1. Introduction
The late Jim Cray [
1] described data-driven science as the evolution from hypotheses to patterns, and the most interesting and useful data patterns involve many more than just two variables. They are High-dimensional (N-D), as opposed to bivariate. Unfortunately, High-dimensional patterns are fragile structures that do not always survive the mapping from N-D space to the 2-D (or even 3-D) space in which the human visual system operates and can visualize them. Let us demonstrate this by way of a simple example, using a 10-D dataset composed of a set of colleges with salient attributes such as US-News score, tuition, athletics, housing quality, etc.
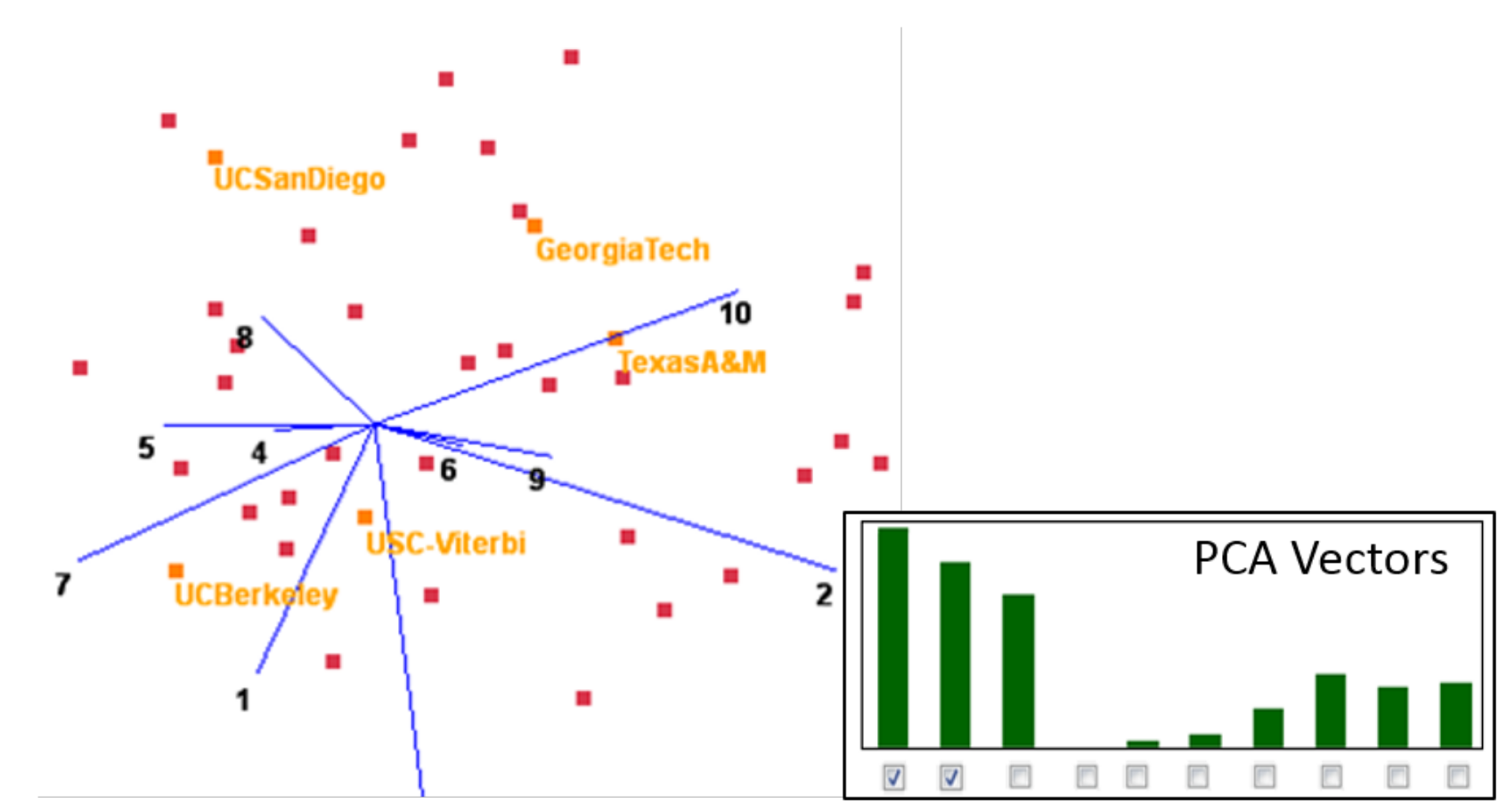
Figure 1 shows a High-dimensional scatterplot (a biplot) of this college dataset. Focusing on dimension 10, tuition, in the upper-right portion of the figure, we observe that, while USC-Viterbi is an expensive school, it ends up located to the left of the cheaper Texas A&M. This is a well-known phenomenon because biplots use the two most dominant Principal Component (PCA) vectors as a basis and project both data and dimension vectors into it. However, as the PCA bar chart shows, there are in fact three significant PCA vectors, and some less significant ones. The visualization only coveys the variance of the two major PCA vectors; the remaining unexplained variance leads to this distortion. These types of distortions occur with any projective N-D to 2-D mapping, linear or non-linear, in all but the most trivial cases. They affect individual point-pair relations as well as overall cluster appearance, such as density, composition, shape, and organization.
Thus, since we cannot observe these patterns directly in 2-D, we require the help of an “agent” that ventures into N-D space, observes the patterns there and then visually explains them to us in our native 2-D space. For this to work, we first need a sufficiently expressive vocabulary that can capture the appearance of the patterns to be conveyed. An attractive framework for this purpose is Scagnostics, first informally proposed by John and Paul Tukey [
2]. More recently, Wilkinson et al. [
3] used graph-theoretic measures to define specific Scagnostics metrics such as density, skewed, clumpy, striated, stringy, straight, and others to gauge cluster appearance. These metrics operate on a bounded continuous scale which can be optionally binned into discrete levels.
Wilkinson et al. employed three graphical representations: minimum spanning tree (MST), alpha hulls and convex hulls, but they only used them for 2-D analyses. Since then Fu [
4] extended Scagnostics to 3-D and Dang et al. [
5] used 2-D Scagnostics to encode High-dimensional time-series. We have opted to only analyze rotation- and dimension-invariant properties, as only those can be reliably ported from N-D to 2-D. The Scagnostics appearance metrics fitting this focus are those that gauge cluster composition, such as skewed, clumpy, and striated. All of these require MST analysis, which, in contrast to alpha and convex hull algorithms, is relatively easy to extend from 2 to D to N-D. Finally, to assess cluster shape while retaining dimension-number invariance, we evaluate a set of statistical measures—variance, skew and kurtosis—along each dimension in N-D space.
