1. Introduction
Yali pears (
Pyrus bretschneideri Rehd.) are also known as white pears [
1]. With a regular and duck head-like shape, this kind of pear has thin skin, a small kernel, and juicy flesh. Yali pears are loved by consumers at home and abroad because they have the functions of relieving cough and thirst, and clearing heat and detoxification [
2]. Yali pears can be easily affected by their environment during storage, especially by carbon dioxide (CO
2). When the CO
2 concentration is greater than 1%, the Yali pears will suffer from internal browning [
3]. Browning is mainly related to the regulation of various genes and relevant enzymes in Yali pears [
4], among which phenolic substances are the main substrates leading to browning. Under aerobic conditions, phenolic substances react with polyphenol oxidase to produce quinones [
5], thereby accelerating the occurrence of browning. The browning of Yali pears starts from the inside of the fruit, so it is difficult to observe from the surface at the initial stage. Only when the browning worsens, it can be observed that the surface of Yali pears will become darker. Browning undermines the quality of Yali pears and makes them less tasty, thus leading to bad sales. Therefore, it is urgent to explore a nondestructive, environment-friendly, and accurate technology to identify browning in Yali pears.
During post-harvest storage, Yali pears are prone to core and pulp browning and lose their commercial value. Therefore, huge economic losses are caused to producers and operators. The traditional method of browning discrimination is usually combined with experience to conduct destructive sampling inspection of internal components [
6]. This will make fruit analysis difficult to achieve quickly, accurately, and non-destructively. It is not suitable for the actual situation of fruit production and sales at present. Visible-near infrared (Vis-NIR) spectroscopy is an indirect measurement method suitable for rapid online analysis. With its environment-friendly, non-destructive, and flexible integrated detection unit, Vis-NIR spectroscopy has been widely used in the detection of fruit components and defects. Sun et al. [
7] adopted Vis-NIR spectroscopy to simultaneously measure online the browned core and soluble solids content (SSC) in Yali pears. They selected a total of 200 samples, including 73 pears with black-heart disease and 127 pears of good quality. The results showed that the classification accuracy of black-heart Yali pears by Vis-NIR spectroscopy was up to 98.3%. The percentages of SSC predictive precision were 97.8% and 99% within deviations of ±0.5 and ±1%, respectively. Qin et al. [
6] conducted online and non-destructive detection of moldy-heart disease in apples through the miniature Vis-NIR spectrometer. After the 96 samples were optimized in terms of placement posture, the accuracy of partial least squares discriminant analysis (PLS-DA) reached 93.75%. By adopting Vis-NIR spectroscopy, Hao et al. [
8] established an AdaBoost integrated model based on k nearest neighbors (kNN), naive Bayes classifier (NBC), and support vector machine (SVM) for 285 Yali samples. The results showed that the AdaBoost model combined with wavelet transform (WT) had the highest discrimination accuracy (92.63%) of black-heart Yali online detection. Cruz et al. [
9] simulated the randomness of fruit positions during spectral acquisition by randomly sampling on the four sides of 1002 ‘Rocha’ pears, so as to figure out the optimal combination of pretreatment method and discrimination method. The results showed that PLS-DA combined with the original spectrum of Yali pears browning classification mode presented the best performance, and the classification accuracy reached 83%. The above results indicated that the research on the discriminant model of browning of Yali pears has basically stayed on machine learning in recent years. These methods are applicable when the amounts of samples are relatively small, and the accuracy requirement is not high. There were few studies on the discriminant of Yali pears by the deep learning model combined with the spectral analysis method. Vis-NIR as an environment-friendly and nondestructive detection technique can be employed to identify browning in Yali pears. When the number of samples is limited, the discrimination accuracy will vary with different identification methods.
In recent years, convolutional neural network (CNN) has been widely and successfully used in image recognition, natural language, video, and other fields. By combining NIR technology with one-dimensional convolutional neural network (1D-CNN), Li et al. [
10] developed a data-driven model to estimate the content of organic matter in
Huangshan Maofeng tea. The results showed that the key features of NIR spectroscopy were successfully extracted, thus providing a new and effective NIR analysis strategy for food analysis. Wu et al. [
11] established a quantitative analysis model to detect olive oil content in a corn oil–olive oil mixture by combining Raman spectroscopy with 1D-CNN. The results showed that the 1D-CNN model based on 315 extended average Raman spectra could quantitatively detect the content of olive oil, in which the predictive determination coefficient (
) and the root mean square error of prediction (RMSEP) were 0.9908 and 0.7183, respectively. Chen et al. [
12] established a CNN calibration model for the NIR quantitative determination of water pollution and verified the applicability of shallow convolutional network modeling architecture in feature extraction of one-dimensional spectral data. Rong et al. [
13] proposed a detection method based on the principle of deep learning. Through the construction of a 1D-CNN model, the Vis-NIR spectral database containing a total of 500 samples of five kinds of peaches was established for identifying peach varieties. The results showed that the accuracy of the deep learning model reached 100% in the validation data set and 94.4% in the test data set. As suggested by multiple studies, when the number of samples for analysis met certain requirements, CNN combined with Vis-NIR can be applied for the identification of material variety and component analysis. In addition, for the NIR spectral analysis based on scientific research instruments or at a static state, the CNN method can obtain better analytical accuracy, because the spectral response has better wavelength accuracy and less external noise interference.
