
Highly Adaptive Linear Actor-Critic for Lightweight Energy-Harvesting IoT Applications


Abstract
:1. Introduction
- To provide better adaptability, we combined and evaluated the LAC algorithm with Adam (LAC-A) using smaller decay factors for transmission (TX) duty-cycle optimization in an application of sensor data TX in a point-to-point network.
- With the use of smaller decay rates in Adam, we can exclude the initialization bias correction terms to reduce the calculations, and we call the algorithm LAC-AB (LAC with Adam Biased).
- We defined the time of convergence quantitatively based on the mean and variance information for evaluating the speed of convergence of different approaches.
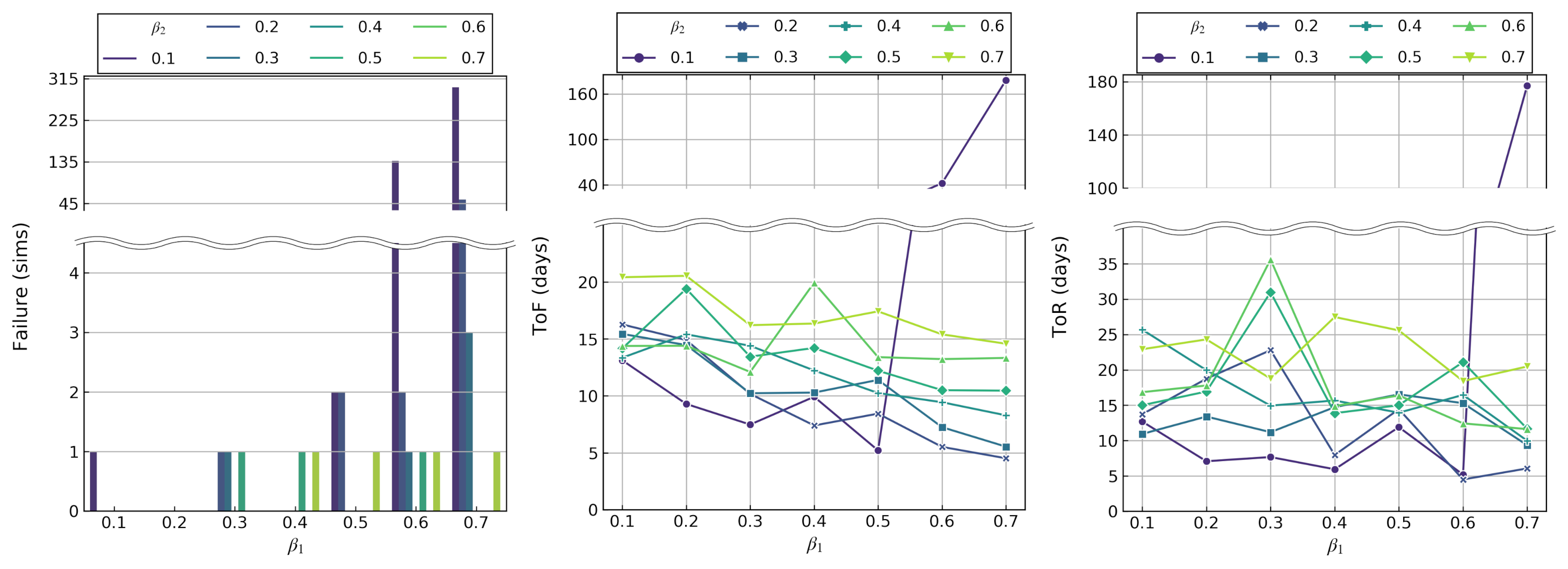
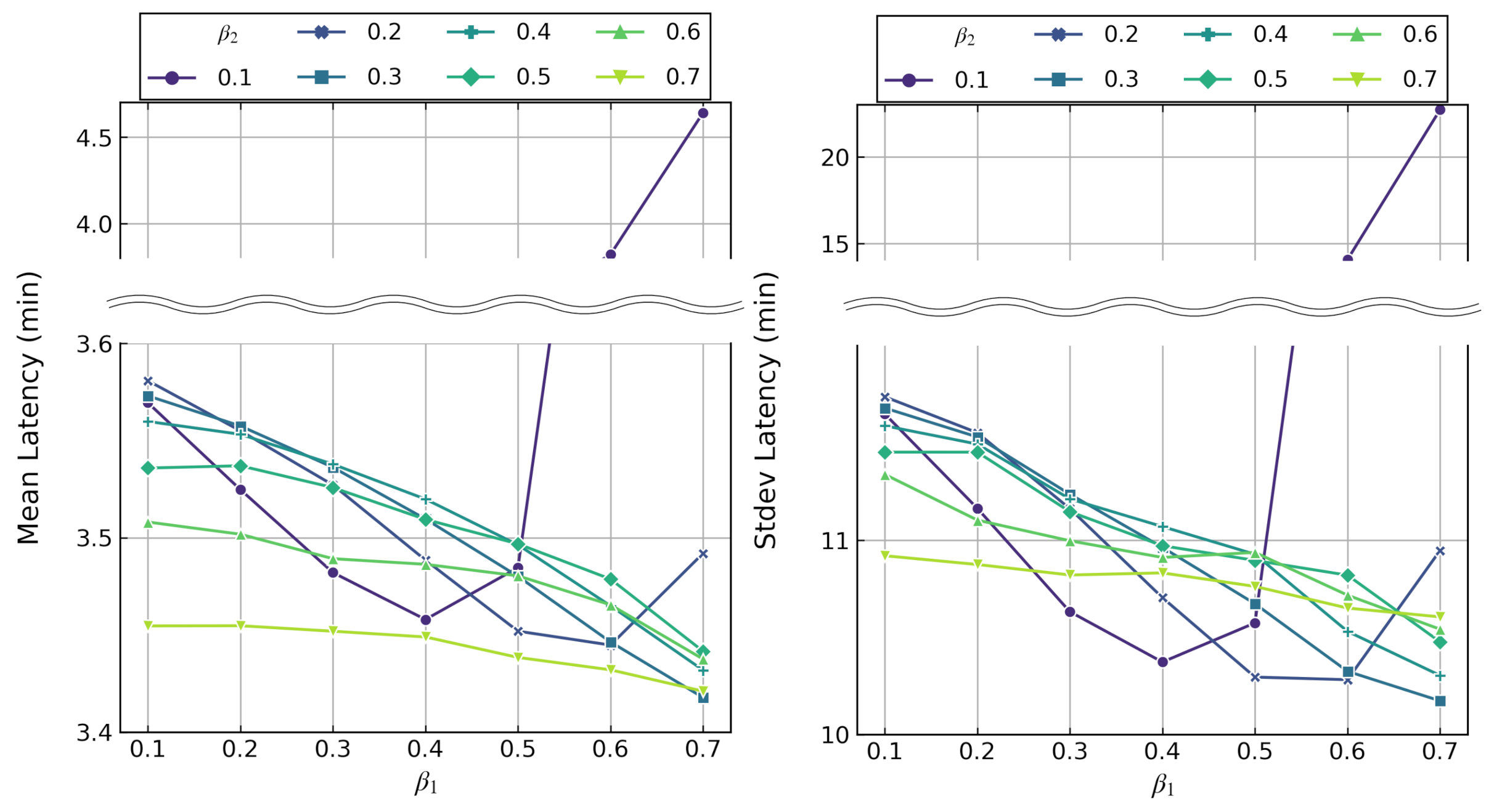
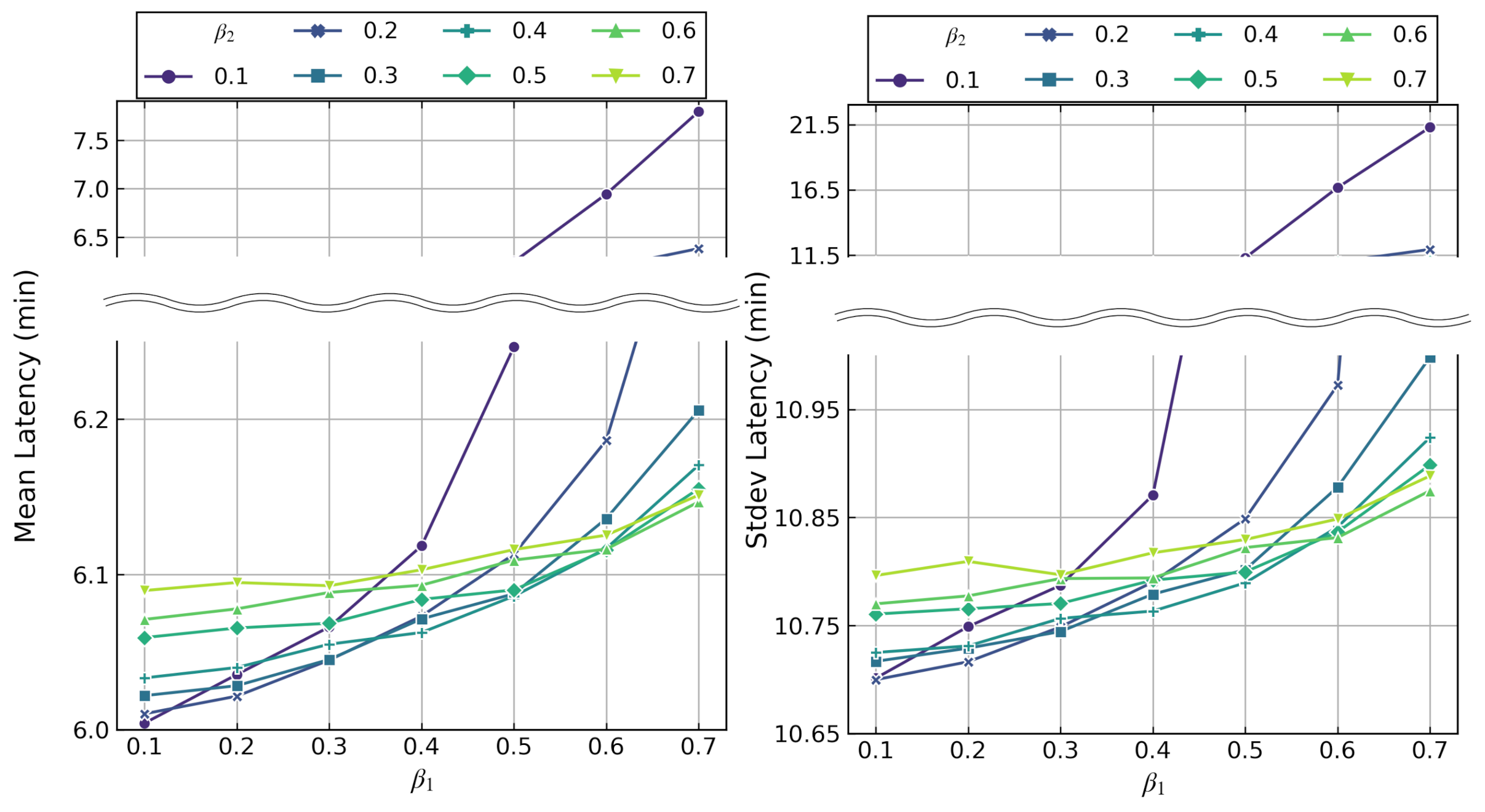
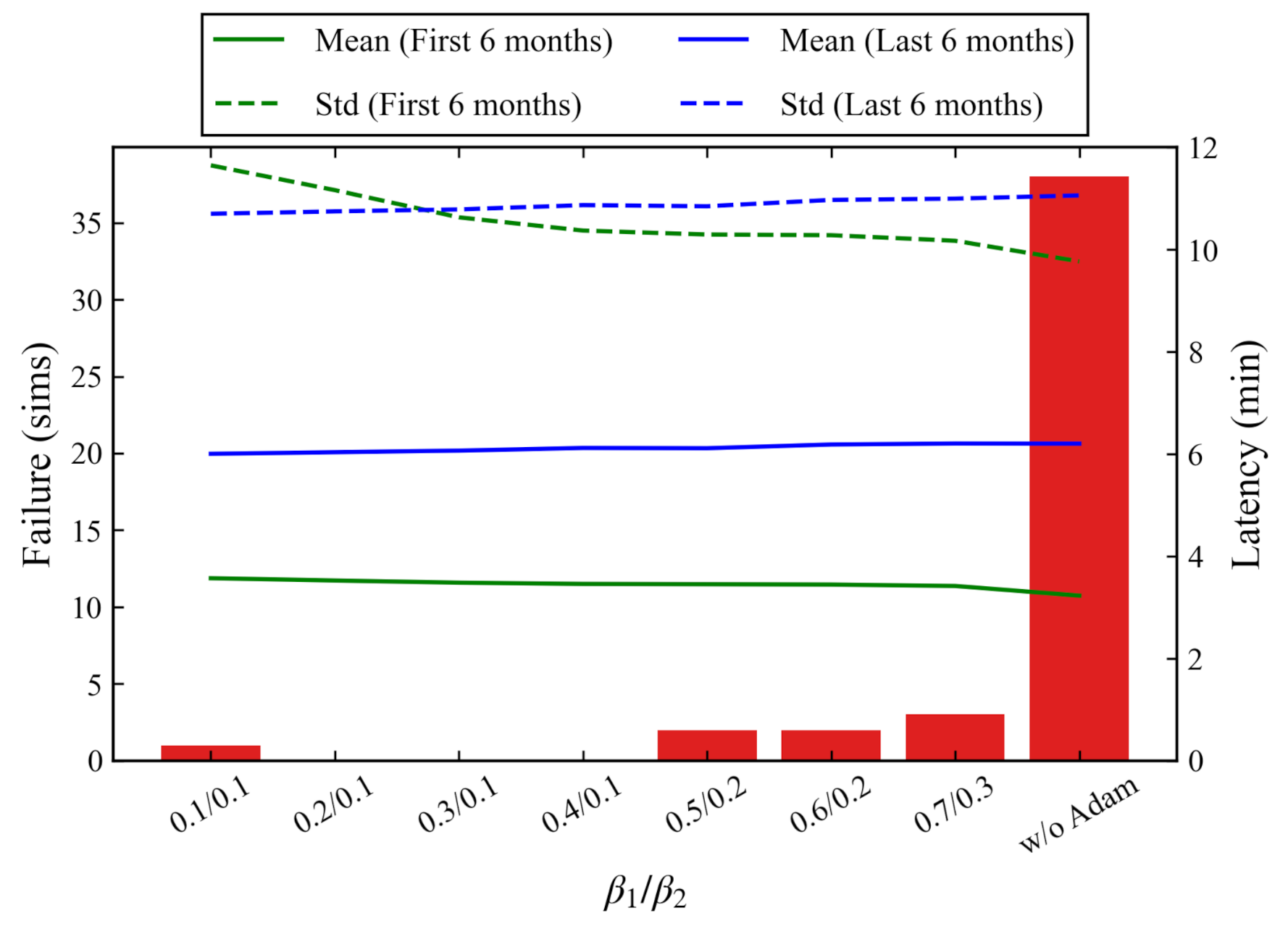
- Simulation results show that, for our application use case, smaller decay rates such as 0.2–0.4 are better for power-failure-sensitive applications and 0.5–0.7 for latency-sensitive applications with in the LAC-AB algorithm.
