
Study of the Yahoo-Yahoo Hash-Tag Tweets Using Sentiment Analysis and Opinion Mining Algorithms



Abstract
:1. Introduction
- Collect tweets based on the Yahoo-yahoo hashtags using the Orange Twitter API.
- Pre-process and tokenize the tweets using a pre-trained tweet tokenizer.
- Conduct unsupervised lexicon-based sentiment analysis on the tweet corpus using the Liu Hu and VADER techniques, respectively.
- Carry out Topic modeling to detect abstract topics on corpus using Latent Dirichlet Allocation (LDA) and Latent Semantic Indexing (LSI) algorithms, respectively.
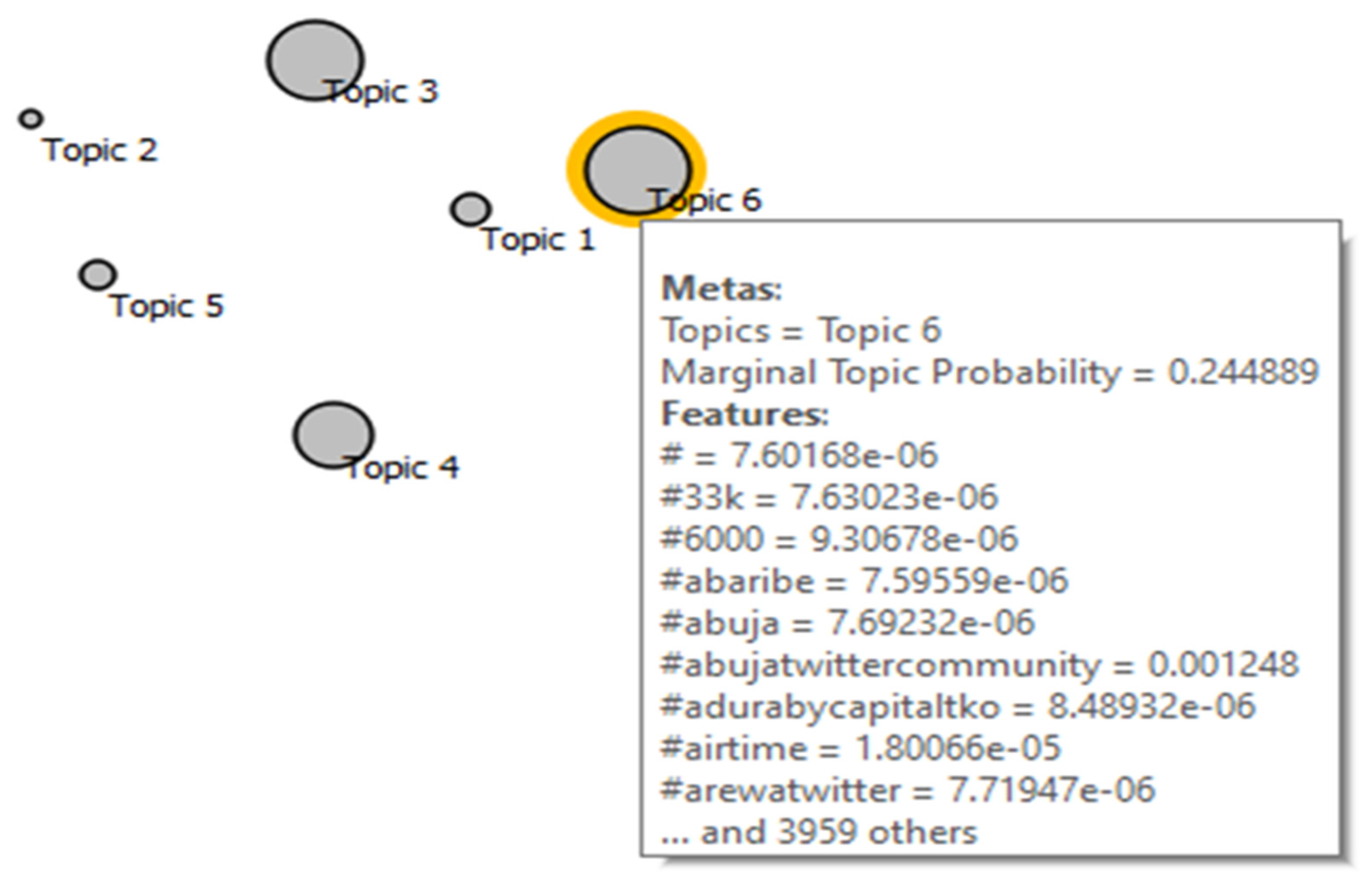
- Validate the topic modeling using Multidimensional Scaling (MDS) graph and Marginal Topic Probability (MTP).
2. Literature Review
3. Research Method
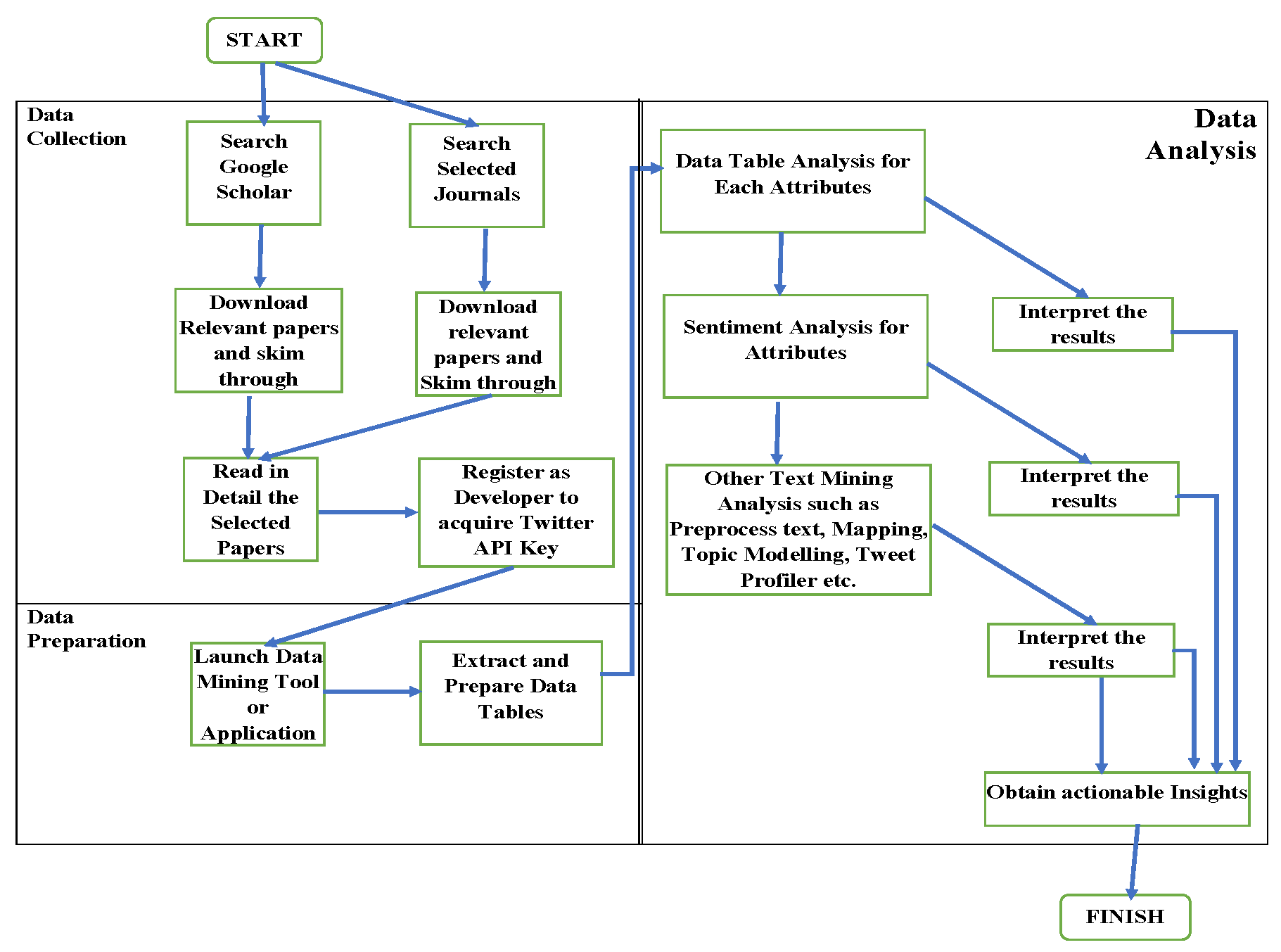
3.1. Data Collection
3.2. Data Pre-Processing
- Converting all characters in the corpus to lowercase;
- Remove all HTML tags from a string;
- Removing all text-based diacritics and accents;
- Removing URLs, articles, and punctuations;
- Filtering stop words, lexicon, Regular expressions.
