In this section, we present: our experimental results through a comparative study of the different reward functions that we propose; various parameter settings that aim to showcase trade-offs between the two objectives; and a comparison between the examined DRL algorithms, namely, DDPG and DQN.
4.1. RL Algorithms’ Setup
First, we specify some technical aspects of the proposed implementation. Regarding the DQN algorithm and its extensions, we employed the Adam [
32] optimization method to update the weight coefficients of the network at each learning step. The
-greedy policy [
18] was employed for action selection, in order to balance exploration and exploitation during training, with
decreasing linearly from 1 (
exploration) to
(
exploration) over the first 200 episodes, and fixed to
thereafter. We utilized DQN and its extension with a deep neural network of 128 neurons in the first hidden layer and 64 in the second hidden layer using a rectified linear unit (ReLU) activation function. The network outputs 9 elements that correspond to the estimated Q-value of each available action.
In the setup for the DDPG algorithm, we also used Adam to train both the actor and the critic. Furthermore, we chose to use the Ornstein–Uhlenbeck process to add noise (as an exploration term) to the action output, as employed in the original paper [
24]. The actor network employed in the DDPG implementation contained 256 neurons in the first hidden layer, 128 in the second hidden layer, and 2 in the output layer. Again, ReLU activation function was used for all hidden layers, and the output used the hyperbolic tangent (tanH) activation function, so as to provide a vector of continuous values within the range
. Similarly, the critic network contained 256 neurons in the first hidden layer, 128 in the second hidden layer, and 1 neuron in the output layer, including a ReLU activation function for all hidden layers and a linear activation unit in the output layer.
Training scenarios included a total of 625 episodes for all experiments. We have empirically examined different parameter tunings concerning the learning rate, discount factor, and the number of training episodes for both DQN and DDPG, with the purpose of finding the configurations that optimize the agent’s behavior. We provide the values of the various parameters in
Table 1. Finally, the obtained results were acquired using a system running Ubuntu 20.04 LTS with an AMD Ryzen 7 2700X CPU, an NVIDIA GeForce RTX 2080 SUPER GPU, and 16 GB RAM. Each episode simulated 200 s on a ring-road with many vehicles. With the system configuration above, each episode required on average 30 s approximately. This execution time included the computational time for training the neural networks at every time-step, meaning that even real-time training would be feasible for a DRL lane-free agent.
4.2. Simulation Setup
The proposed implementation heavily relies on neural network architectures, since all DRL methods incorporate them for function approximation. As such, in the context of this work, we utilized:
TensorFlow [
33]: An open-source platform used for numerical computation, machine learning, and artificial intelligence applications, which was developed by Google. It supports commonly used languages, such as Python and R, and also makes developing neural networks faster and easier.
Keras [
34]: A high level, open-source software library for implementing neural networks. In addition, Keras facilitates multiple backend neural network computations, while providing a Python frontend and being complementary to the TensorFlow library.
We trained and evaluated all methods on a lane-free extension of the Flow [
35] simulation tool, as described in [
8]. Moreover, to facilitate the experiments, we utilized the Keras-RL library [
36]. The Keras-RL library implements some of the most widely used deep reinforcement learning algorithms in Python and seamlessly integrates with Tensorflow and Keras. However, technical adjustments and modifications were necessary to make this library compatible with our problem and environment, as it did not conform to a standard Gym environment setup.
The lane-free driving agent was examined in a highway environment with the specified parameter choices of
Table 2, whereas in
Table 3, we provide the parameter settings related to the MDP formulation and specifically the reward components. Regarding the lane-free environment, we examined a ring-road with a width of
m, which is equivalent to a conventional 3-lane highway. The road’s length and vehicles’ dimensions were selected in order to allow a more straightforward assessment of our methods. The choices for the weighting coefficients and related reward terms were selected after a meticulous experimental investigation.
4.3. Results and Analysis
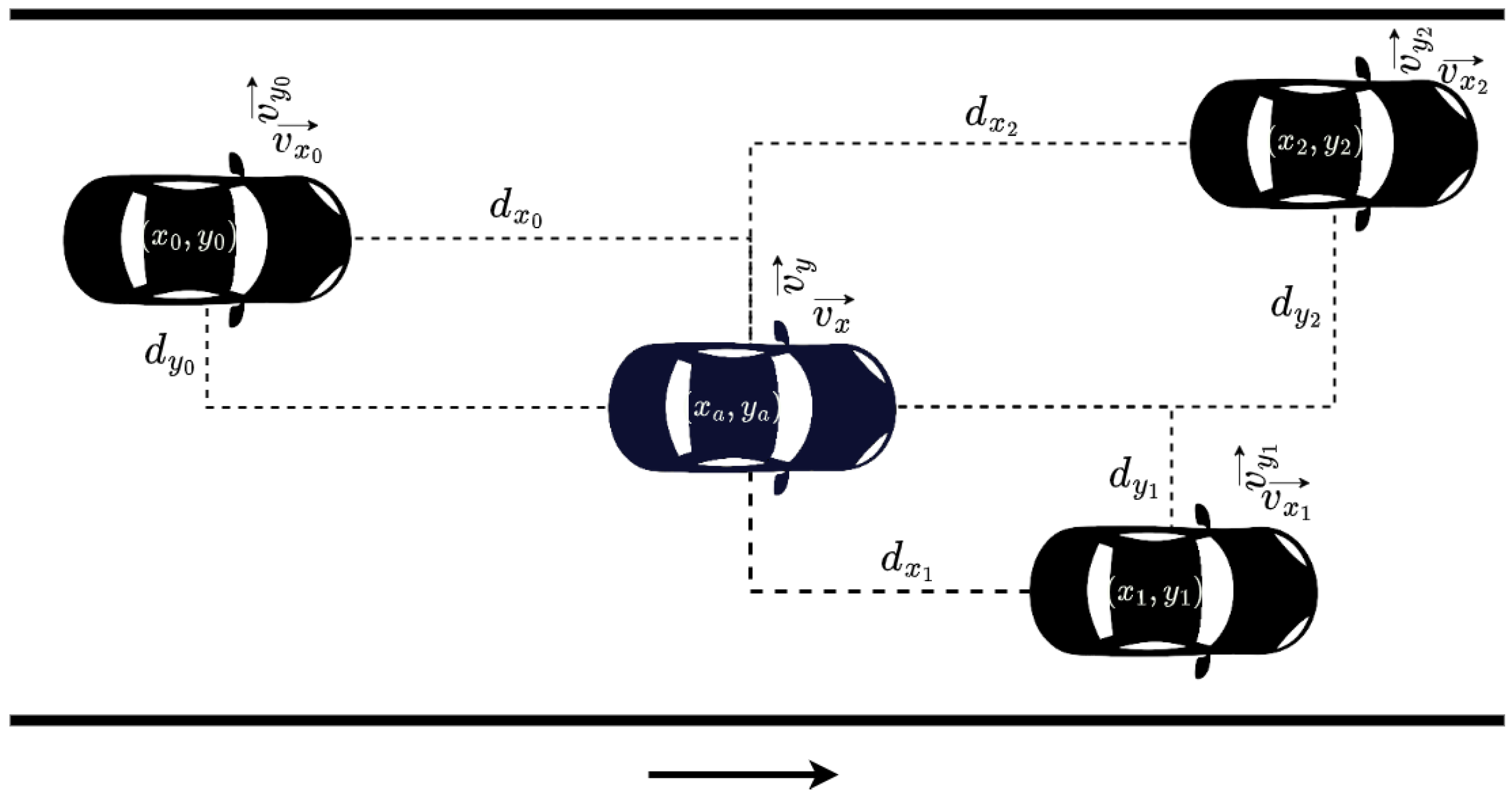
The effectiveness of all reward functions was evaluated based on three metrics. These were: the average reward value, the speed deviation from the desired speed (for each step, we measured the deviation of the current longitudinal speed from the desired one , in m/s), and of course, the average number of collisions. All results were averaged from 10 different runs.