Vis-NIR online analysis technology cannot be successfully applied without a stable, accurate, and concise modeling algorithm. The effectiveness of the algorithm not only depends on the information extraction ability of the algorithm itself, but also the pretreatment of spectra and effective variable screening before modeling. However, a large number of discriminative models need to be established for the continuous selection of multiple spectral pretreatment methods and variable screening methods, and it is hard to maintain the consistency of optimal variables obtained by different variable screening methods, which affects the stability of the model. For this reason, in order to ensure the accuracy of the model while reducing the complexity and differences in the selection of pretreatment methods and spectral variable screening methods, this paper intends to adopt a deep learning method to simultaneously realize the automatic extraction of spectral feature variables and model construction. In other words, the depth features of Vis-NIR of Yali pears are extracted and used for modeling by means of a 1D-CNN algorithm, so that the interference of noise on the feature variables selection can be avoided and the stability of the model is thus improved. This study can provide reference for rapid online analysis of Yali pear quality in an accurate and reliable manner based on deep learning.
3. Results and Discussion
3.1. Vis-NIR Spectral Analysis of Yali Pears
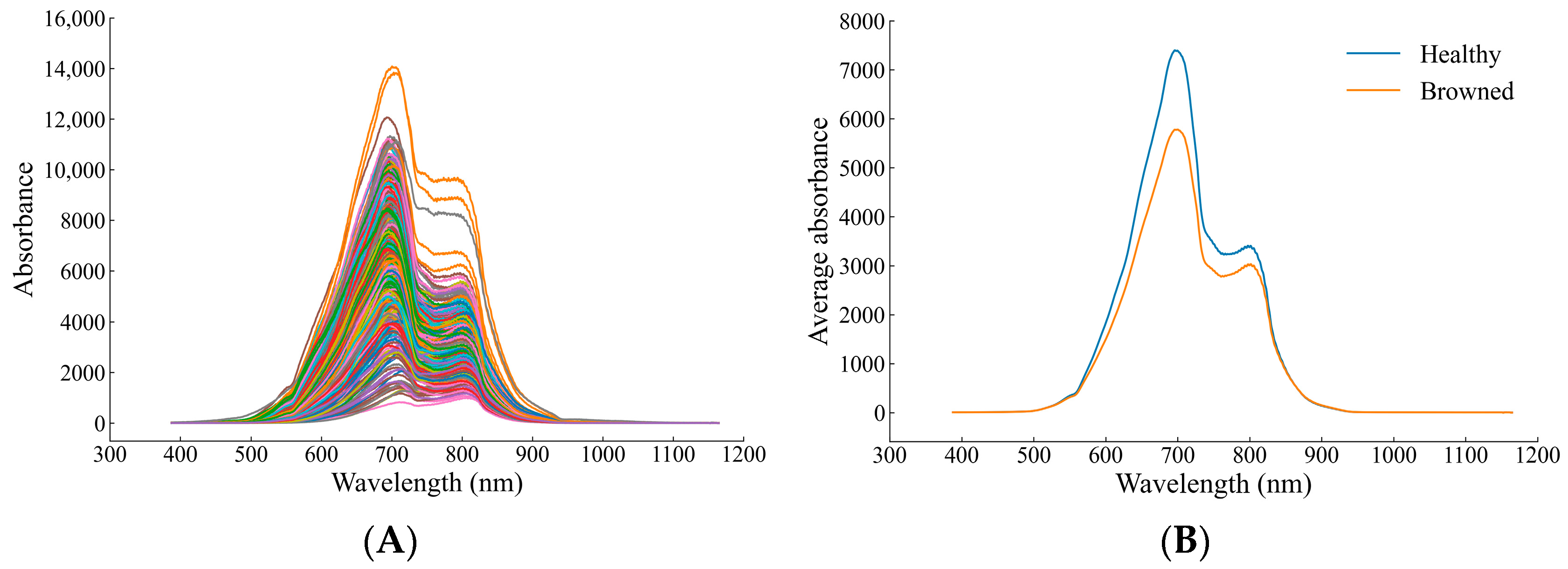
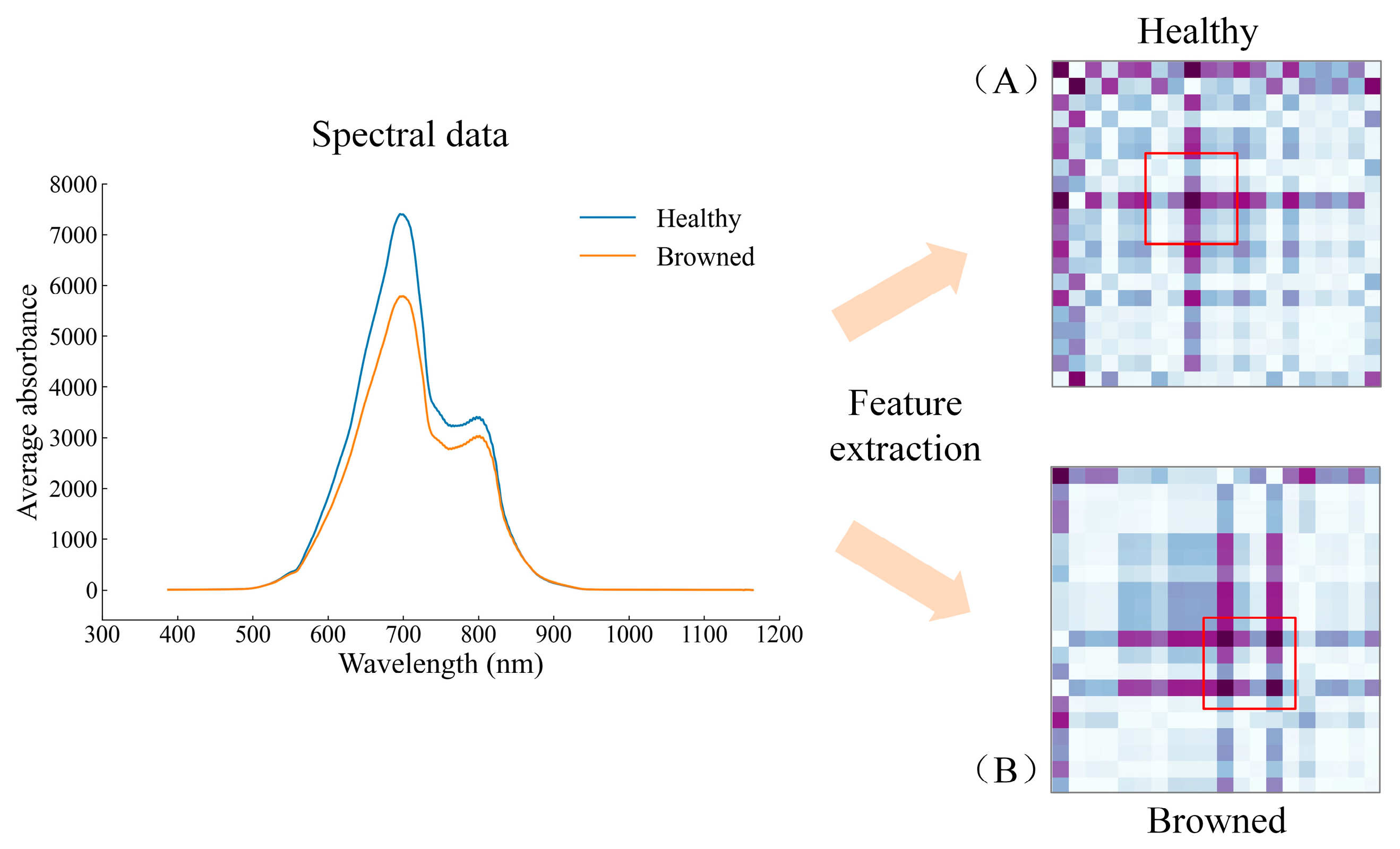
Figure 5 shows the original Vis-NIR spectra of healthy and browning Yali pears, as well as the averaged spectra. It can be seen from
Figure 5A that the spectra of healthy pears and browning pears overlap so seriously that it is impossible to directly distinguish from the spectral graph whether Yali pears were browned or not. It can be seen from
Figure 5B that the average spectrum of healthy pears is higher than that of browned pears on the whole, and the band of 600–800 nm is the most obvious, which may be due to the strong absorption of transmitted light by browning tissue inside the fruit. As shown in the spectral graph, there are two absorption peaks at approximately 700 and 800 nm. In addition, the absorption peak at around 700 nm may result from the stretching and contraction of the fourth overtone of the C-H functional group, while that at around 800 nm may be related to the stretching and contraction of the third overtone of the N-H functional group [