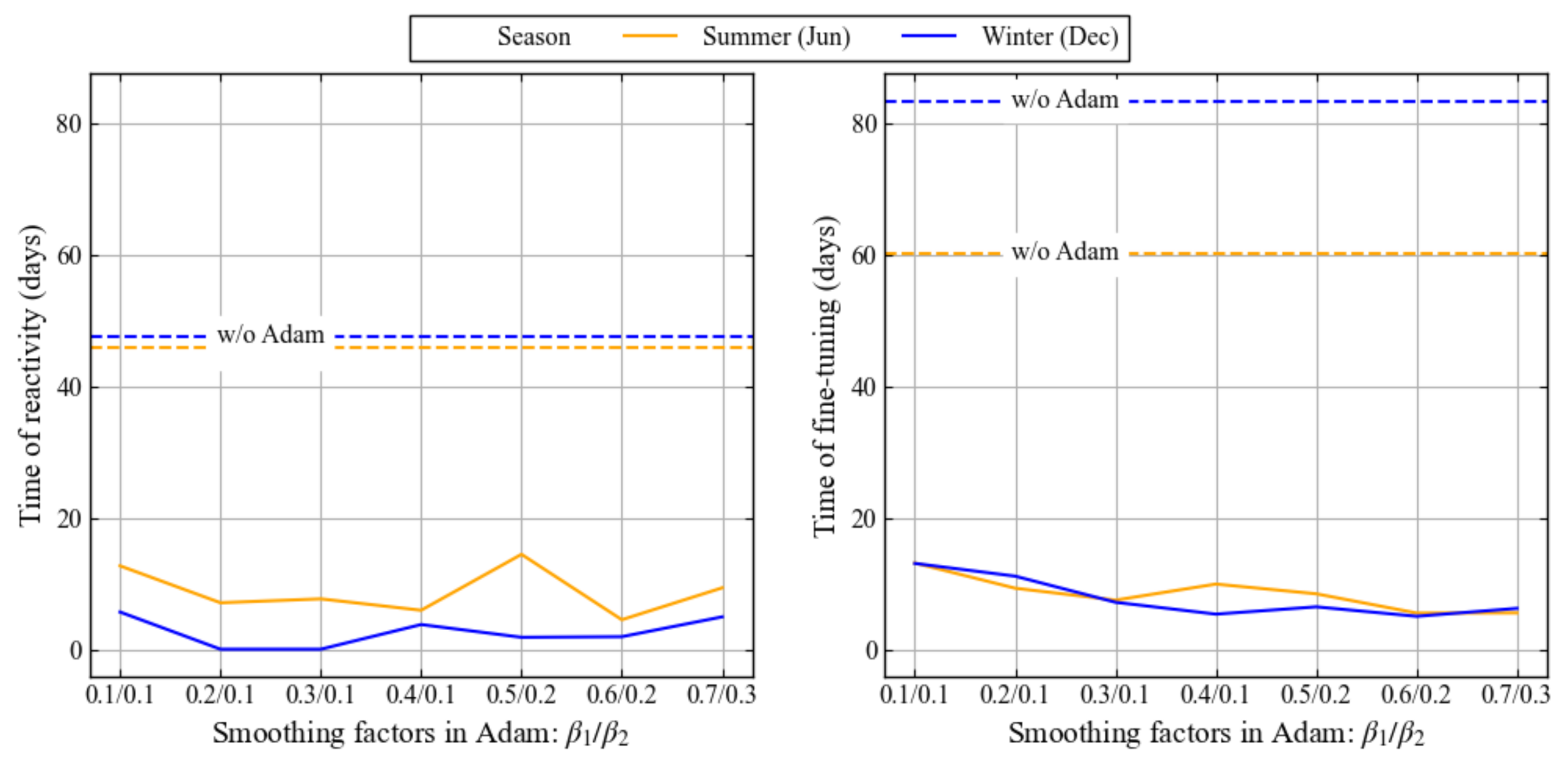
- We show that LAC-AB with such decay rates helps achieve more reactivity and stability to drastic gradient changes, such as doubled workload, and enables fine-tuning the actions to the initial state more quickly.
2. Related Work
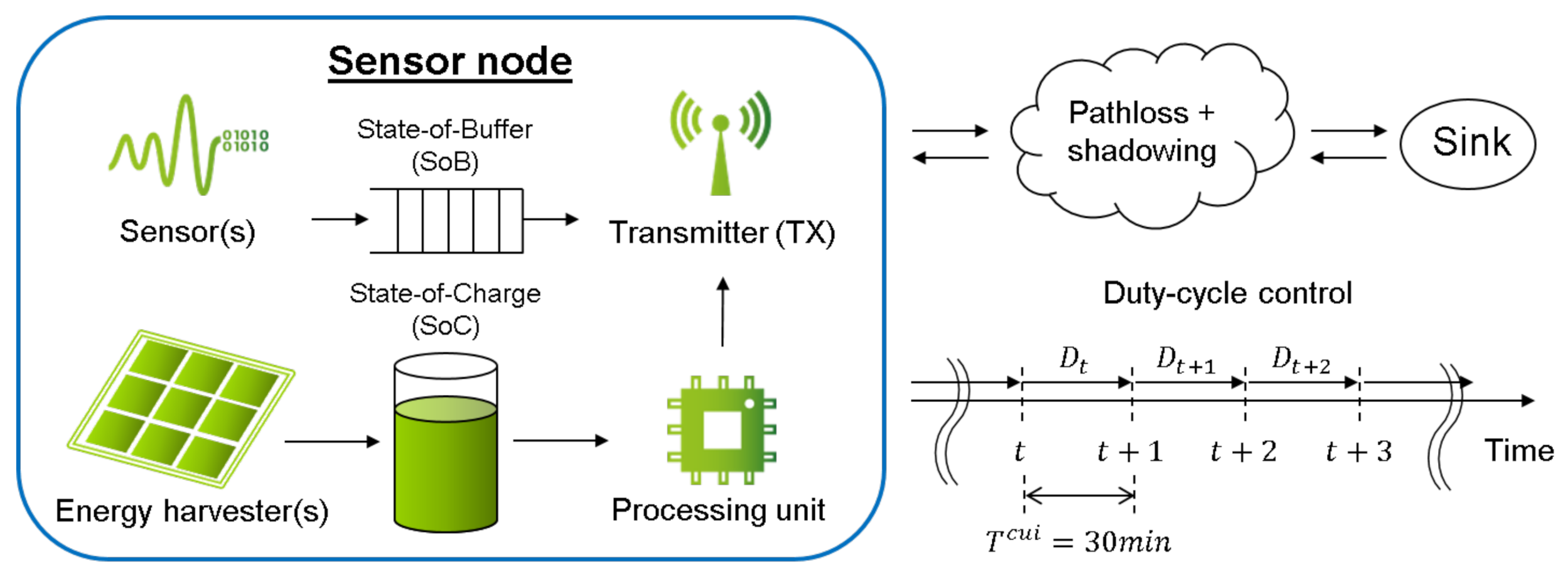
3. System Model
3.1. Energy Harvesting and State-of-Charge Model
3.2. Application Data and State-of-Buffer model
3.3. Power Consumption and Transmission Model
4. Application Scenario
- -
- The control update interval (CUI) is min.
