



Generative Adversarial Networks (GANs) for Audio-Visual Speech Recognition in Artificial Intelligence IoT



Abstract
:1. Introduction
- Introduction of a novel multimodal generative adversarial network AVSR architecture for IoT: We propose an innovative AVSR architecture, leveraging a multimodal generative adversarial network, which combines GFP-GAN and audio-visual speech recognition models. This integration enhances facial feature details, resulting in improved classification performance for IoT applications.
- Exploration of model lightweighting techniques: we investigate various model lightweighting techniques, such as modular task design and the integration of cache modules. These optimizations effectively reduce the computational complexity of the model, while preserving a high performance. This adaptability makes the model well-suited for deployment in resource-constrained IoT devices.
- Focus on privacy and security: we delve into the privacy and security considerations associated with different data sources. Our research includes the establishment of rigorous privacy protocols, authentication mechanisms, and the incorporation of federated learning principles. These measures collectively enhance the privacy and security of model data, which is critical for IoT applications.
- Extensive experimental validation: through extensive experimental evaluations, we demonstrate the versatility of our AVSR architecture in various IoT scenarios, affirming its applicability across diverse real-world contexts.
2. Literature Review
2.1. Generative Adversarial Networks
2.2. Fully Connected Generative Adversarial Network
2.3. Deep Convolutional Generative Adversarial Network
2.4. Laplacian Pyramid Generative Adversarial Network
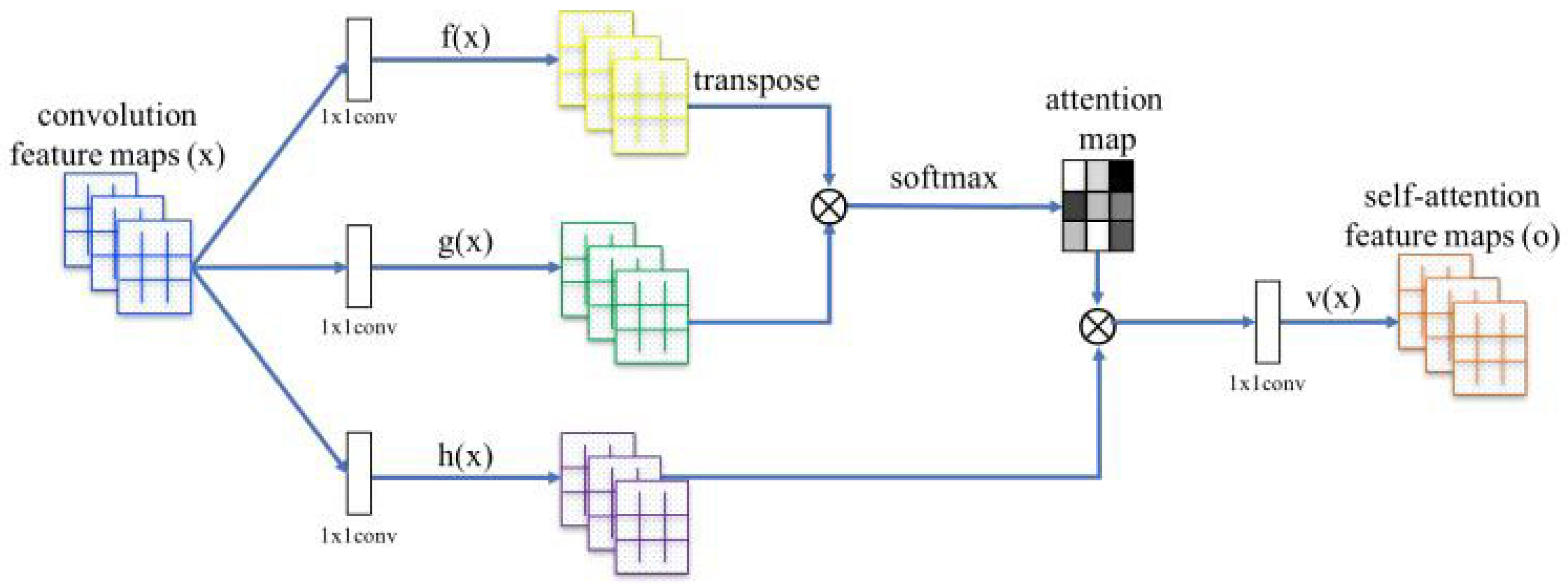
2.5. Self-Attention Generative Adversarial Networks
2.6. Cycle-Consistent Adversarial Networks
2.7. Bicycle Generative Adversarial Networks
2.8. Star Generative Adversarial Networks
2.9. Super-Resolution Generative Adversarial Network
2.10. Diverse Generative Adversarial Network
3. Multimodal Audio-Visual Sensing
3.1. Multimodal Audio-Visual Sensing
3.2. AVSR with GFP-GAN
3.3. AVSR with Wave2Lip-GAN
4. Experiments
4.1. Description of Datasets
4.2. Experiment 1–GFP-GAN
4.3. Experiment 2—Wave2Lip-GAN
4.4. Comparison Results for Classification and Discussion
4.5. Comparison Results for Energy Efficiency Generalizability and Discussion
5. Audio-Visual Speech Recognition for IoT
5.1. Privacy and Security of Audio-Visual Data
5.2. Extension and Application of AVSR
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Atzori, L.; Iera, A.; Morabito, G. The internet of things: A survey. Comput. Netw. 2010, 54, 2787–2805. [Google Scholar] [CrossRef]
- Zhao, F.; Wang, W.; Chen, H.; Zhang, Q. Interference alignment and game-theoretic power allocation in MIMO heterogeneous sensor networks communications. Signal Process. 2016, 126, 173–179. [Google Scholar] [CrossRef]
- Roberts, C.M. Radio frequency identification (RFID). Comput. Secur. 2006, 25, 18–26. [Google Scholar] [CrossRef]
- Stergiou, C.; Psannis, K.E. Recent advances delivered by mobile cloud computing and internet of things for big data applications: A survey. Int. J. Netw. Manag. 2017, 27, e1930. [Google Scholar] [CrossRef]
- Tiippana, K. What is the McGurk effect? Front. Psychol. 2014, 5, 725. [Google Scholar] [CrossRef] [PubMed]
- Kinjo, T.; Funaki, K. On HMM speech recognition based on complex speech analysis. In Proceedings of the IECON 2006—32nd Annual Conference on IEEE Industrial Electronics, Paris, France, 6–10 November 2006; IEEE: Piscataway, NJ, USA, 2006; pp. 3477–3480. [Google Scholar]