23].
3.2. PCA Analysis on Health Status of Yali Pears with Different Pretreatment Methods
In the experiment, principal component analysis (PCA) was applied to analyze the spectral spatial distribution of two kinds of Yali pear samples pretreated by different methods. The core idea of PCA is dimensionality reduction, and its working principle is to transform a group of variables that may have correlation into a set of linearly uncorrelated variables, namely principal components, through orthogonal transformation. The data in the new subspace defined by the principal component are usually easier to interpret [
24].
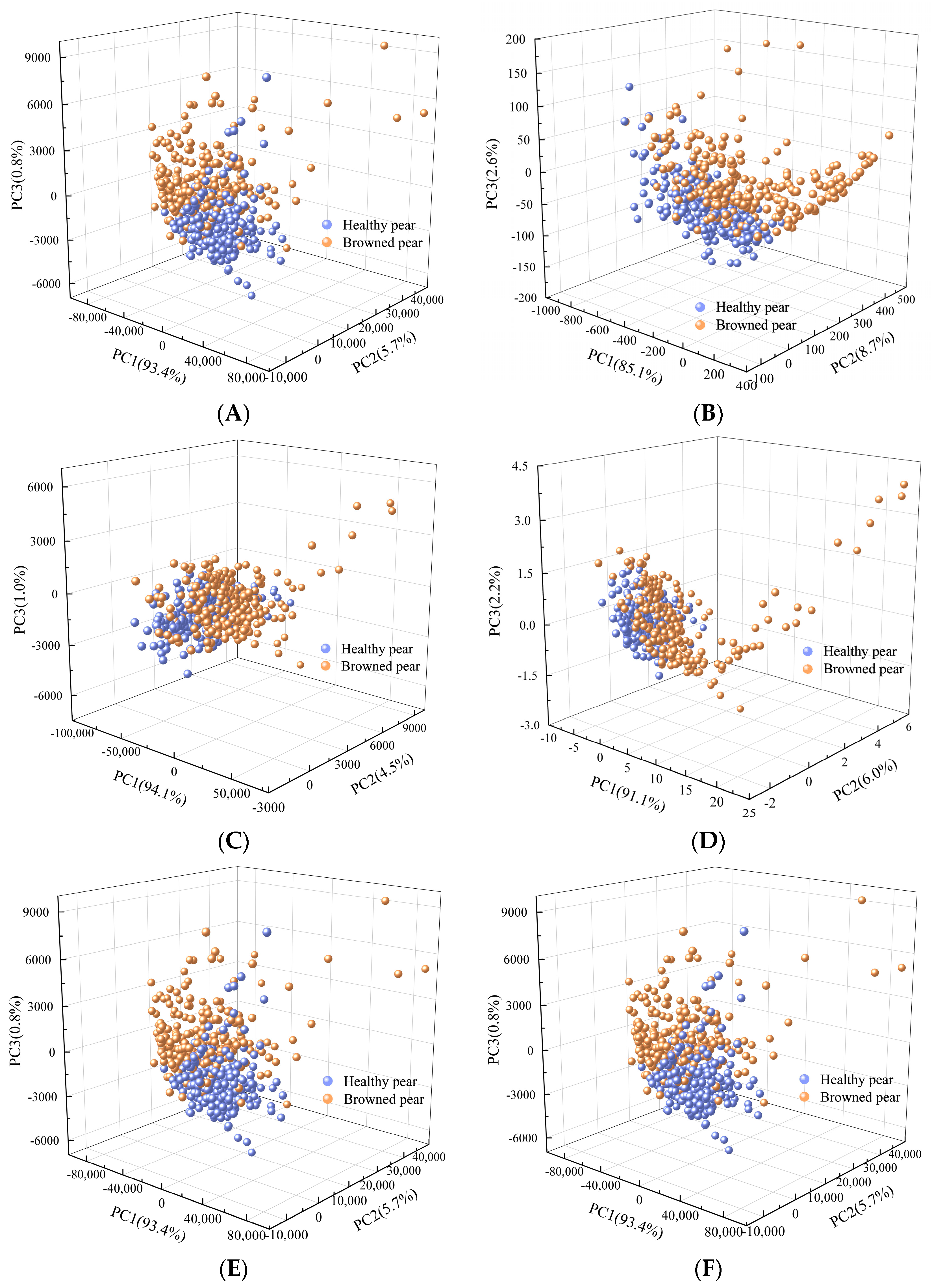
The data set contains 256 healthy pears and 239 browned pears. PCA analysis was conducted on the original spectrum and on the spectra separately pretreated by SG 1st−Der, MSC, SNV, MAS, and WT. The first three principal components were retained for visualization. The results are shown in
Figure 6. It can be observed that the spatial distribution of spectra pretreated by MAS and WT were basically consistent with that of the original spectrum. The spectral points of browned pears and healthy pears were so crossed that they cannot be distinguished, indicating that these two pretreatment methods failed to significantly improve the spectral features of data used in this experiment. Compared with the original spectrum, pretreatment methods of SG 1st−Der, MSC, and SNV have shown better performance. The spectral points of samples pretreated by these three methods presented a trend of classification separation in terms of spatial distribution. The cumulative contribution rates of the first three principal components of SG 1st−Der, MSC, and SNV were 96.4%, 99.6%, and 99.3%, respectively. The cumulative contribution rates of MSC and SNV were both over 99%, indicating that both methods were applicable to the experimental data. In order to further explore the effectiveness of the method, PLS-DA and SVM models were established combined with different pretreated methods. The results of the discrimination are shown in