We typically demonstrate in all figures the designed agent’s average reward and speed deviation, and the average number of collisions for each episode. In the examined reward functions, the longitudinal target reward (
Section 3.4.1) was always employed, whereas other components associated with the collision-avoidance objective were evaluated for many different combinations, in order to provide an ablation study, i.e., show how each component affects the agent. To be exact, for each of the tested reward functions, we employed Equation (
16) while assigning the values of
Table 3 to the corresponding weights when the equated components were used. Otherwise, we set them to 0. We refer the reader to
Table 4 for a complete list of all different reward functions examined, including the associated equations stemming from the general reward function (Equation (
16)) and the subsections relevant to their descriptions. The constant reward terms
were of course not always added, but were according to Equation (
16).
In
Section 4.3.1, we first demonstrate the performance of our reward functions that do not involve the lateral target component, namely, the “Fields RF”, the “Collision Avoidance RF”, the “Overtake and Avoid Collision RF”, the “Fields and Avoid Collision RF”, and the “Fields, Overtake and Avoid Collision RF” functions. Next, in
Section 4.3.2, we introduce the concept of the zones component (with the use of lateral targets) to our experimental procedure, by comparing the “Fields, Overtake and Avoid Collision RF” to the “Fields, Zones, Overtake and Avoid Collision RF” and the “Zones, Overtake and Avoid Collision RF”. In addition, to collate our two most efficient reward functions, we examine, in
Section 4.3.3, their behavior in more complex and demanding lane-free environments with higher traffic densities.
The evaluation described above was conducted using the DDPG algorithm. This was done since extensive empirical testing, along with the results of the comparative evaluation of DRL algorithms presented in
Section 4.3.4, suggest that DDPG is a suitable DRL algorithm for this complex continuous domain (and indeed, exhibits the best overall performance when compared to DQN and its extensions).
4.3.1. Evaluation of the Reward Function Components
We refer to the reward associated with the collision avoidance term (Equation (
9)) as “Collision Avoidance RF”, and the addition of the overtaking motivation (Equation (
8)) as “Overtake and Avoid Collision RF”. Furthermore, the use of the fields (Equation (
13)) for that objective are labeled as “Fields RF”, and “Fields and Avoid Collision RF” when combined with the collision avoidance term. Finally, the assembly of the collision avoidance term, the overtaking motivation, and the potential fields components in a single reward function is referred to as “Fields, Overtake and Avoid Collision RF”, whereas in our previous work [
13] it was presented as the “All-Components RF”. All of the aforementioned functions demonstrate how the agent’s policy has improved over time.
As is evident in
Figure 4,
Figure 5 and
Figure 6, the “Collision Avoidance RF” managed to maintain a longitudinal speed close to the desired one. Still, it did not manage to decrease the number of collisions sufficiently. Moreover, we see that the addition of the overtaking component in “Overtake and Avoid Collision RF” achieved a longitudinal speed slightly closer to the desired one, though the collision number was still relatively high. On the contrary, according to the same figures, the “Fields RF” exhibited similar behavior to the previously mentioned reward functions, but with slight improvement in collision occurrences. Finally, both the “Fields and Avoid Collisions RF” and the “Fields, Overtake and Avoid Collision RF” performed slightly worse in terms of speed deviations. However, they obtained significantly better results in terms of collision avoidance (“Collision Avoidance RF”, “Fields RF” and “Overtake and Avoid Collision RF” performed
-,
- and
-times worse with respect to collision avoidance when compared to “Fields, Overtake and Avoid Collision RF”), thereby balancing the two objectives much better. On closer inspection though, the “Fields, Overtake and Avoid Collision RF” managed to maintain a smaller speed deviation and fewer collisions, thus making it the reward function of choice for a more effective policy overall.
To further demonstrate this point, we present in
Table 5 a detailed comparison between these five reward functions. The reported results were averaged from the last 50 episodes of each variant. The learned policy had converged in all cases, as shown in
Figure 4,
Figure 5 and
Figure 6.
Evidently, higher rewards do not coincide with fewer collisions, meaning that the reward metric should not be taken at face value when we compare different reward functions. This is particularly noticeable in the case of the ”Fields, Overtake and Avoid Collision RF“ and the ”Fields and Avoid Collisions RF”, where there is a reduced reward over episodes, but when observing each objective, they clearly exhibit the best performances. This was expected, since the examined reward functions have different forms. In
Table 5, we can also observe the effect of the “Overtake” component. Its influence on the final policy is apparent only when combined with “Fields and Avoid Collisions RF”, i.e., forming the “Fields, Overtake and Avoid Collision RF”.
Policies resulting from different parameter tunings that give more priority to terms related to collision avoidance () do in fact further decrease collision occurrences, but we always observed a very simplistic behavior where the learned agent just followed the speed of a slower moving vehicle in front; i.e., it was too defensive and never attempted overtake. Such policies did not exhibit intelligent lateral movement, and therefore were of no particular interest given that we were training an agent to operate in lane-free environments. Therefore, these types of parameter tunings that mainly prioritized collision avoidance were neglected.