- Dupont, S.; Luettin, J. Audio-visual speech modeling for continuous speech recognition. IEEE Trans. Multimed. 2000, 2, 141–151. [Google Scholar] [CrossRef]
- Afouras, T.; Chung, J.S.; Senior, A.; Vinyals, O.; Zisserman, A. Deep audio-visual speech recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 44, 8717–8727. [Google Scholar] [CrossRef] [PubMed]
- Zhang, X.; Cheng, F.; Wang, S. Spatio-temporal fusion based convolutional sequence learning for lip reading. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 713–722. [Google Scholar]
- Li, W.; Wang, S.; Lei, M.; Siniscalchi, S.M.; Lee, C.H. Improving audio-visual speech recognition performance with cross-modal student-teacher training. In Proceedings of the ICASSP 2019—2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 6560–6564. [Google Scholar]
- Mehrabani, M.; Bangalore, S.; Stern, B. Personalized speech recognition for Internet of Things. In Proceedings of the 2015 IEEE 2nd World Forum on Internet of Things (WF-IoT), Milan, Italy, 14–16 December 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 369–374. [Google Scholar]
- Dabran, I.; Avny, T.; Singher, E.; Danan, H.B. Augmented reality speech recognition for the hearing impaired. In Proceedings of the 2017 IEEE International Conference on Microwaves, Antennas, Communications and Electronic Systems (COMCAS), Tel-Aviv, Israel, 3–15 November 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1–4. [Google Scholar]
- Ma, Z.; Liu, Y.; Liu, X.; Ma, J.; Li, F. Privacy-preserving outsourced speech recognition for smart IoT devices. IEEE Internet Things J. 2019, 6, 8406–8420. [Google Scholar] [CrossRef]
- Bäckström, T. Speech coding, speech interfaces and IoT-opportunities and challenges. In Proceedings of the 2018 52nd Asilomar Conference on Signals, Systems, and Computers, Pacific Grove, CA, USA, 28–31 October 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1931–1935. [Google Scholar]
- Brock, A.; Donahue, J.; Simonyan, K. Large scale GAN training for high fidelity natural image synthesis. arXiv preprint 2018, arXiv:1809.11096. [Google Scholar]
- Park, T.; Liu, M.; Wang, T.; Zhu, J. Semantic image synthesis with spatially-adaptive normalization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Wang, X.; Yu, K.; Wu, S.; Gu, J.; Liu, Y.; Dong, C.; Qiao, Y.; Loy, C.C. Esrgan: Enhanced super-resolution generative adversarial networks. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Yu, J.; Lin, Z.; Yang, J.; Shen, X.; Lu, X.; Huang, T.S. Generative image inpainting with contextual attention. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 5505–5514. [Google Scholar]
- Salimans, T.; Goodfellow, I.; Zaremba, W.; Cheung, V.; Radford, A.; Chen, X. Improved Techniques for Training Gans. In Advances in Neural Information Processing Systems (NeurIPS); The MIT Press: Cambridge, MA, USA, 2016; pp. 2234–2242. [Google Scholar]
- Xue, Y.; Xu, T.; Zhang, H.; Long, L.R.; Huang, X. Segan: Adversarial network with multi-scale L1 loss for medical image segmentation. Neuroinformatics 2018, 16, 383–392. [Google Scholar] [CrossRef]
- Karras, T.; Laine, S.; Aila, T. A style-based generator architecture for generative adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 4401–4410. [Google Scholar]
- Karras, T.; Aila, T.; Laine, S.; Lehtinen, J. Progressive Growingof GANs for Improved Quality, Stability, and Variation. arXiv preprint 2017, arXiv:1710.10196. [Google Scholar]
- Karras, T.; Laine, S.; Aittala, M.; Hellsten, J.; Lehtinen, J.; Aila, T. Analyzing and improving the image quality of stylegan. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020. [Google Scholar]
