
Review of Tools for Semantics Extraction: Application in Tsunami Research Domain

 ,
,  , ,
, ,  ,
,  ,
, 
Abstract
:1. Introduction
2. Semantics Extraction and Ontology Learning
- (a)
- international characters sets are used for encoding information on the web (Uni-code)
- (b)
- web sources are uniquely identified by the URI (Uniform Resource Identifier) and
- (c)
- the XML (Extensible Markup Language) provides human-readable and machine-readable format for data exchange.
- (a)
- extraction of the most important (representative) terms
- (b)
- extraction of (multilingual) synonymous words from the previous step
- (c)
- concepts extraction from the previous set of terms
- (d)
- concept hierarchy extraction (extraction of IS-A (inheritance) relations)
- (e)
- relationships extraction (extraction of non-taxonomic relations)
- (f)
- relation hierarchy extraction
- (g)
- extraction of axioms and rules (e.g., disjoint concepts)
3. Materials and Methods
3.1. Process of Tools Selection
- (a)
- free solution available (no trial version)
- (b)
- the ontology learning tool has to be downloadable and usable without and limitations
- (c)
- the tool has to provide (semi-)automatic ontology learning
3.2. Tools Evaluation
- Distribution (free/N/A (information not available)
- Instant download: whether the tool can be downloaded without any limitations, e.g., no registration or password setting is required (yes/no)
- Operability: whether the tool can be run with no difficulties (yes/no/restricted/N/A)
- Type of tool: how the tool can be used by the end user (desktop/web service/API/N/A)
- Active development/last update: whether the tool is up-to-date and still actively developed (yes/no/N/A/last update)
- Degree of automation: how the text is processed by the tool (fully automatic/semi-automated/N/A)
- Supported programming language: whether it is possible to develop one’s own ontology learning-based solution (programming languages)
- Documentation: how much the documentation is complete, correct, and comprehensible (pure/good)
- Ease of use: how easy it is to use the tool (poor/good/N/A)
- Installation: how easy it is to install the tool (easy/hard/failed)
