1. Introduction
Computer Vision techniques have seen significant advances in recent years and are increasingly seeing applications in industrial contexts. In particular, Deep Learning-based approaches have been responsible for many breakthrough results in past years [
1,
2]. However, a drawback of these techniques is their demand for very large training data sets [
3,
4], which can be hard or even impossible to obtain when limited to real-life training data. Apart from the need for labeling real-life data, real-life data sets are prone to imbalances as, e.g., rare or uncommon situations tend to be underrepresented, which can affect model performance on these classes [
5]. In addition, some imbalances may be hard to detect without extensive examinations. A way to address these issues can be the generation of synthetic training data, a field of research that has garnered increasing interest in past years [
4,
6,
7]. Approaches reach from physics-based modeling techniques as in [
8] over classic image augmentation techniques, e.g., [
6], to Deep Learning-based modeling as for example in [
9,
10,
11].
Since Deep Learning (DL) has reached process maturity, and DL-based algorithms can be executed on high-performing Graphics Processing Unit (GPU) hardware, new opportunities have come up to augment the production machinery with artificial intelligence. The steel production process is well-established and has been optimized over many years, rendering the appearance of anomalies or aberrations rare. While an anomaly detection does not necessarily rely on data representing the anomalous state, tasks requiring a classification of different anomalies do require data providing characterizations of the various anomalies. If an anomaly classification should be carried out using DL models, a great number of relevant training data are needed in order to develop a model with good performance. Depending on the use case, anomalies are so uncommon in production that the data collection process would take too much time before a model could be trained.
Hence, a synthetic generation of appropriate data is needed to allow for the training of Machine Learning (ML) and DL algorithms. In this work, a hybrid approach for image synthesis was developed combining classical Computer Vision (CV) and Deep Learning techniques. This work is part of the scope of the COGNITWIN project use case pilot on a tracking system in the steel manufacturing industry. The concept of Digital Twin (DT) has attracted increasing attention in the industrial sector and is seen as an enabling technology for Industry 4.0 [
12,
13].
The research question this work aims to address is the impact of the usage of synthetic training data as compared to real-life training data on the performance of a Deep Learning-based instance recognition/detection models for images. While there have been other studies investigating a workflow for image synthesis and the usage of synthetic training data for CV models, such as [
6,
9,
10,
11], a direct comparison of model performances based on the proportion of synthetic training data used and an investigation of performance on subclasses of particular interest is a novel contribution to the best of the authors’ knowledge. For the first time, the actual impact of using synthetic training data as compared to real-life training data on the performance of a DL model is evaluated systematically, providing a new perspective and insights on the training data side of a DL approach. The authors present a novel framework for realizing DL tasks, combining synthetic training data and real-life training data, and thereby also addressing many current hindrances to the applicability of the DL model research results in industrial settings. The novel framework is independent of a particular DL model used for the inference task at hand. Most academic research on DL focuses on abstract use cases with ample data available, whereas research questions tackling the usage or even usability of DL in less-than-ideal settings are often neglected in the scientific community. In academic research, DL approaches are mostly rated purely by model performance metrics, but when it comes to the applicability of DL to real-life tasks, a broader approach for assessing DL solutions’ merit is needed, taking the
efficiency into account. Our framework precisely addresses this problem by showcasing an
efficient implementation of DL independently of the particular inference model used for the task at hand. We hope to provide useful guidelines for the usage of synthetic training data in DL-based Computer Vision tasks and that our work will be beneficial for many areas of industry, helping to increase the applicability of DL techniques to industrial settings.
This paper is structured as follows: In
Section 2, we begin with a short description of the regarded Use Case and an introduction to Generative Adversarial Networks (GANs), which were used for the generation of synthetic training data in this work, followed by a brief description of the methodology of synthesizing the desired images. After this, a more detailed description of the design of the conducted experiments is added.
Section 3 presents the results and discusses them.
Section 4 concludes the study and introduces opportunities for future research.
4. Conclusions and Future Work
In the context of this paper, aberrations in the form of only partially or poorly visible digits were a problem only in so far as these make it harder for a model to correctly identify the corresponding digit. In other potential applications of Deep Learning based Computer Vision models however, such as a defect classification, aberrations will tend to be uncommon and need not only to be detected as an anomaly as such, but will need to be correctly identified as a particular type of aberration, generating a need for corresponding training data. In such cases, synthetic training data can be especially valuable to make DL models a viable option for the task. Our results show that even with only a little real-life training data available, as will be typically the case in many industrial applications, DL based methods can be applied successfully by generating additional synthetic training data.