Now when it comes to the visualization of these metrics it is important to realize that the mapping of a metric tuple to a 2-D scatterplot is not bijective; there are many 2-D scatterplots which, when analyzed, will evaluate to the same tuple configuration. This is mainly because the metrics do not fully characterize the scatterplot’s appearance, i.e., the set of metrics is not complete. A solution is illustrative stylization, i.e., design a dedicated rendition of the property to be conveyed, one that elicits the same semantic response in the viewer than the real-world property, the scatterplot. An important added benefit to this stylization scheme is that the viewer can then also easily distinguish a real projective N-D/2-D mapping from an analyzed one.
Scatterplots are essentially texture patterns, and so we have devised three sets of illustrative texture patterns, each of which is dedicated to one of the three Scagnostics measures we have adopted, and each of which is parameterized by feature strength. Mapping this texture into the 2-D contour derived from the statistical N-D shape analysis then yields what we call a Cluster Appearance Glyph.
While our method can be used within cluster analysis, it does not provide any clustering capabilities [
6,
7] on its own. Rather, it expects a cluster membership tag for each data point, either obtained via prior cluster analysis or classification. Our method then analyzes each such cluster and determines its corresponding cluster appearance glyph. Next it computes a suitable 2-D layout by a cascaded mapping of all data points—using Linear Discriminant Analysis (LDA) and then Multi Dimensional Scaling (MDS). Then it anchors each glyph at the center of its corresponding 2-D-mapped cluster. Here the appearance textures of the glyphs are able to compensate for LDA’s loss of cluster detail. Finally, since the overall layout might lead to overlapping glyphs that undermine readability, we perform a final optimization step that removes these overlaps.
Our research makes the following contributions:
We introduce a set of measures gleaned from Scagnostics that can holistically characterize the point distribution of data clusters in N-D space.
For this purpose we extend a subset of Scagnostics measures from 2-D to N-D, specifically, the striated, clumpy, and skew metrics.
We introduce the concept of Cluster Appearance Glyph, a family of illustrative textures that can graphically encode the three scagnostics measures assessed in N-D.
We introduce a set of graphical enhancements for our cluster appearance glyphs, designed to encode additional statistics assessed from the N-D clusters.
We introduce a cascaded LDA-MDS N-to-2D mapping strategy, devised to preserve global cluster relations while keeping sufficient space for glyph placement.
We validate and refine our various design choices via a series of user studies.
6. Cluster Appearance Glyphs
In this section, we describe how we represent each cluster by a glyph. The glyph boundary is derived from statistical analysis in N-D and its interior is filled with the calculated appearance texture. Each glyph is placed at the center of the MDS-LDA projected cluster, and its boundary is modified by three metrics derived in N-D for each dimension: standard deviation (SD), kurtosis, and skew.
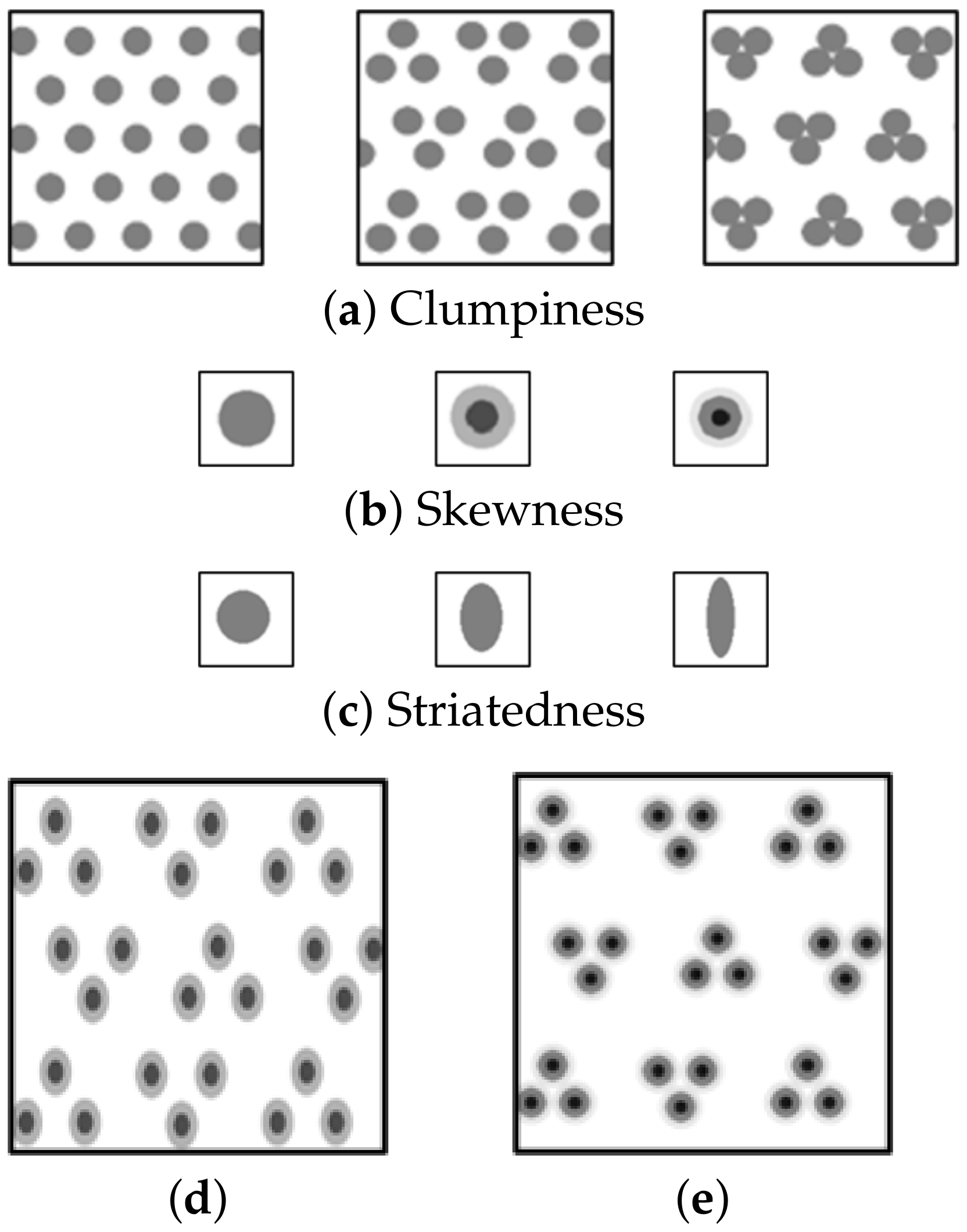
Boundary shape: If a cluster has similar SDs across all dimensions, the N-D shape of the cluster can be considered homogeneous, otherwise it is heterogeneous.