- Batch mode processing of documents: whether more than one document can be processed in one step or whether they are processed one by one
- Classes extraction: whether classes as concepts can be extracted
- Individuals (instances) extraction: whether individuals, as instances of classes, can be extracted
- Taxonomic relations induction (concept hierarchy): whether it is possible to extract the subsumption hierarchy of concepts
- Non-taxonomic relations induction: this parameter corresponds to the extraction of non-taxonomic relations (i.e., domain-specific relationships)
- Word-sense disambiguation: whether the tool is able to detect the correct meaning of the word in a specific context
- Coreference resolution: whether it is possible to find all expressions referring to the same entity in the text
- Entity linking: whether the tool is able to recognize (named) entities in the text and assign a unique identity to their knowledge base counterparts
4. Results
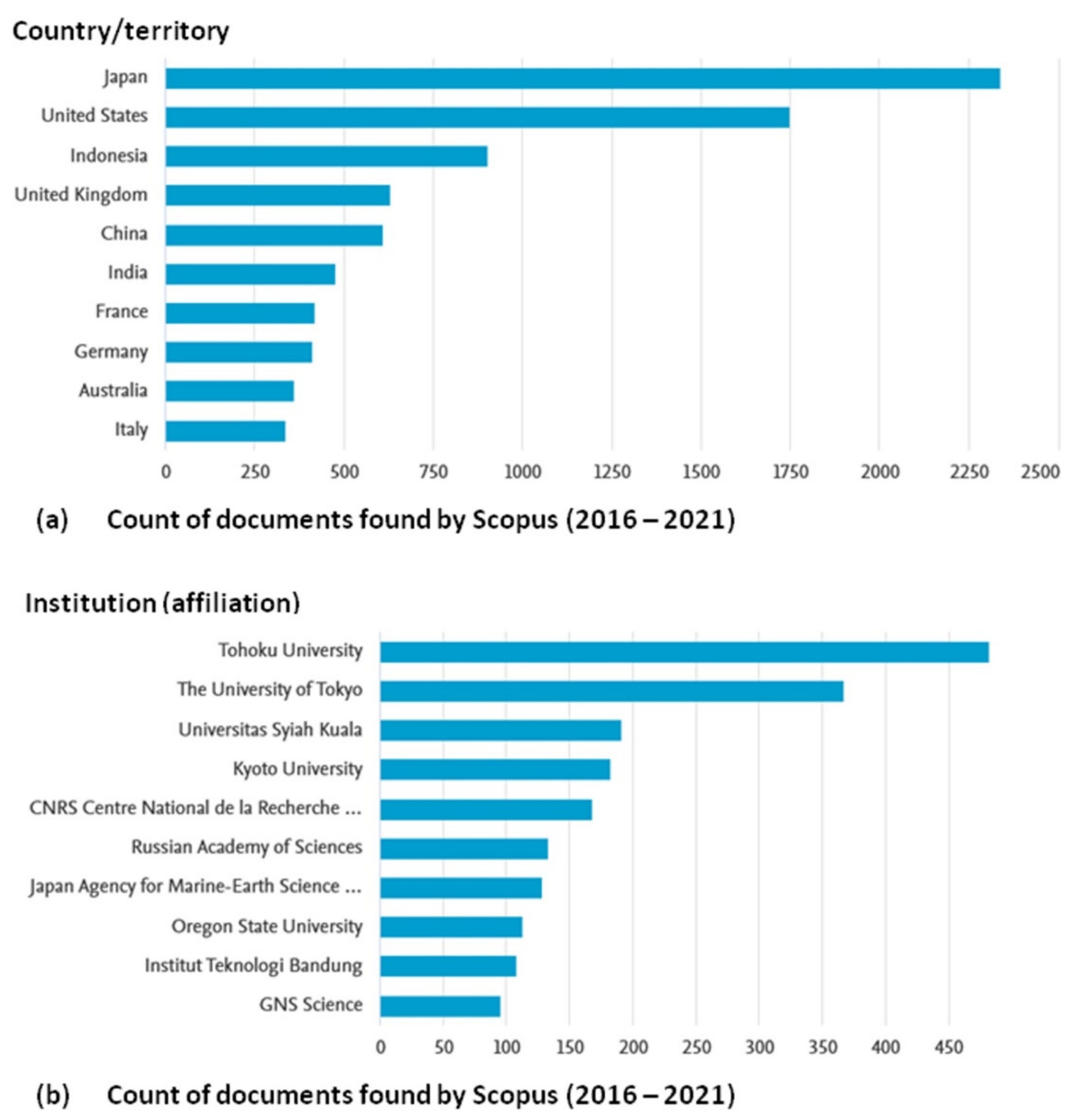
4.1. Ontology Learning Tools: Analysis of Journal Articles
4.2. Evaluation of Ontology Learning Tools
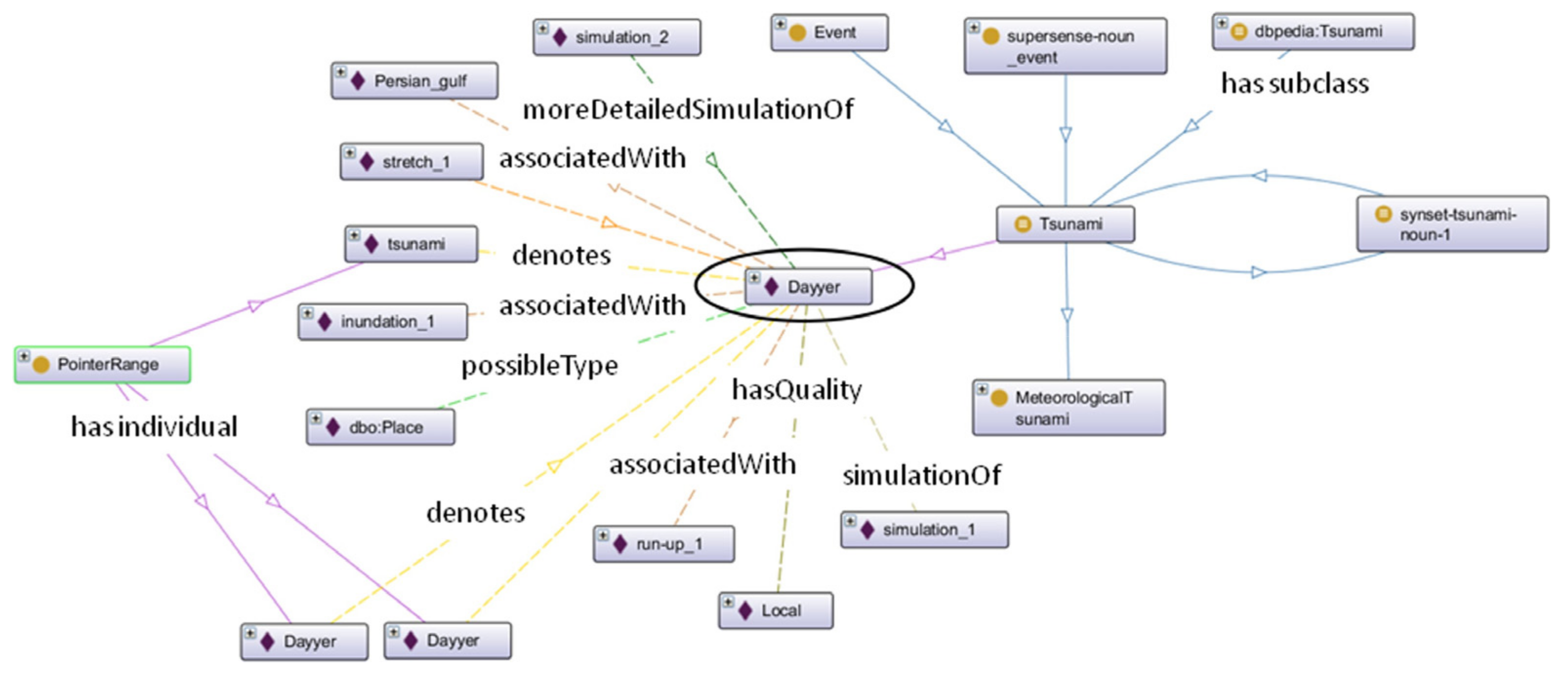
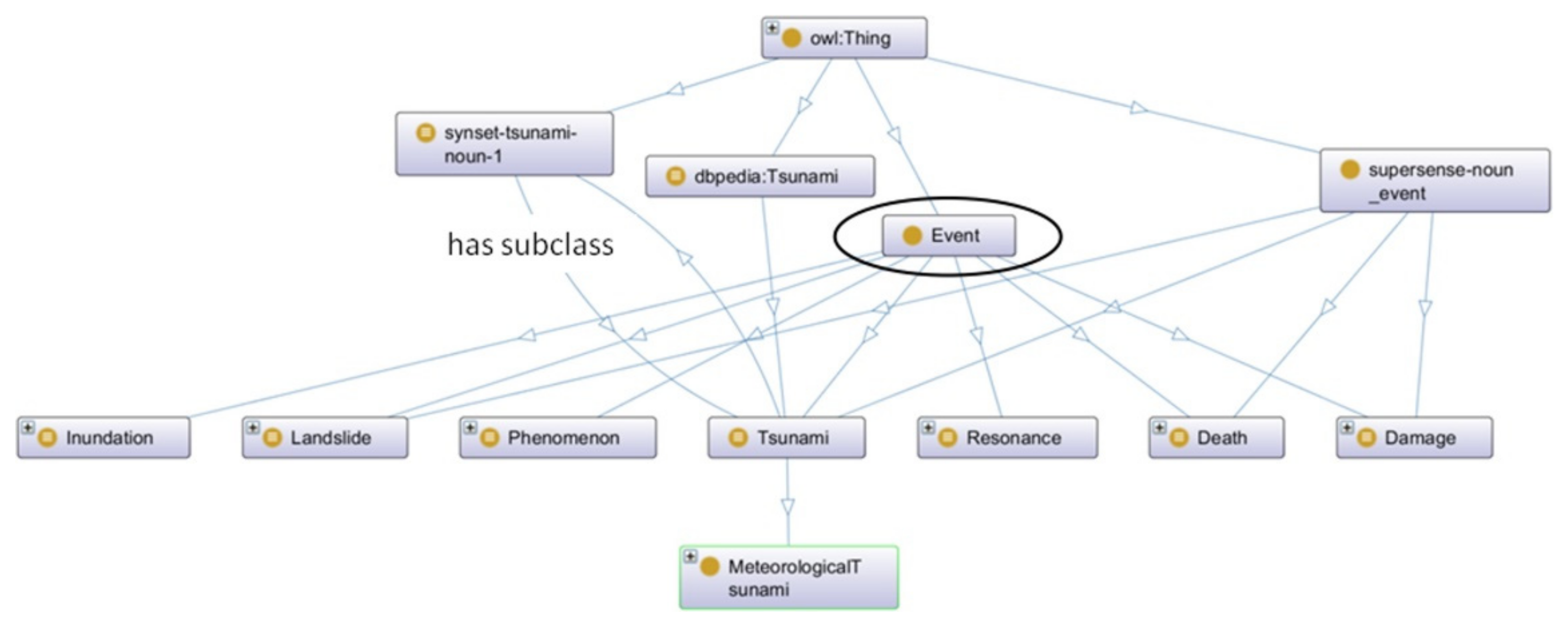
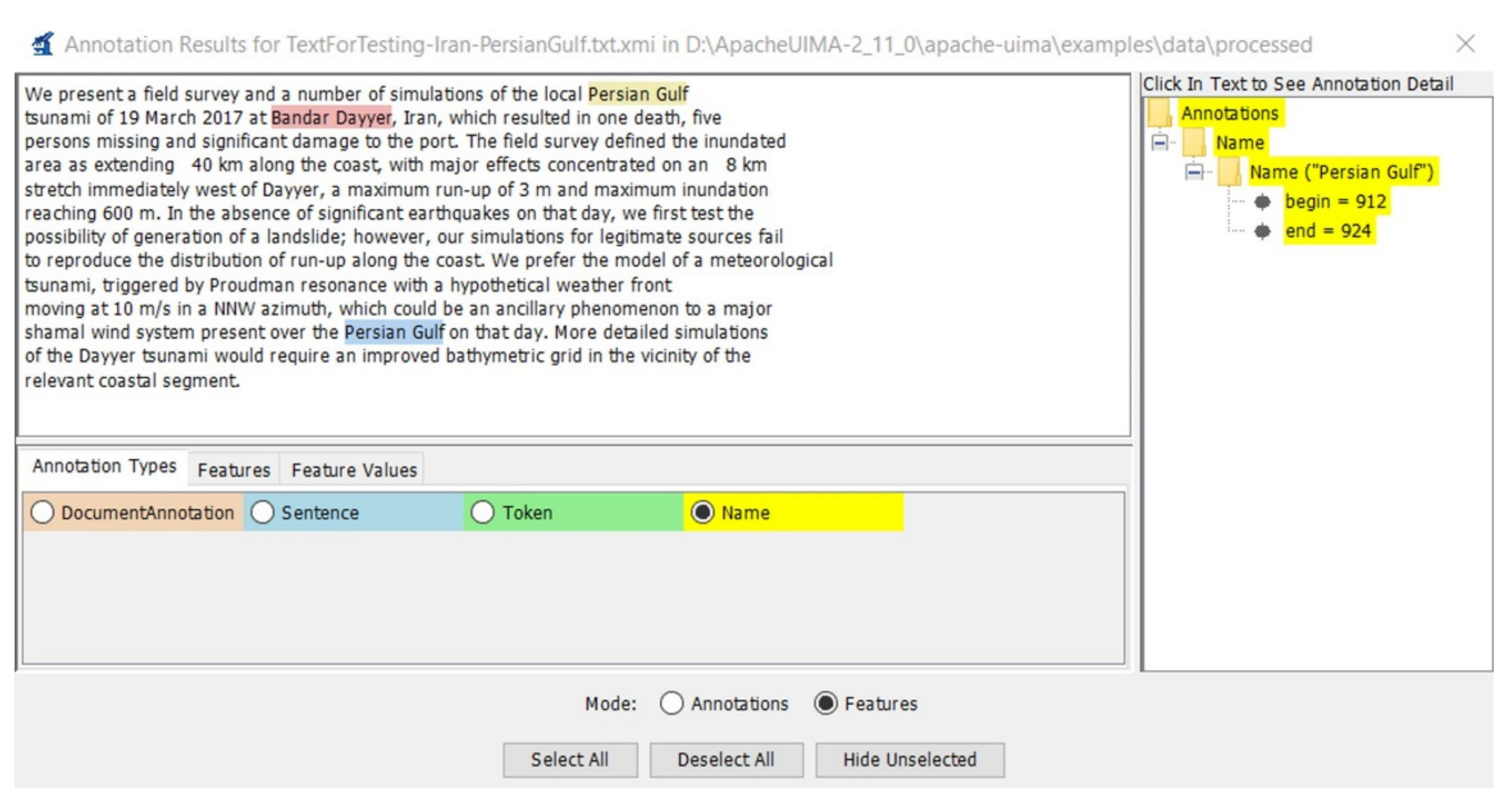
“We present a field survey and a number of simulations of the local Persian Gulf tsunami of 19 March 2017 at Bandar Dayyer, Iran, which resulted in one death, five persons missing and significant damage to the port. The field survey defined the inundated area as extending 40 km along the coast, with major effects concentrated on an 8 km stretch immediately west of Dayyer, a maximum run-up of 3 m and maximum inundation reaching 600 m. In the absence of significant earthquakes on that day, we first test the possibility of generation of a landslide; however, our simulations for legitimate sources fail to reproduce the distribution of run-up along the coast. We prefer the model of a meteorological tsunami, triggered by Proudman resonance with a hypothetical weather front moving at 10 m/s in a NNW azimuth, which could be an ancillary phenomenon to a major shamal wind system present over the Persian Gulf on that day. More detailed simulations of the Dayyer tsunami would require an improved bathymetric grid in the vicinity of the relevant coastal segment.”