For the subsequent experiments, we mostly refrain from commenting on the average reward gained and mainly focus on the results regarding the two objectives of interest—namely, collision avoidance and maintaining a desired speed. Nevertheless, we still demonstrate them, so as to also present the general learning improvement over episodes across all experiments.
As discussed in the related conference paper [
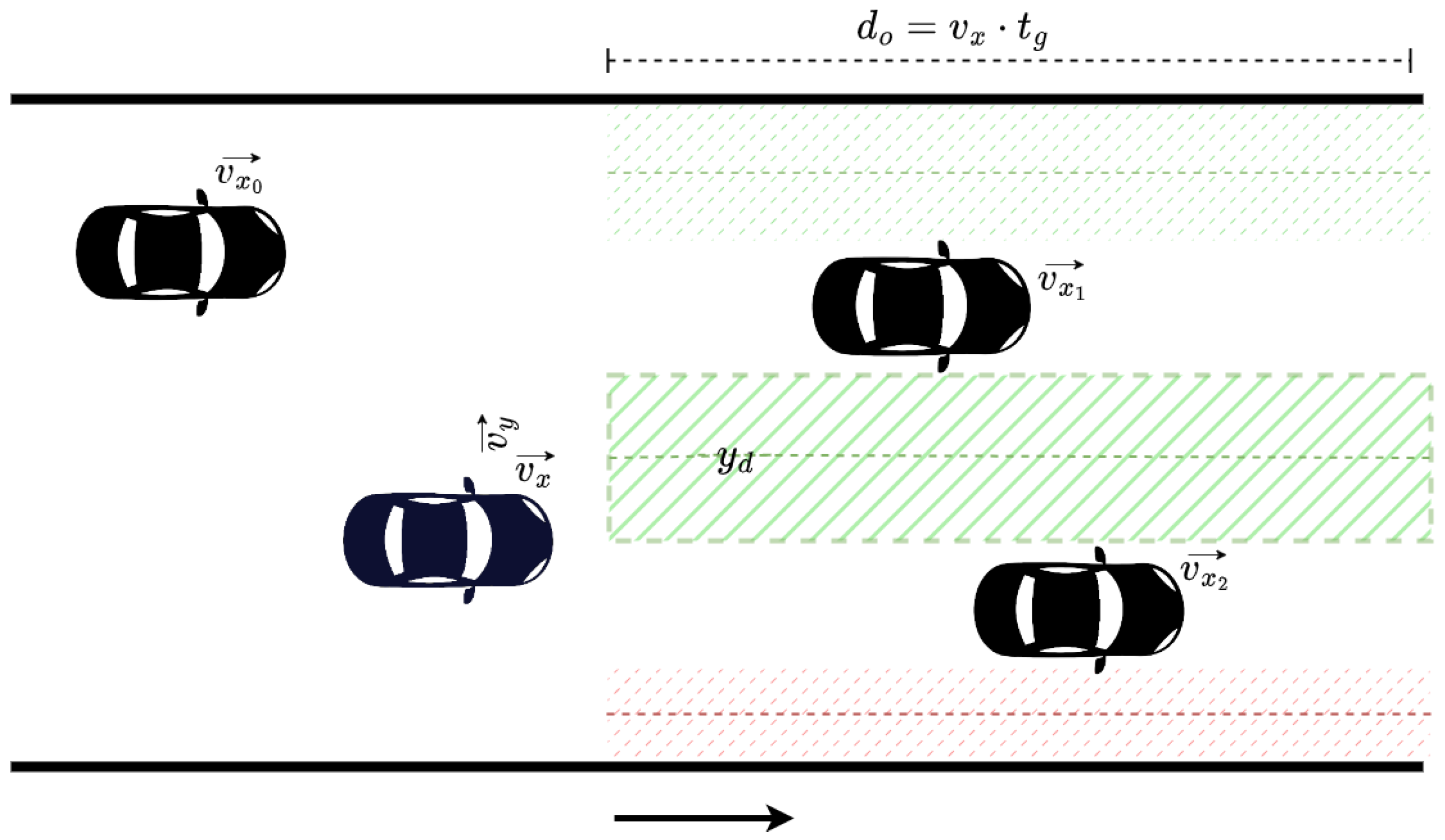
13], the most promising reward function form was at this point the “Fields, Overtake and Avoid Collision RF”. Here, we further investigate the influence of the additional component presented, namely, the lateral target component that makes use of the zone selection technique, as presented in
Section 3.4.5. As we discuss below, the inclusion of the “Zones” component in the reward provided us with marginal improvement with respect to the collision-avoidance objective, at the expense of the desired speed task. However, its contribution regarding collision avoidance was much more evident when investigating intensified traffic conditions with more surrounding lane-free vehicles (see
Section 4.3.3).