- Wang, X.; Li, Y.; Zhang, H.; Shan, Y. Towards real-world blind face restoration with generative facial prior. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 9168–9178. [Google Scholar]
- Deng, L. The mnist database of handwritten digit images for machine learning research [best of the web]. IEEE Signal Process. Mag. 2012, 29, 141–142. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Hinton, G. Learning Multiple Layers of Features from Tiny Images; MIT: Cambridge, MA, USA; NYU: New York, NY, USA, 2009. [Google Scholar]
- Zeiler, M.D.; Fergus, R. Visualizing and understanding convolutional networks. In Proceedings of the Computer Vision—ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Proceedings, Part I 13. Springer International Publishing: Cham, Switzerland, 2014; pp. 818–833. [Google Scholar]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised representation learning with deep convolutional generative adversarial networks. arXiv preprint 2015, arXiv:1511.06434. [Google Scholar]
- Xu, L.; Ren, J.S.; Liu, C.; Jia, J. Deep convolutional neural network for image deconvolution. Adv. Neural Inf. Process. Syst. 2014, 27, 90–1798. [Google Scholar]
- Springenberg, J.T.; Dosovitskiy, A.; Brox, T.; Riedmiller, M. Striving for simplicity: The all convolutional net. arXiv preprint 2014, arXiv:1412.6806. [Google Scholar]
- Santurkar, S.; Tsipras, D.; Ilyas, A.; Madry, A. How does batch normalization help optimization? In Proceedings of the 2018 Conference on Neural Information Processing Systems, Montreal, QC, Canada, 3–8 December 2018; Volume 31. [Google Scholar]
- Li, Y.; Yuan, Y. Convergence analysis of two-layer neural networks with ReLU activation. In Proceedings of the 2017 Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Lai, W.S.; Huang, J.B.; Ahuja, N.; Yang, M.H. Deep Laplacian pyramid networks for fast and accurate super-resolution. arXiv preprint 2017, arXiv:1704.03915. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Zhang, H.; Goodfellow, I.; Metaxas, D.; Odena, A. Self-attention generative adversarial networks. arXiv preprint 2019, arXiv:1805.08318. [Google Scholar]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar]
- Zhu, J.Y.; Zhang, R.; Pathak, D.; Darrell, T.; Efros, A.A.; Wang, O.; Shechtman, E. Toward multimodal image-to-image translation. arXiv preprint 2017, arXiv:1711.11586. [Google Scholar]
- Choi, Y.; Choi, M.; Kim, M.; Ha, J.W.; Kim, S.; Choo, J. Stargan: Unified generative adversarial networks for multi-domain image-to-image translation. arXiv preprint 2018, arXiv:1711.09020. [Google Scholar]
- Ledig, C.; Theis, L.; Huszár, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z.; et al. Photo-realistic single image super-resolution using a generative adversarial network. arXiv preprint 2017, arXiv:1609.04802. [Google Scholar]
- Zareapoor, M.; Celebi, M.E.; Yang, J. Diverse adversarial network for image super-resolution. Signal Process. Image Commun. 2019, 74, 191–200. [Google Scholar] [CrossRef]
- Chung, J.; Zisserman, A. Lip reading in profile. In Proceedings of the Ritish Machine Vision Conference, London, UK, 4–7 September 2017; British Machine Vision Association and Society for Pattern Recognition: Durham, UK, 2017. [Google Scholar]
- Prajwal, K.R.; Mukhopadhyay, R.; Namboodiri, V.P.; Jawahar, C.V. A lip sync expert is all you need for speech to lip generation in the wild. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020; pp. 484–492. [Google Scholar]
- The Oxford-BBC Lip Reading Sentences 2 (LRS2) Dataset. Available online: https://www.robots.ox.ac.uk/~vgg/data/lip_reading/lrs2.html (accessed on 8 March 2023).