Figure 7 illustrates the design process of the glyph boundary shape.
Figure 7a shows 10 boundary points of the glyph to visualize a 10-D cluster. Each point corresponds to a dimension in clockwise order. It has an inner circle to secure an area for the appearance texture. The radius of the inner circle (in black) represents a global minimum SD along all dimensions of all clusters.
Figure 7b shows how the boundary points are computed. The length of a red line represents the magnitude of the SD in the corresponding dimension and is normalized by a global maximum SD along all dimensions of all clusters. The boundary is created by connecting the boundary points. Since this list of points often yields a rather noisy boundary we smooth the set of points by applying an interpolating cubic spline that loses no information (
Figure 7c). As seen, the SDs have variation—some of them are close to the minimum SD but some of them are much larger than it. However, due to the similar magnitude of SDs in the 2nd–5th and 6th–8th dimensions, it is difficult to notice the variation of SDs, i.e., the heterogeneous shape. We found that the heterogeneous shape is hard to recognize when there are consecutive dimensions with similar SDs. Therefore, intermediate points (red points in
Figure 7d) are inserted between the boundary points to minimize the influence of such consecutive dimensions. These intermediate points are computed by a local minimum SD along the SDs of all dimensions of the cluster.
Figure 7e shows that the boundary including the intermediate points visualizes the heterogeneous shape much better.
Figure 7f,g show two different cases by setting different lengths for the global maximum SD, but the same length for the global minimum SD. The boundary is generated with a shorter length for the global maximum SD in
Figure 7g. Our system allows the circle radius and the length for the global maximum and minimum SD be controlled interactively.
Boundary line appearance: We vary the intensity of the boundary line to visualize the 1D statistics of the dimensions in the N-D space. Two metrics—
kurtosis and
skew—are considered. This skew metric is different from the
skew metric used for texture generation, and to avoid confusion we shall refer to it as
asymmetry. A stronger intensity indicates a higher value of the metric. The
asymmetry metric is a measure of asymmetry of the probability distribution of a random variable. The value can be positive, negative or 0. A positive value means a longer right-hand side tail of the distribution, where most of the values lie to the left side of the mean. A negative value means the opposite. When the metric is 0 then the values are relatively distributed evenly on both sides of the mean. It is given by the following equation:
where
is the third moment about the mean
is the standard deviation. In our visualization, the sign of the value is not considered. The variation of the
asymmetry metric along the dimensions is shown in
Figure 8a. Even if several dimensions have a similar SD, their distribution can be diverse like
Figure 8a. Next, the kurtosis metric is a measure of the shape of the probability distribution. The metric estimates whether the distribution is peaked or flat relative to a normal distribution. A high kurtosis has a distinct peak around the mean, declines rapidly, and has heavy tails. A low kurtosis indicates a flat distribution near the mean rather than a sharp peak, Thus, a uniform distribution is the extreme case of low kurtosis. The value is computed as follows:
where
is the fourth moment about the mean
. The minus 3 can be defined as a correction to make the
kurtosis value of the normal distribution 0. Then the intensity of the boundary when varied by the kurtosis metric visualizes how sharp peaked and heavy tailed a dimension’s distribution is.
Figure 8b shows this kurtosis-based boundary. This visualization allows a comparison between different dimensions for both metrics.
Boundary area appearance: With the boundary visualization, an inner shadow is chosen to identify clusters by its color and represent overall distribution. Since the inner circle is generated by the global minimum SD and the intermediate points are generated by the local minimum SD, the thickness of the shadow indicates the difference between the global and local minimum SD. If the cluster has a thick shadow, its minimum SD is larger than the global minimum SD. To secure shadow space for clusters with no differences between them, we define a minimum thickness.
Figure 8c shows the shadow along with boundaries.
Appearance Texture placement:Figure 8d shows how the synthesized Scagnostics texture (here mid
clumpy, mid
skew and low
striated) is mapped to the cluster glyph. The texture is shown only in the inner circle area. If we were to extend the texture outwards, the blobs near the boundary could make the boundary look darker and interfere with the boundary color. As explained in
Section 5, in the texture the clumpy metric can be estimated by distances between blobs of a triad. Thus, at least one triad of blobs should be shown in the glyph by placing them in the middle of the inner circle. The details inside the texture can be zoomed in by modifying the texture size.
10. Case Study
We now turn to a case study. The scenario is file system analysis and we had access to two real life datasets acquired from the systems group at our university. Each dataset has 1400 data points, and each such data point characterizes an instance of one of 28 file system operations (such as ALLOCATE, DELETE, RELEASE, WRITE, etc.) as a 33-D vector. Each vector is a time-series of 33 time-steps, and a value gauges the amount of consumption of some system resource, such as memory bandwidth. Due to its domain of origin we call this dataset the OS (Operating System) dataset.
Our collaborators collected 50 observations for each operation over time. This yields a cluster for each such operation which we identify by a dedicated color in the plots. The capability of our cluster appearance glyphs to highlight cluster heterogeneity and appearance turned out to be highly useful to our collaborators. They could recognize noteworthy operation-specific variations, anomalies and similarities within a file system and compare them with the behavior in a different file system. Their relative locations in the MDS-plot enabled an assessment on the similarity of different operations. The following discussion highlights some observations.