- -
- For the PV cell model, we set the cell area A, conversion efficiency , and tracking factor as 2.5 , , and , respectively [7]. This choice is consistent with an off-the-shelf solar cell that can harvest power from to per cm, depending on the lighting condition [32]. Note that we use the real-life solar irradiance data provided by Oak Ridge National Laboratory [33].
- -
- The self-discharge of a supercapacitor whose capacitor size is is considered per day (detailed in Section 3.1). The harvest–use–store scheme is adopted [25,26] to provide high energy efficiency.
- -
- The wireless link quality is under the influence of path-loss and shadowing.
- -
- The workload follows the Poisson distribution. The average rate doubles after the first six months (where the algorithm is put through the test of fast adaptability/reactivity). More precisely, the system receives the average of 1.0 for the first six months, and it impulsively becomes twice (2.0 ) afterwards.
- EHD1: Non-processed real-life one-year data from 1 June 2018 to 31 May 2019
- EHD2: Real-life one-year data made by stacking 365 one day (1 December 2018) worth of solar irradiance data
- EHD3: Real-life one-year data made by stacking 365 one day (1 June 2018) worth of solar irradiance data
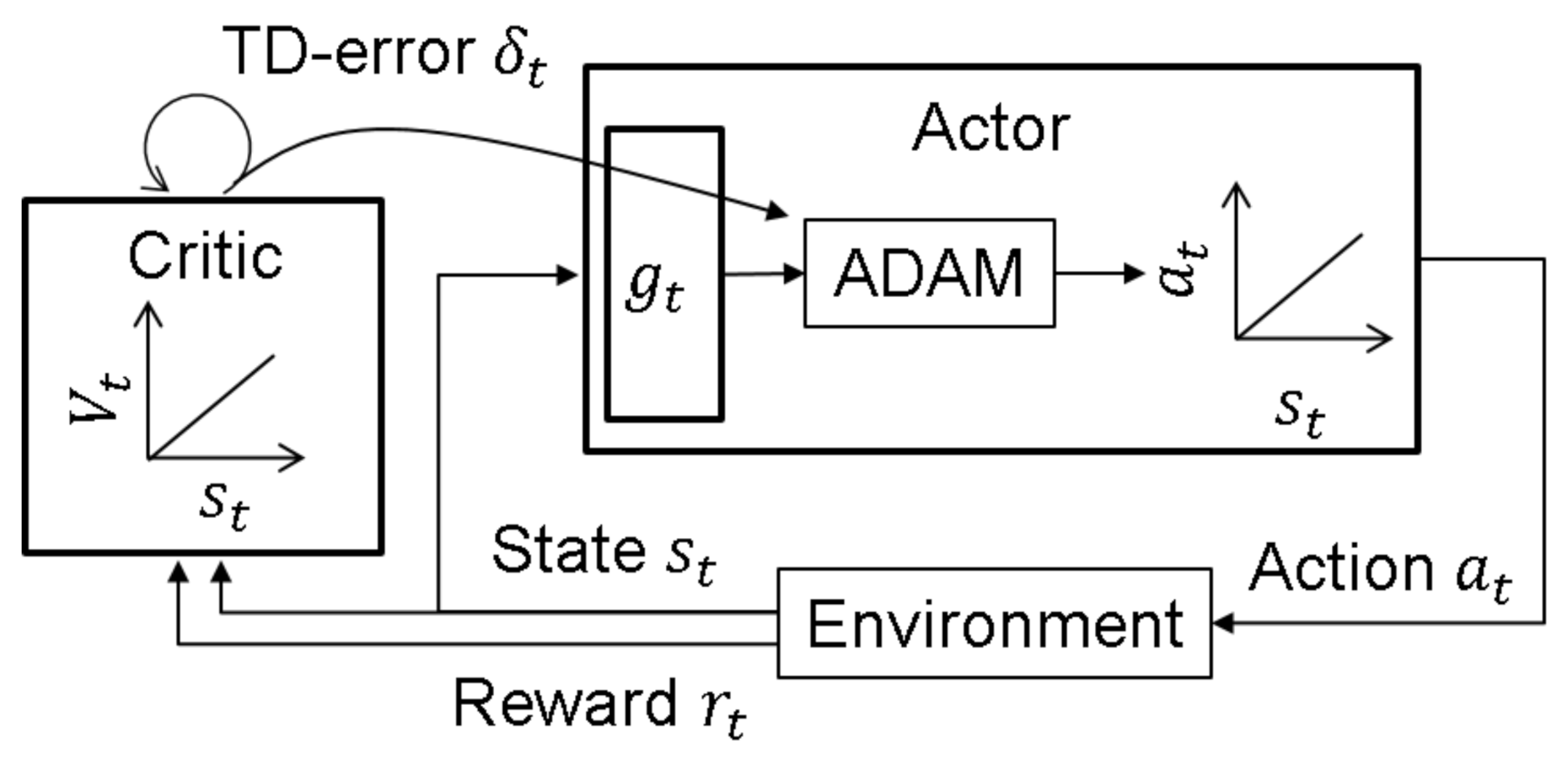
5. Reinforcement Learning
- Find the optimal policy .
- Determine the estimate of the value function under a certain policy;
6. Algorithm: LAC-AB
- -
- Smaller values lead to more weight on recent changes, i.e., faster online adaptation.