4.2.1. Text-To-Onto
- extraction of terms
- extraction of association (without domain/range)
- ontology pruning (automated extraction of irrelevant concepts to the application domain where the ontology generalizes the target domain)
- taxonomy induction
- extraction of instances
- relations learning (including domain/range)
- ontology enrichment (ontology extension with additional concepts/relations)
- ontologies comparison
4.2.2. Text2Onto
- concepts
- taxonomical relations
- concept instantiation
- properties
- domain and range restrictions
- mereological relations, i.e., part-whole relationships
- equivalence
4.2.3. FRED
- Namespace for FRED terms [http://www.ontologydesignpatterns.org/ont/fred/ domain.owl] (accessed on 15 September 2021)
- Do word-sense disambiguation [yes]
- Align concepts to Framester [no]
- Tense [yes]
- Use FrameNet roles [no]
- Always merge discourse referents in case of coreference [no]
- Text annotation format [EARMARK]
- Return the semantic-subgraph only [no]
4.2.4. DOODLE-OWL
- Construction module is responsible for the extraction of the taxonomical (is-a) and the non-taxonomical relations.
- Refinement module is inside the construction module. It identifies significant pairs of concepts in the extracted related pairs of concepts. This is realized interactively with the user.
- Visualisation module is represented by the RDF(S)-based graphical editor, providing visualisation of the ontological structure, including consistency checking of the ontological classes.
- Translation module exports generated structure into the OWL format.
4.2.5. OntoLearn
- terminology extraction from corpus
- semantical interpretation of extracted terms
- arrangement of these terms into the hierarchy
4.2.6. Apache UIMA
- statistical techniques
- rule-based techniques
- information retrieval
- machine learning
- ontologies
- automated reasoning
- integration of knowledge sources (e.g., WordNet)
“...do not support projecting information towards specific RDF vocabularies.”
4.2.7. SProUT
- to provide a system that integrates different modules for texts processing
- to find a compromise between processing efficiency and expressiveness of the formalism
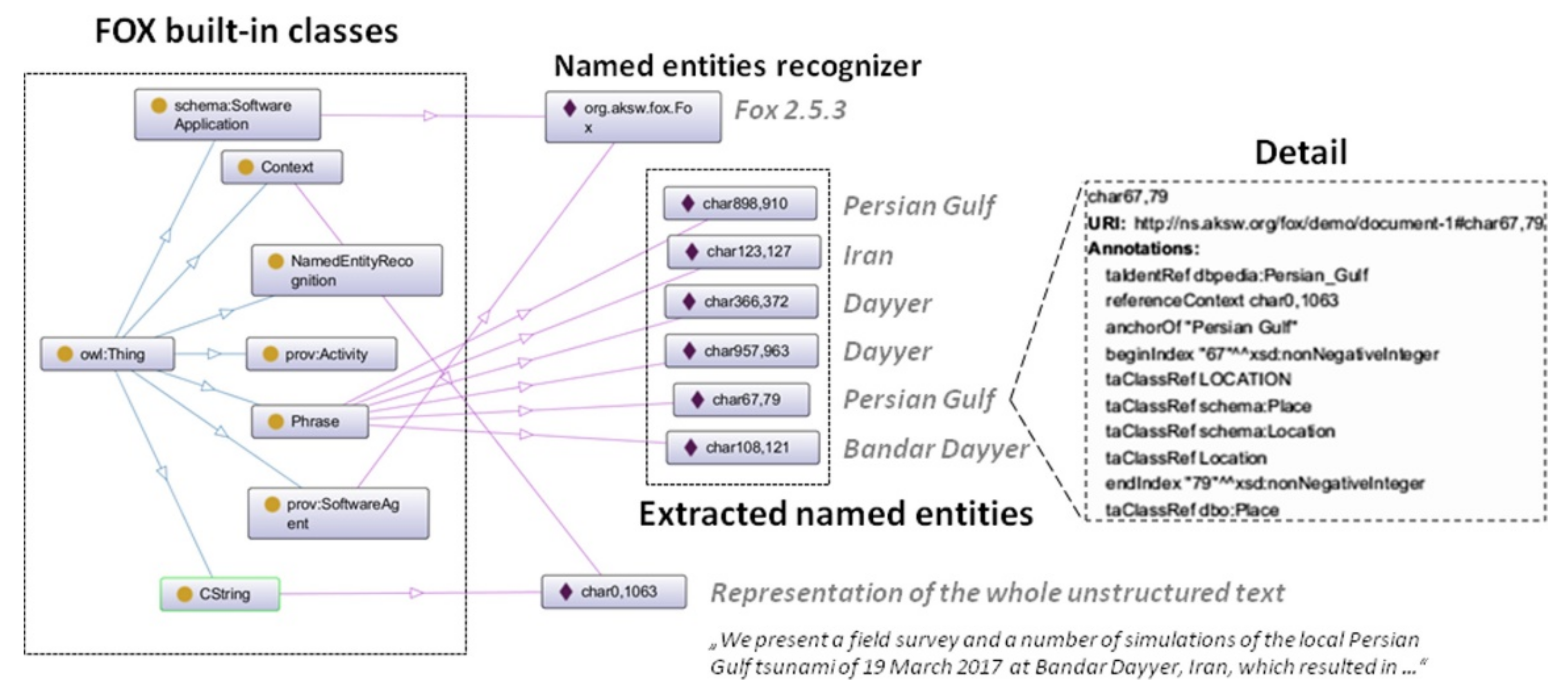
4.2.8. FOX
- Lang (language): en
- Input Format: text/html
- Extraction Type: ner (named entity recognition)
- Input (unstructured text): document about meteotsunami
- Output Format: Turtle
- Fox Light: OFF
5. Discussion and Future Directions
“annotate the OKE graph banks, to build OKE benchmarks, to evaluate OKE tools, to compare heterogeneous tools, and to perform on-demand OKE graph transformations.”
6. Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Miner, G.; Elder, J.; Nisbet, R. Practical Text Mining and Statistical Analysis for Non-Structured Text Data Applications; Academic Press: Cambridge, MA, USA, 2012. [Google Scholar] [CrossRef]
- Husáková, M. Ontology-Based Conceptualisation of Text Mining Practice Areas for Education; Springer: Cham, Switzerland, 2019; pp. 533–542. [Google Scholar] [CrossRef]
- Gómez-Pérez, A.; Manzano-Macho, D. An overview of methods and tools for ontol- ogy learning from texts. Knowl. Eng. Rev. 2004, 19, 187–212. [Google Scholar] [CrossRef]
- Barforoush, A.A.; Rahnama, A. Ontology Learning: Revisited. J. Web Eng. 2012, 11, 269–289. [Google Scholar]
- Gangemi, A. A Comparison of Knowledge Extraction Tools for the Semantic Web. In The Semantic Web: Semantics and Big Data; Cimiano, P., Corcho, O., Presutti, V., Hollink, L., Rudolph, S., Eds.; Springer: Berlin/Heidelberg, Germany, 2013; pp. 351–366. [Google Scholar] [CrossRef] [Green Version]
- Alarfaj, A.; Al-Salman, A. Ontology Construction from Text: Challenges and Trends. Int. J. Artif. Intell. Expert Syst. 2015, 6, 15–26. [Google Scholar]
- Konys, A. Knowledge Repository of Ontology Learning Tools from Text. Procedia Comput. Sci. 2019, 159, 1614–1628. [Google Scholar] [CrossRef]
- Paris, R.; Goto, K.; Goff, J.; Yanagisawa, H. Advances in the study of mega-tsunamis in the geological record. Earth-Sci. Rev. 2020, 210, 103381. [Google Scholar] [CrossRef]
- Goff, J.; Terry, J.P.; Chagué-Goff, C.; Goto, K. What is a mega-tsunami? In the wake of the 2011 Tohoku-oki tsunami—three years on. Marine Geology 2014, 358, 12–17. [Google Scholar] [CrossRef]
- Costa, P.J.; Dawson, S.; Ramalho, R.S.; Engel, M.; Dourado, F.; Bosnic, I.; Andrade, C. A review on onshore tsunami deposits along the Atlantic coasts. Earth-Sci. Rev. 2021, 212, 103441. [Google Scholar] [CrossRef]
- Berners-Lee, T.; Hendler, J.; Lassila, O. The Semantic Web. Sci. Am. 2001, 284, 34–43. [Google Scholar] [CrossRef]
- Husáková, M.; Bureš, V. Formal Ontologies in Information Systems Development: A Systematic Review. Information 2020, 11, 66. [Google Scholar] [CrossRef] [Green Version]
- Protégé A free, Open-Source Ontology Editor and Framework for Building Intelligent Systems. Available online: https://protege.stanford.edu/ (accessed on 29 September 2021).