3.3. Sentiment Analysis
| Algorithm 1: Duplicate Detection and Sentiment Analysis Workflow. |
| Input: {Corpus C; Tweet T (T1, T2, …Tn), Tweet contents: X = {x1, x2, …xn}, distance between rows, d distance threshold, dT = 0.5; distance metrics, m} Output: {Liu Hu: Sentiment Score; VADER: Sentiment Scores (Neg, Neutral, Positive, Score); Heat maps} Start: Procedure Step 1: For ∀ T ϵ C T ← {T1, T2, … Tm} T1 = {, , … }, T2 = {, , … }, ⠇ ⠇ ⠇ ⠇ Tn = {, , … } Step 2: Detect Duplicate Tweets T using Manhattan Distance (d) For i = 1: n \\ distance between rows Calculate: d = ( == ) && ( == ) && … ( == ) Linkage L= single d > =dT remove duplicate Step 3: Apply Sentiment Analysis Method (Liu Hu; VADER) Generate output end |
3.4. Ground Truth Generation for Sentiment Analysis
3.5. Topic Modelling
| Algorithm 2: Workflow for the Topic Modelling. |
| Input: {Corpus C; Tweet T (T1, T2, …Tn), Tweet contents: X (x1, x2, …xn), Authors} Output: {MDS: Marginal Topic Probability (MTP) of LDA topics, Word Cloud for LSI and LDA topics, Boxplots: MTP