
Automatic Fake News Detection for Romanian Online News



Abstract
:1. Introduction
2. Related Work
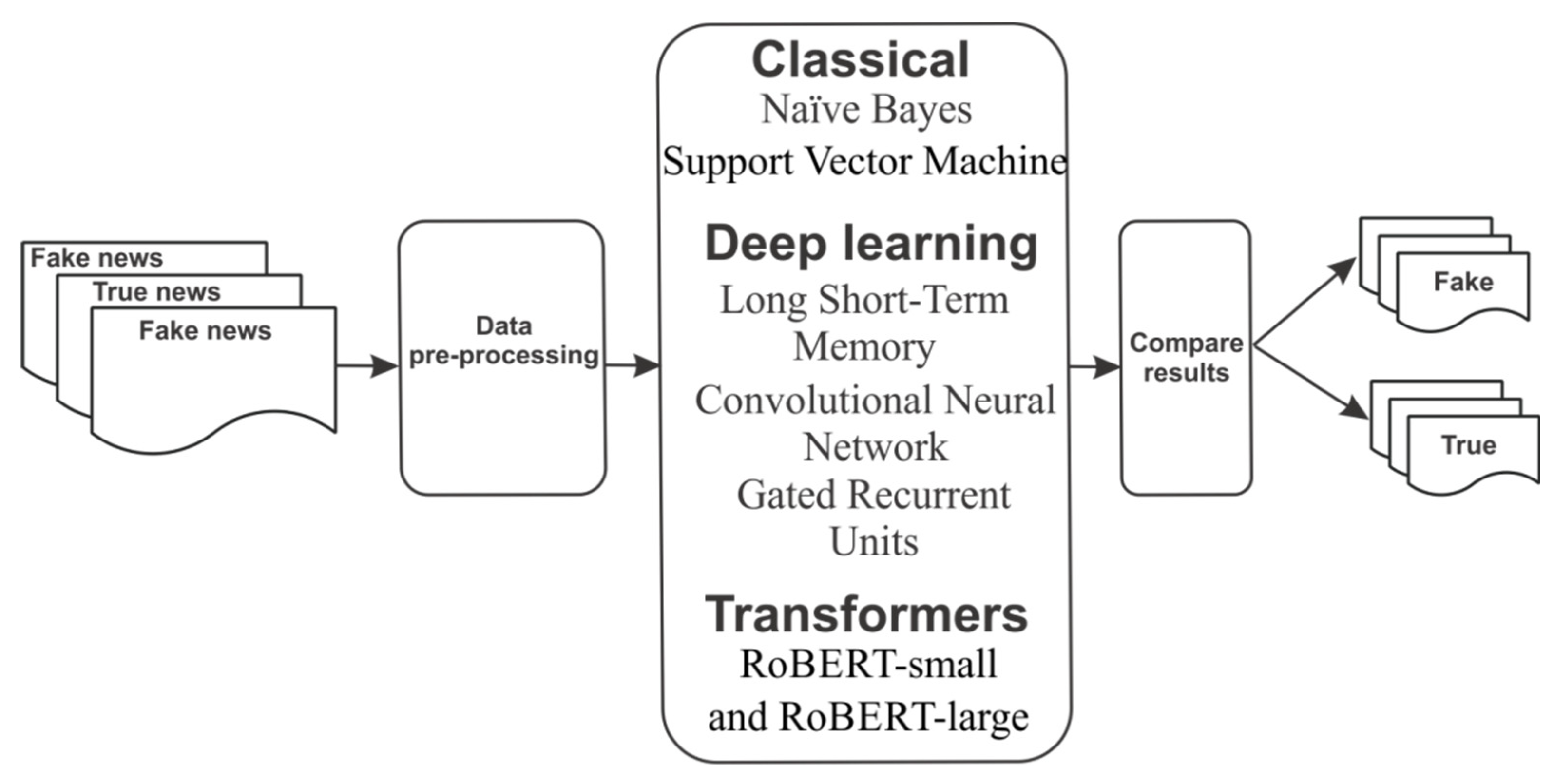
3. Methodology
3.1. Dataset Details
- Fake news: This dataset contains 12,767 news items, and it was automatically crawled from Romanian online platforms such as Fluierul [29], Vremuritulburi [30], and Cunoastelumea [31]. It is based on Rubrika [32], the first fully automatic news aggregator in Romania, which promotes articles only from trustworthy sources and provides a list of websites to avoid [33]. In addition to this automatically collected dataset, there were 297 more news items added that were manually labeled as fake news. For example, after a fake news instance was manually annotated, in the Romanian online environment, several news sites with the same information that was already propagated can be identified, and these news sites are added to the dataset by a human using a web application system, labeling them with a simple button as fake.