- Wątróbski, J. Ontology learning methods from text—An extensive knowledge-based approach. Procedia Comput. Sci. 2020, 176, 3356–3368. [Google Scholar] [CrossRef]
- Asim, M.N.; Wasim, M.; Khan, M.U.G.; Mahmood, W.; Abbasi, H.M. A Survey of Ontology Learning Techniques and Applications. Database 2018. 2018. Available online: https://academic.oup.com/database/article-pdf/doi/10.1093/database/bay101/27329264/bay101.pdf (accessed on 10 October 2021).
- Khadir, A.C.; Aliane, H.; Guessoum, A. Ontology learning: Grand tour and challenges. Comput. Sci. Rev. 2021, 39, 100339. [Google Scholar] [CrossRef]
- Buitelaar, P.; Cimiano, P. Ontology Learning and Population: Bridging the Gap between Text and Knowledge; IOS Press: Amsterdam, The Netherlands, 2008; Volume 167. [Google Scholar]
- Maynard, D.; Bontcheva, K.; Augenstein, I. Natural Language Processing for the Semantic Web; Morgan & Claypool Publishers: San Rafael, CA, USA, 2016. [Google Scholar]
- Gangemi, A.; Presutti, V.; Recupero, D.R.; Nuzzolese, A.G.; Draicchio, F.; Mongiovì, M. Semantic Web Machine Reading with FRED. Semant. Web 2017, 8, 873–893. [Google Scholar] [CrossRef]
- De Maio, C.; Fenza, G.; Loia, V.; Orciuoli, F. Unfolding social content evolution along time and semantics. Future Gener. Comput. Syst. 2017, 66, 146–159. [Google Scholar] [CrossRef]
- Rani, M.; Dhar, A.K.; Vyas, O.P. Semi-automatic terminology ontology learning based on topic modeling. Eng. Appl. Artif. Intell. 2017, 63, 108–125. [Google Scholar] [CrossRef] [Green Version]
- Boufrida, A.; Boufaida, Z. Rule extraction from scientific texts: Evaluation in the specialty of gynecology. J. King Saud Univ. Comput. Inf. Sci. 2020, 108, 33–41. [Google Scholar] [CrossRef]
- Gangemi, A.; Recupero, D.R.; Mongiovì, M.; Nuzzolese, A.G.; Presutti, V. Identifying motifs for evaluating open knowledge extraction on the Web. New Avenues in Knowledge Bases for Natural Language Processing. Knowl. Based Syst. 2016, 108, 33–41. [Google Scholar] [CrossRef]
- Konys, A. Towards Knowledge Handling in Ontology-Based Information Extraction Systems. Procedia Comput. Sci. 2018, 126, 2208–2218. [Google Scholar] [CrossRef]
- Piad-Morffis, A.; Gutiérrez, Y.; Muñoz, R. A corpus to support eHealth Knowledge Discovery technologies. J. Biomed. Inform. 2019, 94, 103172. [Google Scholar] [CrossRef] [Green Version]
- Zouaq, A.; Gagnon, M.; Jean-Louis, L. An assessment of open relation extrac-tion systems for the semantic web. Inf. Syst. 2017, 71, 228–239. [Google Scholar] [CrossRef]
- De Rosa, M.; Fenza, G.; Gallo, A.; Gallo, M.; Loia, V. Pharmacovigilance in the era of social media: Discovering adverse drug events cross-relating Twitter and PubMed. Future Comput. Syst. 2021, 114, 394–402. [Google Scholar] [CrossRef]
- Liu, S.; Yang, H.; Li, J.; Kolmanic, S. Preliminary Study on the Knowledge Graph Construction of Chinese Ancient History and Culture. Information 2020, 11, 186. [Google Scholar] [CrossRef] [Green Version]
- Konys, A.; Drążek, Z. Ontology Learning Approaches to Provide Domain-Specific Knowledge Base. Procedia Comput. Sci. 2020, 176, 3324–3334. [Google Scholar] [CrossRef]
- Mongiovì, M.; Recupero, D.R.; Gangemi, A.; Presutti, V.; Consoli, S. Merging open knowledge extracted from text with MERGILO. New Avenues in Knowledge Bases for Natural Language Processing. Knowl. Based Syst. 2016, 108, 155–167. [Google Scholar] [CrossRef]
- Remolona, M.F.M.; Conway, M.F.; Balasubramanian, S.; Fan, L.; Feng, Z.; Gu, T.; Kim, H.; Nirantar, P.M.; Panda, S.; Ranabothu, N.R.; et al. Hybridontology-learning materials engineering system for pharmaceutical products: Multi-label entity recognition and concept detection. In honor of Professor Rafiqul Gani. Comput. Chem. Eng. 2017, 107, 49–60. [Google Scholar] [CrossRef]
- Wohlgenannt, G.; Sabou, M.; Hanika, F. Crowd-based ontology engineering with the uComp Protege plugin. Semant. Web 2016, 7, 379–398. [Google Scholar] [CrossRef] [Green Version]
- Rupasingha, R.A.H.M.; Paik, I.; Kumara, B.T.G.S. Specificity-Aware Ontology Generation for Improving Web Service Clustering. IEICE Trans. Inf. Syst. 2018, E101D, 2035–2043. [Google Scholar] [CrossRef]
- Rijvordt, W.; Hogenboom, F.; Frasincar, F. Ontology-Driven News Classification with Aethalides. J. Web Eng. 2019, 18, 627–654. [Google Scholar] [CrossRef] [Green Version]
- Mohan, M.J.; Sunitha, C.; Ganesh, A.; Jaya, A. A Study on Ontology Based Abstrac-tive Summarization. Procedia Comput. Sci. 2016, 87, 32–37. [Google Scholar] [CrossRef] [Green Version]
- Amar, F.B.B.; Gargouri, B.; Hamadou, A.B. Generating core domain ontologies from normal-ized dictionaries. Mining the Humanities: Technologies and Applications. Eng. Appl. Artif. Intell. 2016, 51, 230–241. [Google Scholar] [CrossRef]
- Demner-Fushman, D.; Rogers, W.J.; Aronson, A.R. MetaMap Lite: An evaluation of a new Java implementation of MetaMap. J. Am. Med Inform. Assoc. 2017, 24, 841–844. [Google Scholar] [CrossRef]
- Mezghanni, I.B.; Gargouri, F. CrimAr: A Criminal Arabic Ontology for a Benchmark Based Evaluation. Procedia Comput. Sci. 2017, 112, 653–662. [Google Scholar] [CrossRef]
- Hoxha, J.; Jiang, G.; Weng, C. Automated learning of domain taxonomies from text using background knowledge. J. Biomed. Inform. 2016, 63, 295–306. [Google Scholar] [CrossRef]
- Roldan-Molina, G.R.; Ruano-Ordas, D.; Basto-Fernandes, V.; Mendez, J.R. An ontology knowledge inspection methodology for quality assessment and continuous improvement. Data Knowl. Eng. 2021, 133, 101889. [Google Scholar] [CrossRef]
- Barki, C.; Rahmouni, H.B.; Labidi, S. Model-based prediction of oncotherapy risks and side effects in bladder cancer. Procedia Comput. Sci. 2021, 181, 818–826. [Google Scholar] [CrossRef]
- Ghoniem, R.M.; Alhelwa, N.; Shaalan, K. A Novel Hybrid Genetic-Whale Optimiza-tion Model for Ontology Learning from Arabic Text. Algorithms 2019, 12, 182. [Google Scholar] [CrossRef] [Green Version]
- Kethavarapu, U.P.K.; Saraswathi, S. Concept Based Dynamic Ontology Creation for Job Recommendation System. Procedia Comput. Sci. 2016, 85, 915–921. [Google Scholar] [CrossRef] [Green Version]
- Potoniec, J. Mining Cardinality Restrictions in OWL. Found. Comput. Decis. Sci. 2020, 45, 195–216. [Google Scholar] [CrossRef]
- Salatino, A.A.; Thanapalasingam, T.; Mannocci, A.; Birukou, A.; Osborne, F.; Motta, E. The Computer Science Ontology: A Comprehensive Automatically-Generated Taxonomy of Research Areas. Data Intell. 2020, 2, 379–416. [Google Scholar] [CrossRef]
- Xu, D.; Karray, M.H.; Archimède, B. A knowledge base with modularized ontologies for eco-labeling: Application for laundry detergents. Comput. Ind. 2018, 98, 118–133. [Google Scholar] [CrossRef] [Green Version]
- Levin, B.W.; Nosov, M.A. General Information on Tsunami Waves, Seaquakes, and Other Catastrophic Phenomena in the Ocean. In Physics of Tsunamis; Springer International Publishing: Cham, Switzerland, 2016; pp. 1–34. [Google Scholar] [CrossRef]
- Papadopoulos, G.A.; Lorito, S.; Løvholt, F.; Rudloff, A.; Schindelé, F. Understanding Disaster Risk: Hazard Related Risk Issues, Section I: Geophysical risk.; Publications Office of the European Union. 2017. Available online: https://publications.jrc.ec.europa.eu/repository/handle/JRC102482 (accessed on 18 October 2021).