4.3.2. Evaluation of the Zone Selection Reward Component
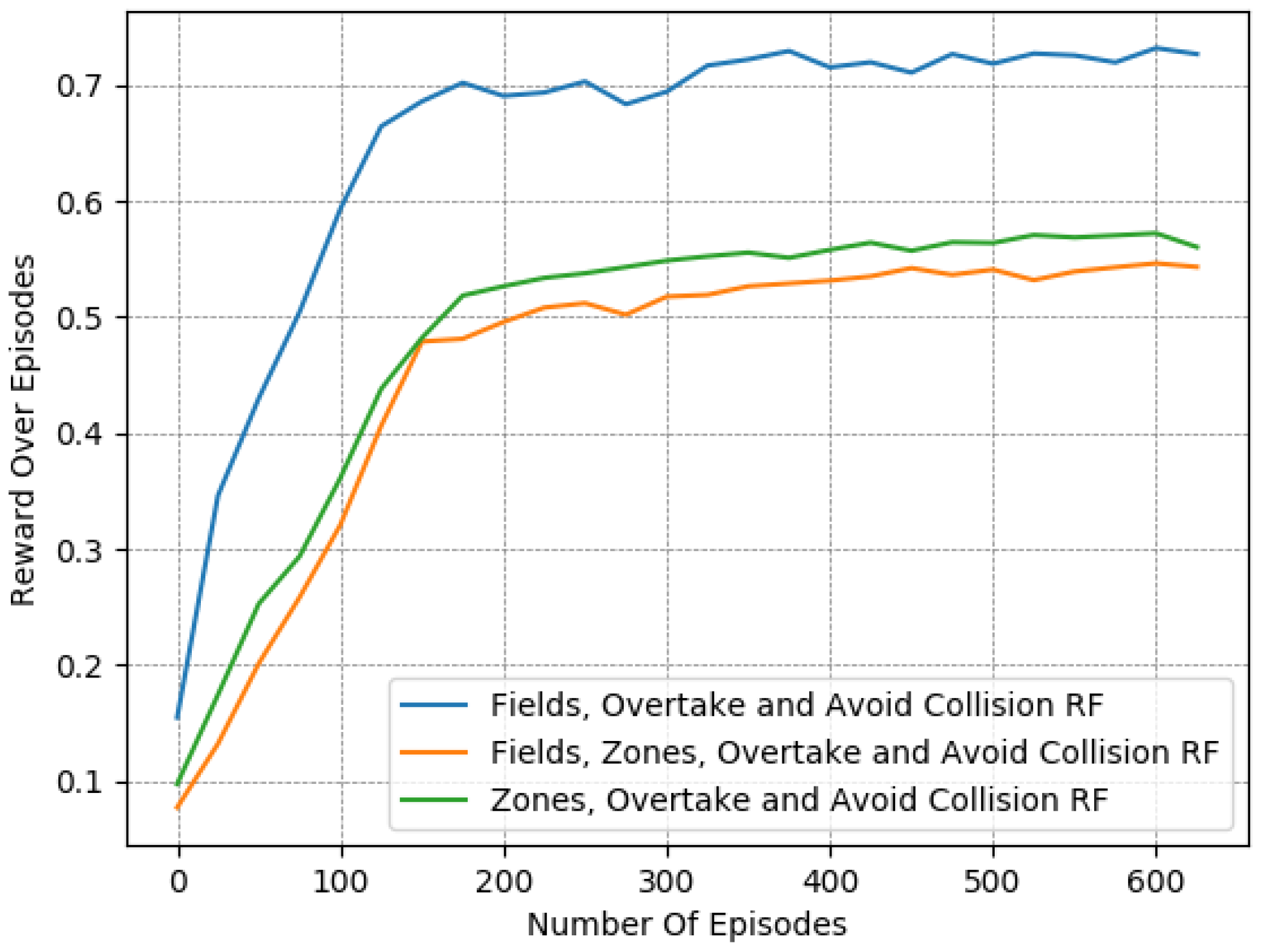
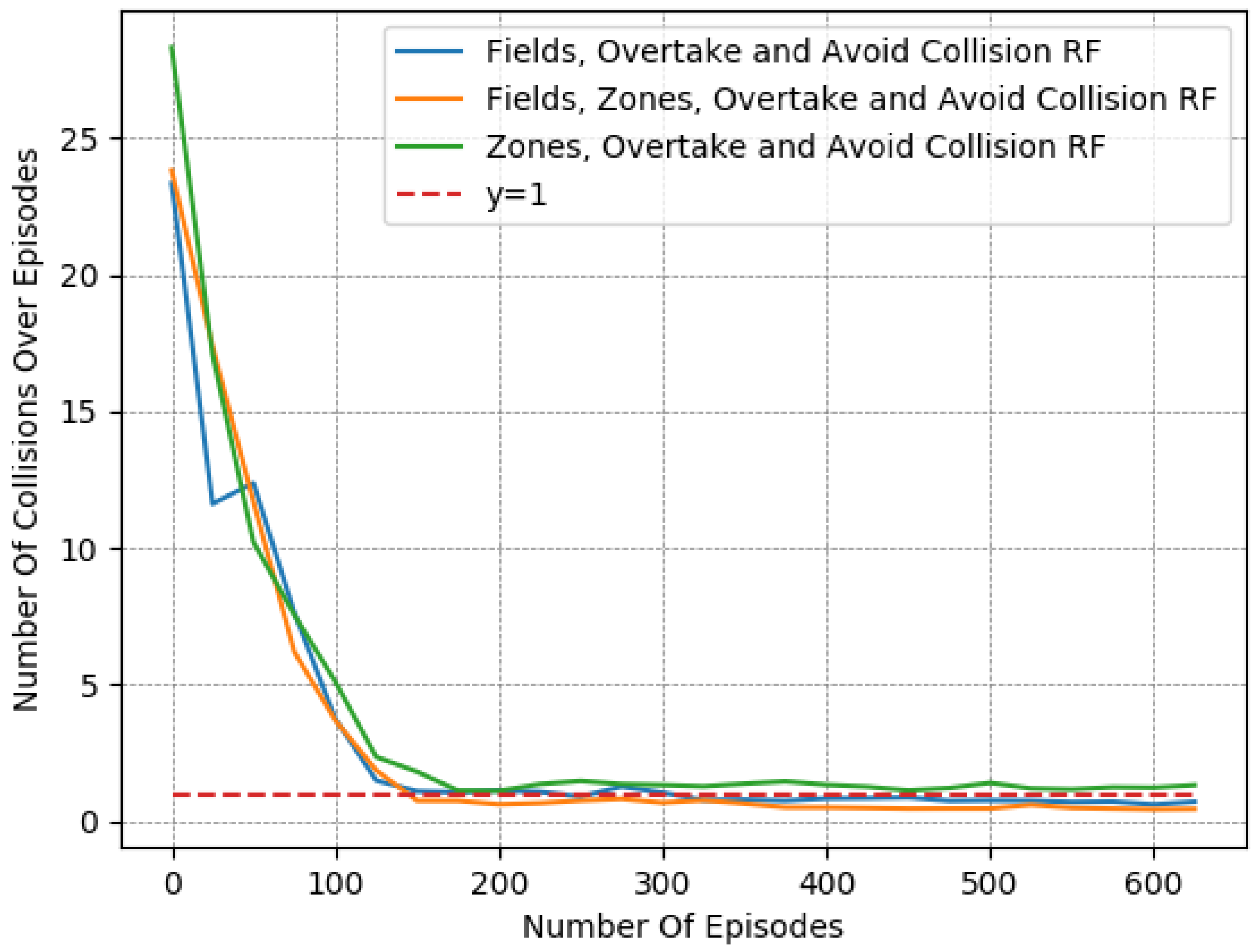
In particular, we present in
Figure 7,
Figure 8 and
Figure 9 a detailed comparison between: the “Fields, Overtake and Avoid Collision RF” and the “Fields, Zones, Overtake and Avoid Collision RF” in Equation (
16). Additionally, we further highlight the impacts of potential fields on the designed reward functions by including one more variant of the reward function for comparison. Accordingly, we present results for another variation titled “Zones, Overtake and Avoid Collision RF” that lacks the field’s related reward component.