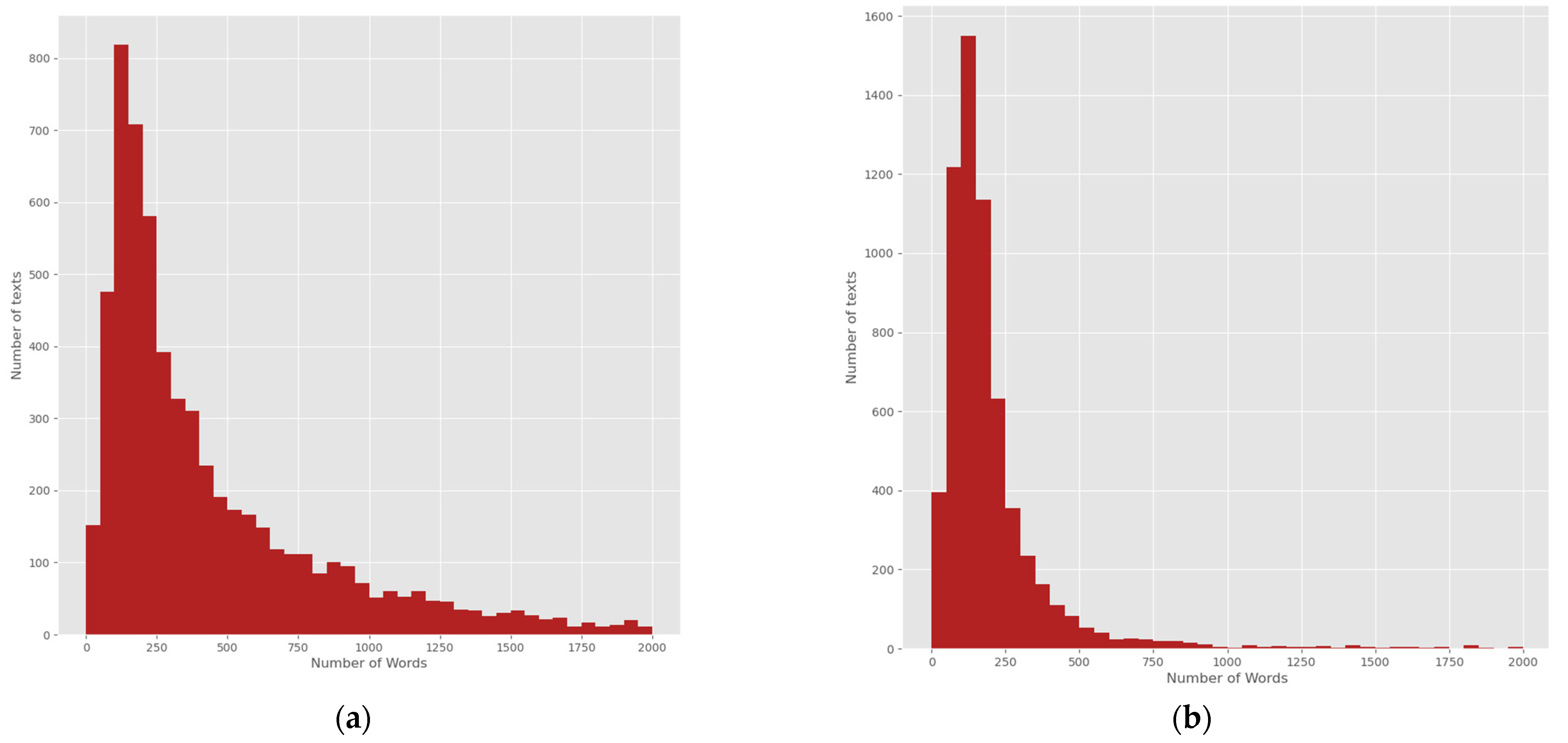
3.2. Dataset Description
3.3. Data Pre-Processing
4. Experiments
4.1. Proposed Models
- Classical algorithms: The classical machine learning models are based on supervised classifiers such as Naïve Bayes and Support Vector Machine. Each traditional algorithm learns in different ways. The Naïve Bayes algorithm is based on Bayes’ theorem to evaluate and choose the highest probability of new data belonging to one of the classes defined in the dataset. The SVM classifier finds the best hyperplane that separates the data into two classes (fake vs. real) with the highest margin. For experiments, the SVM algorithm uses an SVC linear kernel, and the NB algorithm uses multinomial Naive Bayes.