- -
- The gradient variance can become too large and yet carries an important information for parameter updates that can be lost with larger values of and .
| Algorithm 1 LAC-AB: LAC Algorithm Using Adam with No Initialization Bias Correction |
Require:
3: ▹ For minimizing SoB and maximizing SoC 4: ▹ Less SoB and more SoC are better states (better values) 5: TD-error for Actor-Critic 6: ▹ Advantage function: (: state-action value function) Critic: TD() algorithm 7: ▹ Calculate the eligibility trace 8: ▹ Update the critic parameter Actor: Policy gradient theorem using Adam with no initialization bias corrections 9: 10: ▹ Estimate the first-order moment 11: ▹ Estimate the second-order moment 12: ▹ Update the actor parameter Next TX duty-cycle selection 13: ▹ Less SoB, smaller action values; More SoC, higher action values 14: Clamp to 15: ▹ Gaussian policy for action generation 16: Clamp to 17: Return 18: end for each |
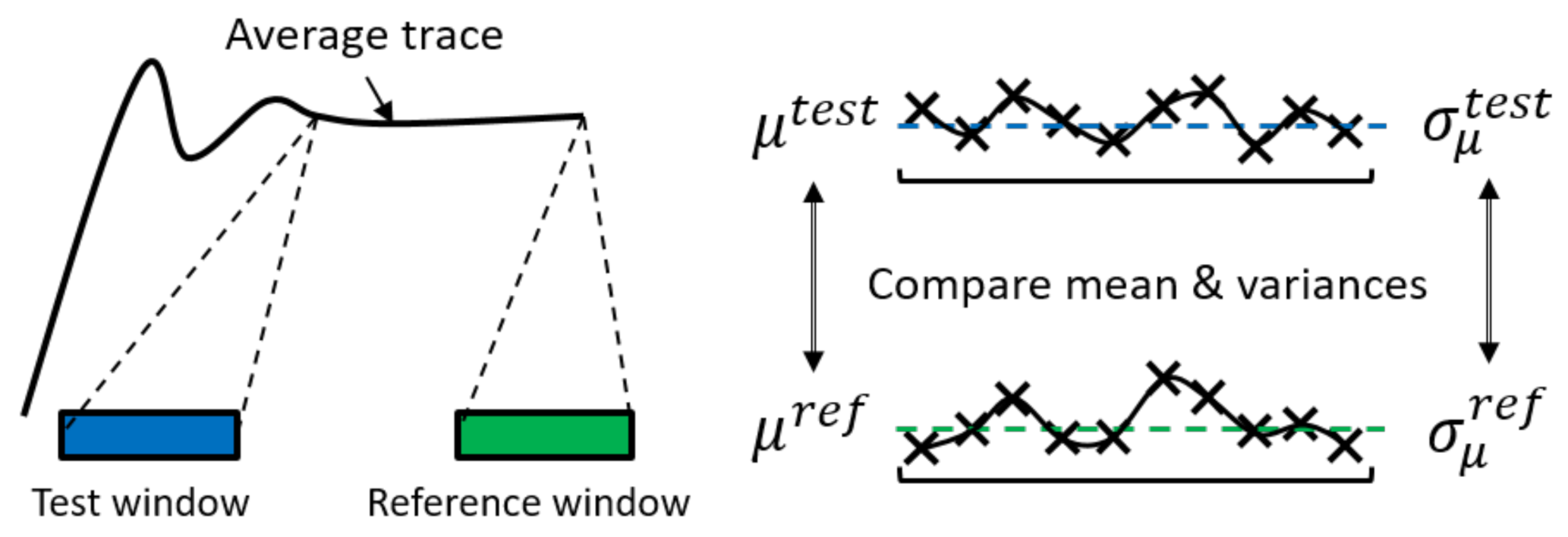
7. Definition of Convergence
- All the mean values (e.g., actor parameter values ) taken over all the simulations at the same time points in a x-day sweeping window are all within error band of the average of all the mean values in the last x-day window under almost the same state (e.g., under the same workload scenario in our test study here).
- The variances of the mean values taken over all the simulations at the same time points are confirmed to be not different, i.e., the homogeneity of variance is tested and confirmed by means of Levene’s test [36], more precisely Brown–Forsythe [37] test, with the confidence interval of (note that we cannot say “the same” mathematically).
8. Simulation Results
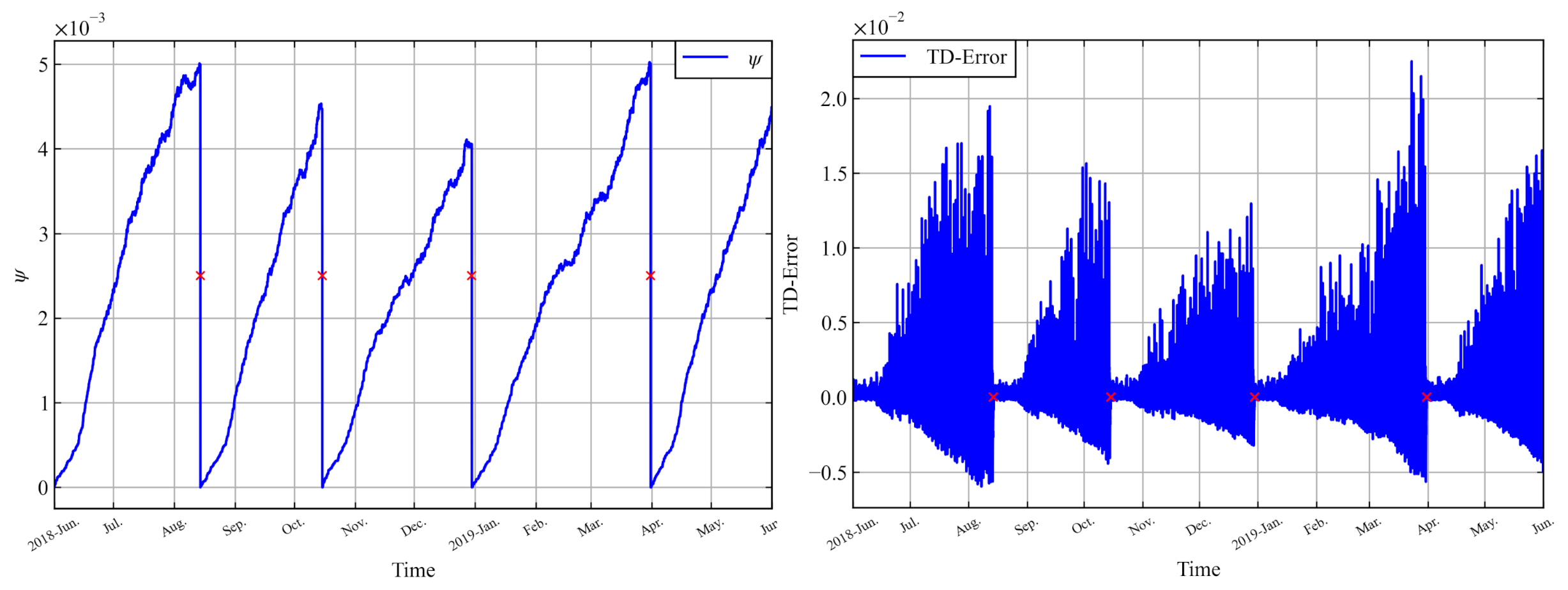
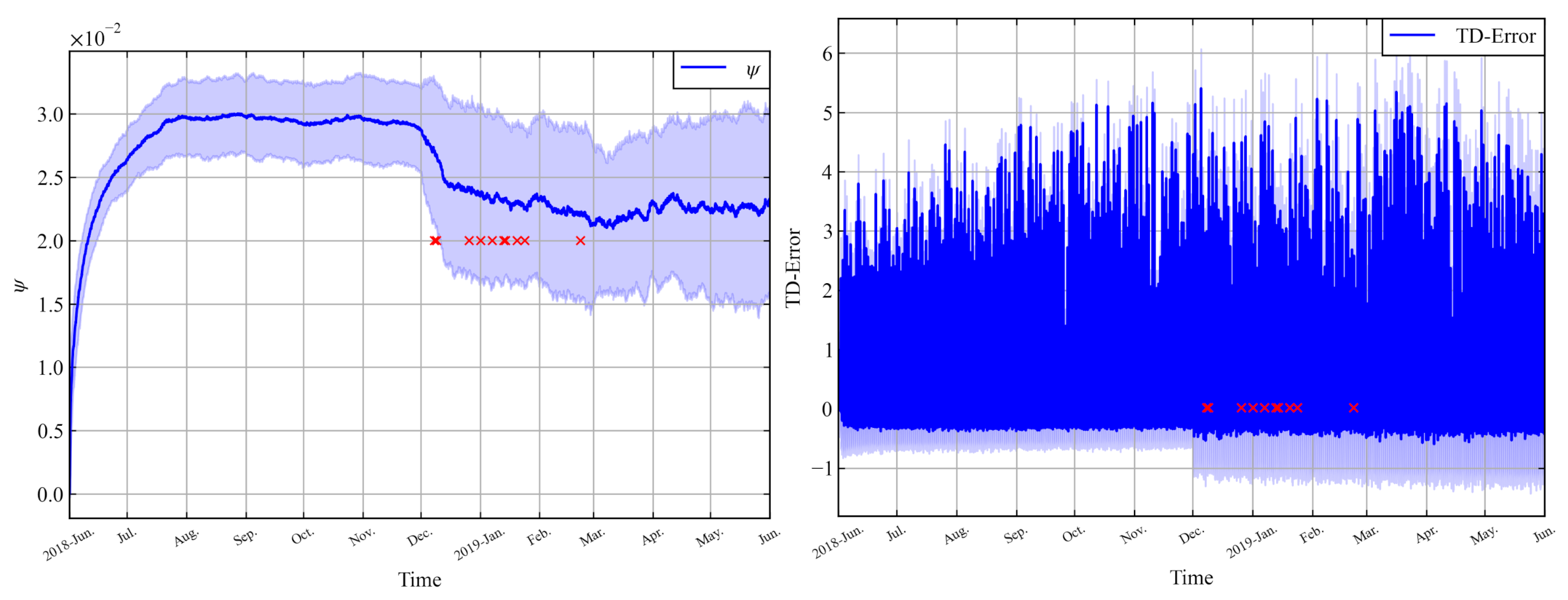
8.1. Divergence and Reactivity Problem
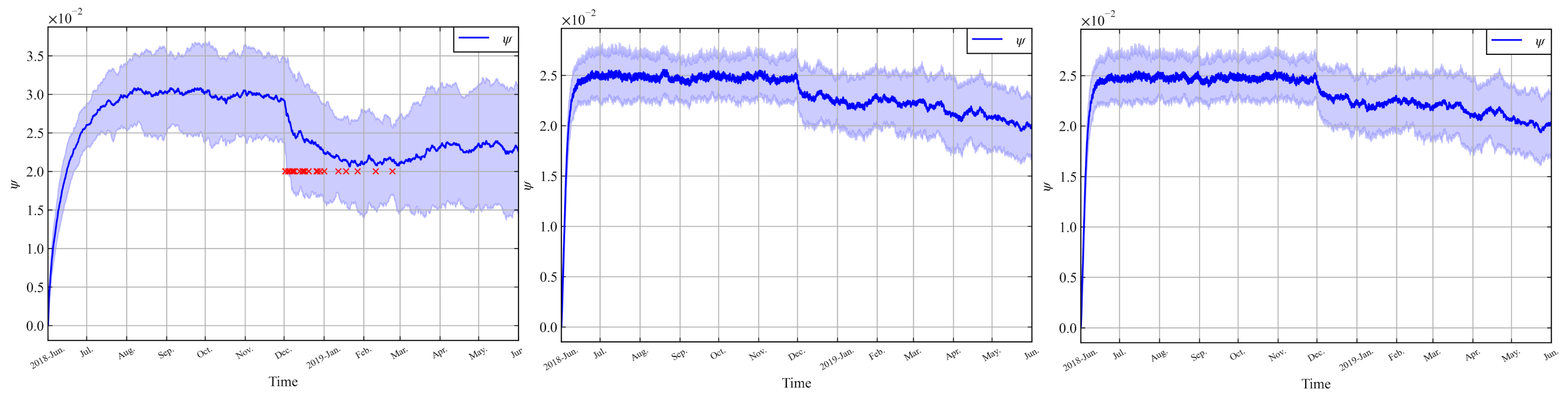
8.2. Effectiveness and Convergence of LAC-AB
8.3. Decay Rates Study for LAC-AB
9. Conclusions and Future Direction
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Lallement, G.; Abouzeid, F.; Cochet, M.; Daveau, J.; Roche, P.; Autran, J. A 2.7 pJ/cycle 16 MHz SoC with 4.3 nW power-off ARM Cortex-M0+ core in 28 nm FD-SOI. In Proceedings of the ESSCIRC 2017—43rd IEEE European Solid State Circuits Conference, Leuven, Belgium, 11–14 September 2017; pp. 153–162. [Google Scholar] [CrossRef] [Green Version]
- Ait Aoudia, F.; Gautier, M.; Berder, O. RLMan: An Energy Manager Based on Reinforcement Learning for Energy Harvesting Wireless Sensor Networks. IEEE Trans. Green Commun. Netw. 2018, 2, 408–417. [Google Scholar] [CrossRef] [Green Version]
- Ortiz, A.; Al-Shatri, H.; Li, X.; Weber, T.; Klein, A. Reinforcement learning for energy harvesting point-to-point communications. In Proceedings of the 2016 IEEE International Conference on Communications (ICC), Kuala Lumpur, Malaysia, 22–27 May 2016; pp. 1–6. [Google Scholar]