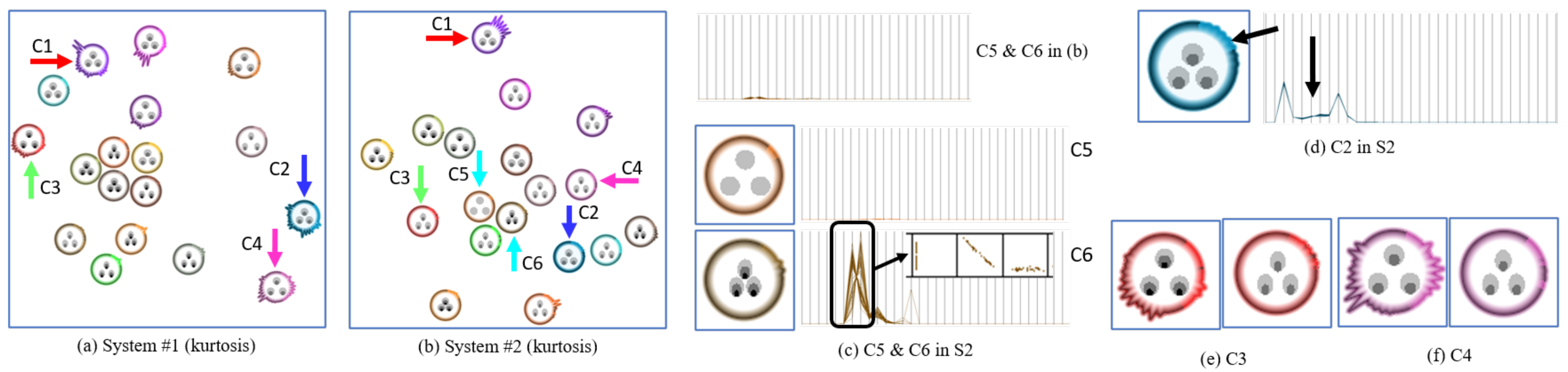
Figure 12a shows an OS dataset collected from file system 1 (S1) and
Figure 12b shows a second OS dataset collected from a different file system (S2). Our visualization helps the analyst to assess (1) how the various file system operations relate to each other, and also (2) how heterogeneous each individual operation is and where.
For example, in S1, from the (boundary) shape of their glyphs we learn that the PERMISSION operation C1, RELEASE operation C2, ALLOC_NODE operation C3 and TRUNCATE operation C4 have an unusually large heterogeneous distribution shape in the 33-D space. Being alerted to this fact, our collaborators would then engage into a detailed shape comparison between the clusters to find the specific reasons for these variations.
Next,
Figure 12c present two clusters—READPAGE operation C5 and WRITE_INODE operation C6 in S2. When we look at the two clusters in S2, their shapes are very similar, which means their distribution is relatively similar and this can be verified by the parallel coordinates display provided at the top of
Figure 12c. However, their textures are very dissimilar. To analyze this in closer detail, we extract only the two clusters and re-normalize them. The re-normalized values are shown in the two parallel coordinates displays in the middle and bottom of
Figure 12c. The parallel coordinates display of C5 shows a low clumpy, skew and striated pattern similar to the pattern stylized in the texture. Unlike C5, the texture of C6 shows a high clumpy, high skew and mid striated pattern. This pattern can also be observed with the parallel coordinates display of C6. Specifically, in the zoomed scatterplots of the dimensions within the black box, we can find distinct sub-clusters and a skewed distribution of points. Since points within the cluster have almost the same values in other dimensions, we can ignore them here. We note that this kind of information might not be noticeable in the point-based distribution and even in the parallel coordinates until rescaling them. Analysts might not suspect that the two clusters have different patterns. However, by visualizing these patterns with the texture, they can easily and quickly recognize the different behavior of these clusters.
Figure 12a,b visualize the kurtosis metric in the boundary. The kurtosis helps in recognizing the one-dimensional distributions. In
Figure 12d, the dimensions pointed to by a black arrow have a lower kurtosis value than others despite the homogeneous shape, i.e., similar SD. In order to explain what this means, we provide a parallel coordinates display (
Figure 12d). We see that these dimensions have a relatively wide distribution. However, it is not easy to recognize the difference even in the parallel coordinates, especially with other clusters. However, by visualizing the kurtosis in the glyph, we can readily assess these clusters.
Our framework generates abstract and concise visualizations of the clusters. Therefore, comparison between two datasets can be easily made. For example, the cluster C1 has a different shape in S2. It has a wider type of distribution in the first few dimensions in S2. However, in S1, the last few dimensions have wider distributions. Likewise, C2 has a homogeneous shape in the S2, while C2 has the heterogeneous shapes in S1. From these observations, we know that the PERMISSION operation C1 and RELEASE operation C2 have very different behaviors in the two file systems. This comparison between systems is useful to characterize the file system. In addition, by comparing the textures of the operations in both systems, differences in their 33-D pattern can also be observed. For example, the ALLOC_INODE operation C3 has low-clumpy, high-skew and low-striated pattern in S1 (see left glyph in
Figure 12e). However, the same operation has different pattern in S2 i.e., it is clumpier, less skewed and more striated (see right glyph in
Figure 12e). Likewise, the TRUNCATE operation C4 also has different patterns in both systems, i.e., it is clumpier and more striated in S2 (see
Figure 12f). From this difference regarding the clumpy metric, analysts might suspect that the operation, in S2, has distinct sub-patterns within it while it has very consistent behavior pattern in S1. So, by exploring both datasets side by side, we quickly find which operations feature different patterns in the two file systems.
Our framework allows users to adjust the visualization to zoom into detail. Users can increase the size of the texture and choose a cluster to obtain more details about the cluster such as the real value of the Scagnostics metric, cluster id etc.
Author Contributions
Conceptualization and visualization: J.H.L. and K.M.; software, resources and data curation: J.H.L.; methodology, validation, investigation and writing: all authors; supervision: K.M. All authors have read and agreed to the published version of the manuscript.
Funding
This work was partly supported by NSF grants IIS-1117132 and IIS-1527200.
Institutional Review Board Statement
An IRB exempt determination letter is on file.
Informed Consent Statement
Not applicable.
Data Availability Statement
Restrictions apply to the availability of the OS data. The data were obtained from the Filesystems and Storage Lab, Stony Brook University and are available with the permission of the Filesystems and Storage lab, Stony Brook University.
