
LAS-Transformer: An Enhanced Transformer Based on the Local Attention Mechanism for Speech Recognition


Abstract
:1. Introduction
- We propose a local attention module based on the highly correlated features of speech frames. The local self-attentive module uses a high correlation of speech frames as a priori knowledge to quickly capture the local information of the speech sequence.
- We propose a depthwise separable convolution subsampling layer, which reduces the parameters of the model and preserves the position information to a great extent.
- We replace the Transformer’s native absolute positional embedding with relative positional embedding. The relative position encoding method can enhance the position information representation, which not only contains the relative position relationship, but also expresses the direction information.
2. Related Work
2.1. Transformer
2.2. CTC-Transformer
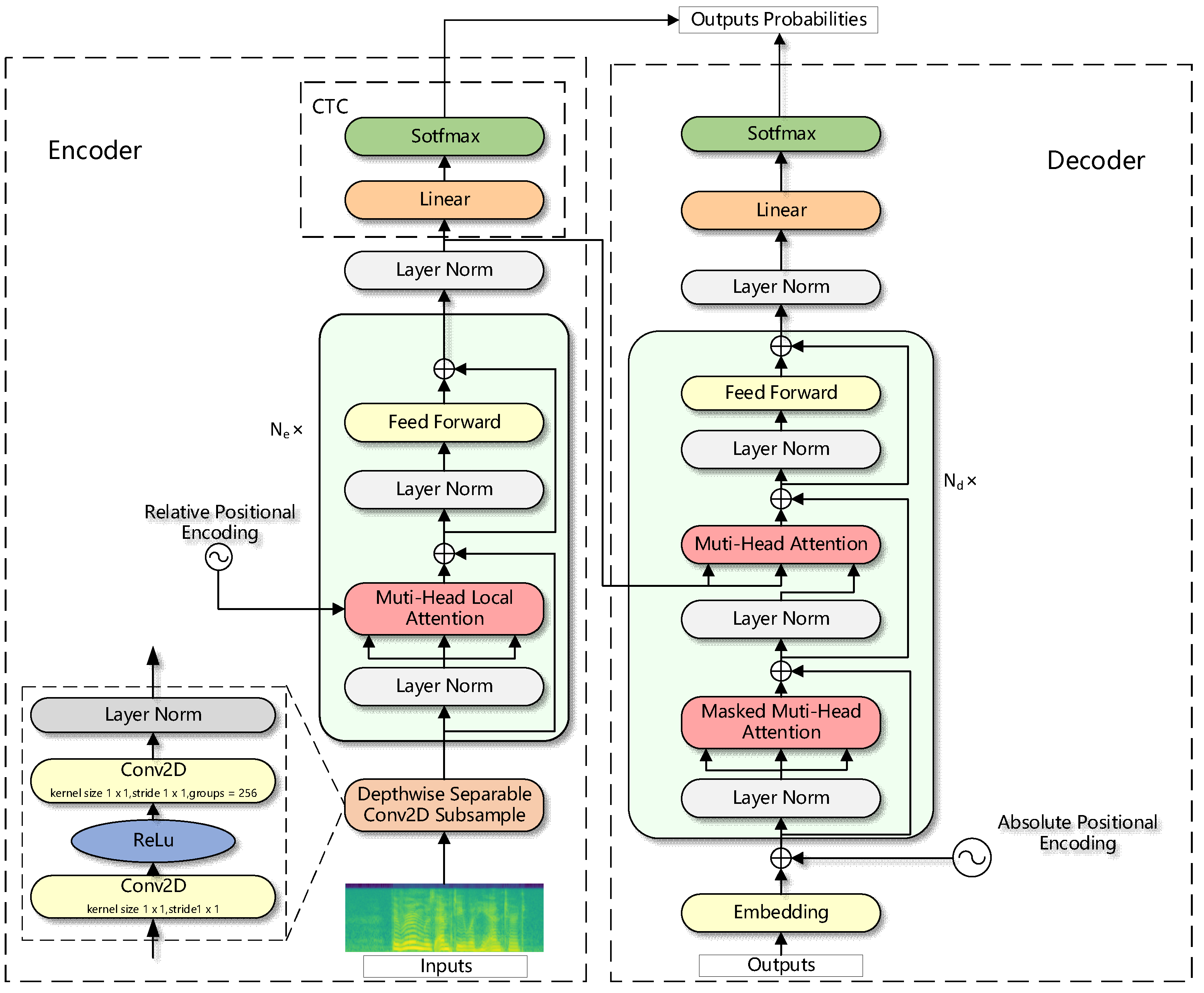
3. Methods
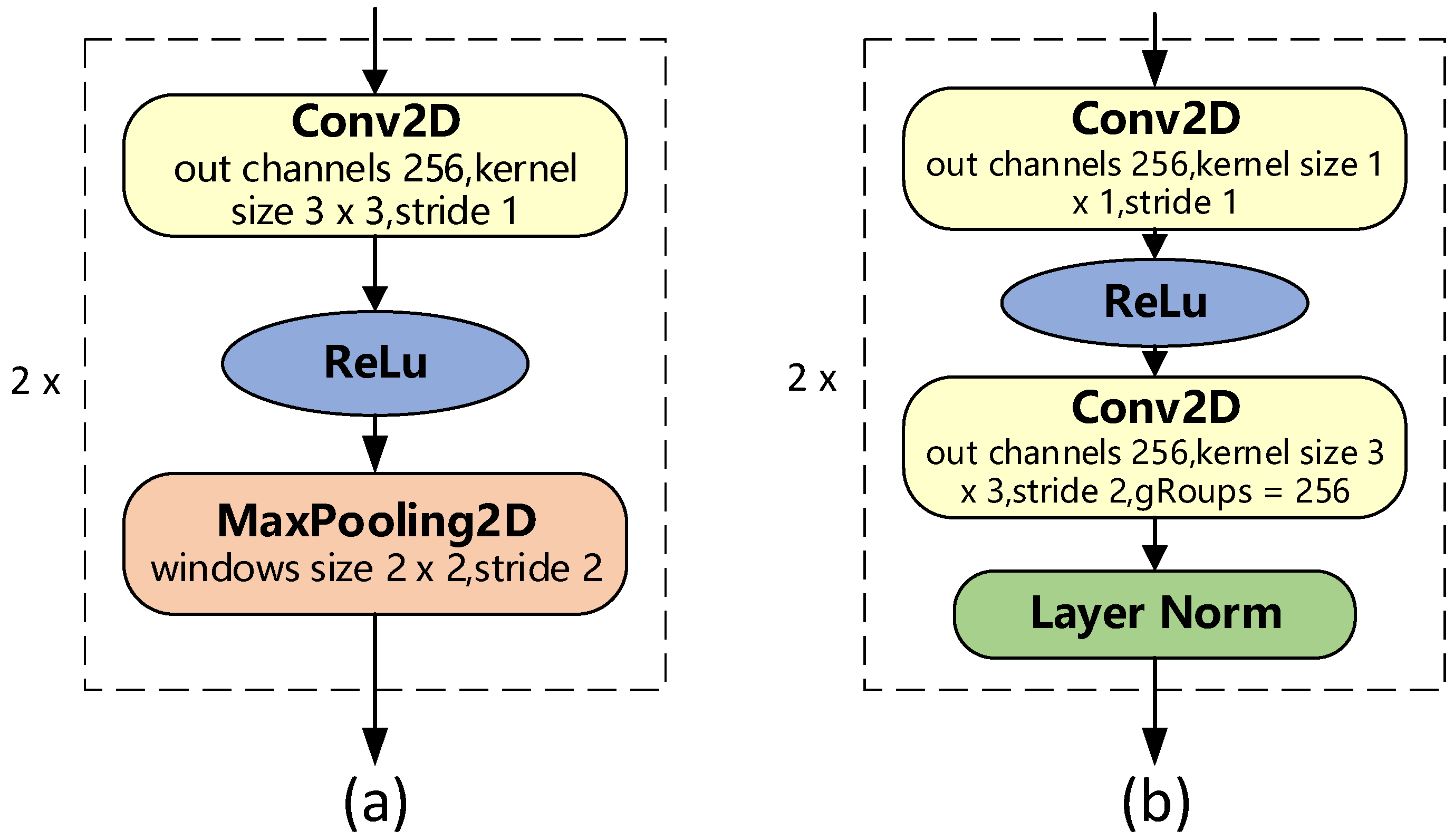
3.1. Depthwise Separable Convolution Subsampling Layer
3.2. Relative Positional Embedding
3.3. Local Attention Layer
3.4. Training and Decoding
4. Experiments
4.1. Datasets and Evaluation Metrics
4.2. Experimental Details
4.3. Comparison Experiments
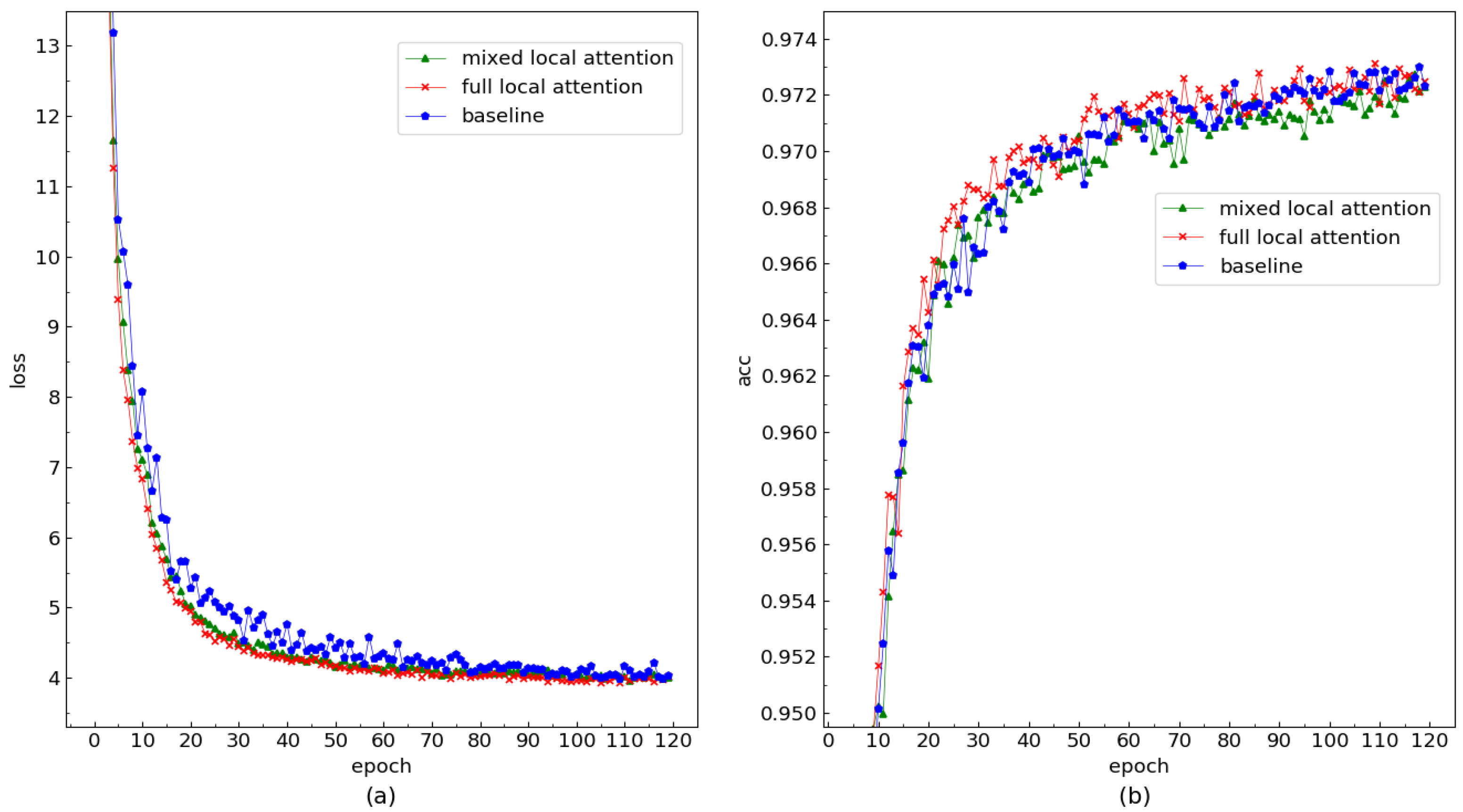
4.4. Ablation Experiments
4.5. Exploratory Experiments
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Povey, D.; Peddinti, V.; Galvez, D.; Ghahremani, P.; Manohar, V.; Na, X.; Wang, Y.; Khudanpur, S. Purely sequence-trained neural networks for asr based on lattice-free MMI. Proc. Interspeech 2016, 1, 2751–2755. [Google Scholar] [CrossRef] [Green Version]