Generally, especially the ratio of billets with all digits identified correctly may seem disappointingly low for a use of any of the models trained in the experiments in this paper in a productive setting. However, to use a model for a productive setting, one could use all training data available rather than restricting training data size artificially to run comparable experiments. Moreover, and more importantly, for the digit-recognition model developed in the scope of the COGNITWIN project, the output of the Deep Learning based digit-recognition model is combined with 1st principles logic, following the Hybrid and Cognitive Twin approach to achieving enhanced performance. In typical cases of ’misread’ billets, just one or very few digits are not recognized correctly. Using prior knowledge on the systematics of billet IDs combined with the Deep Learning-based model output raises the rate of correctly read billet IDs significantly. The fine details of this approach cannot be laid out in this paper however due to privacy restrictions and are not the subject of this work. Apart from this, the results shown in this paper lay a basis for further improvements in the billet ID detection task model as well as making many other DL-based applications at Saarstahl feasible and will hopefully also prove beneficial for many other industrial applications.
A future approach could be some version of curriculum learning as suggested in [
4]. Clearly different types of training data have different effects on the models and some seem to make it easier for a model to learn certain aspects, while other types seem to ease learning other aspects of the overall task. Perhaps instead of using a fixed ratio of synthetic training data throughout the training process, varying this ratio over the training process (e.g., increasing synthetic data ratio over time) and perhaps also varying the ratio of hard examples vs. easy examples in the (synthetic) training data over time could have positive effects. As the authors of [
5] suggest, oversampling techniques for underrepresented classes should generally achieve the best results in raising overall performance, including performance on underrepresented classes. Combined with the suggestions on curriculum learning in [
4], an approach could be to start with oversampled real-life examples from underrepresented classes (i.e., having near duplicates in the training data set, only varying by, e.g., simple data augmentation techniques) to achieve a balanced training data set and gradually switch to more synthetic training data instead for ensuring balancedness without the downside of a lack in variety associated with the simple naive oversampling of real-life data. Further research could also compare the effectiveness of different types of synthetic training data regarding data generation workload and trained model performance or investigate the GAN approach further. For the present work, a basic GAN approach was used, without too much sophistication. The aim was to evaluate how comparatively rudimentary synthetic GAN images would affect DL model performance compared to real-life training data, i.e., synthetic images that can be generated with comparatively little effort. More sophisticated GAN approaches may very well allow for decreasing the ratio of real-life training data further and show a greater positive impact on model performance on underrepresented classes.
In addition, the impact of synthetic training data could be assessed based on the overall training data set size and, e.g., replacing 1 real-life training data item by n synthetic images. Time constraints did not make it feasible to explore these approaches further in the present work, and we believe that the results presented have enough merit as is.
Aside from these considerations, a conclusion of the findings in this paper is that the usage of up to synthetic training data in Deep Learning-based Computer Vision tasks can indeed be a cost-efficient alternative to the manual collection and labeling of vast numbers of real-life training data, providing a means of making CV applications feasible and economically attractive for a wider scope of industrial settings.
Author Contributions
Conceptualization, S.B., T.B., U.F. and M.S.; methodology, S.B., T.B., U.F. and M.S.; software, S.B. and T.B.; validation, S.B., T.B., U.F. and M.S.; formal analysis, T.B. and U.F.; investigation, S.B., T.B., U.F. and M.S.; resources, M.S.; data curation, S.B., T.B., U.F. and M.S.; writing—original draft preparation, T.B. and U.F.; writing—review and editing, S.B., T.B., U.F. and M.S.; visualization, T.B. and U.F.; supervision, M.S.; funding acquisition, U.F. and M.S. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the European Union’s Horizon 2020 research and innovation programme under grant number 870130 (the COGNITWIN project).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data presented in this study are available on request from the corresponding author. The data are not publicly available due to privacy restrictions.