- Deep learning models: Three types of deep neural network models were investigated. The first two were recurrent neural network architectures using LSTM and GRU. The third type was a CNN architecture that is a class of deep neural network mostly used in computer vision tasks. For the experiments, these architectures used the optimal parameters achieved during the random search optimization phase and binary cross-entropy as a loss function.
- Transformer models: Transformers are a type of neural network model, being introduced by Vaswani et al. [38] to solve the issue of sequence transduction or neural machine translation. The most popular NLP model that uses a transformer is BERT, introduced by Devlin et al. [39], which is a model that learns contextual embeddings from both sides of a token’s context during the training phase.
4.2. Deep Learning Architectures
- Long short-term memory: LSTM networks are a type of recurrent neural network having the capability to learn a mapping between the input and output patterns. For the experiments, the LSTM model consisted of 1 layer with 128 units that decreased the embedding vector from 5000 to 128, a dropout layer (0.2), and 2 dense layers, using 32 as the batch size and 32 neurons. The details of the LSTM architecture used in this work are presented in Table 6.
- Convolutional neural network: A CNN is a deep learning architecture successfully used to extract features for images and classify text documents. For this architecture, the convolution layer has 250 filters with a kernel size of 3 that decreases the embedding vector from 5000 to 4998. A max-pooling, Rectified Unit Layer (RELU), activation, and dropout layer were added to the proposed CNN model, passing the outputs through a dense layer. The CNN architecture is described in Table 7.
- Gated recurrent units: GRU are one of the latest generation of recurrent neural networks, being more complex due to a hidden state which transfers useful information based on two gates: a reset gate and an update gate. In this architecture, the GRU model consists of one layer with 128 units and a dropout, activation (TanH, the hyperbolic tangent), and dense layer. The detail of the GRU architecture that is used in this work is presented in Table 8.
4.3. Transformer Architectures
5. Results and Discussion
- Classical algorithms: From Table 12, it can be observed that the Naïve Bayes algorithm obtained a better F1 score of 97.50% for the test dataset compared with the Support Vector Machine algorithm, which obtained an F1 score of 94.70%. The results were slightly similar for the validation set. There are studies and models that suggest using Naïve Bayes with n-gram (bigram TF-IDF) features to outperform the standard machine learning systems for online fake news detection approaches, achieving almost 94% accuracy on multiple corpora [43].
- Deep learning models: In this research, the differences between the neural network models’ performances were small. The CNN architecture obtained an F1 score of 97.80% for the validation dataset and an F1 score of 98.20% for the test dataset, outperforming the LSTM and GRU models. For example, instead of just using CNN models, another study [44] proposed a hybrid deep learning architecture that combines the CNN and RNN models trained on several datasets.
- Transformer models: As already mentioned, this research used for the BERT experiments two Romanian pretrained models. The RoBERT-small model obtained a better F1 score of 92.50%, while RoBERT-large’s was only 88% for the test dataset, achieving similar results for the validation dataset. This was due to the first dense layer of the BERT models, which decreased the dense vector from 1024 to 512 for RoBERT-large and from 256 to 32 for RoBERT-small, indicating that the RoBERT-small model was more efficient for our datasets, generating fewer false positives. Future research should consider the potential effects of Language Understanding with Knowledge-Based Embeddings (LUKE), a new model based on the transformer that outperformed the BERT and RoBERTa [45] models, achieving an F1 score of 95%. LUKE [46] is based on the Stanford Question Answering Dataset [47].