for LDA topics 1 to 6} Start: Step 1: Pre-process Text 1.1 Transformation {Lower case, remove accents, parse html, Remove all html tags from strings, and remove URLs} 1.2 Tokenization: Regexp (\w+) 1.3 Filtering: {Remove stopwords, Regexp (\. |,|:|;|!|\?|\ (|\ )|\||\+|’|”|‘|’|“|”|’|\’|…|\-|–|— |\$|&|\*|>|<|\/|\ [|\ ]), Document Frequency DF = (0.10–0.90)} Step 2: Topic Modelling Methods Apply Latent Semantic Indexing (LSI) Apply Latent Dirichlet Allocation (LDA); Step 3: Plot Multidimensional Scaling (MDS) graph Generate outputs end |
4. Results and Discussion
4.1. Results of Pre-Processing and Tokenization
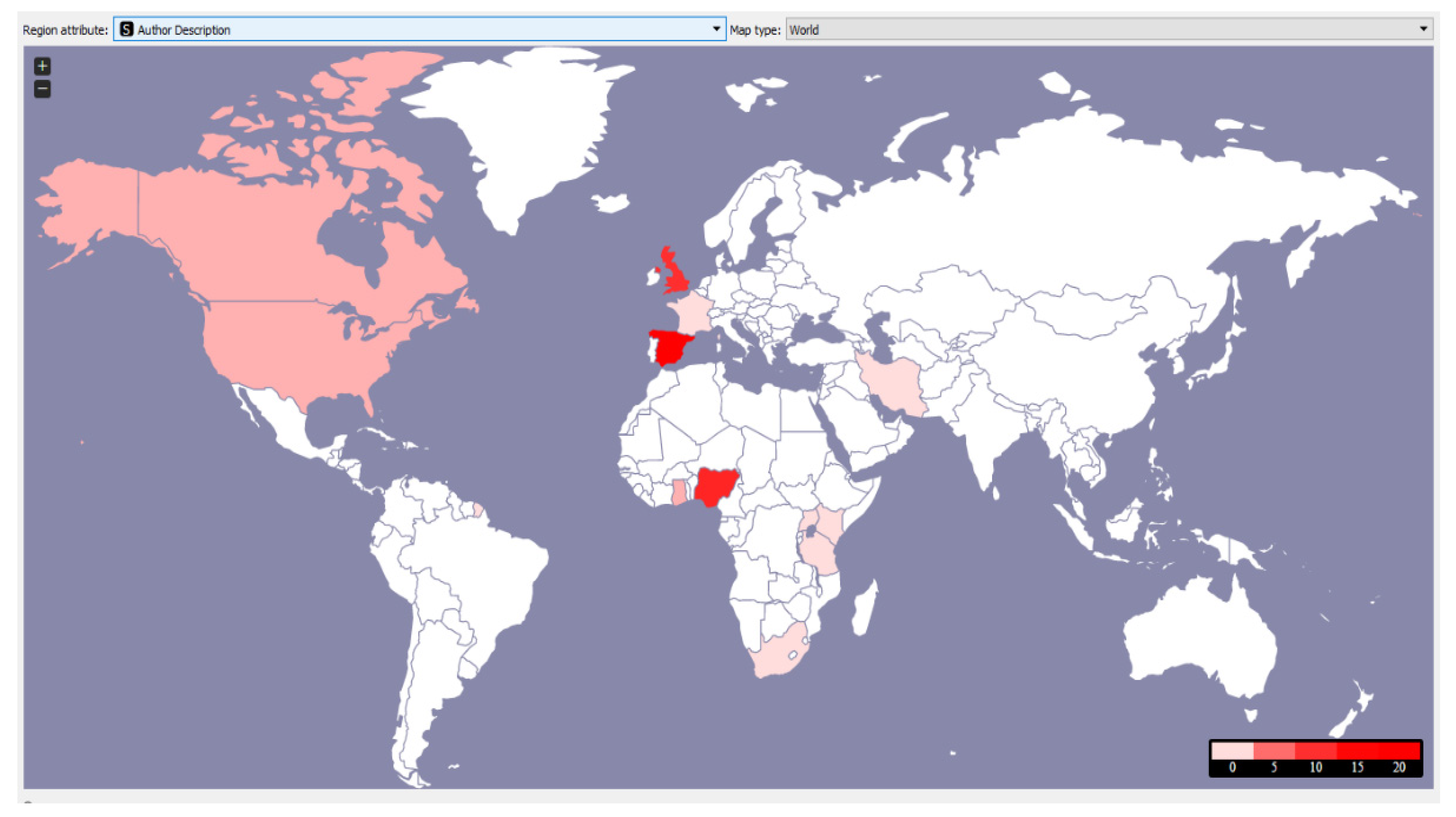
4.2. Results of Geolocation
4.3. Results of Duplicate Detection
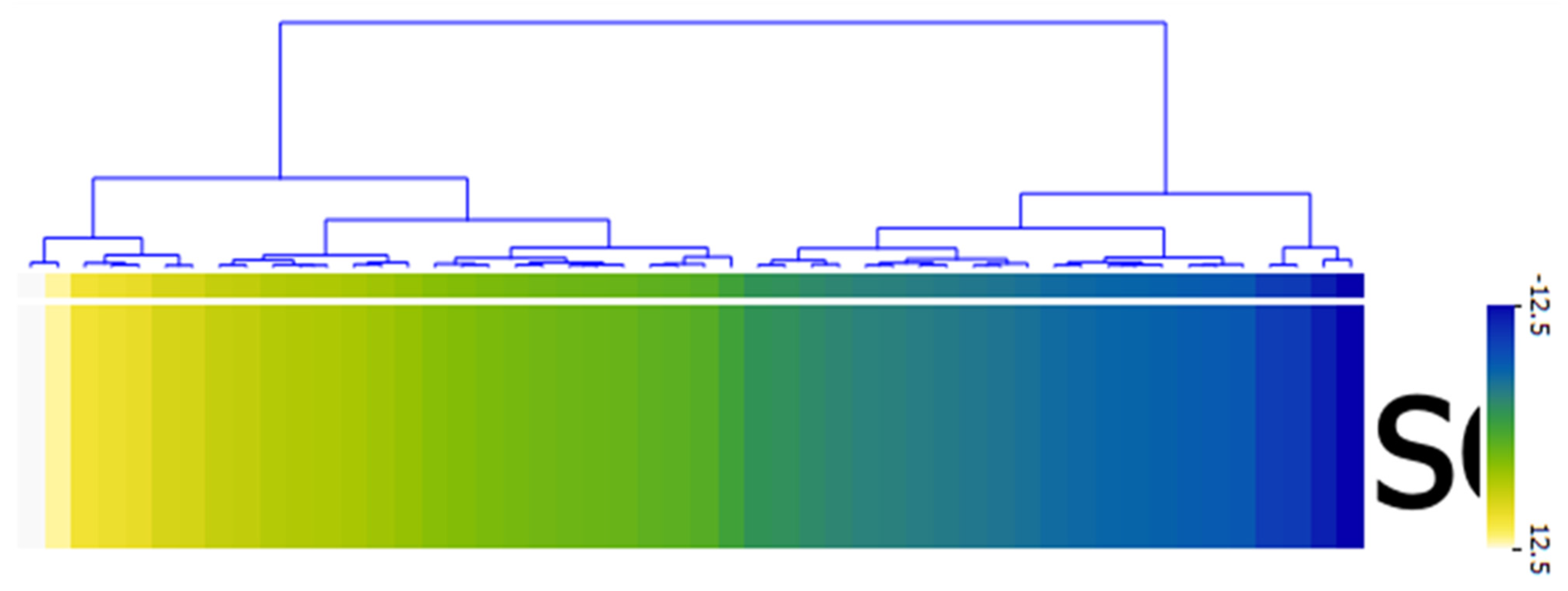
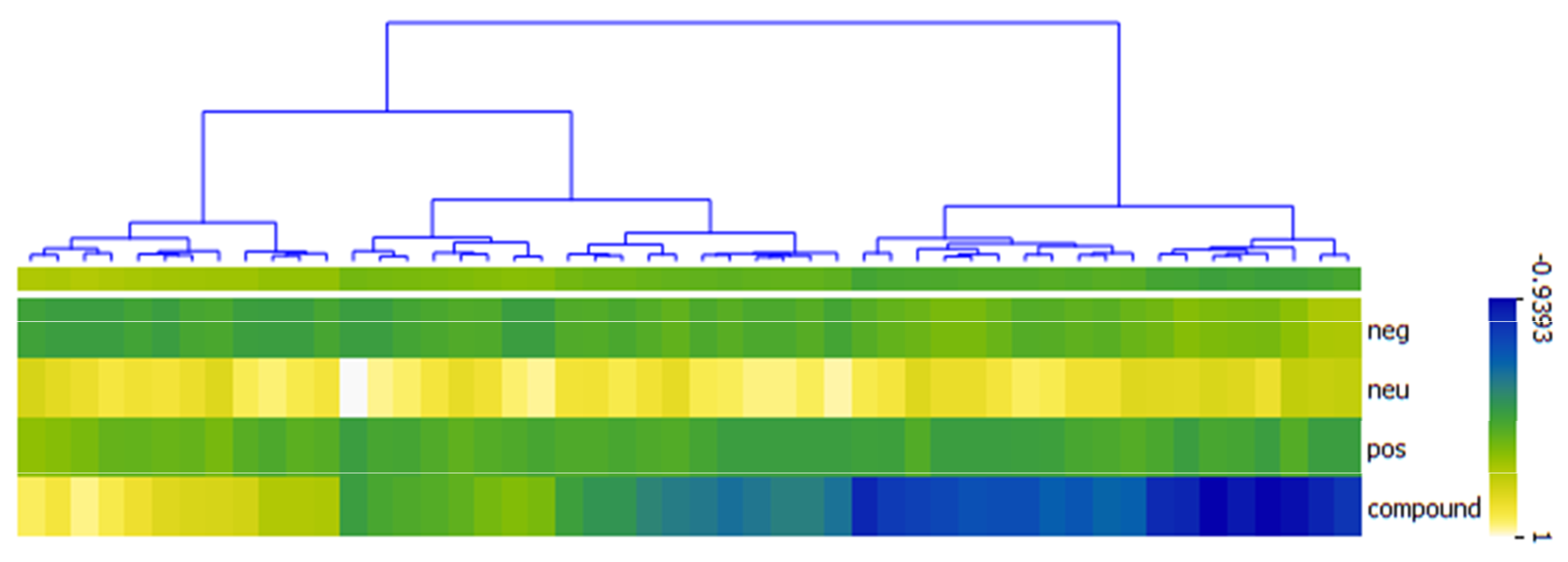
4.4. Result of Sentiment Analysis
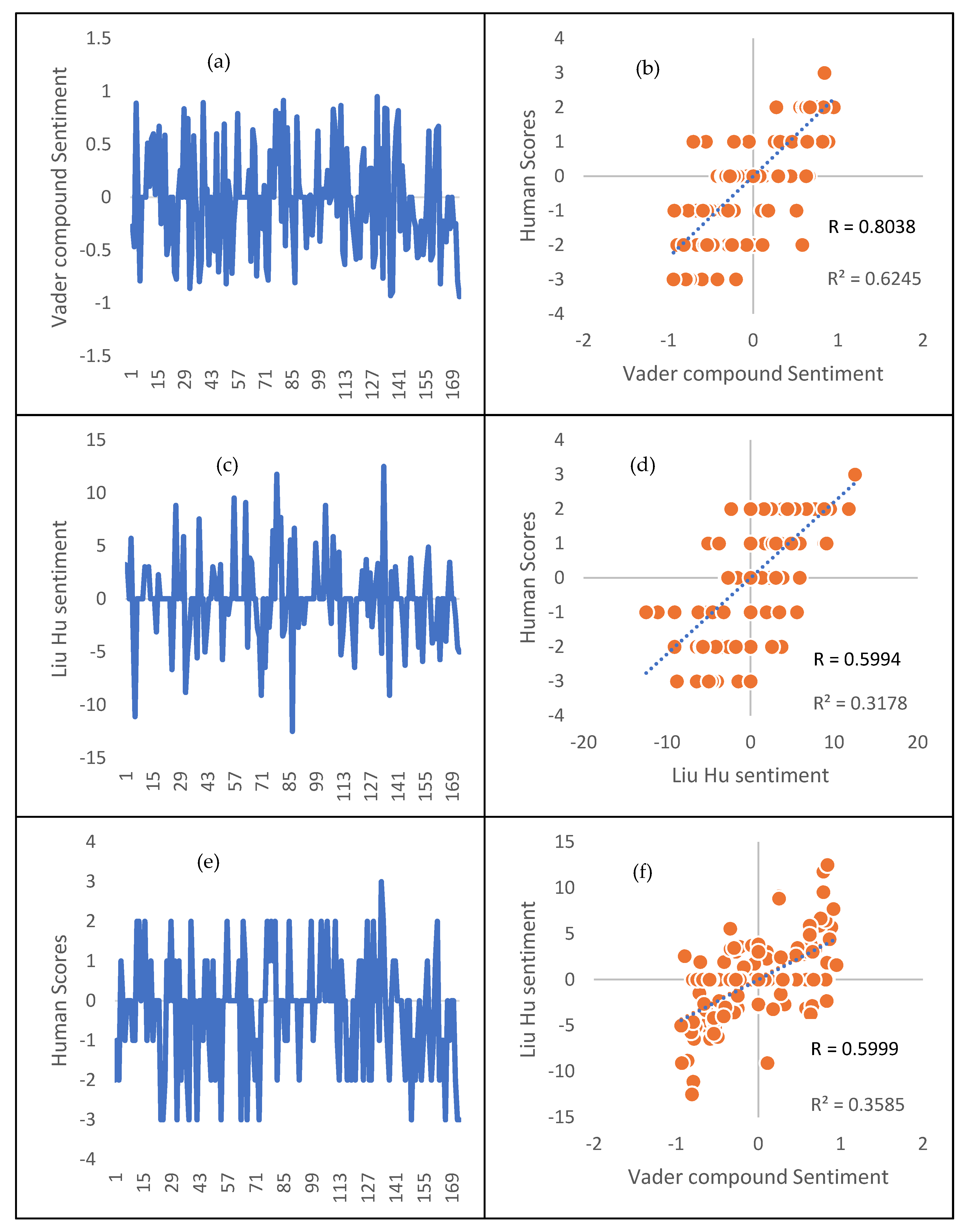
4.5. Results of Ground Truth Generation for Sentiment Analysis
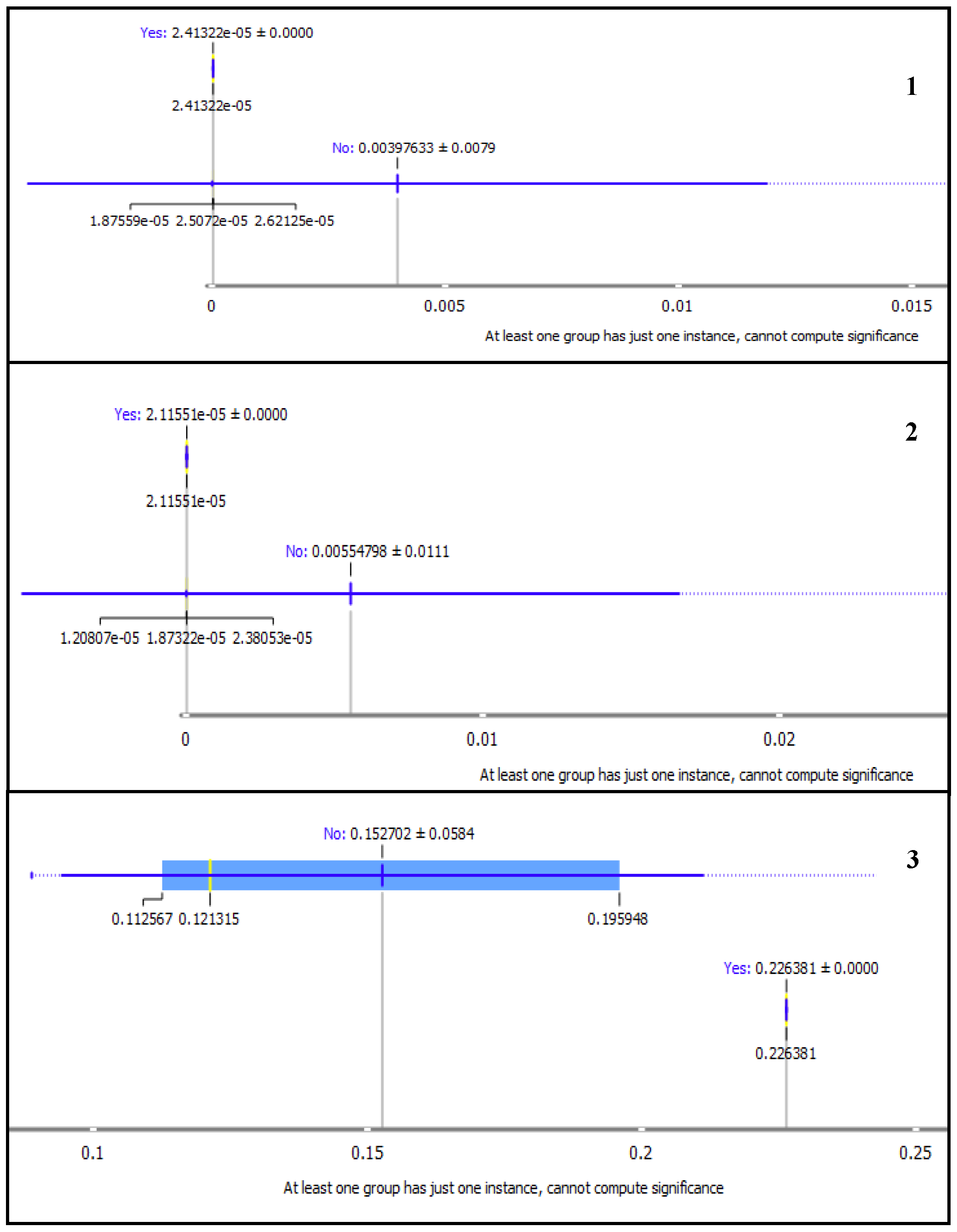
4.6. Results of Topic Modelling
4.7. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Appel, G.; Grewal, L.; Hadi, R.; Stephen, A.T. The future of social media in marketing. J. Acad. Mark. Sci. 2020, 48, 79–95. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sahoo, S.R.; Gupta, B.B. Real-Time Detection of Fake Account in Twitter Using Machine-Learning Approach. Adv. Intell. Syst. Comput. 2020, 1086, 149–159. [Google Scholar] [CrossRef]
- Hariani, K.; Riadi, I. Detection of cyberbullying on social media using data mining techniques. Int. J. Comput. Sci. Inf. Secur. 2017, 15, 244–250. [Google Scholar]
- Sahoo, S.R.; Gupta, B. Multiple features based approach for automatic fake news detection on social networks using deep learning. Appl. Soft Comput. 2021, 100, 106983. [Google Scholar] [CrossRef]
- Sahoo, S.R.; Gupta, B. Hybrid approach for detection of malicious profiles in twitter. Comput. Electr. Eng. 2019, 76, 65–81. [Google Scholar] [CrossRef]
- Boyer, H. Emerging Technologies—Social Media. INALJ Virginia. 2014. Available online: http://inalj.com/?p=62623 (accessed on 15 June 2021).