In
Table 6, we provide a closer look at the comparison between these 3 reward functions. The reported results were averaged from the last 50 episodes of each variant. The learned policy converged in all cases. Here, we observe that just the addition of the lateral target component improved the performance notably, as it managed to moderately mitigate collision occurrences, at a marginal expense to the desired speed objective. However, this deviation from the desired speed in the experiments is to be expected. Maintaining the desired speed throughout an episode is not realistic, since slower downstream traffic will, at least partially, slow down an agent. Still, the use of lateral zones is beneficial only when combined with the fields component; otherwise, we can see that the agent performs worse with respect to the collision-avoidance task, while obtaining quite similar speed deviations.
In general, the use of lateral zones provides important information to the agent that is combined with the overtaking task but can undermine safety. In preliminary work with different parameter tunings, we observed that the bias of this information caused notable performance regression regarding collisions. This occurred when the zones-related component was given more priority, especially in environments with higher vehicle densities. In practice, the selected parameter tuning should not allow for domination of the fields reward by the lateral zones’ reward component.
Throughout our experiments, it was obvious that the two objectives were countering each other. A vehicle operating at a slower speed is more conservative, whereas a vehicle wishing to maintain a higher speed than its neighbors needs to overtake in a safe manner, and consequently has to learn a more complex policy that performs such elaborate maneuvering. Specifically, we do note that the experiments with the smallest speed deviations were those with the highest numbers of collisions, and on the other hand, those that showcased small numbers of collisions deviated the most from the desired speed.
In addition, according to the results presented in
Table 6, it is evident that “Fields, Overtake and Avoid Collision RF” and the “Fields, Zones, Overtake and Avoid Collision RF” result in quite similar policies in the training environment, despite the fact that the second one is much more informative.
4.3.3. Evaluation for Different Traffic Densities
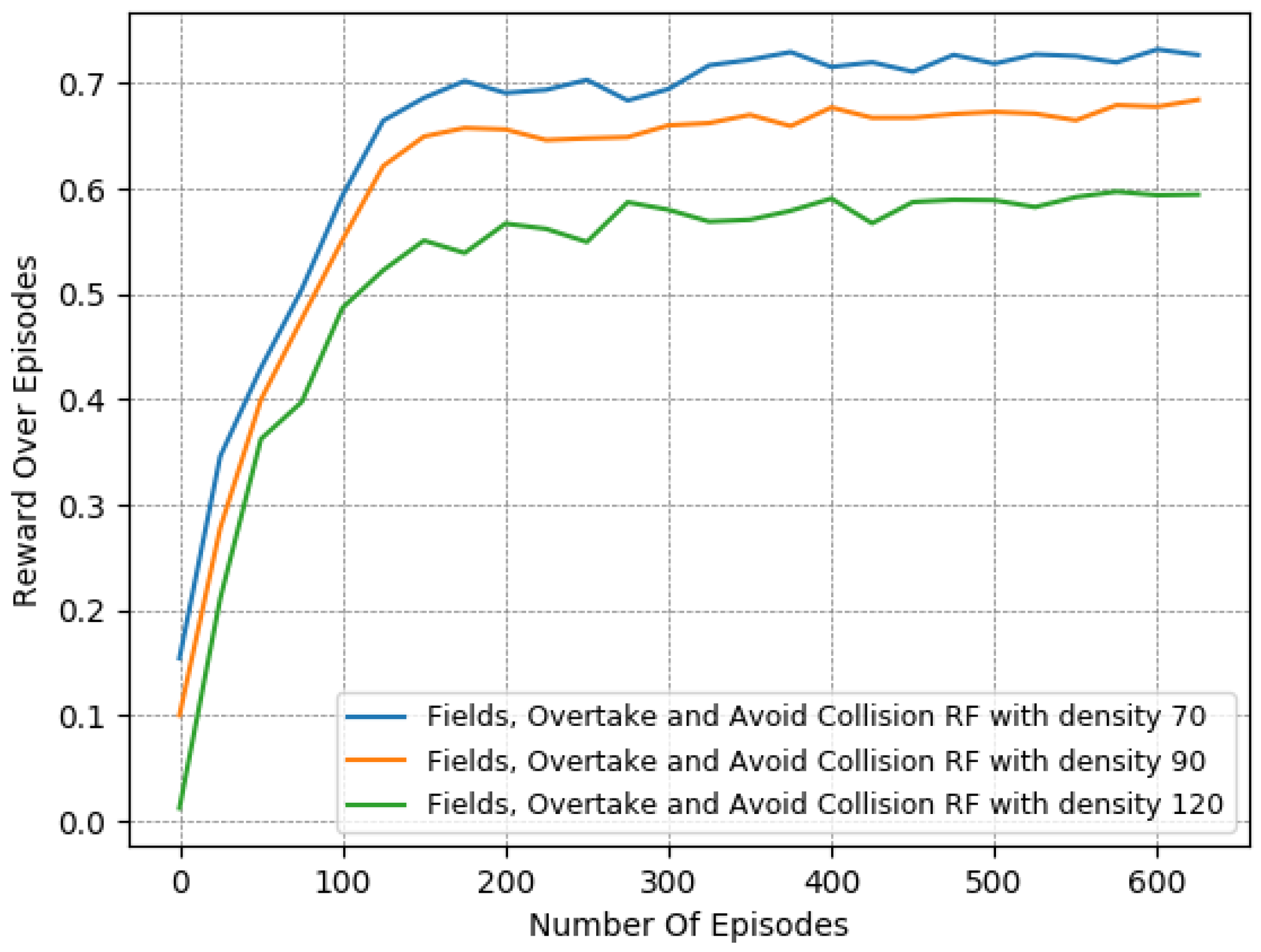
Thus, to perform a more comprehensive and thorough comparison, we decided to test the 2 most promising reward functions in more complex and demanding lane-free environments. We chose to run both “Fields, Overtake and Avoid Collision RF” and the “Fields, Zones, Overtake and Avoid Collision RF”, using a set of different traffic densities. Specifically, in
