google Scholar] [CrossRef]
- Ling, G.; King, I.; Lyu, M.R. A Unified Framework for Reputation Estimation in Online Rating Systems. In Proceedings of the IJCAI ’13, 23th International Joint Conference on Artificial Intelligence, Beijing, China, 3–9 August 2013. [Google Scholar]
- Jayapriya, K.; Mary, N.A.; Rajesh, R.S. Cloud Service Recommendation Based on a Correlated QoS Ranking Prediction. J. Netw. Syst. Manag. 2016, 24, 916–943. [Google Scholar] [CrossRef]
- Mei, H.; Xie, B.; Zhao, J.; Shao, L.; Wei, Y.; Zhang, J. Personalized QoS Prediction forWeb Services via Collaborative Filtering. In Proceedings of the 2007 IEEE International Conference on Web Services, Salt Lake City, UT, USA, 9–13 July 2007. [Google Scholar]
- Linden, G.; Smith, B.; York, J. Amazon.Com Recommendations: Item-to-Item Collaborative Filtering. IEEE Internet Comput. 2003, 7, 76–80. [Google Scholar] [CrossRef] [Green Version]
- Zheng, Z.; Ma, H.; Lyu, M.R.; King, I. WSRec: A Collaborative Filtering Based Web Service Recommender System. In Proceedings of the ICWS ’09, 2009 IEEE International Conference on Web Services, Los Angeles, CA, USA, 6–10 July 2009. [Google Scholar]
- Chen, Z.; Sun, Y.; You, D.; Li, F.; Shen, L. An accurate and efficient web service QoS prediction model with wide-range awareness. Future Gener. Comput. Syst. 2020, 109, 275–292. [Google Scholar] [CrossRef]
- Mnih, A.; Salakhutdinov, R. Probabilistic Matrix Factorization. Adv. Neural. Inf. Process. Syst. 2007, 20, 1257–1264. [Google Scholar]
- Lo, W.; Yin, J.; Deng, S.; Li, Y.; Wu, Z. An Extended Matrix Factorization Approach for QoS Prediction in Service Selection. In Proceedings of the SCC ’12. 2012 IEEE Ninth International Conference on Services Computing, Honolulu, HI, USA, 24–29 June 2012. [Google Scholar]
- Zhang, R.; Li, C.; Sun, H.; Wang, Y.; Huai, J. Quality of Web Service Prediction by Collective Matrix Factorization. In Proceedings of the 2014 IEEE International Conference on Services Computing (SCC), Anchorage, AK, USA, 27 June–2 July 2014. [Google Scholar]
- Tang, M.; Jiang, Y.; Liu, J.; Liu, X.F. Location-Aware Collaborative Filtering for QoS-Based Service Recommendation. In Proceedings of the 2012, ICWS ’12, 2012 IEEE 19th International Conference on Web Services, Honolulu, HI, USA, 24–29 June 2012. [Google Scholar]
- He, P.; Zhu, J.; Zheng, Z.; Xu, J.; Lyu, M.R. Location-Based Hierarchical Matrix Factorization for Web Service Recommendation. In Proceedings of the ICWS ’14, 2014 IEEE International Conference on Web Services, Anchorage, AK, USA, 27 June–2 July 2014. [Google Scholar]
- Yu, D.; Liu, Y.; Xu, Y.; Yin, Y. Personalized QoS Prediction for Web Services Using Latent Factor Models. In Proceedings of the SCC ’14, 2014 IEEE International Conference on Services Computing, Anchorage, AK, USA, 27 June–2 July 2014. [Google Scholar]