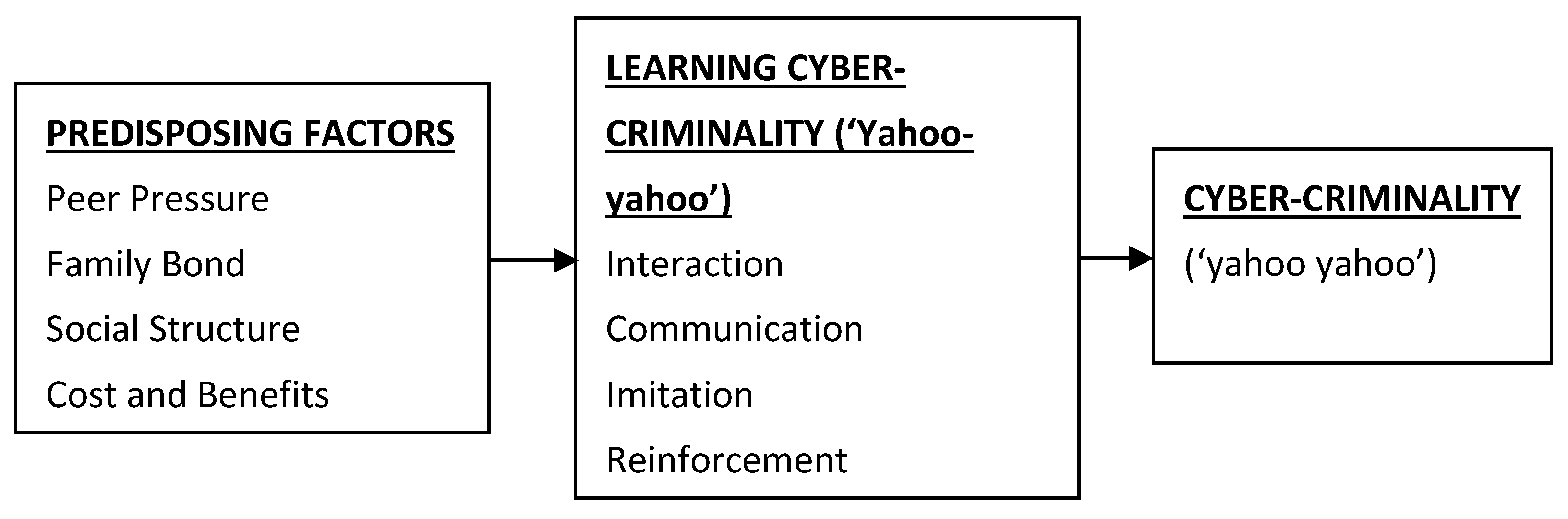
- Ojedokun, U.A.; Eraye, M.C. Socioeconomic lifestyles of the yahoo-boys: A study of perceptions of university stu-dents in Nigeria. Int. J. Cyber Criminol. 2012, 6, 1001–1013. [Google Scholar]
- Tade, O.; Aliyu, I. Social organization of Internet fraud among university undergraduates in Nigeria. Int. J. Cyber Criminol. 2011, 5, 860–875. [Google Scholar]
- Adeniran, A.I. The Internet and emergence of yahoo-boys sub-culture in Nigeria. Int. J. Cyber Criminol. 2008, 2, 368–381. [Google Scholar]
- Ninalowo, A. Nexus of State and Legitimation Crisis; Prime Publications: Lagos, Nigeria, 2016. [Google Scholar]
- Lazarus, S.; Okolorie, G.U. The bifurcation of the Nigerian cybercriminals: Narratives of the Economic and Financial Crimes Commission (EFCC) agents. Telemat. Inform. 2019, 40, 14–26. [Google Scholar] [CrossRef]
- Rossy, Q.; Ribaux, O. Orienting the Development of Crime Analysis Processes in Police Organisations Covering the Digital Transformations of Fraud Mechanisms. Eur. J. Crim. Policy Res. 2020, 26, 335–356. [Google Scholar] [CrossRef]
- Longe, O.; Abayomi-Alli, A.; Shaib, I.L.; Longe, F. Enhanced content analysis of fraudulent Nigeria electronic mails using e-STAT. In Proceedings of the 2009 2nd International Conference on Adaptive Science & Technology (ICAST), Accra, Ghana, 14–16 December 2009; IEEE: Manhattan, NY, USA, 2009; pp. 238–243. [Google Scholar]
- Omoroghomwan, O.B. An Appraisal of the Activities of Economic and Financial Crime Commission (EFCC) on the Administration of Criminal Justice in Nigeria. Acta Univ. Danubius. Relat. Int. 2018, 11, 174–193. [Google Scholar]
- Abayomi-Alli, O.; Misra, S.; Abayomi-Alli, A.; Odusami, M. A review of soft techniques for SMS spam classification: Methods, approaches and applications. Eng. Appl. Artif. Intell. 2019, 86, 197–212. [Google Scholar] [CrossRef]
- AUC: African Union Commission. Cyber Crime & Cyber Security Trends in Africa. 2016. Available online: https://www.thehaguesecuritydelta.com/media/com_hsd/report/135/document/Cyber-security-trends-report-Africa-en.pdf (accessed on 12 July 2021).
- Gupta, B.; Sharma, S.; Chennamaneni, A. Twitter Sentiment Analysis: An Examination of Cybersecurity Attitudes and Behaviour. In Proceedings of the 2016 Pre-ICIS SIGDSA/IFIP WG8.3 Symposium: Innovations in Data Analytics, Dublin, Ireland, 11 December 2016; Available online: https://aisel.aisnet.org/sigdsa2016/17 (accessed on 9 July 2021).
- Kunwar, R.S.; Sharma, P. Social media: A new vector for cyber-attack. In Proceedings of the 2016 International Conference on Advances in Computing, Communication, & Automation (ICACCA) (Spring), Dehradun, India, 8–9 April 2016; IEEE: Manhattan, NY, USA, 2016; pp. 1–5. [Google Scholar]
- Kirik, A.M.; Çetinkaya, A. The Use of Social Media in Online Journalism. In Proceedings of the 3rd International Eurasian Conference on Sport Education and Society, Mardin, Turkey, 15–18 November 2018; Volume 3, pp. 1171–1187. [Google Scholar]
- Can, U.; Alatas, B. A new direction in social network analysis: Online social network analysis problems and applications. Phys. A Stat. Mech. Its Appl. 2019, 535, 122372. [Google Scholar] [CrossRef]
- Hernandez-Suarez, A.; Sanchez-Perez, G.; Toscano-Medina, K.; Martinez-Hernandez, V.; Perez-Meana, H.; Olivares-Mercado, J.; Sanchez, V. Social Sentiment Sensor in Twitter for Predicting Cyber-Attacks Using ℓ1 Regularization. Sensors 2018, 18, 1380. [Google Scholar] [CrossRef] [Green Version]
- Ibrahim, S. Social and contextual taxonomy of cybercrime: Socioeconomic theory of Nigerian cybercriminals. Int. J. Law Crime Justice 2016, 47, 44–57. [Google Scholar] [CrossRef] [Green Version]
- Arimi, C.N. Social-economic factors influencing the crime rate in Meru Municipality Kenya. Master’s Thesis, University of Nairobi, Nairobi, Kenya, 2011. Available online: http://erepository.uonbi.ac.ke:8080/handle/123456789/4688 (accessed on 15 June 2021).