Table 1. It can be seen from the table that the discrimination accuracy of SNV is higher than that of MSC. Therefore, the SNV pretreatment method was finally selected for model optimization in this experiment.
3.3. Robust Variable Selection Based on MCUVE Method
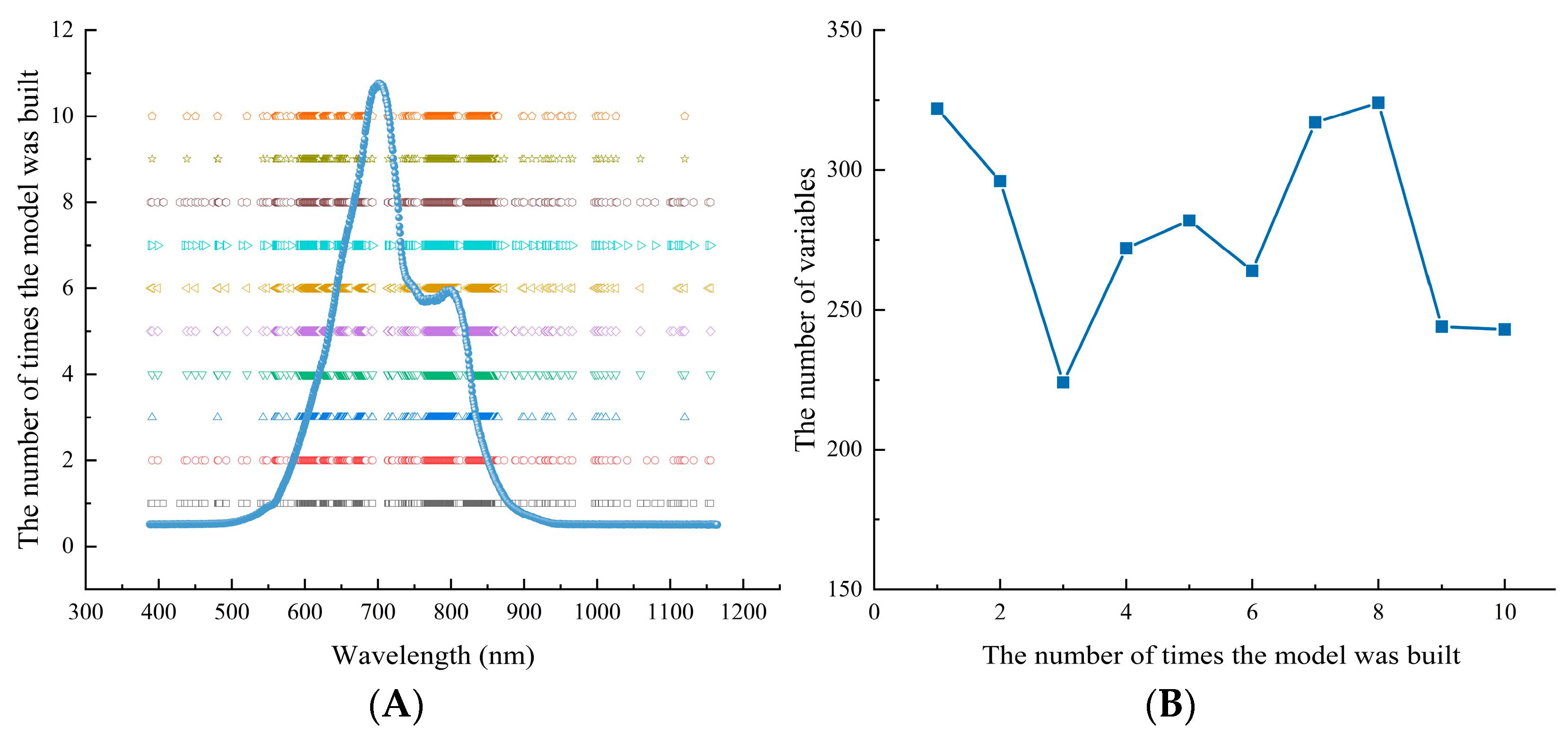
When the spectrum contains a large number of invalid variables, it will undermine the quality of modeling to a certain extent. In order to further simplify the model and improve the accuracy and interpretability of the model, the spectral wavelength was optimized by the MCUVE method after SNV pretreatment. As variables were selected in a random way, each model was selected 10 times. The optimized results are shown in
Figure 7.
Figure 7A shows the corresponding relationship between the variable distribution of the 10-time wavelength selections and the corresponding spectrum. It can be seen that the wavelength distribution of each optimal selection is not completely consistent, but most of the variables are concentrated at the absorption peak of the sample.
Figure 7B shows the number of variables retained after 10 runs of MCUVE, and it can be seen that the number is within the range of 224 to 324. Although the distribution of the selected variables is relatively concentrated, the number of retained variables is different. When the distribution of the modeling samples is not representative or the number is small, although the MCUVE method can improve the accuracy of the model, the number of wavelengths selected for multiple times is unstable, which affects the robustness of the model.
3.4. Evaluation Model for Health Status of Yali Pears Based on PLS-DA Method
PLS, which contains least squares regression analysis and discriminant analysis, is suitable for analyzing cases where the differences between groups are small while differences within groups are large. Unlike PCA, PLS-DA is a supervised discriminant analysis statistical method, which is widely used in the discrimination of Vis-NIR spectral data analysis. The core idea of PLS-DA is to obtain the optimal number of factors (LVs) in the calibration set through Monte Carlo cross-validation combined with an F-test. In this experiment, 10-fold cross-validation was employed to determine LVs. Furthermore, the results show that the root mean square error of the calibration set was the smallest when the LVs were 9, indicating that the model presented the best classification performance when the LVs were 9.