- Lip Reading Sentences 3 (LRS3) Dataset. Available online: https://www.robots.ox.ac.uk/~vgg/data/lip_reading/lrs3.html (accessed on 8 March 2023).
- The Oxford-BBC Lip Reading in the Wild (LRW) Dataset. Available online: https://www.robots.ox.ac.uk/~vgg/data/lip_reading/lrw1.html (accessed on 8 July 2023).


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category/Domain Area | Year | Main Contributions | Datasets | Reference |
|---|---|---|---|---|
| Research work on GANs for image translation | 2017 | CycleGAN: Proposed architecture for image translation without pairing data | CycleGAN Pix2Pix | JunYan Zhu et al. [36] |
| 2018 | BicycleGAN: Implementing multimodal image translation | CycleGAN Pix2Pix | JunYan Zhu et al. [37] | |
| 2018 | StarGAN: Proposed a Unified GAN architecture for multi-domain image translation | CelebA RaFD ImageNet | Yunjey Choi et al. [38] | |
| Research work on GANs for image generation | 2014 | FCGAN: Early generative adversarial network models utilizing fully connected neural networks. | MNIST CIFAR10 | Ian Goodfellow et al. |
| 2014 | DCGAN: The first model to combine deep convolutional neural networks (CNNs) with generative adversarial networks. | MNIST CIFAR10 | Xu et al. [29] | |
| 2019 | SAGAN: Proposed structure for GAN image generation with self-attention. | ImageNet | Han Zhang et al. [35] | |
| Research work on GANs for image super-resolution | 2015 | LAPGAN: Step-by-step image super-resolution using the Laplace pyramid framework. | CIFAR10 | Lai et al. [33] |