- Adejoh, S.O.; Alabi, T.A.; Adisa, W.B.; Emezie, N.M. “Yahoo Boys” Phenomenon in Lagos Metropolis: A Qualitative Investigation. Int. J. Cyber Criminol. 2019, 13, 1–20. [Google Scholar] [CrossRef]
- Aghababaei, S.; Makrehchi, M. Mining Twitter data for crime trend prediction. Intell. Data Anal. 2018, 22, 117–141. [Google Scholar] [CrossRef]
- Kounadi, O.; Lampoltshammer, T.J.; Groff, E.; Sitko, I.; Leitner, M. Exploring Twitter to Analyze the Public’s Reaction Patterns to Recently Reported Homicides in London. PLoS ONE 2015, 10, e0121848. [Google Scholar] [CrossRef] [Green Version]
- Sharma, K.; Bhasin, S.; Bharadwaj, P. A Worldwide Analysis of Cyber Security and Cyber Crime using Twitter. Int. J. Eng. Adv. Technol. 2019, 8, 1051–1056. [Google Scholar]
- Al-Garadi, M.A.; Varathan, K.D.; Ravana, S.D. Cybercrime detection in online communications: The experimental case of cyberbullying detection in the Twitter network. Comput. Hum. Behav. 2016, 63, 433–443. [Google Scholar] [CrossRef]
- Al-Smadi, M.; Qawasmeh, O.; Al-Ayyoub, M.; Jararweh, Y.; Gupta, B. Deep Recurrent neural network vs. support vector machine for aspect-based sentiment analysis of Arabic hotels’ reviews. J. Comput. Sci. 2018, 27, 386–393. [Google Scholar] [CrossRef]
- Founta, A.M.; Chatzakou, D.; Kourtellis, N.; Blackburn, J.; Vakali, A.; Leontiadis, I. A unified deep learning architecture for abuse detection. In Proceedings of the 10th ACM Conference on Web Science, Boston, MA, USA, 30 June–3 July 2019; pp. 105–114. [Google Scholar]
- Drishya, S.V.; Saranya, S.; Sheeba, J.I.; Devaneyan, S.P. Cyberbully Image and Text Detection using Convolutional Neural Networks. CiiT Int. J. Fuzzy Syst. 2019, 11, 25–30. [Google Scholar]
- Zulfikar, M.T. Suharjito Detection Traffic Congestion Based on Twitter Data using Machine Learning. Procedia Comput. Sci. 2019, 157, 118–124. [Google Scholar] [CrossRef]
- Figueira, Á.; Guimarães, N.; Pinto, J. A System to Automatically Predict Relevance in Social Media. Procedia Comput. Sci. 2019, 164, 105–112. [Google Scholar] [CrossRef]
- Donchenko, D.; Ovchar, N.; Sadovnikova, N.; Parygin, D.; Shabalina, O.; Ather, D. Analysis of Comments of Users of Social Networks to Assess the Level of Social Tension. Procedia Comput. Sci. 2017, 119, 359–367. [Google Scholar] [CrossRef]
- Liu, X.; Fu, J.; Chen, Y. Event evolution model for cybersecurity event mining in tweet streams. Inf. Sci. 2020, 524, 254–276. [Google Scholar] [CrossRef]
- van der Walt, E.; Eloff, J.; Grobler, J. Cyber-security: Identity deception detection on social media platforms. Comput. Secur. 2018, 78, 76–89. [Google Scholar] [CrossRef] [Green Version]
- Cheng, L.; Guo, R.; Liu, H. Robust Cyberbullying Detection with Causal Interpretation. In Proceedings of the Companion Proceedings of the 2019 World Wide Web Conference, San Francisco, CA, USA, 13–17 May 2019; pp. 169–175. [Google Scholar]
- Burnap, P.; Williams, M.L. Cyber Hate Speech on Twitter: An Application of Machine Classification and Statistical Modeling for Policy and Decision Making. Policy Internet 2015, 7, 223–242. [Google Scholar] [CrossRef] [Green Version]
- Hu, M.; Liu, B. Mining opinion features in customer reviews. In Proceedings of the 19th national conference on Artificial Intelligence (AAAI’04), San Jose, CA, USA, 25–29 July 2004; pp. 755–760. [Google Scholar]
- Hutto, C.J.; Gilbert, E. VADER: A Parsimonious Rule-based Model for Sentiment Analysis of Social Media Text. In Proceedings of the 8th International AAAI Conference on Weblogs and Social Media, Ann Arbor, MI, USA, 1–4 June 2014; AAAI Press: San Jose, CA, USA, 2015; pp. 1–10. [Google Scholar]
- Demšar, J.; Curk, T.; Erjavec, A.; Gorup, C.; Hočevar, T.; Milutinovič, M.; Polajnar, M.; Toplak, M.; Starič, A.; Štajdohar, M.; et al. Orange: Data mining toolbox in Python. JMLR 2013, 14, 2349–2353. [Google Scholar]
- Abayomi-Alli, A.; Abayomi-Alli, O.; Misra, S.; Fernandez-Sanz, L. Yahoo-Yahoo Hash-Tag Tweets Using Sentiment Analysis and Opinion Mining Algorithms. Zenodo 2021. [Google Scholar] [CrossRef]
- Labille, K.; Gauch, S.; Alfarhood, S. Creating Domain-Specific Sentiment Lexicons via Text Mining. In Proceedings of the Workshop on Issues of Sentiment Discovery and Opinion Mining (WISDOM’17), Halifax, NS, Canada, 14 August 2017; pp. 1–8. [Google Scholar] [CrossRef]
- Rehurek, R.; Sojka, P. Software framework for topic modelling with large corpora. In Proceedings of the LREC 2010 workshop on new challenges for NLP frameworks, Valletta, Malta, 22 May 2010; pp. 45–50. [Google Scholar]
- Ullah, M.A.; Marium, S.M.; Begum, S.A.; Dipa, N.S. An algorithm and method for sentiment analysis using the text and emoticon. ICT Express 2020, 6, 357–360. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Article Sources | Methods | Contributions | Research Domain |
|---|---|---|---|
| [26] | Machine learning based on logistic regression. | Result shows the proposed method could be effective and reliable for investigating the crime. | Homicide detection. |