Acknowledgments
We thank Nafees Ahmed, Puripant Ruchikachorn, Zhiyuan Zhang and Kevin McDonnell for contributions to earlier versions of this manuscript.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Hey, T.; Tansley, S.; Tolle, K. The Fourth Paradigm: Data-Intensive Scientific Discovery; Microsoft Research: Redmond, WA, USA, 2009; Volume 1. [Google Scholar]
- Tukey, J.W.; Tukey, P.A. Computer graphics and exploratory data analysis: An introduction. In Proceedings of the 6th Annual Conference and Exposition: Of the National Computer Graphics Association, Dallas, TX, USA, 14–18 April 1985; pp. 773–785. [Google Scholar]
- Wilkinson, L.; Anand, A.; Grossman, R. Graph-theoretic scagnostics. In IEEE Symposium on Information Visualization; IEEE Computer Society: Washington, DC, USA, 2005; pp. 157–164. [Google Scholar]
- Fu, L. Implementation of Three-Dimensional Scagnostics. Master’s Thesis, University of Waterloo, Department of Mathematics, Waterloo, ON, Canada, 2009. [Google Scholar]
- Dang, T.N.; Anand, A.; Wilkinson, L. Timeseer: Scagnostics for high-dimensional time series. IEEE Trans. Vis. Comput. Graph. 2012, 19, 470–483. [Google Scholar] [CrossRef] [PubMed]
- Kriegel, H.P.; Kröger, P.; Zimek, A. Clustering high-dimensional data: A survey on subspace clustering, pattern-based clustering, and correlation clustering. ACM Trans. Knowl. Discov. Data (TKDD) 2009, 3, 1–58. [Google Scholar] [CrossRef]
- Nam, E.J.; Han, Y.; Mueller, K.; Zelenyuk, A.; Imre, D. Clustersculptor: A visual analytics tool for high-dimensional data. In Proceedings of the 2007 IEEE Symposium Visual Analytics Science and Technology, Sacramento, CA, USA, 30 October–1 November 2007; pp. 75–82. [Google Scholar]
- Bertin, J. Sémiologie Graphique: Les Diagrammes-Les réseaux-Les Cartes; Technical Report; Gauthier-VillarsMouton & Cie: Paris, France, 1973. [Google Scholar]
- Keim, D.A. Designing pixel-oriented visualization techniques: Theory and applications. IEEE Trans. Vis. Comput. Graph. 2000, 6, 59–78. [Google Scholar] [CrossRef] [Green Version]
- Hartigan, J.A. Printer graphics for clustering. J. Stat. Comput. Simul. 1975, 4, 187–213. [Google Scholar] [CrossRef]
- Nguyen, Q.; Simoff, S.; Qian, Y.; Huang, M. Deep Exploration of Multidimensional Data with Linkable Scatterplots. In Proceedings of the 9th International Symposium on Visual Information Communication and Interaction, Dallas, TX, USA, 24–26 September 2016; pp. 43–50. [Google Scholar]
- Kreuseler, M.; Schumann, H. A flexible approach for visual data mining. IEEE Trans. Vis. Comput. Graph. 2002, 8, 39–51. [Google Scholar] [CrossRef]
- Choo, J.; Lee, H.; Kihm, J.; Park, H. iVisClassifier: An interactive visual analytics system for classification based on supervised dimension reduction. In Proceedings of the IEEE VAST, Salt Lake City, UT, USA, 25–26 October 2010; pp. 27–34. [Google Scholar]
- Hinton, G.; Salakhutdinov, R. Reducing the dimensionality of data with neural networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Van der Maaten, L.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- McInnes, L.; Healy, J.; Melville, J. Umap: Uniform manifold approximation and projection for dimension reduction. arXiv 2018, arXiv:1802.03426. [Google Scholar]
- Kandogan, E. Visualizing multi-dimensional clusters, trends, and outliers using star coordinates. In Proceedings of the ACM SIGKDD, San Francisco, CA, USA, 26–29 August 2001; pp. 107–116. [Google Scholar]
- Ankerst, M.; Keim, D.A.; Kriegel, H.P. Circle segments: A technique for visually exploring large multidimensional data sets. In Proceedings of the IEEE Visualization, San Francisco, CA, USA, 27 October–1 November 1996. [Google Scholar]
- Inselberg, A.; Dimsdale, B. Parallel coordinates: A tool for visualizing multi-dimensional geometry. In Proceedings of the IEEE Visualization, San Francisco, CA, USA, 23–26 October 1990; pp. 361–378. [Google Scholar]
- Dang, T.N.; Wilkinson, L. Scagexplorer: Exploring scatterplots by their features. In Proceedings of the 2014 IEEE Pacific Visualization Symposium, Yokohama, Japan, 4–7 March 2014; IEEE: Hoboken, NJ, US, 2014; pp. 73–80. [Google Scholar]
- Jo, J.; Seo, J. Disentangled Representation of Data Distributions in Scatterplots. In Proceedings of the IEEE Visualization, Vancouver, BC, Canada, 20–25 October 2019; pp. 136–140. [Google Scholar]
- Ward, M.O. A taxonomy of glyph placement strategies for multidimensional data visualization. Inf. Vis. 2002, 1, 194–210. [Google Scholar] [CrossRef]
- Borgo, R.; Kehrer, J.; Chung, D.; Maguire, E.; Laramee, R.; Hauser, H.; Ward, M.; Chen, M. Glyph-based Visualization: Foundations, Design Guidelines, Techniques and Applications. In Proceedings of the Eurographics State of the Art Reports, EG STARs, Vienna, Austria, 3–7 May 2013; pp. 39–63. [Google Scholar]
- Ropinski, T.; Oeltze, S.; Preim, B. Survey of glyph-based visualization techniques for spatial multivariate medical data. Comput. Graph. 2011, 35, 392–401. [Google Scholar] [CrossRef] [Green Version]
- Choo, J.; Bohn, S.; Park, H. Two-stage framework for visualization of clustered high dimensional data. In Proceedings of the IEEE VAST, Atlantic City, NJ, USA, 12–13 October 2009; pp. 67–74. [Google Scholar]
- Hartigan, J.A.; Mohanty, S. The runt test for multimodality. J. Classif. 1992, 9, 63–70. [Google Scholar] [CrossRef]
- Gansner, E.R.; Hu, Y. Efficient node overlap removal using a proximity stress model. In International Symposium on Graph Drawing; Springer: Berlin/Heidelberg, Germany, 2008; pp. 206–217. [Google Scholar]
- Krause, J.; Perer, A.; Bertini, E. INFUSE: Interactive feature selection for predictive modeling of high dimensional data. IEEE Trans. Vis. Comput. Graph. 2014, 20, 1614–1623. [Google Scholar] [CrossRef] [PubMed]
- Kovacevic, N.; Wampfler, R.; Solenthaler, B.; Gross, M.; Günther, T. Glyph-Based Visualization of Affective States. In Proceedings of the EuroVis 2020—22nd EG/VGTC Conference on Visualization Norrköping, Sweden, 25–29 May 2020; EuroVis: Short Papers; Eurographics Association: Goslar, Germany, 2020. [Google Scholar]
- Ordinal Regression—Laerd Statistics. Available online: https://statistics.laerd.com/spss-tutorials/ordinal-regression-using-spss-statistics.php (accessed on 4 December 2020).