- Van Hasselt, H.; Wiering, M.A. Using continuous action spaces to solve discrete problems. In Proceedings of the 2009 International Joint Conference on Neural Networks, Atlanta, GA, USA, 14–19 June 2009; pp. 1149–1156. [Google Scholar] [CrossRef] [Green Version]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the 3rd International Conference on Learning Representations (ICLR 2015), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- De Roose, J.; Xin, H.; Andraud, M.; Harpe, P.J.A.; Verhelst, M. Flexible and Self-Adaptive Sense-and-Compress for Sub-MicroWatt Always-on Sensory Recording. In Proceedings of the ESSCIRC 2018—IEEE 44th European Solid State Circuits Conference (ESSCIRC), Dresden, Germany, 3–6 September 2018; pp. 282–285. [Google Scholar] [CrossRef]
- Ju, Q.; Zhang, Y. Predictive Power Management for Internet of Battery-Less Things. IEEE Trans. Power Electron. 2018, 33, 299–312. [Google Scholar] [CrossRef]
- Qiu, C.; Hu, Y.; Chen, Y.; Zeng, B. Lyapunov Optimization for Energy Harvesting Wireless Sensor Communications. IEEE Internet Things J. 2018, 5, 1947–1956. [Google Scholar] [CrossRef]
- Hu, Y.; Qiu, C.; Chen, Y. Lyapunov-Optimized Two-Way Relay Networks With Stochastic Energy Harvesting. IEEE Trans. Wirel. Commun. 2018, 17, 6280–6292. [Google Scholar] [CrossRef]
- Bhat, G.; Park, J.; Ogras, U.Y. Near-optimal energy allocation for self-powered wearable systems. In Proceedings of the 2017 IEEE/ACM International Conference on Computer-Aided Design (ICCAD), Irvine, CA, USA, 13-16 November 2017; pp. 368–375. [Google Scholar] [CrossRef]
- Bhat, G.; Bagewadi, K.; Lee, H.G.; Ogras, U.Y. REAP: Runtime Energy-Accuracy Optimization for Energy Harvesting IoT Devices. In Proceedings of the 2019 56th ACM/IEEE Design Automation Conference (DAC), Las Vegas, NV, USA, 2–6 June 2019; pp. 1–6. [Google Scholar]
- Vigorito, C.M.; Ganesan, D.; Barto, A.G. Adaptive Control of Duty Cycling in Energy-Harvesting Wireless Sensor Networks. In Proceedings of the 2007 4th Annual IEEE Communications Society Conference on Sensor, Mesh and Ad Hoc Communications and Networks, San Diego, CA, USA, 18–21 June 2007; pp. 21–30. [Google Scholar] [CrossRef] [Green Version]
- Debizet, Y.; Lallement, G.; Abouzeid, F.; Roche, P.; Autran, J. Q-Learning-based Adaptive Power Management for IoT System-on-Chips with Embedded Power States. In Proceedings of the 2018 IEEE International Symposium on Circuits and Systems (ISCAS), Florence, Italy, 27–30 May 2018; pp. 1–5. [Google Scholar] [CrossRef]
- Masadeh, A.; Wang, Z.; Kamal, A.E. An Actor-Critic Reinforcement Learning Approach for Energy Harvesting Communications Systems. In Proceedings of the 2019 28th International Conference on Computer Communication and Networks (ICCCN), Valencia, Spain, 29 July–1 August 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Murad, A.; Kraemer, F.A.; Bach, K.; Taylor, G. Autonomous Management of Energy-Harvesting IoT Nodes Using Deep Reinforcement Learning. In Proceedings of the 2019 IEEE 13th International Conference on Self-Adaptive and Self-Organizing Systems (SASO), Umea, Sweden, 16–20 June 2019; pp. 43–51. [Google Scholar] [CrossRef] [Green Version]
- Qian, L.P.; Feng, A.; Feng, X.; Wu, Y. Deep RL-Based Time Scheduling and Power Allocation in EH Relay Communication Networks. In Proceedings of the ICC 2019—2019 IEEE International Conference on Communications (ICC), Shanghai, China, 20–24 May 2019; pp. 1–7. [Google Scholar] [CrossRef]
- Li, M.; Zhao, X.; Liang, H.; Hu, F. Deep Reinforcement Learning Optimal Transmission Policy for Communication Systems With Energy Harvesting and Adaptive MQAM. IEEE Trans. Veh. Technol. 2019, 68, 5782–5793. [Google Scholar] [CrossRef]