Acknowledgments
The authors thank Saarstahl and SHS—Stahl–Holding–Saar for their administrative and technical support.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| cGAN | conditional Generative Adversarial Network |
| CV | Computer Vision |
| DL | Deep Learning |
| DT | Digital Twin |
| Faster R-CNN | Faster Region-based Convolutional Neural Network |
| GAN | Generative Adversarial Network |
| GPU | Graphics Processing Unit |
| IoU | Intersection over Union |
| mAP | mean average precision |
References
- Mathew, A.; Amudha, P.; Sivakumari, S. Deep Learning Techniques: An Overview. In Advanced Machine Learning Technologies and Applications; Hassanien, A.E., Bhatnagar, R., Darwish, A., Eds.; Springer: Singapore, 2021; pp. 599–608. [Google Scholar]
- Emmert-Streib, F.; Yang, Z.; Feng, H.; Tripathi, S.; Dehmer, M. An Introductory Review of Deep Learning for Prediction Models With Big Data. Front. Artif. Intell. 2020, 3, 4. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sun, C.; Shrivastava, A.; Singh, S.; Gupta, A. Revisiting Unreasonable Effectiveness of Data in Deep Learning Era. arXiv 2017, arXiv:1707.02968. [Google Scholar]
- Shorten, C.; Khoshgoftaar, T.M. A survey on Image Data Augmentation for Deep Learning. J. Big Data 2019, 60, 1767–1789. [Google Scholar] [CrossRef]
- Buda, M.; Maki, A.; Mazurowski, M.A. A systematic study of the class imbalance problem in convolutional neural networks. Neural Netw. 2018, 106, 249–259. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Perez, L.; Wang, J. The Effectiveness of Data Augmentation in Image Classification using Deep Learning. arXiv 2017, arXiv:1712.04621. [Google Scholar]
- Mikołajczyk, A.; Grochowski, M. Data augmentation for improving deep learning in image classification problem. In Proceedings of the 2018 International Interdisciplinary PhD Workshop (IIPhDW), Swinoujscie, Poland, 9–12 May 2018; pp. 117–122. [Google Scholar] [CrossRef]
- Schraml, D. Physically based synthetic image generation for machine learning: A review of pertinent literature. In Proceedings of the Photonics and Education in Measurement Science 2019, Jena, Germany, 17–19 September 2019; Rosenberger, M., Dittrich, P.G., Zagar, B., Eds.; International Society for Optics and Photonics, SPIE: Bellingham, WA, USA, 2019; Volume 11144, pp. 108–120. [Google Scholar] [CrossRef] [Green Version]
- Meister, S.; Möller, N.; Stüve, J.; Groves, R.M. Synthetic image data augmentation for fibre layup inspection processes: Techniques to enhance the data set. J. Intell. Manuf. 2021, 32, 1767–1789. [Google Scholar] [CrossRef]
- Kim, K.; Myung, H. Autoencoder-Combined Generative Adversarial Networks for Synthetic Image Data Generation and Detection of Jellyfish Swarm. IEEE Access 2018, 6, 54207–54214. [Google Scholar] [CrossRef]
- Su, Y.H.; Jiang, W.; Chitrakar, D.; Huang, K.; Peng, H.; Hannaford, B. Local Style Preservation in Improved GAN-Driven Synthetic Image Generation for Endoscopic Tool Segmentation. Sensors 2021, 21, 5163. [Google Scholar] [CrossRef] [PubMed]
- Melesse, T.Y.; Pasquale, V.D.; Riemma, S. Digital Twin Models in Industrial Operations: A Systematic Literature Review. Procedia Manuf. 2020, 42, 267–272. [Google Scholar] [CrossRef]
- Liu, M.; Fang, S.; Dong, H.; Xu, C. Review of digital twin about concepts, technologies, and industrial applications. J. Manuf. Syst. 2021, 58, 346–361. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets. In Advances in Neural Information Processing Systems; Ghahramani, Z., Welling, M., Cortes, C., Lawrence, N., Weinberger, K.Q., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2014; Volume 27. [Google Scholar]
- Mirza, M.; Osindero, S. Conditional Generative Adversarial Nets. arXiv 2014, arXiv:1411.1784. [Google Scholar]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-to-Image Translation with Conditional Adversarial Networks. arXiv 2018, arXiv:1611.07004. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. In Advances in Neural Information Processing Systems; Cortes, C., Lawrence, N., Lee, D., Sugiyama, M., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2015; Volume 28. [Google Scholar]
- COCO—Common Objects in Context. Available online: http://cocodataset.org/#download (accessed on 15 January 2019).