Figure 10,
Figure 11 and
Figure 12 we illustrate the results of running the reciprocal RF using densities equal to 70, 90, and even 120 veh/km (vehicles per kilometer). Meanwhile, in
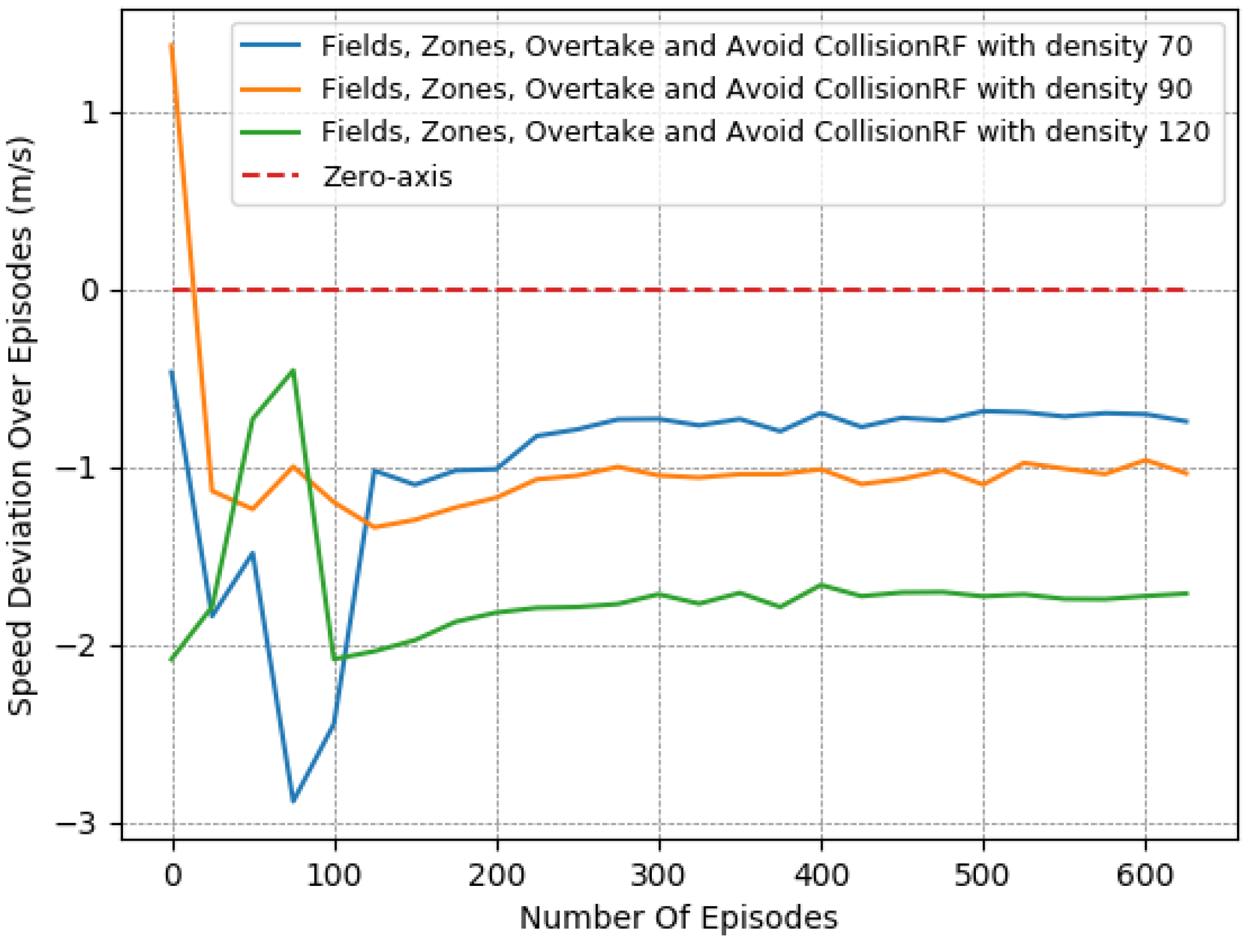
Figure 13,
Figure 14 and
Figure 15, we demonstrate the corresponding outcomes when running the “Fields, Overtake and Avoid Collision RF” for the same set of traffic densities.
We observe that when using the “Fields, Overtake and Avoid Collision RF”, the agent tends to handle the surrounding traffic quite well. In detail, it is noticed that the number of collisions decreased dramatically with the passage of the episodes, and in all cases, at the end of the training, it approached or fell below one on average. At the same time, the collisions and the deviation in the agent’s speed from the desired one scaled according to the density of the surrounding vehicles. However, this behavior is to be expected, since in denser traffic environments, vehicles tend to operate at lower speeds and overtake less frequently, as the danger of collision is more present.
Similarly, according to the results presented in
Figure 13,
Figure 14 and
Figure 15, we note the impact of the “Zones” reward component
Section 3.4.5 in our problem, as it managed to boost the agent’s performance, especially when compared, in denser traffic, to a reward function that incorporated the same other components, namely, the “Fields, Overtake, and Avoid Collision RF”. In particular, while the speed objective did not showcase any significant deviation between the two variants, the difference was quite noticeable in collision avoidance, where the increase was substantially mitigated, resulting in more robust agent policies with respect to the traffic densities. Again, we emphasize that this benefit of the lateral zones is evident only when combined with the other components, and especially with the fields-related reward. Without the use of fields, the other reward components cannot adequately tackle the collision-avoidance task, especially in demanding environments with heavy traffic.
In addition, a more direct comparison of the behavior of the two reward functions is found in
Table 7. The numerical results presented confirm that both of the compared reward functions achieve consistent performance, regardless of the difficulty of the environment. Nevertheless, they also confirm the superiority of the “Fields, Zones, Overtake and Avoid Collision RF”, since even in environments with higher densities, the agent mitigated both of the training objectives simultaneously, and by the end, the number of collisions was much lower and close to
.