| 2017 | SRGAN: A milestone in the successful introduction of GAN into the field of image super-resolution. | Set5 | Christian Ledig et al. [39] | |
| 2019 | DGAN: Implementing a multi-sample image super-resolution architecture. | DIV2K | Masoumeh Zareapoor et al. [40] |
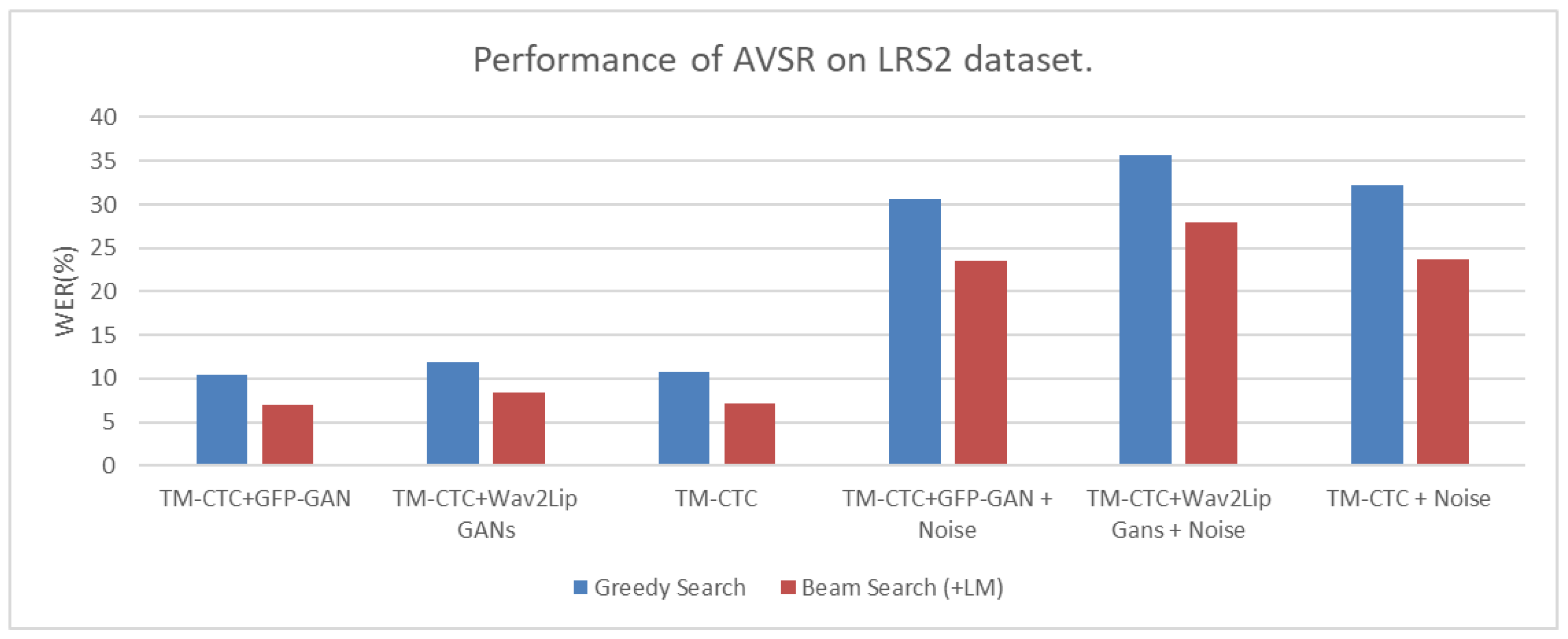
| AVSR Architecture | Greedy Search | Beam Search (+LM) | |
|---|---|---|---|
| Clean Input | |||
| TM-CTC+ GFP-GAN | AV | 10.20% | 6.80% |
| TM-CTC+Wav2Lip GANs | AV | 11.90% | 8.40% |
| TM-CTC | AV | 10.60% | 7.00% |
| Added Noise | |||
| TM-CTC+GFP-GAN | AV | 29.40% | 22.40% |
| TM-CTC+Wav2Lip Gans | AV | 35.70% | 27.90% |
| TM-CTC | AV | 30.30% | 22.80% |
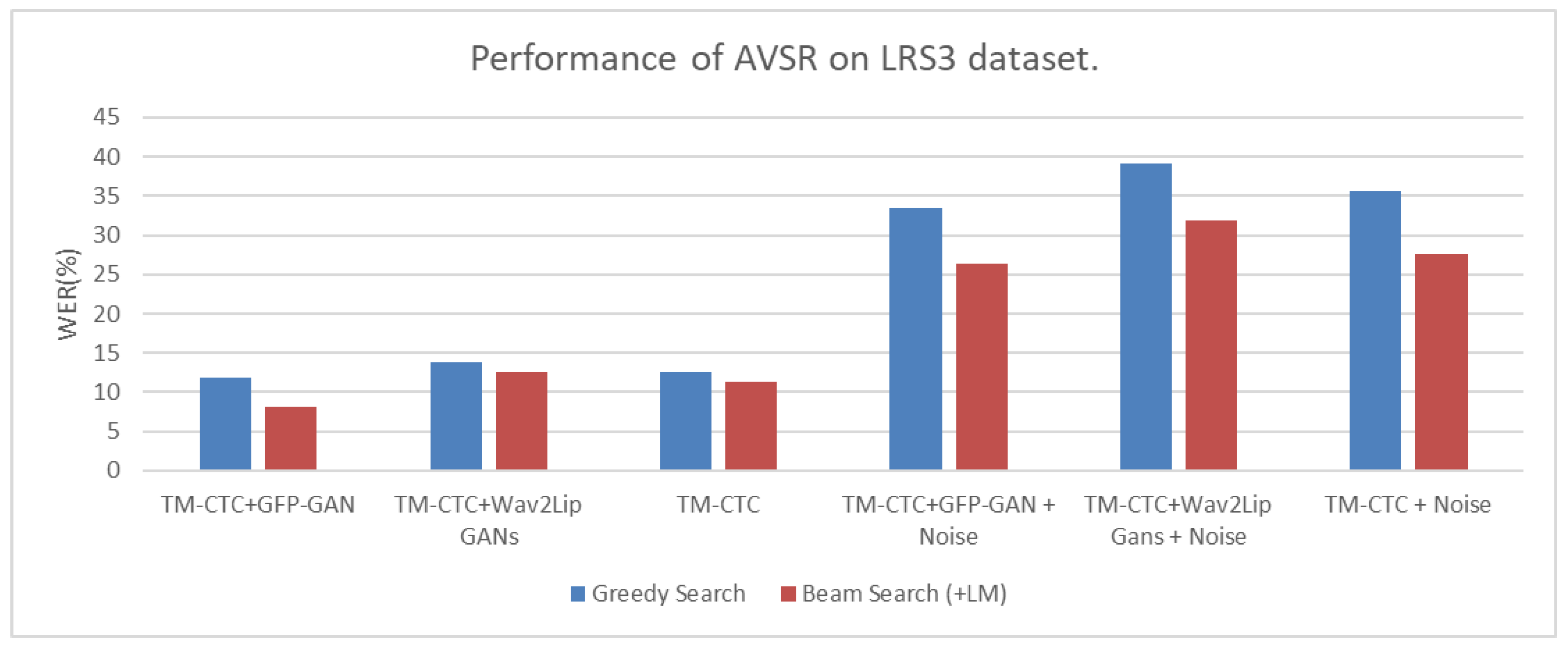
| AVSR Architecture | Greedy Search | Beam Search (+LM) | |
|---|---|---|---|
| Clean Input | |||
| TM-CTC+GFP-GAN | AV | 11.60% | 8.00% |
| TM-CTC+Wav2Lip GANs | AV | 13.80% | 12.60% |
| TM-CTC | AV | 12.20% | 10.80% |
| Added Noise | |||
| TM-CTC+GFP-GAN | AV | 32.40% | 25.50% |
| TM-CTC+Wav2Lip Gans | AV | 39.20% | 31.90% |
| TM-CTC | AV | 34.70% | 26.80% |
| AVSR Architecture | Greedy Search Run Time (h) | Beam Search (+LM) Run Time (h) | |
|---|---|---|---|
| Clean Input | |||
| TM-CTC+GFP-GAN | AV | 72 | 90 |
| TM-CTC+Wav2Lip GANs | AV | 69 | 88 |
| TM-CTC | AV | 96 | 115 |
| Added Noise | |||
| TM-CTC+GFP-GAN | AV | 75 | 97 |
| TM-CTC+Wav2Lip Gans | AV | 72 | 92 |
| TM-CTC | AV | 100 | 122 |
| AVSR Architecture | Greedy Search Run Time (h) | Beam Search (+LM) Run Time (h) | |
|---|---|---|---|