- Wu, Y.; DuBois, C.; Zheng, A.X.; Ester, M. Collaborative Denoising Auto-Encoders for Top-N Recommender Systems. In Proceedings of the WSDM ’16, Ninth ACM International Conference on Web Search and Data Mining, San Francisco, CA, USA, 22–25 February 2016. [Google Scholar]
- He, X.; Liao, L.; Zhang, H.; Nie, L.; Hu, X.; Chua, T.S. Neural Collaborative Filtering. In Proceedings of the WWW ’17, 26th International Conference on World Wide Web, Perth, Australia, 3–7 May 2017; pp. 173–182. [Google Scholar] [CrossRef] [Green Version]
- Liang, W.; Zhang, D.; Lei, X.; Tang, M.; Li, K.C.; Zomaya, A. Circuit Copyright Blockchain: Blockchain-based Homomorphic Encryption for IP Circuit Protection. IEEE Trans. Emerg. Top. Comput. 2020. [Google Scholar] [CrossRef]
- Lei, K.; Zhang, Q.; Xu, L.; Qi, Z. Reputation-Based Byzantine Fault-Tolerance for Consortium Blockchain. In Proceedings of the 2018 IEEE 24th International Conference on Parallel and Distributed Systems (ICPADS), Singapore, 11–13 December 2018. [Google Scholar]
- Zheng, P.; Zheng, Z.; Chen, L. Selecting Reliable Blockchain Peers via Hybrid Blockchain Reliability Prediction. arXiv 2019, arXiv:1910.14614. [Google Scholar]
- Zheng, W.; Zheng, Z.; Chen, X.; Dai, K.; Li, P.; Chen, R. NutBaaS: A Blockchain-as-a-Service Platform. IEEE Access 2019, 7, 134422–134433. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Glorot, X.; Bordes, A.; Bengio, Y. Deep Sparse Rectifier Neural Networks. In Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics, Lauderdale, FL, USA, 11–13 April 2011; pp. 315–323. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. arXiv 2015, arXiv:1502.03167. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Resnick, P.; Iacovou, N.; Suchak, M.; Bergstrom, P.; Riedl, J. GroupLens: An Open Architecture for Collaborative Filtering of Netnews. In Proceedings of the CSCW ’94, 1994 ACM Conference on Computer Supported Cooperative Work, Chapel Hill, NC, USA, 22–26 October 1994. [Google Scholar]
- Sarwar, B.; Karypis, G.; Konstan, J.; Riedl, J. Item-Based Collaborative Filtering Recommendation Algorithms. In Proceedings of the WWW ’01, 10th International Conference on World Wide Web, Hong Kong, 1–5 May 2001. [Google Scholar]
- Zheng, Z.; Lyu, M.R. Collaborative Reliability Prediction of Service-Oriented Systems. In Proceedings of the ICSE ’10, 32nd ACM/IEEE International Conference on Software Engineering, Cape Town, South Africa, 1–8 May 2010. [Google Scholar]
- Wu, H.; Zhang, Z.; Luo, J.; Yue, K.; Hsu, C. Multiple Attributes QoS Prediction via Deep Neural Model with Contexts. IEEE Trans. Serv. Comput. 2018. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Density = 30% | Density = 35% | Density = 40% | Density = 45% | Density = 50% |
|---|---|---|---|---|---|
| UPCC | 0.3646 | 0.3613 | 0.3601 | 0.3618 | 0.3623 |
| IPCC | 0.1022 | 0.1014 | 0.1001 | 0.0961 | 0.0963 |
| UIPCC | 0.1069 | 0.1059 | 0.1045 | 0.1011 | 0.1011 |
| PMF | 0.0946 | 0.0914 | 0.0894 | 0.0870 | 0.0867 |