- Salaree, A.; Mansouri, R.; Okal, E.A. The intriguing tsunami of 19 March 2017 at Bandar Dayyer, Iran: Field survey and simulations. Nat. Hazards 2018, 90, 1277–1307. [Google Scholar] [CrossRef]
- Maedche, A. The TEXT-TO-ONTO Environment. In Ontology Learning for the Semantic Web; Springer: Boston, MA, USA, 2002; pp. 151–170. [Google Scholar] [CrossRef]
- Raimond, Y.; Schreiber, G. RDF 1.1 Primer. W3C note, W3C. 2014. Available online: https://www.w3.org/TR/2014/NOrdf11-primer-20140624/ (accessed on 10 October 2021).
- TopQuadrant. TopBraid: Powerful Integrated Development Environment. Available online: https://www.topquadrant.com/products/topbraid-composer/ (accessed on 5 October 2021).
- Miller, G.; Beckwith, R.; Fellbaum, C.; Gross, D.; Miller, K. Introduction to WordNet: An On-line Lexical Database*; Oxford University: Oxford, UK, 1991; p. 3. [Google Scholar] [CrossRef] [Green Version]
- Cimiano, P.; Völker, J. Text2Onto: A Framework for Ontology Learning and Data-Driven Change Discovery. In Proceedings of the 10th International Conference on Natural Language and Information Systems, Alicante, Spain, 15–17 June 2005; Springer: Berlin/Heidelberg, Germany, 2005; pp. 227–238. [Google Scholar] [CrossRef]
- Mittal, S. Tools for Ontology Building from Texts: Analysis and Improvement of the Results of Text2Onto. IOSR J. Comput. Eng. 2013, 11, 101–117. [Google Scholar] [CrossRef]
- Guha, R.; Brickley, D. RDF Schema 1.1. W3C Recommendation, W3C. 2014. Available online: https://www.w3.org/TR/2rdf-schema-20140225/ (accessed on 10 October 2021).
- OWL 2 Web Ontology Language Document Overview (Second Edition). W3C Recommendation, W3C. 2012. Available online: https://www.w3.org/TR/2012/REC-owl2-overview-20121211/ (accessed on 5 October 2021).
- Kifer, M. Rules and Ontologies in F-Logic. In Reasoning Web: First International Summer School 2005; Eisinger, N., Małuszyn´ski, J., Eds.; Springer: Berlin/Heidelberg, Germany, 2005; pp. 22–34. [Google Scholar] [CrossRef]
- Ledvinka, M.; Křemen, P. Formalizing Object-Ontological Mapping Using F-Logic. In Proceedings of the International Joint Conference on Rules and Reasoning, Bolzano, Italy, 16–19 September 2019; Fodor, P., Montali, M., Calvanese, D., Roman, D., Eds.; Springer International Publishing: Cham, Switzerland, 2019; pp. 97–112. [Google Scholar]
- AIFB. text2onto. Available online: https://code.google.com/archive/p/text2onto/downloads (accessed on 6 October 2021).
- Harth, A. NeOn Homepage. Available online: http://neon-toolkit.org/wiki/Main_Page.html (accessed on 7 October 2021).
- The University of Sheffield. GATE—General Architecture for Text Engineering. Available online: https://gate.ac.uk/ (accessed on 7 October 2021).
- University, P. WordNet—A Lexical Database for English. Available online: https://wordnet.princeton.edu/ (accessed on 7 October 2021).
- Problem Installing Last Text2onto Standalone Version. Available online: https://github.com/martysteer/text2onto/issues/1 (accessed on 6 October 2021).
- Things to Remember while Installing Text2Onto. Available online: https://ryadyo.wordpress.com/2012/02/16/things-to-remember-while-installing-text2onto/ (accessed on 6 October 2021).
- STLab. FRED—Machine Reading for the Semantic Web. Available online: http://wit.istc.cnr.it/stlab-tools/fred/#About (accessed on 4 October 2021).
- Etzioni, O.; Banko, M.; Cafarella, M.J. Machine Reading; AAAI Press: Palo Alto, CA, USA, 2006; Volume 2, pp. 1517–1519. [Google Scholar]
- Lehmann, J.; Isele, R.; Jakob, M.; Jentzsch, A.; Kontokostas, D.; Mendes, P.N.; Hellmann, S.; Morsey, M.; van Kleef, P.; Auer, S.; et al. DBpedia—A Large-scale, Multilingual Knowledge Base Extracted from Wikipedia. Semant. Web J. 2015, 6, 167–195. [Google Scholar] [CrossRef] [Green Version]
- Wang, J.; Aryani, A.; Wyborn, L.; Evans, B. Providing Research Graph Data in JSON-LD Using Schema.org. In Proceedings of the 26th International Conference on World Wide Web Companion, Perth, Australia, 3–7 April 2017; pp. 1213–1218. [Google Scholar] [CrossRef] [Green Version]
- Bekki, D. Combinatory Categorial Grammar as a Substructural Logic. In New Frontiers in Artificial Intelligence; Onada, T., Bekki, D., McCready, E., Eds.; Springer: Berlin/Heidelberg, Germany, 2011; pp. 16–29. [Google Scholar]
- Presutti, V.; Draicchio, F.; Gangemi, A. Knowledge Extraction Based on Discourse Representation Theory and Linguistic Frames. In Knowledge Engineering and Knowledge Management; ten Teije, A., Völker, J., Handschuh, S., Stuckenschmidt, H., d’Acquin, M., Nikolov, A., Aussenac-Gilles, N., et al., Eds.; Springer: Berlin/Heidelberg, Germany, 2012; pp. 114–129. [Google Scholar]
- Kamp, H.; van Genabith, J.; Reyle, U. Discourse Representation Theory. In Handbook of Philosophical Logic; Gabbay, D.M., Guenthner, F., Eds.; Springer: Dordrecht, The Netherlands, 2011; Volume 15, pp. 125–394. [Google Scholar] [CrossRef] [Green Version]
- Tan, H.; Kaliyaperumal, R.; Benis, N. Ontology-Driven Construction of Domain Corpus with Frame Semantics Annotations. In Computational Linguistics and Intelligent Text Processing; Gelbukh, A., Ed.; Springer: Berlin/Heidelberg, Germany, 2012; pp. 54–65. [Google Scholar]
- Liu, W.; Wang, T.; Yang, Z.; Cao, J. A Context-Aware Computing Method of Sentence Similarity Based on Frame Semantics. In Advanced Data Mining and Applications; Yang, X., Wang, C.D., Islam, M.S., Zhang, Z., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 114–126. [Google Scholar]
- STLab. STLAB—FRED. Available online: http://wit.istc.cnr.it/stlab-tools/fred/demo/? (accessed on 4 October 2021).