| Clean Input | |||
| TM-CTC+GFP-GAN | AV | 78 | 104 |
| TM-CTC+Wav2Lip GANs | AV | 80 | 98 |
| TM-CTC | AV | 100 | 118 |
| Added Noise | |||
| TM-CTC+GFP-GAN | AV | 79 | 109 |
| TM-CTC+Wav2Lip Gans | AV | 89 | 115 |
| TM-CTC | AV | 103 | 126 |
| AVSR Architecture | Greedy Search | Beam Search (+LM) | |
|---|---|---|---|
| Clean Input | |||
| TM-CTC+GFP-GAN | AV | 13.40% | 10.50% |
| TM-CTC+Wav2Lip GANs | AV | 17.30% | 16.20% |
| TM-CTC | AV | 15.30% | 13.80% |
| Added Noise | |||
| TM-CTC+GFP-GAN | AV | 34.80% | 27.30% |
| TM-CTC+Wav2Lip Gans | AV | 42.20% | 34.50% |
| TM-CTC | AV | 37.60% | 29.20% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
He, Y.; Seng, K.P.; Ang, L.M. Generative Adversarial Networks (GANs) for Audio-Visual Speech Recognition in Artificial Intelligence IoT. Information 2023, 14, 575. https://doi.org/10.3390/info14100575
He Y, Seng KP, Ang LM. Generative Adversarial Networks (GANs) for Audio-Visual Speech Recognition in Artificial Intelligence IoT. Information. 2023; 14(10):575. https://doi.org/10.3390/info14100575
Chicago/Turabian StyleHe, Yibo, Kah Phooi Seng, and Li Minn Ang. 2023. "Generative Adversarial Networks (GANs) for Audio-Visual Speech Recognition in Artificial Intelligence IoT" Information 14, no. 10: 575. https://doi.org/10.3390/info14100575
APA StyleHe, Y., Seng, K. P., & Ang, L. M. (2023). Generative Adversarial Networks (GANs) for Audio-Visual Speech Recognition in Artificial Intelligence IoT. Information, 14(10), 575. https://doi.org/10.3390/info14100575