| [21] | ℓ1 regularization regression algorithm. | Proposed methods were useful to predict possible cyber-attacks. | Cyber-attack detection. |
| [32] | SVM | Significant improvement in classification accuracy. | Detection Traffic Congestion. |
| [33] | Ensemble method based on Linear SVM, Radial SVM, Polynomial SVM, R.F., and N.B. | The proposed method gave a reliable capacity to predict relevancy with an improvement in accuracy of more than 6%. | Relevance Detection. |
| [34] | Stochastic gradient descent (SGD) approach to training of SVM classifier. | Improved prediction accuracy for the detection of social tension topics in Russia. | Social tension detection. |
| [35] | CyberEM model based on pattern clustering and an NMF-based (non-negative matrix factorization) event aggregation algorithm. | The proposed model was able to discover cybersecurity events and update event aggregation online. | Event detection. |
| [36] | R.F. algorithm. | Developed a low-cost interpretative model. | Identity deception. |
| [28] | SMOTE approach on supervised ML (N.B., SVM, R.F., and KNN). | Develop a cost-sensitive model. | Cyberbullying detection. |
| [37] | K-means clustering algorithm and Random Forest algorithm. | The proposed methods were able to show significant prediction power in detecting cyberbullying. | Cyberbullying behavior |
| [38] | Ensemble machine Classification and Statistical Modelling. | Classification results showed very high levels of performance at reducing false positives and produced promising results with respect to false negatives. | Cyber Hate Speech |
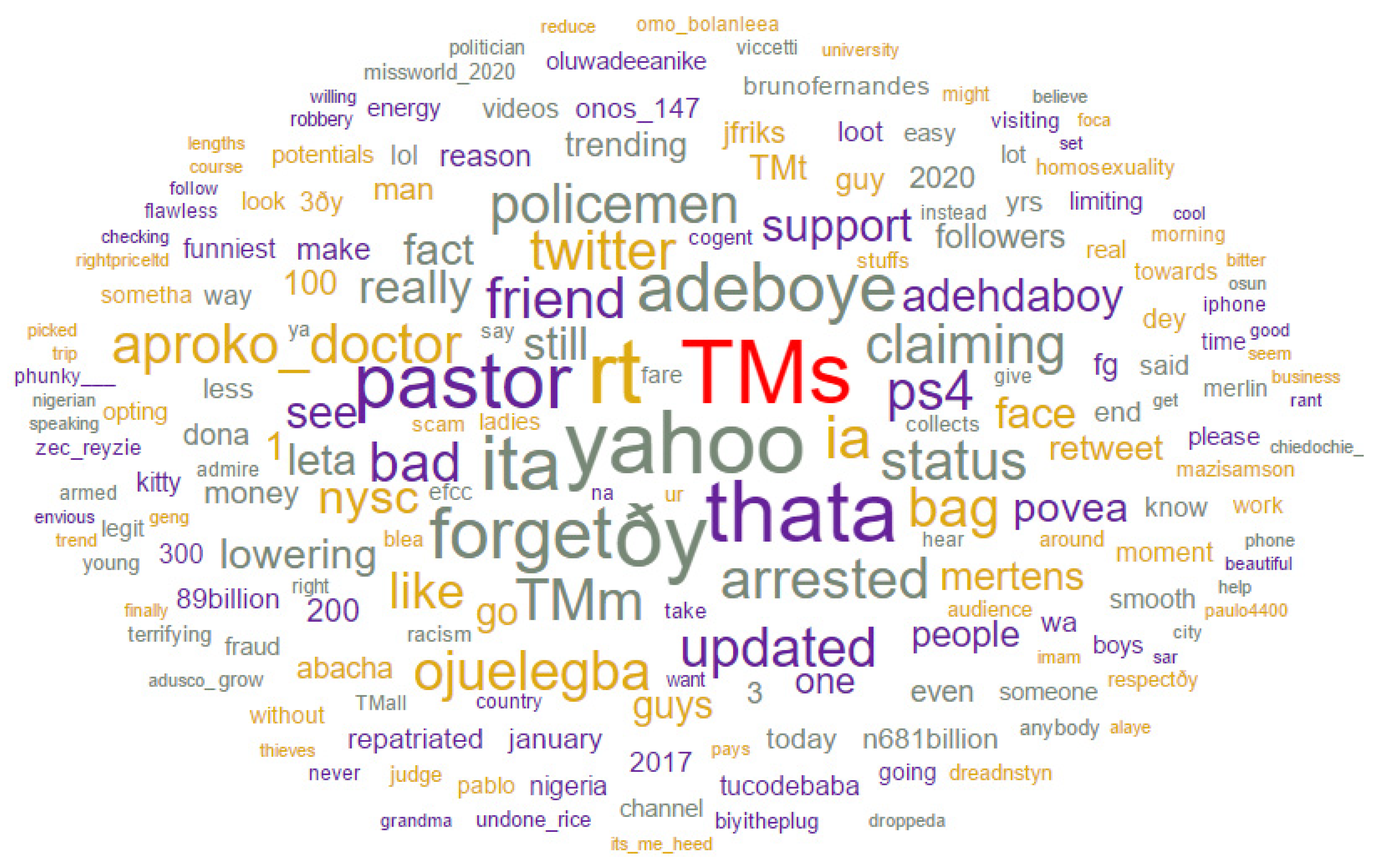
| S/N | Words | Frequency/Weight |
|---|---|---|
| 1 | yahoo | 9555 |
| 2 | pastor | 745 |
| 3 | forget | 668 |
| 4 | adeboye | 628 |
| 5 | arrested | 511 |
| 6 | friend | 499 |
| 7 | bad | 498 |
| 8 | status | 488 |
| 9 | ps4 | 488 |
| 10 | bag | 488 |
| 11 | 487 | |
| 12 | Updated | 486 |
| S/N | Cluster | No. of Retweet | Content |
|---|---|---|---|
| 1 | C91 | 484 | My friend just updated on his status that policemen arrested him at Ojuelegba for having a Ps4 in his bag, claiming that he was a yahoo boy. |
| 2 | C85 | 351 | I’m not in support of Yahoo yahoo; it’s really bad but let’s face the fact that it’s yahoo yahoo that’s still lowering poverty |
| 3 | C110 | 173 | Forget yahoo yahoo for a moment and be as smooth as this kitty. |
| 4 | C80 | 172 | This is one of the funniest video you will see on Twitter today. |
| 5 | C62 | 162 | EFCC Arrests Landlord for housing Yahoo boys. This comprises of more than one form of a tweet (e.g., EFCC, Bad Governance, Landlord, yahoo yahoo government etc.) |
| 6 | C87 | 150 | Yahoo yahoo is like opting for the easy way out, limiting your potentials, why not channel that same energy towards something worthwhile and good. |
| 7 | C123 | 142 | Grow your Twitter audience now. As we can’t do fraud, we can’t do Yahoo yahoo, we can’t steal, and we can’t be lazy |
| 8 | C63 | 141 | This Administration is a scam. EFCC is yahoo yahoo. Every sector of this nation is in Coma. (This talks about the resignation of President Buhari, Fulani Herdsmen, Budget of $12m, EFCC and Yahoo boys) |
| 9 | C79 | 127 | Ladies who collect T-Fare from a man and end up not visiting him without a cogent reason are the real Yahoo Yahoo. |
| 10 | C88 | 127 | Yahoo yahoo—they will brainwash you and make you give them your money. Fraud—you will give them your money on your own free (This emphasis on difference between yahoo yahoo and fraud. Also, it contains tweets on Rochas, linkage with Government and that they are better than politicians) |
| 11 | C103 | 123 | I’m not even going to judge anybody doing yahoo yahoo. |
| 12 | C126 | 122 | Forget, NYSC, Yahoo yahoo, Mertens, Pablo and pastor Adeboye, Twitter people don’t have respect. |
| 13 | C89 | 103 | I don’t know why Yahoo Yahoo is trending, but you all should take your time and admire this flawless makeup |
| 14 | C100 | 103 | The greatest, easiest and most legitimate form of yahoo yahoo in Nigeria is politics |
| 15 | C107 | 99 | D.O. girls also do yahoo yahoo? Or is it only the boys? |
| 16 | C104 | 91 | Problems caused by yahoo yahoo scammers government (This is on corruption, bribery, fraud, yahoo-yahoo and scammers) |
| 17 | C142 | 91 | Legit work that pays. Say No to Yahoo Yahoo. |
| 18 | C102 | 89 | Yahoo yahoo is bad, instead just be a pastor, imam or a politician. |
| 19 | C109 | 81 | Between 2017 and January 2020, F.G. has repatriated $1.89Billion of Abacha Loot. |
| 20 | C96 | 79 | To SARS you are doing yahoo yahoo o. they should just arrest themselves. |
| 21 | C71 | 79 | Someone said Yahoo Yahoo is now a course in his University. |
| LDA Topic Keywords | ||||||
| Topic 1 | Topic 2 | Topic 3 | Topic 4 | Topic 5 | Topic 6 | |
| 1 | Yahoo | yahoo | trending | rt | money | yahoo |
| 2 | rt | rt | 🤣 | geng | 😭 | rt |
| 3 | go | bad | make | 😅 | thiem | pastor |
| 4 | like | arrested | merlin | set | since | retweet |
| 5 | said | updated | nadal | 🙂 | #whatwentwrong | forget |
| 6 | fraud | status | know | order | give | 😂 |