- Morita, T.; Fukuta, N.; Izumi, N.; Yamaguchi, T. DODDLE-OWL: A Domain Ontology Construction Tool with OWL. In Proceedings of the Semantic Web—ASWC 2006, First Asian Semantic Web Conference, Beijing, China, 3–7 September 2017; Mizoguchi, R., Shi, Z., Giunchiglia, F., Eds.; Springer: Berlin/Heidelberg, Germany, 2006; pp. 537–551. [Google Scholar]
- Sikos, L.F. Description Logics: Formal Foundation for Web Ontology Engineering. In Description Logics in Multimedia Reasoning; Springer International Publishing: Cham, Switzerland, 2017; pp. 67–120. [Google Scholar] [CrossRef]
- Baader, F.; Horrocks, I.; Lutz, C.; Sattler, U. An Introduction to Description Logic, 1st ed.; Cambridge University Press: Cambridge, MA, USA, 2017. [Google Scholar]
- Kurematsu, M.; Iwade, T.; Nakaya, N.; Yamaguchi, T. DODDLE II: A Domain Ontology Development Environment Using a MRD and Text Corpus; IEICE Transactions: Tokyo, Japan, 2004; Volume 87, pp. 908–916. [Google Scholar]
- Yamaguchi, T. Constructing Domain Ontologies Based on Concept Drift Analysis. In Proceedings of the IJCAI-99, Workshop on Ontologies and Problem-Solving Methods, Stockholm, Sweden, 2 August 1999. [Google Scholar]
- Yokoi, T. The EDR Electronic Dictionary. Commun. ACM 1995, 38, 42–44. [Google Scholar] [CrossRef]
- Morita, T. DODDLE-OWL Documentation. Available online: http://docs.doddle-owl.org/en/latest/index.html (accessed on 5 October 2021).
- Nakagawa, H.; Mori, T. A Simple but Powerful Automatic Term Extraction Method. In Proceedings of the COLING-02: COMPUTERM 2002: Second International Workshop on Computational Terminology, Taipei, Taiwan, 31 August 2002. [Google Scholar]
- Tsuruoka, Y.; Tsujii, J. Bidirectional Inference with the Easiest-First Strategy for Tagging Sequence Data. In Proceedings of the Conference on Human Language Technology and Empirical Methods in Natural Language Processing, Vancouver, BC, Canada, 6–8 October 2005; pp. 467–474. [Google Scholar] [CrossRef] [Green Version]
- Navigli, R.; Velardi, P.; Cucchiarelli, A.; Neri, F. Quantitative and Qualitative Evaluation of the OntoLearn Ontology Learning System. In Proceedings of the 20th International Conference on Computational Linguistics, Geneva, Switzerland, 23–27 August 2004; p. 1043-es. [Google Scholar] [CrossRef] [Green Version]
- Navigli, R.; Velardi, P. Learning Domain Ontologies from Document Warehouses and Dedicated Web Sites. Comput. Linguist 2004, 30, 151–179. [Google Scholar] [CrossRef] [Green Version]
- Team, T.O. Welcome to Ontolearn’s documentation! Available online: https://ontolearn-docs-dice-group.netlify.app/index.html (accessed on 11 October 2021).
- UIMA, O.T.C. Unstructured Information Management Architecture (UIMA) Version 1.0. Available online: https://docs.oasis-open.org/uima/v1.0/uima-v1.0.html (accessed on 21 October 2021).
- Kluegl, P.; Toepfer, M.; Beck, P.D.; Fette, G.; Puppe, F. UIMA Ruta Workbench: Rule-based Text Annotation. In Proceedings of the COLING 2014, the 25th International Conference on Computational Linguistics: System Demonstrations, Dublin, Ireland, 23–29 August 2014; pp. 29–33. [Google Scholar]
- Foundation, T.A.S. UIMA Overview SDK Setup, Written and Maintained by the Apache UIMA™ Development Community, Version 3.2. Available online: https://uima.apache.org/d/uimaj-current/overview_and_setup.pdf (accessed on 21 October 2021).
- Gede, P.I.B.; Kumara, I.N.S.; Sudarma, M. Systematic Review of Text Mining Application Using Apache UIMA. Int. J. Eng. Emerg. Technol. 2020, 5, 42–51. [Google Scholar] [CrossRef]
- OpenNLP Welcome to Apache OpenNLP. Available online: https://opennlp.apache.org/ (accessed on 21 October 2021).
- Klie, J.C.; Bugert, M.; Boullosa, B.; de Castilho, R.E.; Gurevych, I. The INCEpTION Platform: Machine-Assisted and Knowledge-Oriented Interactive Annotation. In Proceedings of the 27th International Conference on Computational Linguistics: System Demonstrations, Santa Fe, NM, USA, 20–26 August 2018; pp. 5–9. [Google Scholar]
- Julie Component Repository (JCoRe) 2.0. Available online: https://julielab.de/Resources/JCoRe.html (accessed on 21 October 2021).
- Foundation, T.A.S. Welcome to the Apache UIMA project. Available online: https://uima.apache.org/ (accessed on 4 October 2021).
- Toepfer, M.; Fette, G.; Beck, P.D.; Kluegl, P.; Puppe, F. Integrated Tools for Query-driven Development of Light-weight Ontologies and Information Extraction Components. In Proceedings of the Workshop on Open Infrastructures and Analysis Frameworks for HLT, Dublin, Ireland, 23 August 2014; pp. 83–92. [Google Scholar] [CrossRef]
- Cram, D.; Daille, B. Terminology Extraction with Term Variant Detection. In Proceedings of the ACL-2016 System Demonstrations, Berlin, Germany, 7–12 August 2016; pp. 13–18. [Google Scholar] [CrossRef]
- Fiorelli, M.; Pazienza, M.T.; Stellato, A.; Turbati, A. CODA: Computer-Aided Ontology Development Architecture. IBM J. Res. Dev. 2014, 58, 14. [Google Scholar] [CrossRef]
- Fiorelli, M.; Gambella, R.; Pazienza, M.T.; Stellato, A.; Turbati, A. Semi-Automatic Knowledge Acquisition through CODA. In Modern Advances in Applied Intelligence; Ali, M., Pan, J.S., Chen, S.M., Horng, M.F., Eds.; Springer International Publishing: Cham, Switzerland, 2014; pp. 78–87. [Google Scholar]
- ART Research Group University of Rome, T.V. CODA. Available online: http://art.uniroma2.it/coda/team/ (accessed on 21 October 2021).
- Becker, M.; Drozdzynski, W.; Krieger, H.U.; Piskorski, J.; Schäfer, U.; Xu, F. SProUT—Shallow Processing with Typed Feature Structures and Unification. In Proceedings of the International Conference on NLP (ICON 2002), Mumbai, India, 19–21 December 2002. [Google Scholar]
- DFKI. What is SProUT? Available online: https://sprout.dfki.de/ (accessed on 21 October 2021).
- Drozdzynski, W.; Krieger, H.U.; Piskorski, J.; Schäfer, U.; Xu, F. Shallow Processing with Unification and Typed Feature Structures—Foundations and Applications. Künstliche Intell. 2004, 18, 17–23. [Google Scholar]
- Speck, R.; Ngonga Ngomo, A.C. Named Entity Recognition Using FOX. In Proceedings of the International Semantic Web Conference (Posters & Demos), Riva del Garda, Italy, 21 October 2014. [Google Scholar]
- FOX Federated Knowledge Extraction Framework. Available online: https://fox.demos.dice-research.org/#!/home (accessed on 5 November 2021).
- Usbeck, R.; Ngonga Ngomo, A.C.; Röder, M.; Gerber, D.; Coelho, S.; Auer, S.; Both, A. AGDISTIS—Graph-Based Disambiguation of Named Entities Using Linked Data. In The Semantic Web—ISWC 2014; Mika, P., Tudorache, T., Bernstein, A., Welty, C., Knoblock, C., Vrandečić, D., Groth, P., Noy, N., Janowicz, K., Goble, C., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2014; Volume 8796, pp. 457–471. [Google Scholar] [CrossRef] [Green Version]
- Finkel, J.R.; Grenager, T.; Manning, C. Incorporating Non-local Information into Information Extraction Systems by Gibbs Sampling. In Proceedings of the 43rd Annual Meeting of the Association for Computational Linguistics (ACL’05), Ann Arbor, MI, USA, 25–30 June 2005; pp. 363–370. [Google Scholar] [CrossRef] [Green Version]
- Ratinov, L.; Roth, D. Design Challenges and Misconceptions in Named Entity Recognition. In Proceedings of the Thirteenth Conference on Computational Natural Language Learning, CoNLL ’09, Boulder, CO, USA, 4–5 June 2009; pp. 147–155. [Google Scholar]
- Nadeau, D. Balie—Baseline Information Extraction: Multilingual Information Extraction from Text with Machine Learning and Natural Language Techniques; School Infornatics and Technological Eengineering University: Ottawa, ON, Canada, 2005. [Google Scholar]
- Konys, A. Knowledge systematization for ontology learning methods. Procedia Comput. Sci. 2018, 126, 2194–2207. [Google Scholar] [CrossRef]
- Zhong, R.Y.; Newman, S.T.; Huang, G.Q.; Lan, S. Big Data for supply chain management in the service and manufacturing sectors: Challenges, opportunities, and future perspectives. Computers Industrial Engineering 2016, 101, 572–591. [Google Scholar] [CrossRef]
- Hatala, M.; Gasevic, D.; Siadaty, M.; Jovanovic, J.; Torniai, C. Utility of Ontology Extraction Tools in the Hands of Educators. In Proceedings of the 2009 IEEE International Conference on Semantic Computing, Berkeley, CA, USA, 14–16 September 2009; pp. 408–413. [Google Scholar] [CrossRef]
- Explosion. spaCy 101: Everything You Need to Know. Available online: https://spacy.io/usage/spacy-101 (accessed on 12 October 2021).