The model was established based on the calibration set, and then its performance was verified by the sample test set. The modeling results of the full spectrum, the pretreated spectrum, and the optimally selected spectrum (the best model in the 10 selections is chosen, whose number of variables is 264) are shown in
Table 2. It can be seen that after spectral pretreatment and variable selection, the discrimination accuracy of discriminating quality of Yali pears had been improved. The optimal model of PLS-DA is SNV-MCUVE-PLS-DA, and accuracy, RH, and RB of its test set are 97.32%, 100%, and 92.16%, respectively.
3.5. Evaluation Model for Health Status of Yali Pears Based on SVM Method
SVM is a class of generalized linear classifiers that perform binary classification of data based on the supervised learning method. SVM mainly maximizes the interval between different categories by finding the division hyperplane with the largest interval. It is a class of generalized linear classifiers for binary classification of data in a supervised learning manner. The selection of SVM hyperparameters (kernel function, penalty factor C, and kernel function parameter g) is determined by an optimizing algorithm through grid search so as to obtain the best calibration model. Grid search is an exhaustive search method, which uses cross-validation to optimize the estimation function and finally solves the optimal parameters. In this experiment, grid search determines that linear is the optimal kernel function, the value of the optimal penalty factor C is 100, and the value of the optimal kernel function parameter g is 0.001.
It can be seen from
Table 3 that the optimal SVM model is SNV-MCUVE-SVM, and accuracy, RH, and RB of its test set are 98.66%, 100%, and 96.08%, respectively; moreover, the modeling results of the SNV-SVM model are exactly the same as those of the SNV-MCUVE-SVM model. There are only 317 variables involved in the modeling of the SNV-MCUVE-SVM model, which greatly reduces the complexity of the model. Therefore, the optimal SVM model is the SNV-MCUVE-SVM model in which spectra are pretreated by SNV and variables are optimally selected by MCUVE.