- Fake news and sentiment analysis: The sentiment expressed in the fake news dataset had a significant role, and some researchers such as Alonso et al. [48] and Bhutani et al. [49] proposed different fake news detection systems that incorporated sentiment as an important feature. Therefore, a sentiment analysis method [50] was applied to the test dataset, based on an algorithm that achieved an F1 score of 82% using a Romanian dictionary of 42,497 labeled words with 3 levels for the positive and negative polarities. Table 13 shows that 99.96% of the fake news dataset contained a neutral polarity, indicating that in these campaigns of fake news, the impartial connotation was predominant. Moreover, Figure 3 presents as a word cloud several words with positive (left side) and negative polarities (right side) from the fake news employed in the proposed system.
- Fake news and irony: Even if irony was not used as a legitimate way of communication, and most of the recent papers tried to establish a connection between satire and fake news, in this paper, a solution to finding the possible relations between irony and fake newswas provided. Therefore, an automatic irony detection approach [51] was applied to the test dataset based on the Naïve Bayes algorithm, achieving an F1 score of 91%. Table 14 shows that 24.05% of the fake news contained irony, suggesting that ironic articles from online media besides fake news were used very often in misinformation campaigns in order to denigrate institutions or even public figures. There are some potentially open questions about the reliability of several news pieces used in this experiment that were automatically collected from Times New Roman [52] and may have contained fake content.
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Brown, T.B.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language Models are Few-Shot Learners. In Proceedings of the 33th Conference on Neural Information Processing Systems (NeurIPS 2020), Vancouver, BC, Canada, 6–12 December 2020; pp. 1877–1901. [Google Scholar]
- Althuis, J.; Haiden, L. Fake News: A Roadmap; NATO Strategic Communications Centre of Excellence: Riga, Latvia, 2018. [Google Scholar]
- García, A.S.; García, G.G.; Prieto, S.M.; Guerrero, A.J.M.; Jiménez, R.C. The Impact of Term Fake News on the Scientific Community. Sci. Perform. Mapp. Web Sci. Soc. Sci. 2020, 9, 73. [Google Scholar] [CrossRef]
- Nordberg, P.; Kävrestad, J.; Nohlberg, M. Automatic detection of fake news. In Proceedings of the 6th International Workshop on Socio-Technical Perspective in IS Development, Grenoble, France, 8–9 June 2020; pp. 168–179. [Google Scholar]
- Caplan, R.; Hanson, L.; Donovan, J. Dead reckoning: Navigating Content Moderation after “Fake News”. Data & Society Research Institute. 2018. Available online: https://datasociety.net/output/dead-reckoning (accessed on 26 September 2021).
- Van der Linden, S. Beating the hell out of fake news. Ethical Rec. Proc. Conway Hall Ethical Soc. 2017, 122, 4–7. [Google Scholar]
- Meel, P.; Vishwakarma, D.K. Fake news, rumor, information pollution in social media and web: A contemporary survey of state-of-the-arts, challenges and opportunities. Expert Syst. Appl. 2020, 153, 112986. [Google Scholar] [CrossRef]
- Busioc, C.; Dumitru, V.; Ruseti, S.; Terian-Dan, S.; Dascalu, M.; Rebedea, T. What Are the Latest Fake News in Romanian Politics? An Automated Analysis Based on BERT Language Models. In Ludic, Co-design and Tools Supporting Smart Learning Ecosystems and Smart Education: Proceedings of the 6th International Conference on Smart Learning Ecosystems and Regional Development, Bucharest, Romania, 24–25 June 2021; Springer Nature: Singapore, 2021; Volume 249, p. 201. [Google Scholar] [CrossRef]
- Factual. Available online: https://www.factual.ro (accessed on 26 September 2021).