- Sawaguchi, S.; Christmann, J.F.; Molnos, A.; Bernier, C.; Lesecq, S. Multi-Agent Actor-Critic Method for Joint Duty-Cycle and Transmission Power Control. In Proceedings of the 2020 Design, Automation Test in Europe Conference Exhibition (DATE), Grenoble, France, 9–13 March 2020; pp. 1015–1018. [Google Scholar]
- Li, D.; Xu, S.; Zhao, J. Partially Observable Double DQN Based IoT Scheduling for Energy Harvesting. In Proceedings of the 2019 IEEE International Conference on Communications Workshops (ICC Workshops), Shanghai, China, 20–24 May 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Zhao, N.; Liang, Y.; Niyato, D.; Pei, Y.; Jiang, Y. Deep Reinforcement Learning for User Association and Resource Allocation in Heterogeneous Networks. In Proceedings of the 2018 IEEE Global Communications Conference (GLOBECOM), Abu Dhabi, United Arab Emirates, 9–13 December 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Qiu, C.; Hu, Y.; Chen, Y.; Zeng, B. Deep Deterministic Policy Gradient (DDPG)-Based Energy Harvesting Wireless Communications. IEEE Internet Things J. 2019, 6, 8577–8588. [Google Scholar] [CrossRef]
- Biswas, D.; Balagopal, V.; Shafik, R.; Al-Hashimi, B.M.; Merrett, G.V. Machine learning for run-time energy optimisation in many-core systems. In Proceedings of the Design, Automation Test in Europe Conference Exhibition (DATE), Lausanne, Switzerland, 27–31 March 2017; pp. 1588–1592. [Google Scholar] [CrossRef] [Green Version]
- Das, A.; Merrett, G.V.; Tribastone, M.; Al-Hashimi, B.M. Workload Change Point Detection for Runtime Thermal Management of Embedded Systems. IEEE Trans. Comput. Aided Des. Integr. Circuits Syst. 2016, 35, 1358–1371. [Google Scholar] [CrossRef]
- Shafik, R.A.; Yang, S.; Das, A.; Maeda-Nunez, L.A.; Merrett, G.V.; Al-Hashimi, B.M. Learning Transfer-Based Adaptive Energy Minimization in Embedded Systems. IEEE Trans. Comput. Aided Des. Integr. Circuits Syst. 2016, 35, 877–890. [Google Scholar] [CrossRef] [Green Version]
- Yuan, F.; Zhang, Q.T.; Jin, S.; Zhu, H. Optimal Harvest-Use-Store Strategy for Energy Harvesting Wireless Systems. IEEE Trans. Wirel. Commun. 2015, 14, 698–710. [Google Scholar] [CrossRef]
- Christmann, J.F.; Beigne, E.; Condemine, C.; Vivet, P.; Willemin, J.; Leblond, N.; Piguet, C. Bringing Robustness and Power Efficiency to Autonomous Energy-Harvesting Microsystems. IEEE Des. Test Comput. 2011, 28, 84–94. [Google Scholar] [CrossRef]
- Dekimpe, R.; Xu, P.; Schramme, M.; Flandre, D.; Bol, D. A Battery-Less BLE IoT Motion Detector Supplied by 2.45-GHz Wireless Power Transfer. In Proceedings of the International Symposium on Power and Timing Modeling, Optimization and Simulation (PATMOS) 2018, Platja d’Aro, Spain, 2–4 July 2018; pp. 68–75. [Google Scholar] [CrossRef]
- Sangare, F.; Xiao, Y.; Niyato, D.; Han, Z. Mobile Charging in Wireless-Powered Sensor Networks: Optimal Scheduling and Experimental Implementation. IEEE Trans. Veh. Technol. 2017, 66, 7400–7410. [Google Scholar] [CrossRef]
- Texas Instruments. CC2500 Low-Cost Low-Power 2.4 GHz RF Transceiver. 2019. Available online: http://www.ti.com/lit/ds/swrs040c/swrs040c.pdf (accessed on 6 April 2021).