3.6. Evaluation Model for Health Status of Yali Pears Based on 1D-CNN Method
The above research shows that although traditional methods can classify the browning pears, the process is cumbersome. A detection model with good performance requires rich theoretical knowledge and practical experience of the modeler. For this reason, it is necessary to figure out the effect of the deep feature extraction method on discriminating browned pears and healthy pears.
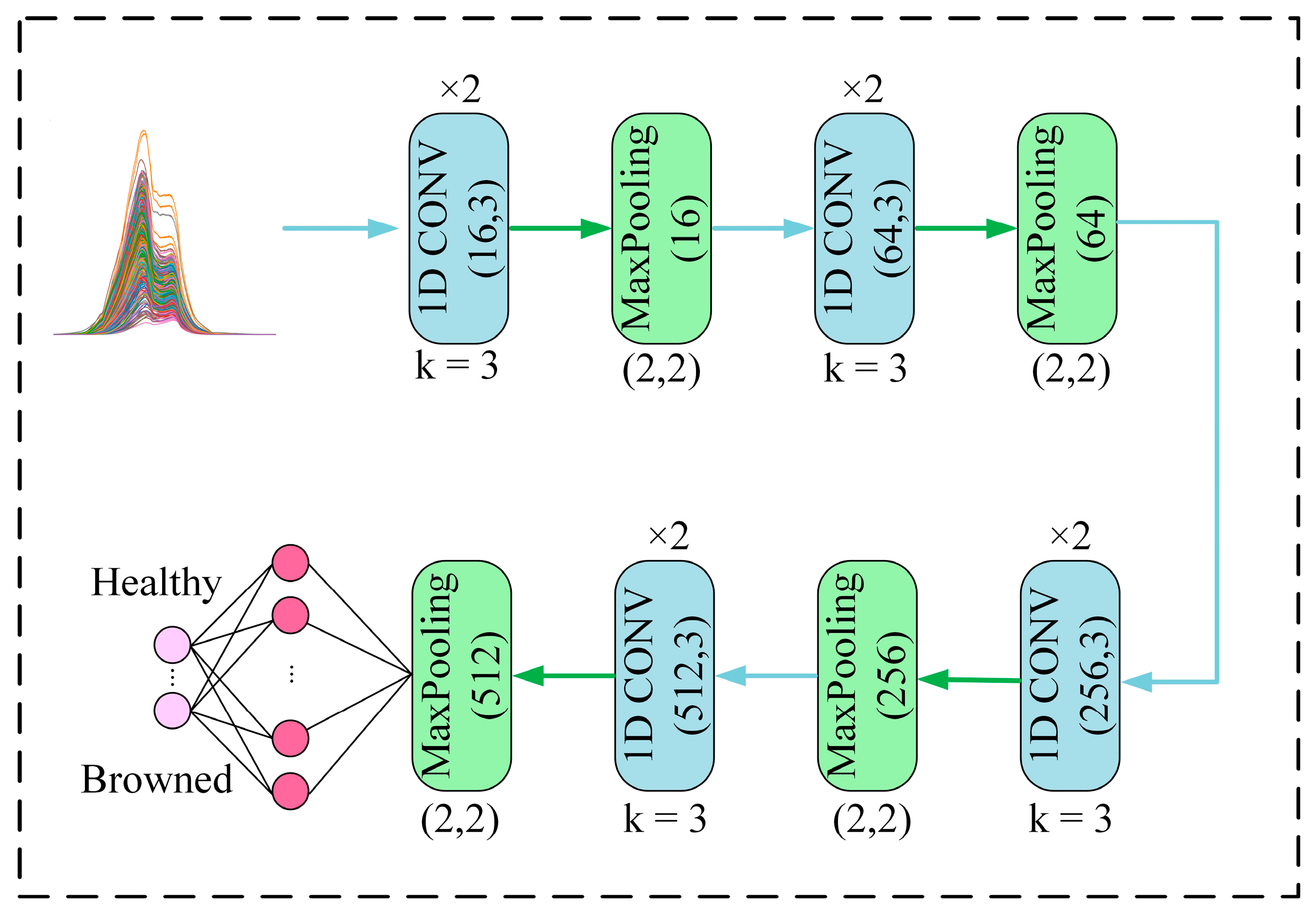
This paper proposed building a 1D-CNN model based on one-dimensional Vis-NIR spectral data in a bid to determine more accurately whether Yali pears are browned or not. The network was composed of an input layer, convolutional layer, pooling layer, and full connection layer. These layers were mainly used for feature extraction and classification. Among them, the convolutional layer and the pooling layer were used to extract the features of the data, while the fully connected layer was used to map the previously extracted features to the output space for subsequent classification. The activation functions of the convolutional layer and the full connection layer were the Relu function and the Sigmoid function, respectively. The dropout rate was set to 0.3. The Adam optimizer was adopted to optimize the network, the learning rate of the training model was set to 0.0001, the batch size was set to 64, and the number of iterations (epochs) was set to 500. The output feature value of the full connection layer which can combine features was set to 400.
The spectral data of the calibration set was read into the initialization network for iterative training, while the spectral data of the test set was used to evaluate the accuracy of the deep learning model. The deep learning model was randomly run 10 times in order to test its robustness, with the training samples and test samples unchanged. The modeling results of 10 runs are shown in
Table 4. It can be seen that the correct discrimination rate of the 1D-CNN discriminant model has the lowest rate of 96.64% and the highest rate of 100%. The difference between the two is only 3.36%, indicating that the model is relatively robust.