- Graves, A.; Fernández, S.; Gomez, F.; Schmidhuber, J. Connectionist temporal classification: Labelling unsegmented sequence data with recurrent neural networks. In Proceedings of the 23rd International Conference on Machine Learning, Pittsburgh, PA, USA, 25–29 June 2006; pp. 369–376. [Google Scholar]
- Eyben, F.; Wöllmer, M.; Schuller, B.; Graves, A. From speech to letters-using a novel neural network architecture for grapheme based ASR. In Proceedings of the Workshop on Automatic Speech Recognition & Understanding, Moreno, Italy, 13 November–17 December 2009; pp. 376–380. [Google Scholar]
- Song, W.; Cai, J. End-to-end deep neural network for automatic speech recognition. Standford CS224D Rep. 2015, 1, 1–8. [Google Scholar]
- Amodei, D.; Ananthanarayanan, S.; Anubhai, R.; Bai, J.; Battenberg, E.; Case, C.; Casper, J.; Catanzaro, B.; Cheng, Q.; Chen, G.; et al. Deep speech 2: End-to-end speech recognition in english and mandarin. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 20–22 June 2016; pp. 173–182. [Google Scholar]
- Graves, A. Sequence transduction with recurrent neural networks. arXiv 2012, arXiv:1211.3711. [Google Scholar]
- Graves, A.; Mohamed, A.; Hinton, G. Speech recognition with deep recurrent neural networks. In Proceedings of the International Conference on Acoustics, Speech and Signal Processing (ICASSP), Vancouver, BC, Canada, 26–31 May 2013; pp. 6645–6649. [Google Scholar]
- Rao, K.; Sak, H.; Prabhavalkar, R. Exploring Architectures, Data and units for streaming end-to-end speech recognition with RNN-Transducer. In Proceedings of the Automatic Speech Recognition and Understanding Workshop (ASRU), Okinawa, Japan, 16–20 December 2017; pp. 193–199. [Google Scholar]