| 7 | end | ps4 | time | @mazedgreat | get | adeboye |
| 8 | reason | bag | someone | everyone | daddy | 💦 |
| 9 | man | friend | take | sars | need | @jfriks |
| 10 | real | ojuelegba | ur | 10 | saying | = |
| LSI Topic keywords | ||||||
| Topic 1 | Topic 2 | Topic 3 | Topic 4 | Topic 5 | Topic 6 | |
| 1 | yahoo | rt | 😂 | 😂 | fg | like |
| 2 | rt | yahoo | = | 2020 | even | |
| 3 | 😂 | = | pastor | pastor | january | lot |
| 4 | bad | arrested | adeboye | nysc | abacha | going |
| 5 | pastor | bag | arrested | adeboye | 3 | terrifying |
| 6 | really | friend | friend | rt | loot | judge |
| 7 | let | ps4 | bag | followers | 2017 | anybody |
| 8 | support | policeman | ps4 | forget | repatriated | racism |
| 9 | still | status | policemen | 200 | n681billion | homosexuality |
| 10 | @adehdaboy | claiming | updated | 100 | yrs | stuffs |
| LDA | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| S/N | Topic 1 | Topic 2 | Topic 3 | Topic 4 | Topic 5 | Topic 6 | ||||||
| Word | Weight | Word | Weight | Word | Weight | Word | Weight | Word | Weight | Word | Weight | |
| 1 | yahoo | 0.17 | nadal | 0.028 | yahoo | 0.101 | rt | 0.095 | rt | 0.04 | yahoo | 0.234 |
| 2 | rt | 0.066 | money | 0.028 | rt | 0.062 | yahoo | 0.092 | #whatwentwrong | 0.018 | rt | 0.075 |
| 3 | 🤣 | 0.028 | geng | 0.026 | pastor | 0.039 | arrested | 0.042 | order | 0.013 | bad | 0.026 |
| 4 | end | 0.022 | thiem | 0.021 | forget | 0.037 | updated | 0.041 | 😅 | 0.011 | really | 0.023 |
| 5 | said | 0.022 | around | 0.02 | 😂 | 0.028 | status | 0.041 | 10 | 0.009 | still | 0.022 |
| 6 | man | 0.02 | crush | 0.018 | adeboye | 0.027 | ps4 | 0.041 | chop | 0.009 | support | 0.022 |
| 7 | someone | 0.019 | pls | 0.017 | 💦 | 0.026 | bag | 0.041 | name | 0.009 | @adehdaboy | 0.021 |
| 8 | real | 0.019 | since | 0.016 | @jfriks | 0.023 | friend | 0.041 | available | 0.009 | let | 0.021 |
| 9 | 😭 | 0.018 | efcc | 0.016 | equal to | 0.023 | claiming | 0.04 | 25 | 0.009 | fact | 0.021 |
| 10 | country | 0.018 | self | 0.016 | followers | 0.022 | ojuelegba | 0.04 | upandan | 0.008 | face | 0.021 |
| Topic 1 | Topic 2 | Topic 3 | Topic 4 | Topic 5 | Topic 6 | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| S/N | Word | Weight | Word | Weight | Word | Weight | Word | Weight | Word | Weight | Word | Weight |
| 1 | yahoo | 0.087 | rt | 0.511 | 😂 | 0.403 | 😂 | −0.382 | fg | 0.226 | like | −0.294 |
| 2 | rt | 0.362 | yahoo | −0.232 | 0.218 | 0.209 | 2020 | 0.224 | even | −0.258 | ||
| 3 | 😂 | 0.092 | 0.200 | pastor | 0.195 | pastor | −0.180 | january | 0.224 | lot | −0.248 | |
| 4 | bad | 0.067 | arrested | 0.194 | adeboye | 0.190 | nysc | −0.173 | abacha | 0.224 | going | −0.246 |
| 5 | pastor | 0.062 | bag | 0.193 | arrested | −0.185 | adeboye | −0.171 | 3 | 0.224 | terrifying | −0.246 |
| 6 | really | 0.060 | friend | 0.193 | friend | −0.185 | rt | 0.165 | loot | 0.224 | judge | −0.245 |
| 7 | let | 0.058 | ps4 | 0.193 | bag | −0.184 | followers | 0.164 | 2017 | 0.224 | anybody | −0.245 |
| 8 | support | 0.058 | policeman | 0.193 | ps4 | −0.184 | forget | −0.160 | repatriated | 0.224 | racism | −0.245 |
| 9 | still | 0.058 | status | 0.193 | policeman | −0.184 | 200 | 0.156 | 1.89 | 0.224 | stuffs | −0.245 |
| 10 | @adehdaboy | 0.057 | ojuelegba | 0.193 | updated | −0.184 | 100 | 0.156 | n681billion | 0.224 | homosexuality | −0.245 |
| S/N | Topic 1 | Topic 2 | Topic 3 | Topic 4 | Topic 5 | Topic 6 |
|---|---|---|---|---|---|---|
| 1 | 😂 | money | Pastor | arrested | order | bad |
| 2 | end | geng | Retweet | updated | whatwentwrong | really |
| 3 | someone | nadal | forget | status | 10 | still |
| 4 | real | thiem | 😂 | ps4 | chop | support |
| 5 | 😭 | around | adeboye | bag | name | @adehdaboy |
| 6 | without | crush | 💦 | friend | available | let |
| 7 | ladies | since | @jfriks | claiming | 25 | fact |
| 8 | collects | efcc | = | ojuelegba | shout | face |
| 9 | t-fare | self | followers | policemen | upandan | lowering |
| 10 | @biyitheplug | laugh | 100 | @aproko_doctor | funds | pove |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Abayomi-Alli, A.; Abayomi-Alli, O.; Misra, S.; Fernandez-Sanz, L. Study of the Yahoo-Yahoo Hash-Tag Tweets Using Sentiment Analysis and Opinion Mining Algorithms. Information 2022, 13, 152. https://doi.org/10.3390/info13030152
Abayomi-Alli A, Abayomi-Alli O, Misra S, Fernandez-Sanz L. Study of the Yahoo-Yahoo Hash-Tag Tweets Using Sentiment Analysis and Opinion Mining Algorithms. Information. 2022; 13(3):152. https://doi.org/10.3390/info13030152
Chicago/Turabian StyleAbayomi-Alli, Adebayo, Olusola Abayomi-Alli, Sanjay Misra, and Luis Fernandez-Sanz. 2022. "Study of the Yahoo-Yahoo Hash-Tag Tweets Using Sentiment Analysis and Opinion Mining Algorithms" Information 13, no. 3: 152. https://doi.org/10.3390/info13030152
APA StyleAbayomi-Alli, A., Abayomi-Alli, O., Misra, S., & Fernandez-Sanz, L. (2022). Study of the Yahoo-Yahoo Hash-Tag Tweets Using Sentiment Analysis and Opinion Mining Algorithms. Information, 13(3), 152. https://doi.org/10.3390/info13030152