Figure 1.
High-dimensional scatterplot, college dataset.
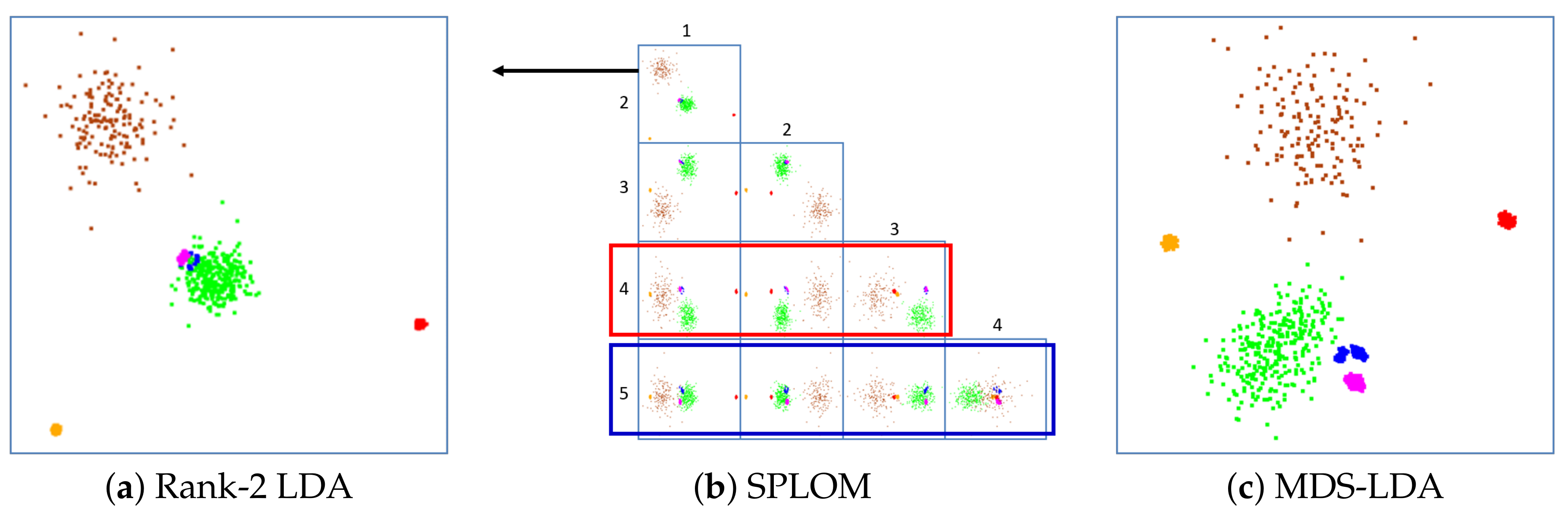
Figure 2.
Artificial dataset with 6 Gaussian clusters originally in 30-D space gives rise to a 5-D LDA embedding. (a) Rank-2 LDA. Three clusters—the green, blue and magenta clusters—are overplotted. (b) 5-D SPLOM. The top scatterplot is Rank-2 LDA (a). None of the scatterplot projections can successfully isolate all clusters, (c) MDS-LDA. We observe that all clusters are now well separated.
Figure 3.
Scatterplots obtained by MDS-LDA with 2-D distance-based MST (top row) and N-D distance-based MST (bottom row).
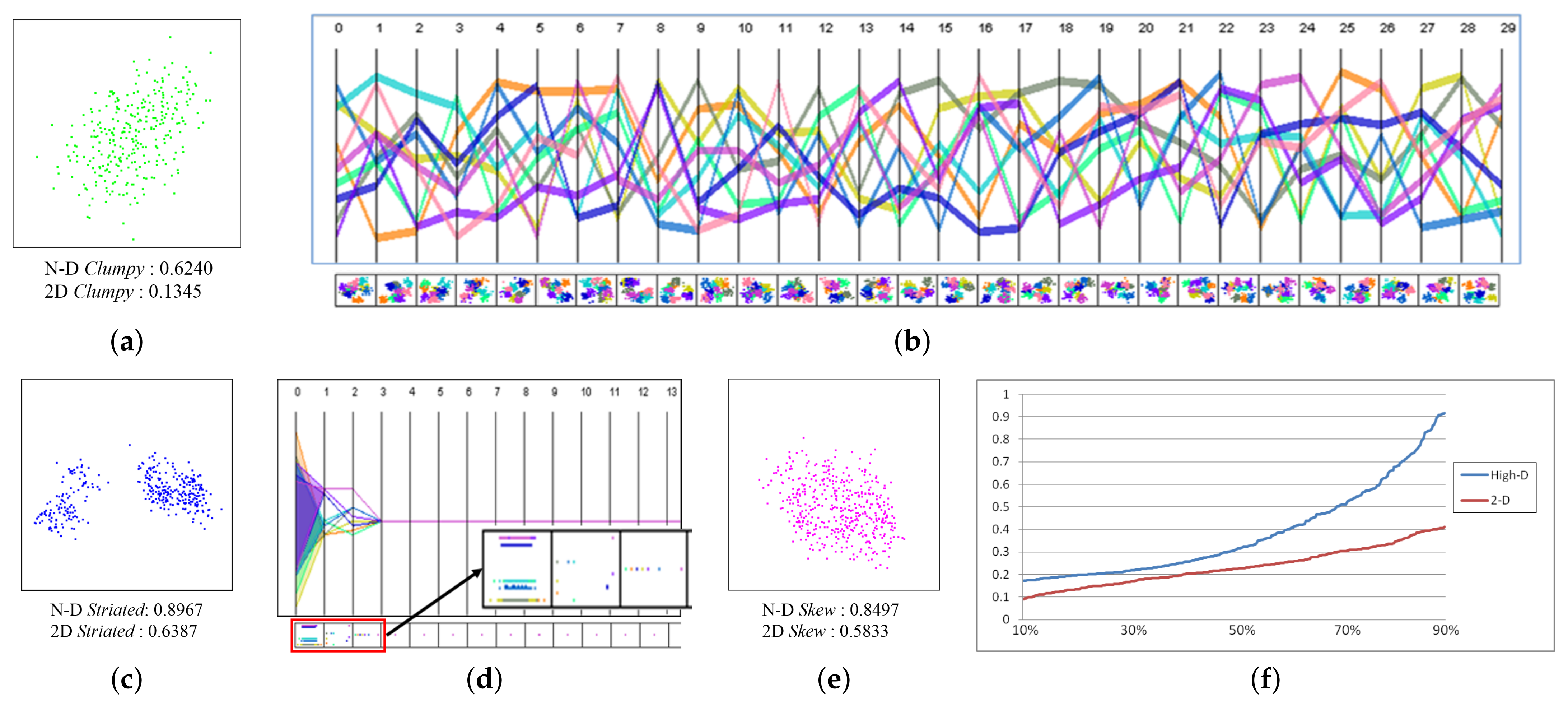
Figure 4.