| HBRP | 0.1017 | 0.0985 | 0.0954 | 0.0945 | 0.0908 |
| MNCF (Single-Task) | 0.0585 | 0.0576 | 0.0570 | 0.0564 | 0.0543 |
| MNCF (Muti-Task) | 0.0537 | 0.0527 | 0.0526 | 0.0515 | 0.0505 |
| Improve (Multi-Task vs. single-task) | 8.93% | 9.30% | 8.37% | 9.51% | 7.52% |
| Method | Density = 30% | Density = 35% | Density = 40% | Density = 45% | Density = 50% |
|---|---|---|---|---|---|
| UPCC | 0.4597 | 0.4576 | 0.4566 | 0.4586 | 0.4591 |
| IPCC | 0.0898 | 0.0877 | 0.0858 | 0.0857 | 0.0861 |
| UIPCC | 0.1003 | 0.0983 | 0.0967 | 0.0966 | 0.0969 |
| PMF | 0.0890 | 0.0880 | 0.0857 | 0.0847 | 0.0852 |
| HBRP | 0.0635 | 0.0624 | 0.0599 | 0.0587 | 0.0565 |
| MNCF (Single-Task) | 0.0618 | 0.0612 | 0.0593 | 0.0572 | 0.0558 |
| MNCF (Multi-Task) | 0.0599 | 0.0580 | 0.0567 | 0.0551 | 0.0536 |
| Improve (Multi-Task vs. single-task) | 3.17% | 5.52% | 4.59% | 3.81% | 4.10% |
| Method | Density = 30% | Density = 40% | Density = 50% |
|---|---|---|---|
| MNCF-ALL | 0.0537 | 0.0526 | 0.0505 |
| MNCF-Without Context | 0.0597 | 0.0572 | 0.0563 |
| MNCF-CT | 0.0569 | 0.0543 | 0.0523 |
| MNCF-AS | 0.0543 | 0.0530 | 0.0518 |
| MNCF-IP | 0.0566 | 0.0559 | 0.0529 |
| MNCF-TZ | 0.0542 | 0.0535 | 0.0524 |
| Method | Density = 30% | Density = 40% | Density = 50% |
|---|---|---|---|
| MNCF-ALL | 0.0599 | 0.0567 | 0.0536 |
| MNCF-Without Context | 0.0671 | 0.0656 | 0.0624 |
| MNCF-CT | 0.0613 | 0.0592 | 0.0563 |
| MNCF-AS | 0.0604 | 0.0589 | 0.0539 |
| MNCF-IP | 0.0650 | 0.0606 | 0.0545 |
| MNCF-TZ | 0.0655 | 0.0587 | 0.0558 |
| Method | Density = 30% | Density = 40% | Density = 50% |
|---|---|---|---|
| MNCF-ALL | 0.0537 | 0.0526 | 0.0505 |
| MNCF-With user’s bias | 0.0567 | 0.0554 | 0.0524 |
| MNCF-With peer’s bias | 0.0571 | 0.0559 | 0.0532 |
| MNCF-Without user’s and peer’s biases | 0.0591 | 0.0586 | 0.0564 |
| Method | Density = 30% | Density = 40% | Density = 50% |
|---|---|---|---|
| MNCF-ALL | 0.0599 | 0.0567 | 0.0536 |
| MNCF-With user’s bias | 0.0611 | 0.0582 | 0.0553 |
| MNCF-With peer’s bias | 0.0618 | 0.0591 | 0.0567 |
| MNCF-Without user’s and peer’s biases | 0.0635 | 0.0621 | 0.0615 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, J.; Zhuang, Z.; Xia, Z.; Li, Y. MNCF: Prediction Method for Reliable Blockchain Services under a BaaS Environment. Information 2021, 12, 242. https://doi.org/10.3390/info12060242
Xu J, Zhuang Z, Xia Z, Li Y. MNCF: Prediction Method for Reliable Blockchain Services under a BaaS Environment. Information. 2021; 12(6):242. https://doi.org/10.3390/info12060242
Chicago/Turabian StyleXu, Jianlong, Zicong Zhuang, Zhiyu Xia, and Yuhui Li. 2021. "MNCF: Prediction Method for Reliable Blockchain Services under a BaaS Environment" Information 12, no. 6: 242. https://doi.org/10.3390/info12060242
APA StyleXu, J., Zhuang, Z., Xia, Z., & Li, Y. (2021). MNCF: Prediction Method for Reliable Blockchain Services under a BaaS Environment. Information, 12(6), 242. https://doi.org/10.3390/info12060242