- Busioc, C.; Ruseti, S.; Dascalu, M. A Literature Review of NLP Approaches to Fake News Detection and Their Applicability to Romanian-Language News Analysis. Transilv. J. 2020, 65–71. [Google Scholar] [CrossRef]
- Manzoor, S.I.; Nikita, J.S. Fake News Detection Using Machine Learning approaches: A systematic Review. In Proceedings of the 3rd International Conference on Trends in Electronics and Informatics (ICOEI), Tirunelveli, India, 23–25 April 2019; pp. 230–234. [Google Scholar]
- Kaliyar, R.K.; Goswami, A.; Narang, P. FakeBERT: Fake news detection in social media with a BERT-based deep learning approach. Multimed. Tools Appl. 2021, 80, 11765–11788. [Google Scholar] [CrossRef] [PubMed]
- Wang, W.Y. Liar, Liar Pants on Fire: A New Benchmark Dataset for Fake News Detection. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, Vancouver, BC, Canada, 30 July–4 August 2017; Volume 2, pp. 422–426. [Google Scholar] [CrossRef]
- Ajao, O.; Deepayan, B.; Shahrzad, Z. Fake News Identification on Twitter with Hybrid CNN and RNN Models. In Proceedings of the 9th International Conference on Social Media and Society, Copenhagen, Denmark, 18–20 July 2018; pp. 226–230. [Google Scholar] [CrossRef] [Green Version]
- Jiang, T.; Li, J.P.; Haq, A.U.; Saboor, A.; Ali, A. A Novel Stacking Approach for Accurate Detection of Fake News. IEEE Access 2021, 9, 22626–22639. [Google Scholar] [CrossRef]
- Saikh, T.; De, A.; Ekbal, A.; Bhattacharyya, P. A deep learning approach for automatic detection of fake news. In Proceedings of the 16th International Conference on Natural Language Processing, Hyderabad, India, 18–21 December 2019; pp. 230–238. [Google Scholar]
- Thota, A.; Tilak, P.; Ahluwalia, S.; Lohia, N. Fake News Detection: A Deep Learning Approach. SMU Data Sci. Rev. 2018, 1, 10. Available online: https://scholar.smu.edu/datasciencereview/vol1/iss3/10 (accessed on 26 September 2021).
- Kumar, S.; Asthana, R.; Upadhyay, S.; Upreti, N.; Akbar, M. Fake news detection using deep learning models: A novel approach. Trans. Emerg. Telecommun. Technol. 2020, 31, e3767. [Google Scholar] [CrossRef]
- Fake News Challenge. Available online: http://www.fakenewschallenge.org (accessed on 26 September 2021).
- Abedalla, A.; Al-Sadi, A.; Abdullah, M. A Closer Look at Fake News Detection: A Deep Learning Perspective. In Proceedings of the 3rd International Conference on Advances in Artificial Intelligence, Istanbul, Turkey, 26–28 October 2019; pp. 24–28. [Google Scholar] [CrossRef]
- Talwar, S.; Dhir, A.; Singh, D.; Virk, G.S.; Salo, J. A Sharing of fake news on social media: Application of the honeycomb framework and the third-person effect hypothesis. J. Retail. Consum. Serv. 2020, 57, 102197. [Google Scholar] [CrossRef]
- Aldwairi, M.; Alwahedi, A. Detecting Fake News in Social Media Networks. In Proceedings of the 9th International Conference on Emerging Ubiquitous Systems and Pervasive Networks, Leuven, Belgium, 5–8 November 2018; Volume 141, pp. 215–222. [Google Scholar] [CrossRef]
- Shu, K.; Sliva, A.; Wang, S.; Tang, J.; Liu, H. Fake News Detection on Social Media: A Data Mining Perspective. ACM SIGKDD Explor. Newsl. 2017, 19, 22–36. [Google Scholar] [CrossRef]
- Guibon, G.; Ermakova, L.; Seffih, H.; Firsov, A.; Noé-Bienvenu, G.L. Multilingual Fake News Detection with Satire. In Proceedings of the International Conference on Computational Linguistics and Intelligent Text Processing, La Rochelle, France, 7–13 April 2019. [Google Scholar]
- Zhang, X.; Cao, J.; Li, X.; Sheng, Q.; Zhong, L.; Shu, K. Mining Dual Emotion for Fake News Detection. In Proceedings of the Web Conference 2021, World Wide Web Conference, Ljubljana, Slovenia, 19–23 April 2021; ACM: New York, NY, USA, 2021; pp. 3465–3476. [Google Scholar] [CrossRef]
- Ross, J.; Thirunarayan, K. Features for Ranking Tweets Based on Credibility and Newsworthiness. In Proceedings of the 2016 International Conference on Collaboration Technologies and Systems, Orlando, FL, USA, 31 October–4 November 2016; pp. 18–25. [Google Scholar] [CrossRef] [Green Version]
- Dumitrescu, S.D.; Avram, A.; Pyysalo, S. The birth of Romanian BERT. In Findings of the Association for Computational Linguistics, Proceedings of the EMNLP 2020, Online Conference, 16–20 November 2020; Association for Computational Linguisticsy: Stroudsburg, PA, USA, 2020; pp. 4324–4328. [Google Scholar] [CrossRef]
- Masala, M.; Ruseti, S.; Dascalu, M. RoBERT—A Romanian BERT Model. In Proceedings of the 28th International Conference on Computational Linguistics, International Committee on Computational Linguistics, Barcelona, Spain, 8–13 December 2020; pp. 6626–6637. [Google Scholar] [CrossRef]
- Fluierul. Available online: https://www.fluierul.ro (accessed on 26 September 2021).