- Zeyer, A.; Merboldt, A.; Michel, W.; Schlüter, R.; Ney, H. Librispeech transducer model with internal language model prior correction. arXiv 2021, arXiv:2104.03006. [Google Scholar]
- Chorowski, J.; Bahdanau, D.; Serdyuk, D.; Cho, K.; Bengio, Y. Attention-based models for speech recognition. In Proceedings of the 28th International Conference on Neural Information Processing Systems-Volume 1, Montreal, QC, Canada, 7–12 December 2015; MIT Press: Cambridge, MA, USA, 2015; pp. 577–585. [Google Scholar]
- Bahdanau, D.; Chorowski, J.; Serdyuk, D.; Brakel, P.; Bengio, Y. End-to-end attention-based large vocabulary speech recognition. In Proceedings of the International Conference on Acoustics, Speech and Signal Processing (ICASSP), Shanghai, China, 20–25 March 2016; pp. 4945–4949. [Google Scholar]
- Chan, W.; Jaitly, N.; Le, Q.; Vinyals, O. Listen, Attend and Spell: A neural network for large vocabulary conversational speech recognition. In Proceedings of the International Conference on Acoustics, Speech and Signal Processing (ICASSP), Shanghai, China, 20–25 March 2016; pp. 4960–4964. [Google Scholar]
- Weng, C.; Cui, J.; Wang, G.; Wang, J.; Yu, C.; Su, D.; Yu, D. Improving attention based sequence-to-sequence models for end-to-end english conversational speech recognition. Proc. Interspeech 2018, 1, 761–765. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Dong, L.; Xu, S.; Xu, B. Speech-Transformer: A no-recurrence sequence-to-sequence model for speech recognition. In Proceedings of the International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 5884–5888. [Google Scholar]