- Urard, P.; Romagnello, G.; Banciu, A.; Grasset, J.C.; Heinrich, V.; Boulemnakher, M.; Todeschni, F.; Damon, L.; Guizzetti, R.; Andre, L.; et al. A self-powered IPv6 bidirectional wireless sensor amp; actuator network for indoor conditions. In Proceedings of the 2015 Symposium on VLSI Circuits (VLSI Circuits), Kyoto, Japan, 17–19 June 2015; pp. C100–C101. [Google Scholar] [CrossRef]
- Goldsmith, A. Wireless Communications; Cambridge University Press: Cambridge, UK, 2005. [Google Scholar] [CrossRef] [Green Version]
- Panasonic Industry. Available online: https://www.panasonic-electric-works.com/cps/rde/xbcr/pew_eu_en/ca_amorton_solar_cells_en.pdf (accessed on 6 April 2021).
- Oak Ridge National Laboratory (RSR) Daily Plots and Raw Data Files. Available online: https://midcdmz.nrel.gov/apps/sitehome.pl?site=ORNL (accessed on 6 April 2021).
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction, 2nd ed.; The MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Devlin, S.; Yliniemi, L.; Kudenko, D.; Tumer, K. Potential-based Difference Rewards for Multiagent Reinforcement Learning. In Proceedings of the 2014 International Conference on Autonomous Agents and Multi-agent Systems (AAMAS’14), Paris, France, 5–9 May 2014; pp. 165–172. [Google Scholar]
- Gleser, L.J.; Perlman, M.D.; Press, S.J.; Sampson, A.R. Contributions to Probability and Statistics: Essays in Honor of Harold Hotelling; Springer: Berlin/Heidelberg, Germany, 1960; pp. 278–292. [Google Scholar]
- Brown, M.B.; Forsythe, A.B. Robust Tests for the Equality of Variances. J. Am. Stat. Assoc. 1974, 69, 364–367. [Google Scholar] [CrossRef]
- Sheskin, D.J. Handbook of Parametric and Nonparametric Statistical Procedures, 5th ed.; CRC Press: Boca Raton, FL, USA, 2011. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Paper | Method | SoB | SoC | Harvester | Action | Neural? | LR |
|---|---|---|---|---|---|---|---|
| [6] | Online statistics & offline optimization | - | Finite | - | Sense & Compress setups | No | NA |
| [7] | Prediction & online stepwise adjustment | - | Finite | Solar | Duty-cycle, TX power | No | Fixed |
| [8] | Lyapunov optimization | - | Finite | Solar | TX modulation | No | NA |
| [9] | Lyapunov optimization | - | Finite | Solar | TX power | No | NA |
| [10] | Online KKT & prediction | - | Finite | Solar | Duty-cycle | No | Fixed |
| [11] | Simplex algorithm with prediction and offline data | - | Finite | Solar | Active time (Duty-cycle), accuracy | No | NA |
| [13] | Q-learning | - | Finite | - | Suspension mode selection | No | Fixed |
| [14] | Actor-Critic | Infinite | Finite | Solar | TX power | 3 layers (3-10-5-1) | Fixed |
| [12] | Linear-Quadratic Regulator | - | Finite | Solar | Duty-cycle | No | Fixed |
| [15] | DRL | - | Finite | Solar | Duty-cycle | 3 layers (4-64-64-2) | Fixed |
| [16] | Asynchronous Advantage Actor-Critic | Finite | Finite | Uniform distribution | Duty-cycle, TX power (source and relay) | 3 layers (5-300-200-3(1)) | Fixed |
| [17] | Deep RL | Infinite | Finite | Uniform distribution | TX modulation (=TX power) | 3 layers (3-10-10-1) | Fixed or decaying |
| [2] | Linear Actor-Critic | - | Finite | Solar, wind | Packet rate | No (Linear function) | Fixed |
| [18] | Multi-Agent Actor-Critic | Finite | Finite | Solar | Duty-cycle, TX power | No (Linear function) | Fixed |
| [19] | Double Deep Q-Network | - | Finite | Two-state Markov process | Uplink scheduling policy | Yes (No details) | Adam (less adaptive) |
| [20] | Multi-Agent Double Deep Q-Network | - | - | - | Base station and channel selections | 4-layers (50-64-32-32-26(30)) | Adam (less adaptive) |
| [21] | Deep Deterministic Policy Gradient | - | Finite | Solar | Energy budget | Actor: 3(4)-60-30-1, Critic: 3(4)-60-60-60-60-60-1 | Adam (less adaptive) |
| This paper | Linear Actor-Critic | Finite | Finite | Solar | Duty-cycle | Linear function | Adam (highly adaptive) |
| Algorithm | ||||||
|---|---|---|---|---|---|---|
| LAC | ||||||
| LAC-A | ||||||
| LAC-AB |
| Algorithm | LAC-A | LAC-AB | ||
|---|---|---|---|---|
| Latency (Mean/Std) | First 6 months | |||
| Last 6 months | ||||
| # of power failures/# of failed simulations | ||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sawaguchi, S.; Christmann, J.-F.; Lesecq, S. Highly Adaptive Linear Actor-Critic for Lightweight Energy-Harvesting IoT Applications. J. Low Power Electron. Appl. 2021, 11, 17. https://doi.org/10.3390/jlpea11020017
Sawaguchi S, Christmann J-F, Lesecq S. Highly Adaptive Linear Actor-Critic for Lightweight Energy-Harvesting IoT Applications. Journal of Low Power Electronics and Applications. 2021; 11(2):17. https://doi.org/10.3390/jlpea11020017
Chicago/Turabian StyleSawaguchi, Sota, Jean-Frédéric Christmann, and Suzanne Lesecq. 2021. "Highly Adaptive Linear Actor-Critic for Lightweight Energy-Harvesting IoT Applications" Journal of Low Power Electronics and Applications 11, no. 2: 17. https://doi.org/10.3390/jlpea11020017
APA StyleSawaguchi, S., Christmann, J. -F., & Lesecq, S. (2021). Highly Adaptive Linear Actor-Critic for Lightweight Energy-Harvesting IoT Applications. Journal of Low Power Electronics and Applications, 11(2), 17. https://doi.org/10.3390/jlpea11020017