- Vremuritulburi. Available online: https://vremuritulburi.com (accessed on 26 September 2021).
- Cunoastelumea. Available online: https://www.cunoastelumea.ro (accessed on 26 September 2021).
- Rubrika. Available online: https://rubrika.ro (accessed on 26 September 2021).
- Mediafax & Rubrika. Available online: https://www.mediafax.ro/life-inedit/aplicatia-de-necrezut-vaneaza-fake-news-urile-din-romania-care-sunt-cele-70-de-site-uri-vizate-16156645 (accessed on 26 September 2021).
- Agerpres. Available online: https://www.agerpres.ro (accessed on 26 September 2021).
- Mediafax. Available online: https://mediafax.ro (accessed on 26 September 2021).
- Rador. Available online: https://rador.ro (accessed on 26 September 2021).
- Text Language Detect. Available online: https://pear.php.net/package/Text_LanguageDetect (accessed on 26 September 2021).
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT, Minneapolis, MN, USA, 2–7 June 2019; Volume 1, pp. 4171–4186. [Google Scholar] [CrossRef]
- Suarez, P.O.; Sagot, B.; Romary, L. Asynchronous Pipeline for Processing Huge Corpora on Medium to Low Resource Infrastructures. In Proceedings of the 7th Workshop on the Challenges in the Management of Large Corpora (CMLC-7), Cardiff, UK, 22 July 2019; Leibniz-Institut für Deutsche Sprache: Mannheim. Germany, 2019; pp. 9–16. [Google Scholar] [CrossRef]
- RoTex Corpus Builder-Builds a Corpus of Romanian Text, Suitable for NLP Research, from Different Online Sources. Available online: https://github.com/aleris/ReadME-RoTex-Corpus-Builder (accessed on 26 September 2021).
- Kingma, D.; Ba, J. Adam: A Method for Stochastic Optimization. International Conference on Learning Representations. arXiv 2015, arXiv:1412.6980. [Google Scholar]
- Khan, J.Y.; Khondaker, T.I.; Afroz, S.; Uddin, G.; Iqbal, A. A benchmark study of machine learning models for online fake news detection. Mach. Learn. Appl. 2021, 4, 100032. [Google Scholar] [CrossRef]
- Nasir, J.A.; Khan, O.S.; Varlamis, I. Fake news detection: A hybrid CNN-RNN based deep learning approach. Int. J. Inf. Manag. Data Insights 2021, 1, 100007. [Google Scholar] [CrossRef]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. RoBERTa: A Robustly Optimized BERT Pretraining Approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Yamada, I.; Asai, A.; Shindo, H.; Takeda, H.; Matsumoto, Y. LUKE: Deep Contextualized Entity Representations with Entity-aware Self-attention. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing, Online Conference, 16–20 November 2020; pp. 6442–6454. [Google Scholar] [CrossRef]
- Rajpurkar, P.; Zhang, J.; Lopyrev, K.; Liang, P. SQuAD: 100,000+ Questions for Machine Comprehension of Text. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, Austin, TX, USA, 1–5 November 2016; pp. 2383–2392. [Google Scholar] [CrossRef]
- Alonso, M.A.; Vilares, D.; Gómez-Rodríguez, C.; Vilares, J. Sentiment Analysis for Fake News Detection. Electronics 2021, 10, 1348. [Google Scholar] [CrossRef]
- Bhutani, B.; Rastogi, N.; Sehgal, P.; Purwar, A. Fake News Detection Using Sentiment Analysis. In Proceedings of the Twelfth International Conference on Contemporary Computing (IC3), Noida, India, 8–10 August 2019; pp. 1–5. [Google Scholar] [CrossRef]
- Buzea, M.C.; Trăuşan-Matu, Ș.; Rebedea, T. A Three Word-Level Approach Used in Machine Learning for Romanian Sentiment Analysis. In Proceedings of the 18th RoEduNet Conference: Networking in Education and Research, Galati, Romania, 10–12 October 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Buzea, M.C.; Trăuşan-Matu, Ș.; Rebedea, T. Automatic Irony detection for Romanian online news. In Proceedings of the 24th International Conference on System Theory, Control and Computing (ICSTCC), Sinaia, Romania, 8–10 October 2020; pp. 72–77. [Google Scholar] [CrossRef]
- Times New Roman. Available online: https://www.timesnewroman.ro (accessed on 26 September 2021).