- Karita, S.; Soplin, N.E.Y.; Watanabe, S.; Delcroix, M.; Ogawa, A.; Nakatani, T. Improving transformer-based end-to-end speech recognition with connectionist temporal classification and language model integration. In Proceedings of the Interspeech 2019, ISCA, Graz, Austria, 15–19 September 2019; pp. 1408–1412. [Google Scholar]
- Karita, S.; Chen, N.; Hayashi, T.; Hori, T.; Inaguma, H.; Jiang, Z.; Someki, M.; Soplin, N.E.Y.; Yamamoto, R.; Wang, X. A comparative study on transformer vs rnn in speech applications. In Proceedings of the Automatic Speech Recognition and Understanding Workshop (ASRU), Sentosa, Singapore, 14–18 December 2019; pp. 449–456. [Google Scholar]
- Gulati, A.; Qin, J.; Chiu, C.-C.; Parmar, N.; Zhang, Y.; Yu, J.; Han, W.; Wang, S.; Zhang, Z.; Wu, Y. Conformer: Convolution-augmented transformer for speech recognition. arXiv 2020, arXiv:2005.08100. [Google Scholar]
- Battaglia, P.W.; Hamrick, J.B.; Bapst, V.; Sanchez-Gonzalez, A.; Zambaldi, V.; Malinowski, M.; Tacchetti, A.; Raposo, D.; Santoro, A.; Faulkner, R. Relational inductive biases, deep learning, and graph networks. arXiv 2018, arXiv:1806.01261. [Google Scholar]
- Guo, Q.; Qiu, X.; Liu, P.; Shao, Y.; Xue, X.; Zhang, Z. Star-Transformer. arXiv 2019, arXiv:1902.09113. [Google Scholar]
- Hinton, G.E.; Krizhevsky, A.; Wang, S.D. Transforming auto-encoders. In Proceedings of the International Conference on Artificial Neural Networks, Espoo, Finland, 14–17 June 2011; pp. 44–51. [Google Scholar]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]
- Panayotov, V.; Chen, G.; Povey, D.; Khudanpur, S. Librispeech: An asr corpus based on public domain audio books. In Proceedings of the International Conference on Acoustics, Speech and Signal Processing (ICASSP), South Brisbane, QLD, Australia, 19–24 April 2015; pp. 5206–5210. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Xiong, R.; Yang, Y.; He, D.; Zheng, K.; Zheng, S.; Xing, C.; Zhang, H.; Lan, Y.; Wang, L.; Liu, T. On layer normalization in the Transformer architecture. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual Event, 13–18 July 2020; pp. 10524–10533. [Google Scholar]
- Dai, Z.; Yang, Z.; Yang, Y.; Carbonell, J.; Le, Q.V.; Salakhutdinov, R. Transformer-xl: Attentive language models beyond a fixed-length context. arXiv 2019, arXiv:1901.02860. [Google Scholar]
- Park, D.S.; Chan, W.; Zhang, Y.; Chiu, C.-C.; Zoph, B.; Cubuk, E.D.; Le, Q.V. Specaugment: A simple data augmentation method for automatic speech recognition. arXiv 2019, arXiv:1904.08779. [Google Scholar]
- Ko, T.; Peddinti, V.; Povey, D.; Khudanpur, S. Audio augmentation for speech recognition. In Proceedings of the Sixteenth Annual Conference of the International Speech Communication Association, Dresden, Germany, 6–10 September 2015. [Google Scholar]
- Kriman, S.; Beliaev, S.; Ginsburg, B.; Huang, J.; Kuchaiev, O.; Lavrukhin, V.; Leary, R.; Li, J.; Zhang, Y. Quartznet: Deep automatic speech recognition with 1d time-channel separable convolutions. In Proceedings of the International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 6124–6128. [Google Scholar]
- Wang, Y.; Mohamed, A.; Le, D.; Liu, C.; Xiao, A.; Mahadeokar, J.; Huang, H.; Tjandra, A.; Zhang, X.; Zhang, F. Transformer-based acoustic modeling for hybrid speech recognition. In Proceedings of the International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 6874–6878. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Network Structure | Dev-Clean | Dev-Other | Test-Clean | Test-Other |
|---|---|---|---|---|
| QuartzNet | - | - | 2.69 | 7.25 |