- Bird, S.; Klein, E.; Loper, E. Natural Language Processing with Python: Analyzing Text with the Natural Language Toolkit; O’Reilly: Beijing, China, 2009; Available online: http://my.safaribooksonline.com/9780596516499 (accessed on 10 October 2021).
- Meinl, T.; Jagla, B.; Berthold, M.R. 6—Integrated data analysis with KNIME. In Open Source Software in Life Science Research; Harland, L., Forster, M., Eds.; Woodhead Publishing Series in Biomedicine; Woodhead Publishing: Amsterdam, The Netherlands, 2012; pp. 151–171. [Google Scholar] [CrossRef]
- Radosevic, N.; Duckham, M.; Liu, G.J.; Sun, Q. Solar radiation modeling with KNIME and Solar Analyst: Increasing environmental model reproducibility using scientific workflows. Environ. Model. Softw. 2020, 132, 104780. [Google Scholar] [CrossRef]
- Zotero: Your Personal Research Assistant. Available online: https://www.zotero.org/ (accessed on 29 January 2021).









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Year | Count of Documents |
|---|---|
| 2021 | 1072 |
| 2020 | 1568 |
| 2019 | 1574 |
| 2018 | 1551 |
| 2017 | 1453 |
| 2016 | 1616 |
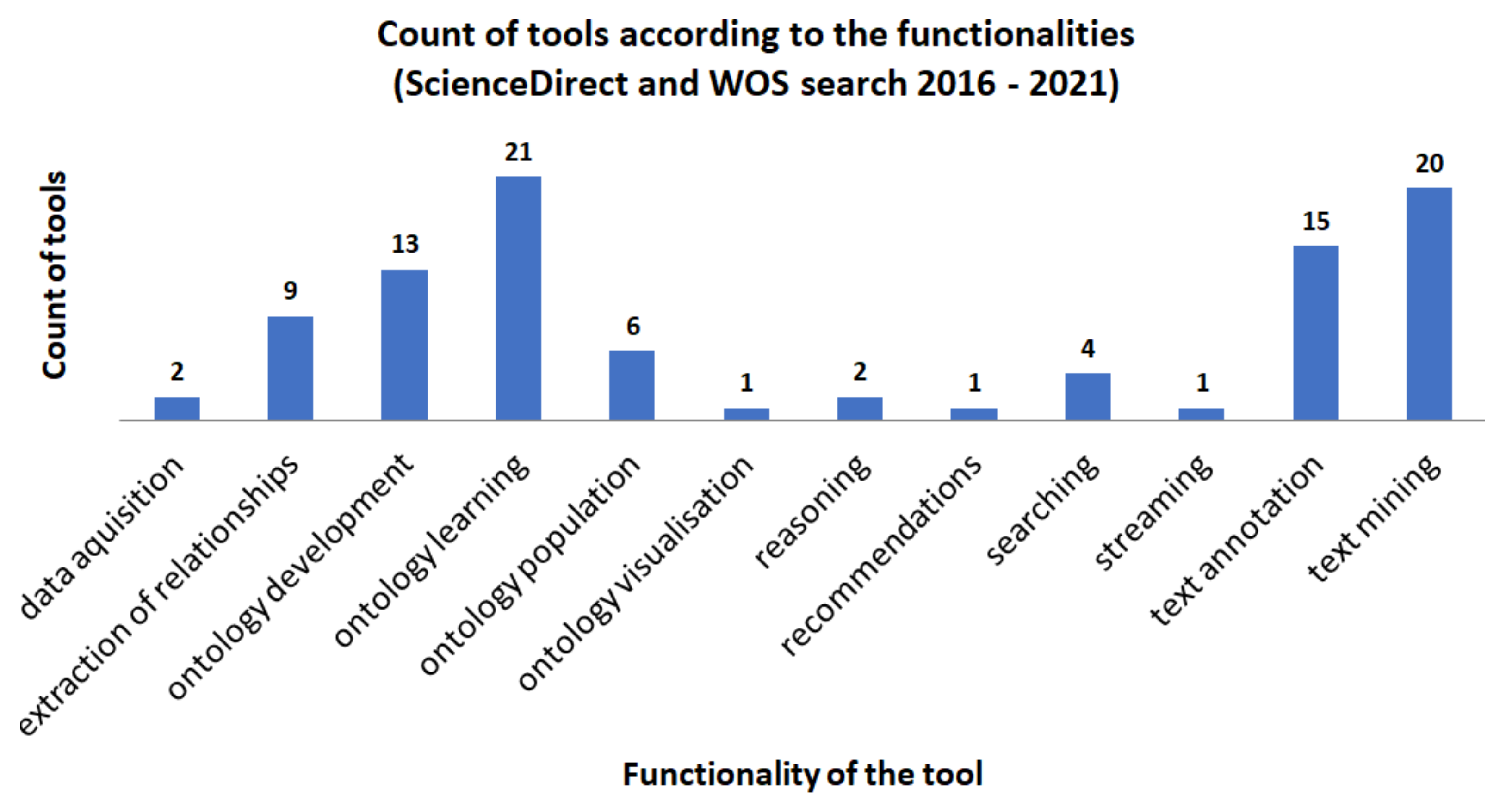
| Tool | Data Aquisition | Extraction of Relationships | Ontology Development | Ontology Learning | Ontology Population | Ontology Visualisation | Reasoning | Recommendations | Searching | Streaming | Text Annotation | Text Mining |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| AIDA | x | x | ||||||||||
| Alchemy API | x | |||||||||||
| Altova SemanticWorks | x | |||||||||||
| Apache Jena | x | |||||||||||
| Apache Stanbol | x | x | x | x | ||||||||
| Apache UIMA | x | x | ||||||||||
| BRAT | x | |||||||||||
| Caméléon | x | |||||||||||
| CiceroLite | x | x | ||||||||||
| ClausIE | x | |||||||||||
| DBPedia Spotlight | x | |||||||||||
| DeepKE | x | |||||||||||
| DOE | x | |||||||||||
| DOODLE | x | |||||||||||
| FOX | x | x | x | |||||||||
| FRED | x | |||||||||||
| GATE | x | x | x | |||||||||
| GEDITERM | x | |||||||||||
| HOLMES | x | |||||||||||
| HOZO | x | |||||||||||
| ISOLDE | x | x | ||||||||||
| Jaguar-KAT (JaguarTM) | x | |||||||||||
| Jambalaya | x | |||||||||||
| LinkFactory | x | |||||||||||
| LODr | x | |||||||||||
| MetaMap Lite | x | x | ||||||||||
| NERD | x | x | ||||||||||
| NooJ | x | x | ||||||||||
| OilEd | x | |||||||||||
| Ollie | x | |||||||||||
| OntoBuilder | x | |||||||||||
| OntoCmaps | x | |||||||||||
| OntoEdit | x | |||||||||||
| Ontofier | x | x | ||||||||||
| OntoLearn | x |
| Tool | Data Aquisition | Extraction of Relationships | Ontology Development | Ontology Learning | Ontology Population | Ontology Visualisation | Reasoning | Recommendations | Searching | Streaming | Text Annotation | Text Mining |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| OntoLiFT | x | |||||||||||
| Ontolingua | x | |||||||||||
| Ontology Learning Tool | x | |||||||||||
| OntoLT | x | |||||||||||
| OntoPOP | x | x | ||||||||||
| Ontosaurus | x | |||||||||||
| Ontotext | x | |||||||||||
| OntoX | x | |||||||||||
| OpenCalais | x | |||||||||||
| OpenIE 4.0 | x | |||||||||||
| OWLExporter | x | |||||||||||
| Pellet | x | |||||||||||
| PoolParty KD | x | x | x | |||||||||
| Protégé | x | |||||||||||
| Protégé-OWL API | x | |||||||||||
| RapidMiner | x | |||||||||||
| ReVerb | x | |||||||||||
| SEISD | x | |||||||||||
| Semiosearch (Wikifier) | x | x | x | |||||||||
| SOBA | x | x | ||||||||||
| sProUT | x | x | ||||||||||
| Stanford CoreNLP | x | |||||||||||
| TaxGen | x | |||||||||||
| TERMINAE | x | |||||||||||
| Text2Onto | x | |||||||||||
| TextRunner | x | |||||||||||
| Text-To-Onto | x | |||||||||||
| TopBraid Composer | x | |||||||||||
| TRIPS | x | |||||||||||
| Twitter Streaming API | x | |||||||||||
| Twitter’s API | x | |||||||||||
| Twitter´s Search API | x | |||||||||||
| WebODE | x | |||||||||||
| Welkin | x | |||||||||||
| Wikimeta | x | |||||||||||
| Wikipedia Miner | x | |||||||||||
| WOE | x | |||||||||||
| Zemanta | x |
| Tool | Directly Used in | Mentioned in | Downloadable | Free Solution |
|---|---|---|---|---|
| AIDA | [19] | yes | free | |
| Alchemy API | [19,20] | no | N/A | |
| Altova SemanticWorks | [21] | no | N/A | |
| Apache Jena | [22] | [20] | yes | free |
| Apache Stanbol | [19,23] | yes | free | |
| Apache UIMA | [24] | yes | free | |
| BRAT | [25] | yes | free | |
| Caméléon | [14] | no | free | |
| CiceroLite | [19] | no | free | |
| ClausIE | [26] | yes | free | |
| DBPedia Spotlight | [27] | [19,20] | yes | free |
| DeepKE | [28] | no | free | |
| DOE | [14] | no | free | |
| DOODLE | [29] | yes | free | |
| FOX | [19,23] | yes | free | |
| FRED | [19,23,30] | [22] | yes | free |
| GATE | [22] | [24,29,31,32] | yes | free |
| GEDITERM | [14] | no | free | |
| HOLMES | [31] | yes | free | |
| HOZO | [33] | yes | free | |
| ISOLDE | [34] | no | N/A | |
| Jaguar-KAT | [35] | on request | N/A | |
| Jambalaya | [36] | yes | free | |
| LinkFactory | [21] | no | N/A | |
| LODr | [27] | no | free | |
| MetaMap Lite | [37] | yes | free | |
| NERD | [19,23] | no | free | |
| NooJ | [38] | yes | free | |
| OilEd | [21] | yes | free | |
| Ollie | [26,31] | yes | free | |
| OntoBuilder | [29] | no | free | |
| OntoCmaps | [26] | no | free | |
| OntoEdit | [21,33] | no | N/A | |