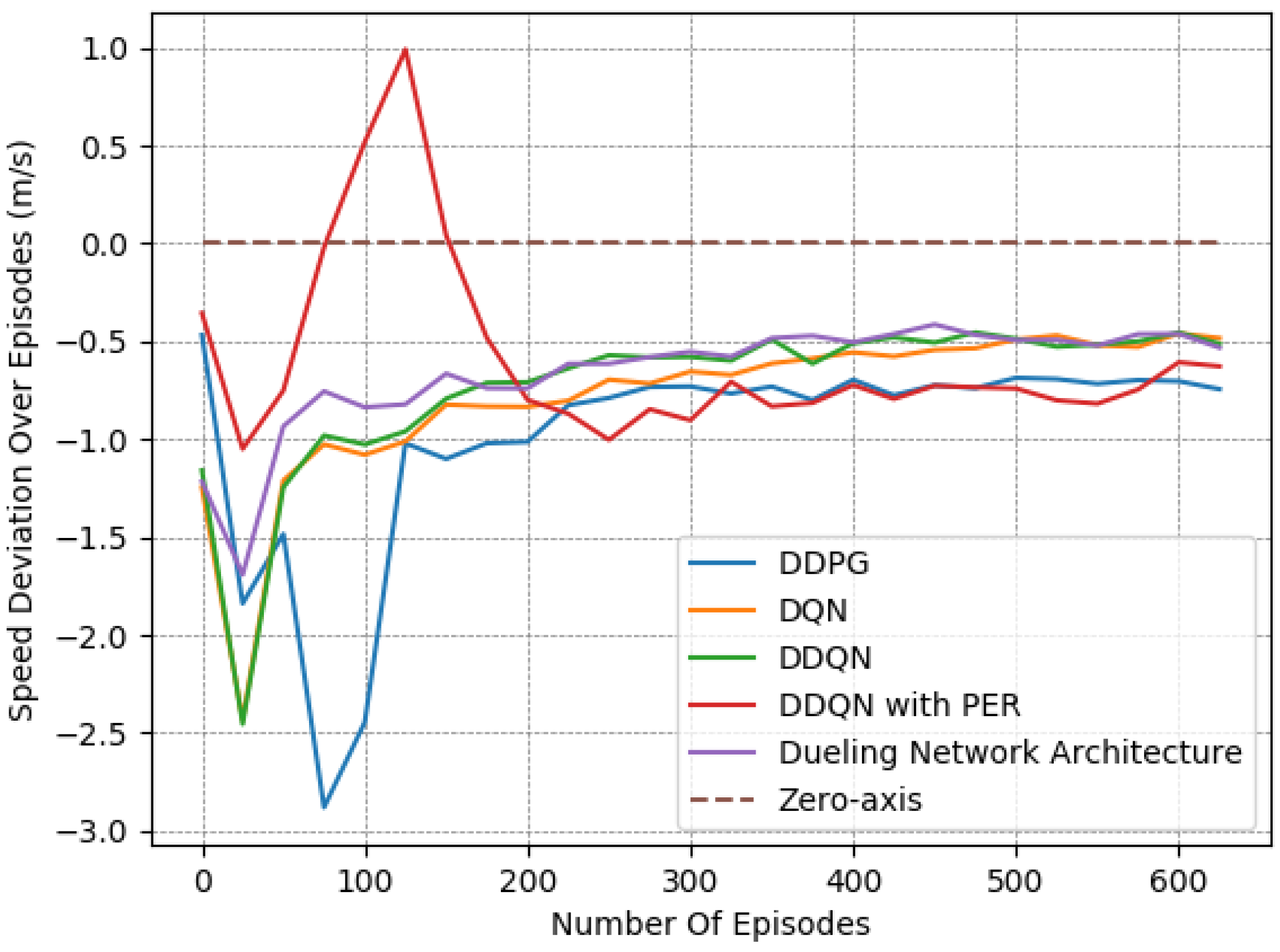
4.3.4. Comparison of Different DRL Algorithms
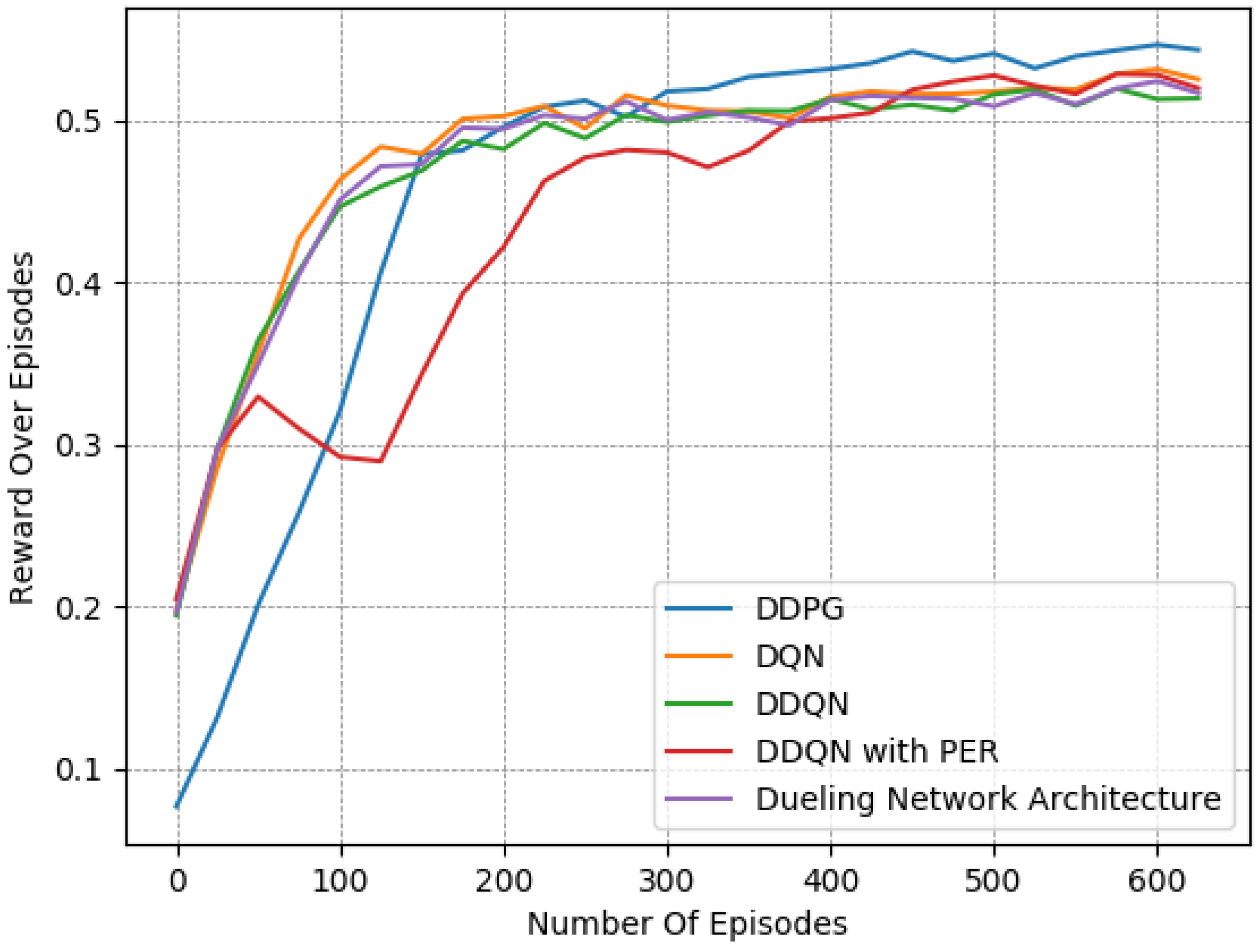
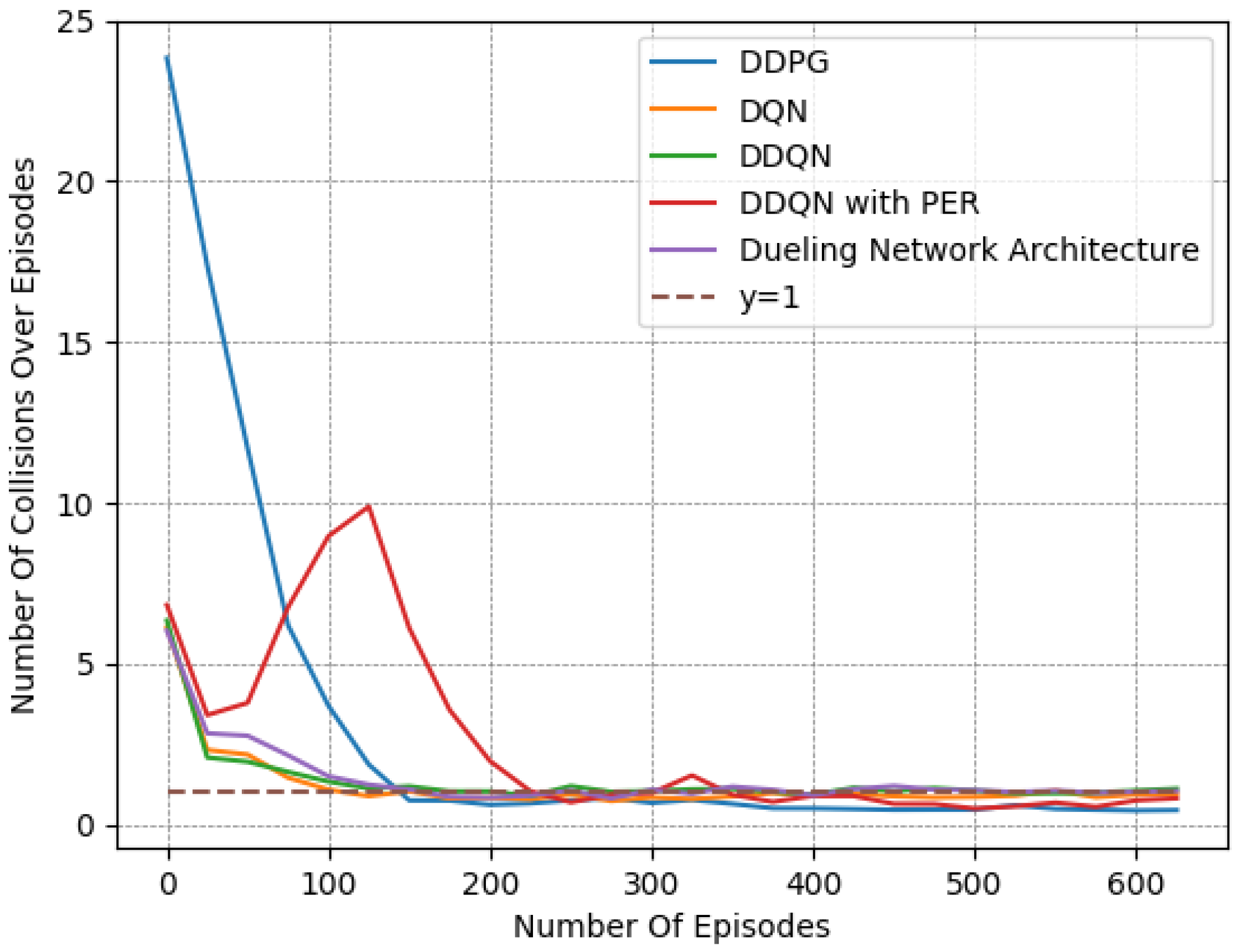
Finally, we provide a set of experiments that compared different DRL algorithms in
Figure 16,
Figure 17 and
Figure 18. We employed the “Fields, Zones, Overtake and Avoid Collision RF”, using DQN, double DQN (DDQN), DDQN with dueling architectures (DNA), and DDQN with prioritized experience replay (PER), and compare their performances to that of DDPG.
It is apparent for all five methods that the learning process attempts to guide the agent to the expected behavior. However, DDPG clearly exhibited the best performance, as it is the only method that resulted in a number of collisions under
on average while managing to preserve a speed that was close to the desired one. Upon closer examination, by observing the averaged results extracted from the last episodes of each variant, as presented in
Table 8, DQN, DDQN, DNA, and PER resulted in smaller speed deviations, yet they caused significantly higher numbers of collisions. All DQN-related methods exhibited quite similar behavior in our lane-free environment, as visible in the related figures. Only the PER variant exhibited a notable deviation within the learning curves. Evidently, when utilizing PER memory, i.e., using the TD error to influence the probability of sampling, the agent results temporarily in a worse policy around training episodes ≈ [50–150]. This was apparent for multiple random seeds. Still, the collision avoidance metric under PER is still
worse compared to the DDPG at the end of training.
It is apparent that DDPG tackles the problem at hand more efficiently, as it is a method that was designed for continuous action spaces. Meanwhile, DQN requires discretizing the action space, which may not lead to the ideal solution. Moreover, we attribute the improved performance to the complexity of the reward function and training environment, as DDPG typically tends to outperform DQN.