| Espnet Transformer | 2.2 | 5.6 | 2.6 | 5.7 |
| LAS+Specaugment | - | - | 3.2 | 9.8 |
| LSTM Transducer | 2.17 | 5.28 | 2.23 | 5.74 |
| Hybrid model with Transformer rescoring | - | - | 2.60 | 5.59 |
| baseline | 2.5 | 5.9 | 2.8 | 6.1 |
| LAS-Transformer | 2.2 | 5.2 | 2.2 | 5.5 |
| Network Structure | Dev-Clean | Dev-Other | Test-Clean | Test-Other |
|---|---|---|---|---|
| baseline | 2.5 | 5.9 | 2.8 | 6.1 |
| baseline + relative position coding | 2.3 | 5.6 | 2.4 | 5.7 |
| baseline + local attention | 2.4 | 5.5 | 2.5 | 5.6 |
| baseline + depthwise separable convolution subsampling | 2.5 | 5.8 | 2.7 | 5.9 |
| LAS-Transformer | 2.2 | 5.2 | 2.2 | 5.5 |
| Network Structure | Dev-Clean | Dev-Other |
|---|---|---|
| baseline | 2.5 | 5.9 |
| baseline + mixed local attention | 2.5 | 6.2 |
| baseline + full local attention | 2.4 | 5.5 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fu, P.; Liu, D.; Yang, H. LAS-Transformer: An Enhanced Transformer Based on the Local Attention Mechanism for Speech Recognition. Information 2022, 13, 250. https://doi.org/10.3390/info13050250
Fu P, Liu D, Yang H. LAS-Transformer: An Enhanced Transformer Based on the Local Attention Mechanism for Speech Recognition. Information. 2022; 13(5):250. https://doi.org/10.3390/info13050250
Chicago/Turabian StyleFu, Pengbin, Daxing Liu, and Huirong Yang. 2022. "LAS-Transformer: An Enhanced Transformer Based on the Local Attention Mechanism for Speech Recognition" Information 13, no. 5: 250. https://doi.org/10.3390/info13050250
APA StyleFu, P., Liu, D., & Yang, H. (2022). LAS-Transformer: An Enhanced Transformer Based on the Local Attention Mechanism for Speech Recognition. Information, 13(5), 250. https://doi.org/10.3390/info13050250