| Ontofier | [39] | no | free | |
| OntoLearn | [14] | no | free |
| Tool | Directly Used in | Mentioned in | Downloadable | Free Solution |
|---|---|---|---|---|
| OntoLiFT | [29] | no | free | |
| Ontolingua | [21] | no | free | |
| Ontology Learning Tool | [14] | no | free | |
| OntoLT | [22,34] | no | free | |
| OntoPOP | [31] | no | free | |
| Ontosaurus | [21] | no | N/A | |
| Ontotext | [24] | no | free* | |
| OntoX | [24] | no | free | |
| OpenCalais | [19,20,27] | yes | free | |
| OpenIE 4.0 | [26] | yes | free | |
| OWLExporter | [40] | yes | free | |
| Pellet | [36,41] | yes | free | |
| PoolParty KD | [19] | yes | free | |
| Protégé | [14,42] [24,29] [43] | [21,33,40,44] | yes | free |
| Protégé-OWL API | [22] | [20] | yes | free |
| RapidMiner | [31] | yes | free*, trial | |
| ReVerb | [19,26] | yes | free | |
| SEISD | [29] | no | free | |
| Semiosearch (Wikifier) | [19] | yes | free | |
| SOBA | [24] | no | free | |
| sProUT | [24] | on request | free | |
| Stanford CoreNLP | [27] | [30] | yes | free |
| TaxGen | [45] | no | N/A | |
| TERMINAE | [14] | no | free | |
| Text2Onto | [46] | [40,45] | yes | free |
| TextRunner | [26] | no | free | |
| Text-To-Onto | [14,24,34] | yes | free | |
| TopBraid Composer | [27] | yes | free*, trial | |
| TRIPS | [24] | no | free | |
| Twitter Steaming API | [20] | on request | free* | |
| Twitter´s API | [20] | on request | free* | |
| Twitter´s Search API | [20] | on request | free* | |
| WebODE | [21,33] | yes | free | |
| Welkin | [14] | no | free | |
| Wikimeta | [19] | no | N/A | |
| Wikipedia Miner | [20] | no | free | |
| WOE | [26] | no | free | |
| Zemanta | [19,27] | yes | free* |
| Tool | Distribution | Instant Download | Operability | Type of Tool | Active Development/Last Update | Degree of Automation | Supported Language | Documentation | Ease of Use | Installation |
|---|---|---|---|---|---|---|---|---|---|---|
| Apache UIMA | free | yes | yes | desktop (SDK) | yes/2021 | semi | Java, C++ (Pearl, Python, TCL) | good | poor | hard |
| DOODLE-OWL | free | yes | restricted | desktop | no/2015 | semi | N/A | poor | good | easy |
| FOX | free | yes | yes | Webservices, API | yes/2020 | full | Java, Python | poor | good | easy |
| FRED | free | yes | yes | Webservice, API | yes/N/A | full | Python | poor | good | easy |
| OntoLearn | free | no | no | N/A | N/A | full | N/A | poor | N/A | failed |
| sProUT | N/A | no | N/A | N/A | no/2005 | N/A | Java | poor | N/A | failed |
| Text2Onto | free | yes | no | desktop | no/2009 | semi, full | N/A | poor | N/A | failed |
| Text-To-Onto | free | yes | restricted | desktop | no/2004 | semi, full | N/A | poor | good | easy |
| Tool | Batch Mode Processing of Documents | Classes Extraction | Individuals (Instances) Extraction | Taxonomic Relations Induction (Concept Hierarchy) | Non-Taxonomic Relations Induction | Word-Sense Disambiguation | Coreference Resolution | Entity Linking |
|---|---|---|---|---|---|---|---|---|
| Apache UIMA | yes | partially 1 | yes 3 | N/A | N/A | N/A | N/A | N/A |
| DOODLE-OWL | yes | no | no | no | no | no | no | no |
| FOX | no | indirectly 2 | yes 3 | no | partially 4 | yes | N/A | yes |
| FRED | no | yes | yes | yes | yes | yes | yes | yes |
| OntoLearn | N/A | N/A | N/A | N/A | N/A | N/A | N/A | N/A |
| sProUT | N/A | N/A | N/A | N/A | N/A | N/A | N/A | N/A |
| Text2Onto | N/A | N/A | N/A | N/A | N/A | N/A | N/A | N/A |
| Text-To-Onto | yes | yes | yes | yes | yes | no | no | no |
| Tool | Supported Input Format | Supported Output Format | Graph-Based Visualisation of the Output |
|---|---|---|---|
| Apache UIMA | txt | html, xml | N/A |
| DOODLE-OWL | txt | owl | no |
| FOX | txt, html, url | text/turtle, rdf/xml, rdf/json, json-Id, trig, n-quads | no |
| FRED | txt (string values) | rdf/xml, text/turtle, rdf/json, n3, nt, png, dag | yes |
| OntoLearn | N/A | N/A | N/A |
| sProUT | N/A | N/A | N/A |
| Text2Onto | N/A | N/A | N/A |
| Text-To-Onto | txt, hrml, xml, pdf | rdf | yes |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Babič, F.; Bureš, V.; Čech, P.; Husáková, M.; Mikulecký, P.; Mls, K.; Nacházel, T.; Ponce, D.; Štekerová, K.; Triantafyllou, I.; et al. Review of Tools for Semantics Extraction: Application in Tsunami Research Domain. Information 2022, 13, 4. https://doi.org/10.3390/info13010004
Babič F, Bureš V, Čech P, Husáková M, Mikulecký P, Mls K, Nacházel T, Ponce D, Štekerová K, Triantafyllou I, et al. Review of Tools for Semantics Extraction: Application in Tsunami Research Domain. Information. 2022; 13(1):4. https://doi.org/10.3390/info13010004
Chicago/Turabian StyleBabič, František, Vladimír Bureš, Pavel Čech, Martina Husáková, Peter Mikulecký, Karel Mls, Tomáš Nacházel, Daniela Ponce, Kamila Štekerová, Ioanna Triantafyllou, and et al. 2022. "Review of Tools for Semantics Extraction: Application in Tsunami Research Domain" Information 13, no. 1: 4. https://doi.org/10.3390/info13010004
APA StyleBabič, F., Bureš, V., Čech, P., Husáková, M., Mikulecký, P., Mls, K., Nacházel, T., Ponce, D., Štekerová, K., Triantafyllou, I., Tučník, P., & Zanker, M. (2022). Review of Tools for Semantics Extraction: Application in Tsunami Research Domain. Information, 13(1), 4. https://doi.org/10.3390/info13010004