- TensorFlowModelZoo/Garden. Available online: https://github.com/tensorflow/models (accessed on 15 January 2019).
- TensorFlow. Available online: https://www.tensorflow.org/ (accessed on 13 October 2021).
- Elsayed, G.F.; Shankar, S.; Cheung, B.; Papernot, N.; Kurakin, A.; Goodfellow, I.; Sohl-Dickstein, J. Adversarial Examples that Fool both Computer Vision and Time-Limited Humans. arXiv 2018, arXiv:1802.08195. [Google Scholar]
| Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).












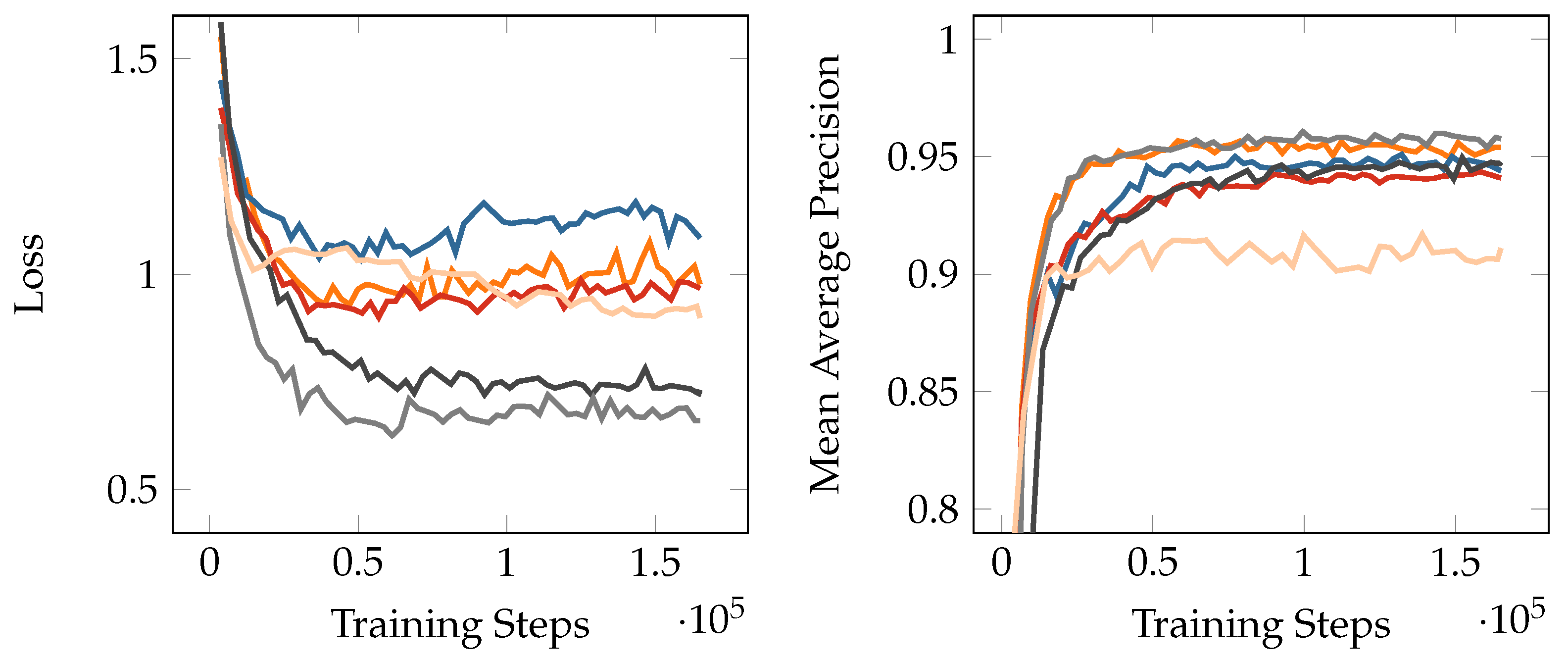
 Experiment 1,
Experiment 1,  Experiment 2,
Experiment 2,  Experiment 3,
Experiment 3,  Experiment 4,
Experiment 4,  Experiment 5,
Experiment 5,  Experiment 6).
Experiment 6).


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