2-D example scatterplots for each metric we have encoded. For each of them we chose a high value level for better illustration of their real-world graphical appearance.
Figure 5.
Three clusters of the Gaussian dataset. (a) MDS-LDA of the green cluster with N-D and 2-D clumpy values. The green cluster is composed of 10 sub-clusters. (b) The green cluster in parallel coordinates display (PCD). The 10 sub-cluster centers shown in different colors. The clusters themselves are well distinguishable in the bivariate scatterplots below. (c) MDS-LDA of the blue cluster with N-D and 2-D striated values. It has 9 sub-clusters which run along parallel lines. (d) Partial PCD of ranges of the sub-clusters shown in different colors and the first 3 zoomed scatterplots of adjacent dimensions. (e) MDS-LDA of the magenta cluster with N-D and 2-D skew values. (f) Distribution of edge lengths in the 2-D MST and N-D MST. The vertical axis indicates the ratio of edge length to the longest edge length.
Figure 6.
Textures; low, mid, and high level (from left to right); other metrics are similar except for the displayed metric in the left label; (a–c) sample textures for conveying Scagnostics metrics. (d,e) two synthesized textures—mid clumpy, skew and striated (d), high clumpy and skew, and low striated (e).
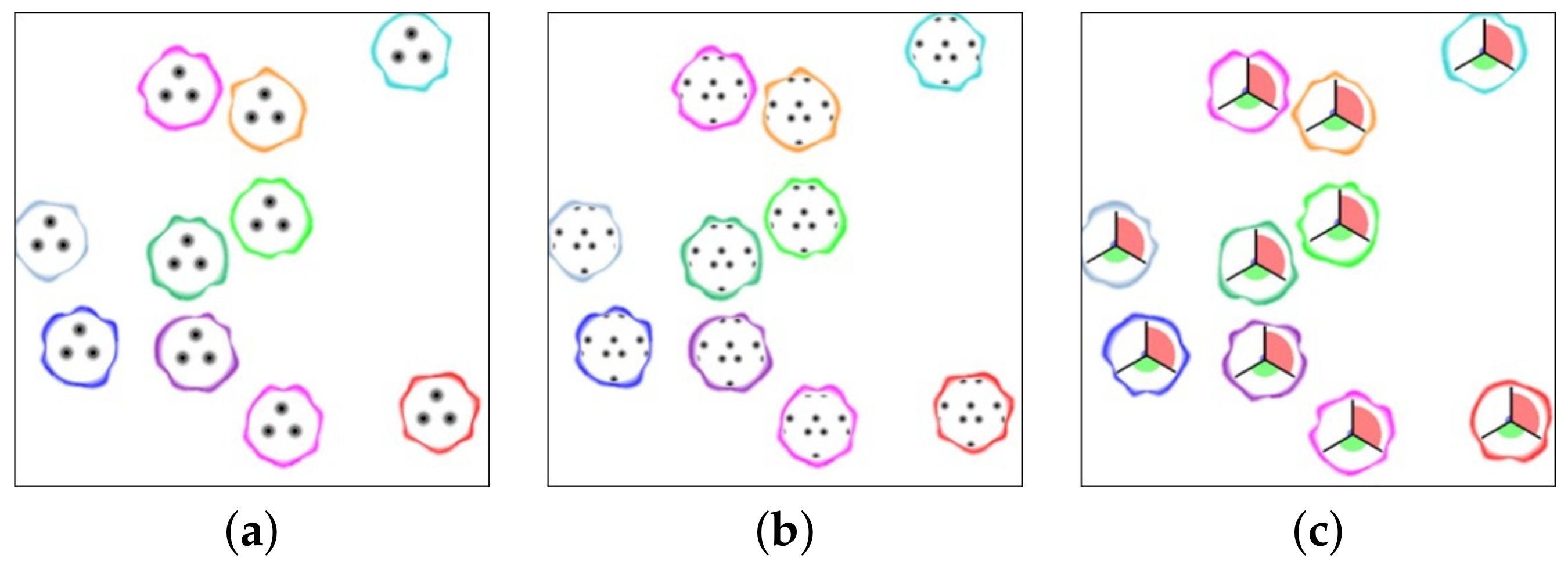
Figure 7.
Glyph generation of a 10-D cluster. (a) Boundary points representing each dimension. (b) Visualization of variances of dimensions (red lines from the center). (c) Boundary generated by points in (a). (d) Insertion of intermediate points with length of local minimum standard deviation (SD) from the center between every pair of the initial boundary points. (e,f) Boundary generated by points in (d)—it visualizes the heterogeneous shape much better. (g) Boundary generated by smaller maximum radius.