- Kaliyar, R.K.; Goswami, A.; Narang, P.; Sinha, S. FNDNet—A deep convolutional neural network for fake news detection. Cogn. Syst. Res. 2020, 61, 32–44. [Google Scholar] [CrossRef]
- Martínez-Gallego, K.; Álvarez-Ortiz, A.M.; Arias-Londoño, J.D. Fake news detection in spanish using deep learning techniques. arXiv 2021, arXiv:2110.06461. [Google Scholar]
- Buzea, M.C.; Trăuşan-Matu, Ș.; Rebedea, T. Targeted Romanian Online News in a Mobile Application Using AI. In Proceedings of the RoCHI-International Conference on Human-Computer Interaction, Sibiu, Romania, 22–23 October 2020; pp. 54–60. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
| Dataset | Fake | Real | Total |
|---|---|---|---|
| Training | 7768 | 7768 | 15,536 |
| Validation | 2648 | 2648 | 5296 |
| Test | 2648 | 2648 | 5296 |
| Total | 13,064 | 13,064 | 26,128 |
| Label | Source | Text |
|---|---|---|
| Fake | constantadeazi.ro | Militar român rănit în Afganistan, trecut în rezervă cu o pensie de 360 lei. “Am stat trei luni în comă, am suferit 85 de fracturi. Dar atât costă viața unui militar” … (English translation: Romanian soldier injured in Afghanistan, retired with a 360 lei pension. “I was in a coma for three months and suffered 85 fractures. But this is how much a soldier’s life is worth” …) https://www.constantadeazi.ro/militar-roman-ranit-in-afganistan-trecut-in-rezerva-cu-o-pensie-de-360-lei-am-stat-trei-luni-in-coma-am-suferit-85-de-fracturi-dar-atat-costa-viata-unui-militar |
| True | adevarul.ro | MApN a demontat „povestea tragică“ a eroului impostor de la „Chefi la cuţite“, rănit în Afganistan şi trecut în rezervă cu o pensie mica … (English translation: MoND dismantled the “tragic story“ of the impostor hero from “Chefi la cuţite“ who was injured in Afghanistan and retired with a small pension …) https://adevarul.ro/entertainment/tv/mapn-demontat-povestea-tragica-eroului-impostor-chefi-cutite-ranit-afagnistan-trecut-rezerva-pensie-mica-spune-antena-1-motivul-nu-l-elimina-1_5aeb1b3edf52022f758a8c01/index.html |
| Words | Fake | Real |
|---|---|---|
| Romanian unique words | 102,006 | 44,969 |
| Average words per news | 413 | 155 |
| Software or Packages | Version |
|---|---|
| CUDA | 11.2 |
| Python | 3.8.5 |
| Keras | 2.4.3 |
| Nltk | 3.5 |
| TensorFlow-GPU | 1.14.0 |
| Parameter Name | Value of Parameter |
|---|---|
| Learning rate | 0.001 |
| Neurons | 32 |
| Optimizer | Adam |
| Weights | random |
| Dropout | 0.2 |
| Batch size | 32 |
| Vocabulary size | 50,000 |
| Number of words | 5000 |
| Label | Output Size | Param Number |
|---|---|---|
| Embedding | 5000 × 32 | 1,600,000 |
| LSTM | 128 | 82,432 |
| Dropout | 128 | 0 |
| Dense | 5 | 645 |
| Dense | 1 | 6 |
| Label | Output Size | Param Number |
|---|---|---|
| Embedding | 5000 × 32 | 1,600,000 |
| Conv1D | 4998 × 250 | 24,250 |
| Maxpool1D | 250 | 0 |
| Activation | 250 | 0 |
| Dropout | 250 | 0 |
| Dense | 1 | 251 |
| Label | Output Size | Param Number |
|---|---|---|
| Embedding | 5000 × 32 | 1,600,000 |
| GRU | 128 | 62,208 |
| Activation | 128 | 0 |