Summarizing, as mentioned already, to the best of our knowledge, this is one of the earliest endeavors to introduce the concept of deep reinforcement learning to the lane-free environment. Thus, the main focus here was not to deploy a “perfect” policy that eliminates collisions, but to examine the limitations and potential of DRL in a novel and evidently quite challenging domain. In this approach, the MDP formulation places the agent in a populated traffic environment, where the agent directly controls its acceleration values. This constitutes a low-level operation that renders the task of learning a driving policy much more difficult, since it forces the agent to learn to act in the 2-dimensional space, where speed and position change according to the underlying dynamics, and more importantly, without any fall-back mechanism or underlying control structures that address safety or stability. That is in contrast to other related approaches that do manage to provide experimental results [
14] with zero collisions and smaller speed deviations. However, there, the focus is quite different, since the RL agent acts in a hybrid environment alongside a rule-based approach (see
Section 2.4).
We tackled a very important problem, that of reward function design, which is key for the construction of effective and efficient DRL algorithms for this domain. These DRL algorithms can then be extended considering realistic hard constraints and fallback mechanisms, which are necessary for a real-world deployment. The proper employment of such constraints and mechanisms is even more crucial for algorithms that rely on deep learning (and machine learning in general), where explainability endeavors are still not mature enough [
37]. As such, for a more realistic scenario, one should also design and incorporate underlying mechanisms that explicitly address safety and comfort, where the RL agent will then learn to act in compliance with the regulatory control structures.





 ,
, 


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}