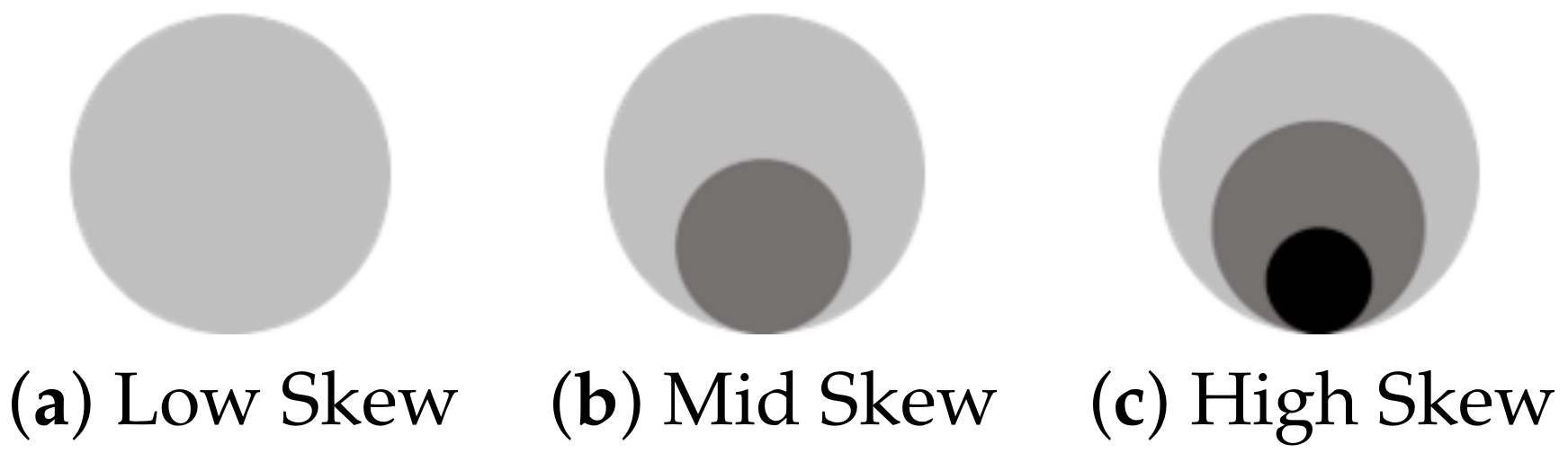
Figure 8.
Asymmetry/Kurtosis visualization. (a,b) Boundary visualizing the variation of the asymmetry/kurtosis metric along the dimensions. (c) Boundary (a) with color emphasis. (d) Boundary (a) with texture.
Figure 9.
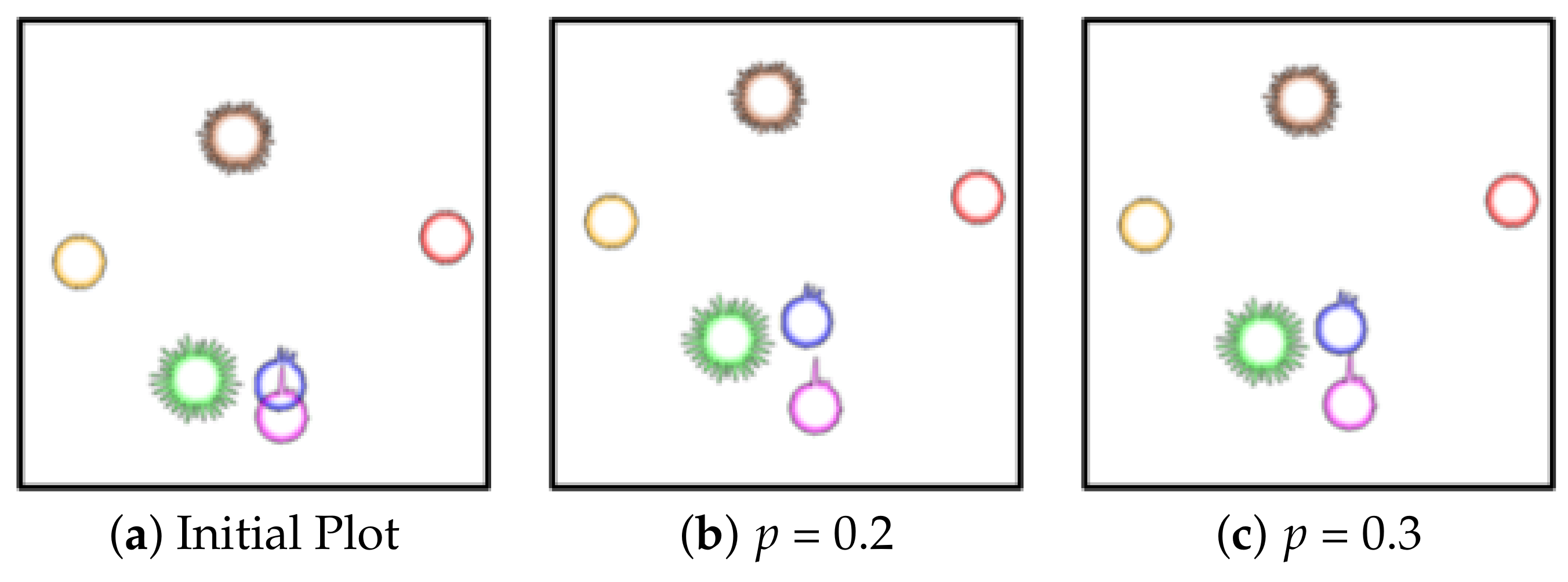
Overlap removal according to permitted overlap ratio p.
Figure 10.
Examples of our texture glyph used in our user study (a) periodic, (b) non-periodic, (c) the baseline pie glyph.
Figure 11.
The redesigned texture to represent skewness.
Figure 12.
Cluster visualization with two OS datasets from System #1 (S1) and System #2 (S2). (a) S1 data with kurtosis metric (b) S2 data with kurtosis metric (c) Cluster C5 and C6 in S2 with parallel coordinates display (d) Cluster C2 in S2 with parallel coordinates display (e,f) Cluster C3 and C4 (left: S1, right: S2). The color corresponds to the cluster. See Supplement for larger versions of the images.
Table 1.
Results from user study 1. Entries are read as RIGHT/TOTAL (% Correct).
| | Plot | Texture | Connect |
|---|
| Clumpy | 164/180 (91%) | 173/180 (96%) | Better than scatterplots with 95% significance |
| Skew | 101/108 (91%) | 102/108 (96%) | As good as scatterplots with 95% significance |
| Striated | 134/180 (91%) | 169/180 (96%) | Better than scatterplots with 95% significance |
Table 2.
Results from user study 2. Entries are read as RIGHT/TOTAL (% Correct).
| | Changing Clumpy | Changing Skew | Changing Striated | Others Constant |
|---|
| Clumpy | X | 232/255 (90.98%) | 341/365 (93.42%) | 113/117 (96.58%) |
| Skew | 196/225 (87.11%) | X | 213/246 (86.59) | 130/150 (86.67) |
| Striated | 207/228 (90.79%) | 231/247 (93.52%) | X | 135/150 (90.00%) |
Table 3.
Users’ performance.
| Glyph Design | Accuracy |
|---|
| Clummpiness | Skewness | Striatedness |
|---|
| Pie (Baseline) | 64.17% | 62.5% | 65% |
| Texture | 76.67% | 42.5% | 62.5% |
| Texture (Redesign) | 86.42% | 98.76% | 83.95% |
| Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}