3.7. Establishment and Error Analysis of the Optimal Evaluation Model for Health Status of Yali Pears
PLS-DA, SVM, and 1D-CNN discriminant methods were separately used to establish online models for identifying healthy pears and browned pears. These models were then adopted to qualitatively discriminate healthy pears and browned pears that were not involved in the modeling. In order to optimize the model and improve the discriminant performance of the model, the spectral preprocessing and variable selection were performed before PLS-DA and SVM modeling. As errors of spectral rotation and shift were eliminated, the model became less complicated. After the network was completely designed, the 1D-CNN discriminant model can be directly constructed based on the original spectrum of Yali pears, because 1D-CNN had excellent performance in integrating pretreatment and extracting features.
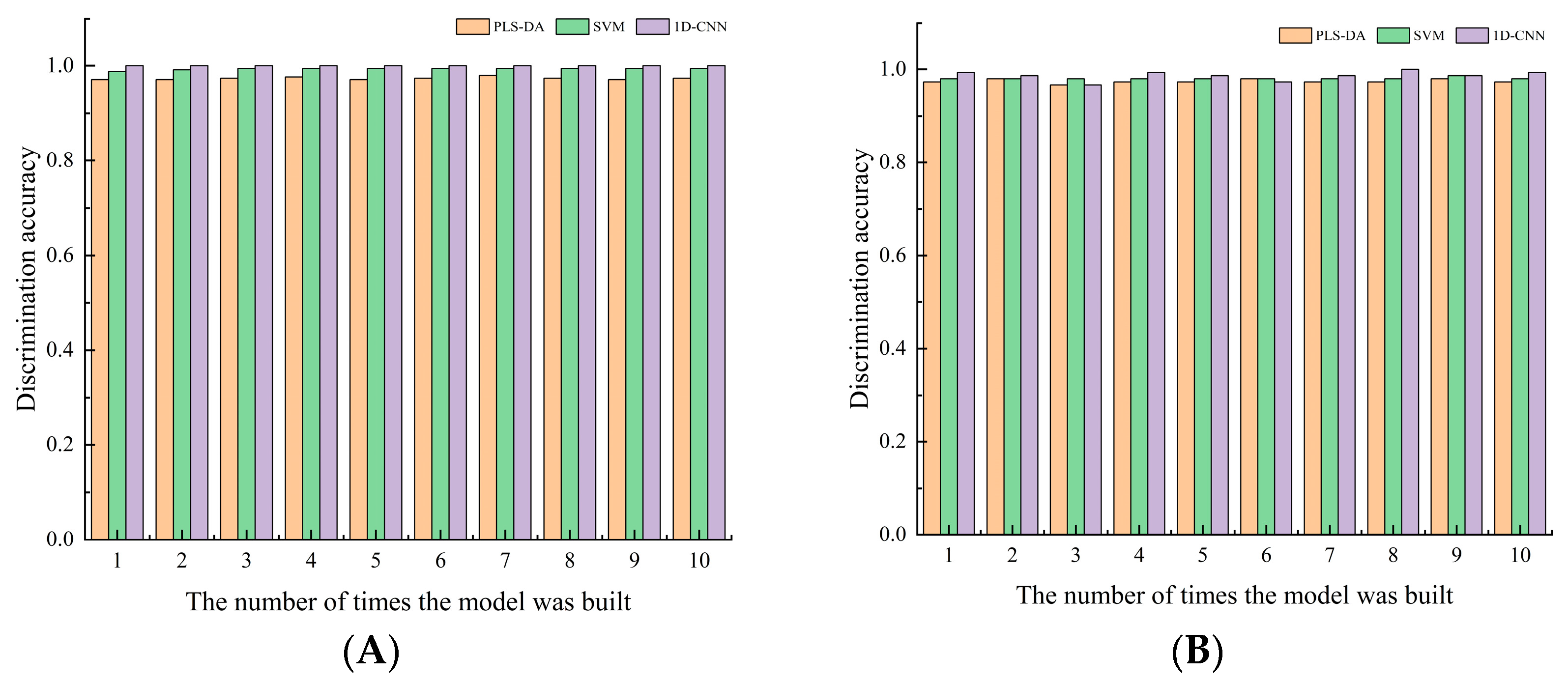
The discrimination results of training sets and test sets in 10 PLS-DA, SVM, and 1D-CNN models are shown in
Figure 8. It can be seen that 1D-CNN has better discriminant performance than PLS-DA and SVM, as evidenced by better modeling and testing accuracy of all its discriminant models. Moreover, in the 1D-CNN method, there is no requirement for preprocessing and variable selection of sample spectra. The model with the highest discrimination accuracy in 10 times of 1D-CNN modeling is selected as the final model, and the discrimination results are shown in
Table 5.
It can be seen from the table that the PLS-DA, SVM, and 1D-CNN models all can correctly identify healthy pears, but there are also cases in which browned pears are misjudged as healthy pears. From the perspective of the data in experiment, the overall discrimination performance of the 1D-CNN model is better than that of PLS-DA and SVM models, as the discrimination accuracy of its test set was as high as 100%. Furthermore, the calculation time of the 1D-CNN model in predicting the test set samples was about 0.0256 s, which met the requirements of online classification. Compared with the traditional models, the 1D-CNN model can automatically identify important features and has better classification performance. Furthermore, this model is so simple to operate that even those without much basic knowledge of modeling can use it properly. In summary, the 1D-CNN model is the optimal model for discriminating browned pears.