| Dropout | 128 | 0 |
| Dense | 1 | 129 |
| Model | W | V | L | H | A |
|---|---|---|---|---|---|
| RoBERT-small | 19M | 38,000 | 12 | 256 | 8 |
| RoBERT-large | 341M | 38,000 | 24 | 1024 | 16 |
| Parameters Name | Value of Parameter |
|---|---|
| Number of epochs | 30 |
| Batch size | 32 |
| Optimizer | Adam |
| Loss function | Categorical cross-entropy |
| Dropout | 0.2 |
| Learning rate | 0.00003 |
| Model Type | Model Name | Acc | Pre | Rec | F1 | TP | TN | FP | FN |
|---|---|---|---|---|---|---|---|---|---|
| Classical | SVM | 0.944 | 0.904 | 0.988 | 0.944 | 2519 | 2480 | 266 | 31 |
| NB | 0.976 | 0.957 | 0.994 | 0.975 | 2534 | 2633 | 113 | 16 | |
| Deep learning | LSTM | 0.967 | 0.939 | 0.997 | 0.967 | 2542 | 2581 | 165 | 8 |
| CNN | 0.978 | 0.965 | 0.991 | 0.978 | 2528 | 2654 | 92 | 22 | |
| GRU | 0.961 | 0.927 | 0.997 | 0.961 | 2543 | 2545 | 201 | 7 | |
| Transformers | RoBERT-small | 0.933 | 0.896 | 0.975 | 0.934 | 2485 | 2457 | 289 | 65 |
| RoBERT-large | 0.907 | 0.851 | 0.976 | 0.910 | 2490 | 2311 | 435 | 60 |
| Model Type | Model Name | Acc | Pre | Rec | F1 | TP | TN | FP | FN |
|---|---|---|---|---|---|---|---|---|---|
| Classical | SVM | 0.945 | 0.912 | 0.985 | 0.947 | 2609 | 2397 | 251 | 39 |
| NB | 0.975 | 0.964 | 0.986 | 0.975 | 2610 | 2551 | 97 | 38 | |
| Deep learning | LSTM | 0.979 | 0.964 | 0.994 | 0.979 | 2633 | 2551 | 97 | 15 |
| CNN | 0.981 | 0.971 | 0.992 | 0.982 | 2628 | 2569 | 79 | 20 | |
| GRU | 0.975 | 0.958 | 0.992 | 0.975 | 2627 | 2534 | 114 | 21 | |
| Transformers | RoBERT-small | 0.919 | 0.866 | 0.992 | 0.925 | 2628 | 2240 | 408 | 20 |
| RoBERT-large | 0.870 | 0.816 | 0.955 | 0.880 | 2529 | 2078 | 570 | 119 |
| 2648 Fake News Items | 2648 True News Items | ||||
|---|---|---|---|---|---|
| Neutral polarity (no. of news) | Positive polarity (no. of news) | Negative polarity (no. of news) | Neutral polarity (no. of news) | Positive polarity (no. of news) | Negative polarity (no. of news) |
| 99.96% (2647) | 0% (0) | 0.04% (1) | 78.73% (2085) | 15.18% (402) | 6.09% (161) |
| 2648 Fake News Items | 2648 True News Items | ||
|---|---|---|---|
| Ironic (no. of news) | Non ironic (no. of news) | Ironic (no. of news) | Non ironic (no. of news) |
| 24.05% (637) | 75.95% (2011) | 0.08% (2) | 99.92% (2646) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Buzea, M.C.; Trausan-Matu, S.; Rebedea, T. Automatic Fake News Detection for Romanian Online News. Information 2022, 13, 151. https://doi.org/10.3390/info13030151
Buzea MC, Trausan-Matu S, Rebedea T. Automatic Fake News Detection for Romanian Online News. Information. 2022; 13(3):151. https://doi.org/10.3390/info13030151
Chicago/Turabian StyleBuzea, Marius Cristian, Stefan Trausan-Matu, and Traian Rebedea. 2022. "Automatic Fake News Detection for Romanian Online News" Information 13, no. 3: 151. https://doi.org/10.3390/info13030151
APA StyleBuzea, M. C., Trausan-Matu, S., & Rebedea, T. (2022). Automatic Fake News Detection for Romanian Online News. Information, 13(3), 151. https://doi.org/10.3390/info13030151