3.8. Deep Feature Analysis on Vis-NIR Spectra of Yali Pears
It can be seen from the above studies that the deep learning model has excellent performance in extracting features of Vis-NIR spectral analysis for Yali pears. In order to carry out a further expression and analysis of the spectral features extracted by the 1D-CNN method, the Gramian angular field (GAF) was used to transform the spectral data into graphs. The GAF has been used for visual expression of one-dimensional time series signals and the good classification results have been obtained [
25,
26]. The main advantage of the GAF is that features of the original one-dimensional spectral signal of the image during encoding are maintained and bidirectionally mapped to the two-dimensional image [
27]. The feature data extracted by 1D-CNN are converted into a 20 × 20 image by the GAF. The GAF encoding process of the Yali pears’ spectral data is shown in
Figure 9.
Figure 9A,B show the results of the GAF transformation of healthy pears and browned pears, respectively.
Figure 10 shows five pictures randomly selected from the two types of pear samples. Among them,
Figure 10A,B correspond to the GAF expression of healthy and browned pears in the test set, respectively. It can be seen from
Figure 10 that the model can adaptively learn the separable features from the original spectral information. The GAF graphs of healthy pears are similar (all in the shape of ‘+’); the GAF graphs of browned pears are slightly different due to the different browning degrees of tissue cells near the fruit core, but most of the graphs are shown in
Figure 10B (in the shape of ‘#’). It can be distinguished that the GAF graphs of the two types of samples are quite different, which further confirms that the deep learning model works excellently in feature extraction and classification. Meanwhile, the local and global features of Vis-NIR which can be easily classified and distinguished, if integrated by the feature combination layer (the full connection layer), can save calculation time while retaining important information.
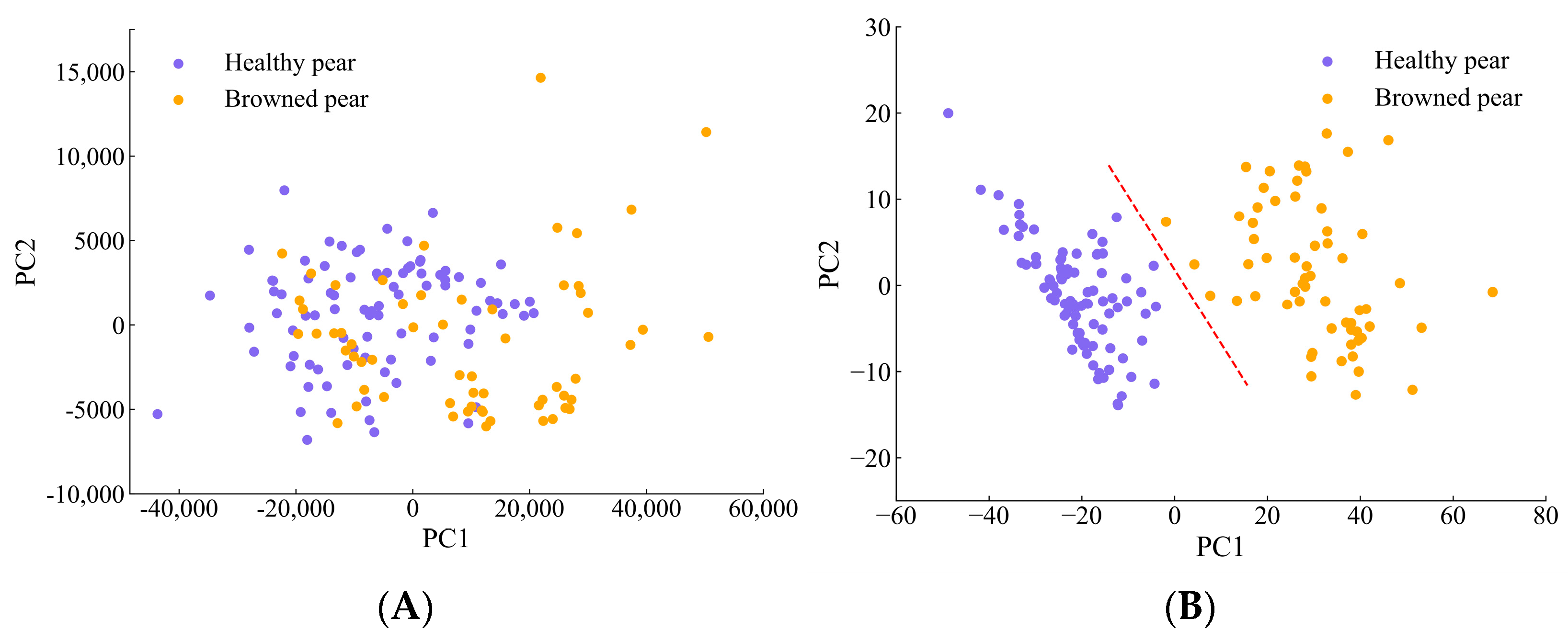
The GAF features were visualized by the PCA method. The two-dimensional feature distributions of the original spectral data and of features extracted by the 1D-CNN are shown in
Figure 11A,B. It can be seen from
Figure 11A that the spatial distribution of the original spectral data is relatively chaotic; the spectral points of the two types of samples overlap each other, so the feature distinction is not obvious. It can be seen from
Figure 11B that the data features of 1D-CNN after dimensionality reduction by PCA have better aggregation and feature distinction.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}